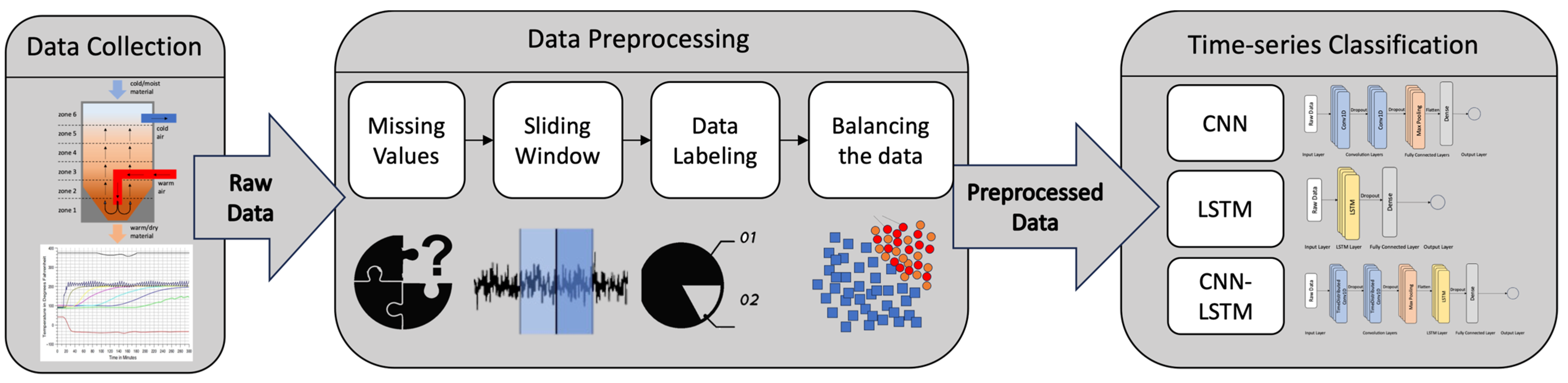
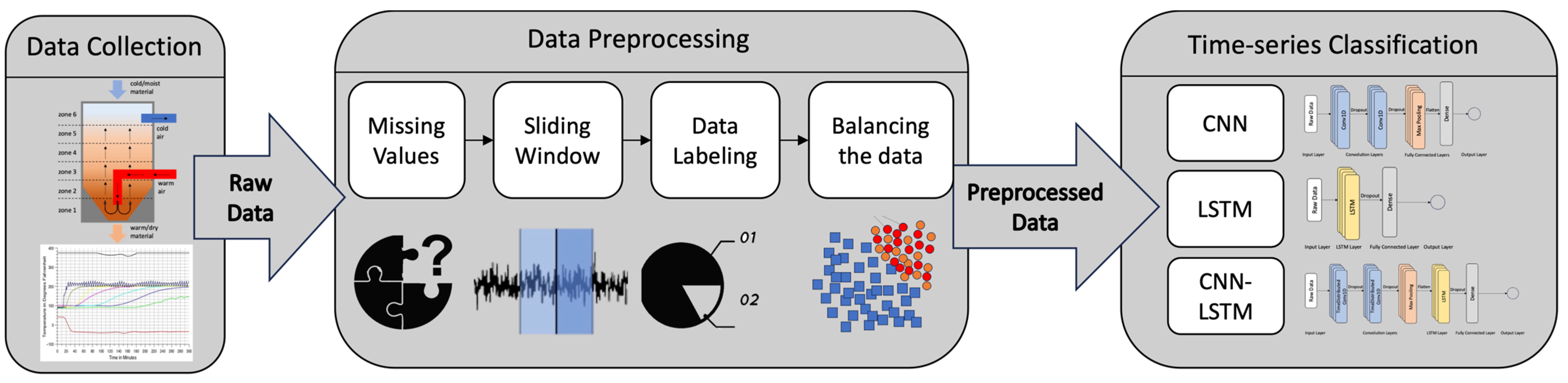
3.1.1. Dataset Exploration and Missing Values
In this case study, there are twelve distinct temperature measures, and the raw data obtained from the machine tool undergo preprocessing to remove missing values and outliers. The temperature values for these twelve variables are measured using sensors over a period of one year, although the obtained data file only contains sensor readings for six months. The final dataset is prepared using a sampling interval of one minute. Since temperature values for all twelve variables are measured over time, the dataset represents MTS data. The dataset can be represented as an n*m matrix, where m refers to the number of UTS and n refers to the length of each time series. The timestamps in the dataset are in UNIX format (Epoch time). Based on the timestamps, ideally, we should have 264,960 data points available, yet the dataset includes 263,476 points, indicating that the dataset contains 1484 missing values.
Missing values are a common issue in the time-series analysis, particularly in the manufacturing domain. Various reasons can lead to missing data, such as power outages at sensor nodes, local interference [
62], or data missing during preprocessing steps. In this study, two approaches were employed to address the missing value problem. Firstly, if the missing values occur during time steps without any preceding or subsequent events of the same length, they are filled using a moving average. Secondly, if time steps within an event have missing values, they are imputed using the moving average of the sixty observations within the event, either occurring before or after the missing time steps. These approaches aim to address and mitigate the impact of missing values in the time-series data analysis process with as little bias as possible.
3.1.2. Dataset Labeling
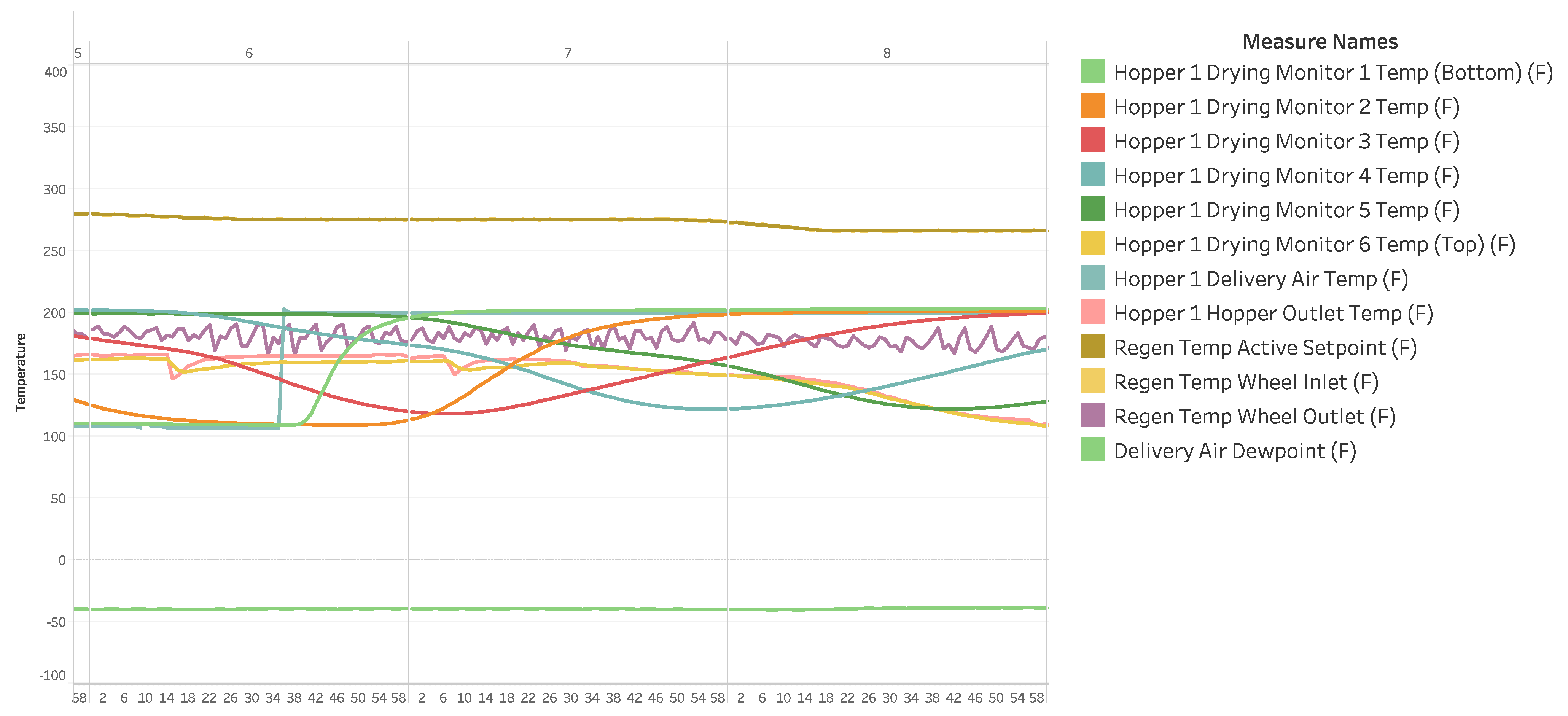
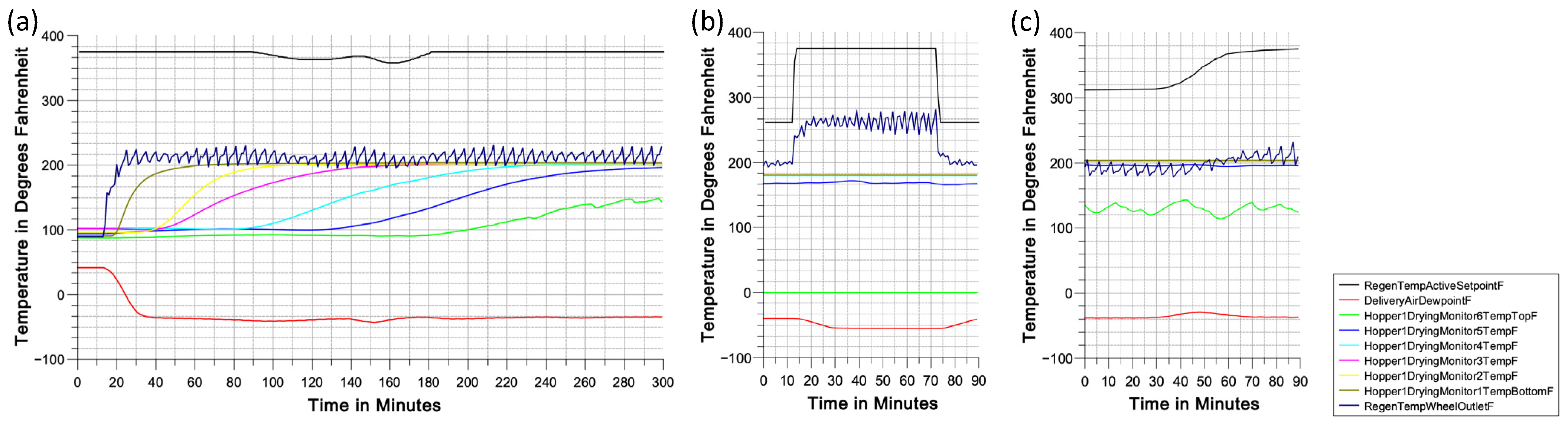
In this case study, three major events that occur regularly and affect operations have been identified: the
startup procedure,
cleaning cycle, and
conveying issues [
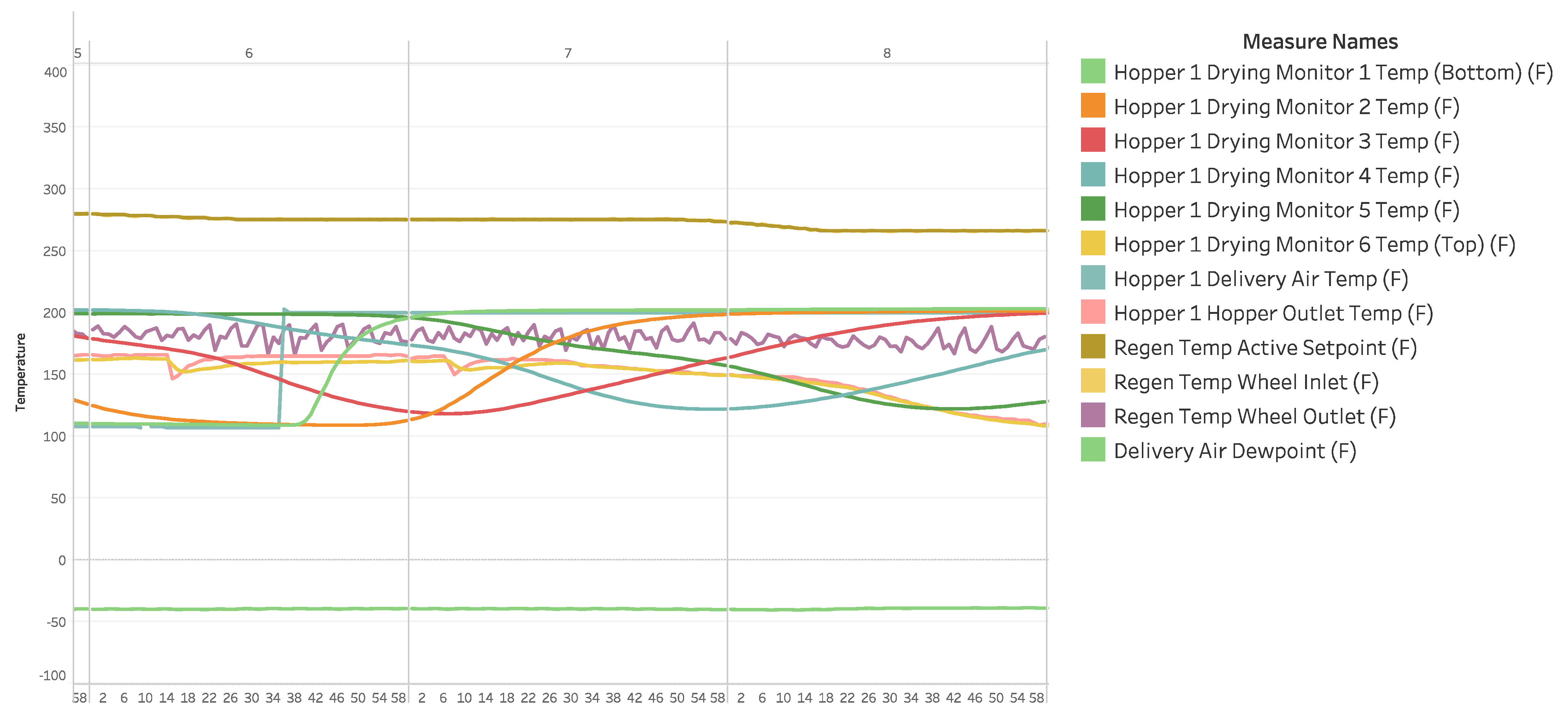
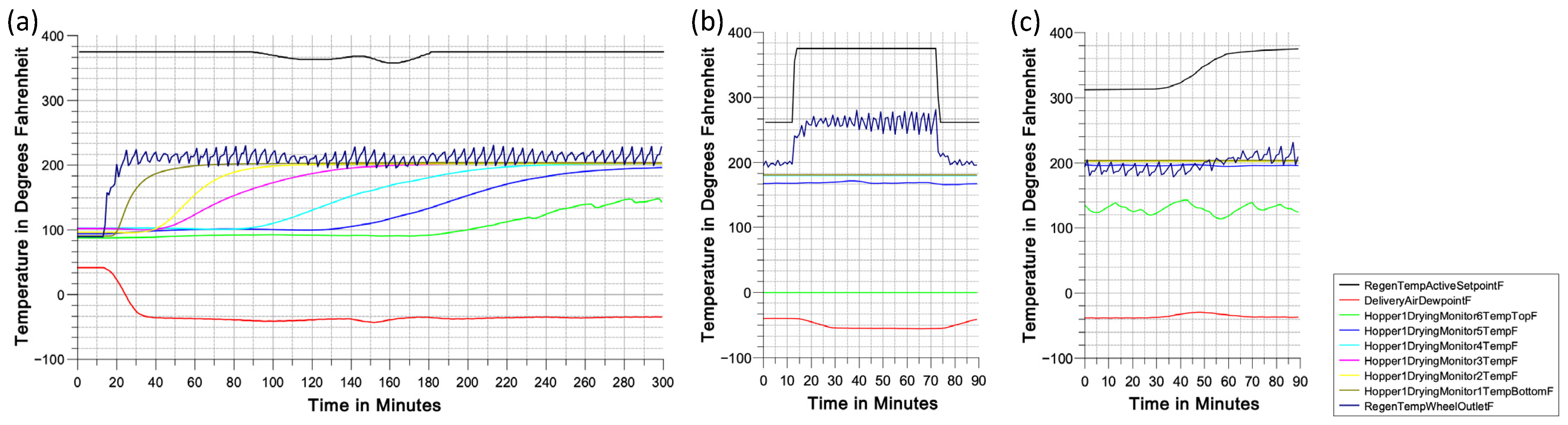
37]. These three events are shown as a snapshot of a visualization in the dataset in
Figure 4. However, these events exhibit significant variation, making it difficult to define and label them precisely without having access to the domain expert. Moreover, having a limited number of samples in each event poses difficulty for a multiclass classification. Therefore, the primary objective of this study is to categorize events as either failures (unusual events) or regular events, rather than specifically detecting and classifying different types of unusual events. Unusual events are identified, selected, and labeled as one class, while the remaining events that represent the steady state are classified separately. If this approach proves successful, the subsequent goal is to identify the class of any labeled unusual event (beyond the steady state). This would enable valuable applications, such as providing context for process planners and operators, predicting necessary maintenance steps, and informing the design of future systems.
Two approaches can be used to label the data, focusing on either one main event or multiple major events: manual labeling and semi-supervised learning. Manual labeling requires significant time and effort from an expert who has a deep understanding of the process, making it a costly and time-consuming task, especially for datasets spanning a long period. Although manual labeling provides accurate labels, it may not be feasible for large datasets. The semi-supervised learning approach, on the other hand, requires only a small amount of labeled data, which are then used to predict the classes of the remaining unlabeled dataset. This enables the labeling of the entire dataset, which can be further trained to identify classes in the test set or future datasets. In this case study, manual labeling by a subject matter expert is performed to obtain the final labeled dataset. The labeling process aims to convert the dataset into a binary classification format, where steady state or regular events are treated as one class, and any unusual patterns or behaviors are treated as the other class. During labeling, we consider the whole one-hour window as an event if any major event happens anytime during that time window.
To label the time-series data, the original event duration data files are required. A sample rate of 60,000 is used to convert the time durations from the event duration dataset into milliseconds. An iterable variable is created with the time column of the original data. Using this variable and the event markings data, a column of 1 s and 0 s is generated to match the rows of the original dataset, indicating whether each minute is part of an event or non-event. However, labeling a minute of data may not accurately define an event, so instead, one hour of data consisting of sixty minutes or sixty rows is considered as an example. Each hour of data is treated as a subsequence, and subsequences are extracted from the long sequence of data with a specific length of sixty minutes (e.g., from 5:01:00 AM to 6:00:00 AM).
The labeling process involves assigning labels to each sixty-minute subsequence extracted from the time-series data. The sliding window algorithm is used to extract these subsequences, where a window length and sliding step need to be defined. In this case, the window length is set to sixty minutes, and the sliding step is also set to sixty minutes. The primary labeling assigns the same label to all sixty rows or minutes within each hour. After extracting the subsequences, the label for each hour is determined based on the labels assigned to all sixty rows or minutes within that hour. The sliding window algorithm is a common technique used for extracting subsequences from a longer time series, allowing for the extraction and labeling of multiple subsequences of a sixty-minute length [
34]. In our case, the length of the time series,
n, is 264,960; the window length, L, is 60; and the sliding step,
p, is 60. So, m = (264,960 − 60)/60 + 1 = 4416. Hence, using a window length of sixty and sliding step of sixty, 4416 subsequences can be extracted from this time-series data.
After labeling each subsequence, the dataset can be viewed as a three-dimensional dataset with dimension
N*L*M, where
N represents the number of examples or subsequence,
L represents the window or time-series length, and
M represents the number of sensors or input variables of the MTS. Each subsequence has a dimension of
L*M. In this case, L = 60 and M = 12, so, each subsequence has 60×12 = 720 features of the MTS. A basic summary of the labeled dataset is provided in
Table 1.
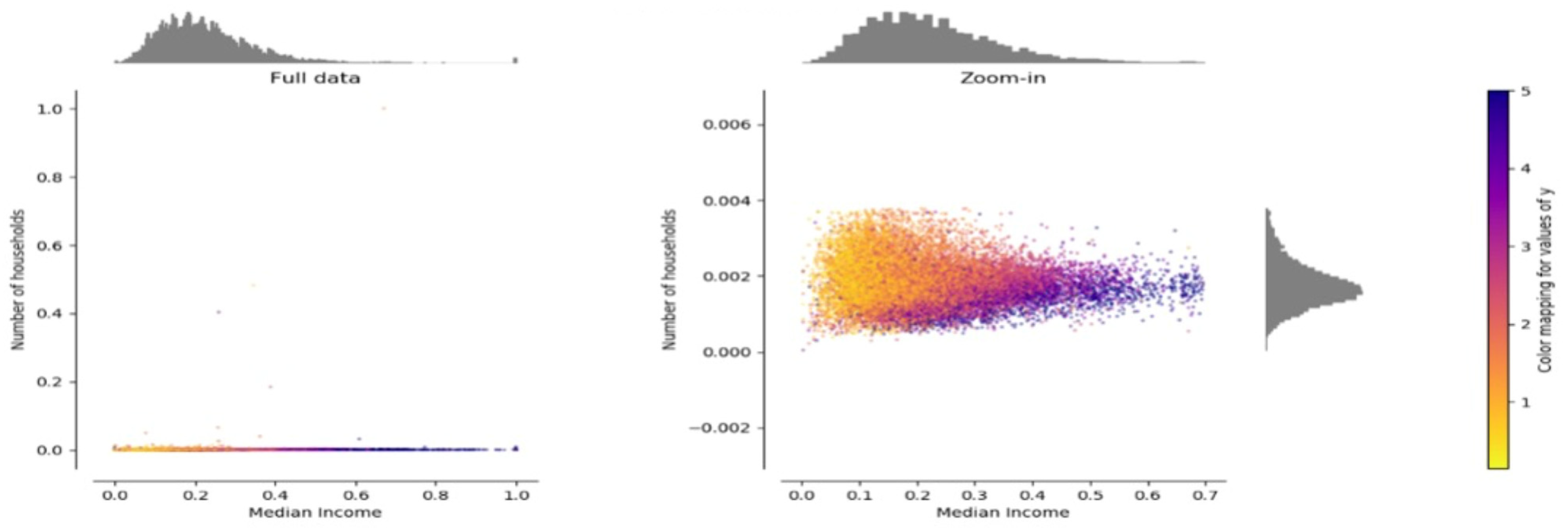
Data normalization, specifically via scaler transformation techniques, is highly recommended for machine learning and deep learning algorithms when dealing with skewed datasets. Skewed datasets can lead to imbalanced weights and distance measures between examples, affecting the performance of models such as SVM and K-nearest neighbor. For instance, in the given dataset, the delivery air temperature differs significantly from other temperatures in the drying hopper. By applying data normalization, the input variables are transformed to a standardized range, such as 0 to 1, making the learning process easier for algorithms, especially deep learning algorithms. Scaling helps avoid issues like high error gradient values and uncontrollable weight updates. Overall, pre-processing transformations, like data normalization, improve the performance and stability of models during learning [
63]. Data normalization changes the distribution of the input variables, as shown in
Figure 5.
3.1.3. Addressing the Imbalance Dataset Issue
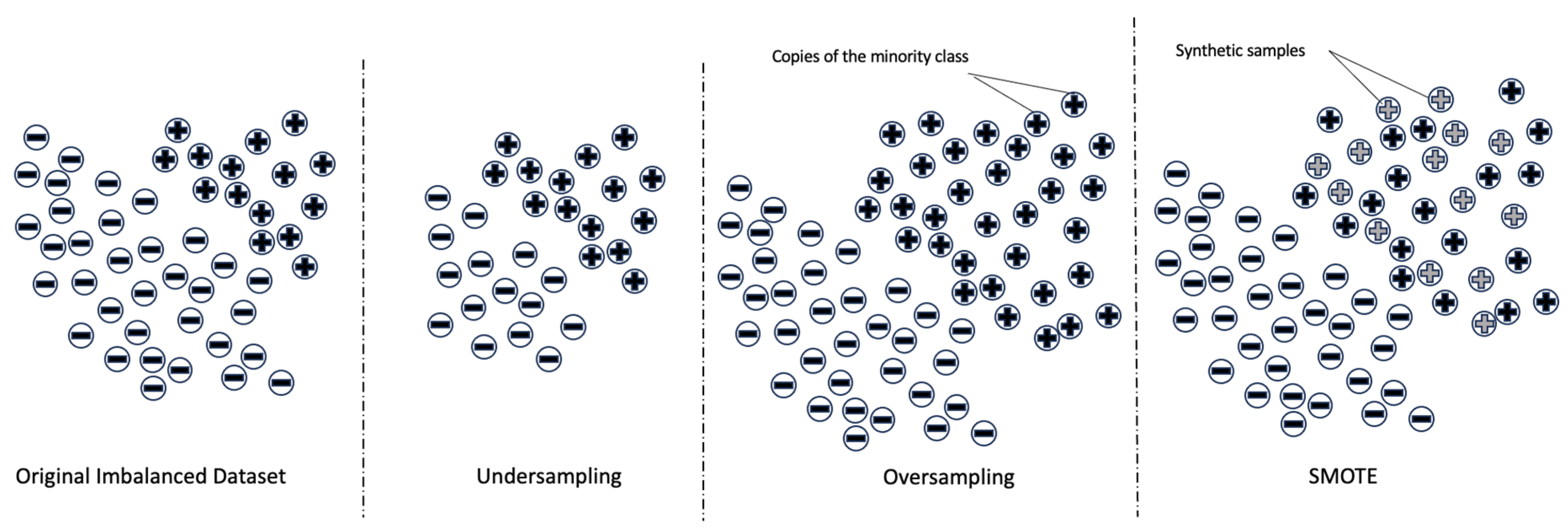
The dataset used in this study faces the challenge of imbalanced classification, in which one class has significantly fewer examples than the other. Imbalanced datasets are common in real-world scenarios, especially in manufacturing, where failure events are rare compared to normal operations. While imbalanced datasets are very common in manufacturing settings and in fault detection problems, it is crucial to deal with the issue as a preprocessing step before fitting any ML algorithm to the dataset. DL algorithms are more sensitive in this sense and struggle more with imbalanced data due to their assumption of balanced datasets. To address this issue, the study explores four techniques: undersampling, oversampling, SMOTE, and ensemble learning with undersampling.
The simplest technique to address the imbalanced data issue is
random undersampling, where a portion of the majority class data is dropped to achieve a balanced dataset for binary classification. In our case study, there are 845 examples in the minority class and 3571 examples in the majority class. The dataset is divided into training and test sets, with the first 80% of the data used for training and the remaining portion for testing. After the split, there were 791 training examples from the minority class and 2742 training examples from the majority class. Randomly selecting 791 examples from the majority class, a total of 1582 examples are used for training with a classification algorithm. The number of test examples after the split is 883, which are used to evaluate the algorithm. However, random undersampling can result in the loss of valuable information without considering the importance of the removed examples in determining the decision boundary between the classes [
65].
Oversampling is another technique that can be utilized to deal with imbalanced datasets. The simplest oversampling technique involves duplicating the minority class randomly until it is equal in size to the majority class, thus achieving a balanced dataset. In our case, 791 training examples from the minority class are duplicated randomly to create 2742 examples, which are then added to the training dataset. This technique increases the number of training examples from 3533 to 5484. However, random oversampling can lead to overfitting, and the duplicated examples may not provide meaningful information to the dataset [
66].
A more sophisticated approach called the
Synthetic Minority Oversampling Technique (SMOTE) can be used, which synthesizes new data points based on existing examples [
66]. SMOTE is a method that synthesizes new examples for the minority class. The technique, originally described in [
67], is based on selecting examples that are nearest in the feature space. It creates a synthetic example by randomly selecting a neighbor from the K-nearest neighbors of a minority class example [
68]. A line is then drawn in the feature space to connect the minority example and the selected neighbor. The synthetic examples are generated as a convex combination of the minority example and its nearest neighbors. SMOTE can produce as many synthetic examples as needed to achieve a balanced dataset. In this study, SMOTE will be used to oversample the minority class and balance the class distribution. The advantage of SMOTE over random oversampling is that the synthetic examples it generates are more reasonable and closer to the minority examples in the feature space. However, SMOTE has some drawbacks, such as not considering the majority class, which can lead to the creation of ambiguous examples that may not accurately represent the dataset. The visuals of undersampling, oversampling, and SMOTE techniques are shown in
Figure 6.
Ensemble learning is a powerful technique that can be used to deal with imbalanced data. Ensemble learning combines the results of multiple learning techniques to improve overall performance. In the context of dealing with imbalanced data,
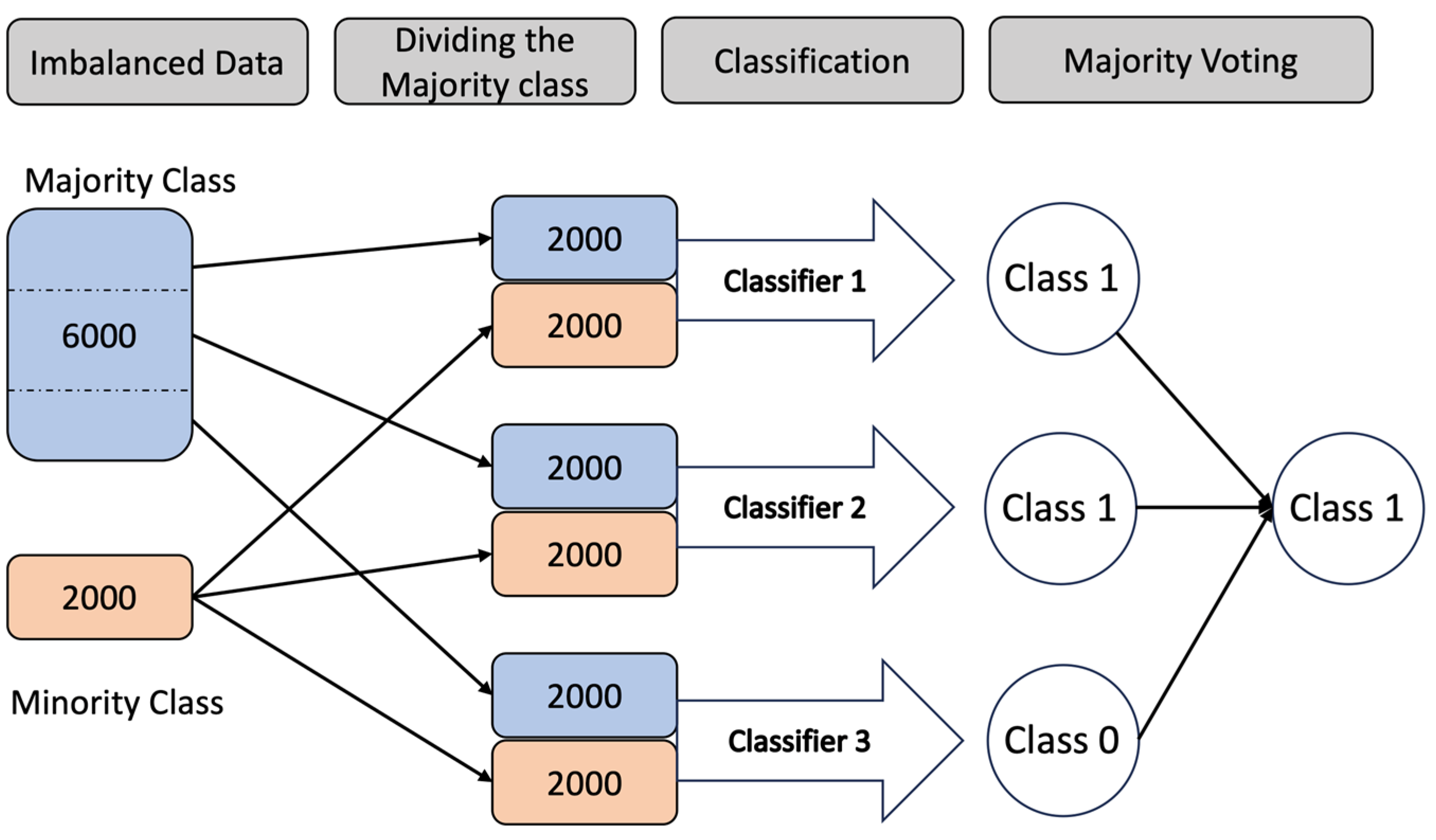
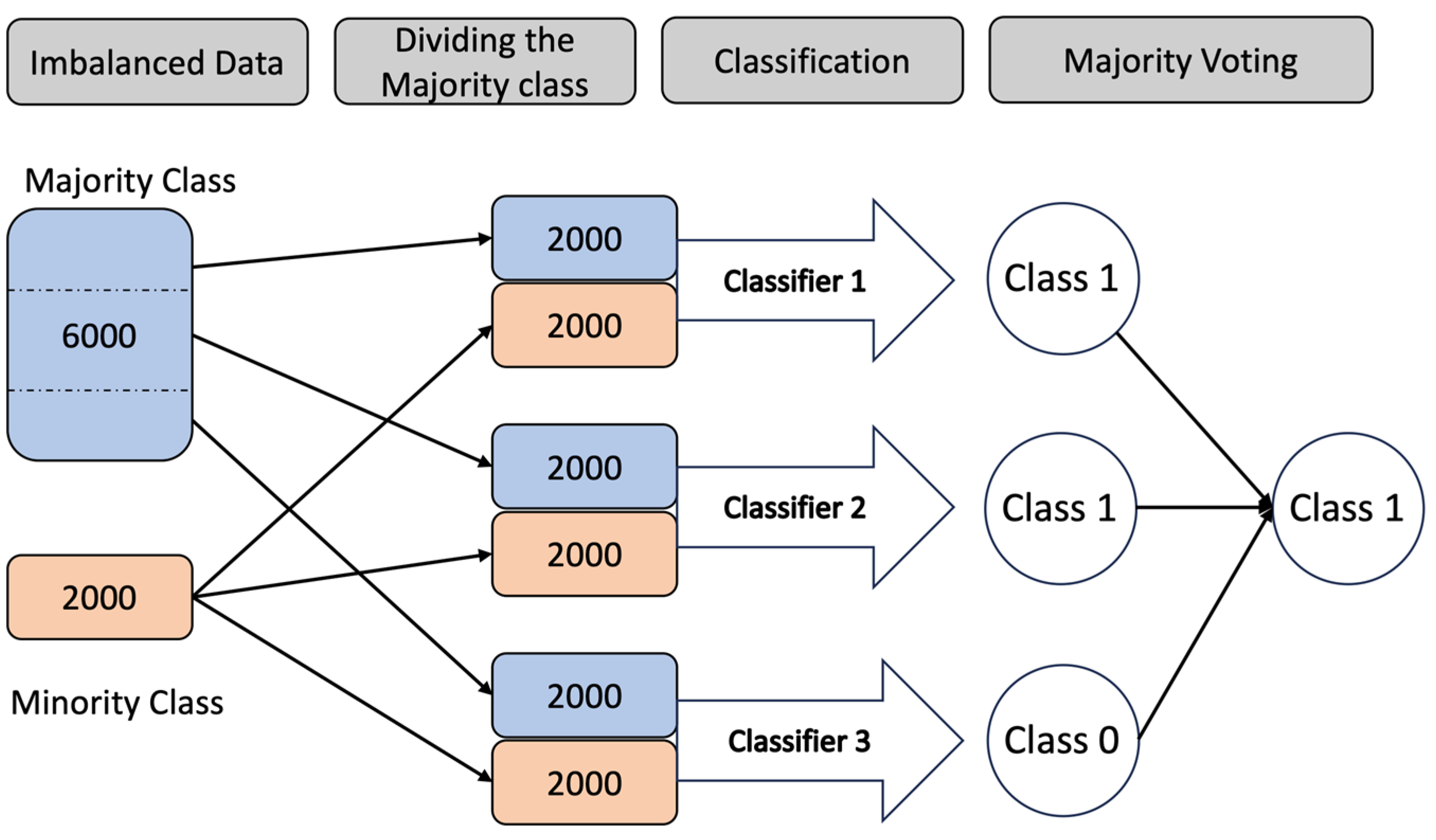
ensemble learning with undersampling can be employed. This involves dividing the majority class into segments and combining each segment with the minority class to train the dataset. An example of this approach is illustrated in
Figure 7, where 3000 majority-class examples are divided into three segments, each containing 1000 randomly selected examples. These three sets of data, along with the entire minority class, are then used to train three classifiers. During testing, each classifier predicts the class for a given example, and the class with the majority vote is chosen as the ensemble prediction. In this study, three different approaches to ensemble learning are explored and their results are presented. By leveraging the collective knowledge of multiple classifiers, ensemble learning aims to enhance classification performance and address the challenges posed by imbalanced datasets [
69].








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
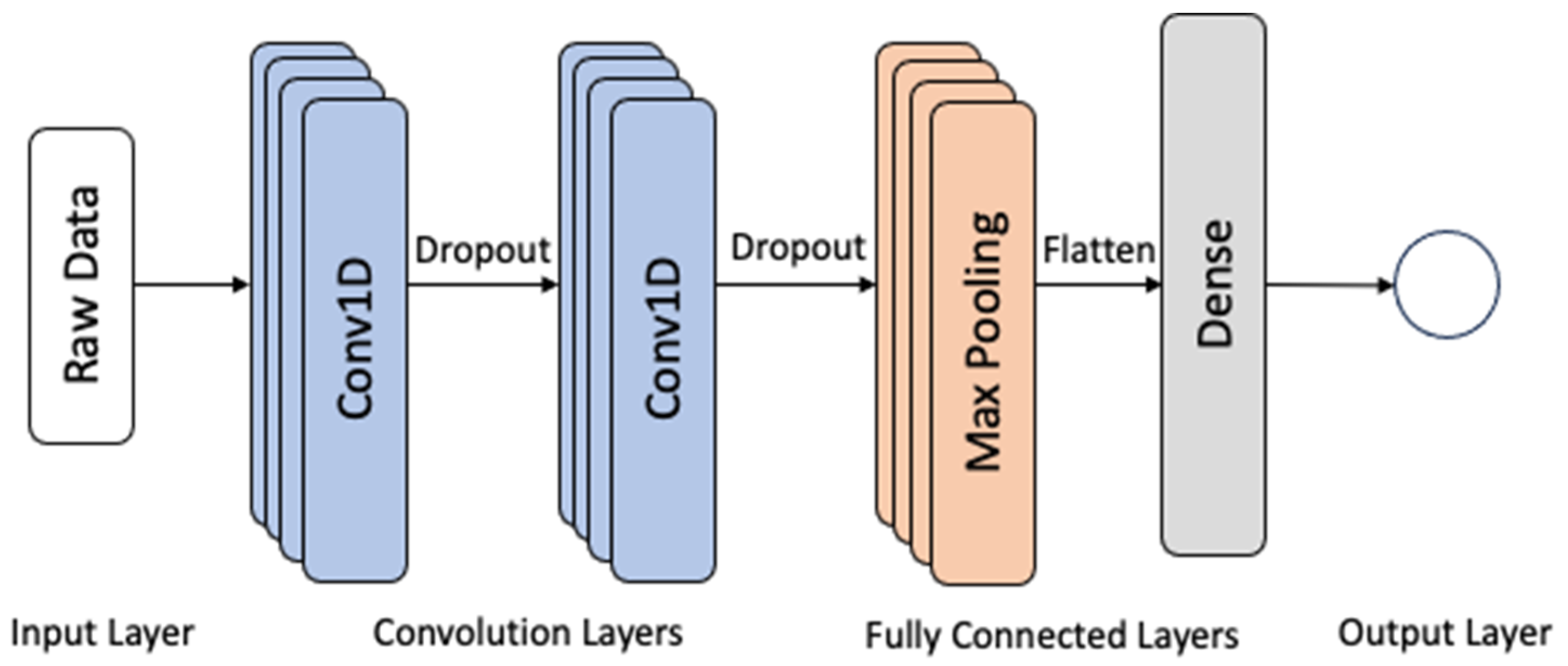
{kind=link}
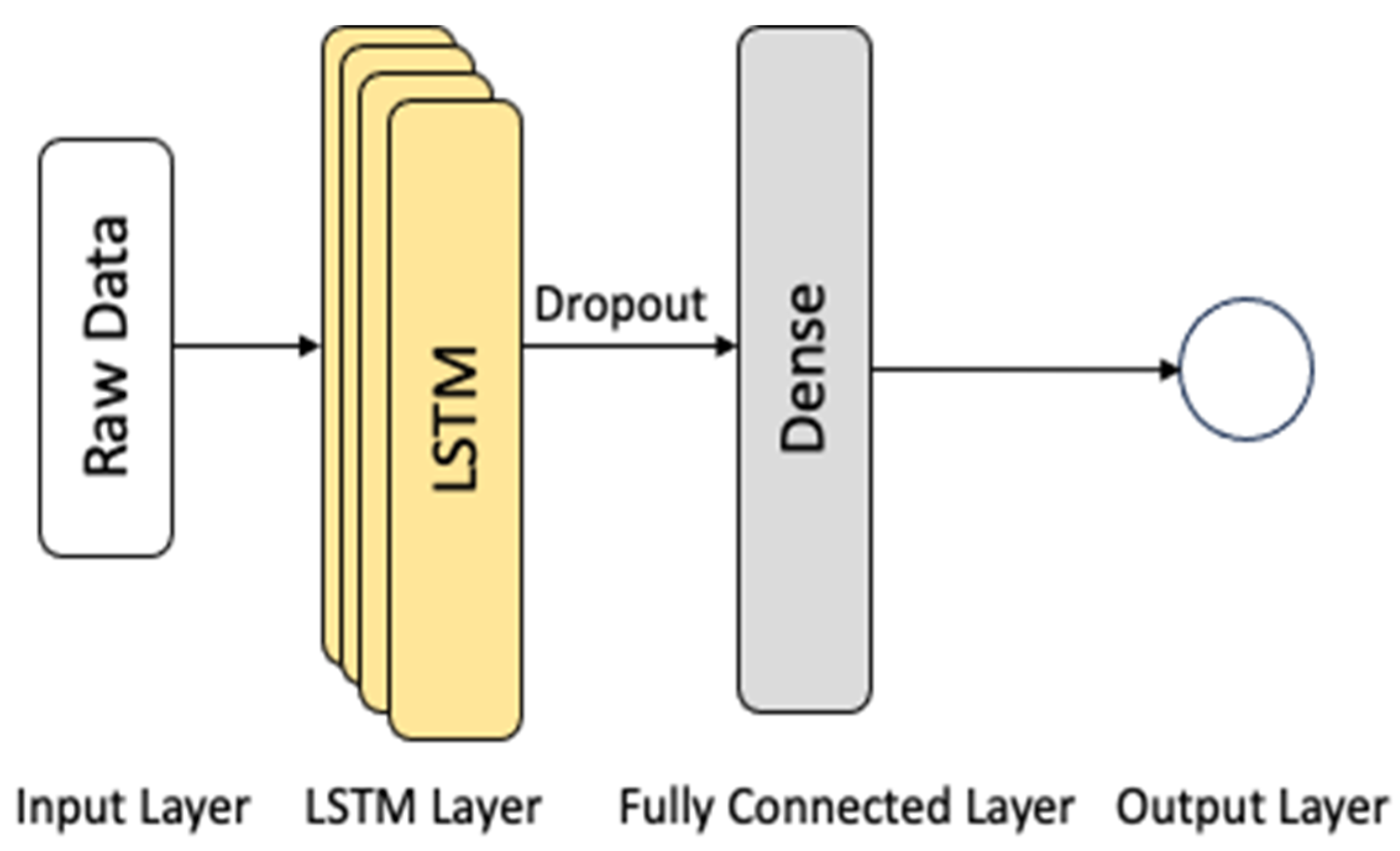
{kind=link}
{kind=link}
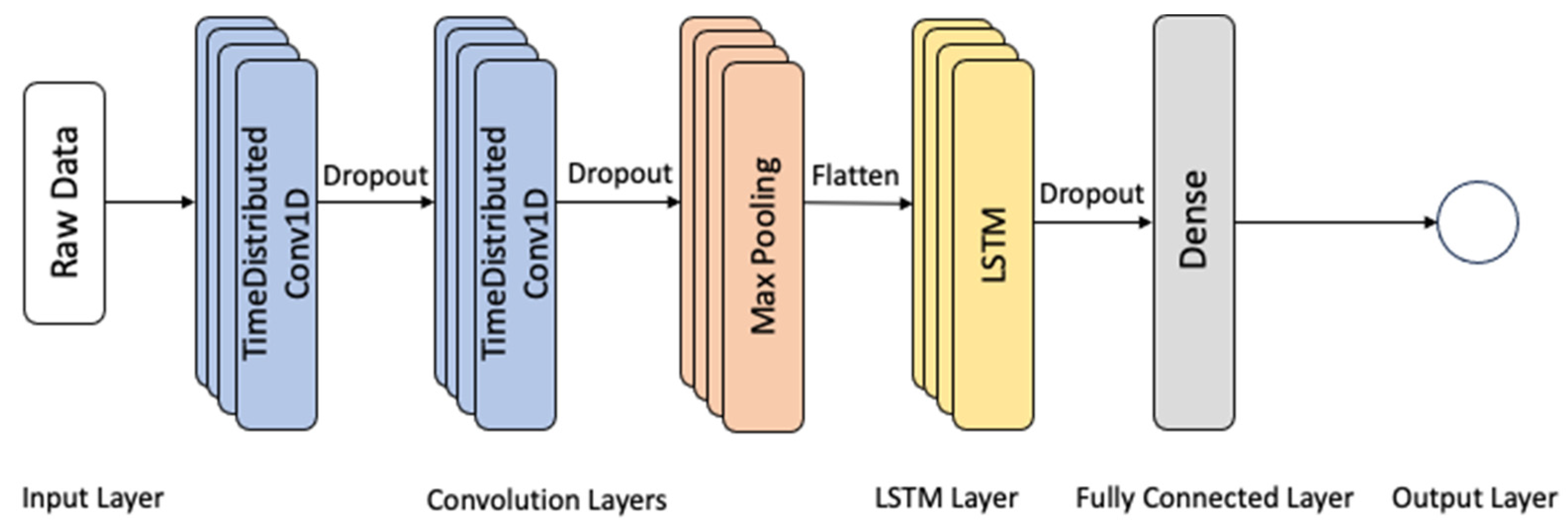{kind=link}
{kind=link}
{kind=link}