

Superpixel-Based Graph Convolutional Network for UAV Forest Fire Image Segmentation



Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset
- (1)
- FLAME dataset
- (2)
- Chongli dataset
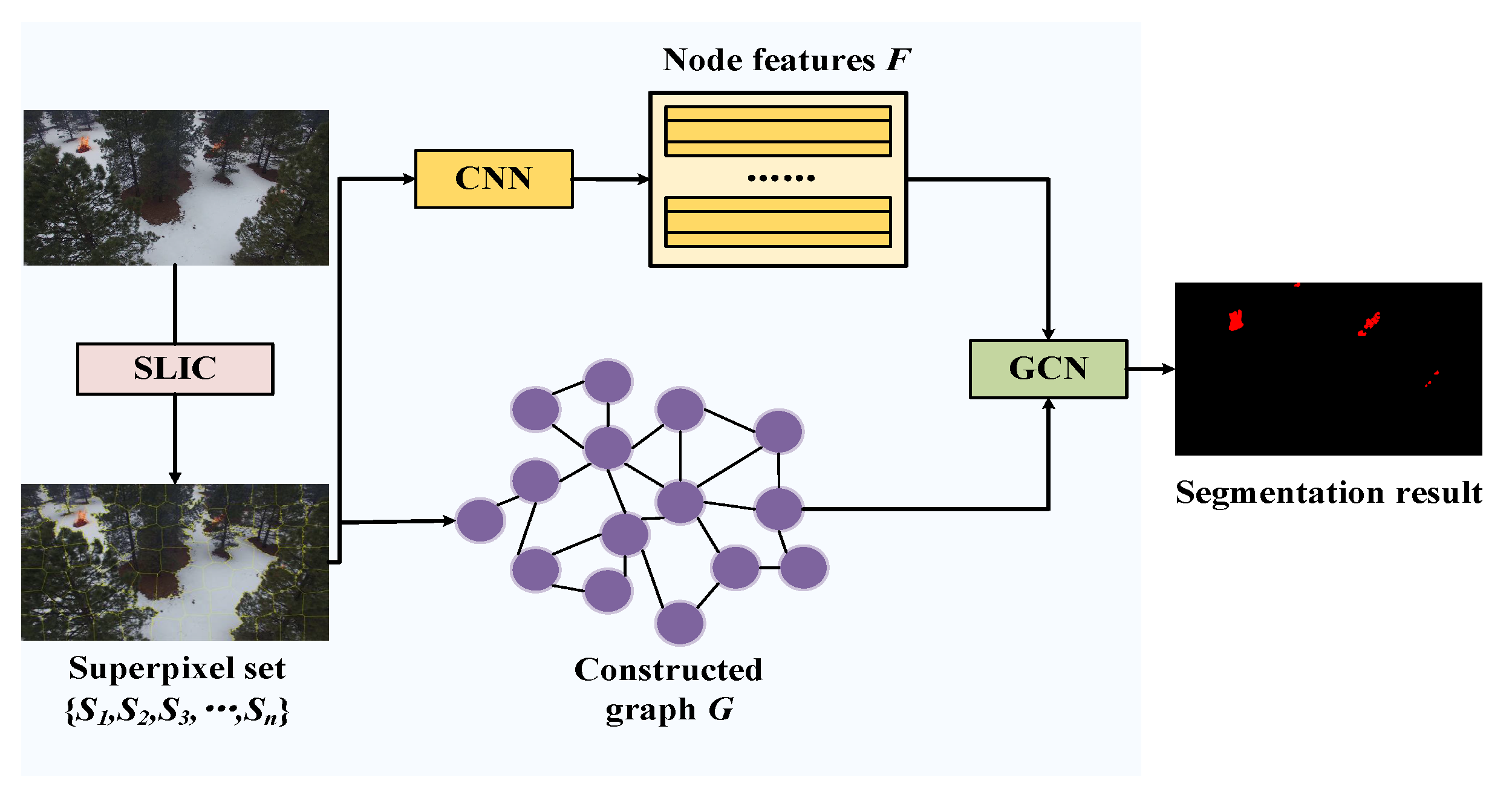
2.2. Method
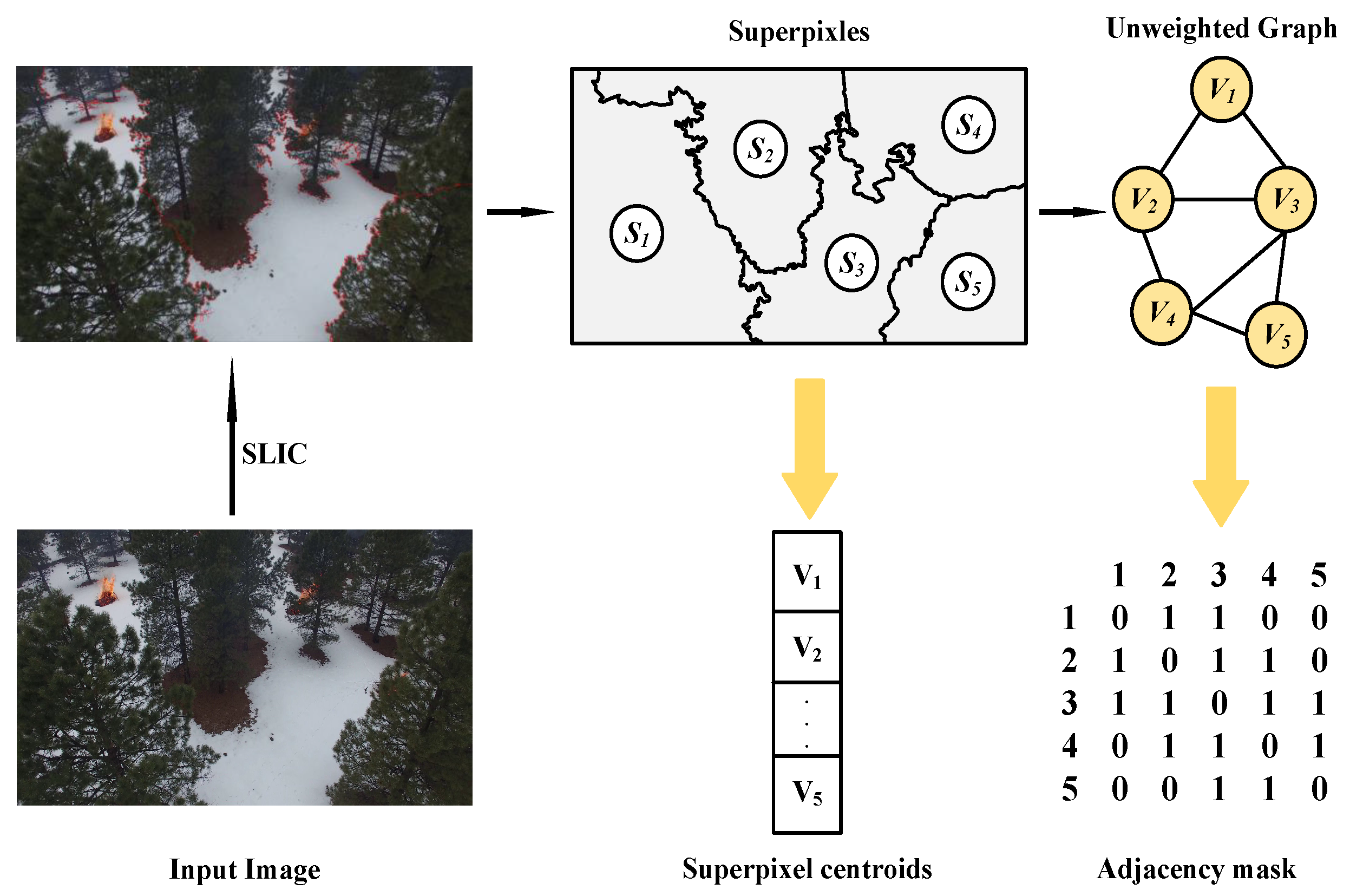
2.2.1. Graph Construction
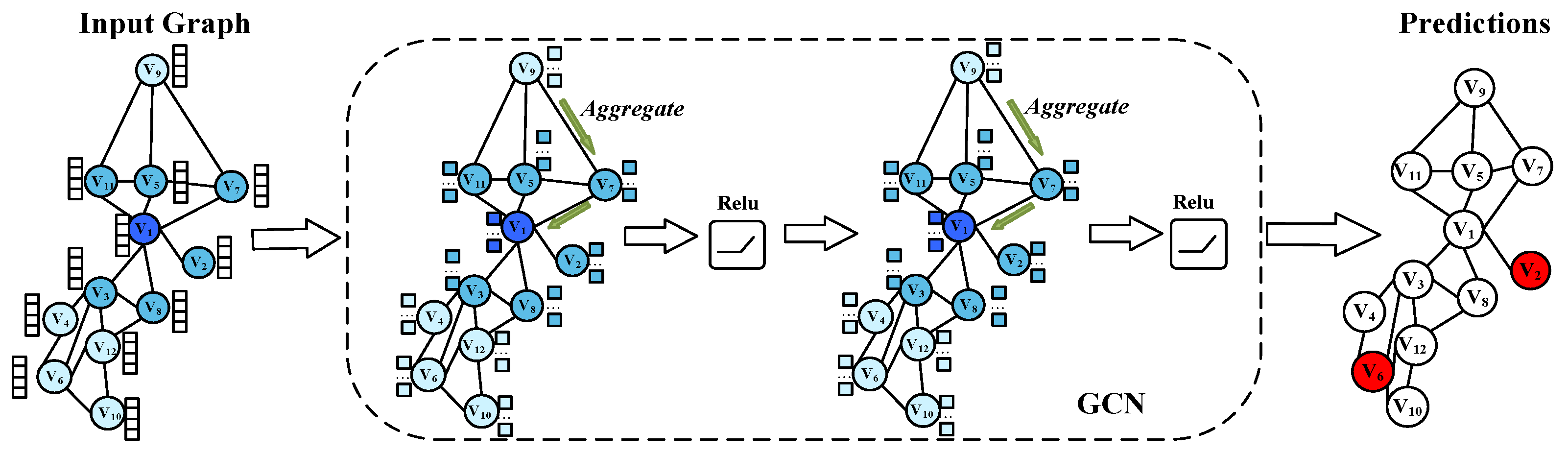
2.2.2. Node Classification with GCN
| Algorithm 1: Training SCGCN for Image Segmentation |
| ine : the forest fire image dataset . 1. Segment images from by SLIC. 2. Use CNN to extract features . 3. Construct graph nodes . Regions segmented by SLIC are used as graph nodes . 4. Construct graph edges . Take the first order adjacency relationship of a graph node with the smallest weight as the edge of the graph. 5. Classify the graph nodes when the GCN trainning ends. 6. Assign the class of each node to the superpixel of this node. : the semantic segmentation. |
2.2.3. Loss Function
2.2.4. Evaluation Metrics
2.2.5. Implementation Details
3. Experimental Results
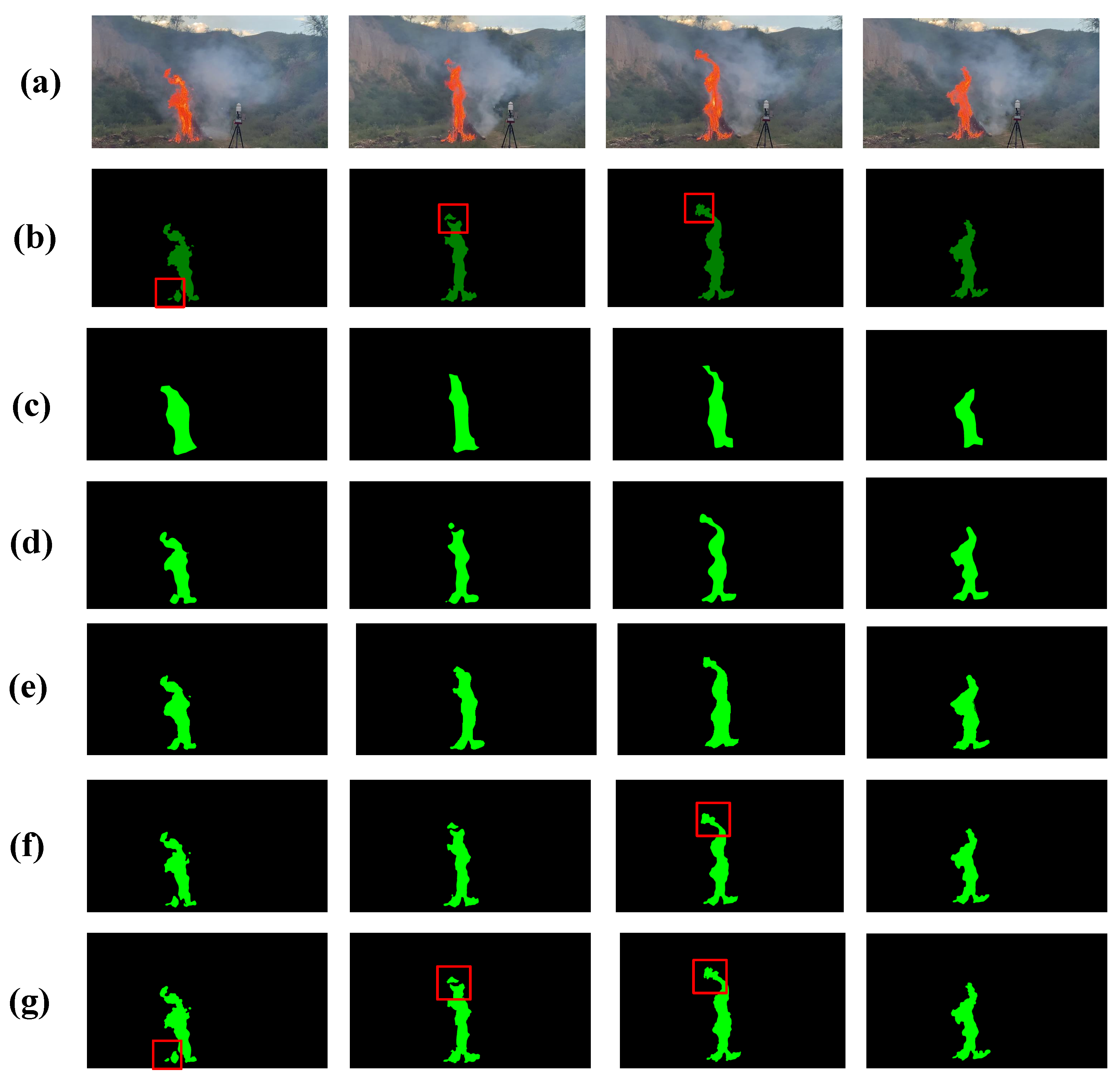
3.1. Results of FLAME Dataset
3.2. Results of Chongli Dataset
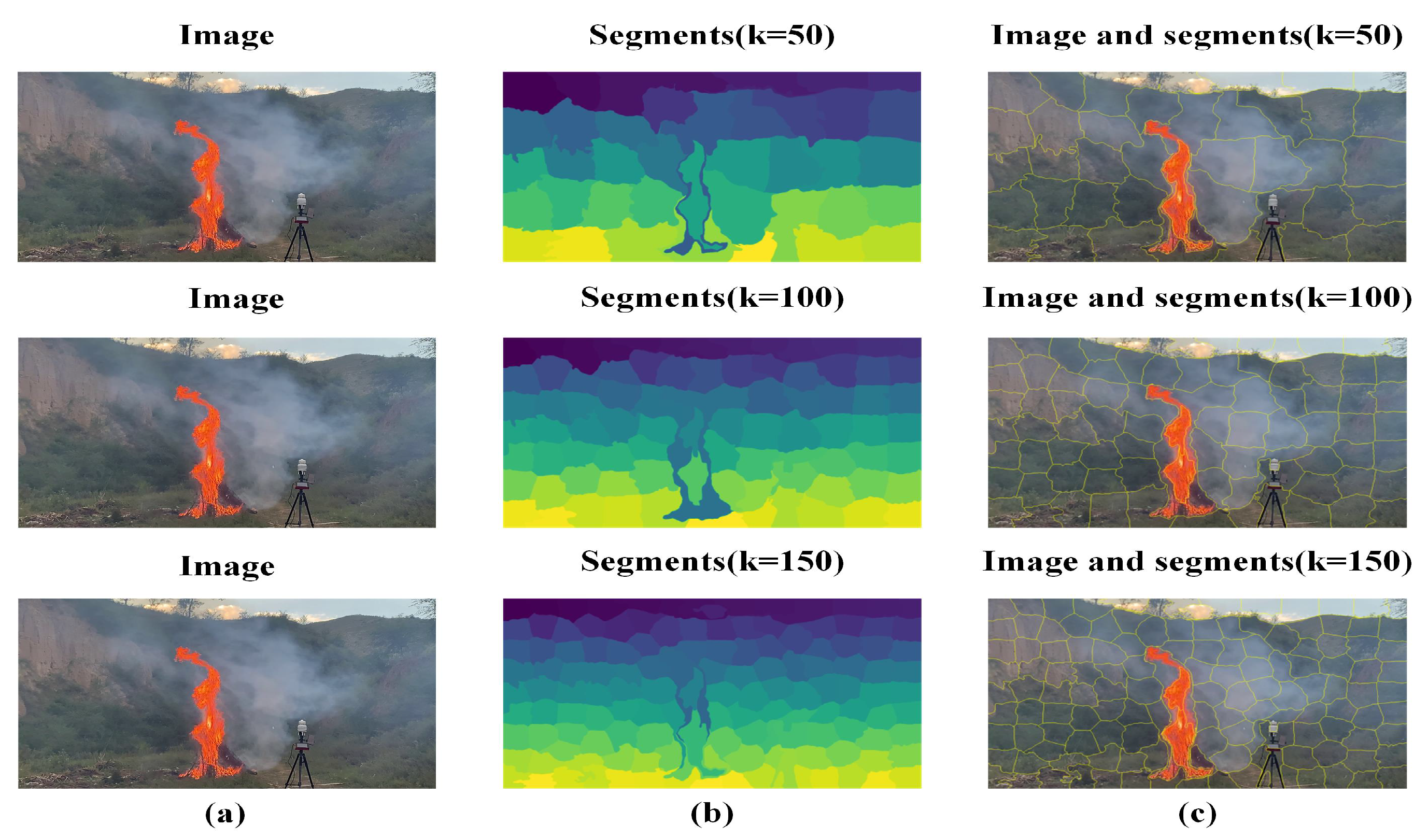
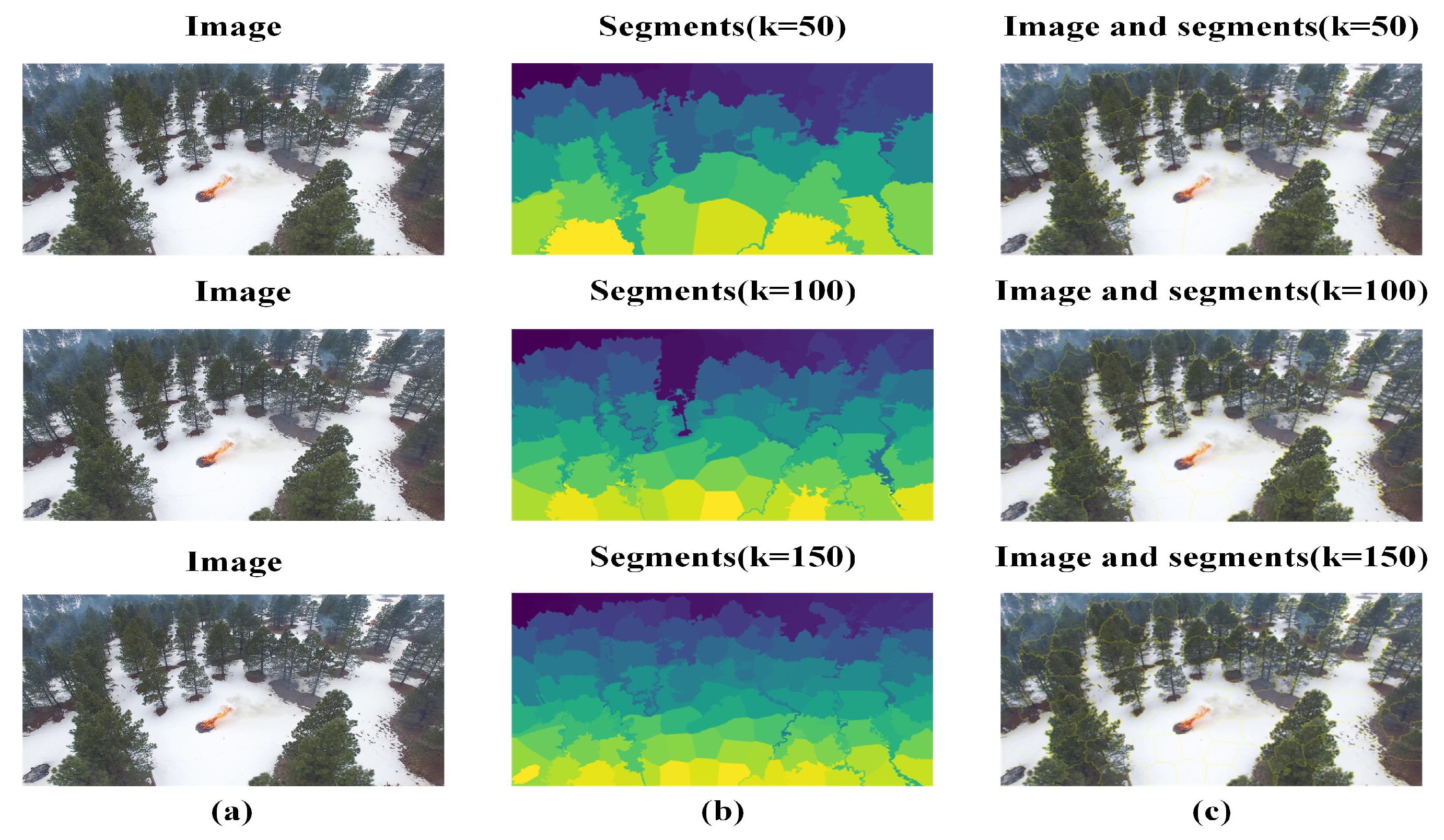
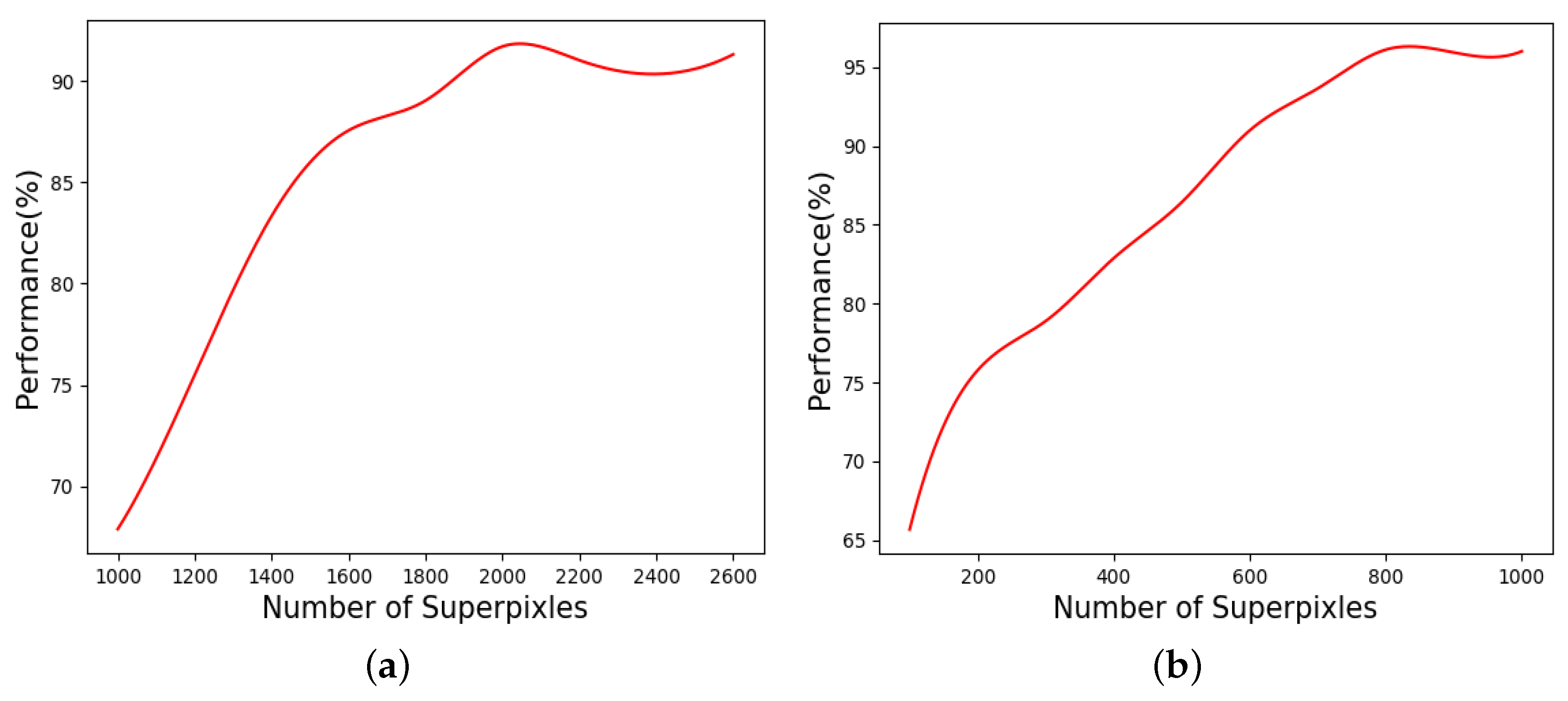
3.3. Superpixel Number
3.4. Ablation Experiment
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hu, Y.; Zhan, J.; Zhou, G.; Chen, A.; Cai, W.; Guo, K.; Hu, Y.; Li, L. Fast forest fire smoke detection using mvmnet. Knowl.-Based Syst. 2022, 241, 108219. [Google Scholar] [CrossRef]
- Ghali, R.; Akhloufi, M.A.; Jmal, M.; Souidene Mseddi, W.; Attia, R. Wildfire segmentation using deep vision transformers. Remote Sens. 2021, 13, 3527. [Google Scholar] [CrossRef]
- Zhu, Y.; Li, D.; Fan, J.; Zhang, H.; Eichhorn, M.P.; Wang, X.; Yun, T. A reinterpretation of the gap fraction of tree crowns from the perspectives of computer graphics and porous media theory. Front. Plant Sci. 2023, 14, 1109443. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Sun, Y.; Zhang, F.; Jiang, H. Modeling Fire Boundary Formation Based on Machine Learning in Liangshan, China. Forests 2023, 14, 1458. [Google Scholar] [CrossRef]
- Gao, D.; Wang, H.; Guo, X.; Gui, G.; Wang, W.; Yin, Z.; Wang, S.; Liu, Y.; He, T. Federated learning based on CTC for heterogeneous internet of things. IEEE Internet Things J. 2023, 10, 22673–22685. [Google Scholar] [CrossRef]
- Xue, X.; Jin, S.; An, F.; Zhang, H.; Fan, J.; Eichhorn, M.P.; Jin, C.; Chen, B.; Jiang, L.; Yun, T. Shortwave radiation calculation for forest plots using airborne LiDAR data and computer graphics. Plant Phenom. 2022, 2022, 9856739. [Google Scholar] [CrossRef]
- Gao, D.; Wang, L.; Hu, B. Spectrum efficient communication for heterogeneous IoT networks. IEEE Trans. Netw. Sci. Eng. 2022, 9, 3945–3955. [Google Scholar] [CrossRef]
- Shi, C.; Zhang, F. A forest fire susceptibility modeling approach based on integration machine learning algorithm. Forests 2023, 14, 1506. [Google Scholar] [CrossRef]
- Zhao, Y.; Komachi, M.; Kajiwara, T.; Chu, C. Region-attentive multimodal neural machine translation. Neurocomputing 2022, 476, 1–13. [Google Scholar] [CrossRef]
- Wang, S.; Zhao, J.; Ta, N.; Zhao, X.; Xiao, M.; Wei, H. A real-time deep learning forest fire monitoring algorithm based on an improved pruned+ kd model. J. Real-Time Image Process. 2021, 18, 2319–2329. [Google Scholar] [CrossRef]
- Khryashchev, V.; Larionov, R. Wildfire segmentation on satellite images using deep learning. In Proceedings of the 2020 Moscow Workshop on Electronic and Networking Technologies (MWENT), Moscow, Russia, 11–13 March 2020; pp. 1–5. [Google Scholar]
- Hori, T.; Watanabe, S.; Zhang, Y.; Chan, W. Advances in joint ctc-attention based end-to-end speech recognition with a deep cnn encoder and rnn-lm. arXiv 2017, arXiv:1706.02737. [Google Scholar]
- Meng, Y.; Wei, M.; Gao, D.; Zhao, Y.; Yang, X.; Huang, X.; Zheng, Y. Cnn-gcn aggregation enabled boundary regression for biomedical image segmentation. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2020, Proceedings of the 23rd International Conference, Lima, Peru, 4–8 October 2020; Part IV 23; Springer: Berlin/Heidelberg, Germany, 2020; pp. 352–362. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef] [PubMed]
- Gallicchio, C.; Micheli, A. Graph echo state networks. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar]
- Liu, Q.; Xiao, L.; Yang, J.; Wei, Z. Cnn-enhanced graph convolutional network with pixel-and superpixel-level feature fusion for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 8657–8671. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. Unetformer: A unet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Wu, D.; Zhang, C.; Ji, L.; Ran, R.; Wu, H.; Xu, Y. Forest fire recognition based on feature extraction from multi-view images. Trait. Du Signal 2021, 38, 775–783. [Google Scholar] [CrossRef]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral networks and locally connected networks on graphs. arXiv 2013, arXiv:1312.6203. [Google Scholar]
- Dong, X.; Zhang, C.; Fang, L.; Yan, Y. A deep learning based framework for remote sensing image ground object segmentation. Appl. Soft Comput. 2022, 130, 109695. [Google Scholar] [CrossRef]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. Slic superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed]
- Bergh, M.V.d.; Boix, X.; Roig, G.; Capitani, B.d.; Gool, L.V. Seeds: Superpixels extracted via energy-driven sampling. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 13–26. [Google Scholar]
- Ban, Z.; Liu, J.; Cao, L. Superpixel segmentation using gaussian mixture model. IEEE Trans. Image Process. 2018, 27, 4105–4117. [Google Scholar] [CrossRef]
- Belizario, I.V.; Linares, O.C.; Neto, J.d.E.S.B. Automatic image segmentation based on label propagation. IET Image Proc. 2021, 15, 2532–2547. [Google Scholar] [CrossRef]
- Xiong, D.; Yan, L. Early smoke detection of forest fires based on svm image segmentation. J. For. Sci. 2019, 65, 150–159. [Google Scholar] [CrossRef]
- Martins, J.; Junior, J.M.; Menezes, G.; Pistori, H.; Sant, D.; Gonçalves, W. Image segmentation and classification with slic superpixel and convolutional neural network in forest context. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 6543–6546. [Google Scholar]
- Tian, Z.; Li, X.; Zheng, Y.; Chen, Z.; Shi, Z.; Liu, L.; Fei, B. Graph-convolutional-network-based interactive prostate segmentation in mr images. Med. Phys. 2020, 47, 4164–4176. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Chen, R.; Zhang, Y.; Li, H. A cnn-gcn framework for multi-label aerial image scene classification. In Proceedings of the IGARSS 2020–2020 IEEE International Geoscience and Remote Sensing Symposium, Virtual, 26 September–2 October 2020; pp. 1353–1356. [Google Scholar]
- Zhao, C.; Qin, B.; Feng, S.; Zhu, W. Multiple superpixel graphs learning based on adaptive multiscale segmentation for hyperspectral image classification. Remote Sens. 2022, 14, 681. [Google Scholar] [CrossRef]
- Peng, Z.; Liu, H.; Jia, Y.; Hou, J. Attention-driven graph clustering network. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 935–943. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Filtjens, B.; Vanrumste, B.; Slaets, P. Skeleton-based action segmentation with multi-stage spatial-temporal graph convolutional neural networks. IEEE Trans. Emerg. Top. Comput. 2022, 12, 202–212. [Google Scholar] [CrossRef]
- Avelar, P.H.; Tavares, A.R.; da Silveira, T.L.; Jung, C.R.; Lamb, L.C. Superpixel image classification with graph attention networks. In Proceedings of the 2020 33rd SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Porto de Galinhas, Brazil, 7–10 November 2020; pp. 203–209. [Google Scholar]
- Sasaki, Y. The truth of the f-measure. Teach. Tutor. Mater. 2007, 1, 1–5. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 5693–5703. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Wang, Y.; Wei, H.; Ding, X.; Tao, J. Video background/foreground separation model based on non-convex rank approximation rpca and superpixel motion detection. IEEE Access 2020, 8, 157493–157503. [Google Scholar] [CrossRef]
- Ma, F.; Gao, F.; Sun, J.; Zhou, H.; Hussain, A. Attention graph convolution network for image segmentation in big sar imagery data. Remote Sens. 2019, 11, 2586. [Google Scholar] [CrossRef]
- Zhang, L.; Li, J.; Zhang, F. An efficient forest fire target detection model based on improved YOLOv5. Fire 2023, 6, 291. [Google Scholar] [CrossRef]
- Zheng, S.; Gao, P.; Wang, W.; Zou, X. A Highly Accurate Forest Fire Prediction Model Based on an Improved Dynamic Convolutional Neural Network. Appl. Sci. 2022, 12, 6721. [Google Scholar] [CrossRef]
- Cao, X.; Su, Y.; Geng, X.; Wang, Y. YOLO-SF: YOLO for fire segmentation detection. IEEE Access 2023, 11, 111079–111092. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | MIoU (%) | Acc (%) | (%) |
|---|---|---|---|
| PSPnet [38] | 34.65 | 47.56 | 74.32 |
| Deeplabv3+ [35] | 69.40 | 81.85 | 82.02 |
| Unet++ [36] | 79.52 | 86.68 | 90.60 |
| HRnet [37] | 77.71 | 85.70 | 88.28 |
| SCGCN (ours) | 79.87 | 87.53 | 91.69 |
| Method | MIoU (%) | Acc (%) | (%) |
|---|---|---|---|
| PSPnet [38] | 56.0 | 65.71 | 79.12 |
| Deeplabv3+ [35] | 83.65 | 90.48 | 91.72 |
| Unet++ [36] | 91.50 | 95.04 | 96.09 |
| HRnet [37] | 88.54 | 93.65 | 92.31 |
| SCGCN (ours) | 92.34 | 96.69 | 97.56 |
| Method | MIoU (%) | Acc (%) | (%) |
|---|---|---|---|
| GCN + SLIC + CE | 76.51 | 83.46 | 86.23 |
| GraphSAGE + SLIC + CE | 77.49 | 86.23 | 89.61 |
| GraphSAGE + SLIC + SL (ours) | 79.87 | 87.53 | 91.69 |
| Method | MIoU (%) | Acc (%) | (%) |
|---|---|---|---|
| GCN + SLIC + CE | 87.65 | 91.26 | 93.58 |
| GraphSAGE + SLIC + CE | 90.79 | 95.87 | 95.70 |
| GraphSAGE + SLIC + SL (ours) | 92.34 | 96.69 | 97.56 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mu, Y.; Ou, L.; Chen, W.; Liu, T.; Gao, D. Superpixel-Based Graph Convolutional Network for UAV Forest Fire Image Segmentation. Drones 2024, 8, 142. https://doi.org/10.3390/drones8040142
Mu Y, Ou L, Chen W, Liu T, Gao D. Superpixel-Based Graph Convolutional Network for UAV Forest Fire Image Segmentation. Drones. 2024; 8(4):142. https://doi.org/10.3390/drones8040142
Chicago/Turabian StyleMu, Yunjie, Liyuan Ou, Wenjing Chen, Tao Liu, and Demin Gao. 2024. "Superpixel-Based Graph Convolutional Network for UAV Forest Fire Image Segmentation" Drones 8, no. 4: 142. https://doi.org/10.3390/drones8040142
APA StyleMu, Y., Ou, L., Chen, W., Liu, T., & Gao, D. (2024). Superpixel-Based Graph Convolutional Network for UAV Forest Fire Image Segmentation. Drones, 8(4), 142. https://doi.org/10.3390/drones8040142