1. Introduction
With the deployment of the Internet of Things (IoT) in more fields, there is an increasing number of connected devices working together to jointly serve various applications. These devices have sensing and computing capabilities, which support them in collecting raw data in the environment for further processing [
1]. As an important extension of the IoT, the Internet of Vehicles (IoV) has established a wide range of vehicle-to-vehicle (V2V) and vehicle-to-infrastructure (V2I) connections [
2,
3]. Vehicle users (VUs) are equipped with more powerful integrated sensors to capture information in the road environment.
The extensive data collected by VUs have become a new driving force for emerging applications [
4], such as autopilot, location management, traffic prediction, etc. However, traditional cloud computing requires VUs to transfer raw data to the cloud, which brings the challenges of a high communication overhead, a high transmission delay, and privacy disclosure [
5]. Federated learning (FL) [
6] has been proposed as a distributed machine learning architecture to push the computing process to the devices to protect users’ data privacy.
However, communication inefficiency remains a key bottleneck in FL. Vehicles are constantly moving, leading to a dynamic and changing network topology. This mobility can result in frequent changes in the availability of communication links between vehicles and roadside units (RSUs), affecting the reliability and stability of FL. In addition, due to the mobility of vehicles, connections between them may be intermittent. This can lead to challenges in maintaining continuous communication for model updates and coordination between vehicles. Inspired by the recent advancements in unmanned aerial vehicles’ (UAVs’) assisted cellular communications, we propose an UAV-assisted FL framework in the Internet of Vehicles (IoV) network, which can bring several advantages and motivations:
Edge computing capabilities: UAVs can serve as edge services for federated learning, performing computation and learning tasks locally. This reduces the need for extensive data transfers and minimizes latency. Edge computing on UAVs enhances the scalability and efficiency of federated learning in distributed environments.
Communication efficiency and mobility enhancement: By processing model aggregation locally on UAVs, there is a significant reduction in the need to transmit large amounts of raw data to a central server. What is more, UAVs can cover a wide geographic area efficiently, which addresses the training challenges associated with the high dynamicity of vehicles in IoV.
Privacy-preserving surveillance: Federated learning allows for model training on decentralized data, addressing privacy concerns. UAVs can collect data or models locally without transmitting sensitive information to a central server. Privacy-preserving techniques, such as differential privacy, can be integrated into federated learning to further protect individual privacy.
Network resilience: UAVs can operate in areas with limited network infrastructure or during network failures. Federated learning’s decentralized nature makes it resilient to intermittent connectivity, aligning well with the mobility and varying connectivity conditions in the IoV.
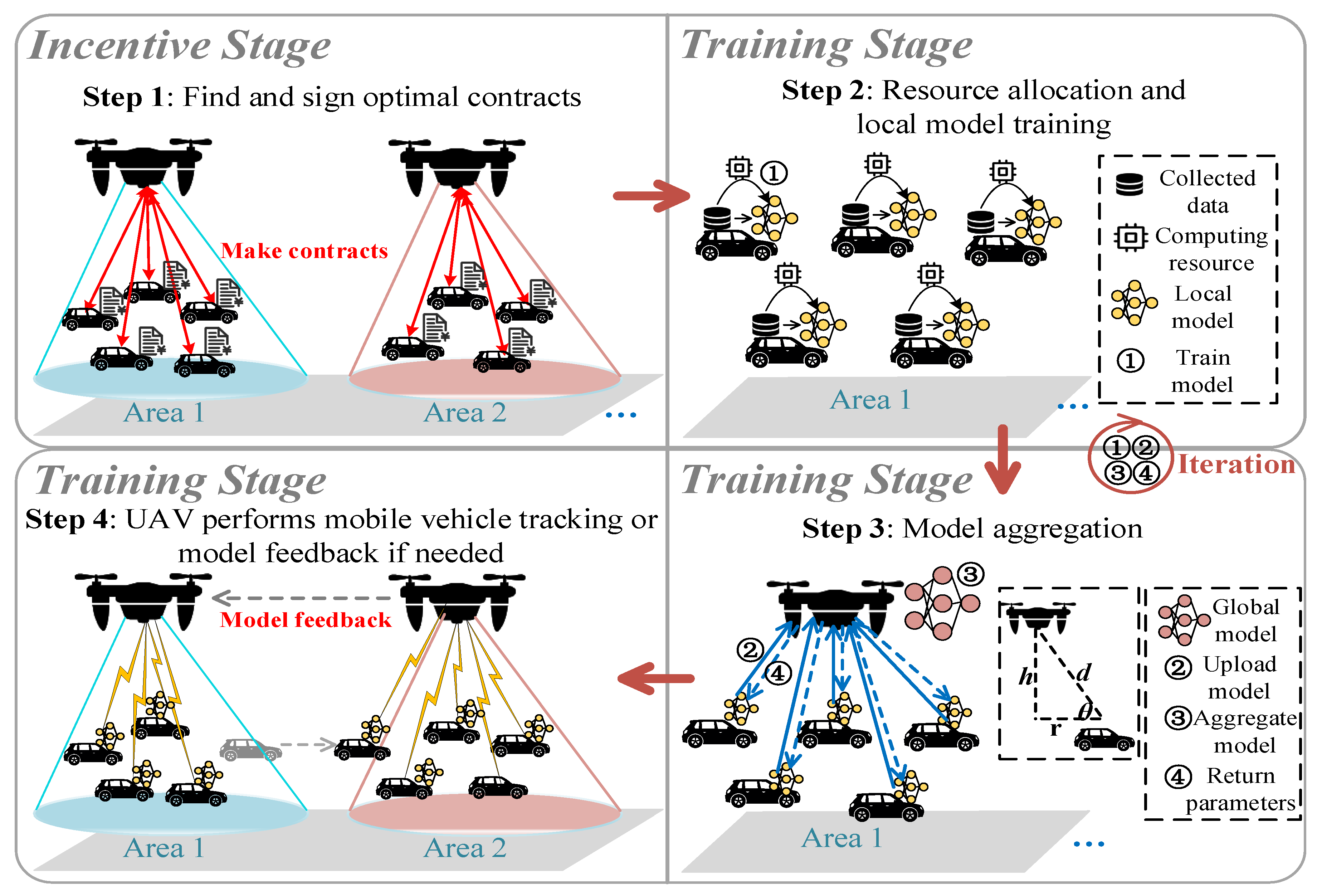
The proposed framework involves two stages: the incentive stage and the training stage. In the incentive stage, a contract-based incentive mechanism is designed to encourage VUs to proactively contribute their data. In the training stage, an energy-efficient resource allocation algorithm is designed between the UAVs and the VUs to manage the process of federated training, which allocates VUs’ computing and communication resources according to the result of the contract. The contributions of this article are as follows:
We propose a UAV-assisted FL framework in the IoV. Each UAV acts as a central server to provide the model aggregation or model parameter relay in the sky, which increases the reliability of FL under the uncertain and high-mobility conditions in the IoV network.
We design a contract-based incentive mechanism between UAVs and UVs. UAVs make contracts to assist VUs in responding to task publishers’ service requests and participating in federated training. Moreover, the contract mechanism determines VUs’ contributed local data based on their specific types in the presence of information asymmetry. VUs can receive corresponding revenues according to their data contributions.
We design an energy-efficient resource allocation algorithm to minimize total energy consumption in the training stage. According to the contract’s specific willingness and types, UAV manages VUs’ computing and communication resources to achieve energy-efficient federated training.
The rest of this paper is organized as follows. We review the relevant literature in
Section 2. Then, we present the UAV-assisted FL framework in
Section 3. We present the design of the contract incentive mechanism in
Section 4 and the energy-efficient resource allocation algorithm in
Section 5.
Section 6 provides the performance of the proposed system. Finally, we give the discussion and conclusions of the paper in
Section 7 and
Section 8.
2. Literature Review
In this section, we review the most relevant achievements and milestones of incentive mechanism and resource allocation in FL.
2.1. Incentive Mechanism in FL
Incentive is a concept in the field of economics that is often used in crowdsensing [
7,
8], edge computing [
9], and other fields to encourage members to participate in certain tasks. Classified according to the design method of incentive mechanisms, most of the existing research adopts the Stackelberg game [
10,
11,
12,
13,
14], contract theory [
15,
16,
17,
18,
19,
20], and auction [
21,
22,
23,
24,
25].
In the Stackelberg game, both sides choose their own strategies according to the possible strategies of the other side to ensure the maximization of their own interests. Y. Sarikaya et al. [
10] established a Stackelberg game between the terminal devices and the central server. The central server allocates revenue according to the CPU power consumption of the devices, and both parties optimize their utility functions individually.
Contract theory maximizes utility functions by designing contract optimization problems between the two parties. A contract optimization problem is designed between mobile users and mobile application providers in [
17], and an iterative contract algorithm is designed to maximize the utility function of all agents.
Like contract theory, auction can solve the problem of information asymmetry. Auction is divided into unilateral auction and double auction. Double auction can protect the interests of both buyers and sellers through incentive mechanisms and maximize the total welfare of the whole market. Work [
21] used multi-dimensional procurement auction to select multiple edge nodes to participate in FL, and adopted the Nash equilibrium strategy for edge nodes. Matched double auction is used to model between edge computing servers and terminal devices in [
22]. The device requests computing services from the server with a bid, and the server also asks for a price to sell services.
2.2. Resources Allocation in FL
At present, there are a large number of resource allocation studies on the energy-saving optimization of FL in wireless communication scenarios [
26,
27,
28,
29,
30]. Here, we focus on resource allocation in the IoV scenario.
In the IoV, the research on resource allocation mostly aims at high performance or energy efficiency. Among them, the research on resource allocation with high performance as the optimization goal focuses more on performance indicators, delay, and transmission rate. L. Feng et al. jointly carried out calculation and URLLC resource allocation in [
31] to ensure the stability of the C-V2X network. Work [
32,
33] used the deep reinforcement learning method to allocate resources. S. Bhadauria et al. allocated communication resources in [
32] to ensure the low transmission delay of users, and H. Ye et al. allocated V2V resources in [
33] to seek the optimal transmission bandwidth and power according to the interaction between V2V communication link agents and the environment.
The research on resource allocation with high energy efficiency as the optimization goal focuses more on energy consumption. Work [
34] proposed a cellular network uplink energy-saving transmission scheme based on V2X relay communication. Work [
35] studied the resource management problem of maximizing vehicle energy efficiency and proposed a new resource allocation scheme based on Lyapunov theory.
In the research on resource allocation, the above papers have either considered high performance or high energy efficiency, but there exist few studies that have combined the two goals to optimize them. Moreover, few studies simultaneously consider optimizing both the data quantity and resources for VUs.
3. Proposed FL Framework in UAV-Assisted IoV
We consider an application scenario that consists of task publishers, a fleet of UAVs, and VUs, as illustrated in
Figure 1.
Task publishers are automobile enterprises that want to train intelligent road applications, such as automatic driving applications, road landmark recognition applications, traffic management applications, etc. They employ VUs to utilize local data to train intelligent applications. The set of task publishers is denoted as and K is the number of publishers.
Due to the limited coverage of UAVs, a UAV often serves as the wireless relay for a specific area of the road, and it is carrying a specific task from the task publishers. The UAV incentivizes VUs to participate and organizes VUs to train models within its coverage area. It is responsible for aggregating the models of VUs and distributing new models. Assuming that there are M UAVs, their set is defined as . The UAV at position has a coverage radius .
VUs use their collected data for local training, and only need to upload the trained model parameters to UAVs. Assume that N VUs are selected to participate in training in one area. The set of VUs is denoted as , and the location of as .
Our proposed UAV-assisted FL framework in the IoV involves an incentive stage and a training stage, as shown in
Figure 2.
During the incentive stage, the UAV is responsible for signing contracts with VUs participating in FL within the coverage area. The VUs are stimulated to select contracts that align with their respective types and determine the data quantity needed for local training. In the training stage, UAVs organize the VUs for FL in their areas. Each VU conducts local training using the needed data quantity and allocated computing resources. Subsequently, the VUs upload the local model parameters to the UAV. The UAV aggregates local models of all participating VUs and updates the global model. The global model is then distributed to the VUs again, and the training process is iterated until the global model converges. It should be noted that if a VU exceeds the coverage range of the UAV in the current area during the training process, the UAV can obtain the model parameters of the VU through mobile vehicle tracking or model feedback. Each UAV submits the final global model to the corresponding task publisher.
Notations used in this paper are listed in
Table 1.
4. Incentive Mechanism for Contracts of Vehicles
As mentioned earlier, we have introduced an incentive stage to boost the enthusiasm of VUs to respond to task publishers and finalize the amount of data that different types of VUs need to contribute during training. Due to the information asymmetry between the task publishers and VUs, the UAVs should design specific contracts for different types of VUs with different data orders of magnitude to improve their profits. The UAVs provide different reward packages from publishers to VUs based on the VU type to reward them for providing local data.
For VUs with a different amount of data, the UAV provides a contract (
) to VU
, where
refers to the amount of data contributed by j-VU,
, and
refers to the corresponding reward for that VU. Assume that
denotes the proportion of type-j VU, which satisfies
, and
x denotes the number of participating VUs. Focusing on a task publisher, the utility function (i.e., publisher’s revenue from achieving models) can be modeled as follows:
where
is the transformation parameter from model performance to revenue, and
b is the dynamical parameter. The log function captures the relationship between the data quantity and the performance of the model.
Correspondingly, the utility function
for the VU of type-j is as follows:
where
is the willingness of type-j VU to participate in training,
, and
c is VU’s unit cost required for the training of data.
As such, the optimization problem can be expressed as follows:
where
is the total amount of the data contributed by VUs.
4.1. Contract Feasibility
For feasibility, each contract must satisfy the following conditions:
Definition 1. Individual rationality (IR): Each VU only participates in the federated learning task when the utility of the VU is not less than zero, i.e., Definition 2. Incentive compatibility (IC): Each VU of type-j only chooses the contract designed for its type, i.e., instead of any other contracts to maximize utility, i.e., Lemma 1. Monotonicity: For contract and , we can see that , if and only if and , .
Proof. Based on the IC constraints of type-
m VU and type-
z VU, we can see that
This paper first proves adequacy: adding Equations (
6) and (
7) by transformation, we can obtain
Combining Equations (
8) and (
9), we can obtain
. Note that
, thus it can be proven that
. Similarly, this demonstrates necessity: we can obtain
. If
, it follows that
. As such, Lemma 1 is proven. □
Lemma 2. If the IR constraint of type-1 is satisfied, then other IR constraints will also hold.
According to the IC constraint, , we can obtain and, because , we can obtain Therefore, by combining Equations (10) and (11), we can obtain Equation (12) indicates that when the IR constraint of type-1 VUs is satisfied, other IR constraints will automatically remain unchanged. Therefore, other IR constraints can be limited to the IR conditions of type-1 VUs. Lemma 3. According to the monotonicity in Lemma 1, the IC constraints can be simplified to local downward incentive constraints (LDICs), expressed as follows: Proof. The IC constraint between type-j and type-z, , is defined as a downward IC (DIC), expressed as .
First, it is proven that the DIC can be reduced to two adjacent types of DIC, which are called LDICs. Given that
, we can obtain
By utilizing the monotonicity, i.e.,
, if and only if
,
, and
, we can obtain
Equation (
15) can be transformed to obtain the following equation:
Combining Equations (
16) and (
17), we can obtain
Combining Equations (
14) and (
18), we can obtain
The above formula can be generalized to prove that all DICs can be preserved to type-1, and thus can be obtained:
Similarly, we can prove that all the UICs can be held until type-J, expressed as follows:
□
Proof. The IC constraint between type-m and type-z, , is defined as an upward IC (UIC), expressed as .
First, it is proven that an UIC can be reduced to two adjacent types of UIC, which are called LUICs. Given that
, we can obtain
By utilizing the monotonicity, i.e.,
if and only if
,
, and
, we can obtain:
Equation (
23) can be transformed to obtain the following equation:
Combining Equations (
24) and (
25), we can obtain
Combining Equations (
22) and (
26), we can obtain
Hence, with the LUIC, all the UICs hold and can be reduced, i.e., Equation (
27) can be extended to Equation (
21). □
4.2. Optimal Contract
In order to derive the optimal contract in Equation (
3), we first solve the relaxation problem of Equation (
3) without the monotonic constraint, and then test whether the obtained solution satisfies the monotonic condition. By using the iterative method on IC conditions and IR conditions, we can obtain the optimal reward, expressed as
According to [
7], the optimal rewards can be expressed as
where
and
. By plugging
into
, we can obtain
where
and
.
By plugging Equation (
30) into the problem in Equation (
3) and getting rid of all
, we can rewrite Equation (
3) as
By dividing by , we can obtain , so we can find that is a concave function. The maximized concave function is actually a convex optimization problem. Therefore, we can use convex optimization toolkits such as CVX to solve for the optimal data quantity and the corresponding reward .
5. Contract-Based Energy-Efficient Resource Allocation for UAV-Assisted FL
In the incentive stage, the UAVs have already incentivized VUs to sign the corresponding optimal contract based on their willingness, and the contract determines the VUs’ contributed data quantity for local training. During the training stage, the VUs utilize the results of the contract for local training. In this section, we design a resource allocation problem based on the contract’s willingness to minimize the VUs’ total energy consumption in training.
UAVs broadcast the applications to VUs in their coverage, and the responding VUs are further scheduled by the UAVs to form federations. VUs use local data for training and upload the trained model to the current UAV. UAVs aggregate when receiving all models and then distribute new model parameters. The whole process repeats a number of rounds to reach convergence.
Assuming that the initial model is defined as
,
trains local models according to its assigned dataset
in each iteration
t. If the local model of
at
t timeslot is denoted as
, the local training process can be expressed as
where
is the learning rate,
,
is one batch size, and
is the loss function of
.
In each iteration
t, VUs upload local models to the current UAV. The UAV uses the federated averaging algorithm (FedAvg) to aggregate all models. Assume the number of VUs involved is
J, where
, then the aggregation process can be expressed as
5.1. System Models
During the FL process, the real-time communication model, computation model, and mobility model are formulated as follows.
5.1.1. Communication Model
The channel states of VUs vary at different periods. Different from terrestrial channel models, the channel between the UAV and VU is affected by line-of-sight (LoS) and none-line-of-sight (NLoS) propagation modes. We can define the probability of having a LoS link between the UAV and VU as
, which can be represented as Equation (
34):
where a and b are determined by the environment and
is the elevation angle, which is equal to
, where h(t) is the height of the UAV and r(t) is the horizontal distance between the UAV and VU, as depicted in
Figure 2. The probability increases with the enlargement of angle
.
Assume that the path loss between the VU and the UAV is defined as
, and we can express it in Equation (
35):
where
is the carrier frequency, d(t) is the distance between the UAV and the VU, and c is the speed of light.
is the probability of having a NLoS link and is equal to
.
and
are the path loss coefficients. The values of
, and
are referenced in [
36].
Assume that the UAV allocates the subchannels equally to all VUs and that the bandwidth of each VU is
B. The achievable data rate of
in iteration
t is
where
is the transmission power and
is the noise power.
When
broadcasts local model
, the real-time communication delay through the process is computed by
The corresponding communication energy consumption is computed by
5.1.2. Computation Model
is the CPU cycle frequency of
and
is the number of CPU cycles required to train one data sample. The computation energy consumption through the local training of
can be computed as
where
is the capacitance coefficient of computing chipset. The computation delay through the local training of
can be computed as
In this paper, the landmark recognition application is taken as an example. The amount of VUs’ training data will affect the accuracy and the local iterations of the local model. Define the local iterations and the global iterations as
and
, respectively, where
is calculated in
Section 4. Therefore, the total time consumed by the communication and computation processes of
can be computed as
in Equation (
41):
Similarly, the total energy consumption is
5.1.3. Mobility Model
In this work, we consider the VU’s sojourn time under the current UAV to ensure that its current training process can be completed within that time. When the VU enters the next UAV’s coverage, it may participate in other services. According to [
37], the remaining distance of
under the coverage of
can be computed as
:
Assuming the average speed of
under the UAV as
, the sojourn time of it in the coverage of
is defined by
in Equation (
44):
5.2. Problem Formulation
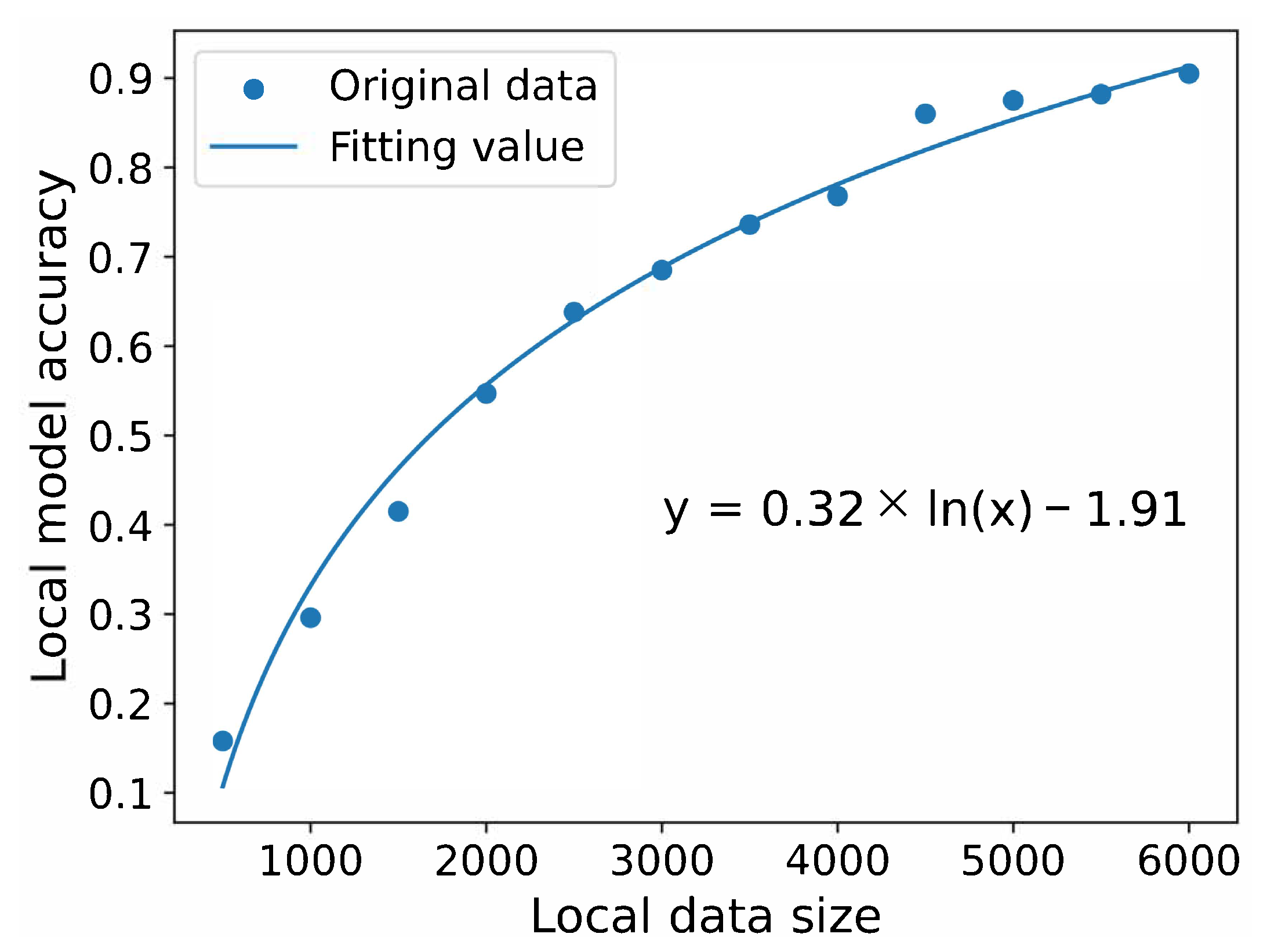
Due to the use of landmark recognition as the VUs’ local task, the classic MNIST dataset is used to fit the local training accuracy. According to the fitting of a large number of experimental results using the MNIST dataset, we can obtain the relationship between the accuracy of the VU’s local model and the data size, as shown in
Figure 3.
In
Figure 3, the x axis represents the data size of a VU, and the y axis represents the model accuracy of its local training. We define the local model accuracy as
. According to [
26], we represent
, where
is the difficulty coefficient.
According to the results of the contract during the incentive stage, the optimal data quantity for each VU is
. By substituting
into the fitted formula, the local iterations for each VU can be obtained. Our optimization problem is the minimization of the total energy consumption of VUs, which is the sum of local training and model transmission energy consumption. The variables to be optimized are the CPU frequency
and transmission power
. Based on the energy consumption defined in Equation (
42), an optimization problem can be formulated as
:
Constraint (
45a) restricts the training time of a VU within its sojourn time under the current UAV, where
s means the model size needed to be transmitted.
corresponds to the degree of willingness in the contract. The higher the willingness of the VU to participate in training, the larger the value of
. Here, we design a VU with a greater willingness to have a longer sojourn time for training. Constraints (
45b) and (
45c) set the ranges of the computation frequency and transmission power of each VU.
In the contract, the greater the willingness to participate, the higher the data quantity allocated to the vehicle. Due to the constraint of sojourn time in constraint (
45a), VUs with higher data quantities are more likely to use more computing and transmission resources to ensure that training can be completed within the time limit. Therefore, in the contract-based resource allocation problem designed, each optimization variable is mutually restrictive.
Since several products in the objective function and constraint (
45a) are not convex,
is non-convex and thus can be difficult to solve. Consequently, we decompose this problem to make it solvable.
We characterize
’s solution by decomposing it into simpler sub-problems about variables
and
, called
and
, respectively. If we fix a set of
first, the sub-problem
is only about variable
.
When
is solved and substituted into
, the sub-problem
becomes an optimization problem only related to variable
.
5.3. Solution of the Optimization Problem
5.3.1. Solution to P2
It is obvious that Equation (
46) is about the quadratic function of
, and the quadratic coefficient is positive, so
is a convex quadratic optimization problem. Among the constraints, Equation (
46a) is a linear constraint that does not affect the convexity property. Although Equation (
46b) is a non-linear constraint, its denominator only exists with the variable
, so it is also a convex function.
Therefore, classical Karush–Kuhn–Tucker (KKT) conditions can be used to solve
. A set of initial solutions
should be defined. We then have the Lagrangian of
by transferring the constraints to the objective.
where
is the multiplier corresponding to the constraint (
46a). By applying KKT conditions, we obtain
From condition (
49) we can obtain
From condition (
50), since
cannot be 0, we have
Therefore, the optimal solution of
is
in Equation (
52).
5.3.2. Solution to P3
Theorem 1. is quasiconvex on .
Since the quasiconvex problem is also a unimodal problem, we use the bisection method to solve it. To translate constraint (
47a) into Equation (
53), the lower limit of the bisection method can be obtained.
where
is defined in Equation (
36), and from Equation (
53), we can derive the lower limit of
:
Let the right-hand side of Equation (
54) be equal to
, which represents the lower limit of
. It should be noted that
is very close to 0, so
must be greater than
. If
is greater than
, it means that the VU has a short sojourn time or a long local training time, resulting in higher requirements for transmission power. In this case, the local optimal solution of this VU is set as
, and the optimal solution will be obtained by iterating the solutions of
and
.
The bisection process of solving the optimal
is given in Algorithm 1.
| Algorithm 1 Bisection Method for Transmission Power Allocation Algorithm |
Input: Initial section maximum tolerance ,
Set , ,
Output:
1: while = 0 do
2:
3: Compute
4: if then
5: , set
6: end if
7: if then
8: Update the section to
9: if then
10: , set
11: set
12: end if
13: end if
14: if then
15: Update the section to
16: if then
17: , set
18: set
19: end if
20: end if
21: end while |
We achieve the optimal
and
by solving the sub-problems iteratively. The whole solution of
is shown in Algorithm 2.
| Algorithm 2 Iterative Algorithm for the Whole Optimization Problem |
Input: Initial , , , maximum tolerance
Output: Optimal
1: while = 0 do
2: Solve to obtain according to Equation (52)
3: Solve to obtain according to Algorithm 1
4: , and set
5: Check the convergence of
6: if then
7: , and set
8: end if
9: end while |
6. Experimental Evaluation
In this section, we analyze the performance of the contract incentive mechanism and resource allocation algorithm for UAV-assisted FL.
6.1. Simulation Settings
In the contract incentive algorithm, we use the CVX tool to solve the optimization problem. In the resource allocation algorithm, we deploy 20 to 50 VUs under the coverage of one UAV. The coverage radius of the UAV is set to 3 km, the coordinates of the VUs are randomly generated with the UAV located directly above the road, and the height of the UAV is set to 100 m. The values of
, and
are set to 12.08, 0.11, 1.6, and 23, as employed in [
36].
Taking the landmark recognition task as an example, we conduct the VUs’ FL experiments on the MNIST dataset, which is a grayscale handwritten image dataset that includes 60,000 training pictures and 10,000 test pictures. The CNN model is used as the backbone model of FL, which is composed of two convolutional layers, two activation functions, two pooling layers, and two fully connected layers. Among them, the two convolutional layers have 10 and 20 (5 × 5) convolution kernels. The two fully connected layers have 50 and 10 neurons, respectively. We exported the CNN parameter file (including all weights and biases) with a size of approximately 0.05 Mbit.
Due to the small size of the transmission parameters, only one RB is needed to complete the transmission. An RB is typically set to 180 kHz in the 4G protocol and also in the 5G protocol. The other simulation parameters are set as in
Table 2. Among them, the maximum transmission power refers to the definition of 3GPP [
38,
39].
6.2. Contract Optimality
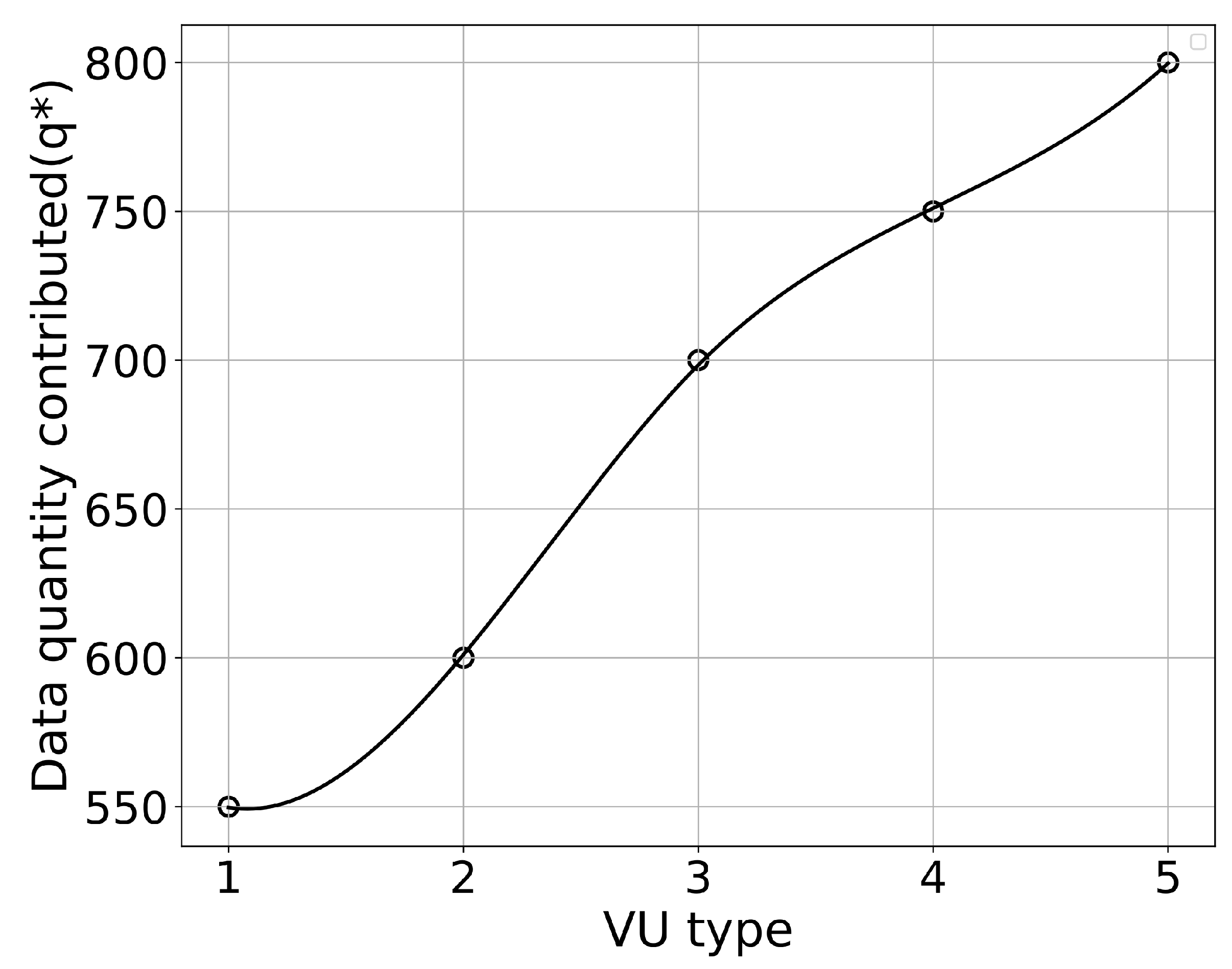
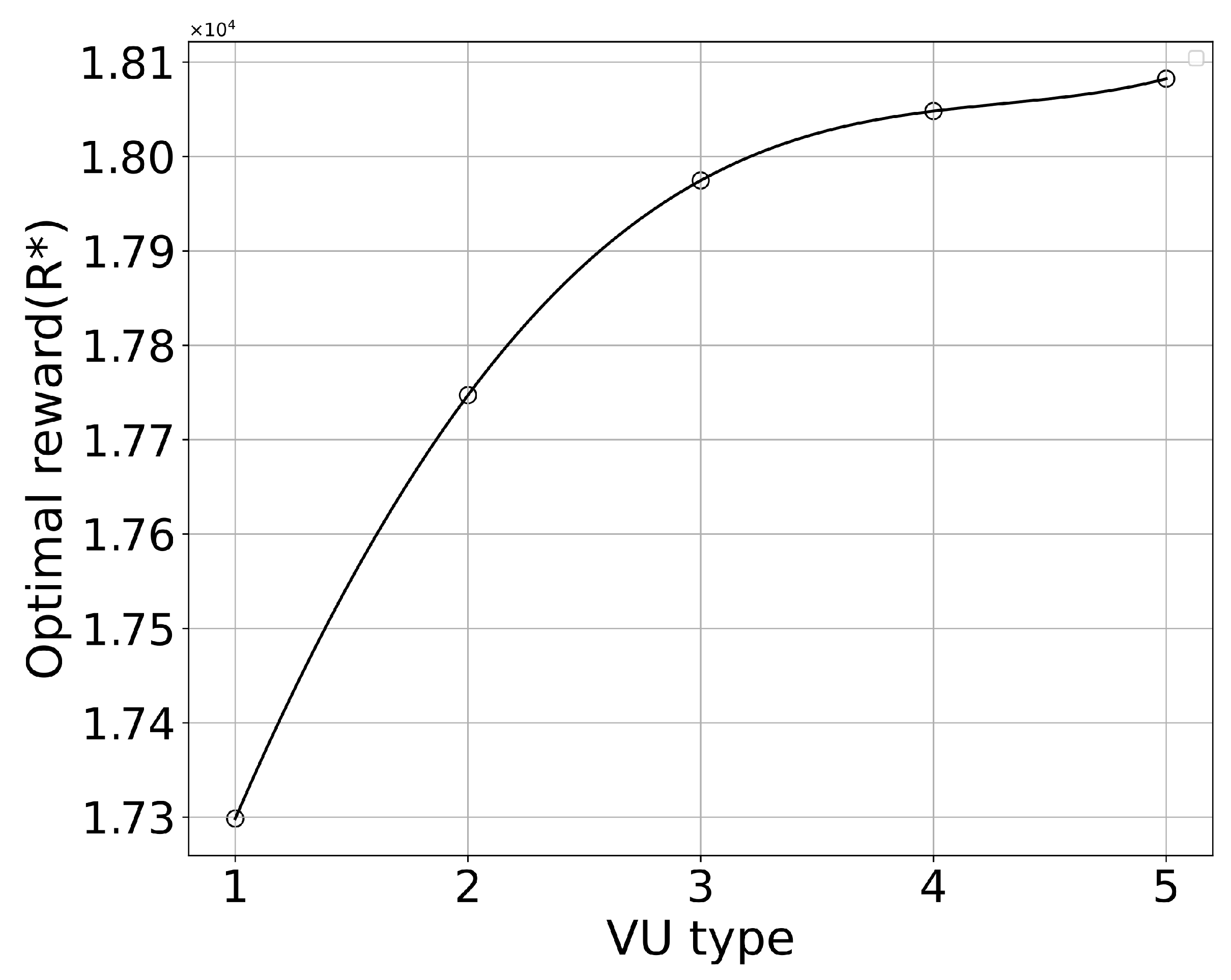
Firstly, a total of 20 VUs and 5 VU types are set up to determine the optimal data quantity and optimal reward based on the contract. We obtained solutions for the optimal data quantity for 5 VU types, which are 550, 600, 700, 750, and 800. The distribution of the 20 VUs in the 5 types is 5, 4, 6, 3, and 2.
We can see from
Figure 4 and
Figure 5 that, as the VU type increases, both the data quantity and the reward for the VU type increase. This means that the contract we designed satisfies the monotonicity constraint, which is proved in Lemma 1.
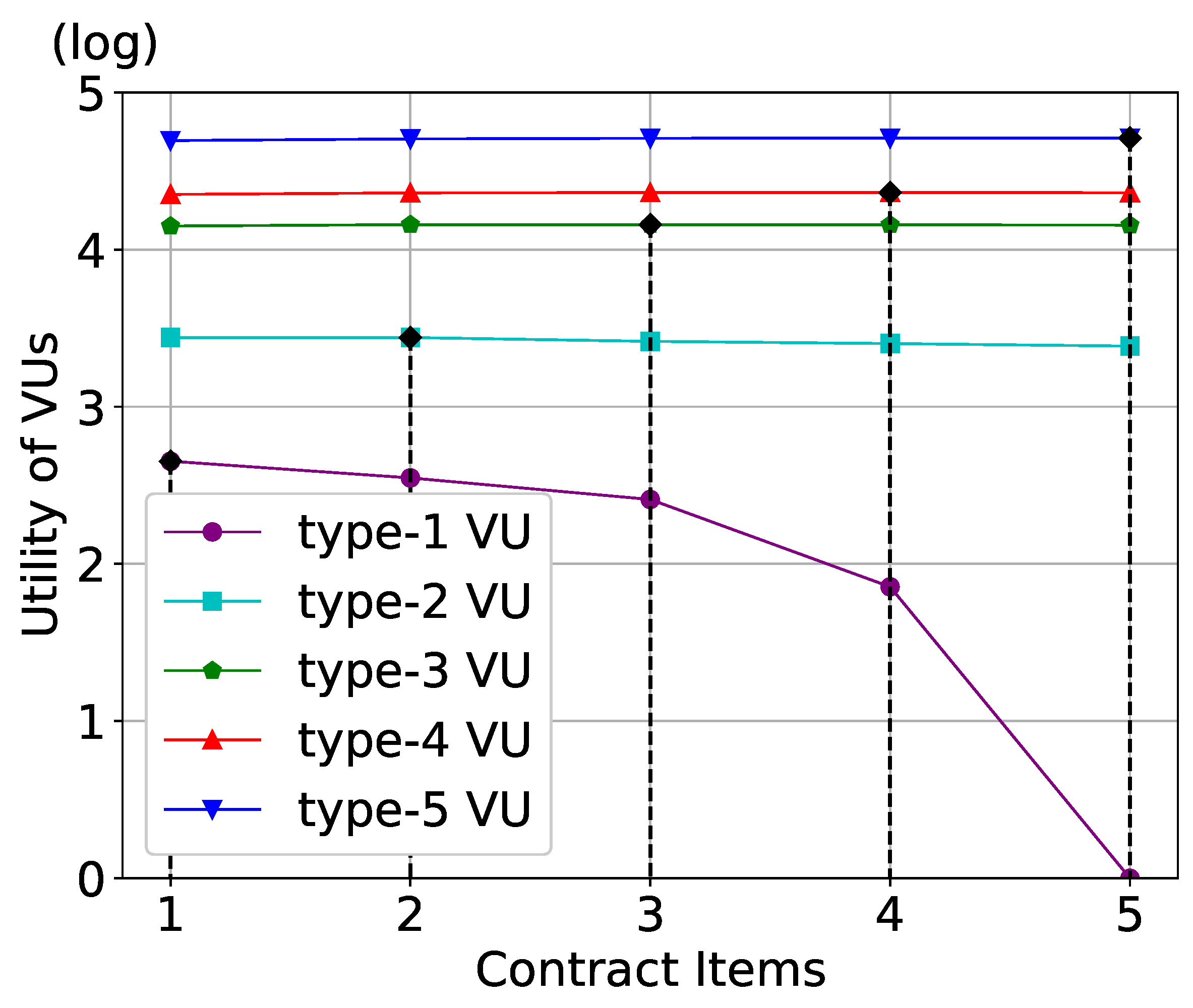
The utility of VUs is shown in
Figure 6. We can observe that all types of VUs achieve their maximum utility only when they choose the contract item designed entirely for their type, which explains the IC constraints. In addition, each VU can obtain a non-negative utility when selecting the contract item corresponding to their type, thus validating the IR constraints.
6.3. Performance of the Resource Allocation
In this part, we evaluate the performance of the proposed energy-efficient resource allocation. By substituting the solution of the optimal data quantity obtained from the contract into the optimization problem, the optimal computing resource, transmission power, and total energy consumption corresponding to resource allocation can be obtained. To demonstrate the energy-efficient performance of the proposed algorithm, we set up three baseline algorithms as follows.
DCM: DCM [
40] is a resource allocation algorithm in mobile edge computing that aims at capturing the trade-off between learning efficiency and energy consumption. It optimizes CPU frequency, data volume, and total FL delay.
Benchmark1: Compared with the proposed algorithm, the CPU frequency of the vehicle is directly set to .
Benchmark2: Compared with the proposed algorithm, the power of the vehicle is directly set to .
Benchmark3: Compared with the proposed algorithm, the data volume of vehicles is randomly allocated.
Figure 7 illustrates the relationship between different transmission parameter sizes and energy consumption. It can be observed that, as the parameter size increases, the total energy consumption also increases. This is because larger parameters require more energy for transmission.
The proposed algorithm achieves the lowest energy consumption. This is attributed to our algorithm considering the sojourn time based on the degree of contract willingness. The higher the willingness of the VU, the longer its sojourn time, and even if the transmission delay increases, there is still enough time for training. However, in the case of increased transmission delay, the DCM algorithm will reduce training time due to the limitation of total sojourn time, thereby allocating more CPU frequency and resulting in greater energy consumption.
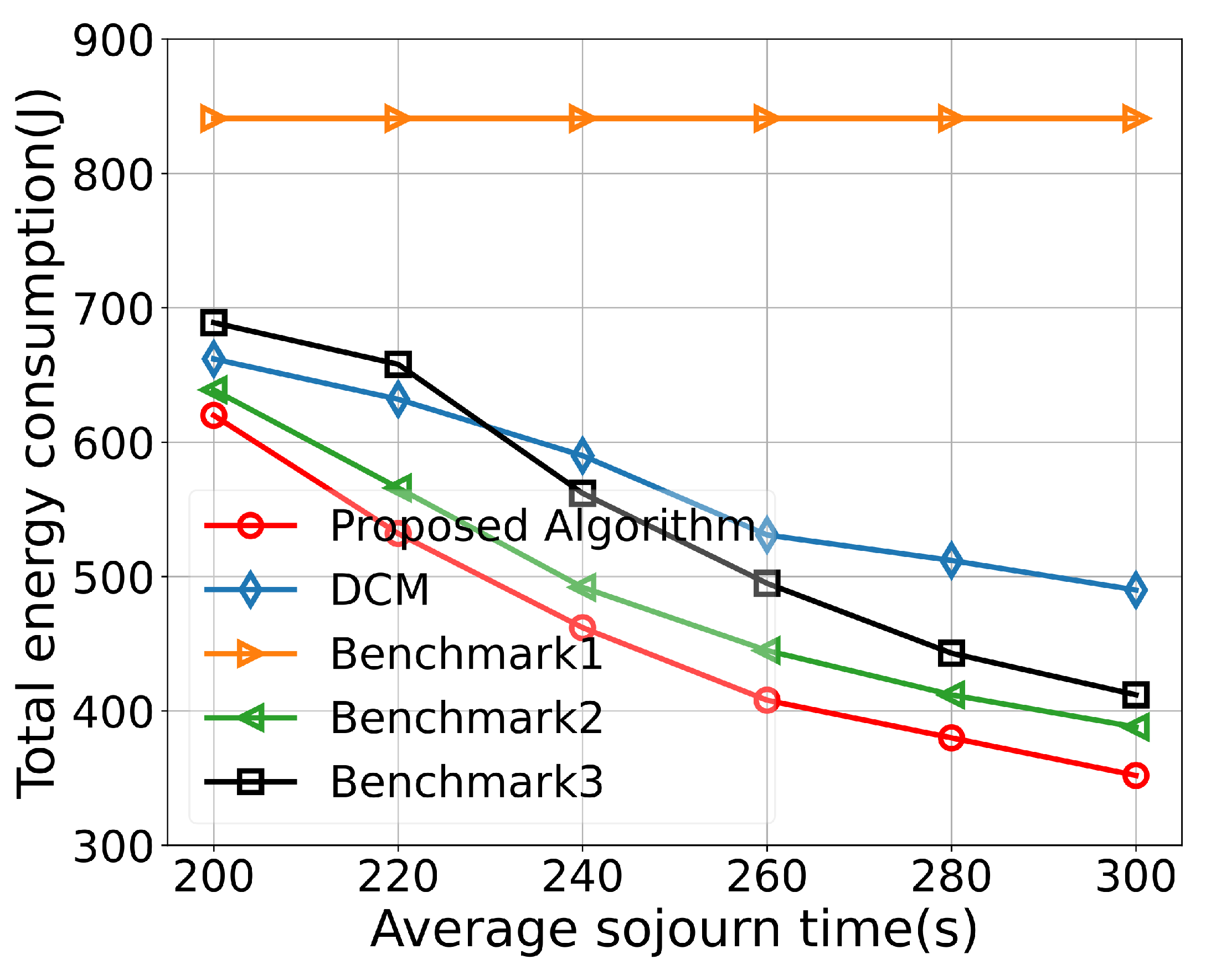
Figure 8 illustrates the relationship between VU’s sojourn time and energy consumption. It can be observed that, as the sojourn time increases, the energy consumption decreases. This is because VUs have a longer training time, leading to a lower allocated CPU frequency and transmission power, resulting in reduced computational and transmission energy consumption. The curve’s trend gradually flattens out as the computation or communication resources reach their minimum values. Among the compared algorithms, Benchmark1 exhibits the least significant decrease in energy consumption. This is because its CPU frequency is set to the maximum value and cannot be reduced. In the DCM algorithm, latency is optimized, which may lead to a trade-off between latency and energy consumption, resulting in higher energy consumption compared to the proposed algorithm in this paper. The proposed algorithm comprehensively considers contract-based sojourn time, computational capacity, and transmission capacity, aiming to minimize the total energy consumption within a given sojourn time requirement.
Figure 9 illustrates the relationship between the number of VUs (J) and the total energy consumption in FL. As the number of VUs increases, the energy consumption inevitably increases. For Benchmark1 and Benchmark2, the allocation of maximum CPU frequency and transmission power, respectively, results in high energy consumption. For Benchmark3, the data allocation to VUs is not optimized, resulting in many VUs being assigned the minimum amount of data, which may lead to poor model performance. As the number of VUs increases, the performance gap between the DCM algorithm and the proposed algorithm significantly increases. This is because the DCM algorithm optimizes the total latency and model accuracy and may allocate as much data and as many resources as possible to improve accuracy and reduce latency, but it ignores the consideration of the willingness of VUs. The proposed algorithm outperforms all benchmarks when the number of VUs increases, demonstrating that the designed algorithm achieves good stability.
6.4. Performance of Federated Learning
We validated the performance of FL on the MNIST dataset. Taking 20 VUs as an example, we substituted the data quantity obtained from the contract algorithm into the fitting formula mentioned earlier to determine the number of local training iterations for each VU. By incorporating these values into FL, we obtain the corresponding model accuracy and loss in
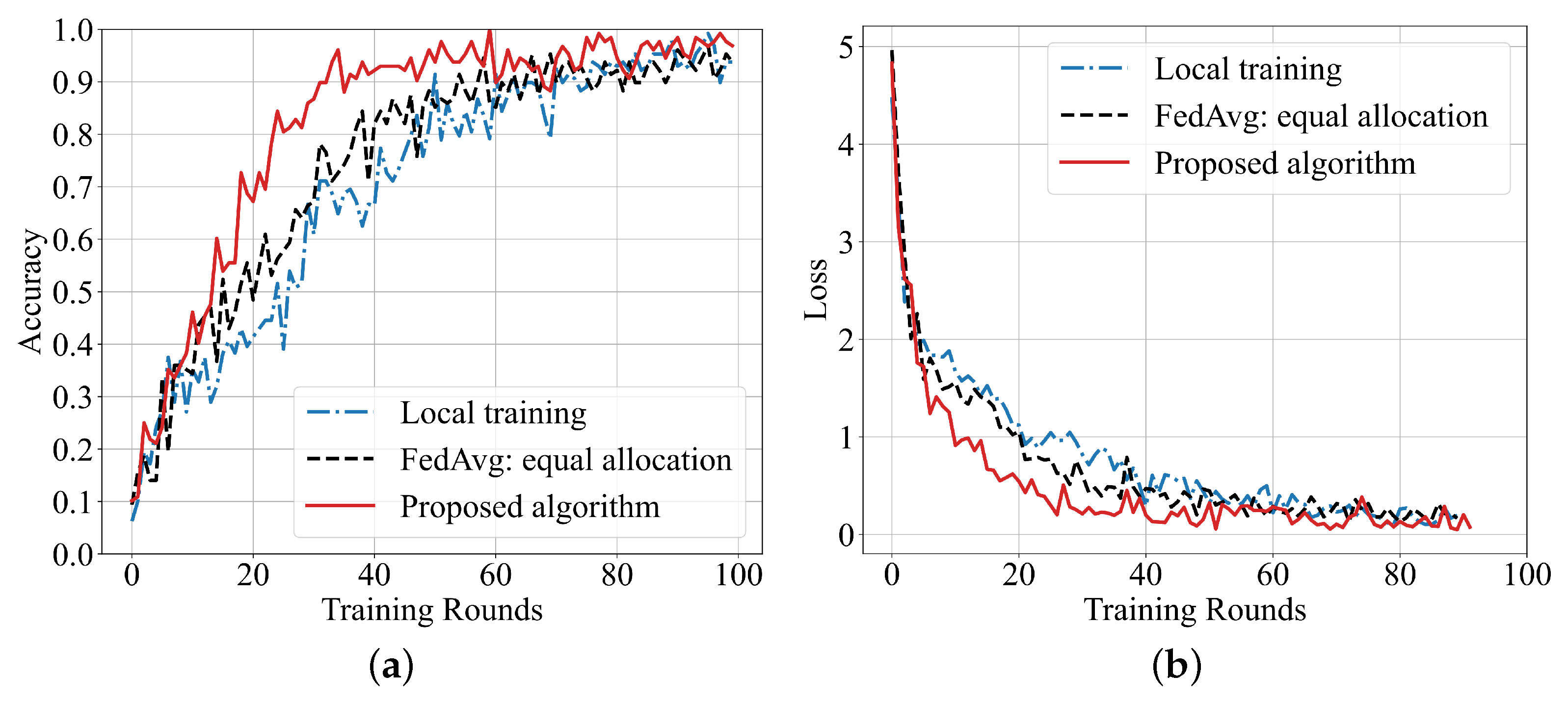
Figure 10.
Figure 10 shows the comparison of the proposed algorithm’s accuracy with local training and the classical federated averaging (FedAVG) algorithm with an equal dataset allocation. The results show that the accuracy of the proposed scheme is higher and the convergence speed is faster than other algorithms on the MNIST dataset. This is because the proposed algorithm assigns a training dataset size for VUs, and for the group of datasets, a large number of experimental fitting results are used to calculate the training rounds of each VU. Our algorithm makes up for the insufficient training caused by the small amount of data compared with local training. Compared with classical FedAVG, it also employs FedAvg, but performs data allocation and iteration rounds more accurately, which makes the model’s performance improve faster. The results of the training loss further confirm the better performance of the proposed algorithm.
7. Discussion
With the emergence of a large number of intelligent road applications and the increasing competition in the intelligent transportation industry, more and more intelligent transportation application enterprises (task publishers) tend to dispatch intelligent VUs to assist in completing the training of application models. Currently, a large number of studies have proposed applying the FL framework to IoV scenarios, utilizing VUs’ resources for local training, thereby greatly reducing communication latency and improving training efficiency. However, the dynamicity, low participation, and limited resources of VUs are all challenges faced by FL in the IoV.
The proposed UAV-assisted FL framework utilizes UAVs to enhance connectivity. The contract incentive mechanism proposed in the system aims to stimulate VUs to participate and determine VUs’ data quantity used for training. The experiments show that VUs of different types should contribute different amounts of data and achieve corresponding optimal rewards. In addition, VUs can obtain their maximum utility and ensure non-negative utility only when they choose appropriate contract items, which verifies the IC and IR principles of the contract mechanism.
The energy-efficient resource allocation algorithm is designed to manage VUs’ computing and communication resources during the training process. This algorithm determines the local training iterations and training willingness of different VUs based on the results of the contract mechanism, and then constructs and solves the energy consumption minimization problem. Experiments show that the energy consumption of the proposed algorithm is lower than that of the baseline algorithms under the conditions of different transmission parameters, different sojourn times, and different numbers of participating VUs.
Utilizing the data quantity determined by the contract for FL, it is observed that the accuracy and convergence speed of the proposed system surpass those of the comparative algorithms. This further validates the efficacy of the proposed system, demonstrating its ability to effectively incentivize VUs to participate in federated training using appropriate resources.
The UAV-assisted FL framework leverages the role of UAVs as edge servers, enhancing connectivity in dynamic vehicular networks and assisting in the training process of federated models. Future research needs to focus more on the augmenting role of UAVs in system communication, addressing issues such as reliability and stability. More attention should be given to the UAVs’ contribution to reducing the risk of communication interruptions and minimizing data transmission latency.
8. Conclusions
In this study, we have proposed a UAV-assisted FL framework in the context of the IoV to overcome the challenges of VUs’ intermittent connectivity, low proactivity, and limited resources. An incentive stage and a training stage are involved in this framework, where a contract-based incentive mechanism and an energy-efficient resource allocation algorithm are designed separately. With the assistance of UAVs, VUs can benefit from enhanced communication efficiency and mobility, thus ensuring better training performance. The experimental results show that the proposed framework achieves effectiveness in terms of incentives and outperforms the baseline methods in terms of FL performance.
Due to the energy consumption during FL and the limited computing resources, VUs with a higher data quantity and quality might be reluctant to participate in federated training because their standalone local training could yield better-performing models. To address this challenge of low proactivity, we have designed a contract-based incentive mechanism that categorizes VUs into different types, each signing distinct contracts. Due to the information asymmetry between task publishers and VUs, UAVs serve as intermediaries to assist in contract signing. These contracts specify the amount of data required for training for each vehicle type and the corresponding rewards. This contract mechanism enhances the proactive involvement of VUs in training and effectively manages data resources. The corresponding experiments verify the effectiveness of the contract mechanism.
During the federated training process, it is necessary to consider both model performance and the total energy consumption induced by training to comprehensively manage training resources. Given the variation in data collected by VUs and their limited computing and communication resources, the complexity of resource management increases. Existing resource management studies mostly focus on single metrics of federated training and rarely optimize both performance and energy consumption simultaneously. The proposed contract-based efficient resource allocation algorithm in this paper addresses both performance and energy consumption in FL. It formulates the energy minimization problem based on contract results. As the contract mechanism manages data based on VU types and determines the training iterations, it enhances the performance of FL. Moreover, by introducing VUs’ participation willingness in the energy optimization problem, the algorithm effectively manages computing and communication resources for training, thereby reducing the total energy consumption. The experiments have demonstrated that the proposed algorithm reduces energy consumption and improves performance in FL.
In summary, this study addresses the challenges of VUs’ intermittent connectivity, low proactivity, and limited resources in the context of FL. In potential future work, we would primarily focus on two aspects. Firstly, while we have already considered the role of UAVs as edge servers to assist FL, future attention could be directed towards evaluating the contribution of UAVs to system communication metrics. This includes assessing the extent to which UAVs contribute to reducing the risk of communication interruptions and minimizing data transmission latency, among other factors. Secondly, we have not yet considered issues of cooperation and competition among UAVs. Future research could explore the formation of alliances among UAVs to enhance the overall efficiency of the system.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}