1. Introduction
The use of additive manufacturing (AM) technologies to produce small batches of highly customized, complex parts in a reduced development cycle is extremely attractive to all industries. For AM parts to be fully adopted in industrial scenarios, engineers have to be able to confidently assess the structural integrity of the finished part under its intended loading conditions. However, the set of printing conditions that lead to an optimal part in terms of mechanical properties are not fully comprehended due to a confluence of two factors: the nuances associated with the interacting effects of the processing conditions and material behavior, paired with a commonplace lack of standardization in the field of AM as a whole.
These challenges present an interesting case for employing different sensors to oversee the additive manufacturing process. Given the pivotal role of melting processing in determining the ultimate performance of specimens produced by Material Extrusion (ME) additive manufacturing, there has been extensive exploration into conducting in-line measurements of temperature and pressure. These measurements aim to establish correlations with shear viscosity [
1], interlayer strength [
2], and deposition rate [
3]. However, when printing at high speeds, the model of melting changes to melting with pressure flow removal [
4], and the pressure in the melt region would change significantly at different locations in the nozzle. Therefore, to capture the behavior of both slow and fast printing processes in a more general way, the utilization of force sensors has emerged [
5].
Research to explore the effects of different printing parameters on extrusion force and sample mechanical properties through experiments or derivation has never stopped. A comprehensive review [
6] underscores the pivotal printing parameters over the mechanical properties of extrusion-based additive manufacturing products, which include raster angle, layer thickness, build orientation, filling ratio, printing speed, printing temperature, and bead width. Notably, Koch’s study proposed product build orientation and the impact of the solidity ratio determined by layer thickness and nozzle diameter on tensile strength [
7]. Li’s research showed trends in tensile strength and bonding degree with the increase in printing speed [
8]. In the study of extrusion force, the melting model solved by Osswald, etc. shows how nozzle diameter, print speed, and nozzle temperature have an analytical influence on extrusion force [
4]. In the computational fluid dynamics (CFD) model, the nozzle diameter plays an important role in the filament feed force under consideration of viscoelasticity [
9]. Through experiments, Mazzei Capote, etc. summarized the impact of printing speed on the extrusion force of ABS and PLA at different temperatures [
5]. In the pursuit of a balance between the practicality of data collection through experimentation and the reliability inherent in predictive models, our study casts a spotlight on build orientation, layer thickness, nozzle diameter, and printing speed. These parameters serve as the focal points for predicting extrusion force and tensile properties, signifying their paramount importance in the realm of extrusion-based additive manufacturing research.
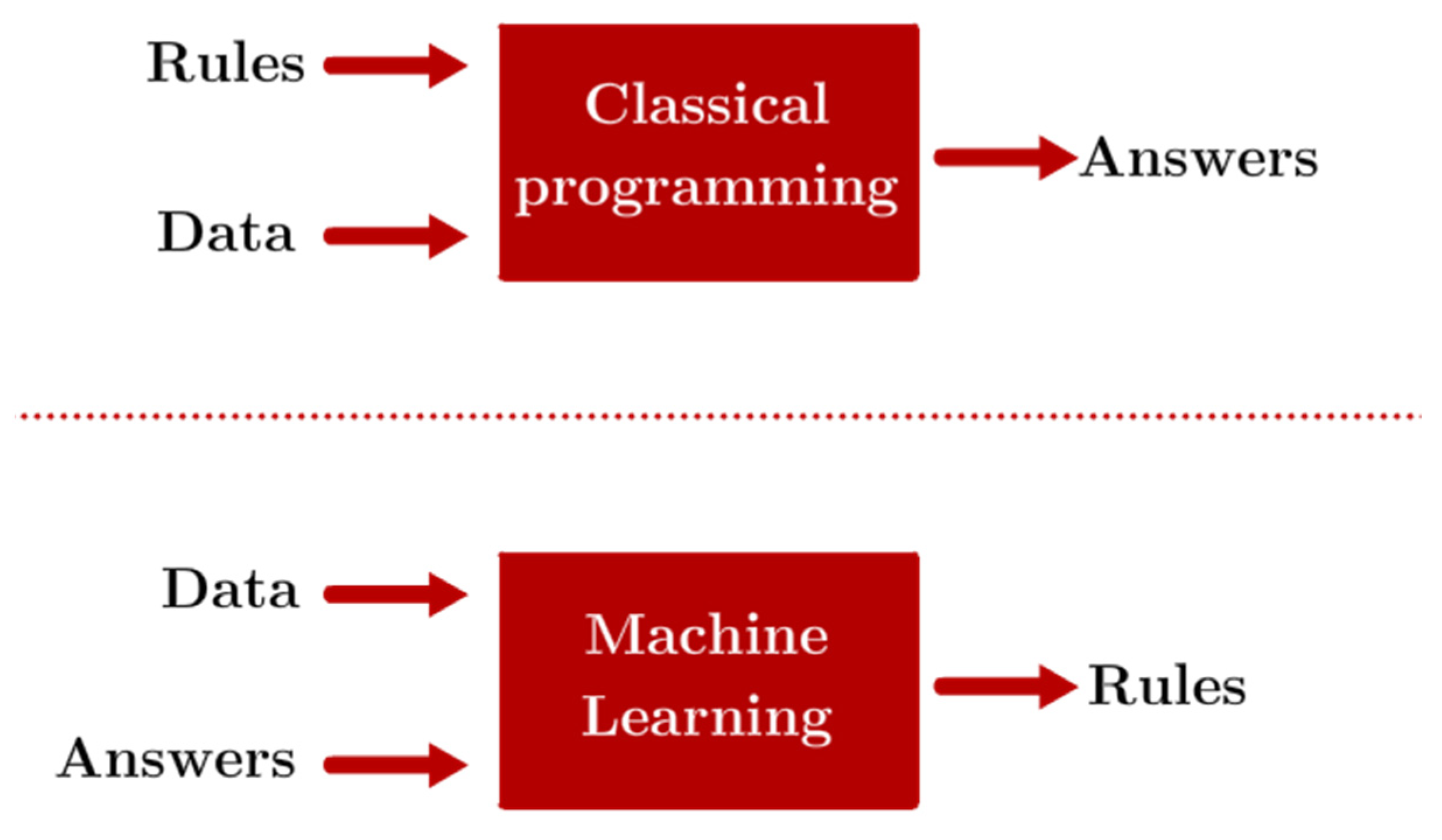
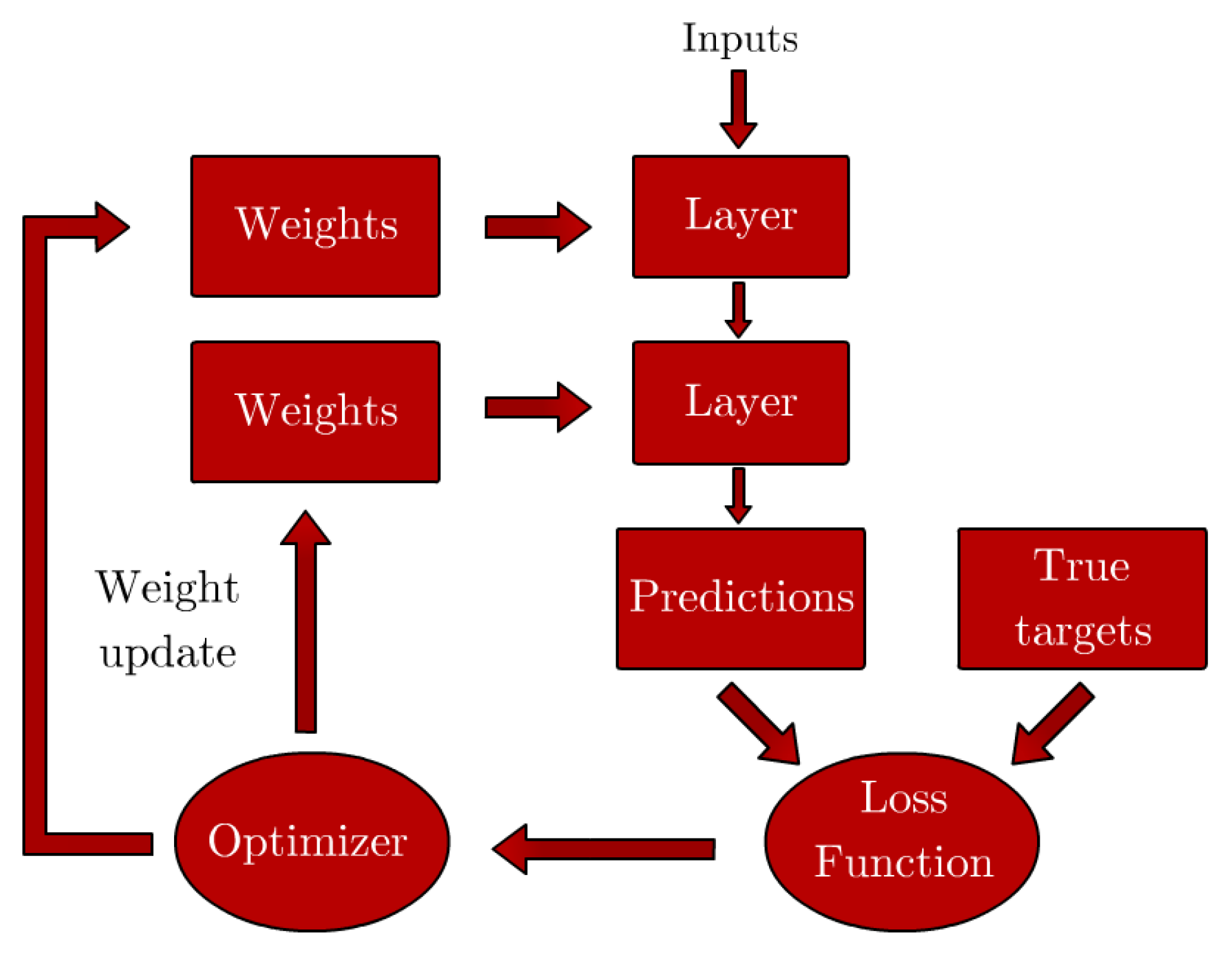
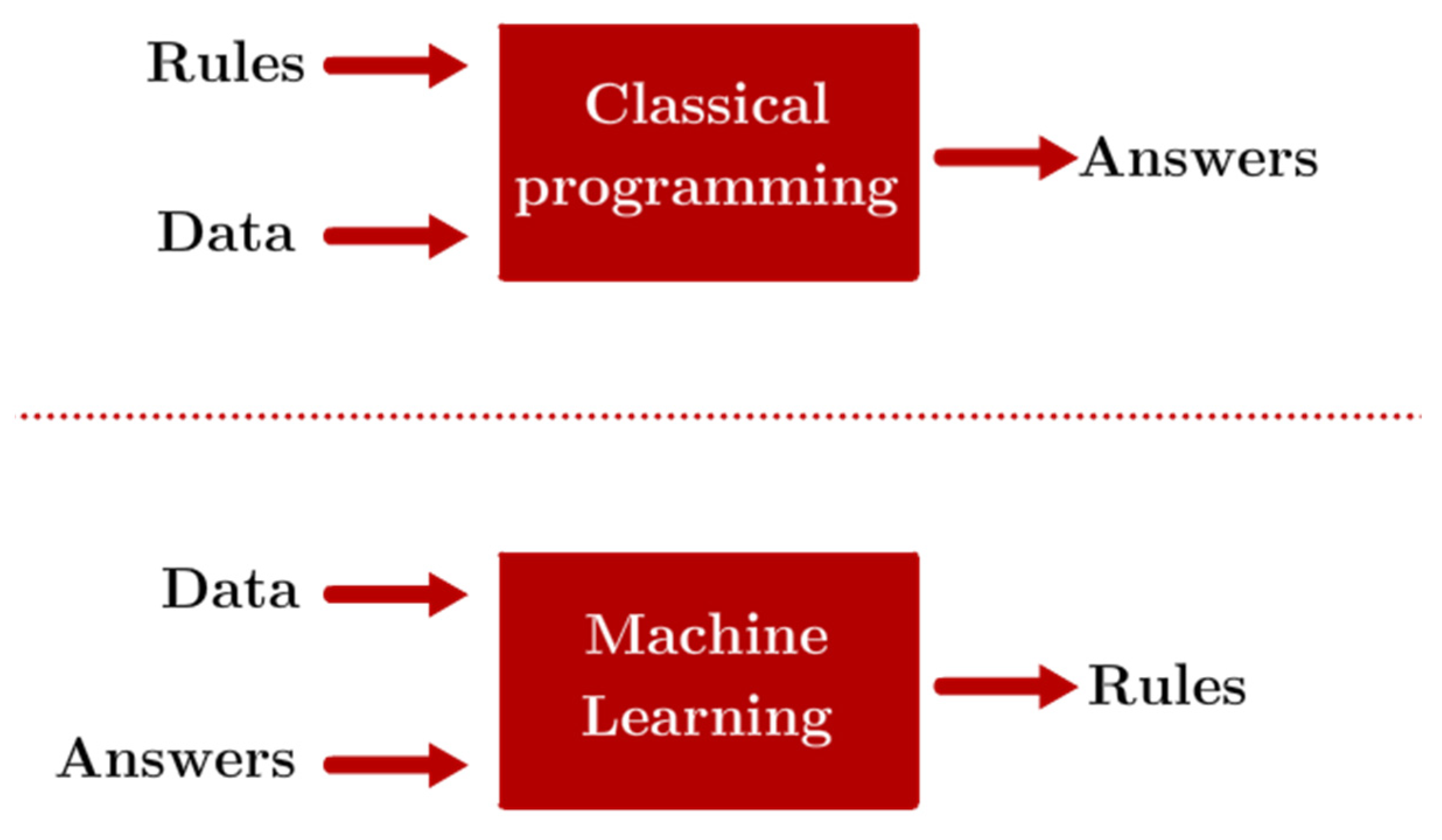
Recent advancements in processing power and algorithms have made it easier than ever to deploy machine learning (ML) solutions, and the intricacies of the processing-properties relationships of AM techniques represent an interesting case for the development of ML algorithms. These excel in cases where the inputs and outcomes of a particular phenomenon or task are known, but connecting the two through an explicit set of rules or relationships can be extremely complex and time-consuming [
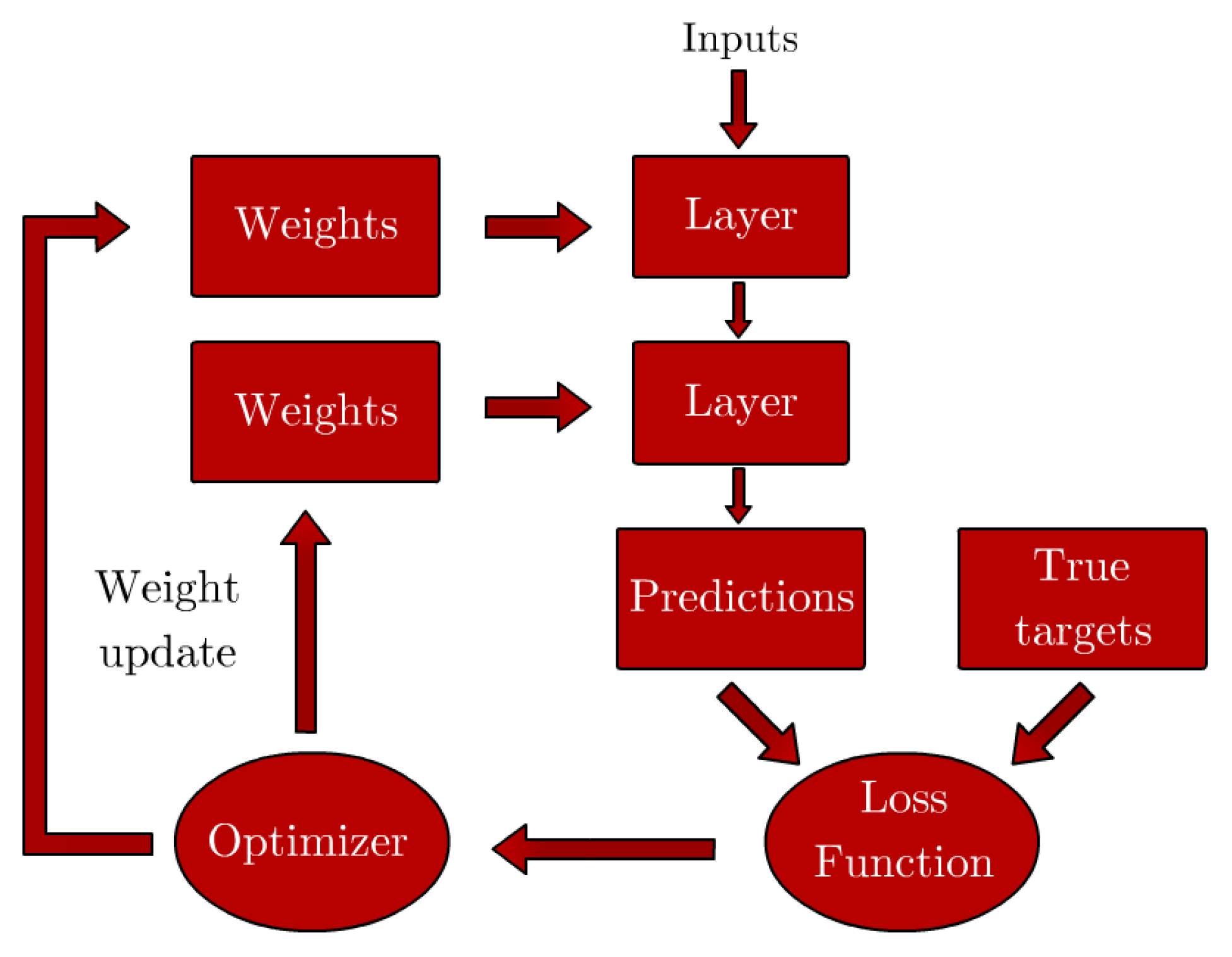
10]. In this manner, ML models are trained as opposed to explicitly programmed, as illustrated in
Figure 1, where the differences between ML and traditional programming philosophies are compared. ML techniques are applicable in situations where the inputs and outputs of a particular phenomenon are known, but there’s a lack of explicit rules that indicate a relationship between the two.
The application of ML in AM can be mainly divided into three directions: printer health state monitoring, part quality detection, and resource management. In health state monitoring of 3D printers, the filament feeding state has been investigated by different sensors with various ML methods for data processing and classification. The feature space reduction and unsupervised cluster center identifications were employed to classify normal, block, semi-block, and run-out of material states [
11]. Synthetic acceleration and the back propagation neural network (BPNN) were applied to preprocess the data from vibration sensors and classify normal and filament jam states [
12]. Regarding part quality control, both final part performance and layer-wise defect detection were studied. Feed stock characteristics and processing parameters are the main variables for part performance. The combination of two main factors was applied to the prediction of the compressive modulus and shore hardness of PolyJet-printed multi-material anatomical models [
13]. In the realm of predicting the mechanical properties of finished parts, Bayraktar et al. [
14] generated three mathematical models, corresponding to three different raster patterns, to predict tensile strength (
σt) by inputting layer thickness and nozzle temperature. However, the network architectures were trained separately for each raster pattern, which is not convenient for mechanical property prediction with varying orientations in a single print. For layer-wise detection, the convolutional neural network used for camera data analysis was applied for depositing defect detection [
15], and multiple regression algorithms were compared in surface roughness prediction with mounted infrared temperature sensors and accelerators [
16]. Except for product quality, optimization of resource consumption during processing is also important during the evaluation of processing parameters. The potential time, cost, and feedstock quantity were predicted with fuzzy inputs [
17].
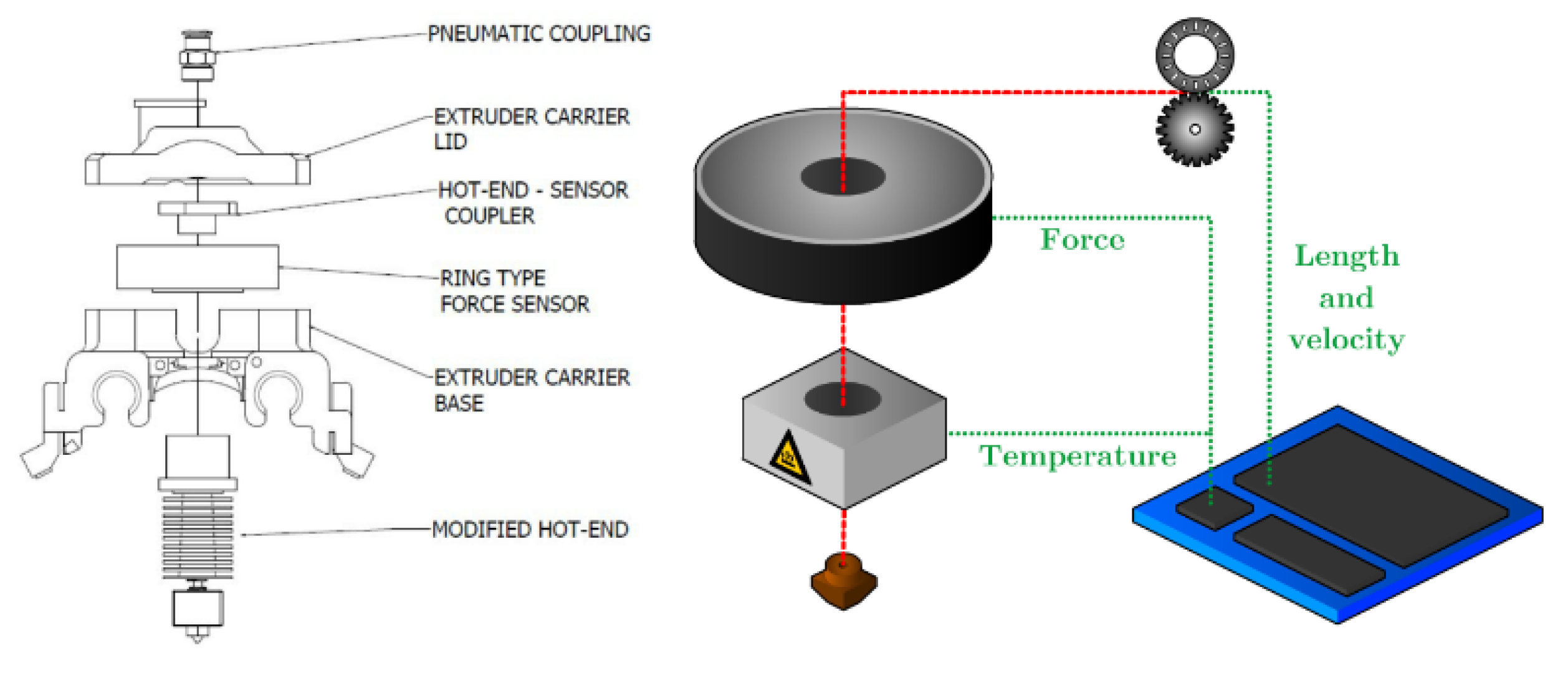
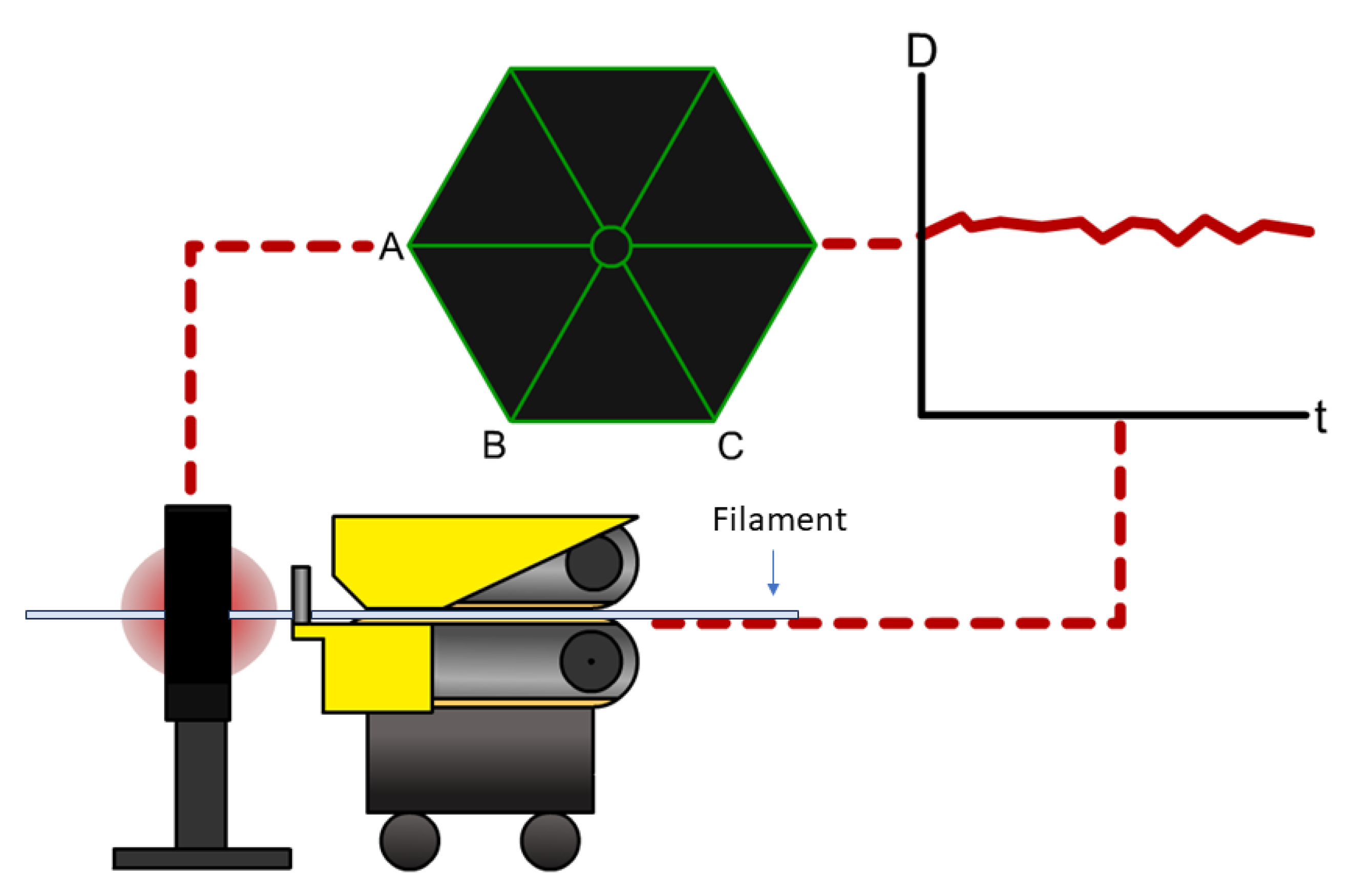
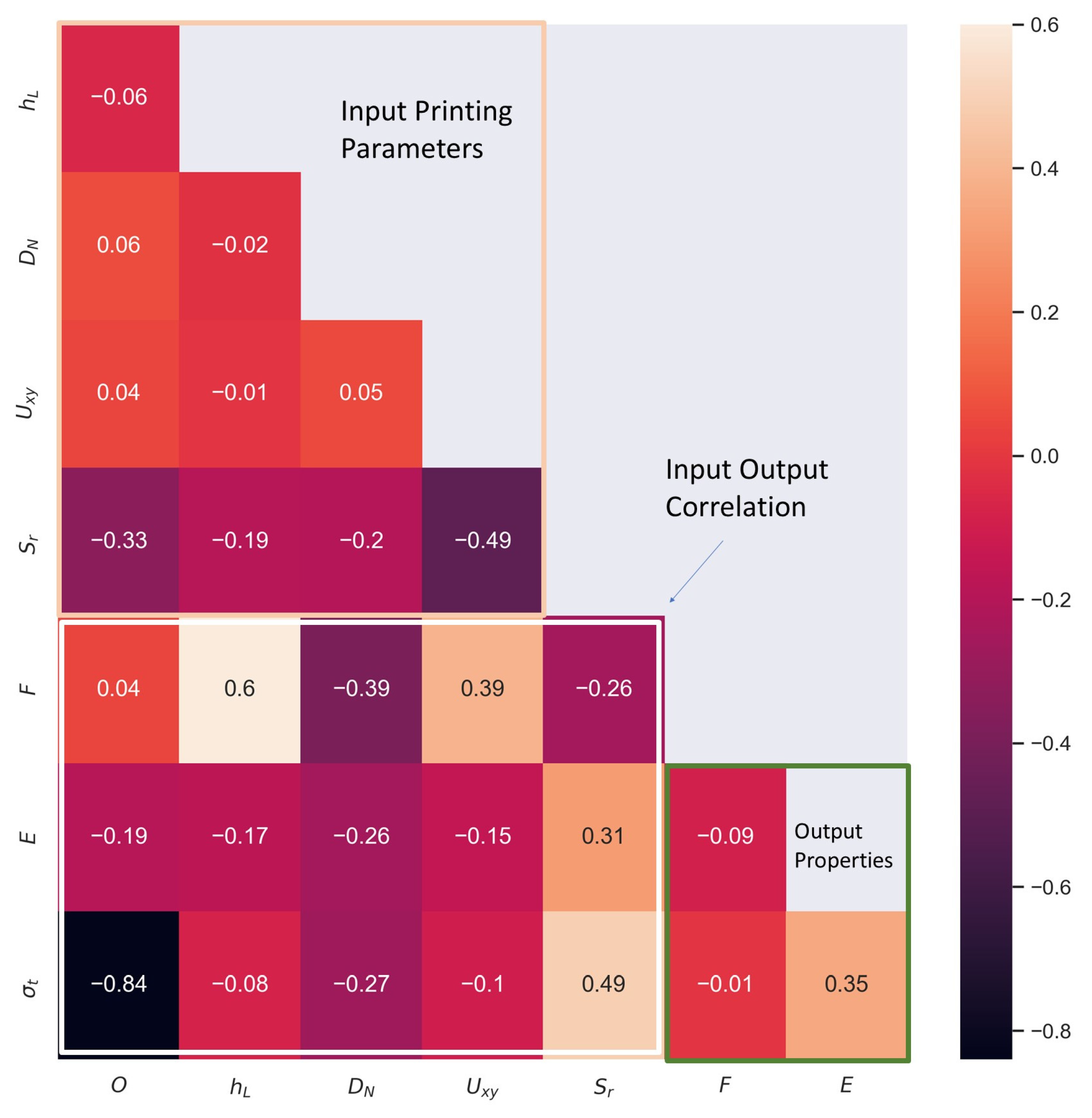
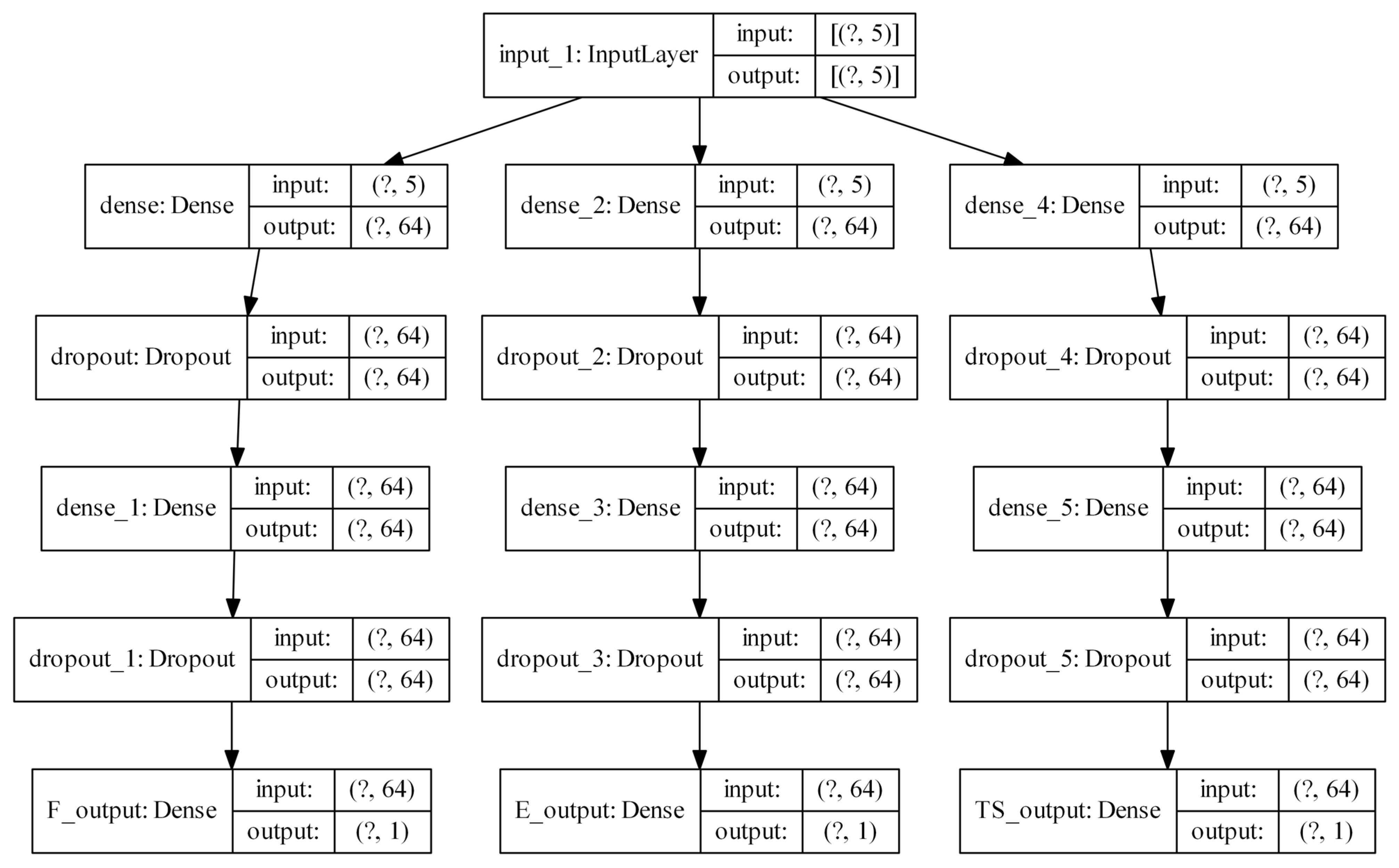
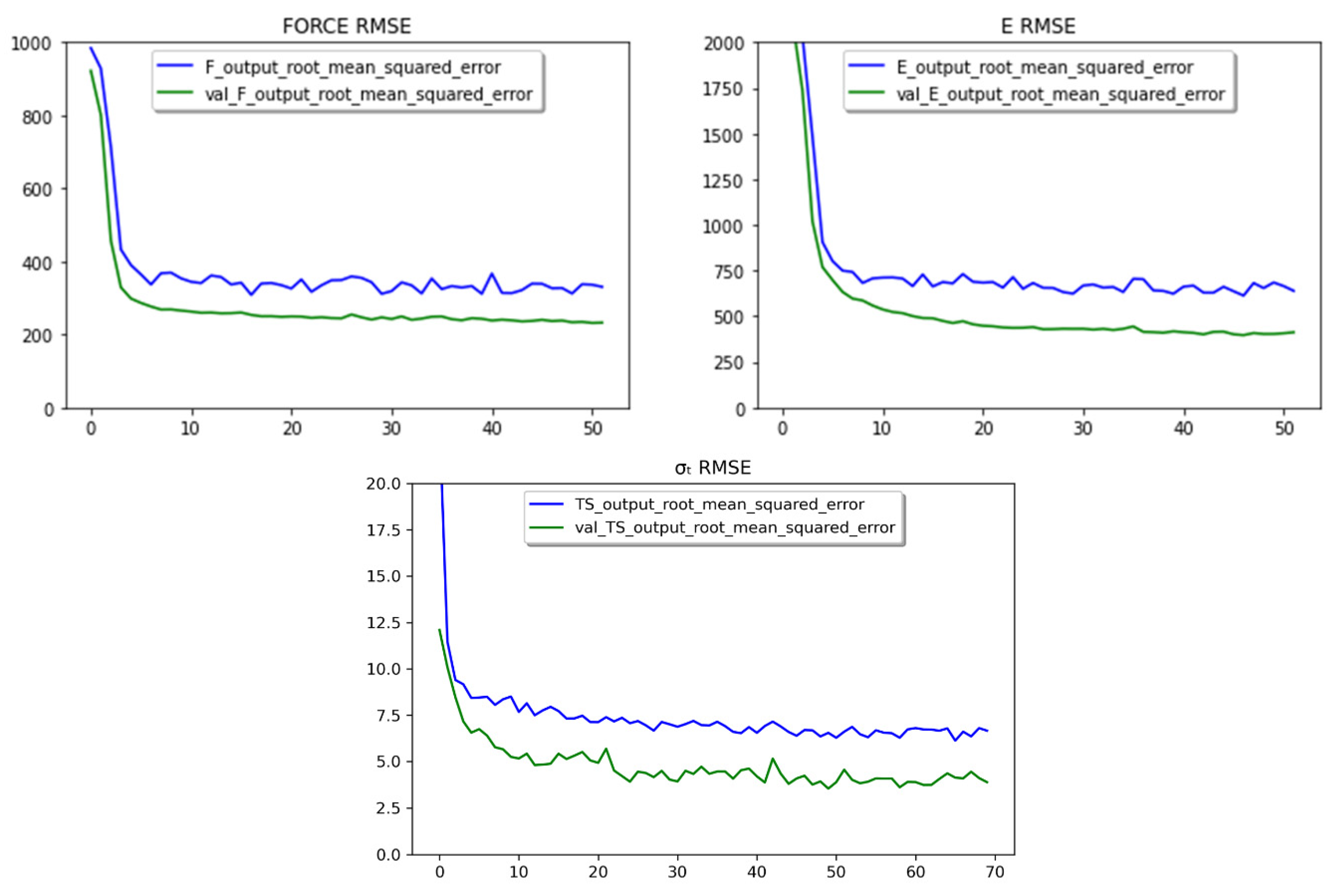
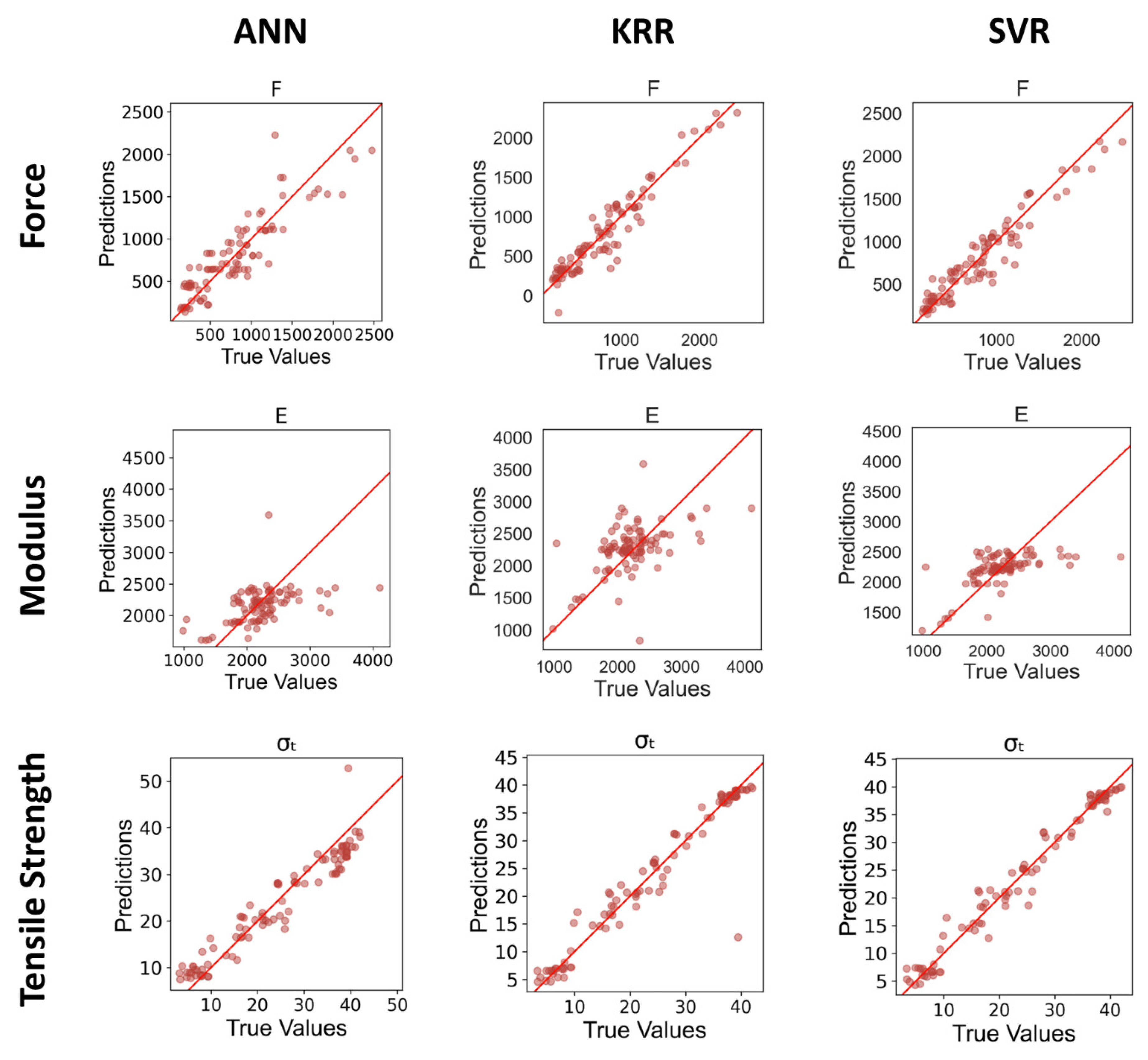
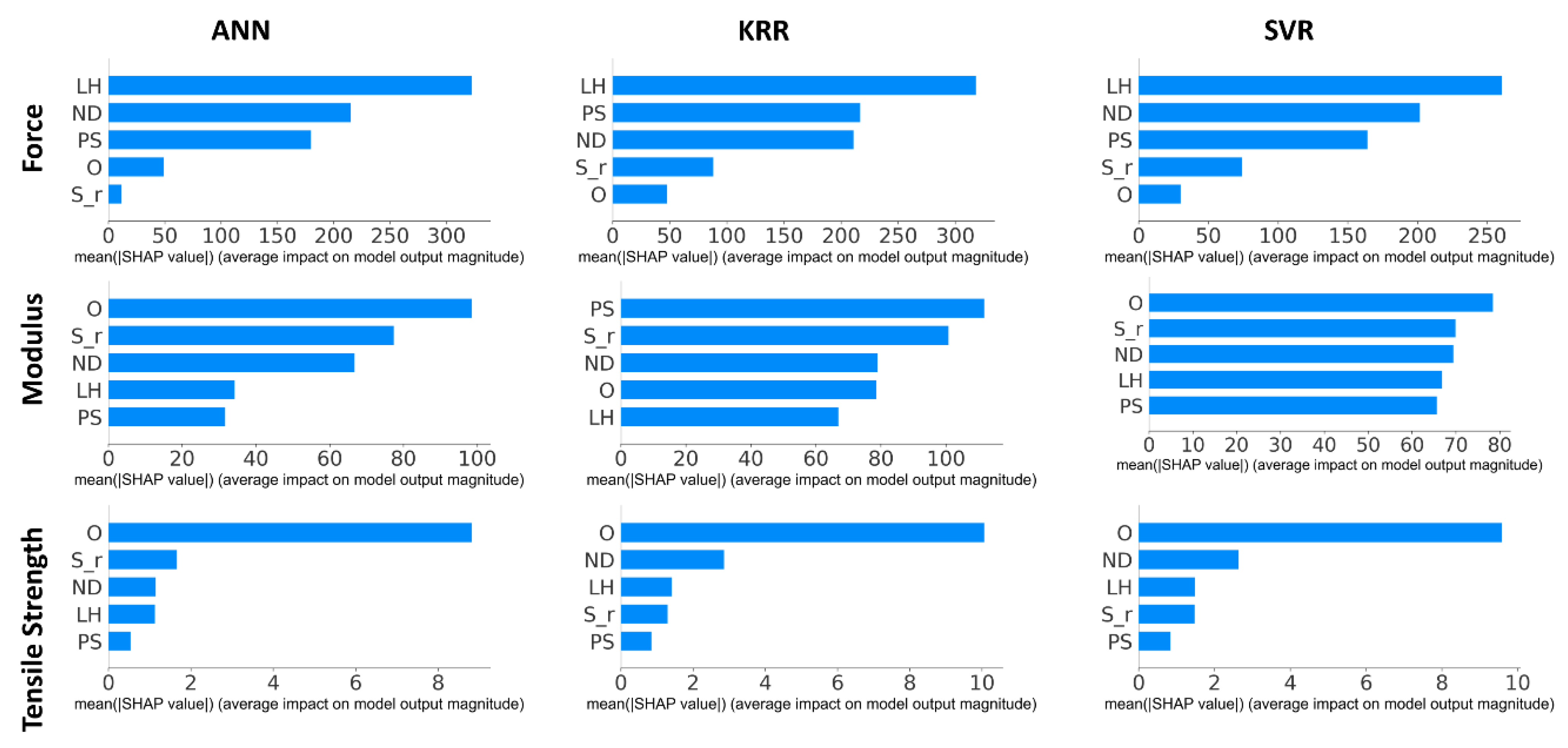
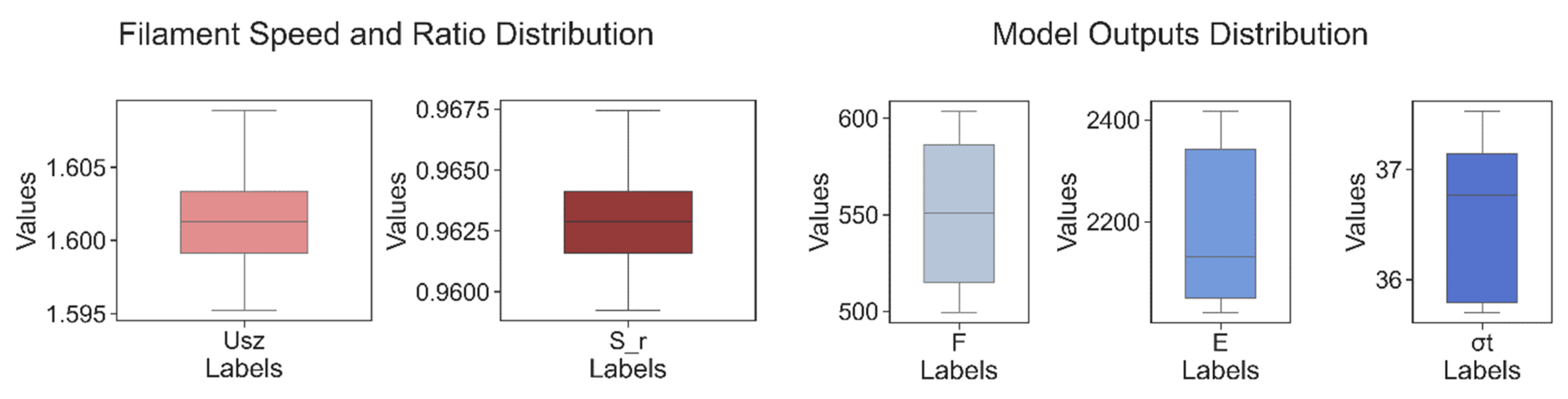
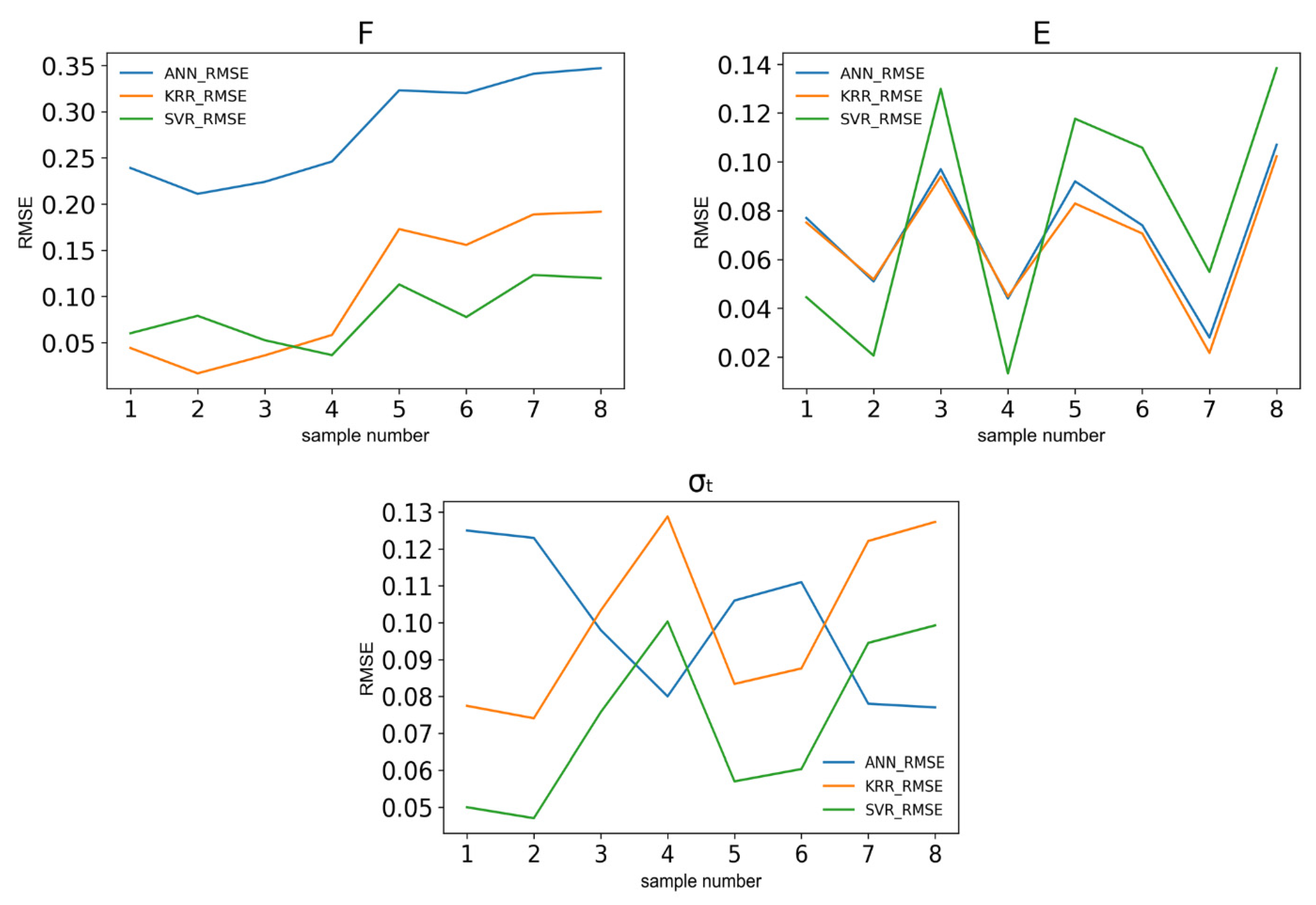
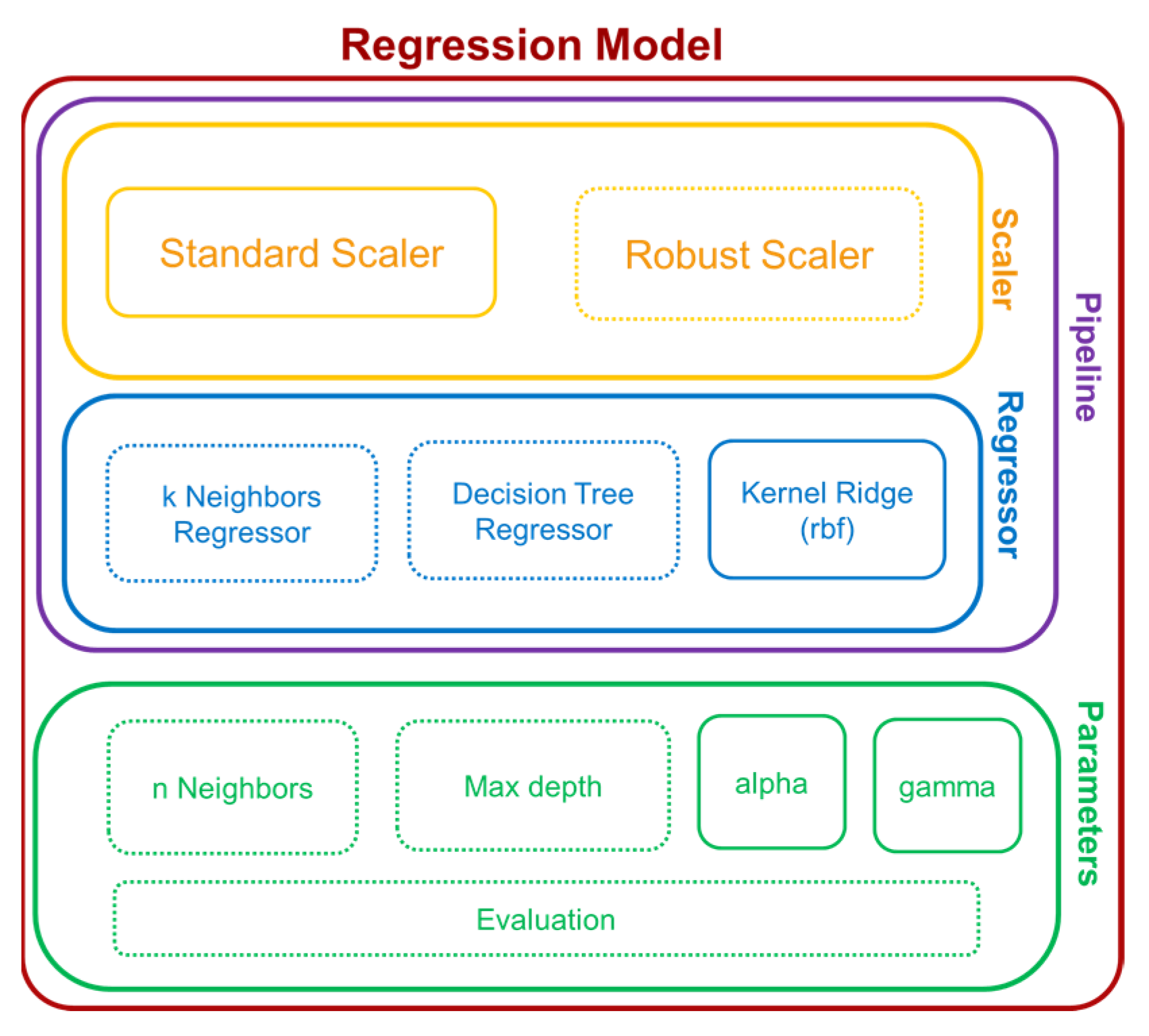
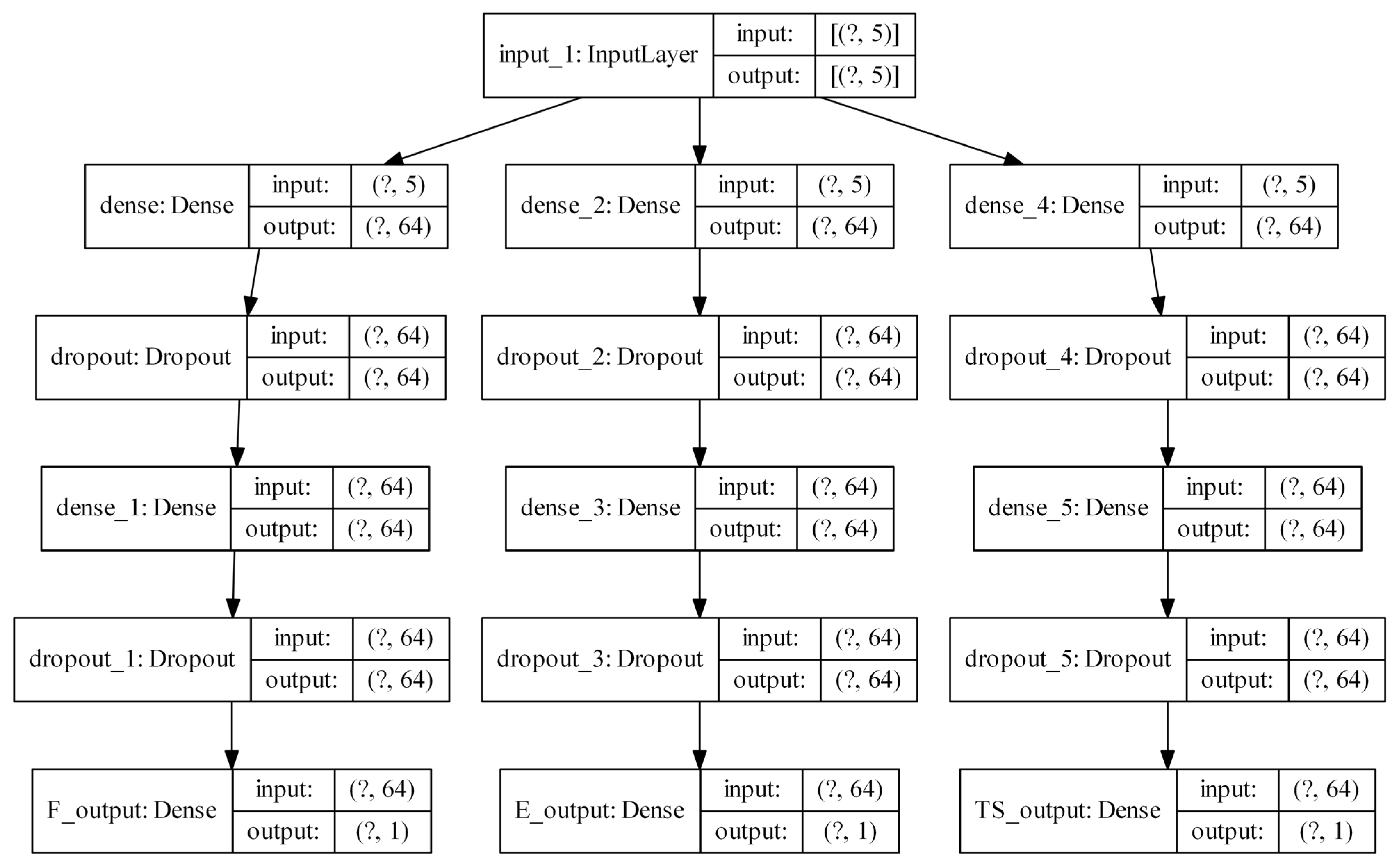
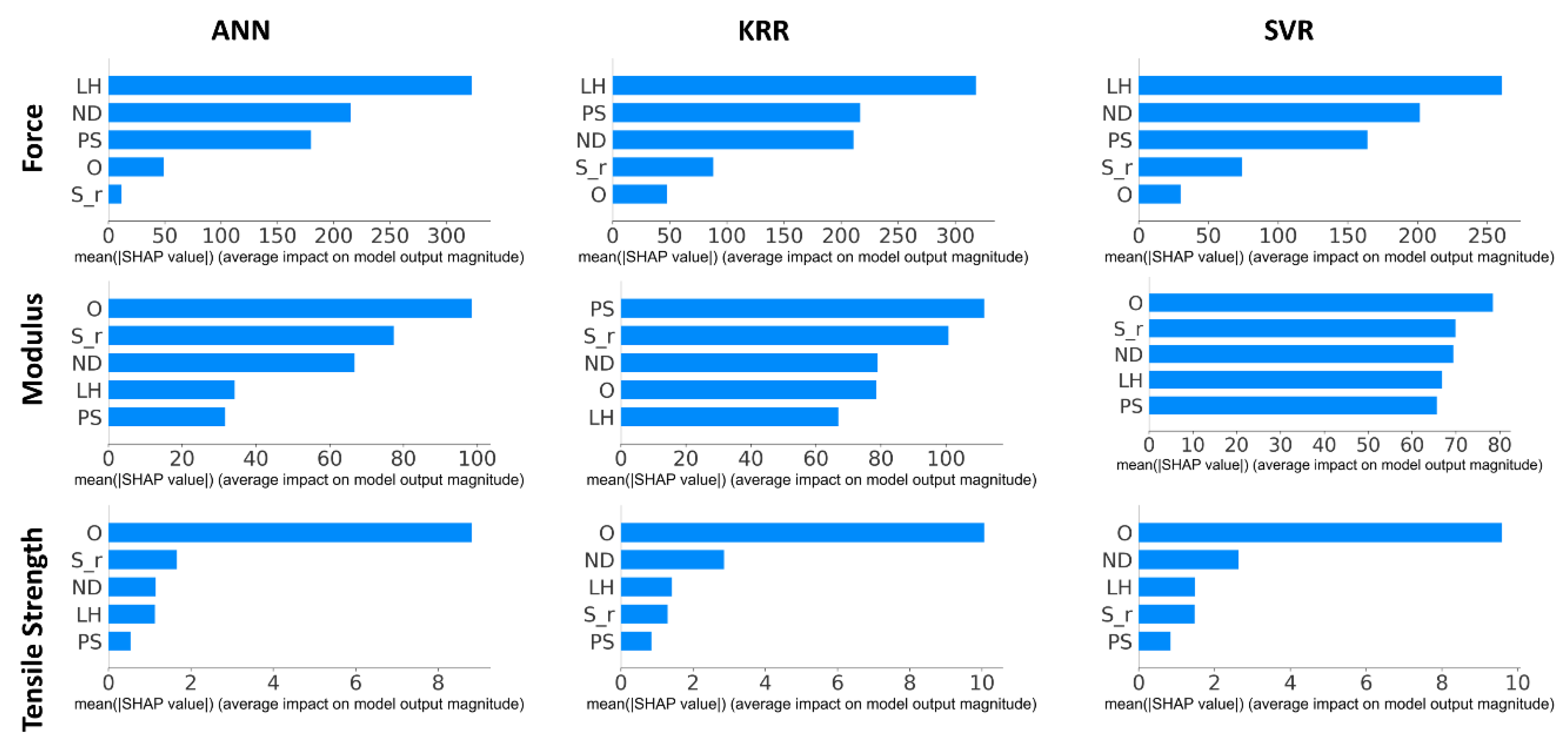
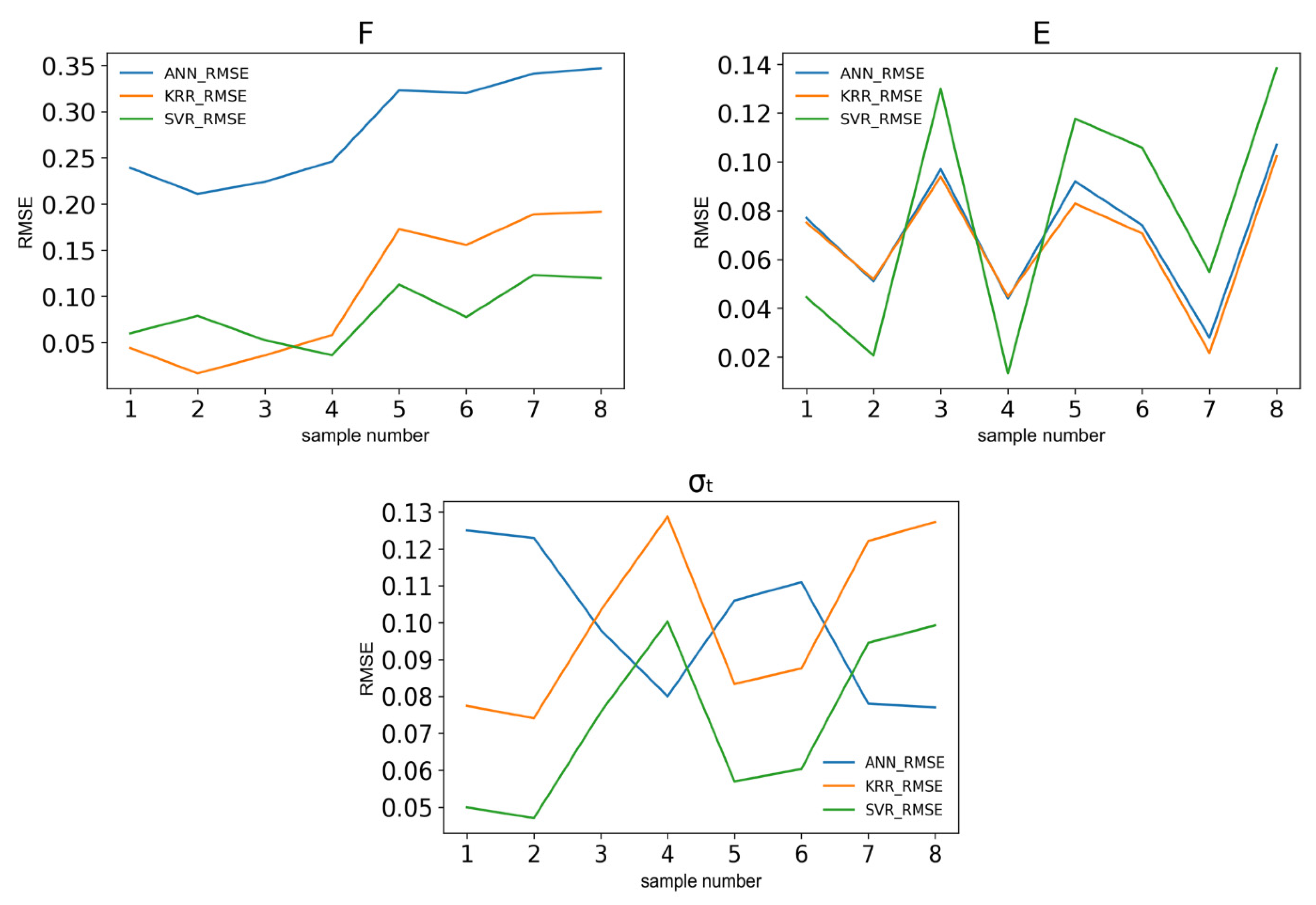
This work based on the material extrusion process not only establishes a multi-output algorithm encompassing both printer health detector—extrusion force—and the final part performance—tensile properties, which are highly related to the selection of various printing parameters, but also draws conclusions on the degree of influence wielded by each parameter on the prediction of these critical properties, which would be beneficial to elucidating the intricate relationships between inputs and outputs. Experimental work involved producing 476 tensile coupons, developed under various printing conditions, where the filament extrusion speed and filament extrusion force were measured in real-time using machines fitted with in-line sensors. These coupons were then tested up to tensile failure. The collective data of printing parameters, measured process indicators, and mechanical test results were used to train multi-output algorithms capable of predicting the tensile properties and extrusion force. To have a peek inside each prediction model, the Shapley value was studied and revealed the contributions of each input factor to the output prediction. In the end, the ML resources developed can potentially support the application of AM technology in the assessment of part structural integrity through simulation and also be integrated into a control loop that can pause or even correct a failing print if the expected filament force-speed pairing is trailing outside a tolerance zone stemming from ML predictions.


 ,
, 


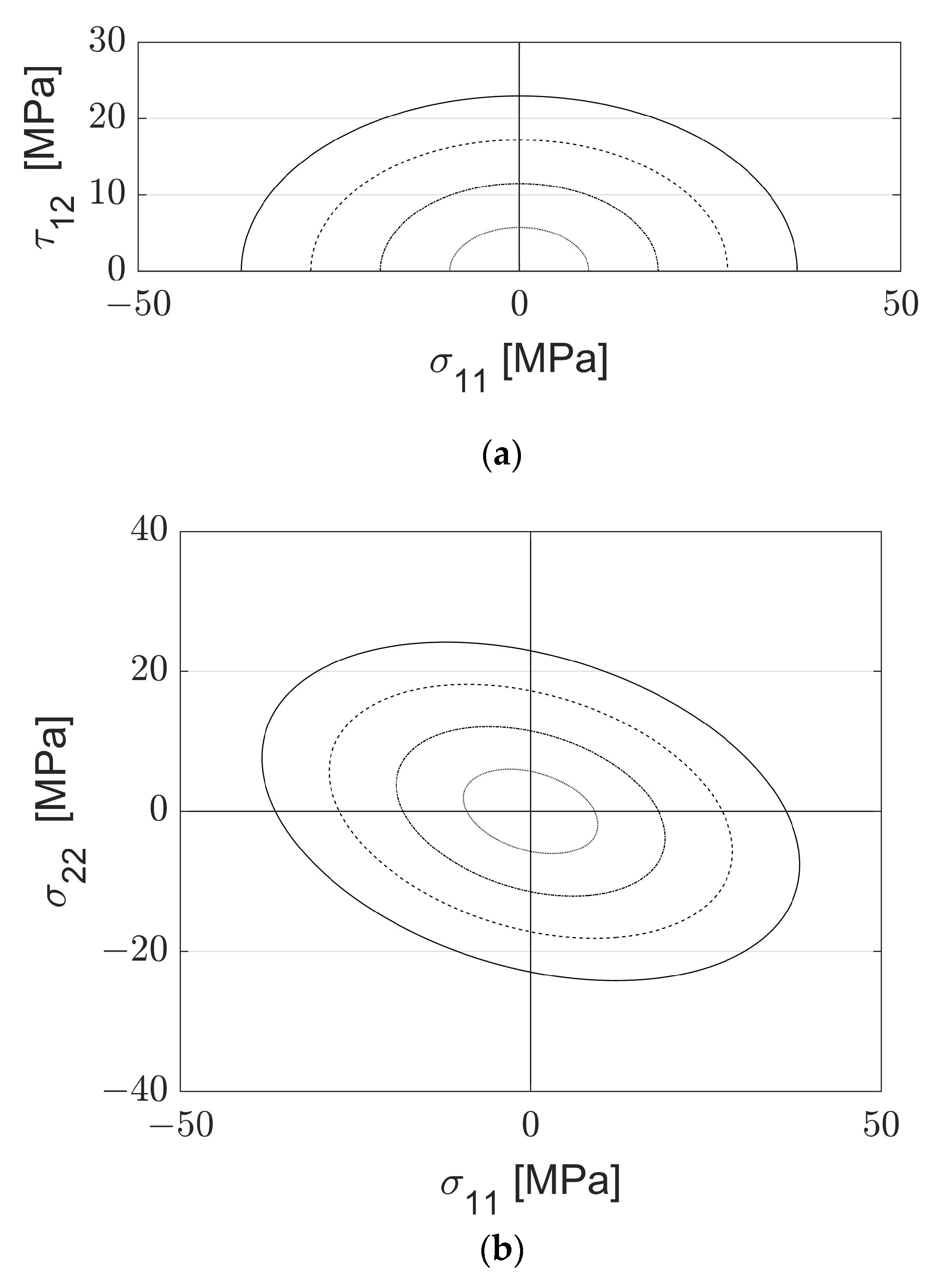
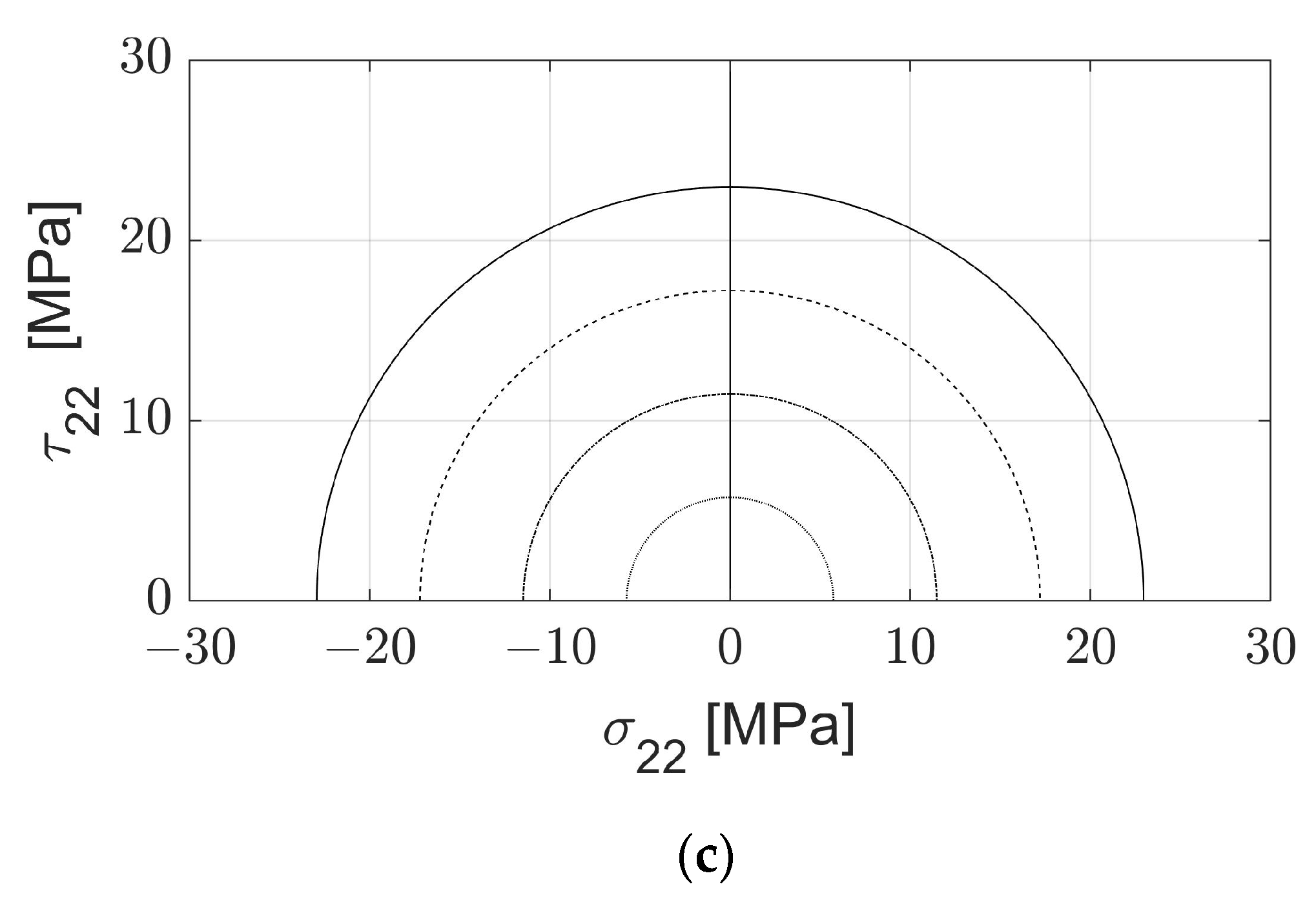

{kind=link}
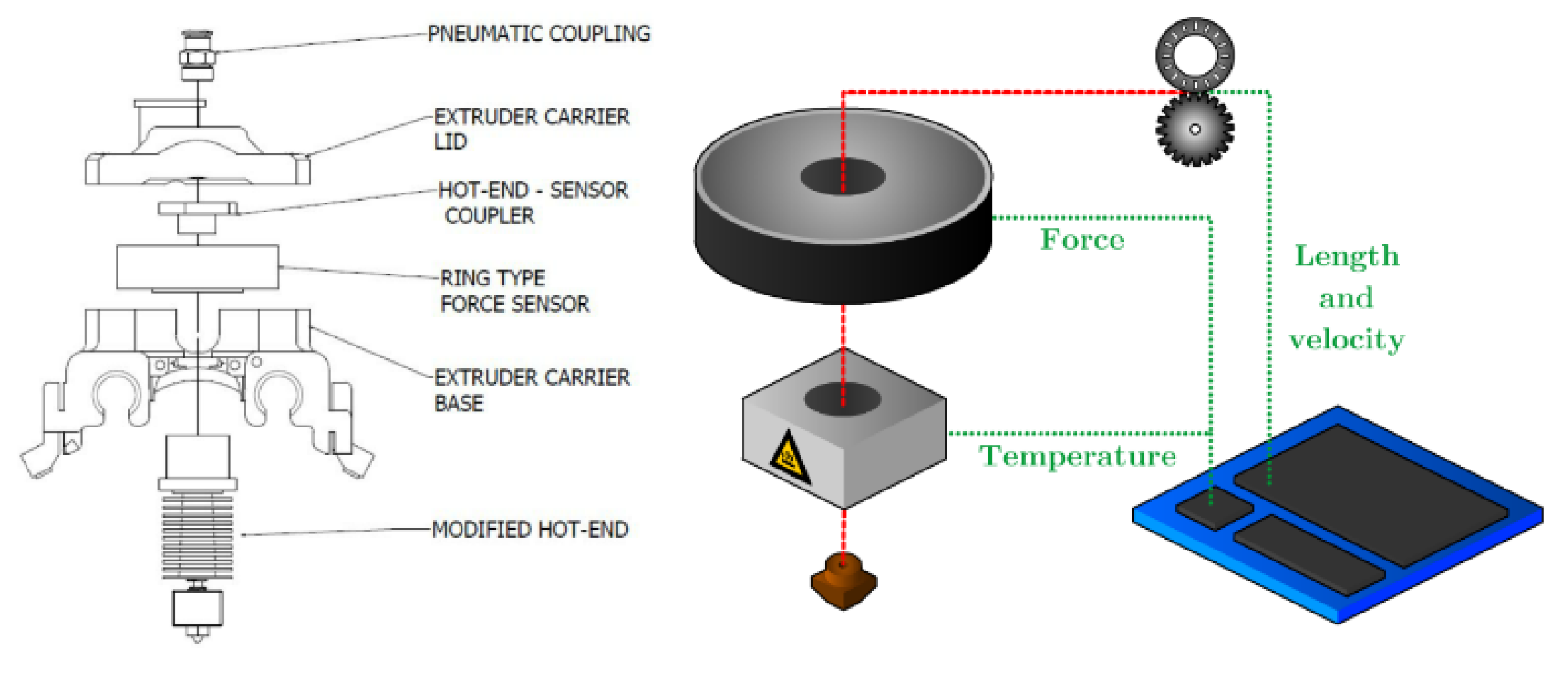{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}