
From the Digital Data Revolution toward a Digital Society: Pervasiveness of Artificial Intelligence


Abstract
1. Introduction
2. Digital Medicine and Digital Health
3. Digital Economy and Business
- e-Business;
- e-Commerce;
- Industry 4.0;
- Sharing economy;
- Crowdsourcing.
- Freelancing platforms (labor market consisting of short-term contracts);
- Coworking platforms (individuals working independently or collaboratively in shared office space);
- P2P lending platforms;
- Fashion platforms.
4. Pervasiveness of Artificial Intelligence
5. Discussion
5.1. Smart Cities and Smart Government
- Question: Should the UK leave the European Union?
5.2. Human–Machine Interaction
5.3. Data Privacy, Cybersecurity and Bias in AI
5.4. From Big Data and Cloud Computing toward Advanced Analytics
- Semi-supervised learning;
- Reinforcement learning;
- Transfer learning;
- Adversarial learning.
5.5. From Digital Economy to Digital Society

6. Conclusions
Funding
Conflicts of Interest
References
- Chang, R.M.; Kauffman, R.J.; Kwon, Y. Understanding the paradigm shift to computational social science in the presence of big data. Decis. Support Syst. 2014, 63, 67–80. [Google Scholar] [CrossRef]
- Chen, H.; Chiang, R.H.; Storey, V.C. Business intelligence and analytics: From big data to big impact. MIS Q. 2012, 36, 1165–1188. [Google Scholar] [CrossRef]
- Helbing, D. Thinking Ahead-Essays on Big Data, Digital Revolution, and Participatory Market Society; Springer: Berlin, Germany, 2015; Volume 10. [Google Scholar]
- Ma’ayan, A.; Rouillard, A.; Clark, N.; Wang, Z.; Duan, Q.; Kou, Y. Lean Big Data integration in systems biology and systems pharmacology. Trends Pharmacol. Sci. 2014, 35, 450–460. [Google Scholar] [CrossRef]
- Olshannikova, E.; Olsson, T.; Huhtamäki, J.; Kärkkäinen, H. Conceptualizing big social data. J. Big Data 2017, 4, 3. [Google Scholar] [CrossRef]
- Kitchin, R. The Data Revolution: Big Data, Open Data, Data Infrastructures and Their Consequences; Sage: Thousand Oaks, CA, USA, 2014. [Google Scholar]
- Schena, M.; Shalon, D.; Davis, R.W.; Brown, P.O. Quantitative monitoring of gene expression patterns with a complementary DNA microarray. Science 1995, 270, 467–470. [Google Scholar] [CrossRef]
- Marx, V. Biology: The big challenges of big data. Nature 2013, 498, 255–260. [Google Scholar] [CrossRef] [PubMed]
- Quackenbush, J. The Human Genome: The Book of Essential Knowledge; Curiosity Guides, Imagine Publishing: New York, NY, USA, 2011. [Google Scholar]
- Shendure, J.; Ji, H. Next-generation DNA sequencing. Nat. Biotechnol. 2008, 26, 1135–1145. [Google Scholar] [CrossRef] [PubMed]
- Dehmer, M.; Emmert-Streib, F.; Graber, A.; Salvador, A. (Eds.) Applied Statistics for Network Biology: Methods for Systems Biology; Wiley-Blackwell: Weinheim, Germany, 2011. [Google Scholar]
- Emmert-Streib, F.; Altay, G. Local network-based measures to assess the inferability of different regulatory networks. IET Syst. Biol. 2010, 4, 277–288. [Google Scholar] [CrossRef] [PubMed]
- Shah, D.V.; Cappella, J.N.; Neuman, W.R. Big data, digital media, and computational social science: Possibilities and perils. Ann. Am. Acad. Political Soc. Sci. 2015, 659, 6–13. [Google Scholar] [CrossRef]
- Conte, R.; Gilbert, N.; Bonelli, G.; Cioffi-Revilla, C.; Deffuant, G.; Kertesz, J.; Loreto, V.; Moat, S.; Nadal, J.P.; Sanchez, A.; et al. Manifesto of computational social science. Eur. Phys. J. Spec. Top. 2012, 214, 325. [Google Scholar] [CrossRef]
- Emmert-Streib, F.; Yli-Harja, O.; Dehmer, M. Data analytics applications for streaming data from social media: What to predict? Front. Big Data 2018, 1, 1. [Google Scholar] [CrossRef]
- Matz, S.C.; Kosinski, M.; Nave, G.; Stillwell, D.J. Psychological targeting as an effective approach to digital mass persuasion. Proc. Natl. Acad. Sci. USA 2017, 114, 12714–12719. [Google Scholar] [CrossRef] [PubMed]
- Emmert-Streib, F.; Dehmer, M. Data-driven computational social network science: Predictive and inferential models for Web-enabled scientific discoveries. Front. Big Data 2021, 4, 10. [Google Scholar]
- Petricoin, E.F.; Liotta, L.A. SELDI-TOF-based serum proteomic pattern diagnostics for early detection of cancer. Curr. Opin. Biotechnol. 2004, 15, 24–30. [Google Scholar] [CrossRef]
- Marzese, D.M.; Hoon, D.S. Emerging technologies for studying DNA methylation for the molecular diagnosis of cancer. Expert Rev. Mol. Diagn. 2015, 15, 647–664. [Google Scholar] [CrossRef]
- Wang, Z.; Gerstein, M.; Snyder, M. RNA-Seq: A revolutionary tool for transcriptomics. Nat. Rev. Genet. 2009, 10, 57–63. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.E.; Harrington, R.A.; Desai, S.A.; Mahaffey, K.W.; Turakhia, M.P. Characteristics of digital health studies registered in ClinicalTrials. gov. JAMA Intern. Med. 2019, 179, 838–840. [Google Scholar] [CrossRef]
- Steinhubl, S.R.; Topol, E.J. Digital medicine, on its way to being just plain medicine. NPJ Digit. Med. 2018, 1, 20175. [Google Scholar] [CrossRef] [PubMed]
- Kostkova, P. Grand challenges in digital health. Front. Public Health 2015, 3, 134. [Google Scholar] [CrossRef]
- Ali, F.; El-Sappagh, S.; Islam, S.R.; Ali, A.; Attique, M.; Imran, M.; Kwak, K.S. An intelligent healthcare monitoring framework using wearable sensors and social networking data. Future Gener. Comput. Syst. 2021, 114, 23–43. [Google Scholar] [CrossRef]
- Ali, F.; El-Sappagh, S.; Islam, S.R.; Kwak, D.; Ali, A.; Imran, M.; Kwak, K.S. A smart healthcare monitoring system for heart disease prediction based on ensemble deep learning and feature fusion. Inf. Fusion 2020, 63, 208–222. [Google Scholar] [CrossRef]
- Kumar, V.; Jangirala, S.; Ahmad, M. An efficient mutual authentication framework for healthcare system in cloud computing. J. Med. Syst. 2018, 42, 1–25. [Google Scholar] [CrossRef]
- Srinivas, J.; Das, A.K.; Kumar, N.; Rodrigues, J.J. Cloud centric authentication for wearable healthcare monitoring system. IEEE Trans. Dependable Secur. Comput. 2018, 17, 942–956. [Google Scholar] [CrossRef]
- Fogel, A.L.; Kvedar, J.C. Artificial intelligence powers digital medicine. NPJ Digit. Med. 2018, 1, 1–4. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, L.; Yang, Y.; Zhou, L.; Ren, L.; Wang, F.; Liu, R.; Pang, Z.; Deen, M.J. A novel cloud-based framework for the elderly healthcare services using digital twin. IEEE Access 2019, 7, 49088–49101. [Google Scholar] [CrossRef]
- Barricelli, B.R.; Casiraghi, E.; Fogli, D. A survey on digital twin: Definitions, characteristics, applications, and design implications. IEEE Access 2019, 7, 167653–167671. [Google Scholar] [CrossRef]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef] [PubMed]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef]
- Labovitz, D.L.; Shafner, L.; Reyes Gil, M.; Virmani, D.; Hanina, A. Using artificial intelligence to reduce the risk of nonadherence in patients on anticoagulation therapy. Stroke 2017, 48, 1416–1419. [Google Scholar] [CrossRef]
- Emmert-Streib, F.; Yli-Harja, O.; Dehmer, M. Explainable Artificial Intelligence and Machine Learning: A reality rooted perspective. WIREs Data Min. Knowl. Discov. 2020, 10, e1368. [Google Scholar] [CrossRef]
- Vayena, E.; Ienca, M. Digital medicine and ethics: Rooting for evidence. Am. J. Bioeth. 2018, 18, 49–51. [Google Scholar] [CrossRef]
- Milosevic, Z. Ethics in Digital Health: A deontic accountability framework. In Proceedings of the 2019 IEEE 23rd International Enterprise Distributed Object Computing Conference (EDOC), Paris, France, 28–31 October 2019; pp. 105–111. [Google Scholar]
- Lee, H.; Kim, S.; Kim, J.W.; Chung, Y.D. Utility-preserving anonymization for health data publishing. BMC Med. Inform. Decis. Mak. 2017, 17, 104. [Google Scholar] [CrossRef]
- El Emam, K.; Rodgers, S.; Malin, B. Anonymising and sharing individual patient data. BMJ 2015, 350, h1139. [Google Scholar] [CrossRef] [PubMed]
- Bukht, R.; Heeks, R. Defining, conceptualising and measuring the digital economy. Development Informatics working paper. SSRN Electron. J. 2017. [Google Scholar] [CrossRef]
- Bharadwaj, A.; El Sawy, O.A.; Pavlou, P.A.; Venkatraman, N. Digital business strategy: Toward a next generation of insights. MIS Q. 2013, 37, 471–482. [Google Scholar] [CrossRef]
- Mesenbourg, T.L. Measuring the Digital Economy; US Bureau of the Census: Washington, DC, USA, 2001; pp. 5–6. [Google Scholar]
- Lu, Y. Industry 4.0: A survey on technologies, applications and open research issues. J. Ind. Inf. Integr. 2017, 6, 1–10. [Google Scholar] [CrossRef]
- Xu, L.D.; Xu, E.L.; Li, L. Industry 4.0: State of the art and future trends. Int. J. Prod. Res. 2018, 56, 2941–2962. [Google Scholar] [CrossRef]
- Kagermann, H.; Helbig, J.; Hellinger, A.; Wahlster, W. Recommendations for Implementing the Strategic Initiative Industrie 4.0: Securing the Future of German Manufacturing Industry; Final Report of the Industrie 4.0 Working Group; Forschungsunion; National Academy of Science and Engineering: München, Germany, 2013. [Google Scholar]
- Wang, Y.; Ma, H.S.; Yang, J.H.; Wang, K.S. Industry 4.0: A way from mass customization to mass personalization production. Adv. Manuf. 2017, 5, 311–320. [Google Scholar] [CrossRef]
- Chen, M.; Wan, J.; Li, F. Machine-to-machine communications: Architectures, standards and applications. Ksii Trans. Internet Inf. Syst. 2012, 6. [Google Scholar] [CrossRef]
- Wan, J.; Chen, M.; Xia, F.; Di, L.; Zhou, K. From machine-to-machine communications towards cyber-physical systems. Comput. Sci. Inf. Syst. 2013, 10, 1105–1128. [Google Scholar] [CrossRef]
- Stojmenovic, I. Machine-to-machine communications with in-network data aggregation, processing, and actuation for large-scale cyber-physical systems. IEEE Internet Things J. 2014, 1, 122–128. [Google Scholar] [CrossRef]
- Wu, F.J.; Kao, Y.F.; Tseng, Y.C. From wireless sensor networks towards cyber physical systems. Pervasive Mob. Comput. 2011, 7, 397–413. [Google Scholar] [CrossRef]
- Madakam, S.; Lake, V.; Lake, V.; Lake, V. Internet of Things (IoT): A literature review. J. Comput. Commun. 2015, 3, 164. [Google Scholar] [CrossRef]
- Monostori, L. Cyber-Physical Systems. In CIRP Encyclopedia of Production Engineering; Chatti, S., Tolio, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Cheng, M. Sharing economy: A review and agenda for future research. Int. J. Hosp. Manag. 2016, 57, 60–70. [Google Scholar] [CrossRef]
- Botsman, R.; Rogers, R. What’s Mine Is Yours: The Rise of Collaborative Consumption; Harper Business: New York, NY, USA, 2010. [Google Scholar]
- Schlagwein, D.; Schoder, D.; Spindeldreher, K. Consolidated, systemic conceptualization, and definition of the “sharing economy”. J. Assoc. Inf. Sci. Technol. 2020, 71, 817–838. [Google Scholar] [CrossRef]
- Taeihagh, A. Crowdsourcing, sharing economies and development. J. Dev. Soc. 2017, 33, 191–222. [Google Scholar] [CrossRef]
- Hrazdil, K.; Trottier, K.; Zhang, R. A comparison of industry classification schemes: A large sample study. Econ. Lett. 2013, 118, 77–80. [Google Scholar] [CrossRef]
- Lim, W.M. Sharing economy: A marketing perspective. Australas. Mark. J. (AMJ) 2020, 28, 4–13. [Google Scholar] [CrossRef]
- UNCTAD. Digital Economy Report 2019: Value Creation and Capture—Implications for Developing Countries; UNCTAD: New York, NY, USA, 2019. [Google Scholar]
- Grall, A.; Dieulle, L.; Bérenguer, C.; Roussignol, M. Continuous-time predictive-maintenance scheduling for a deteriorating system. IEEE Trans. Reliab. 2002, 51, 141–150. [Google Scholar] [CrossRef]
- Lee, W.J.; Wu, H.; Yun, H.; Kim, H.; Jun, M.B.; Sutherland, J.W. Predictive maintenance of machine tool systems using artificial intelligence techniques applied to machine condition data. Procedia CIRP 2019, 80, 506–511. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529. [Google Scholar] [CrossRef] [PubMed]
- Gu, S.; Holly, E.; Lillicrap, T.; Levine, S. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3389–3396. [Google Scholar]
- Shearer, C. The CRISP-DM model: The new blueprint for data mining. J. Data Warehous. 2000, 5, 13–22. [Google Scholar]
- Tripathi, S.; Muhr, D.; Manuel, B.; Emmert-Streib, F.; Jodlbauer, J.; Dehmer, M. Ensuring the Robustness and Reliability of Data-Driven Knowledge Discovery Models in Production and Manufacturing. arXiv 2020, arXiv:2007.14791. [Google Scholar]
- Brynjolfsson, E.; McAfee, A. The Second Machine Age: Work, Progress, and Prosperity in a Time of Brilliant Technologies; WW Norton & Company: New York, NY, USA, 2014. [Google Scholar]
- Bughin, J.; Seong, J.; Manyika, J.; Chui, M.; Joshi, R. Notes from the AI Frontier: Modeling the Impact of AI on the World Economy; McKinsey Global Institute: San Francisco, CA, USA, 2018. [Google Scholar]
- Abu-Mostafa, Y.S.; Magdon-Ismail, M.; Lin, H.T. Learning from Data; AMLBook: New York, NY, USA, 2012; Volume 4. [Google Scholar]
- Theodoridis, S.; Koutroumbas, K. Pattern Recognition; Elsevier Academic Press: San Diego, CA, USA, 2003. [Google Scholar]
- Haste, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference and Prediction; Springer: New York, NY, USA, 2009. [Google Scholar]
- Emmert-Streib, F.; Yli-Harja, O.; Dehmer, M. A clarification of misconceptions, myths and desired status of artificial intelligence. Front. Artif. Intell. 2020, 3, 91. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Lee, H.; Pham, P.; Largman, Y.; Ng, A.Y. Unsupervised feature learning for audio classification using convolutional deep belief networks. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2009; pp. 1096–1104. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2013; pp. 3111–3119. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Perera, N.; Dehmer, M.; Emmert-Streib, F. Named Entity Recognition and Relation Detection for Biomedical Information Extraction. Front. Cell Dev. Biol. 2020, 8, 673. [Google Scholar] [CrossRef]
- Lau, J.H.; Baldwin, T. An empirical evaluation of doc2vec with practical insights into document embedding generation. arXiv 2016, arXiv:1607.05368. [Google Scholar]
- Mahler, R.P. Statistical Multisource-Multitarget Information Fusion; Artech House, Inc.: Norwood, MA, USA, 2007. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Huynh, B.Q.; Li, H.; Giger, M.L. Digital mammographic tumor classification using transfer learning from deep convolutional neural networks. J. Med. Imaging 2016, 3, 034501. [Google Scholar] [CrossRef]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef]
- Caruana, R. Multitask learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Emmert-Streib, F.; Yang, Z.; Feng, H.; Tripathi, S.; Dehmer, M. An introductory review of deep learning for prediction models with big data. Front. Artif. Intell. 2020, 3, 4. [Google Scholar] [CrossRef]
- Cohen, G.; Afshar, S.; Tapson, J.; van Schaik, A. EMNIST: An extension of MNIST to handwritten letters. arXiv 2017, arXiv:1702.05373. [Google Scholar]
- Emmert-Streib, F.; Dehmer, M. Evaluation of Regression Models: Model Assessment, Model Selection and Generalization Error. Mach. Learn. Knowl. Extr. 2019, 1, 521–551. [Google Scholar] [CrossRef]
- Emmert-Streib, F.; Dehmer, M.; Yli-Harja, O. Ensuring Quality Standards and Reproducible Research for Data Analysis Services in Oncology: A Cooperative Service Model. Front. Cell Dev. Biol. 2019, 7, 349. [Google Scholar] [CrossRef]
- Baggerly, K.A.; Coombes, K.R. Deriving chemosensitivity from cell lines: Forensic bioinformatics and reproducible research in high-throughput biology. Ann. Appl. Stat. 2009, 3, 1309–1334. [Google Scholar] [CrossRef]
- Djahel, S.; Doolan, R.; Muntean, G.M.; Murphy, J. A communications-oriented perspective on traffic management systems for smart cities: Challenges and innovative approaches. IEEE Commun. Surv. Tutor. 2014, 17, 125–151. [Google Scholar] [CrossRef]
- Barba, C.T.; Mateos, M.A.; Soto, P.R.; Mezher, A.M.; Igartua, M.A. Smart city for VANETs using warning messages, traffic statistics and intelligent traffic lights. In Proceedings of the 2012 IEEE Intelligent Vehicles Symposium, Madrid, Spain, 3–7 June 2012; pp. 902–907. [Google Scholar]
- Ejaz, W.; Naeem, M.; Shahid, A.; Anpalagan, A.; Jo, M. Efficient energy management for the internet of things in smart cities. IEEE Commun. Mag. 2017, 55, 84–91. [Google Scholar] [CrossRef]
- Kankanhalli, A.; Charalabidis, Y.; Mellouli, S. IoT and AI for smart government: A research agenda. Gov. Inf. Q. 2019, 36, 304–309. [Google Scholar] [CrossRef]
- Xu, F.; Uszkoreit, H.; Du, Y.; Fan, W.; Zhao, D.; Zhu, J. Explainable AI: A brief survey on history, research areas, approaches and challenges. In CCF International Conference on Natural Language Processing and Chinese Computing; Springer: Berlin, Germany, 2019; pp. 563–574. [Google Scholar]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Holzinger, A.; Kieseberg, P.; Weippl, E.; Tjoa, A.M. Current advances, trends and challenges of machine learning and knowledge extraction: From machine learning to explainable ai. In International Cross-Domain Conference for Machine Learning and Knowledge Extraction; Springer: Berlin, Germany, 2018; pp. 1–8. [Google Scholar]
- Gorecky, D.; Schmitt, M.; Loskyll, M.; Zühlke, D. Human–machine-interaction in the industry 4.0 era. In Proceedings of the 2014 12th IEEE International Conference on Industrial Informatics (INDIN), Porto Alegre, Brazil, 27–30 July 2014; pp. 289–294. [Google Scholar]
- Card, S.K. The Psychology of Human—Computer Interaction; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Holzinger, A. Interactive machine learning for health informatics: When do we need the human-in-the-loop? Brain Inform. 2016, 3, 119–131. [Google Scholar] [CrossRef] [PubMed]
- Carmigniani, J.; Furht, B.; Anisetti, M.; Ceravolo, P.; Damiani, E.; Ivkovic, M. Augmented reality technologies, systems and applications. Multimed. Tools Appl. 2011, 51, 341–377. [Google Scholar] [CrossRef]
- Emmert-Streib, F.; Moutari, S.; Dehmer, M. The process of analyzing data is the emergent feature of data science. Front. Genet. 2016, 7, 12. [Google Scholar] [CrossRef]
- Tuptuk, N.; Hailes, S. Security of smart manufacturing systems. J. Manuf. Syst. 2018, 47, 93–106. [Google Scholar] [CrossRef]
- Isaak, J.; Hanna, M.J. User data privacy: Facebook, Cambridge Analytica, and privacy protection. Computer 2018, 51, 56–59. [Google Scholar] [CrossRef]
- Buccafurri, F.; Lax, G.; Nicolazzo, S.; Nocera, A. Comparing Twitter and Facebook user behavior: Privacy and other aspects. Comput. Hum. Behav. 2015, 52, 87–95. [Google Scholar] [CrossRef]
- Winfield, A.F.; Jirotka, M. Ethical governance is essential to building trust in robotics and artificial intelligence systems. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2018, 376, 20180085. [Google Scholar] [CrossRef] [PubMed]
- Mehrabi, N.; Morstatter, F.; Saxena, N.; Lerman, K.; Galstyan, A. A survey on bias and fairness in machine learning. arXiv 2019, arXiv:1908.09635. [Google Scholar]
- Ntoutsi, E.; Fafalios, P.; Gadiraju, U.; Iosifidis, V.; Nejdl, W.; Vidal, M.E.; Ruggieri, S.; Turini, F.; Papadopoulos, S.; Krasanakis, E.; et al. Bias in data-driven artificial intelligence systems? An introductory survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1356. [Google Scholar] [CrossRef]
- Courtland, R. The bias detectives. Nature 2018, 558, 357–360. [Google Scholar] [CrossRef] [PubMed]
- Yapo, A.; Weiss, J. Ethical implications of bias in machine learning. In Proceedings of the 51st Hawaii International Conference on System Sciences, Hilton Waikoloa Village, HI, USA, 3–6 January 2018. [Google Scholar]
- Challen, R.; Denny, J.; Pitt, M.; Gompels, L.; Edwards, T.; Tsaneva-Atanasova, K. Artificial intelligence, bias and clinical safety. BMJ Qual. Saf. 2019, 28, 231–237. [Google Scholar] [CrossRef]
- Franks, B. Taming the Big Data Tidal Wave: Finding Opportunities in Huge Data Streams with Advanced Analytics; John Wiley & Sons: New York, NY, USA, 2012; Volume 49. [Google Scholar]
- Halper, F. Advanced Analytics: Moving Toward AI, Machine Learning, and Natural Language Processing. TDWI Best Practices Report. 2017. Available online: https://analyticsconsultores.com.mx/wp-content/uploads/2019/03/Advanced-Analyhtics.-Moving-Toward-AI-Machine-Learning-and-Natural-Language-Processing-Fern-Halper-TDWI-SAS-2017.pdf (accessed on 4 March 2021).
- Ma, Y.; Zhu, L. A review on dimension reduction. Int. Stat. Rev. 2013, 81, 134–150. [Google Scholar] [CrossRef]
- Tukey, J. Exploratory Data Analysis; Addison-Wesley: New York, NY, USA, 1977. [Google Scholar]
- Baldi, P. Autoencoders, unsupervised learning, and deep architectures. In Proceedings of the ICML Workshop on Unsupervised and Transfer Learning, Bellevue, WA, USA, 27 June 2012; pp. 37–49. [Google Scholar]
- Emmert-Streib, F.; Dehmer, M. Understanding Statistical Hypothesis Testing: The Logic of Statistical Inference. Mach. Learn. Knowl. Extr. 2019, 1, 945–961. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin, Germany, 2006. [Google Scholar]
- Emmert-Streib, F.; Dehmer, M. High-Dimensional LASSO-Based Computational Regression Models: Regularization, Shrinkage, and Selection. Mach. Learn. Knowl. Extr. 2019, 1, 359–383. [Google Scholar] [CrossRef]
- Kingma, D.P.; Mohamed, S.; Rezende, D.J.; Welling, M. Semi-supervised learning with deep generative models. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2014; pp. 3581–3589. [Google Scholar]
- Li, Y. Deep reinforcement learning: An overview. arXiv 2017, arXiv:1701.07274. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]
- Han, T.; Liu, C.; Yang, W.; Jiang, D. A novel adversarial learning framework in deep convolutional neural network for intelligent diagnosis of mechanical faults. Knowl. Based Syst. 2019, 165, 474–487. [Google Scholar] [CrossRef]
- Skobelev, P.; Borovik, S.Y. On the way from Industry 4.0 to Industry 5.0: From digital manufacturing to digital society. Industry 4.0 2017, 2, 307–311. [Google Scholar]
- Granovetter, M. Economic action and social structure: The problem of embeddedness. Am. J. Sociol. 1985, 91, 481–510. [Google Scholar] [CrossRef]
- Dufva, T.; Dufva, M. Grasping the future of the digital society. Futures 2019, 107, 17–28. [Google Scholar] [CrossRef]
- Makridakis, S. The forthcoming Artificial Intelligence (AI) revolution: Its impact on society and firms. Futures 2017, 90, 46–60. [Google Scholar] [CrossRef]
- Brockman, J. Possible Minds: Twenty-Five Ways of Looking at AI; Penguin Books: London, UK, 2020. [Google Scholar]
- Joy, B. Why the future doesn?t need us. Wired Mag. 2000, 8, 238–262. [Google Scholar]
- Marcus, G.; Davis, E. Rebooting AI: Building Artificial Intelligence We Can Trust; Pantheon: New York, NY, USA, 2019. [Google Scholar]
- Helbing, D. Societal, economic, ethical and legal challenges of the digital revolution: From big data to deep learning, artificial intelligence, and manipulative technologies. In Towards Digital Enlightenment; Springer: Berlin, Germany, 2019; pp. 47–72. [Google Scholar]
- Lankshear, C.; Knobel, M. Digital Literacies: Concepts, Policies and Practices; Peter Lang: Bruxelles, Belgium, 2008. [Google Scholar]
- Herrlich, P. The responsibility of the scientist: What can history teach us about how scientists should handle research that has the potential to create harm? EMBO Rep. 2013, 14, 759–764. [Google Scholar] [CrossRef] [PubMed]


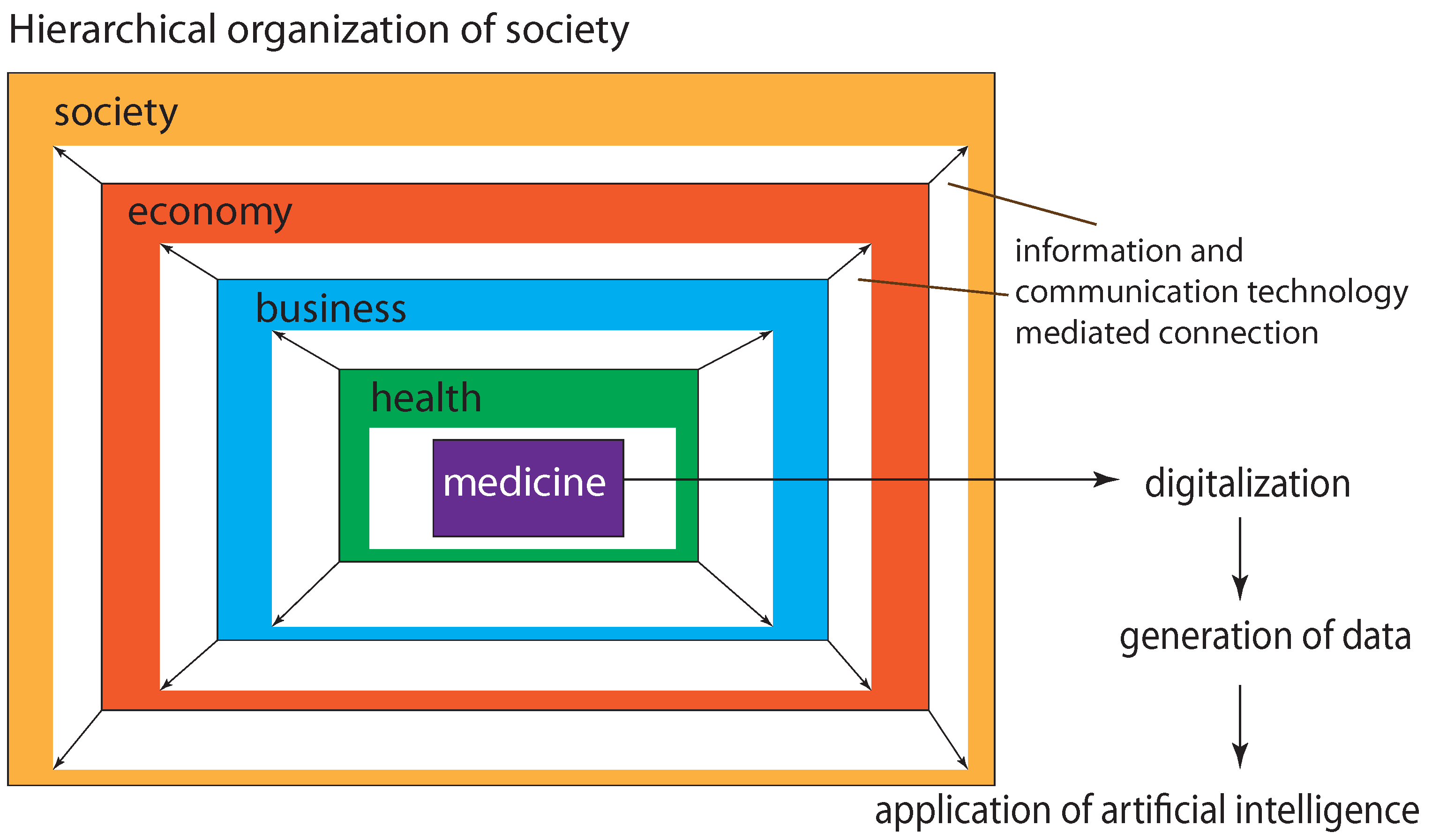{kind=link}
| Technology | Definition | Reference |
|---|---|---|
| Machine-to-machine communication (M2M) | “Machine-to-Machine (M2M) paradigm enables ma-chines (sensors, actuators, robots, and smart meter readers) tocommunicate with each other with little or no human intervention.M2M is a key enabling technology for the cyber-physical systems(CPSs)”. | [48] |
| Wireless sensor networks (WSN) | “WSN is designed particularly for delivering sensor-related data”. | [49] |
| Internet of Things (IoT) | “An open and comprehensive network of intelligent objects that have the capacity to auto-organize, share information, data and resources, reacting and acting in face of situations and changes in the environment”. | [50] |
| Cyber-physical systems (CPS) | “CPS are systems of collaborating computational entities which are in intensive connection with the surrounding physical world and its on-going processes, providing and using, at the same time, data-accessing and data-processing services available on the internet”. | [51] |
| Sector | Industry | Sub-Industry |
|---|---|---|
| Energy | Oil, Gas and Consumable Fuels | Coal and Consumable Fuels |
| Materials | Chemicals | Fertilizers and Agricultural Chemicals |
| Industrials | Machinery and Agricultural | Farm Machinery |
| Consumer Discretionary | Hotels, Restaurants and Leisure | Restaurants |
| Consumer Staples | Food, Beverage and Tobacco | Tobacco |
| Health Care | Pharmaceuticals, Biotechnology and Life Sciences | Biotechnology |
| Financials | Banks | Regional Banks |
| Information Technology | Software and Services | Internet Services and Infrastructure |
| Communication Services | Media and Entertainment | Publishing |
| Utilities | Utilities | Independent Power and Renewable Electricity Producers |
| Real Estate | Real Estate | Real Estate Development |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Emmert-Streib, F. From the Digital Data Revolution toward a Digital Society: Pervasiveness of Artificial Intelligence. Mach. Learn. Knowl. Extr. 2021, 3, 284-298. https://doi.org/10.3390/make3010014
Emmert-Streib F. From the Digital Data Revolution toward a Digital Society: Pervasiveness of Artificial Intelligence. Machine Learning and Knowledge Extraction. 2021; 3(1):284-298. https://doi.org/10.3390/make3010014
Chicago/Turabian StyleEmmert-Streib, Frank. 2021. "From the Digital Data Revolution toward a Digital Society: Pervasiveness of Artificial Intelligence" Machine Learning and Knowledge Extraction 3, no. 1: 284-298. https://doi.org/10.3390/make3010014
APA StyleEmmert-Streib, F. (2021). From the Digital Data Revolution toward a Digital Society: Pervasiveness of Artificial Intelligence. Machine Learning and Knowledge Extraction, 3(1), 284-298. https://doi.org/10.3390/make3010014