



Joint Computation Offloading and Trajectory Optimization for Edge Computing UAV: A KNN-DDPG Algorithm


Abstract
1. Introduction
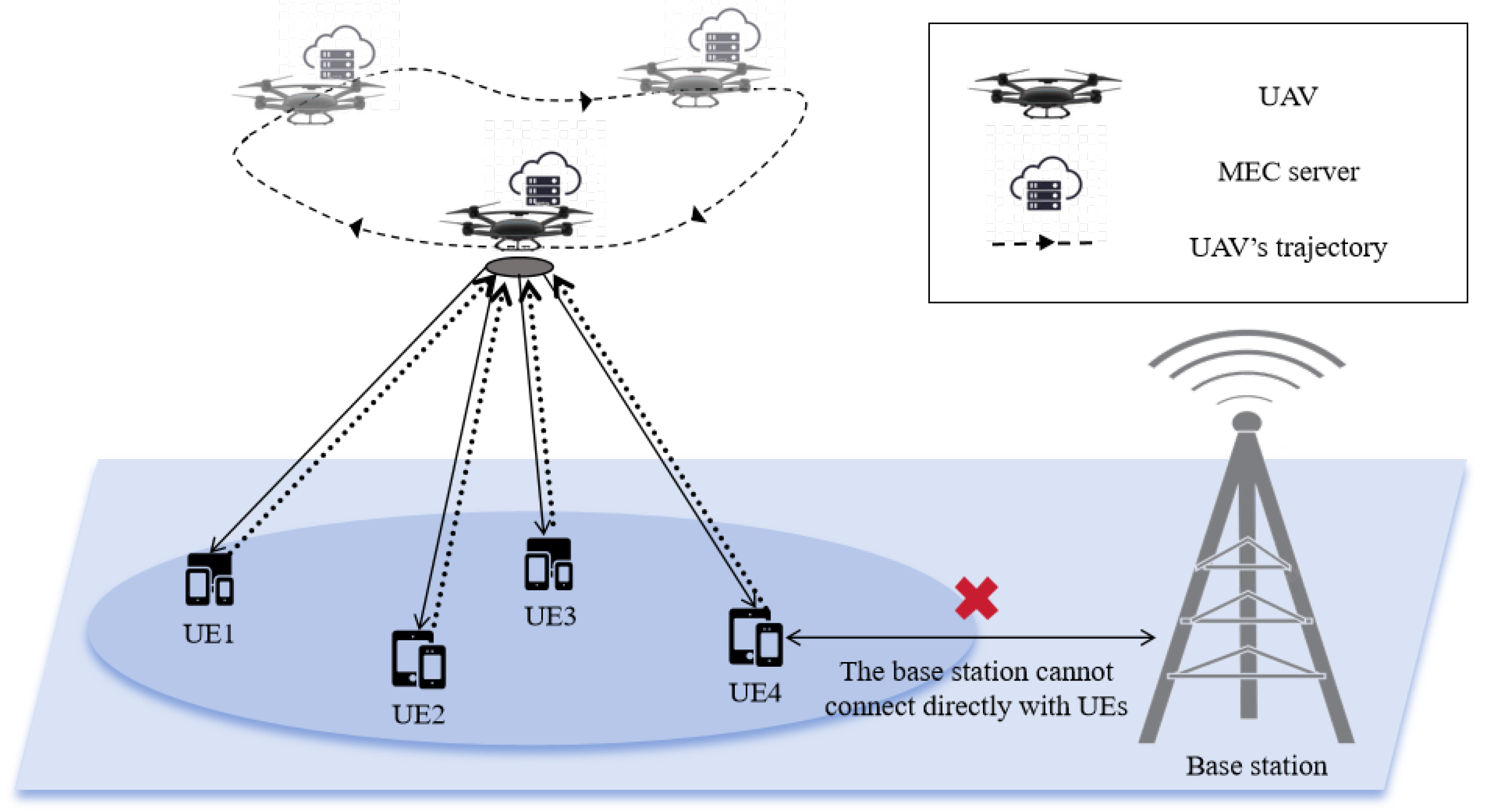
- Considering the UAV-assisted MEC system in the presence of obstacle blocked, the joint computation offloading and trajectory optimization (JCOT) problem under a dynamic channel is modeled. Under energy constraints, the JCOT problem is solved by jointly optimizing UE scheduling, computation offloading ratio of UE, UAV trajectory to minimize the maximum computational delay.
- For the JCOT problem, the corresponding Markov decision process (MDP) is designed and formulated, and the KNN-DDPG algorithm is proposed based on the constructed problem. The developed program improves the exploration capabilities of the DDPG in two ways. It enhances the exploration breadth of algorithm by utilizing categorical counting based on the KNN algorithm. Additionally, it improves the algorithm depth of exploration for important data by utilizing sampling based on the PER algorithm.
- Extensive simulations validate that the proposed algorithm improves DDPG under different parameters and communication conditions, and is more stable than other baseline algorithms.
2. Related Work
2.1. Literature Summary
- Minimize energy consumption for the entire system or mobile UE. Wang et al. proposed a collaborative resource optimization problem to minimize the total energy consumption of the system by jointly optimizing computation offloading, UAV flight trajectory and edge computing resource allocation [18]. However, this strategy does not effectively exploit the advantages of UAVs in terms of flexibility, mobility and ease of deployment. Wang et al. minimized the total UAV energy consumption through joint partitioning and UAV trajectory scheduling to extend UAV flight time and network lifetime [19].
- Minimize task completion time. Nath et al. studied a multi-user cache-assisted MEC system with stochastic task arrivals and proposed a DDPG-based dynamic scheduling strategy to jointly optimize dynamic caching, computation offloading, and resource allocation in the system [20]. Gao et al. developed a deep reinforcement learning-based approach for trajectory optimization and resource allocation, which intelligently manages the time allocation of TDs to maximize safe computation capacity using Deep Q-Learning. This method considers constraints such as time, UAV motion, minimum computation capacity, and data stability [21]. However, obstacle blocking in practical applications was not considered.
- Balancing energy consumption and latency. Zeng et al. employed method of Lyapunov to transform the long-term optimization problem into two deterministic online optimization subproblems, which were solved iteratively to balance the trade-off between energy consumption and queue stability for users with heterogeneous demands [22]. Their approach minimized both the energy consumption and completion time of UAVs. Zhang et al. considered random UE data arrivals to minimize the long-term average weighted system energy while ensuring queue stability and adhering to UAV trajectory constraints [23,24]. However, their method does not take into account the movement of UE and the entire trajectory of the UAV from the initial position to the destination is recomputed for each time slot, which increases the computational complexity.
2.2. Motivation and Contribution
3. System Model and Problem Formulation
3.1. Communication Model
3.2. Computation Model
3.3. Problem Formulation
4. The Proposed KNN-DDPG Algorithm
4.1. MDP Modeling
4.1.1. State
4.1.2. Action
4.1.3. Reward
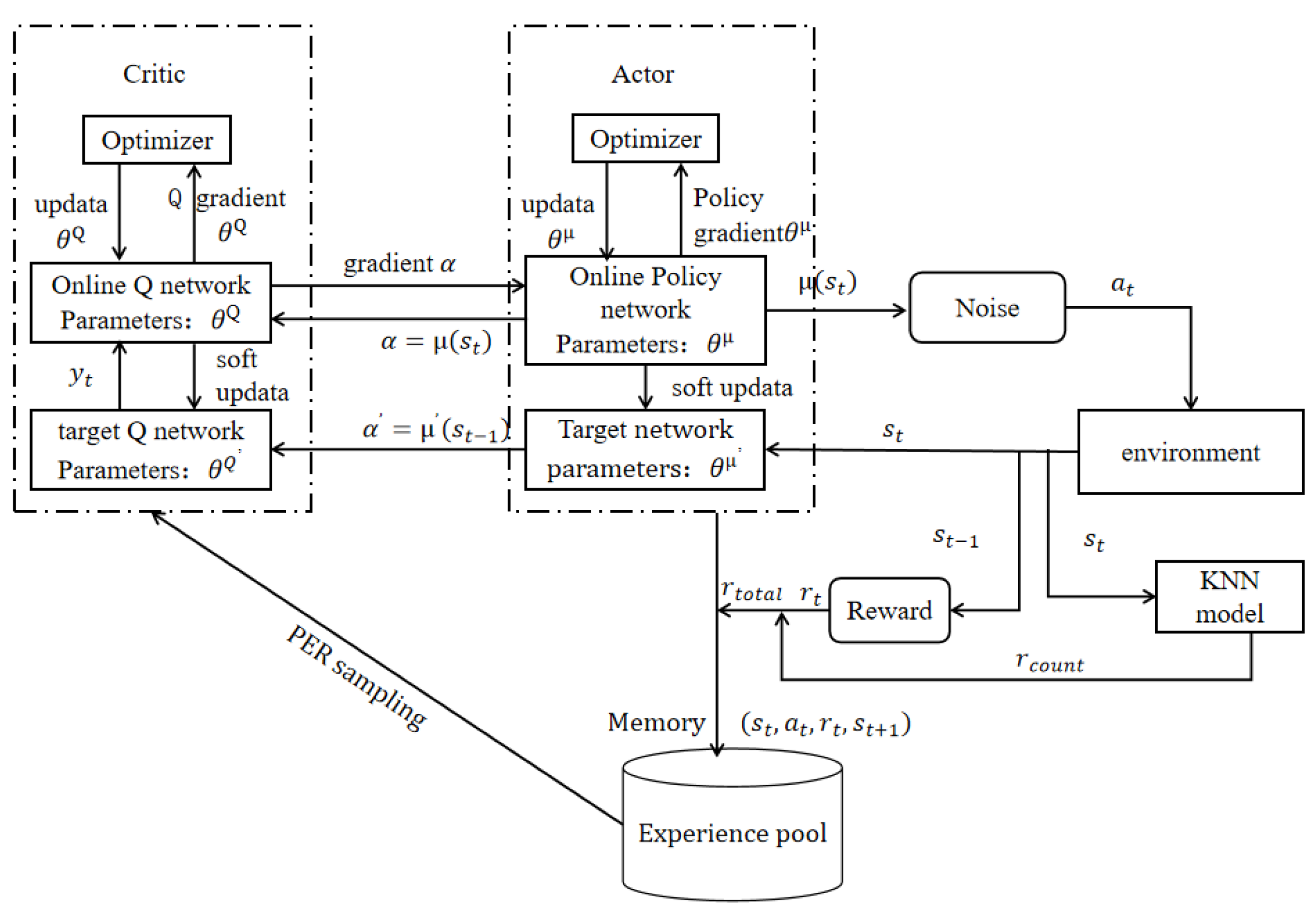
4.2. KNN-DDPG Solution
| Algorithm 1: The proposed KNN-DDPG algorithm |
 |
5. Simulations
5.1. Simulation Setting
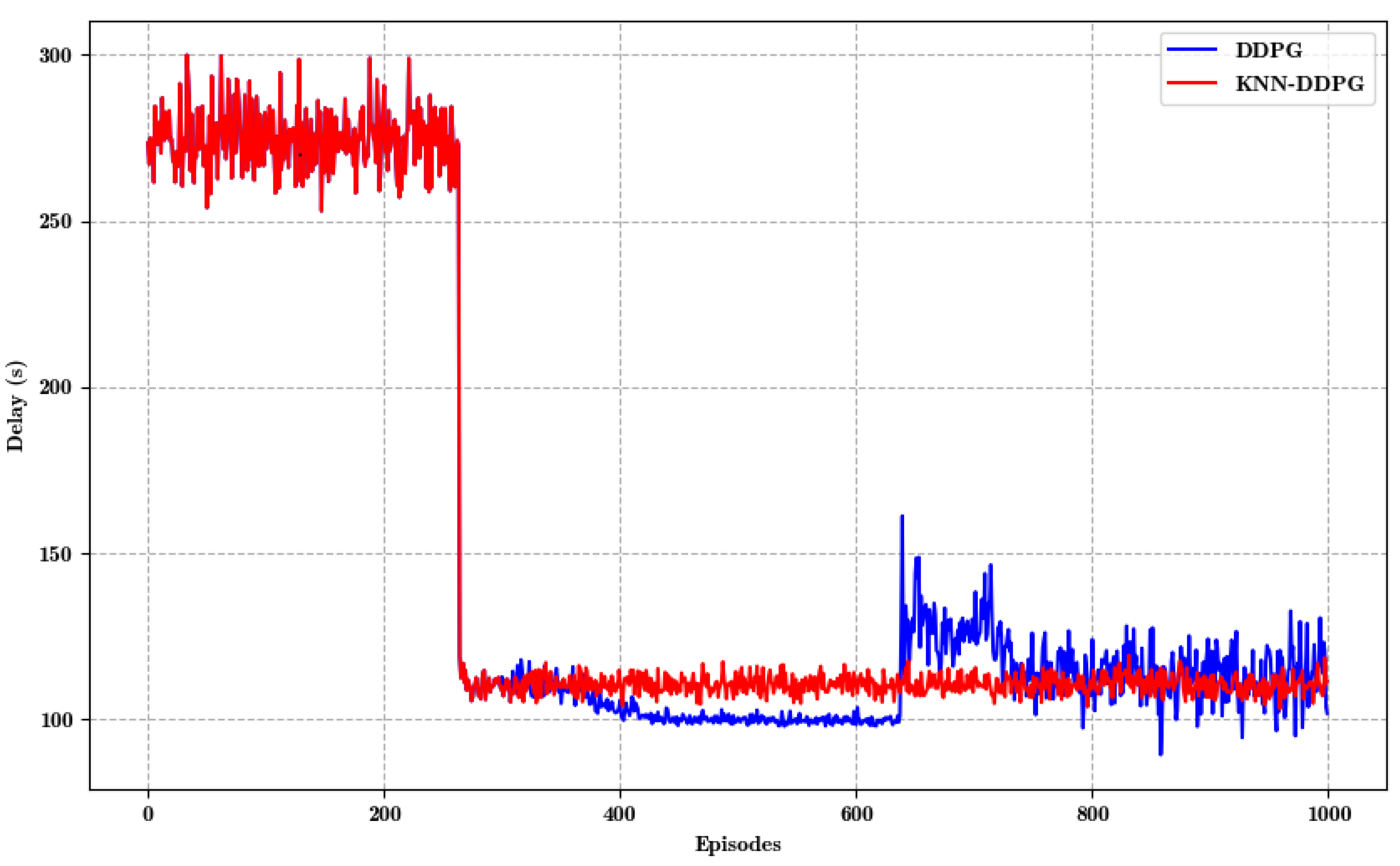
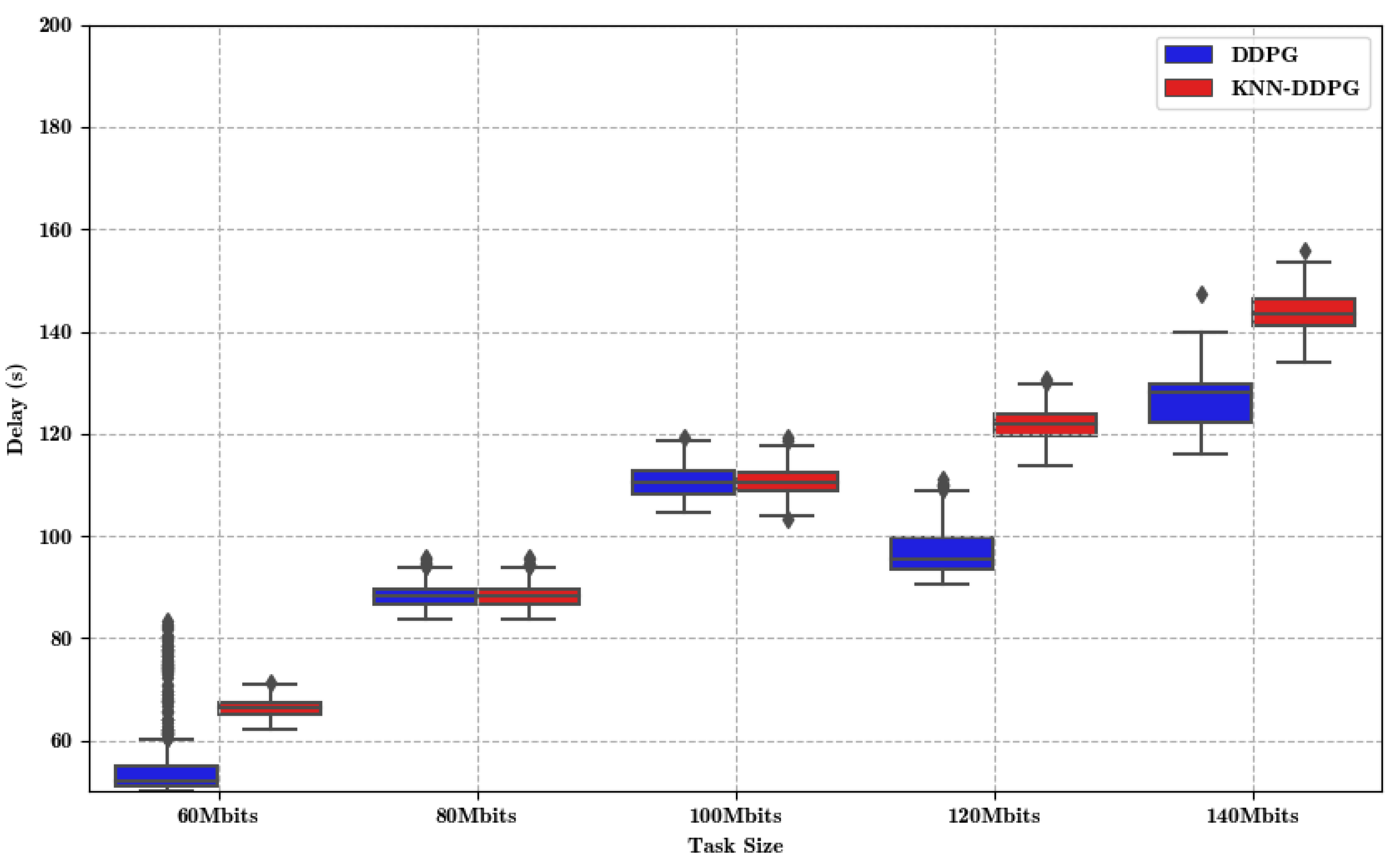
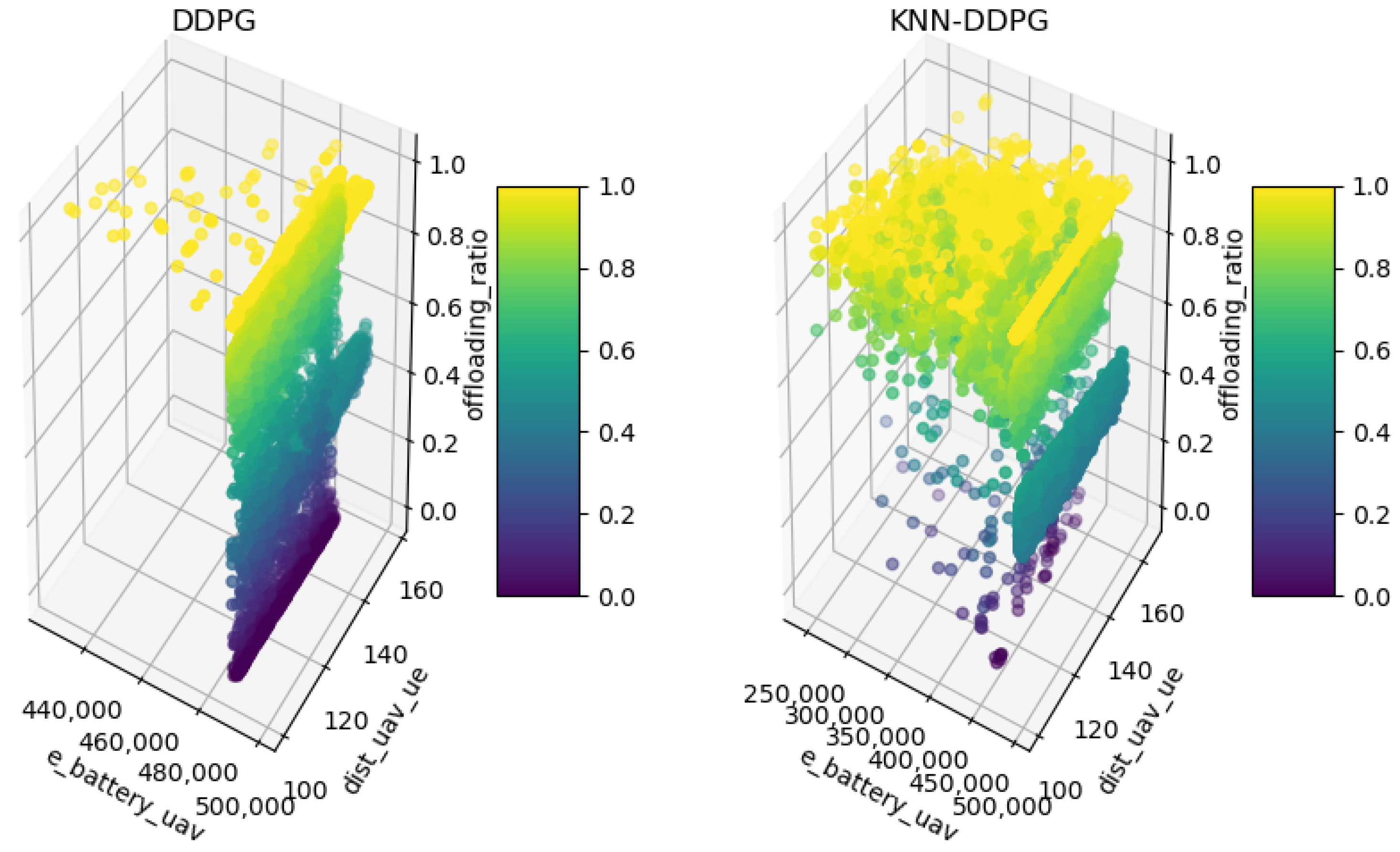
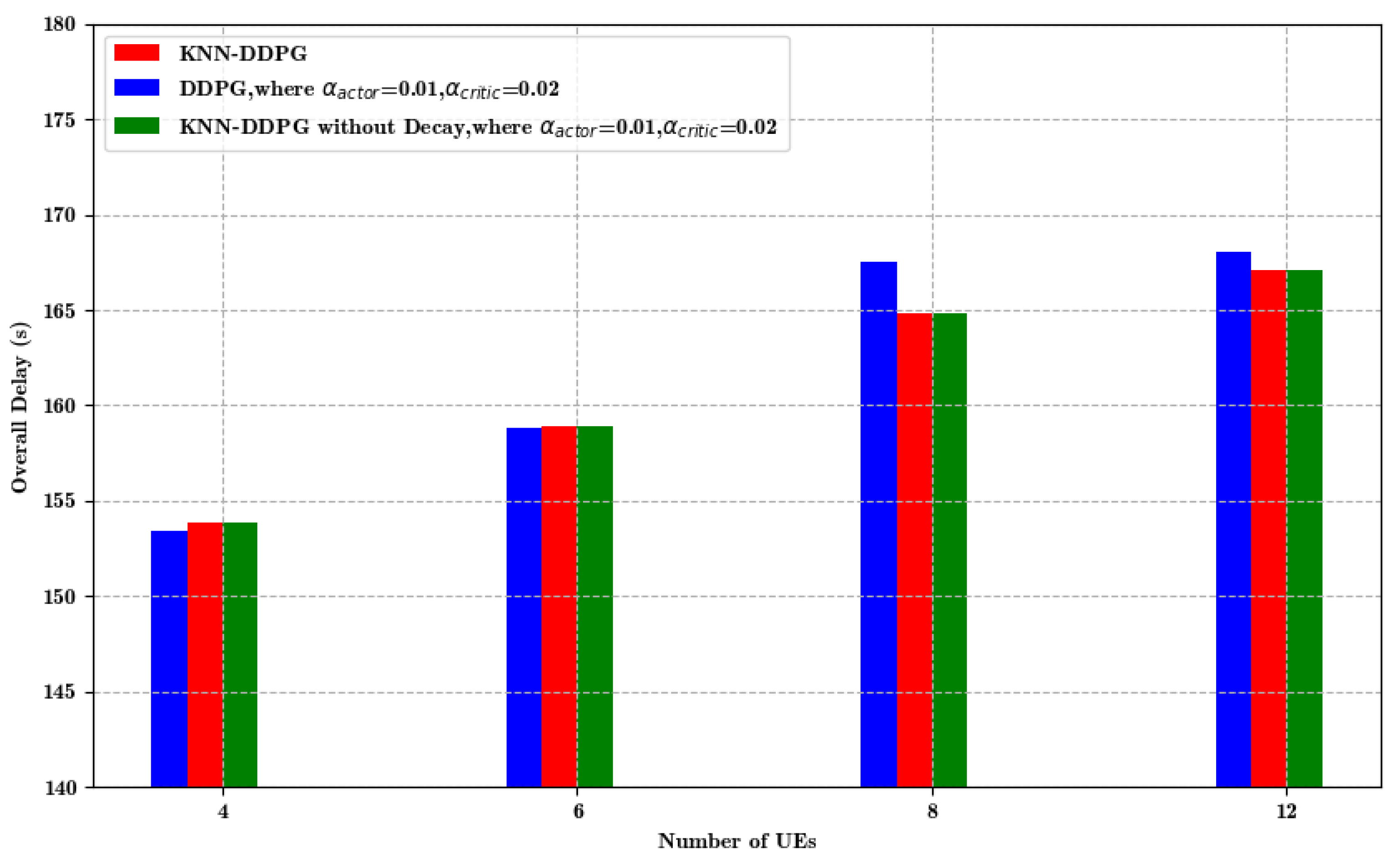
5.2. Result Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cheng, J.; Chen, W.; Tao, F.; Lin, C. Industrial IoT in 5G Environment Towards Smart Manufacturing. J. Ind. Inf. Integr. 2018, 10, 10–19. [Google Scholar] [CrossRef]
- Xu, C.; Yu, H.; Jin, X.; Xia, C.; Li, D.; Zeng, P. Industrial Internet for intelligent manufacturing: Past, present, and future. Front. Inf. Technol. Electron. Eng. 2024, 25, 1173–1192. [Google Scholar] [CrossRef]
- Mach, P.; Becvar, Z. Mobile edge computing: A Survey on Architecture and Computation Offloading. IEEE Commun. Surv. Tutor. 2017, 19, 1628–1656. [Google Scholar] [CrossRef]
- Xu, C.; Zhang, P.; Yu, H.; Li, Y. D3QN-Based Multi-Priority Computation Offloading for Time-Sensitive and Interference-Limited Industrial Wireless Networks. IEEE Trans. Veh. Technol. 2024, 73, 13682–13693. [Google Scholar] [CrossRef]
- Zhao, J.; Li, Q.; Zhang, K. Computation Offloading and Resource Allocation for Cloud Assisted Mobile Edge Computing in Vehicular Networks. IEEE Trans. Veh. Technol. 2019, 18, 7944–7956. [Google Scholar] [CrossRef]
- Lyu, J.; Zeng, Y.; Zhang, R. UAV-Aided Offloading for Cellular Hotspot. IEEE Trans. Wirel. Commun. 2018, 17, 3988–4001. [Google Scholar] [CrossRef]
- Wang, H.; Ding, G.; Gao, F.; Chen, J.; Wang, J.; Wang, L. Power Control in UAV-Supported Ultra Dense Networks: Communications, Caching, and Energy Transfer. IEEE Commun. Mag. 2017, 56, 28–34. [Google Scholar] [CrossRef]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A Survey on Mobile Edge Computing: The Communication Perspective. IEEE Commun. Surv. Tutor. 2017, 19, 28–34. [Google Scholar] [CrossRef]
- Zeng, Y.; Zhang, R.; Lim, T.J. Wireless Communications with Unmanned Aerial Vehicles: Opportunities and Challenges. IEEE Commun. Mag. 2016, 54, 36–42. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, H.; He, Q.; Bian, K.; Song, L. Joint Trajectory and Power Optimization for UAV Relay Networks. IEEE Commun. Lett. 2018, 22, 161–164. [Google Scholar] [CrossRef]
- Xu, C.; Tang, Z.; Yu, H.; Zeng, P.; Kong, L. Digital Twin-Driven Collaborative Scheduling for Heterogeneous Task and Edge-End Resource via Multi-Agent Deep Reinforcement Learning. IEEE J. Sel. Areas Commun. 2023, 41, 3056–3069. [Google Scholar] [CrossRef]
- Ren, X.; Chen, X.; Jiao, L.; Dai, X.; Dong, Z. Joint Optimization of Trajectory, Caching and computation offloading for Multi-Tier UAV MEC Networks. In Proceedings of the 2024 IEEE Wireless Communications and Networking Conference (WCNC), Dubai, United Arab Emirates, 21–24 April 2024; pp. 1–6. [Google Scholar]
- Wei, Q.; Zhou, Z.; Chen, X. DRL-Based Energy-Efficient Trajectory Planning, Computation Offloading, and Charging Scheduling in UAV-MEC Network. In Proceedings of the 2022 IEEE/CIC International Conference on Communications in China (ICCC), Foshan, China, 11–13 August 2022; pp. 1056–1061. [Google Scholar]
- Du, S.; Chen, X.; Jiao, L.; Wang, Y.; Ma, Z. Deep Reinforcement Learning-Based UAV-assisted Mobile Edge Computing Offloading and Resource Allocation Decision. In Proceedings of the 2022 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Prague, Czech Republic, 9–12 October 2022; pp. 2728–2734. [Google Scholar]
- Peng, Y.; Liu, Y.; Zhang, H. Deep Reinforcement Learning Based Path Planning for UAV-assisted Edge Computing Networks. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; pp. 1–6. [Google Scholar]
- He, H.; Yang, X.; Mi, X.; Shen, H.; Liao, X. Multi-Agent Deep Reinforcement Learning Based Dynamic computation offloading in a Device-to-Device Mobile-Edge Computing Network to Minimize Average Task Delay with Deadline Constraints. Sensors 2024, 24, 5141. [Google Scholar] [CrossRef]
- Zhang, M.; Zhang, Y.; Gao, Z.; He, X. An Improved DDPG and its Application Based on the Double-Layer BP neural network. IEEE Access 2020, 8, 177734–177744. [Google Scholar] [CrossRef]
- Wang, M.; Li, R.; Jing, F.; Gao, M. Multi-UAV Assisted Air–Ground Collaborative MEC System: DRL-Based Joint computation offloading and Resource Allocation and 3D UAV Trajectory Optimization. Drones 2021, 8, 510. [Google Scholar] [CrossRef]
- Wang, D.; Tian, J.; Zhang, H.; Wu, D. Task offloading and Trajectory Scheduling for UAV-Enabled MEC Networks: An Optimal Transport Theory Perspective. IEEE Wirel. Commun. Lett. 2022, 11, 150–154. [Google Scholar] [CrossRef]
- Nath, S.; Wu, J. Deep Reinforcement Learning for Dynamic Computation Offloading and Resource Allocation in Cache-Assisted Mobile Edge Computing Systems. Intell. Converg. Netw. 2020, 1, 181–198. [Google Scholar] [CrossRef]
- Gao, Y.; Ding, Y.; Wang, Y.; Lu, W.; Guo, Y.; Wang, P.; Cao, J. Deep Reinforcement Learning-Based Trajectory Optimization and Resource Allocation for Secure UAV-Enabled MEC Networks. In Proceedings of the 2024 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Vancouver, BC, Canada, 20–23 May 2024; pp. 1–5. [Google Scholar]
- Zeng, Y.; Chen, S.; Li, J.; Cui, Y.; Du, J. Online Optimization in UAV-Enabled MEC System: Minimizing Long-Term Energy Consumption Under Adapting to Heterogeneous Demands. IEEE Internet Things J. 2024, 11, 32143–32159. [Google Scholar] [CrossRef]
- Zhang, J. Stochastic Computation Offloading and Trajectory Scheduling for UAV-Assisted Mobile Edge Computing. IEEE Internet Things J. 2019, 6, 3688–3699. [Google Scholar] [CrossRef]
- Yan, T.; Liu, C.; Gao, M.; Jiang, Z.; Li, T. A Deep Reinforcement Learning-Based Intelligent Maneuvering Strategy for the High-Speed UAV Pursuit-Evasion Game. Drones 2024, 8, 309. [Google Scholar] [CrossRef]
- Peng, Y.; Liu, Y.; Li, D.; Zhang, H. Deep Reinforcement Learning Based Freshness-Aware Path Planning for UAV-Assisted Edge Computing Networks with Device Mobility. Remote Sens. 2022, 14, 4016. [Google Scholar] [CrossRef]
- Dai, Y.; Xu, D.; Maharjan, S.M. Artificial Intelligence Empowered Edge Computing and Caching for Internet of Vehicles. IEEE Wirel. Commun. 2019, 26, 12–18. [Google Scholar] [CrossRef]
- Xiong, J.; Guo, H.; Liu, J. Task offloading in UAV Aided Edge Computing: Bit Allocation and Trajectory Optimization. IEEE Commun. Lett. 2019, 23, 538–541. [Google Scholar] [CrossRef]
- Wang, D.; Liu, Y.; Yu, H.; Hou, Y. Three-Dimensional Trajectory and Resource Allocation Optimization in Multi-Unmanned Aerial Vehicle Multicast System: A Multi-Agent Reinforcement Learning Method. Drones 2023, 7, 641. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, W.; Ding, Y. Computation Offloading Optimization for UAV-Assisted Mobile Edge Computing: A Deep Deterministic Policy Gradient Approach. Wirel. Netw. 2021, 27, 2991–3006. [Google Scholar] [CrossRef]
- Hu, Q.; Cai, Y.; Yu, G.; Qin, Z.; Zhao, M.; Li, G. Joint Offloading and Trajectory Design for UAV-Enabled Mobile Edge Computing Systems. IEEE Internet Things J. 2019, 6, 879–1892. [Google Scholar] [CrossRef]
- Zhan, C.; Hu, H.; Sui, X.; Liu, Z.; Niyato, D. Completion Time and Energy Optimization in the UAV-Enabled Mobile-Edge Computing System. IEEE Internet Things J. 2020, 7, 7808–7822. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Full Name | Abbreviation |
|---|---|
| Base station | BS |
| Deep reinforcement learning | DRL |
| Deep deterministic policy gradient | DDPG |
| Industrial Internet of Things | IIoT |
| Joint computation offloading and trajectory optimization | JCOT |
| K-nearest neighbor | KNN |
| Line-of-sight | LoS |
| Markov decision process | MDP |
| Mobile edge computing | MEC |
| Prioritized experience replay | PER |
| Reinforcement learning | RL |
| Temporal difference | TD |
| Unmanned aerial vehicle | UAV |
| User equipment | UE |
| Reference | Optimization Objective | Optimization Variables | Algorithms |
|---|---|---|---|
| [18] | Minimize total system energy consumption | Computation offloading; UAV flight trajectory; Resource allocation | Multi-agent delayed deterministic policy gradient; Karush–Kuhn–Tucker conditions |
| [19] | Minimize total system energy consumption | Regional division; UAV trajectory | Semi-discrete optimal transmission problems; Determine the shortest route |
| [20] | Minimize task completion time | Dynamic caching; Computation offloading; Resource allocation | DDPG |
| [21] | Minimize task completion time | Trajectory optimization; Resource allocation | Deep Q-Learning |
| [22] | Balancing energy consumption and latency | Energy consumption; Queue stability for users | Lyapunov; Successive convex approximation |
| [23] | Balancing energy consumption and latency | Average weighted energy consumption of UE and UAV | Lyapunov |
| Parameter Name | Parameter | Default Value |
|---|---|---|
| Communication cycle | T | 320 s |
| Number of time slots | I | 40 |
| Flight area | X, Y, H | 100 m |
| UAV weight | G | 9.65 kg |
| Transmission loss | −80 dB | |
| Noise power of the receiver | −100 dB | |
| Transmission bandwidth | B | 1 MHz |
| Maximum UAV flight speed | 50 m/s | |
| UAV flight time | 1 s | |
| UE movement speed | 1 m/s | |
| Battery capacity | E | 500 KJ |
| Transmission power | P | 0.1 W |
| CPU cycles | s | 1000 cycles/bit |
| UE computing capability | 0.6 GHz | |
| UAV computing capability | 1.2 GHz |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, Y.; Xu, C.; Wang, Y. Joint Computation Offloading and Trajectory Optimization for Edge Computing UAV: A KNN-DDPG Algorithm. Drones 2024, 8, 564. https://doi.org/10.3390/drones8100564
Lu Y, Xu C, Wang Y. Joint Computation Offloading and Trajectory Optimization for Edge Computing UAV: A KNN-DDPG Algorithm. Drones. 2024; 8(10):564. https://doi.org/10.3390/drones8100564
Chicago/Turabian StyleLu, Yiran, Chi Xu, and Yitian Wang. 2024. "Joint Computation Offloading and Trajectory Optimization for Edge Computing UAV: A KNN-DDPG Algorithm" Drones 8, no. 10: 564. https://doi.org/10.3390/drones8100564
APA StyleLu, Y., Xu, C., & Wang, Y. (2024). Joint Computation Offloading and Trajectory Optimization for Edge Computing UAV: A KNN-DDPG Algorithm. Drones, 8(10), 564. https://doi.org/10.3390/drones8100564