
Templated Text Synthesis for Expert-Guided Multi-Label Extraction from Radiology Reports

 , , , , and
, , , , and
Abstract
:1. Introduction
- Building on our work in [3], we propose to use templates to strategically augment the training dataset with rare cases obtained from a medical knowledge graph and with difficult cases obtained from rules created by human experts during the course of manual annotation, enabling expert-guided learning via text data synthesis.
- We analyse the impact of the vocabulary arising from domain-specific pre-training of BERT, and show why this improves accuracy.
- We perform extensive validation of our methods, including a prospective validation on data which was unseen at the point of annotating the training dataset, and show that our methods enable improved generalisation and a convenient mechanism for adaptation.
2. Related Work
2.1. Radiology Report Labelling
2.2. Pre-Training for Text Deep Learning Models
2.3. Text Data Synthesis
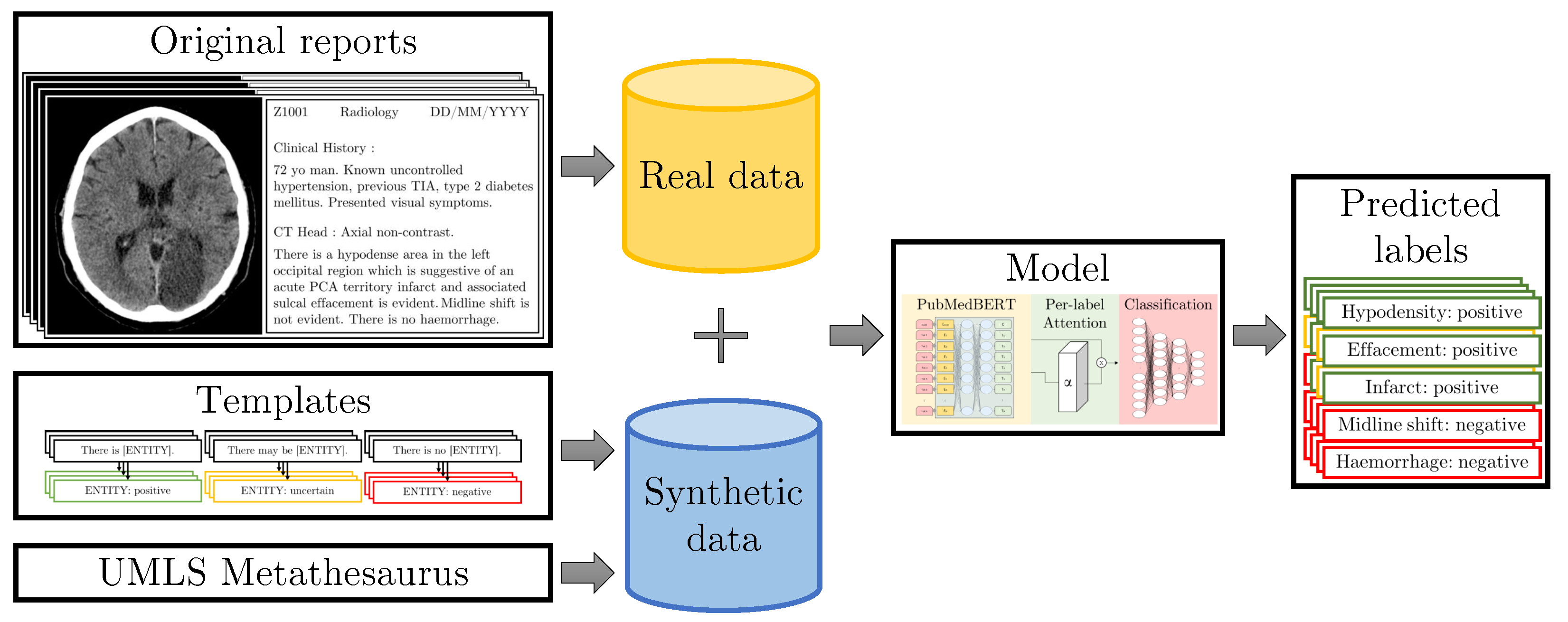
3. Materials and Methods
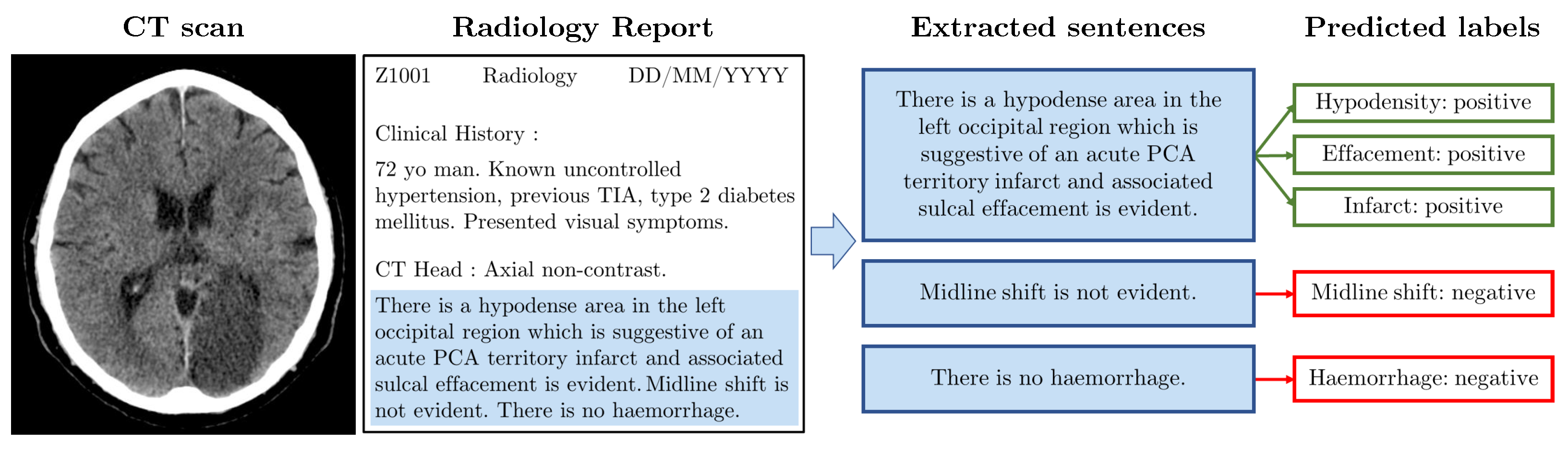
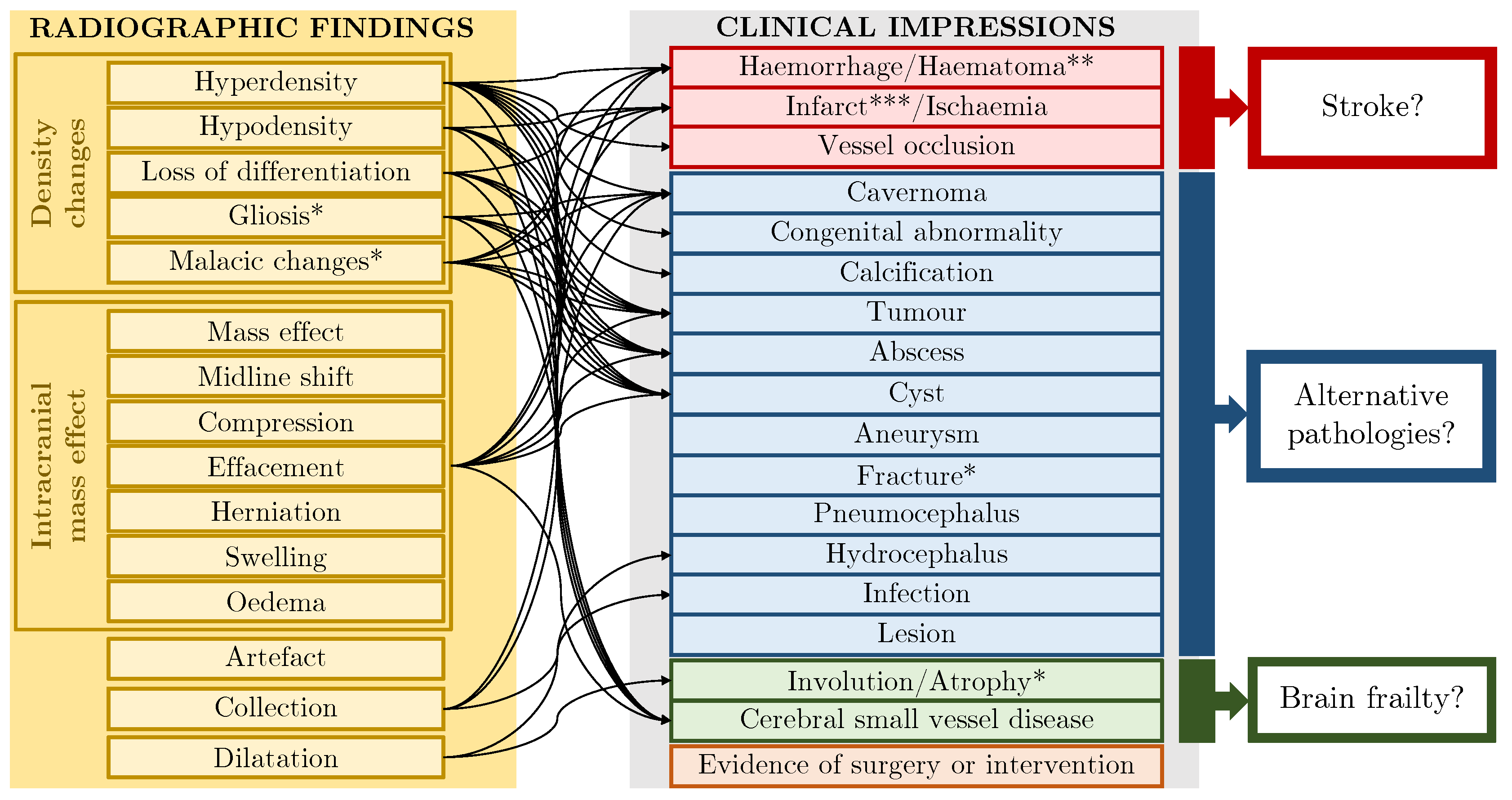
3.1. NHS GGC Dataset
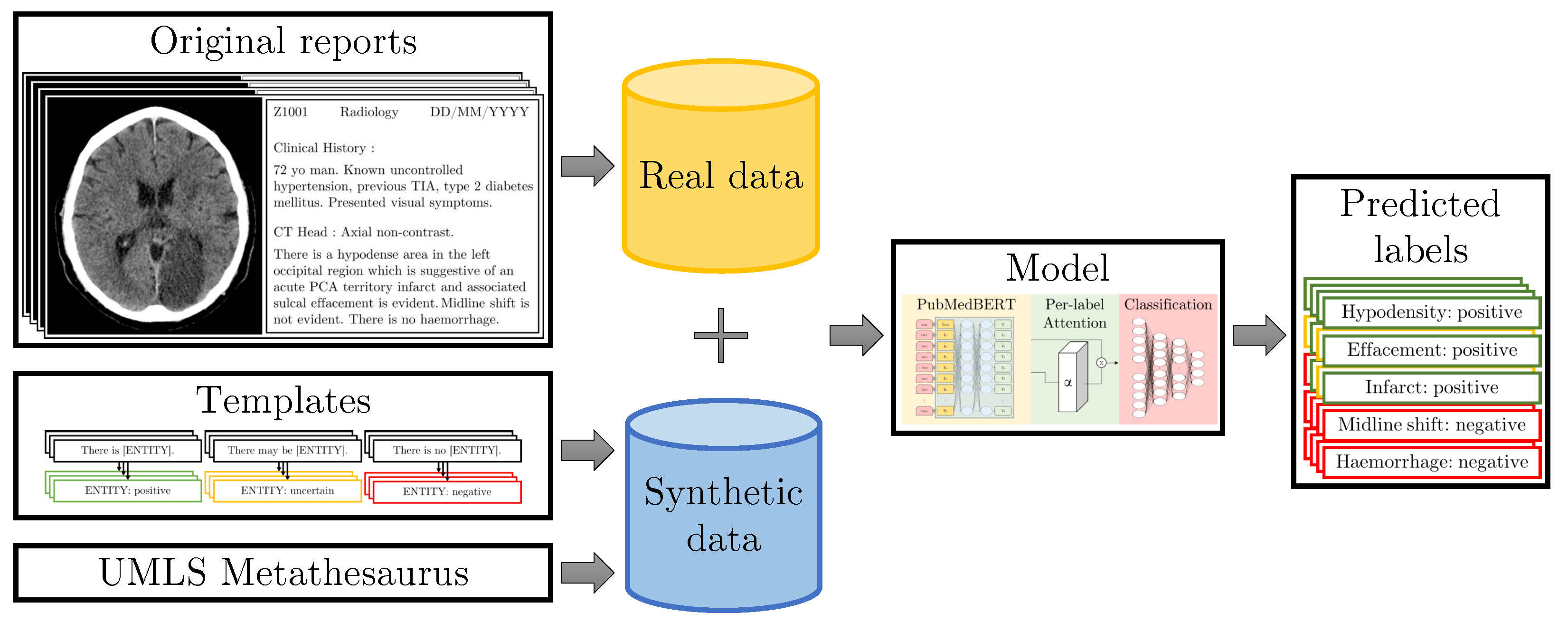
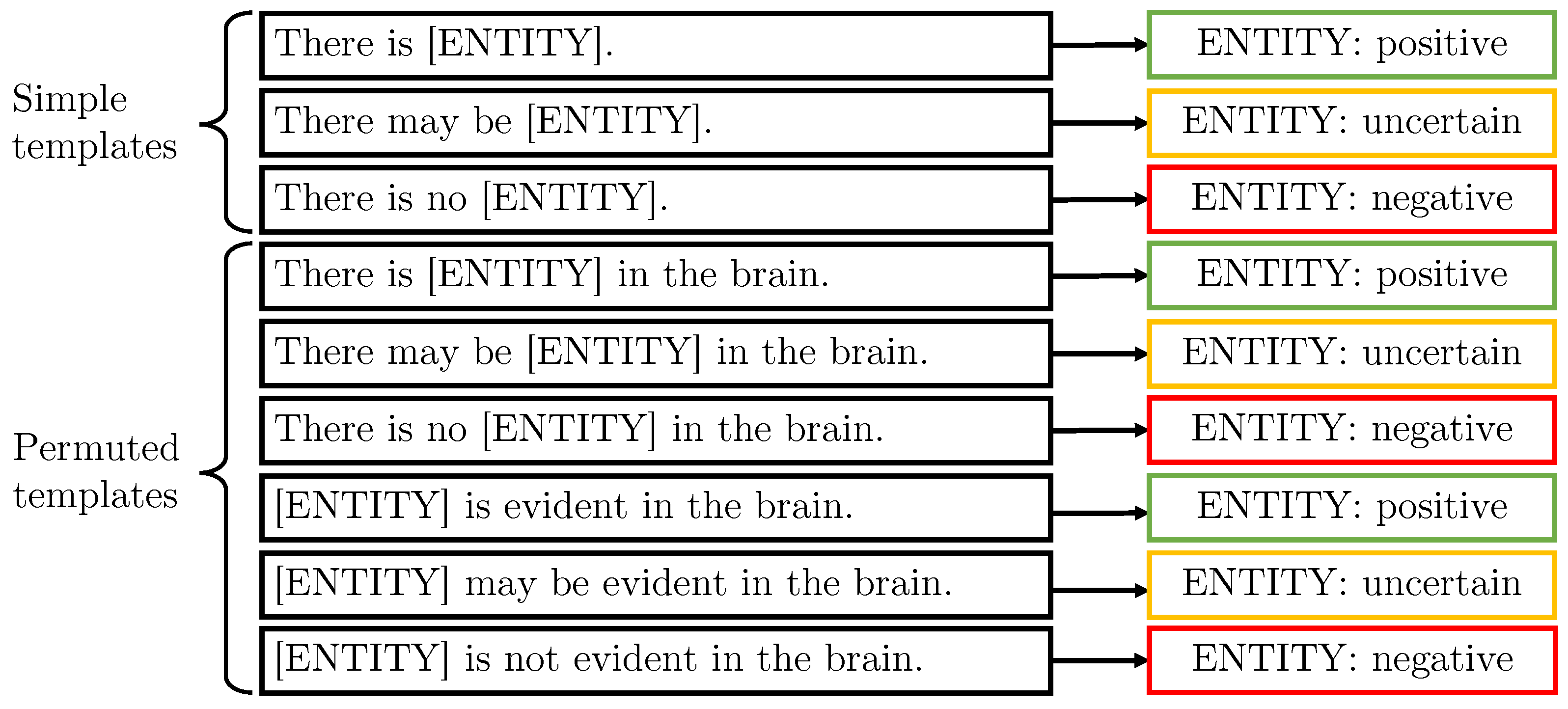
3.2. Templates for Text Data Synthesis
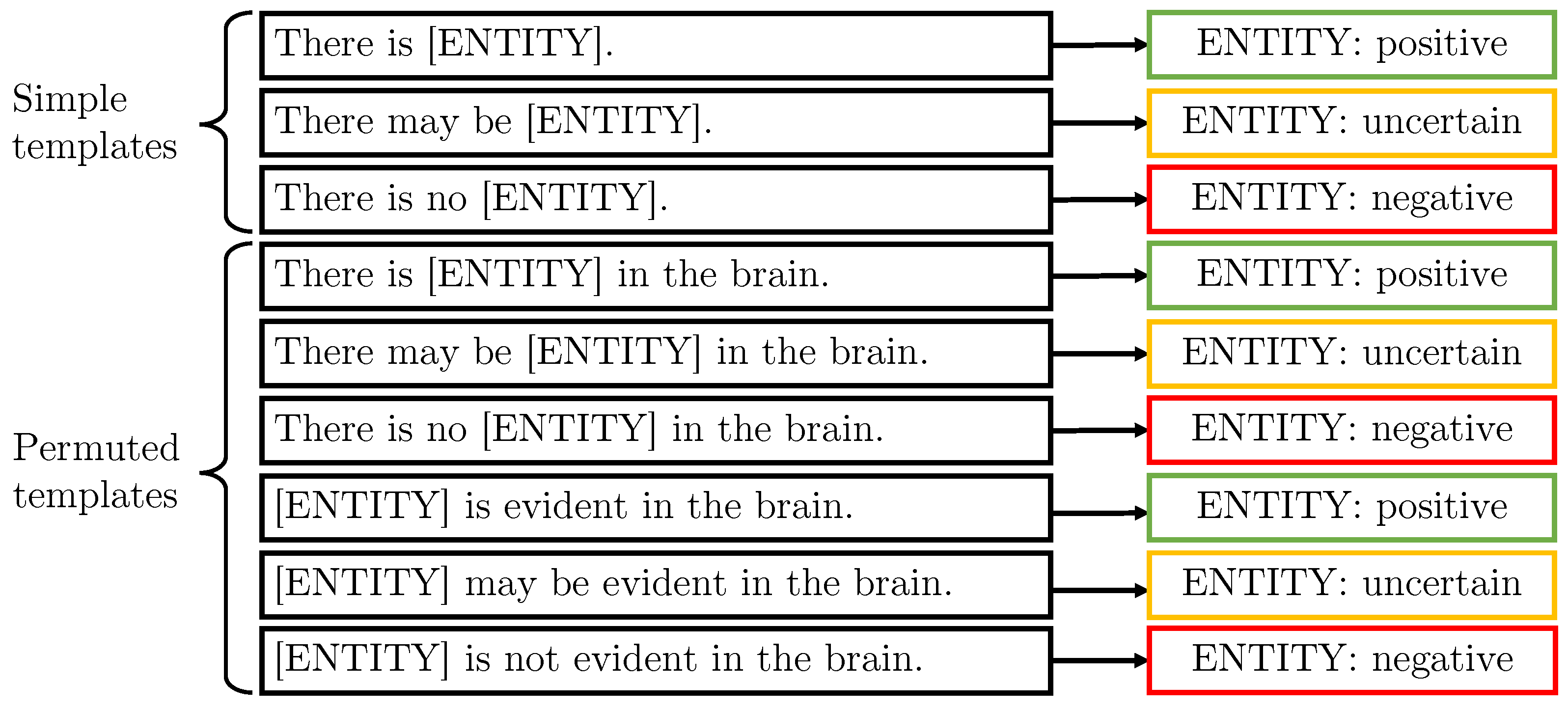
3.2.1. Generic Templates
3.2.2. Combining Templates
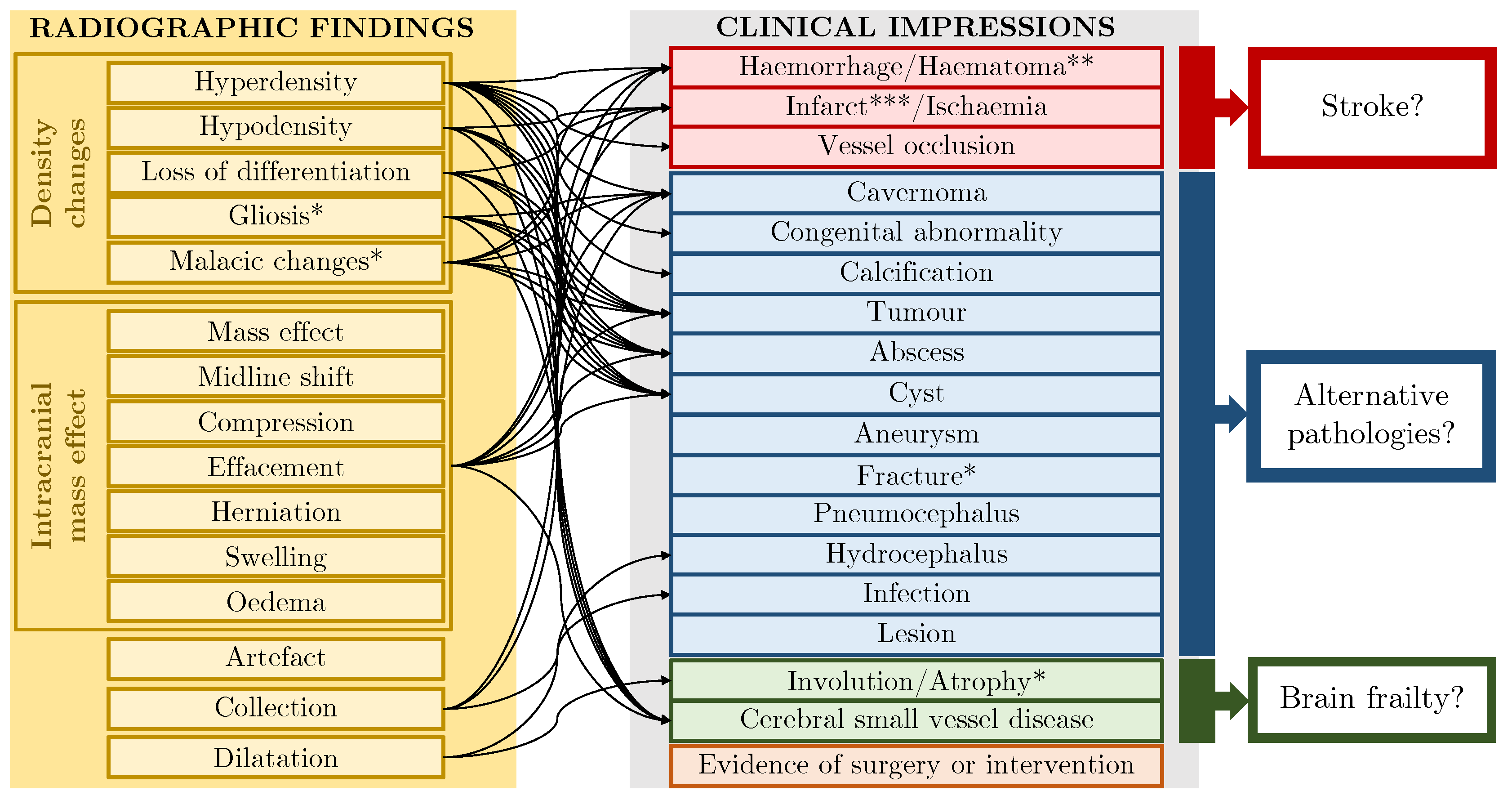
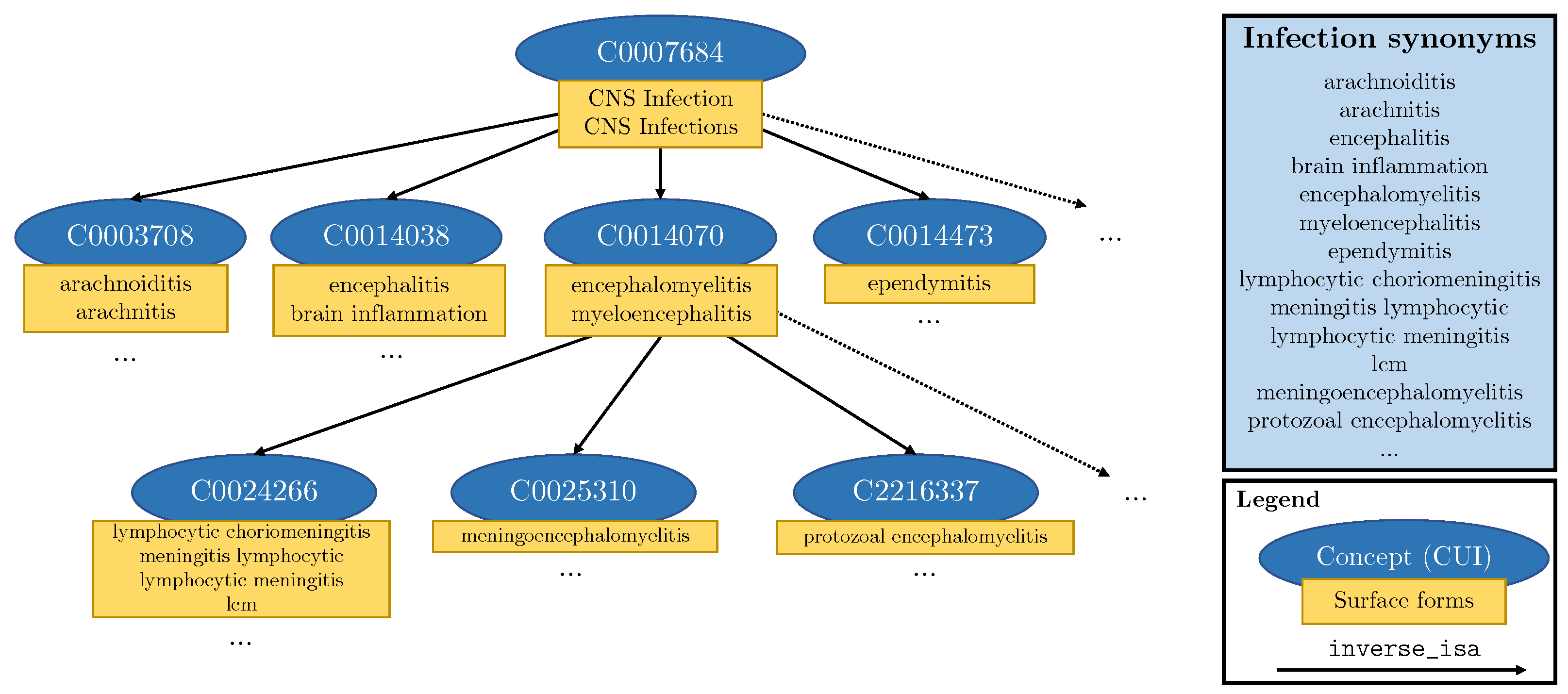
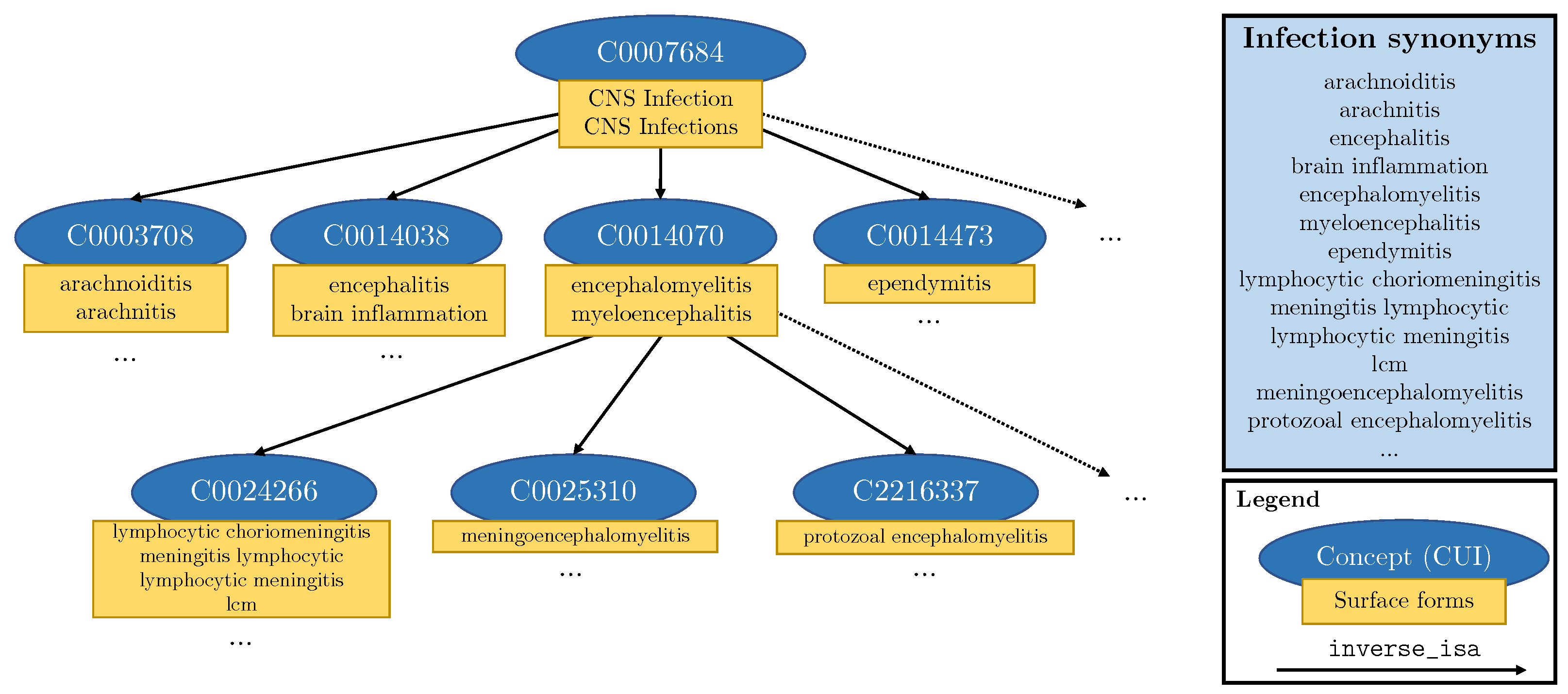
3.2.3. Knowledge Injection into Templates
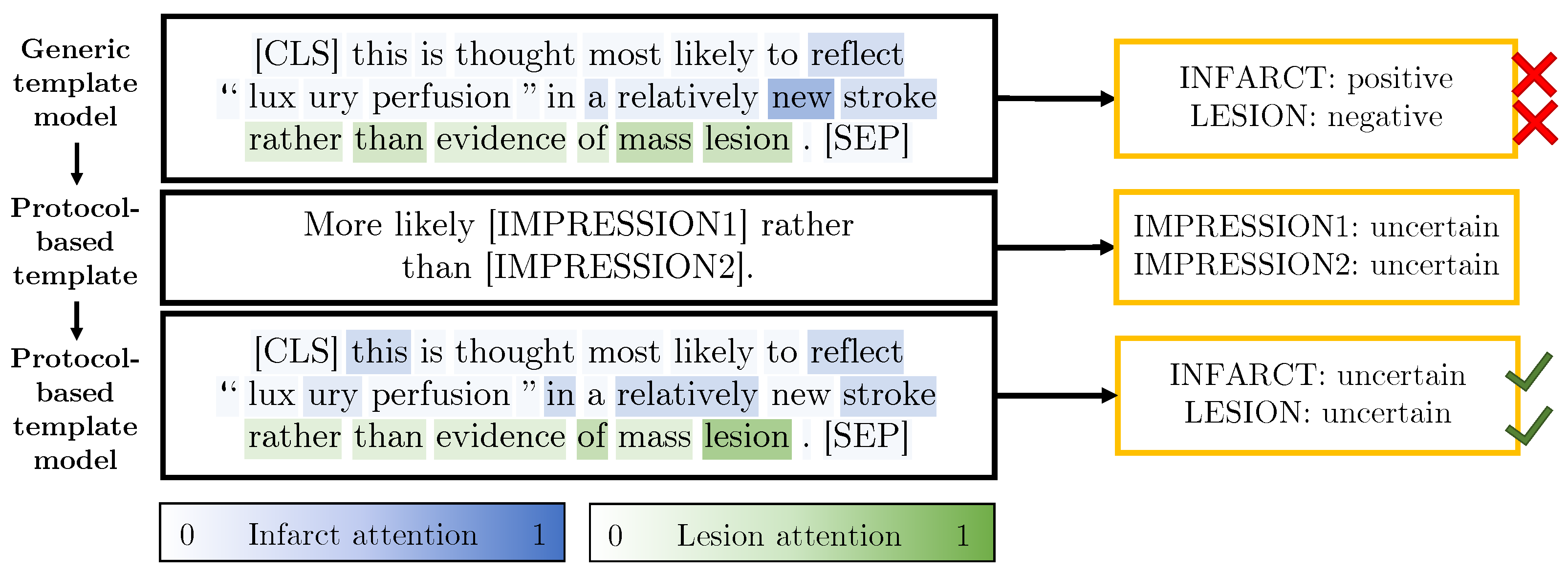
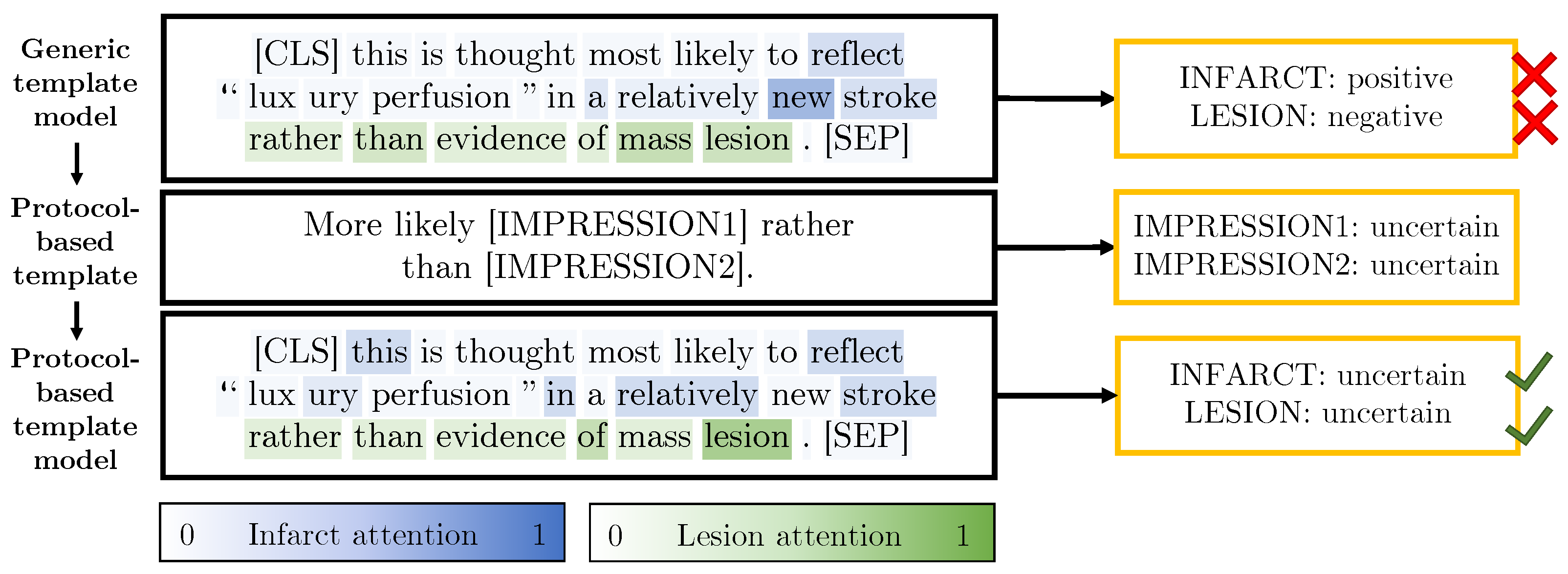
3.2.4. Protocol-Derived Templates
3.2.5. Synthetic Dataset Summary
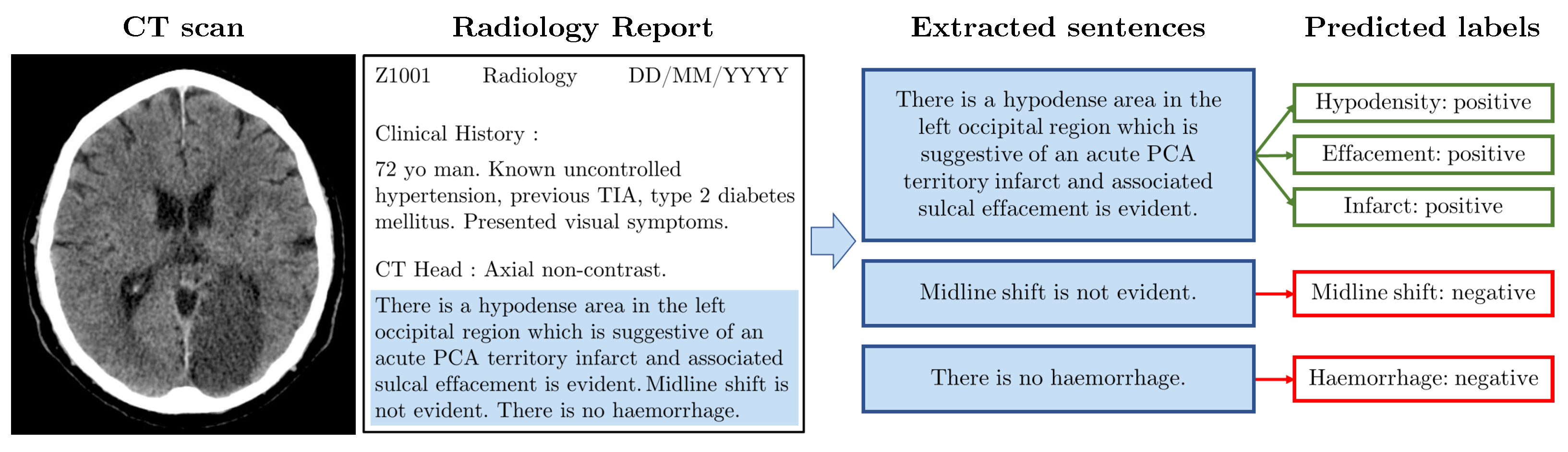
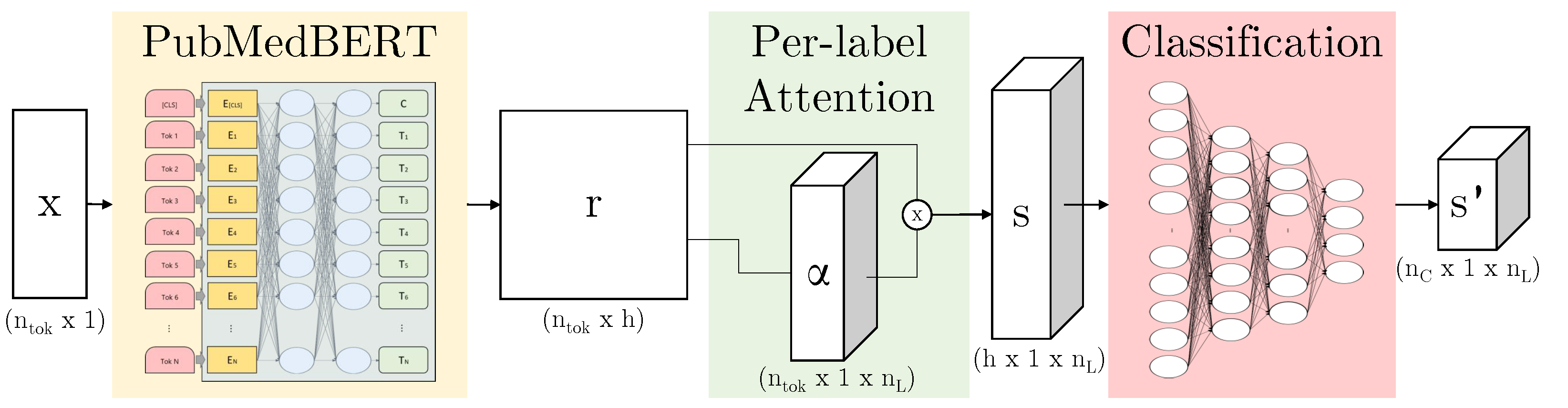
3.3. Models
3.3.1. BERT Pre-Training Variants
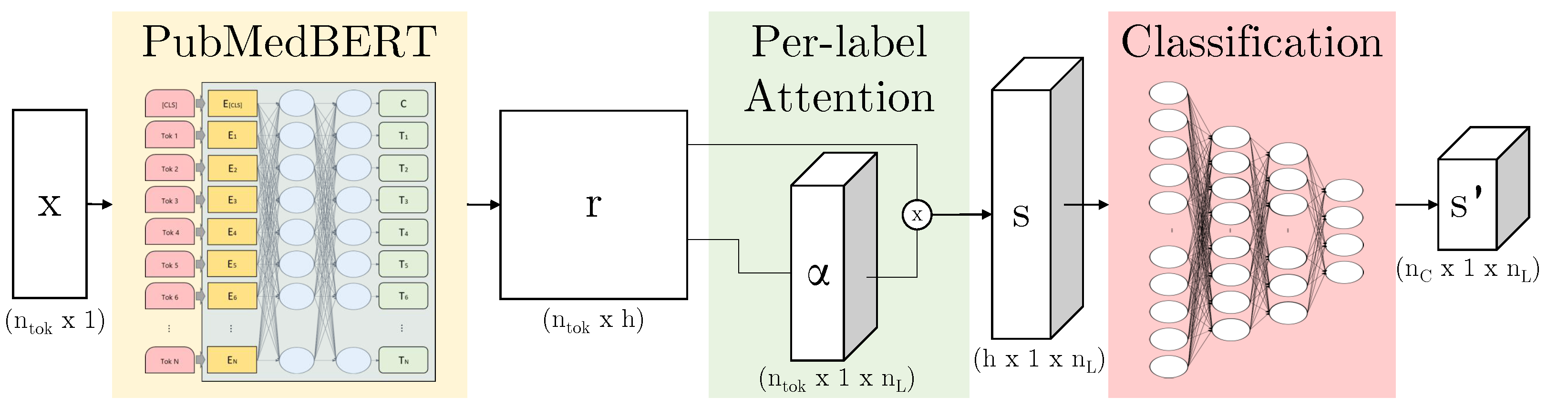
3.3.2. ALARM-Based Models
4. Results
4.1. What Impact Does the Pre-Training Dataset Have on Task Accuracy?
4.2. What Impact Does Data Synthesis Have on Task Accuracy?
4.3. What Impact Does Data Synthesis Have on Task Accuracy for Prospective Data?
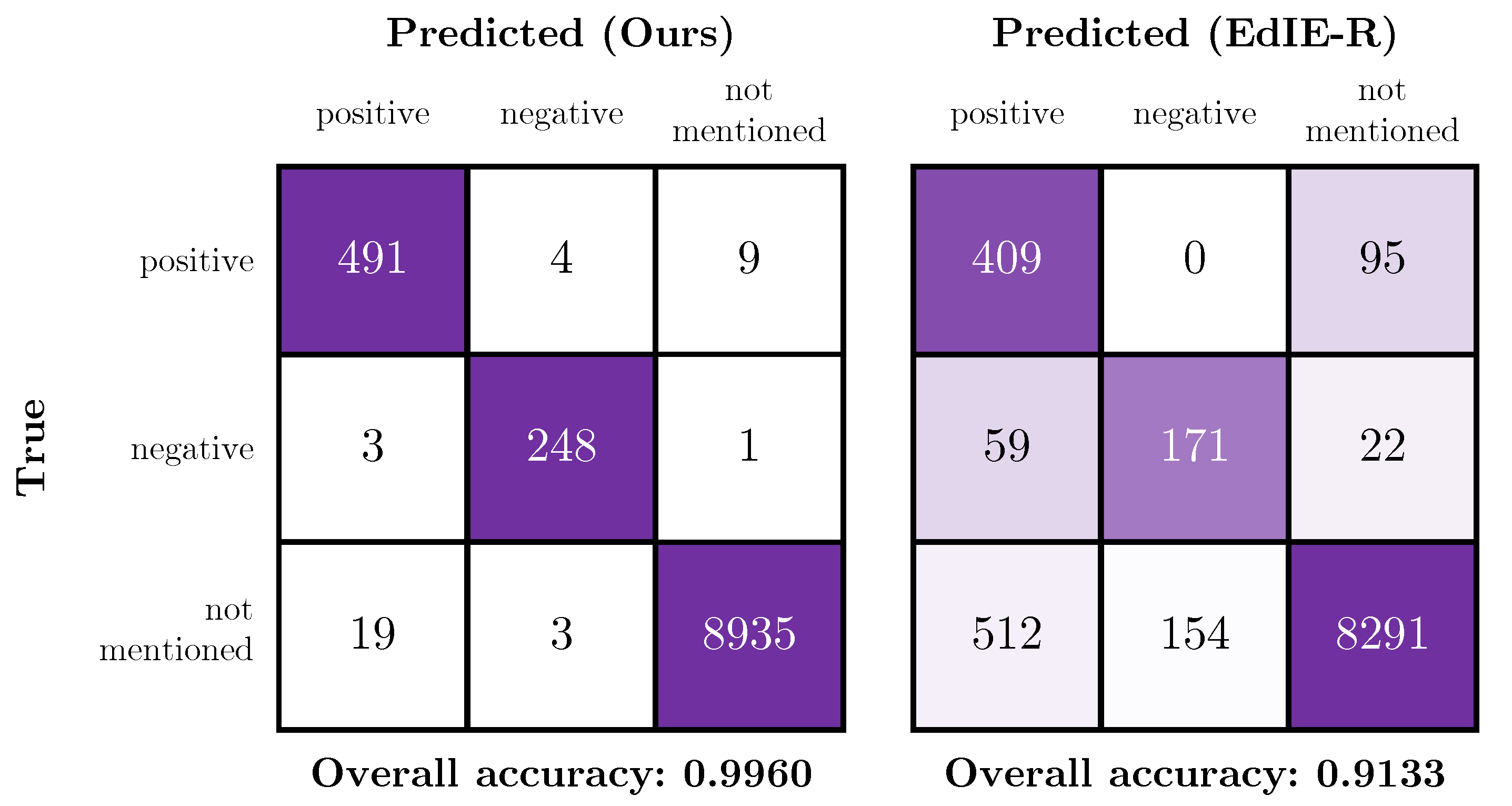
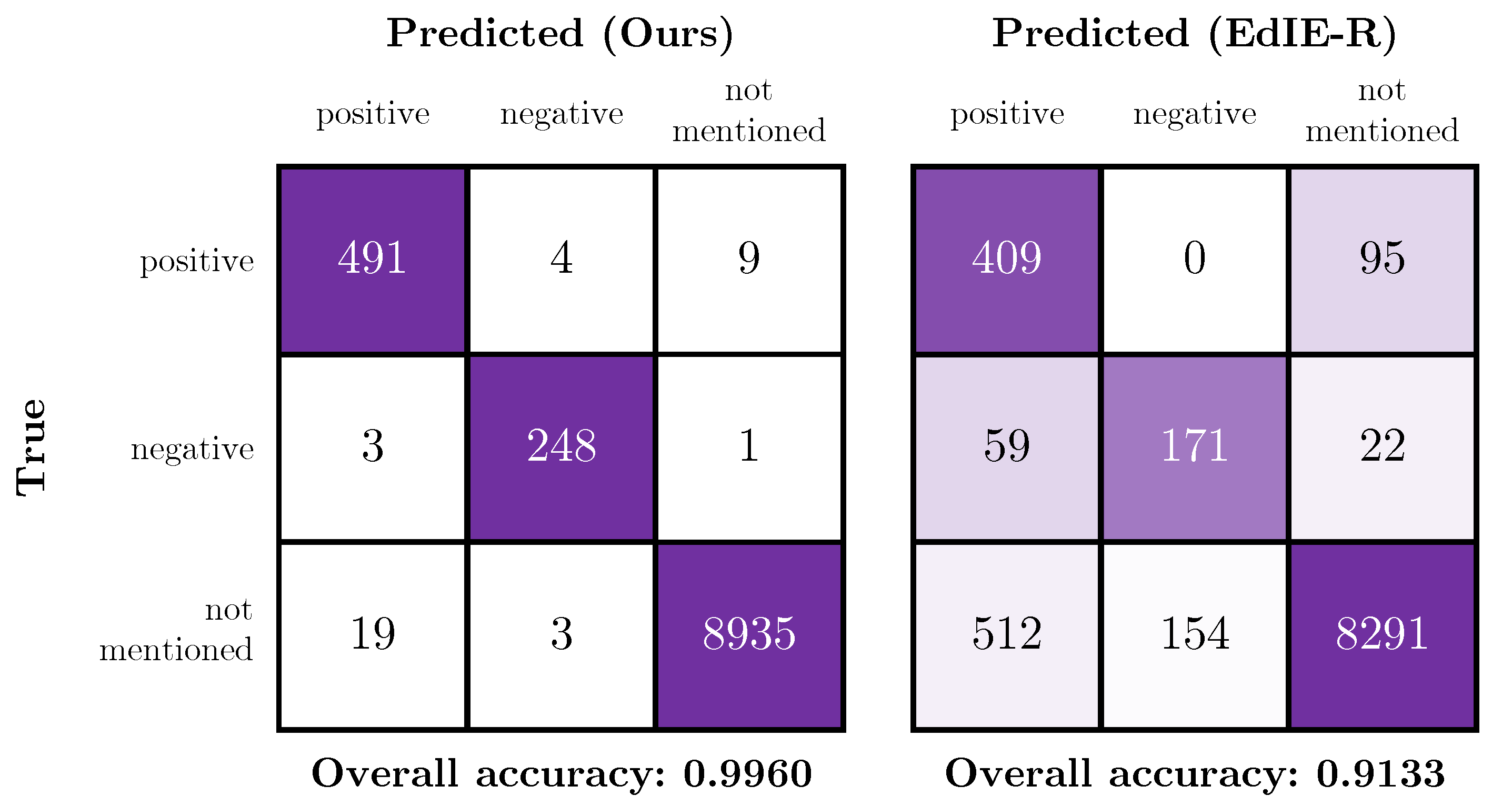
4.4. Comparison of the Proposed Method with a Rules-Based System
5. Discussion
5.1. Difference in Accuracy between Phase 1 and Phase 2 Test Data
5.2. Limitations of the Comparison with EdIE-R
5.3. Synthetic Data Distribution
5.4. Utilising Templates in an Online Learning Setting
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ALARM | automated labelling using an attention model for radiology reports of MRI scans |
| BERT | bidirectional encoder representations from transformers |
| BioBERT | bidirectional encoder representations from transformers for biomedical text mining |
| CAML | convolutional attention for multi-label classification |
| CNS | central nervous system |
| CPU | central processing unit |
| CSVD | cerebral small vessel disease |
| CT | computed tomography |
| CUI | concept unique identifier |
| EdiE-R | Edinburgh information extraction for radiology reports |
| GGC | Greater Glasgow and Clyde |
| GHz | giga hertz |
| GPU | graphics processing unit |
| iCAIRD | Industrial Centre for AI Research in digital Diagnostics |
| MIMIC | medical information mart for intensive care |
| NHS | national health service |
| NLI | natural language inference |
| NLP | natural language processing |
| NLTK | natural language toolkit |
| OOV | out of vocabulary |
| PubMedBERT | bidirectional encoder representations from transformers pre-trained using PubMed |
| RSNA | Radiological Society of North America |
| UKRI | United Kingdom Research and Innovation |
| UMLS | unified medical language system |
| VRAM | video random access memory |
Appendix A. Training and Inference Times

{kind=link}
{kind=link}
{kind=link}
{kind=link}
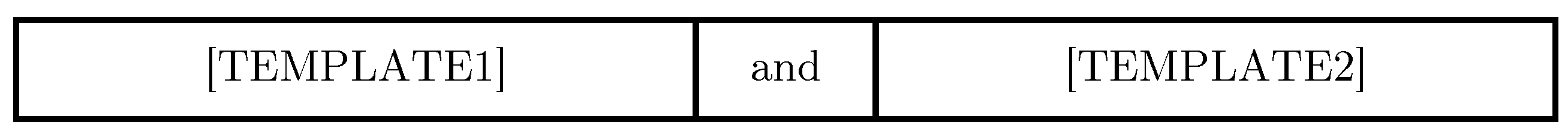{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training | Inference Time | |||
|---|---|---|---|---|
| Model Architecture | Pre-Trained Weights | # Parameters | Time [s] | [s/sample] |
| BERT | BERT [4] | 109,586,824 | ||
| BERT | BioBERT [20] | 108,414,856 | ||
| BERT | PubMedBERT [9] | 109,586,824 | ||
| ALARM + per-label attention | BERT | 127,985,800 | ||
| ALARM + per-label attention | BioBERT | 126,813,832 | ||
| ALARM + per-label attention | PubMedBERT | 127,985,800 |
Appendix B. Label Details
| Train | Validation | Ind. Test | Prosp. Test | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Finding | + | ? | − | + | ? | − | + | ? | − | + | ? | − |
| Hypodensity | 164 | - | - | 91 | - | - | 358 | 9 | - | 143 | 4 | - |
| Hyperdensity | 35 | 3 | 5 | 23 | 1 | 1 | 85 | 9 | 11 | 45 | 5 | 5 |
| Dilatation | 33 | 8 | - | 13 | 2 | 1 | 48 | 16 | - | 32 | - | 1 |
| Collection | 13 | - | 26 | 4 | 1 | 14 | 14 | 2 | 43 | 11 | 1 | 31 |
| Mass effect | 24 | - | 11 | 12 | 1 | 13 | 60 | 1 | 39 | 35 | - | 20 |
| Midline shift | 21 | - | 13 | 8 | - | 10 | 52 | - | 39 | 19 | - | 21 |
| Effacement | 28 | 1 | 1 | 11 | - | - | 52 | - | 4 | 21 | - | - |
| Herniation | 16 | - | 4 | 2 | - | 3 | 23 | - | 16 | 11 | 2 | 4 |
| Loss of differentiation | 14 | - | 6 | 7 | 1 | - | 41 | 1 | 4 | 13 | - | 3 |
| Compression | 11 | - | - | 7 | - | 1 | 16 | - | 2 | 5 | - | 2 |
| Oedema | 10 | - | - | 12 | - | - | 35 | 3 | 4 | 11 | 3 | 4 |
| Artefact | 6 | - | - | 2 | - | - | 16 | 2 | - | 18 | 1 | - |
| Swelling | 2 | - | - | 1 | - | - | 7 | - | - | 7 | - | - |
| Malacic changes | 2 | - | - | - | - | - | 15 | - | - | 18 | - | - |
| Gliosis | 2 | - | - | - | - | - | 14 | - | 1 | 5 | - | - |
| Train | Validation | Ind. Test | Prosp. Test | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Impression | + | ? | − | + | ? | − | + | ? | − | + | ? | − |
| Haemorrhage/Haematoma | 160 | 7 | 136 | 97 | 7 | 74 | 338 | 20 | 289 | 116 | 8 | 151 |
| Infarct/Ischaemia | 150 | 24 | 57 | 93 | 19 | 37 | 386 | 60 | 145 | 190 | 20 | 69 |
| Cerebral small vessel disease | 60 | 2 | 1 | 37 | - | 2 | 149 | 5 | 2 | 97 | - | 1 |
| Lesion | 11 | - | 47 | 1 | 1 | 35 | 8 | - | 127 | 13 | 2 | 72 |
| Involution/Atrophy | 54 | 1 | - | 50 | 2 | 3 | 129 | 1 | 1 | 69 | 1 | 1 |
| Hydrocephalus | 13 | 3 | 13 | 5 | 2 | 11 | 21 | 3 | 33 | 13 | - | 22 |
| Calcification | 18 | 1 | - | 4 | 1 | - | 24 | 1 | - | 16 | 2 | - |
| Vessel occlusion | 6 | 7 | 1 | 7 | 3 | - | 16 | 13 | - | 6 | 7 | 1 |
| Fracture | 1 | - | 10 | - | - | 6 | - | 1 | 21 | 14 | - | 19 |
| Evidence of surgery/intervention | 10 | - | - | 3 | 1 | - | 5 | - | - | 26 | - | - |
| Aneurysm | 6 | 1 | - | - | 2 | - | 3 | 1 | - | 3 | 1 | - |
| Tumour | 2 | - | 3 | - | 2 | - | 7 | 4 | 1 | 3 | 4 | 1 |
| Cavernoma | - | 2 | - | - | - | - | 2 | 1 | - | - | - | - |
| Congenital abnormality | - | 1 | - | 2 | 2 | - | 4 | 2 | - | 1 | 1 | - |
| Cyst | - | 1 | - | 1 | - | - | 3 | 1 | - | 4 | 1 | - |
| Abscess | - | 1 | - | - | - | - | - | - | - | - | - | - |
| Infection | - | - | - | - | - | - | - | - | - | 6 | 5 | - |
| Pneumocephalus | - | - | - | - | - | - | - | - | - | 9 | - | 3 |
References
- Irvin, J.; Rajpurkar, P.; Ko, M.; Yu, Y.; Ciurea-Ilcus, S.; Chute, C.; Marklund, H.; Haghgoo, B.; Ball, R.; Shpanskaya, K.; et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 590–597. [Google Scholar]
- Radiological Society of North America. RSNA Intracranial Hemorrhage Detection (Kaggle Challenge). Available online: https://www.kaggle.com/c/rsna-intracranial-hemorrhage-detection/overview (accessed on 1 November 2020).
- Schrempf, P.; Watson, H.; Mikhael, S.; Pajak, M.; Falis, M.; Lisowska, A.; Muir, K.W.; Harris-Birtill, D.; O’Neil, A.Q. Paying Per-Label Attention for Multi-label Extraction from Radiology Reports. In Interpretable and Annotation-Efficient Learning for Medical Image Computing; Cardoso, J., Van Nguyen, H., Heller, N., Henriques Abreu, P., Isgum, I., Silva, W., Cruz, R., Pereira Amorim, J., Patel, V., Roysam, B., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 277–289. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 3–5 June 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Mullenbach, J.; Wiegreffe, S.; Duke, J.; Sun, J.; Eisenstein, J. Explainable Prediction of Medical Codes from Clinical Text. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 2–4 June 2018; Association for Computational Linguistics: New Orleans, LA, USA, 2018; Volume 1, pp. 1101–1111. [Google Scholar] [CrossRef] [Green Version]
- Wood, D.A.; Kafiabadi, S.; Al Busaidi, A.; Guilhem, E.; Lynch, J.; Townend, M.; Montvila, A.; Siddiqui, J.; Gadapa, N.; Benger, M.; et al. Labelling Imaging Datasets on the Basis of Neuroradiology Reports: A Validation Study. In Interpretable and Annotation-Efficient Learning for Medical Image Computing; Cardoso, J., Van Nguyen, H., Heller, N., Henriques Abreu, P., Isgum, I., Silva, W., Cruz, R., Pereira Amorim, J., Patel, V., Roysam, B., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 254–265. [Google Scholar]
- McCoy, T.; Pavlick, E.; Linzen, T. Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 3428–3448. [Google Scholar] [CrossRef]
- Bodenreider, O. The Unified Medical Language System (UMLS): Integrating biomedical terminology. Nucleic Acids Res. 2004, 32, 267D–270D. [Google Scholar] [CrossRef] [Green Version]
- Gu, Y.; Tinn, R.; Cheng, H.; Lucas, M.; Usuyama, N.; Liu, X.; Naumann, T.; Gao, J.; Poon, H. Domain-specific language model pretraining for biomedical natural language processing. arXiv 2020, arXiv:2007.15779. [Google Scholar]
- Yetisgen-Yildiz, M.; Gunn, M.L.; Xia, F.; Payne, T.H. A text processing pipeline to extract recommendations from radiology reports. J. Biomed. Inform. 2013, 46, 354–362. [Google Scholar] [CrossRef] [Green Version]
- Grivas, A.; Alex, B.; Grover, C.; Tobin, R.; Whiteley, W. Not a cute stroke: Analysis of Rule- and Neural Network-based Information Extraction Systems for Brain Radiology Reports. In Proceedings of the 11th International Workshop on Health Text Mining and Information Analysis, 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Association for Computational Linguistics: Monroe County, PA, USA, 2020; pp. 24–37. [Google Scholar] [CrossRef]
- Zech, J.; Pain, M.; Titano, J.; Badgeley, M.; Schefflein, J.; Su, A.; Costa, A.; Bederson, J.; Lehar, J.; Oermann, E.K. Natural language–based machine learning models for the annotation of clinical radiology reports. Radiology 2018, 287, 570–580. [Google Scholar] [CrossRef]
- Yadav, K.; Sarioglu, E.; Choi, H.; Cartwright IV, W.B.; Hinds, P.S.; Chamberlain, J.M. Automated Outcome Classification of Computed Tomography Imaging Reports for Pediatric Traumatic Brain Injury. Acad. Emerg. Med. 2016, 23, 171–178. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Banerjee, S.; Akkaya, C.; Perez-Sorrosal, F.; Tsioutsiouliklis, K. Hierarchical Transfer Learning for Multi-label Text Classification. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 6295–6300. [Google Scholar]
- Drozdov, I.; Forbes, D.; Szubert, B.; Hall, M.; Carlin, C.; Lowe, D.J. Supervised and unsupervised language modelling in Chest X-ray radiological reports. PLoS ONE 2020, 15, e0229963. [Google Scholar] [CrossRef] [PubMed]
- Wood, D.; Guilhem, E.; Montvila, A.; Varsavsky, T.; Kiik, M.; Siddiqui, J.; Kafiabadi, S.; Gadapa, N.; Busaidi, A.A.; Townend, M.; et al. Automated Labelling using an Attention model for Radiology reports of MRI scans (ALARM). In Proceedings of the Third Conference on Medical Imaging with Deep Learning; Montréal, QC, Canada, 6–9 July 2020; Proceedings of Machine Learning Research, Montréal, QC, Canada, 2020; pp. 811–826.
- Smit, A.; Jain, S.; Rajpurkar, P.; Pareek, A.; Ng, A.Y.; Lungren, M.P. CheXbert: Combining Automatic Labelers and Expert Annotations for Accurate Radiology Report Labeling Using BERT. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Association for Computational Linguistics: Monroe County, PA, USA, 2020; pp. 1500–1519. [Google Scholar] [CrossRef]
- Falis, M.; Pajak, M.; Lisowska, A.; Schrempf, P.; Deckers, L.; Mikhael, S.; Tsaftaris, S.; O’Neil, A. Ontological attention ensembles for capturing semantic concepts in ICD code prediction from clinical text. In Proceedings of the Tenth International Workshop on Health Text Mining and Information Analysis (LOUHI 2019), Hong Kong, China, 3 November 2019; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 168–177. [Google Scholar] [CrossRef]
- Alsentzer, E.; Murphy, J.; Boag, W.; Weng, W.H.; Jindi, D.; Naumann, T.; McDermott, M. Publicly Available Clinical BERT Embeddings. In Proceedings of the 2nd Clinical Natural Language Processing Workshop, 2019 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 6–7 June; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 72–78. [Google Scholar] [CrossRef] [Green Version]
- Wei, J.; Zou, K. EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 6382–6388. [Google Scholar] [CrossRef]
- Kryscinski, W.; McCann, B.; Xiong, C.; Socher, R. Evaluating the Factual Consistency of Abstractive Text Summarization. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP); Online, 16–20 November 2020; Association for Computational Linguistics: Monroe County, PA, USA, 2020; pp. 9332–9346. [Google Scholar] [CrossRef]
- Mercadier, Y.; Azé, J.; Bringay, S. Divide to Better Classify. In Artificial Intelligence in Medicine; Michalowski, M., Moskovitch, R., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 89–99. [Google Scholar]
- Mallinson, J.; Sennrich, R.; Lapata, M. Paraphrasing Revisited with Neural Machine Translation. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; Association for Computational Linguistics: Valencia, Spain, 2017; Volume 1, pp. 881–893. [Google Scholar]
- Iyyer, M.; Wieting, J.; Gimpel, K.; Zettlemoyer, L. Adversarial Example Generation with Syntactically Controlled Paraphrase Networks. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Association for Computational Linguistics: New Orleans, LA, USA, 2018; Volume 1, pp. 1875–1885. [Google Scholar] [CrossRef]
- Appelgren, M.; Schrempf, P.; Falis, M.; Ikeda, S.; O’Neil, A.Q. Language Transfer for Early Warning of Epidemics from Social Media. arXiv 2019, arXiv:1910.04519. [Google Scholar]
- IST-3 Collaborative Group. Association between brain imaging signs, early and late outcomes, and response to intravenous alteplase after acute ischaemic stroke in the third International Stroke Trial (IST-3): Secondary analysis of a randomised controlled trial. Lancet Neurol. 2015, 14, 485–496. [Google Scholar] [CrossRef] [Green Version]
- Loper, E.; Bird, S. NLTK: The Natural Language Toolkit. In Proceedings of the ACL Workshop on Effective Tools and Methodologies for Teaching Natural Language Processing and Computational Linguistics. In Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing (EMNLP 2002), Philadelphia, PA, USA, 6–7 July 2002; Association for Computational Linguistics: Philadelphia, PA, USA, 2002. [Google Scholar]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, MA, USA, 2008. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR, Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. HuggingFace’s Transformers: State-of-the-art Natural Language Processing. arXiv 2019, arXiv:1910.03771. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the 3rd International Conference on Learning Representations, ICLR, Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Alex, B.; Grover, C.; Tobin, R.; Sudlow, C.; Mair, G.; Whiteley, W. Text mining brain imaging reports. J. Biomed. Semant. 2019, 10, 1–11. [Google Scholar] [CrossRef] [PubMed]
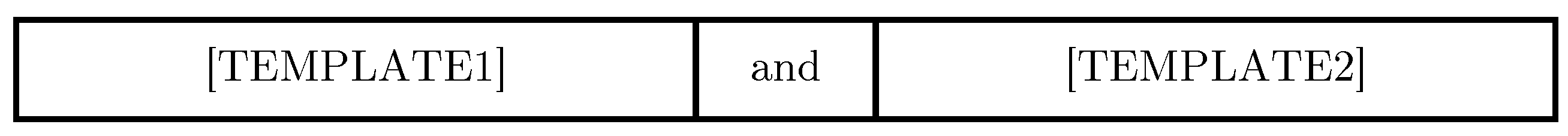

| Dataset | # Patients | # Reports | # Sentences | |
|---|---|---|---|---|
| Phase 1 (Initial) | Training | 138 | 138 | 839 |
| Validation | 92 | 92 | 515 | |
| Test—Independent | 317 | 317 | 1950 | |
| Phase 2 (Prospective) | Test—Prospective | 197 | 200 | 1411 |
| Test—Unlabelled | 10,112 | 27,940 | 228,170 |
| Comparison | Cohen’s Kappa | F1 Micro | F1 Macro |
|---|---|---|---|
| Annotator 1 vs. Annotator 2 | 0.900 | 0.945 | 0.897 |
| Annotator 1 vs. Reviewed | 0.918 | 0.953 | 0.865 |
| Annotator 2 vs. Reviewed | 0.970 | 0.983 | 0.939 |
| # Generated | # Generated | |||
|---|---|---|---|---|
| Data Synthesis Method | # Templates | Template [Label] | Sentences | |
| Baselines | Random insertion | - | - | 840 |
| Random deletion | - | - | 840 | |
| Templated data synthesis | Simple templates | 3 | 99 | |
| Permuted templates | 6 | 198 | ||
| Combined templates | 1 | 400 | (UB) | |
| Protocol-derived templates | 4 | 400 | + (UB) |
| Model Architecture | Pre-Trained Weights | F1 Micro | F1 Macro |
|---|---|---|---|
| BERT | BERT [4] | ||
| BERT | BioBERT [20] | ||
| BERT | PubMedBERT [9] | ||
| ALARM + per-label attention | BERT | ||
| ALARM + per-label attention | BioBERT | ||
| ALARM + per-label attention | PubMedBERT |
| # Words Not in Vocabulary (% of Total) | ||||
|---|---|---|---|---|
| Model | Train | Validation | Test | All |
| BERT | 356 (34%) | 236 (30%) | 539 (37%) | 710 (39%) |
| BioBERT | 400 (38%) | 268 (34%) | 594 (41%) | 784 (43%) |
| PubMedBERT | 211 (20%) | 148 (19%) | 370 (26%) | 496 (27%) |
| Input Word | BERT Tokeniser Output | PubMedBERT Tokeniser Output | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| haemorrhage | (5) | ha | ## em | ## or | ## r | ## hage | (1) | haemorrhage | |||
| hydrocephalus | (5) | h | ## ydro | ## ce | ## pha | ## lus | (1) | hydrocephalus | |||
| haematoma | (4) | ha | ## ema | ## tom | ## a | (2) | haemat | ## oma | |||
| hyperdensity | (4) | h | ## yper | ## den | ## sity | (4) | hyper | ## den | ## si | ## ty | |
| hypodensity | (5) | h | ## y | ## po | ## den | ## sity | (4) | hypo | ## den | ## si | ## ty |
| All Labels | Tumour | |||
|---|---|---|---|---|
| Data Synthesis Method | F1 Micro | F1 Macro | F1 Micro | |
| Real data only | ||||
| Baselines | Random word deletion | |||
| Random stop word insertion | ||||
| Templated data synthesis | [Label names] Simple templates | |||
| +[Label names] Permuted templates | ||||
| +[Label names] Combined templates | ||||
| +[UMLS synonyms] Simple & Permuted | ||||
| Ablations | Template synthesis only, label names | |||
| Template synthesis only, inc. UMLS synonyms | ||||
| All Labels | Infection | ||
|---|---|---|---|
| Data Synthesis Method | F1 Micro | F1 Macro | F1 Micro |
| Real data only | |||
| Generic templates | |||
| Protocol-derived templates | |||
| Haemorrhage | Ischaemia | CSVD | Atrophy | Tumour | ||
|---|---|---|---|---|---|---|
| Model | F1 Macro | F1 Micro | F1 Micro | F1 Micro | F1 Micro | F1 Micro |
| EdIE-R [11] | ||||||
| Our model, real data only | ||||||
| Our model |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schrempf, P.; Watson, H.; Park, E.; Pajak, M.; MacKinnon, H.; Muir, K.W.; Harris-Birtill, D.; O’Neil, A.Q. Templated Text Synthesis for Expert-Guided Multi-Label Extraction from Radiology Reports. Mach. Learn. Knowl. Extr. 2021, 3, 299-317. https://doi.org/10.3390/make3020015
Schrempf P, Watson H, Park E, Pajak M, MacKinnon H, Muir KW, Harris-Birtill D, O’Neil AQ. Templated Text Synthesis for Expert-Guided Multi-Label Extraction from Radiology Reports. Machine Learning and Knowledge Extraction. 2021; 3(2):299-317. https://doi.org/10.3390/make3020015
Chicago/Turabian StyleSchrempf, Patrick, Hannah Watson, Eunsoo Park, Maciej Pajak, Hamish MacKinnon, Keith W. Muir, David Harris-Birtill, and Alison Q. O’Neil. 2021. "Templated Text Synthesis for Expert-Guided Multi-Label Extraction from Radiology Reports" Machine Learning and Knowledge Extraction 3, no. 2: 299-317. https://doi.org/10.3390/make3020015
APA StyleSchrempf, P., Watson, H., Park, E., Pajak, M., MacKinnon, H., Muir, K. W., Harris-Birtill, D., & O’Neil, A. Q. (2021). Templated Text Synthesis for Expert-Guided Multi-Label Extraction from Radiology Reports. Machine Learning and Knowledge Extraction, 3(2), 299-317. https://doi.org/10.3390/make3020015