
YOLO-UIR: A Lightweight and Accurate Infrared Object Detection Network Using UAV Platforms


Abstract
1. Introduction
2. Related Works
2.1. Generic Object Detection
2.2. UAV Infrared Object Detection
2.3. Model Lightweighting Methods
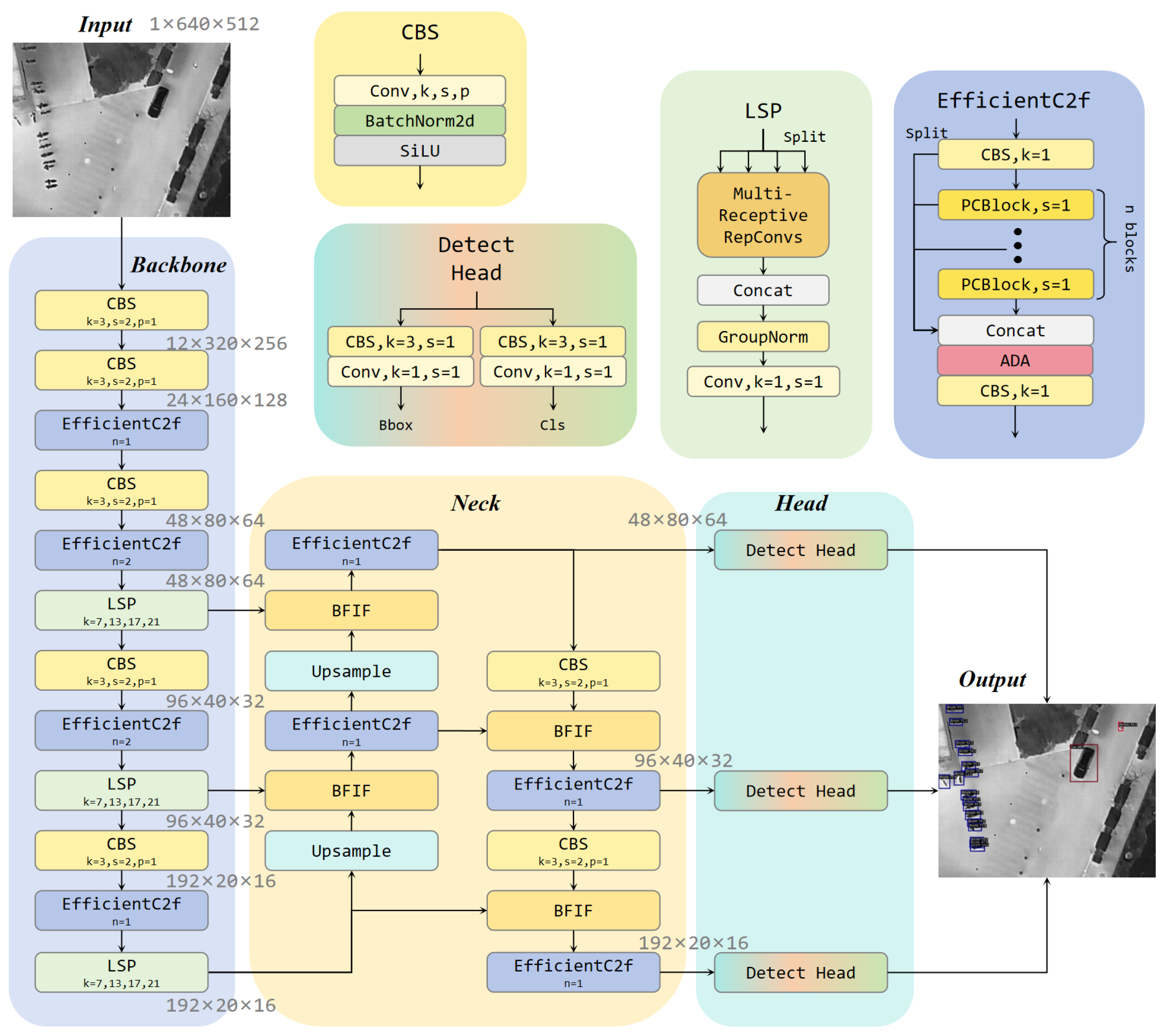
3. Proposed Method
3.1. Overview
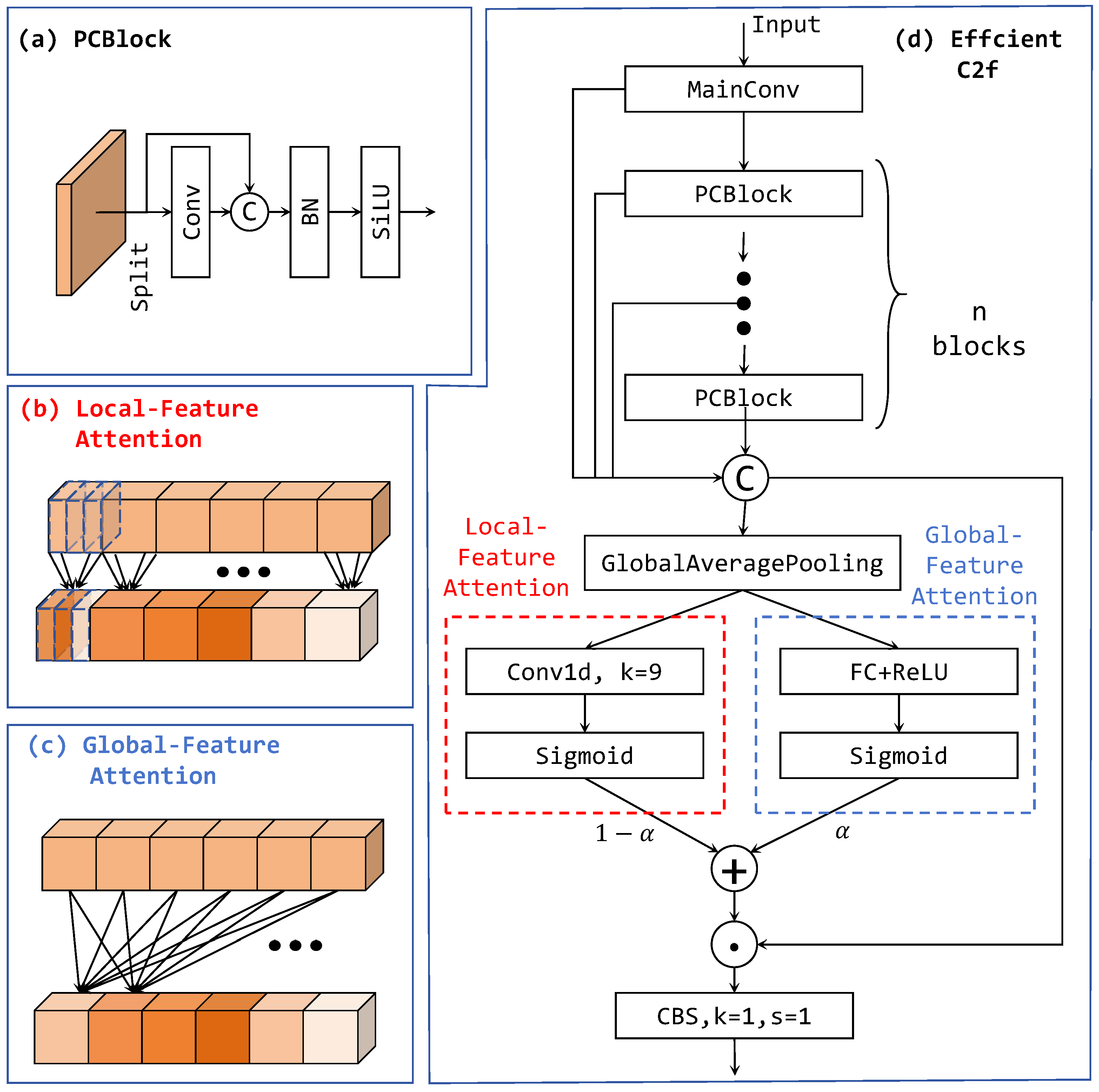
3.2. Efficient C2f
3.3. Lightweight Spatial Perception
3.4. Bidirectional Feature Interaction Fusion
3.5. Loss Function
4. Experiments and Analysis
4.1. Experiment Datasets
4.2. Evaluation Metrics
4.3. Implementation Details
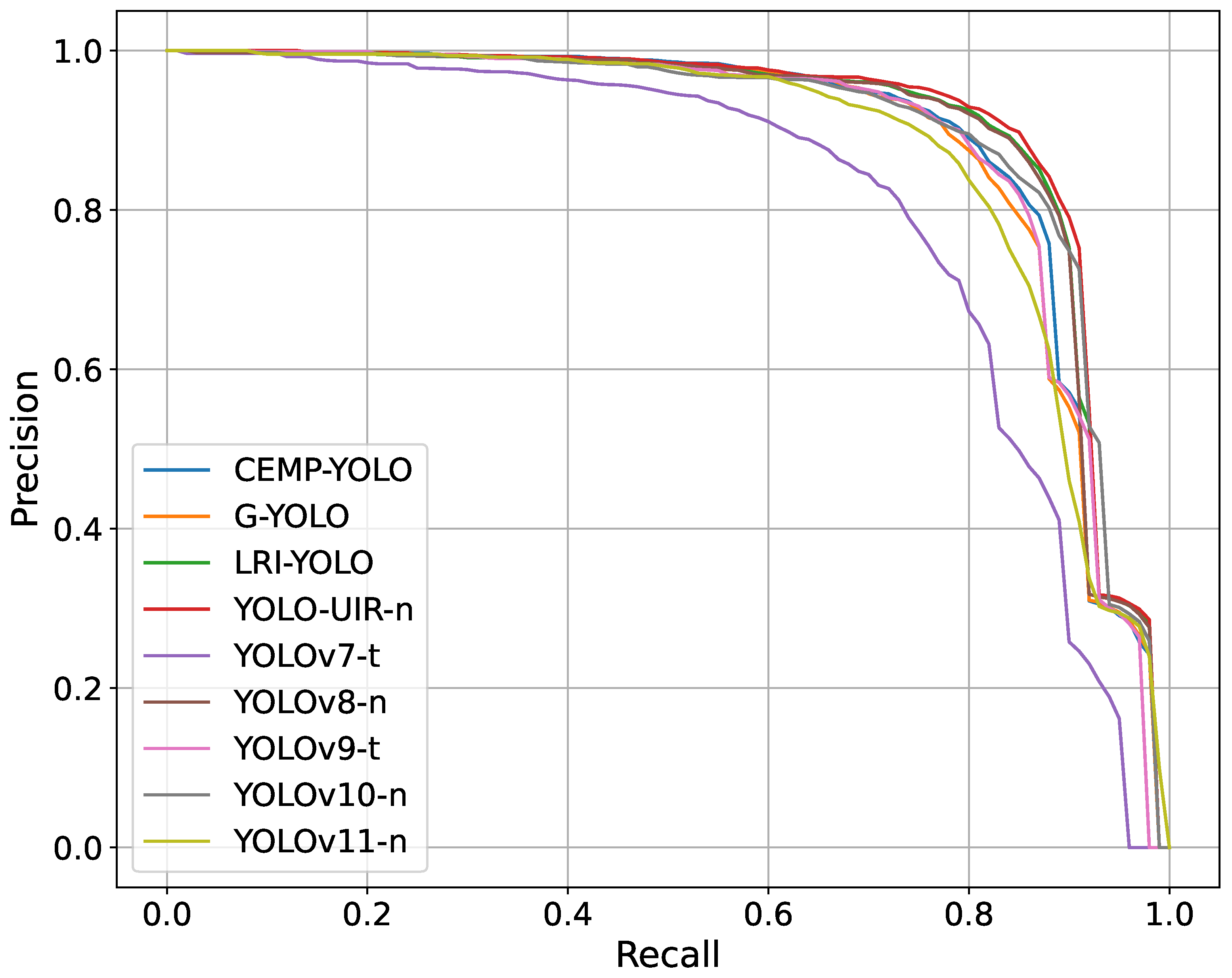
4.4. Comparative Experiments
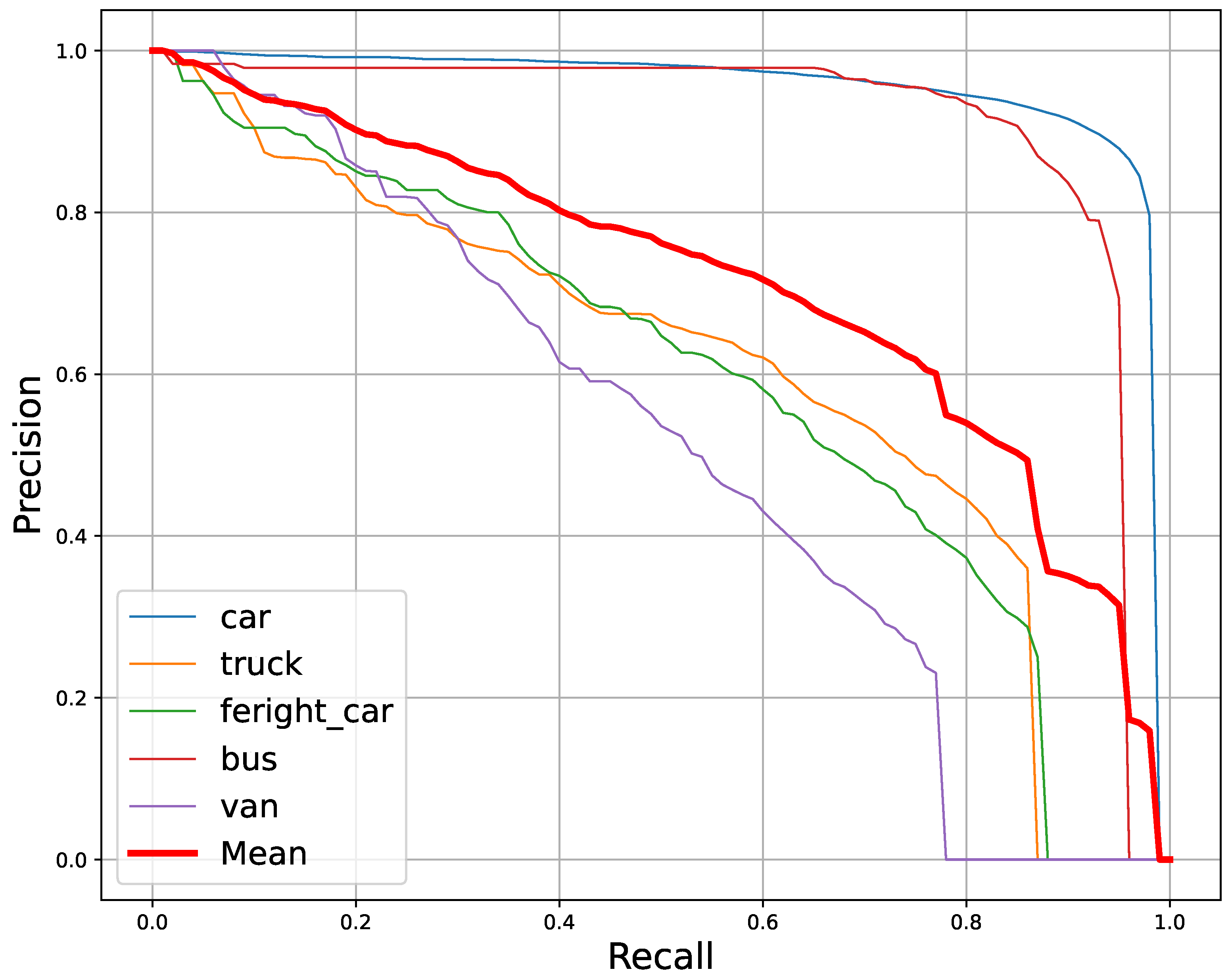
4.4.1. Results on DroneVehicle Dataset
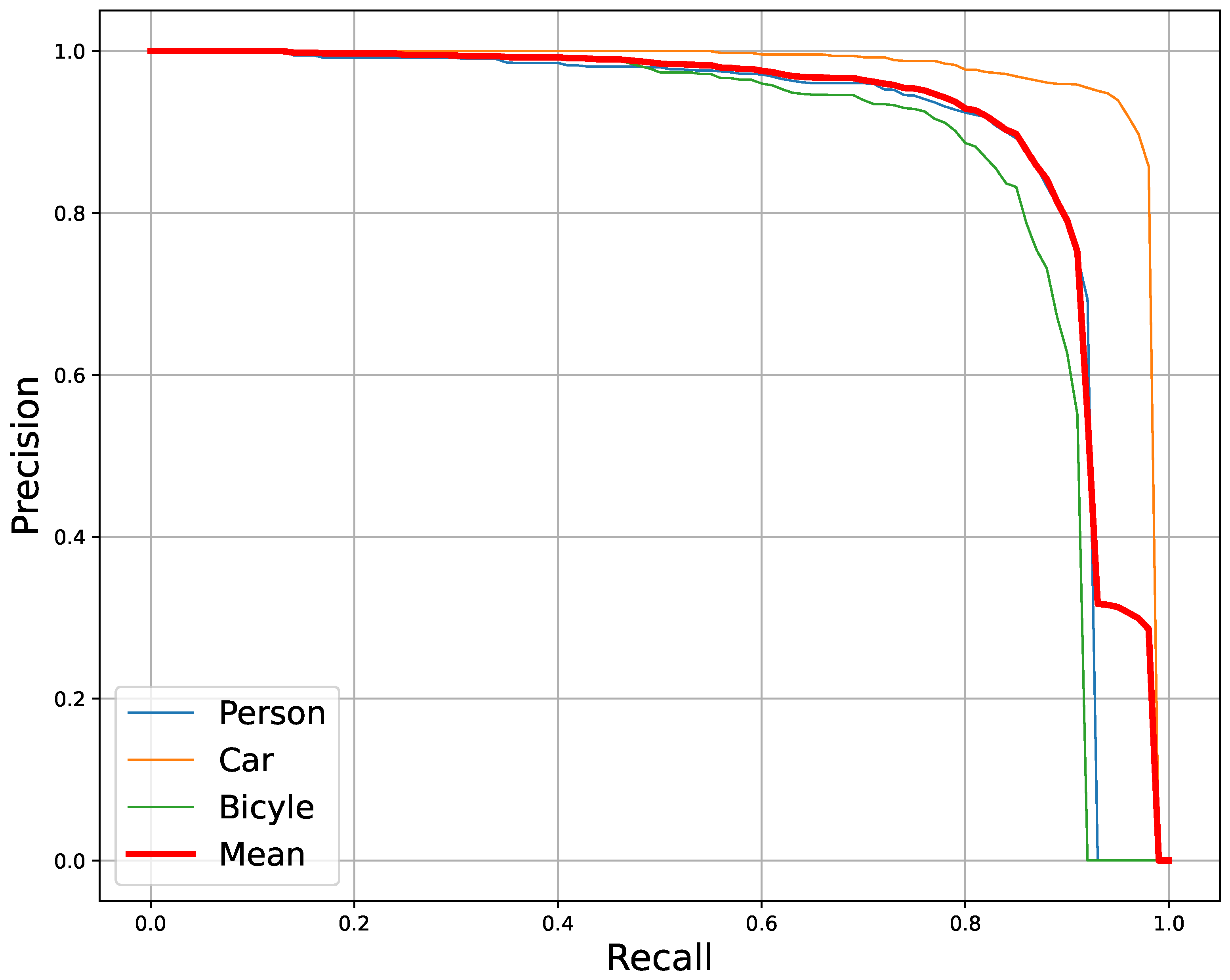
4.4.2. Results on HIT-UAV Dataset
4.5. Ablation Studies and Analysis
4.5.1. Ablation Study on Efficient C2f Module
4.5.2. Ablation Study on Lightweight Spatial Perception
4.5.3. Ablation Study on Bidirectional Feature Interaction Fusion Module
4.6. Supplemental Experiments
4.6.1. Computational and Training Efficiency Analysis
4.6.2. Infrared Detection in Non-UAV Perspectives
4.6.3. Hyperparameter and Data Augmentation Effects
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Feroz, S.; Abu Dabous, S. Uav-based remote sensing applications for bridge condition assessment. Remote Sens. 2021, 13, 1809. [Google Scholar] [CrossRef]
- Duan, Z.; Liu, J.; Ling, X.; Zhang, J.; Liu, Z. Ernet: A rapid road crack detection method using low-altitude UAV remote sensing images. Remote Sens. 2024, 16, 1741. [Google Scholar] [CrossRef]
- Xue, H.; Liu, K.; Wang, Y.; Chen, Y.; Huang, C.; Wang, P.; Li, L. MAD-UNet: A Multi-Region UAV Remote Sensing Network for Rural Building Extraction. Sensors 2024, 24, 2393. [Google Scholar] [CrossRef]
- Zhu, J.; Li, Y.; Wang, C.; Liu, P.; Lan, Y. Method for Monitoring Wheat Growth Status and Estimating Yield Based on UAV Multispectral Remote Sensing. Agronomy 2024, 14, 991. [Google Scholar] [CrossRef]
- Liu, S.; Wu, R.; Qu, J.; Li, Y. HDA-Net: Hybrid convolutional neural networks for small objects recognization at airports. IEEE Trans. Instrum. Meas. 2022, 71, 1–14. [Google Scholar] [CrossRef]
- Debnath, D.; Vanegas, F.; Sandino, J.; Hawary, A.F.; Gonzalez, F. A Review of UAV Path-Planning Algorithms and Obstacle Avoidance Methods for Remote Sensing Applications. Remote Sens. 2024, 16, 4019. [Google Scholar] [CrossRef]
- Min, X.; Zhou, W.; Hu, R.; Wu, Y.; Pang, Y.; Yi, J. Lwuavdet: A lightweight uav object detection network on edge devices. IEEE Internet Things J. 2024. [Google Scholar] [CrossRef]
- Sagar, A.S.; Tanveer, J.; Chen, Y.; Dang, L.M.; Haider, A.; Song, H.K.; Moon, H. BayesNet: Enhancing UAV-Based Remote Sensing Scene Understanding with Quantifiable Uncertainties. Remote Sens. 2024, 16, 925. [Google Scholar] [CrossRef]
- Bouguettaya, A.; Zarzour, H.; Kechida, A.; Taberkit, A.M. Vehicle detection from UAV imagery with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6047–6067. [Google Scholar] [CrossRef]
- Ni, J.; Zhu, S.; Tang, G.; Ke, C.; Wang, T. A small-object detection model based on improved YOLOv8s for UAV image scenarios. Remote Sens. 2024, 16, 2465. [Google Scholar] [CrossRef]
- Wang, S.; Jiang, H.; Yang, J.; Ma, X.; Chen, J. Amfef-detr: An end-to-end adaptive multi-scale feature extraction and fusion object detection network based on uav aerial images. Drones 2024, 8, 523. [Google Scholar] [CrossRef]
- Li, J.; Xu, Y.; Nie, K.; Cao, B.; Zuo, S.; Zhu, J. PEDNet: A lightweight detection network of power equipment in infrared image based on YOLOv4-tiny. IEEE Trans. Instrum. Meas. 2023, 72, 1–12. [Google Scholar] [CrossRef]
- Fu, J.; Li, F.; Zhao, J. Regional Saliency Combined With Morphological Filtering for Infrared Maritime Target Detection in Unmanned Aerial Vehicles Images. IEEE Trans. Instrum. Meas. 2025. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLO. 2023. Version 8.0.0, AGPL-3.0 License. Available online: https://github.com/ultralytics/ultralytics (accessed on 3 July 2025).
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 21–23 September 2005; IEEE: New York, NY, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; IEEE: New York, NY, USA, 2008; pp. 1–8. [Google Scholar]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Redmon, J. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; Volume 1804, pp. 1–6. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature selective anchor-free module for single-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 840–849. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Wang, G.; Chen, Y.; An, P.; Hong, H.; Hu, J.; Huang, T. UAV-YOLOv8: A small-object-detection model based on improved YOLOv8 for UAV aerial photography scenarios. Sensors 2023, 23, 7190. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Zhang, W.; Xia, Y.; Zhang, H.; Zheng, C.; Ma, J.; Zhang, Z. G-YOLO: A Lightweight Infrared Aerial Remote Sensing Target Detection Model for UAVs Based on YOLOv8. Drones 2024, 8, 495. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Ding, B.; Zhang, Y.; Ma, S. A Lightweight Real-Time Infrared Object Detection Model Based on YOLOv8 for Unmanned Aerial Vehicles. Drones 2024, 8, 479. [Google Scholar] [CrossRef]
- Chen, J.; Kao, S.h.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Cohen, T.; Welling, M. Group equivariant convolutional networks. In Proceedings of the International Conference on Machine Learning. PMLR, New York, NY, USA, 19–24 June 2016; pp. 2990–2999. [Google Scholar]
- Zhang, Y.; Cai, Z. CE-RetinaNet: A channel enhancement method for infrared wildlife detection in UAV images. IEEE Trans. Geosci. Remote Sens. 2023. [Google Scholar] [CrossRef]
- Wang, H.; Wang, C.; Fu, Q.; Si, B.; Zhang, D.; Kou, R.; Yu, Y.; Feng, C. YOLOFIV: Object detection algorithm for around-the-clock aerial remote sensing images by fusing infrared and visible features. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11534–11542. [Google Scholar]
- He, A.; Li, X.; Wu, X.; Su, C.; Chen, J.; Xu, S.; Guo, X. Alss-yolo: An adaptive lightweight channel split and shuffling network for tir wildlife detection in uav imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024. [Google Scholar] [CrossRef]
- Fang, H.; Xia, M.; Zhou, G.; Chang, Y.; Yan, L. Infrared small UAV target detection based on residual image prediction via global and local dilated residual networks. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Wang, Q.; Chi, Y.; Shen, T.; Song, J.; Zhang, Z.; Zhu, Y. Improving RGB-infrared object detection by reducing cross-modality redundancy. Remote Sens. 2022, 14, 2020. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 13733–13742. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Tang, Y.; Han, K.; Guo, J.; Xu, C.; Xu, C.; Wang, Y. GhostNetv2: Enhance cheap operation with long-range attention. Adv. Neural Inf. Process. Syst. 2022, 35, 9969–9982. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2021, 52, 8574–8586. [Google Scholar] [CrossRef] [PubMed]
- Suo, J.; Wang, T.; Zhang, X.; Chen, H.; Zhou, W.; Shi, W. HIT-UAV: A high-altitude infrared thermal dataset for Unmanned Aerial Vehicle-based object detection. Sci. Data 2023, 10, 227. [Google Scholar] [CrossRef]
- Sun, Y.; Cao, B.; Zhu, P.; Hu, Q. Drone-based RGB-infrared cross-modality vehicle detection via uncertainty-aware learning. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6700–6713. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, SC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. Yolov9: Learning what you want to learn using programmable gradient information. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 1–21. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2025, 37, 107984–108011. [Google Scholar]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Hong, Y.; Wang, L.; Su, J.; Li, Y.; Fang, S.; Li, W.; Li, M.; Wang, H. CEMP-YOLO: An infrared overheat detection model for photovoltaic panels in UAVs. Digit. Signal Process. 2025, 161, 105072. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Desai, S.; Ramaswamy, H.G. Ablation-cam: Visual explanations for deep convolutional network via gradient-free localization. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 983–991. [Google Scholar]
- Jia, X.; Zhu, C.; Li, M.; Tang, W.; Zhou, W. LLVIP: A visible-infrared paired dataset for low-light vision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3496–3504. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | ||||||||
|---|---|---|---|---|---|---|---|---|
| YOLOv7-t | 94.0 | 53.8 | 52.3 | 89.1 | 37.4 | 65.3 ± 0.3 | 10.6 | 6.0 |
| YOLOv8-n | 94.7 | 55.6 | 57.0 | 91.4 | 47.9 | 69.3 ± 0.3 | 6.6 | 3.0 |
| YOLOv9-t | 94.4 | 52.3 | 51.4 | 91.3 | 44.5 | 66.8 ± 0.2 | 6.2 | 3.2 |
| YOLOv10-n | 94.5 | 49.1 | 49.9 | 88.4 | 42.4 | 64.9 ± 0.4 | 7.8 | 3.0 |
| YOLOV11-n | 94.8 | 54.0 | 53.5 | 91.4 | 39.0 | 66.6 ± 0.6 | 5.2 | 2.6 |
| G-YOLO | 93.4 | 53.8 | 49.4 | 89.1 | 42.9 | 65.7 ± 0.4 | 3.7 | 0.8 |
| LRI-YOLO | 94.5 | 56.5 | 54.3 | 91.1 | 46.6 | 68.6 ± 0.3 | 3.8 | 1.6 |
| CEMP-YOLO | 94.3 | 57.9 | 53.5 | 91.8 | 50.7 | 69.2 ± 0.2 | 3.8 | 2.1 |
| YOLO-UIR-n (Ours) | 94.9 | 60.1 | 59.2 | 90.8 | 50.6 | 71.1 ± 0.3 | 3.0 | 1.4 |
| YOLOv8-s | 94.7 | 62.6 | 62.7 | 93.0 | 53.6 | 73.3 ± 0.2 | 22.8 | 11.1 |
| YOLOv9-s | 94.3 | 62.5 | 63.5 | 91.8 | 51.2 | 72.7 ± 0.2 | 21.1 | 9.6 |
| YOLOv10-s | 94.4 | 57.8 | 61.6 | 90.6 | 50.2 | 70.9 ± 0.6 | 22.0 | 9.3 |
| YOLOV11-s | 95.4 | 63.4 | 59.9 | 92.4 | 49.1 | 72.0 ± 0.3 | 18.8 | 8.5 |
| YOLO-UIR-s (Ours) | 94.9 | 65.8 | 66.4 | 92.4 | 54.1 | 74.7 ± 0.2 | 8.7 | 4.6 |
| YOLOv8-m | 94.7 | 61.0 | 60.1 | 92.9 | 52.1 | 72.2 ± 0.4 | 63.2 | 25.9 |
| YOLOv9-m | 94.0 | 64.9 | 67.0 | 92.4 | 54.9 | 74.6 ± 0.1 | 61.0 | 32.6 |
| YOLOv10-m | 94.8 | 61.1 | 65.1 | 92.5 | 53.0 | 73.3 ± 0.2 | 62.4 | 19.7 |
| YOLOV11-m | 95.7 | 62.0 | 58.5 | 92.8 | 49.8 | 71.8 ± 0.3 | 54.2 | 20.1 |
| Swin-Transformer | 93.4 | 39.0 | 46.7 | 82.8 | 31.5 | 58.7 ± 1.7 | 152.2 | 38.5 |
| Cascade-RCNN | 93.7 | 41.6 | 46.4 | 84.4 | 40.7 | 61.4 ± 0.9 | 208.1 | 69.4 |
| YOLO-UIR-m (Ours) | 94.6 | 69.9 | 70.7 | 92.8 | 59.7 | 77.5 ± 0.2 | 19.2 | 9.1 |
| Method | ||||||
|---|---|---|---|---|---|---|
| YOLOv7-tiny | 80.6 | 91.1 | 70.4 | 80.7 ± 0.5 | 10.6 | 6.0 |
| YOLOv8-n | 89.2 | 96.9 | 83.8 | 90.0 ± 0.2 | 6.6 | 3.0 |
| YOLOv9-t | 88.0 | 95.8 | 81.2 | 88.3 ± 0.2 | 6.2 | 3.2 |
| YOLOv10-n | 88.1 | 96.5 | 84.3 | 89.6 ± 0.2 | 7.8 | 3.0 |
| YOLOv11-n | 85.0 | 96.6 | 80.2 | 87.3 ± 0.2 | 5.2 | 2.7 |
| G-YOLO | 87.2 | 96.2 | 81.4 | 88.3 ± 0.2 | 3.7 | 0.8 |
| LRI-YOLO | 88.4 | 96.7 | 85.3 | 90.1 ± 0.1 | 3.8 | 1.6 |
| CEMP-YOLO | 87.2 | 96.3 | 83.0 | 88.8 ± 0.2 | 3.8 | 2.1 |
| YOLO-UIR-n (Ours) | 88.6 | 96.9 | 86.6 | 90.7 ± 0.1 | 3.0 | 1.4 |
| YOLOv8-s | 90.1 | 97.3 | 86.9 | 91.4 ± 0.1 | 22.8 | 11.1 |
| YOLOv9-s | 89.0 | 97.0 | 86.0 | 90.7 ± 0.2 | 21.1 | 9.6 |
| YOLOv10-s | 89.4 | 96.9 | 87.3 | 91.2 ± 0.1 | 22.0 | 9.3 |
| YOLOv11-s | 88.3 | 96.9 | 83.7 | 89.6 ± 0.1 | 18.8 | 8.5 |
| YOLO-UIR-s (Ours) | 90.2 | 97.1 | 88.0 | 91.8 ± 0.1 | 8.7 | 4.6 |
| YOLOv8-m | 89.8 | 97.2 | 88.4 | 91.8 ± 0.1 | 63.2 | 25.9 |
| YOLOv9-m | 90.3 | 97.1 | 87.2 | 91.6 ± 0.1 | 61.0 | 32.6 |
| YOLOv10-m | 89.9 | 97.2 | 89.4 | 92.1 ± 0.1 | 62.4 | 19.7 |
| YOLOv11-m | 86.3 | 96.6 | 85.0 | 89.3 ± 0.1 | 54.2 | 20.1 |
| Swin-Transformer | 60.4 | 87.3 | 67.7 | 71.8 ± 2.6 | 152.2 | 38.5 |
| Cascade-RCNN | 71.5 | 90.4 | 75.7 | 79.2 ± 1.7 | 208.1 | 69.4 |
| YOLO-UIR-m (Ours) | 90.0 | 96.6 | 90.1 | 92.3 ± 0.1 | 19.2 | 9.1 |
| EfficientC2f | LSP | BIFI | (%) | ||
|---|---|---|---|---|---|
| 68.2 | 4.2 | 1.8 | |||
| ✓ | 69.5 | 3.3 | 1.4 | ||
| ✓ | 69.9 | 4.0 | 1.7 | ||
| ✓ | 70.0 | 4.0 | 1.9 | ||
| ✓ | ✓ | 70.2 | 3.1 | 1.3 | |
| ✓ | ✓ | ✓ | 71.1 | 3.0 | 1.4 |
| Method | SE | ECA | CBAM | ADA (Ours) |
|---|---|---|---|---|
| 69.0 | 69.1 | 68.0 | 69.5 |
| Model | Inference Speed (frames/s) | Training Time (h) |
|---|---|---|
| Yolov7-t | 40 | 3.0 |
| Yolov8-n | 36 | 2.1 |
| Yolov9-t | 16 | 8.4 |
| Yolov10-n | 25 | 2.2 |
| Yolov11-n | 39 | 2.3 |
| G-YOLO | 38 | 2.4 |
| LRI-YOLO | 22 | 2.6 |
| CEMP-YOLO | 30 | 2.4 |
| Yolo-UIR (Ours) | 47 | 1.7 |
| Model | |||
|---|---|---|---|
| Yolov7-t | 89.9 | 10.6 | 6.0 |
| Yolov8-n | 94.0 | 6.6 | 3.0 |
| Yolov9-t | 93.8 | 6.2 | 3.2 |
| Yolov10-n | 92.7 | 7.8 | 3.0 |
| Yolov11-n | 94.0 | 5.2 | 2.7 |
| G-YOLO | 93.7 | 3.7 | 0.8 |
| LRI-YOLO | 92.9 | 3.8 | 1.6 |
| CEMP-YOLO | 94.2 | 3.8 | 2.1 |
| Yolo-UIR (Ours) | 94.3 | 3.0 | 1.4 |
| 0.1 | 0.5 | 2 | |
| 58.9 | 71.1 | 71.0 | |
| 1 | 7.5 | 20 | |
| 71.1 | 71.1 | 64.4 | |
| 0.1 | 0.375 | 1 | |
| 67.9 | 71.1 | 65.9 |
| Method | w/o Blur | w/o Flip | w/o Mirror |
|---|---|---|---|
| 67.2 | 70.6 | 69.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Wang, R.; Wu, Z.; Bian, Z.; Huang, T. YOLO-UIR: A Lightweight and Accurate Infrared Object Detection Network Using UAV Platforms. Drones 2025, 9, 479. https://doi.org/10.3390/drones9070479
Wang C, Wang R, Wu Z, Bian Z, Huang T. YOLO-UIR: A Lightweight and Accurate Infrared Object Detection Network Using UAV Platforms. Drones. 2025; 9(7):479. https://doi.org/10.3390/drones9070479
Chicago/Turabian StyleWang, Chao, Rongdi Wang, Ziwei Wu, Zetao Bian, and Tao Huang. 2025. "YOLO-UIR: A Lightweight and Accurate Infrared Object Detection Network Using UAV Platforms" Drones 9, no. 7: 479. https://doi.org/10.3390/drones9070479
APA StyleWang, C., Wang, R., Wu, Z., Bian, Z., & Huang, T. (2025). YOLO-UIR: A Lightweight and Accurate Infrared Object Detection Network Using UAV Platforms. Drones, 9(7), 479. https://doi.org/10.3390/drones9070479