
Parallel Task Offloading and Trajectory Optimization for UAV-Assisted Mobile Edge Computing via Hierarchical Reinforcement Learning


Abstract
1. Introduction
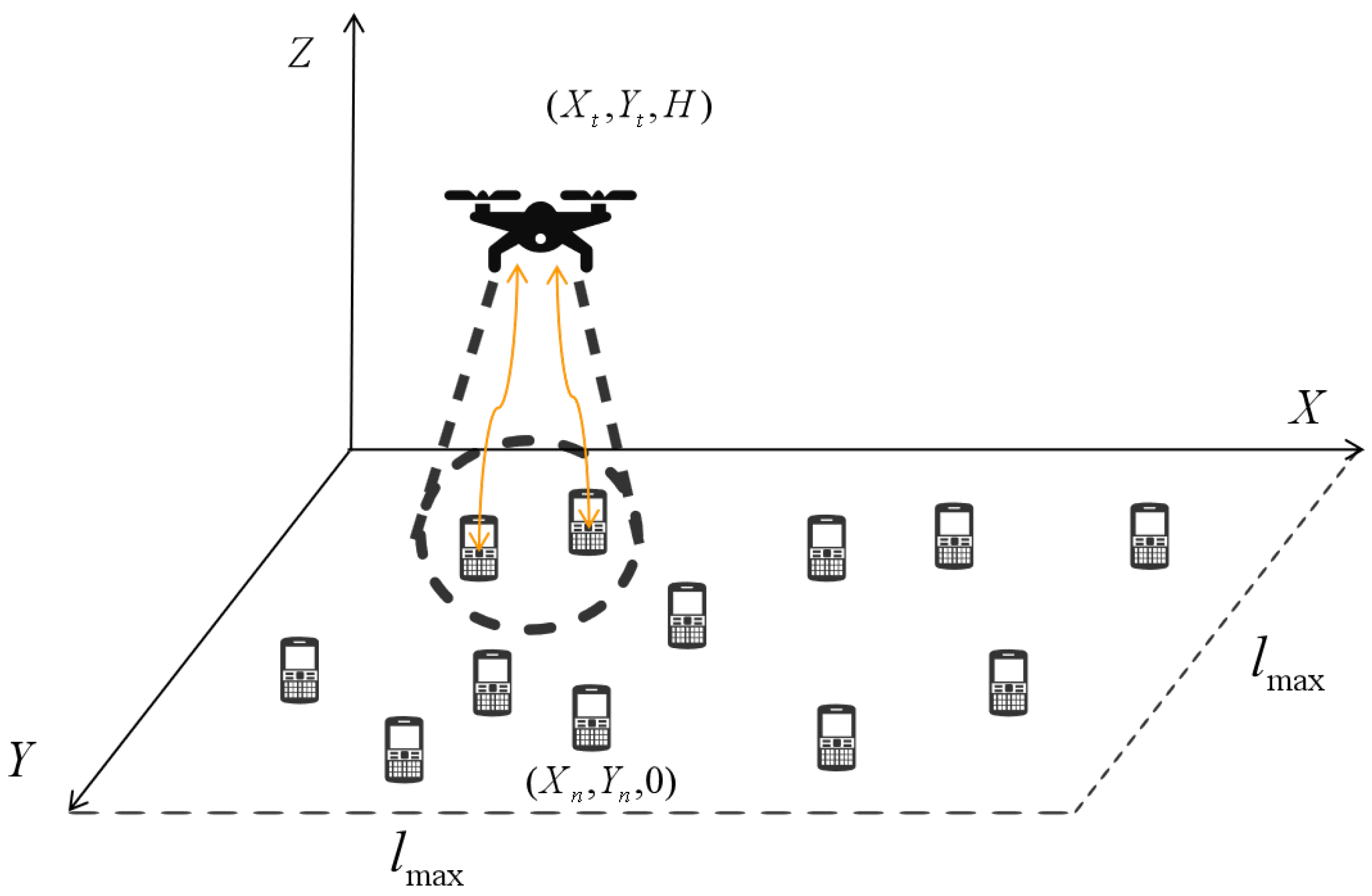
2. System Model
2.1. Basic Definitions
Offloading Decision
2.2. Computation Model
UAV Energy Consumption
2.3. Objective Function
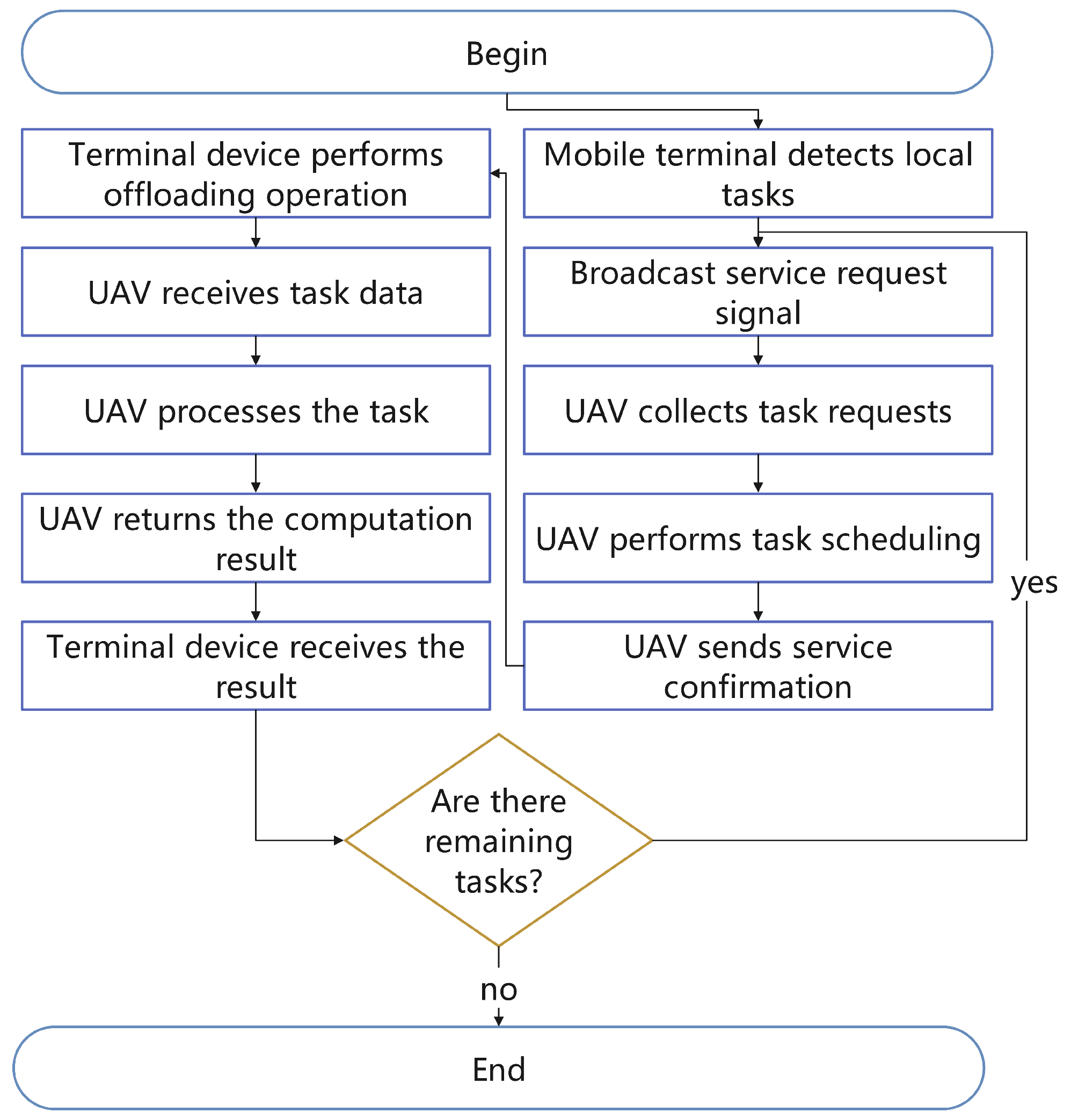
3. Hierarchical Optimization via SAC and IAM-Enhanced Discrete SAC
3.1. Hierarchical Decomposition of the Optimization Problem
- Location Optimization (): At the beginning of time slot i, determine the UAV’s new position under constraints (16), (18)–(20). This affects the distances to users and thus the transmission rate, indirectly influencing the offloading performance within the slot. Formally:
- Offloading Optimization (): Given the UAV’s position within a time slot, decide which users to serve (i.e., which tasks to offload) to minimize the total user latency:
3.2. Hierarchical Reinforcement Learning Framework
- Location Optimization Layer: Observes the environment state and outputs a continuous action representing the UAV’s next position (or equivalently, its velocity direction and speed ). Once the UAV reaches the new position, control is passed to the lower layer.
- Offloading Decision Layer: Given the UAV’s current location, it determines which users to serve within the time slot using discrete actions, while ensuring the parallel channel and capacity constraints are respected.
3.3. Implementation of the Offloading Decision Layer
3.3.1. State Space, Action Space, and Reward Design
- UAV position ;
- Relative user positions: ;
- Task demand of each user ;
- User availability indicator (selectable or not);
- Current UAV battery level , remaining channel count , and remaining memory (if applicable).
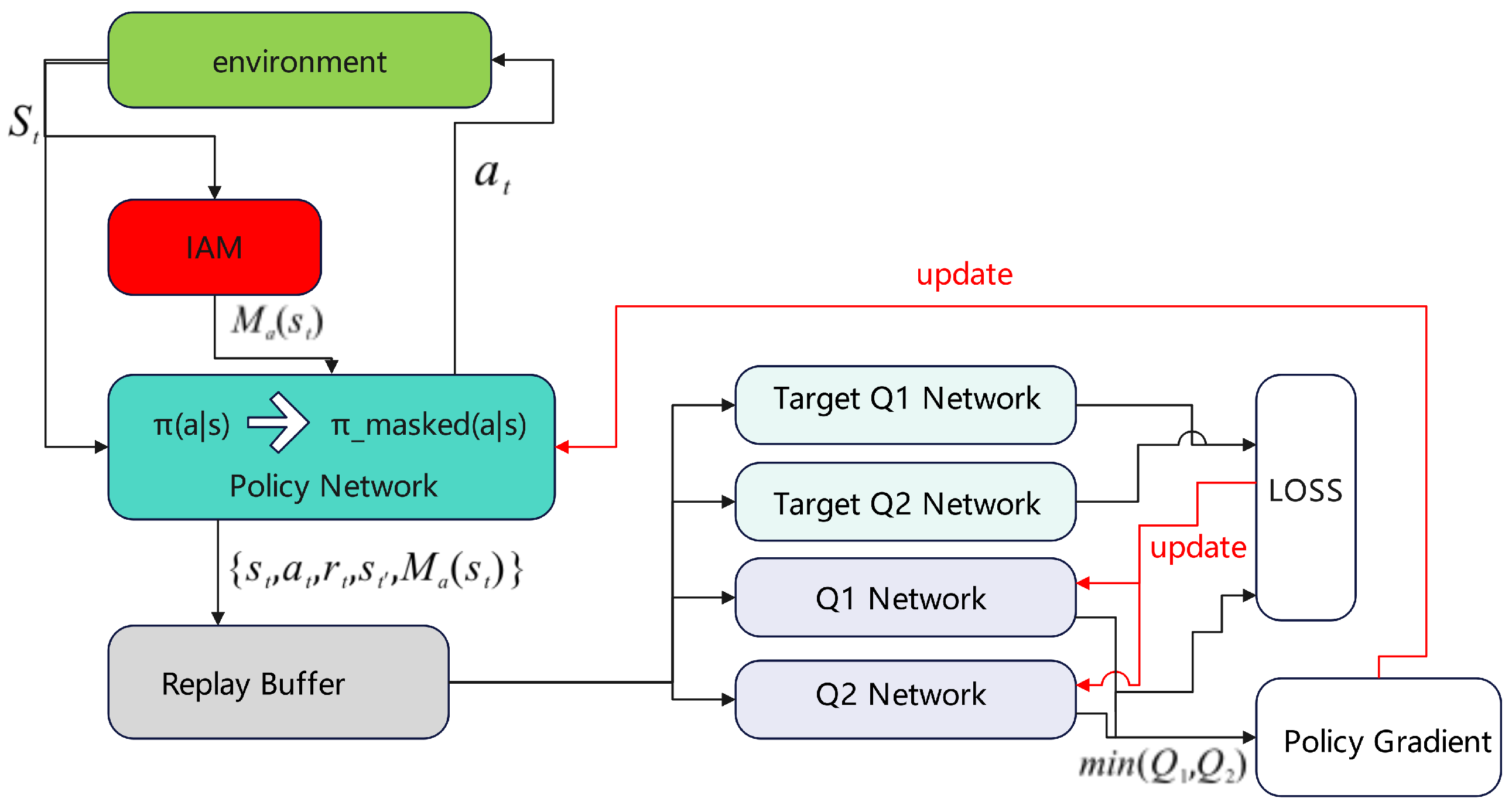
3.3.2. Discrete-SAC with Invalid Action Masking
3.3.3. Invalid Action Masking (IAM)
3.3.4. Iterative Offloading Decision Strategy
3.3.5. Offloading Decision Layer Training Pseudocode
| Algorithm 1 Offloading decision with IAM-SAC. |
|
3.4. Implementation of the Location Optimization Layer
3.4.1. State Space, Action Space, and Reward Design
- UAV current position ;
- Positions of all users relative to the UAV;
- Task demand and status (waiting/served) of each user;
- UAV status: battery level , available channels, memory, etc.
3.4.2. Training via Continuous Soft Actor–Critic (SAC)
3.4.3. Location Layer Training Pseudocode
| Algorithm 2 Location Optimization with SAC. |
|
4. Simulation Results
4.1. Experimental Setup
- H-SAC (Proposed): A hierarchical RL framework with a continuous SAC for trajectory planning and a discrete SAC with IAM for offloading.
- SAC: A unified single-layer SAC that jointly outputs movement (continuous) and offloading decisions (discretized).
- DDPG: A single-layer DDPG using continuous outputs for both movement and offloading.
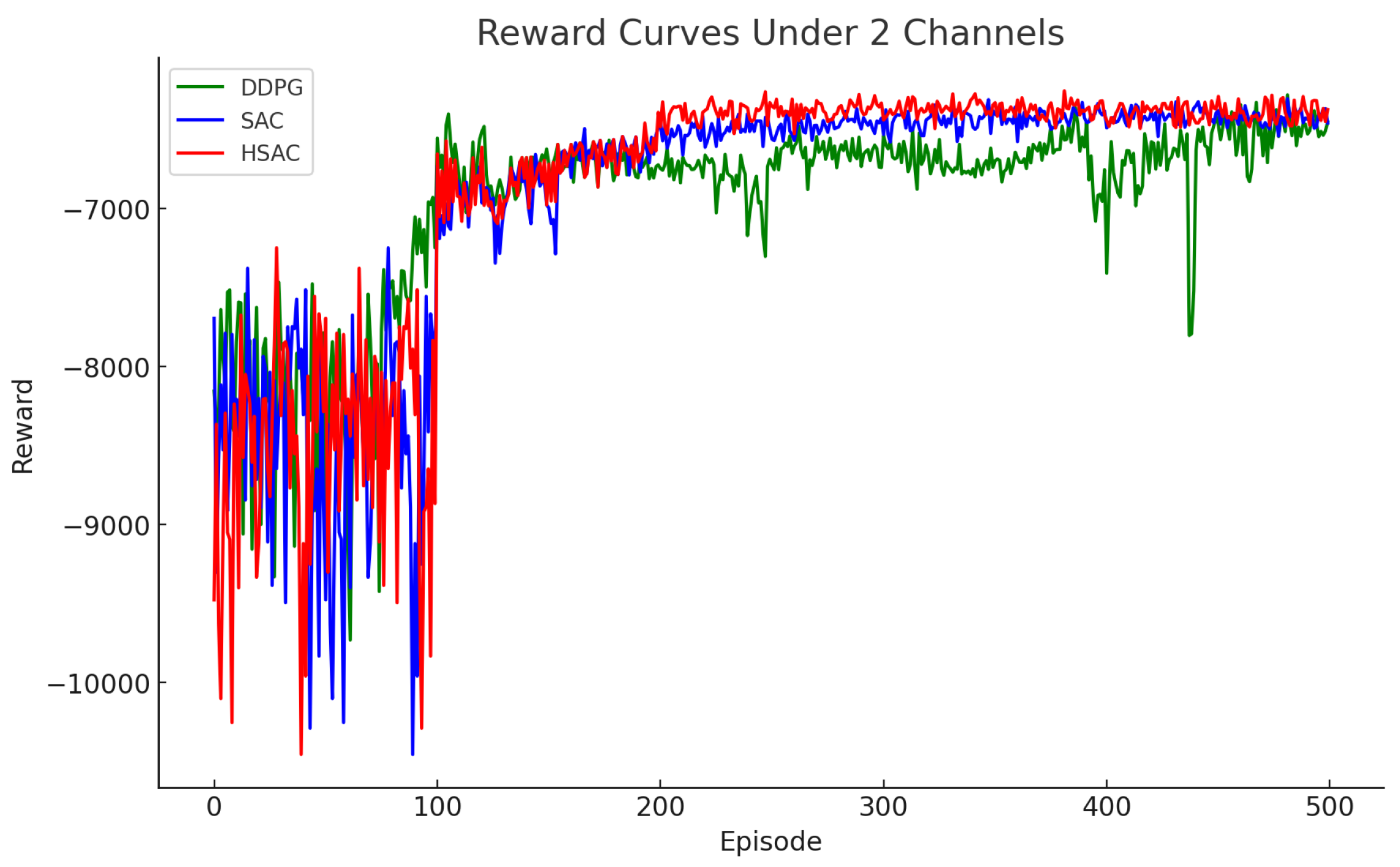
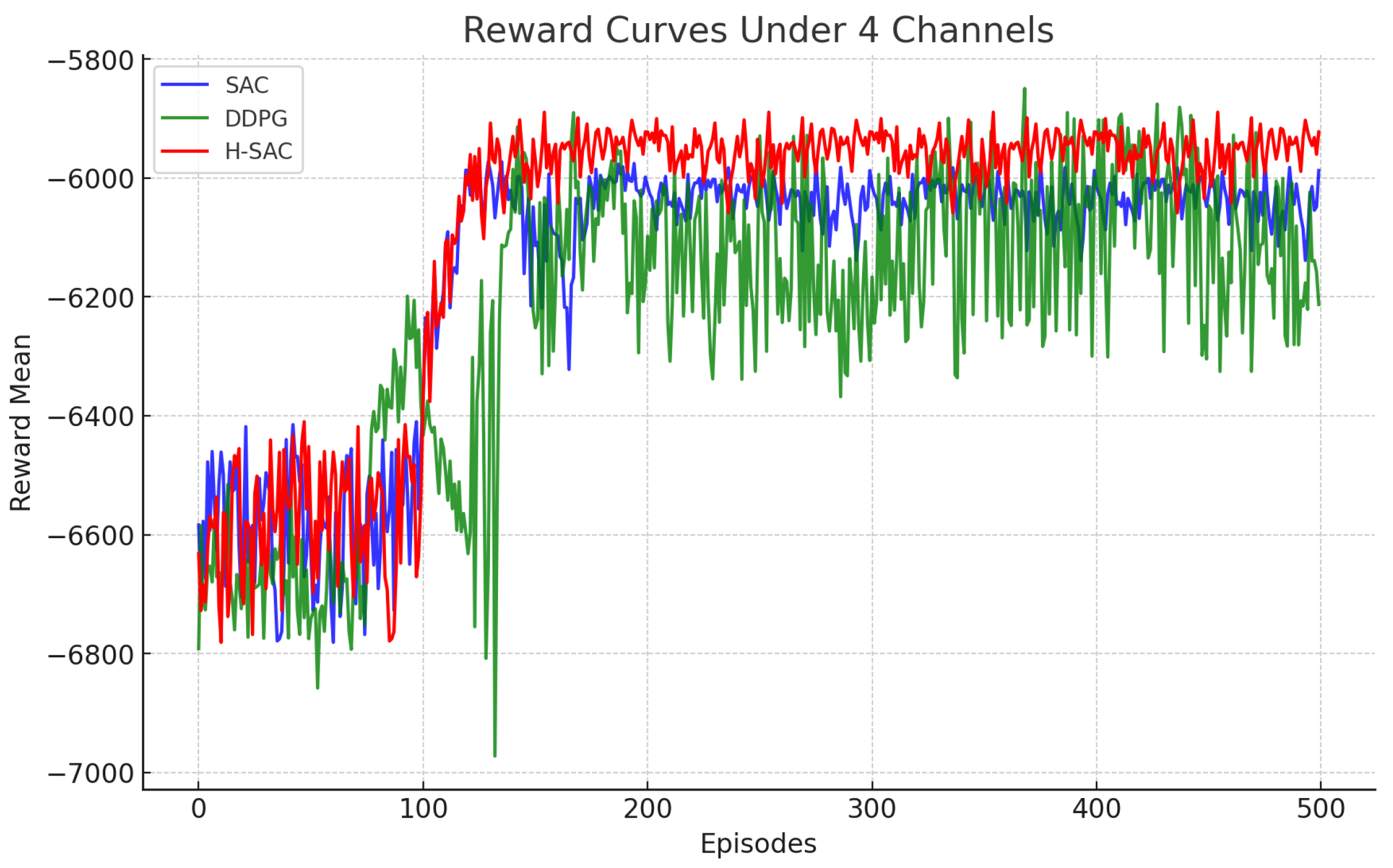
4.2. Convergence Analysis
4.3. Latency Performance
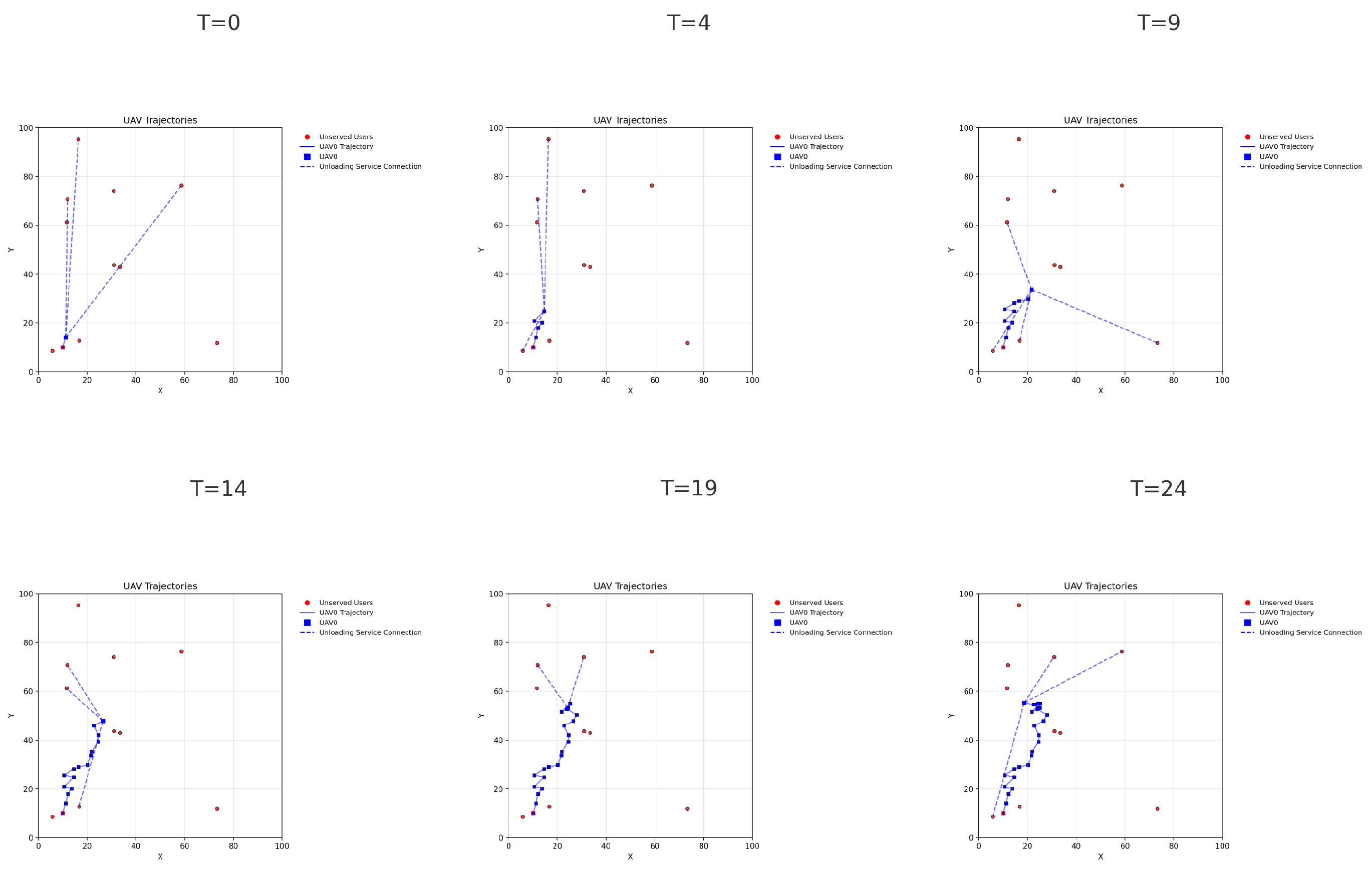
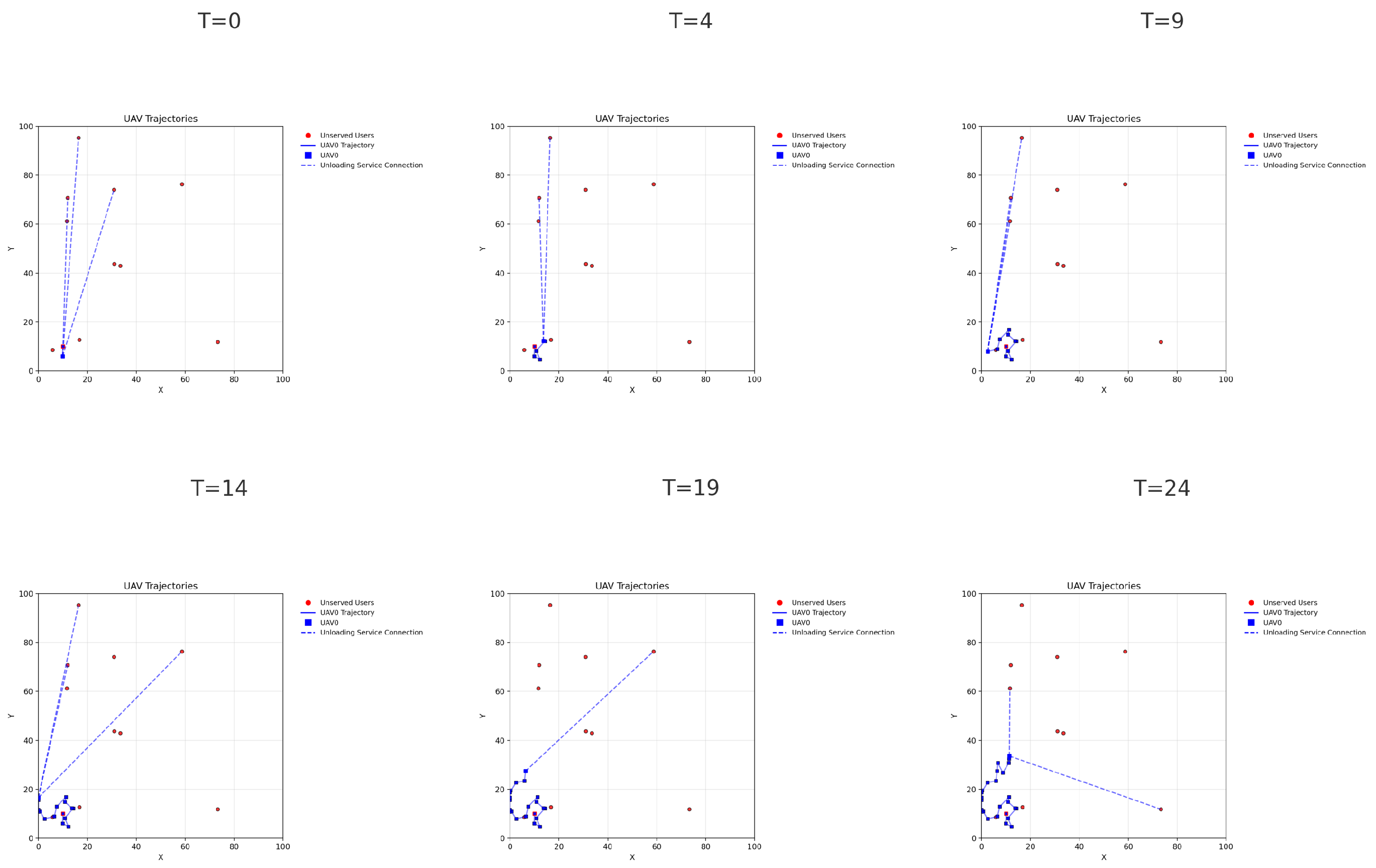
4.4. Trajectory and Offloading Comparison
- H-SAC: The UAV rapidly navigates toward task-dense regions and adapts its flight direction strategically at each time slot. The resulting path is smooth and purposeful, minimizing unnecessary deviations.
- SAC: The UAV’s trajectory is less efficient, with more erratic and indirect movements. It takes longer to approach areas with high task demands, and the path exhibits more abrupt changes.
- H-SAC: The UAV consistently offloads tasks to the maximum allowed number of users per slot (K), with no task conflicts. The IAM-enhanced decision layer ensures valid and non-redundant selections, maximizing channel utilization.
- SAC: Offloading behavior is occasionally suboptimal. Some users may be selected multiple times or channels may be left unused due to uncoordinated decisions, leading to resource underutilization and longer delays.
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| UAV | Unmanned Aerial Vehicle |
| MEC | Mobile Edge Computing |
| IoT | Internet of Things |
| QoS | Quality of Service |
| SAC | Soft Actor–Critic |
| DDPG | Deep Deterministic Policy Gradient |
| H-SAC | Hierarchical Soft Actor–Critic |
| RL | Reinforcement Learning |
| IAM | Invalid Action Masking |
| UE | User Equipment |
References
- Liu, S.; Yu, Y.; Lian, X.; Feng, Y.; She, C.; Yeoh, P.L.; Guo, L.; Vucetic, B.; Li, Y. Dependent Task Scheduling and Offloading for Minimizing Deadline Violation Ratio in Mobile Edge Computing Networks. IEEE J. Sel. Areas Commun. 2023, 41, 538–554. [Google Scholar] [CrossRef]
- Azfar, T.; Huang, K.; Ke, R. Enhancing disaster resilience with UAV-assisted edge computing: A reinforcement learning approach to managing heterogeneous edge devices. arXiv 2025, arXiv:2501.15305. [Google Scholar]
- Sun, G.; He, L.; Sun, Z.; Wu, Q.; Liang, S.; Li, J.; Niyato, D.; Leung, V.C. Joint task offloading and resource allocation in aerial-terrestrial UAV networks with edge and fog computing for post-disaster rescue. arXiv 2023, arXiv:2309.16709. [Google Scholar] [CrossRef]
- Zhang, G.; He, Z.; Cui, M. Energy consumption optimization in UAV-assisted mobile edge computing systems based on deep reinforcement learning. J. Electron. Inf. Technol. 2023, 45, 1635–1643. (In Chinese) [Google Scholar]
- Zhang, J.; Zhou, L.; Tang, Q.; Ngai, E.C.-H.; Hu, X.; Zhao, H.; Wei, J. Stochastic Computation Offloading and Trajectory Scheduling for UAV-Assisted Mobile Edge Computing. IEEE Internet Things J. 2018, 6, 3688–3699. [Google Scholar] [CrossRef]
- Wan, S.; Lu, J.; Fan, P.; Letaief, K.B. Toward Big Data Processing in IoT: Path Planning and Resource Management of UAV Base Stations in Mobile-Edge Computing System. IEEE Internet Things J. 2019, 7, 5995–6009. [Google Scholar] [CrossRef]
- Wang, L.; Huang, P.; Wang, K.; Zhang, G.; Zhang, L.; Aslam, N.; Yang, K. RL-based user association and resource allocation for multi-UAV enabled MEC. In Proceedings of the 2019 15th International Wireless Communications & Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; pp. 741–746. [Google Scholar]
- Asheralieva, A.; Niyato, D. Hierarchical Game-Theoretic and Reinforcement Learning Framework for Computational Offloading in UAV-Enabled Mobile Edge Computing Networks with Multiple Service Providers. IEEE Internet Things J. 2019, 6, 8753–8769. [Google Scholar] [CrossRef]
- Wang, L.; Wang, K.; Pan, C.; Xu, W.; Aslam, N.; Nallanathan, A. Deep Reinforcement Learning Based Dynamic Trajectory Control for UAV-Assisted Mobile Edge Computing. IEEE Trans. Mob. Comput. 2021, 21, 3536–3550. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, W.; Ding, Y.; Xiong, N. Computation offloading optimization for UAV-assisted mobile edge computing: A deep deterministic policy gradient approach. Wirel. Netw. 2021, 27, 2991–3006. [Google Scholar] [CrossRef]
- Peng, Y.; Liu, Y.; Li, D.; Zhang, H. Deep Reinforcement Learning Based Freshness-Aware Path Planning for UAV-Assisted Edge Computing Networks with Device Mobility. Remote Sens. 2022, 14, 4016. [Google Scholar] [CrossRef]
- Zhang, L. Research on UAV Dynamic Deployment For Mobile Edge Computing. Master’s Thesis, University of Technology, Xi’an, China, 2023. (In Chinese). [Google Scholar]
- Wang, Y.; Gao, Z.; Zhang, J.; Cao, X.; Zheng, D.; Gao, Y.; Ng, D.; Di Renzo, M. Trajectory design for UAV-based Internet of Things data collection: A deep reinforcement learning approach. IEEE Internet Things J. 2021, 9, 3899–3912. [Google Scholar] [CrossRef]
- Li, K.; Ni, W.; Yuan, X.; Noor, A.; Jamalipour, A. Exploring graph neural networks for joint cruise control and task offloading in UAV-enabled mobile edge computing. In Proceedings of the 2023 IEEE 97th Vehicular Technology Conference (VTC2023-Spring), Florence, Italy, 20–23 June 2023; pp. 1–6. [Google Scholar]
- Ren, T.; Niu, J.; Dai, B.; Liu, X.; Hu, Z.; Xu, M.; Guizani, M. Enabling Efficient Scheduling in Large-Scale UAV-Assisted Mobile-Edge Computing via Hierarchical Reinforcement Learning. IEEE Internet Things J. 2021, 9, 7095–7109. [Google Scholar] [CrossRef]
- Birman, Y.; Ido, Z.; Katz, G.; Shabtai, A. Hierarchical deep reinforcement learning approach for multi-objective scheduling with varying queue sizes. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–10. [Google Scholar]
- Zhang, Y.; Mou, Z.; Gao, F.; Xing, L.; Jiang, J.; Han, Z. Hierarchical Deep Reinforcement Learning for Backscattering Data Collection With Multiple UAVs. IEEE Internet Things J. 2020, 8, 3786–3800. [Google Scholar] [CrossRef]
- Shi, W.; Li, J.; Wu, H.; Zhou, C.; Cheng, N.; Shen, X. Drone-Cell Trajectory Planning and Resource Allocation for Highly Mobile Networks: A Hierarchical DRL Approach. IEEE Internet Things J. 2020, 8, 9800–9813. [Google Scholar] [CrossRef]
- Geng, Y.; Liu, E.; Wang, R.; Liu, Y. Hierarchical Reinforcement Learning for Relay Selection and Power Optimization in Two-Hop Cooperative Relay Network. IEEE Trans. Commun. 2021, 70, 171–184. [Google Scholar] [CrossRef]
- Zhou, H.; Long, Y.; Zhang, W.; Xu, J.; Gong, S. Hierarchical multi-agent deep reinforcement learning for backscatter-aided data offloading. In Proceedings of the 2022 IEEE Wireless Communications and Networking Conference (WCNC), Austin, TX, USA, 10–13 April 2022; pp. 542–547. [Google Scholar]
- Yao, Z.; Xia, S.; Li, Y.; Wu, G. Cooperative Task Offloading and Service Caching for Digital Twin Edge Networks: A Graph Attention Multi-Agent Reinforcement Learning Approach. IEEE J. Sel. Areas Commun. 2023, 41, 3401–3413. [Google Scholar] [CrossRef]
- Xu, J.; Chen, L.; Zhou, P. Joint service caching and task offloading for mobile edge computing in dense networks. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 207–215. [Google Scholar]
- Fang, C.; Xu, H.; Zhang, T.; Li, Y.; Ni, W.; Han, Z.; Guo, S. Joint Task Offloading and Content Caching for NOMA-Aided Cloud-Edge-Terminal Cooperation Networks. IEEE Trans. Wirel. Commun. 2024, 23, 15586–15600. [Google Scholar] [CrossRef]
- Lin, N.; Han, X.; Hawbani, A.; Sun, Y.; Guan, Y.; Zhao, L. Deep Reinforcement Learning-Based Dual-Timescale Service Caching and Computation Offloading for Multi-UAV Assisted MEC Systems. IEEE Trans. Netw. Serv. Manag. 2024, 22, 605–617. [Google Scholar] [CrossRef]
- Xu, Y.; Peng, Z.; Song, N.; Qiu, Y.; Zhang, C.; Zhang, Y. Joint Optimization of Service Caching and Task Offloading for Customer Application in MEC: A Hybrid SAC Scheme. IEEE Trans. Consum. Electron. 2024. [Google Scholar] [CrossRef]
- Wang, Z.; Zhao, W.; Hu, P.; Zhang, X.; Liu, L.; Fang, C.; Sun, Y. UAV-Assisted Mobile Edge Computing: Dynamic Trajectory Design and Resource Allocation. Sensors 2024, 24, 3948. [Google Scholar] [CrossRef]
- Sun, G.; Wang, Y.; Sun, Z.; Wu, Q.; Kang, J.; Niyato, D.; Leung, V.C.M. Multi-Objective Optimization for Multi-UAV-Assisted Mobile Edge Computing. IEEE Trans. Mob. Comput. 2024, 23, 14803–14820. [Google Scholar] [CrossRef]
- Cui, J.; Wei, Y.; Wang, J.; Shang, L.; Lin, P. Joint trajectory design and resource allocation for UAV-assisted mobile edge computing in power convergence network. EURASIP J. Wirel. Commun. Netw. 2025, 2025, 4. [Google Scholar] [CrossRef]
- Hui, M.; Chen, J.; Yang, L.; Lv, L.; Jiang, H.; Al-Dhahir, N. UAV-Assisted Mobile Edge Computing: Optimal Design of UAV Altitude and Task Offloading. IEEE Trans. Wirel. Commun. 2024, 23, 13633–13647. [Google Scholar] [CrossRef]
- Premsankar, G.; Ghaddar, B. Energy-Efficient Service Placement for Latency-Sensitive Applications in Edge Computing. IEEE Internet Things J. 2022, 9, 17926–17937. [Google Scholar] [CrossRef]
- Ko, S.-W.; Kim, S.J.; Jung, H.; Choi, S.W. Computation Offloading and Service Caching for Mobile Edge Computing Under Personalized Service Preference. IEEE Trans. Wirel. Commun. 2022, 21, 6568–6583. [Google Scholar] [CrossRef]
- Hortelano, D.; de Miguel, I.; Barroso, R.J.D.; Aguado, J.C.; Merayo, N.; Ruiz, L.; Asensio, A.; Masip-Bruin, X.; Fernández, P.; Lorenzo, R.M.; et al. A comprehensive survey on reinforcement-learning-based computation offloading techniques in Edge Computing Systems. J. Netw. Comput. Appl. 2023, 216, 103669. [Google Scholar] [CrossRef]
- Hayal, M.R.; Elsayed, E.E.; Kakati, D.; Singh, M.; Elfikky, A.; Boghdady, A.I.; Grover, A.; Mehta, S.; Mohsan, S.A.H.; Nurhidayat, I. Modeling and investigation on the performance enhancement of hovering UAV-based FSO relay optical wireless communication systems under pointing errors and atmospheric turbulence effects. Opt. Quantum Electron. 2023, 55, 625. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| System Model | |
| N, | Number and set of user equipments (UEs) |
| T, I, , | Total task duration, number of slots, slot length, and set of slots |
| Task data size (Mbits) generated by UE n at slot i | |
| Required CPU cycles for UE n’s task at slot i | |
| s | CPU cycles required per unit data |
| K | Maximum number of tasks the UAV can process in parallel per slot |
| Maximum data volume (Mbits) the UAV can process per slot | |
| 2D coordinate of the UAV in slot i | |
| H | Fixed altitude of the UAV |
| , | UAV speed and heading angle in slot i |
| , | UAV velocity components in x and y direction at slot i |
| Blade profile power in flight energy model | |
| Rotor blade tip speed | |
| Induced power in hover | |
| Mean rotor induced velocity in hover | |
| Fuselage drag ratio | |
| Air density | |
| S | Rotor disk area |
| A | UAV frame area |
| UAV flight duration within each slot | |
| 2D position of UE n | |
| Horizontal distance between UAV and UE n at slot i | |
| Transmission rate from UE n to UAV at slot i | |
| B, | Bandwidth and transmit power of UE n |
| Path loss function including altitude and distance effects | |
| Binary offloading decision variable for UE n at slot i | |
| Set of offloading decisions in slot i | |
| , | CPU frequencies of UAV and UE, respectively, |
| Transmission delay for UE n’s task at slot i | |
| Computation delay on UAV for UE n’s task at slot i | |
| Local computation delay at UE n | |
| Total delay of UE n at slot i | |
| UAV flight power at speed | |
| UAV flight energy in slot i | |
| UAV hovering power | |
| Hovering energy in slot i | |
| , | Constants in UAV computation energy model |
| CPU usage indicator in slot i | |
| UAV computation energy in slot i | |
| Total UAV energy consumption in slot i | |
| Remaining UAV battery after slot i | |
| Minimum allowed UAV battery level | |
| Problem Formulation and Optimization | |
| UAV’s control variables: speed and heading | |
| Offloading decision set across all slots | |
| Objective | (Minimize total user delay) |
| (C1) | Total offloaded data must not exceed in any slot, Formula (5) |
| (C2) | Number of offloaded tasks in each slot, Formula (6) |
| (C3) | UAV position constraints within , Formula (18) |
| (C4) | UAV speed and heading constraints, Formula (19) |
| (C5) | UAV battery dynamics across slots, Formula (20) |
| (C6) | UAV battery level must stay above , Formula (16) |
| Symbol | Value | Description |
|---|---|---|
| Time UAV fly length | ||
| K | Number of parallel channels | |
| UAV memory limit | ||
| N | 10 | Number of UEs |
| s | 1000 | CPU cycles per bit |
| Area side length | ||
| H | UAV altitude | |
| B | Channel bandwidth | |
| UE transmit power | ||
| Noise power | ||
| UE CPU frequency | ||
| UAV CPU frequency | ||
| 5 | Power exponent in CPU energy model | |
| Reference channel gain | ||
| Max x-axis velocity | ||
| Max y-axis velocity | ||
| 3 | Number of tasks per UE | |
| UAV hovering power | ||
| UAV battery capacity | ||
| T | 8 | Time slot length |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, T.; Na, X.; Nie, Y.; Liu, J.; Wang, W.; Meng, Z. Parallel Task Offloading and Trajectory Optimization for UAV-Assisted Mobile Edge Computing via Hierarchical Reinforcement Learning. Drones 2025, 9, 358. https://doi.org/10.3390/drones9050358
Wang T, Na X, Nie Y, Liu J, Wang W, Meng Z. Parallel Task Offloading and Trajectory Optimization for UAV-Assisted Mobile Edge Computing via Hierarchical Reinforcement Learning. Drones. 2025; 9(5):358. https://doi.org/10.3390/drones9050358
Chicago/Turabian StyleWang, Tuo, Xitai Na, Yusen Nie, Jinglong Liu, Wenda Wang, and Zhenduo Meng. 2025. "Parallel Task Offloading and Trajectory Optimization for UAV-Assisted Mobile Edge Computing via Hierarchical Reinforcement Learning" Drones 9, no. 5: 358. https://doi.org/10.3390/drones9050358
APA StyleWang, T., Na, X., Nie, Y., Liu, J., Wang, W., & Meng, Z. (2025). Parallel Task Offloading and Trajectory Optimization for UAV-Assisted Mobile Edge Computing via Hierarchical Reinforcement Learning. Drones, 9(5), 358. https://doi.org/10.3390/drones9050358