1. Introduction
Wetlands are essential components of ecosystems and hold significant ecological value, including ecological biodiversity, water quality restoration, habitat provision, and climate regulation [
1]. Given the global environmental changes caused by climate change, wetland conservation has gained increasing importance [
2,
3]. Therefore, classifying the habitat and environmental conditions of species within wetland ecosystems is 2, crucial [
4]. To achieve this, effective methods and approaches for data collection and analysis pertaining to wetland coverage are needed.
Wetland surveys play a vital role in comprehending and conserving complex ecosystems, thus contributing to the sustainable management of wetlands [
5]. While traditional surveys rely heavily on human involvement, recent advances in remote sensing (RS) have facilitated surveys and data collection in a more cost-effective and efficient manner [
6,
7]. Remote-based surveys allow for non-invasive approaches and quantitative data acquisition [
8,
9]. Particularly, unmanned aerial vehicles (UAVs) have emerged as effective tools for acquiring various types of remote sensing data [
10]. High-resolution imagery captured by UAVs encompasses a wide electromagnetic spectrum, including visible and infrared light [
11]. Spectral-based data acquisition has been employed in research focused on classification and detection due to its ability to acquire biochemical and biophysical parameters [
12]. Integrating spectral data with RS-based studies enables the mapping of large-scale target sites [
13]. Mapping research utilizing high-resolution spectral data, such as multispectral and hyperspectral data, proves valuable in monitoring wetlands composed of diverse surface textures [
14]. Furthermore, the use of UAV imagery has expanded to various fields, including ecosystem monitoring, environmental assessment, land use analysis, and mapping [
15,
16].
The utilization of high-resolution UAV imagery is an effective approach for land cover classification; however, several factors must be considered in the classification process [
17]. Given that these approaches rely on captured images, factors such as spatial resolution, altitude, shooting time, classification techniques, and data sampling must be accounted for during drone flights and image acquisition [
18]. Among these factors, data sampling and algorithm selection play a crucial role in the classification methods [
19,
20]. Currently, statistical analysis and machine learning methods such as support vector machines (SVMs), spectral angle mappers (SAMs), and k-nearest neighbors (KNNs) have been proven to be effective [
21,
22,
23]. Nevertheless, traditional learning methods often struggle to meet high classification accuracy, posing limitations for analysts [
24]. Therefore, recent research has embraced methods that leverage computer vision, such as machine learning and deep learning, which require extensive training data [
25]. This approach offers the advantage of achieving high-accuracy results by processing complex and functional data compared to conventional learning methods [
26]. Therefore, there are ongoing efforts to enhance the efficiency and accuracy of classification through computer vision techniques, including machine learning and deep learning [
27].
A substantial amount of data is needed for effective classification when utilizing computer vision for land cover classification. However, obtaining quantitative data can be challenging due to the wide range of variations within each class [
28]. Therefore, quantitative data extraction plays a critical role as a fundamental analysis component. This study proposes an effective classification method utilizing image cluster techniques and pixel purity index (PPI)-based end member extraction to evaluate quantitative data composition.
Various classification methods exist for analyzing images based on the classification criteria by establishing data sampling and reference libraries [
29,
30]. Among these methods, the image cluster technique involves dividing the target site into several clusters and assigning a cluster to each class for data sampling [
31,
32]. Additionally, the endmember technique aims to extract the purest value within an image. The PPI technique calculates the n-D scatterplot by repeatedly projecting it onto any unit vector, defining the pixel with the most repeated projection as the endmember [
33,
34]. Since the spectra generated through these two sampling techniques represent data values for significant components in the image, a comparison between them is necessary, as they have the potential to influence the classification outcomes. Furthermore, to evaluate the accuracy based on the training data configuration suitable for each class, the accuracy was assessed through a supervised classification by comparing classes.
In this study, data were acquired using unmanned aerial vehicles equipped with multispectral and hyperspectral camera sensors, thus facilitating wetland mapping. Moreover, the data sampling method was evaluated to ensure effective wetland mapping, along with an assessment of the classification method aligned with the chosen technique.
2. Materials and Methods
2.1. Study Site
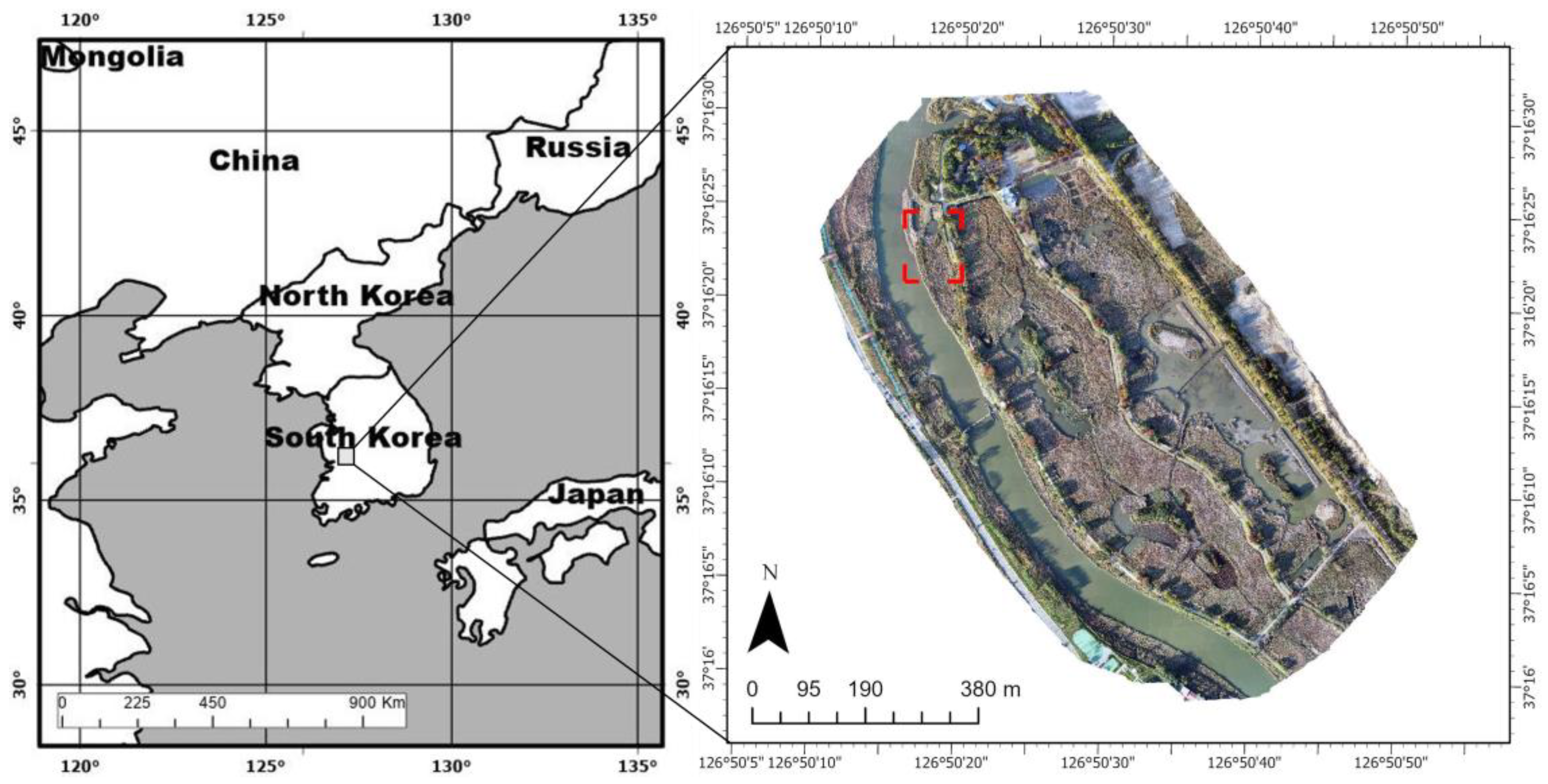
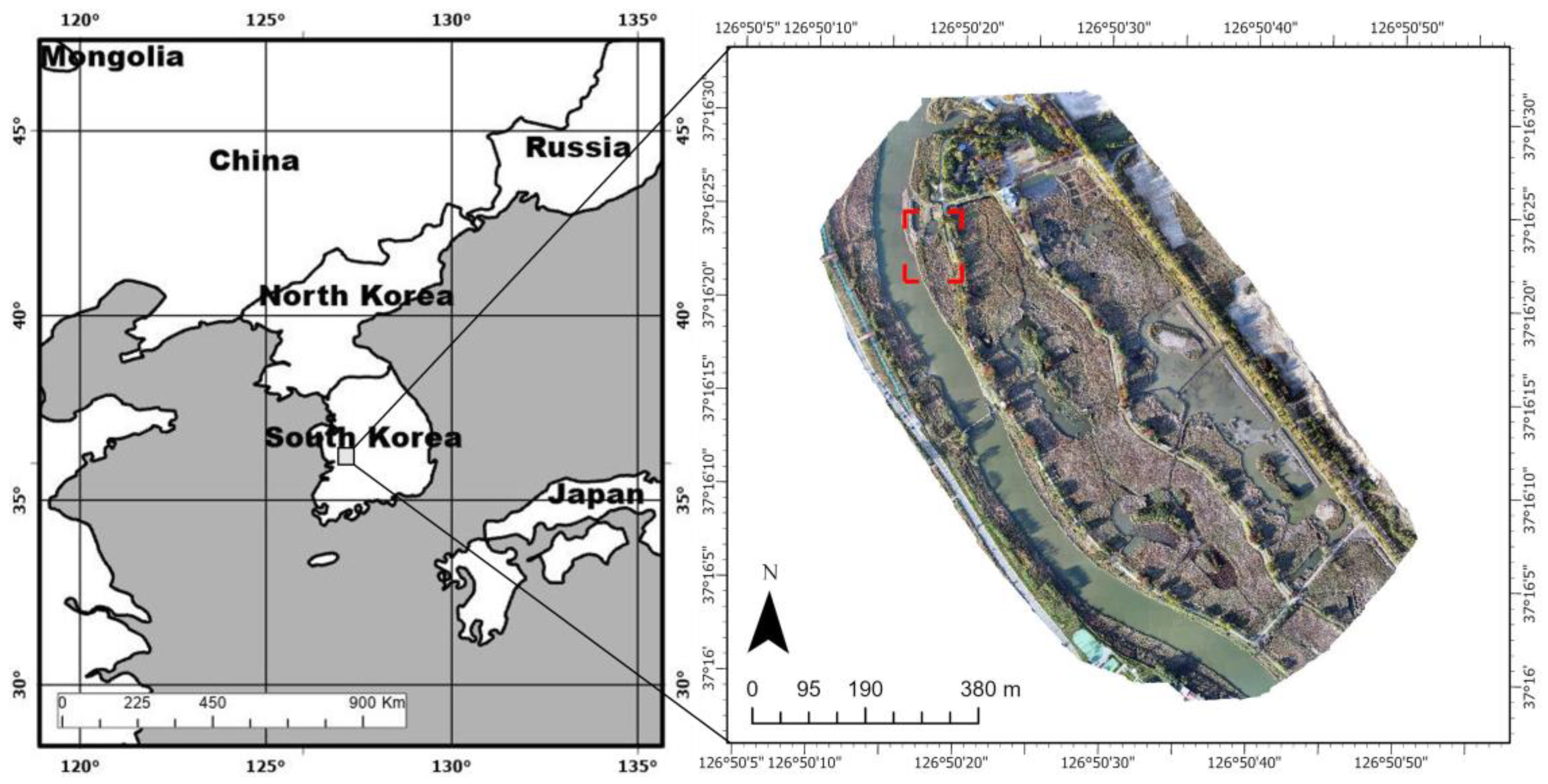
This study was conducted at Ansan Reed Wetland, located in Ansan-si, Korea. The wetland is situated at 37°16′21.32 N, 126°50′21.64 E, with a total area of 1,037,500 m
2. Since its establishment in September 1997, the wetland has been designated as a protected area and managed accordingly. Ansan Reed Wetland serves as a wetland park, aimed at treating non-point pollutants and providing habitats for organisms in the surrounding basin. Currently, the wetland supports the distribution of 290 species of vegetation and accommodates 150 species of migratory birds [
35].
For the purpose of this study, a specific area within Ansan Reed Wetland was selected and photographed, thus capturing the present status of the ecosystem. The filming was conducted in an area measuring 11,059 m2, which was selected to represent the complex classes of the entire target site’s ecosystem.
2.2. UAV Flight and Data Acquisition
On 24 October 2022, a UAV survey was conducted over Ansan Reed Wetland (
Figure 1). The target site aerial imagery was acquired using DJI Matrice 300 RTK and Matrice 600 drones (
http://www.dji.com (accessed on 2 October 2022), see
Table 1). For filming, DJI Zenmuse L1 and MicaSense Redge-MX cameras were attached to the Matrice 300 RTK drone, ensuring a coordinate error of less than 1 cm through the DJI D-RTK2 (Real-Time Kinematic) method for orthographic images, multispectral, and data collection [
36,
37]. The Matrice 600 drone was equipped with a Headwall Nano-Hyperspec VNIR camera to obtain hyperspectral data [
38]. The hyperspectral VNIR camera acquired DEM data through the Velodyne LiDAR option (
https://www.headwallphotonics.com/products/vnir-400-1000nm (accessed on 2 October 2022)). During the acquisition of hyperspectral data, Trimble R4s was utilized for post-processed kinematic (PPK) GNSS correction, thus ensuring that the geometric accuracy aligned with that of D-RTK2.
Filming was conducted at a 100 m altitude, primarily at noon to minimize the impact of shadows. The timing was carefully selected, considering the solar altitude angle, and to ensure effective data acquisition, an 80% longitudinal/transverse overlap was maintained. Filming took place on clear days with minimal wind interference to optimize the results.
2.3. UAV Image Processing
The data acquired by the UAVs underwent various processing steps. The orthographic image was generated by mosaicking the captured images using DJI Terra software (DJI, Shenzhen, China). For the correction of multispectral data, real-time light measurements were conducted using the DLS 2 sensor, and the values obtained from the Calibrated Reflection Panel (CRP) were used to account for solar angle and lighting conditions during image acquisition. Mosaicking and radiometric correction were performed using the Pix4D Mapper software (Pix4D SA, Lausanne, Switzerland) [
39,
40]. Afterward, each extracted band was aligned with the corresponding multispectral image using the band stack function [
41].
Hyperspectral images were acquired using the Hyperspec III sensor from Headwall (Headwall Photonics, Inc., Bolton, MA, USA) [
42]. During image processing, a correction factor was derived by utilizing a correction tarpaulin, which was pre-treated to have a reflectance of 56%. This correction factor was applied for radiometric correction [
43,
44]. Geometric correction was performed based on a digital elevation model (DEM) and GPS/IMU data generated through LiDAR technology integrated with the Nano-Hyperspec VNIR sensor. To reduce noise present in the spectrum, smoothing was applied using the Savitzky–Golay filter [
45,
46].
2.4. Field Cover Type Investigation
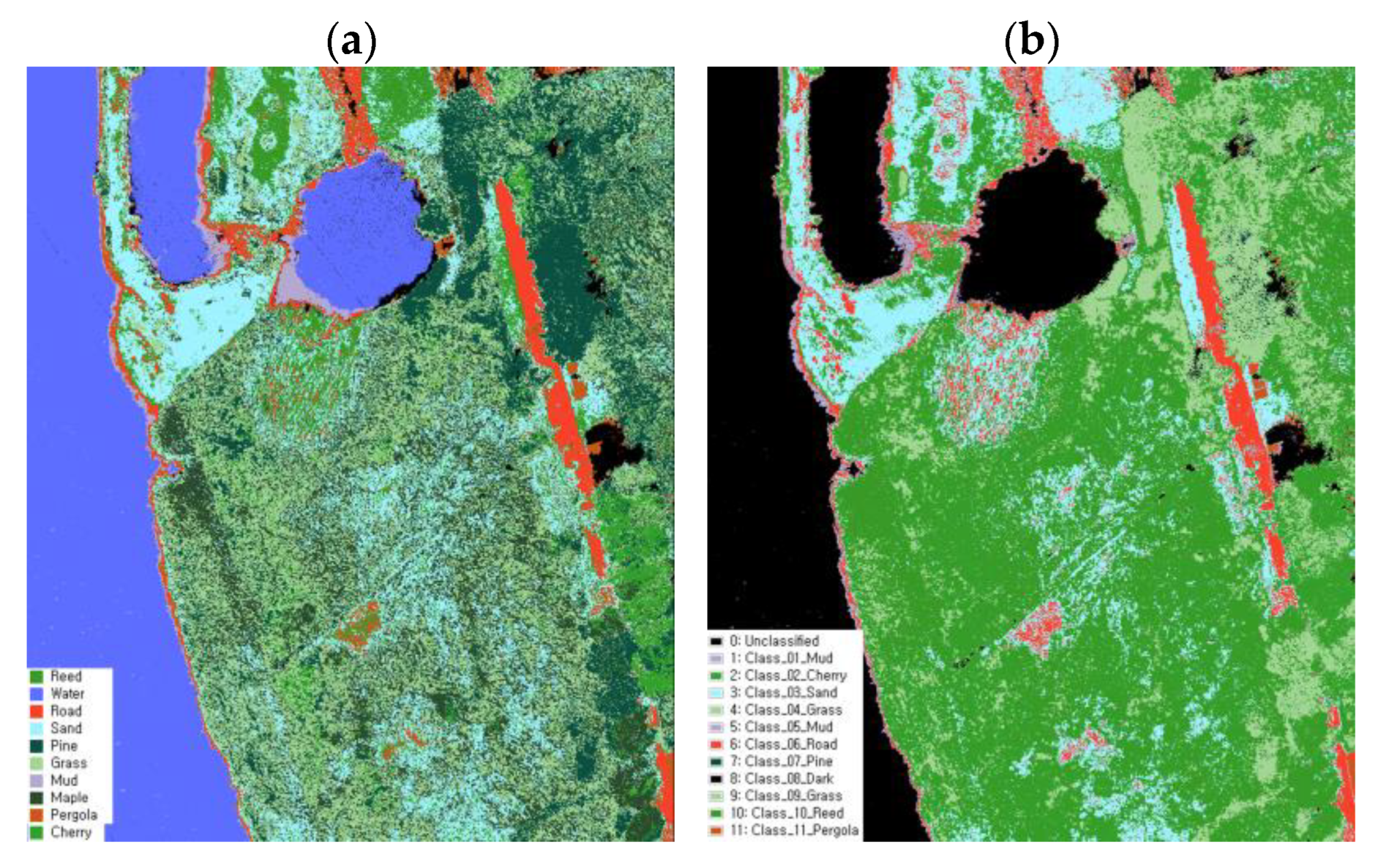
Field surveys were conducted in the study target site to investigate the main land class types. During the field survey, the field classes were recorded by directly examining the site and referring to the Aerial image of DJI L1. The survey took place on 17 October 2022. Ten classes were identified based on the on-site investigation, including conifers (pines), two types of broadleaf trees (red maple and cherry trees), mud, grass (other vegetation), sand, road (concrete), water bodies, reeds, and pergola (urethane). The land cover types determined from the field survey were digitized using the ArcGIS Pro software (Environmental Systems Research Institute, Inc., Redlands, CA, USA). These digitized data served as reference and verification data for evaluating the accuracy of the classification models.
2.5. Classification Algorithm
The classification of classes within the study site was performed using widely used classification models, including SAM (Spectral Angle Mapper), SVM (Support Vector Machine), and ANN (Artificial Neural Network). SAM identifies and classifies similarities by analyzing the interior of the vector in the n-dimensional space between the selected pixel or reference spectrum and the spectrum of the image [
47,
48,
49]. One advantage of SAM is its ability to achieve effective classification by reducing the dimensionality of the data and classifying the image based on the direction of the angle, regardless of vector size [
50]. In SAM classification, a smaller angle indicates a higher degree of agreement with the reference spectrum, whereas angles greater than a set threshold are not classified. The SAM classification process is described in Equation (1) below:
where
t represents the spectrum of the pixel,
r represents the reference spectrum pixel, α represents the spectral angle between
t and
r, and
n represents the number of bands. In this study, classification was performed using a threshold value of 0.4 [
51].
SVM is a statistics-based supervised classification learning method that aims to maximize margins by constructing reference training data in the form of margins on a hyperplane [
52,
53,
54]. However, given that the linear separation of data has its limits, SVM maps and separates the data in a high-dimensional feature space using various kernel methods [
55]. Furthermore, SVM allows for the classification of multiple classes by conducting pairwise classification, and the adjustment of parameters can help reduce misclassifications [
56]. In this study, SVM utilized a radial basis function (RBF) kernel for pairwise classification [
57] (2).
Furthermore, the classification method employed various input parameters, including the values of the gamma (γ) kernel functions, pyramid levels, penalty parameters, and classification probability thresholds. For the SVM classification, the penalty parameter was set to its maximum value (100) to minimize misclassifications. The gamma (γ) kernel function value was set to 0.007, and the classification probability threshold was set to 0 to ensure proper classification of the training data into each class [
58].
Artificial neural network (ANN) is a multi-layer neural network classification technique comprising multiple layers. In this study, the ANN configuration utilized a feedforward-based backpropagation algorithm with supervised learning, analyzing the data using a chain structure [
59,
60]. Specifically, a segment-based U-Net algorithm was employed to establish corresponding areas of interest (ROIs) and convert them into training data. Deep learning requires the configuration of detailed parameters, including training contributions, training rates, training end values, training iterations, and hidden layer configurations [
61]. In this paper, the parameters with the highest accuracy and reliability for neural networks were chosen as a reference, considering previous studies. Here, the training contribution was set to 90%, the training rate was set to 90%, the training exercise was set to 0.1, the RMSEC (root mean square error of calibration) was set to 0.08, the hidden layer was set to 1, and the training repetitions were set to 1000 times.
2.6. Training Data Processing
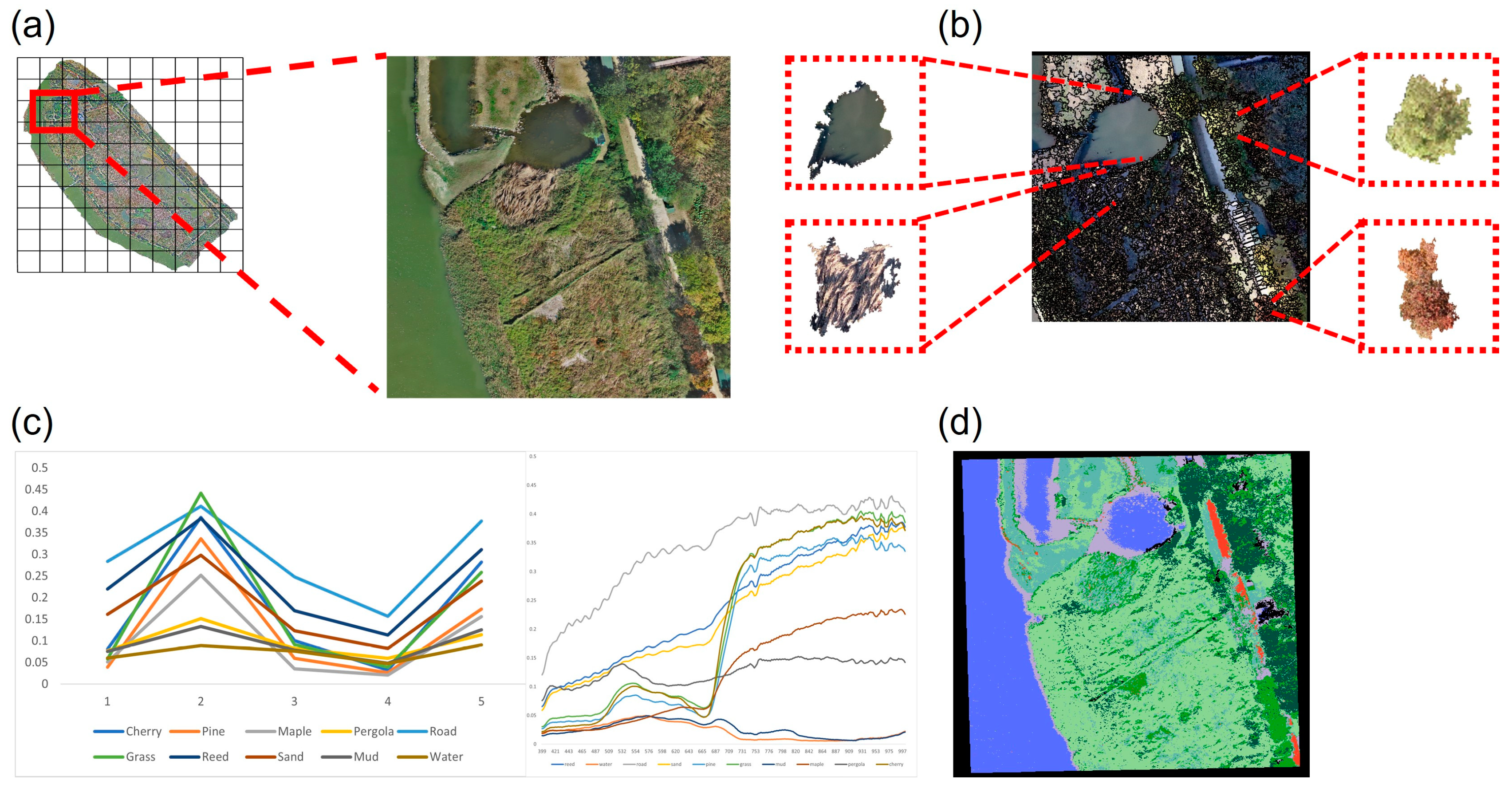
2.6.1. Pixel Sampling
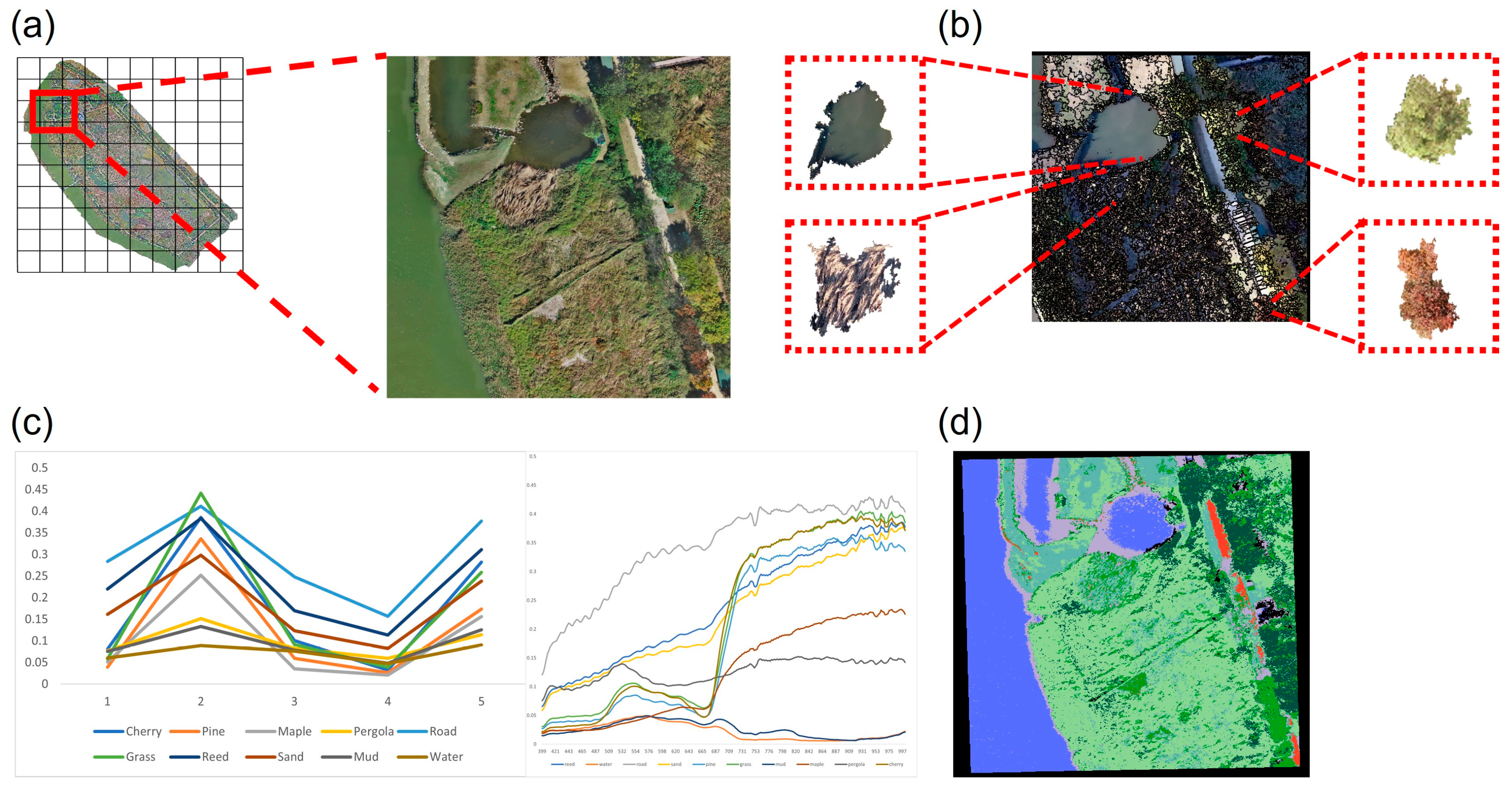
The process of generating training data involves four stages. Firstly, since each image has a different spatial resolution, resampling was performed to ensure uniform pixel size and coordinates for both multispectral and hyperspectral data. Secondly, object image segmentation was conducted to divide the clusters within the images. Thirdly, the unsupervised classification algorithm ISO-DATA was applied to organize the training data based on the average values within the appropriate class-defined segments. ISODATA performs classification using pixel thresholds across the entire image and conducts class-specific classification based on standard deviation, distance threshold, and other factors [
62,
63]. This approach facilitated pixel-based classification within the target site. The segmented images were saved as shapefiles, class-specific configurations were edited using ArcGIS Pro, and normalization was performed through masking using the ENVI 5.6 software. Finally, pixel data for each class were extracted from the original image based on the corresponding classified image and unsupervised classification results (
Table 2). The collected pixel sampling data were then utilized as training data for subsequent classification models. The preprocessing workflow incorporating pixel sampling is illustrated in
Figure 2. The ENVI 5.6 (Exelis Visual Information Solutions, Inc., Boulder, CO, USA) and ArcGIS Pro software were employed for data extraction and processing.
2.6.2. Spectral Sampling
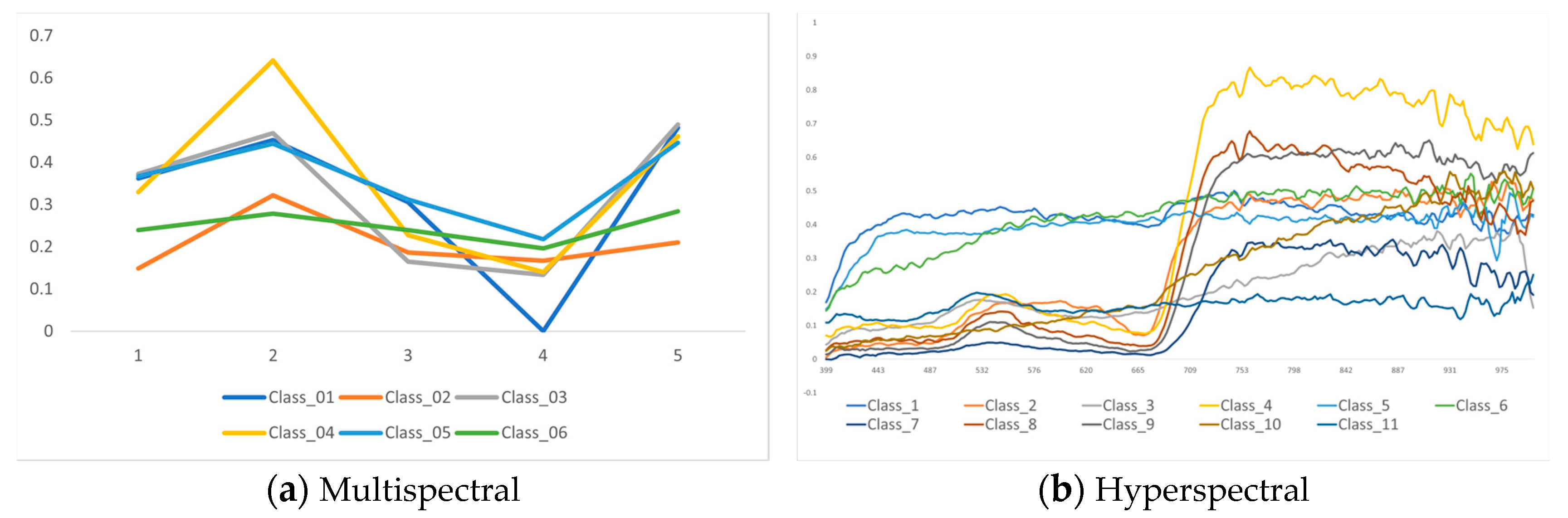
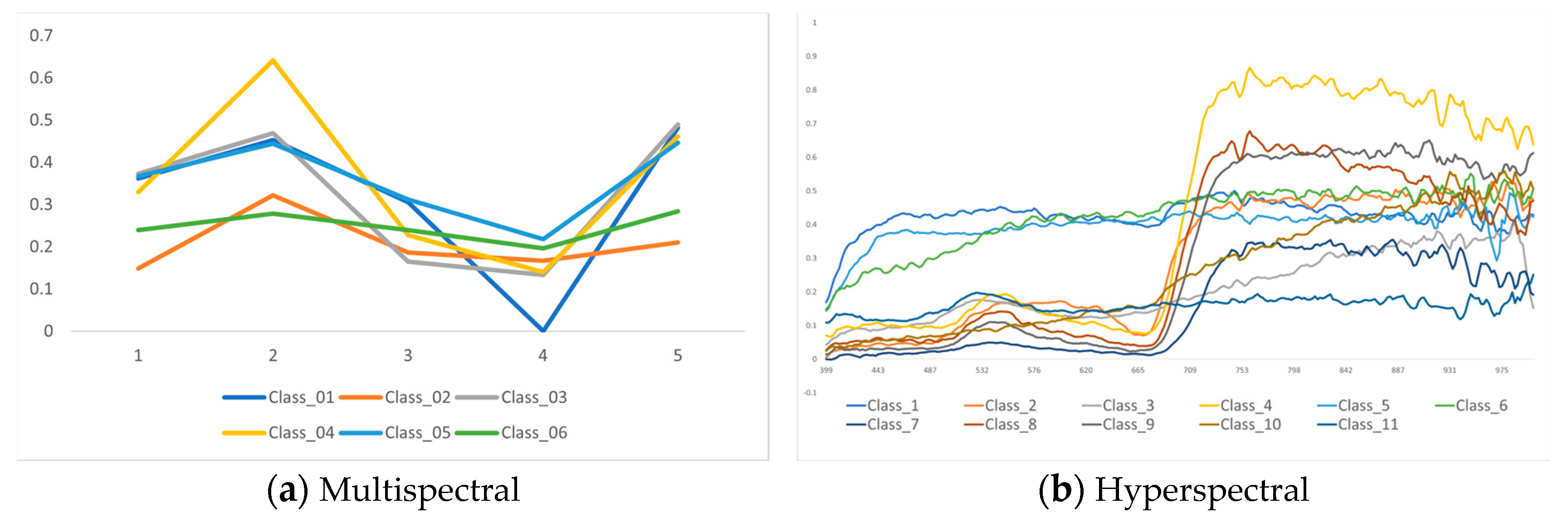
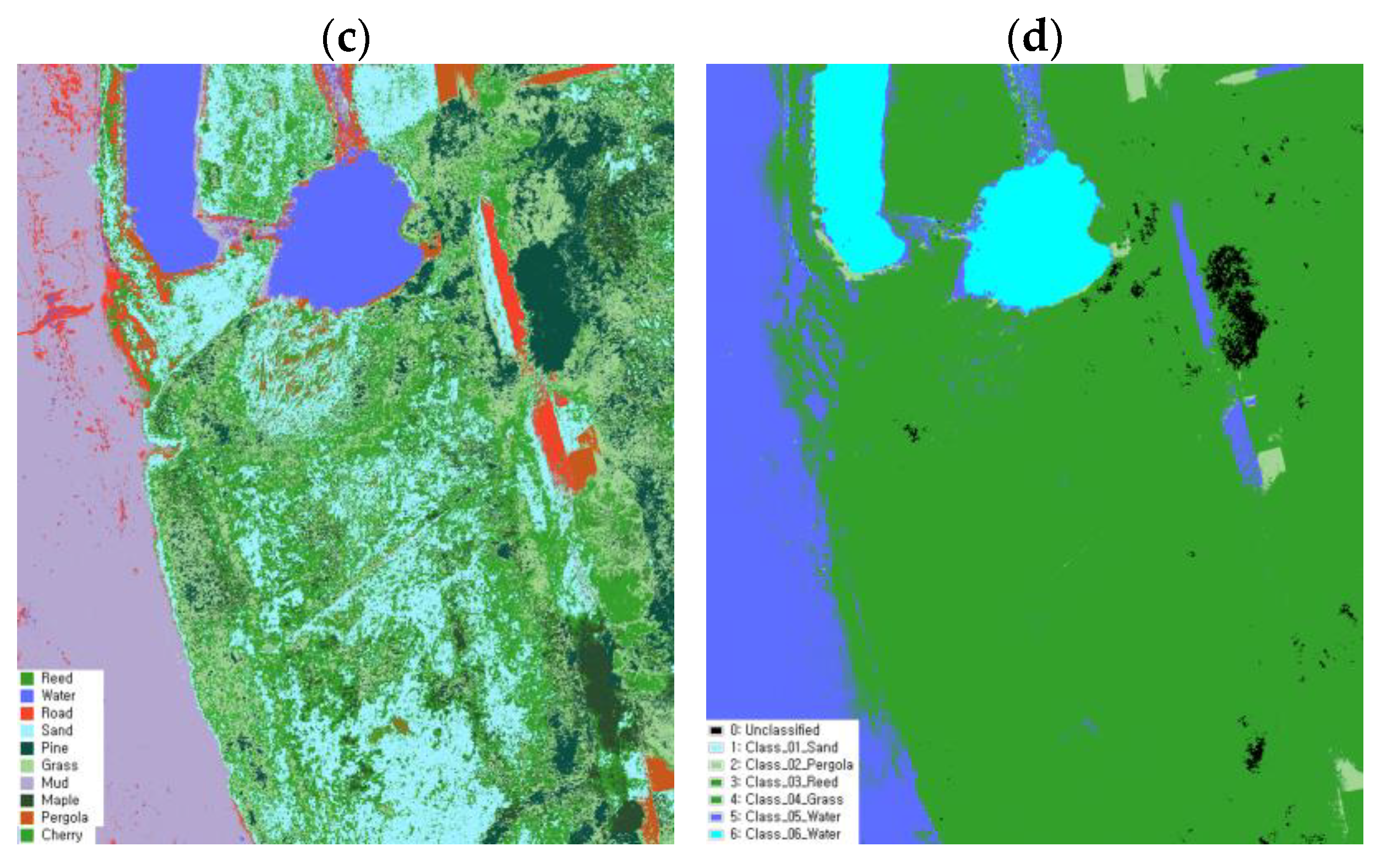
Endmember extraction using the PPI was performed in three main stages. Firstly, data dimensional reduction was carried out using a minimal noise fraction (MNF) transformation [
64]. MNF transformation helps to identify pure pixels with minimal noise and minimizes distortion caused by noise in the pixels [
65,
66]. Through this process, the MNF transformation determined the location of pure pixels, after which the PPI technique was applied to process the data through 10,000 repetitions [
67]. The extracted endmembers were validated using the PPI technique. Six bands were selected from the five bands available in the multispectral image, whereas forty-eight bands were selected from the two hundred and seventy-three bands in the hyperspectral image. This endmember quantification approach was adopted because 10 classes were identified through the field survey and the number of multispectral images was limited, whereas there were many numerous hyperspectral images. Pearson correlation analysis was conducted by applying it to each image to select the band that had the highest correlation with the selected class among the endmembers extracted using the PPI technique (
Figure 3).
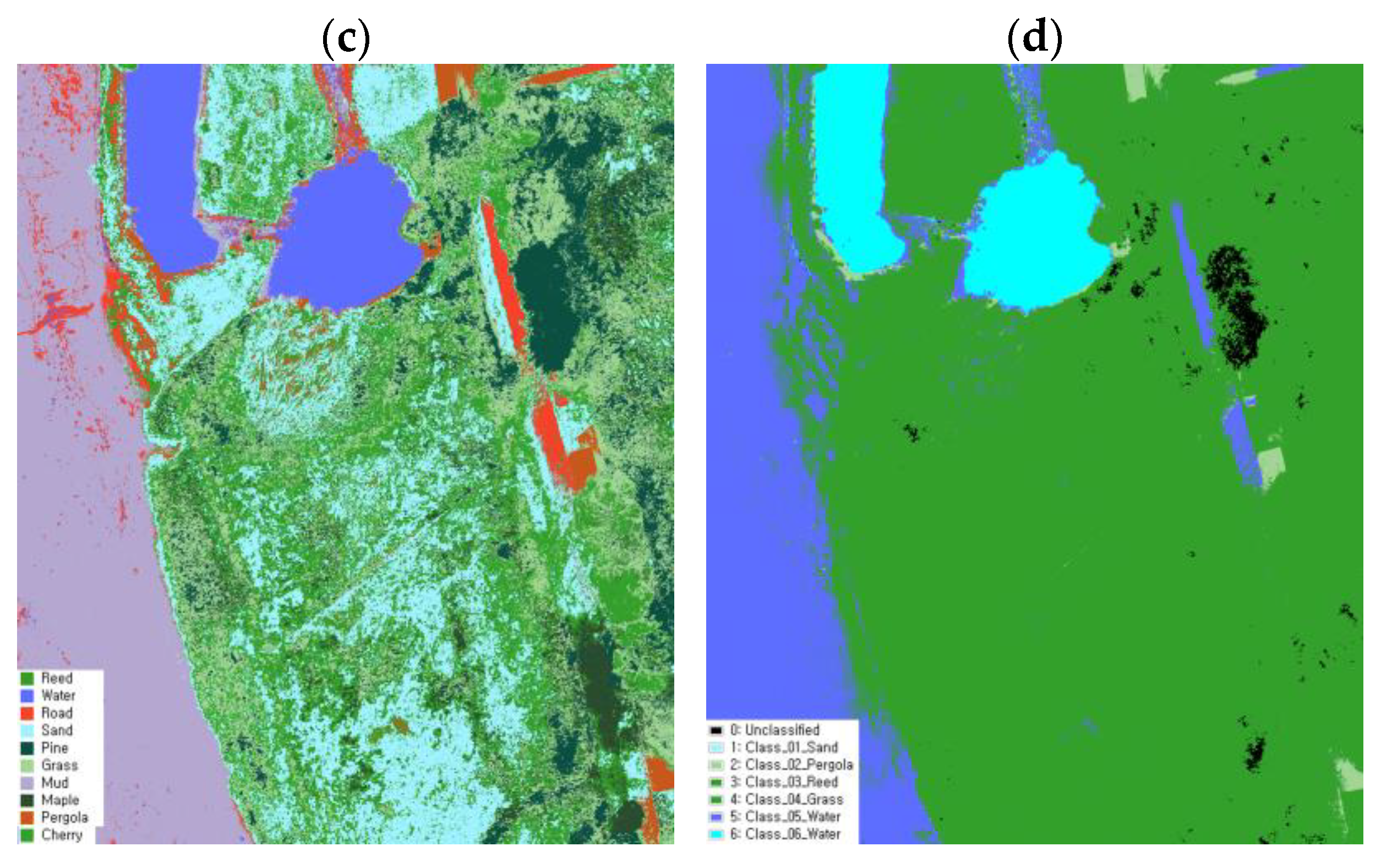
Class classification between the images obtained through the selected endmember and pixel sampling methods was performed to validate the effectiveness of the data sampling approaches. Furthermore, SAM classification was conducted to compare the pixel sampling data and examine the correlation and classification accuracy between the two datasets. A comparative analysis was then conducted using the verification data.
2.7. Accuracy Assessment
2.7.1. Producing Verification Data
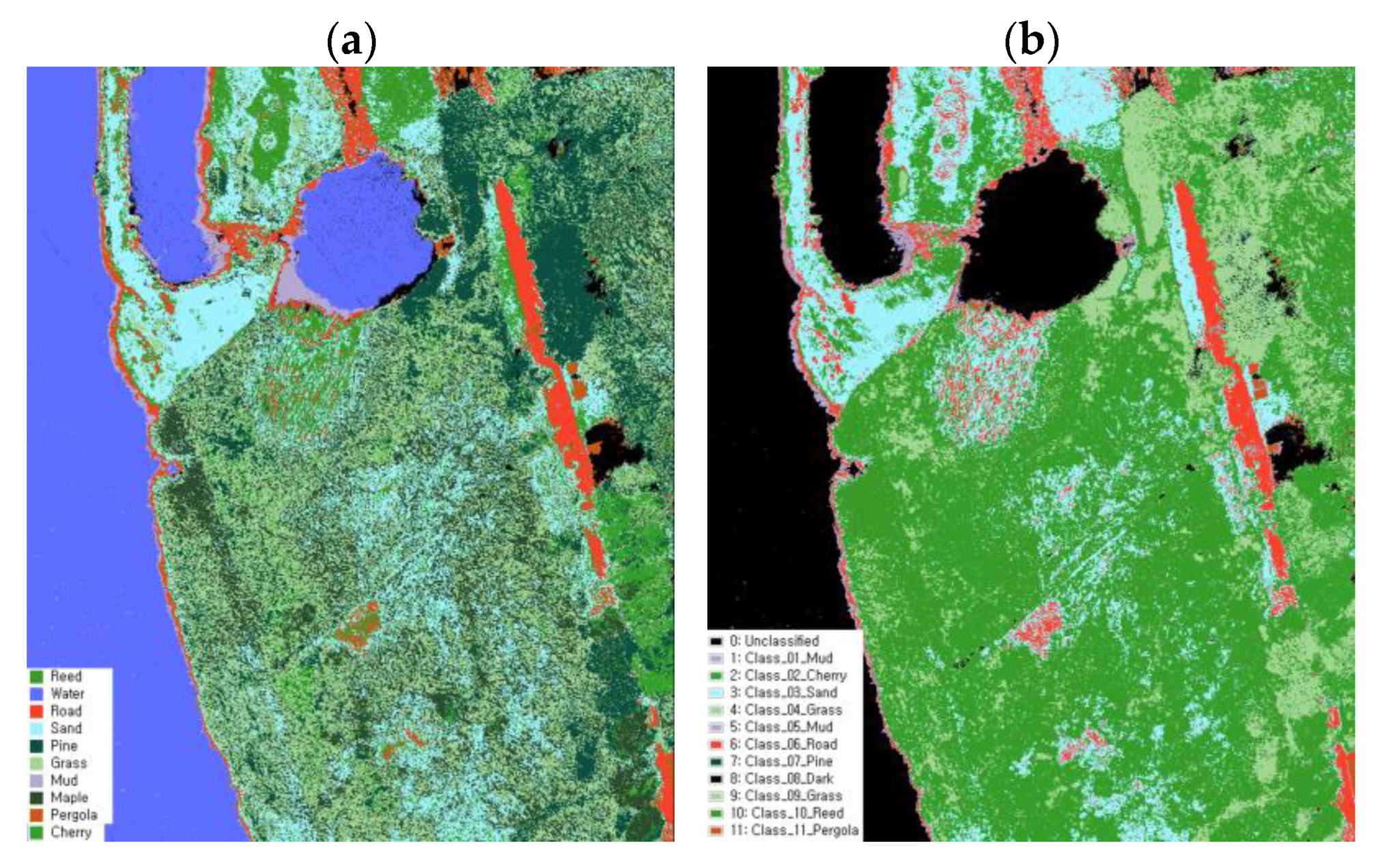
To construct accurate verification data for image validation, an on-site survey was conducted in five test beds on 17 and 24 October 2022. The verification data were generated based on the object segmentation image. High-resolution orthophotos and field verification were used to ensure the correct classification of each pixel-based class. A random 10 m
2 grid was generated within each of the five squares to establish the verification data. The data were edited using ArcGIS Pro, and segment classification was performed using the orthophotos. The class was then edited using the corresponding image (
Figure 4).
2.7.2. Evaluating Validation Data Accuracy
To assess the accuracy of each land cover classification method using UAV images, data verification was conducted using a confusion matrix based on Ground Truth, Kappa coefficients, and F1 scores [
68]. The Kappa coefficient is used as a traditional method to measure reliability, but it is not appropriate for an unbalanced distribution of classes, so we further evaluated reliability using F1 scores [
69,
70]. The F1 score is evaluated using the confusion-matrix-based precision and recall values [
71]. The evaluation involved dividing the entire image into 10 × 10 square meters. A land cover map was generated using a classifier for five random points, after which the accuracy was verified by comparing the resulting map with the reference image. The comparison between the two images was evaluated based on overall accuracy (OA) and reliability using the Kappa coefficient and F1 score. This allowed for an assessment of the overall accuracy for each image and classification method [
72].
5. Conclusions
This study sought to achieve effective wetland mapping by applying various classification methods based on UAVs. Mapping wetlands accurately using multispectral and hyperspectral images poses significant challenges. However, through the normalization of a wetland map creation, our study validated the effectiveness of establishing a spectrum library through pixel sampling and comparing it with endmember extraction. The accuracy of the spectrum library was further verified by comparing it with actual field verification data using SAM, SVM, and ANN classification. The results demonstrate the potential for effective data mapping in wetlands. Using the SAM methodology, hyperspectral images achieved an accuracy of 91.91%, whereas multispectral images achieved an 80.36% accuracy. Compared to other methods, the SAM method showed the highest effect with a difference of about 10% in multispectral data and about 7.15% in hyperspectral data. In addition, the effectiveness of the pixel-based sampling method was confirmed, and an accuracy difference of up to 38.62% was confirmed compared to the final member and sampling method. Future work should focus on evaluating the classification accuracy using multiple target sites, incorporating ground spectrometers, and applying pixel sampling techniques with a larger number of data samples. This study contributes to the literature by proposing an effective data sampling and classification technique evaluation not only for wetland mapping but also for other spectral image applications. Moreover, our findings highlight the importance of developing effective classification methods for the accurate mapping and monitoring of various environments.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}