4.1. Description of Genetic Algorithm Framework for MABS Path Planning
This sub-section describes the design of the MABS path planning Genetic Algorithm (MABS-GA), which incorporates the process of evolution to identify the optimal solution for a given problem.
To address this, GA employs a metaheuristic approach. This algorithm mimics the natural principles of evolution, where mutations introduce new patterns. In this evolutionary approach, unique survival products, often known as specimens, exist alongside both mutation and reproduction to create new, somewhat better specimens capable of dealing with modern circumstances [
54,
55].
Each chromosome comprises adjustable parameters to be polished according to the problem’s requirements. It is valuable to examine every chromosome critically and decide what is suitable for mutations. This analysis, termed fitting, provides the stress, or rather the load the system has to sustain while the species are chosen. In UE, the clustering, affinity propagation clustering, is a non-supervised approach that is employable when several geo-dispersed UEs demand clustering centroids centered on spatial density. Initially, given the advantages of k-means clustering (simplicity and effectiveness), it was chosen. Nevertheless, it was rejected in favor of using several clusters to group the unserved UEs. Unlike the competition, affinity propagation determines this balance through an implicit message exchanged between each node and its neighbors using a broadcast mechanism. An internal relation matrix shows how one entity should present the other.
In contrast, the external relation matrix provides information about the other entity’s representation level by the other entity. The process begins by proposing UEs as potential representatives. The next step involves using proximity for vectorization, with the final step ensuring that the cluster centers remain unchanged. In [
56], this approach is proposed as a UE clustering method based on the ownership and management of networks with responsibilities and accessibility.
In the field of GA, chromosomes serve as the elementary particle or gene of the species that must undergo mutation or combine with another chromosome to endow the future generation with objects that possess better attributes, such as inventiveness [
54] and robustness [
55], After classifying a group of chromosomes into clusters, Equations (
14) and (
15) are identified for the graph. In the graph, centroid
V and Euclidean distances between segments are called
E. According to Equation (
16), A slot refers to a measured segment point. Theoretically, chromosome length (m) should be greater than or equal to three.
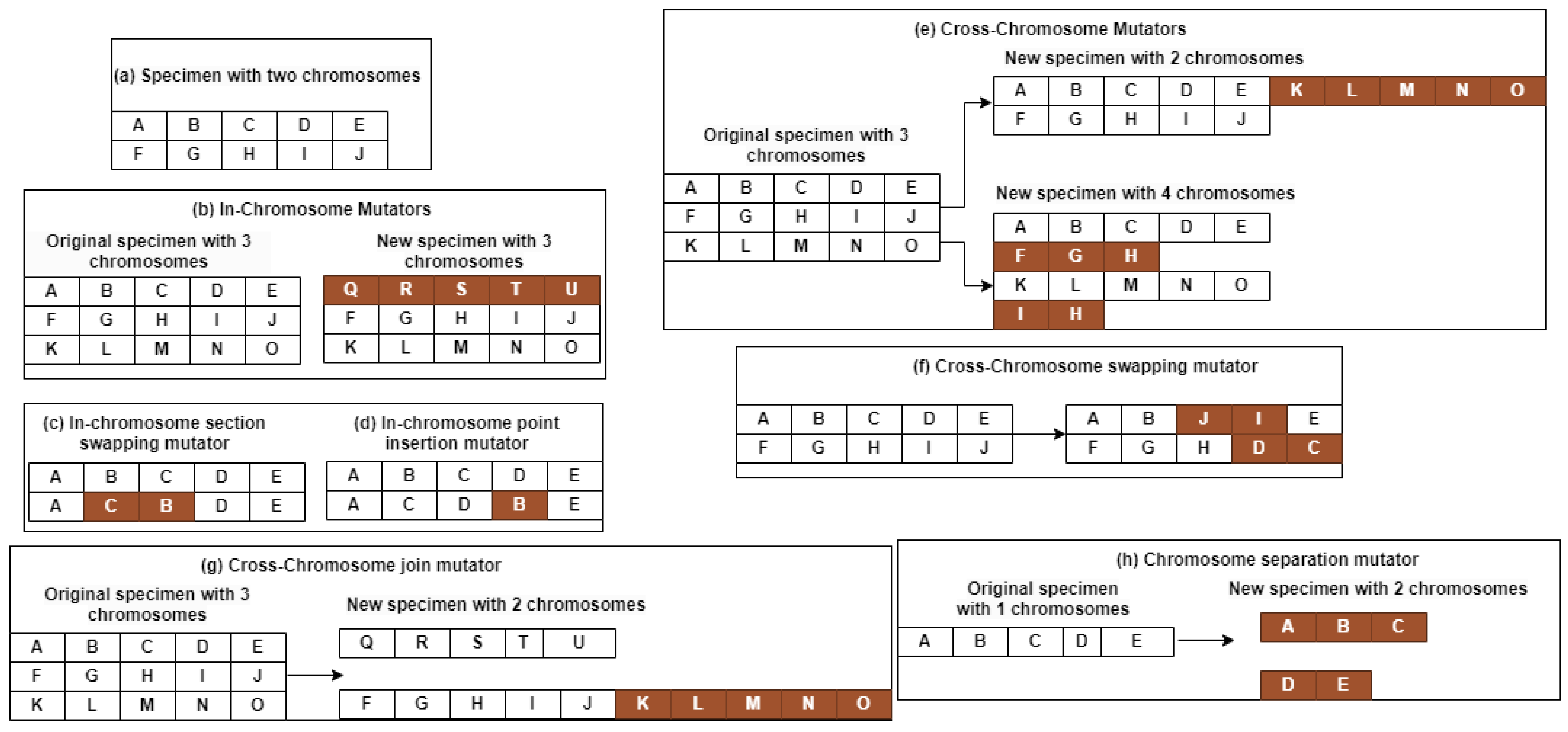
Figure 3a indicates that the specimen comprises two chromosomes. Each genetic locus is evaluated on an individual basis, with differently influenced markers, as previously described. Chromosome 1 pases through study points A, B, D, C, and E, whereas Chromosome 2 passes through units F, G, H, I, and J. This is the case when mutators are applied to create a kind of detailed development within organizational limits. In this way, each specimen involved is divided into three and six other specimens, in accordance with their type and nimber of chromosomes they had. Chromosome transfers involve a variable number of chromosomes per material and employ transposition systems to complete the crossover process [
23,
24]. This does not allow for effective reproduction through a chromosomal mix or mutation. In addition, a uniform random distribution is utilized for any random selection procedure within the mutation functions to achieve randomness.
The mutator assembly is intended to produce a new specimen with the same chromosome length as the original ancestor [
54,
55]. The mutators strive to ensure the optimum visiting sequence of the cluster centres with a given number of drones. This method creates a one-chromosome specimen with the same number of chromosomes and a mutated chromosome, as shown in
Figure 3b. In this case, Chromosome 1 is changed from A, B, C, D, and E to Q, R, S, T, and U, which results in the same number of chromosomes. The in-chromosome section swapping mutator is called a random chromosome from the selected specimen and chooses a segment of that chromosome for swapping, creating new chromosomes and new specimens [
23,
24].
Figure 3c shows how points B and C are selected to change the order; the resulting configuration is shown in the figure. In the swapping mutator, two points are randomly chosen for exchange, as shown in
Figure 3d. This results in a more complex order than the original combination operators. The in-chromosome point insertion mutator removes only one point on the selected chromosome and inserts it into another location [
23,
24].
Figure 3e shows how point B receives a boost of four spots. The new chromosome does not significantly interfere with the original chromosome.
The ability of cross-chromosomal interactions to create or destroy chromosomes in a specimen results in either the reduction in or addition of the genetic paths needed for the survival of a specimen. This concept is illustrated in
Figure 3f, where one specimen can give rise to many individuals. The mutations are reproduced by a number of chromosomes and the points within each chromosome, which must not be less than three to establish a sound, closed graph for the number of mutators. In two-chromosome-swapping mutators, a pair of the two selected chromosomes are exchanged, and the resulting specimen keeps the same number of chromosomes as its parents. Still, chromosomes shuffle [
23,
24].
This makes the pairing of chromosomes easier, and pairs that provide an advantage to the offspring are favored. The Cross-Chromosome Join Mutator generates a third chromosome by fusing two desired chromosomes from a specimen, which results in a specimen with one chromosome less than the initial instance. Similarly, Chromosomes 2 and 3 as shown in
Figure 3g are combined to create a single one. This makes the subject’s genome much shorter and requires fewer sampling drones. However, the Chromosome Separation Mutator divides away from a three-horizon-long section of the chromosome, leading to two chromosomes for new beings. As shown in
Figure 3h, Chromosome 1 is divided in half. The following specimens have two chromosomes rather than one. This mutator yields another deterministic specimen that may be consumed based on fitness evaluation.
4.2. Integration of Proposed Fitness Function and Mutation for Optimization
The fitness functions are constructed to evaluate the specimens based on various parameters. Then, the magnitudes of the specimen’s performance in a given scenario can be measured [
23,
24]. In this research, five fitness function metrics were implemented to ensure that the sample worked out. The drone path was evaluated, which is the most effective, efficient, and sound option to solve the problem. The weight of the fitness function is computed based on the score of a particular specimen according to Equation (
17). This equation serves to combine
SR (Service Ratio),
AR (Angle Ratio),
DR (Distance Ratio),
IR (Intersection Ratio), and
PSR (Path Smoothness Ratio), obtained from corresponding fitness functions of service, angle, distance, intersection, and path smoothness.
The solution to the optimization process used the proposed fitness function described in Algorithm 1. It is used to act on a set of chromosomes, a population of unchecked chromosomes, and a threshold for determining fitness values. This structure is divided into two parts. The first part of the condition considers the product of the (A) and (B) differences and compares it against a specific value. The second part analyzes the direction () and returns a particular number when the conditions are achieved. Subsequently, the function initializes paths, segments, and intersections, and then, after copying each path to the chromosome set to the end of the path, it appends it into the segments. It splits each path into pieces and then adds them to a list. The intersection analyzer then studies the intersections of various lines and updates the intersection count by iterating over the parts. Additionally, it sums the sum of the distances between the points next to each other during each path to another variable, named “suma”. It also calculates and records the distance between the first and the last points of each path.
The optimization procedure is described in Algorithm 2 that represents the fitness function. The systolic function compares different ideas in establishing MABS in disaster response networks using path qualities such as angle, capacity, and unserviced area. By assigning fitness scores to the routes of MABS deployment, the algorithm can select the best and most efficient path to follow. This rating uses an algorithm to score the different paths and investigate the most effective ones. Fitness functions are calculated to compare specimens with other parameters, thus showing their fitness in that specific scenario. Five fitness functions were used in this study to select a particular solution that is the most suitable and can adequately deal with the problem of choosing a specimen, which is the MABS path. The weight coefficient for score specimens is calculated using (
18). It takes into account the
SR,
AR,
DR,
IR, and
PSR as the result of the fitness functions of the specimens.
| Algorithm 1: Fitness Function—Part 1 |
![Drones 08 00272 i001]() |
Our proposed Equation (
18) is the best fit for the given example, resulting from the weighting and compensation analysis of a specific population [
22,
23,
24]. In this case, assigning 0.5 of the ponderation to
SR implies that the candidate with the most extensive coverage have a higher likelihood of propagation. In the selection process, specimens with superior flying range are favored, even if they have slightly worse coverage, prioritizing distance over comprehensiveness. The
AR performs better regarding the side score than the
DR and IR, ensuring it is always in the best-effort mode to avoid close angles. The resultant specimens show flyable paths, one of the most critical parameters. Lastly,
DR and IR are just as vital and share similarities with the other two ratios to finalize the adjustment. In the next step, all specimens within a population are characterized by similar scores for
SR,
PSR, and
AR. Thus,
DR and IR are distinguishing traits and should be kept among the chosen traits for reproduction. Therefore, the shortest and most likely free-from-path crossing is selected. This function computes the number of unserviced UEs with at least a single connection for all drone travel paths. To achieve this, Equations (
1) and (
3) are employed, where the constant height is 50 m. To save some computer power requirements, the unserviced UE dataset is updated whenever a UE is considered with service, and calculations are performed every 3 km along the drone path. For
AR, this function computes a ratio by employing (
19) and (
20), where
n is the total number of angles in the given path (i.e., chromosome) and
N is the total number of the paths (i.e., the total number of chromosomes) within the specimen [
22].
| Algorithm 2: Fitness Function—Part 2 |
![Drones 08 00272 i002]() |
As Equations (
18) and (
19) are used, the score of the specimen is boosted with a path flow featuring more acute angles; this is because the single-angle ratio is calculated based on the accuracy with which it approximates a straight angle, which is defined as
in Radians. Additionally, the mean of all ratios
AR of the angles is given equal significance; therefore, an acute angle negatively affects the solution. If a triangular formation exists despite the high obtuse angle, it still leaves two acute angles, which, in a triangular path, cause a lower score for that sample. The single-angle (
) values for each specimen are presented in
Table 3 from left to right. Consequently,
AR cannot be perfect because no graph that approximates a line graph with parallel lines can be drawn. The Distance Fitness Function
DR is chosen as there is no way to determine the optimal distance from the inside perspective of a specimen. The method of considering all the specimens and their relative values is adopted to determine the distance value (
) using (
20). Here, (
15) determines
E.
The minimum value (min (
)) is desired to achieve the shortest distance. Consequently, the value of each
is tested with
; therefore, DR =
according to (
21). By contrast,
i takes the place of the value of
presented for a particular entity.
Also, it is worth noting that this role does not guarantee an all-sufficient result for a specific situation, as many suitable candidates may have been overlooked. Nevertheless, this particular method brings up operations that may ensure different approximations for each of the
values obtained. Function Intersecting Line Segments
IR was developed to determine whether two line segments overlap or cross at a given point. In this case, it is unnecessary to distinguish between zero-recombination genome specimens and the best specimen with two or more recombination events, so the whole population is selected. This is based on the fact that each exhibit is (
) crossed not only in one path but also in all possible paths or chromosomes. Therefore, the minimum value of chromosomes min (
) at all possible intersections is considered, and this value is used here as a comparison criterion. Having (
22) implies that the number of intersections in this viewed data contrasts the minimum value.
In addition, Algorithm 3 enables an indirect comparison of the lowest
to the Distance function without the guarantee that the specimen with the lowest
is the fittest in the cluster. The APC algorithm was proposed to determine the clustering of centroids in the disaster recovery network, and the function of the cluster centroids was employed to generate an empty array by an initial assignment of UE coordinates provided by iterations. The assignment was converted to a
numpy array using a damping value of 0.6. When trained, the algorithm only keeps the resulting k-clusters, which are further stored in “k” as a variable. The main code reads UE data from a CSV file. The code then uses a Poisson distribution model to simulate the random placement of UEs across a designated area. These simulated UE coordinates are then used to calculate the optimal location of cluster centroids, which are central points representing groups of UEs. The algorithm computes the cluster centroids, which are crucial for deciding the suitable locations for deployment of MABS that can regularly provide wireless communications to widely dispersed users. Cluster centres are instrumental in planning the shortest paths and coverage of disaster-affected regions.
| Algorithm 3: UE Cluster Centroids |
![Drones 08 00272 i003]() |
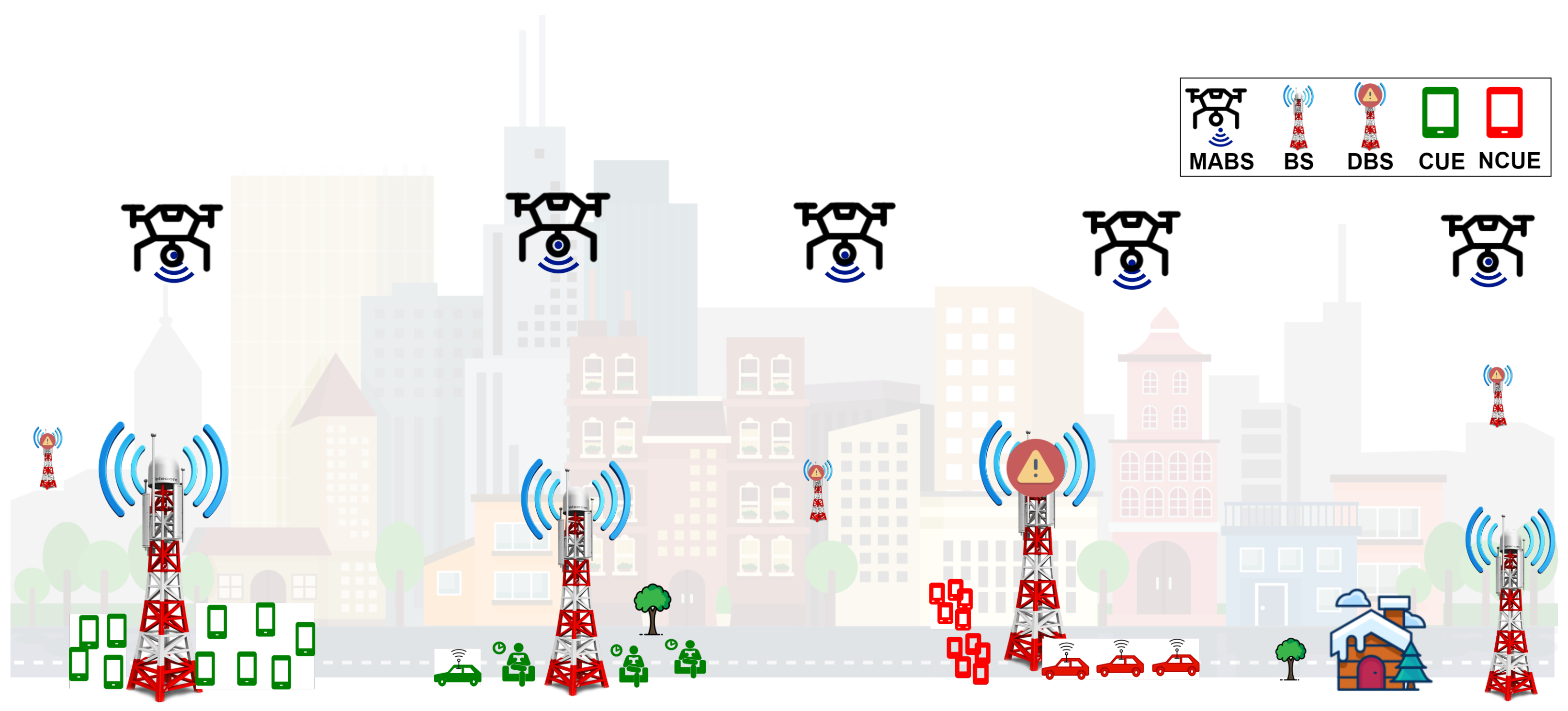
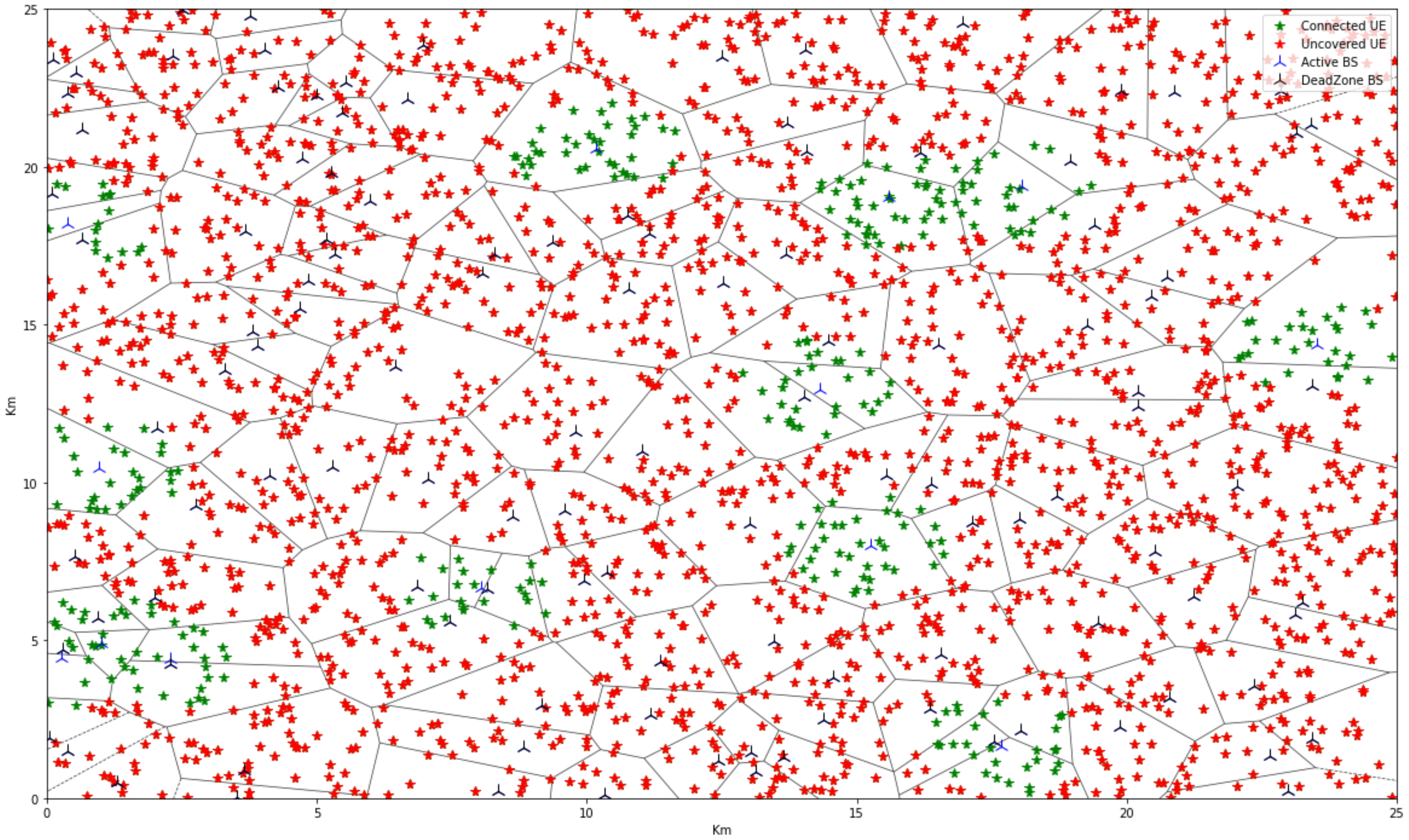
As shown in
Figure 4, it is the first example of UEs within the epicenter of the disaster response network that is captured by the clustering algorithm. It entails emergency managers assigning people to clusters that may be placed at suitable structures/temporary accommodation centres. The initial organization of the UE is of significant importance because it determines the way to include and utilize the MBSs in the DRN. UE distributions plays a crucial role in the entire process of the MABS communication services, and therefore it should be at the very top of the priorities during disaster relief response. The detailed placement of UEs improves monitoring of coverage gaps, connectivity problems, and network performance at large, which are the fundamental issues for increasing the quality of service available to the users who happen to be in the accessible area.
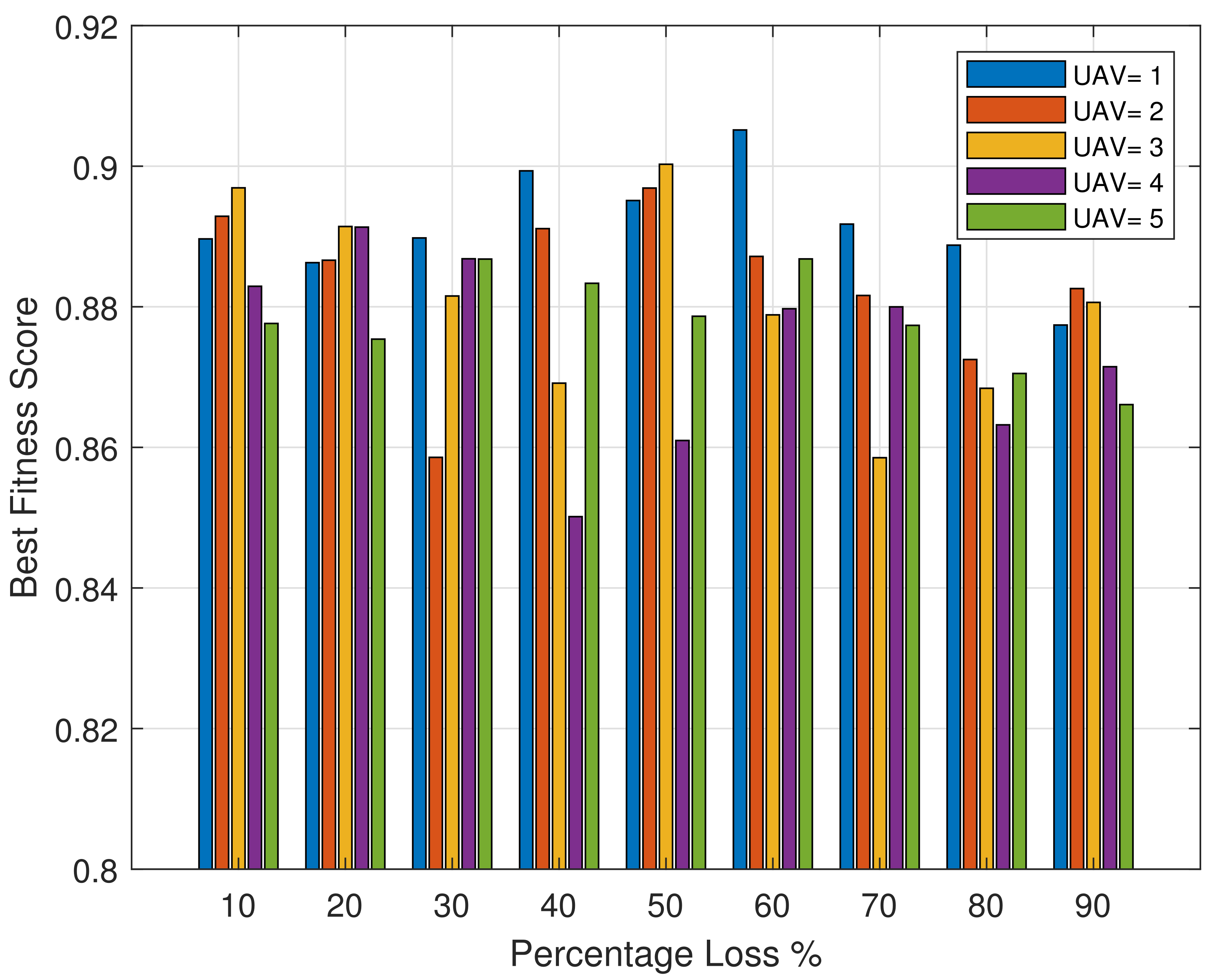
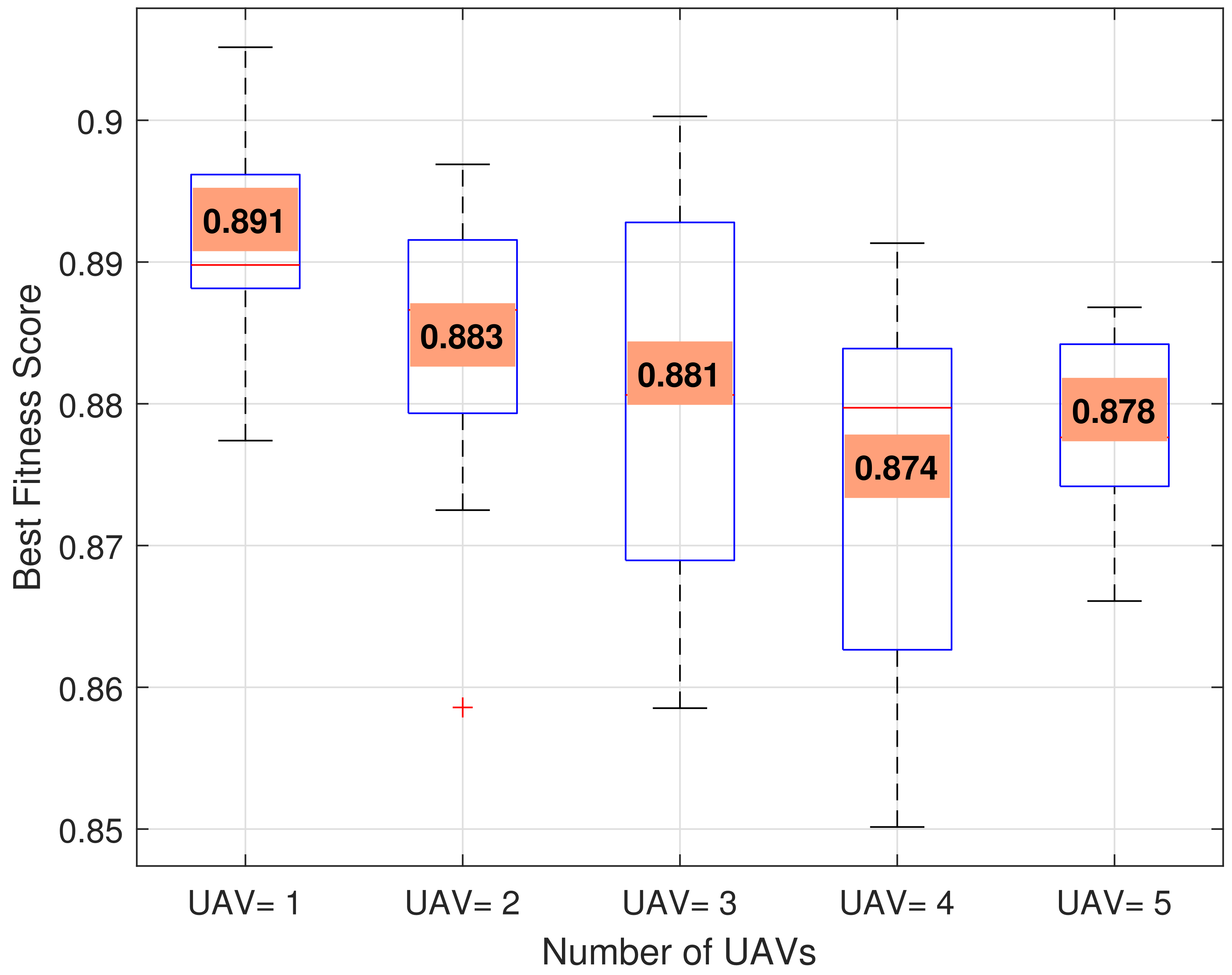
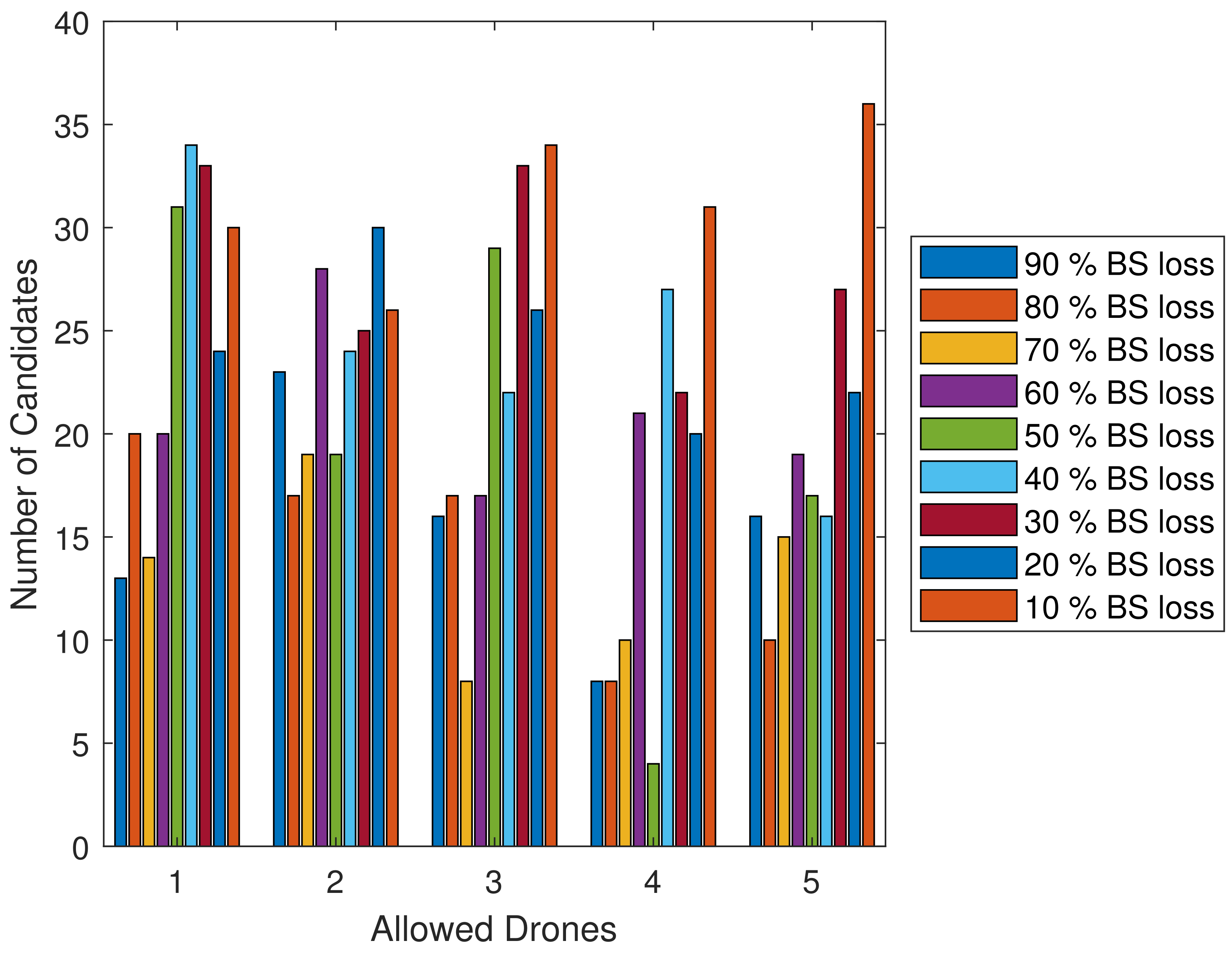
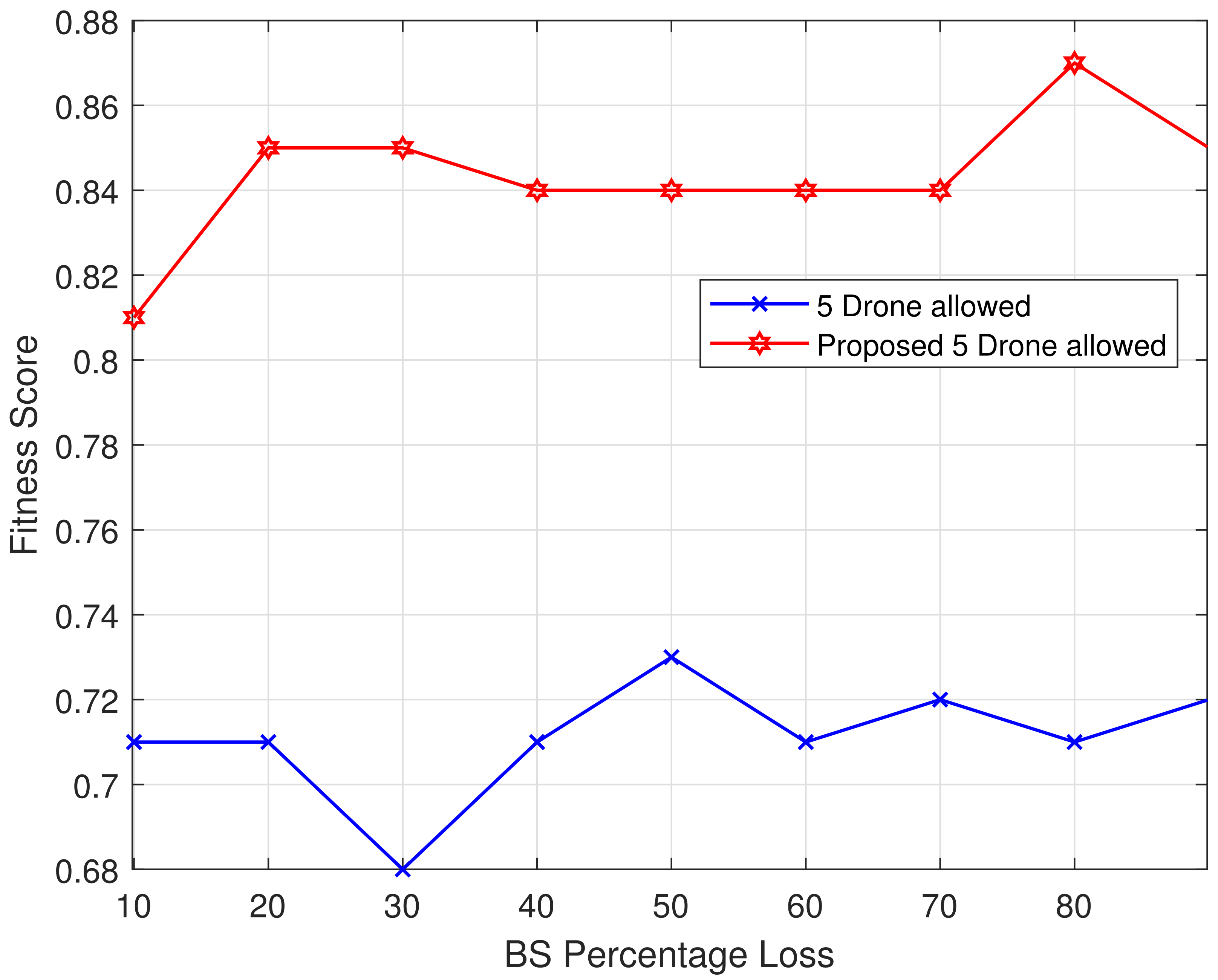
Figure 5 illustrates the correlation between the number of locations where the base station fails to provide network service (unserviced centroids) and the percentage of loss experienced by the BS during its operation. The unserviced centroids vs. base station percentage loss is a crucial factor for evaluating the effectiveness of the MABS deployment strategy and understanding the impact of unserviced centroids on the overall performance of the BS. Analyzing this relationship enables researchers and practitioners to identify areas for improvement in disaster response networks and optimize the path planning of the MABS to minimize unserviced centroids and percentage loss. The BS failure to provide network service at centroids due to the issues experienced is shown, with the number of unserviced centroids defining the degree of loss undergone. Through this analysis, we can identify flaws in the emergency response network and develop strategies to minimize both percentage loss and the number of unserviced centroids.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}