Robust Learning with Implicit Residual Networks



Abstract
:1. Introduction and Related Works
2. Description of the Method
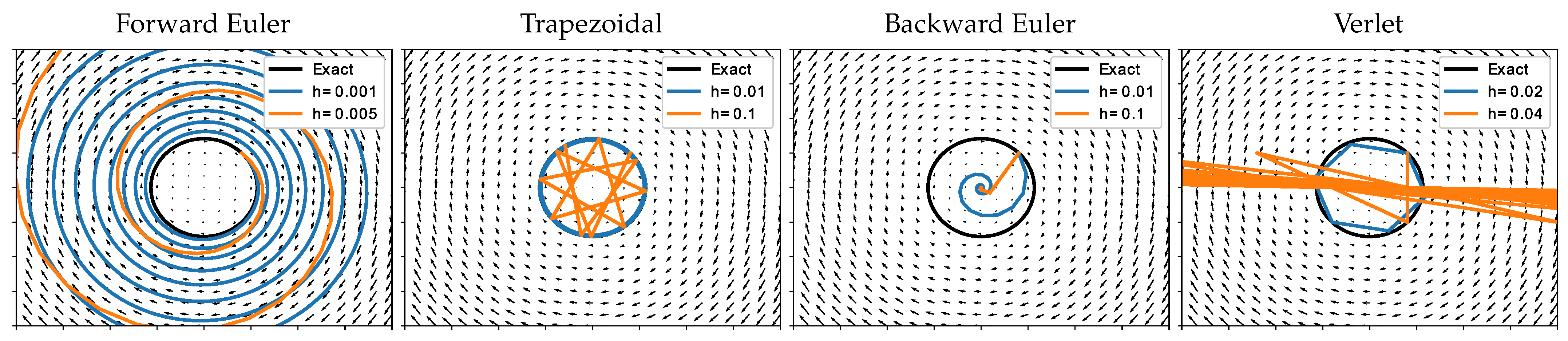
2.1. Linear Stability Analysis
| Forward Euler: | |
| Backward Euler: | |
| Trapezoidal: | |
| Verlet: |
2.2. Implicit ResNet
2.2.1. Forward Propagation
2.2.2. Backpropagation
2.3. fpResNet
2.4. Regularization
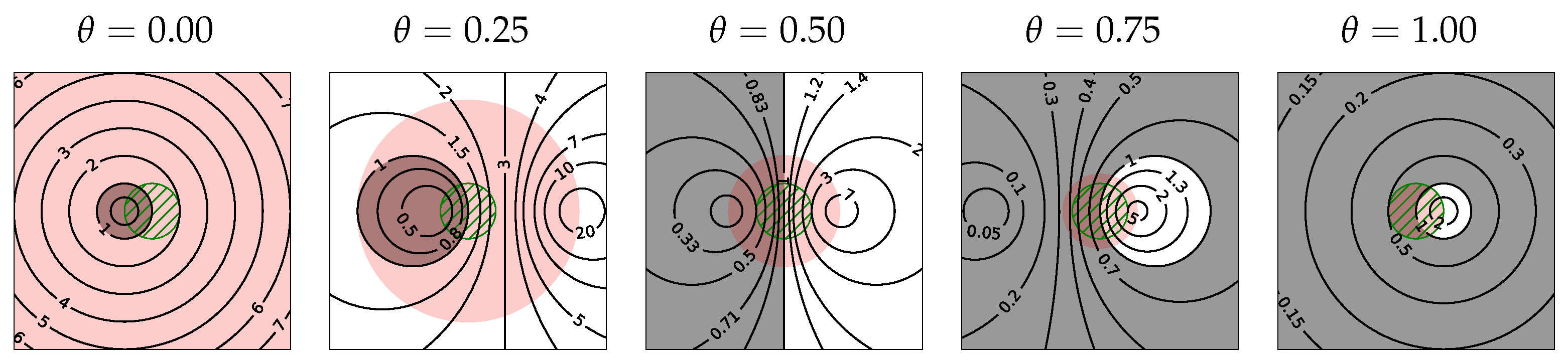
2.4.1. Lipschitz Continuous Architectures
| Algorithm 1 Power iteration method |
|
2.4.2. Trajectory Regularization
| Algorithm 2 Stochastic diagonal estimator |
|
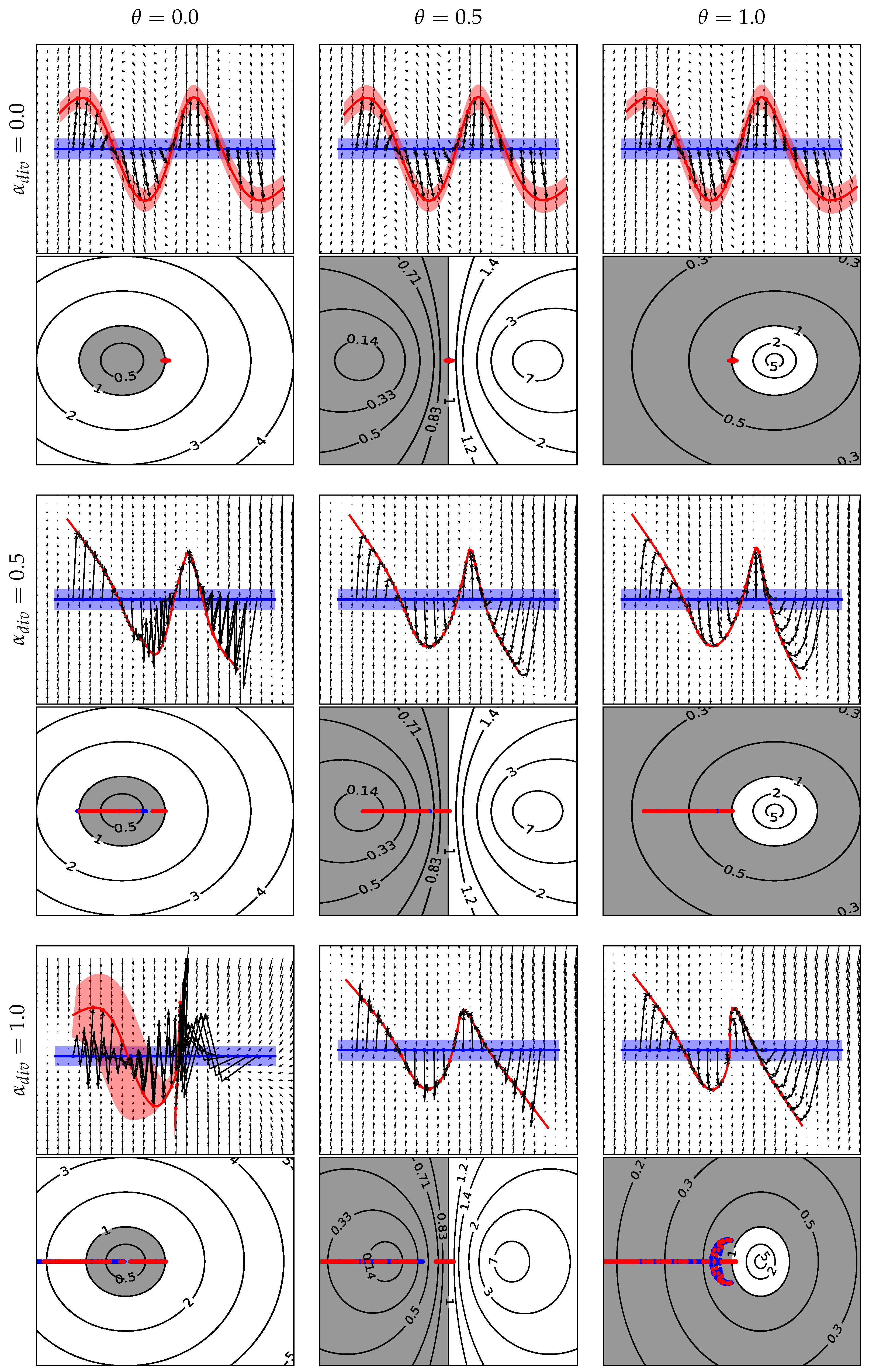
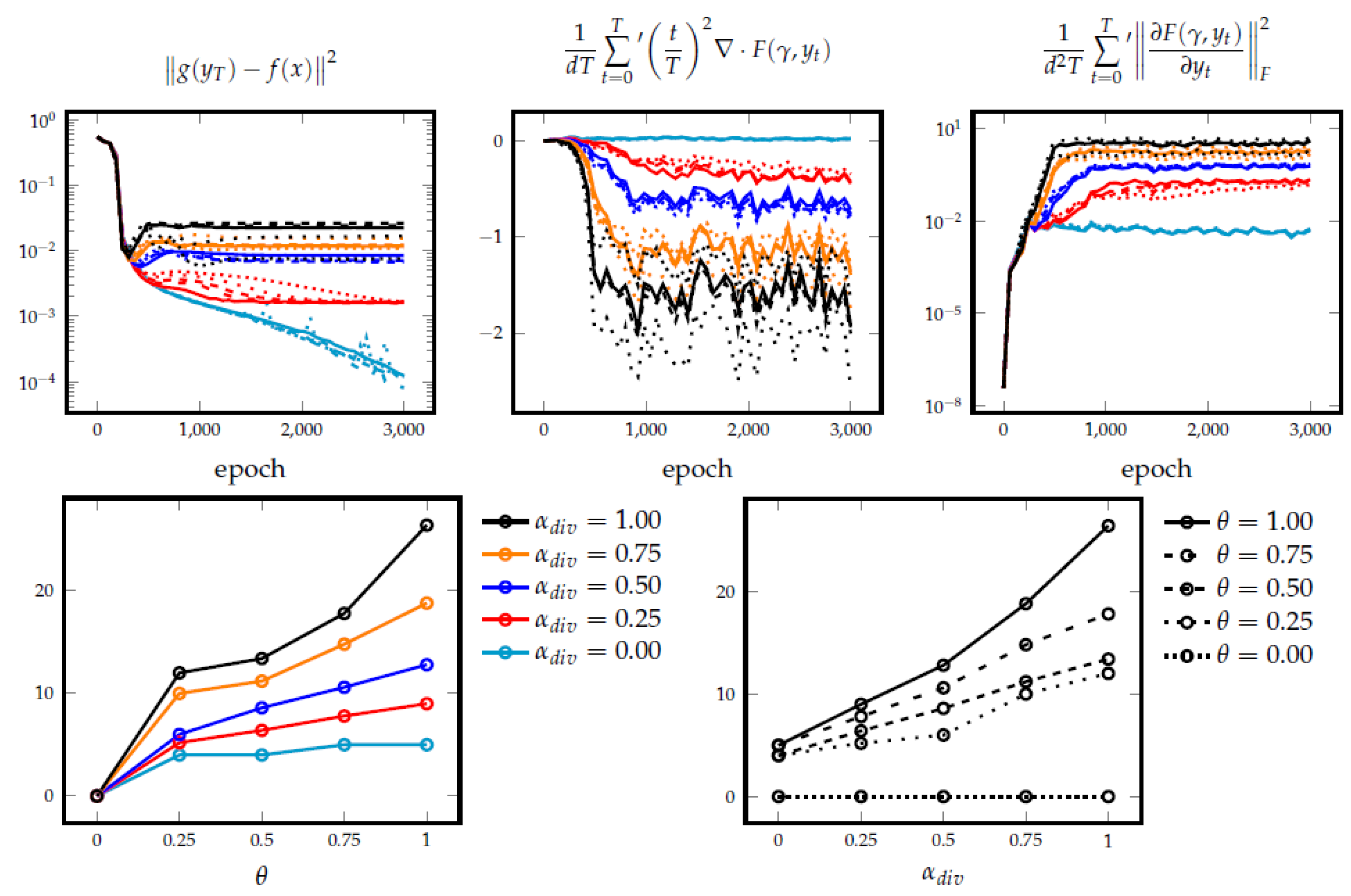
3. Results
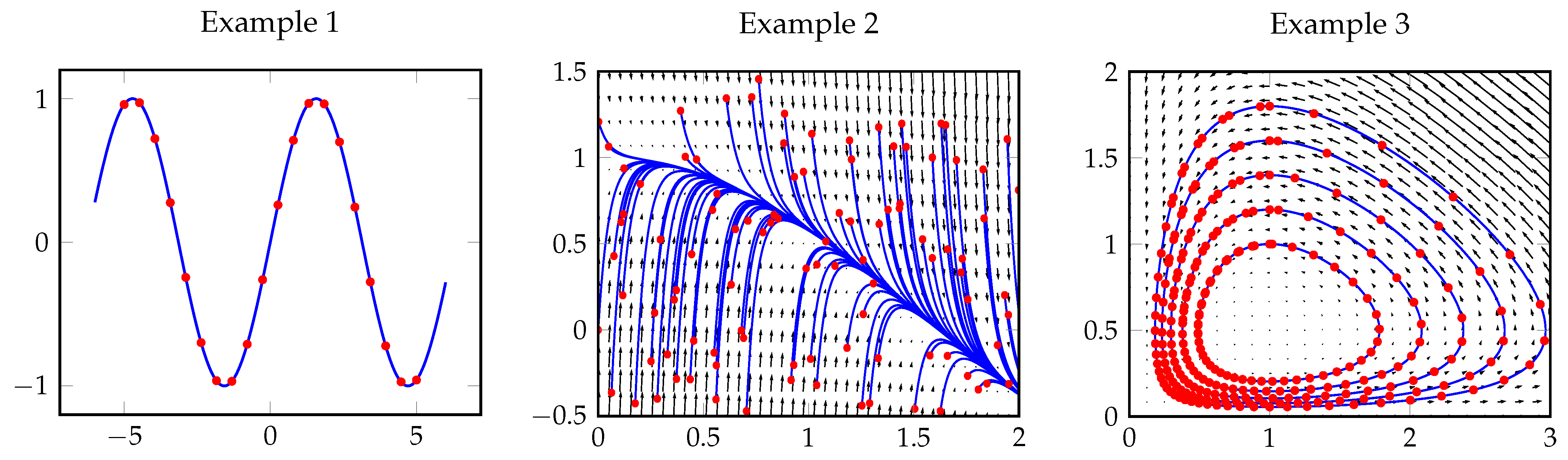
3.1. Example 1. (Regression)
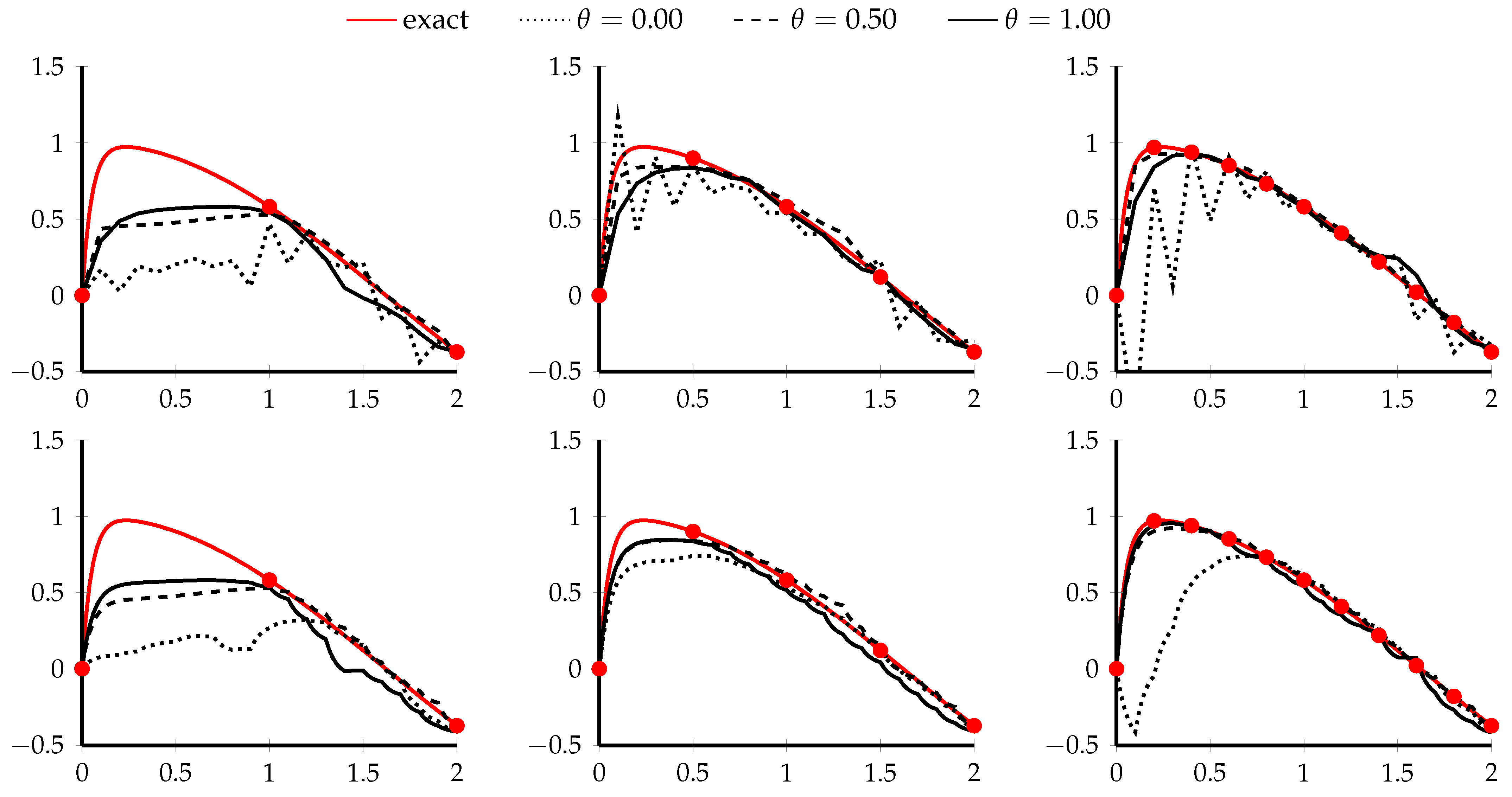
3.2. Example 2. (Stiff ODE)
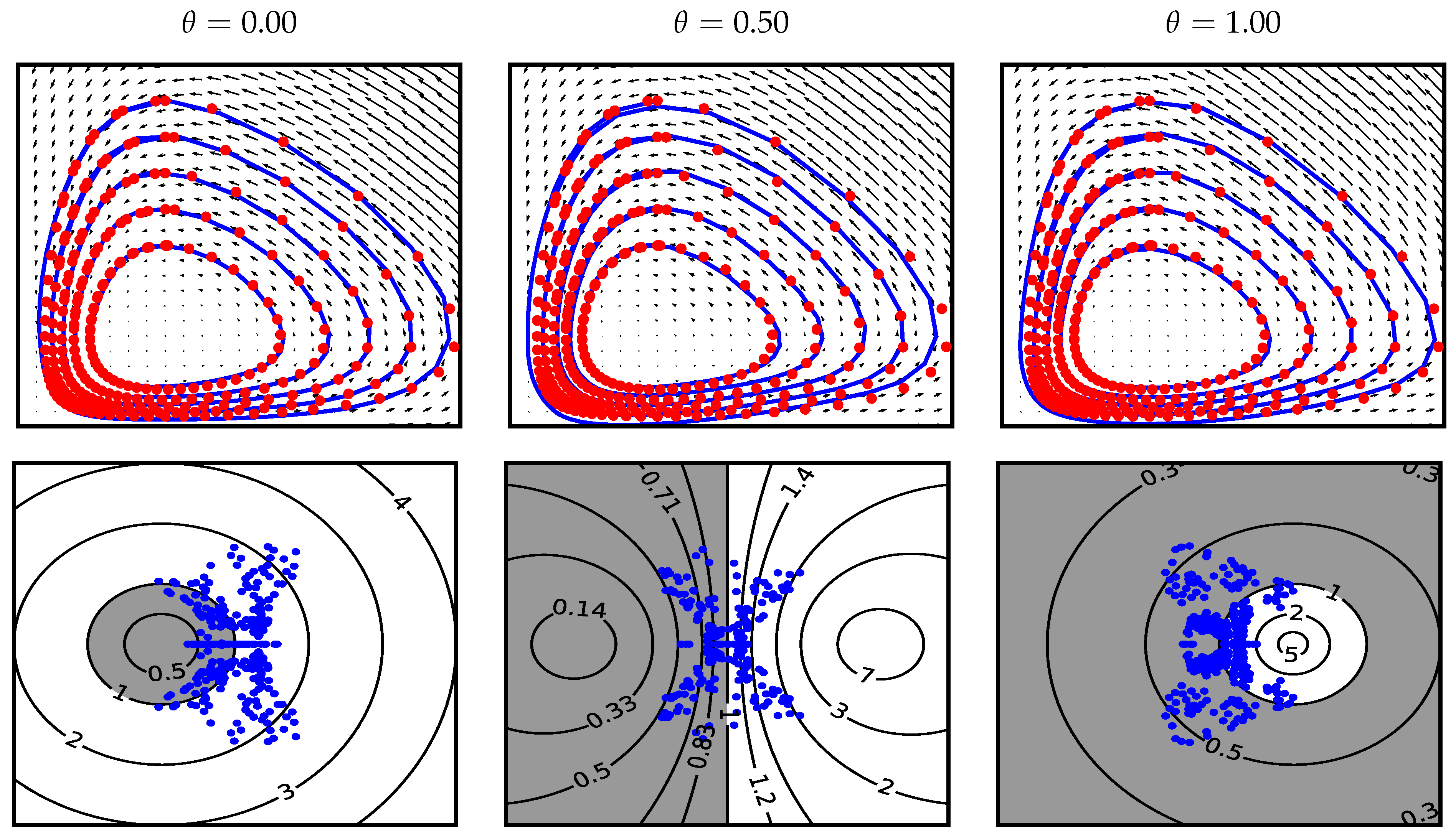
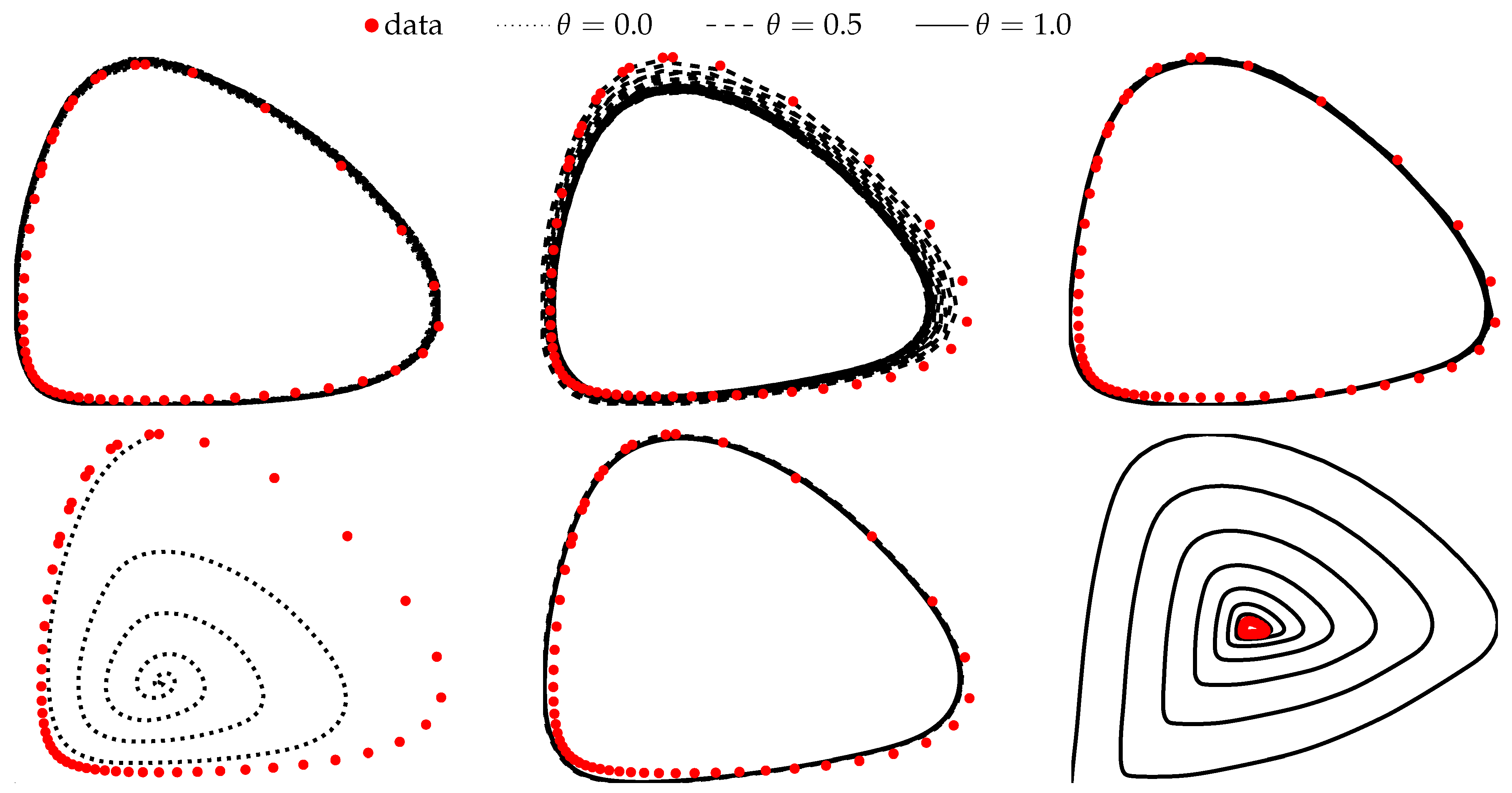
3.3. Example 3. (Periodic ODE)
3.4. Example 4. (MNIST Classification)
4. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Hanin, B. Universal function approximation by deep neural nets with bounded width and ReLU activations. Mathematics 2019, 7, 992. [Google Scholar] [CrossRef] [Green Version]
- Lu, Z.; Pu, H.; Wang, F.; Hu, Z.; Wang, L. The Expressive Power of Neural Networks: A View from the Width. In Advances in Neural Information Processing Systems 30: 31st Annual Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 6231–6239. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Weinan, E. A Proposal on Machine Learning via Dynamical Systems. Commun. Math. Stat. 2017, 5, 1–11. [Google Scholar] [CrossRef]
- Weinan, E.; Han, J.; Li, Q. A mean-field optimal control formulation of deep learning. Res. Math. Sci. 2018, 6, 10. [Google Scholar] [CrossRef] [Green Version]
- Ruthotto, L.; Haber, E. Deep Neural Networks Motivated by Partial Differential Equations. J. Math. Imaging Vis. 2020, 62, 352–364. [Google Scholar] [CrossRef] [Green Version]
- Sonoda, S.; Murata, N. Double continuum limit of deep neural networks. In Proceedings of the ICML Workshop on Principled Approaches to Deep Learning (ICML 2017), Sydney, Australia, 10 August 2017. [Google Scholar]
- Chen, T.Q.; Rubanova, Y.; Bettencourt, J.; Duvenaud, D.K. Neural Ordinary Differential Equations. In Advances in Neural Information Processing Systems 31: 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montreal, QC, Canada, 3–8 December 2018; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 6571–6583. [Google Scholar]
- Haber, E.; Ruthotto, L. Stable architectures for deep neural networks. Inverse Probl. 2017, 34, 014004. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y. A theoretical framework for back-propagation. In Proceedings of the 1988 Connectionist Models Summer School; Touretzky, D., Hinton, G., Sejnowsky, T., Eds.; Morgan Kaufmann, CMU: Pittsburgh, PA, USA, 1988; pp. 21–28. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the 14th European Conference on Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 11–14 October 2016; Lecture Notes in Computer Science. Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; Volume 9908, pp. 630–645. [Google Scholar] [CrossRef] [Green Version]
- Hairer, E.; Nørsett, S.P.; Wanner, G. Solving Ordinary Differential Equations I, Nonstiff Problems; Springer Series in Computational Mathematics; Springer: Berlin/Heidelberg, Germany, 1993; Volume 8. [Google Scholar]
- Hairer, E.; Lubich, C.; Wanner, G. Geometric Numerical Integration: Structure-Preserving Algorithms for Ordinary Differential Equations; Springer Series in Computational Mathematics; Springer: Berlin/Heidelberg, Germany, 2006; Volume 31. [Google Scholar]
- Gomez, A.N.; Ren, M.; Urtasun, R.; Grosse, R.B. The Reversible Residual Network: Backpropagation Without Storing Activations. In Advances in Neural Information Processing Systems 30: 31st Annual Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 2214–2224. [Google Scholar]
- Chang, B.; Meng, L.; Haber, E.; Ruthotto, L.; Begert, D.; Holtham, E. Reversible architectures for arbitrarily deep residual neural networks. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, LA, USA, 2–7 February 2018; AAAI Press: Palo Alto, CA, USA, 2018. [Google Scholar]
- Targ, S.; Almeida, D.; Lyman, K. Resnet in resnet: Generalizing residual architectures. arXiv 2016, arXiv:1603.08029. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 2261–2269. [Google Scholar] [CrossRef] [Green Version]
- Haber, E.; Lensink, K.; Treister, E.; Ruthotto, L. IMEXnet A Forward Stable Deep Neural Network. In Proceedings of the 36th International Conference on Machine Learning (ICML 2019), Long Beach, CA, USA, 9–15 June 2019; Chaudhuri, K., Salakhutdinov, R., Eds.; Volume 97, pp. 2525–2534. [Google Scholar]
- El Ghaoui, L.; Gu, F.; Travacca, B.; Askari, A. Implicit deep learning. arXiv 2019, arXiv:1908.06315. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. Deep Equilibrium Models. In Advances in Neural Information Processing Systems 32: 32nd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; pp. 690–701. [Google Scholar]
- Pineda, F.J. Generalization of back-propagation to recurrent neural networks. Phys. Rev. Lett. 1987, 59, 2229. [Google Scholar] [CrossRef]
- Hunt, K.J.; Sbarbaro, D.; Żbikowski, R.; Gawthrop, P.J. Neural networks for control systems—A survey. Automatica 1992, 28, 1083–1112. [Google Scholar] [CrossRef]
- Li, M.; He, L.; Lin, Z. Implicit Euler Skip Connections: Enhancing Adversarial Robustness via Numerical Stability. In Proceedings of the 37th International Conference on Machine Learning (ICML 2020), Vienna, Austria, 12–18 July 2020; Volume 119, pp. 5874–5883. [Google Scholar]
- Reshniak, V.; Webster, C. Robust Learning with Implicit Residual Networks. Unpublished work. 2020. [Google Scholar]
- Nocedal, J.; Wright, S. Numerical Optimization, 2nd ed.; Springer Series in Operations Research and Financial Engineering; Springer: New York, NY, USA, 2006. [Google Scholar]
- Sokolić, J.; Giryes, R.; Sapiro, G.; Rodrigues, M.R. Robust large margin deep neural networks. IEEE Trans. Signal Process. 2017, 65, 4265–4280. [Google Scholar] [CrossRef]
- Tsuzuku, Y.; Sato, I.; Sugiyama, M. Lipschitz-margin training: Scalable certification of perturbation invariance for deep neural networks. In Advances in Neural Information Processing Systems 31: 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montreal, QC, Canada, 3–8 December 2018; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 6541–6550. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved Training of Wasserstein GANs. In Advances in Neural Information Processing Systems 30: 31st Annual Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 5767–5777. [Google Scholar]
- Qi, G.J. Loss-Sensitive Generative Adversarial Networks on Lipschitz Densities. Int. J. Comput. Vis. 2020, 128, 1118–1140. [Google Scholar] [CrossRef] [Green Version]
- Jakubovitz, D.; Giryes, R. Improving DNN robustness to adversarial attacks using Jacobian regularization. In Proceedings of the 15th European Conference on Computer Vision (ECCV 2018), Munich, Germany, 8–14 September 2018; Lecture Notes in Computer Science. Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; pp. 514–529. [Google Scholar] [CrossRef] [Green Version]
- Hoffman, J.; Roberts, D.A.; Yaida, S. Robust learning with Jacobian regularization. arXiv 2019, arXiv:1908.02729. [Google Scholar]
- Alain, G.; Bengio, Y. What regularized auto-encoders learn from the data-generating distribution. J. Mach. Learn. Res. 2014, 15, 3563–3593. [Google Scholar]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral normalization for generative adversarial networks. In Proceedings of the Sixth International Conference on Learning Representations (ICLR 2018), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Gouk, H.; Frank, E.; Pfahringer, B.; Cree, M. Regularisation of neural networks by enforcing Lipschitz continuity. Mach. Learn. 2020. [Google Scholar] [CrossRef]
- Yoshida, Y.; Miyato, T. Spectral norm regularization for improving the generalizability of deep learning. arXiv 2017, arXiv:1705.10941. [Google Scholar]
- Behrmann, J.; Grathwohl, W.; Chen, R.T.; Duvenaud, D.; Jacobsen, J.H. Invertible Residual Networks. In Proceedings of the 36th International Conference on Machine Learning (ICML 2019), Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 573–582. [Google Scholar]
- Golub, G.H.; Van Loan, C.F. Matrix computations, 4 ed.; The Johns Hopkins University Press: Baltimore, MD, USA, 2013. [Google Scholar]
- Finlay, C.; Jacobsen, J.H.; Nurbekyan, L.; Oberman, A.M. How to train your neural ODE: The world of Jacobian and kinetic regularization. In Proceedings of the 37th International Conference on Machine Learning (ICML 2020), Vienna, Austria, 12–18 July 2020; Volume 119, pp. 3154–3164. [Google Scholar]
- Kelly, J.; Bettencourt, J.; Johnson, M.J.; Duvenaud, D. Learning Differential Equations that are Easy to Solve. In Proceedings of the 34st Annual Conference on Neural Information Processing Systems (NIPS 2020), Vancouver, BC, Canada, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H.T., Eds.; [Google Scholar]
- Hutchinson, M. A Stochastic Estimator of the Trace of the Influence Matrix for Laplacian Smoothing Splines. Commun. Stat. Simul. Comput. 1989, 18, 1059–1076. [Google Scholar] [CrossRef]
- Grathwohl, W.; Chen, R.T.; Bettencourt, J.; Sutskever, I.; Duvenaud, D. Ffjord: Free-form continuous dynamics for scalable reversible generative models. In Proceedings of the Seventh International Conference on Learning Representations (ICLR 2019), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Bekas, C.; Kokiopoulou, E.; Saad, Y. An estimator for the diagonal of a matrix. Appl. Numer. Math. 2007, 57, 1214–1229. [Google Scholar] [CrossRef] [Green Version]
- Dupont, E.; Doucet, A.; Teh, Y.W. Augmented neural ODEs. In Advances in Neural Information Processing Systems 32: 32nd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; pp. 3140–3150. [Google Scholar]












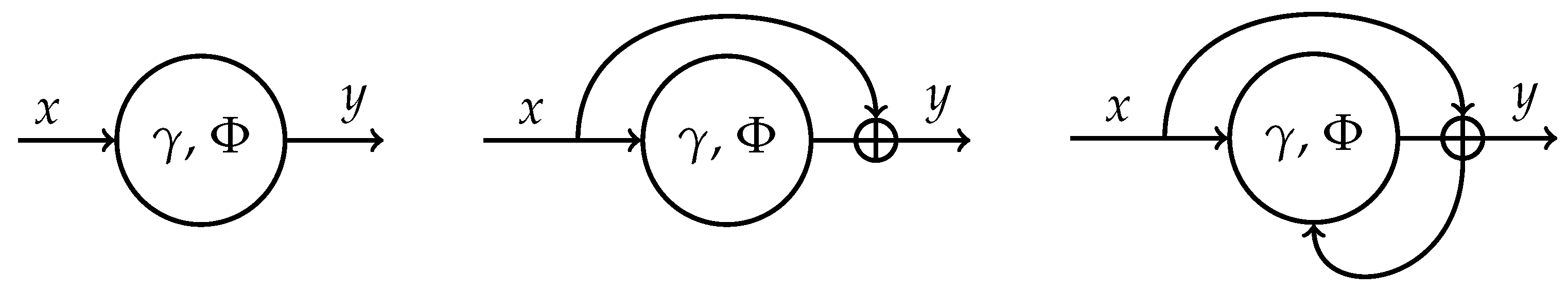{kind=link}
{kind=link}
{kind=link}
{kind=link}
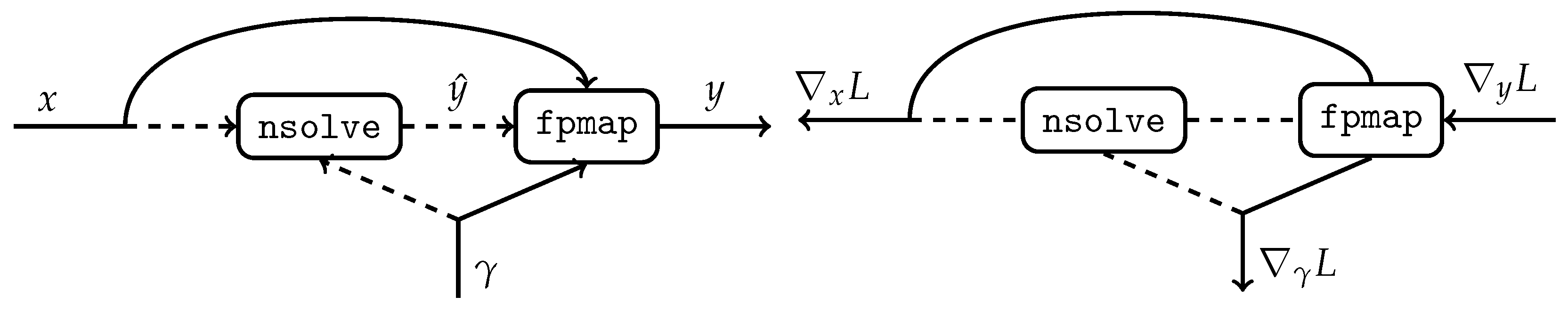{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Parameters | ||
|---|---|---|---|
| gradient descent | Wolfe conditions | scaling matrix momentum vector | |
| quasi-Newton | Wolfe conditions | approximate Hessian | |
| conjugate gradient | conjugate direction parameters |
| Noise | Top-1 Accuracy | Top-2 Accuracy | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Intensity | 0.25 | 0.50 | 0.75 | 1.00 | 0.25 | 0.50 | 0.75 | 1.00 | ||
| 0.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
| 0.1 | 98.2 | 99.6 | 99.9 | 99.9 | 99.9 | 99.7 | 100.0 | 100.0 | 100.0 | 100.0 |
| 0.2 | 89.2 | 95.7 | 96.3 | 98.3 | 98.4 | 96.7 | 99.3 | 99.8 | 100.0 | 100.0 |
| 0.3 | 74.7 | 86.0 | 89.3 | 93.2 | 93.6 | 89.0 | 95.2 | 97.8 | 99.0 | 98.8 |
| 0.4 | 59.3 | 74.1 | 77.2 | 81.8 | 84.7 | 75.5 | 89.1 | 91.1 | 94.4 | 95.0 |
| 0.5 | 47.2 | 60.4 | 64.7 | 69.8 | 73.0 | 65.7 | 79.6 | 83.4 | 87.1 | 87.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Reshniak, V.; Webster, C.G. Robust Learning with Implicit Residual Networks. Mach. Learn. Knowl. Extr. 2021, 3, 34-55. https://doi.org/10.3390/make3010003
Reshniak V, Webster CG. Robust Learning with Implicit Residual Networks. Machine Learning and Knowledge Extraction. 2021; 3(1):34-55. https://doi.org/10.3390/make3010003
Chicago/Turabian StyleReshniak, Viktor, and Clayton G. Webster. 2021. "Robust Learning with Implicit Residual Networks" Machine Learning and Knowledge Extraction 3, no. 1: 34-55. https://doi.org/10.3390/make3010003