
A Vision-Based End-to-End Reinforcement Learning Framework for Drone Target Tracking

Abstract
1. Introduction
- We propose an advanced end-to-end reinforcement learning framework named VTD3, specifically designed for drone target tracking. This framework synergistically incorporates the YOLOv8 detection model, the BoT-SORT tracking algorithm, and the TD3 algorithm. Through this integration, the TD3 algorithm is trained to function as the drone’s high-level controller, thereby facilitating efficient and autonomous target tracking.
- We introduce a vision-based navigation strategy that significantly reduces reliance on GPS and ancillary sensors. This advancement enhances the system’s adaptability and reliability in complex environments while reducing hardware demands and overall system complexity.
- We showcase the tracking performance of our proposed VTD3, which significantly enhances the system’s handling of nonlinear and highly dynamic target motions. Experiments reveal notable gains for VTD3 in tracking accuracy, jitter reduction, and motion smoothness over traditional PD controllers.
2. Related Works
2.1. Drone Target Tracking
2.2. Drone Reinforcement Learning
3. Methods
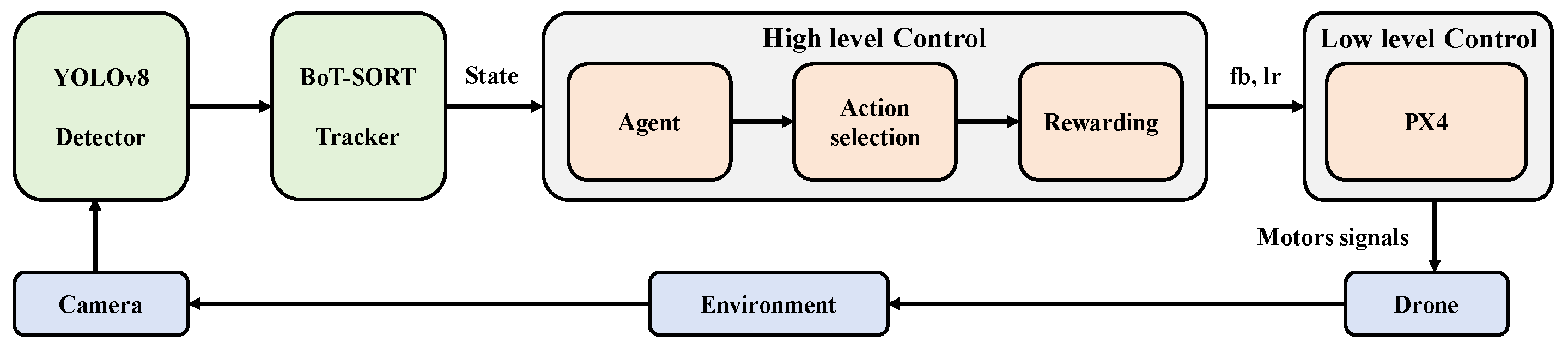
3.1. Framework
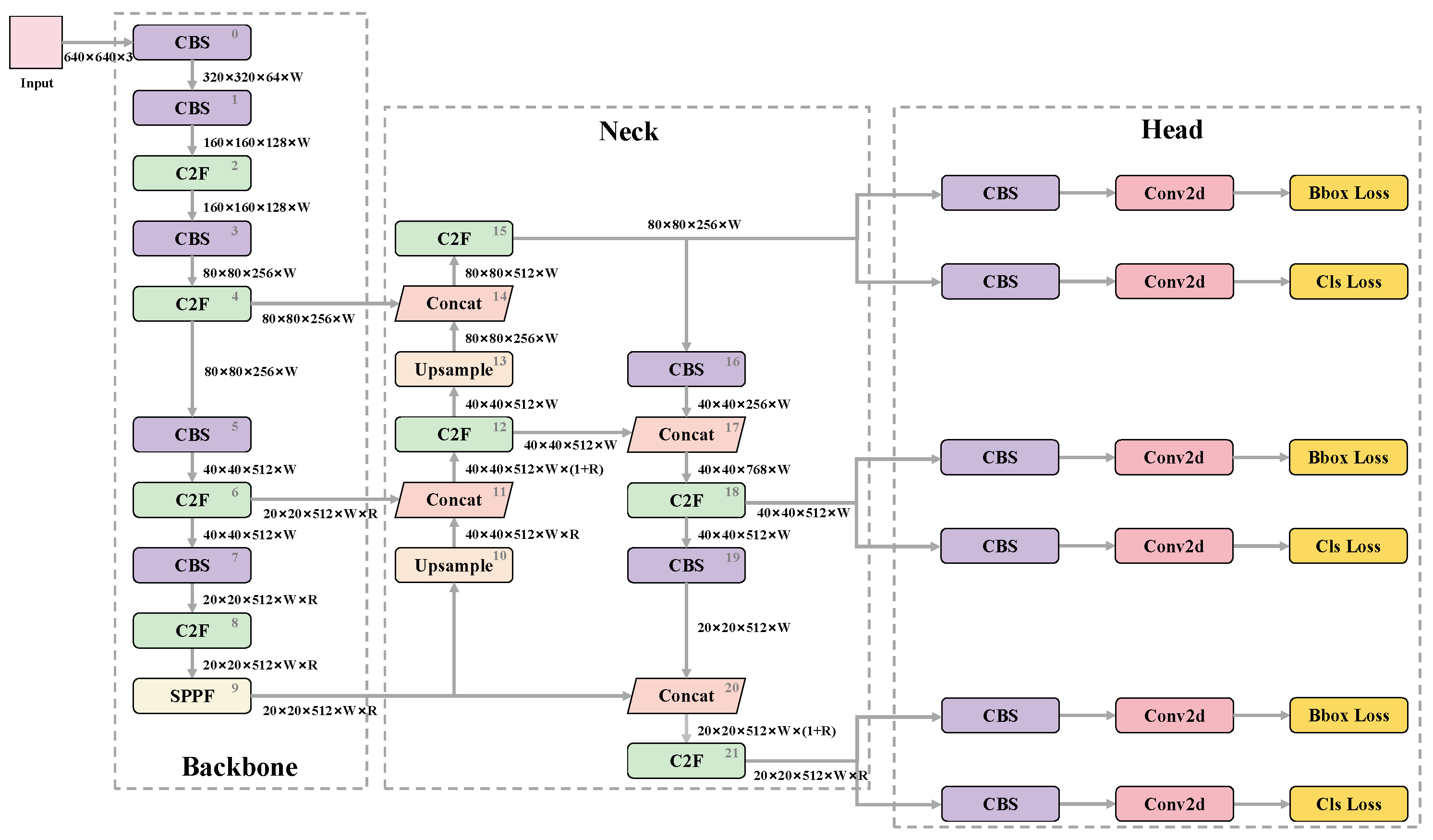
3.2. YOLOv8 Detector
3.2.1. Model Structure
3.2.2. Loss Function
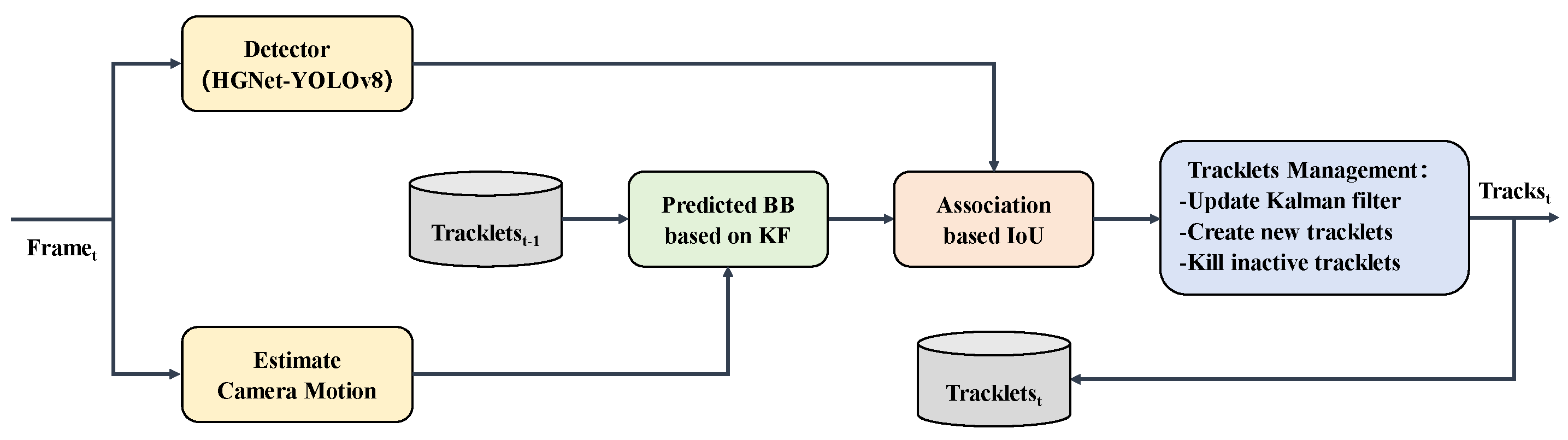
3.3. BoT-SORT Tracker
3.4. TD3-Based Controller
3.4.1. TD3 Algorithm Architecture
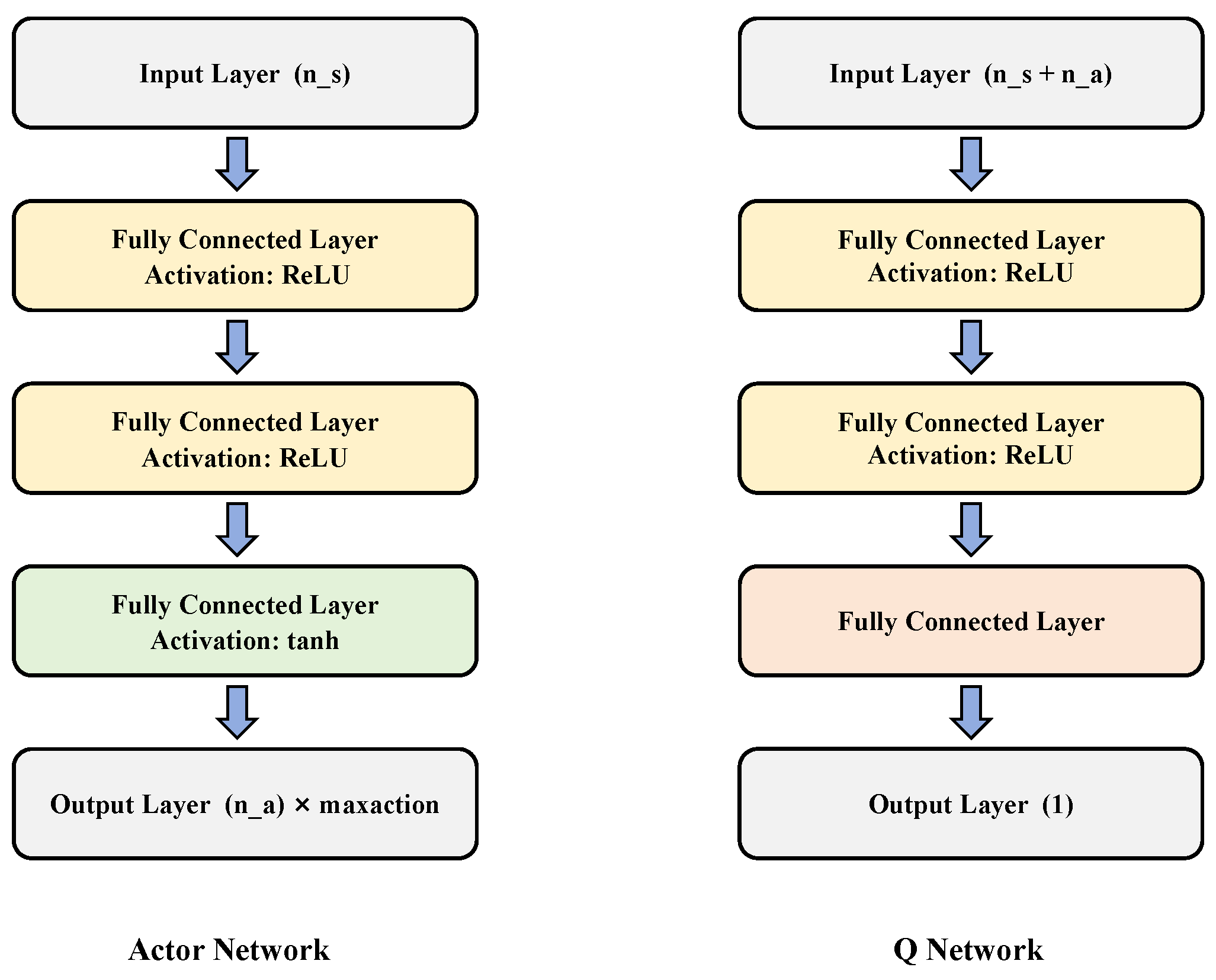
3.4.2. Actor and Q Network Structures
3.4.3. State and Action
3.4.4. Reward Function
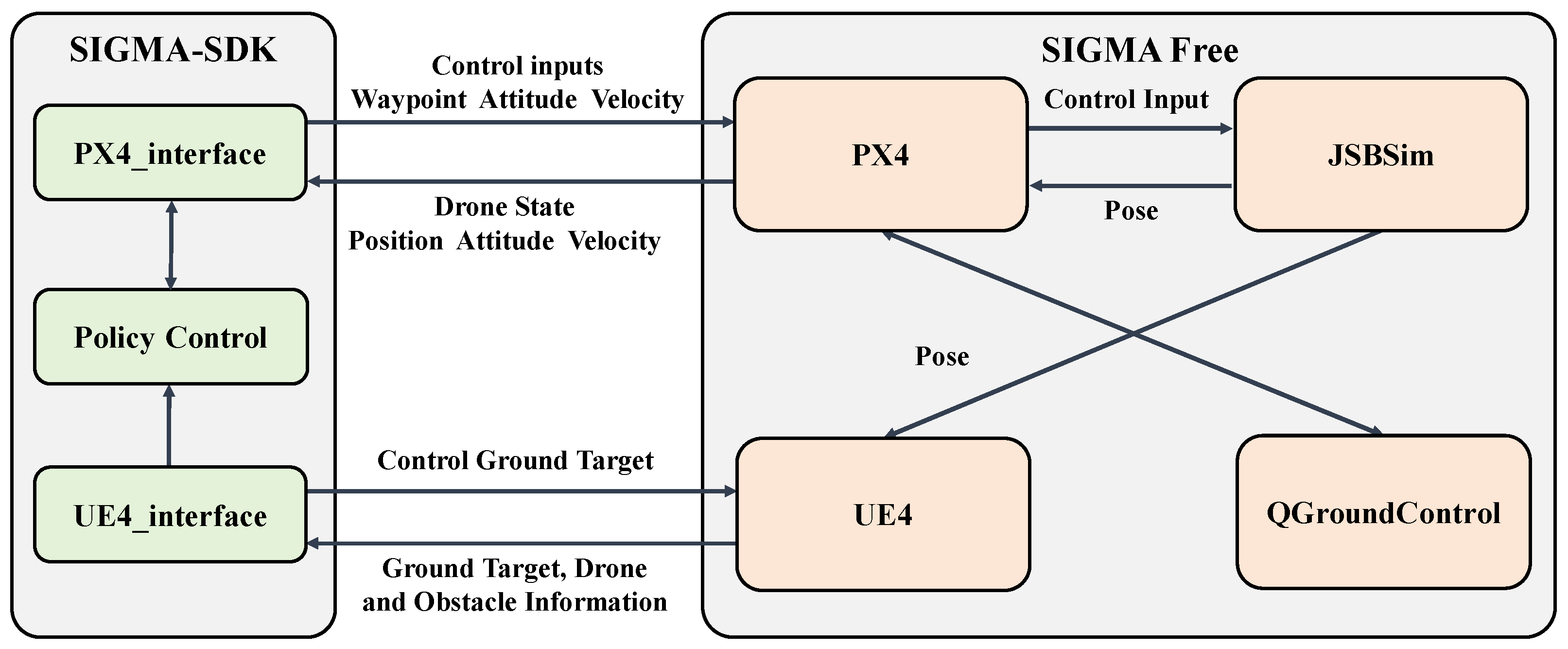
3.4.5. Simulation Environment
4. Experiments and Results
4.1. YOLOv8 Model Training Process
4.1.1. Dataset
4.1.2. Model Configuration and Parameter Settings
4.1.3. Evaluation Metrics
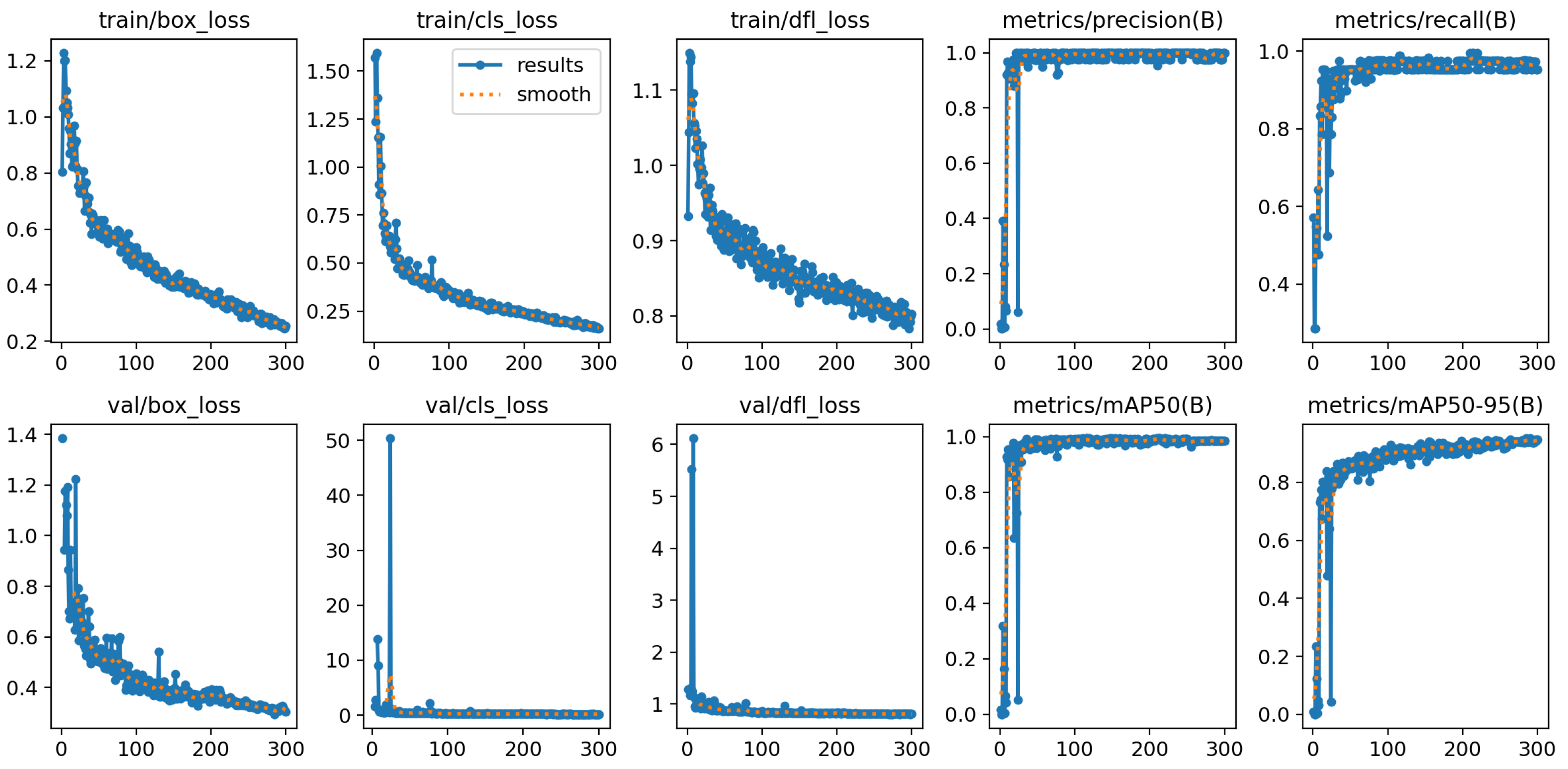
4.1.4. YOLOv8 Model Training Results
4.2. TD3 Network Training Process
4.2.1. TD3 Network Training Framework and Strategy
- Visual Perception: The drone captures real-time video streams via its onboard camera and processes the current frame using a YOLOv8 object detection algorithm.
- Target Tracking: The detection results are fed into a BoT-SORT tracker, enabling continuous target identification and verification.
- State Representation: Based on the detected target information (the bbox coordinates), the system computes and generates a state vector.
- Action Generation: The state vector is input into the TD3 network, which outputs control actions for the drone, including forward/backward and left/right control magnitudes.
- Reward Calculation and Learning: The system computes reward values based on the current state and executed actions. Information pertaining to state, action, and reward is archived in an experience replay buffer for network training and policy optimization.
- Action Execution: Control commands, generated by the TD3 network, are transmitted to the drone’s PX4 flight control system, which subsequently modulates the rotational speed of the four rotors to implement the specified actions.
- Environmental Interaction: The drone performs actions within the simulation environment and acquires new image data via its onboard camera, thereby initiating the subsequent processing cycle.
- Iterative Optimization: The system perpetually executes the aforementioned pipeline, progressively improving the target tracking performance of the TD3 controller through iterative interactions and learning.
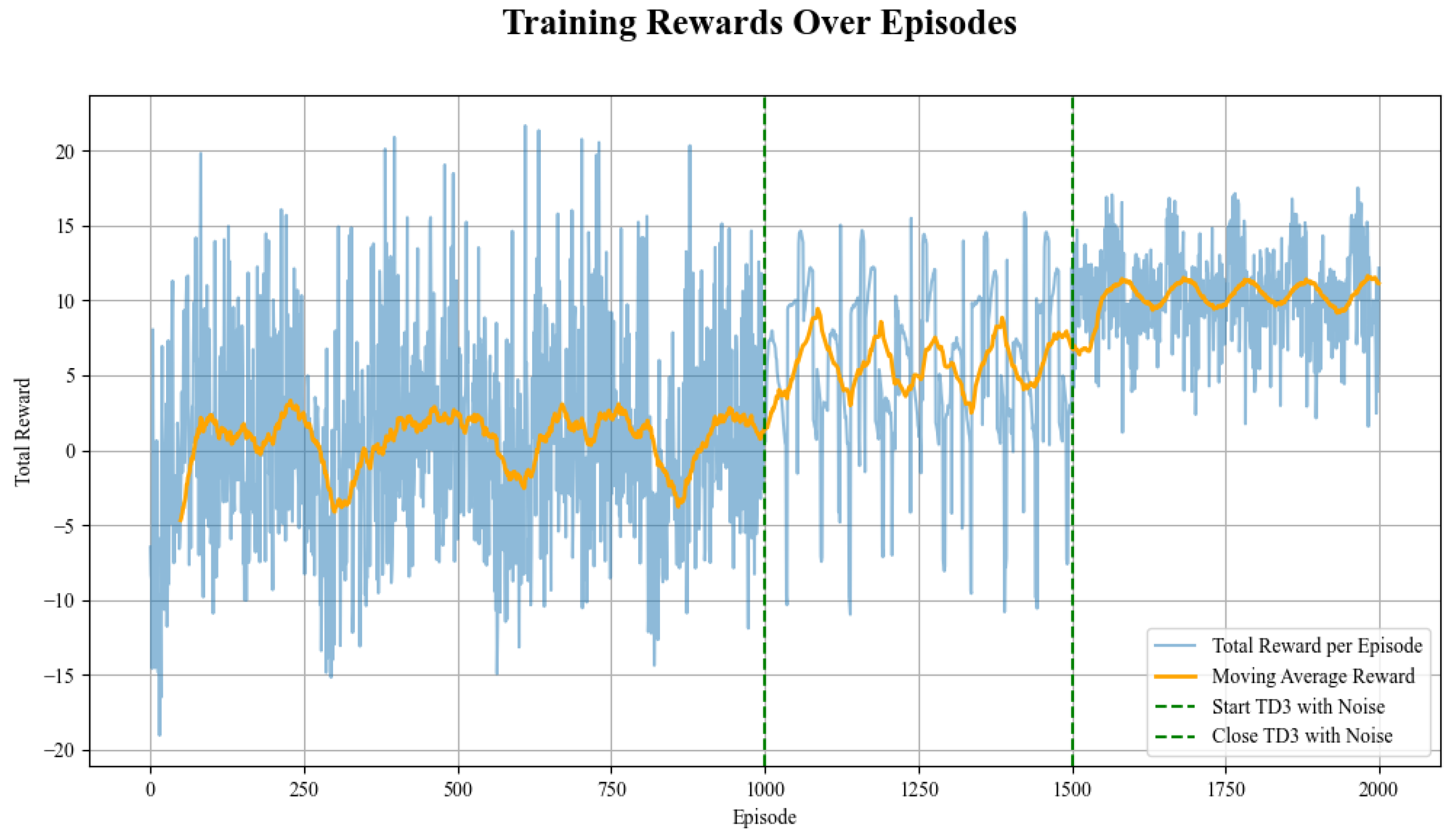
- Random Exploration Stage: This stage involves the TD3 network generating random control actions. This phase is designed to comprehensively explore the state space, thereby gathering a diverse set of experiential data that serves as a foundational basis for subsequent learning stages.
- Noisy Exploration Stage: As training advances, the TD3 network starts to produce intentional control actions. To enhance the learning process, Gaussian noise is introduced to the network’s output actions. This strategy effectively balances exploration and exploitation, thereby augmenting the diversity of data in the experience replay buffer and enabling the network to learn more robust control policies.
- Pure Policy Stage: During the final training stage, the TD3 network autonomously generates control actions without additional noise. This phase is dedicated to policy optimization, enabling the network to leverage the experiential knowledge acquired in the preceding stages to fine-tune the optimal control strategy.
| Algorithm 1 TD3: Vision-Based End-to-End TD3 Reinforcement Learning Method |
|
4.2.2. Simulation Platform and Parameter Settings
4.2.3. TD3 Network Training Results
4.3. Comparative Experiments
4.3.1. Experimental Setup
- Initial Conditions:
- Vehicle starting position: (30 m, 100 m, 0 m);
- Drone initial position: (30 m, 60 m, 4 m);
- To simulate real-world hovering instabilities, the drone’s actual initial position in the simulation is subjected to a maximum random deviation of from the ideal position.
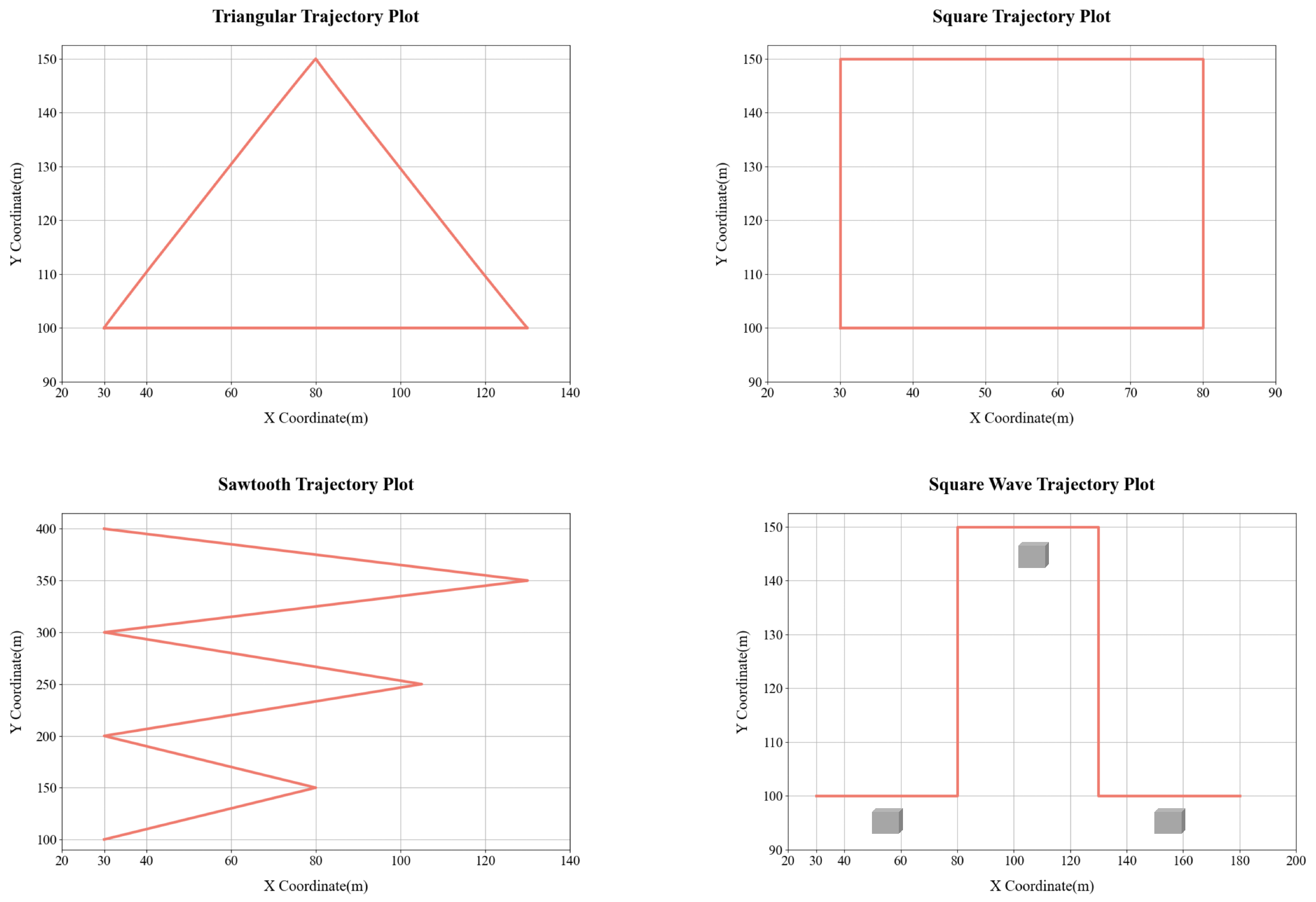
- Occlusion Setup:
- For the square wave trajectory, three occlusion walls are strategically positioned:
- •
- Position 1: (55 m, 95 m, 0 m);
- •
- Position 2: (105 m, 145 m, 0 m);
- •
- Position 3: (155 m, 105 m, 0 m).
- Each occlusion wall measures 8 m in width and 5 m in height, designed to create
- realistic visual obstruction scenarios.
- Vehicle Trajectory Design:
- The simulated vehicle’s trajectory consists of multiple consecutive start–end segments, each completed in a fixed duration of s. Each segment adheres to a standard three-phase motion pattern: uniform acceleration, constant velocity, and uniform deceleration, mimicking typical vehicular movement characteristics. After completing each motion segment, the vehicle undergoes a 2 s pause to alter its direction. This segmented design enables the construction of complex overall trajectories (such as triangular, square, sawtooth, and square wave patterns) while ensuring uniformity within each motion segment. Consequently, it offers a dependable benchmark for assessing the performance of drone tracking controllers across a variety of motion scenarios.
4.3.2. Evaluation Metrics
- X-Axis Average Tracking Error ()
- This metric reflects the tracking precision of the drone in the lateral direction. We record the positions of both the vehicle and the drone at 0.1 s intervals. We then compute the mean absolute difference in their X-axis positions across the entire trajectory. N denotes the total number of samples, and xdrone,i and xtarget,i represent the X-coordinates of the drone and target vehicle at the i-th sample, respectively. A lower Xdif value signifies higher precision in lateral tracking. The formula is defined as follows:
- Y-Axis Average Tracking Error ()
- This metric evaluates the drone’s ability to sustain a specified tracking distance along the longitudinal axis. The computational approach parallels that of Xdif but with a target value set at 40 m. The proximity of Ydif to 40mserves as an indicator of the controller’s precision in maintaining the designated tracking distance, thereby reflecting enhanced control performance. The formula is as follows:
- Z-Axis Average Altitude Error ()
- This metric quantifies the mean absolute deviation of the drone’s actual flight altitude from the initial set altitude of 4 m. Despite the lack of direct altitude control in the experiment, variations in altitude still arise due to the inherent dynamics of the quadrotor drone during planar motion execution. A smaller Zdif value indicates higher precision and the superior dynamic compensation capability of the controller during complex planar maneuvers. The formula is as follows:
- Velocity Jitter Metric ()
- The velocity jitter metric quantifies the extent of rapid velocity fluctuations over brief temporal intervals. In this study, utilizing velocity data sampled at 0.1 s intervals, it is determined by calculating the standard deviation of the first-order difference in velocity across the entire duration of observation. Let vi be the velocity at the i-th sample. A lower mean value of the velocity jitter indicates smoother overall motion, reflecting the controller’s ability to maintain stable velocity changes. The formula is as follows:
- Jerk Root Mean Square Metric ()
- The Jerk Root Mean Square (Jerk RMS) indicator is the root mean square value of the time derivative of acceleration, thereby reflecting the intensity of the variations in acceleration. This metric is derived by computing the root mean square of the second-order differences in velocity data, utilizing a sampling interval of 0.1 s. Let Δt be the time interval between samples (0.1 s in this study). A lower average Jerk RMS value indicates the controller’s capability to produce smoother acceleration changes, thus enhancing the fluidity and efficiency of motion control. The formula for Jerk RMS is as follows:
4.3.3. Comparative Experiments Results
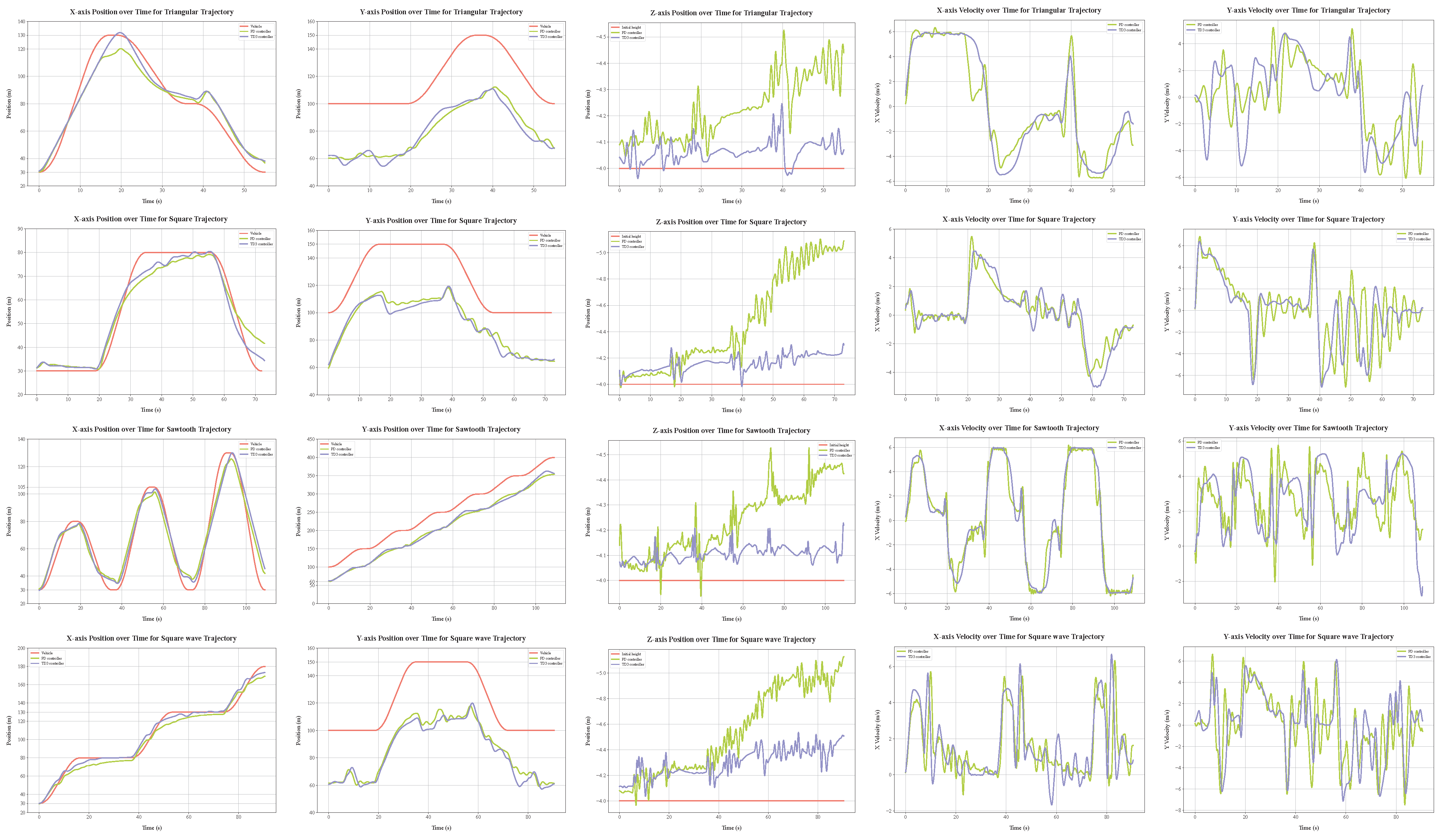
Qualitative Analysis
Quantitative Analysis of Four Trajectory Types
- (1)
- Tracking Accuracy and Trajectory Characteristics Analysis
- (2)
- Motion Smoothness Analysis
- (3)
- Comprehensive Analysis
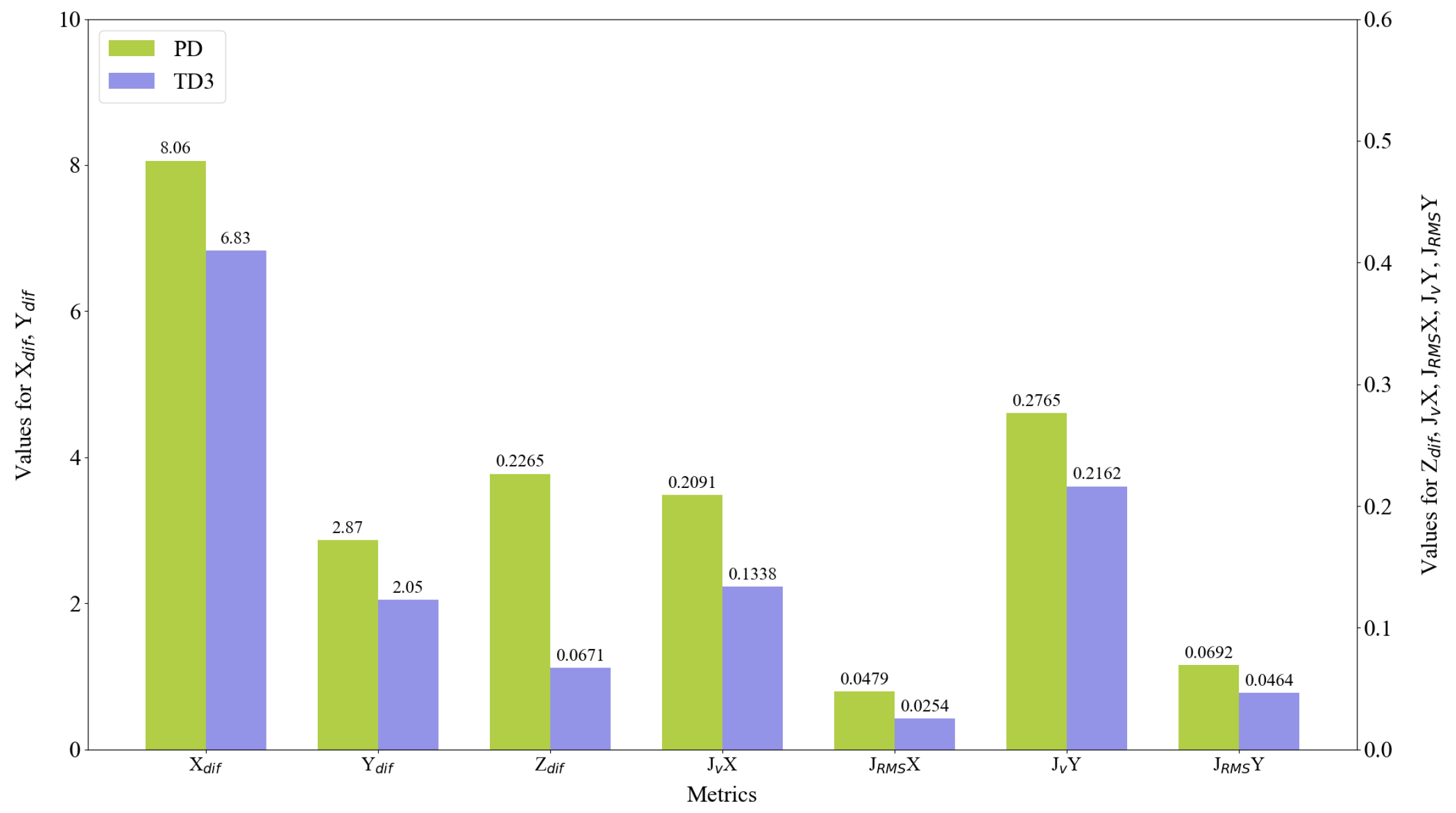
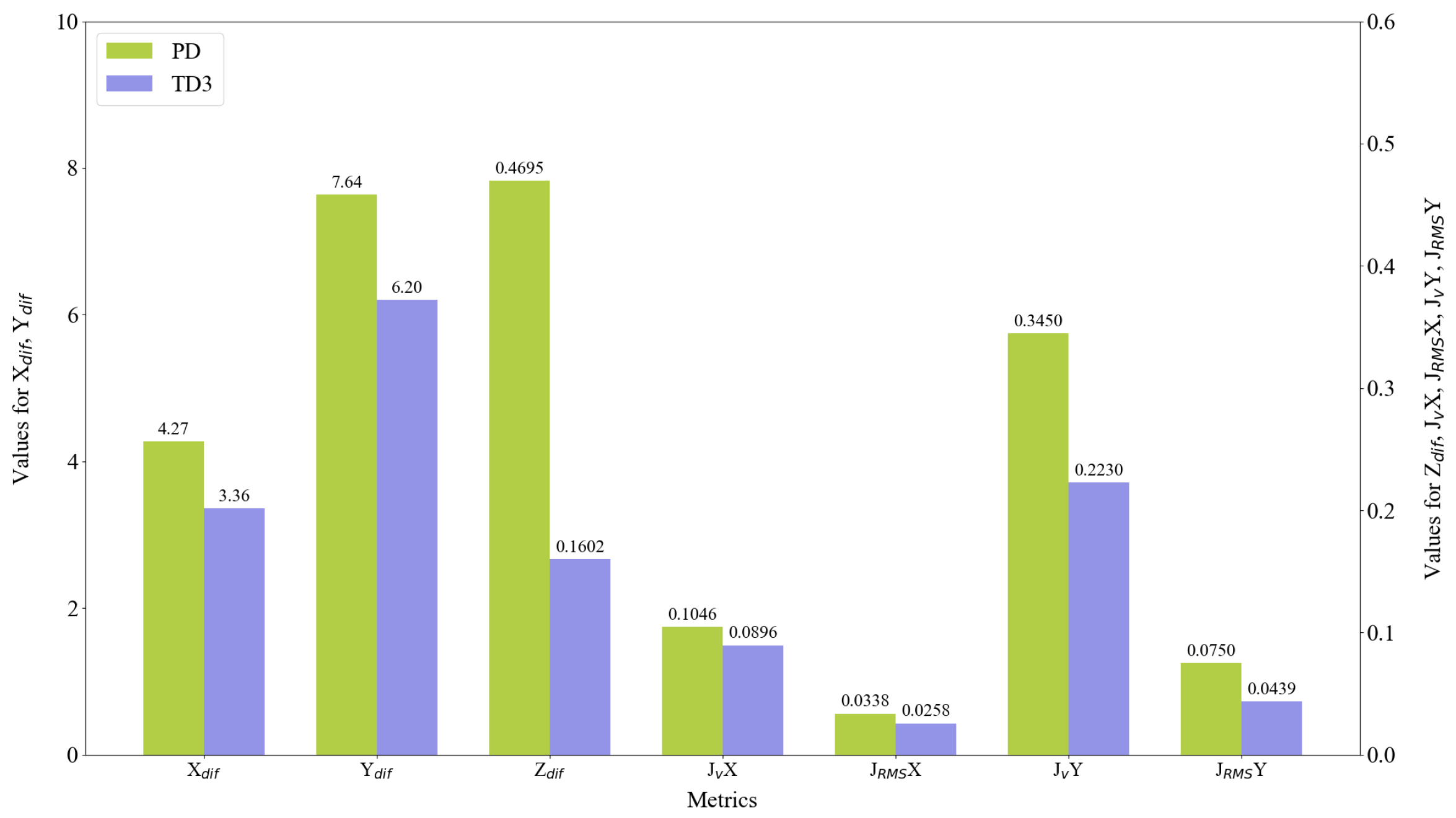
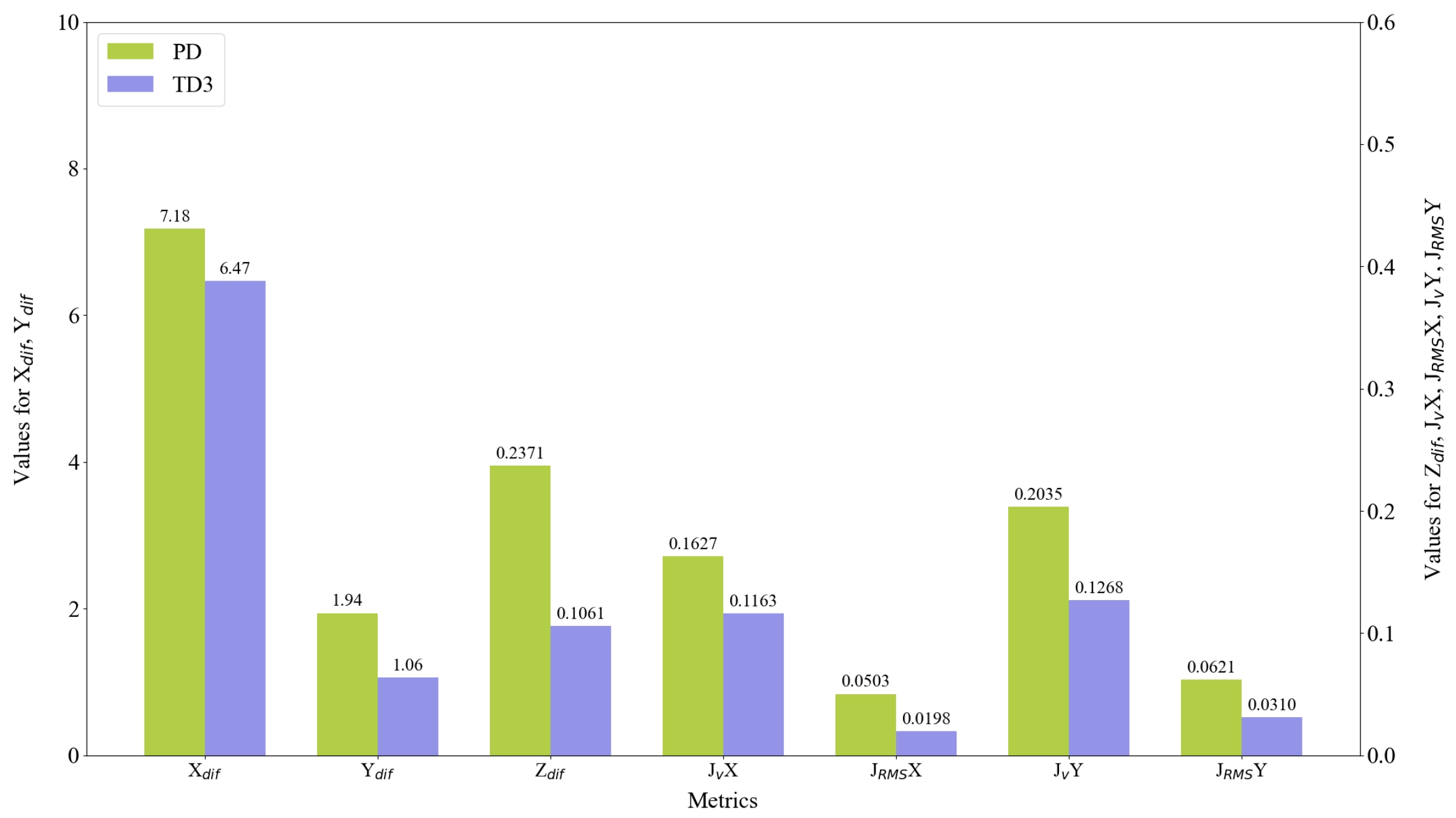
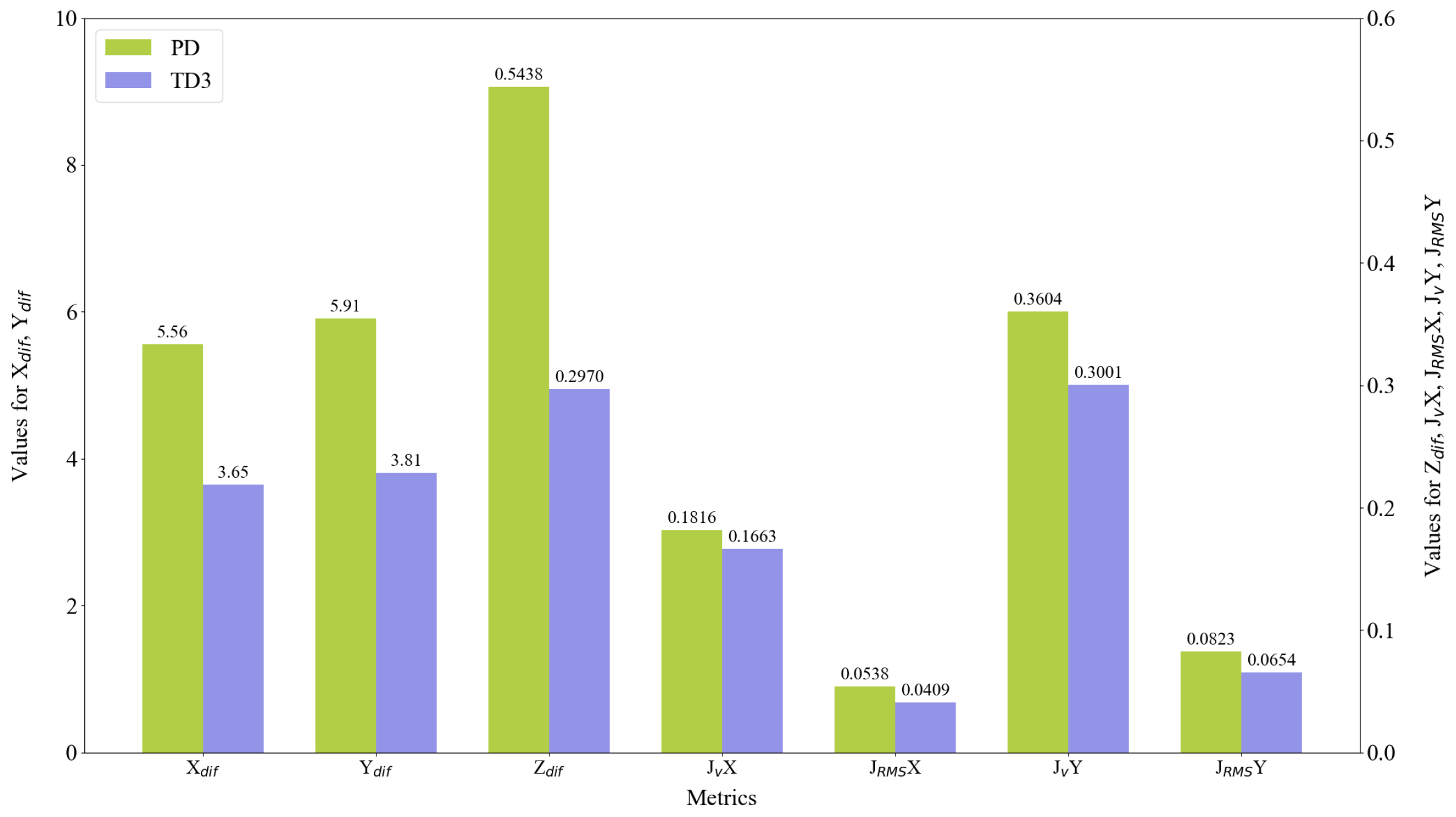
- The TD3 controller outperforms the PD controller in all evaluation metrics, demonstrating significant advantages in complex trajectory tracking tasks.
- Altitude control (Z-axis) shows the most substantial improvement, with an average of 59.22%, which is crucial for maintaining a stable tracking perspective.
- The reduction in velocity jitter is also notable, especially in the Y-axis direction, with an average improvement of 27.90%, contributing to enhanced flight stability and energy efficiency.
- In the square wave trajectory, which includes target occlusion scenarios, the TD3 maintains significant performance advantages, particularly in XY-plane tracking accuracy (a 34.35% and 35.52% improvement, respectively), demonstrating strong robustness and adaptability.
- In the sawtooth trajectory, the TD3 performs best in Y-axis tracking accuracy and X-axis velocity jerk reduction, with improvements of 45.36% and 60.64%, respectively, indicating its superior handling of frequent direction changes.
- For the square trajectory, the TD3 shows the greatest improvement in Z-axis control (66.10%), suggesting its particular effectiveness in scenarios requiring stable altitude maintenance.
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Aliloo, J.; Abbasi, E.; Karamidehkordi, E.; Parmehr, E.G.; Canavari, M. Dos and Don’ts of using drone technology in the crop fields. Technol. Soc. 2024, 76, 102456. [Google Scholar] [CrossRef]
- Liu, H.; Tsang, Y.; Lee, C. A cyber-physical social system for autonomous drone trajectory planning in last-mile superchilling delivery. Transp. Res. Part C Emerg. Technol. 2024, 158, 104448. [Google Scholar] [CrossRef]
- Khosravi, M.; Arora, R.; Enayati, S.; Pishro-Nik, H. A search and detection autonomous drone system: From design to implementation. IEEE Trans. Autom. Sci. Eng. 2024, 1–17. [Google Scholar] [CrossRef]
- Aboelezz, A.; Wetz, D.; Lehr, J.; Roghanchi, P.; Hassanalian, M. Intrinsically Safe Drone Propulsion System for Underground Coal Mining Applications: Computational and Experimental Studies. Drones 2023, 7, 44. [Google Scholar] [CrossRef]
- Sheng, H.; Chen, G.; Xu, Q.; Li, X.; Men, J.; Zhou, L.; Zhao, J. An advanced gas leakage traceability & dispersion prediction methodology using unmanned aerial vehicle. J. Loss Prev. Process. Ind. 2024, 88, 105276. [Google Scholar]
- Ardiny, H.; Beigzadeh, A.; Mahani, H. Applications of unmanned aerial vehicles in radiological monitoring: A review. Nucl. Eng. Des. 2024, 422, 113110. [Google Scholar] [CrossRef]
- Do, T.T.; Ahn, H. Visual-GPS combined ‘follow-me’tracking for selfie drones. Adv. Robot. 2018, 32, 1047–1060. [Google Scholar] [CrossRef]
- Upadhyay, J.; Rawat, A.; Deb, D. Multiple drone navigation and formation using selective target tracking-based computer vision. Electronics 2021, 10, 2125. [Google Scholar] [CrossRef]
- Sun, X.; Wang, Q.; Xie, F.; Quan, Z.; Wang, W.; Wang, H.; Yao, Y.; Yang, W.; Suzuki, S. Siamese Transformer Network: Building an autonomous real-time target tracking system for UAV. J. Syst. Archit. 2022, 130, 102675. [Google Scholar] [CrossRef]
- Li, S.; Ozo, M.M.; de Wagter, C.; de Croon, G.C. Autonomous drone race: A computationally efficient vision-based navigation and control strategy. Robot. Auton. Syst. 2020, 133, 103621. [Google Scholar] [CrossRef]
- Song, Y.; Scaramuzza, D. Policy search for model predictive control with application to agile drone flight. IEEE Trans. Robot. 2022, 38, 2114–2130. [Google Scholar] [CrossRef]
- Nonami, K. Present state and future prospect of autonomous control technology for industrial drones. IEEJ Trans. Electr. Electron. Eng. 2020, 15, 6–11. [Google Scholar] [CrossRef]
- Liu, H.; Suzuki, S. Model-Free Guidance Method for Drones in Complex Environments Using Direct Policy Exploration and Optimization. Drones 2023, 7, 514. [Google Scholar] [CrossRef]
- Qin, S.J.; Badgwell, T.A. A survey of industrial model predictive control technology. Control Eng. Pract. 2003, 11, 733–764. [Google Scholar] [CrossRef]
- Sun, D.; Jamshidnejad, A.; de Schutter, B. Optimal Sub-References for Setpoint Tracking: A Multi-level MPC Approach. IFAC-PapersOnLine 2023, 56, 9411–9416. [Google Scholar] [CrossRef]
- Chua, K.; Calandra, R.; McAllister, R.; Levine, S. Deep reinforcement learning in a handful of trials using probabilistic dynamics models. Adv. Neural Inf. Process. Syst. 2018, 31, 4759–4770. Available online: https://proceedings.neurips.cc/paper_files/paper/2018/file/3de568f8597b94bda53149c7d7f5958c-Paper.pdf (accessed on 24 October 2024).
- Wen, R.; Huang, J.; Li, R.; Ding, G.; Zhao, Z. Multi-Agent Probabilistic Ensembles with Trajectory Sampling for Connected Autonomous Vehicles. IEEE Trans. Veh. Technol. 2024, 2025–2030. [Google Scholar] [CrossRef]
- Janner, M.; Fu, J.; Zhang, M.; Levine, S. When to trust your model: Model-based policy optimization. Adv. Neural Inf. Process. Syst. 2019, 32, 12519–12530. Available online: https://proceedings.neurips.cc/paper_files/paper/2019/file/5faf461eff3099671ad63c6f3f094f7f-Paper.pdf (accessed on 24 October 2024).
- Zhou, Q.; Li, H.; Wang, J. Deep model-based reinforcement learning via estimated uncertainty and conservative policy optimization. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 6941–6948. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Cheng, Y.; Guo, Q.; Wang, X. Proximal Policy Optimization with Advantage Reuse Competition. IEEE Trans. Artif. Intell. 2024, 5, 3915–3925. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1587–1596. [Google Scholar]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLO v8.0.0 [Software]. Available online: https://github.com/ultralytics/ultralytics (accessed on 24 October 2024).
- Aharon, N.; Orfaig, R.; Bobrovsky, B.Z. BoT-SORT: Robust associations multi-pedestrian tracking. arXiv 2022, arXiv:2206.14651. [Google Scholar]
- Sun, N.; Zhao, J.; Shi, Q.; Liu, C.; Liu, P. Moving Target Tracking by Unmanned Aerial Vehicle: A Survey and Taxonomy. IEEE Trans. Ind. Inform. 2024, 20, 7056–7068. [Google Scholar] [CrossRef]
- Ajmera, Y.; Singh, S.P. Autonomous UAV-based target search, tracking and following using reinforcement learning and YOLOFlow. In Proceedings of the 2020 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), Abu Dhabi, United Arab Emirates, 4–6 November 2020; pp. 15–20. [Google Scholar]
- Liu, X.; Xue, W.; Xu, X.; Zhao, M.; Qin, B. Research on Unmanned Aerial Vehicle (UAV) Visual Landing Guidance and Positioning Algorithms. Drones 2024, 8, 257. [Google Scholar] [CrossRef]
- Farkhodov, K.; Park, J.H.; Lee, S.H.; Kwon, K.R. Virtual Simulation based Visual Object Tracking via Deep Reinforcement Learning. In Proceedings of the 2022 International Conference on Information Science and Communications Technologies (ICISCT), Tashkent, Uzbekistan, 28–30 September 2022; pp. 1–4. [Google Scholar]
- Sha, P.; Wang, Q. Autonomous Navigation of UAVs in Resource Limited Environment Using Deep Reinforcement Learning. In Proceedings of the 2022 37th Youth Academic Annual Conference of Chinese Association of Automation (YAC), Beijing, China, 19–20 November 2022; pp. 36–41. [Google Scholar]
- Li, B.; Yang, Z.P.; Chen, D.Q.; Liang, S.Y.; Ma, H. Maneuvering target tracking of UAV based on MN-DDPG and transfer learning. Def. Technol. 2021, 17, 457–466. [Google Scholar] [CrossRef]
- Srivastava, R.; Lima, R.; Das, K.; Maity, A. Least square policy iteration for ibvs based dynamic target tracking. In Proceedings of the 2019 International Conference on Unmanned Aircraft Systems (ICUAS), Atlanta, GA, USA, 11–14 June 2019; pp. 1089–1098. [Google Scholar]
- Ma, M.Y.; Huang, Y.H.; Shen, S.E.; Huang, Y.C. Manipulating Camera Gimbal Positioning by Deep Deterministic Policy Gradient Reinforcement Learning for Drone Object Detection. Drones 2024, 8, 174. [Google Scholar] [CrossRef]
- Mosali, N.A.; Shamsudin, S.S.; Alfandi, O.; Omar, R.; Al-Fadhali, N. Twin delayed deep deterministic policy gradient-based target tracking for unmanned aerial vehicle with achievement rewarding and multistage training. IEEE Access 2022, 10, 23545–23559. [Google Scholar] [CrossRef]
- Vankadari, M.B.; Das, K.; Shinde, C.; Kumar, S. A reinforcement learning approach for autonomous control and landing of a quadrotor. In Proceedings of the 2018 International Conference on Unmanned Aircraft Systems (ICUAS), Dallas, TX, USA, 12–15 June 2018; pp. 676–683. [Google Scholar]
- Du, W.; Guo, T.; Chen, J.; Li, B.; Zhu, G.; Cao, X. Cooperative pursuit of unauthorized UAVs in urban airspace via Multi-agent reinforcement learning. Transp. Res. Part Emerg. Technol. 2021, 128, 103122. [Google Scholar] [CrossRef]
- Jocher, G. Ultralytics YOLOv5 [Software]. AGPL-3.0 License. Available online: https://github.com/ultralytics/yolov5 (accessed on 24 October 2024). [CrossRef]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Airlines, B.D. Sigma Free Project. Available online: https://gitee.com/beijing-daxiang-airlines/sigma-free/ (accessed on 10 July 2024).
- Tian, Y.; Li, X.; Wang, K.; Wang, F.Y. Training and testing object detectors with virtual images. IEEE/CAA J. Autom. Sin. 2018, 5, 539–546. [Google Scholar] [CrossRef]
- Ye, H.; Sunderraman, R.; Ji, S. UAV3D: A Large-scale 3D Perception Benchmark for Unmanned Aerial Vehicles. Adv. Neural Inf. Process. Syst. arXiv 2024, arXiv:2410.11125. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | Concept |
|---|---|
| Hidden layers number | Determines the depth of neural networks |
| Hidden layer width | Defines the number of neurons in each hidden layer |
| Buffer size | Capacity of the experience replay memory |
| Batch size | Number of samples used in each training iteration |
| UPDATE_INTERVAL | Frequency of policy updates in environment steps |
| Learning rate for actor networks | Controls the step size for updating the actor network |
| Learning rate for Q networks | Controls the step size for updating the critic network |
| Discount factor | Weighs the importance of future rewards |
| Explore_noise | Magnitude of noise added for action exploration |
| Explore_noise_decay | Rate at which exploration noise decreases over time |
| Parameter Name | Value |
|---|---|
| Hidden layer number | 2 |
| Hidden layer width | 64 |
| Dimension of states | 2 |
| Dimension of actions | 2 |
| Max_action | 6 m/s |
| Control period | 0.3 s |
| Buffer size | |
| Batch size | 64 |
| MAX_STEPS | 2000 |
| RANDOM_STEPS | 1000 |
| TD3_NOISE_STEPS | 500 |
| TD3_STEPS | 500 |
| UPDATE_INTERVAL | 50 |
| Optimizer | Adam |
| Learning rate for actor networks | 0.001 |
| Learning rate for Q networks | 0.001 |
| Discount factor | 0.99 |
| Explore_noise | 0.15 |
| Explore_noise_decay | 0.998 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, X.; Huang, X.; Cheng, J.; Xia, Z.; Tu, Z. A Vision-Based End-to-End Reinforcement Learning Framework for Drone Target Tracking. Drones 2024, 8, 628. https://doi.org/10.3390/drones8110628
Zhao X, Huang X, Cheng J, Xia Z, Tu Z. A Vision-Based End-to-End Reinforcement Learning Framework for Drone Target Tracking. Drones. 2024; 8(11):628. https://doi.org/10.3390/drones8110628
Chicago/Turabian StyleZhao, Xun, Xinjian Huang, Jianheng Cheng, Zhendong Xia, and Zhiheng Tu. 2024. "A Vision-Based End-to-End Reinforcement Learning Framework for Drone Target Tracking" Drones 8, no. 11: 628. https://doi.org/10.3390/drones8110628
APA StyleZhao, X., Huang, X., Cheng, J., Xia, Z., & Tu, Z. (2024). A Vision-Based End-to-End Reinforcement Learning Framework for Drone Target Tracking. Drones, 8(11), 628. https://doi.org/10.3390/drones8110628