



UAV-Mounted RIS-Aided Mobile Edge Computing System: A DDQN-Based Optimization Approach
 , , ,
, , ,
Abstract
1. Introduction
1.1. Related Work and Motivation
1.2. Contributions and Novelty
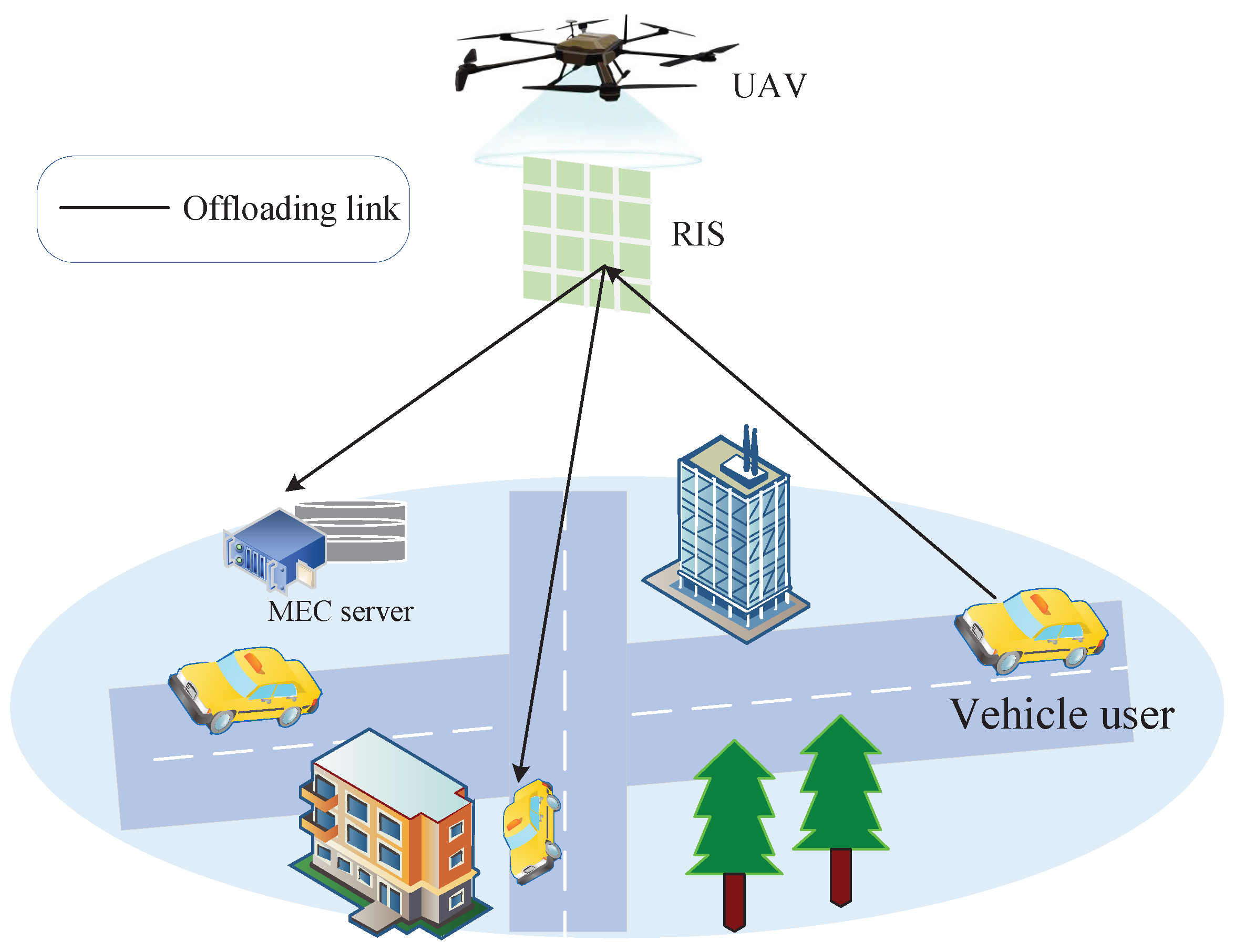
- First, in complex environments such as densely populated urban areas hosting large-scale events, the line-of-sight link between terrestrial vehicle users (VUs) and the MEC server may be weakened by obstacles. To overcome this challenge, we propose the strategy of deploying RIS-carrying UAVs to assist users in offloading tasks. By reflecting VU signals through the UAV–RIS system, they are able reach the ground MEC servers effectively.
- Second, this computational offloading policy optimization problem can be categorized as a mixed-integer nonlinear fractional programming problem. To tackle this, we develop the DDQN-empowered algorithm, which aims to achieve the goal of maximizing energy efficiency. This algorithm offers low computational complexity while allowing for easy scalability across various system configurations.
- Finally, the numerical results obtained from our experiments demonstrate significant improvements in energy efficiency within the MEC system compared to other benchmark schemes. Furthermore, our proposed algorithm makes notable trade-offs in trajectory optimization, enhancing the overall performance of the system.
2. System Model Description
2.1. Signal Transmission Model
2.2. Computational Offloading Model
2.3. Energy Dissipation Model
2.4. Problem Formulation
3. Proposed DDQN-Enabled Approach
3.1. Preliminaries of DDQN
3.2. MDP Description
| Algorithm 1: The DDQN-based beamforming design and task allocation algorithm | |
| 1: | Initialize experience replay memory buffer D; |
| 2: | Initialize and of the target and main neural networks and , respectively, and set ; |
| 3: | Input: The relevant channel vector, the initial UAV position and the total offloading tasks; |
| 4: | Output: Phase shift , UAV trajectory , |
| and the ratio of total-local task assignments; | |
| 5: | for do |
| 6: | Initially set the state as ; |
| 7: | for do |
| 8: | Obtain the current state |
| 9: | Choose an action |
| 10: | Compute the current reward , and transfer to the next state |
| 11: | Store in D with maximal priority using Equation (19). |
| 12: | for to do |
| 13: | Randomly select size of d transitions |
| 14: | Calculate the loss function with Equation (15) |
| 15: | Update the main neural network weights |
| 16: | Update the target neural network weights |
| 17: | end for; |
| 18: | Choose the next action; |
| 19: | end for |
| 20: | end for |
3.3. Convergence and Complexity Analysis
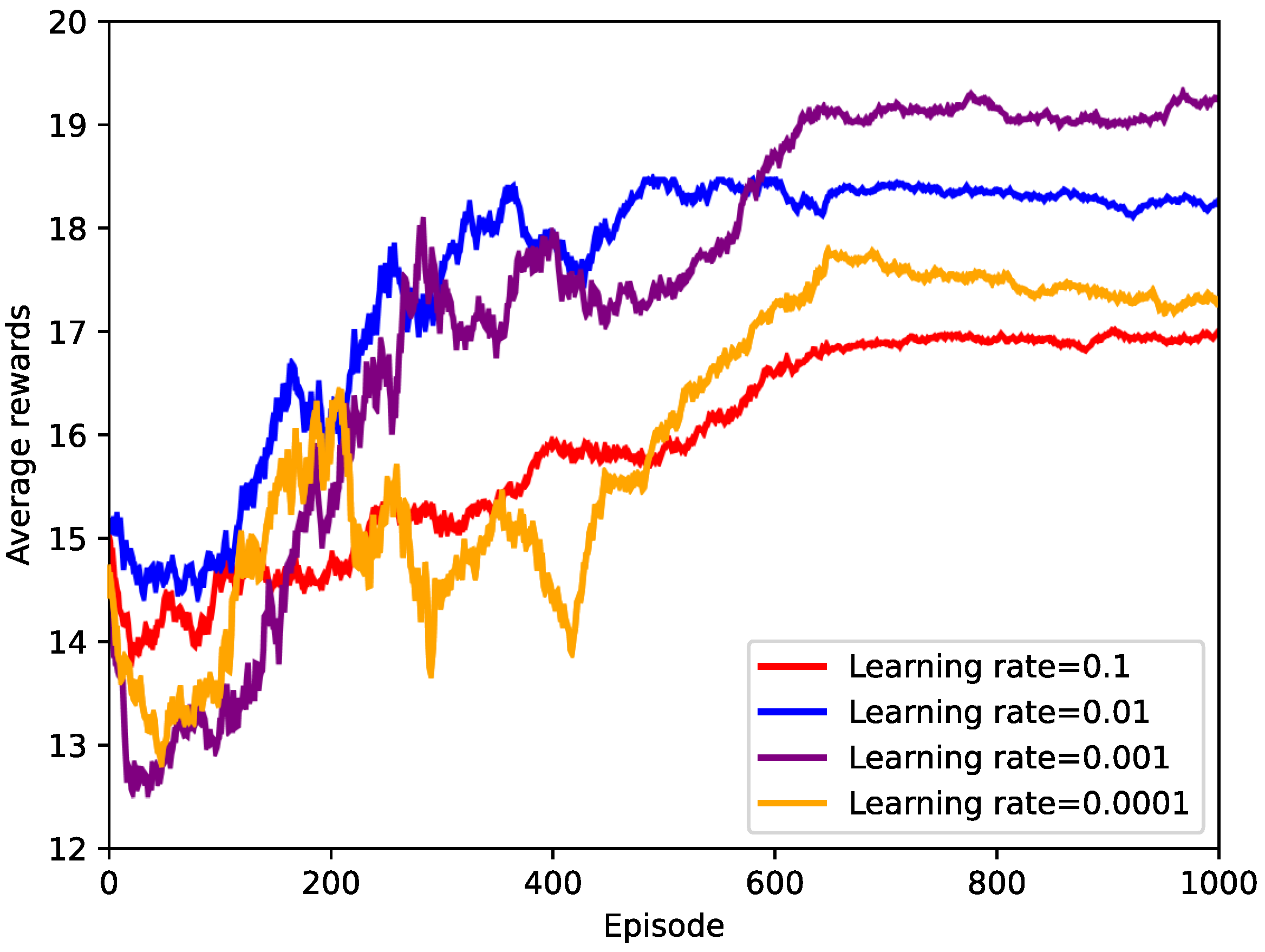
4. Simulation and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hwang, J.; Nkenyereye, L.; Sung, N.; Kim, J.; Song, J. IoT service slicing and task offloading for edge computing. IEEE Internet Things J. 2021, 8, 11526–11547. [Google Scholar] [CrossRef]
- Xia, Y.; Deng, X.; Yi, L.; Tang, L.; Tang, X.; Zhu, C.; Tian, Z. AI-driven and MEC-empowered confident information coverage hole recovery in 6G-enabled IoT. IEEE Trans. Netw. Sci. Eng. 2023, 10, 1256–1269. [Google Scholar] [CrossRef]
- Wang, F.; Zhang, X. IRS/UAV-based edge-computing/traffic-offloading over RF-rowered 6G mobile wireless networks. In Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC), Austin, TX, USA, 10–13 April 2022; pp. 1272–1277. [Google Scholar]
- Li, M.; Cheng, N.; Gao, J.; Wang, Y.; Zhao, L.; Shen, X. Energy efficient UAV-assisted mobile edge computing: Resource allocation and trajectory optimization. IEEE Trans. Veh. Technol. 2020, 69, 3424–3438. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, T.; Liu, Y.; Yang, D.; Xiao, L.; Tao, M. UAV-assisted MEC networks with aerial and ground cooperation. IEEE Trans. Wirel. Commun. 2021, 20, 7712–7727. [Google Scholar] [CrossRef]
- Guo, K.; Wu, M.; Li, X.; Song, H.; Kumar, N. Deep reinforcement learning and NOMA-based multiobjective RIS-assisted IS-UAV-TNs: Trajectory optimization and beamforming design. IEEE Trans. Intell. Transp. Syst. 2023, 24, 10197–10210. [Google Scholar] [CrossRef]
- Bai, T.; Pan, C.; Deng, Y.; Elkashlan, M.; Nallanathan, A.; Hanzo, L. Latency minimization for intelligent reflecting surface aided mobile edge computing. IEEE J. Sel. Areas Commun. 2020, 38, 2666–2682. [Google Scholar] [CrossRef]
- Yang, Z.; Chen, M.; Liu, X.; Liu, Y.; Chen, Y.; Cui, S.; Poor, H.V. AI-driven UAV-NOMA-MEC in next generation wireless networks. IEEE Wirel. Commun. 2021, 28, 66–73. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, Y.; Li, H.; Hou, S.; Song, Z. Resource allocation for energy efficient STAR-RIS aided MEC systems. IEEE Wirel. Commun. Lett. 2023, 12, 610–614. [Google Scholar] [CrossRef]
- Kim, J.; Hong, E.; Jung, J.; Kang, J.; Jeong, S. Energy minimization in reconfigurable intelligent surface-assisted unmanned aerial vehicle-enabled wireless powered mobile edge computing systems with rate-splitting multiple access. Drones 2023, 7, 688. [Google Scholar] [CrossRef]
- Zhai, Z.; Dai, X.; Duo, B.; Wang, X.; Yuan, X. Energy-efficient UAV-mounted RIS assisted mobile edge computing. IEEE Wirel. Commun. Lett. 2022, 11, 2507–2511. [Google Scholar] [CrossRef]
- Zhuo, Z.; Dong, S.; Zheng, H.; Zhang, Y. Method of minimizing energy consumption for RIS assisted UAV mobile edge computing system. IEEE Access 2024, 12, 39678–39688. [Google Scholar] [CrossRef]
- Wu, M.; Guo, K.; Li, X.; Lin, Z.; Wu, Y.; Tsiftsis, T.A.; Song, H. Deep reinforcement learning-based energy efficiency optimization for RIS-aided integrated satellite-aerial-terrestrial relay networks. IEEE Trans. Commun. 2024; early access. [Google Scholar] [CrossRef]
- Liu, Y.; Yu, H.; Xie, S.; Zhang, Y. Deep reinforcement learning for offloading and resource allocation in vehicle edge computing and networks. IEEE Trans. Veh. Technol. 2019, 68, 11158–11168. [Google Scholar] [CrossRef]
- Ale, L.; Zhang, N.; Fang, X.; Chen, X.; Wu, S.; Li, L. Delay-aware and energy-efficient computation offloading in mobile-edge computing using deep reinforcement learning. IEEE Trans. Cognit. Commun. Netw. 2021, 7, 881–892. [Google Scholar] [CrossRef]
- Subburaj, B.; Jayachandran, U.; Arumugham, V.; Amalraj, M. A self-adaptive trajectory optimization algorithm using fuzzy logic for mobile edge computing system assisted by unmanned aerial vehicle. Drones 2023, 7, 266. [Google Scholar] [CrossRef]
- Hu, X.; Wong, K.K.; Yang, K.; Zheng, Z. UAV-assisted relaying and edge computing: Scheduling and trajectory optimization. IEEE Trans. Wirel. Commun. 2019, 18, 4738–4752. [Google Scholar] [CrossRef]
- Liu, Y.; Xiong, K.; Ni, Q.; Fan, P.; Letaief, K.B. UAV-assisted wireless powered cooperative mobile edge computing: Joint offloading, CPU control, and trajectory optimization. IEEE Internet Things J. 2020, 7, 2777–2790. [Google Scholar] [CrossRef]
- Zeng, Y.; Xu, J.; Zhang, R. Energy minimization for wireless communication with rotary-wing UAV. IEEE Trans. Wirel. Commun. 2019, 18, 2329–2345. [Google Scholar] [CrossRef]
- Zhang, H.; Huang, M.; Zhou, H.; Wang, X.; Wang, N.; Long, K. Capacity Maximization RIS-UAV Networks: A DDQN-Based Trajectory Phase Shift Optimization Approach. IEEE Trans. Wirel. Commun. 2023, 22, 2583–2591. [Google Scholar] [CrossRef]
- Yang, R.; Wang, D.; Qiao, J. Policy gradient adaptive critic design with dynamic prioritized experience replay for wastewater treatment process control. IEEE Trans. Ind. Inf. 2022, 18, 3150–3158. [Google Scholar] [CrossRef]
- Zhang, G.; Wu, Q.; Cui, M.; Zhang, R. Securing UAV communications via joint trajectory and power control. IEEE Trans. Wirel. Commun. 2019, 18, 1376–1389. [Google Scholar] [CrossRef]
- Yang, H.; Xiong, Z.; Zhao, J.; Niyato, D.; Xiao, L.; Wu, Q. Deep reinforcement learning-based intelligent reflecting surface for secure wireless communications. IEEE Trans. Wirel. Commun. 2021, 20, 375–388. [Google Scholar] [CrossRef]
- Zhang, T.; Liu, G.; Zhang, H.; Kang, W.; Karagiannidis, G.K.; Nallanathan, A. Energy-efficient resource allocation and trajectory design for UAV relaying systems. IEEE Trans. Commun. 2020, 68, 6483–6498. [Google Scholar] [CrossRef]
- Huang, C.; Mo, R.; Yue, Y. Reconfigurable intelligent surface assisted multiuser MISO systems exploiting deep reinforcement learning. IEEE J. Sel. Areas Commun. 2020, 38, 1839–1850. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meaning |
|---|---|
| The channel gain coefficient from RIS to MEC server | |
| The channel gain coefficient from k-th VU to RIS | |
| The position of UAV at the n-th time slots | |
| The RIS phase shift matrix at the n-th time slots | |
| M | The number of RIS reflective elements |
| K | The number of ground vehicle users |
| The aggregate offloaded tasks for k-th VU at the n-th time slots | |
| The locally computed tasks for k-th VU at the n-th time slots | |
| The CPU frequency for aggregate offloaded tasks | |
| The CPU frequency for locally computed tasks | |
| The energy consumption for aggregate offloaded tasks | |
| The energy consumption for locally computed tasks | |
| The content scheduling variables at the k-th VU |
| System Parameter | Value |
|---|---|
| Frequency | |
| Channel bandwidth | |
| Carrier wavelenghth | = |
| Variance of the noise | |
| UAV fixed altitude | |
| UAV initial position | |
| Power allocated to k-th VU | |
| Total offloaded tasks | |
| Number of VUs | 8 |
| Service areas | |
| Number of CPU cycles | |
| Number of RIS relfective elements | |
| Time slot length | 1 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, M.; Zhu, S.; Li, C.; Zhu, J.; Chen, Y.; Liu, X.; Liu, R. UAV-Mounted RIS-Aided Mobile Edge Computing System: A DDQN-Based Optimization Approach. Drones 2024, 8, 184. https://doi.org/10.3390/drones8050184
Wu M, Zhu S, Li C, Zhu J, Chen Y, Liu X, Liu R. UAV-Mounted RIS-Aided Mobile Edge Computing System: A DDQN-Based Optimization Approach. Drones. 2024; 8(5):184. https://doi.org/10.3390/drones8050184
Chicago/Turabian StyleWu, Min, Shibing Zhu, Changqing Li, Jiao Zhu, Yudi Chen, Xiangyu Liu, and Rui Liu. 2024. "UAV-Mounted RIS-Aided Mobile Edge Computing System: A DDQN-Based Optimization Approach" Drones 8, no. 5: 184. https://doi.org/10.3390/drones8050184
APA StyleWu, M., Zhu, S., Li, C., Zhu, J., Chen, Y., Liu, X., & Liu, R. (2024). UAV-Mounted RIS-Aided Mobile Edge Computing System: A DDQN-Based Optimization Approach. Drones, 8(5), 184. https://doi.org/10.3390/drones8050184