1. Motivation
Estimating the classification accuracy of a machine-learning model is particularly important in incremental and life-long learning tasks, where a continuous stream of new training data adapts the classifier state over time. We can imagine service robots that will adapt to their application environment by continued human teaching and error correction to improve their performance during operation. Current examples are vacuum or mowing robots that may already have some limited adaptivity to the spatial working area layout and configuration. It could be very helpful to allow a home user to incrementally teach those service robots how to deal with special obstacles or objects in the home environment. Consider for example an autonomous lawn mower with a camera for object recognition in the garden. The robot mows the lawn at regular intervals and concurrently stores views of objects which were encountered during operation. Occasionally the robot will ask the user to classify the objects and how to deal with them (e.g., “mow over leaves but avoid flowers”). This raises the question when the robot is good enough in object recognition to fulfill this task autonomously. To limit the teaching effort, it first makes sense to choose requested labeling examples according to standard active learning approaches. These methods select those training examples that offer the largest expected performance gain. Secondly, additional training data is only needed to be requested as long as the classifier accuracy is below a user-defined threshold. This requires a robust estimation of the current accuracy. Also, if the system accuracy does not improve with additional labeled data, the task cannot be carried out autonomously by the robot [
1].
The research topics of incremental and life-long learning have gained more attention in recent years. Humans and animals are especially good in perceiving, integrating and transferring information from continuous data streams. In this article, we are interested in the special topic of accuracy estimation for an incrementally learning classifier. This is highly relevant information for initiating and managing the learning process.
Our approach is to train a regression model using the confidence information of an arbitrary classification model to predict its accuracy on a test set with only a fraction of supervised labeled data. This semi-supervised technique allows us to predict the classifier’s accuracy while training (also illustrated in
Figure 1). So, our goal is to determine it in each stage of training and not only to predict the final accuracy after training is completed like in most of the other related work. The selection of training data has a strong influence on the classifier accuracy gain, which is well-known from active learning research [
2]. We investigate the relation of this effect towards the estimation of the incremental classifier performance. However, no new methods for active learning are proposed here, we rather analyze the problematic effect of active query strategies on using standard supervised accuracy estimation techniques.
We evaluate our method on several analytical and real-world data sets and within an object recognition task, both with random and active querying, where uncertainty sampling is used to select the most uncertain samples for training. Our algorithm clearly outperforms cross-validation (CV) and interleaved test/train error (ITT) in both cases but especially while querying actively. To further motivate our approach, an incremental life-long learning experiment is simulated, where new data is inserted while training and the accuracy estimation module is used to determine the time of retraining to achieve a minimum desired task accuracy.
2. Related Work
Accuracy estimation for classification algorithms can be considered to be a tool for judging the suitability of machine-learning methods for certain applications. Since this is a subdomain of the rising research field of explainable artificial intelligence (XAI), we first position our work in relation to this. We then discuss recent approaches for accuracy estimation in offline or batch learning and finally review methods applied for online or incremental learning.
In recent years, the research field of explainable artificial intelligence (XAI) has gained a lot of attention [
3,
4,
5]. The key goals of XAI are to determine if or if not an AI system satisfies application-centered requirements [
6] and to explain why it behaves as it does [
4]. The latter question becomes more and more important today, since generic models like deep neural networks have become more and more complex. This complexity induces opaqueness about which feature leads to a decision [
7] or what characteristics of a sample is responsible for a certain model output [
8]. Our focus is an estimation of how well an AI system for classification will perform. Being able to answer this question is essential for human users to build trust in the reliability of the model [
9,
10,
11].
The reliability of a classifier can be quantified by computing accuracy on a hold-out test set or by accumulating confidences from predicting single examples [
12]. While probabilistic classifiers have an integrated confidence prediction, non-probabilistic models are using model-specific heuristics estimating confidences (see
Section 4). There are also model-agnostic approaches for estimating confidences like Conformal Prediction [
13]. Jiang et al. suggest comparing the output of any classifier with a high-density nearest neighbor model to get high quality confidence estimates [
14].
Let us now review approaches for accuracy estimation in offline settings. Platanios et al. [
15] estimated classifier accuracy by considering the agreement rate of multiple classifiers of different types trained with independent features, possibly underestimating performance gains using all features. Another recent approach by Donmez et al. [
16] is also applicable with a single classifier but requires the label distribution
for evaluating a maximum likelihood. This is applicable, e.g., for medical diagnosis or handwriting recognition, where the marginal frequency of each class is known. Aghazadeh and Carlsson [
17] proposed a method to determine the quality of a train and test set by evaluating local and global moments for each class, like intra-class variation and connectivity. They evaluated this fully supervised approach via a leave one out cross-validation on Pascal VOC 2007 and could predict the final mean absolute error (MAE) of the held-out class with about 4–5% accuracy. Welinder et al. [
12] showed that it is possible to estimate a binary classifiers precision and recall class-wise by fitting a mixture model per class in a histogram of confidences and sample those mixture models with various techniques. This comes closest to our problem setting but it is most likely only applicable on binary classification problems.
After discussing offline learning approaches let us now focus on incremental learning scenarios. Artificial models can be fragile if they cannot access the entire training data at once [
18,
19]. Catastrophic forgetting [
20,
21] describes the problem of new information suppressing information from earlier training. Especially if new classes occur during training this is a problem [
22]. Another problem can be imbalance of data [
23] that is quite natural for, e.g., a robot that acquires a high proportion of samples of one particularly “dominant” class and must be, therefore, very attentive for classes that it perceives rarely. Concept drift [
24,
25] describes the problem of sample distributions that change over time. This can be an abrupt event in the data stream, but it also can be a gradual, reoccurring or even virtual process [
26]. Gomes et al. [
27] mention other possible research directions within incremental learning like anomaly detection [
28], ensemble learning, recurrent neural networks and reinforcement learning.
Active learning is an efficient technique for incrementally training a classifier. One variant is pool-based active learning, which is also evaluated later in this manuscript. By using a querying method for selecting useful unlabeled samples for training, it is possible to boost the training process. There are a variety of querying approaches for finding the best samples to be queried [
2]. An often-used querying technique is uncertainty sampling [
29] which requests the samples with the least certainty for labeling. Other strategies select samples based on the expected model output change [
30], or they consider a committee of different classifiers [
31] for choosing the samples to be queried. A current trend is to train data-driven approaches for querying [
32,
33].
Although these are the main research fields in incremental and active learning, comparably less research has been done related to accuracy estimation in incremental or active learning, which requires the accuracy estimation model to adapt to an evolving classifier. A common choice for estimating the accuracy in incremental learning is storing a fraction of the labeled training data and to perform a cross-validation [
34]. Another common approach is called interleaved test/train error [
19,
35]. It requires a classification of each new sample before using it for training. The classifier’s accuracy is then estimated by averaging over a window of past classifications. However, both approaches solely estimate the accuracy based on labeled instances. In the following we investigate a novel semi-supervised approach that also takes confidences on unlabeled data into account.
3. Accuracy Estimation of Incrementally Trained Classifiers
In this contribution we want to answer the following question: “How can we best estimate the current accuracy of an incremental learning classifier, taking previous learning sessions into account?”
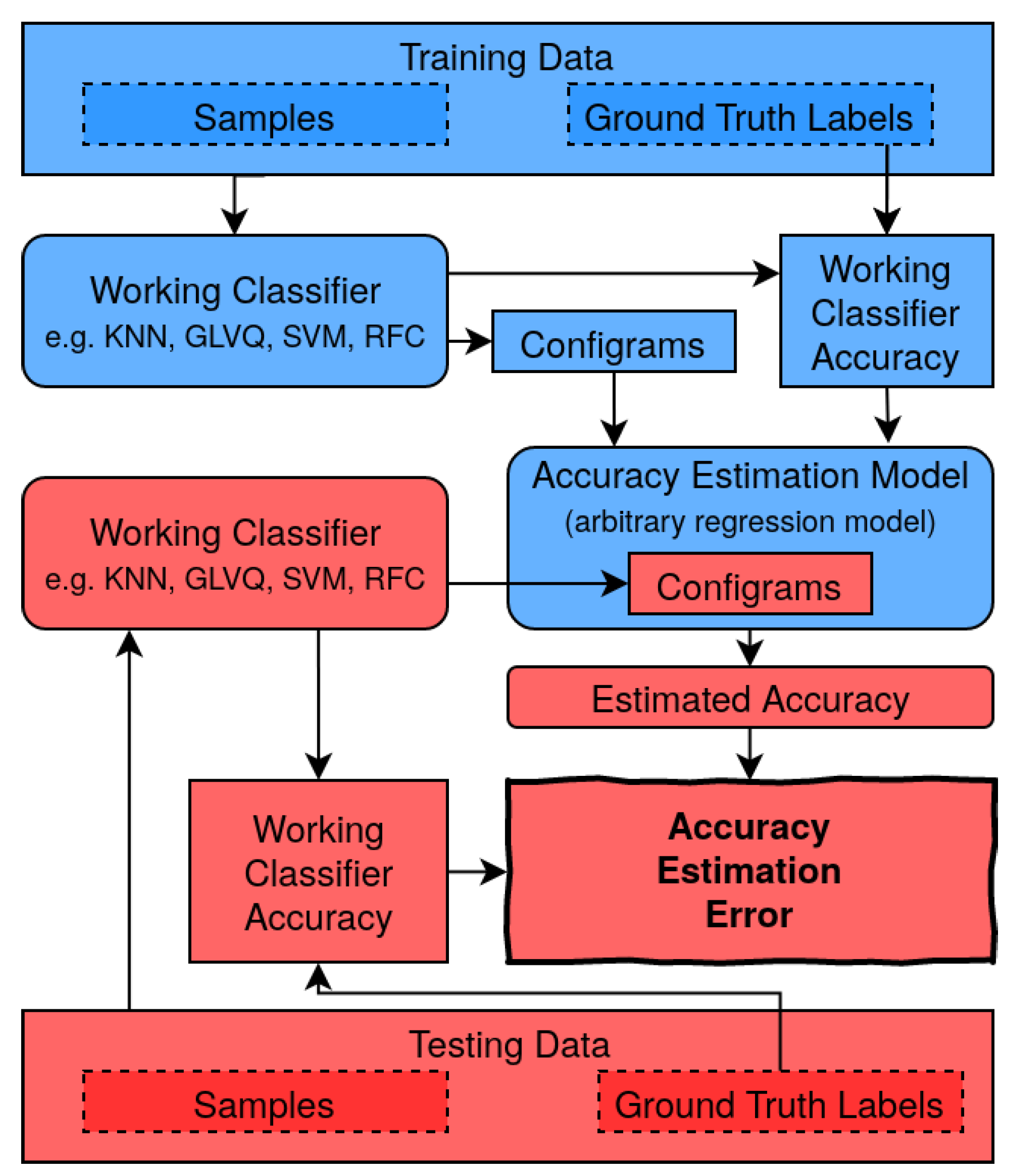
We wish to create an accuracy estimator for a classifier trained by incremental learning. In such a setting one frequently wishes to monitor the accuracy of the classifier as more and more training examples are added (e.g., in order to be able to stop learning when a requested accuracy threshold is surpassed). Ideally, changes in accuracy can be detected that may be caused by changes in the statistics of the data (e.g., when dynamically adding new or removing existing classes).
Although it is straightforward to detect such accuracy changes by permanently sampling many examples and querying their labels, this straightforward strategy may be too expensive for many applications. Therefore, we aim for
an estimator that can predict the accuracy of the trained classifier on the basis of a sufficiently large sample of
unlabeled examples (compare
Figure 1). Such an estimator could then predict accuracy changes of a trained classifier under changes of the pool of unlabeled examples. For instance, changes in the relative frequencies of examples that are associated with particular classes, or addition of new examples which represent existing classes in modified ways. Obviously, such a flexible accuracy monitoring that is based only on unlabeled examples is of high value in many applications (one specific example is presented in
Section 6).
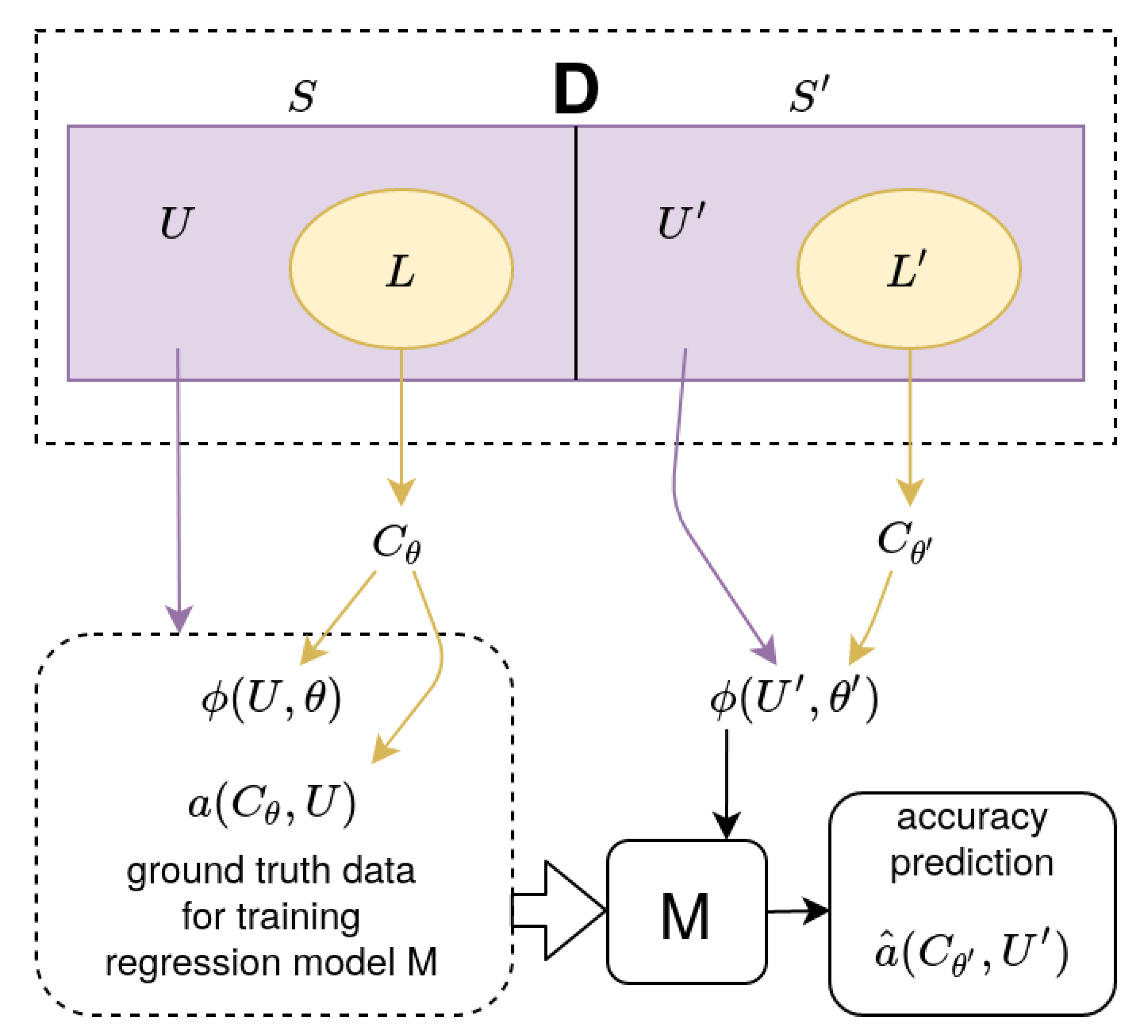
To fix our notation we denote by
D the data set that characterizes our domain. Subsets
S and
denote possible training data pools within
D (see
Figure 2). Each subset consists of an unlabeled pool (
) and a labeled pool (
).
We make use of a standard incremental learning paradigm [
19] to train an incremental classifier either with random or active sampling.
The beginning of training starts with an empty L. A querying function selects samples, either randomly or uncertainty-based, from the unlabeled set U in mini-batches with size B. These batches are labeled by an oracle. This is in most cases a human annotator, whereas in our experiments ground-truth label data were used. As the training progresses, samples from the unlabeled pool U are labeled and moved into the labeled pool L. Simultaneously, the classifier C is trained online with the new labeled batch. The classifier is trained with N batches.
Formally, the classifier is given as a function
that maps some unlabeled data item
u into its class label
y. In the following, it will be denoted as
working classifier and
denotes its adaptive parameters. Additionally, it is required that the working classifier comes with a confidence measure
that reflects the reliability of its output on a given input item
u when training led to parameters
.
Section 4 outlines some classifiers which were used in the evaluation together with their unique approaches for
.
The construction of the accuracy estimator M for the chosen working classifier requires the one-off solution of an associated learning or regression task. After that the estimator becomes available for subsequent monitoring of incremental training of various instances of the chosen same working classifier. As will be seen shortly, this associated regression task will make use of some initial incremental training runs of several working classifier instances to generate the ground-truth data to compute the regression model that provides M.
Formally, the accuracy estimator M will have to map from a suitably chosen input feature vector . This input feature vector captures information about the accuracy of the working classifier with parameters when classifying samples from the pool U. The accuracy value is the desired output of the desired mapping (for M the explicit notation of its own adaptive parameters is omitted).
The input feature vector
is obtained from
confidence histograms (“configrams”) that are computed from the working classifier’s confidence measure as follows:
J-dimensional confidence histograms over “confidence bins” of width
in the confidence interval [0,1] are created, based on sampling a “representative” subset of our data pool. The histogram count
of bin
j,
, is thus given as
with the bin membership indicator function
and
U a suitably large subset of
D. Each histogram
will be a single input point for the regression model M. To determine this model, many such points are needed.
For the monitoring, the model must be appropriate for working classifiers in different incremental states. Therefore, configrams are created not for just a single, but instead for a sequence n = 1,2,…
N of different such training states. This sequence is obtained in a similar fashion as in the later application: samples from the data pool are grouped into mini-batches which are counted by the index
n. Each new mini-batch leads to an incremental update of the working classifier with changed adaptive parameters
and corresponding histogram counts
(that now depend on training state
n together with bin number
j). This generates a sequence of input feature vectors
component-wise given as:
with the bin membership indicator function
Finally, each training state n and sample u requires checking of whether the prediction coincides with the true label or not:
The average
represents the ground-truth accuracy that belongs to histogram vector
(note that this last step of ground-truth computation for the regression model requires the access of all labels in subset
). Finally, all
and
become concatenated into two vectors. To generate more of these configram-accuracy pairs, not only one classifier instance but a classifier ensemble with
Q instances
of the same classifier is trained with different initializations (random queries from
).
After training the ensemble of classifiers and collecting several configram sets, they are stacked to a feature vector . Analogously the ground-truth accuracies are stacked to a vector . The accuracy estimator M is an arbitrary regression model, trained with as features and target values.
Once the Configram Estimation Model (CGEM) M has been obtained, it can be applied to further incremental learning tasks. These are drawn from the domain
D that may use pool
whose statistics may differ from the “model-training” pool
. The model will then extrapolate what is has learned from
about the relationship between configrams and output accuracy of an incrementally trained working classifier instance. Therefore, it permits on
very quick accuracy predictions
without needing to query any labels in . This extrapolation assumes that the domain
D is sufficiently homogeneous so that new pools drawn from
D have a high likelihood to be sufficiently similar to the model-training pool
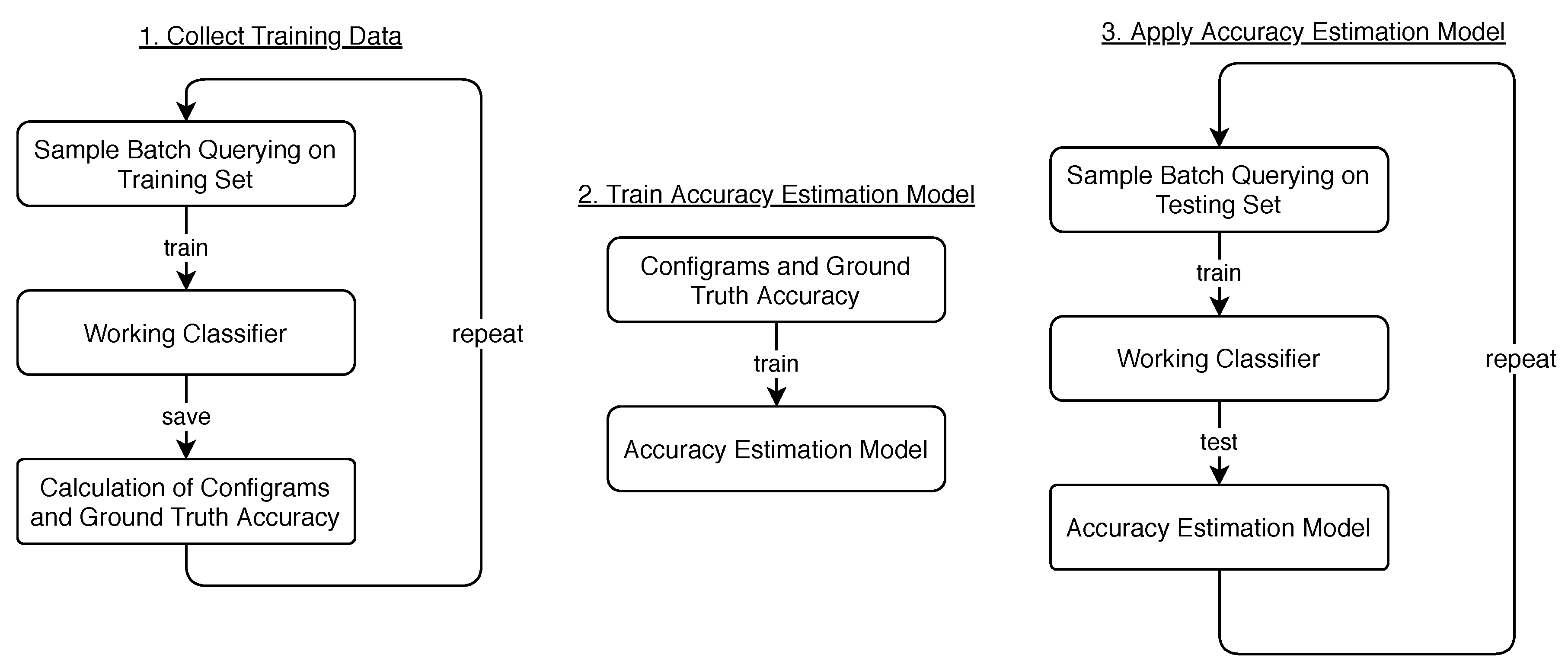
S to admit the above accuracy extrapolation through the model M. The workflow of training and applying M is also visualized in
Figure 3.
Also note that two different quality measures are discussed: the accuracy of
, defined as Working Classifier Accuracy (
WCA). And—as a more important quality measure for this contribution—the error estimated with
M on test set
and denoted Accuracy Estimation Error (
AEE). It is defined as
For
M common regression models [
36] were tested, like a neural net (mlp), nearest neighbor regression (NNR), ridge regression (ridge), XGB regression (XGB), gaussian process regression (GPR) and support vector regression (SVR).
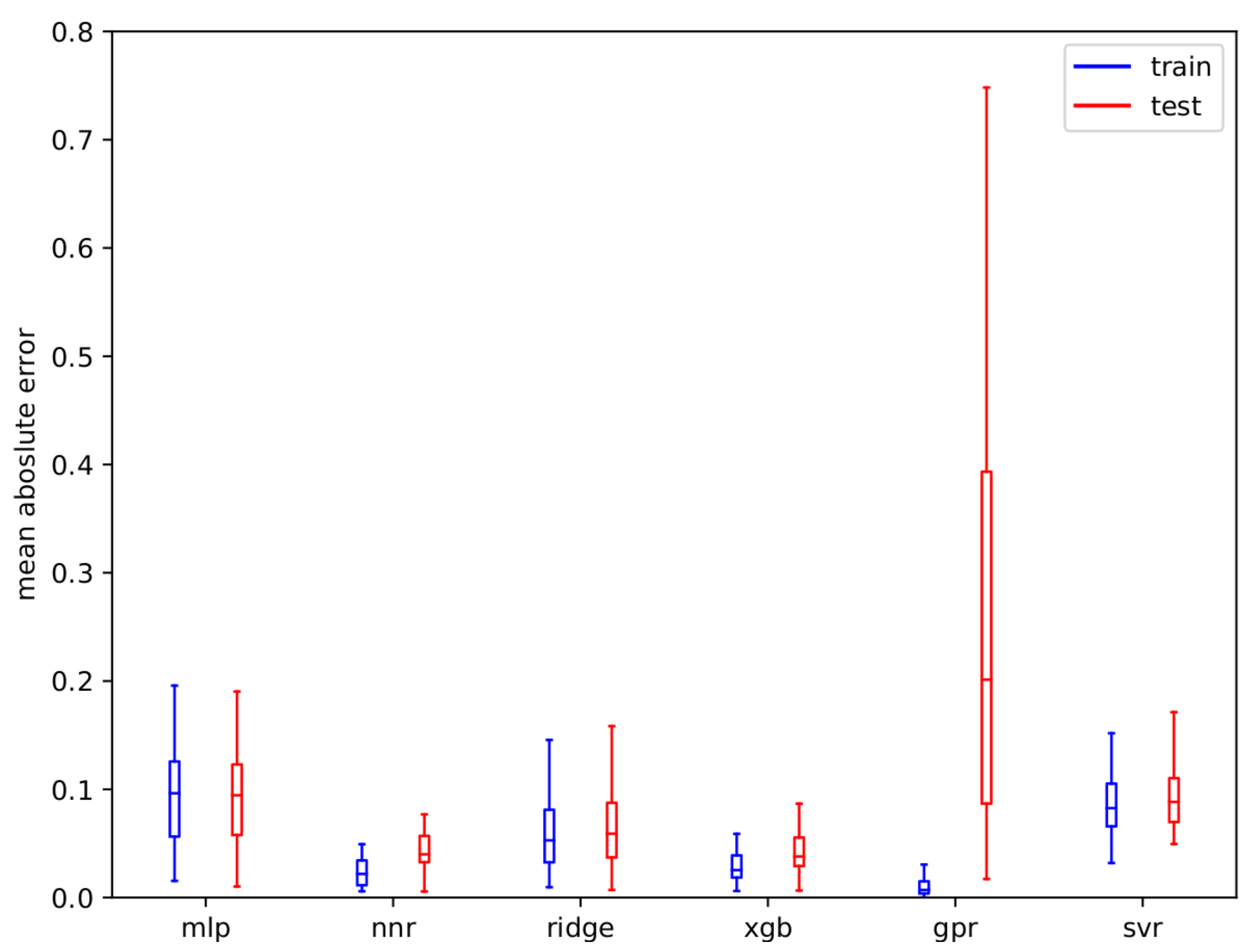
The different regression models were compared by evaluating them on collected configram-accuracy-pairs from trainings of all tested working classifiers on all data sets that are evaluated later in this article in Table 4. The averaged
AEE of all models is displayed in
Figure 4 where the performance of the models for both the training set
with blue boxes (this is the training error for estimating the configrams used for training the model itself) and on the test set
with red boxes is shown. Although GPR has the lowest
AEE on
, the model is highly overfitting and thus has by far the largest error on
. We experienced that regression using the neural net (mlp) can deliver high performance for certain configrams, but is under-performing on others. Also, we experienced a high oscillation of accuracy in terms of the number of trained epochs. Nearest neighbor regression (nnr) is the most reliable approach on our data, so we select nnr to be used in our further evaluation as the overall best performing regression model.
5. Evaluation
We evaluate the CGEM approach on static analytical data sets and show properties on drifting analytical data. We further evaluate a variety of real-world data sets and we finally test CGEM in a simulated human–robot interaction experiment.
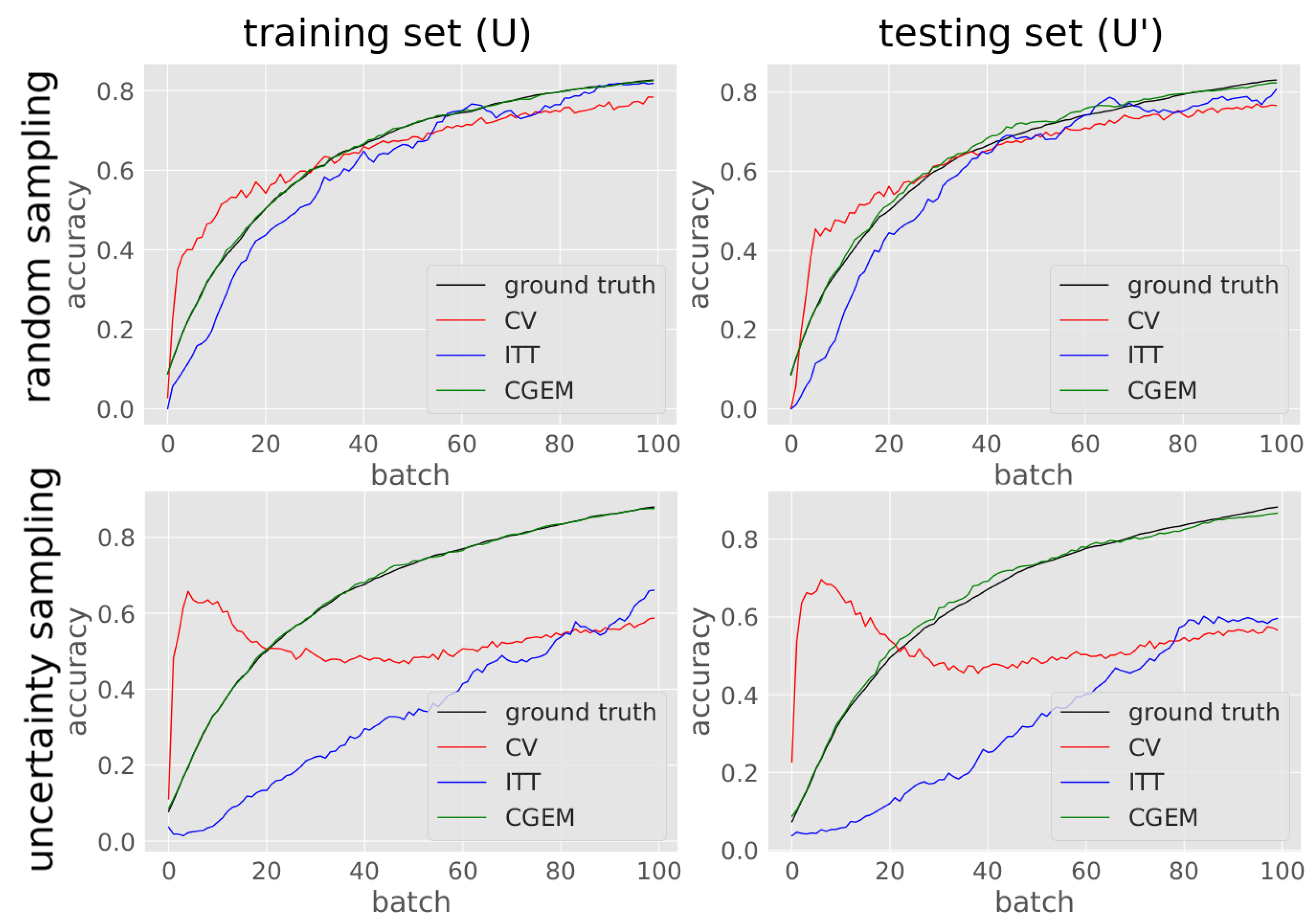
For evaluating the regression model M, the data set D is split into an equal sized train set S and a test set S’ randomly. For training M, the classifier ensemble is trained on S with mini-batches for the analytical experiments and with mini-batches for the real-world experiments. Each batch has the size samples. The regression model M is trained as described earlier. To test M, a second classifier ensemble is trained on S’, analogously to the training of C before. After each trained batch of , the configrams were extracted for evaluating M. Also, two baseline methods are evaluated for comparison: interleaved test/train error (ITT) and stratified 5-fold cross-validation (CV) where the implementation of the sklearn python package is used. For the window size parameter of ITT, we found out that 30 is a good value. If too few samples are in the labeled pool in the early stage of training, both the number of folds for CV and the window size for ITT are adjusted to a lower number.
As mentioned earlier we deal with two different quality measures. On the one hand we evaluate the Working Classifier Accuracy (WCA) of after training for N batches. More important for us in this contribution is the Accuracy Estimation Error (AEE) which we define as the mean absolute error (MAE) of the respective accuracy estimation approach compared to the ground-truth accuracy, both computed on . This is evaluated after each trained batch and averaged over all N batches for defining a mean accuracy over the entire training of .
For our analytical experiments a classifier ensemble with instances of the same classifier is used and each experiment is repeated times with a shuffled train test split (only for static data) to average our results. For the real-world experiments instances of the same classifier are trained, and each experiment is repeated times since these experiments were significantly more resource-intensive.
5.1. Analytical Static Data Sets
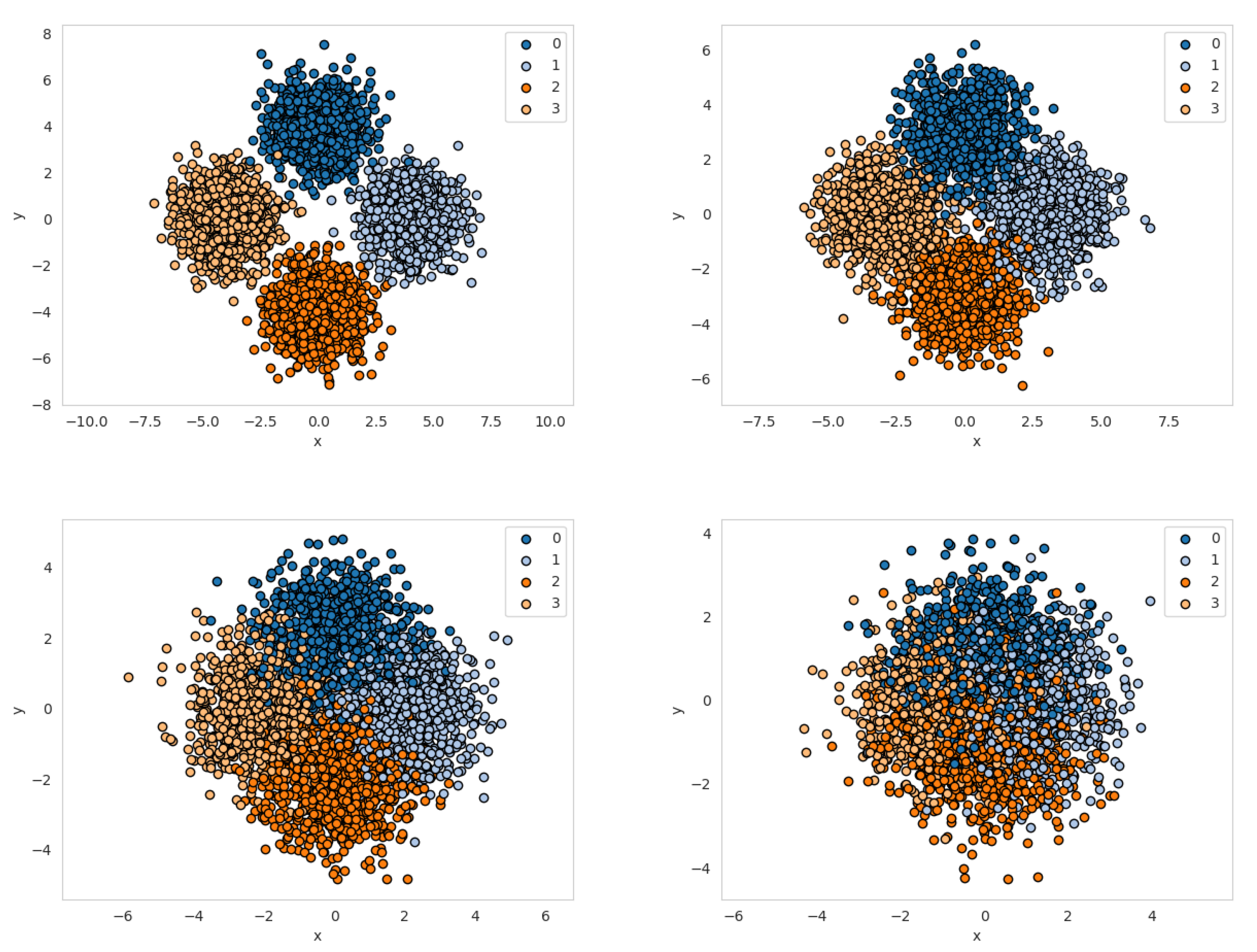
In our first evaluation step we choose to classify samples drawn from four Gaussian distributions (“Four Gaussian data set”). All Gaussian distributions have a standard deviation
and are located on a circle with various radii (see
Figure 5).
The final Working Classifier Accuracy (
WCA) after training the classifiers is listed in
Table 1. Also, an Optimal Bayes Classifier (OBC) is evaluated to provide the best possible
WCA on the respective data set.
The classifiers’ performance is mostly comparable on all data sets. On r1, the data set with the largest overlap, KNN and RFC performed worse.
The mean Accuracy Estimation Error (
AEE) can be seen in
Table 2. CGEM is outperforming cross-validation (CV) and interleaved test/train error (ITT) by a significant margin. As expected, with a smaller
r (i.e., a harder classification problem),
AEE is getting higher for all tested approaches, this is similar for CV and ITT.
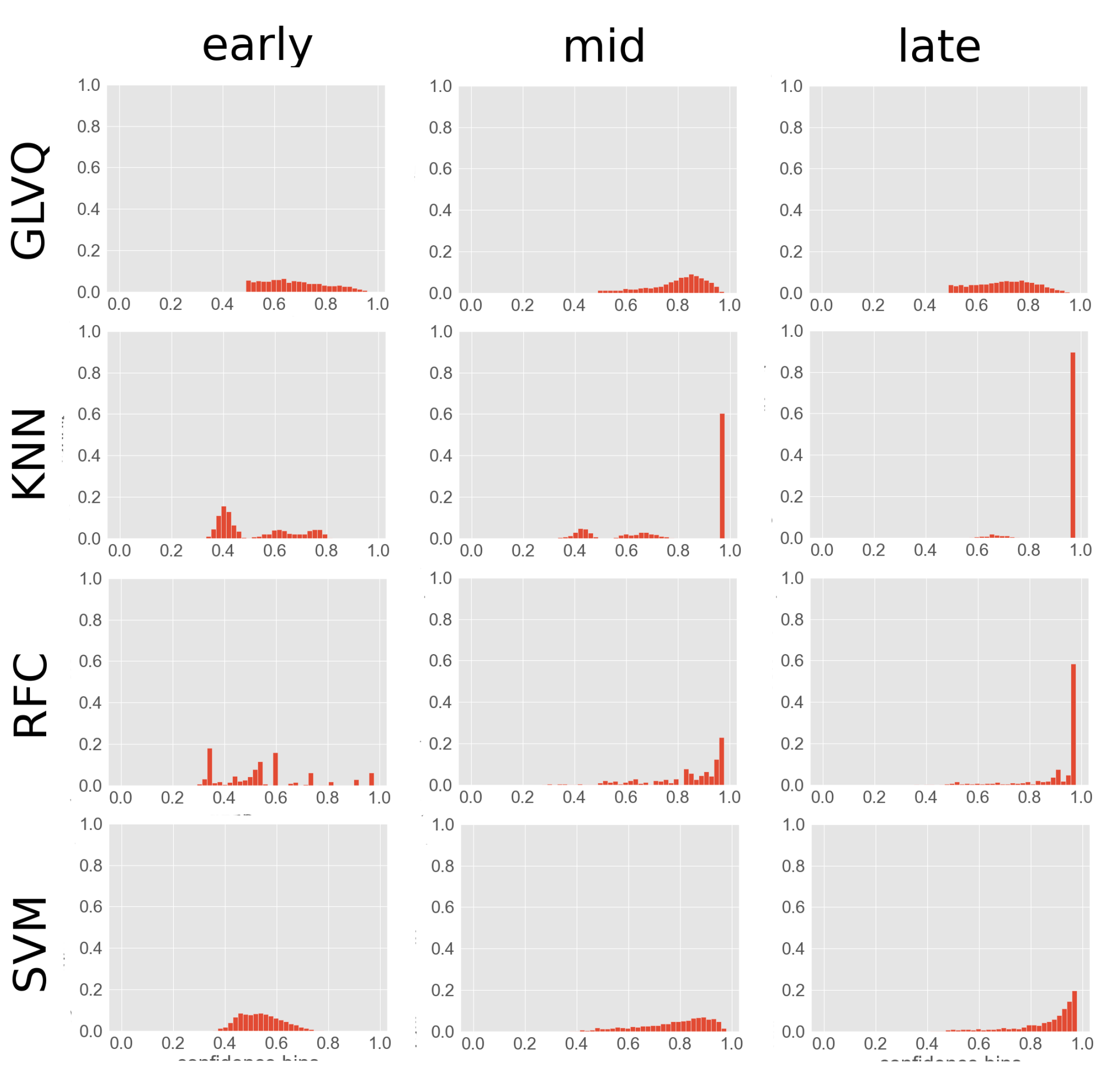
To better understand CGEM, several configrams from the Four Gaussians r3 data set were visualized in
Figure A1. It is visible that during training the confidences are shifting nearer to 1. An exception is the GLVQ classifier, which is in our case first placing prototypes for representing classes (mid plot) and then moving those prototypes (late plot). M needs to adapt to this. GLVQ also has the flattest configrams, which may also explain the poorer performance compared to the other classifiers.
5.2. Analytical Drifting Data Sets
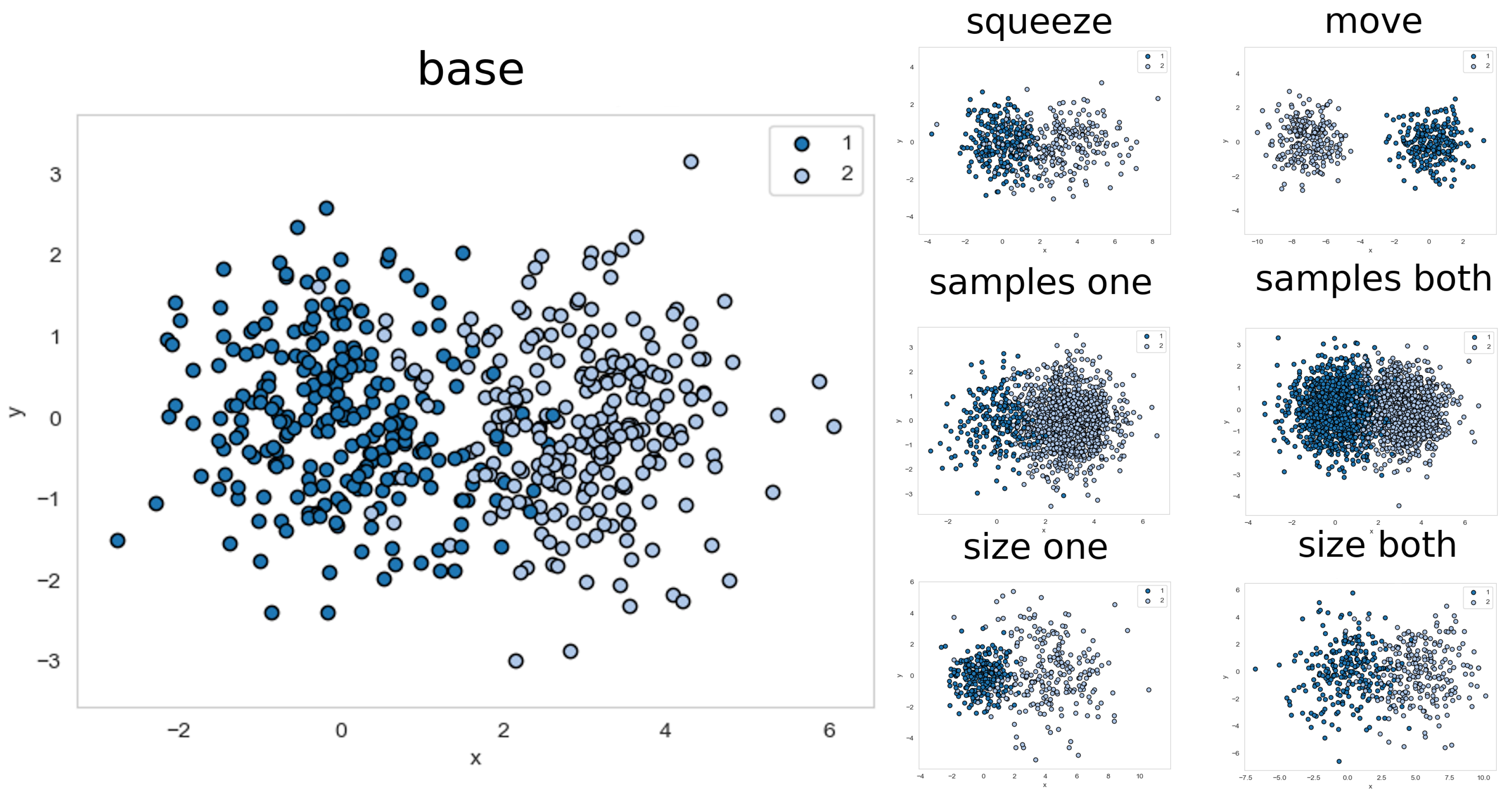
We also want to show properties of CGEM with drifting data, where it is assumed that
S’ is drawn from a different distribution that ’drifted away’ from
S. This evaluation sections uses a different setting as described earlier. Here, a base data set is used consisting of two classes
and
, which were sampled from Gaussian distributions as pool
S with 500 samples per class (see
Figure 6 top). Both distributions are isotropic with standard deviation of
, and the means
and
. The base data set is then modified in 6 different ways and with 6 different intensities each (see
Figure 6) for use as
S’. The maximum intensity is denoted as
, where all other intensities are sampled uniformly from the respective parameter of the base data set to
(which is described in the following list).
one size: is multiplied by 2. Translating by ensures that both classes have the same margin.
both size: and are multiplied by 2. To ensure that both classes have the same margin is translated by .
one samples: number of samples drawn from are multiplied by 5.
both samples: number of samples drawn from and are both multiplied by 5.
move: is translated by .
squeeze: is multiplied by 3
The
AEE is mostly affected by moving one class (see
Table 3). By moving one class over the other the quality decreases until both classes are in the same spatial relation as in the base set, leading us to the assumption that it is only important to have roughly the same relations between classes. Squeezing one class is also affecting
AEE negatively because the amount of overlap changes.
5.3. Real-World Data
5.3.1. Data Sets
We used five real-world data sets in this part of the evaluation. For WDBC [
43] no preprocessing was done at all. For CALTECH101 [
44], PASCALVOC2012 [
45] and OUTDOOR [
35] the VGG19 deep convolutional neural net [
46] was used without the last SoftMax layer and with the weights from the image net competition as a feature representation. For extracting facial features for CELEBA [
47] dlib (
http://dlib.net/) was used. The target at CELEBA was to differentiate between males and females.
5.3.2. Incremental Learning
The accuracy estimation error (
AEE) from incremental learning with random querying can be seen in
Table 4. CGEM is outperforming the baseline methods in nearly all cases with an
AEE of 2.3% to 4.0%. The final working classifier accuracy (
WCA) is shown in
Table 5.
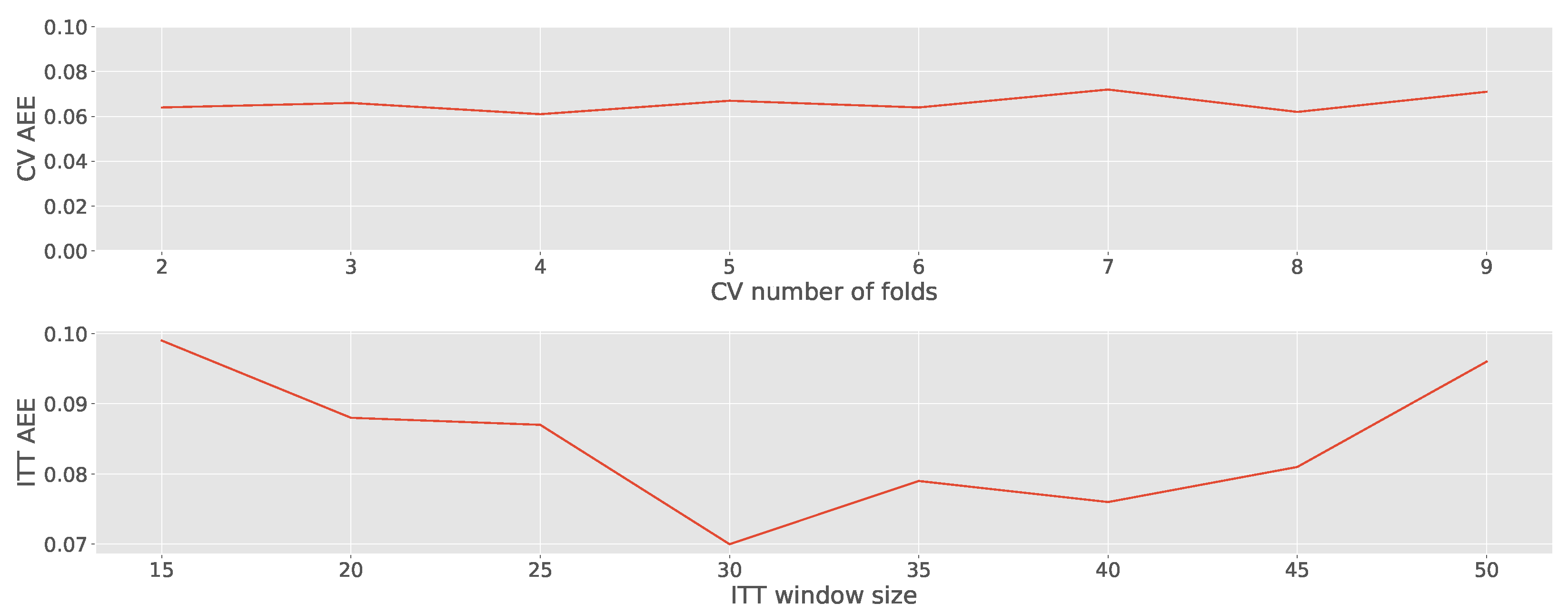
Also, we wanted to analyze parameter choices for the baseline methods.
Figure 7 depicts different number of folds for CV and different window sizes for ITT related to their AEE on the OUTDOOR data set for the GLVQ classifier. Changing the number of folds for CV does not seem to have a huge effect in estimating the accuracy. If the ITT window size is too small there can be noise and calculating the average of a smaller window results in coarser granularity. On the other hand, if the window is too big, there is too much delay and information from older states of the classifier has a negative impact. Choosing a window size of 30 seems to be a good trade-off.
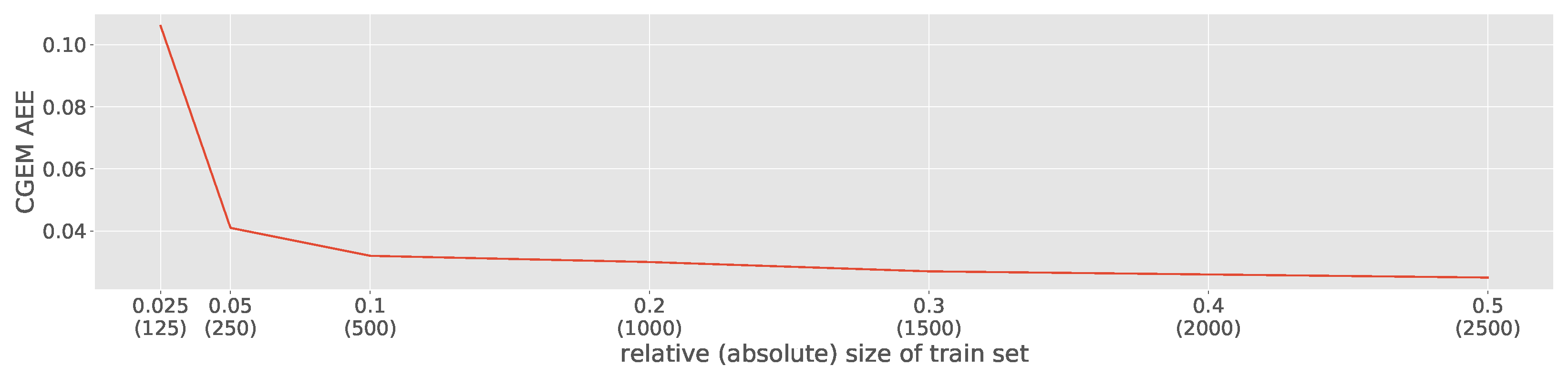
Furthermore, we want to analyze different ratios for train/test splits or in other words how many samples training set
S and test set
S’ contains. For the other experiments, we choose to have a 50/50 split.
Figure 8 shows different ratios of the train/test split, again for the GLVQ classifier on the OUTDOOR data set. The results are supporting our findings with the analytical data set from
Section 5.2. The AEE remains stable also if the training set
S consists of only 10% of the samples from the data set. The error raises to 4%, which is still better than the baseline models, if only 250 samples are in the training set
S. However, if the train set is defined too small, CGEM is not capable of building an accurate estimation model.
5.3.3. Active Learning
For active learning experiments, uncertainty sampling was used to query the samples with the lowest classifier confidence (see
Table 6 and
Table 7). The final
WCA is usually better compared to random sampling (see
Table 5). However, the
AEE predicted with CGEM is with 2.3% to 7.2% slightly higher as in the random sampling experiments.
Predicting the accuracy of the classifier when applying an active querying strategy is challenging for the baseline methods, because they are relying on the samples of
only and those samples have lowest confidence, meaning they are hard to classify. So, the estimated accuracy is pessimistic in this case. CGEM is adapting to this and still estimates the accuracy with high precision. In
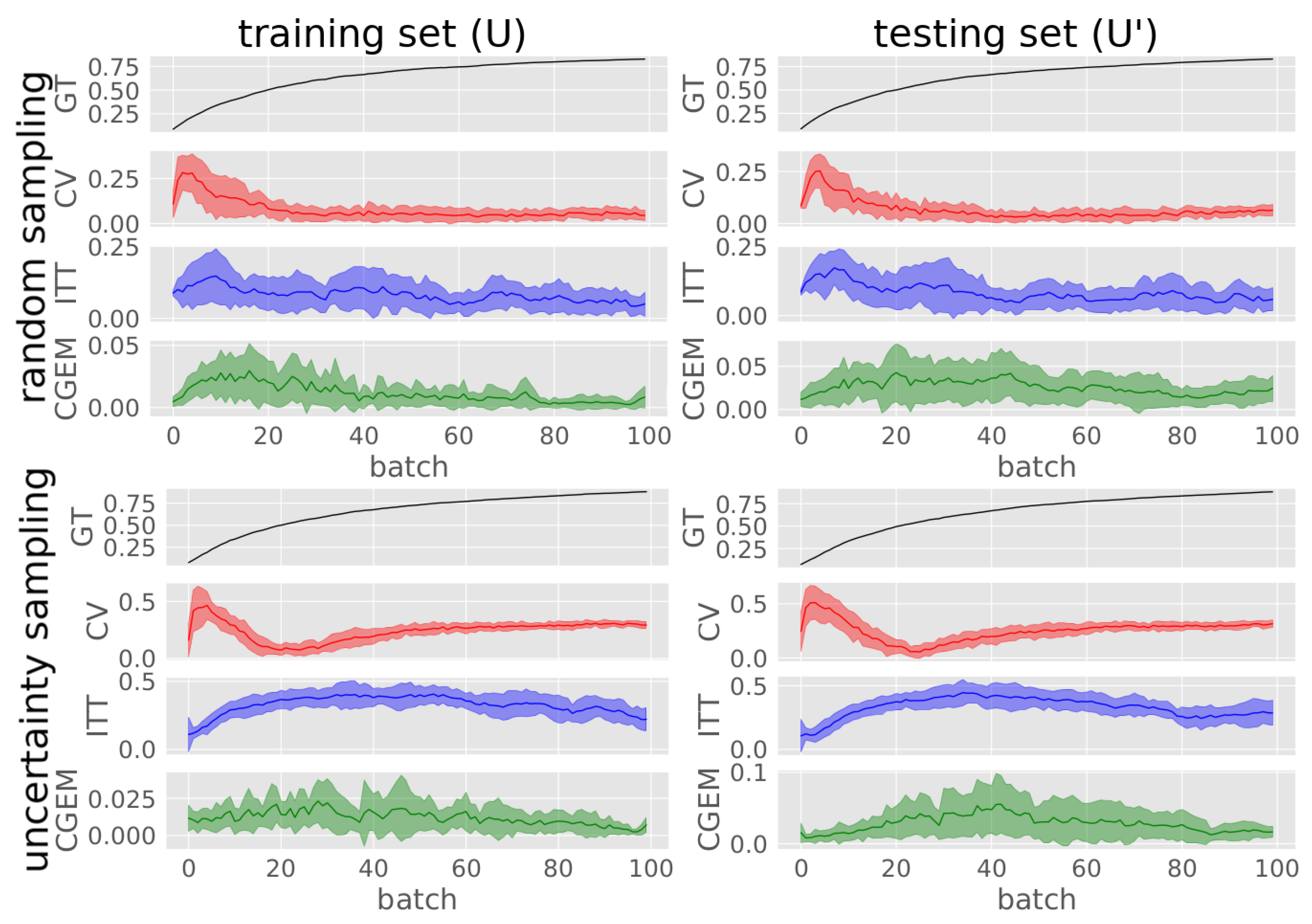
Figure 9 averaged incremental training runs are displayed showing the absolute ground-truth and estimated accuracies of training GLVQ on the OUTDOOR data set with both random and active sampling.
Figure A2 visualizes the standard deviation of
AEE for these trainings.
5.4. Comparison in Resource Demands
CGEM needs to be train beforehand. This requires a labeled data set for extracting configrams to be used to train the regression model. CV and ITT do not need such a preparation phase; however, after training CGEM it can be applied on demand and with no further overhead. Only the regression model must be saved and for estimating the accuracy, confidences of unlabeled samples must be calculated for creating a configram to be fed into CGEM.
ITT is maybe the approach which needs less resources. Memory-wise it is relatively cheap, because only the window of the last classifications must be saved. However, before training any sample, it must be classified because ITT relies on the information whether these classifications were correct or not. This makes ITT relatively inflexible, because these classifications must be done, even if accuracy estimates are not necessary.
CV is the most resource demanding approach. Memory-wise it is expensive because a sufficient number of trained samples must be saved for applying the CV, which is possibly not an option on some mobile robot applications. In our evaluation we saved all yet trained samples for the best possible performance of CV. However, also computation-wise CV is resource demanding, since for estimating the accuracy k classifiers must be trained, where k is the number of CV-folds.
6. Competence-Based Human Machine Interaction
To have a look at a more practical evaluation, we want to know how CGEM can be used as a helper for an efficient human–robot interaction in an more flexible incremental learning setting, where new classes appear while in training. This relates to our use case of a service robot that regularly does a particular job and must adapt to new conditions occasionally. In our training setting, the classifier is not only trained incrementally, but also new samples (including new classes) are inserted to the unlabeled pool U while training. To define the state of sufficient robot capability, a minimum desired task accuracy (MDTA) is defined. If CGEM estimates a lower accuracy than MDTA, the robot stops the task and waits for its supervision. The supervision is done by querying unlabeled samples and asking the user for the respective labels. As in our former evaluation, CGEM is applied after each batch of samples to determine the accuracy increase. This is done until the accuracy is equal to or above the MDTA. If accuracy estimation detects a drop in accuracy again because of newly appearing unknown classes, the robot stops and is retrained until the MDTA is reached again.
To simulate this use case in an experimental setting, the GLVQ classifier is trained on the OUTDOOR data set, which is related to our scenario. We choose GLVQ because it is a very flexible classifier, needs less resources compared to the other evaluated methods and because it is well suited for efficient incremental training [
48]. Also, GLVQ performed best on the OUTDOOR data set when using uncertainty sampling and second best when querying randomly.
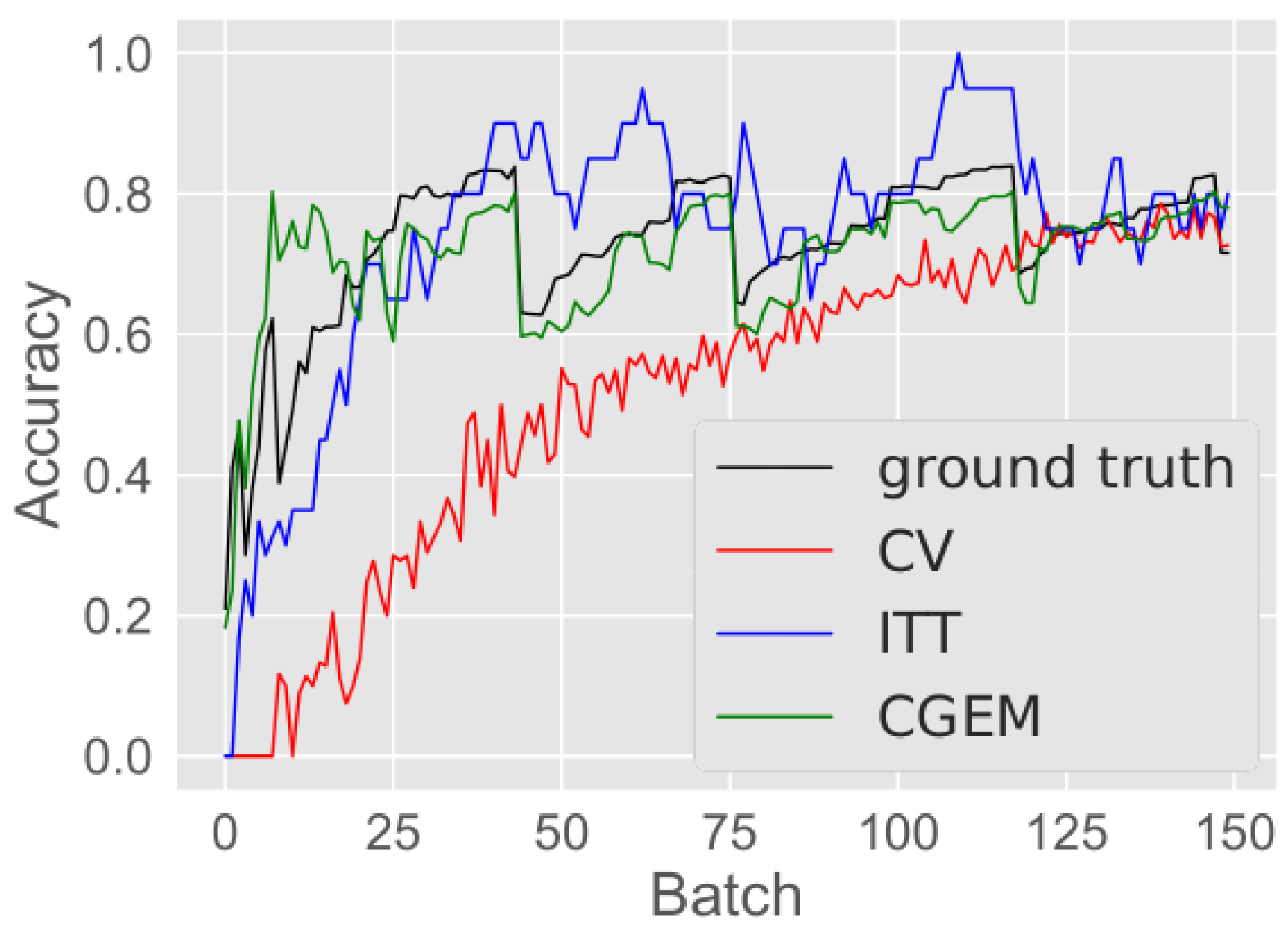
In our experimental setting the train test split in S and S’ is applied as described earlier. The training of C is commences with only 10 classes from OUTDOOR. The training is done in mini-batches as described earlier. After each mini-batch, the accuracy on is calculated and if it is above an MDTA of 80% the classifier is expected to be good enough until new objects appear. To simulate this, 5 new classes are put in U and continue training until N batches are trained. M is then trained with the extracted configram-accuracy pairs . After that, M is applied to S’ in a similar fashion: is trained as long as its estimated accuracy predicted by CGEM is below 80%. Please note that we do not use ground-truth accuracy data here, but we are capturing it for comparison. Again similar to before, 5 unknown classes are put in if the predicted accuracy is equal or above an MDTA of 80%.
The accuracy plot of
can be seen in
Figure 10. In the plot the adding of the new samples to
is noticeable in a drop of accuracy when the predicted accuracy (green line) is on or above 80%. After the adding, the estimated accuracy is below 0.8 and the classifier is trained again until the MDTA is reached again. Then new samples are added again, the classifier is retrained again and so on. It is visible from the plot that CGEM is also capable of predicting the accuracy in this incremental learning use case, except for some fluctuations in the beginning of training.
7. Conclusions
We showed that the CGEM approach improves the prediction of accuracy for four incremental trained classifiers with their specific confidence estimates. Our analytical experiments show that data distributions need to be similar for training and test conditions, excluding strong drift scenarios. Our in-depth evaluation of several state-of-the-art real-world data sets shows that CGEM estimates the classifier’s accuracy for both random and active learning. Especially for active learning this is crucial, because baseline methods are relying on the labeled training set which is not representative for the whole data distribution. Our CGEM method can resolve this problem by also taking into account the unlabeled data. Further we have shown that CGEM also deals with more interactive learning scenarios where new samples are added while training incrementally.
For using CGEM, it needs to be trained with a labeled training data set first. After being trained once, it can be applied in a very flexible manner and only if needed, without any extra overhead. CGEM also has a very fast reaction time, which is crucial when dealing with fast changing environments as our incremental learning use case has shown. The baseline methods CV and ITT both have a high latency because they are working on a window of trained instances. The main qualitative difference to CV and ITT is the additional exploitation of unlabeled data with respect to the confidences of the targeted classifier.
There is little research done concerning the quality surveillance of continuously learning autonomous intelligent systems. We think that this is an important goal for building adaptive cooperative robots and we hope that a first step towards this was done with this contribution. Further research is needed in analyzing how to apply CGEM to data that is different from the training data and if domain adaptation techniques are applicable here. Also, it would be beneficial to have a confidence for the estimated accuracy to further reject uncertain predictions. For reducing the label effort to create set
for training CGEM, it can be explored if data set reduction techniques as described in [
14] can be applied, since our experiments show that CGEM is robust in terms of a varying number of samples.
As already motivated in the introduction, a possible application for CGEM could be, e.g., a household service robot. As such a consumer robot is shipped from a factory to a customer it has to learn the individual user environment, where the robot should do a certain task like cleaning the room. The robot is trained incrementally by getting user supervision via a label interface [
49] from time to time. In this use case a first simplified goal could be to determine if the accuracy in recognizing key objects in the environment can be estimated if CGEM is pre-trained with other objects within the goal domain. The estimated accuracy could then be used to determine if the robot needs more training or if the user must take a higher workload ratio to accomplish a needed minimal accuracy.
A second goal could be to determine if the estimated accuracy is related to the actual task performance the robot has in its current state (like how good is the robot in cleaning up the environment). Other interesting research within such a real-world application of CGEM could be to determine if the whole task should be delegated, if the performance is not increasing while training. Also, it could be interesting to evaluate a trade-off for training the robot compared to the user is doing the task on his or her own.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}