
Detection and Geolocation of Peat Fires Using Thermal Infrared Cameras on Drones

 ,
,  ,
,  , and
, and 
Abstract
1. Introduction
2. Background
3. Methodology
3.1. Data Collection
3.2. Data Annotation
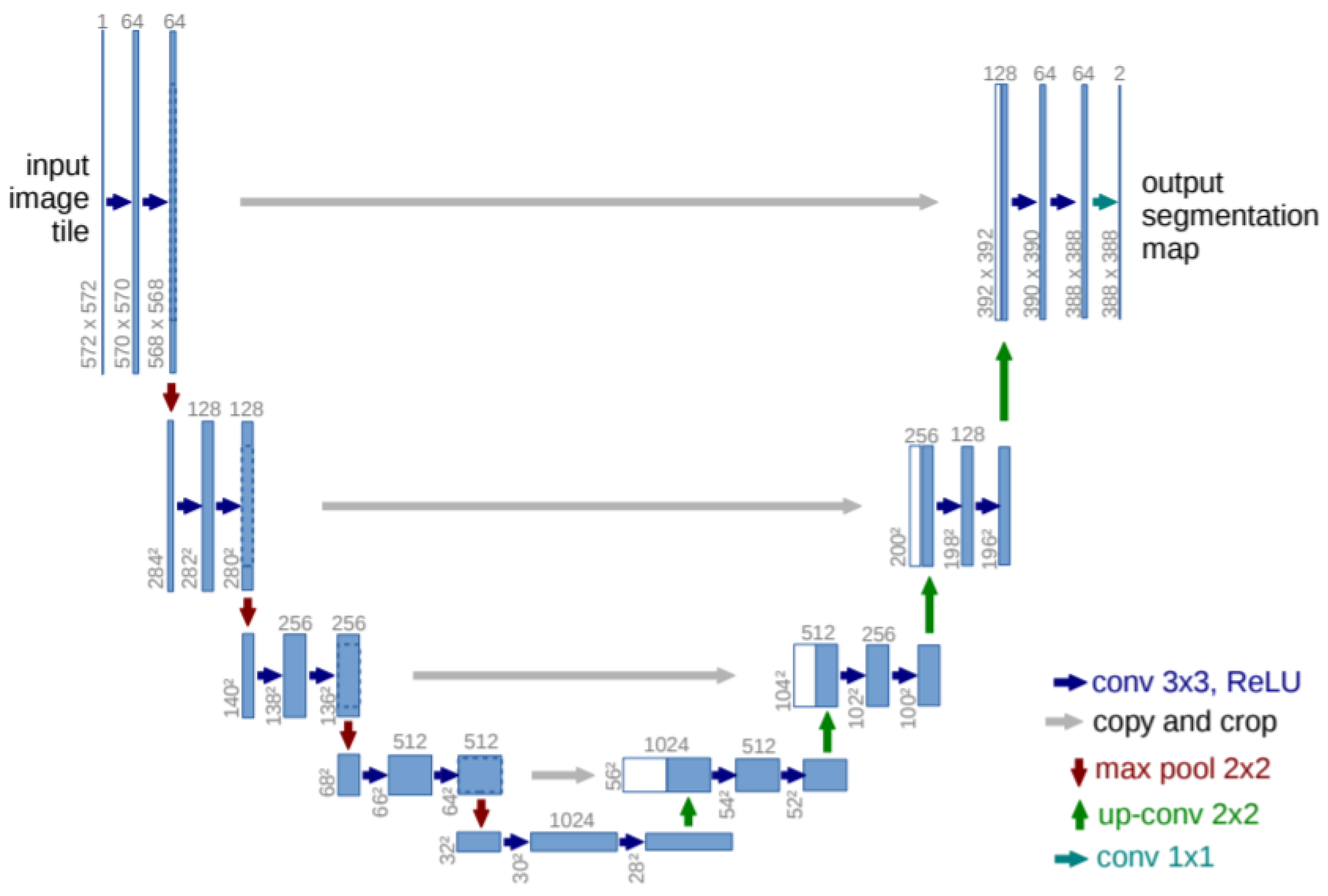
3.3. Deep Learning Network Architecture
3.4. ResNet-50 as Encoder
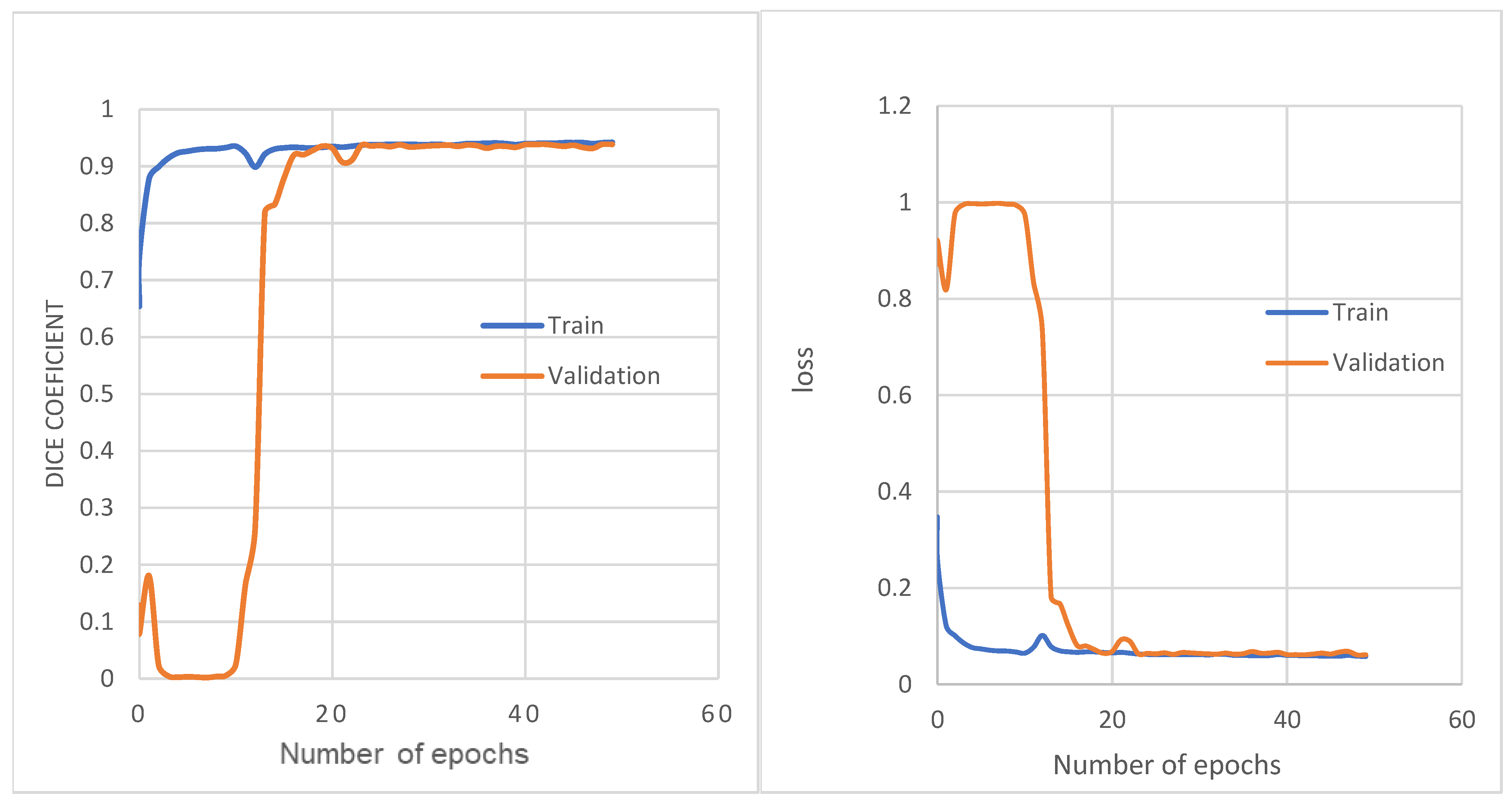
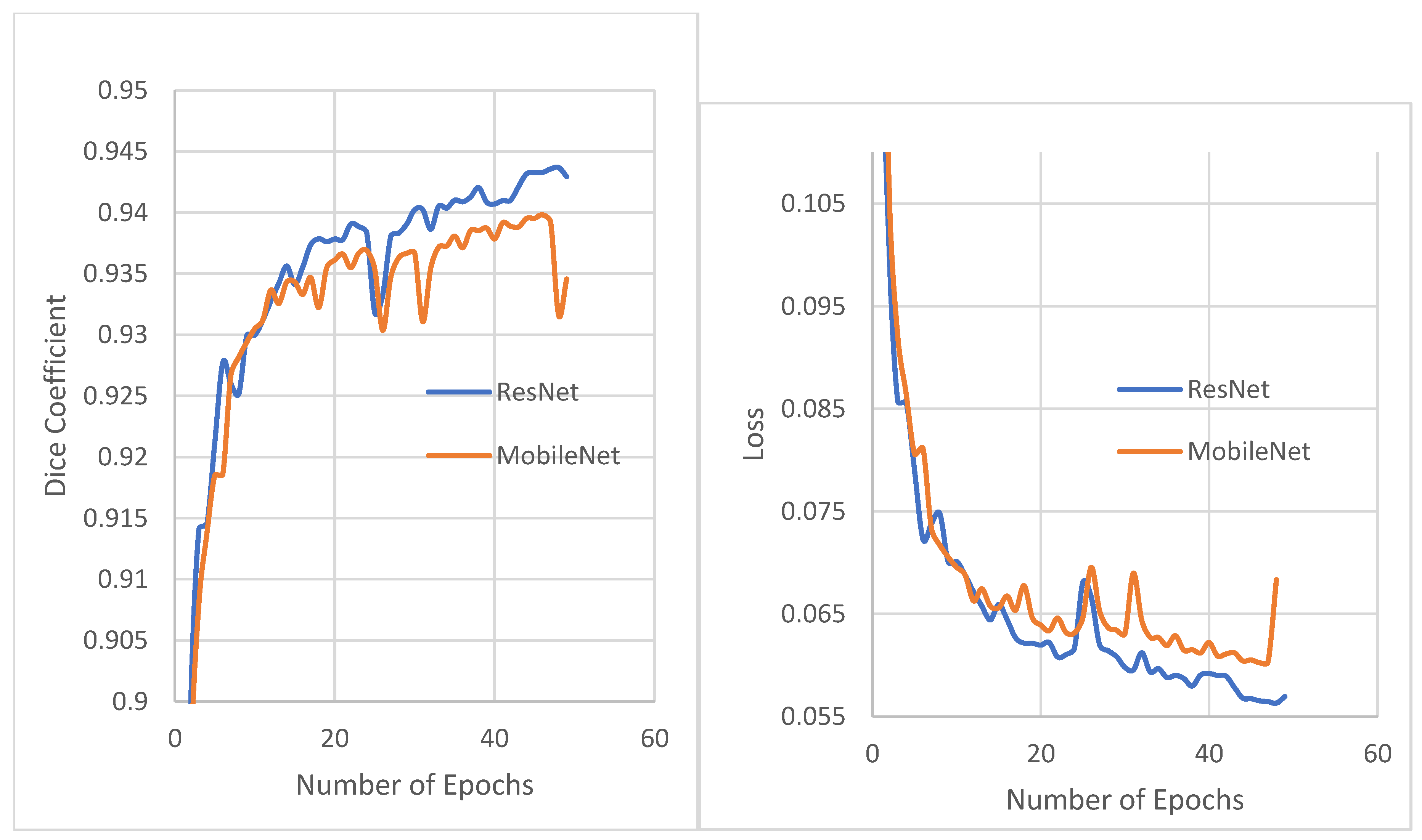
3.5. Model Training
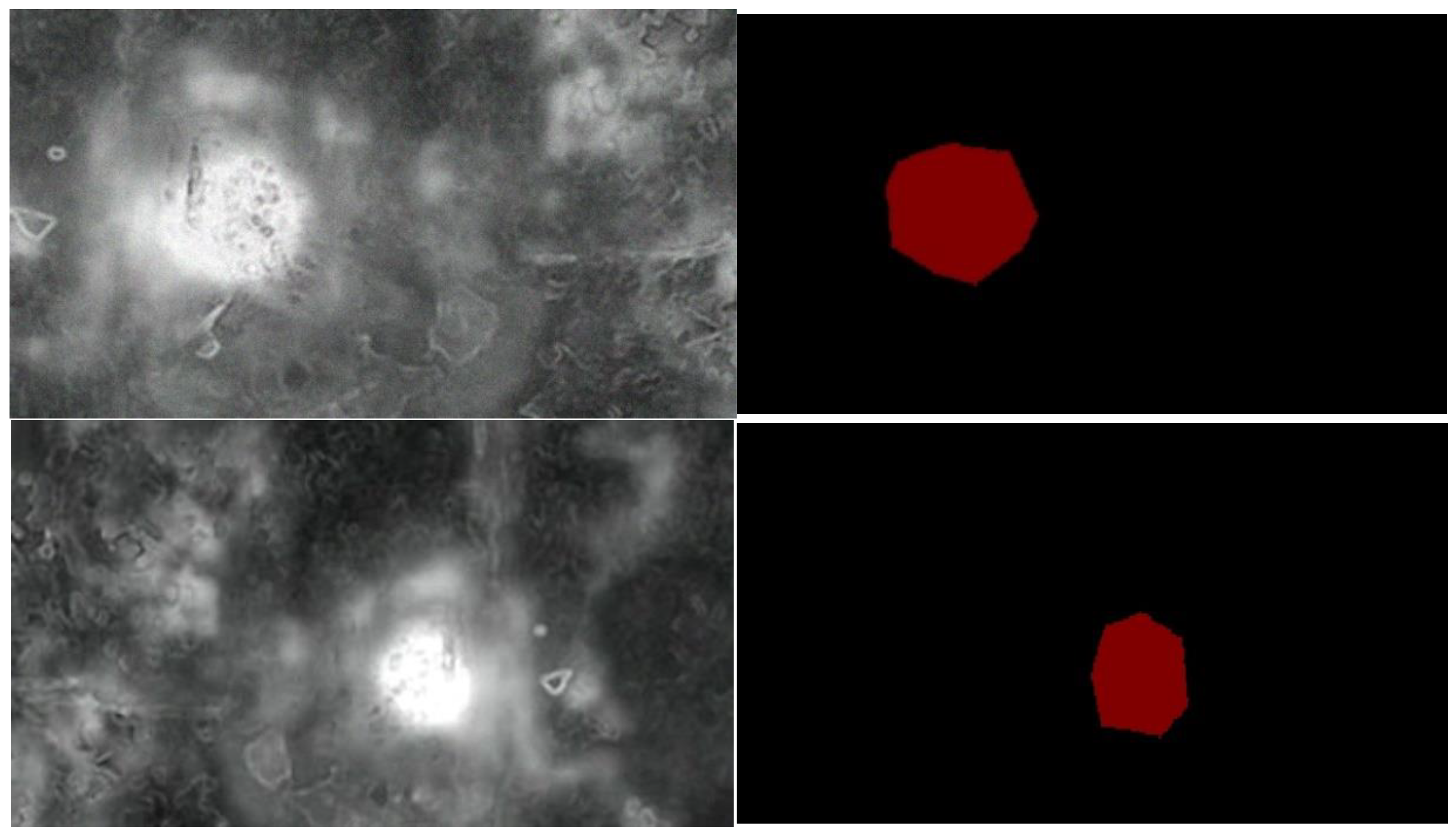
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Fire Geolocation Algorithm
Appendix A.1. Geolocation Pipeline
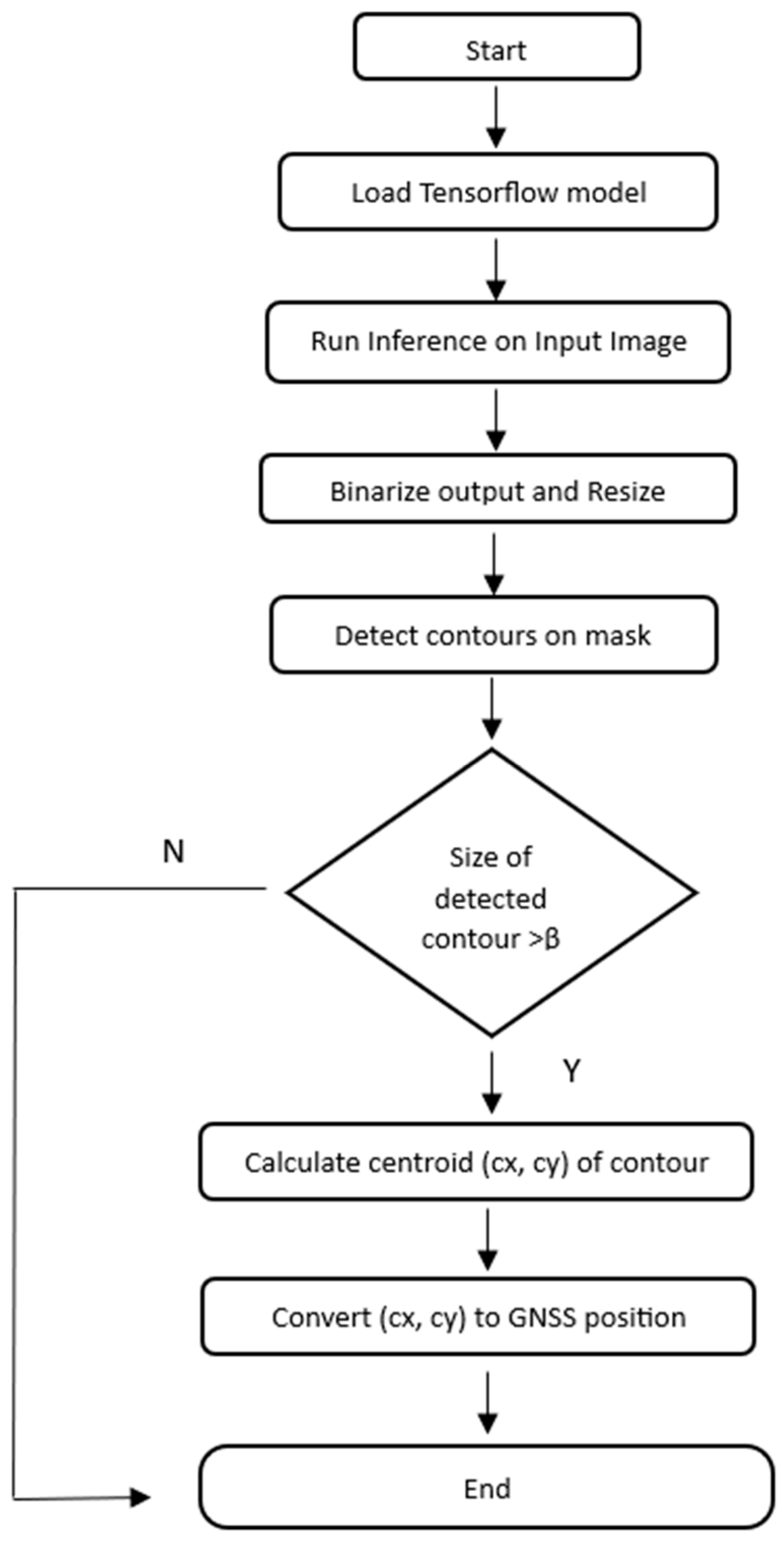
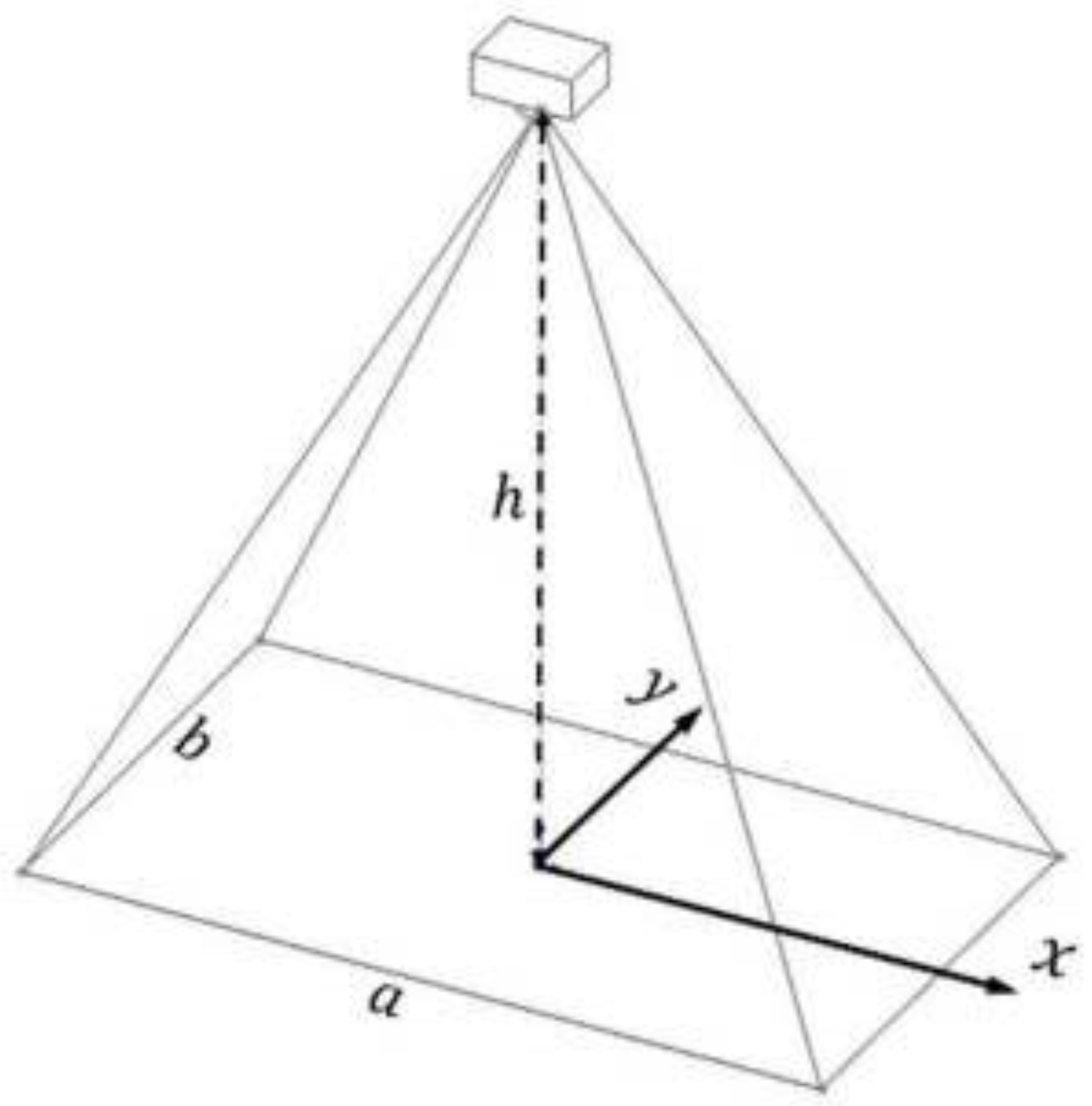
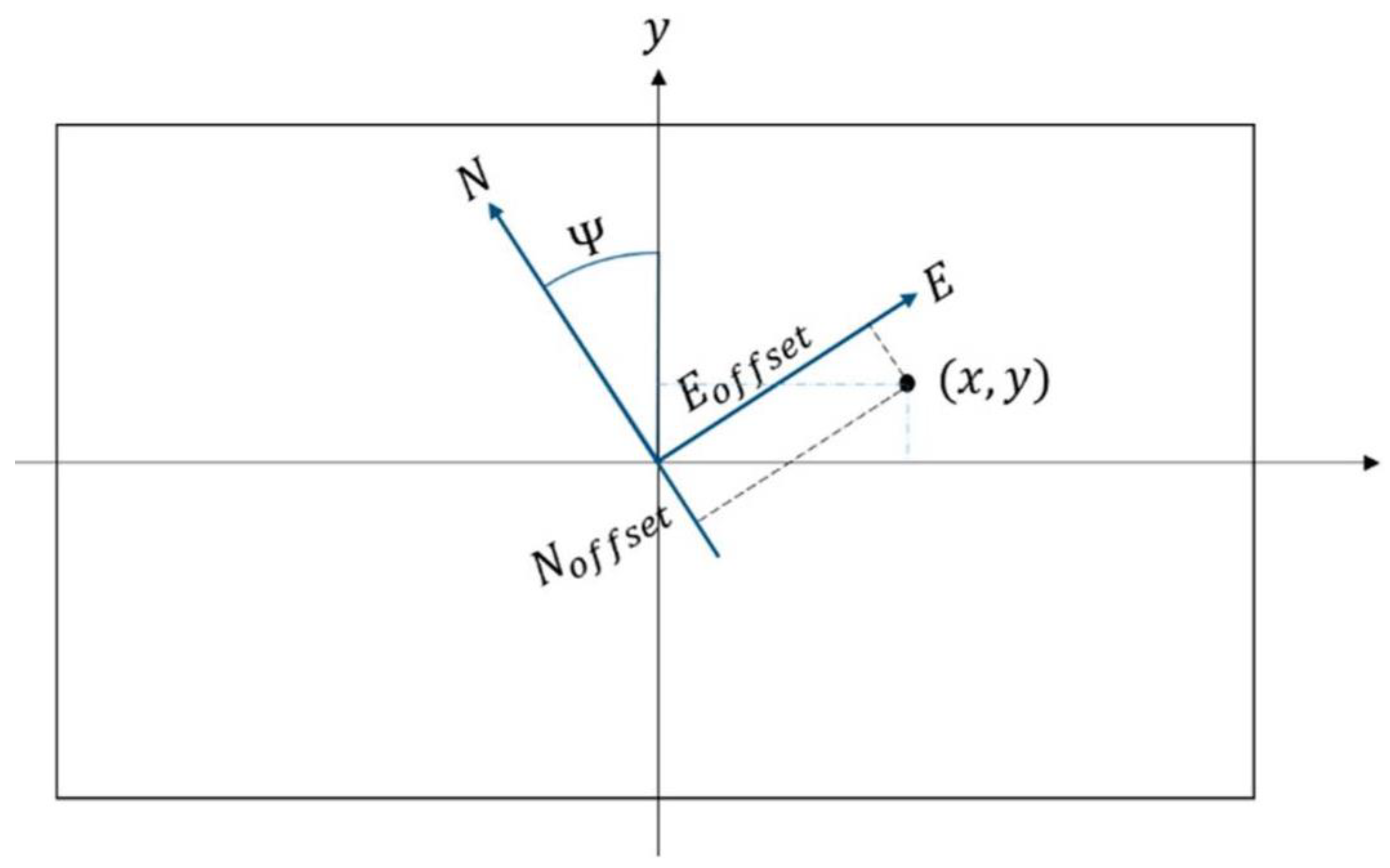
Appendix A.2. GNSS Transformation to Locate Fire Pixels

References
- Rein, G.; Cleaver, N.; Ashton, C.; Pironi, P.; Torero, J.L. The severity of smouldering peat fires and damage to the forest soil. CATENA 2008, 74, 304–309. [Google Scholar] [CrossRef]
- Page, S.E.; Hooijer, A. In the line of fire: The peatlands of Southeast Asia. Philos. Trans. R. Soc. B Biol. Sci. 2016, 371, 20150176. [Google Scholar] [CrossRef] [PubMed]
- Lohberger, S.; Stängel, M.; Atwood, E.C.; Siegert, F. Spatial evaluation of Indonesia’s 2015 fire-affected area and estimated carbon emissions using Sentinel-1. Glob. Change Biol. 2018, 24, 644–654. [Google Scholar] [CrossRef] [PubMed]
- Crippa, P.; Castruccio, S.; Archer-Nicholls, S.; Lebron, G.B.; Kuwata, M.; Thota, A.; Sumin, S.; Butt, E.; Wiedinmyer, C.; Spracklen, D.V. Population exposure to hazardous air quality due to the 2015 fires in Equatorial Asia. Sci. Rep. 2016, 6, 37074. [Google Scholar] [CrossRef] [PubMed]
- Kelhä, V.; Rauste, Y.; Häme, T.; Sephton, T.; Buongiorno, A.; Frauenberger, O.; Soini, K.; Venäläinen, A.; San Miguel-Ayanz, J.; Vainio, T. Combining AVHRR and ATSR satellite sensor data for operational boreal forest fire detection. Int. J. Remote Sens. 2003, 24, 1691–1708. [Google Scholar] [CrossRef]
- He, L.; Li, Z. Enhancement of a fire-detection algorithm by eliminating solar contamination effects and atmospheric path radiance: Application to MODIS data. Int. J. Remote Sens. 2011, 32, 6273–6293. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, B.; Peng, W.; Li, C.; Lu, Z.; Guo, Y. A Method for Forest Fire Detection Using UAV. In Proceedings of the Computer Science and Technology 2015, Zurich, Switzerland, 2–3 January 2015; pp. 69–74. [Google Scholar] [CrossRef]
- Yuan, C.; Liu, Z.; Zhang, Y. UAV-based forest fire detection and tracking using image processing techniques. In Proceedings of the 2015 International Conference on Unmanned Aircraft Systems (ICUAS), Denver, CO, USA, 9–12 June 2015; pp. 639–643. [Google Scholar] [CrossRef]
- Christensen, B.R. Use of UAV or remotely piloted aircraft and forward-looking infrared in forest, rural and wildland fire management: Evaluation using simple economic analysis. N. Z. J. For. Sci. 2015, 45, 16. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25. Available online: https://code.google.com/archive/p/cuda-convnet/ (accessed on 23 September 2021). [CrossRef]
- Zhao, Y.; Ma, J.; Li, X.; Zhang, J. Saliency detection and deep learning-based wildfire identification in UAV imagery. Sensors 2018, 18, 712. [Google Scholar] [CrossRef] [PubMed]
- Tang, Z.; Liu, X.; Chen, H.; Hupy, J.; Yang, B. Deep Learning Based Wildfire Event Object Detection from 4K Aerial Images Acquired by UAS. AI 2020, 1, 166–179. [Google Scholar] [CrossRef]
- Jiao, Z.; Zhang, Y.; Mu, L.; Xin, J.; Jiao, S.; Liu, H.; Liu, D. A YOLOv3-based Learning Strategy for Real-time UAV-based Forest Fire Detection. In Proceedings of the 2020 Chinese Control and Decision Conference (CCDC), Hefei, China, 22–24 August 2020; pp. 4963–4967. [Google Scholar] [CrossRef]
- Burke, C.; McWhirter, P.R.; Veitch-Michaelis, J.; McAree, O.; Pointon, H.A.G.; Wich, S.; Longmore, S. Requirements and Limitations of Thermal Drones for Effective Search and Rescue in Marine and Coastal Areas. Drones 2019, 3, 78. [Google Scholar] [CrossRef]
- Burke, C.; Wich, S.; Kusin, K.; McAree, O.; Harrison, M.E.; Ripoll, B.; Ermiasi, Y.; Mulero-Pázmány, M.; Longmore, S. Thermal-Drones as a Safe and Reliable Method for Detecting Subterranean Peat Fires. Drones 2019, 3, 23. [Google Scholar] [CrossRef]
- Tlig, M.; Bouchouicha, M.; Sayadi, M.; Moreau, E. Visible and infraredimage fusion framework for fire semantic segmentation using U-Net-ResNet50. In Proceedings of the 2022 IEEE Information Technologies & Smart Industrial Systems (ITSIS), Paris, France, 15–17 July 2022; pp. 1–5. [Google Scholar]
- Zhang, P.; Ban, Y.; Nascetti, A. Learning U-Net without forgetting for near real-time wildfire monitoring by the fusion of SAR and optical time series. Remote Sens. Environ. 2021, 261, 112467. [Google Scholar] [CrossRef]
- Mavic 2 Enterprise Series—Specifications—DJI. Available online: https://www.dji.com/uk/mavic-2-enterprise/specs (accessed on 5 April 2022).
- Liao, P.-S.; Chen, T.-S.; Chung, P.-C. A Fast Algorithm for Multilevel Thresholding. J. Inf. Sci. Eng. 2001, 17, 713–727. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2323. [Google Scholar] [CrossRef]
- Rocha, L.; Velho, L.; Carvalho, P.C.P. Image moments-based structuring and tracking of objects. In Proceedings of the XV Brazilian Symposium on Computer Graphics and Image Processing, Fortaleza, Brazil, 10 October 2002; pp. 99–105. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Solver Type | Base Learning Rate | Gamma | Momentum | Batch Size |
|---|---|---|---|---|
| SGD | 0.001 | 0.1 | 0.9 | 32 |
| Models | Average Precision | Average Recall | Average IoU | Parameters |
|---|---|---|---|---|
| ResNet50 | 0.942 | 0.915 | 0.876 | 20,670,359 |
| MobileNetV2 | 0.978 | 0.547 | 0.579 | 3,630,593 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sam-Odusina, T.; Perkasa, P.; Chalmers, C.; Fergus, P.; Longmore, S.N.; Wich, S.A. Detection and Geolocation of Peat Fires Using Thermal Infrared Cameras on Drones. Drones 2025, 9, 459. https://doi.org/10.3390/drones9070459
Sam-Odusina T, Perkasa P, Chalmers C, Fergus P, Longmore SN, Wich SA. Detection and Geolocation of Peat Fires Using Thermal Infrared Cameras on Drones. Drones. 2025; 9(7):459. https://doi.org/10.3390/drones9070459
Chicago/Turabian StyleSam-Odusina, Temitope, Petrisly Perkasa, Carl Chalmers, Paul Fergus, Steven N. Longmore, and Serge A. Wich. 2025. "Detection and Geolocation of Peat Fires Using Thermal Infrared Cameras on Drones" Drones 9, no. 7: 459. https://doi.org/10.3390/drones9070459
APA StyleSam-Odusina, T., Perkasa, P., Chalmers, C., Fergus, P., Longmore, S. N., & Wich, S. A. (2025). Detection and Geolocation of Peat Fires Using Thermal Infrared Cameras on Drones. Drones, 9(7), 459. https://doi.org/10.3390/drones9070459