1. Introduction
With the continuous development of drone control technology, the application mode of “drone+” is becoming increasingly widespread [
1]. Aerial robots can become flight carriers for various aerial operations in different industries by carrying various devices and targeted configurations that meet application requirements. Many aerial drones are used as operational tasks for flight platforms, such as inspection, monitoring, obstacle removal, and cargo handling [
2,
3,
4,
5,
6,
7], which require drones to be able to hover for long periods of time. In addition to high requirements for the platform’s translational stability, the large inertia of the pitch and yaw channels caused by the operational tools loaded on the platform, as well as the impact of contact forces during operation, also require the platform to have strong anti-interference abilities. The use of flight control strategies with disturbance resistance and higher efficiency has also received attention. At present, the flight control methods for drones mainly include linear control methods [
8,
9,
10], nonlinear control methods [
11,
12,
13], and intelligent control methods [
14,
15,
16,
17]. The learning-based robot control method has received widespread attention in the field of automatic control [
18,
19,
20], as it ignores the dynamic model of the robot and learns control methods through a large amount of motion data. In the latest Nature journal, Elia Kaufmann et al. [
21], from the Robotics and Perception Group at the University of Zurich, studied the unmanned aerial vehicle autonomous system, Swift, which used deep reinforcement learning (DRL) algorithms to successfully defeat human champions in racing competitions, setting new competition records. It can be seen that reinforcement learning frameworks have become a promising algorithmic tool for improving the autonomous behavior of aerial robots [
22,
23,
24,
25]. Deep reinforcement learning, as a currently popular unsupervised learning framework, utilizes the perception ability of deep learning and the decision-making ability of reinforcement learning to achieve end-to-end control from input to output. It can be effectively applied to high-level decision-making systems and is becoming a commonly used framework for scholars from all walks of life to study aerial robot control algorithms [
26].
At present, many researchers are trying to combine reinforcement learning with unmanned aerial vehicle systems to solve the autonomous control problem of flight robot systems [
27,
28,
29,
30]. Most reinforcement learning algorithms applied to unmanned aerial vehicle systems cannot be applied to real scenarios due to simple simulation scenario settings, and overly complex simulation scenarios can reduce learning efficiency. In response to this issue, Lee Myoung Hoon et al. [
31] proposed a soft actor-critic (SAC) algorithm with post experience replay (HER), called SACHER, which is a type of deep reinforcement learning (DRL) algorithm. Their proposed SACHER can improve the learning performance of SAC and adopt SACHER in the path planning and collision avoidance control of drones. In addition, the paper also demonstrates the effectiveness of SACHER in terms of success rate, learning speed, and collision avoidance performance in drone operation. Zhongxing Li et al. [
32] proposed using the reinforcement learning method to control the motor speed of quadcopter drones for hover control in order to improve the intelligent control level of quadcopter drones. Jia Zhenyu et al. [
33] proposed introducing traditional control models to improve the training speed of reinforcement learning algorithms. By optimizing the proximal strategy in deep reinforcement learning, the control learning task of attitude stability was achieved, and it was verified that the algorithm can effectively control the stability of quadcopters in any attitude and is more versatile and converges faster than general reinforcement learning methods. The above references provide ideas for the innovative algorithm in this article.
In this article, we will apply a new reinforcement learning algorithm, the WAC (watcher-actor-critic), to drone hover control, which can achieve high robustness of drone hover control while improving learning efficiency and reducing learning costs, preventing human manipulation from being affected by uncontrollable factors. The hover control of drones is part of low-level flight control with continuous and large-scale behavior space. Basic algorithms such as Monte Carlo reinforcement learning based on complete sampling and temporal differential reinforcement learning based on incomplete sampling will have low efficiency and may even fail to achieve good solutions. Even the deep Q-network algorithm (DQN) finds it difficult to learn a good result. The policy gradient algorithm based on Monte Carlo learning is not widely used in practical applications, mainly because it requires a complete state sequence to calculate the harvest. At the same time, using harvest instead of behavioral value also has high variability, which may lead to many parameter updates in a direction that is not the true direction of the policy gradient. The DQN proposed by Mnih V. et al. [
22] is value-based reinforcement learning. Although it can solve many problems excellently, it still appears inadequate when facing learning problems with continuous behavior space, limited observation, and random strategies. To address this issue, Lillicrap, T.P. et al. [
34] proposed a joint algorithm, the DDPG, based on value function and policy function, known as the actor-critic algorithm. It combines DQN on the basis of the PG algorithm proposed by Peters, J. et al. [
35] and the DPG proposed by Silver, D. et al. [
36]. In this context, this article will directly learn the strategy, which is viewed as a policy function with parameters for the drone state and propeller power output. By establishing an appropriate objective function and utilizing the rewards generated by drone interaction with the environment, the parameters of the policy function can be learned.
This article first uses the actor-critic algorithm based on behavioral value (QAC) and the deep deterministic policy gradient algorithm (DDPG) for drone hover control learning. By establishing approximate functions and policy functions for drone state value, on the one hand, policy evaluation and optimization can be based on the value function, and on the other hand, the optimized policy function will make the value function more accurately reflect the value of the state. The two mutually promote and ultimately obtain the optimal hovering strategy for drones. However, due to the unsupervised nature of this algorithm in reinforcement learning, the consequence of doing so is that the initial learning stage begins with a random exploration strategy, not to mention correct off-field guidance. The update of the strategy is also arbitrary or even explores in the opposite direction, resulting in a lower initial iteration speed and ultimately reducing the convergence speed of the objective function. In response to the above issues, this article proposes a deep deterministic policy gradient algorithm that adds a supervised network. Considering that most aircrafts currently use PID as the control algorithm in practical combat and the control effect is quite good and the excessive supervision can also affect the flexibility of the learning process, a PID controller with parameters provided by a three-layer neural network is used as the monitor in this article. The monitor will perform dynamic supervision during the strategy learning stage—that is, it will change the supervision intensity as the strategy learning progress changes. At the beginning of each learning episode, the supervision intensity is the highest, and by the end of the episode, the supervision is mostly removed. After the learning process reaches a certain stage, the supervision task is withdrawn, achieving unsupervised online learning. Finally, this article uses a classic reinforcement learning environment library, Python, and a current mainstream reinforcement learning framework, PARL, for simulation and deploys the algorithm to actual environments. A lightweight, drift-free multi-sensor fusion strategy for unmanned aerial vehicles as an autonomous localization method is used for practical exercises. The simulation and experimental results show that the reinforcement learning algorithm designed in this paper has a higher learning efficiency, faster convergence speed, and smoother hovering effect compared to the QAC and DDPG. This article takes improving the learning efficiency of drone hovering tasks as the starting point and adopts a PID controller combined with neural networks for supervised learning with reinforcement learning as the main approach and supervised control as the auxiliary to achieve the effect of rapid learning and smooth hovering of drones. From the above description, it can be seen that the advantages of the algorithm in this article are fast convergence speed and high training efficiency.
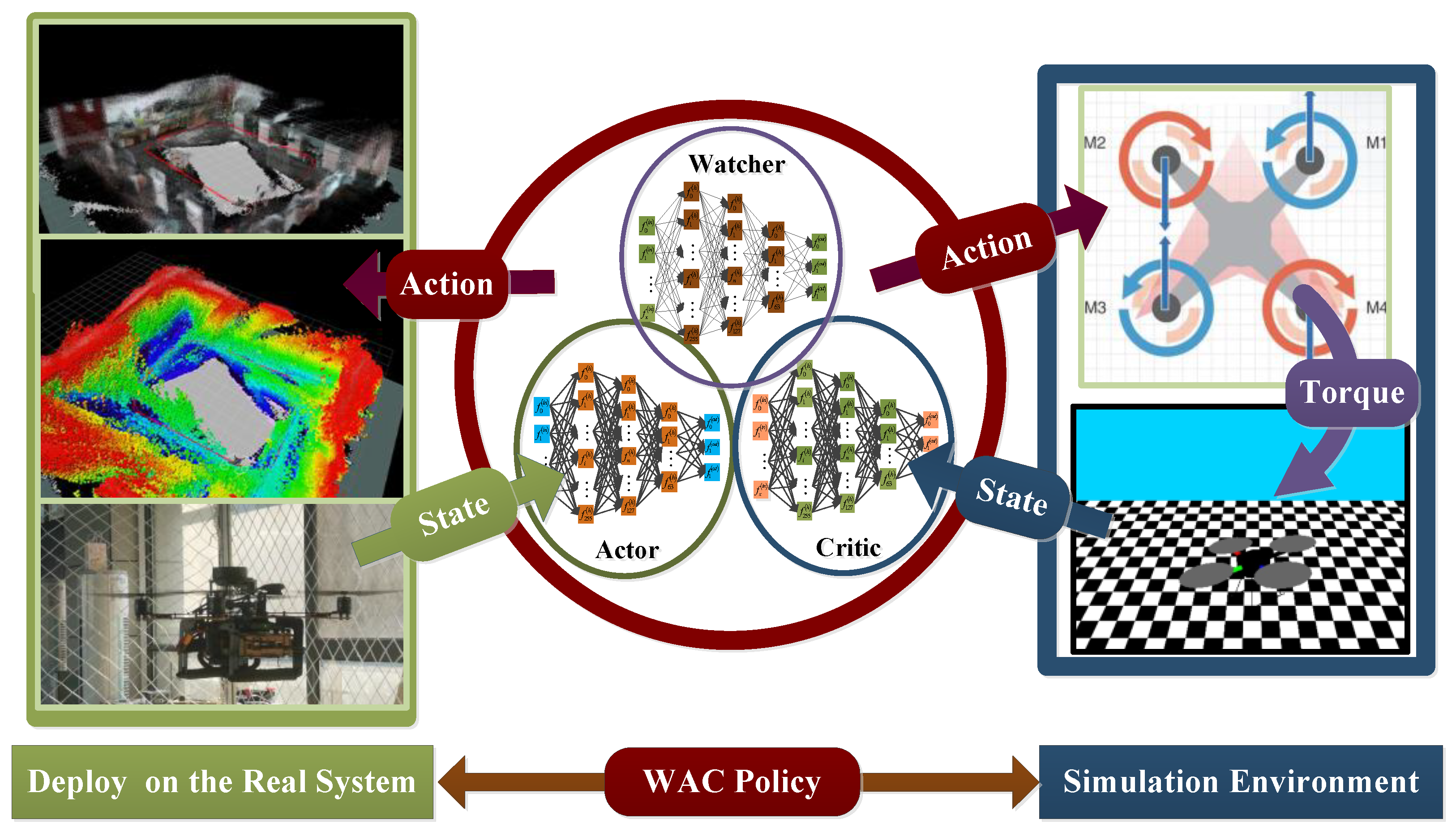
Figure 1 illustrates the control strategy of this article. The right section describes how the algorithm guides the drone in simulation by providing the predicted actions for the drone propeller. This process is presented in the visualization window through the render() function in Gym. The left part is to deploy the trained strategy in the experimental environment.
The rest of this article is organized as follows.
Section 2 introduces the proposed control method. The performance of this method is verified through simulation results in
Section 3.
Section 4 deploys this method to real drone systems.
Section 5 focuses on concluding remarks.
3. Simulations and Results Discussion
The open-source toolkit OpenAI Gym for reinforcement learning algorithms and the current mainstream reinforcement learning framework PARL are our simulation tools. PARL is a reinforcement learning framework based on PaddlePaddle, characterized by the following: (1) high flexibility and support for most reinforcement learning algorithms; (2) an open-source algorithm library for reinforcement learning with large-scale distributed capabilities; (3) the algorithm library has strong usability for industrial-level scenarios. The render function in the Gym library can be used to render the simulation environment and visually display the simulation effect. The drone in the PARL framework is a quadcopter aircraft equipped with an inertial module, which obtains its real-time position , velocity , acceleration , angular velocity , Euler angle , and flight altitude, , in the body coordinate system by simulating sensors such as accelerometers and gyroscopes. This makes it easy to obtain the current drone’s flight status and transmit it to the input of the WAC algorithm. Output behavior, , describes the control variables executed in the four propeller axis directions under system control, and its learning process is the repetitive strategy function solving process. During drone hovering, the inertial module provides the current state data at each time step and determines the reward value: the greater the hovering error, the lower the reward value. The simulated computer configuration is an Intel(R) Core(TM) i5-7300HQ, and the simulation environment is Python 3.7.
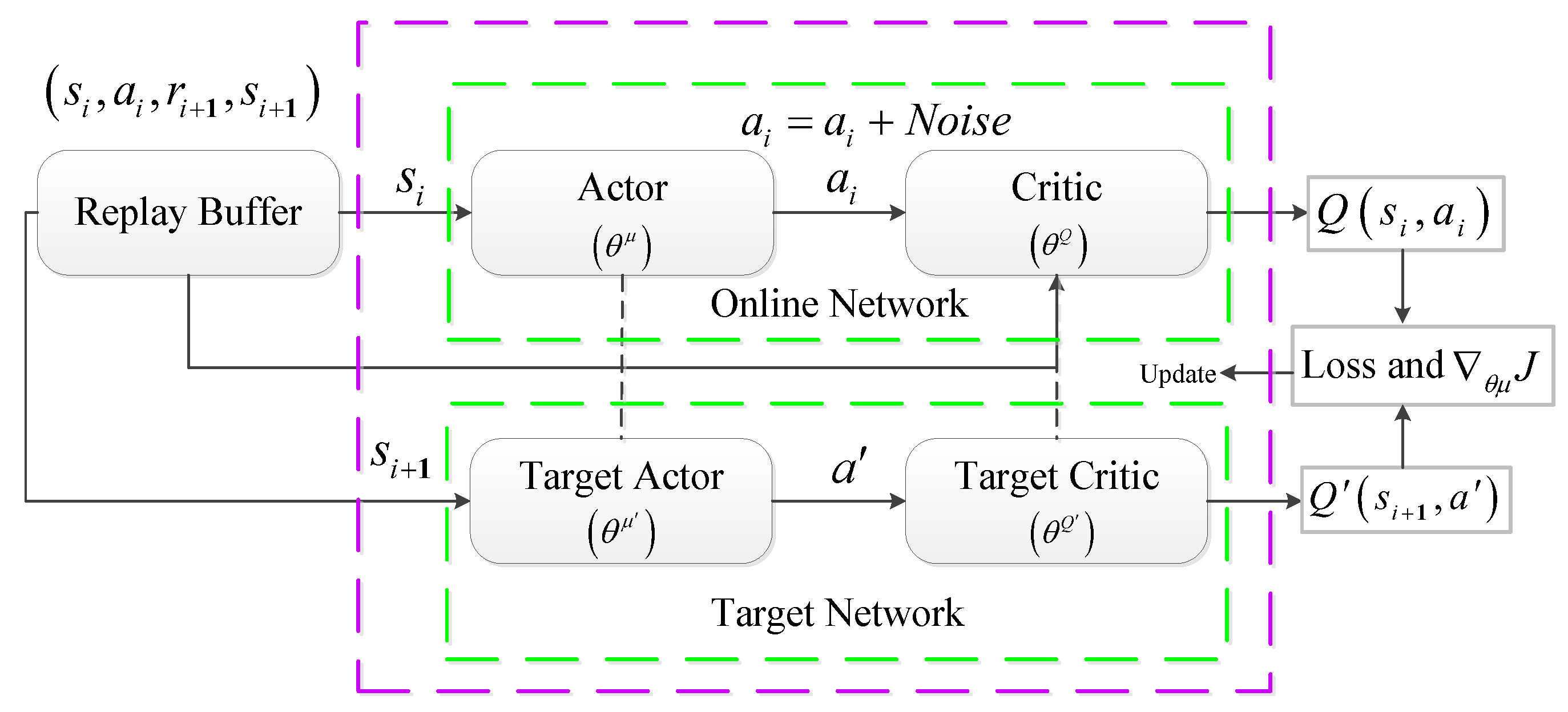
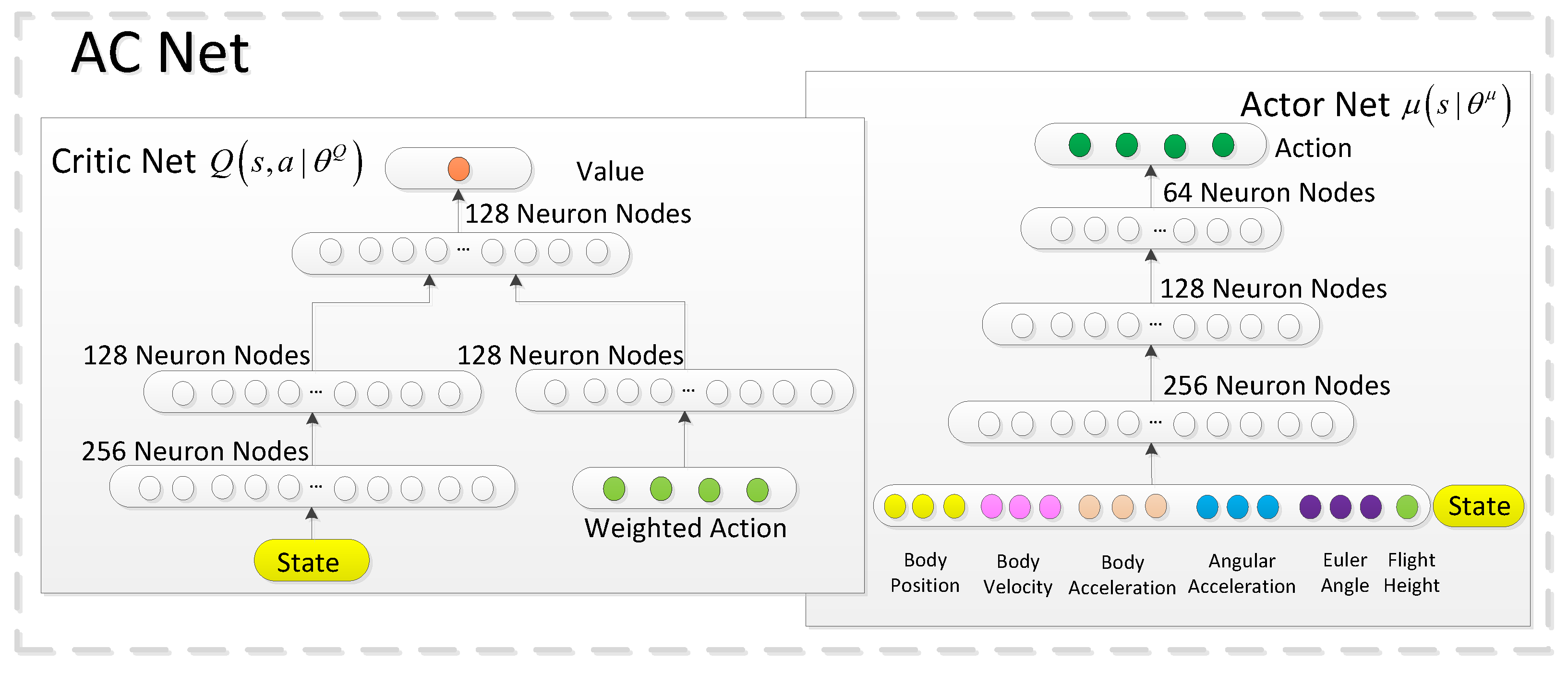
In the WAC, the actor and critic network structures are the same as the target actor and target critic network structures, respectively. The architecture of the actor-critic network (AC Net) is shown in
Figure 4. Considering the need for the drone to extract features from observed states, we designed a total of three hidden layers for the critic. The hidden layers for the processing states and behaviors are first separated for operation, and the final hidden layer is fully connected together to output the value of state and behavior. The input received by the actor network is the number of features observed by the drone, and the specific value of each behavioral feature is the output. The actor network is designed with three hidden layers and fully connected layers. In order to achieve exploration, the algorithm uses the Ornstein–Uhlenbeck process as the noise model and adds a random noise to the generated behavior to achieve a certain range of exploration around the exact behavior. The neural network in the watcher is designed with three hidden layers and fully connected layers. The architecture is shown in
Figure 5.
In the simulation, the reward rule set is that the closer the drone hovering height,
, is to the set hovering height (5 m), the greater the reward obtained. The target range is set to 0.5 m. If the hovering height is within 0.5 m of the target height, a reward value of 10 is obtained. If it exceeds the target range, a penalty value of −20 is obtained. If the height difference exceeds 20 m, a negative distance difference is chosen as the reward. The time step limit for one episode is
. If the time step exceeds the limit or the drone crashes (
), the current episode is stopped and reset to the next episode. The original intention was to adopt a dynamically supervised intervention behavior strategy, where the weights of watcher behavior and actor behavior gradually change with the training progress. Since our goal is to train high-quality actor networks, we place more emphasis on actor behavior in simulations. At the beginning of the initial training setting, both behaviors accounted for 50% each. Over time, the actor behavior gradually becomes dominant with increasing weights. At the same time, the watcher behavior weight gradually decreases and eventually tends to zero. The simulation time step is set to
and the total number of simulation training steps to
with
. The learning rate setting is as follows:
and
, assuming
and
. The weight in formula 12 is set as follows:
Due to the fact that during the simulation process, the more time steps (iterations) spent on each episode (reaching the time step setting for hovering or crashing), the better the hovering effect, in episodes that reach the specified time step, the drone is always in the hovering state. If a crash occurs, it means that the next episode starts with less than 1000 steps per episode. Therefore, under the same total training steps, the more the crashes, the more the episodes, and the fewer time steps you take each time, the fewer the rewards you will receive.
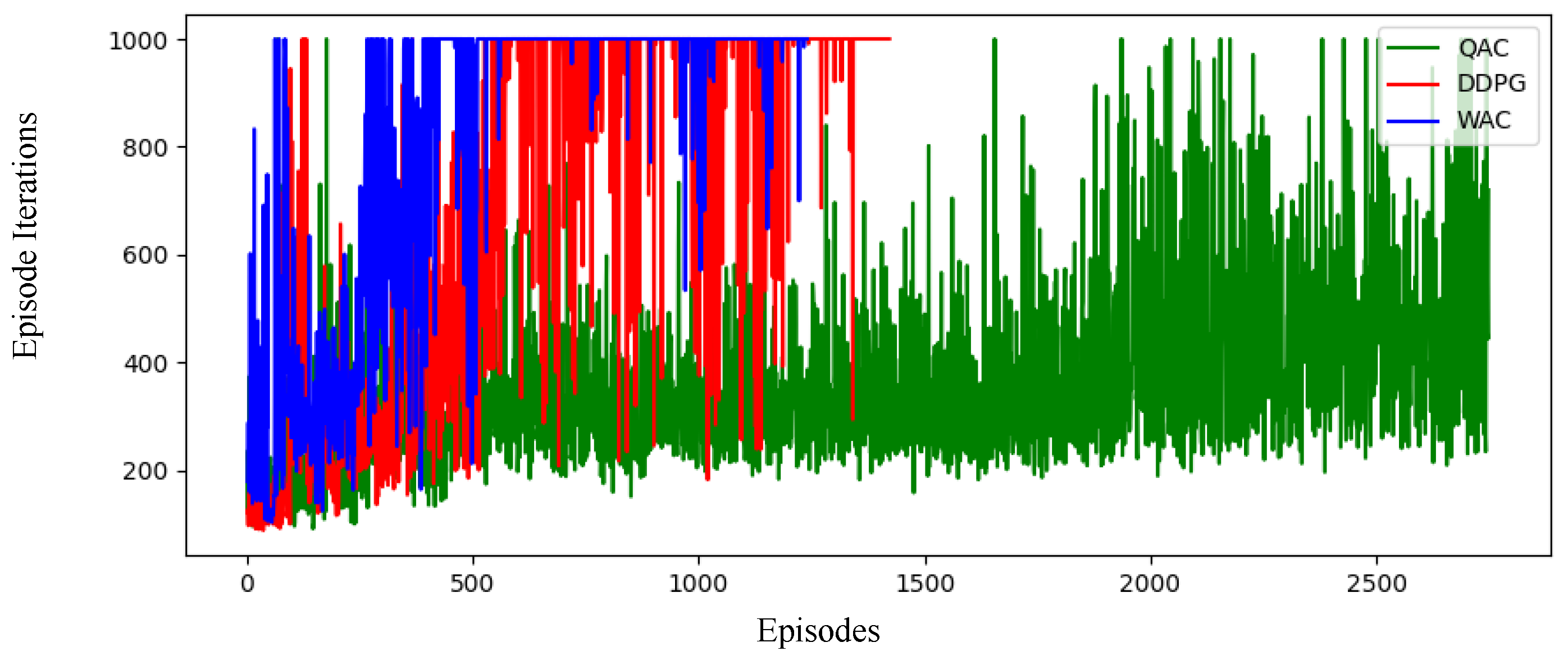
Figure 6 shows the reward values trained using the three algorithms with the horizontal axis representing the number of episodes. When the total time steps are the same, the fewer the episodes, the longer the duration of the hover state during each training process, and the more times the limited time steps are reached.
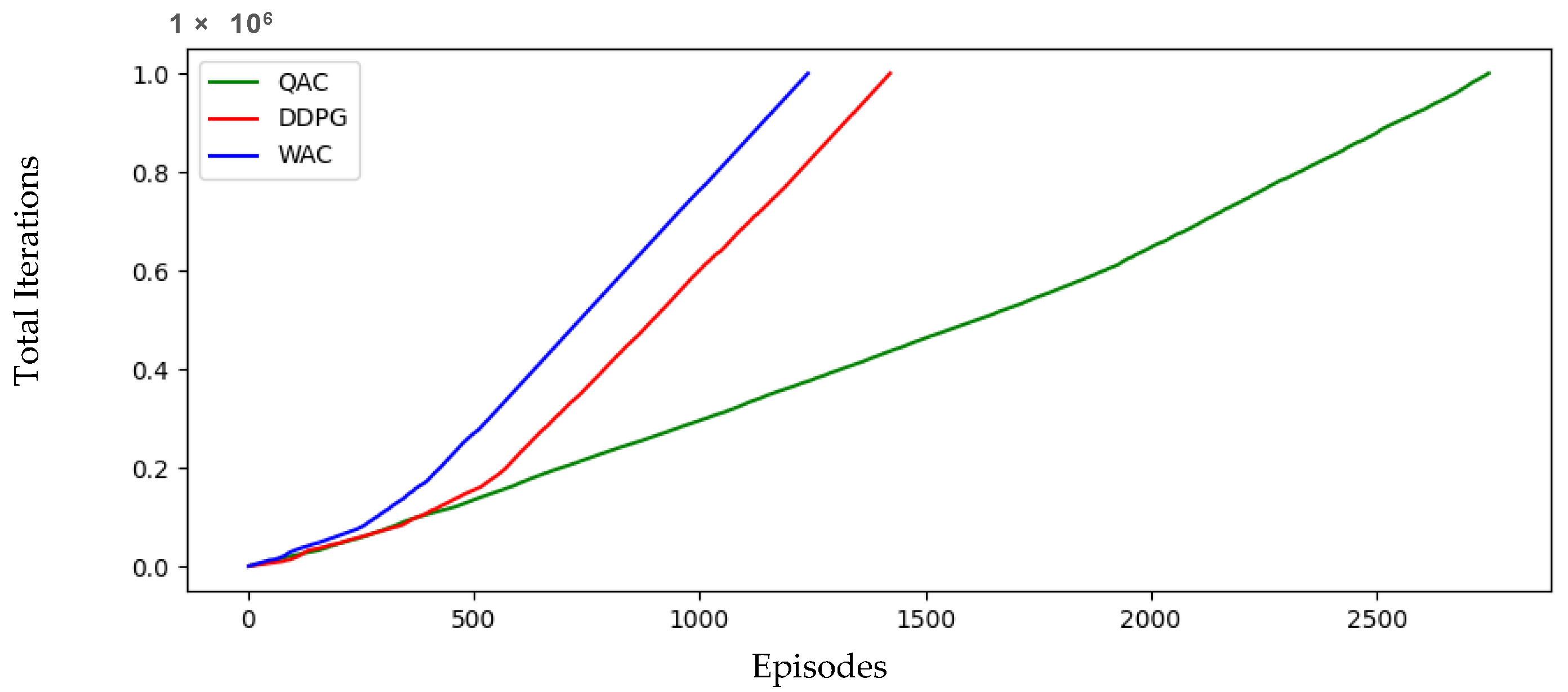
Figure 7 shows the number of iterations taken per episode, while
Figure 8 shows the total number of iterations. The training episodes of the WAC are reduced by 20% compared to the DDPG and 55% compared to the QAC. It is evident that the WAC algorithm has the lowest number of episodes, the highest reward value, and the most time steps in each episode, followed by the DDPG and QAC, which confirms the above statement. This indicates that our algorithm has significantly fewer crashes during training compared to the other two, and the chance of crashes during the learning process directly reduces training efficiency and effectiveness, indirectly indicating that the WAC has the highest training efficiency and effectiveness.
After simulation training, the network models of the three algorithms are separately loaded and flight data collected from the drone hovering state for 1000 iterations for analysis. Related simulation videos can be found in the
Supplementary Materials section at the end of the article.
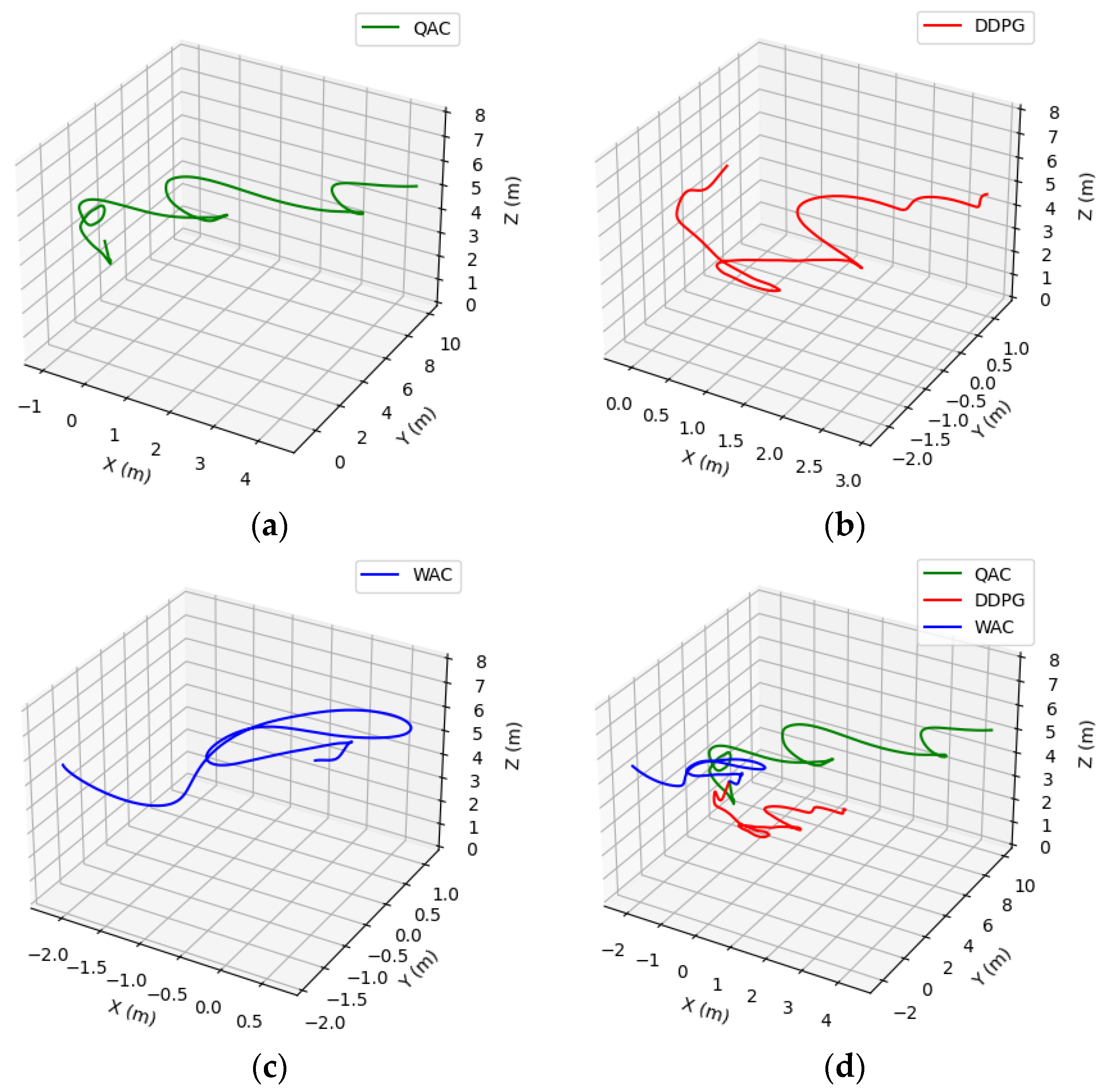
Figure 9a–c show the hovering trajectories of the drone after loading the three network models, respectively. It can be seen that none of the three algorithms have experienced a crash, while the hovering trajectory using the QAC algorithm has significant drift. From the trajectory integrated display in
Figure 9d, it can also be seen that the drone under the WAC algorithm framework has the smallest hovering range, the best effect, and the lowest degree of drift. The following is a detailed introduction to the simulation results.
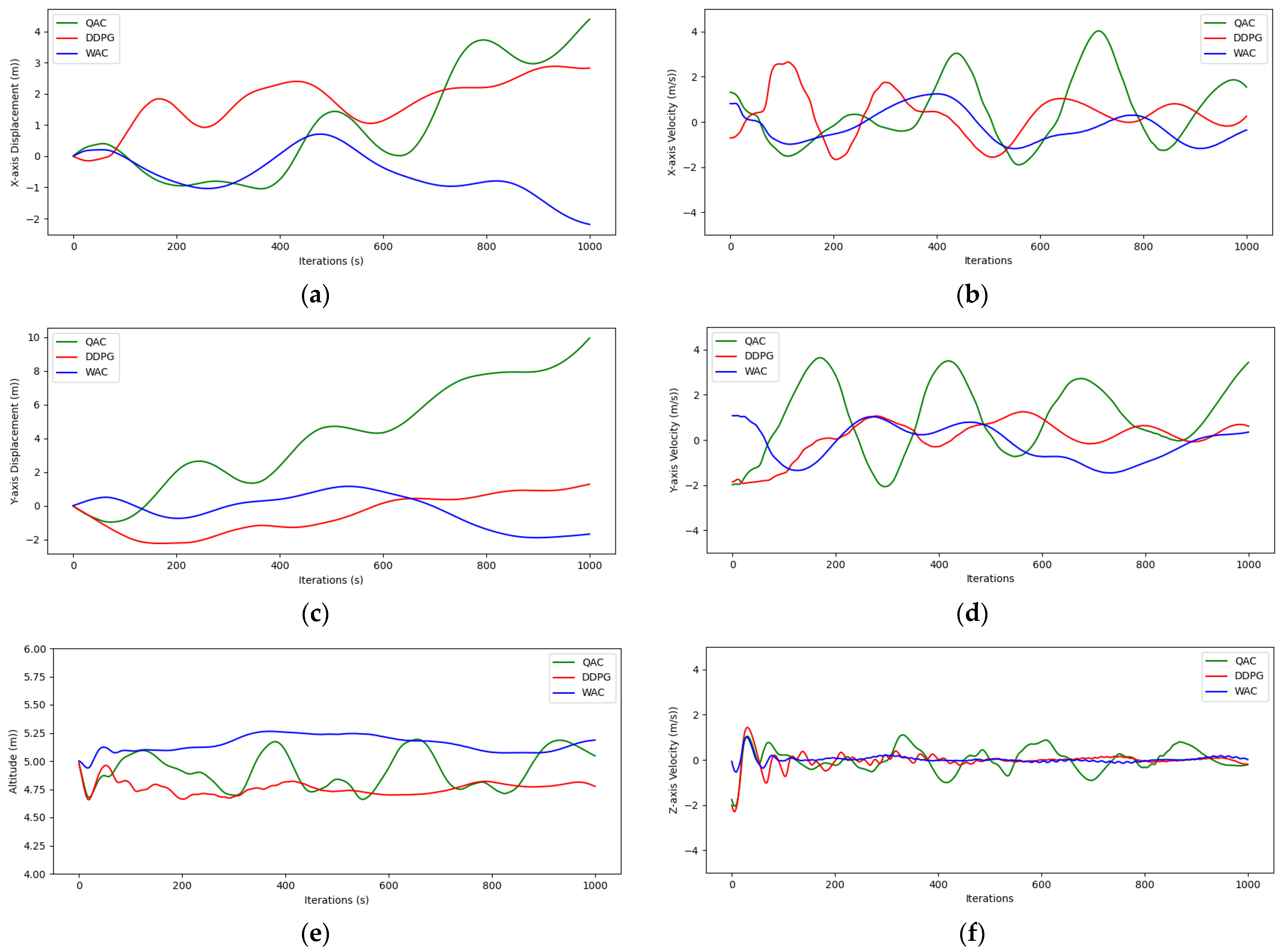
Figure 10a,c,e depict the displacement of the three algorithms on various coordinate axes. From the graph, it can be analyzed that the QAC has an increasing displacement deviation in the
X and
Y directions (the
X-axis direction exceeds 4 m, and the
Y-axis direction exceeds 10 m), while the other two algorithms are significantly more stable and hover near the specified point. The hovering altitude in
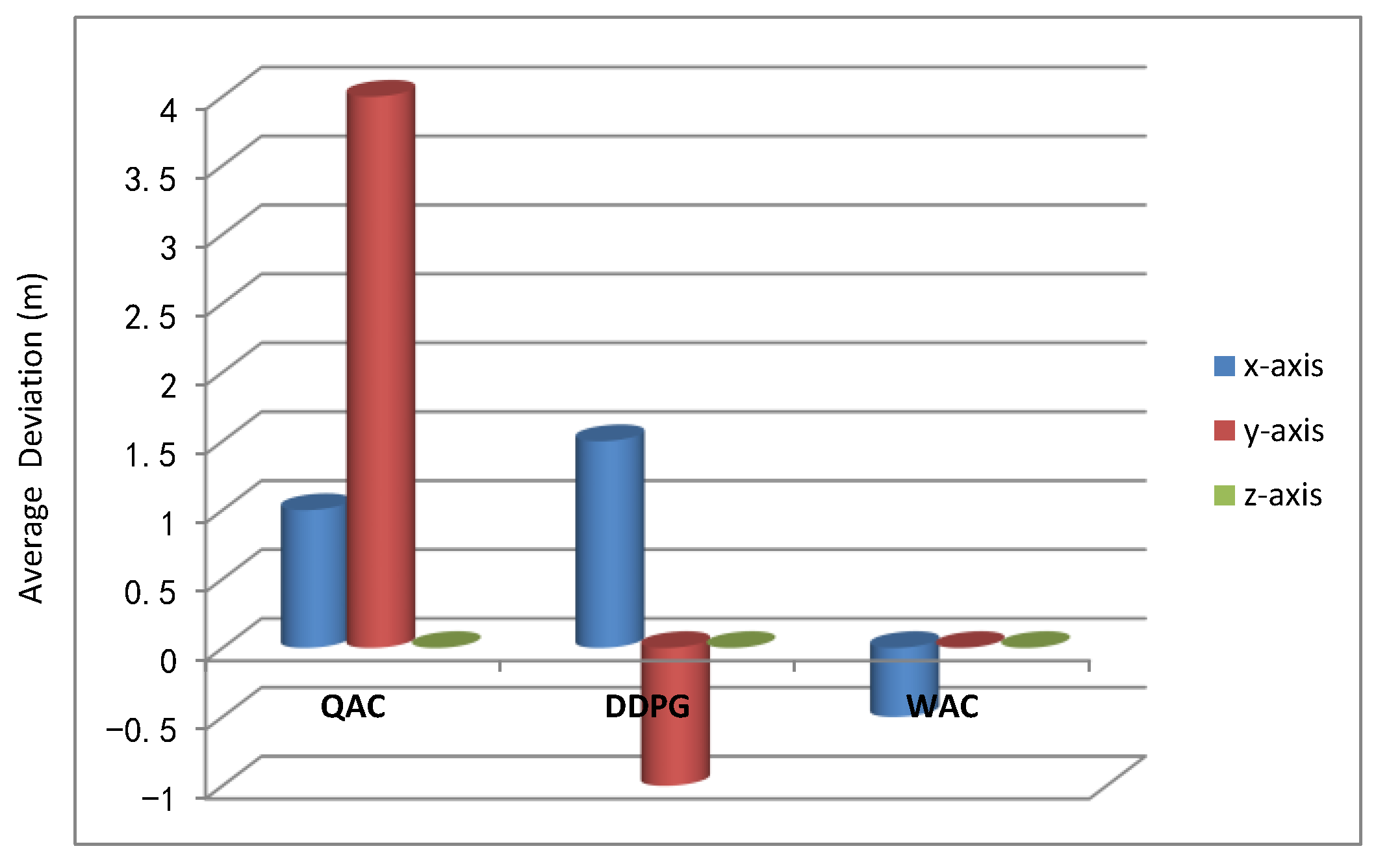
Figure 10e indicate that the DDPG and WAC have better stability than the QAC in hovering altitude, and compared to the DDPG, the average hovering altitude of the WAC is closer to the target altitude. In order to more clearly demonstrate these deviations, we plotted a bar chart comparing the average deviations of each axis under the three algorithms in
Figure 11. It is not difficult to see from the figure that the WAC exhibits good hovering characteristics followed by the DDPG, while the QAC is the most unstable. During drone hovering, the comparison of velocities in various axis directions under different algorithm frameworks in the geodetic coordinate system (Cartesian coordinate system) is shown in
Figure 10b,d,f. From the figure, it can be concluded that the WAC and DDPG are equally stable in hovering flight speed and significantly superior to the QAC. And regarding the height aspect that we are most concerned about, the speed of the three algorithms is better than the other two coordinate axes, and the
Z-axis speed of the WAC is basically stable at zero.
Since our research focuses on the hovering effect of drones, and the variation of drone yaw angle has little effect on hovering stability, we assume it to be always zero.
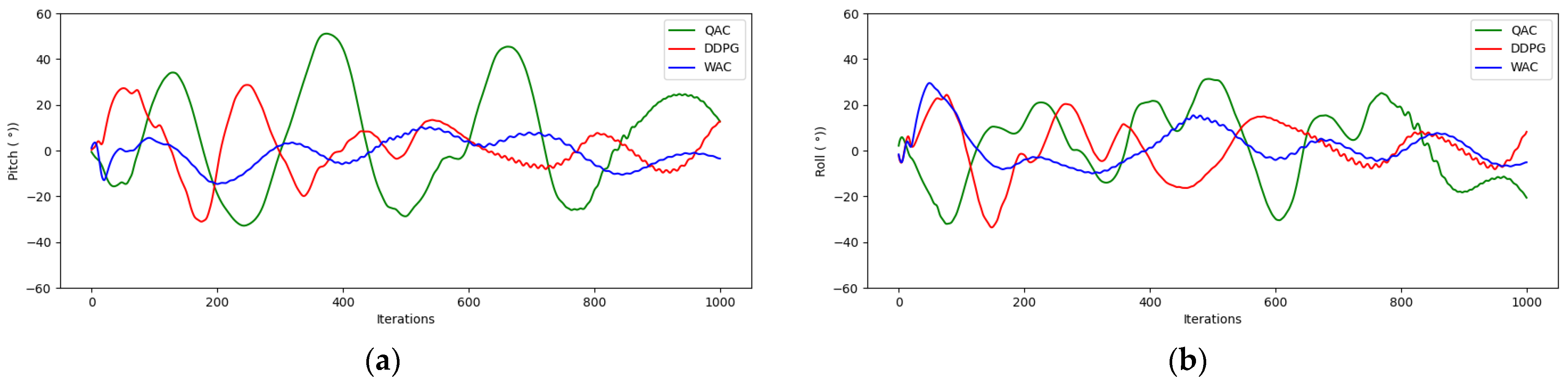
Figure 12a,b show a comparison of pitch angle and roll angle changes during hovering using the three algorithms. The changes in pitch angle and roll angle represent the stationarity of the drone hovering flight. It can be seen that the amplitude of the WAC change is the smallest, and it is superior in the stationarity of hovering flight. The above simulation results all indicate that the WAC algorithm applied to drone hover control is more stable, and the hovering effect has been greatly improved compared to the DDPG and QAC. Next, we studied the training time cost of the three algorithms.
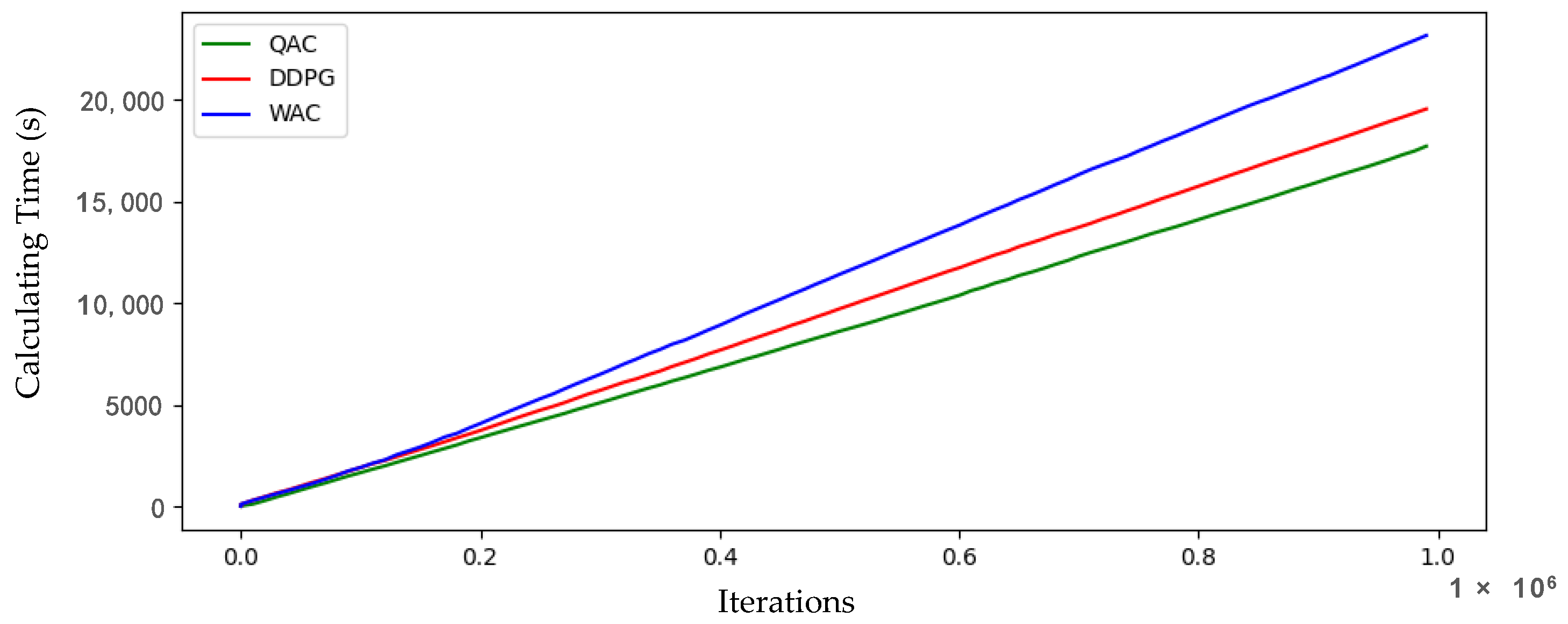
Figure 13 shows the cumulative training time curves of the various algorithms implemented by the computer. The WAC algorithm has a slightly longer training time than the other two algorithms due to the addition of the target network and supervised network. Compared to the QAC, DDPG also increases computational costs due to the addition of two backup networks. In order to quantitatively analyze the computational time cost of each algorithm, in the comparison of the computational cost per 10,000 iterations in
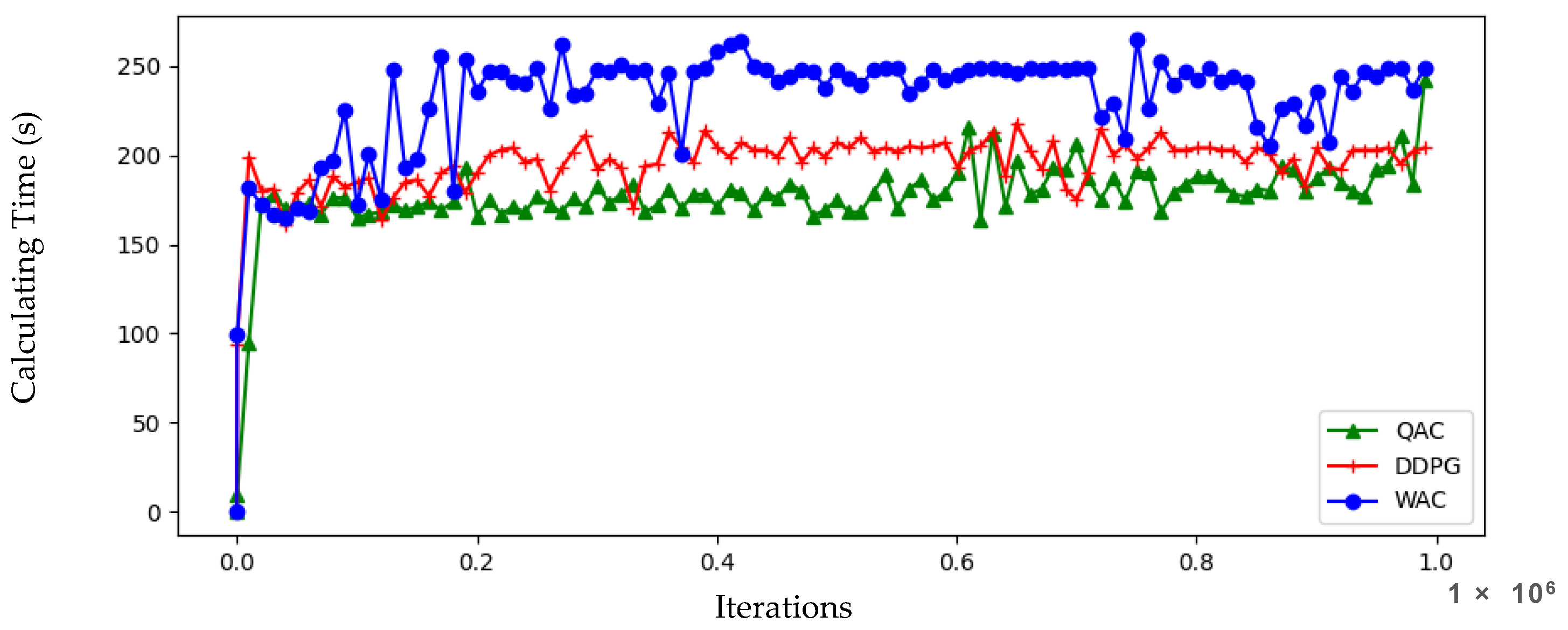
Figure 14, the training time cost of the three algorithms is basically in an arithmetic sequence, and the elongation of this computational cost is within an acceptable range. From the simulation results in the previous text, it can be seen that the learning efficiency and hovering effect of using the WAC algorithm are significantly better than the other algorithms. However, our algorithm did not excessively increase the time cost due to the increase in supervised networks, and it is worth investing a small amount of computational cost to obtain larger learning results. With the increase of training frequency in the later stage and relying on high-quality models in the early stage, the training effects of the three algorithms will become better and better, but the WAC is undoubtedly the first model that meets the requirements. The three training models are loaded separately and the optimization time for each step is analyzed, as shown in
Figure 15. The single step optimization time of the three algorithms shown in the figure remains below 1 millisecond with no significant difference, indicating that the proposed algorithm did not lag behind in optimization time.
We will deploy the WAC algorithm on a real drone in
Section 4 and demonstrate its practical performance.
4. Algorithm Deployment
In order to verify the effect of our algorithm, we deployed the WAC algorithm on a self-developed quadcopter. The computing platform on the drone uses NVIDIA Jetson Xavier NX, and the flight control firmware is Pixhawk4, which uses Ethernet communication. Due to the tendency of IMU integration to cause deviation in the attitude, which affects the experimental results, and in order to more accurately describe the position and attitude of the drone, we added a visual system in the experiment. IMU can provide visual positioning during rapid motion, and visual positioning information can be used to correct IMU drift. The two are actually complementary. We adopted a lightweight and drift-free fusion strategy for drone autonomy and safe navigation [
37]. The drone is equipped with a front facing camera, which can create visual geometric constraints and generate 3D environmental maps. The GNSS receiver is used to continuously provide pseudorange, Doppler frequency shift, and UTC time pulse signals to the drone navigation system. The Kanade–Lucas algorithm is used to track multiple visual features in each input image. Then, the position and attitude of the drone itself is monitored through multiple sensors installed on the body. The specific algorithm deployment process is shown in
Figure 16. Our deployment environment is a laboratory of length × width × height of 10 m × 10 m × 4 m. With the help of SLAM mapping already completed by the drone, drone hovering experiments are carried out in this environment. The desired state is obtained as the state input of the WAC strategy through the combination of inertial module, visual module, and GNSS module, forming a cyclic iteration of state-decision-action, and hover flight verification is completed. The detailed configuration of the deployed drone is shown in
Table 1. Related experimental videos can be found in the
Supplementary Materials section at the end of the article.
To verify the stability of the proposed algorithm, we loaded the trained network model into the quadcopter system and conducted three hovering experiments. Due to the height limitation of the experimental environment, the hovering altitude was set to 2 m, and the first 20 s of hovering flight data were selected for analysis.
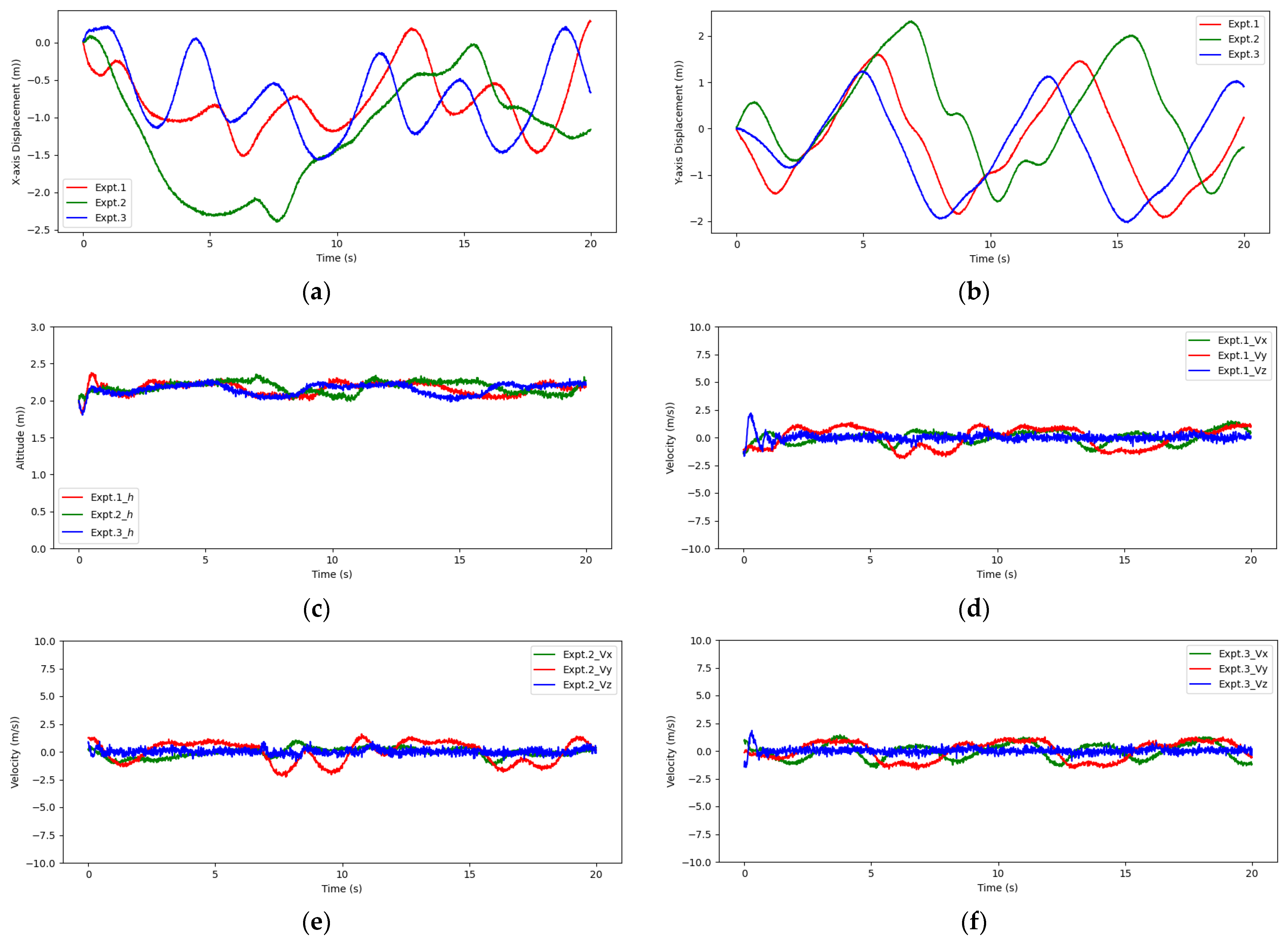
Figure 17a–c show the three hovering flight trajectories, while
Figure 17d depicts the hovering trajectory in the same space for macroscopic observation. It can be seen that the three hovering flights of the drone revolve around the hovering target point, and the operation is good without any crashes. The hovering altitude curves of the three experiments (
Figure 18c) also indicate that the hovering flight is very stable with a hovering altitude maintained around 2 m and a small fluctuation amplitude, which is basically consistent with the simulation experiment results.
Figure 18d–f illustrate the velocity changes along the three coordinated axes of three sets of experiments in the world coordinated system. The variation patterns of the three sets of flight data are fundamentally consistent with significant velocity changes on the
X and
Y axes, but they soon adjust to a slightly stable state. The
Z-axis velocity that we are concerned about remained largely unchanged, which also provides stability to the drone’s hovering and achieves our expected hovering effect.
Figure 19a,b show the performance of the pitch angles and roll angles of the drone in three sets of experiments, respectively. The translation range of the two Euler angles (±20°) is within our tolerance range. From the above curve, it can be seen that our algorithm has been deployed to real drones and performs well in all aspects, which is fundamentally consistent with the simulation results.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}