AI System Engineering—Key Challenges and Lessons Learned †

 ,
,  , , , , , , and
, , , , , , and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- Hurdles from Current Machine Learning Paradigms, see Section 2. These modelling and system development steps are made much more challenging by hurdles resulting from current machine learning paradigms. Such hurdles result from limitations of nowadays theoretical foundations in statistical learning theory and peculiarities or shortcomings of today’s deep learning methods.
- −
- Theory-practice gap in machine learning with impact on reproducibilty and stability;
- −
- Lack of uniqueness of internal configuration of deep learning models with impact on reproducibility, transparancy and interpretability;
- −
- Lack of confidence measure of deep learning models with impact on trustworthiness and interpretability;
- −
- Lack of control of high-dimensionality effects of deep learning model with impact on stability, integrity and interpretability.
- Key Challenges of AI Model Lifecycle, see Section 3. The development of data-driven AI models and software systems therefore faces novel challenges at all stages of the AI model and AI system lifecycle, which arise along transforming data to learning models in the design and training phase, particularly.
- −
- Data challenge to fuel the learning models with sufficiently representative data or to otherwise compensate for their lack, as for example by means of data conditioning techniques like data augmentation;
- −
- Information fusion challenge to incorporate constraints or knowledge available in different knowledge representation;
- −
- Model integrity and stability challenge due to unstable performance profiles triggered by small variations in the implementation or input data (adversarial noise);
- −
- Security and confidentiality to shield machine learning driven systems from espionage or adversarial interventions;
- −
- Interpretability and transparancy challenge to decode the ambiguities of hidden implicit knowledge representation of distributed neural parametrization;
- −
- Trust challenge to consider ethical aspects as a matter of principle, for example, to ensure correct behavior even in case of a possible malfunction or failure.
- Key Challenges of AI System Lifecycle, see Section 4. Once a proof of concept of a data-driven solution to a machine learning problem has been tackled by means of sufficient data and appropriate learning models, requirements beyond the proper machine learning performance criteria have to be taken into account to come up with a software system for a target computational platform intended to operate in a target operational environment. Key challenges arise from application specific requirements:
- −
- Deployment challenge and computational resource constraints, for example, on embedded systems or edge hardware;
- −
- Data and software quality;
- −
- Model validation and system verification including testing, debugging and documentation, for example, certification and regulation challenges resulting from highly regulated target domains such as in a bio-medical laboratory setting.
Outline and Structure
- Overview of challenges and analysis
- Outline of approaches from selected ongoing research projects
- (1)
- Automated and Continuous Data Quality Assurance (see Section 5.1)
- (2)
- Domain Adaptation Approach for Tackling Deviating Data Characteristics at Training and Test Time (see Section 5.2)
- (3)
- Hybrid Model Design for Improving Model Accuracy (see Section 5.3)
- (4)
- Interpretability by Correction Model Approach (see Section 5.4)
- (5)
- Software Quality by Automated Code Analysis and Documentation Generation (see Section 5.5)
- (6)
- The ALOHA Toolchain for Embedded Platforms (see Section 5.6)
- (7)
- Confidentiality-Preserving Transfer Learning (see Section 5.7)
- (8)
- Human AI Teaming as Key to Human Centered AI (see Section 5.8)
2. Hurdles from Current Machine Learning Paradigms
2.1. Theory-Practice Gap in Machine Learning
2.2. Lack of Uniqueness of Internal Configuration
2.3. Lack of Confidence Measure
2.4. Lack of Control of High-Dimensionality Effects
3. Key Challenges of AI Model Lifecycle
3.1. Data Challenge: Data Augmentation with Pitfalls
3.2. Information Fusion Challenge
- Current deep learning models cannot capture the fully semantic knowledge of the multimodal data. Although attention mechanisms can be used to mitigate these problems partly, they work implicitly and cannot be actively controlled. In this context the combination of deep learning with semantic fusion and reasoning strategies are promising approaches [39].
- In contrast to the widespread use of convenient and effective knowledge transfer strategies in the image and language domain, similar methods are not yet available for audio or video data, not to mention other fields of applications for example, in manufacturing.
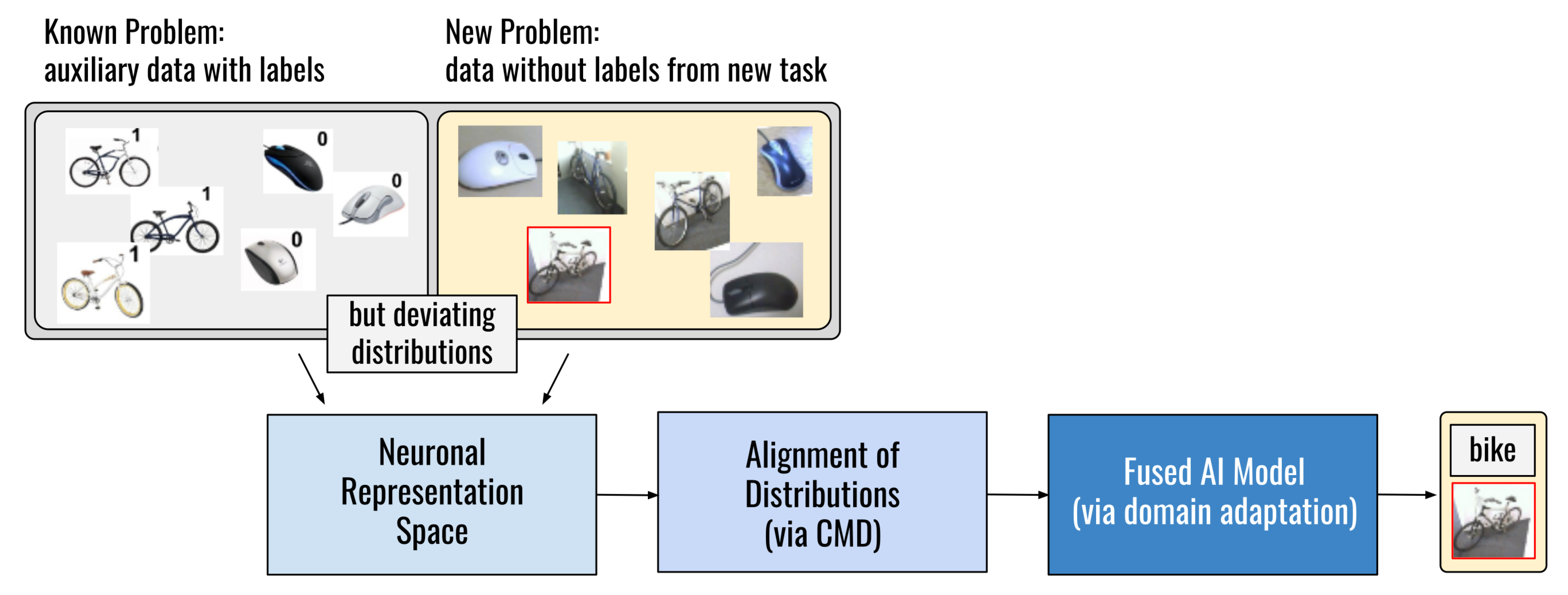
- The situation is worsened when it comes to dynamically changing data with shifts in its distribution. The traditional method of deep learning for adopting to dynamic multimodal data is to train a new model when the data distribution changes. This, however, takes too much time and is therefore not feasible in many applications. A promising approach is the combination with transfer learning techniques, which aim to handle deviating distributions as outlined in References [40,41]. See also Section 2.1.
3.3. Model Integrity and Stability Challenge
3.4. Security and Confidentiality Challenge
3.5. Interpretability Challenge
3.6. Trust Challenge
- in terms of high level ethical guidelines (e.g., ethics boards such as algorithmwatch.org (https://algorithmwatch.org/en/project/ai-ethics-guidelines-global-inventory/), EU’s Draft Ethics Guidelines (https://ec.europa.eu/digital-single-market/en/news/ethics-guidelines-trustworthy-ai));
- in terms of regulatory postulates for current AI systems regarding for example, transparency (working groups on standardization, for example, ISO/IEC JTC 1/SC 42 on artificial intelligence (https://www.iso.org/committee/6794475/x/catalogue/p/0/u/1/w/0/d/0));
- in terms of trust modelling approaches (e.g., multi-agent systems community [76]).
4. Key Challenges of AI System Lifecycle
4.1. Deployment Challenge and Computational Resource Constraints
4.2. Data and Software Quality
4.2.1. Data Quality Assurance Challenge
- Missing data is a prevalent problem in data sets. In industrial use cases, faulty sensors or errors during data integration are common causes for systematically missing values. Historically, a lot of research into missing data comes from the social sciences, especially with respect to survey data, whereas little research work deals with industrial missing data [24]. In terms of missing data handling, it is distinguished between deletion methods (where records with missing values are simply not used), and imputation methods, where missing values are replaced with estimated values for a specific analysis [24]. Little & Rubin [92] state that “the idea of imputation is both seductive and dangerous”, pointing out the fact that the imputed data is pretended to be truly complete, but might have substantial bias that impairs inference. For example, the common practice of replacing missing values with the mean of the respective variable (known as mean substitution) clearly disturbs the variance of the respective variable as well as correlations to other variables. A more sophisticated statistical approach as investigated in Reference [24] is multiple imputation, where each missing value is replaced with a set of plausible values to represent the uncertainty caused by the imputation and to decrease the bias in downstream prediction tasks. In a follow-up research, also the integration of knowledge about missing data pattern is investigated.
- Semantic shift (also: semantic change, semantic drift) is a term originally stemming from linguistics and describes the evolution of word meaning over time, which can have different triggers and development [93]. In the context of data quality, semantic shift is defined as the circumstance when “the meaning of data evolves depending on contextual factors” [94]. Consequently, when these factors are modeled accordingly (e.g., described with rules), it is possible to handle semantic shift even in very complex environments as outlined in Reference [94]. While the most common ways to overcome semantic shift are rule-based approaches, more sophisticated approaches take into account the semantics of the data to reach a higher degree of automation. Example information about contextual knowledge are the respective sensor or machine with which the data is collected [94].
- Duplicate data describes the issue that one real-world entity has more than one representation in an information system [95,96,97,98]. This subtopic of data quality is also commonly referred to as entity resolution, redundancy detection, record linkage, record matching, or data merging [96]. Specifically, the detection of approximate duplicates has been researched intensively over the last decades [99].
4.2.2. Software Quality: Configuration Maintenance Challenge
5. Approaches, In-Progress Research and Lessons Learned
- (1)
- Automated and Continuous Data Quality Assurance, see Section 5.1;
- (2)
- Domain Adaptation Approach for Tackling Deviating Data Characteristics at Training and Test Time, see Section 5.2;
- (3)
- Hybrid Model Design for Improving Model Accuracy, see Section 5.3;
- (4)
- Interpretability by Correction Model Approach, see Section 5.4;
- (5)
- Software Quality by Automated Code Analysis and Documentation Generation, see Section 5.5;
- (6)
- The ALOHA Toolchain for Embedded Platforms, see Section 5.6;
- (7)
- Confidentiality-Preserving Transfer Learning, see Section 5.7;
- (8)
- Human AI Teaming as Key to Human Centered AI, see Section 5.8.
5.1. Approach 1 on Automated and Continuous Data Quality Assurance
5.2. Approach 2 on Domain Adaptation Approach for Tackling Deviating Data Characteristics at Training and Test Time
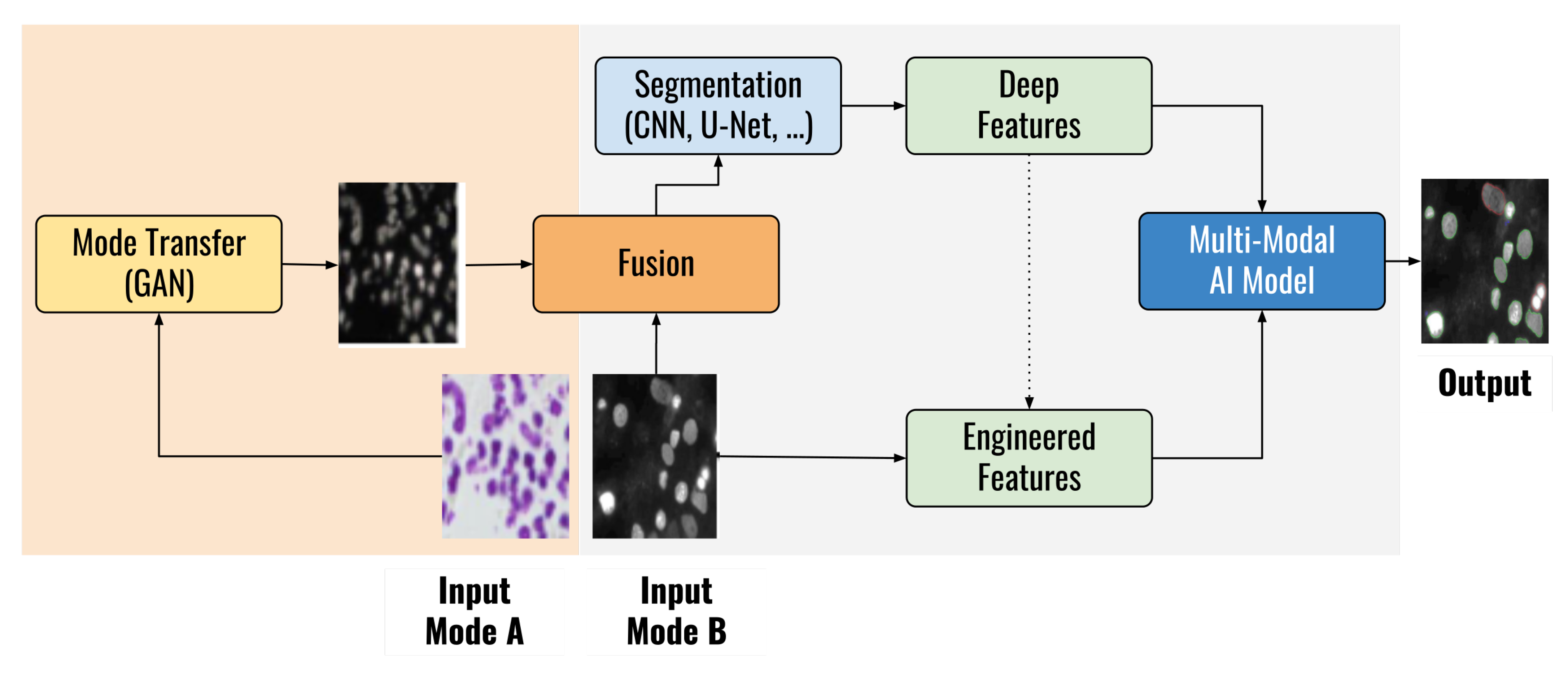
5.3. Approach 3 on Hybrid Model Design for Improving Model Accuracy by Integrating Expert Hints in Biomedical Diagnostics
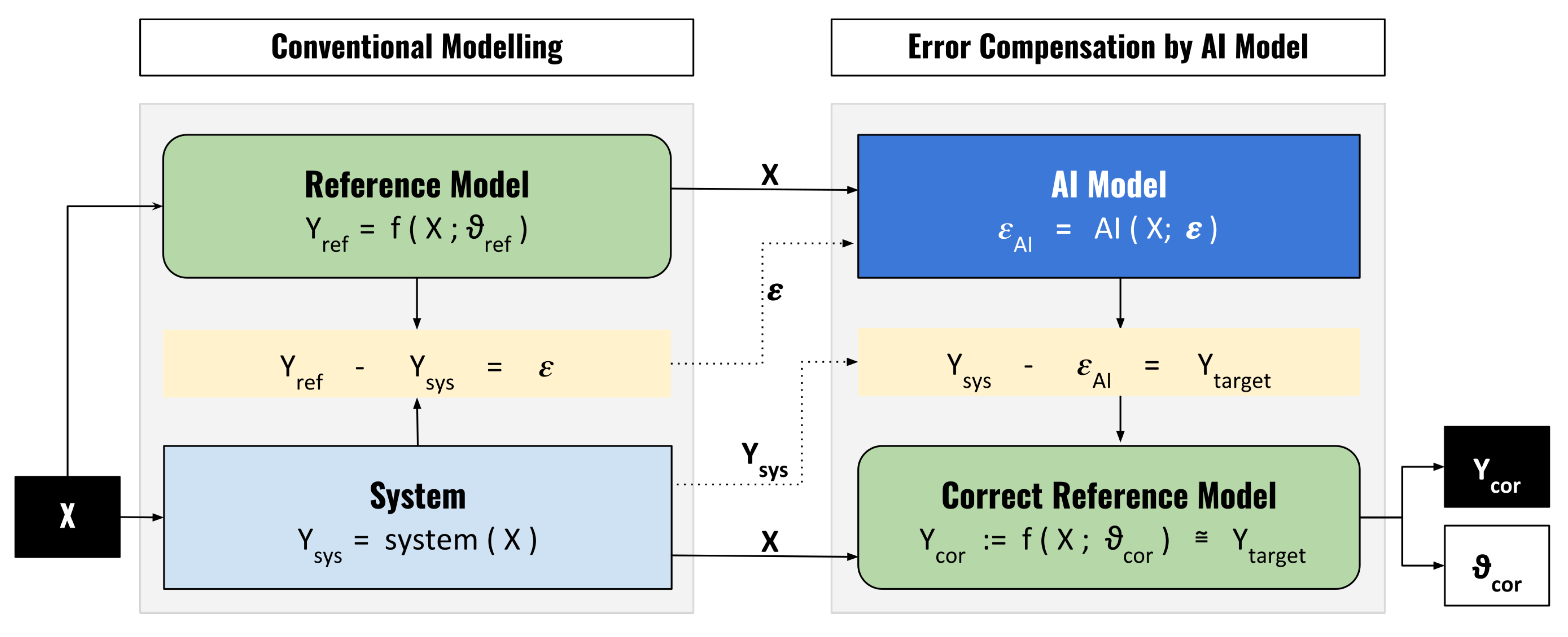
5.4. Approach 4 on Interpretability by Correction Model Approach
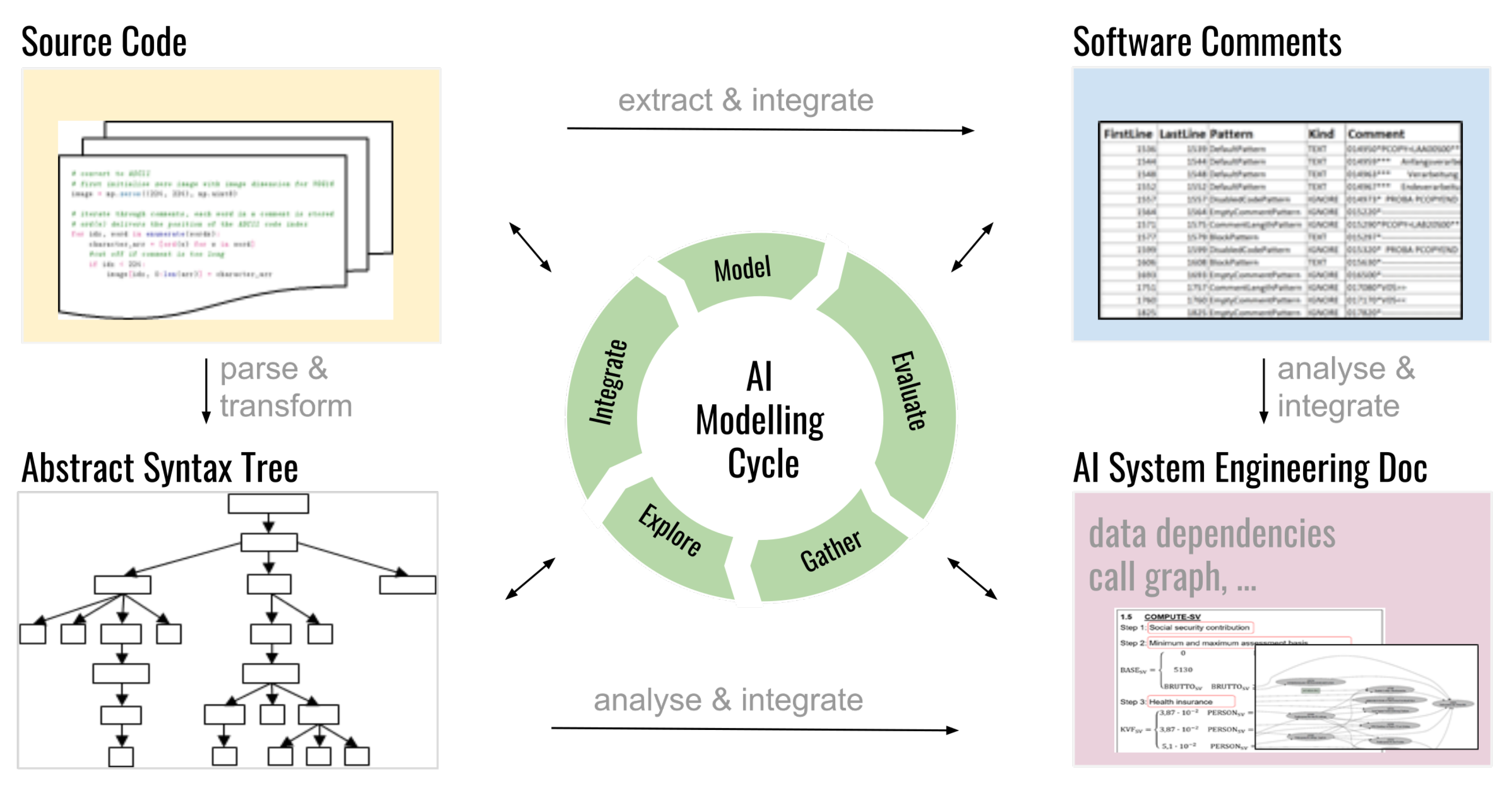
5.5. Approach 5 on Software Quality by Code Analysis and Automated Documentation
5.6. Approach 6 on the ALOHA Toolchain for Embedded AI Platforms
- (Step 1) algorithm selection,
- (Step 2) application partitioning and mapping, and
- (Step 3) deployment on target hardware.
5.7. Approach 7 on Confidentiality-Preserving Transfer Learning
- (1)
- How to design a noise adding mechanism that achieves a given differential privacy-loss bound with the minimum loss in accuracy?
- (2)
- How to quantify the privacy-leakage? How to determine the noise model with optimal tradeoff between privacy-leakage and the loss of accuracy?
- (3)
- What is the scope of applicability in terms of assumptions on the distribution of the input data and, what is about model fusion in a transfer learning setting?
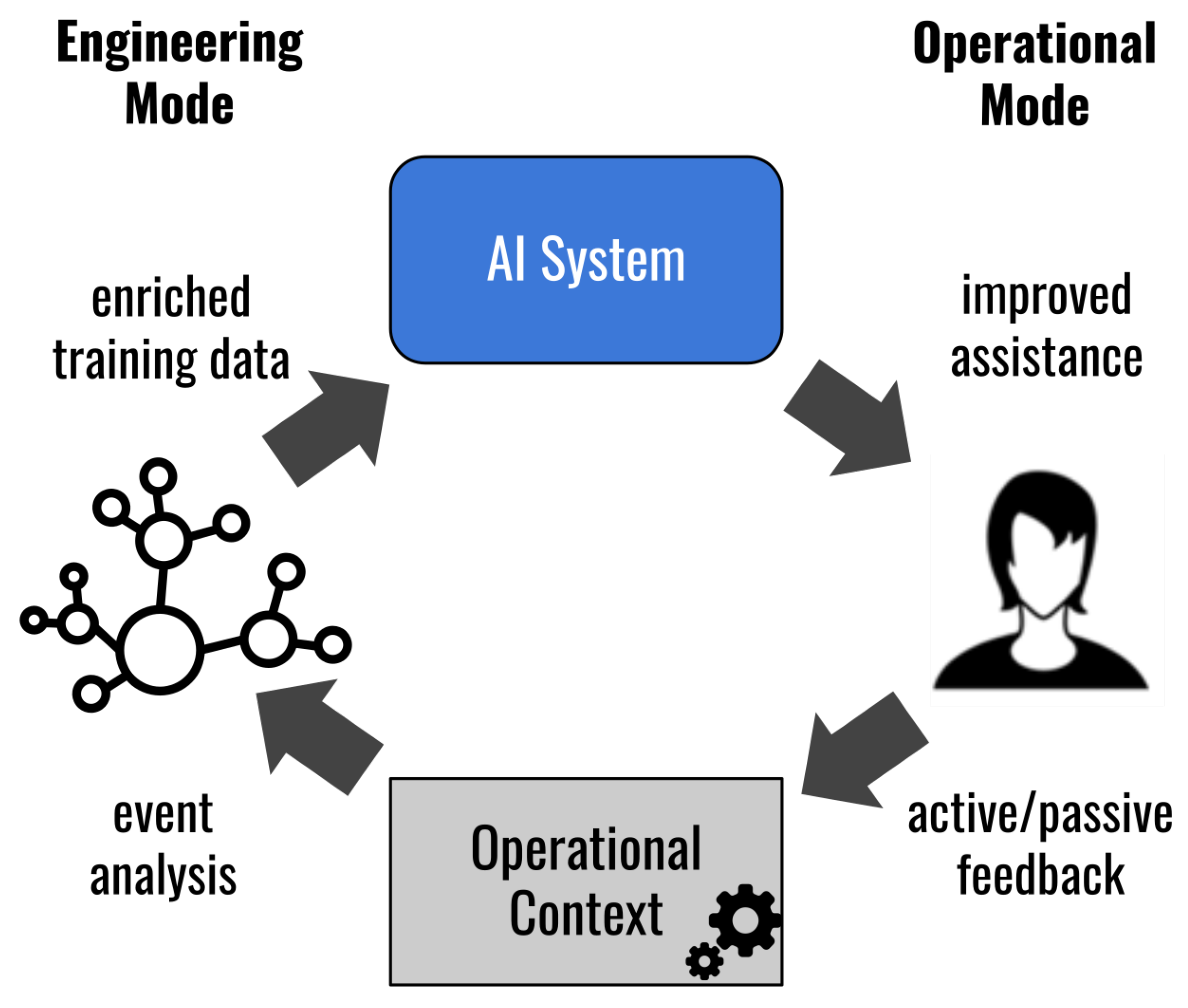
5.8. Approach 8 on Human AI Teaming as Key to Human Centered AI
6. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| AOW | Architecture Optimization Workbench |
| BAPC | Before and After Correction Parameter Comparison |
| CMD | Centralized Moment Discrepancy |
| DaQL | Data Quality Library |
| DL | Deep Learning |
| DNN | Deep Neural Networks |
| GAN | Generative Adversarial Network |
| KG | Knowledge Graph |
| MDPI | Multidisciplinary Digital Publishing Institute |
| ML | Machine Learning |
| NLP | Natural Language Processing |
| ONNX | Open Neural Network Exchange |
| SNPa | Single-Nucleotide Polymorphism array |
| XAI | Explainable AI |
References
- Holzinger, A. Introduction to machine learning and knowledge extraction (MAKE). Mach. Learn. Knowl. Extr. 2017, 1, 1. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Sünderhauf, N.; Brock, O.; Scheirer, W.; Hadsell, R.; Fox, D.; Leitner, J.; Upcroft, B.; Abbeel, P.; Burgard, W.; Milford, M.; et al. the limits and potentials of deep learning for robotics. Int. J. Robot. Res. 2018, 37, 405–420. [Google Scholar] [CrossRef]
- Fischer, L.; Ehrlinger, L.; Geist, V.; Ramler, R.; Sobieczky, F.; Zellinger, W.; Moser, B. Applying AI in Practice: Key Challenges and Lessons Learned. In Proceedings of the Machine Learning and Knowledge Extraction—4th IFIP TC 5, TC 12, WG 8.4, WG 8.9, WG 12.9 International Cross-Domain Conference (CD-MAKE 2020), Dublin, Ireland, 25–28 August 2020; Lecture Notes in Computer, Science. Holzinger, A., Kieseberg, P., Tjoa, A.M., Weippl, E.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12279, pp. 451–471. [Google Scholar]
- Paleyes, A.; Urma, R.G.; Lawrence, N.D. Challenges in Deploying Machine Learning: A Survey of Case Studies. arXiv 2020, arXiv:2011.09926. [Google Scholar]
- Vapnik, V.N. Statistical Learning Theory; Wiley-Interscience: Hoboken, NJ, USA, 1998. [Google Scholar]
- Quionero-Candela, J.; Sugiyama, M.; Schwaighofer, A.; Lawrence, N.D. Dataset Shift in Machine Learning; The MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Jiang, J.; Zhai, C. Instance weighting for domain adaptation in NLP. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, Prague, Czech Republic, 25–27 June 2007; pp. 264–271. [Google Scholar]
- Zellinger, W.; Grubinger, T.; Lughofer, E.; Natschläger, T.; Saminger-Platz, S. Central Moment Discrepancy (CMD) for Domain-Invariant Representation Learning. In Proceedings of the 5th International Conference on Learning Representations (ICLR 2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Zellinger, W.; Moser, B.A.; Grubinger, T.; Lughofer, E.; Natschläger, T.; Saminger-Platz, S. Robust unsupervised domain adaptation for neural networks via moment alignment. Inf. Sci. 2019, 483, 174–191. [Google Scholar] [CrossRef]
- Xu, G.; Huang, J.Z. Asymptotic optimality and efficient computation of the leave-subject-out cross-validation. Ann. Stat. 2012, 40, 3003–3030. [Google Scholar] [CrossRef]
- Little, M.A.; Varoquaux, G.; Saeb, S.; Lonini, L.; Jayaraman, A.; Mohr, D.C.; Kording, K.P. Using and understanding cross-validation strategies. Perspectives on Saeb et al. GigaScience 2017, 6, gix020. [Google Scholar] [CrossRef]
- Samek, W.; Wiegand, T.; Müller, K.R. Explainable Artificial Intelligence: Understanding, Visualizing and Interpreting Deep Learning Models. arXiv 2017, arXiv:1708.08296. [Google Scholar]
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding deep learning requires rethinking generalization. In Proceedings of the 5th International Conference on Learning Representations (ICLR 2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Vidal, R.; Bruna, J.; Giryes, R.; Soatto, S. Mathematics of Deep Learning. arXiv 2017, arXiv:1712.04741. [Google Scholar]
- Gal, Y. Uncertainty in Deep Learning. Ph.D. Thesis, University of Cambridge, Cambridge, UK, 2016. [Google Scholar]
- Guo, C.; Pleiss, G.; Sun, Y.; Weinberger, K.Q. On Calibration of Modern Neural Networks. In Proceedings of the 34th International Conference on Machine Learning (ICML’17), Sydney, Australia, 6–11 August 2017; Volume 70, pp. 1321–1330. [Google Scholar]
- Hein, M.; Andriushchenko, M.; Bitterwolf, J. Why ReLU networks yield high-confidence predictions far away from the training data and how to mitigate the problem. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 41–50. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. In Proceedings of the 33rd International Conference on International Conference on Machine Learning (ICML’16), New York, NY, USA, 19–24 June 2016; Volume 48, pp. 1050–1059. [Google Scholar]
- Gorban, A.N.; Tyukin, I.Y. Blessing of dimensionality: Mathematical foundations of the statistical physics of data. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2018, 376, 20170237. [Google Scholar] [CrossRef]
- Galloway, A.; Taylor, G.W.; Moussa, M. Predicting Adversarial Examples with High Confidence. arXiv 2018, arXiv:1802.04457. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2014, arXiv:1312.6199. [Google Scholar]
- Athalye, A.; Engstrom, L.; Ilyas, A.; Kwok, K. Synthesizing Robust Adversarial Examples. arXiv 2017, arXiv:1707.07397. [Google Scholar]
- Ehrlinger, L.; Grubinger, T.; Varga, B.; Pichler, M.; Natschläger, T.; Zeindl, J. Treating Missing Data in Industrial Data Analytics. In Proceedings of the 2018 IEEE Thirteenth International Conference on Digital Information Management (ICDIM), Berlin, Germany, 24–26 September 2018; pp. 148–155. [Google Scholar]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Antoniou, A.; Storkey, A.J.; Edwards, H. Data Augmentation Generative Adversarial Networks. arXiv 2017, arXiv:1711.04340. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Papernot, N.; Oliver, A.; Raffel, C.A. Mixmatch: A holistic approach to semi-supervised learning. In Proceedings of the 33rd Annual Conference on Neural Information Processing Systems, Vancouver, Canada, 8–14 December 2019; pp. 5050–5060. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2018, arXiv:1710.09412. [Google Scholar]
- Verma, V.; Lamb, A.; Beckham, C.; Najafi, A.; Mitliagkas, I.; Lopez-Paz, D.; Bengio, Y. Manifold Mixup: Better Representations by Interpolating Hidden States. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; Chaudhuri, K., Salakhutdinov, R., Eds.; PMLR: Long Beach, CA, USA, 2019; Volume 97, pp. 6438–6447. [Google Scholar]
- Xiao, C.; Li, B.; Zhu, J.Y.; He, W.; Liu, M.; Song, D. Generating Adversarial Examples with Adversarial Networks. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI-18), Stockholm, Sweden, 13–19 July 2018; pp. 3905–3911. [Google Scholar]
- Battaglia, P.W.; Hamrick, J.B.; Bapst, V.; Sanchez-Gonzalez, A.; Zambaldi, V.; Malinowski, M.; Tacchetti, A.; Raposo, D.; Santoro, A.; Faulkner, R.; et al. Relational inductive biases, deep learning, and graph networks. arXiv 2018, arXiv:1806.01261. [Google Scholar]
- Eghbal-zadeh, H.; Koutini, K.; Primus, P.; Haunschmid, V.; Lewandowski, M.; Zellinger, W.; Moser, B.A.; Widmer, G. On Data Augmentation and Adversarial Risk: An Empirical Analysis. arXiv 2020, arXiv:2007.02650. [Google Scholar]
- Wang, Y.; Wu, C.; Herranz, L.; van de Weijer, J.; Gonzalez-Garcia, A.; Raducanu, B. Transferring GANs: Generating Images from Limited Data. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 220–236. [Google Scholar]
- Xu, K.; Ba, J.L.; Kiros, R.; Cho, K.; Courville, A.; Salakhutdinov, R.; Zemel, R.S.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the 32nd International Conference on International Conference on Machine Learning (ICML’15), Lille, France, 7–9 July 2015; Volume 37, pp. 2048–2057. [Google Scholar]
- Chen, X.; Lin, X. Big Data Deep Learning: Challenges and Perspectives. IEEE Access 2014, 2, 514–525. [Google Scholar] [CrossRef]
- Lahat, D.; Adali, T.; Jutten, C. Multimodal Data Fusion: An Overview of Methods, Challenges, and Prospects. Proc. IEEE 2015, 103, 1449–1477. [Google Scholar] [CrossRef]
- Lv, Z.; Song, H.; Basanta-Val, P.; Steed, A.; Jo, M. Next-Generation Big Data Analytics: State of the Art, Challenges, and Future Research Topics. IEEE Trans. Ind. Inform. 2017, 13, 1891–1899. [Google Scholar] [CrossRef]
- Guo, W.; Wang, J.; Wang, S. Deep Multimodal Representation Learning: A Survey. IEEE Access 2019, 7, 63373–63394. [Google Scholar] [CrossRef]
- Thangarajah, A.; Wu, Q.; Yang, Y.; Safaei, A. Fusion of transfer learning features and its application in image classification. In Proceedings of the 2017 IEEE 30th Canadian Conference on Electrical and Computer Engineering (CCECE), Windsor, ON, Canada, 30 April–3 May 2017; pp. 1–5. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Darrell, T.; Saenko, K. Simultaneous Deep Transfer Across Domains and Tasks. In Proceedings of the IEEE International Conference on Computer Vision 2015, Santiago, Chile, 7–13 December 2015; pp. 4068–4076. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2015, arXiv:1412.6572. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial examples in the physical world. arXiv 2017, arXiv:1607.02533. [Google Scholar]
- Biggio, B.; Roli, F. Wild patterns: Ten years after the rise of adversarial machine learning. Pattern Recognit. 2018, 84, 317–331. [Google Scholar] [CrossRef]
- Carlini, N.; Liu, C.; Erlingsson, U.; Kos, J.; Song, D. The Secret Sharer: Evaluating and Testing Unintended Memorization in Neural Networks. In Proceedings of the 28th USENIX Conference on Security Symposium (SEC’19), Santa Clara, CA, USA, 14–16 August 2019; USENIX Association: Berkeley, CA, USA, 2019; pp. 267–284. [Google Scholar]
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model Inversion Attacks That Exploit Confidence Information and Basic Countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security (CCS ’15), Denver, CO, USA, 12–16 October 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1322–1333. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership Inference Attacks Against Machine Learning Models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–24 May 2017; pp. 3–18. [Google Scholar]
- Nasr, M.; Shokri, R.; Houmansadr, A. Comprehensive Privacy Analysis of Deep Learning: Passive and Active White-box Inference Attacks against Centralized and Federated Learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 739–753. [Google Scholar]
- Truex, S.; Liu, L.; Gursoy, M.; Yu, L.; Wei, W. Demystifying Membership Inference Attacks in Machine Learning as a Service. IEEE Trans. Serv. Comput. 2019. [Google Scholar] [CrossRef]
- Long, Y.; Bindschaedler, V.; Wang, L.; Bu, D.; Wang, X.; Tang, H.; Gunter, C.A.; Chen, K. Understanding membership inferences on well-generalized learning models. arXiv 2018, arXiv:1802.04889. [Google Scholar]
- Ganju, K.; Wang, Q.; Yang, W.; Gunter, C.A.; Borisov, N. Property Inference Attacks on Fully Connected Neural Networks Using Permutation Invariant Representations. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; Association for Computing Machinery: New York, NY, USA, 2018. CCS ’18. pp. 619–633. [Google Scholar]
- Rigaki, M.; Garcia, S. A Survey of Privacy Attacks in Machine Learning. arXiv 2020, arXiv:2007.07646. [Google Scholar]
- Konečný, J.; McMahan, B.; Ramage, D. Federated Optimization:Distributed Optimization Beyond the Datacenter. arXiv 2015, arXiv:1511.03575. [Google Scholar]
- Dwork, C.; Roth, A. The Algorithmic Foundations of Differential Privacy. Found. Trends theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Yang, M.; Song, L.; Xu, J.; Li, C.; Tan, G. the Tradeoff Between Privacy and Accuracy in Anomaly Detection Using Federated XGBoost. arXiv 2019, arXiv:1907.07157. [Google Scholar]
- Ah-Fat, P.; Huth, M. Optimal accuracy privacy trade-off for secure computations. IEEE Trans. Inf. Theory 2019, 65, 3165–3182. [Google Scholar] [CrossRef]
- Hiessl, T.; Schall, D.; Kemnitz, J.; Schulte, S. Industrial Federated Learning—Requirements and System Design. In Highlights in Practical Applications of Agents, Multi-Agent Systems, and Trust-Worthiness; The PAAMS Collection, De La Prieta, F., Mathieu, P., Rincón Arango, J.A., El Bolock, A., Del Val, E., Jordán Prunera, J., Carneiro, J., Fuentes, R., Lopes, F., Julian, V., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 42–53. [Google Scholar]
- Zellinger, W.; Wieser, V.; Kumar, M.; Brunner, D.; Shepeleva, N.; Gálvez, R.; Langer, J.; Fischer, L.; Moser, B. Beyond Federated Learning: On Confidentiality-Critical Machine Learning Applications in Industry. In Proceedings of the International Conference on Industry 4.0 and Smart Manufacturing (ISM), Dublin, Ireland, 7–11 June 2020. in press. [Google Scholar]
- London, A. Artificial Intelligence and Black-Box Medical Decisions: Accuracy versus Explainability. Hastings Cent. Rep. 2019, 49, 15–21. [Google Scholar] [CrossRef]
- Holzinger, A.; Kieseberg, P.; Weippl, E.; Tjoa, A. Current Advances, Trends and Challenges of Machine Learning and Knowledge Extraction: From Machine Learning to Explainable AI; CD-MAKE; Lecture Notes in Computer Science; Springer International: Cham, Switzerland, 2018; pp. 1–8. [Google Scholar]
- Skala, K. (Ed.) Explainable Artificial Intelligence: A Survey. In Proceedings of the Croatian Society for Information and Communication Technology, Electronics and Microelectronics—MIPRO 2018, Opatija, Croatia, 21–25 May 2018; pp. 210–215. [Google Scholar]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine Learning Interpretability: A Survey on Methods and Metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef]
- Doshi-Velez, F.; Kim, B. Towards A Rigorous Science of Interpretable Machine Learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A Survey of Methods for Explaining Black Box Models. ACM Comput. Surv. 2018, 51, 1–42. [Google Scholar] [CrossRef]
- Obermeyer, Z.; Powers, B.; Vogeli, C.; Mullainathan, S. Dissecting racial bias in an algorithm used to manage the health of populations. Science 2019, 366, 447–453. [Google Scholar] [CrossRef]
- Char, D.S.; Shah, N.H.; Magnus, D. Implementing Machine Learning in Health Care—Addressing Ethical Challenges. N. Engl. J. Med. 2018, 378, 981–983. [Google Scholar] [CrossRef]
- Deeks, A. the Judicial Demand for Explainable Artificial Intelligence. Columbia Law Rev. 2019, 119, 1829–1850. [Google Scholar]
- Lombrozo, T. Explanatory preferences shape learning and inference. Trends Cogn. Sci. 2016, 20, 748–759. [Google Scholar] [CrossRef] [PubMed]
- Forcier, M.B.; Gallois, H.; Mullan, S.; Joly, Y. Integrating artificial intelligence into health care through data access: Can the GDPR act as a beacon for policymakers? J. Law Biosci. 2019, 6, 317–335. [Google Scholar] [CrossRef] [PubMed]
- Holzinger, A.; Langs, G.; Denk, H.; Zatloukal, K.; Müller, H. Causability and explainability of artificial intelligence in medicine. WIREs Data Min. Knowl. Discov. 2019, 9, e1312. [Google Scholar] [CrossRef] [PubMed]
- Zou, J.; Schiebinger, L. AI can be sexist and racist—It’s time to make it fair. Nature 2018, 559, 324–326. [Google Scholar] [CrossRef] [PubMed]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining Explanations: An Overview of Interpretability of Machine Learning. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; pp. 80–89. [Google Scholar]
- Holzinger, A. Interactive Machine Learning for Health Informatics: When do we need the human-in-the-loop? Brain Inform. 2016, 3, 119–131. [Google Scholar] [CrossRef] [PubMed]
- Holzinger, A.; Carrington, A.; Müller, H. Measuring the Quality of Explanations: The System Causability Scale (SCS). In KI-Künstliche Intelligenz (German J. Artif. Intell.); Special Issue on Interactive Machine Learning; Kersting, K., Ed.; TU Darmstadt: Darmstadt, Germany, 2020; Volume 34, pp. 193–198. [Google Scholar]
- Amershi, S.; Weld, D.; Vorvoreanu, M.; Fourney, A.; Nushi, B.; Collisson, P.; Suh, J.; Iqbal, S.; Bennett, P.N.; Inkpen, K.; et al. Guidelines for Human-AI Interaction. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems (CHI ’19), Glasgow, UK, 4–9 May 2019. [Google Scholar]
- Cohen, R.; Schaekermann, M.; Liu, S.; Cormier, M. Trusted AI and the Contribution of Trust Modeling in Multiagent Systems. In Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems (AAMAS ’19), Montreal, QC, Canada, 13–17 July 2019; pp. 1644–1648. [Google Scholar]
- Gunning, D. DARPA’s Explainable Artificial Intelligence (XAI) Program. In Proceedings of the 24th International Conference on Intelligent User Interfaces (IUI ’19), Marina del Ray, CA, USA, 16–20 March 2019; Association for Computing Machinery: New York, NY, USA, 2019; p. ii. [Google Scholar]
- Hoffman, R.R.; Mueller, S.T.; Klein, G.; Litman, J. Metrics for Explainable AI: Challenges and Prospects. arXiv 2019, arXiv:1812.04608. [Google Scholar]
- Ehrlinger, L.; Wöß, W. Automated Data Quality Monitoring. In Proceedings of the 22nd MIT International Conference on Information Quality (ICIQ 2017), Little Rock, AR, USA, 6–7 October 2017; pp. 15.1–15.9. [Google Scholar]
- Sculley, D.; Holt, G.; Golovin, D.; Davydov, E.; Phillips, T.; Ebner, D.; Chaudhary, V.; Young, M.; Crespo, J.F.; Dennison, D. Hidden Technical Debt in Machine Learning Systems. In Proceedings of the 28th International Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 2503–2511. [Google Scholar]
- Wang, Y.E.; Wei, G.Y.; Brooks, D. Benchmarking TPU, GPU, and CPU Platforms for Deep Learning. arXiv 2019, arXiv:1907.10701. [Google Scholar]
- Yu, T.; Zhu, H. Hyper-Parameter Optimization: A Review of Algorithms and Applications. arXiv 2020, arXiv:2003.05689. [Google Scholar]
- Bensalem, M.; Dizdarevć, J.; Jukan, A. Modeling of Deep Neural Network (DNN) Placement and Inference in Edge Computing. In Proceedings of the 2020 IEEE International Conference on Communications Workshops (ICC Workshops), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Breck, E.; Zinkevich, M.; Polyzotis, N.; Whang, S.; Roy, S. Data Validation for Machine Learning. Proc. Mach. Learn. Syst. 2019, 1, 334–347. [Google Scholar]
- Ehrlinger, L.; Haunschmid, V.; Palazzini, D.; Lettner, C. A DaQL to Monitor Data Quality in Machine Learning Applications. In Proceedings of the International Conference on Database and Expert Systems Applications (DEXA), Linz, Austria, 26–29 August 2019; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2019; Volume 11706, pp. 227–237. [Google Scholar]
- Apel, D.; Behme, W.; Eberlein, R.; Merighi, C. Datenqualität erfolgreich steuern: Praxislösungen für Business-Intelligence-Projekte [Successfully Governing Data Quality: Practical Solutions for Business-Intelligence Projects]; TDWI, Ed.; dpunkt.verlag GmbH: Heidelberg, Germany, 2015. [Google Scholar]
- Sebastian-Coleman, L. Measuring Data Quality for Ongoing Improvement; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Ehrlinger, L.; Werth, B.; Wöß, W. Automated Continuous Data Quality Measurement with QuaIIe. Int. J. Adv. Softw. 2018, 11, 400–417. [Google Scholar]
- Cagala, T. Improving data quality and closing data gaps with machine learning. In Data Needs and Statistics Compilation for Macroprudential Analysis; Settlements, B.F.I., Ed.; Bank for International Settlements: Basel, Switzerland, 2017; Volume 46. [Google Scholar]
- Ramler, R.; Wolfmaier, K. Issues and effort in integrating data from heterogeneous software repositories and corporate databases. In Proceedings of the Second ACM-IEEE International Symposium on Empirical Software Engineering and Measurement, Kaiserslautern, Germany, October 2008; pp. 330–332. [Google Scholar]
- Wang, R.Y.; Strong, D.M. Beyond Accuracy: What Data Quality Means to Data Consumers. J. Manag. Inf. Syst. 1996, 12, 5–33. [Google Scholar] [CrossRef]
- Little, R.J.A.; Rubin, D.B. Statistical Analysis with Missing Data, 2nd ed.; John Wiley & Sons, Inc.: New York, NY, USA, 2002. [Google Scholar]
- Bloomfield, L. Language; Allen & Unwin: Crows Nest, Australia, 1933. [Google Scholar]
- Ehrlinger, L.; Lettner, C.; Himmelbauer, J. Tackling Semantic Shift in Industrial Streaming Data Over Time. In Proceedings of the Twelfth International Conference on Advances in Databases, Knowledge, and Data Applications (DBKDA 2020), Lisbon, Portugal, 27 September–1 October 2020; pp. 36–39. [Google Scholar]
- Maydanchik, A. Data Quality Assessment; Technics Publications, LLC.: Bradley Beach, NJ, USA, 2007. [Google Scholar]
- Talburt, J.R. Entity Resolution and Information Quality; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Talburt, J.R.; Zhou, Y. A Practical Guide to Entity Resolution with OYSTER. In Handbook of Data Quality; Springer: Berlin/Heidelberg, Germany, 2013; pp. 235–270. [Google Scholar]
- Ehrlinger, L.; Wöß, W. A Novel Data Quality Metric for Minimality. In Data Quality and Trust in Big Data; Lecture Notes in Computer Science; Hacid, H., Sheng, Q.Z., Yoshida, T., Sarkheyli, A., Zhou, R., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 11235, pp. 1–15. [Google Scholar]
- Stonebraker, M.; Bruckner, D.; Ilyas, I.F.; Beskales, G.; Cherniack, M.; Zdonik, S.B.; Pagan, A.; Xu, S. Data Curation at Scale: The Data Tamer System. In Proceedings of the 6th Biennial Conference on Innovative Data Systems Research (CDIR’13), Asilomar, CA, USA, 6–9 January 2013. [Google Scholar]
- Aggarwal, C.C. Outlier Analysis, 2nd ed.; Springer International Publishing: New York, NY, USA, 2017; p. 446. [Google Scholar]
- Ehrlinger, L.; Rusz, E.; Wöß, W. A Survey of Data Quality Measurement and Monitoring Tools. arXiv 2019, arXiv:1907.08138. [Google Scholar]
- Islam, M.J.; Nguyen, G.; Pan, R.; Rajan, H. A comprehensive study on deep learning bug characteristics. In Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Tallinn, Estonia, August 2019; pp. 510–520. [Google Scholar]
- Heinrich, B.; Hristova, D.; Klier, M.; Schiller, A.; Szubartowicz, M. Requirements for Data Quality Metrics. J. Data Inf. Qual. 2018, 9, 1–32. [Google Scholar] [CrossRef]
- Ehrlinger, L.; Huszar, G.; Wöß, W. A Schema Readability Metric for Automated Data Quality Measurement. In Proceedings of the Eleventh International Conference on Advances in Databases, Knowledge, and Data Applications (DBKDA 2019), Athens, Greece, 2–6 June 2019; pp. 4–10. [Google Scholar]
- Lettner, C.; Stumptner, R.; Fragner, W.; Rauchenzauner, F.; Ehrlinger, L. DaQL 2.0: Measure Data Quality Based on Entity Models. In Proceedings of the International Conference on Industry 4.0 and Smart Manufacturing (ISM 2020); Elsevier: Amsterdam, The Netherlands, 2020. [Google Scholar]
- Chrisman, N. The role of quality information in the long-term functioning of a Geographic Information System. Cartogr. Int. J. Geogr. Inf. Geovis. 1983, 21, 79–88. [Google Scholar]
- Ehrlinger, L.; Wöß, W. Towards a Definition of Knowledge Graphs. In Proceedings of the 12th International Conference on Semantic Systems—SEMANTiCS2016 and 1st International Workshop on Semantic Change & Evolving Semantics (SuCCESS16), Sun SITE Central Europe (CEUR), Technical University of Aachen (RWTH), Leipzig, Germany,, 12–15 September 2016; Volume 1695, pp. 13–16. [Google Scholar]
- Zellinger, W.; Moser, B.A.; Saminger-Platz, S. On generalization in moment-based domain adaptation. Ann. Math. Artif. Intell. 2020, 1–37. [Google Scholar] [CrossRef]
- Sun, B.; Saenko, K. Deep coral: Correlation alignment for deep domain adaptation. In Workshop of the European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2016; pp. 443–450. [Google Scholar]
- Zellinger, W.; Grubinger, T.; Zwick, M.; Lughofer, E.; Schöner, H.; Natschläger, T.; Saminger-Platz, S. Multi-source transfer learning of time series in cyclical manufacturing. J. Intell. Manuf. 2020, 31, 777–787. [Google Scholar] [CrossRef]
- Nikzad-Langerodi, R.; Zellinger, W.; Lughofer, E.; Saminger-Platz, S. Domain-Invariant Partial-Least-Squares Regression. Anal. Chem. 2018, 90, 6693–6701. [Google Scholar] [CrossRef]
- Nikzad-Langerodi, R.; Zellinger, W.; Saminger-Platz, S.; Moser, B.A. Domain adaptation for regression under Beer–Lambert’s law. Knowl.-Based Syst. 2020, 210, 106447. [Google Scholar] [CrossRef]
- Zellinger, W.; Moser, B.A.; Chouikhi, A.; Seitner, F.; Nezveda, M.; Gelautz, M. Linear optimization approach for depth range adaption of stereoscopic videos. Electron. Imaging 2016, 2016, 1–6. [Google Scholar] [CrossRef]
- Zellinger, W. Moment-Based Domain Adaptation: Learning Bounds and Algorithms. Ph.D. Thesis, JKU, Linz, Austria, 2020. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Eghbal-zadeh, H.; Zellinger, W.; Widmer, G. Mixture density generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5820–5829. [Google Scholar]
- Méhes, G.; Luegmayr, A.; Kornmüller, R.; Ambros, I.M.; Ladenstein, R.; Gadner, H.; Ambros, P.F. Detection of disseminated tumor cells in neuroblastoma: 3 log improvement in sensitivity by automatic immunofluorescence plus FISH (AIPF) analysis compared with classical bone marrow cytology. Am. J. Pathol. 2003, 163, 393–399. [Google Scholar] [CrossRef]
- Jung, C.; Kim, C. Impact of the accuracy of automatic segmentation of cell nuclei clusters on classification of thyroid follicular lesions. Cytom. Part A J. Int. Soc. Anal. Cytol. 2014, 85, 709–718. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Medical Image Computing and Computer-Assisted Intervention—MICCAI; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Kromp, F.; Fischer, L.; Bozsaky, E.; Ambros, I.; Doerr, W.; Taschner-Mandl, S.; Ambros, P.; Hanbury, A. Deep Learning architectures for generalized immunofluorescence based nuclear image segmentation. arXiv 2019, arXiv:1907.12975. [Google Scholar]
- Kromp, F.; Bozsaky, E.; Rifatbegovic, F.; Fischer, L.; Ambros, M.; Berneder, M.; Weiss, T.; Lazic, D.; Dörr, W.; Hanbury, A.; et al. An annotated fluorescence image dataset for training nuclear segmentation methods. Sci. Data 2020, 7, 1–8. [Google Scholar] [CrossRef]
- Eghbal-Zadeh, H.; Fischer, L.; Popitsch, N.; Kromp, F.; Taschner-Mandl, S.; Gerber, T.; Bozsaky, E.; Ambros, P.F.; Ambros, I.M.; Widmer, G.; et al. DeepSNP: An End-to-End Deep Neural Network with Attention-Based Localization for Breakpoint Detection in Single-Nucleotide Polymorphism Array Genomic Data. J. Comput. Biol. 2018, 26, 572–596. [Google Scholar] [CrossRef]
- Sobieczky, F. Explainability of models with an interpretable base model: Explainability vs. accuracy. Proceedings of Symposium on Predictive Analytics, Austin, TX, USA, 24–25 September 2020. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference and Prediction, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Grancharova, A.; Johansen, T.A. Nonlinear Model Predictive Control. In Explicit Nonlinear Model Predictive Control: Theory and Applications; Springer: Berlin/Heidelberg, Germany, 2012; pp. 39–69. [Google Scholar]
- Sobieczky, F. An Interlacing Technique for Spectra of Random Walks and Its Application to Finite Percolation Clusters. J. Theor. Probab. 2010, 23, 639–670. [Google Scholar] [CrossRef][Green Version]
- Sobieczky, F. Bounds for the annealed return probability on large finite percolation graphs. Electron. J. Probab. 2012, 17, 17. [Google Scholar] [CrossRef]
- Neugebauer, S.; Rippitsch, L.; Sobieczky, F.; Geiß, M. Explainability of AI-predictions based on psychological profiling. Procedia Comput. Sci. 2021, unpublished work. [Google Scholar]
- Lipton, Z.C. The Mythos of Model Interpretability. Queue 2018, 16, 31–57. [Google Scholar] [CrossRef]
- Anand, S.; Burke, E.K.; Chen, T.Y.; Clark, J.; Cohen, M.B.; Grieskamp, W.; Harman, M.; Harrold, M.J.; Mcminn, P.; Bertolino, A. An orchestrated survey of methodologies for automated software test case generation. J. Syst. Softw. 2013, 86, 1978–2001. [Google Scholar] [CrossRef]
- Nielson, F.; Nielson, H.R.; Hankin, C. Principles of Program Analysis; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Moser, M.; Pichler, J.; Fleck, G.; Witlatschil, M. Rbg: A documentation generator for scientific and engineering software. In Proceedings of the 2015 IEEE 22nd International Conference on Software Analysis, Evolution, and Reengineering (SANER), Montreal, QC, Canada, 2–6 March 2015; pp. 464–468. [Google Scholar]
- Baldoni, R.; Coppa, E.; D’elia, D.C.; Demetrescu, C.; Finocchi, I. A survey of symbolic execution techniques. ACM Comput. Surv. (CSUR) 2018, 51, 1–39. [Google Scholar] [CrossRef]
- Felderer, M.; Ramler, R. Integrating risk-based testing in industrial test processes. Softw. Qual. J. 2014, 22, 543–575. [Google Scholar] [CrossRef]
- Ramler, R.; Felderer, M. A process for risk-based test strategy development and its industrial evaluation. In International Conference on Product-Focused Software Process Improvement; Springer: Berlin/Heidelberg, Germany, 2015; pp. 355–371. [Google Scholar]
- Pascarella, L.; Bacchelli, A. Classifying code comments in Java open-source software systems. In Proceedings of the 2017 IEEE/ACM 14th International Conference on Mining Software Repositories (MSR), Buenos Aires, Argentina, 20–21 May 2017; pp. 227–237. [Google Scholar]
- Shinyama, Y.; Arahori, Y.; Gondow, K. Analyzing code comments to boost program comprehension. In Proceedings of the 2018 IEEE 25th Asia-Pacific Software Engineering Conference (APSEC), Nara, Japan, 4–7 December 2018; pp. 325–334. [Google Scholar]
- Steidl, D.; Hummel, B.; Juergens, E. Quality analysis of source code comments. In Proceedings of the 2013 IEEE 21st International Conference on Program Comprehension (ICPC), San Francisco, CA, USA, 20–21 May 2013; pp. 83–92. [Google Scholar]
- Menzies, T.; Milton, Z.; Turhan, B.; Cukic, B.; Jiang, Y.; Bener, A. Defect prediction from static code features: Current results, limitations, new approaches. Autom. Softw. Eng. 2010, 17, 375–407. [Google Scholar] [CrossRef]
- Van Geet, J.; Ebraert, P.; Demeyer, S. Redocumentation of a legacy banking system: An experience report. In Proceedings of the Joint ERCIM Workshop on Software Evolution (EVOL) and International Workshop on Principles of Software Evolution (IWPSE), Antwerp, Belgium, 20–21 September 2010; pp. 33–41. [Google Scholar]
- Dorninger, B.; Moser, M.; Pichler, J. Multi-language re-documentation to support a COBOL to Java migration project. In Proceedings of the 2017 IEEE 24th International Conference on Software Analysis, Evolution and Reengineering (SANER), Klagenfurt, Austria, 20–24 February 2017; pp. 536–540. [Google Scholar]
- Ma, L.; Artho, C.; Zhang, C.; Sato, H.; Gmeiner, J.; Ramler, R. Grt: Program-analysis-guided random testing (t). In Proceedings of the 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), Lincoln, NE, USA, 9–13 November 2015; pp. 212–223. [Google Scholar]
- Ramler, R.; Buchgeher, G.; Klammer, C. Adapting automated test generation to GUI testing of industry applications. Inf. Softw. Technol. 2018, 93, 248–263. [Google Scholar] [CrossRef]
- Fischer, S.; Ramler, R.; Linsbauer, L.; Egyed, A. Automating test reuse for highly configurable software. In Proceedings of the 23rd International Systems and Software Product Line Conference-Volume A, Paris, France, 9–13 September 2019; pp. 1–11. [Google Scholar]
- Hübscher, G.; Geist, V.; Auer, D.; Hübscher, N.; Küng, J. Integration of Knowledge and Task Management in an Evolving, Communication-intensive Environment. In Proceedings of the 22nd International Conference on Information Integration and Web-based Applications & Services (iiWAS2020), Chiang Mai, Thailand, 30 November–2 December 2020; ACM: New York, NY, USA, 2020; pp. 407–416. [Google Scholar]
- Geist, V.; Moser, M.; Pichler, J.; Beyer, S.; Pinzger, M. Leveraging Machine Learning for Software Redocumentation. In Proceedings of the 2020 IEEE 27th International Conference on Software Analysis, Evolution and Reengineering (SANER), London, ON, Canada, 18–21 February 2020; pp. 622–626. [Google Scholar]
- Geist, V.; Moser, M.; Pichler, J.; Santos, R.; Wieser, V. Leveraging machine learning for software redocumentation—A comprehensive comparison of methods in practice. Softw. Pract. Exp. 2020, 1–26. [Google Scholar] [CrossRef]
- Meloni, P.; Loi, D.; Deriu, G.; Pimentel, A.D.; Saprat, D.; Pintort, M.; Biggio, B.; Ripolles, O.; Solans, D.; Conti, F.; et al. Architecture-aware design and implementation of CNN algorithms for embedded inference: The ALOHA project. In Proceedings of the 2018 30th International Conference on Microelectronics (ICM), Sousse, Tunisia, 16–19 December 2018; pp. 52–55. [Google Scholar]
- Meloni, P.; Loi, D.; Deriu, G.; Pimentel, A.D.; Sapra, D.; Moser, B.; Shepeleva, N.; Conti, F.; Benini, L.; Ripolles, O.; et al. ALOHA: An architectural-aware framework for deep learning at the edge. In Proceedings of the Workshop on INTelligent Embedded Systems Architectures and Applications—INTESA, Turin, Italy, 4 October 2018; ACM Press: New York, NY, USA, 2018; pp. 19–26. [Google Scholar]
- Meloni, P.; Loi, D.; Busia, P.; Deriu, G.; Pimentel, A.D.; Sapra, D.; Stefanov, T.; Minakova, S.; Conti, F.; Benini, L.; et al. Optimization and Deployment of CNNs at the Edge: The ALOHA Experience. In Proceedings of the 16th ACM International Conference on Computing Frontiers (CF ’19), Alghero, Italy, April 2019; pp. 326–332. [Google Scholar]
- Newman, S. Building Microservices, 1st ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2015. [Google Scholar]
- Li, L.; Jamieson, K.; DeSalvo, G.; Rostamizadeh, A.; Talwalkar, A. Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization. J. Mach. Learn. Res. 2017, 18, 6765–6816. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2704–2713. [Google Scholar]
- Pimentel, A.D.; Erbas, C.; Polstra, S. A Systematic Approach to Exploring Embedded System Architectures at Multiple Abstraction Levels. IEEE Trans. Comput. 2006, 55, 99–112. [Google Scholar] [CrossRef]
- Masin, M.; Limonad, L.; Sela, A.; Boaz, D.; Greenberg, L.; Mashkif, N.; Rinat, R. Pluggable Analysis Viewpoints for Design Space Exploration. Procedia Comput. Sci. 2013, 16, 226–235. [Google Scholar] [CrossRef]
- Meloni, P.; Capotondi, A.; Deriu, G.; Brian, M.; Conti, F.; Rossi, D.; Raffo, L.; Benini, L. NEURAghe: Exploiting CPU-FPGA Synergies for Efficient and Flexible CNN Inference Acceleration on Zynq SoCs. CoRR 2017, 11, 1–24. [Google Scholar]
- Kumar, M.; Rossbory, M.; Moser, B.A.; Freudenthaler, B. Deriving An Optimal Noise Adding Mechanism for Privacy-Preserving Machine Learning. In Proceedings of the 3rd International Workshop on Cyber-Security and Functional Safety in Cyber-Physical (IWCFS 2019), Linz, Austria, 26–29 August 2019; Anderst-Kotsis, G., Tjoa, A.M., Khalil, I., Elloumi, M., Mashkoor, A., Sametinger, J., Larrucea, X., Fensel, A., Martinez-Gil, J., Moser, B., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 108–118. [Google Scholar]
- Kumar, M.; Rossbory, M.; Moser, B.A.; Freudenthaler, B. An optimal (ϵ,δ)-differentially private learning of distributed deep fuzzy models. Inf. Sci. 2021, 546, 87–120. [Google Scholar] [CrossRef]
- Kumar, M.; Rossbory, M.; Moser, B.A.; Freudenthaler, B. Differentially Private Learning of Distributed Deep Models. In Proceedings of the Adjunct Publication of the 28th ACM Conference on User Modeling, Adaptation and Personalization (UMAP ’20 Adjunct), Genoa, Italy, 12–18 July 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 193–200. [Google Scholar]
- Kumar, M.; Brunner, D.; Moser, B.A.; Freudenthaler, B. Variational Optimization of Informational Privacy. In Database and Expert Systems Applications; Springer International Publishing: Cham, Switzerland, 2020; pp. 32–47. [Google Scholar]
- Gusenleitner, N.; Siedl, S.; Stübl, G.; Polleres, A.; Recski, G.; Sommer, R.; Leva, M.C.; Pichler, M.; Kopetzky, T.; Moser, B.A. Facing mental workload in AI-transformed working environments. In Proceedings of the H-WORKLOAD 2019: 3rd International Symposium on Human Mental Workload: Models and Applications, Rome, Italy, 14–15 November 2019. [Google Scholar]
- Nickel, M.; Murphy, K.; Tresp, V.; Gabrilovich, E. A Review of Relational Machine Learning for Knowledge Graphs. Proc. IEEE 2016, 104, 11–33. [Google Scholar] [CrossRef]
- Paulheim, H. Knowledge graph refinement: A survey of approaches and evaluation methods. Semant. Web 2017, 8, 489–508. [Google Scholar] [CrossRef]
- Noy, N.; Gao, Y.; Jain, A.; Narayanan, A.; Patterson, A.; Taylor, J. Industry-scale Knowledge Graphs: Lessons and Challenges. Commun. ACM 2019, 62, 36–43. [Google Scholar] [CrossRef]
- Johnson, M.; Vera, A. No AI Is an Island: The Case for Teaming Intelligence. AI Mag. 2019, 40, 16–28. [Google Scholar] [CrossRef]
- Cai, H.; Zheng, V.W.; Chang, K.C.C. A Comprehensive Survey of Graph Embedding: Problems, Techniques and Applications. IEEE Trans. Knowl. Data Eng. 2017, 30, 1616–1637. [Google Scholar] [CrossRef]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge Graph Embedding: A Survey of Approaches and Applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Li, S.; Wang, Y. Research on Interdisciplinary Characteristics: A Case Study in the Field of Artificial Intelligence. IOP Conf. Ser. Mater. Sci. Eng. 2019, 677, 052023. [Google Scholar] [CrossRef]










Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fischer, L.; Ehrlinger, L.; Geist, V.; Ramler, R.; Sobiezky, F.; Zellinger, W.; Brunner, D.; Kumar, M.; Moser, B. AI System Engineering—Key Challenges and Lessons Learned. Mach. Learn. Knowl. Extr. 2021, 3, 56-83. https://doi.org/10.3390/make3010004
Fischer L, Ehrlinger L, Geist V, Ramler R, Sobiezky F, Zellinger W, Brunner D, Kumar M, Moser B. AI System Engineering—Key Challenges and Lessons Learned. Machine Learning and Knowledge Extraction. 2021; 3(1):56-83. https://doi.org/10.3390/make3010004
Chicago/Turabian StyleFischer, Lukas, Lisa Ehrlinger, Verena Geist, Rudolf Ramler, Florian Sobiezky, Werner Zellinger, David Brunner, Mohit Kumar, and Bernhard Moser. 2021. "AI System Engineering—Key Challenges and Lessons Learned" Machine Learning and Knowledge Extraction 3, no. 1: 56-83. https://doi.org/10.3390/make3010004
APA StyleFischer, L., Ehrlinger, L., Geist, V., Ramler, R., Sobiezky, F., Zellinger, W., Brunner, D., Kumar, M., & Moser, B. (2021). AI System Engineering—Key Challenges and Lessons Learned. Machine Learning and Knowledge Extraction, 3(1), 56-83. https://doi.org/10.3390/make3010004