1. Introduction
Unmanned aerial vehicles (UAVs)/drones have emerged as a pivotal technology within contemporary wireless networks, leveraging their distinctive aerial advantages and operational flexibility [
1]. They play an increasingly prominent role in applications requiring real-time data acquisition and dissemination, such as environmental monitoring, traffic surveillance, and military reconnaissance [
2,
3,
4,
5]. These applications demand not only efficient data collection but also rapid response capabilities, rendering UAVs indispensable for covert and time-sensitive missions where operational secrecy is paramount. Consequently, the significance of UAVs in covert operations is evident. Their value in such missions is further amplified by their stealth capabilities and ability to access otherwise inaccessible areas.
With the advent of 6G technology, the increasing demand for high data rates, low latency, and enhanced connectivity has positioned integrated sensing and communication (ISAC) systems as a promising framework to address these challenges [
6]. ISAC systems are broadly categorized into three fundamental types: time division multiplexing (TDM), frequency division multiplexing (FDM), and simultaneous same-frequency ISAC [
2]. Each type employs distinct strategies to manage the separation or integration of sensing and communication functionalities at the physical layer, optimizing performance and resource utilization. TDM ISAC sequentially performs sensing and communication tasks, offering straightforward implementation and mitigating direct interference [
7]. For instance, in [
8], researchers utilized a millimeter-wave dual-mode radar in intelligent vehicle and highway systems to control vehicle distances effectively. The radar mode was employed to measure distance, while the communication mode facilitated the exchange of critical data, demonstrating the potential of time-division technology in enhancing road safety and communication efficiency. However, TDM physically segregates sensing and communication functions, which potentially compromises system efficiency or spectral utilization. Thus, simultaneous same-frequency ISAC, which executes sensing and communication tasks concurrently, has garnered significant attention for its ability to share antennas and RF chains, thereby significantly enhancing spectrum efficiency. For instance, a direct sequence ultra-wideband-based integrated radar and communication system employs distinct pseudo-noise codes for code division multiplexing, boosting overall system performance [
9]. Simultaneous same-frequency ISAC often encounters significant design complexity due to mutual interference between sensing and communication signals [
10]. To address this challenge, optimizing resource allocation becomes essential for balancing the trade-off between communication and sensing to enhance overall system performance [
11]. Unlike simultaneous same-frequency ISAC, frequency division multiplexing (FDM) ISAC operates sensing and communication on distinct frequency bands, improving spectral resource utilization. For instance, an orthogonal frequency-division multiple (OFDM) ISAC system in [
12] optimized OFDM signal structures, enhancing accuracy in angle, distance, and velocity estimation and significantly improving ISAC performance. Building on this, we propose a dynamic frequency division multiplexing (DFDM) ISAC scheme, which dynamically allocates bandwidth between sensing and communication tasks [
13]. DFDM retains the flexibility of traditional FDM while offering enhanced adaptability through real-time adjustments based on operational requirements. Unlike TDM, DFDM eliminates inefficiencies caused by time-switching and reduces interference by assigning separate frequency bands for sensing and communication. These features make DFDM particularly advantageous in scenarios demanding efficient spectrum utilization and interference management, such as UAV-assisted covert communication systems.
Given these advantages, UAVs can serve as cost-effective airborne platforms to support ISAC services. The integration of UAVs with ISAC systems is critical for various applications, including traffic accident rescue operations, detection of unauthorized surveillance activities, and connectivity enhancement in areas with surging temporary service demands. Numerous studies have investigated UAV-assisted ISAC systems to further leverage UAVs’ mobility, covert communication capabilities, and cost-efficiency [
14,
15,
16,
17,
18,
19,
20]. For example, in [
18], the authors proposed a framework for beamforming design and trajectory optimization in a UAV-empowered adaptable ISAC system, enhancing system performance by jointly optimizing the UAV’s trajectory and beamforming strategies. An alternating optimization algorithm was employed to address the non-convex problem, maximizing average throughput while ensuring quality of service for both communication and sensing. Similarly, ref. [
19] explored cooperative trajectory planning and resource allocation, formulating a joint problem to minimize Cramér-Rao lower bounds (CRLB) for target location estimation under communication QoS constraints. By decomposing the problem into sub-problems, efficient algorithms were proposed to achieve optimal solutions. Another study [
20] focused on real-time trajectory design for secure UAV-ISAC communications, using an EKF-based method to track the legitimate user’s location and an iterative algorithm based on successive convex approximation (SCA) to solve the non-convex optimization problem.
Despite significant theoretical and methodological advancements, UAV trajectory design and resource allocation in ISAC and covert communication still face practical challenges. Many studies rely on convex optimization approaches, which struggle to handle the dynamic and complex nature of real-world scenarios. Approximation methods that transform non-convex problems into convex ones or use iterative solutions often fail to achieve global optima. Additionally, existing research always oversimplifies the motion of adversarial UAVs, assuming stationary or known trajectories, which is rarely realistic. Moreover, the issue of UAVs’ limited battery capacity is often ignored, which significantly impacts mission sustainability and performance, particularly in covert communication operations where energy constraints can be a major bottleneck. To address these challenges, deep reinforcement learning (DRL) provides a more adaptive and efficient solution. Algorithms like DQN [
16] and TD3 [
17] have been applied to UAV navigation and control, while the Soft Actor-Critic (SAC) algorithm has shown promise in balancing exploration and exploitation. SAC has been successfully used in mobile edge computing for secure data transfer [
21], demonstrating its effectiveness in stochastic and dynamic environments, making it well suited for UAV applications. Hence, this study proposes a novel framework incorporating the SAC-CC algorithm into the UAV-assisted ISAC system, with a particular emphasis on energy constraints in covert communication scenarios. Specifically, our framework addresses an eavesdropping confrontation scenario involving friendly and adversarial UAVs. In this context, the friendly UAV, referred to as Alice (A-UAV), is tasked with conducting covert communication with the base station (BS). Meanwhile, the adversarial UAV, referred to as Willie (W-UAV), operates with an unknown trajectory and aims to eavesdrop on the communication between A-UAV and the BS. To counter this threat, the A-UAV needs to estimate the trajectory of the W-UAV using its sensing capabilities and then strategically plan its own flight path and dynamically allocate bandwidth resources to more effectively accomplish the covert communication mission. Thus, the primary objective of this study is to maximize the cumulative covert transmission rate (CCTR) by jointly optimizing the A-UAV’s trajectory and dynamic bandwidth allocation between sensing and communication under limited bandwidth.
This study aims to maximize the CCTR by jointly optimizing the A-UAV’s trajectory and dynamic bandwidth allocation under limited battery capacity. To achieve this, the A-UAV must design its flight path based on the W-UAV’s trajectory, which is unknown and must be estimated using its sensing capabilities. However, radar position estimation errors directly impact the A-UAV’s ability to predict the W-UAV’s movements, thereby affecting covert communication performance. Additionally, the A-UAV operates under strict battery energy constraints, as flying, sensing, and communication tasks all consume energy. When the remaining energy is not sufficient to support both the upcoming ISAC task and the flying to the nearest charging station after the task, the A-UAV must immediately charge to avoid depletion. Charging interrupts sensing and communication tasks, leading to increased radar estimation errors, disrupted W-UAV tracking, and degraded covert communication quality due to suboptimal trajectory planning. In summary, energy constraints and the charging mechanism serve as objective constraints, while radar estimation errors indirectly affect covert communication performance. Results of this study emphasize the trade-off between covert communication performance, radar accuracy, and energy efficiency, highlighting their joint impact on optimizing system performance under real-world scenarios. The key contributions of this work are as follows:
This study introduces a dynamic bandwidth allocation framework for UAV-assisted ISAC, integrating energy management into A-UAV trajectory optimization. It dynamically tracks W-UAV trajectories to optimize covert communication and reconnaissance under energy and charging constraints. This design ensures efficient task execution in energy-constrained environments, facilitating real-world deployment.
A specialized DRL algorithm, SAC-CC, is developed to address the high dynamics of the optimization problem. SAC-CC is tailored to adapt to stochastic rewards and real-time online adjustments, significantly improving A-UAV performance and adaptability in complex W-UAV scenarios compared to traditional methods.
3. Deep Reinforcement Learning Solution
3.1. Markov Decision Process Formulation
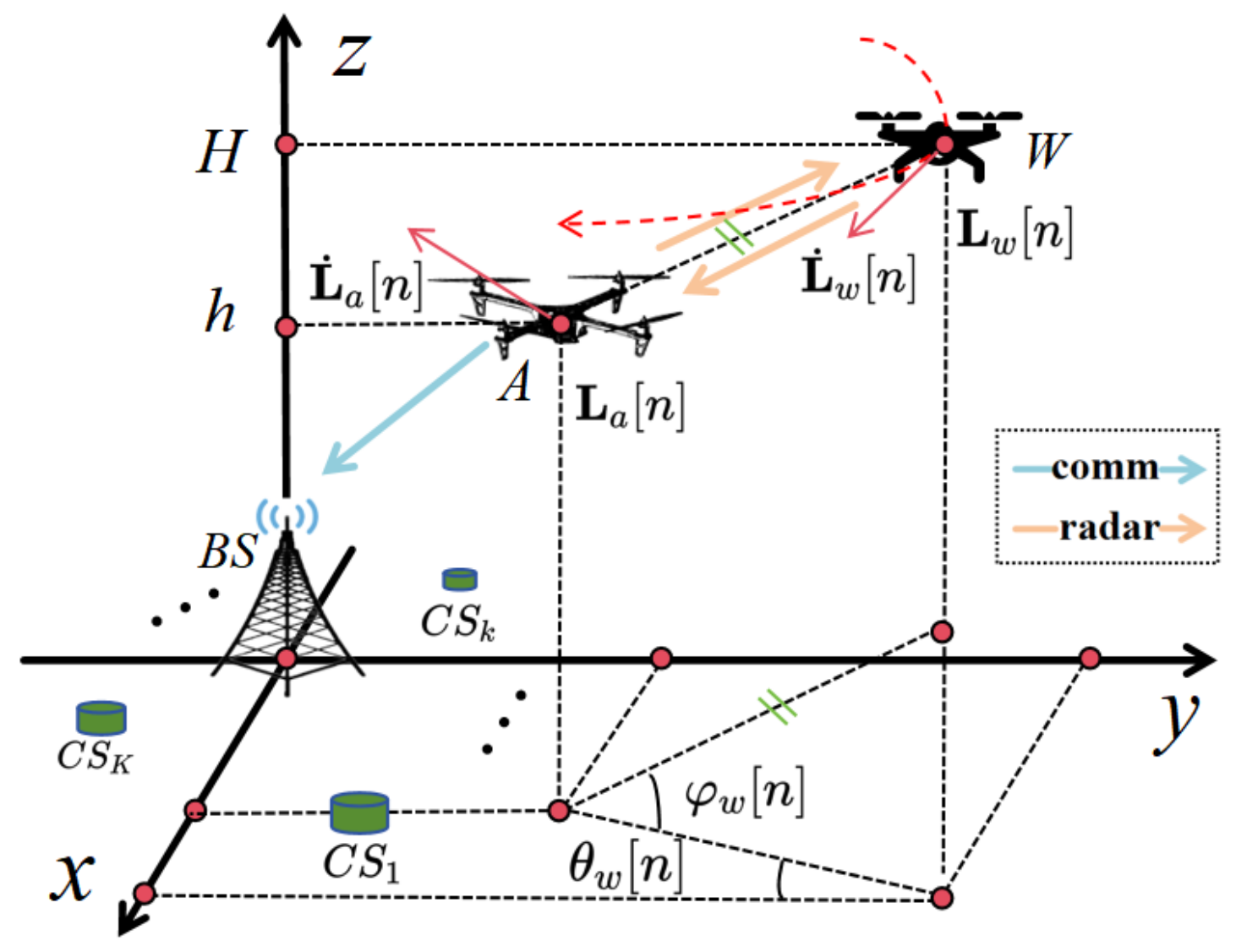
In this section, we reformulate Problem (19a) by optimizing A-UAV trajectory and bandwidth allocation between sensing and communications as a discrete-time Markov Decision Process (MDP). A DRL-based algorithm, SAC-CC, is developed as the solution to this MDP problem. The MDP is represented by the quadruple , where is the state space, is the action space, is the state transition probability, and is the reward function. The state, action, reward, and state transition probability are defined as follows:
(1) The state at the n-th time slot is given by , where is the horizontal position of the A-UAV, is the estimated position of the W-UAV, is the estimated speed of the W-UAV, and represents the remaining energy.
(2) The action is defined as .
(3) To facilitate better convergence and optimization, a reward shaping mechanism is introduced to address the requirements of the charging selection mechanism, communication rewards, radar position estimation error penalties, and anti-eavesdropping penalties. Specifically, when the A-UAV is charging, we set
. When not charging, the radar position error and eavesdropping penalties are incorporated into the communication reward. The reward shaping is defined as
where
is the radar position estimation error at the
n-th time slot, and
is the eavesdropping penalty factor.
(4) The state transition probability is denoted as , which represents the probability of transitioning from state to with action .
3.2. Proposed SAC-CC Algorithm
In this paper, we address environmental uncertainty by employing a policy-based, model-free DRL approach known as SAC. This off-policy actor-critic algorithm is particularly suitable for scenarios involving continuous action spaces [
25]. We have tailored the SAC algorithm to handle charging scenarios and covert communication, referred to as SAC-CC. The goal is to optimize the A-UAV’s trajectory and bandwidth allocation between sensing and communications, while adhering to constraints such as covertness, energy limitations, and maximum propulsion power to maximize the CCTR.
As illustrated in
Figure 2, to encourage exploration and avoid premature convergence, the SAC-CC incorporates an entropy regularization term. It consists of one actor network parameterized as
, and two critic networks parameterized as
and
with their corresponding target networks parameterized as
and
, respectively. The actor network generates a policy
, which defines the probability distribution of actions given a state
s. The critic networks estimate the state-action value functions,
and
. The SAC-CC updates the actor network to maximize the expected cumulative reward, which includes an entropy term, and updates the critic networks by minimizing the temporal difference errors between predicted and target values. For the actor network, the updates are given by the following formulas:
Here, (22) is the gradient of the actor network’s loss function that takes into account the impact of the entropy regularization, with respect to its parameters
. In the SAC-CC,
is the entropy regularization coefficient which adjusts the randomness of the policy to control the trade-off between exploration and exploitation. For the critic networks, one quantifies the mean squared error between the the estimated state-action value of the critic’s and the target’s as
Thus, the gradient of (23) can be derived in a similar form to that of (22) and subsequently applied in the training process. To stabilize the learning process, the SAC-CC algorithm employs a soft update rule for the target critic networks:
This soft update rule gradually aligns the target network’s parameters with those of the learned critic networks, where
is the soft-update rate, facilitating a smoother learning curve.
The SAC-CC algorithm initializes the replay buffer B and the network weights. The reward function is designed to account for two key aspects: (1) a reduction in communication rewards due to potential eavesdropping by the W-UAV, and (2) penalties for radar position estimation errors. At each time slot n, the agent’s experience, consisting of the current state , the selected action , the received reward , and the subsequent state , is stored as a tuple in the replay buffer B. Once experiences have been accumulated in B, a mini-batch is sampled to update the network parameters. Each training episode begins with the A-UAV in its initial state and continues until the maximum mission duration T is reached.
We now focus on SAC-CC’s core network structure—the actor network and two critic networks—to provide an in-depth analysis of its computational complexity. Assume each network contains
M layers. In the actor network
, the
m-th layer consists of
nodes, while in the critic networks,
and
, the
m-th layers have
and
nodes, respectively. For this analysis, the computational cost associated with batch normalization and ReLU activation layers is excluded. During each training iteration, the batch size is
B, influencing both forward and backward propagation. The computational complexity of the actor network for forward propagation through a single layer is
. Similarly, the computational complexities for the critic networks
and
are
and
, respectively. Considering both forward and backward propagation, the overall computational complexity of the SAC-CC algorithm is multiplied by a factor of 2 and can be expressed as
This formula integrates the complexity of the actor network and the two critic networks, and takes into account the impact of the batch size on the overall complexity, as well as the double computation of forward and backward propagation. This analysis allows us to more accurately assess the computational resource requirements of the SAC-CC algorithm under different network configurations, ensuring that our assessment is both comprehensive and accurate.
4. Numerical Results
The numerical simulations are conducted based on the environmental parameters specified in
Table 1. We first compare our proposed SAC-CC with other policy gradient-based DRL algorithms—DDPG [
26], TD3 [
27], PPO [
28], and A3C [
29]—in terms of average reward over training episodes. The numerical simulations are based on the environmental parameters in
Table 1. As shown in
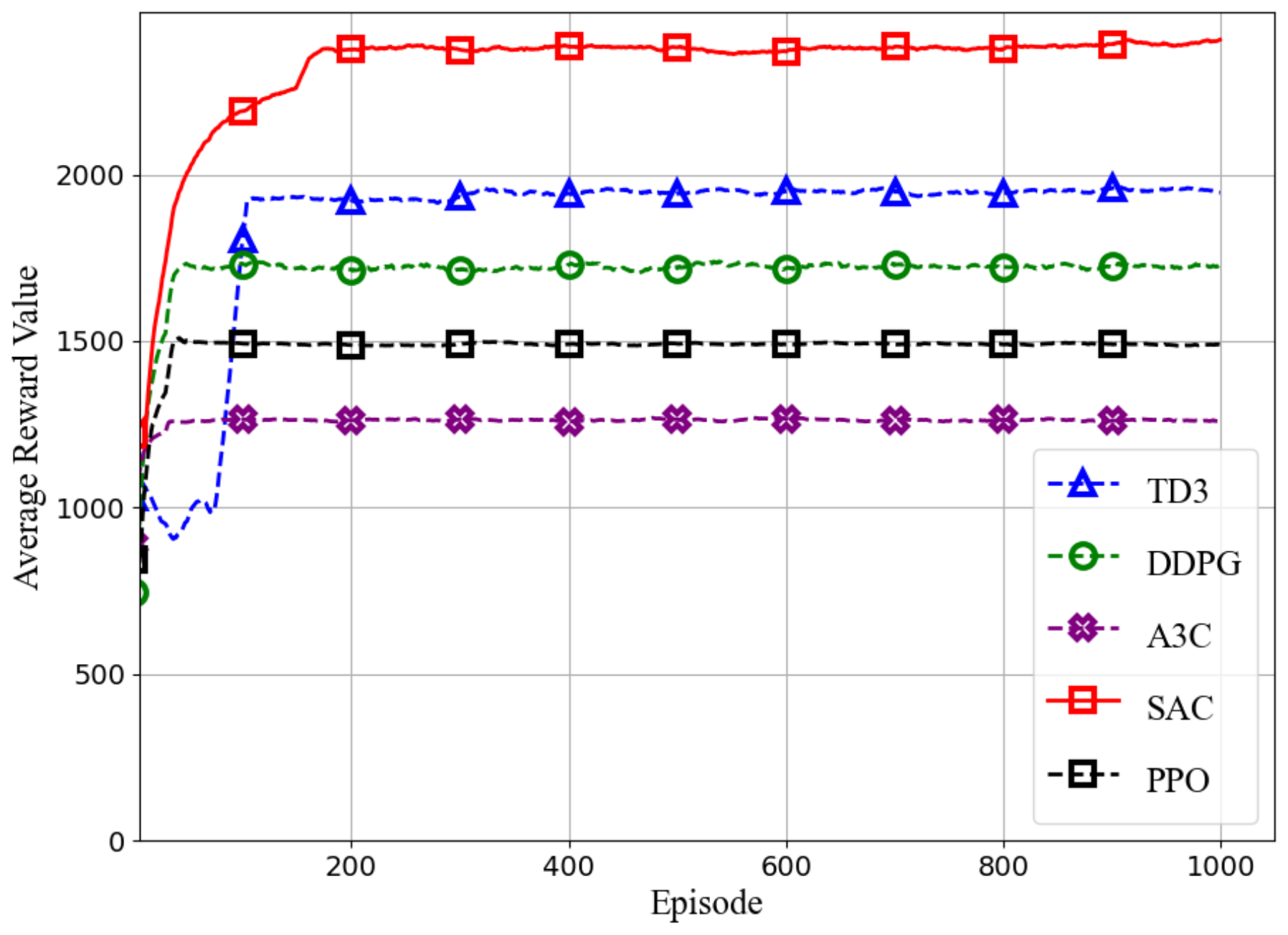
Figure 3, SAC-CC achieves rapid convergence and high stability, reaching an average reward of approximately 2398. This is due to its entropy-regularized exploration strategy, which effectively balances exploration and exploitation in complex environments. Minor reward fluctuations after convergence are attributed to environmental dynamics, entropy regularization, and the reward function’s variability. TD3, which uses delayed policy updates and dual critic networks to reduce overestimation, converges more slowly at around 1950, while improving stability, it limits exploration compared to SAC-CC. DDPG achieves an average reward of 1725, with delayed updates and noise reduction enhancing stability, but its deterministic policy limits exploration diversity relative to SAC-CC’s stochastic policy. PPO and A3C perform worse, with average rewards of 1488 and 1261, respectively. PPO’s conservative policy updates hinder aggressive exploration, while A3C’s asynchronous execution introduces high variance, leading to instability and suboptimal performance. These results demonstrate SAC-CC’s superiority in UAV-assisted ISAC tasks, excelling in balancing exploration, exploitation, stability, and convergence speed, which are essential for optimizing UAV trajectories and bandwidth allocation in dynamic and adversarial environments.
All experiments are conducted on an NVIDIA GeForce RTX 3060 Laptop GPU. The SAC-CC algorithm achieves an average decision-making time of 0.6 milliseconds per step. For comparison, other state-of-the-art DRL algorithms—A3C, DDPG, TD3, and PPO—have average decision-making times of 0.9 ms, 4.4 ms, 0.8 ms, and 0.6 ms per step, respectively. These results demonstrate that DRL methods, including SAC-CC, can meet the millisecond-level response demands of high-dynamic UAV tracking scenarios. Notably, SAC-CC outperforms other policy gradient DRL methods in real-time performance, underscoring its efficiency and effectiveness in addressing real-time challenges in UAV covert communication and tracking tasks.
In
Figure 3, the performance of different DRL algorithms was analyzed from the perspective of training convergence, focusing on their ability to maximize the reward function defined in (20) and (21). Building on this,
Figure 4 directly compares the CCTR, which represents the original optimization objective of our UAV-assisted ISAC problem in (19a), across various DRL algorithms. This analysis provides a comprehensive evaluation of DRL algorithms’ adaptability under varying levels of eavesdropping threshold
defined in (13). The results in
Figure 4 demonstrate that the SAC-CC algorithm achieves the CCTR within the range of 3215–4230 bps/Hz across all values of
, significantly surpassing the 1299–3198 bps/Hz range achieved by other DRL algorithms. The graph exhibits an upward trend in the average covert transmission rate for all algorithms as
increases. This trend reflects the fact that a larger
value allows for greater flexibility in the A-UAV’s covert communication, enabling higher transmission rates while maintaining covertness. Notably, the consistently steep trajectory of the SAC-CC algorithm underscores its advanced capability to balance the trade-off between transmission rate and covertness. Therefore, the conclusions derived from both figures collectively validate the optimality of our proposed algorithm over other DRL algorithms, and subsequent experimental results and analyses will focus on SAC-CC.
To explore the trade-off between radar position estimation error
and CCTR, the results are shown in
Figure 5. When
is low, the improved accuracy of position estimation reduces tracking errors but consumes more bandwidth resources, which could otherwise be used for communication, leading to a decrease in CCTR. Conversely, a higher
saves radar bandwidth but may compromise position estimation accuracy, increasing tracking errors and similarly reducing CCTR. This highlights the existence of an optimal
that maximizes CCTR while maintaining covert communication quality. Additionally,
Figure 5 demonstrates that the SAC-CC algorithm consistently achieves a higher CCTR compared to other DRL algorithms across different
values, further demonstrating its superior performance in optimizing UAV trajectory and bandwidth allocation in dynamic environments.
To thoroughly evaluate the effectiveness of the SAC-CC algorithm under various W-UAV flight trajectories, we present the A-UAV’s trajectory, along with the total rewards, the CCTR, and the average covertness indicator
derived from (14), as shown in
Figure 6. In Scenario W1, the W-UAV stays in close proximity to the BS, requiring the A-UAV to increase its distance from the W-UAV to maintain covert communication, which also increases its distance from the BS. This constraint yields the lowest CCTR of 3436 bps/Hz and an average covertness indicator
of 0.0078, remaining below the eavesdropping threshold of 0.01 and highlighting the challenges of maintaining covert communication in such proximity to the BS. In Scenario W2, the W-UAV follows an expanded trajectory, increasing its distance from the BS and providing the A-UAV with greater flexibility in flight. This results in the highest CCTR of 3914 bps/Hz and an average
of 0.0082, still below the eavesdropping threshold of 0.01, demonstrating the A-UAV’s improved covert communication performance when the W-UAV is farther from the BS. In Scenario W3, the W-UAV maintains a stable flight pattern consistently on one side of the BS, enabling the A-UAV to operate in a fixed mission area on the opposite side. This configuration minimizes trajectory adjustments and optimizes the balance between covert communication and energy efficiency. The A-UAV achieves a CCTR of 3610 bps/Hz and an average
of 0.0019, which remains below the eavesdropping threshold of 0.01. These results underscore the SAC-CC algorithm’s capability to effectively balance covert communication, energy efficiency, and trajectory optimization, ensuring reliable performance across diverse scenarios.
Next, we analyze the effectiveness of the algorithm under varying CS quantities and spatial distributions, with the W-UAV’s trajectory fixed to W2 in
Figure 7. In the CS1 distribution, the limited number of charging stations, which are only concentrated in the second quadrant, often places the A-UAV (our unmanned aerial vehicle) in close proximity to the W-UAV, thereby increasing the risk of eavesdropping. Under this setup, the A-UAV achieves a CCTR of 4089 bps/Hz, maintaining effective covertness despite the proximity to the W-UAV. The CS2 distribution, which is only in the first quadrant and far from the origin BS, poses greater challenges for the A-UAV in terms of both charging and communication. As a result, the A-UAV’s CCTR decreases to its lowest value of 3590 bps/Hz, with
reaching 0.0072, still below the eavesdropping threshold of 0.01, demonstrating the trade-off challenges between charging and communication in terms of the overall reward. In contrast, the CS3 distribution features a greater number of CSs distributed evenly across all four quadrants, providing the A-UAV with more options. This setup allows for a wider range of trajectories and dynamic adjustments to the distance from the W-UAV, resulting in the highest CCTR of 4271 bps/Hz, and
of 0.0059, still below the eavesdropping threshold of 0.01. These results highlight that a well-planned layout of CSs is essential for optimizing the A-UAV’s performance under covert communication and energy constraints.
To thoroughly evaluate the SAC-CC algorithm, we extend its functionality and compare its performance in different multi-adversary UAV scenarios. In Scenario 1, as shown in
Figure 8, four W-UAVs with distinct trajectories are located in the first, second, third, and fourth quadrants, respectively. To maximize the CCTR, the A-UAV strategically flies near multiple charging stations (CS) close to the central BS. This setup enables the A-UAV to dynamically plan its trajectory with sufficient energy supply, effectively avoid eavesdropping by adversarial UAVs, and maintain a reliable communication link with the BS. The SAC-CC algorithm achieves high CCTR in this scenario by optimizing trajectory and bandwidth allocation while minimizing eavesdropping risks. In Scenario 2, two adversarial UAVs with broader trajectories span the first–third and third–fourth quadrants, respectively. Here, the A-UAV opts to stay near a charging station in the second quadrant, avoiding the charging stations near the BS due to the proximity of adversarial UAVs, which increases the risk of eavesdropping. This strategy balances the distance between the A-UAV, adversarial UAVs, and the BS, optimizing the trade-off between covert communication and link quality. A comparison of these scenarios highlights the SAC-CC algorithm’s adaptability and robustness in multi-adversary environments. It dynamically adjusts flight strategies based on adversarial UAV layouts and trajectories, ensuring optimal covert communication performance. These results highlight the SAC-CC algorithm’s effectiveness in handling complex adversarial threats, offering strong technical support for real-world multi-adversary UAV scenarios.
Moreover, the impact of algorithm settings and total bandwidth on the CCTR is assessed in
Figure 9. We compare three SAC-CC variants: SAC-CC (full covert communication and charging), SAC-FP (fixed propulsion power with velocity at 10 m/s), and SAC-FB (fixed bandwidth allocation ratio of 0.5). The results verify that SAC-CC consistently performs the best under different bandwidths. Also, the CCTRs of all algorithms first increase and then decline after reaching their peaks as the total bandwidth increases from 1 MHz to 15 MHz. This reflects the fundamental trade-off between bandwidth resources and energy consumption, as a larger total bandwidth increases energy consumption, directly affecting the A-UAV’s trajectory and CCTR by necessitating more frequent charging. Furthermore, the SAC-FB model performs the worst, highlighting the importance of effective bandwidth allocation in improving the CCTR. These insights are crucial for adjusting system parameters based on the available bandwidth in practical applications.
Next, we conduct an in-depth analysis of the impact of PSD and A-UAV’s total energy (energy capacity) in
Figure 10. The results follow a trend similar to
Figure 9: as the A-UAV’s total energy increases, the CCTR initially improves but eventually declines. This occurs because higher total energy extends the A-UAV’s endurance; however, it also prolongs a single charging time, which may reduce the number of effective ISAC tasks. When the drawbacks of extended charging outweigh the benefits of increased endurance, the CCTR begins to decrease. Additionally, the optimal PSD is found to be 10 W/MHz. Moreover, although a higher PSD supports better ISAC performance, it also negatively affects the CCTR due to greater energy consumption and more frequent charging. These findings provide valuable insights and practical recommendations for efficient A-UAV mission planning in the future. For long-duration missions, excessive PSD should be avoided to prevent unnecessary energy consumption. Additionally, the total energy should be optimized rather than maximized, taking into account the trade-off between endurance and charging time.
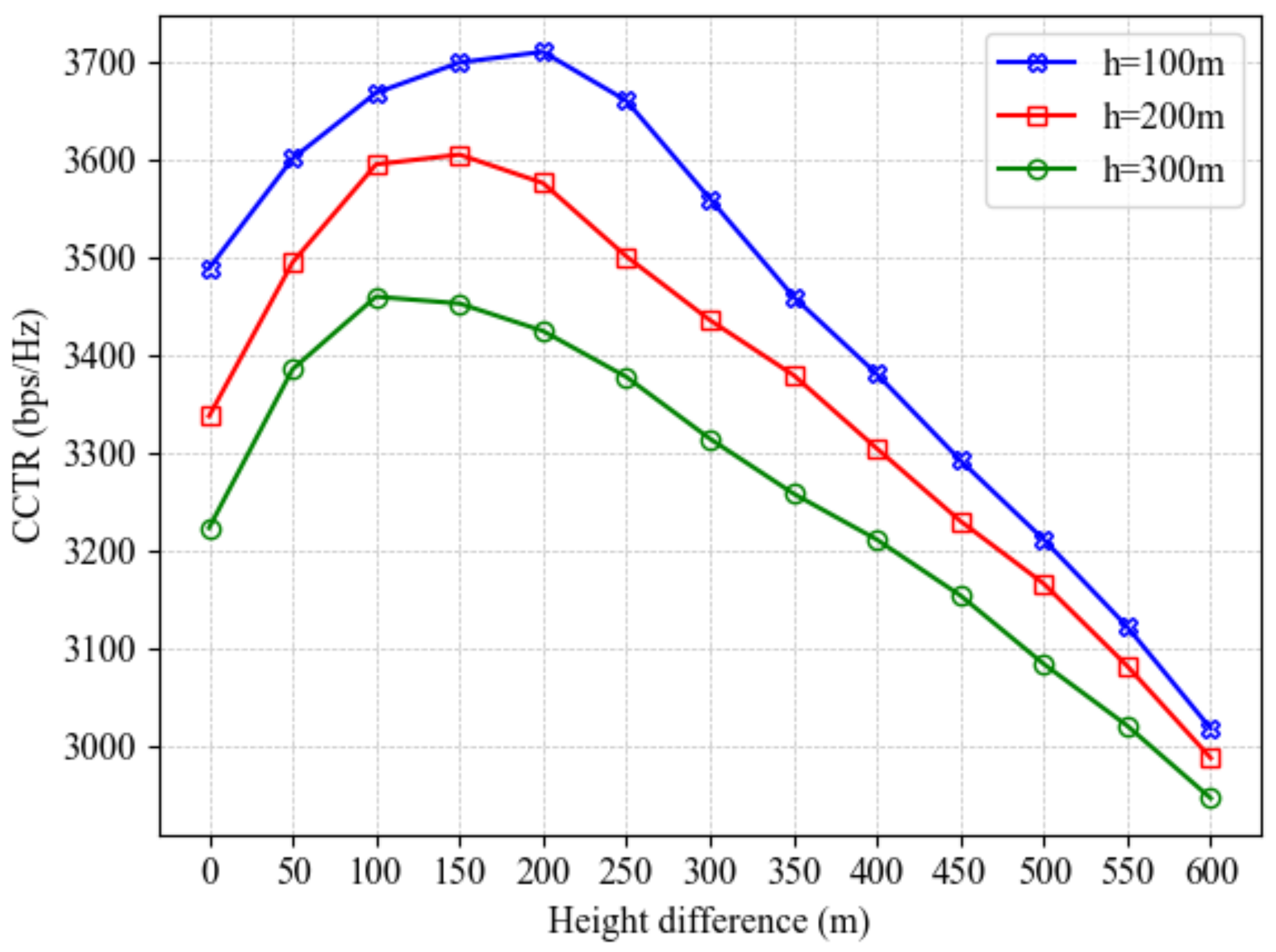
Figure 11 illustrates the impact of the height and height difference between the A-UAV and W-UAV on the CCTR under varying A-UAV altitudes (100 m, 200 m, and 300 m). The x-axis represents the height difference, defined as the W-UAV’s altitude minus the A-UAV’s altitude. Since the W-UAV typically operates at a higher altitude for enhanced stealth and reconnaissance range, the simulations set its flight altitude to be greater than or equal to that of the A-UAV. The results reveal that a lower A-UAV altitude, such as 100 m, achieves a higher CCTR peak and exhibits stronger adaptability. This is because lower altitudes minimize communication link loss between the A-UAV and the ground BS, ensuring a more reliable foundation for covert communication. Even with a small height difference, the A-UAV can maintain high communication quality, resulting in superior CCTR performance. Conversely, higher A-UAV altitudes increase communication link loss with the BS, leading to reduced overall CCTR performance. This highlights the significant influence of A-UAV altitude on covert communication, with lower altitudes being more favorable for maintaining high-quality communication links. For each curve, the CCTR initially increases and then decreases as the height difference grows. When the height difference is small, the W-UAV’s proximity to the A-UAV enhances its eavesdropping capability, limiting the CCTR. However, as the height difference increases, the W-UAV’s eavesdropping capability diminishes due to the greater separation, reducing the likelihood of signal interception and allowing the CCTR to rise. Beyond a certain point, further increases in the height difference significantly impair the A-UAV’s ability to estimate the W-UAV’s position accurately. Since the A-UAV relies on radar signals to track the W-UAV and plan its trajectory, increased estimation errors hinder its ability to maintain efficient covert communication. Ultimately, the negative impact of higher estimation errors outweighs the benefits of reduced eavesdropping capability, causing the CCTR to decline. This analysis suggests that there exists an optimal height difference where the A-UAV can effectively balance the W-UAV’s reduced eavesdropping capability and its own position estimation accuracy, thereby achieving the best covert communication performance.
5. Conclusions
This study proposes an innovative optimization framework for deploying ISAC systems on UAVs, designed to enhance long-term endurance and covert communication performance in dynamic environments. We present the SAC-CC algorithm, which jointly optimizes A-UAV trajectories and bandwidth allocation to maximize the CCTR. Numerical results validate the superiority of the SAC-CC algorithm over other DRL methods, highlighting its robustness and adaptability in complex adversarial scenarios. This study also explores the trade-offs among key parameters, including bandwidth, sensing accuracy, energy consumption, and power spectral density (PSD), offering practical insights for parameter configuration in real-world applications. The proposed SAC-CC algorithm framework demonstrates broad application potential thanks to its robust covert communication planning capabilities and adaptability in highly dynamic UAV confrontation scenarios. In military reconnaissance and patrol missions—characterized by extended durations, high dynamics, and environmental complexity—UAVs must navigate challenging and ever-changing conditions while operating in hostile environments. These scenarios demand long-term covert communication capabilities to minimize the detection risk. The SAC-CC algorithm addresses these challenges by optimizing UAV flight trajectories and communication spectrum allocation, dynamically adjusting paths and strategies to ensure efficient, reliable, and covert communication under such complex conditions. Additionally, the SAC-CC algorithm exhibits strong adaptability to varying distributions of charging stations, allowing it to perform effectively across scenarios with differing levels of charging support, such as in urban and suburban environments. This flexibility further underscores its suitability for diverse real-world applications.
Although this study primarily focuses on optimizing covert communication in one-on-one UAV confrontation scenarios, the proposed SAC-CC algorithm framework exhibits strong scalability, making it adaptable to more complex network environments. As discussed, the extended SAC-CC algorithm maintains robust covert communication capabilities even in scenarios involving multiple adversarial UAVs. Moreover, the algorithm holds promising potential for further extensions. For instance, in scenarios involving a network of multiple friendly UAVs, the SAC-CC algorithm can be adapted to the MASAC (Multi-Agent Soft Actor–Critic) algorithm by incorporating joint actions, shared rewards, updated policy and value function mechanisms, as well as communication and coordination strategies, effectively addressing interactions among multiple agents [
30]. Furthermore, the algorithm is capable of adapting to more sophisticated energy management requirements by dynamically optimizing charging strategies and task prioritization. These scalability features open new avenues for future research on covert communication within large-scale UAV confrontation networks, further enhancing the algorithm’s applicability and versatility in complex and dynamic environments.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}