1. Introduction
In current localized conflicts, unmanned aerial vehicles (UAVs) are being equipped for high-risk, high-difficulty tasks such as intelligence reconnaissance, fire strikes, and communication support [
1,
2]. Due to their high cost-effectiveness, UAVs are gradually becoming a significant force in transforming the nature of warfare. In civilian scenarios, countries frequently suffer from natural disasters. Drones can be used for communication support and reconnaissance in disaster-stricken areas [
3]. Compared to single drone operations, drone swarms offer more flexible applications, greater environmental adaptability, and more significant economic advantages [
4,
5,
6]. Due to their strong anti-interference capability [
7], high network capacity [
8], long-distance communication ability [
9,
10], and high security advantages [
11], directional antennas are increasingly employed in UAV networks for networking to meet the high-rate traffic, safety, and other demands of UAV networks. The spatial resources provided by directional antennas allow for the network to support multiple parallel communication links, meaning that multiple links can occupy the same time slot to enhance network capacity and communication rate [
12,
13]. However, only by reasonably scheduling the time slot and power can internal network interference be reduced and the spatial reuse capability of directional networks be fully utilized, thus improving the transmission rate of the network. In a directional UAV network (DUANET), in addition to the scheduling of the time slot and power, the scheduling of main lobe directions is a novel feature that determines which part of the spatial resources nodes will use for communication. By main lobe directions scheduling, it is possible to further reduce interference between nodes in the network as well as external interference. In a DUANET, the data transmission demands for multiple links change dynamically. Hence, it is necessary to dynamically schedule the time slot, power, and main lobe direction. Therefore, how to achieve dynamic scheduling communication resources in the time domain, power domain, and spatial domain to meet the dynamic communication demands is a current research challenge.
In order to address the problem of joint link scheduling and power optimization to achieve strong interference avoidance, a near interference-free (NIF) transmission method is proposed in [
14]. This paper transforms the formulated optimization problem into an integer convex optimization problem under NIF conditions and proposes a user scheduling and power control scheme. In a directional network, the user scheduling can be regarded as the time slot scheduling. The main lobe direction control, as a unique feature of directional networks, is an unavoidable issue in the study of such networks. A heuristic algorithm that improves network throughput by scheduling spatial resources and allocating power is proposed in [
15], but it only considers the application scenario of base stations, not ad hoc networks. The time slot, main lobe direction, and power joint control problem in the DUANET is modeled as a mixed integer nonlinear programming (MINLP) problem in [
16]. Furthermore, a dual-based iterative search algorithm (DISA) and a sequential exhausted allocation algorithm (SEAA) are proposed to solve the proposed MINLP problem in [
16]. However, in [
16], each link occupies at most one time slot within a frame, failing to achieve full reuse of time slots and spatial resources in directional networks. When solving optimization problems using heuristic methods, block coordinate descent (BCD), successive convex approximation (SCA), and other convex optimization methods [
14,
15,
16,
17,
18,
19,
20], the algorithms struggle to adapt to a dynamic number of packets in packet buffers and require solving the problem in different states, which cannot ensure real-time resource scheduling. Therefore, reinforcement learning methods that can adapt to dynamic states are intended to be used in this paper.
The study of resource scheduling in wireless communication networks based on reinforcement learning has been ongoing for a long time, particularly in recent years with device-to-device (D2D) issues and vehicle-to-vehicle (V2V) issues in vehicular networks, both of which are self-organizing network resource scheduling studies. Generally, in scenarios with dynamic traffic demands for D2D or V2V links that remain unchanged over a period of time, the goal is to maximize the data transmission volumes for these links through power control. A distributed power and channel resource scheduling method for D2D links is proposed in [
21]. Power control schemes in vehicular network scenarios are proposed in [
22,
23,
24] by constructing multiple V2V links with dynamic traffic demand and utilizing multi-agent reinforcement learning algorithms such as IDQN and federated D3QN. However, these studies do not consider scenarios involving directional antennas and transmission fairness among links. Ensuring data transmission fairness among links can guarantee the satisfaction and quality of all links in the network, preventing a few links from continuously monopolizing the transmission. Nonetheless, these studies provide valuable insights for this paper in terms of dynamic traffic demands and network modeling.
In recent years, reinforcement learning algorithms have been applied to directional networks for resource scheduling [
25,
26,
27,
28,
29,
30,
31,
32,
33]. In subsequent discussions, the beamforming control can be regarded as the main lobe direction scheduling. In order to optimize power and beamforming for achieving objectives such as maximizing throughput and energy efficiency in static scenarios, several methods using different reinforcement learning algorithms are proposed in [
25,
26,
27]. A hybrid reinforcement learning algorithm for controlling time-frequency blocks and beamforming is introduced in [
28]. This approach schedules time-frequency blocks using D3QN and controls the main lobe direction using TD3, aiming to reduce latency in drone-to-base station communications. However, both D3QN and TD3 require iterative processes to achieve optimal solutions, leading to slow convergence and inaccurate results. For distributed directional network scenarios, directional network resource allocation using multi-agent deep reinforcement learning (MADRL) algorithms are extensively studied in [
29,
30,
31]. By employing various MADRL algorithms to schedule power and beamforming, improvements in network performance metrics are achieved. Nevertheless, these studies do not consider resource scheduling under dynamic traffic demands.
An algorithm based on MADRL is proposed to achieve resource scheduling in directional networks under dynamic traffic demands in [
32,
33]. For dynamic ground traffic demands, a method based on the QMIX algorithm for multi-satellite beam control is proposed in [
32]. In [
33], a MADRL algorithm is proposed to schedule the time slot, channel, and main lobe direction, aiming to maximize network throughput and minimize latency. The methods in [
32,
33] adopt a fixed-dimension observation processing approach using multilayer perceptrons (MLP). Due to the narrow beam communication characteristics of directional antennas, the number of neighboring nodes observed by each node varies, leading to changes in observation dimensions. The methods in [
32,
33] do not consider the dynamic changes in observation dimensions.
To more flexibly and effectively represent the complex relationships between UAV observations, an attention mechanism is employed to process these observations. In [
34], a MADRL algorithm with attention mechanism is proposed to aggregate features from all entities [
35]. In [
36], a MADRL algorithm based on graph neural network (GNN) observation processing method is proposed to enhance the performance of algorithm [
37]. Building on existing research, a QMIX observation processing method based on graph attention network (GAT) is proposed to extract fixed-dimensional dynamic observation features [
38], achieving better training performance in this paper. Therefore, this paper proposes a MADRL with a multi-head attention mechanism to achieve joint scheduling of the time slot, power, and main lobe direction in directional UAV networks. In summary, the contributions of this paper are summarized as follows:
A multi-dimensional resource scheduling (MDRS) optimization problem is constructed to ensure both the total count of transmitted data packets and transmission fairness by scheduling of the time slot, power, and main lobe direction. To balance the total count of transmitted data packets and transmission fairness, the fairness-weighted count of transmitted data packets is defined as the optimization objective [
39,
40,
41].
To implement real-time distributed multi-dimensional resource scheduling (DMDRS) optimization using MADRL, the MDRS is reformulated as a decentralized partially observable Markov decision process (Dec-POMDP) with dynamic observations.
To process the dynamic observations within the main lobe, this paper proposes an observation processing method based on a multi-head attention mechanism to replace the MLP of QMIX, thereby enhancing communication performance.
Finally, based on the constructed Dec-POMDP and multi-head attention mechanism, a DMDRS algorithm based on QMIX with attention mechanism (DMDRS-QMIX-Attn) is proposed. The simulation results show that the DMDRS-QMIX-Attn algorithm improves the fairness-weighted count of transmitted data packets compared with baseline algorithms. Further simulation and analysis verify the effectiveness and advancement of the proposed algorithm under scenarios with different parameters.
To clearly highlight the novelty of this paper, a comparison between related research and this study is shown in the
Table 1.
The remaining parts of this paper are organized as follows.
Section 2 introduces the system model and problem formulation. The optimization problem is reformulated into a Dec-POMDP in
Section 3.
Section 4 describes the attention mechanism and MADRL algorithms.
Section 5 presents the simulation and analysis.
Section 6 discusses the potential applications and future research work, and
Section 7 concludes the paper.
3. The Dec-POMDP for the MDRS Problem
For the Dec-POMDP, the environment information is described by state. The observation provides partial information about the state, and each agent receives an individual observation for the decentralized execution. Subsequently, each agent selects an action according to the received individual observation. The joint action of all agents results in a transition to the next state. Meanwhile, all agents receive a shared reward . The experience is composed of state, observation, action, and reward, represented by tuple . The experiences are stored in the experience replay buffer for centralized training.
In solving the problem defined in Equation (
19), algorithm deployments must be considered. The time slot occupancy
and power control
are controlled at the transmitter, while the main lobe direction control
pertains to both the transmitter and receiver. Therefore, in this paper, each link is regarded as an agent, with the network trained using MADRL deployed at the transmitter of each link for decision-making.
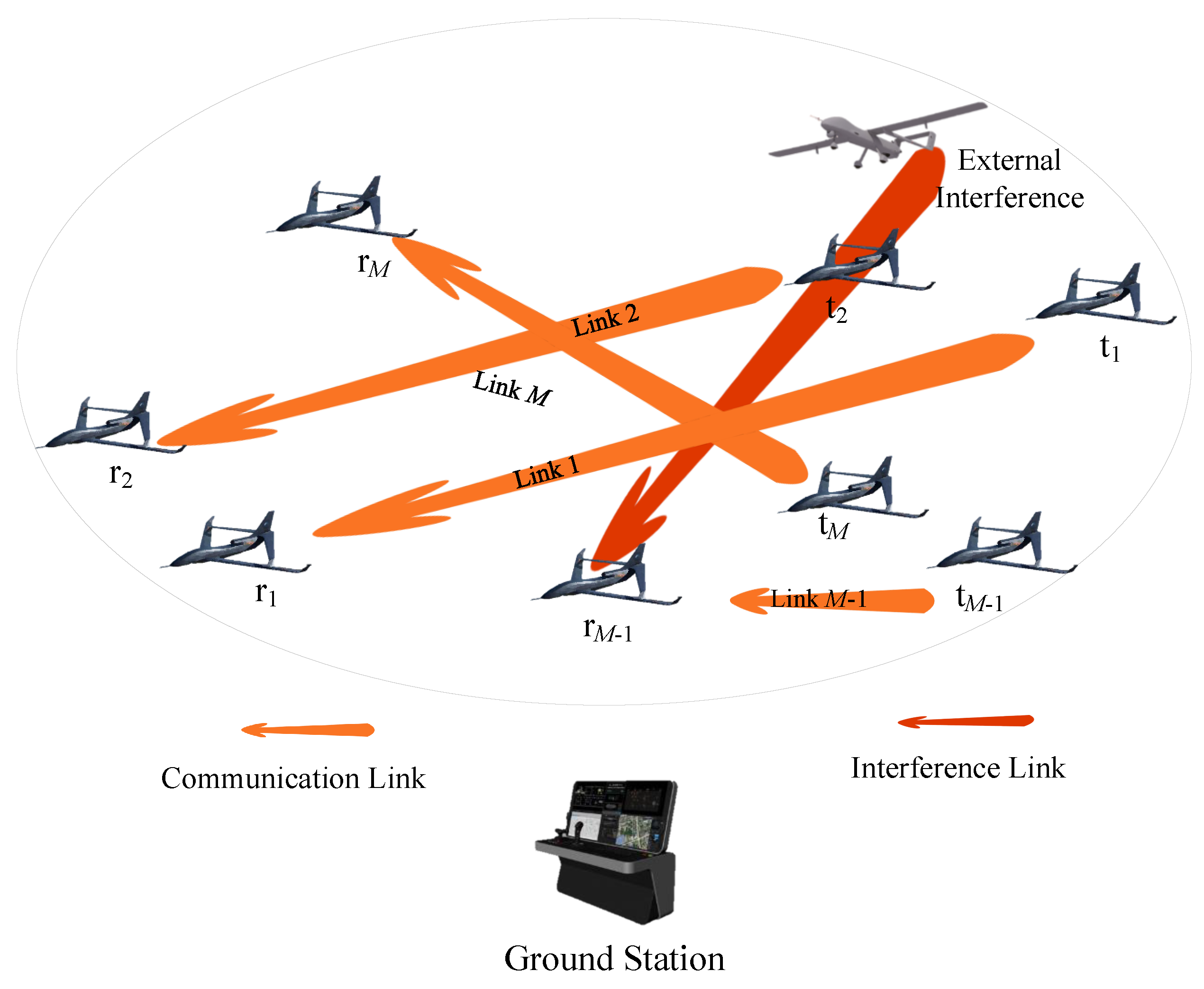
In the MADRL with centralized training and decentralized execution (CTDE), the centralized training is conducted at the ground station depicted in
Figure 1. The ground station distributes the trained neural networks to the transmitters of each link for decentralized execution.
3.1. Action of the Dec-POMDP
According to Equation (
19), the four-dimensional action space is described as
where
,
, and
represent the power action space, transmitter main lobe direction action space, and receiver main lobe direction action space, respectively. Therefore,
,
, and
are as shown as
where a 0 in
and
indicates that the main lobe direction is the same as the communication direction. The action space for
is the Cartesian product of the action spaces for
,
,
, and
; thus, the size of the action space size is
. To further reduce the action space, when link
i does not occupy time slot
k, both the power and main lobe directions of link
i are set to 0. Therefore, the size of the action space is
.
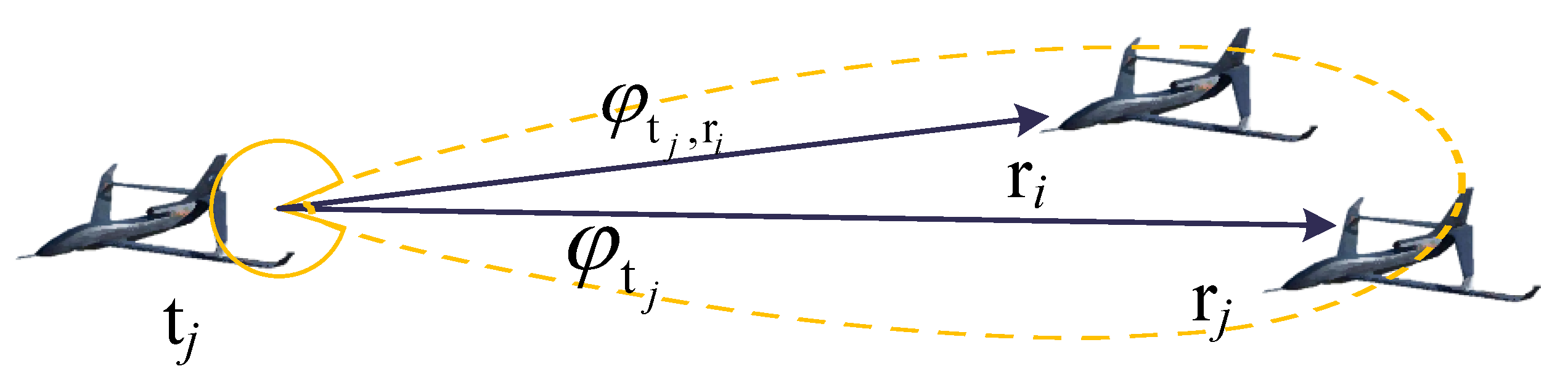
The transmitter interferes with the receivers of other links within its main lobe range with the same power. Therefore, each link’s transmitter makes main lobe direction decisions by maximizing the following equation:
where
represents the set of receivers of other links within the main lobe range of transmitter
i. Therefore, the size of the reinforcement learning action space is reduced to
.
3.2. State of the Dec-POMDP
In MADRL based on QMIX [
47], global state information is used for centralized training, while during execution, each agent has only observation information. At time slot
k, the global state is represented as
where
represents the set of channel state information at time slot
k.
and
have the same meaning.
and
are the same meaning. Based on channel symmetry,
and
are the same.
denotes the set of directional gain among all transmitters and receivers at time slot
k.
indicates the remaining data packet in packet buffer at each time slot.
represents the interference power of external interference on receivers of all links.
3.3. Observation of the Dec-POMDP
An agent can only observe a portion of the global state to decide its action. In practical scenarios, at the transmitter and receiver of link
i, only the state information of links within its main lobe and links that cover the transmitter and receiver of link
i by the main lobe can be observed. The observations by the transmitter and receiver of link
i at time slot
k are represented as
where
represents the channel state information from the receiver and transmitter of link
i to all links whose transmitters and receivers are within the main lobe of link
i, as well as to other links whose transmitters and receivers can cover link
i’s receiver and transmitter within the main lobe range.
is the set of the links that can be observed by link
i at time slot
k.
represents the directional gain from the receiver and transmitter of link
i to transmitters and receivers of all links within the main lobe range of link
i, as well as to other links whose transmitters and receivers can cover the receiver and transmitter of link
i within the main lobe range.
and
have the same meaning as
and
, respectively.
and
indicate the count of transmitted packets and the number of packets in a packet buffer for the link itself and links within the observed range, respectively.
denotes the received interference power from the external interference node to receivers of link
i and link
i’s neighbors. At time slot
k, the observations of all links are combined as
3.4. Reward of the Dec-POMDP
For the DUANET, all links strive for a common global goal. The global reward function, which describes the communication performance of all links, is shown as
where
is the number of data packets actually transmitted by link
i at time slot
k, which is shown as
4. Attention Mechanism and MADRL Algorithm
This section primarily introduces the observation processing methods for variable dimension observations and MADRL algorithms. Due to varying numbers of neighboring UAVs observed within different main lobe ranges, the dimensions of the observation to be processed differ. It is necessary to map observed features into vectors of equal length while ensuring essential information is preserved during the dimensional transformation of observation data. To address this, a multi-head attention mechanism to solve this issue is proposed in this paper, ensuring inputs for the MADRL algorithm’s training and execution.
The main goal of this paper is to maximize rewards across the network through collaborative interactions among agents, necessitating the use of fully cooperative reinforcement learning algorithms. Building on the Dec-POMDP framework introduced in the previous section, this section combines the Value-Decomposition Network (VDN) [
48], QMIX [
47], and the newly proposed QMIX algorithm with the multi-head attention mechanism (QMIX-Attn) to form the DMDRS based on VDN (DMDRS-VDN), DMDRS based on QMIX (DMDRS-QMIX), and DMDRS-QMIX-Attn algorithms to slove the MDRS problem. In this section, we first propose the attention mechanism for observation processing and then introduce VDN, QMIX, and QMIX-Attn.
4.1. Observation Processing Based on Attention Mechanism
Most MADRL algorithms employ MLP [
32,
33,
49,
50] to process observation data. However, MLP can only handle fixed-dimensional observations and is not suitable for varying-dimensional observations data within the main lobe range as described in (
24). In practice, observation data exhibit certain patterns that can be utilized to extract features and construct equally sized observation vectors. Therefore, a method based on graph attention mechanisms [
51] is proposed to extract dynamic dimensional observation features in this paper. In the observation of link
i, the initial features of links to self-link and neighboring links are represented by expressions
and
in the following equation, respectively.
where ∖ represents the set difference operation in mathematics,
is the concatenation function, and
represents the received interference power from the external interference node to receivers of link
i. Based on observed initial features, the weighting coefficient for link
i observing link
j in time
k is given by
where LeakyRelu represents Leaky Relu function [
52]. Parameters
,
,
are weights to be trained. Thus, the abstracted features derived from the observations are the weighted sum of the features obtained from other neighboring links for the current link
i, which is shown as
where
represents non-linear activation function.
To further enhance training stability, the process can be independently repeated as described above, and multiple output results can be combined to form a multi-head attention mechanism [
51]. At time slot
k, the features of other links obtained by agent
i’s observation range are given by
4.2. QMIX Algorithm and QMIX-Attn Algorithm
The VDN algorithm [
48] links the global Q-value with local Q-values through value decomposition, overcoming the instability of IQL [
53]. The joint action-value function of VDN is
.
represents the Q-value function of agent
i.
represents the network policy parameters of agent
i. In VDN, maximizing the system’s
is equivalent to maximizing each agent’s
. Therefore, we can obtain their decentralized policies by maximizing each agent’s
individually.
VDN approximates the global Q-value
by summing local Q-values
, but the addition cannot represent the complexity of
and
. If the relationship between
and
is complex, the trained policy may deviate from the optimization goal. Therefore, the QMIX [
47] method is proposed to approximate
using a neural network, better fitting the relationship between
and
. It should be noted that when each
’s weight is approximately equal, VDN may slightly outperform QMIX.
Since VDN ignores the global state information available during the training phase, QMIX uses the global state
in addition to approximating
. To better approximate
, QMIX ensures that
and each agent’s
have the same monotonicity by restricting the parameters in the neural network to be non-negative, thus satisfying (
32).
By ensuring that
and
have the same monotonicity, the argmax operation on
is equivalent to the argmax operation on each
. The relationship of
’s monotonicity and
’s monotonicity can be expressed as
Combining the multi-head attention mechanism in
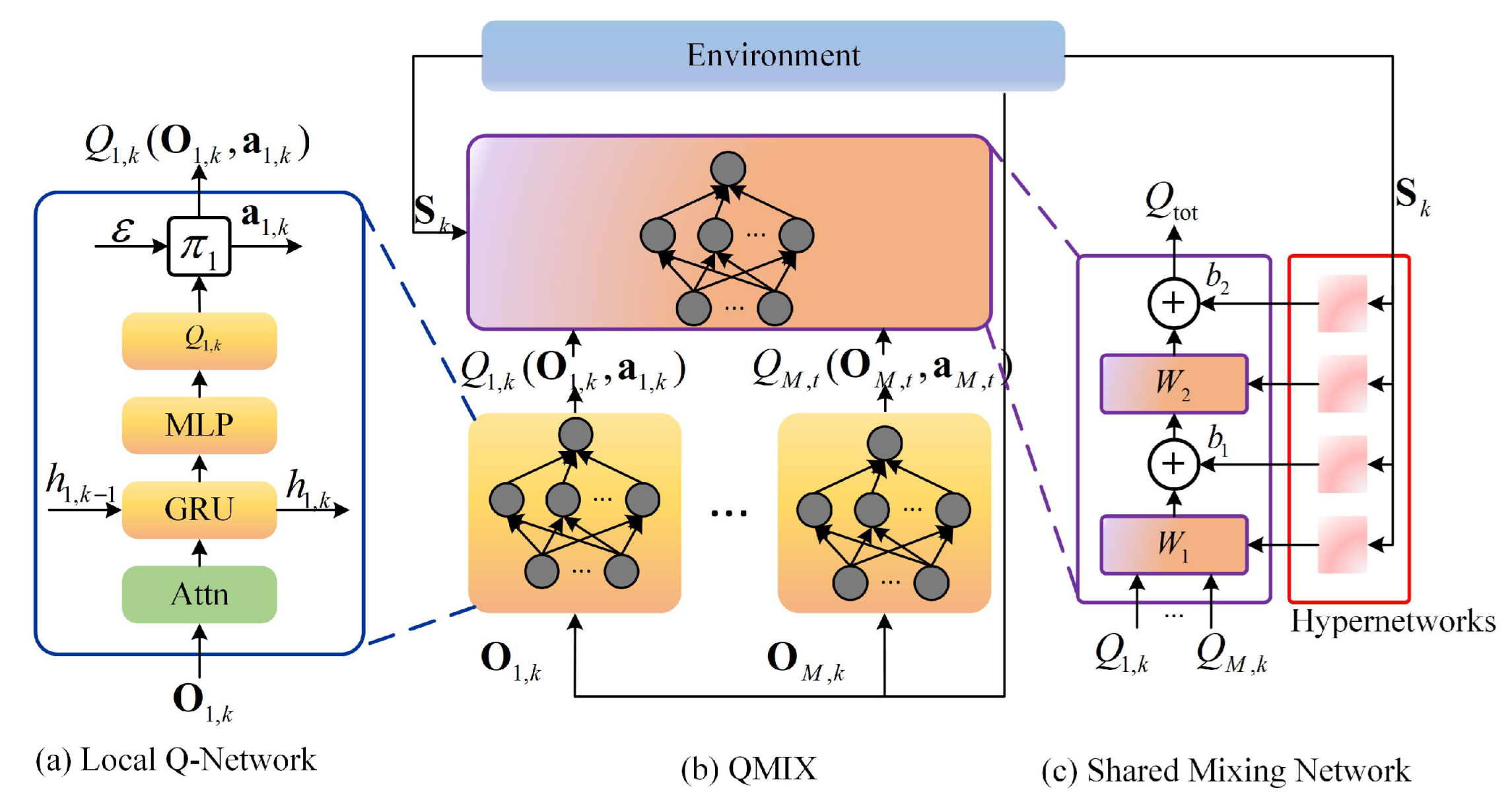
Section 4.1, the architecture of the QMIX-Attn algorithm is shown in
Figure 3. Compared to the QMIX algorithm, the QMIX-Attn algorithm replaces the fully-connected (FC) layer in the Q-network input layer of QMIX with an attention mechanism layer. In
Figure 3a, the local Q-network represents
for each agent. It computes Q-values for all actions in the action space based on the agent’s observation features processed by the multi-head attention mechanism. Based on these Q-values, the optimal action is determined by using an arbitrary policy.
Figure 3c depicts the hypernetworks and the mixing network. Each hypernetwork takes global state information
as input and generates the weights of a layer of the mixing network. To ensure the non-negativity of the weights, a linear network with an absolute value activation function is used to ensure that the output is not negative. The bias is treated similarly but without the non-negativity constraint. The bias of the last layer of the mixing network is obtained through a two-layer network with a ReLU activation function for nonlinear mapping.
This paper adopts the CTDE framework. The agent selects an action based on an
-greedy policy and interacts with the environment. The training process is divided into
epochs, and each epoch consists of
episodes, and each episode has
steps. At the beginning of each episode, to ensure the generalization capability of the training results, the state space is initialized with an initial state. During time slot
k, the tuple
representing the interaction between the agent and the environment is stored in the experience replay buffer
. Experiences are sampled from
and utilized for parameter optimization using stochastic gradient descent (SGD). The DQN approach is adopted for algorithm update, and the cost function is given by
where
represents the batch of episodes sampled from the experience replay buffer, and
is defined as
Algorithm 1 presents the QMIX-Attn algorithm process. Compared to the QMIX algorithm, the attention mechanism for observation processing is added.
| Algorithm 1 Training process of QMIX-Attn |
- 1:
Initialization: - 2:
Setting: The target-network parameters , the learning rate , the discount factor , the batch size , maximum training epoch, episode, slot: , , , the maximum train step L
- 3:
while do - 4:
for do - 5:
for do - 6:
for Each agent i do - 7:
Get observation feature from observations based on the multi-head attention mechanism, action based on -greedy; - 8:
end for - 9:
Take the joint action , and get the reward . Get the next observations from the next state ; - 10:
Store the to the experience buffer; - 11:
end for - 12:
Store the episode data to the replay buffer ; - 13:
end for - 14:
for in each epoch do - 15:
Sample a batch of episodes from ; - 16:
for Each slot in each sampled episode do - 17:
Get and from the evaluate-network and the target-network, respectively; - 18:
end for - 19:
Calculate the loss function by ( 34), and update the evaluate-network parameters ; - 20:
Update the target-network parameters ; - 21:
end for - 22:
end while
|
4.3. Complexity Analysis for QMIX-Attn
Since the training is offline, we focus on the computational complexity during the online execution phase. The computational complexity for each agent during the execution phase primarily depends on the forward computation of the well-trained Q-network. The Q network of each agent consists of an input layer with an attention mechanism module, an output layer with FC layers, and a gated recurrent unit (GRU). The computational complexity of the multi-head attention mechanism is
[
54], where
represents the number of attention heads, and
and
represent the input and output dimensions of the multi-head attention mechanism, respectively.
represents the number of observed neighboring links. The main operations of the FC layer include multiplying the input vector by a weight matrix and adding a bias term. Its computational complexity is
[
55], where
and
represent the input and output dimensions of the FC layer, respectively. The computation in the GRU layer requires two matrix multiplications and a series of element-wise operations, including the reset gate, update gate, and hidden state gate. The computational complexity is
[
56], where
and
represent the input dimension and hidden state dimension of the GRU layer, respectively. Therefore, the computational complexity of the Q-network is
, where
and
represent the input dimension of the observations and the dimension of observation features based on the multi-head attention mechanism, respectively.
denotes the size of the action space.
The main difference between QMIX and QMIX-Attn lies in the input layer of the Q network. The input layer of QMIX is an FC layer, so the computational complexity of the input layer is . and represent the dimensions of the input and output of the input FC layer, respectively. Therefore, the computational complexity of QMIX is . Compared to the QMIX algorithm, the computational complexity of QMIX-Attn is slightly higher.
5. Simulation and Analysis
In this paper, the effectiveness and advancement of the QMIX-Attn algorithm are verified through a comparison of the DMDRS-VDN, DMDRS-QMIX, and DMDRS-QMIX-Attn algorithms. The algorithms were simulated to analyze and validate their performance in scenarios with different parameters. To compare the effectiveness of the main lobe direction scheduling, the main lobe directions of the transmitters and receivers of all links were both 0, with only the time slot and power scheduling, to verify that scheduling the main lobe direction can further improve the fairness-weighted count of transmitted data packets. Consequently, DMDRS-VDN, DMDRS-QMIX, and DMDRS-QMIX-Attn are simplified to DMDRS based on VDN without the main lobe direction scheduling (DMDRS-VDN-ND), DMDRS based on QMIX without the main lobe direction scheduling (DMDRS-QMIX-ND), and DMDRS based on QMIX-Attn without the main lobe direction scheduling (DMDRS-QMIX-Attn-ND), respectively.
5.1. Simulation Scenarios and Algorithm Parameters
5.1.1. Simulation Scenarios
In a DUNET, assume there are 10 links ready to perform data transmission. The 20 UAVs for these 10 links are deployed in a 10 km by 10 km area, forming a fixed topology. Each UAV randomly moves to any position within a circle of radius (0, 40 m, 80 m, 120 m, 160 m, 200 m) centered at its deployment location for broader reconnaissance.
Using the Jakes model to simulate dynamic small-scale fading channels [
44], the Doppler frequency was set to 1000 Hz. Large-scale fading was simulated using the path loss formula [
57], with the carrier frequency set to 5 GHz. The power spectral density of additive white Gaussian noise (AWGN) was −174 dBm/Hz. The maximum transmission power was 38 dBm, and the minimum transmission power was 5 dBm. The number of power levels
D was 9. Both
and
were 5.
Unless otherwise specified, the main lobe angle of the directional antenna was 20°, the main lobe gain of the directional antenna was 15 dB, and the side lobe gain of the directional antennas was 0 dB. Each data packet size was set to 50 kbits. The maximum number of packet in a packet buffer
was 50, the data packet generation rate
was 12 packets per time slot, and the minimum communication rate was 22.5 Mbps. The parameter settings are shown in
Table 2.
5.1.2. Algorithm Parameters
In this study, each training episode (frame) consisted of 20 steps (time slots), with 20 episodes per epoch. Each algorithm included 10 policy networks for agents, structured as DRQN with a convolutional layer and 256 GRUs. The QMIX algorithm and QMIX-Attn additionally featured a mixer network and hypernetwork. The mixer network comprised a hidden layer with 64 neurons using the ELU activation function. The hypernetwork, responsible for non-negative network weights training for the mixer network, included a hidden layer with 64 neurons and utilized the ReLU activation function.
During the training phase, each agent employd a
-greedy policy for exploring the action space. The exploration rate decayed from 0.4 to 0.05 over 10,000 steps, after which it remained constant at 0.05. The discount factor for reinforcement learning was set to 0.98. Network parameters were updated using the RMSprop optimizer [
58] with a learning rate of 0.0005. Each time, we sampled a batch of 32 episodes from the experience replay buffer. The target networks were updated every 40 steps. In the observation processing based on multi-head attention mechanisms, the number of heads was 4.
The algorithm parameters are as shown in
Table 3. The number of steps in an episode is also the number of slots in a frame.
The environment and algorithms for simulation were implemented in Python 3.10.9 and PyTorch 1.12.1.
5.2. Comparison of Different Algorithms
In this section, we mainly compare DMDRS-VDN, DMDRS-QMIX, DMDRS-QMIX-Attn, DMDRS-VDN-ND, DMDRS-QMIX-ND, and DMDRS-QMIX-Attn-ND to validate the performance of different algorithms.
The main optimization goal of this paper is to maximize the fairness-weighted total count of transmitted data packets by scheduling the time slot, power, and main lobe direction. Hence, this section primarily compares the performance of the proposed algorithm and baselines in terms of the fairness-weighted count of transmitted data packets, the fairness index, and the total count of transmitted data packets [
39,
40]. The calculation method for the fairness-weighted count of transmitted data packets and the total count of transmitted data packets are obtained through the optimization objectives in Equations (
17) and (
19), respectively. The calculation method for the fairness index is obtained in Equation (
18), in which
k is 20.
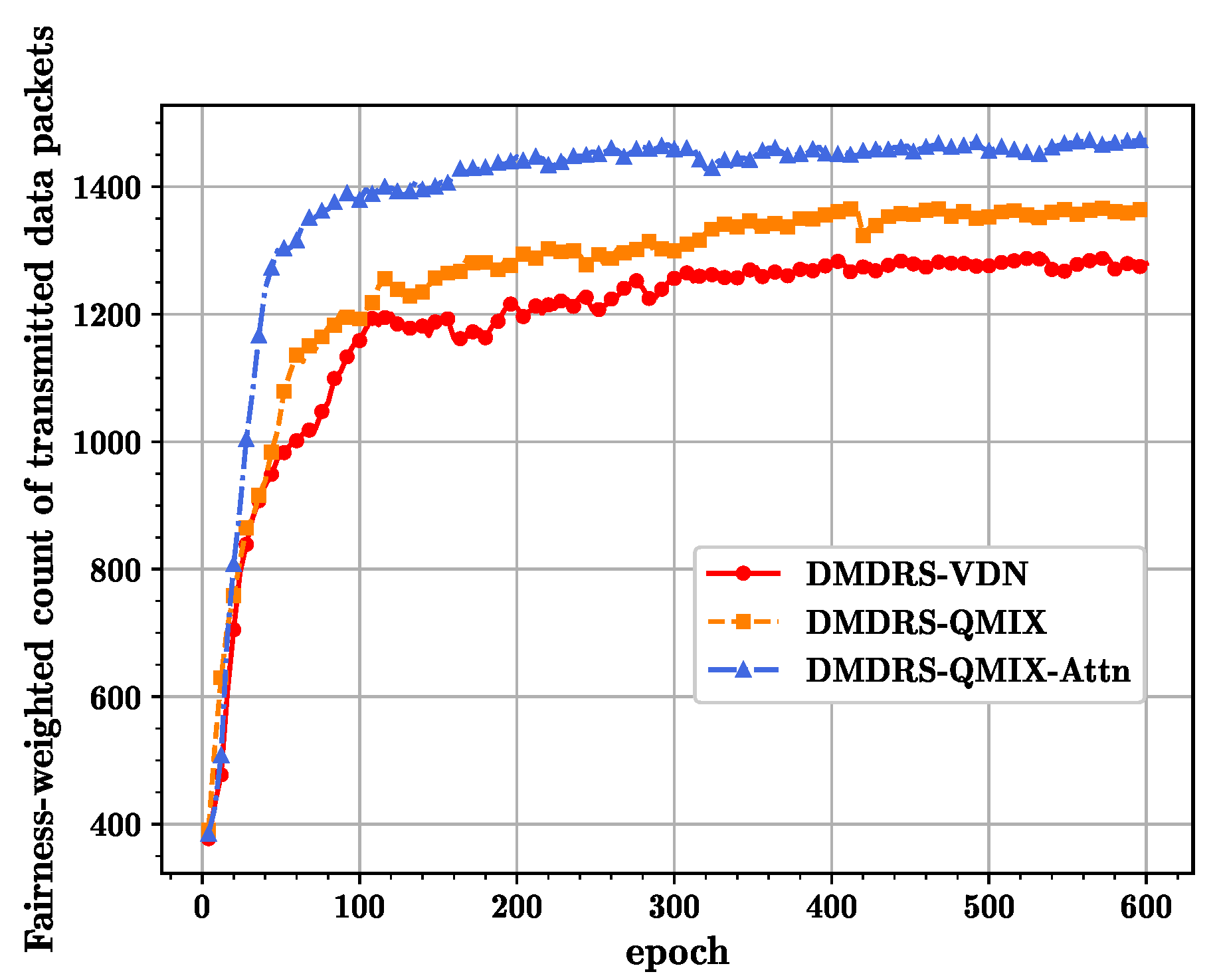
Figure 4 shows the convergence curves of different algorithms in terms of the fairness-weighted count of transmitted data packets, which shows that the QMIX-Attn algorithm obtained the best performance. For processing observations, the self-attention mechanism has an advantage over the MLP encoder due to its use of smaller parameter vectors for training and execution. Essentially, the permutation invariance of QMIX-Attn reduces the dimension of the observation-action space, thus enhancing the algorithm’s performance. Compared to DMDRS-VDN, DMDRS-QMIX performs better due to the stronger fitting characteristics of its mixing network.
In terms of training efficiency, the proposed QMIX-Attn outperforms the QMIX and VDN algorithms. This is mainly because the attention mechanism extracts more effective features, enabling the algorithm to converge quickly.
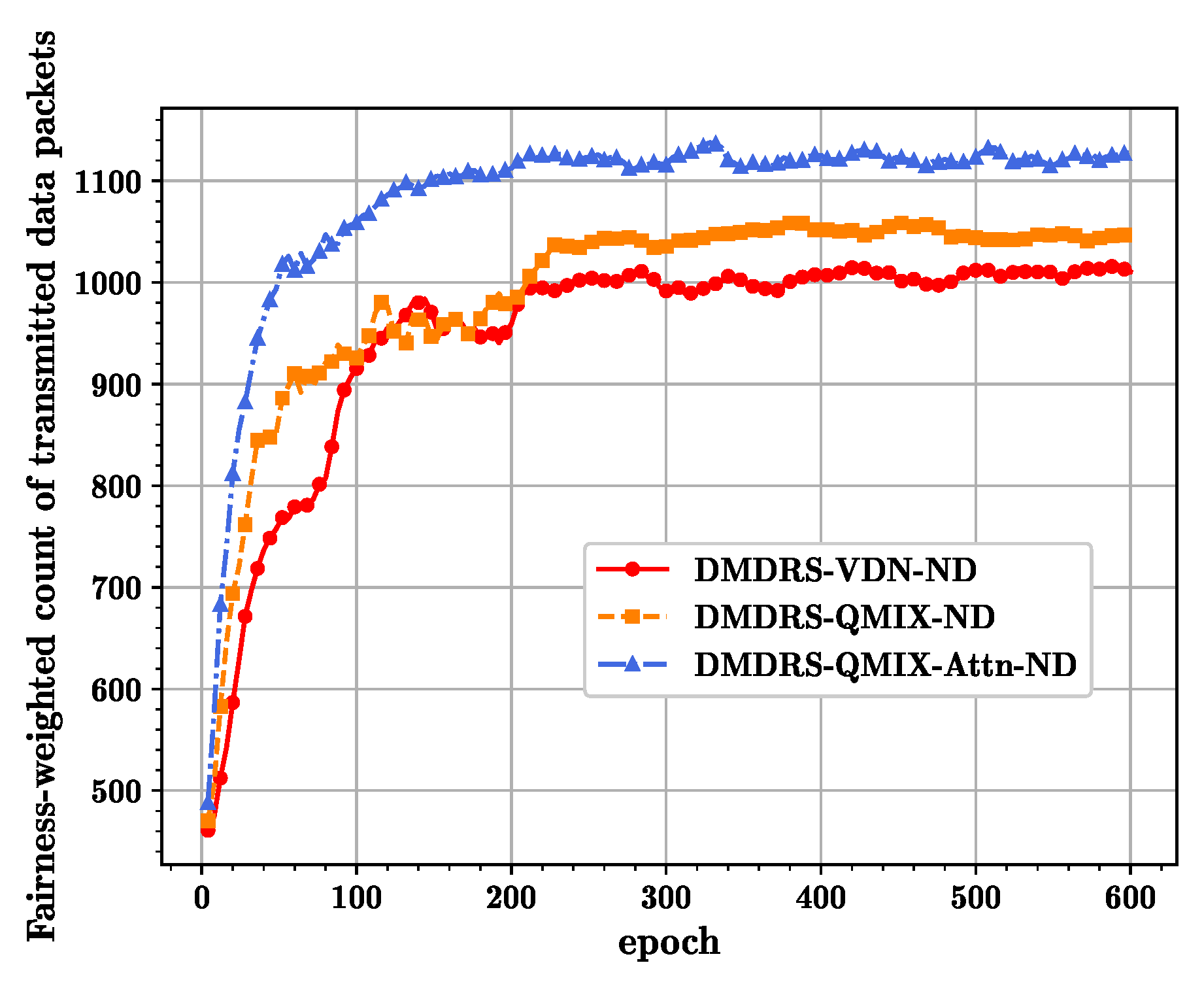
Figure 5 shows the convergence curves for different algorithms without the main lobe direction scheduling in terms of the fairness-weighted count of transmitted data packets, where the QMIX-Attn algorithm still performs the best. Comparing
Figure 4 and
Figure 5, the fairness-weighted count of transmitted data packets with the main lobe direction scheduling is better than that without the main lobe direction scheduling. The main reason is that the main lobe direction scheduling reduces external and internal interference, thus enhancing network transmission performance.
Based on the networks trained with the algorithms from
Figure 4 and
Figure 5,
Figure 6,
Figure 7 and
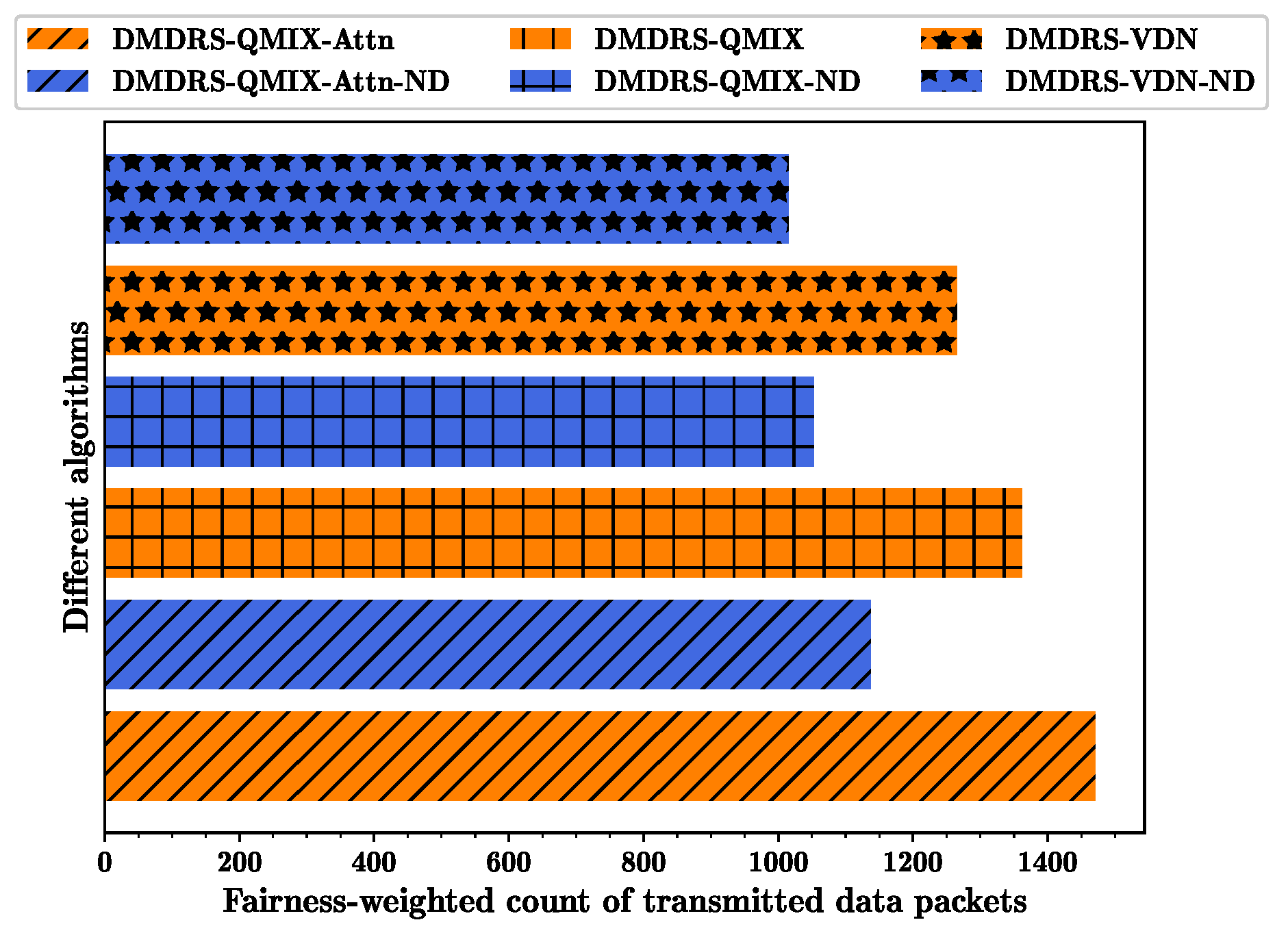
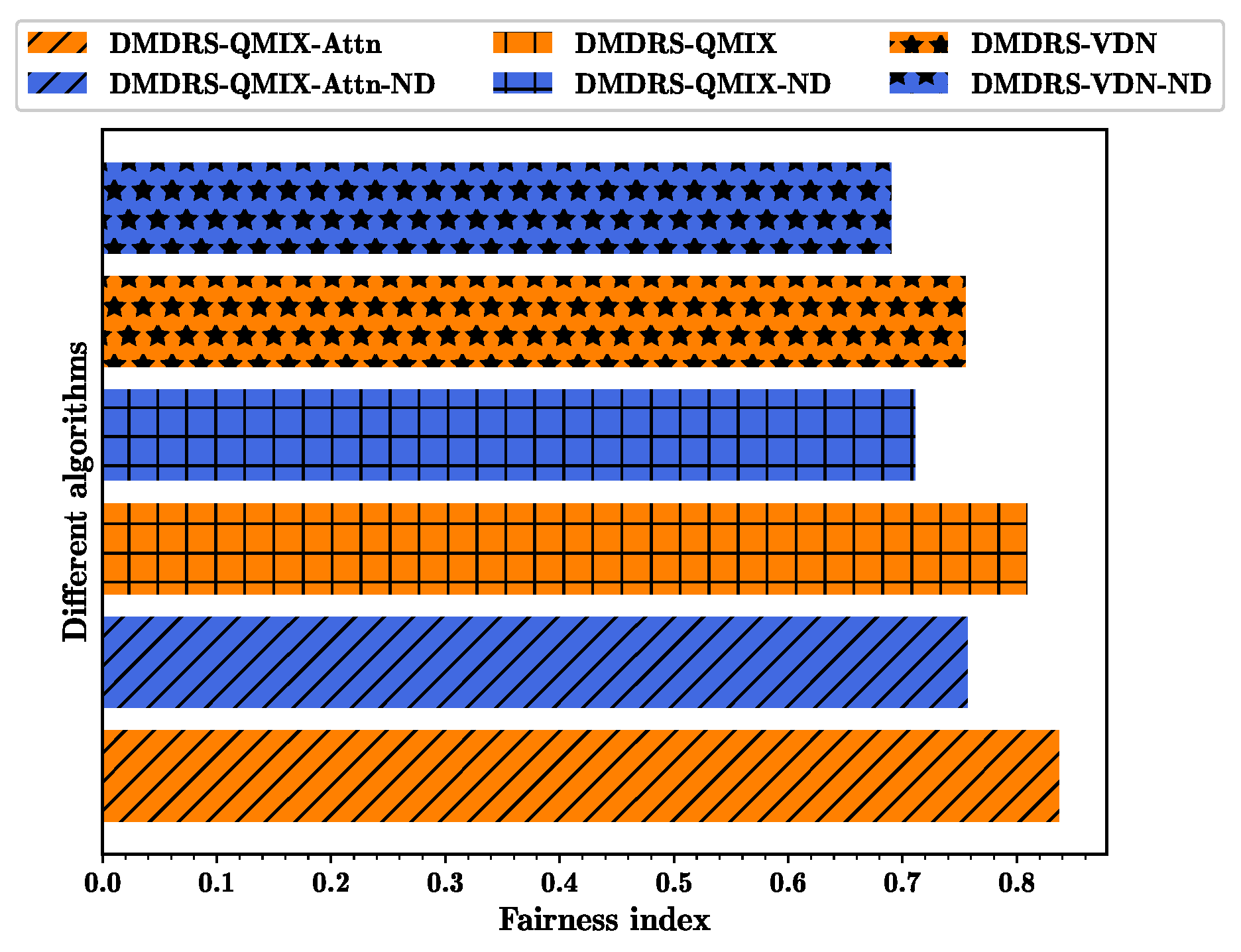
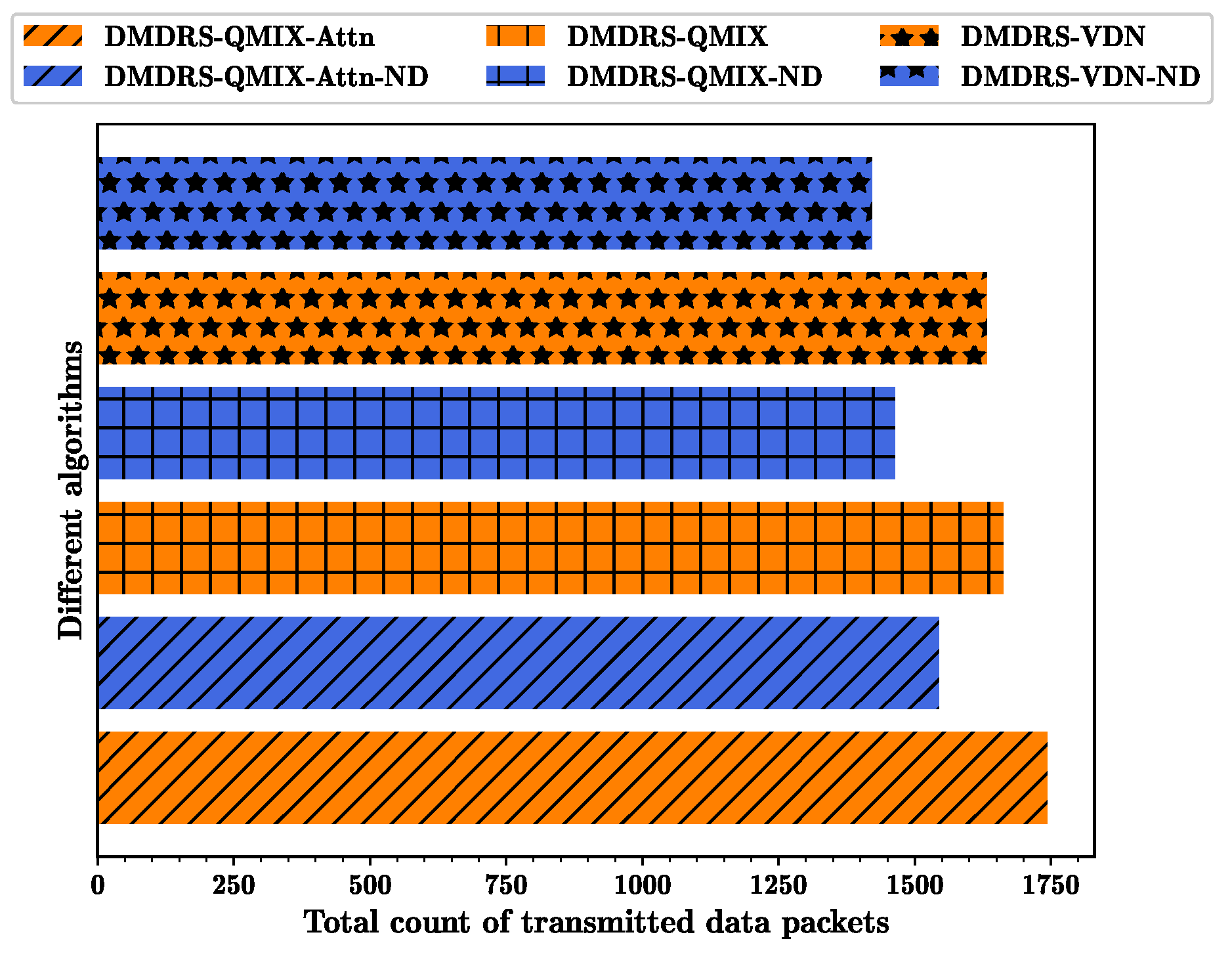
Figure 8 show the fairness-weighted count of transmitted data packets, the fairness index, and the total count of transmitted data packets per frame for different algorithms, respectively. In
Figure 6, the DMDRS-QMIX-Attn demonstrates the best performance in terms of the fairness-weighted count of transmitted data packets, resulting in better fairness and transmission performance compared to DMDRS-QMIX and DMDRS-VDN. Compared with the algorithms without the main lobe direction scheduling, the algorithms with the main lobe direction scheduling can enhance the DUANET’s fairness and packet transmission performance. The primary reason is that an algorithm with the main lobe direction scheduling can reduce interference from neighboring UAVs and the external interference node, thereby improving the network’s transmission performance.
5.3. Comparison of Scenarios with Different Parameters
In this section, we mainly verify the superiority of the proposed algorithm under different scenarios. Hence, we conducted a simulation and analysis on scenarios with different data packet generation rates, different main lobe gains, and different main lobe widths. The following simulation results are based on the execution after 600 epochs of training. In order to verify the adaptability and scalability of the proposed algorithm in dynamic environments, the channel environment is randomly generated according to the set parameters, and the number of packets to be transmitted for each link is randomly generated based on a Poisson distribution.
From
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8, DMDRS-QMIX-Attn and DMDRS-QMIX outperform DMDRS-VDN to solve the MDRS problem. For DMDRS algorithms without main direction scheduling, DMDRS-QMIX-Attn-ND outperforms DMDRS-QMIX-ND and DMDRS-VDN-ND. Therefore, we further compare the three algorithms: DMDRS-QMIX-Attn, DMDRS-QMIX, and DMDRS-QMIX-Attn-ND. The comparison between DMDRS-QMIX-Attn and DMDRS-QMIX validates the effectiveness of the proposed attention mechanism, while the comparison between DMDRS-QMIX-Attn and DMDRS-QMIX-Attn-ND validates the advantages of the main lobe direction scheduling.
5.3.1. The Performance with Different Data Packet Generation Rates
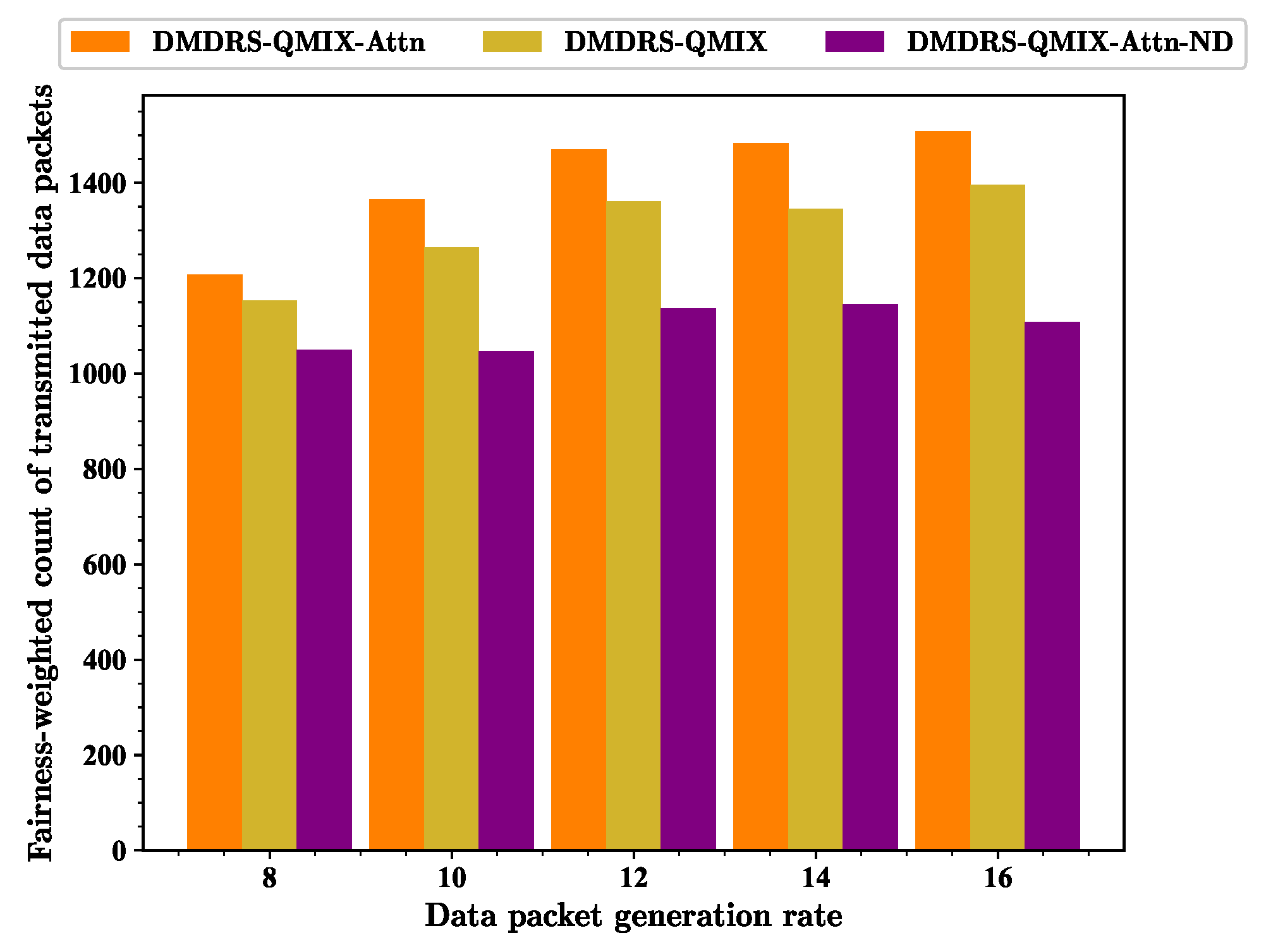
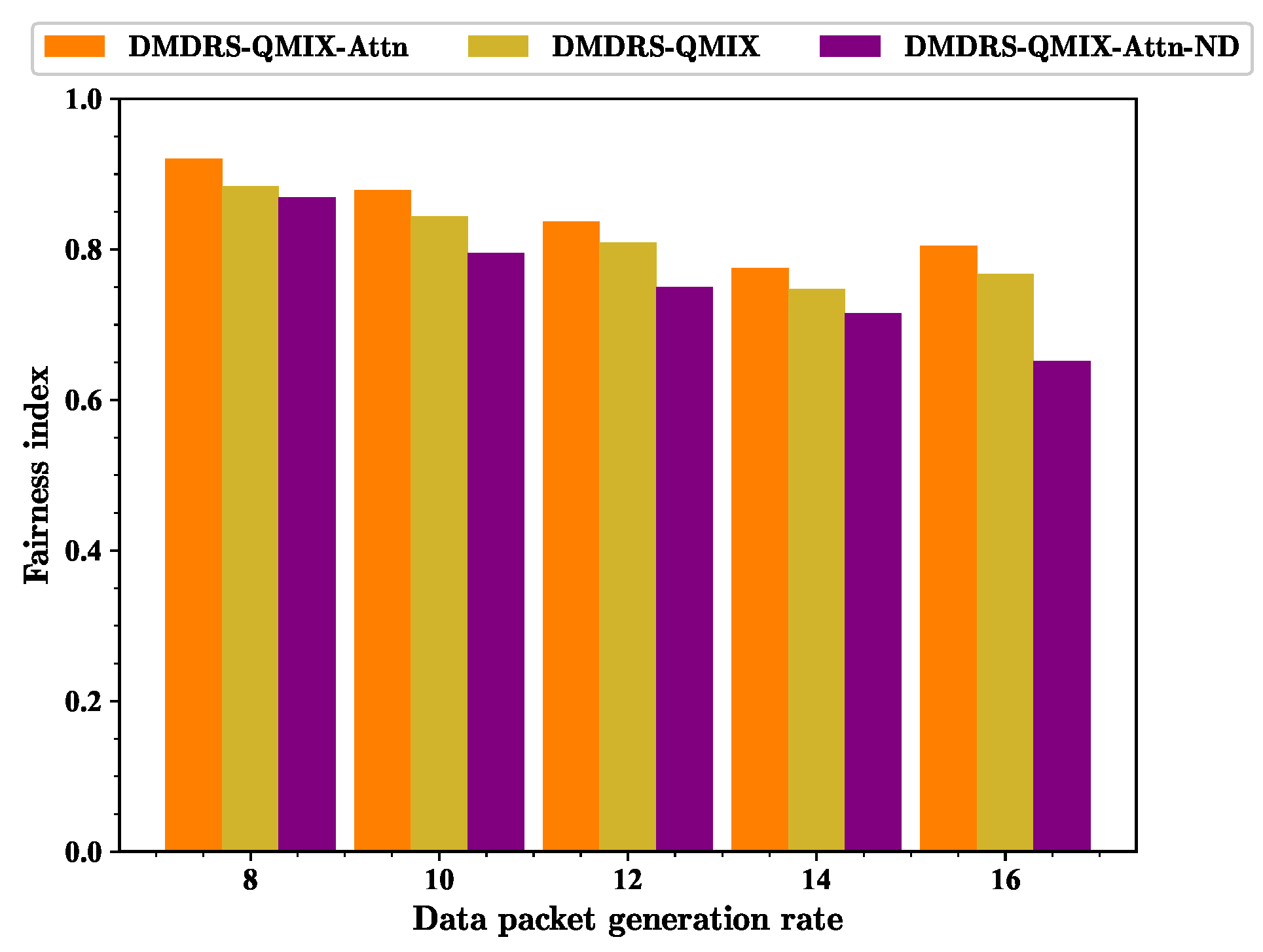
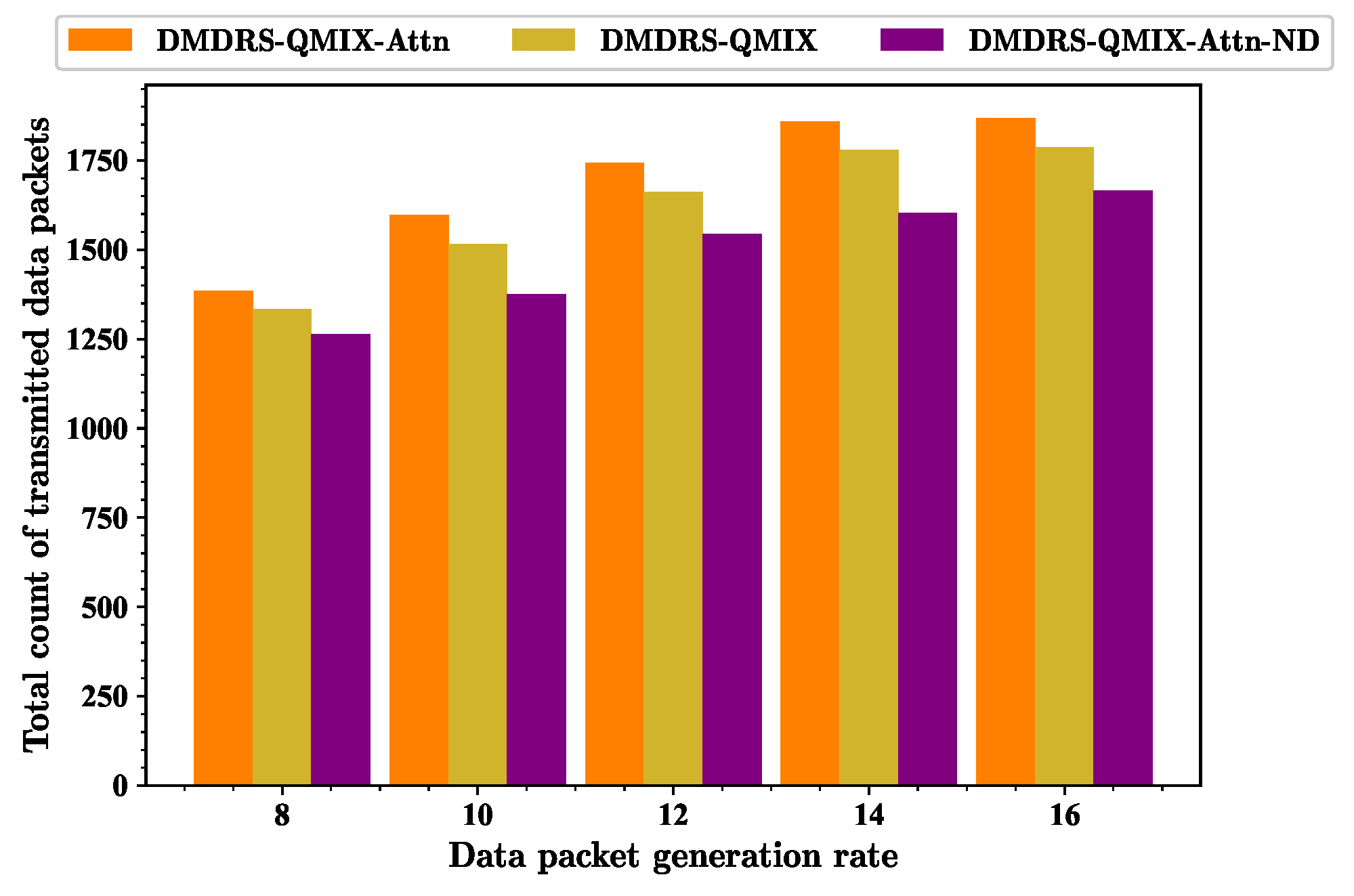
First, the impact of different Poisson distribution parameters on the proposed algorithm is considered. The essence of the different Poisson distribution parameters is the different data packet generation rates.
Figure 9,
Figure 10 and
Figure 11 show the performance of three different metrics under scenarios with different data packet generation rates for various algorithms. As the data packet generation rate increases, the fairness-weighted count of transmitted data packets does not always increase. The main reason is that as the data packet generation rate increases, the fairness index tends to decrease while the total count of transmitted data packets increases. The fairness index and the total count of transmitted data packets jointly affect the fairness-weighted count of transmitted data packets.
As the data packet generation rate increases, the fairness index gradually decreases. The fundamental reason for this is that as each link generates more data packets, the algorithm tends to allow links with better interference scenarios to transmit data for the better fairness-weighted count of transmitted data packets, leading to a decline in transmission fairness.
As the data packet generation rate increases, the total count of transmitted data packets of all algorithms shows an upward trend. The proposed attention mechanism for observation processing and the main lobe direction scheduling improves the fairness index and the total count of transmitted data packets with different data packet generation rates.
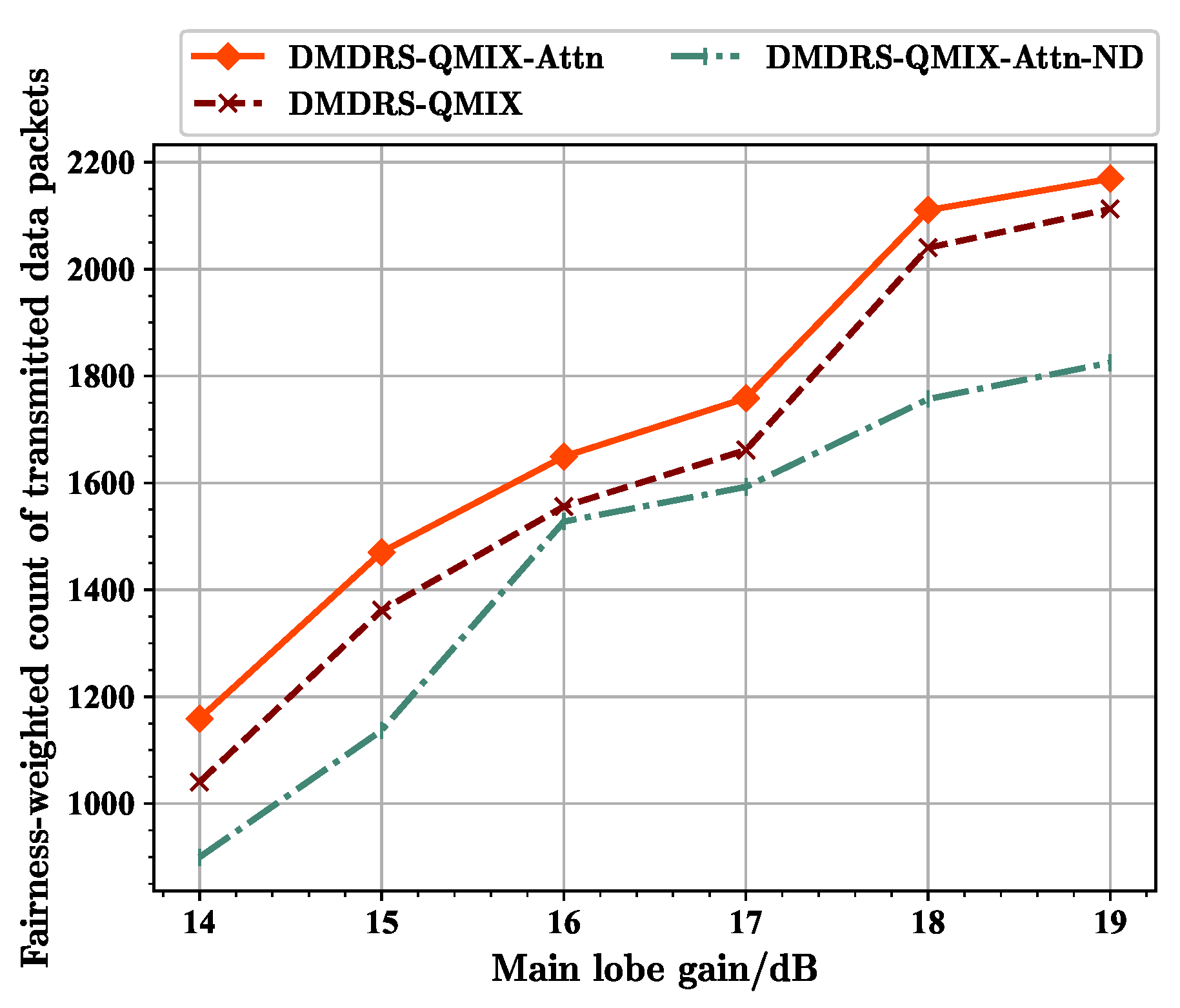
5.3.2. The Performance with Different Main Lobe Gains
Next, we conducted a simulation and analysis of different algorithms under varying main lobe gains. The performance of three different metrics for different main lobe gains are shown in
Figure 12,
Figure 13, and
Figure 14, respectively. As the main lobe gain increases, three metrics for different algorithms exhibit an upward trend.
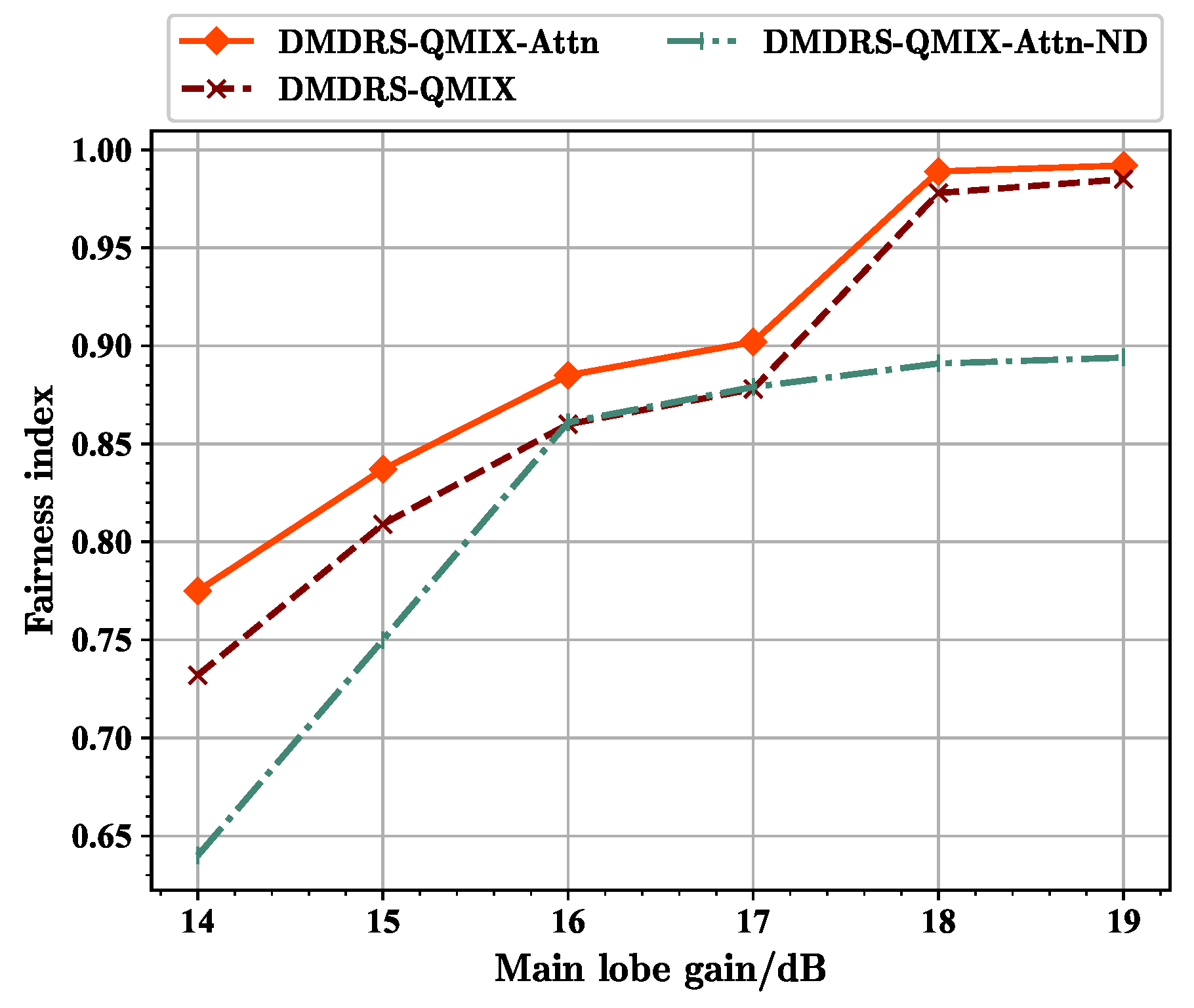
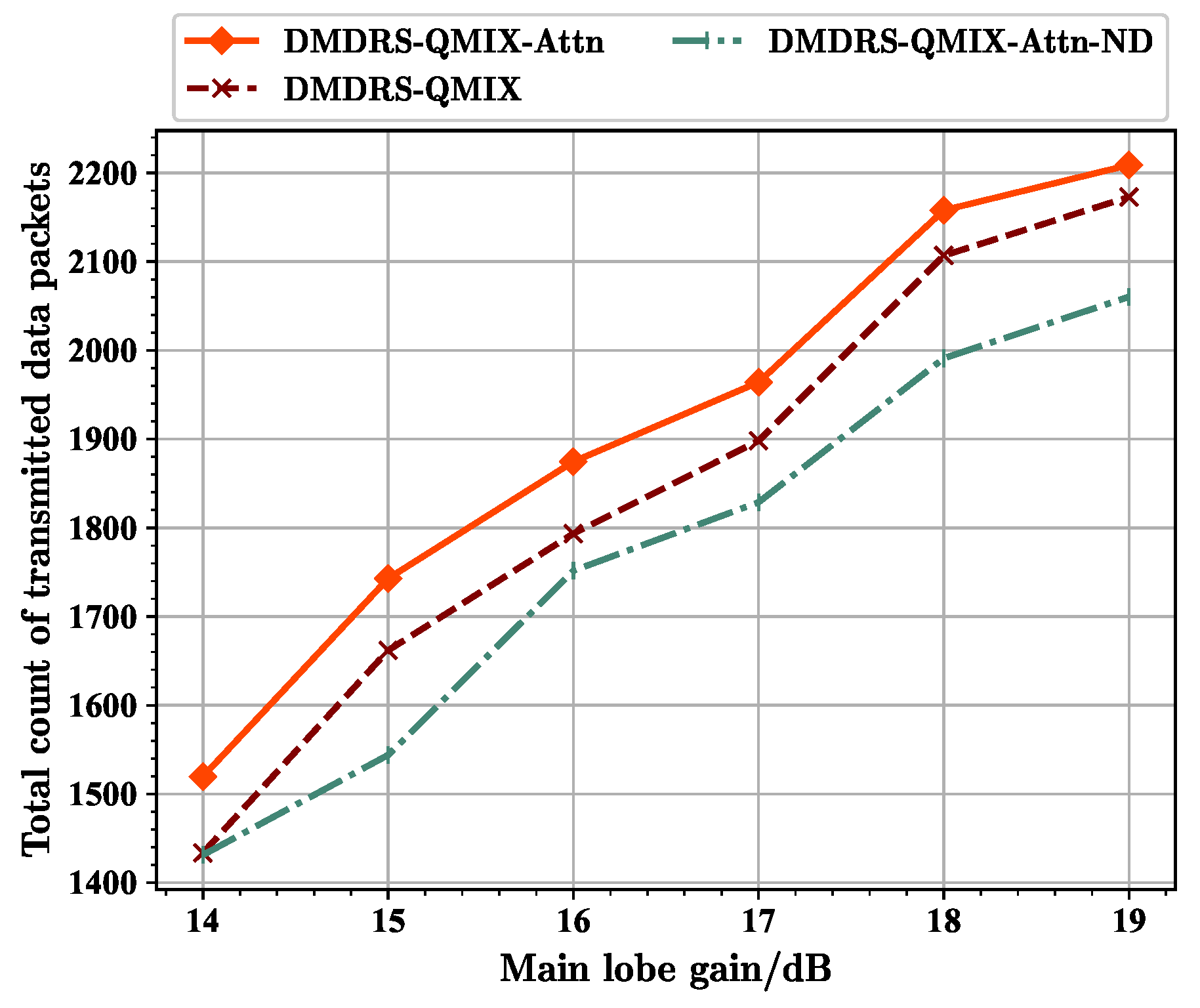
From
Figure 12, it can be seen that at 16 dB, the fairness-weighted count of transmitted data packet of the DMDRS-QMIX-Attn-ND algorithm approaches that of the DMDRS-QMIX algorithm. This is related to different main lobe gains. Under the scenario with a gain of 16 dB, the benefit of algorithm with the main lobe direction scheduling is small, resulting in the DMDRS-QMIX-Attn-ND using only the attention mechanism and achieving a performance close to the DMDRS-QMIX algorithm. From
Figure 13, it can be seen that at main lobe gains of 16 dB and 17 dB, the fairness index of the DMDRS-QMIX-Attn-ND algorithm is even slightly better than that of the DMDRS-QMIX algorithm. However, from
Figure 14, it can be seen that the DMDRS-QMIX algorithm obtained a better performance in terms of the total count of transmitted data packets compared with the DMDRS-QMIX-Attn-ND algorithm. The strategy learned by the DMDRS-QMIX algorithm is to achieve a better performance by increasing the total count of transmitted data packets.
Overall, due to the attention mechanism and main lobe direction scheduling, the DMDRS-QMIX-Attn algorithm obtained a better performance under scenarios with different main lobe gains.
5.3.3. The Performance with Different Main Lobe Widths
Finally, the impact of main lobe beamwidth on network and algorithm performance was examined by varying the main lobe width. Additionally, changing the main lobe beamwidth will alter the number of UAVs observed within the main lobe range. Here, the maximum gain of directional communication remains unchanged, which is 15dB. By varying the main lobe width, the proposed algorithm’s superiority under dynamic numbers of neighboring nodes is further validated.
For the fairness-weighted count of transmitted data packets, it can be seen that the proposed DMDRS-QMIX-Attn performs the best in
Figure 15. When the beamwidth is 10°, the fairness-weighted count of transmitted data packets is optimal due to the reduced mutual interference between each link in the DUANET. Additionally, because the observation range is smaller and the number of observed nodes is lower, the performance advantage of the self-attention mechanism in feature extraction is only improved by 3.57%. Thus, the performance improvement in terms of the fairness-weighted count of transmitted data packets of DMDRS-QMIX-Attn based on the attention mechanism is not significant compared to DMDRS-QMIX based on MLP. When the beamwidth is 30°, the mutual interference and external interference among the links in the network increase, leading to a decrease in communication performance. However, since the number of observed nodes increases, the performance advantage of the self-attention mechanism in feature extraction becomes more significant, improving by 22.17%. Therefore, the DMDRS-QMIX-Attn algorithm, based on the attention mechanism, can achieve better performance in terms of the fairness-weighted count of transmitted data packets compared with the DMDRS-QMIX based on MLP.
From
Figure 6,
Figure 7 and
Figure 8, it can be seen that the the main lobe direction scheduling can mitigate mutual interference between networks. Combined with
Figure 15, it can be further concluded that the main lobe direction scheduling cannot completely avoid internal and external interference in the communication system but can only reduce internal network interference. This is also the reason why narrowing the main lobe width reduces mutual interference between links and external interference, thereby further improving the fairness-weighted count of transmitted data packets of the entire network.
When the main lobe width increases and the mutual interference between links grows, the main lobe direction scheduling for improving the fairness-weighted count of transmitted data packets becomes more significant. At this time, the adjustable range of the main lobe also expands. When the beamwidth is 10°, the DMDRS-QMIX-Attn algorithm only improves the fairness-weighted count of transmitted data packets by 2.78% compared to the DMDRS-QMIX-Attn-ND algorithm. However, when the beamwidth is 30°, the fairness-weighted count of transmitted data packets of DMDRS-QMIX-Attn and DMDRS-QMIX-Attn-ND are 1125.89 and 673.94, respectively. Therefore, we can conclude that the DMDRS-QMIX-Attn algorithm improves the fairness-weighted count of transmitted data packets by 67.06% compared to the DMDRS-QMIX-Attn-ND algorithm under this beamwidth scenario.
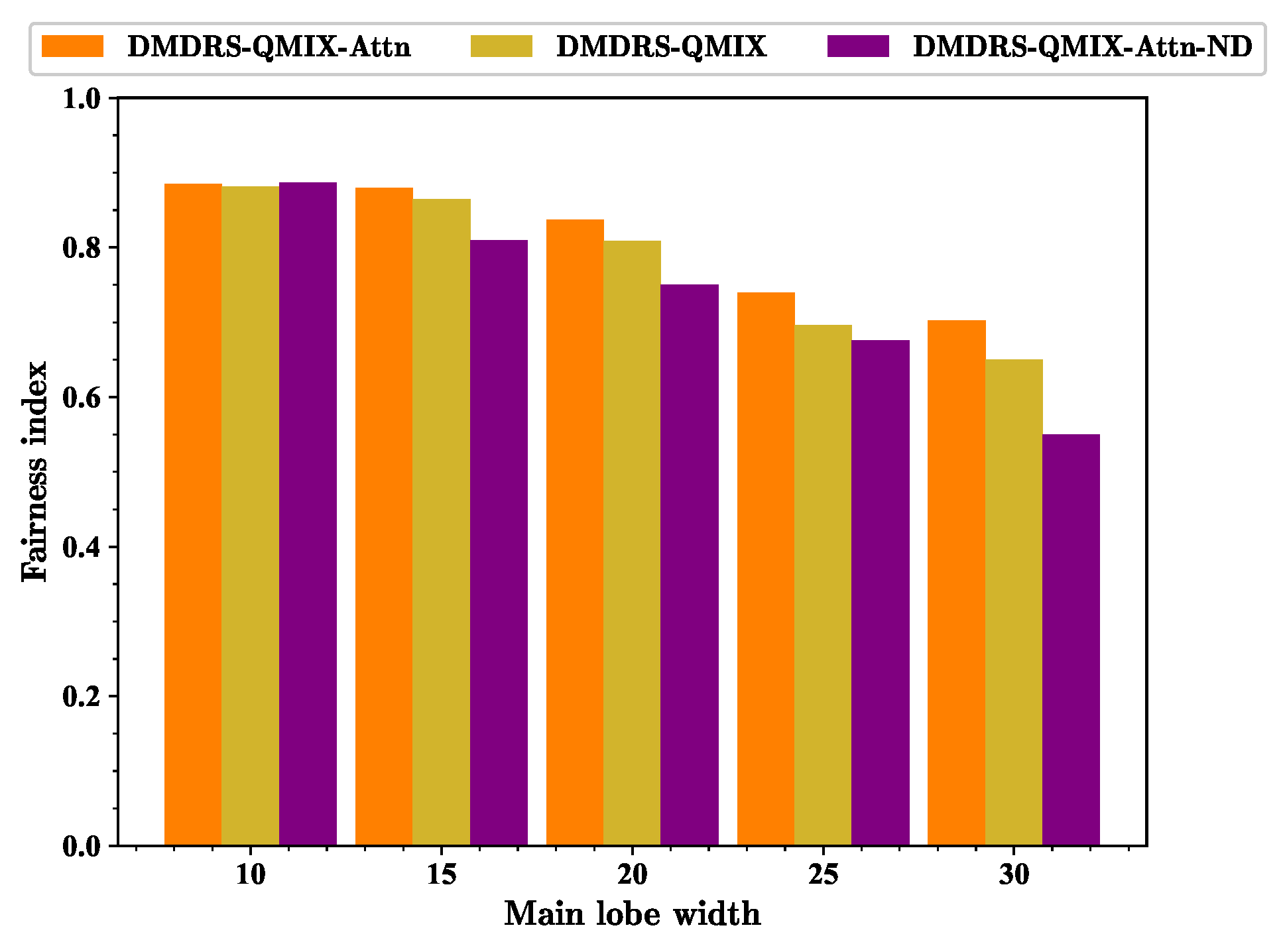
Figure 16 shows the fairness index of different algorithms. The DMDRS-QMIX-Attn algorithm is not always optimal in terms of the fairness index. This is mainly because the optimization goal is to maximize the fairness-weighted count of transmitted data packets rather than the fairness index. As shown in
Figure 17, DMDRS-QMIX-Attn has the best performance in terms of the total count of transmitted data packets. Therefore, it can be concluded that a better fairness index does not necessarily improve the performance in terms of the fairness-weighted count of transmitted data packets. Combining
Figure 9 and
Figure 10, it is further demonstrated that the fairness-weighted count of transmitted data packets is jointly determined by the fairness index and the total count of transmitted data packets.
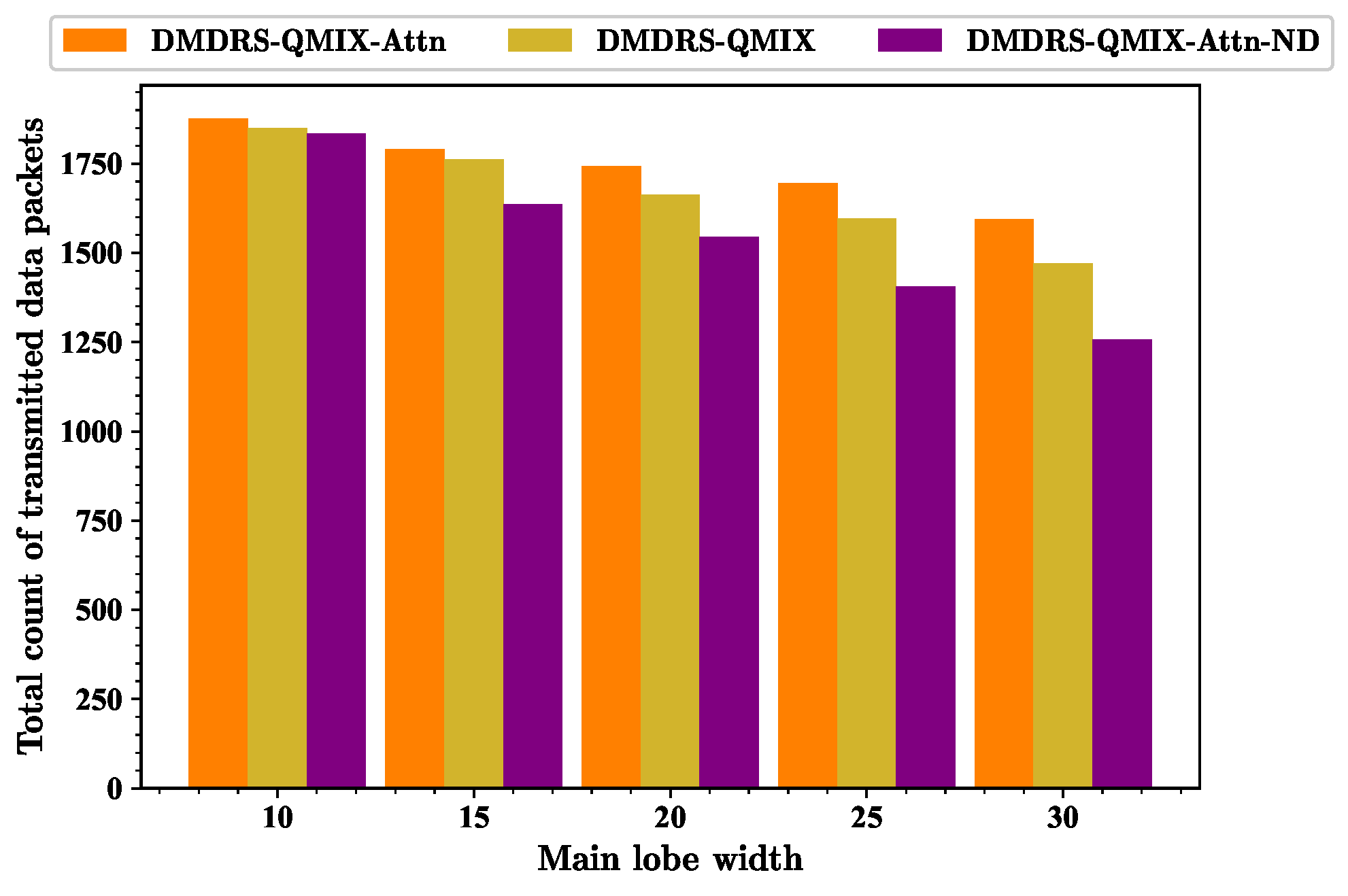
Figure 17 shows the total count of transmitted data packets of different algorithms. As the beamwidth is 30°, the fairness index of DMDRS-QMIX-Attn and DMDRS-QMIX is 0.702 and 0.65, respectively. The performance of DMDRS-QMIX-Attn and DMDRS-QMIX is 1594.2 and 1469.9 in terms of the total count of transmitted data packets, respectively. Therefore, the attention mechanism achieves better performance than MLP. The performance of DMDRS-QMIX-Attn-ND is 0.55 and 1256.9 in terms of the fairness index and the total count of transmitted data packets, respectively. Hence, compared with DMDRS-QMIX-Attn, we can conclude that the scheduling of the time slot, power, and main lobe direction achieves better communication performance than the scheduling of only the time slot and power. For the scenarios with different main lobe widths, DMDRS-QMIX-Attn achieves the best performance of the total count of transmitted data packets. Its performance improvement mainly stems from the algorithm’s attention mechanism and main lobe direction scheduling.
6. Discussion
The proposed algorithm can be applied to various DUANET scenarios, such as collaborative military reconnaissance, earthquake rescue, and communication support in civilian applications. For future applications, we plan to deploy the training phase of the algorithm at a ground station and then deploy the Q-network trained by the ground station at the transmitters to enable autonomous resource scheduling decisions by UAVs. Since MADRL algorithms generally assume clock synchronization, ensuring the synchronization of clocks across all network nodes is crucial in practical applications. However, achieving strict clock synchronization in an engineering application is challenging. Therefore, how to perform resource scheduling with clock errors is a key issue that needs to be addressed for the proposed algorithm in practical engineering. This is a system design issue that involves the coupling of the physical layer, the Media Access Control (MAC) layer, and the proposed algorithm. We plan to adopt a more precise network synchronization algorithm and a MAC layer protocol designed for information exchange to ensure resource scheduling even in the presence of errors.
Next, we will consider using directional antenna models in practical engineering to achieve multi-dimensional resource scheduling for time, frequency, spatial, and power domains. The scheduling of the main lobe direction is related to the granularity of the actual directional antenna, so the action space for the main lobe direction needs to be adjusted according to the actual granularity [
3]. Another challenge lies in the fact that reinforcement learning optimization for more dimensions of resources will lead to an excessively large action space, resulting in less effective multi-dimensional resource scheduling. Therefore, addressing the issue of large action spaces in reinforcement learning will be a key challenge for future work.
7. Conclusions
This paper proposes a MADRL algorithm to enhance network transmission performance by joint scheduling of the time slot, power, and main lobe direction in DUANETs. First, The MDRS problem is formulated to maximize the fairness-weighted count of transmitted data packets, which can be reformulated as the Dec-POMDP. Then, an attention mechanism is proposed to handle the dynamic dimensional observations of Dec-POMDP, and a QMIX-Attn algorithm is introduced by combining this attention mechanism with the QMIX algorithm. Finally, VDN, QMIX, and QMIX-Attn are used to solve the constructed Dec-POMDP. Simulation comparisons in various scenarios show that the proposed QMIX-Attn algorithm outperforms both QMIX and VDN algorithms in terms of the fairness-weighted count of transmitted data packets. Compared with algorithms without the main lobe direction scheduling, the proposed algorithm achieves better transmission fairness and total count of transmitted data packets. As the main lobe width increases, the performance of the attention mechanism and main lobe direction scheduling improves further. With a main lobe width of 30°, the attention mechanism and main lobe direction scheduling improve the optimization objectives by 22.17% and 67.06%, respectively.
In the discussion, we address the practical applications, limitations, and challenges of the proposed algorithms. We also provide an outlook on our future work.






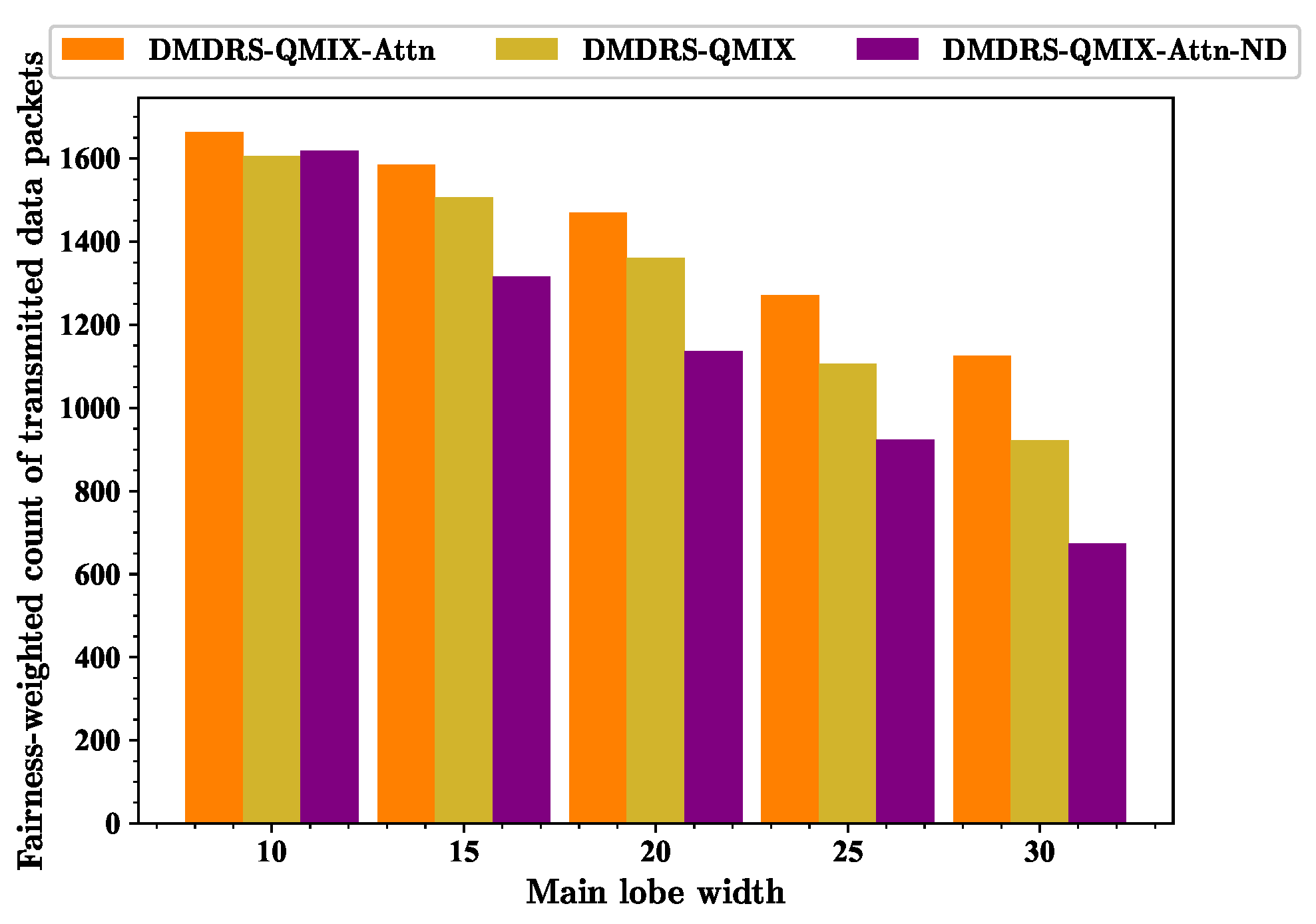

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}