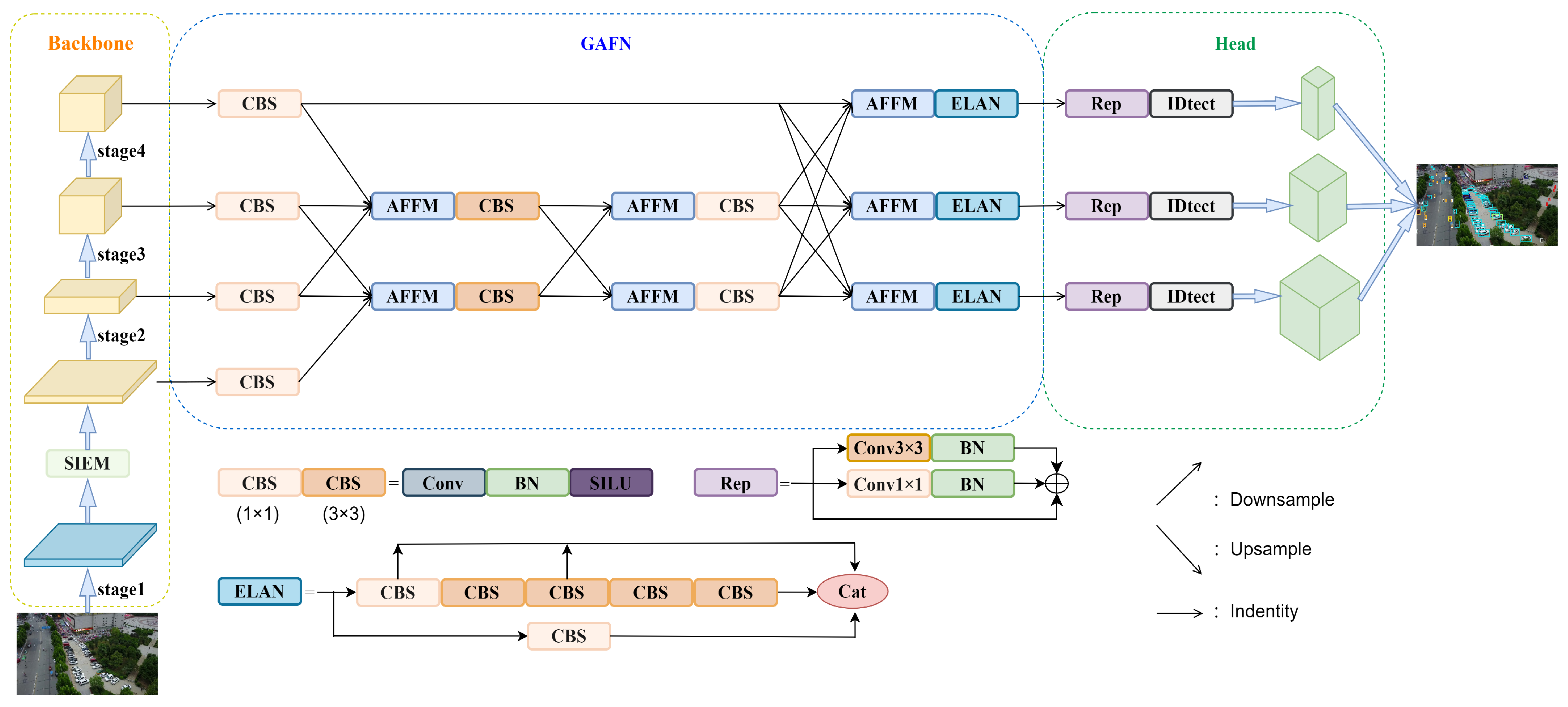
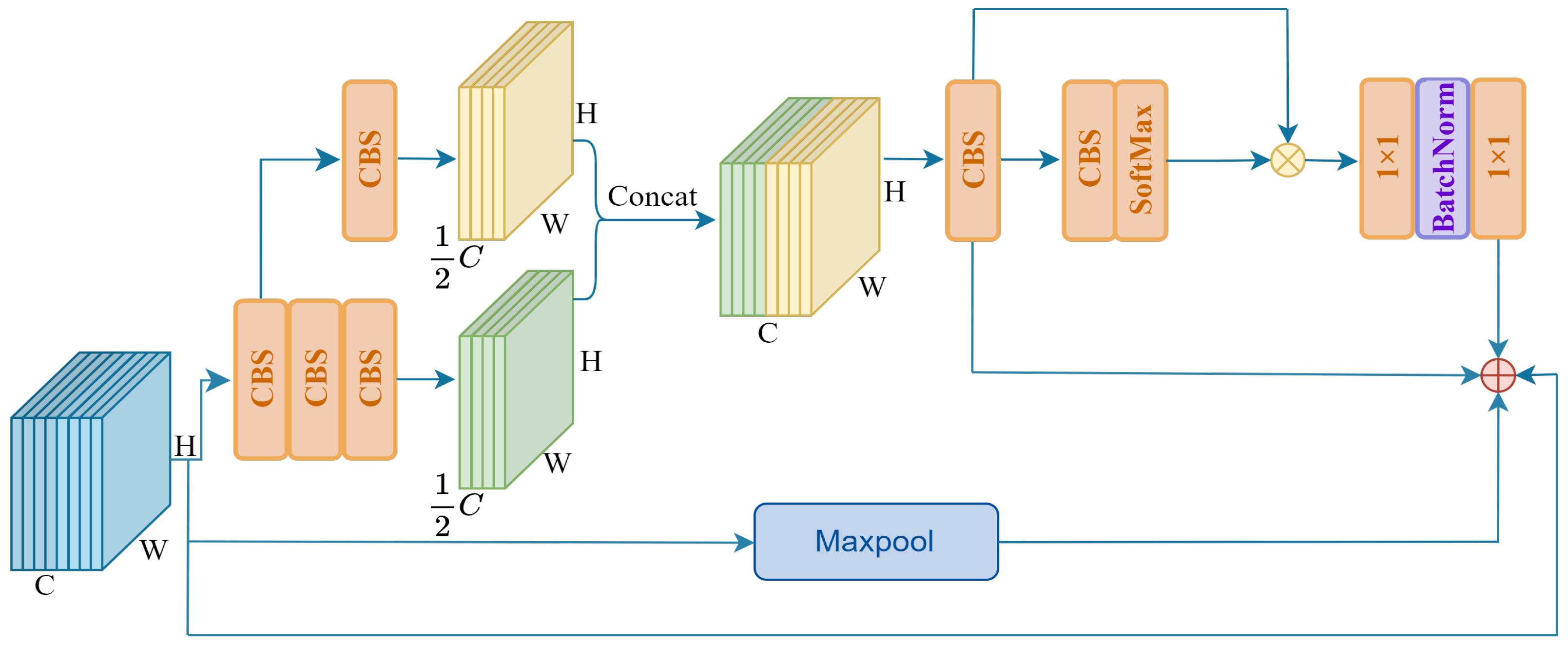
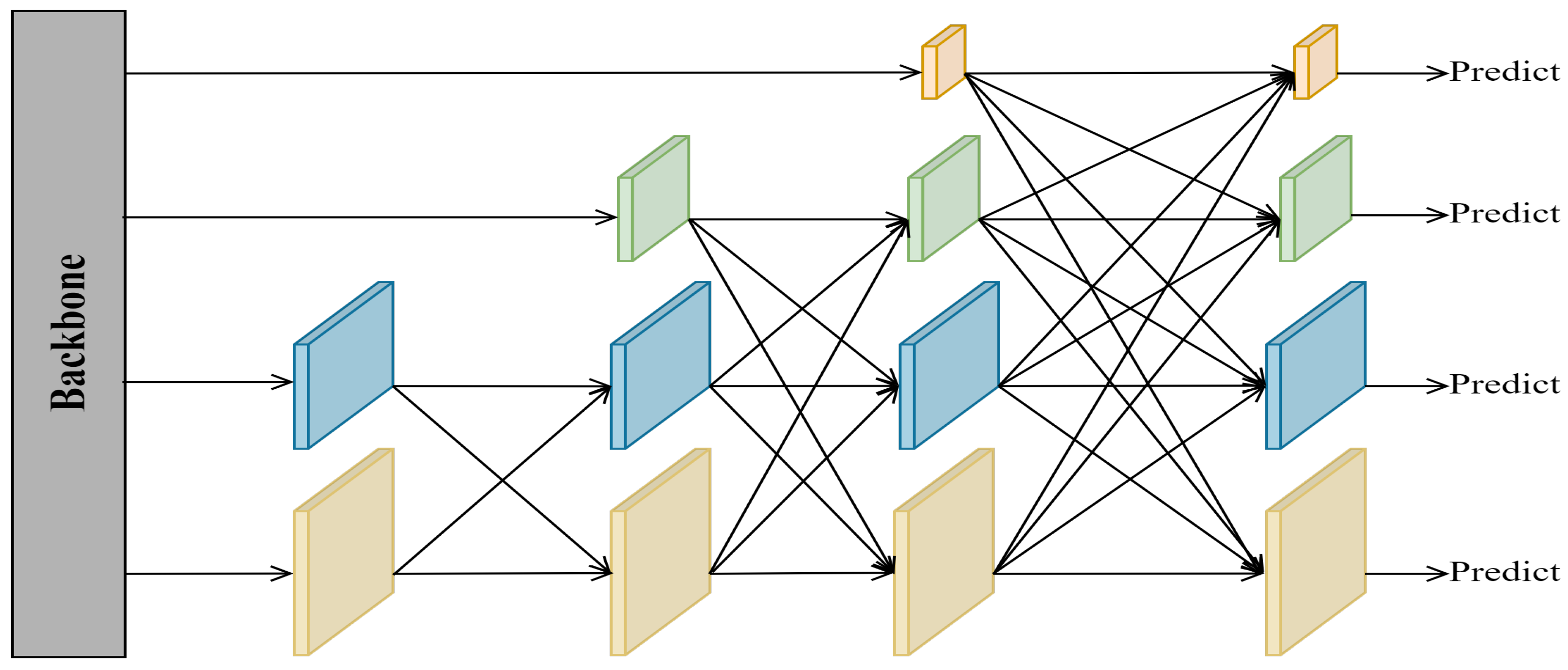
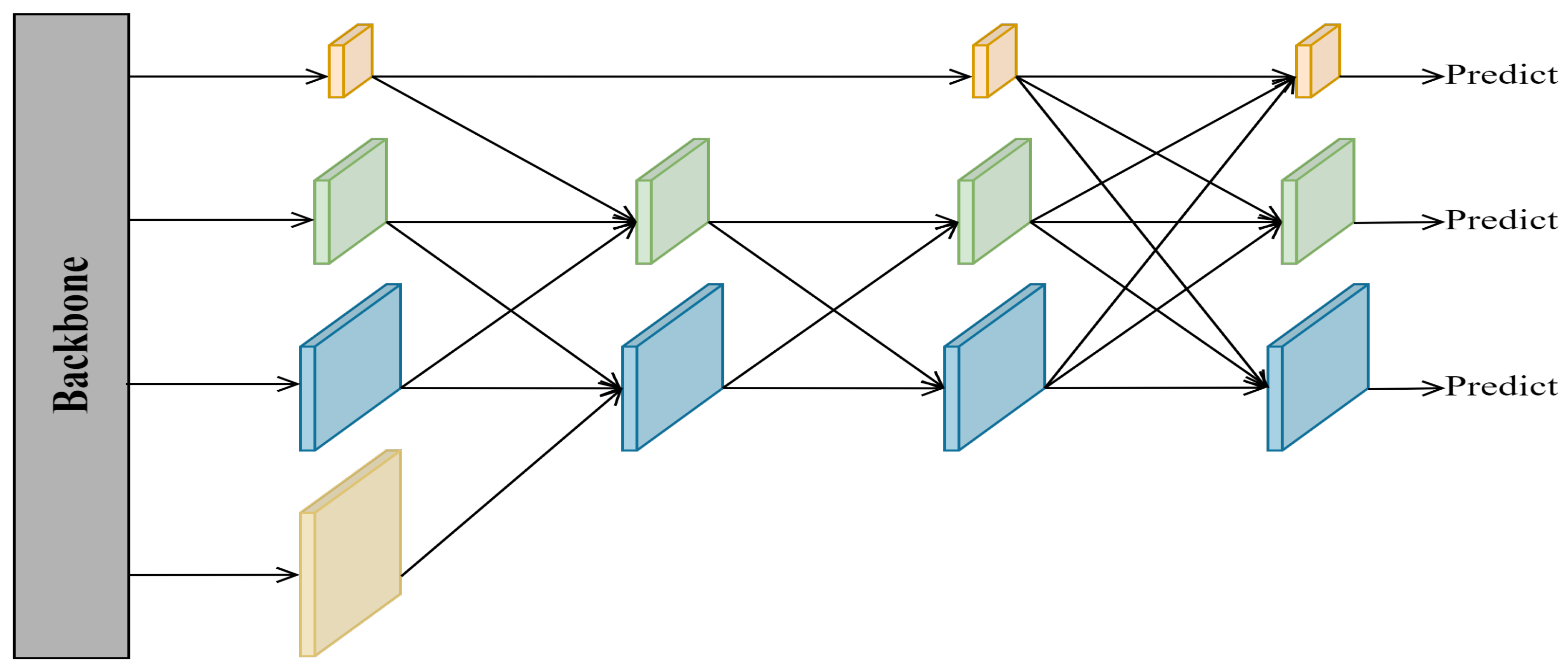
4.1. Datasets
This section introduces the datasets, evaluation metrics, and parameter settings adopted for our experiments. In addition, we introduce a series of qualitative and quantitative experimental methods to evaluate and contrast our model with other advanced methods.
In the experimental stage, we adopted two public UAV datasets.
(1) The VisDrone dataset [
40] is mainly used for objection detection and image classification, with a total of 10,209 images, of which the training set consists of 6471 images, the test set consists of 3190 images, and the verification set consists of 548 images. The resolution of each image is 2000 × 1500 pixels. The images in the dataset were obtained from 14 different cities under different weather conditions, equipment conditions, and surroundings. After careful manual annotation, the dataset contained 342,391 objects and is divided into the following 10 categories: people, pedestrian, motor, awning-tricycle, bicycle, car, van, truck, tricycle, and bus. This dataset is the main dataset used in our experiments.
(2) The UAVDT dataset [
41] consists of a total of 40,735 images, of which the training set consists of 24,206 images and the validation set consists of 16,529 images, each with a resolution of 1080 × 540 pixels. In contrast to the VisDrone dataset, UAVDT mainly focuses on vehicle detection tasks from the perspective of drones, including images of urban roads in different weather, different angles, and different scenes. The dataset includes only three predefined categories of vehicles, namely car, bus, and truck.
4.4. Experimental Results on the VisDrone Dataset
We performed experiments using the VisDrone dataset and contrasted them with the latest object detection methods, where the number of training iterations was 300. To verify the authority of MFEFNet, COCO evaluation metrics [
42] were used to evaluate the model’s object detection ability at various scales; indicators include
,
, and
. Under the COCO standard, objects with pixel values below 32 × 32 are categorized as small objects, objects with pixel values between 32 × 32 and 96 × 96 are categorized as medium objects, and objects with pixel values higher than 96 × 96 are categorized as big objects. The experimental results are shown in
Table 1. According to the table, the methods proposed by us achieved the highest values of mAP0.5, mAP0.75, and mAP0.5:0.95, which reached 51.9%, 29.8%, and 29.9%, respectively, corresponding to improvements of 2.7%, 2.3%, and 2.1%, respectively, compared with the baseline YOLOv7. In addition, MFEFNet’s value of
also achieves the highest score of all object detection methods by reaching 41.4%, an improvement of 2.6% compared to YOLOv7. In terms of small object detection accuracy, our method achieves a 20.6% higher value than YOLOv7, which corresponds to a 2.0% improvement. On the other hand, our MFEFNet exhibits a decline in the accuracy of large object detection compared with YOLOv7 but still achieving 2.0% higher accuracy than the baseline for other indicators, which further proves that our MFEFNet has better multi-scale object detection ability. In addition, compared with CGMDet [
43], which has the second highest mAP0.5 value, our MFEFNet significantly improves in all five other indicators, except the value of
. Compared with the four commonly used versions of YOLOv8 [
44], except that the
value of MFEFNet is slightly lower than that of YOLOv8x by about 0.2%, other indicators are greatly improved. Although NWD and DMNet [
45] exhibit the highest accuracy in detecting small objects and large objects, their mAP0.5 values are much smaller than that of MFEFNet proposed by us. In general, our proposed object detector has better multi-scale object detection capability and is more suitable for UAV aerial images with complex backgrounds.
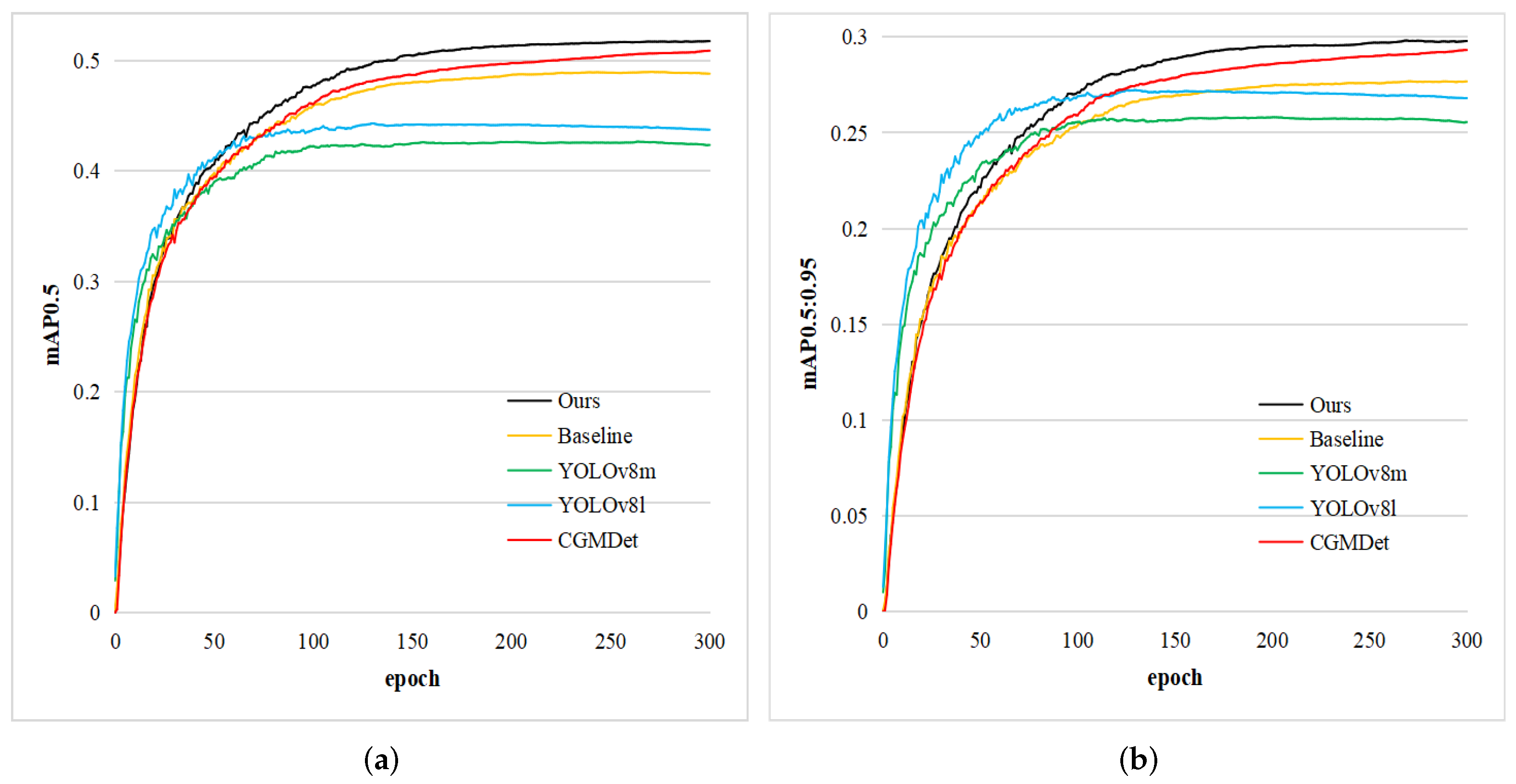
To visualize the detection capability of our MFEFNet, we select several state-of-the-art object detection methods and plot their values of mAP0.5 and mAP0.5:0.95 as the number of iterations increases. As shown in
Figure 7, although YOLOv8 series algorithms have a faster convergence speed, they lack the ability of continuous learning. In contrast, our MFEFNet has a stronger learning ability and achieves a large improvement over the baseline model.
To further validate our model’s effectiveness, we compared the detection precision of each category on the VisDrone dataset with some state-of-the-art detection methods.
Table 2 shows the experimental results. The detection accuracy of our MFEFNet is higher than that of YOLO7 in all 10 categories, with an average of a 2.8% improvement. Compared with CGMDet, except for the two categories of car and bus, whose accuracy is slightly lower, the remaining eight categories have higher accuracy than CGMDet. Although YOLO-DCTI [
54] has the best performance on various larger object types, our MFEFNet performs better on small and medium objects and outperforms other object detection methods on larger object types. Relative to Faster-RCNN, YOLOv3, YOLOv5l, YOLOv5s-pp, and the YOLOv8 series of mainstream algorithms, our MFEFNet achieves superior accuracy values in each category.
Simultaneously, we present the visualization results of the baseline model and MFEFNet in different scenarios. We select five groups of representative comparison results from a large number of comparison pictures. In
Figure 8, the obvious contrast part is marked with yellow dotted boxes and red arrows. As shown in
Figure 8(a1), YOLOv7 incorrectly detects the top-left bicycle as a pedestrian, while our proposed MFENet accurately detects two side-by-side bicycles. In
Figure 8(a2), YOLOv7 misses an awning tricycle in the dim background, but our model can still correctly detect the awning tricycle in the face of such a complex, dim background.
Figure 8(a3,b3) show the detection results of an outdoor parking lot. YOLOv7 mistakenly detects the chimney on the lower-right roof as a pedestrian, while our MFENet does not produce such an error. To prove the detection performance of our model under an extremely dim and complex background, we conduct a comparative experiment, as shown in
Figure 8(a4,b4). Our MFENet successfully detects a pedestrian under an extremely chaotic background at the bottom right of the picture. In addition, we show the detection results located achieved in a suburban area in
Figure 8(a5,b5). YOLOv7 misdetects the roof on the right as a van and misses the awning tricycle in the middle of the picture, while our model does not produce such errors.
To verify our theoretical ideas about the location of the SIEM mentioned above, we place the module in four different locations in the backbone network and conduct comparative experiments.
Table 3 shows the experimental results. From the experimental results, it is easy to see that the most ideal position of the SIEM is after Stage 1, which achieves the best results for each evaluation index with the fewest model parameters. Experimental results prove that the theoretical ideas we put forward above are scientific and valid.
To confirm the efficacy of our proposed GAFN for multi-scale fusion, we designed a set of comparative experiments on feature fusion networks, and
Table 4 shows the experimental results. Although PAFPN has the highest precision value, it has a low recall value and a lot of parameters. Although BIFPN has the highest recall value, it has a lower precision value and a larger number of parameters. AFPN has the lowest number of parameters, but it has the lowest mAP0.5 value. Our GAFN has the highest mAP0.5 value and mAP0.5:0.95 value, and its precision and recall values are about the same as the highest values. All in all, the GAFN can better extract multi-scale feature information and has better detection capability in UAV aerial images.
In addition, a special experiment to verify the effectiveness of MPDIoU for UAV aerial image detection is presented in
Table 5. The MPDIoU is compared with five mainstream boundary box regression loss calculation methods, obtaining the highest value of mAP0.5. In addition, in 5 of the 10 categories of the VisDrone dataset, MFEFNet achieves the highest value, among which pedestrians, people, awning tricycles, and motors are all small objects. The highest values of other categories are similar to ours. The above results further demonstrate the superiority of our method for detecting multi-scale objects.
In addition, in order to further demonstrate the effectiveness of our proposed SIEM, present a visual comparison of the intermediate feature map after Stage 1.
Figure 9 shows the comparison results. It can be clearly seen that when we add the SIEM after Stage 1, our model has stronger spatial information extraction ability. The SIEM can not only extract more feature information but also distinguish foreground information from background information effectively and reduce the interference of background information.
To observe the effectiveness of our improved methods more directly, this study further uses an ablation experiment to discuss each method. The results of the ablation experiment are shown in
Table 6 and analyzed as follows:
(1) SIEM: After adding the SIEM, the values of mAP0.5 and mAP0.5:0.95 on the VisDrone dataset increase by 2.2% and 1.6%, respectively. This shows that the SIEM can effectively extract the rich object representation information in the shallow backbone network, establish the context-dependence relationship around the object, and reduce the negative impact of the background. Although the complex branch structure of the SIEM increases the number of parameters, this additional overhead is acceptable in terms of the benefits achieved.
(2) GAFN: To improve feature fusion efficiency and the detection effectiveness of multi-scale objects, we designed a feature fusion network, GAFN, based on AFFM. The addition of this structure improves the values of mAP0.5 and mAP0.5:0.95 on the VisDrone dataset by 0.3% and 0.2%, respectively. It is worth noting that this network greatly reduces the bloated degree of the original feature fusion network and the generation of redundant intermediate feature maps, resulting in a 3.3M reduction in the total number of parameters.
(3) MPDIoU: MPDIoU provides a new idea for us to design an object boundary regression loss function with simpler operation. The comparison results in
Table 6 show that when CIoU is replaced by MPDIoU, the precision value of MFEFNet is improved, while the mAP0.5:0.95 value does not change. However, when we added the SIEM and GAFN to the experiment with MPDIoU, the value of mAP0.5 improves by 0.2%, and the value of precision improves by 2.7%. This proves that MPDIoU is useful for UAV image detection.
Table 6.
Ablation experiments on the VisDrone dataset.
Table 6.
Ablation experiments on the VisDrone dataset.
| SIEM | GAFN | MPDIoU | Precision | Recall | mAP0.5 | mAP0.5:0.95 | Param (M) |
|---|
| | | 59.1 | 48.9 | 49.2 | 27.8 | 34.8 |
| ✓ | | | 60.0 | 51.3 | 51.4 | 29.4 | 36.9 |
| | ✓ | | 57.9 | 50.0 | 49.5 | 28.0 | 31.5 |
| | ✓ | 59.6 | 48.2 | 49.2 | 27.8 | 34.8 |
| ✓ | ✓ | | 59.3 | 52.9 | 51.7 | 29.9 | 33.6 |
| ✓ | ✓ | ✓ | 62.0 | 50.8 | 51.9 | 29.9 | 33.6 |
To further demonstrate the background interference resistance of our method, we use Grad-CAMTable [
59] to generate heat maps of the model visualization results.
Figure 10 shows the visualization results. From the first row picture, it can be seen that our method focuses on the sequential van better than YOLOv7. The second and third rows are for detecting densely distributed small objects in a complex background. It can be seen that our method can better eliminate the interference of the surrounding environment and pay more attention to the object. The fourth and fifth lines are multi-scale object detection on the road. It can be seen that YOLOv7 pays attention to both objects and unnecessary background information, while our model reduces the attention to unnecessary background information.
In order to test the effect of the values of
,
, and
in Formula (15) on the performance of MFEFNet, we perform a set of comparison experiments. The experimental results are shown in
Table 7; precision and mAP0.5 reach the highest values when
,
, and
. Recall reach the highest value when
,
, and
, but precision and mAP0.5 present differences in terms of their highest values. In summary, our model achieves the best balance when
,
, and
, so we choose them as the final values.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}