
PVswin-YOLOv8s: UAV-Based Pedestrian and Vehicle Detection for Traffic Management in Smart Cities Using Improved YOLOv8




Abstract
1. Introduction
- We introduce the PVswin-YOLOv8s model by utilizing YOLOv8s as a baseline model with a Swin Transformer block for pedestrians and vehicle detection based on UAVs. This integration involved replacing the last C2f layer from the backbone network of YOLOV8s with a Swin Transformer block. The models incorporate global feature extraction for detecting extremely small items;
- Then, to overcome the issues of missed detection, we incorporate the CBAM module into the YOLOv8s neck network. This works well for extracting feature information flow inside the network;
- We implement Soft-NMS in YOLOv8s as a replacement for NMS to improve detection achievement in occlusion scenarios. Occlusion is a major problem in the detection of objects for UAVs, and NMS methods frequently lead to missed identifications. Soft-NMS enhances accuracy for detection and manages overlapped bounding boxes with efficacy.
2. Related Work
3. Proposed Method
3.1. Network Framework of YOLOv8s
3.2. Pedestrian and Vehicle Detection Network (PVswin-YOLOv8s)
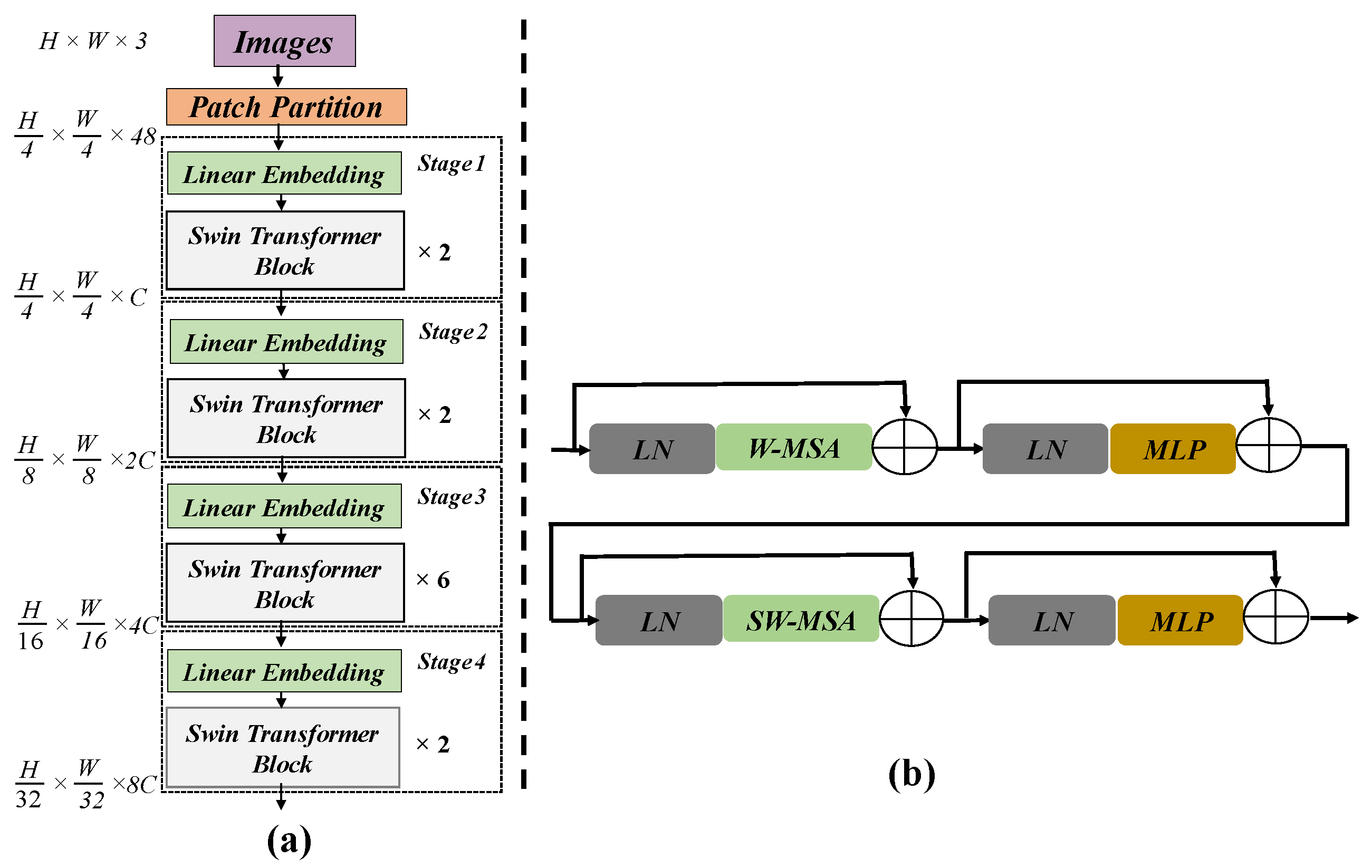
3.3. Swin Transformer Block
3.4. CBAM
3.5. Soft-NMS
4. Experimental Results
4.1. Overview of the Experiment
4.1.1. Dataset and Hyper Parameters
4.1.2. Evaluation Matrix
4.1.3. Precision and Recall
4.1.4. F1-Score
4.1.5. Mean Average Precision (mAP)
4.2. Results and Analysis
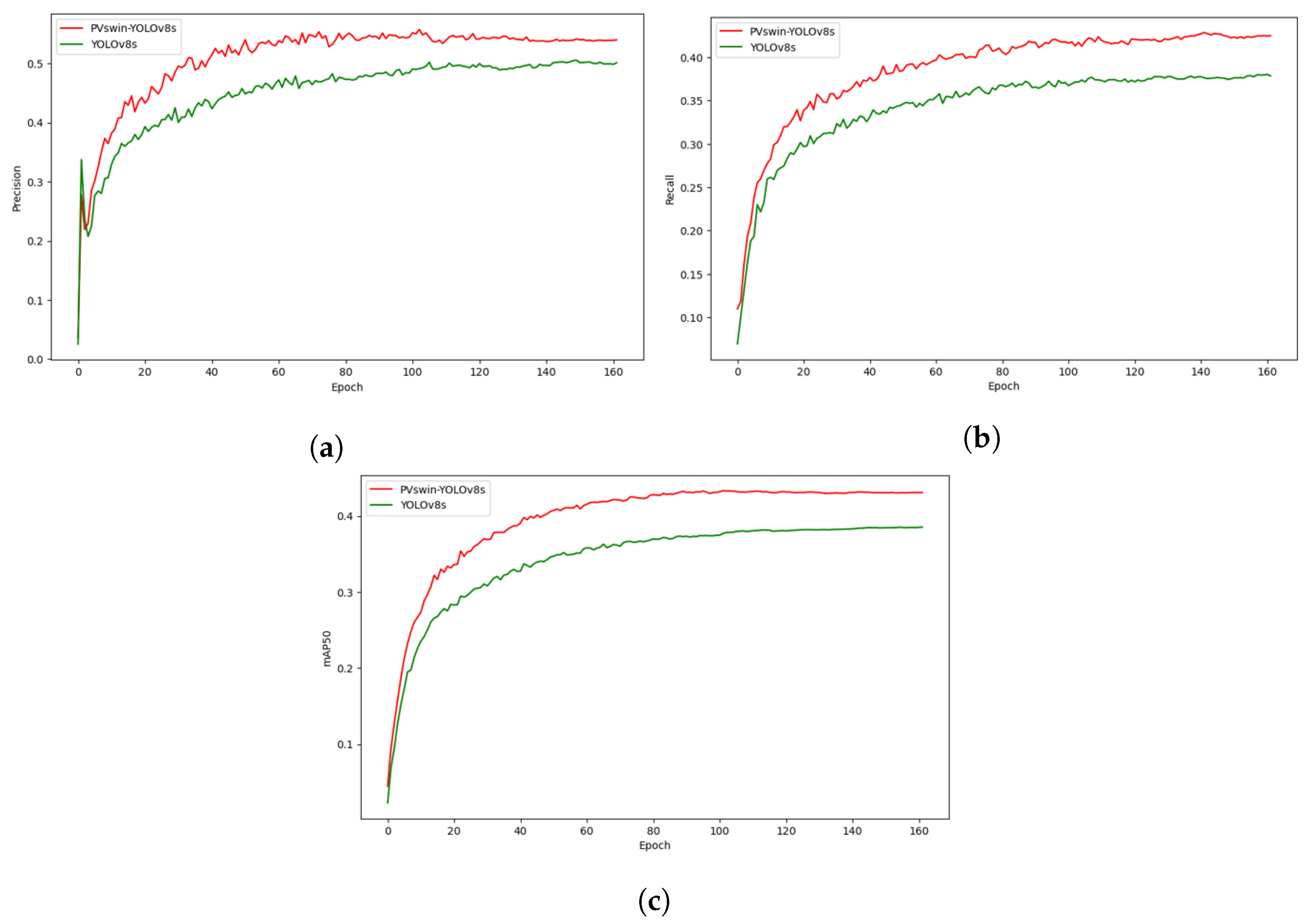
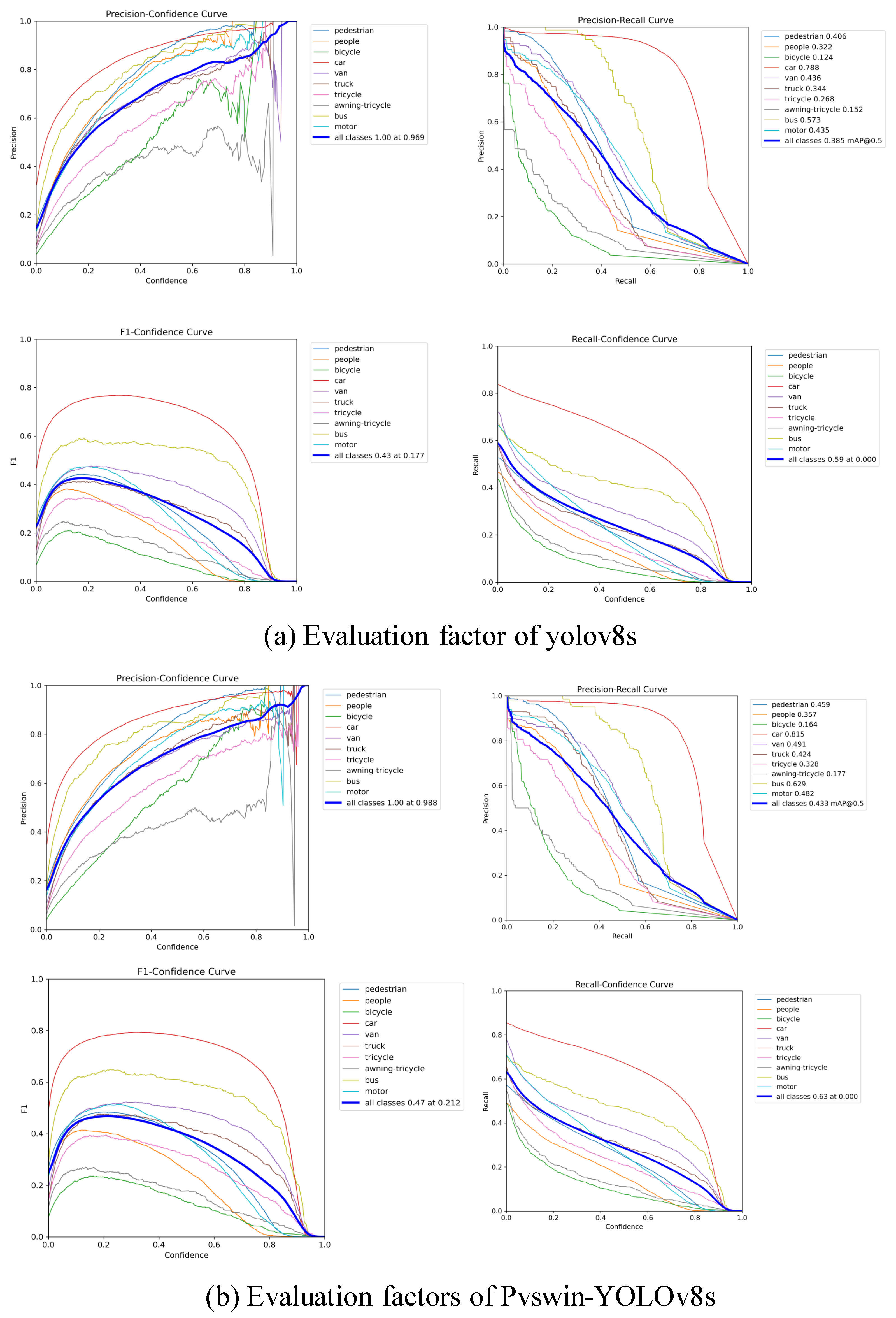
4.2.1. Comparison with YOLOv8s
4.2.2. Comparison with Other Versions of YOLOv8
4.2.3. Comparison with Other Versions of YOLO
4.2.4. Comparison with the Classical Model
4.3. Ablation Test
4.4. Visual Analysis
4.5. Discussion
- We compared our model with the baseline model YOLOv8s. Table 3 shows the mAP values for each class, as well as the mAP0.5 values for all classes. As can be seen, with the proposed PVswin-YOLOv8s model, detection accuracy improved by 4.8% compared to the baseline model on the Visdrone2019 dataset;
- We compared our model against four versions of YOLOV8, specifically, YOLOv8n, YOLOv8s, YOLOv8m, and YOLOv8l. The results are presented in Table 4 using the VisDrone2019-val dataset and in Table 5 using the test set. PVswin-YOLOv8s outperforms YOLOv8n, YOLOv8s, and YOLOv8m, exhibiting the highest values for precision and mAP0.5. Additionally, its F1-score is comparable to YOLOv8l, with mAP0.5:0.95 only 0.1% lower than YOLOv8l based on the results in Table 4. AS can be seen in Table 5, PVswin-YOLOv8s’s precision, F1 score, and mAP0.5 are superior to YOLOv8l, indicating superior detection performance despite a smaller model size. The experimental findings underscore the effective enhancement of detection accuracy for extremely small objects in our proposed structure;
- We compared our model with previous versions of YOLO, specifically, YOLOv3-tiny, YOLOv5, YOLOv6, and YOLOv7. Here, our model also outperformed these previous version of YOLO, as shown in Table 6;
- We carried out experiments to evaluate the performance of our proposed model against classical start-of-the-art (SOTA) models, namely, Faster-RCNN, Cascade R-CNN, RetinaNet, and CenterNet. The results are presented in Table 7. Based on these findings, our model outperforms these SOTA models in terms of detection performance;
- We performed an ablation test that demonstrated that the integration of the Swin Transformer led to a 2.1% increase in mAP0.5 and a 1.7% increase in mAP0.5:0.95, highlighting the model’s improved detection of small objects in complex scenes as shown in Table 8. The CBAM module contributed an additional 1.3% to mAP0.5 and 0.9% to mAP0.5:0.95, while Soft-NMS further improved these metrics by 1.1% and 0.8%, respectively, ensuring robust detection in occluded environments.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nie, X.; Peng, J.; Wu, Y.; Gupta, B.B.; Abd El-Latif, A.A. Real-time traffic speed estimation for smart cities with spatial temporal data: A gated graph attention network approach. Big Data Res. 2022, 28, 100313. [Google Scholar] [CrossRef]
- Iftikhar, S.; Asim, M.; Zhang, Z.; Muthanna, A.; Chen, J.; El-Affendi, M.; Sedik, A.; Abd El-Latif, A.A. Target Detection and Recognition for Traffic Congestion in Smart Cities Using Deep Learning-Enabled UAVs: A Review and Analysis. Appl. Sci. 2023, 13, 3995. [Google Scholar] [CrossRef]
- Hazarika, A.; Poddar, S.; Nasralla, M.M.; Rahaman, H. Area and energy efficient shift and accumulator unit for object detection in IoT applications. Alex. Eng. J. 2022, 61, 795–809. [Google Scholar] [CrossRef]
- Waheed, S.R.; Suaib, N.M.; Rahim, M.S.M.; Khan, A.R.; Bahaj, S.A.; Saba, T. Synergistic Integration of Transfer Learning and Deep Learning for Enhanced Object Detection in Digital Images. IEEE Access 2024, 12, 13525–13536. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Terven, J.; Cordova-Esparza, D. A comprehensive review of YOLO: From YOLOv1 to YOLOv8 and beyond. arXiv 2023, arXiv:2304.00501. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. (CSUR) 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Li, Y.; Mao, H.; Girshick, R.; He, K. Exploring plain vision transformer backbones for object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2022; pp. 280–296. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Hatamizadeh, A.; Nath, V.; Tang, Y.; Yang, D.; Roth, H.R.; Xu, D. Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images. In Proceedings of the International MICCAI Brainlesion Workshop, Singapore, 18 September 2021; pp. 272–284. [Google Scholar]
- Liu, Z.; Tan, Y.; He, Q.; Xiao, Y. SwinNet: Swin transformer drives edge-aware RGB-D and RGB-T salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4486–4497. [Google Scholar] [CrossRef]
- Jannat, F.E.; Willis, A.R. Improving classification of remotely sensed images with the swin transformer. In Proceedings of the SoutheastCon 2022, Mobile, AL, USA, 26 March–3 April 2022; pp. 611–618. [Google Scholar]
- Srinivas, A.; Lin, T.Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck transformers for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16519–16529. [Google Scholar]
- Zhao, H.; Jia, J.; Koltun, V. Exploring self-attention for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10076–10085. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Naseer, M.M.; Ranasinghe, K.; Khan, S.H.; Hayat, M.; Shahbaz Khan, F.; Yang, M.H. Intriguing properties of vision transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 23296–23308. [Google Scholar]
- Mittal, P.; Sharma, A.; Singh, R.; Dhull, V. Dilated convolution based RCNN using feature fusion for Low-Altitude aerial objects. Expert Syst. Appl. 2022, 199, 117106. [Google Scholar] [CrossRef]
- Liu, Z.; Qiu, S.; Chen, M.; Han, D.; Qi, T.; Li, Q.; Lu, Y. CCH-YOLOX: Improved YOLOX for Challenging Vehicle Detection from UAV Images. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, Australia, 18–23 June 2023; pp. 1–9. [Google Scholar]
- Deng, L.; Bi, L.; Li, H.; Chen, H.; Duan, X.; Lou, H.; Zhang, H.; Bi, J.; Liu, H. Lightweight aerial image object detection algorithm based on improved YOLOv5s. Sci. Rep. 2023, 13, 7817. [Google Scholar] [CrossRef] [PubMed]
- Lou, H.; Duan, X.; Guo, J.; Liu, H.; Gu, J.; Bi, L.; Chen, H. DC-YOLOv8: Small-Size Object Detection Algorithm Based on Camera Sensor. Electronics 2023, 12, 2323. [Google Scholar] [CrossRef]
- Hui, Y.; Wang, J.; Li, B. STF-YOLO: A small target detection algorithm for UAV remote sensing images based on improved SwinTransformer and class weighted classification decoupling head. Measurement 2024, 224, 113936. [Google Scholar] [CrossRef]
- Tang, S.; Fang, Y.; Zhang, S. HIC-YOLOv5: Improved YOLOv5 for Small Object Detection. arXiv 2023, arXiv:2309.16393. [Google Scholar]
- Sirisha, M.; Sudha, S.V. An Advanced Object Detection Framework for UAV Imagery Utilizing Transformer-Based Architecture and Split Attention Module: PvSAMNet. Trait. Signal 2023, 40, 1661. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLOv8. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 20 December 2023).
- Wang, C.Y.; Liao, H.Y.M.; Yeh, I.H. Designing network design strategies through gradient path analysis. arXiv 2022, arXiv:2211.04800. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Cao, Y.; Chen, K.; Loy, C.C.; Lin, D. Prime sample attention in object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11583–11591. [Google Scholar]
- Li, X.; Lv, C.; Wang, W.; Li, G.; Yang, L.; Yang, J. Generalized focal loss: Towards efficient representation learning for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3139–3153. [Google Scholar] [CrossRef]
- Ju, R.Y.; Cai, W. Fracture Detection in Pediatric Wrist Trauma X-ray Images Using YOLOv8 Algorithm. arXiv 2023, arXiv:2304.05071. [Google Scholar] [CrossRef]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-aligned one-stage object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 3490–3499. [Google Scholar]
- Oksuz, K.; Cam, B.C.; Kalkan, S.; Akbas, E. Imbalance problems in object detection: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3388–3415. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Fan, H.; Hu, Q.; Ling, H. Detection and tracking meet drones challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7380–7399. [Google Scholar] [CrossRef] [PubMed]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Boyd, K.; Eng, K.H.; Page, C.D. Area under the precision-recall curve: Point estimates and confidence intervals. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2013, Prague, Czech Republic, 23–27 September 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 451–466. [Google Scholar]
- Adarsh, P.; Rathi, P.; Kumar, M. YOLO v3-Tiny: Object Detection and Recognition using one stage improved model. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 687–694. [Google Scholar]
- Ultralytics. YOLOv5: A State-of-the-Art Real-Time Object Detection System. 2021. Available online: https://docs.ultralytics.com (accessed on 19 December 2023).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Configuration |
|---|---|
| CPU | I5-6300U |
| GPU | NVIDIA A10, 22,592 MiB |
| GPU memory | 24 GB |
| Python | 3.10.13 |
| Ultralytics | YOLOv8.0.25 |
| DL architecture | Pytorch2.0.1 + cu117, CUDA |
| Parameters | Setup |
|---|---|
| Epochs | 200 |
| Learning rate | 0.01 |
| Image size | 640 × 640 |
| Batch size | 8 |
| optimizer | SGD |
| Weight decay | 5 × 10−4 |
| Momentum | 0.932 |
| Mosaic | 1.0 |
| Patience | 50 |
| Close mosaic | last 10 epochs |
| Models | Pedestrian | People | Bicycle | Car | Van | Truck | Tricycle | Awning-Tricycle | Bus | Motor | mAP0.5 (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv8s | 40.6 | 32.2 | 12.4 | 78.8 | 43.6 | 34.4 | 26.8 | 15.2 | 57.3 | 43.5 | 38.5 |
| PVswin-YOLOv8s | 45.9 | 35.7 | 16.4 | 81.5 | 49.1 | 42.4 | 32.8 | 17.7 | 62.9 | 48.2 | 43.3 |
| Models | Precision (%) | Recall (%) | F1-Score | mAP0.5 (%) | mAP-0.5:0.9 (%) | Detection Time () | Model Size () |
|---|---|---|---|---|---|---|---|
| YOLOv8n | 43.2 | 32.5 | 0.37 | 32.6 | 18.9 | 4.4 | 6.2 |
| YOLOv8s | 49.9 | 38 | 0.43 | 38.5 | 23 | 6.0 | 22.5 |
| YOLOv8m | 52.5 | 41 | 0.46 | 41.7 | 25.2 | 11.4 | 49.2 |
| YOLOv8l | 54.2 | 42.4 | 0.47 | 43 | 26.5 | 14.8 | 87.6 |
| Proposed: PVswin-YOLOv8s | 54.5 | 41.8 | 0.47 | 43.3 | 26.4 | 6.2 | 21.6 |
| Models | Precision (%) | Recall (%) | F1-Score | mAP0.5 (%) | mAP-0.5:0.9 (%) | Model Size (MB) |
|---|---|---|---|---|---|---|
| YOLOv8n | 38.2 | 28.7 | 0.32 | 26.1 | 14.6 | 6.2 |
| YOLOv8s | 44.5 | 32.3 | 0.37 | 30.5 | 17.4 | 22.5 |
| YOLOv8m | 46.3 | 35.3 | 0.40 | 33.4 | 19.4 | 49.2 |
| YOLOv8l | 48.1 | 37 | 0.41 | 35 | 20.6 | 87.6 |
| Proposed: PVswin-YOLOv8s | 49.7 | 36.4 | 0.42 | 35.2 | 20.4 | 21.6 |
| Models | Precision (%) | Recall (%) | mAP0.5 (%) | mAP0.5:0.95 (%) | Detection Time (ms) | Model Size (MB) |
|---|---|---|---|---|---|---|
| YOLOv3 (tiny) | 37.2 | 24.1 | 23.2 | 12.9 | 2.7 | 24 |
| YOLOv5 | 42.3 | 31.9 | 31.5 | 18 | 3.8 | 5.3 |
| YOLOv6 | 39.8 | 29.4 | 29.1 | 17 | 3.3 | 8.7 |
| YOLOv7 | 50.2 | 41.1 | 37.9 | 19.9 | 1.9 | 72 |
| YOLOv8s | 49.9 | 38 | 38.5 | 23 | 6.0 | 22.5 |
| PVswin-YOLOv8s | 54.5 | 41.8 | 43.3 | 26.4 | 6.2 | 21.6 |
| Models | mAP0.5 (%) | mAP0.5:0.95 (%) |
|---|---|---|
| Faster RCNN | 37.2 | 21.9 |
| Cascade R-CNN | 39.1 | 24.3 |
| RetinaNet | 19.1 | 10.6 |
| leftNet | 33.7 | 18.8 |
| PVswin-YOLOv8s | 43.3 | 26.4 |
| Models | mAP0.5 (%) | mAP0.5:0.95 (%) |
|---|---|---|
| Baseline YOLOv8s | 38.5 | 23 |
| YOLOv8s + Swin Transformer | 40.6 (↑ 2.1% ) | 24.7 (↑ 1.7%) |
| YOLOv8s + Swin + CBAM | 42.2 (↑ 1.3 %) | 25.6 (↑ 0.9 %) |
| PVswin-YOLOv8s | 43.3 (↑ 1.1%) | 26.4 (↑ 0.8 %) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tahir, N.U.A.; Long, Z.; Zhang, Z.; Asim, M.; ELAffendi, M. PVswin-YOLOv8s: UAV-Based Pedestrian and Vehicle Detection for Traffic Management in Smart Cities Using Improved YOLOv8. Drones 2024, 8, 84. https://doi.org/10.3390/drones8030084
Tahir NUA, Long Z, Zhang Z, Asim M, ELAffendi M. PVswin-YOLOv8s: UAV-Based Pedestrian and Vehicle Detection for Traffic Management in Smart Cities Using Improved YOLOv8. Drones. 2024; 8(3):84. https://doi.org/10.3390/drones8030084
Chicago/Turabian StyleTahir, Noor Ul Ain, Zhe Long, Zuping Zhang, Muhammad Asim, and Mohammed ELAffendi. 2024. "PVswin-YOLOv8s: UAV-Based Pedestrian and Vehicle Detection for Traffic Management in Smart Cities Using Improved YOLOv8" Drones 8, no. 3: 84. https://doi.org/10.3390/drones8030084
APA StyleTahir, N. U. A., Long, Z., Zhang, Z., Asim, M., & ELAffendi, M. (2024). PVswin-YOLOv8s: UAV-Based Pedestrian and Vehicle Detection for Traffic Management in Smart Cities Using Improved YOLOv8. Drones, 8(3), 84. https://doi.org/10.3390/drones8030084