
A Mean-Field-Game-Integrated MPC-QP Framework for Collision-Free Multi-Vehicle Control


 ,
,  , and
, and
Abstract
1. Introduction
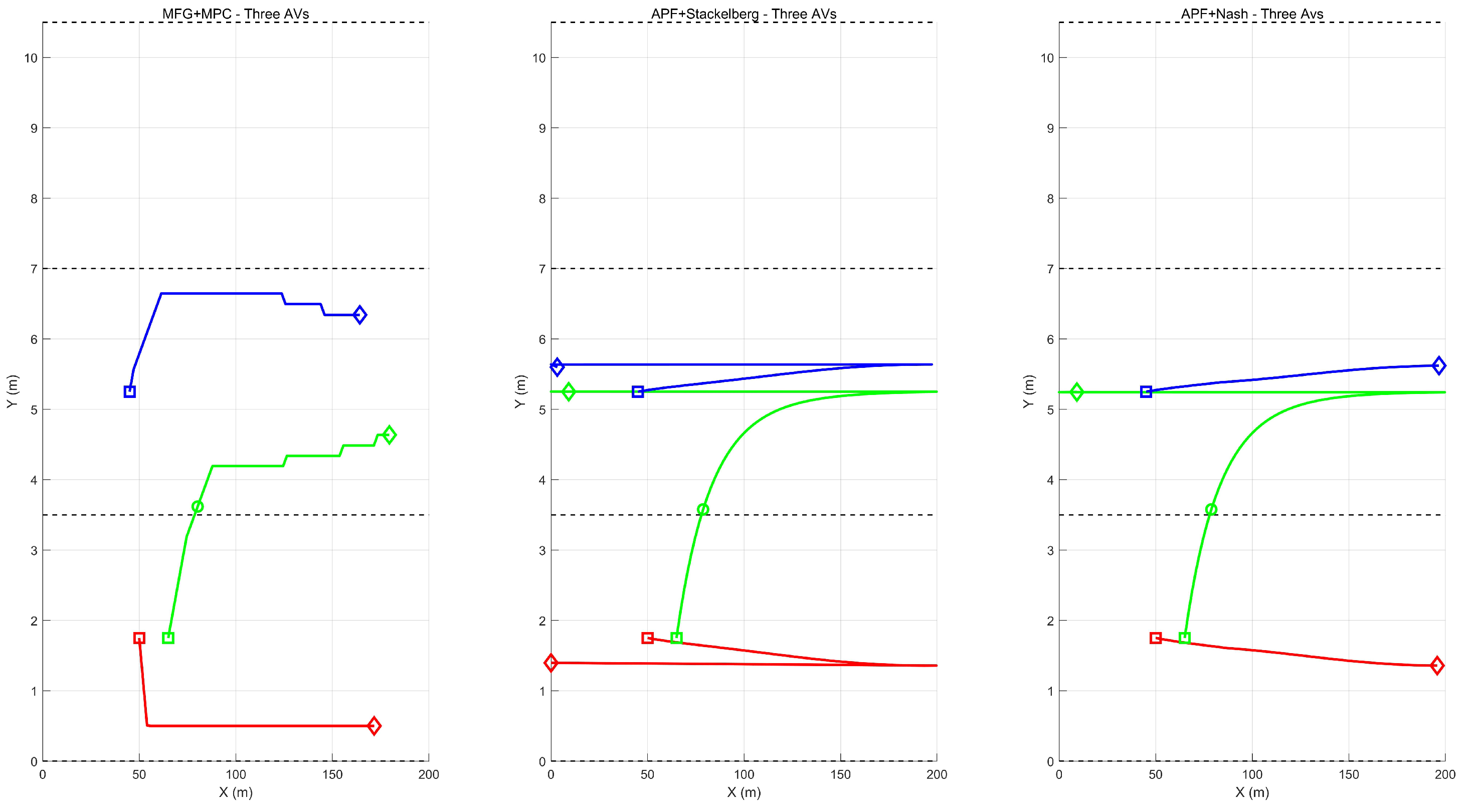
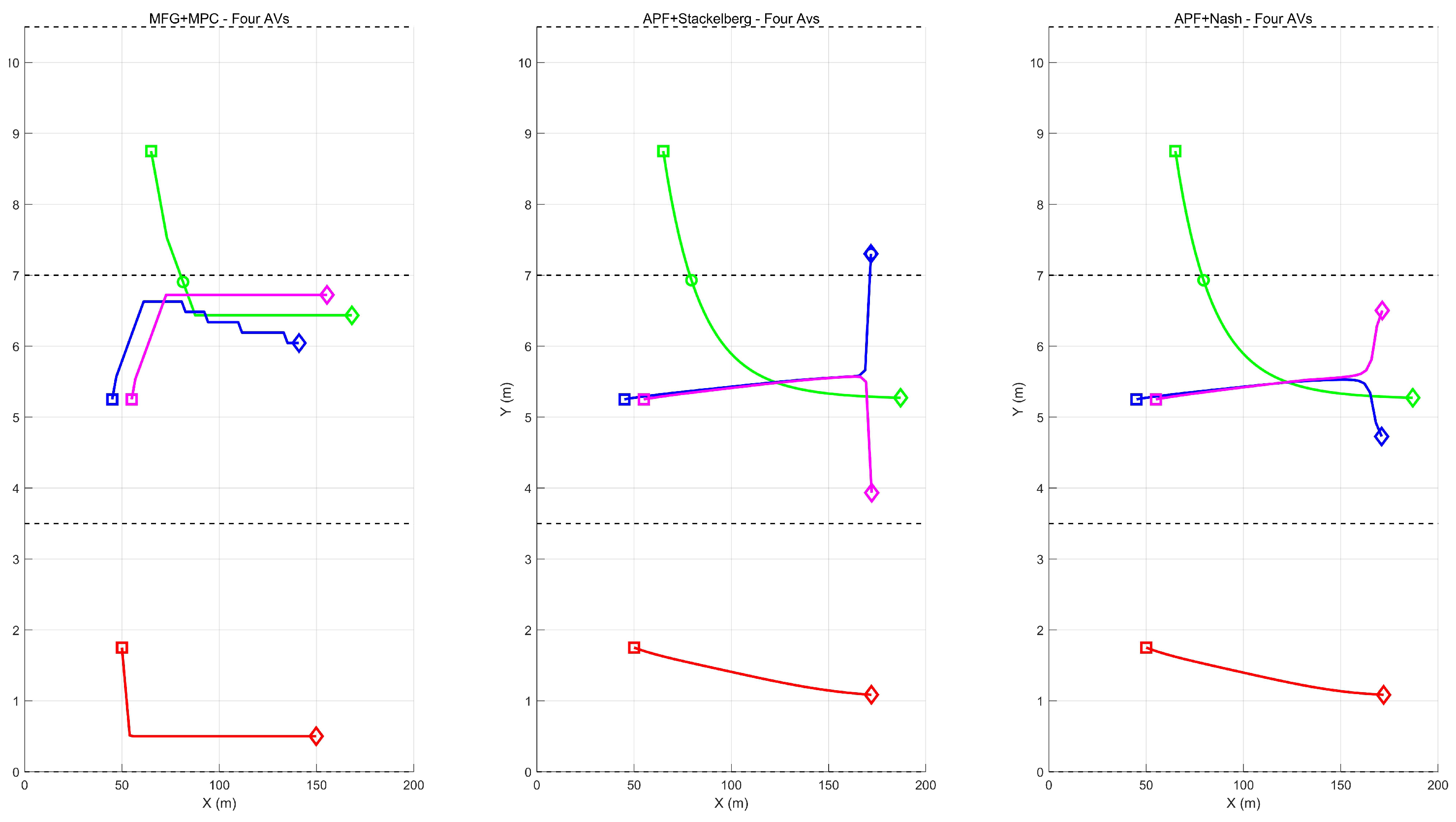
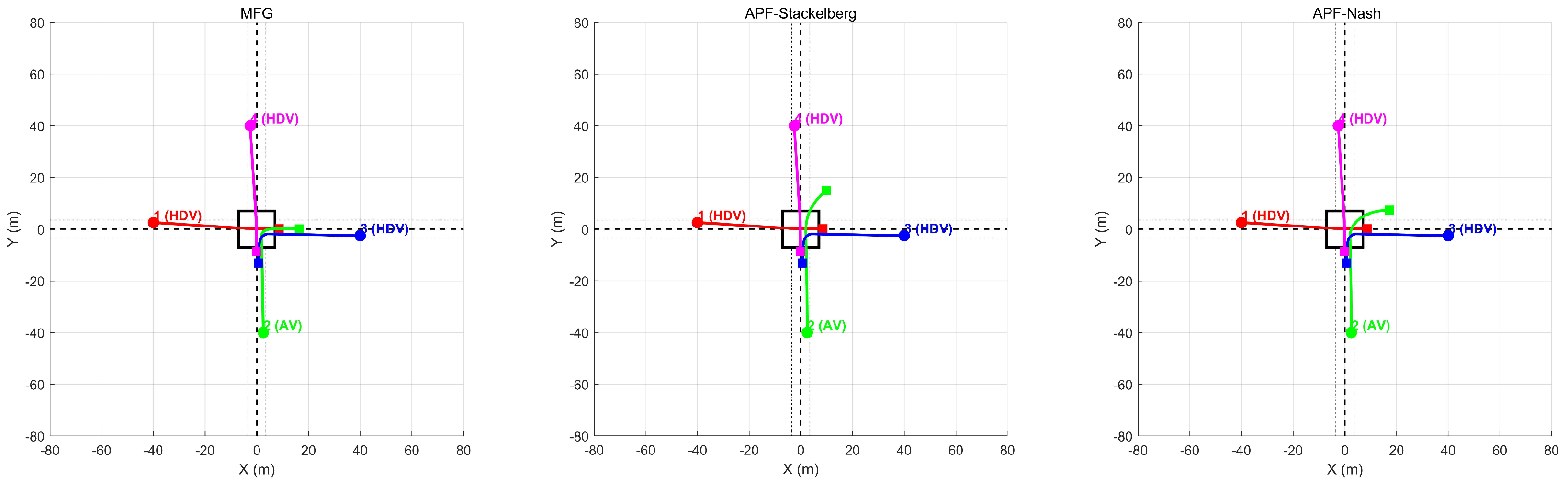
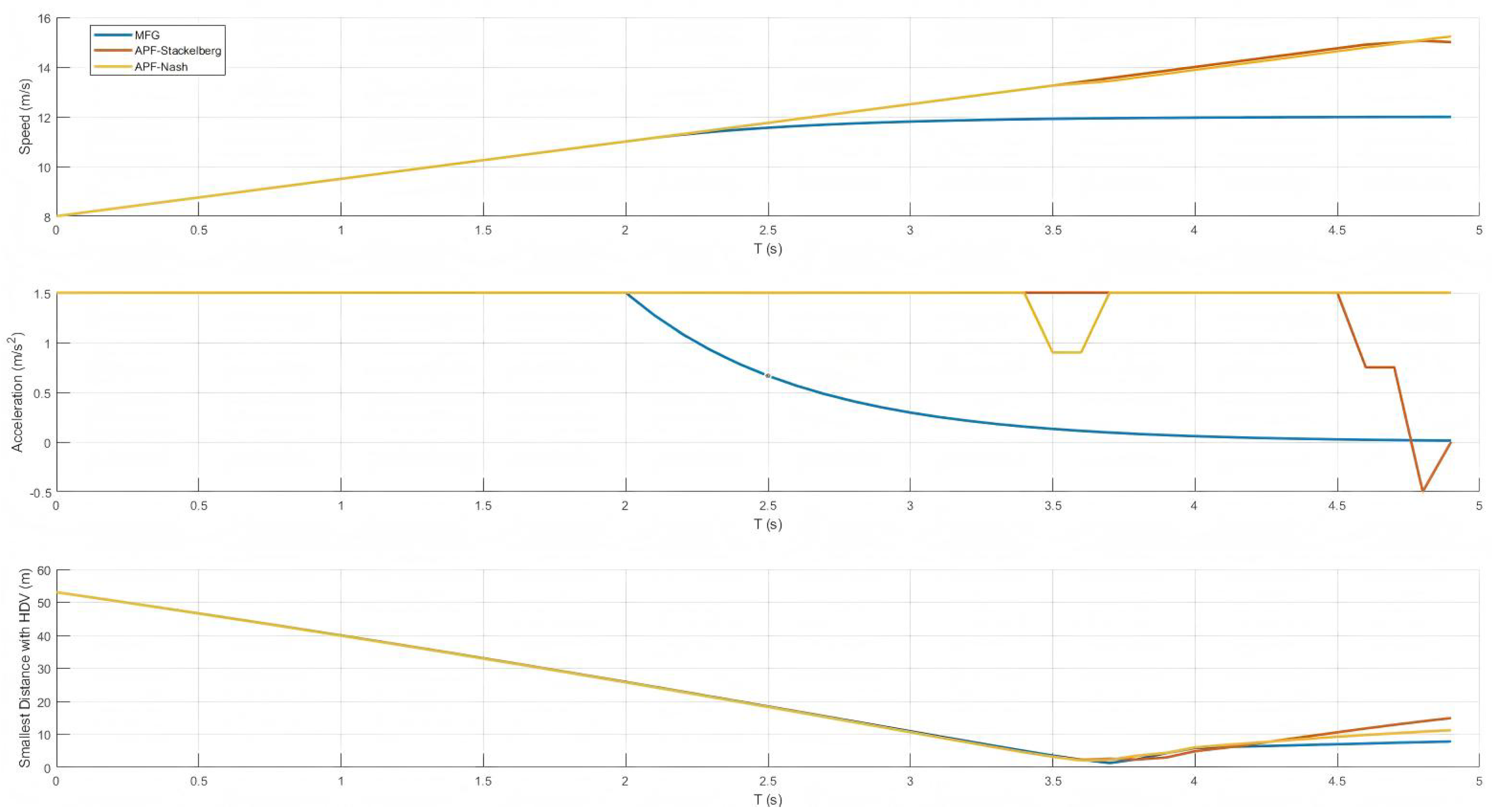
- The proposed framework utilizes mean field approximations to capture the aggregate behavior of surrounding vehicles, providing a more efficient representation of interactive driving scenarios. Our experimental results demonstrate smoother ane-changing trajectories compared to Nash and Stackelberg formulations, enhancing driving comfort, and enabling more human-like behavior. Critically, our method achieves collision-free operation throughout testing, while compared methods record over 30 collisions. In intersection scenarios, our approach consistently maintains vehicles within road boundaries, unlike alternative methods where boundary violations occurr frequently.
- By integrating these mean field predictions into a receding-horizon MPC-QP framework, our framework effectively handles the nonlinear dynamics of vehicles while ensuring real-time computation of optimal control actions.
- Extensive simulation results demonstrate that our framework not only guarantees collision-free operation but also produces smoother trajectories and enhanced overall traffic performance compared to existing game-based approaches.
2. Related Works
2.1. Challenges in Interactive Decision-Making
2.2. Shortcomings of Current Game-Based Approaches
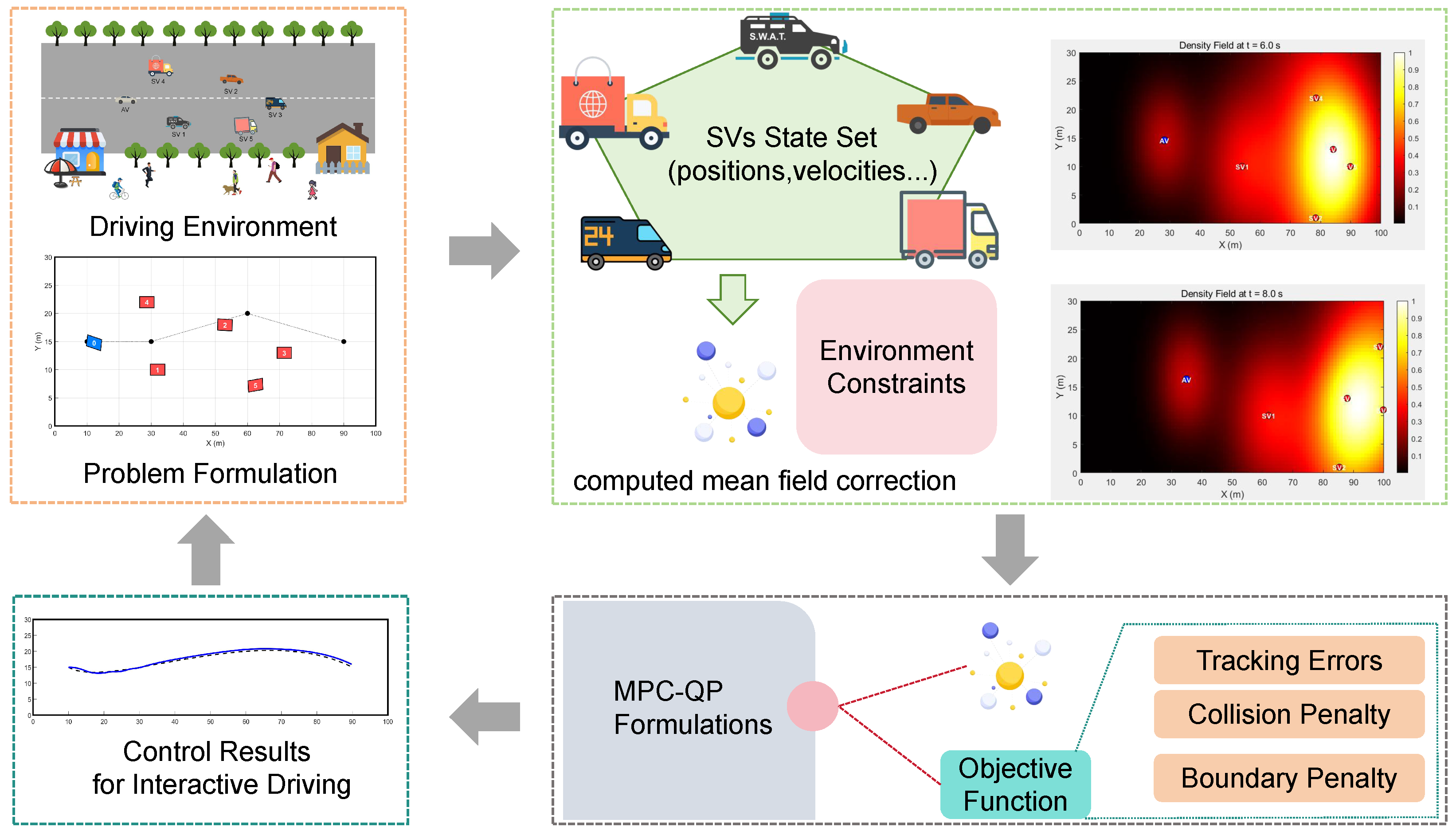
3. System Overview
4. Methodology
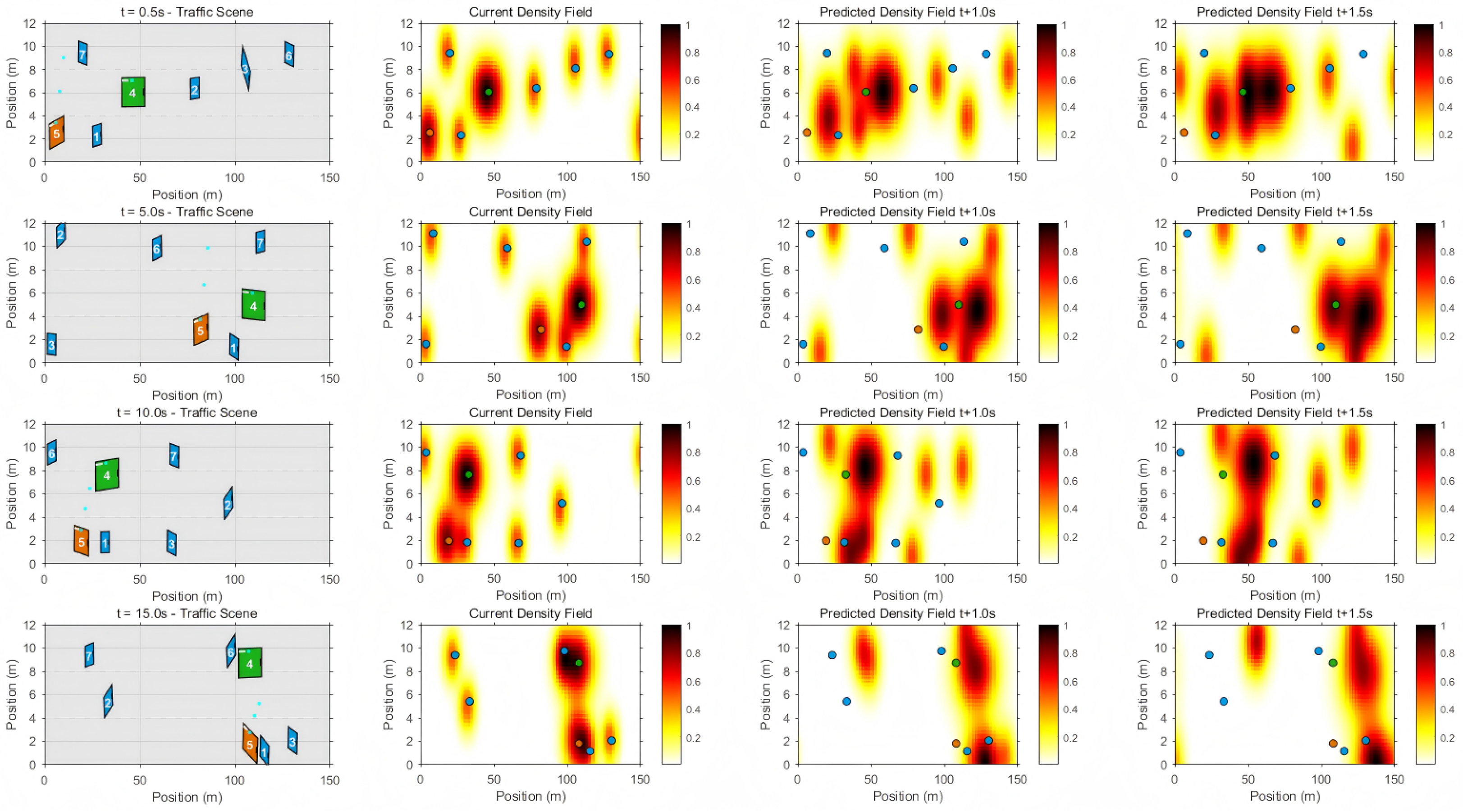
4.1. Interactive Prediction via MFG
4.2. MPC-QP Formulation with Environmental and Safety Constraints
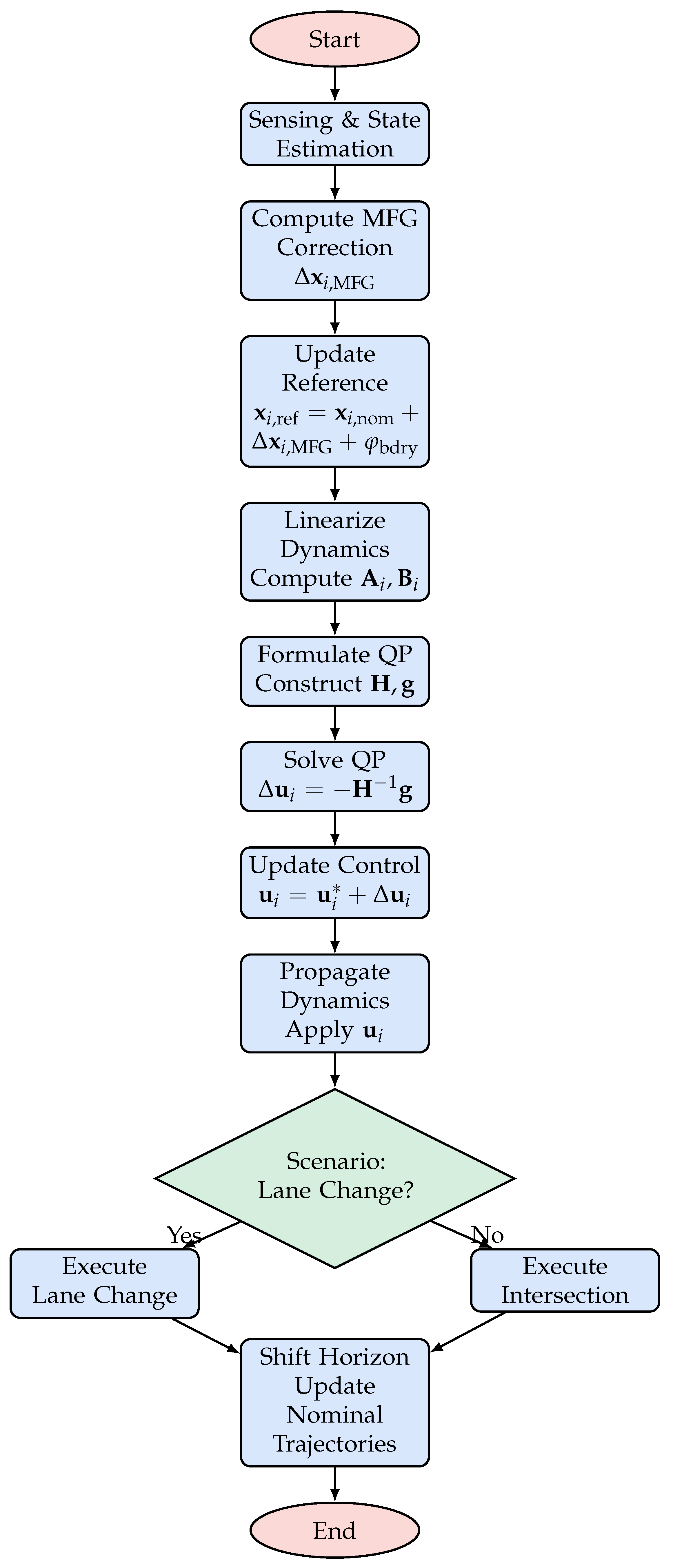
| Algorithm 1 Extended MFG Integrated MPC-QP Algorithm with Environmental and Safety Constraints |
|
- Start: This is the initialization step where the system oads all sensor data, initial vehicle states, and environmental parameters. The controller is set up to begin the receding-horizon control oop.
- Sensing & State Estimation: In this step, all vehicles (both the AV and HDVs) gather sensor data (e.g., from LiDAR, cameras, radar) to estimate their current states (position, velocity, heading). Accurate state estimation is critical for reliable prediction and control.
- Compute MFG Correction: The MFG module processes the states of all vehicles (except the one under consideration) to compute an aggregate correction term, . This term approximates the collective influence of surrounding vehicles, reducing the complexity of pairwise interaction modeling. It is then used to update the nominal reference state, so that the adjusted reference becomesthereby ensuring that the control policy dynamically incorporates real-time interactive effects.
- Update Reference: The nominal reference state is updated by incorporating the MFG correction along with a boundary penalty that accounts for the proximity to the environment boundaries. This yields the new reference state:
- Linearize Dynamics: The vehicle’s nonlinear dynamics (given by the kinematic bicycle model) are inearized around the nominal trajectory . The Jacobian matrices and capture the sensitivity of the state with respect to state and control inputs, respectively.
- Formulate QP Matrices: Using the inearized model, the Hessian matrix and gradient vector for the QP are constructed. Specifically, is computed by accumulating the termsand the gradient is given bywhere is the terminal cost weight matrix. These matrices encapsulate the tracking errors, control efforts, and indirectly include collision penalties from .
- Solve QP: The quadratic programming problem is solved to obtain the optimal control correction:This step yields the necessary adjustment to the nominal control inputs to reduce the overall cost.
- Update Control: The control input is updated by adding the correction term to the nominal control:This new control command is what is applied to the vehicle.
- Propagate Dynamics: The updated control inputs are applied to the nonlinear dynamics model to propagate the vehicle states forward. Additionally, environmental constraints are enforced to ensure that all vehicle states remain within the designated region .
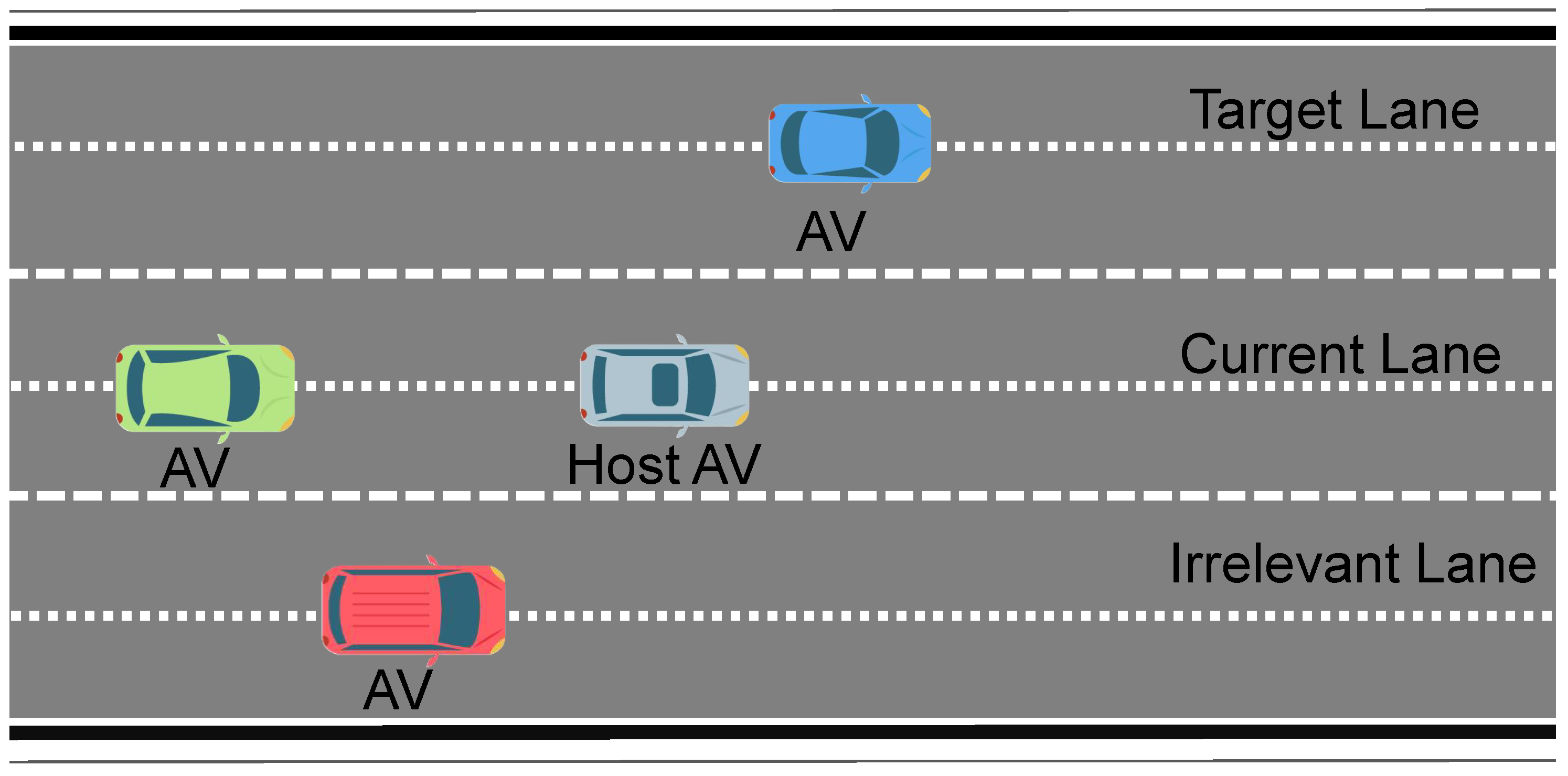
- Scenario Decision: A decision node determines the driving scenario (e.g., ane change or intersection negotiation) based on the current state and predicted vehicle interactions. This decision may trigger additional scenario-specific maneuvers.
- Execute Maneuver: Depending on the scenario decision, the system executes the corresponding maneuver—either a ane change or an intersection negotiation—adjusting the control inputs as necessary.
- Shift Horizon: After control actions are applied and states are updated, the prediction horizon is shifted forward. The nominal trajectories are updated, and the process repeats in a receding-horizon fashion.
- End: The control oop terminates when the driving task is complete or when the specified time horizon is reached.
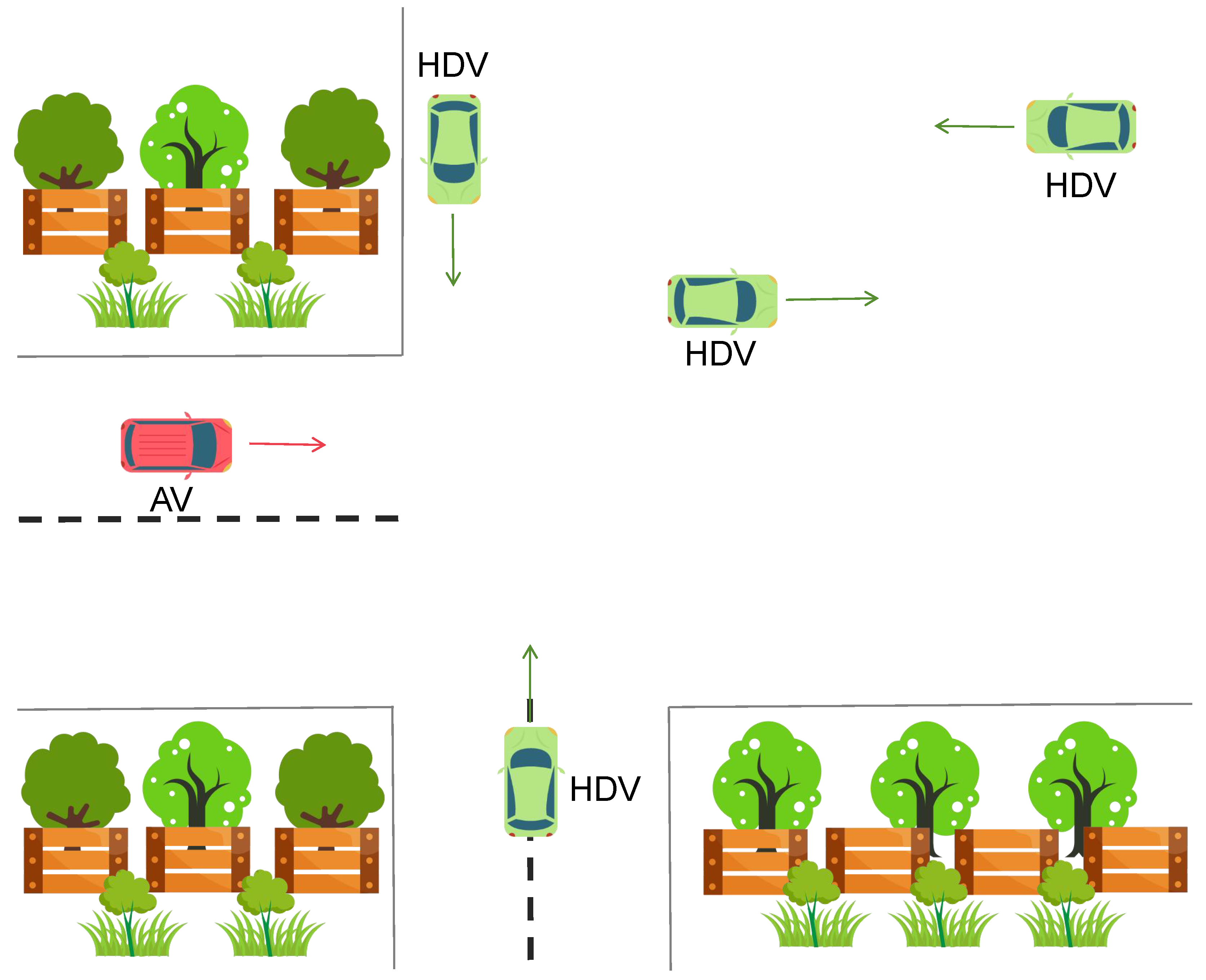
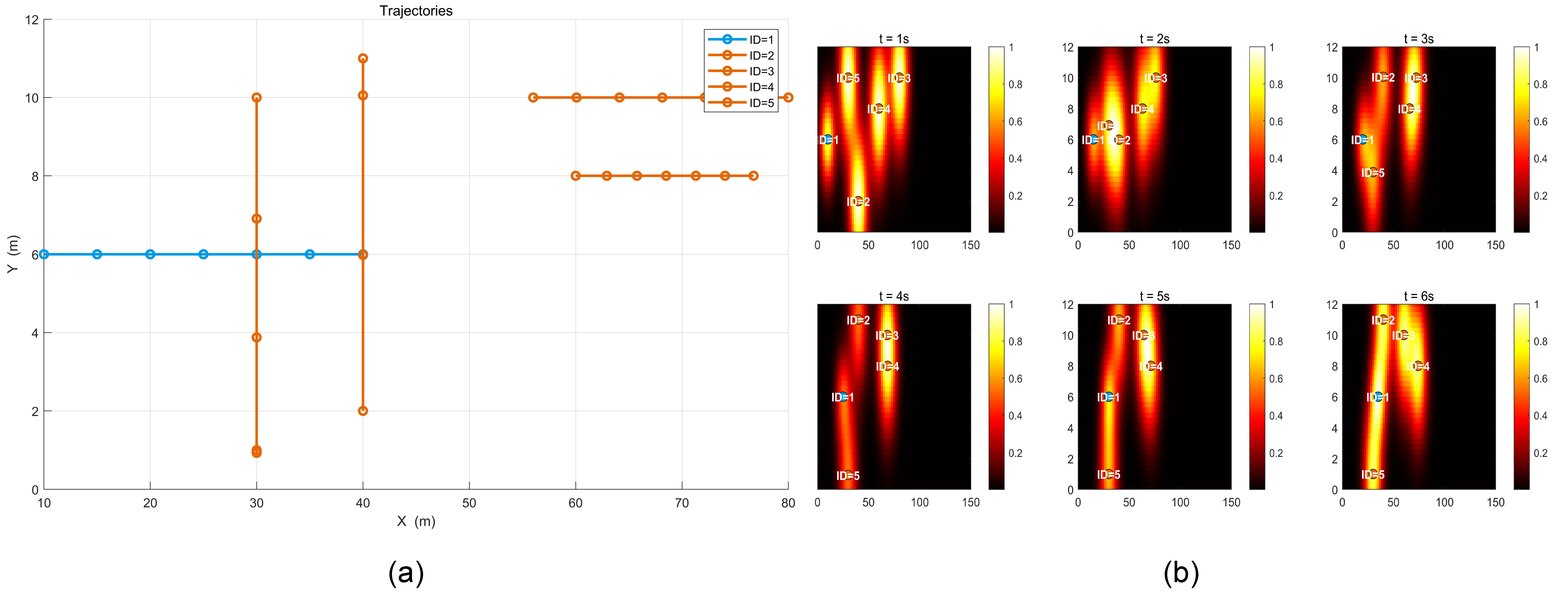
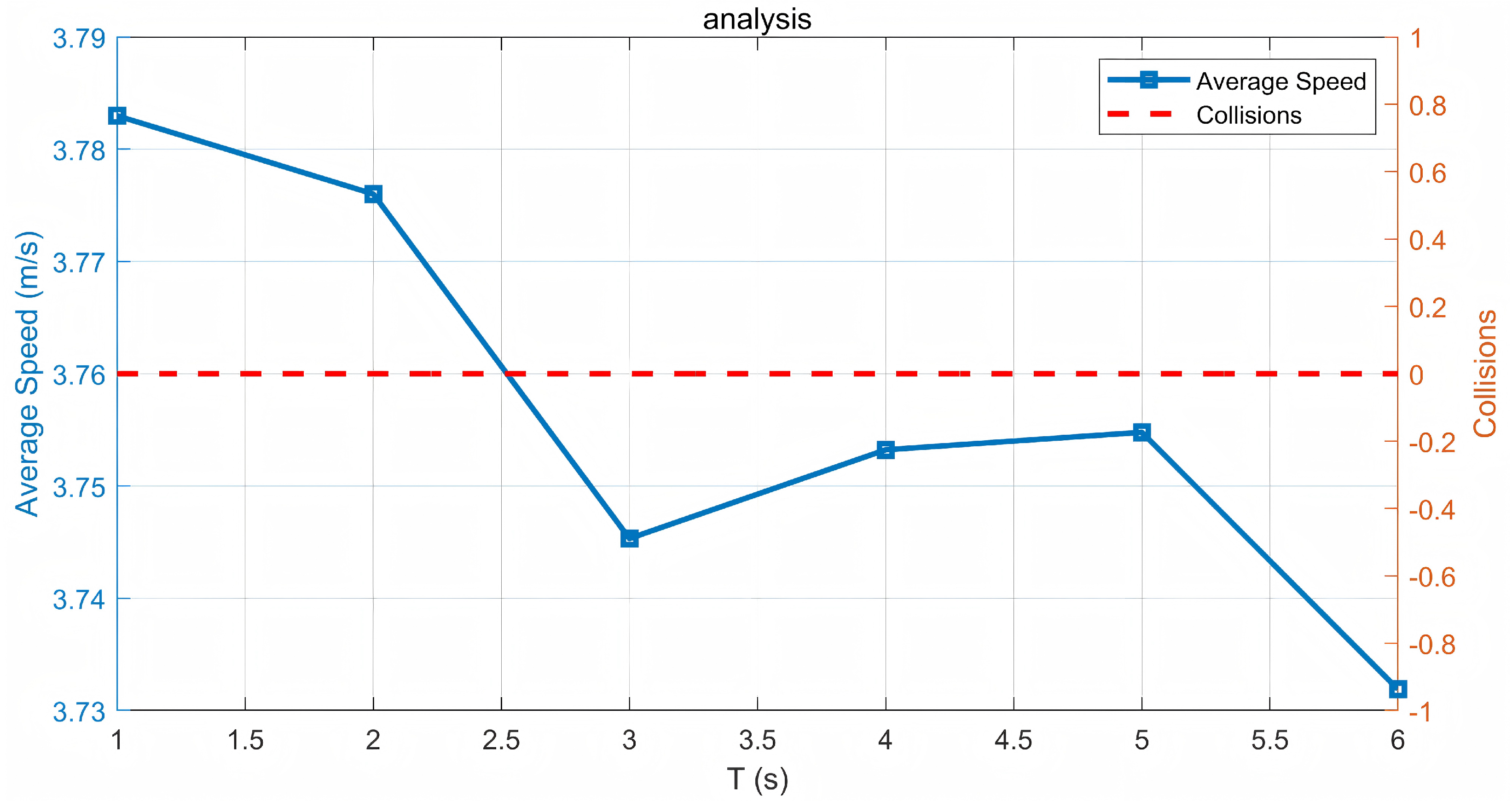
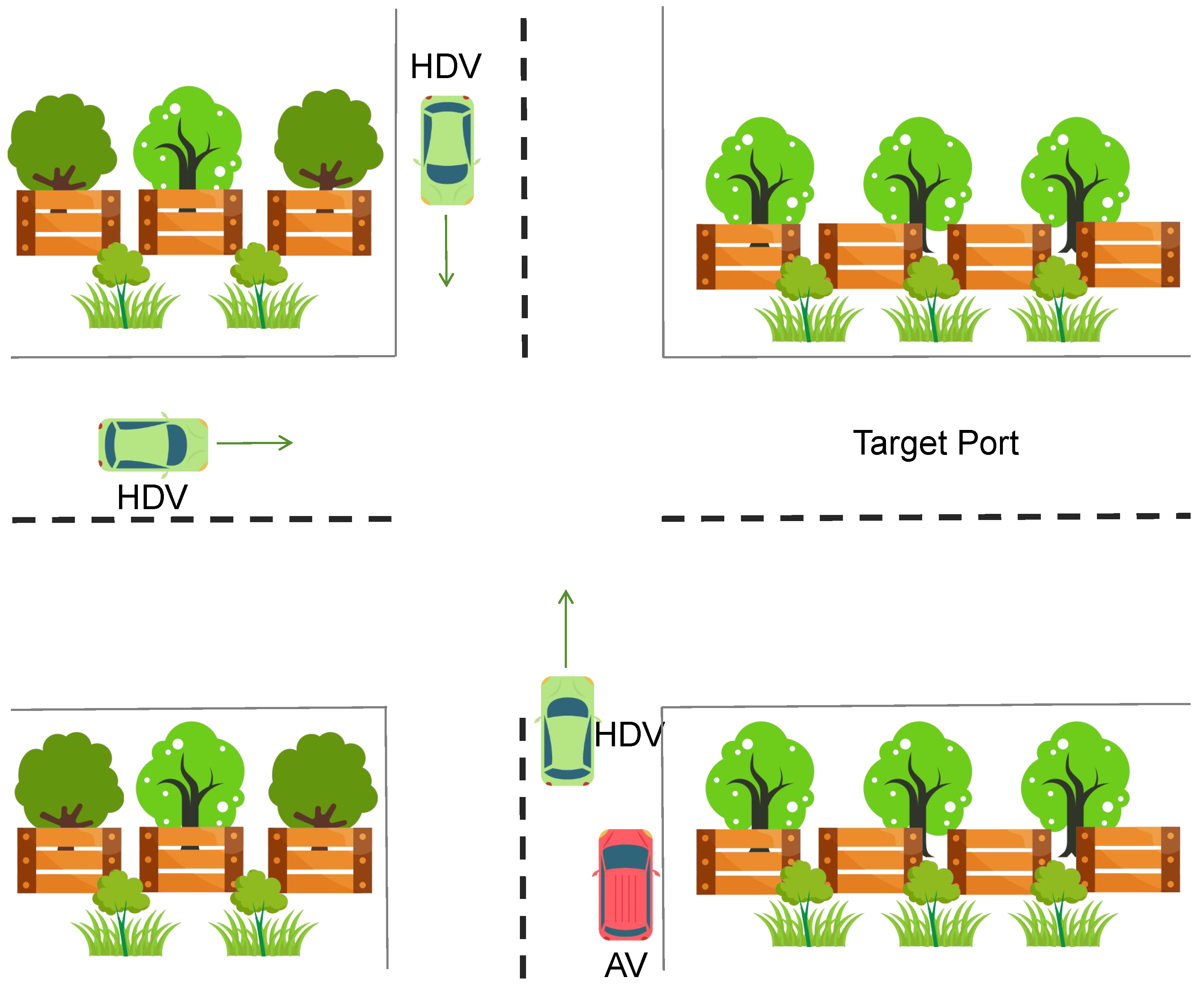
5. ExperimentalEvaluation
Verification for Scenario 1
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Slade, P.; Atkeson, C.; Donelan, J.M.; Houdijk, H.; Ingraham, K.A.; Kim, M.; Kong, K.; Poggensee, K.L.; Riener, R.; Steinert, M.; et al. On human-in-the-loop optimization of human–robot interaction. Nature 2024, 633, 779–788. [Google Scholar] [CrossRef]
- Wang, T.; Zheng, P.; Li, S.; Wang, L. Multimodal human–robot interaction for human-centric smart manufacturing: A survey. Adv. Intell. Syst. 2024, 6, 2300359. [Google Scholar] [CrossRef]
- Iskandar, M.; Albu-Schäffer, A.; Dietrich, A. Intrinsic sense of touch for intuitive physical human-robot interaction. Sci. Robot. 2024, 9, eadn4008. [Google Scholar] [CrossRef]
- Safavi, F.; Olikkal, P.; Pei, D.; Kamal, S.; Meyerson, H.; Penumalee, V.; Vinjamuri, R. Emerging frontiers in human–robot interaction. J. Intell. Robot. Syst. 2024, 110, 45. [Google Scholar] [CrossRef]
- Song, Z.; Liu, L.; Jia, F.; Luo, Y.; Jia, C.; Zhang, G.; Yang, L.; Wang, L. Robustness-aware 3d object detection in autonomous driving: A review and outlook. IEEE Trans. Intell. Transp. Syst. 2024, 25, 15407–15436. [Google Scholar] [CrossRef]
- Zhu, Z.; Li, X.; Ma, Q.; Zhai, J.; Hu, H. FDNet: Fourier transform guided dual-channel underwater image enhancement diffusion network. Sci. China Technol. Sci. 2025, 68, 1100403. [Google Scholar] [CrossRef]
- Aravind, R.; Deon, E.; Surabhi, S. Developing Cost-Effective Solutions For Autonomous Vehicle Software Testing Using Simulated Environments Using AI Techniques. Educ. Adm. Theory Pract. 2024, 30, 4135–4147. [Google Scholar] [CrossRef]
- Chen, P.; Ni, H.; Wang, L.; Yu, G.; Sun, J. Safety performance evaluation of freeway merging areas under autonomous vehicles environment using a co-simulation platform. Accid. Anal. Prev. 2024, 199, 107530. [Google Scholar] [CrossRef]
- Zhao, X.; Fang, Y.; Min, H.; Wu, X.; Wang, W.; Teixeira, R. Potential sources of sensor data anomalies for autonomous vehicles: An overview from road vehicle safety perspective. Expert Syst. Appl. 2024, 236, 121358. [Google Scholar] [CrossRef]
- Verma, H.; Siruvuri, S.V.; Budarapu, P. A machine earning-based image classification of silicon solar cells. Int. J. Hydromechatron. 2024, 7, 49–66. [Google Scholar] [CrossRef]
- Singh, S.; Ali, Y.; Haque, M.M. A Bayesian extreme value theory modelling framework to assess corridor-wide pedestrian safety using autonomous vehicle sensor data. Accid. Anal. Prev. 2024, 195, 107416. [Google Scholar] [CrossRef]
- Zhu, Z.; Li, X.; Zhai, J.; Hu, H. PODB: A earning-based polarimetric object detection benchmark for road scenes in adverse weather conditions. Inf. Fusion 2024, 108, 102385. [Google Scholar] [CrossRef]
- Lin, Z.; Tian, Z.; Zhang, Q.; Ye, Z.; Zhuang, H.; Lan, J. A conflicts-free, speed-lossless KAN-based reinforcement earning decision system for interactive driving in roundabouts. arXiv 2024, arXiv:2408.08242. [Google Scholar]
- Reda, M.; Onsy, A.; Haikal, A.Y.; Ghanbari, A. Path planning algorithms in the autonomous driving system: A comprehensive review. Robot. Auton. Syst. 2024, 174, 104630. [Google Scholar] [CrossRef]
- Chen, L.; Wu, P.; Chitta, K.; Jaeger, B.; Geiger, A.; Li, H. End-to-end autonomous driving: Challenges and frontiers. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 10164–10183. [Google Scholar] [CrossRef]
- Teng, S.; Hu, X.; Deng, P.; Li, B.; Li, Y.; Ai, Y.; Yang, D.; Li, L.; Xuanyuan, Z.; Zhu, F.; et al. Motion planning for autonomous driving: The state of the art and future perspectives. IEEE Trans. Intell. Veh. 2023, 8, 3692–3711. [Google Scholar] [CrossRef]
- Tsai, J.; Chang, Y.T.; Chen, Z.Y.; You, Z. Autonomous Driving Control for Passing Unsignalized Intersections Using the Semantic Segmentation Technique. Electronics 2024, 13, 484. [Google Scholar] [CrossRef]
- Barruffo, L.; Caiazzo, B.; Petrillo, A.; Santini, S. A GoA4 control architecture for the autonomous driving of high-speed trains over ETCS: Design and experimental validation. IEEE Trans. Intell. Transp. Syst. 2024, 25, 5096–5111. [Google Scholar] [CrossRef]
- Mao, Z.; Peng, Y.; Hu, C.; Ding, R.; Yamada, Y.; Maeda, S. Soft computing-based predictive modeling of flexible electrohydrodynamic pumps. Biomim. Intell. Robot. 2023, 3, 100114. [Google Scholar] [CrossRef]
- Mao, Z.; Kobayashi, R.; Nabae, H.; Suzumori, K. Multimodal Strain Sensing System for Shape Recognition of Tensegrity Structures by Combining Traditional Regression and Deep Learning Approaches. IEEE Robot. Autom. Lett. 2024, 9, 10050–10056. [Google Scholar] [CrossRef]
- Lau, S.L.; Lim, J.; Chong, E.K.; Wang, X. Single-pixel image reconstruction based on block compressive sensing and convolutional neural network. Int. J. Hydromechatron. 2023, 6, 258–273. [Google Scholar] [CrossRef]
- Vishnu, C.; Abhinav, V.; Roy, D.; Mohan, C.K.; Babu, C.S. Improving multi-agent trajectory prediction using traffic states on interactive driving scenarios. IEEE Robot. Autom. Lett. 2023, 8, 2708–2715. [Google Scholar] [CrossRef]
- Tan, H.; Lu, G.; Liu, M. Risk field model of driving and its application in modeling car-following behavior. IEEE Trans. Intell. Transp. Syst. 2021, 23, 11605–11620. [Google Scholar] [CrossRef]
- Triharminto, H.H.; Wahyunggoro, O.; Adji, T.; Cahyadi, A.; Ardiyanto, I. A novel of repulsive function on artificial potential field for robot path planning. Int. J. Electr. Comput. Eng. 2016, 6, 3262. [Google Scholar]
- Wu, P.; Gao, F.; Li, K. Humanlike decision and motion planning for expressway ane changing based on artificial potential field. IEEE Access 2022, 10, 4359–4373. [Google Scholar] [CrossRef]
- Lin, Z.; Tian, Z.; Zhang, Q.; Zhuang, H.; Lan, J. Enhanced visual slam for collision-free driving with ightweight autonomous cars. Sensors 2024, 24, 6258. [Google Scholar] [CrossRef]
- Dai, S.; Li, S.; Tang, H.; Ning, X.; Fang, F.; Fu, Y.; Wang, Q.; Cheng, L. MARP: A Cooperative Multi-Agent DRL System for Connected Autonomous Vehicle Platooning. IEEE Internet Things J. 2024, 11, 32454–32463. [Google Scholar] [CrossRef]
- Gao, H.; Yen, C.C.; Zhang, M. DRL based platooning control with traffic signal synchronization for delay and fuel optimization. Transp. Res. Part C Emerg. Technol. 2024, 163, 104655. [Google Scholar] [CrossRef]
- Tian, Z.; Zhao, D.; Lin, Z.; Zhao, W.; Flynn, D.; Jiang, Y.; Tian, D.; Zhang, Y.; Sun, Y. Efficient and Balanced Exploration-driven Decision Making for Autonomous Racing Using Local Information. IEEE Trans. Intell. Veh. 2024, 1–17. [Google Scholar] [CrossRef]
- D’Alfonso, L.; Giannini, F.; Franzè, G.; Fedele, G.; Pupo, F.; Fortino, G. Autonomous vehicle platoons in urban road networks: A joint distributed reinforcement earning and model predictive control approach. IEEE/CAA J. Autom. Sin. 2024, 11, 141–156. [Google Scholar] [CrossRef]
- Dhinakaran, M.; Rajasekaran, R.T.; Balaji, V.; Aarthi, V.; Ambika, S. Advanced deep reinforcement earning strategies for enhanced autonomous vehicle navigation systems. In Proceedings of the 2024 2nd International Conference on Computer, Communication and Control (IC4), Indore, India, 8–10 February 2024; IEEE: New York, NY, USA, 2024; pp. 1–4. [Google Scholar]
- Tarekegn, G.B.; Juang, R.T.; Tesfaw, B.A.; Lin, H.P.; Hsu, H.C.; Tarekegn, R.B.; Tai, L.C. A Centralized Multi-Agent DRL-Based Trajectory Control Strategy for Unmanned Aerial Vehicle-Enabled Wireless Communications. IEEE Open J. Veh. Technol. 2024, 5, 1230–1241. [Google Scholar] [CrossRef]
- Paparella, F.; Olivieri, G.; Volpe, G.; Mangini, A.M.; Fanti, M.P. A Deep Reinforcement Learning Approach for Route Planning of Autonomous Vehicles. In Proceedings of the 2024 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Kuching, Malaysia, 6–10 October 2024; IEEE: New York, NY, USA, 2024; pp. 2047–2052. [Google Scholar]
- Xu, C.; Deng, Z.; Liu, J.; Kong, A.; Huang, C.; Hang, P. Towards Safe and Robust Autonomous Vehicle Platooning: A Self-Organizing Cooperative Control Framework. arXiv 2024, arXiv:2408.09468. [Google Scholar]
- Rasol, M.A.; Abdulqader, A.F.; Hussain, A.; Imneef, Z.M.; Goyal, B.; Dogra, A.; Mittal, M. Exploring the Effectiveness of Deep Reinforcement Learning for Autonomous Robot Navigation. In Proceedings of the 2024 11th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 14–15 March 2024; IEEE: New York, NY, USA, 2024; pp. 1–5. [Google Scholar]
- Peng, Y.; Wang, Y.; Hu, F.; He, M.; Mao, Z.; Huang, X.; Ding, J. Predictive modeling of flexible EHD pumps using Kolmogorov–Arnold Networks. Biomim. Intell. Robot. 2024, 4, 100184. [Google Scholar] [CrossRef]
- Boin, C.; Lei, L.; Yang, S.X. AVDDPG-Federated reinforcement earning applied to autonomous platoon control. Intell. Robot. 2022, 2, 45–167. [Google Scholar] [CrossRef]
- Yuan, F.; Zuo, Z.; Jiang, Y.; Shu, W.; Tian, Z.; Ye, C.; Yang, J.; Mao, Z.; Huang, X.; Gu, S.; et al. AI-Driven Optimization of Blockchain Scalability, Security, and Privacy Protection. Algorithms 2025, 18, 263. [Google Scholar] [CrossRef]
- Luo, Y.; Chen, K.; Zhu, M. GRANP: A Graph Recurrent Attentive Neural Process Model for Vehicle Trajectory Prediction. In Proceedings of the 2024 IEEE Intelligent Vehicles Symposium (IV), Jeju Island, Republic of Korea, 2–5 June 2024; IEEE: New York, NY, USA, 2024; pp. 370–375. [Google Scholar]
- Chen, K.; Luo, Y.; Zhu, M.; Yang, H. Human-Like Interactive Lane-Change Modeling Based on Reward-Guided Diffusive Predictor and Planner. IEEE Trans. Intell. Transp. Syst. 2024, 26, 3903–3916. [Google Scholar] [CrossRef]
- Hassija, V.; Chamola, V.; Mahapatra, A.; Singal, A.; Goel, D.; Huang, K.; Scardapane, S.; Spinelli, I.; Mahmud, M.; Hussain, A. Interpreting black-box models: A review on explainable artificial intelligence. Cogn. Comput. 2024, 16, 45–74. [Google Scholar] [CrossRef]
- Zhang, C.; Chen, J.; Li, J.; Peng, Y.; Mao, Z. Large anguage models for human–robot interaction: A review. Biomim. Intell. Robot. 2023, 3, 100131. [Google Scholar]
- Yang, D.; Cao, B.; Qu, S.; Lu, F.; Gu, S.; Chen, G. Retrieve-then-compare mitigates visual hallucination in multi-modal arge anguage models. Intell. Robot. 2025, 5, 248–275. [Google Scholar] [CrossRef]
- Huang, K.; Di, X.; Du, Q.; Chen, X. A game-theoretic framework for autonomous vehicles velocity control: Bridging microscopic differential games and macroscopic mean field games. arXiv 2019, arXiv:1903.06053. [Google Scholar] [CrossRef]
- Chen, Y.; Veer, S.; Karkus, P.; Pavone, M. Interactive joint planning for autonomous vehicles. IEEE Robot. Autom. Lett. 2023, 9, 987–994. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, Y.; Li, W.; Cui, Y.; Wu, C.; Guo, G. Designing External Displays for Safe AV-HDV Interactions: Conveying Scenarios Decisions of Intelligent Cockpit. In Proceedings of the 2023 7th CAA International Conference on Vehicular Control and Intelligence (CVCI), Changsha, China, 27–29 October 2023; IEEE: New York, NY, USA, 2023; pp. 1–8. [Google Scholar]
- Liang, J.; Tan, C.; Yan, L.; Zhou, J.; Yin, G.; Yang, K. Interaction-Aware Trajectory Prediction for Safe Motion Planning in Autonomous Driving: A Transformer-Transfer Learning Approach. arXiv 2024, arXiv:2411.01475. [Google Scholar]
- Gong, B.; Wang, F.; Lin, C.; Wu, D. Modeling HDV and CAV mixed traffic flow on a foggy two-lane highway with cellular automata and game theory model. Sustainability 2022, 14, 5899. [Google Scholar] [CrossRef]
- Yao, Z.; Deng, H.; Wu, Y.; Zhao, B.; Li, G.; Jiang, Y. Optimal ane-changing trajectory planning for autonomous vehicles considering energy consumption. Expert Syst. Appl. 2023, 225, 120133. [Google Scholar] [CrossRef]
- Liu, Y.; Zhou, B.; Wang, X.; Li, L.; Cheng, S.; Chen, Z.; Li, G.; Zhang, L. Dynamic ane-changing trajectory planning for autonomous vehicles based on discrete global trajectory. IEEE Trans. Intell. Transp. Syst. 2021, 23, 8513–8527. [Google Scholar] [CrossRef]
- Chai, R.; Tsourdos, A.; Chai, S.; Xia, Y.; Savvaris, A.; Chen, C.P. Multiphase overtaking maneuver planning for autonomous ground vehicles via a desensitized trajectory optimization approach. IEEE Trans. Ind. Inform. 2022, 19, 74–87. [Google Scholar] [CrossRef]
- Palatti, J.; Aksjonov, A.; Alcan, G.; Kyrki, V. Planning for safe abortable overtaking maneuvers in autonomous driving. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; IEEE: New York, NY, USA, 2021; pp. 508–514. [Google Scholar]
- Wang, Y.; Liu, Z.; Wang, J.; Du, B.; Qin, Y.; Liu, X.; Liu, L. A Stackelberg game-based approach to transaction optimization for distributed integrated energy system. Energy 2023, 283, 128475. [Google Scholar] [CrossRef]
- Ji, K.; Orsag, M.; Han, K. Lane-merging strategy for a self-driving car in dense traffic using the stackelberg game approach. Electronics 2021, 10, 894. [Google Scholar] [CrossRef]
- Hang, P.; Huang, C.; Hu, Z.; Xing, Y.; Lv, C. Decision making of connected automated vehicles at an unsignalized roundabout considering personalized driving behaviours. IEEE Trans. Veh. Technol. 2021, 70, 4051–4064. [Google Scholar] [CrossRef]
- Kreps, D.M. Nash equilibrium. In Game Theory; Springer: Berlin/Heidelberg, Germany, 1989; pp. 167–177. [Google Scholar]
- Hang, P.; Lv, C.; Huang, C.; Cai, J.; Hu, Z.; Xing, Y. An Integrated Framework of Decision Making and Motion Planning for Autonomous Vehicles Considering Social Behaviors. IEEE Trans. Veh. Technol. 2020, 69, 14458–14469. [Google Scholar] [CrossRef]
- Tamaddoni, S.H.; Taheri, S.; Ahmadian, M. Optimal VSC design based on Nash strategy for differential 2-player games. In Proceedings of the 2009 IEEE International Conference on Systems, Man and Cybernetics, San Antonio, TX, USA, 11–14 October 2009; IEEE: New York, NY, USA, 2009; pp. 2415–2420. [Google Scholar]
- Huang, K.; Chen, X.; Di, X.; Du, Q. Dynamic driving and routing games for autonomous vehicles on networks: A mean field game approach. Transp. Res. Part C: Emerg. Technol. 2021, 128, 103189. [Google Scholar] [CrossRef]
- Mao, Z.; Hosoya, N.; Maeda, S. Flexible electrohydrodynamic fluid-driven valveless water pump via immiscible interface. Cyborg Bionic Syst. 2024, 5, 0091. [Google Scholar] [CrossRef]
- Alawi, O.A.; Kamar, H.M.; Shawkat, M.M.; Al-Ani, M.M.; Mohammed, H.A.; Homod, R.Z.; Wahid, M.A. Artificial intelligence-based viscosity prediction of polyalphaolefin-boron nitride nanofluids. Int. J. Hydromechatron. 2024, 7, 89–112. [Google Scholar] [CrossRef]
- Peng, Y.; Yang, X.; Li, D.; Ma, Z.; Liu, Z.; Bai, X.; Mao, Z. Predicting flow status of a flexible rectifier using cognitive computing. Expert Syst. Appl. 2025, 264, 125878. [Google Scholar] [CrossRef]
- Liu, J.; Cui, Y.; Duan, J.; Jiang, Z.; Pan, Z.; Xu, K.; Li, H. Reinforcement earning-based high-speed path following control for autonomous vehicles. IEEE Trans. Veh. Technol. 2024, 73, 7603–7615. [Google Scholar] [CrossRef]
- Yu, J.; Chen, C.; Arab, A.; Yi, J.; Pei, X.; Guo, X. RDT-RRT: Real-time double-tree rapidly-exploring random tree path planning for autonomous vehicles. Expert Syst. Appl. 2024, 240, 122510. [Google Scholar] [CrossRef]
- Hu, S.; Fang, Z.; Fang, Z.; Deng, Y.; Chen, X.; Fang, Y.; Kwong, S.T.W. Agentscomerge: Large anguage model empowered collaborative decision making for ramp merging. IEEE Trans. Mob. Comput. 2025, 1–15. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vehicle Model | Collisions | Avg. Speed (m/s) | Success Rate |
|---|---|---|---|
| S2/S3 | S2/S3 | S2/S3 | |
| Kinematic Bicycle Model | 0/0 | 20.5/20.8 | 1.0/1.0 |
| Ackermann Steering | 0/0 | 19.8/20.1 | 1.0/1.0 |
| Linear Tire Model | 0/0 | 18.5/19.7 | 1.0/1.0 |
| Single-track model with Slip | 0/0 | 18.3/19.2 | 1.0/1.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, L.; Wang, X.; Li, F.; Mao, Z.; Tian, Z.; Peng, Y.; Yuan, F.; Yuan, C. A Mean-Field-Game-Integrated MPC-QP Framework for Collision-Free Multi-Vehicle Control. Drones 2025, 9, 375. https://doi.org/10.3390/drones9050375
Zheng L, Wang X, Li F, Mao Z, Tian Z, Peng Y, Yuan F, Yuan C. A Mean-Field-Game-Integrated MPC-QP Framework for Collision-Free Multi-Vehicle Control. Drones. 2025; 9(5):375. https://doi.org/10.3390/drones9050375
Chicago/Turabian StyleZheng, Liancheng, Xuemei Wang, Feng Li, Zebing Mao, Zhen Tian, Yanhong Peng, Fujiang Yuan, and Chunhong Yuan. 2025. "A Mean-Field-Game-Integrated MPC-QP Framework for Collision-Free Multi-Vehicle Control" Drones 9, no. 5: 375. https://doi.org/10.3390/drones9050375
APA StyleZheng, L., Wang, X., Li, F., Mao, Z., Tian, Z., Peng, Y., Yuan, F., & Yuan, C. (2025). A Mean-Field-Game-Integrated MPC-QP Framework for Collision-Free Multi-Vehicle Control. Drones, 9(5), 375. https://doi.org/10.3390/drones9050375