1. Introduction
Machine Learning (ML) and Deep Neural Networks (DNN) gained popularity in the last few years due to technology advancement. ML and DNN infrastructures can analyse a vast amount of information to predict a certain case [
1,
2,
3]. DNN is a part of ML that tries to replicate a human’s brain neurons’ functionalities to achieve a prediction. This analysis and prediction functionalities can deal with complex problems that were previously considered to be unsolvable. ML predictions become more valuable when the analysis involves highly sensitive private data such as health records. Consequently, data holders cannot simply share their private data with ML algorithms and experts [
4]. Many defensive techniques proposed in the past as countermeasures to the information leakage of sensitive data, such as anonymisation and obfuscation techniques [
5]. Other research focused on non-iterative Artificial Neural Network (ANN) approaches for data security [
6,
7]. Nevertheless, due to the advancement of technology, similar techniques cannot anymore guarantee the privacy of the underlying data [
8,
9]. Malicious users are able to reverse and reconstruct, anonymised and obfuscated data, in order to identify the identities of the data subjects.
It is common knowledge that data is the most valuable asset of our century. Since ML algorithms require vast amounts of it, it is frequently targeted by malicious parties. Several attacks exist that can hack, reconstruct, reverse or poison ML algorithms [
10,
11]. The common goal of these attacks is to identify the underlying data. Several of them require access during the ML algorithm training to succeed, while others are able to interfere later in the testing or publication phase. In the literature, there are several defensive methods and techniques proposed against the aforementioned mistreats. However, when reinforcing a ML algorithm with security and privacy features against adversarial attacks, there is an impact on efficiency, thus ending up with the produced predictions not related to the associated tasks and with often a lower accuracy. Hence, a balance between tolerable defence and usability is a critical point of interest that many researchers are trying to solve. Most of the aforementioned attacks are applicable and target centralised ML infrastructures, in which the model owners have access and acquire all the training data [
12].
Due to the importance of the ML field and the associated privacy risks, a new division of ML was created, namely Privacy-Preserving ML (PPML) [
13]. This area is focused on the advancement and development of countermeasures against information leakage in ML, by shedding light on the privacy of the underlying data subjects. When a few of these ML risks and attacks were introduced, they were purely theoretical; hence, due to the rapid advancement and evolution of ML, attackers led to the exploitation of those weaknesses in order to breach, steal, and profit from this data. Several techniques and countermeasures were proposed in the PPML field. It is a common belief that if data never leave their holders possession to be used from a ML algorithm, then the data privacy is higher. The most extended and researched area related to this is Federated Learning (FL) [
14,
15,
16,
17].
In a FL scenario, the ML model owners are able to send their model to the data holders for training. From a high-level perspective, this scenario is secure; however, there are still many security flaws that need to be solved [
10]. For example, the ML model owners could reverse their model and identify the underlying training data [
18,
19]. A suggested solution is to use a secure aggregator, often an automated procedure or program, as a middle-ware, which aggregates all the participants’ trained models and then sends the updates to the ML model owners [
20]. This solution is robust against several attacks [
18,
19,
21,
22,
23], but still involves issues, such as the possibility of a Man-In-The-Middle (MITM) attack that is able to interfere and trick both parties or even the scenario where one or more participants are malicious. In the latter scenario, malicious data providers can poison the ML model [
24,
25,
26] in order to miss-classify specific predictions in its final testing phase; thus, the ML model owner could never distinguish a poisoned model from a benign. This model poisoning scenario could happen in a healthcare auditing scheme, where the trusted auditing organisation uses a ML algorithm to audit other healthcare institutions to predict financial profits and losses in the future. A potential malicious healthcare institution is able to poison the ML model using indistinguishable data that could lead to false predictions from the final trained model by miss-classifying the economic losses of the healthcare institution and approve its operation, as usual.
The aforementioned attacks share some common issues and concerns such as the lack of trust between the participating parties, or the lack of a secure communication channel to transmit private ML model updates. In this work, we redefine the privacy and trust in federated machine learning by creating a Trusted Federated Learning (TFL) framework as an extension of the privacy-preserving technique to facilitate trust amongst federated machine learning participants [
27]. In our scheme, the ML participants need to get a certification before their participation, from a trusted governmental body such as the National Health Service (NHS) Trust in the United Kingdom. Following, the ML training procedure is distributed among the participants similarly to FL. The main difference is that the model updates are being sent through a secure communication end-to-end encrypted channel. Before learning commences, the respective parties must authenticate themselves against some predetermined policy. Policies can be flexibly determined based on the ecosystem, trusted entities and associated risk; this paper gives an example of using a healthcare scenario. The proof-of-concept developed in this paper is built using open-source Hyperledger technologies such as Aries/Indy/Ursa [
28,
29,
30] and developed within the PyDentity-
Aries FL project [
31,
32] of the OpenMined open-source privacy-preserving machine learning organisation. Our scheme is based on advanced privacy-enhancing attribute-based credential cryptography [
33,
34] and is aligned with emerging decentralised identity standards; Decentralized Identifiers (DIDs) [
35], Verifiable Credentials (VCs) [
36] and DID Communication [
37]. The implementation enables participating entities mutually authenticate digitally signed attestations (Credentials), issued by trusted entities specific to the use-case. The presented authentication mechanisms could be applied to any regulatory workflow, data collection, and data processing and are not limited solely to the healthcare domain. The contributions of our work could be summarised as follows:
We enable stakeholders in the learning process to define and enforce a trust model for their domain through the application of decentralised identity standards. We also extended the credentialing and authentication system by separating Hyperledger Aries agents and controllers into isolated entities.
We present a decentralised peer-to-peer infrastructure, namely TFL, which uses DIDs and VCs in order to perform mutual authentication and federated machine learning specific to a healthcare trust infrastructure. Development and evaluation of explicitly designed libraries for federated machine learning through secure Hyperledger Aries communication channels.
We demonstrate performance improvement upon our previous trusted federated learning state-of-the-art without sacrificing the privacy guarantees of the authentication techniques and privacy-preserving workflows.
Section 2 provides the background knowledge and describes the related literature. Furthermore,
Section 3 outlines our implementation overview and architecture, followed by
Section 4, in which we provide an extensive security and performance evaluation of our system. Finally, our work concludes with
Section 5 that draws the conclusions, limitations, and outlines approaches for future work.
2. Background Knowledge and Related Work
Recent ML advancements can accurately predict specific circumstances using relevant data. Hence, that led businesses and organisations to collect vast amounts of data to predict a situation before their competitors. The rationale is often to analyse people’s behaviour patterns to predict the next trend they will follow [
38]. However, the European Union tried to minimise and constrain this massive collection of data with the General Data Protection Regulation (GDPR) legislation [
39].
Another field that can take advantage of the recent ML progression is the healthcare sector. However, in that case, the underlying data used for ML training is sensitive and private. Thus, its privacy must be ensured first prior to the improvement of its ML predictions. The aforementioned procedure’s complexity raises when it is being outsourced to a third-party organisation specialising on the ML task; since the ML practitioners have the expertise to solve the task, but a healthcare organisation is holding the required sensitive data.
2.1. Trust and the Data Industry
The notion of trust has been defined as domain and context-specific since it specifies the amount of control a party provides to another [
40,
41]. It is often represented as a calculation of risk since it can only be restrained and not fully eradicated [
42]. Accordingly, patients trust healthcare institutions when giving their consent to collect their data. However, huge volumes of medical data can be valuable in-context to ML algorithms that aim to predict particular cures or conditions.
In 2015, Royal Free London NHS Trust outsourced patients sensitive data to a third-party ML company, particularly DeepMind, to train ML algorithms for the early detection of kidney failure [
43,
44]. However, this sensitive data usage was not regulated, raised concerns about data privacy and later judged as illegal by the Information Commissioner’s Office [
45]. This misbehaviour did not cause other researchers to use sensitive data for ML predictions and led them to obtain proper authorisation from the Health Research Authority first and then use the sensitive medical records to analyse retinal imaging automatically [
46], and the segmentation of tumour volumes and organs of risk [
47].
2.2. Decentralised Identifiers
Recently, Decentralised Identifiers (DIDs) were established as a digital identifier in a World Wide Web Consortium (W3C) working group [
35], that can magnify trust in distributed environments. DIDs can be controlled solely by their owners and grant a person the ability to be authenticated similar to a login system, but without relying on a trusted third-party company. Consequently, DIDs are often stored in distributed ledgers such as blockchain ledgers, which are not managed by a single authority. Distributed storage systems such as Ethereum, Bitcoin and Sovrin ledgers, or InterPlanetary File System (IPFS) are often used to store DID specifications, each with their own resolution method [
48]. An outline of a DID document that would have been resolved from
did:example:123456789abcdefghi, using the DID method
example and the identifier
123456789abcdefghi, can be seen in Listing 1. A DID document consists of:
| Listing 1. An example DID document. |
- 1
{ - 2
"@context": "https://example.org/example-method/v1", - 3
"id": "did:example:123456789abcdefghi", - 4
"publicKey": [{ - 5
"id": "did:example:123456789abcdefghi#keys-1", - 6
"type": "RsaVerificationKey2018", - 7
"controller": "did:example:123456789abcdefghi", - 8
"publicKeyPem": "-----BEGIN PUBLIC KEY...END PUBLIC KEY-----\r\n" - 9
}], - 10
"authentication": [ - 11
"did:example:123456789abcdefghi#keys-1", - 12
], - 13
"service": [{ - 14
"id": "did:example:123456789abcdefghi#agent", - 15
"type": "AgentService", - 16
"serviceEndpoint": "https://agent.example.com/8377464" - 17
}] - 18
}
|
DID specifications assure the interoperability across the DID schemes in order to interact and resolve a DID from any storage system. Nonetheless, Peer DIDs implementations are used in peer-to-peer connections that do not require any storage system, in which each peer stores and maintains their own list of DID documents [
49].
Decentralised Identifiers Communication Protocol
Hyperledger Aries is an open-source project [
28], that uses decentralised identifiers to provide a public key infrastructure for a set of privacy-enhancing attribute-based credential protocols [
34]. Hyperledger Aries implements DID Communication (DIDComm) [
37], a communication protocol similar to one first outlined by David Chaum [
50]. DIDComm is an asynchronous encrypted communication protocol that uses information from the DID document, such as the public key and their associated endpoint, in order to exchange secure messages; the authenticity and integrity of the messages are verifiable. DIDComm protocol is actively developed by the Decentralised Identity Foundation [
51].
An example using the DIDComm protocol can be seen in Algorithm 1, in which Alice and Bob want to communicate securely and privately. Alice encrypts and signs a message for Bob. Alice’s endpoint sends the signature and the encrypted message to Bob’s endpoint. Bob can verify the message’s integrity by resolving the DID and checking if it corresponds to Alice’s public key, decrypt and read the message. All the associated information required for this interaction are defined in each person’s respective DID document. The encryption techniques used by DIDComm include ElGamal [
52], RSA [
53] and elliptic curve-based [
54].
| Algorithm 1 DID Communication Between Alice and Bob [27] |
- 1:
Alice has a private key and a DID Document for Bob containing an endpoint () and a public key (). - 2:
Bob has a private key (), and a DID Document for Alice containing her public key (). - 3:
Alice encrypts plaintext message (m) using and creates an encrypted message (). - 4:
Alice signs using her private key () and creates a signature (). - 5:
Alice sends to . - 6:
Bob receives the message from Alice at . - 7:
Bob verifies using Alice’s public key - 8:
if Verify then - 9:
Bob decrypts using . - 10:
Bob reads the plaintext message (m) sent by Alice - 11:
end if
|
2.3. Verifiable Credentials
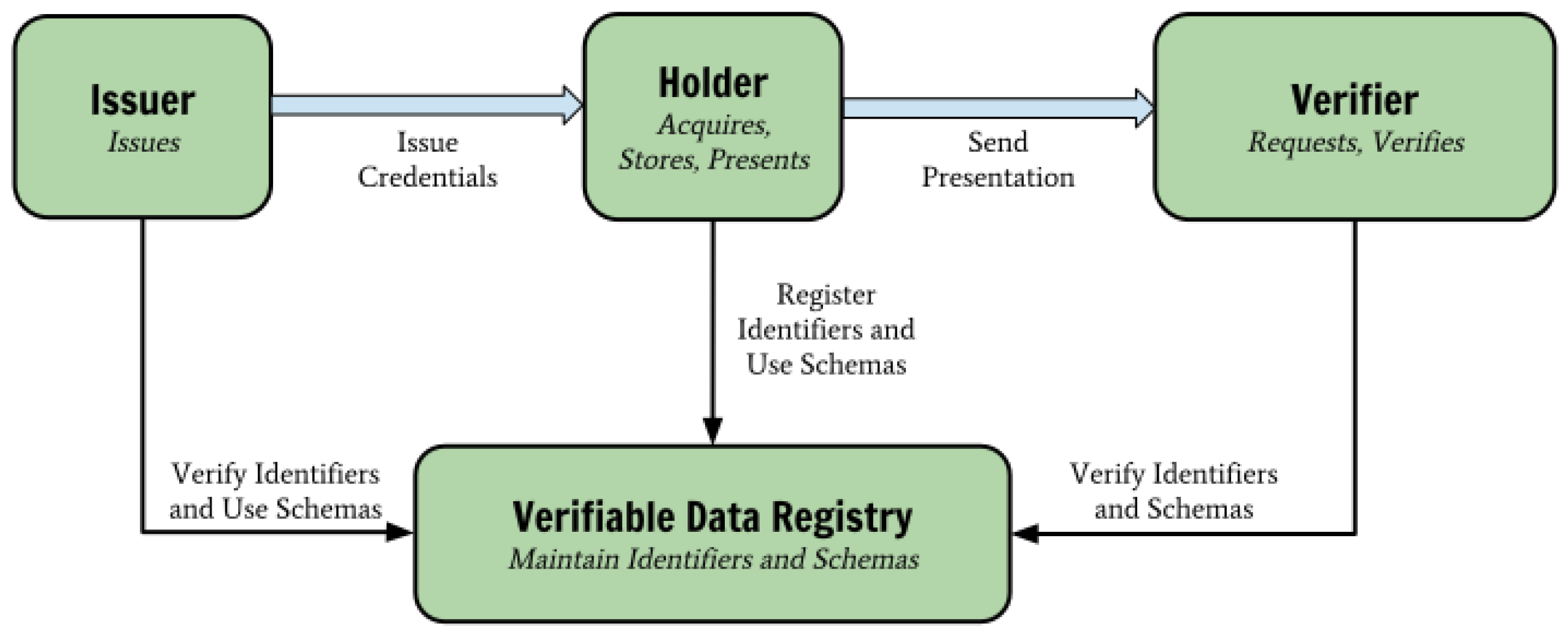
Verifiable Credentials (VCs) [
36], is a set of tamper-proof claims that used by three different entities,
Issuers,
Holders and
Verifiers, as it can be seen in
Figure 1. VC model specification became a W3C standard in November 2019. A distributed ledger is often used for the storage of the credential schemes, DIDs, and Issuers’ DID documents.
The Issuer to create a new credential needs to generate a signature using their private key corresponded to their public key defined in their DID document. There are three valid categories of signature schemes such as Camenisch-Lysyanskaya (CL) signatures [
33,
55], Linked Data signatures [
56] and JSON Web signatures [
57]. Hyperledger Aries uses CL signatures to create a blinded link secret, in which credentials are tied to their intended entities by including a private number within them, without the Issuers be aware of their values. It is a production implementation of a cryptographic system for achieving security without authentication first outlined in 1985 [
58].
The Verifier in order to accept the received credential from its Holder needs to confirm the following:
The Issuer’s DID can be resolved to a DID document stored on the public ledger. The DID document contains the public key that can be used to ensure the credential’s integrity.
The credential Holder can prove the blinded linked secret by creating a zero-knowledge proof to demonstrate it.
The issuing DID has the authority to issue this kind of credential. The signature solely proves integrity, but if the Verifier accepts credentials from any Issuers, it would be prone to obtain fraudulent credentials. It is possible to form a legal document outlining the operating parameters of the ecosystem [
59].
The Issuer has not revoked the presented credential. This is done by checking that a revocation identifier for the credential is not present within a revocation registry (a cryptographic accumulator [
60]) stored on the public ledger.
Finally, the Verifier needs to check that the credential attributes meet authorisation criteria in the system. It is common for a credential attribute to be valid only for a certain period.
All the communication between the participating entities transmits peer-to-peer through a DIDComm protocol. It should be noted that a Verifier does not require to contact the credential’s Issuer to verify a credential.
2.4. Docker Containers
All the participating entities presented in our work, take the form of Docker containers [
61]. Docker containers are lightweight, autonomous, virtualised systems similar to virtual machines [
62]. The main difference between virtual machines is that Docker containers use the host’s underlying operating system and bridge the network traffic in a virtual network card instead of being fully isolated. Moreover, Docker containers are being developed into deployable images that are executed and operate as expected invariably in any system that supports the Docker environment. Hence, applications that could be built using Docker containers are favourable for reproducibility and code replication purposes. However, since Docker containers use a virtual network card in their host machine’s to redirect the network traffic, a security testing in their ecosystem varies [
63].
2.5. Federated Machine Learning
FL can be expressed as the decentralisation of the ML. Opposed to centralised ML, in a FL scenario, the training data remain at their respective owners instead of transmitting to a central location to be used by a ML practitioner. There are several FL variations such as Vanilla FL, Trusted Model Aggregator, and Secure Multi-Party Aggregation [
10,
20,
27,
64]. Consequently, the ML model is primarily distributed among the data holders, who train it using their private data, and then send it back to the ML model owner. ML training decentralisation permits data holders with sensitive data such as healthcare institutions to train useful ML algorithms to predict a cure or a disease. One of the FL advancements, namely Secure Multi-Party Aggregation, developed to further enhance the system’s security by encrypting the models into multiple shares and aggregating all the trained models to eliminate the possibility of a malicious ML model owner [
17,
65].
To measure the accuracy of FL algorithm is similar to the traditional ML. Four metrics described in the list below [
66,
67], are used for the calculation as follows:
True positive (TP): the model correctly predicts the positive prediction; correct
True negative (TN): the model correctly predicts the negative prediction; correct
False positive (FP): the model incorrectly predicts the positive prediction; false
False negative (FN): the model incorrectly predicts the negative prediction; false
The accuracy of the model is calculated from the number of
TPs and
TNs, divided by the total number of outcomes, as you can see in Equation (
1).
2.6. Attacks on Federated Learning
Since that in FL, data never leaves their owners’ premises, one could naively assume that FL is entirely protected against misuses. However, even if FL is more secure than traditional ML approaches, it is still susceptible to several privacy attacks that aim to identify the underlying training data or trigger a miss-classification on the final trained model [
10,
68].
Model Inversion attack [
18,
19,
69], is the first of its kind that aim to reconstruct the training data. A potential attacker with access to the target labels can query the final trained model and exploit the returned classification scores to reconstruct the rest of the data.
In Membership Inference attacks [
22,
23], the attacker tries to identify if some data was part of the training. As with model inversion attacks, the attacker exploits the returned classification scores in order to create several
shadow models that have similar classification boundaries as the original model under attack.
In Model Encoding attacks [
21], the attacker with white-box access to the model tries to identify the training data that have been
memorised by the model’s weights. In a black-box situation, the attacker overfits the original training model in order for it to leak part of the target labels.
From the other side, Model Stealing attacks [
70], present the scenario of a malicious participant that tries to
steal the model. Since the model is being sent to the participants for training, malicious participants can construct a second model that mimics the original model’s decision boundaries. In that scenario, the malicious participants could avoid paying usage fees to the original model’s ML experts or sell the model to third parties.
Likewise, in Model Poisoning attacks [
24,
25,
26,
71], since the malicious participants contribute to the training of the model, they are able to inject backdoor triggers to the trained model. According to [
24], a negligible number of malicious participants is able to poison a large model. Hence, the final trained model would seem legitimate to the ML experts and react maliciously only on the given backdoor trigger inputs. In that case, the malicious participant could potentially
trick the original model when certain inputs are given. Contrary to the Data Poisoning attacks [
12,
72,
73,
74,
75], in which the poison backdoor triggers are part of the training data, and the ML model’s accuracy may drop [
76].
In Adversarial Examples [
77,
78,
79,
80,
81,
82], the attacker tries to
trick the model in order to classify falsely a prediction. The threat model for this type of attacks is both white-box and black-box; thus the attacker does not require access to the training procedure, with a potential attacking scenario to be a malware that evades the detection of a ML intrusion detection system.
2.7. Defensive Methods and Techniques
Due to the sensitivity of the underlying training data in ML, there are several defensive techniques, albeit several of them are still in the theoretical stage and therefore are not applicable [
10,
27].
2.7.1. Differential Privacy
The most eminent defensive countermeasure against many privacy attacks in ML is Differential Privacy (DP), a mathematical guarantee that ensures the ML algorithm’s output, despite if a particular person’s data used for the training procedure [
83,
84]. The formal mathematical proof can be seen in Equation (
2), where the probability
A for all
C that are in range (
A), is differentially private, if for any two adjusted databases
D and
D’ that alter in only one element exists:
DP elaborates noise techniques to protect a ML algorithm from attacks; however, its accuracy drops significantly according to the designated privacy level [
85]. Researchers, further extended and relaxed this mathematical proof into (
,
)-DP, which introduced an extra
feature that limits the probability for errors [
85,
86,
87,
88].
2.7.2. Secure Multi-Party Computation
Secure Multi-Party Computation (SMPC) [
89], is a cryptographic function that allows several participants to compute a procedure mutually, such a ML training procedure. Only the outcome of the function is disclosed to the participating parties and not the underlying training information. Using SMPC, gradients and parameters can be computed and updated encrypted in a decentralised manner. In this case, each data item’s custody is split into shares to be held by relevant participating entities. SMPC is able to protect ML algorithms against privacy attacks that target the training procedure; however, attacks during the testing phase are still viable.
2.7.3. Homomorphic Encryption
Homomorphic Encryption (HE) [
90], is a complex cryptographic protocol, which allows the mathematical computation of encrypted data. The outcome of the computation is still encrypted. HE is a promising method to protect both the training and testing procedures; however, such an intensive technique’s high computational cost is not tolerable in real-world situations. Several HE schemes in the literature propose alterations and evaluations of the method [
10,
91,
92,
93,
94].
2.8. Related Work
Our work is not another defensive method or technique that mitigates the aforementioned FL attacks, as seen in
Section 2.6. Hence, a comparison with defensive techniques such as Knowledge Distillation [
95,
96], Anomaly Detection [
21], Privacy Engineering [
97], Privacy-Preserving Record Linkage [
98], Adversarial Training [
99], ANTIDOTE [
100], Activation Clustering [
101], Fine-pruning [
102], STRIP [
103], or similar, is not comparable and out of the scope of this paper.
The concern related to the privacy of the stored data has been extensively researched in the literature. Many researchers proposed and presented novel infrastructures and concepts that could partially or fully protect data. However, the privacy-preservation of critical data such as medical records often is more important than the actual procedure that it has been used, such as the training of a ML algorithm. There are works that presented the use of another emerging technology such as blockchain, which could be combined with ML. In the work of [
104,
105] the authors’ presented infrastructures that could protect certain private data from the stored records and display of other non-private. However, the feasibility of performing ML in data stored in their blockchain has not been tested and remains an open question.
Another state-of-the-art technology that is similar to our work is the Private Set Intersection (PSI). Using PSI, participants of an infrastructure can compare the private records they share, without disclosing them to the other participants [
106]. There are applications that use PSI for privacy-preserving contact tracing systems and machine learning on vertically partitioned datasets [
107].
The value of developing an ecosystem and associated governance framework to facilitate the issuance and verification of integrity assured attributes had been considered previously in a different setting [
108]. This work develops user-led requirements for a staff passporting system to reduce the administrative burden placed on healthcare professionals as they interact with different services, employers and educational bodies throughout their careers. These domain-specific systems that digitally define trustworthy entities, policies and information flows have multiple use cases and appear to be a positive indication of the likelihood of broader adoption of the technologies discussed in this paper.
Achieving privacy-enhancing identity management systems has been a focus of cryptographic research since Chaum published his seminal paper in 1985 [
58]. The Hyperledger technology stack used in this work is an implementation of a set of protocols formalised by Camenisch and Lysyanskya [
33,
109] and follows a technical architecture closely aligned to the one produced as part of an EU grant ABC4Trust [
110]. Self-Sovereign Identity (SSI) has popularised the model of issuer/verifier/holder, with many different projects and implementations building to the emerging standards in this area [
111], although not all of these projects use privacy-enhancing cryptography. Furthermore, the major focus of these systems has been the identification and authentication of individuals by issuing and verifying their credentials within a certain context [
108,
112].
Our work differentiates from the other approaches since we focus on modelling trust relationships between organisations using the mental model of SSI and the technology stack under development in the Hyperledger foundation. More specifically, in our proof-of-concept, we establish trusted connections among only authorised participants and then perform FL over secure communication channels. In our previous work [
27], we presented a proof-of-concept that is able to establish trust between the participating parties and perform FL on their data. Thus, to achieve it, we used the basic messages protocol provided by Hyperledger Aries, encoded the ML model and updates into text format and sent it through DIDComm encrypted channels. However, in this paper, we have refactored this functionality into libraries that developed mutually within the OpenMined open-source community in PyDentity [
31], for that purpose. Additionally, we have thoroughly presented their communication details in
Section 3.2, and have tested their security in
Section 4.1.1.
5. Conclusions and Future Work
In this paper, we extended our previous work [
27] by merging the privacy-preserving ML field with VCs and DIDs while addressing trust concerns within the data industry. These areas focus on people’s security, privacy and especially on the protection of their sensitive data. In our work, we presented a trusted FL process for a mental health dataset distributed among hospitals. We proved that it is possible to use the established secure channels to obtain a digitally signed contract for ML training or manage pointer communications on remote data [
17].
This extension of our previous work [
27] retains the same high-level architecture of the participating entities, but the proof-of-concept is a complete refactor of our experimental setup. More specifically, as described in
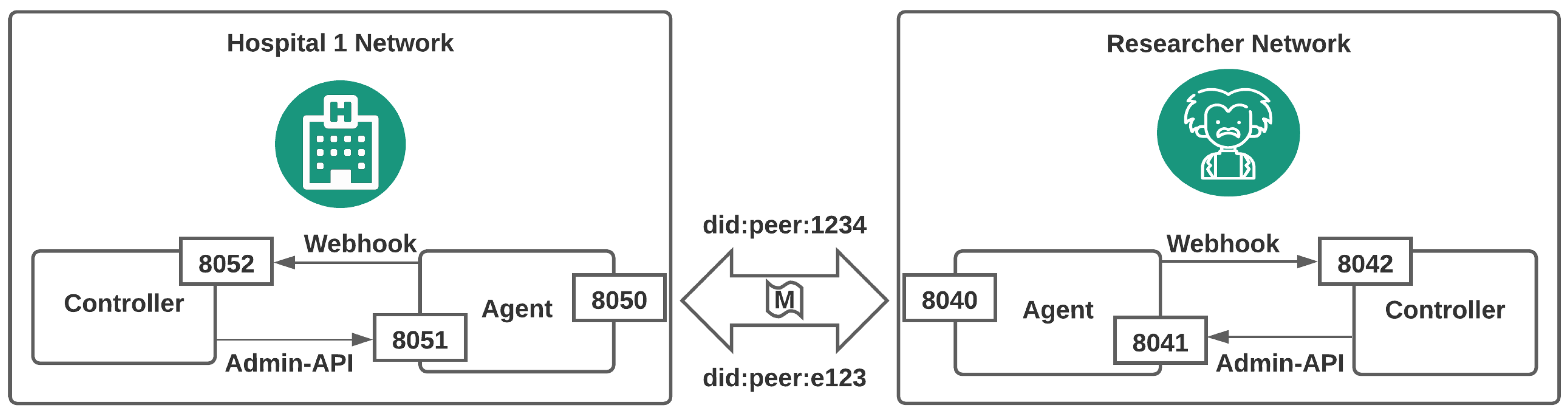
Section 4.1.1, each participant’s controller and agent entities are separated into their own isolated Docker containers. That separation is adjacent to a real-world scenario in which each controller and agent reside in different systems (
Appendix A). Furthermore, in our technical codebase, we now use our novel libraries written in Python programming language and demonstrated thoroughly using Jupyter notebooks. We further performed an extensive security and performance evaluation in each stage of our proposed infrastructure, which was lacking in our previous work, and our findings are presented in
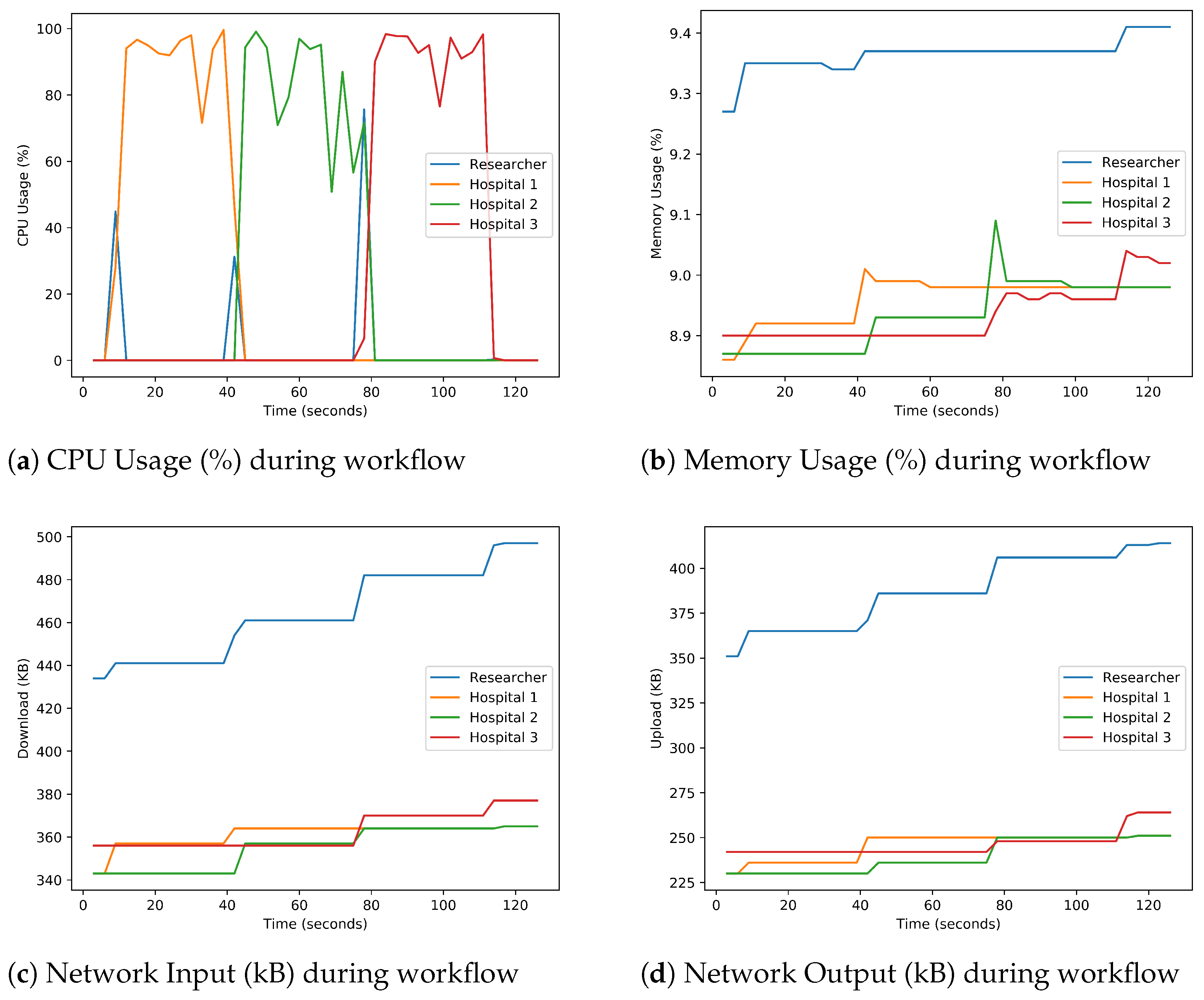
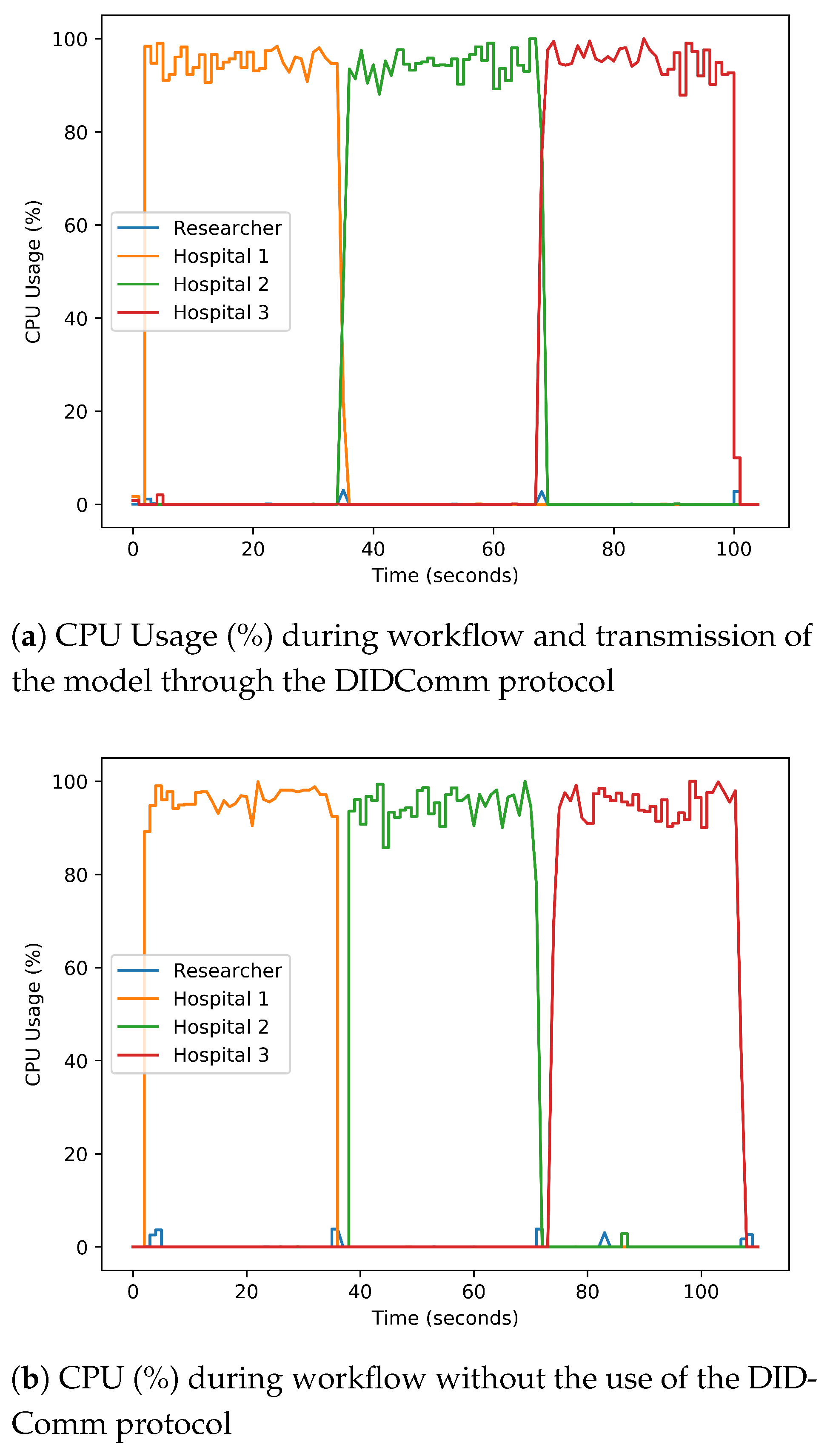
Section 4. The performance metrics identified that the performance of our trusted FL procedure and the accuracy of the ML model are similar, albeit the model is transmitted through the encrypted DIDcomm protocol. Additionally, using our designed FL libraries, the ML training process completes faster. It should be noted that there are no conflicts with other defensive methods and techniques, and they could be incorporated into our framework and libraries.
While FL is vulnerable to attacks as described in
Section 4.1, the purpose of this work is to develop a proof-of-concept for the demonstration that distributed ML can be achieved through the same encrypted communication channels used to establish domain-specific trust. We exhibited how this distributed trust framework could be used by other fields and not FL explicitly. This will allow the application of the trust framework to a wide range of privacy-preserving workflows. Additionally, it allows us to enforce trust, mitigating FL attacks using differentially private training mechanisms [
84,
85,
88]. Various techniques can be incorporated to our framework in order to train a differentially private model; such as Opacus [
127], PyDP [
128], PyVacy [
129] and LATENT [
130]. To reduce the model stealing and training data inference risks, the SMPC can be leveraged to split data and model parameters into shares [
131].
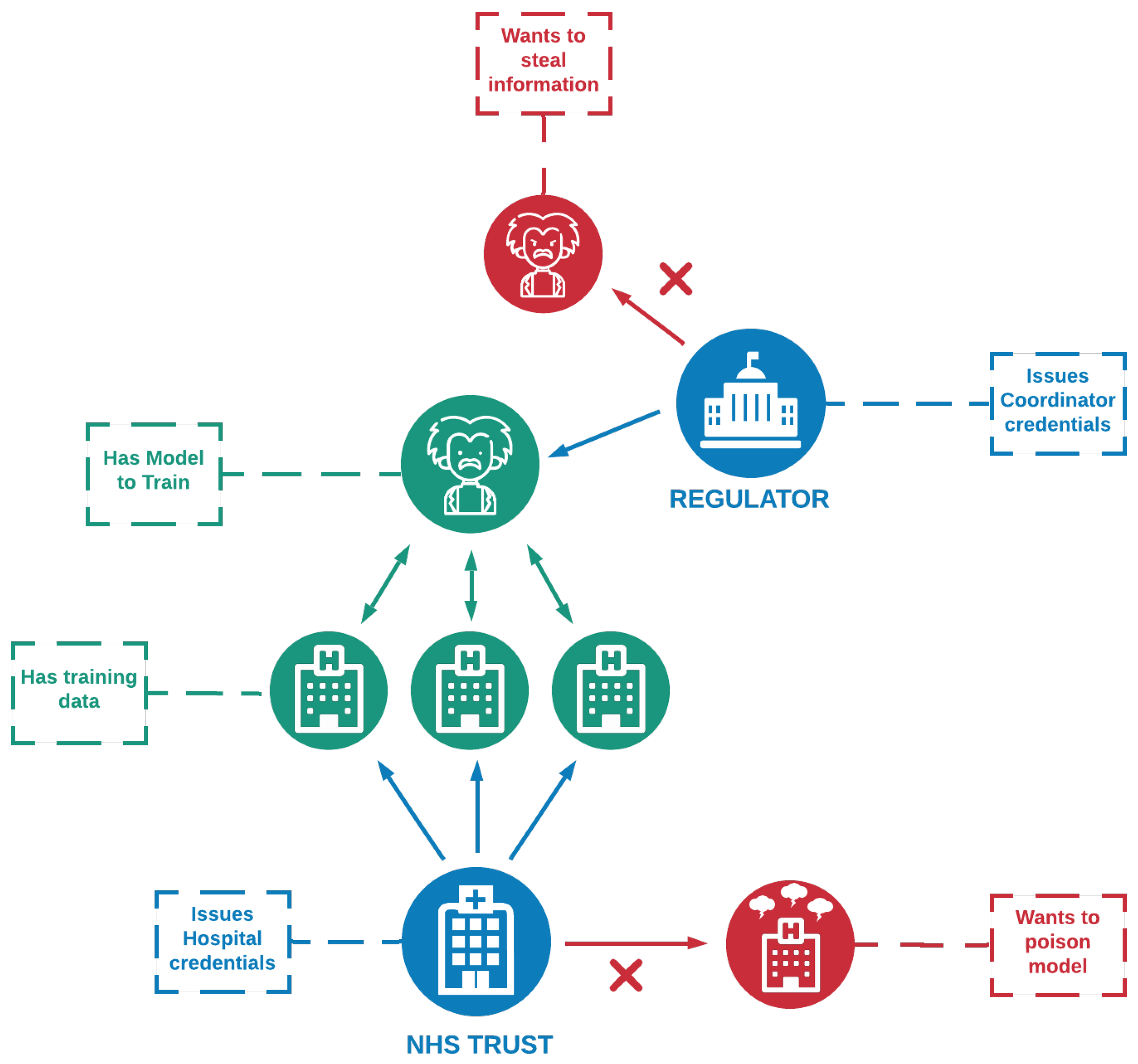
Our proof-of-concept detailed the established architecture between three hospitals, a researcher, a hospital trust and a regulatory authority. Firstly, the hospitals and the researcher need to obtain a VC from their corresponding trust or regulatory authority, and then follow a mutual authentication process in order to exchange information. Further, the researcher instantiates a basic FL procedure between only the authenticated and trusted hospitals, we refer to this process as Vanilla FL, and then transmits the ML model through the encrypted communication channels using Hyperledger Aries framework. Each hospital receives the model, trains it using their private dataset and sends it back to the researcher. The researcher validates the trained model using its validation dataset to calculate its accuracy. One of the limitations of this work is that the presented Vanilla FL process acts only as a proof-of-concept to demonstrate that FL is possible through the encrypted DIDComm channels. However, to incorporate it in a production environment, it should be extended and introduce a secure aggregator entity, placed in-between the researcher and the hospitals that would act as a mediator of the ML model and updates. In that production environment, the researcher entity would simultaneously send the ML model to all the authorised participants and not have a validation dataset. This is a crucial future improvement we need to undertake to help the research community further. Another potential limitation of our work is training a large-scale convolutional neural network, which left as out-of-scope, but needs to be tested.
Future work also includes integrating the Hyperledger Aries communication protocols, which enables the trust model demonstrated in this work, into an existing framework for facilitating distributed learning within the OpenMined open-source organisation such as PySyft, Duet and PyGrid [
17,
132,
133]. Our focus is to extend the Hyperledger Aries functionalities, the libraries designed for ML communication, and distribute this framework as open-source to the academic and industrial community on the PyDentity project [
31]. We hope that our work can motivate more people to work on the same subject. Additionally, our scope is to incorporate and evaluate further PPML techniques to create a fully trusted and secure environment for ML computations.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}