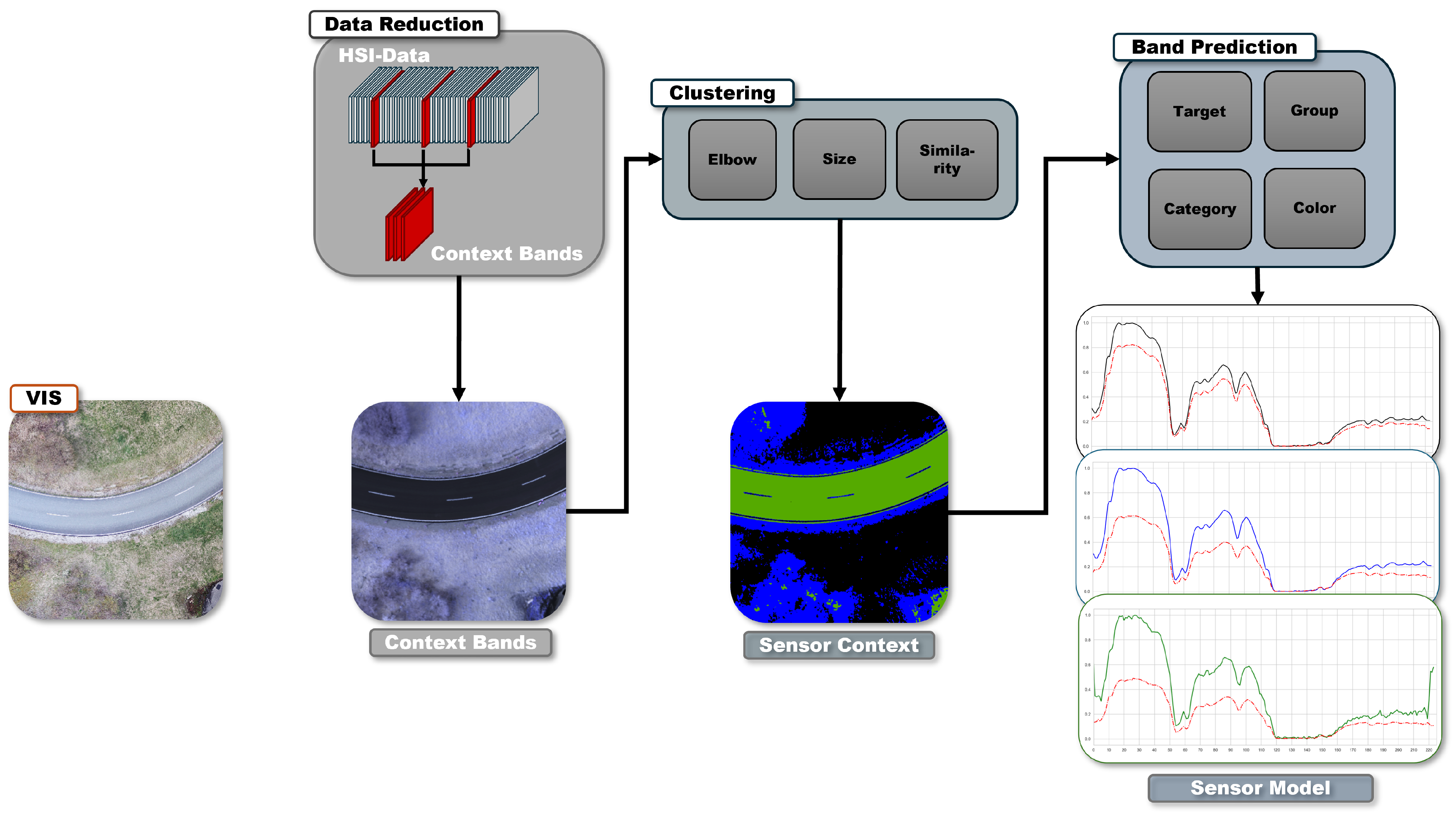
The Results Section is divided into three parts to analyze the correlation and performance of the BS, the anomaly detectors, and the mission and sensor context. First, the anomaly detectors and the different parameter settings are analyzed on their anomaly detection performance. On the one hand, the impact of the sensor context on the detection performance of the detectors and their combination is investigated. On the other hand, the general performance of the detectors is evaluated to demonstrate the suitability of their use for further testing. Subsequently, the performance of the Sensor Management and its BS is analyzed by considering context knowledge. For this purpose, the implemented BS is compared with a statistical band selection methodology and the use of the full set of bands by analyzing the detection results of the implemented detectors. The results provide insights into the impact of contextual knowledge on BS, determining whether no consideration, a general approach, or a dynamic selection provided by the Sensor Management can lead to improved anomaly detection performance. Finally, different combinations of architectures to connect the Sensor Management and the detectors are evaluated and recommendations for a managed system architectures of anomaly detectors are derived. All tests are CPU-based and run on Windows 11 with an Intel i7-1260P 12th Gen and 34 GB memory.
3.1. Performance Anomaly Detectors
As described in the Introduction, the performance of an anomaly detector changes with the targets themselves and their location, position, and image scene. Therefore, multiple anomaly detectors are used in this paper to improve the anomaly detection performance by selecting the best detector setting for each mission context. For this, the detection performance of each image and each of the detector settings in
Table 1 is calculated by the weighted
f1-score, called
f:
where
p is the precision and
r the recall of the detection result. The weighting factor,
, is set to 1.1, which leads to a slightly higher prioritization of the recall and thus to a higher sensitivity. This is due to the planned architecture and the use case of camouflage and UXO detection. The detection process should be followed by a sensor context-based classification, which reduces false positives by taking the context into account. Therefore, a higher recall is preferred over a lower sensitivity, which results in a higher probability of undetected targets. In the context of the use case, an undetected UXO is also more destructive than a few more false positives. In addition to the
f, the overall percentage of detected targets
ht in the samples is determined by dividing the total number of targets detected with at least one of each labeled target pixel by the number of labeled targets, whereas
ht determines the total detected target rate independent of the sample for the entire dataset, and
t determines the average target detection rate per sample. Furthermore, the calculated
f and the
t are added to a weighted sum, called
fh. For this purpose, weighting factors of 0.6 and 0.4 are used for
ht and
f. The additional performance metric
fh is caused by the missing information of detected targets in the
f. The
f score increases with the accuracy of the detected targets but does not distinguish the assignment of the detected target pixels. Thus, detecting one target in the sample with high accuracy can result in a
f score equal to detecting all targets in the sample with low accuracy. However, the latter is preferable in a tactical reconnaissance scenario, where the automated processing workflow assists by highlighting areas of interest, thereby reducing the sensor and missions operator’s workload and improving the total detection rate. Therefore, it is more important to detect as many targets in the scenario as possible than to detect a few targets and their contours with high accuracy, especially when the subsequent classification of the targets is based on spectral information rather than contours. This aspect is taken into account by the new metric
fh with the higher weight of
ht. These metrics are computed for each detector on dataset 1. For this purpose, each of them receives as input a selected set of bands depending on the assigned workflow and its target group. This band set recognizes the best minimum unique bands with respect to all extracted environments of one target group.
Table 2 shows the average detector performance for the detector in
Table 1 tested on dataset 1. For the target group of UXO, the highest score of
is achieved for the LRX detector with parameter setting
ID = 7. However, for
ID = 7 only an average of 32.93% targets per sample are detected for the dataset. This is the lowest value for all UXO detector settings. Therefore the highest
h is achieved for
ID = 1 with 80.95% of average detected targets per sample, which is also the overall maximum. Furthermore, the results show relatively low precision values for all detector
ID’s of the target group UXO, which means that many positive predictions are wrong, but this is also typical for the detection task of detecting small UXO in complex scenarios, see [
43]. The detector settings for UXO contain relatively high thresholds
t for the detection map, which means that many low significant anomalies are already left out. However, the targets are small, and the results show that even a few incorrectly predicted pixels relative to the few target pixels result in a low precision score. The recall score is in a higher value range. Again, the obtained scores show the expected performance values for the dataset and the recognition task. The evaluation of the detector settings by the determined
h would lead to a first rank of the detector with
ID = 1, while the target pixels in the samples are correctly identified with a relatively high score of 0.6678 but so are many false-positive target predictions. This picture is similar for the camouflage detector settings.
The precision scores of the detectors are also low. Since the target sizes are much larger and therefore large image areas must be falsely classified as positive, the low precision scores must be interpreted more critically. At the same time, the recall scores are higher and show a moderate performance. Overall, the
- and
h-scores are comparable to the UXO results. However, a lower overall
t of 72.71 is achieved, suggesting that the performance is to be evaluated more critically. Regarding
h, the detector setting with
ID = 1 has the highest total detection performance for dataset 1. The best performance results of the detector groups are determined for the LRX, followed by the C-HDBSCAN and the bandpass filter. Overall, there are small differences in performance, but none of the four detector groups can outperform the others, and the detector performances are generally low. Therefore, in addition to the general detector performances, the performance behavior of each detector is of particular interest. As already introduced, the detector performance changes with context, and thus, each detector has a sweet point with its highest detection performances. Therefore, the next step will be an analysis of how the consideration of this factor can lead to an improvement in the detection results. First, each image is analyzed by the
h-score for the detector with the best assigned detection performance.
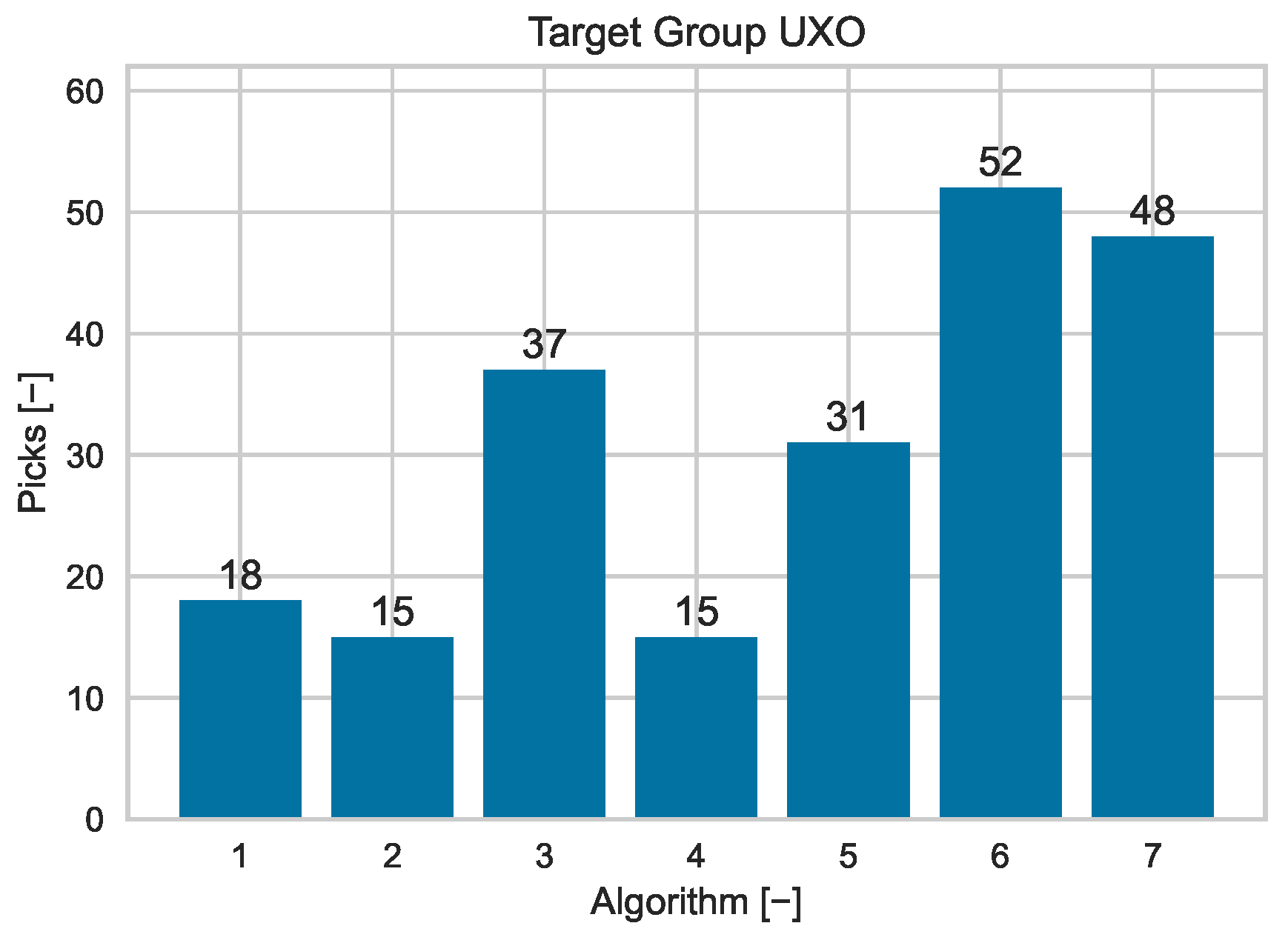
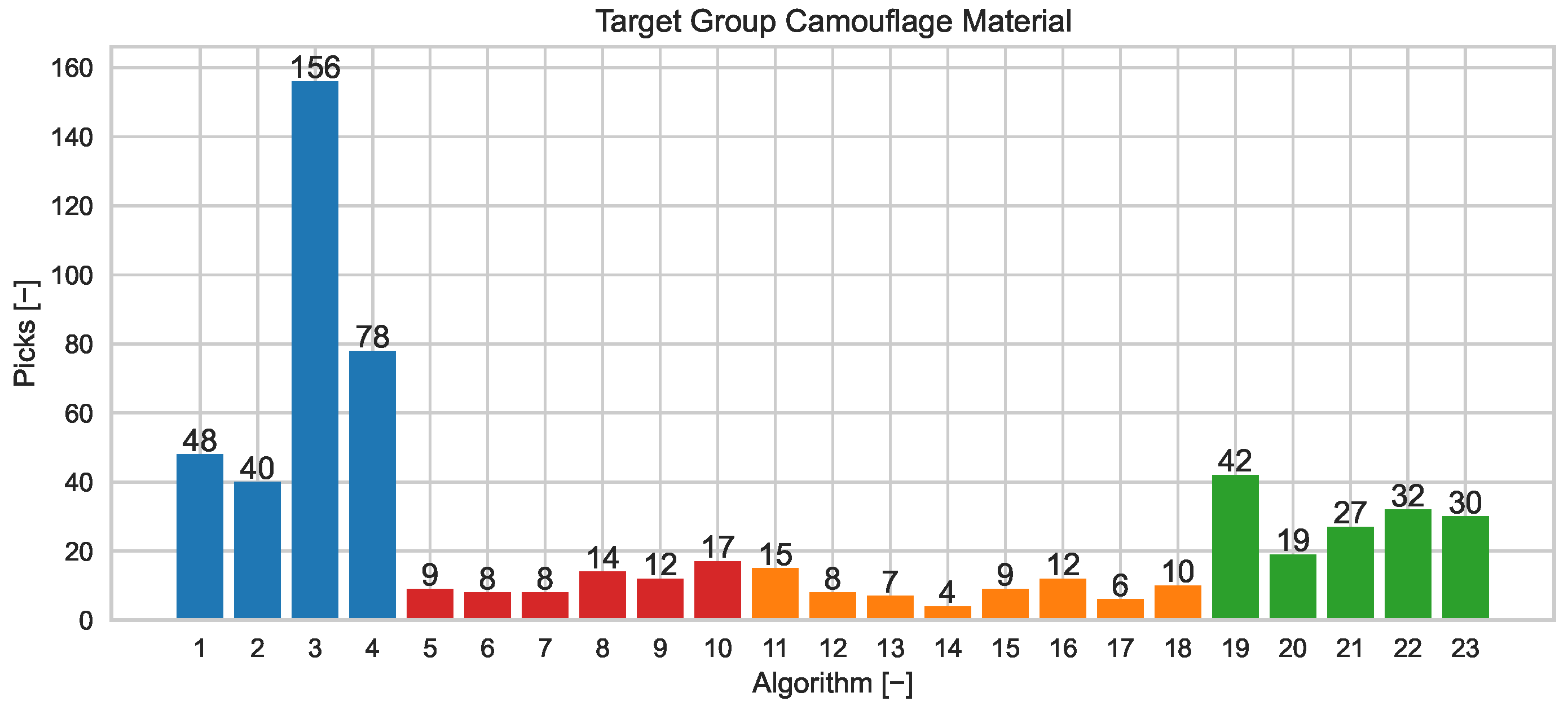
Figure 7 and
Figure 8 visualize the instances where each detector achieved the highest performance across dataset 1. Only samples where at least one detector identified at least one of the targets were considered for this analysis. Otherwise, none of the detectors has a higher performance and can be evaluated as best.
For the UXO workflow, it can be seen in
Figure 7 that the counts of selections are well distributed for all implemented detector settings. This means that all detector settings work best for specific contexts and can help improve overall detection results. The settings with
ID = 6 and
ID = 7 have the most selections and are slightly decreased. For the camouflage materials workflow, all detector settings are selected and can contribute to improve overall detection results. As visualized in
Figure 8, the different detector settings are colored by detector group, where the counts of the LRX detector settings are colored in blue, the C-HDBSCAN in red, the C-NCC in orange, and the bandpass filter in green. Here, the distribution is more spread out, but there are more detector groups and settings available for a similar number of targets. The best-performing detector group is the LRX, followed by the bandpass filter. The C-HDBSCAN and the C-NCC have a lower number of selections, but for the few selections as best detector setting, they bring good performance results, see
Table 3. In addition to analyzing the distribution of detectors as the best performers, the overall detection improvement achieved by combining them is also examined. Here, for each sample, the best-performing detector, defined by the highest
h, is determined and selected for each sample of dataset 1. Thus, the detector varies dynamically with the actual context for each sample, leading to the results in
Table 3. This table shows the average performance metrics for each detector in the cases where it was determined to be the best performer, as well as the overall average detection performance metrics independent of the detector. For that purpose, dataset 1 was used.
Regarding the camouflage material detectors, the following can be observed: The performance results within the C-NCC detector group are similar to the bandpass detector group. There are some slight differences, such as the generally higher precision score of C-NCC and the lower
t, but overall, none of the detectors within these two groups outperform the others. Looking at the counts of the best performers in
Figure 8, it can be concluded that the C-NCC detectors have similar detection performance but are less robust to changes in mission context and have a smaller range of contexts with high detection performance compared to the bandpass detectors. However, the remaining two detector groups show slight differences. The C-HDBSCAN detectors have a relatively low precision and a slightly higher recall compared to the other groups. As a result, the
and
h scores are slightly lower, but again, the detector group and its detector are comparable to the others. Furthermore, C-HDBSCAN, like C-NCC, is a detector for very specific contexts, which can be seen in the distribution of
Figure 8. The detectors of the LRX show a more spread-out performance, which is caused by the varying parameter
t. The lower the significance of the target anomaly, the more false-positive classifications are taken into account, while at the same time the number of missing positively classified target pixels increases. This typical behavior can also be observed in the results for the LRX detectors of the UXO workflow. However, the
h is often below the others, while the LRX detector group has the highest number of best performers. Thus, the LRX detectors have a broad context where higher performance can be achieved and robust detection is possible.
Overall, the dynamic selections of detectors for each sample and its context show good performance scores for both target groups. The single detectors generally have a very high rate of detected targets per sample. This rate is much higher compared to the results in
Table 2. Especially for the camouflage material, there are great improvements in the detection accuracy. All scores, the precision, the recall,
and
h, are higher than before. This causes a high
and
h, which show great results and robust detection performance for the challenging mission contexts of the camouflage materials in dataset 1. The overall detection result for dynamic contextual selection is significantly improved for all metrics. Due to the targeted selection, the rate of detected targets per sample is improved to 88.08%, while precision, recall, and
are also improved compared to the best single detector with the
ID = 1 in
Table 2. The dynamic selection of the detector thus leads to large improvements in detection performance.
The target group UXO shows good improvements in the detection results too. For the individual detectors, the UXO target group does not exhibit as significant an increase in precision and recall scores as the camouflage materials. However, overall, the
h score has improved. With context knowledge and the dynamic selection, an overall result of 0.1407 for
and 0.5420 for
h was achieved with no loss of detected targets, which is a significant improvement over the results of the best single detector
ID = 1 in
Table 2. Although the recall has been reduced, the loss has been compensated by a higher recall, resulting in the higher
. Overall, the dynamic selection of detectors for detecting UXO can increase the challenging detection precision under preservation of the detected targets. Due to the high
ht-scores, many targets in the dataset were detected, which is even more important here. Without target detection, no detection can be achieved, even with postprocessing optimization. Thus, the result of still-low precision scores must be considered and emphasized for further system architecture, postprocessing steps, and high accuracy in the final target classification. This importance is much higher compared to camouflage materials, where these efforts can be reduced in this development of system design. Concluding the results, the evaluation shows a great impact of the context on the detector performance. A context-based and targeted selection of the detectors by the introduced metric
f can improve the detection results significantly and should be part of future system architectures.
3.2. Performance Sensor Management
Next, the performance improvements achieved by considering context knowledge for BS are investigated. For this analysis, the introduced Sensor Management is evaluated and analyzed based on the previous detectors and their context selection. The selected sensor bands identified by the Sensor Management are compared with the anomaly detection performance of the full band set and a statistically determined band set.
First, the anomaly detection performance of the BS in the
Sensor Management is analyzed and compared to the processing of all 224 HSI sensor bands simulating a missing BS. Due to the hundreds of bands that must be processed in this test, it consumes a large amount of processing resources and processing time, denoted as
tp. Therefore, the test is performed only for the previously identified best detector of each target group. For UXO and camouflage material, it is the detector with
ID = 1 both times. The tests were carried out on dataset 1, and the results are visualized in
Table 4. When analyzing these performance metrics, the significantly higher detection performance of
Sensor Management stands out. The determined relative performance differences show high deviations for all metrics in favor of the BS. Especially for the challenging target group UXO, the relative deviations are the highest. Processing all sensor bands will result in lower average precision, recall,
, and, most importantly, significantly fewer detected targets and therefore lower
h. Considering the higher processing requirements, the use of all sensor bands via
Sensor Management is not recommended.
The next test therefore examines whether the
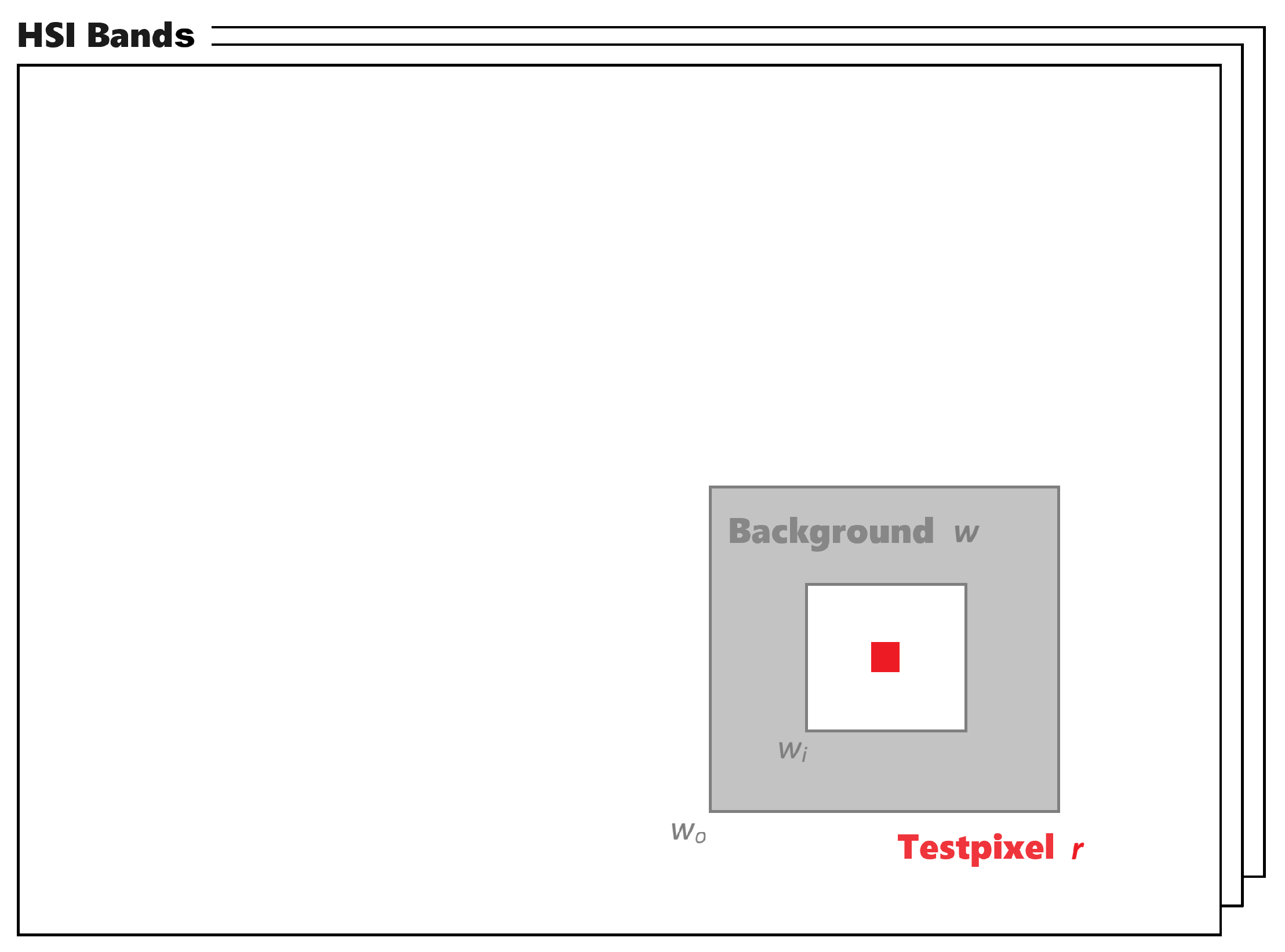
Sensor Management, and its context-based BS also offers an advantage over statistical BS. For this purpose, the statistically best bands are determined for dataset 1 and dataset 2, and thus for both of the previously introduced testsites. Therefore, for each target in each sample of the dataset, the target deviation is calculated by taking the absolute value of the subtraction of the target’s immediate environment and the average target vector. The target’s immediate environment is represented by the associated environment cluster centroid
ck, which is also the reference vector for the target deviation. This determined deviation is then reduced for each target and each sample to the three best bands with the highest target deviation. Then, from these sets of best bands, the unique bands for the targets within the two target groups are determined. This analysis is performed for both datasets and results in the following
Table 5.
Based on these statistically best bands and the dynamic, context-based bands selected by the
Sensor Management, the anomaly detection performance is evaluated for two reconnaissance scenarios. In the first scenario, the targets and the mission environment are known from previous reconnaissance flights. Therefore, the
Sensor Management is trained for the mission environment and the targets with a dataset containing the targets and the mission environment. The statistically best bands are also determined for this dataset and are also known for the reconnaissance mission. This scenario is simulated with dataset 1 for testsite 1. For each of the dataset samples, the
Sensor Management predicts a band set to be processed by the best-performing detection algorithm for that sample. The same procedure is performed for the statistically best bands of the two target groups for the first testsite. The evaluated performance metrics are visualized in
Table 6, where the column “Stat. Bands” represents the detection results of the statistically selected bands and the “BS Bands” column represents the results of the dynamically selected bands by the
Sensor Management.
The results show significantly better anomaly detection results for the Sensor Management and the target group UXO. As visualized by the relative improvements in the last column, the performance increase in detected targets ht must be emphasized. Because of the Sensor Management, many more targets can be found, which is a critical metric in reconnaissance missions. Furthermore, the other performance metrics can also be improved, and the Sensor Management can outperform the statistical approach. However, this performance improvement is not achievable for the camouflage material. Here, the statistical approach leads to higher detection performance. The precision of the detections with the statistical bands is higher, while the recall is lower. This can be a result of the Sensor Management’s methodology, where the model is trained only to predict the bands with a respective high deviation from the environment. The characteristics of the background, such as uniformity, are not taken into account. Therefore, it is possible that the Sensor Management’s bands have a lower uniformity and therefore more background anomalies, which can lead to a lower precision score but a higher recall due to the higher target information. The high precision score of the statistical approach leads to a higher and also to a higher h. The number of targets detected differs for only one target. Due to the small difference, it is difficult to interpret this as a performance improvement due to the statistical approach alone. Such small deviations can be caused by many influences such as hardware, rounding errors, etc., and are difficult to reproduce by recalculation. The results rather indicate that the statistical bands are more beneficial for background uniformity and the Sensor Management is more beneficial for target contour accuracy, but the target information is nearly equal for both approaches and not high enough for fundamental differences in the number of detected targets. In contrast to the small UXO, a few falsely negative classified pixels of the large camouflage materials do not lead to a complete lack of target detection in the form of a significantly changed ht as quickly. Overall, the statistical approach has slightly better detection performance but does not outperform Sensor Management.
The next scenario simulates a reconnaissance mission in an unknown area with partially unknown targets. Often, many of the targets of interest have been seen before in another reconnaissance mission and are already known in some way but not in the actual specific mission context. Thus, in the second scenario, some targets are known, while the mission area is completely unknown. For this purpose, the
Sensor Management is trained on the first dataset and the statistical bands are evaluated for the first dataset. Then, both approaches are tested on dataset 2 with its unknown testsite and the additional and unknown targets that were not part of dataset 1. The results of this analysis can be found in
Table 7. Again, the
Sensor Management outperforms the statistical approach for the UXO. The performance values of all metrics are significantly higher for the
Sensor Management, and the relative performance improvements are increased compared to the first reconnaissance scenario. In this more challenging scenario, the statistical approach is less applicable and the rate of detected targets is relatively improved by 77.00% to a high absolute value of 89.00%. The
Sensor Management’s model can transfer the knowledge much better to the scenario and is able to select the sensor bands that lead to a significantly higher anomaly detection performance. Furthermore, the
Sensor Management has higher detection performance for the camouflage materials as well. In this case, the statistically selected bands perform worse for all performance metrics except for
ht. Again, the same performance was found for both approaches. Overall, the relative performance differences for this target group have increased compared to the first scenario. The performance improvements are not significant and only slight, but the same tendency of higher robustness and adaptability of the
Sensor Management for use cases with lower correlation with previous training or configuration scenarios can be observed. However, none of the approaches can outperform the other for camouflage materials, but the performance improvements of
Sensor Management are significant enough to recommend its use. Again, the results can be interpreted as the target sizes allow for an equal detection hit rate, and the different approaches can only change the performance metrics in terms of precision and recall.
For the evaluation of the sensor management performance, it can be concluded that the methodology of context-based band selection brings significant detection performance improvements with respect to the full band set. With respect to a statistical approach, the significant improvements can also be observed for the target group of UXO. The more the actual scenario differs from the initial training and configuration scenario, the more the benefits of Sensor Management become apparent. However, a performance improvement through Sensor Management can only be achieved for unknown mission scenarios with the camouflage materials. The model shows slightly higher performance values for this use case and seems to be more robust. The amount of training the model and analyzing the statistical best bands is the same for the methods used here in this paper. Due to the higher robustness for unknown mission scenarios and therefore a higher variability for changing mission scenarios, the Sensor Management can be recommended for all use cases.
3.3. Performance of Architectural Design
Now that the performance of the
Sensor Management has been evaluated, the interaction between the
Sensor Management and the detector architecture is examined. In the previous test, the model predicted a set of bands for each target group based on all known targets and all environments in the sample, and the anomaly detector was analyzed for the entire image scene. Due to the
Sensor Management’s methodology, the different environments within a sample can be distinguished and predicted by the model. Therefore, it should be investigated if a more detailed decomposition of the BS into several band sets, one for each environment, can improve the anomaly detection performance. Thus, two different architectures are implemented. The first architecture corresponds to the previous tests, with one band set per audience for all environments in the scene. The second architecture provides as many band sets per target group as there are environments in the image scene. The methodology of band selection is similar, but this time the selection is made separately for each environment area, resulting in multiple band sets. In addition, this test is designed to examine the impact of architecture. Therefore, the sensor model’s prediction is considered only for the targets that are actually in the sample, so the performance results are not affected by the prediction for targets that are not in the sample, and only the effect of the environment breakdown can be observed. Multiple band sets are also used to process multiple anomaly detectors. For each extracted environment, the best-performing anomaly detector is processed with the assigned band set, resulting in multiple detection maps for a single sample. Those areas of the resulting detection maps that are not assigned to the corresponding environment are masked. Subsequently, the performance metrics of the masked detection maps are determined with respect to the likewise masked label mask and for each environment and each sample. This second architecture allows the use of a specific anomaly detector in addition to the specific band sets for each environment. In this way, the effect of a more detailed architecture based on the sensor context can be investigated. In addition to the two architectures focusing on this influence, the influence of a further separation of the camouflage materials into improvised and military materials is also tested and combined for both architectures. The workflow and detectors introduced in
Section 2.5 are the same, but the band selection process and the processing by the anomaly detectors are split into a different target group. The results of the test on dataset 1 are presented in
Table 8, where the first column shows the prediction results for targets in the samples without the additional split, and the second column shows the results with the additional split in their environments.
The results show that an architecture based on a more detailed subdivision based on environment areas does not lead to performance improvements. The number of detected targets is significantly lower, as are the precision and recall values. Only the processing time is lower due to the smaller band sets. In general, the more detailed architecture allows multiple anomaly detection tasks and thus a better possibility of computational parallelization. However, the performance values are too low to recommend this architecture. This is not the case for the additional separation of improvised and military camouflage materials into two target groups. There are good performance improvements for the first architecture. Besides the processing time, all metrics are increased and more targets can be detected with higher precision and recall. With the further separation into two groups of camouflage materials, the rate of detected targets can be improved from 87.03% to a total rate of 88.20% for all camouflaged targets. Even with an almost constant processing time, the less detailed target groups with their fewer detection tasks do not necessarily lead to an advantage in terms of computational costs. Again, the additional target group and its additional detection task allows for a possible computational parallelization and does not have to cause negative effects. Overall, an architecture that considers the available environments per image and performs a BS and detector selection based on this is the most advantageous. An additional subdivision into further target groups with their own processing workflows can also have a positive effect. On the other hand, too much detail of the sensor contexts in the form of detailed dependent process chains overweights the sensor context and is not recommended.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}