1. Introduction
With the emergence of unmanned aerial vehicles (UAVs), they are widely used to establish wireless communication networks, utilizing their characteristics of flying in the air to provide relatively stable and reliable communication services [
1,
2,
3]. Due to their high efficiency, low cost, and wide deployment potential, particularly in achieving the next-generation mobile communication standards, UAVs have come to play a dominant role [
4]. This not only requires strict compliance with the necessary conditions for communication by network technology, but also requires conceptual processing to ensure excellent performance and the promotion of the application of unmanned aerial vehicles in 5G networks [
5]. In the future, we can expect to use unmanned aerial vehicles extensively in various human activity domains and leverage their capabilities for diverse intelligent applications. These applications may include, but are not limited to search and rescue, environmental monitoring, agricultural management, logistics delivery, and so on. It is expected that, with the development of unmanned aerial vehicle technology and the increase in application scenarios, we will enter an era of drone-assisted networks [
6].
In recent years, the broadband communication industry has achieved rapid development, including various types of fixed and mobile broadband communications, which can be seen globally. However, not all areas have full coverage of broadband communication, especially in some remote or mountainous areas. In the event of accidents in these areas, it is difficult to accurately locate them, so drones can play a role in this situation, replacing traditional fixed APs and solving the problem of zero-point coverage. In [
7], the researchers proposed a new UAV localization method that uses ultra-wideband radio signals as localization signals and can effectively improve the localization performance in non-line-of-sight situations by applying the correction values of ray-tracing algorithms to ultra-wideband ranging data. However, this approach requires the deployment of multiple positioning base stations to collect enough signal data to enable the positioning of the UAV. As a result, the cost of deploying base stations increases accordingly. The work [
8] proposed indoor positioning of UAVs using WiFi signal ranging. However, this method needs to obtain the exact location of each AP in advance to achieve distance-based WiFi localization. This further increases the difficulty and complexity of UAV positioning. A new method for indoor UAV localization was proposed in [
9], which utilizes camera optical flow data and inertial sensor information for fusion. However, the method requires processing a large amount of image information in visual localization, which puts higher demands on the computing power of computers, and general computers are unable to perform such high-intensity operations, resulting in high energy consumption and low real-time performance.
With the rapid development of technology, the demand for positioning technology on mobile terminals has also increased. Mobile-terminal-positioning technology has become a very important research area in the applications of the Internet of Things and device-to-device communication [
10,
11]. In the Internet of Things (IoT), communication and collaboration between devices are crucial [
12]. To ensure effective interaction and resource utilization, location information is essential. The location information of mobile terminals enables the quick establishment of direct communication links and facilitates resource sharing. Whether indoors or outdoors, the location information of mobile terminals is necessary. GPS and base station positioning technologies meet outdoor positioning needs, but people spend most of their time indoors. However, in indoor environments, buildings obstruct signals, resulting in rapid attenuation or even complete unavailability of GNSS signals, which cannot fulfill the indoor navigation and positioning requirements [
13]. In indoor positioning, better performance can be obtained by using WiFi [
14], Bluetooth [
15], RFID [
16], ultrasound technology [
17], frequency modulation broadcasting [
18], infrared technology, and other positioning technologies. Among the above methods, WiFi positioning technology has a wide infrastructure and is easy to deploy, so WiFi-based positioning technology is widely used for indoor positioning [
19,
20,
21,
22]. Fingerprint positioning, as a WiFi-signal-based indoor positioning technology, has received widespread attention in recent years due to its high accuracy, low cost, and easy implementation.
The WLAN-based RSSI positioning fingerprint algorithm is mainly divided into offline and online phases [
23,
24]. In the offline phase, the first step is to deploy some reference points in the positioning area and record the WiFi signal strength indicator (RSSI) values at each reference point. Data collection can be performed by placing specific access points (APs) at certain locations inside the building. Then, at each known location, mobile devices are used to scan and record the RSSI values between each AP. Next, the collected fingerprint data are processed and stored. The processing involves preprocessing of the signal strength indicator, such as removing outliers, smoothing, etc. Then, the processed fingerprint data are stored in a database for subsequent positioning queries. In the online phase, when a mobile device needs to be located, it scans for available APs in the vicinity and obtains the RSSI values at the current location. Then, these real-time measured RSSI values are compared and matched with the stored fingerprint database from the offline phase. Typically, matching algorithms such as the
k-nearest neighbor algorithm are used to find the best-matching fingerprint set, thereby determining the location of the mobile device.
In order to solve the problem of the indoor environment being able to affect the localization, researchers have proposed various preprocessing methods for fingerprint data, aiming to reduce the influence of the indoor environment on the fingerprint database and avoid the influence of outliers and noise on the fingerprint database, so as to improve the accuracy of building thefingerprint database. Li et al. proposed a KPCA-based indoor localization method [
25], which hinges on mapping data from the original space to a high-dimensional feature space using nonlinear mapping, followed by linear principal component analysis (PCA). To better handle nonlinear transformations, KPCA introduces the kernel function trick, which replaces the dot product between data vectors in the feature space [
26] with a similarity measure calculated by the kernel function. However, despite its commitment to capturing the nonlinear features of the data by introducing kernel functions, the algorithm used by KPCA suffers from the same shortcomings as PCA. That is, only the global Euclidean structure (or global variance) of the data is preserved, while the local neighborhood structure of the data is ignored. This global nature makes it difficult for KPCA to completely capture the complex relationships and local features between the data, resulting in its poor performance in some cases.
He et al. used the locally preserving projection (LPP) method to reduce the dimensionality of the original data and used KLPP as the kernel function expansion method for LPP [
27]. Compared with PCA and KPCA, the design ideas of LPP and KLPP focus on retaining the local structural information of the data while ignoring the global data structure, and this design idea may lead to a certain loss of data variance [
28]. In performing data dimensionality reduction, the LPP and KLPP methods focus on preserving the local structural information of the data. This approach may result in a distorted global data structure, and the data points are restricted to a very small area [
29]. This is because these methods do not properly restrict the projection distance between non-adjacent data points, which leads to unsatisfactory processing of the algorithm for large datasets. To obtain a reliable feature representation, we must take into account the global and local structure of the dataset and perform dimensionality reduction using appropriate processing. In recent research on data dimensionality reduction, some scholars have combined the PCA and LPP algorithms to be able to preserve both global and local data structures in low-dimensional spaces [
28,
29,
30,
31]. In the process of studying the combination of PCA and LPP, a technique proposed by the scholar Luo [
31], namely the global locally preserving projection (GLPP) method, successfully integrates two dimensionality-reduction methods, PCA and LPP, under the same framework. After experimental validation, the GLPP method can better maintain the global and local characteristics of the data and combine the advantages of both, while avoiding the effects of problems such as principal component rotation and no samples in the neighborhood.
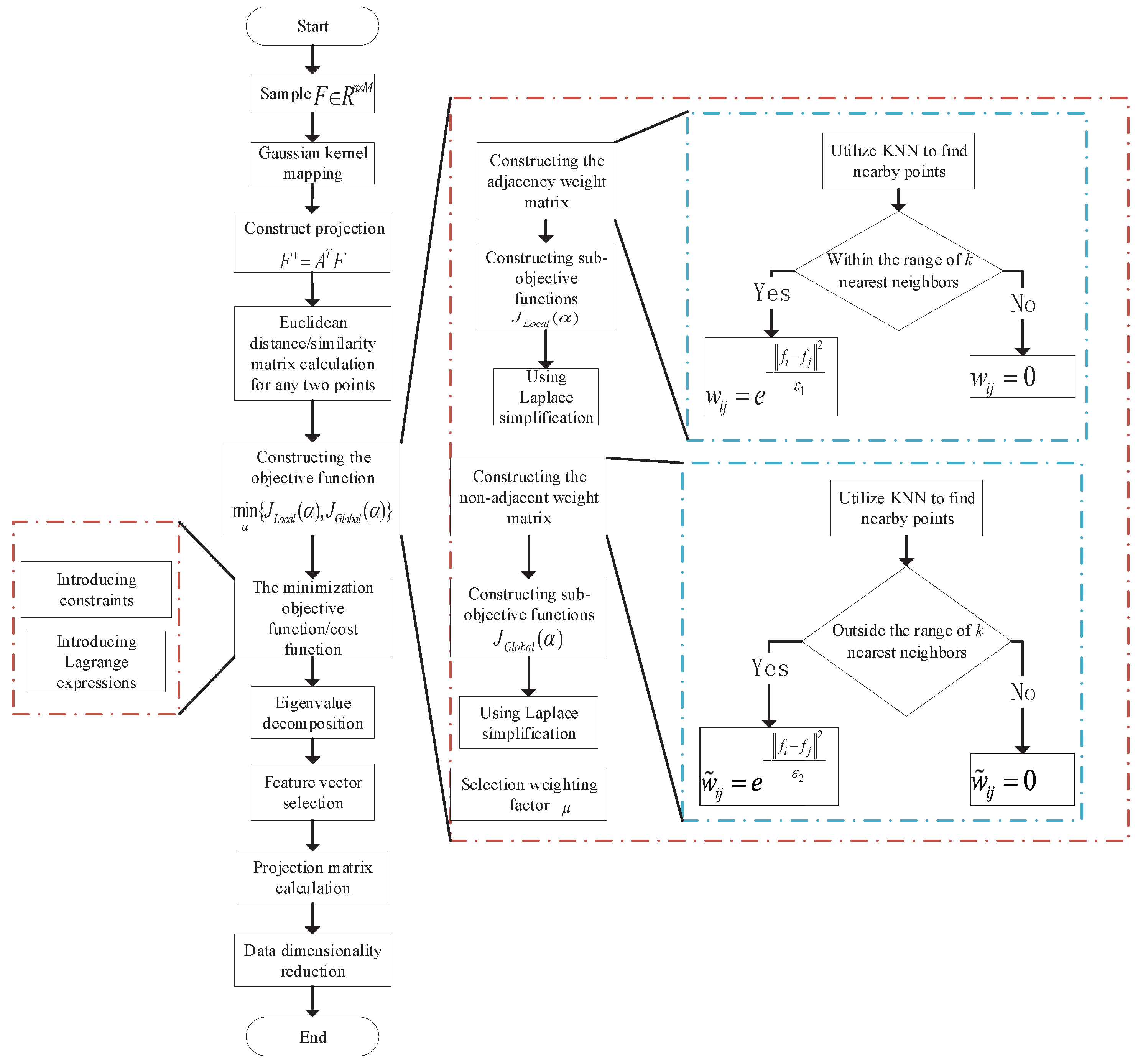
This paper proposes a novel nonlinear dimensionality-reduction method, called kernel global locally preserving projection (KGLPP). The proposed method is an extension and improvement of the global locally preserving projection (GLPP) algorithm, which employs kernel techniques to map and process data for better preservation of the global and local structure of the dataset. Compared to other dimensionality-reduction methods, KGLPP offers significant advantages in reducing data redundancy, improving the accuracy and reliability of feature selection. It is shown that we can obtain KPCA and KLPP methods through the derivation of KGLPP. Both methods are the basis laid by KGLPP [
32] and can be considered as a special case of KGLPP. Based on this, KGLPP-based drone-assisted fingerprint localization is proposed. The connection between the KGLPP algorithm and the drone AP solution is as follows: (1) In the drone AP solution, drones are used as carriers for APs, allowing them to freely move and adjust their positions within indoor environments. (2) In this scenario, the KGLPP algorithm can be used to process the fingerprint data collected from drone APs. It can reduce the high-dimensional fingerprint data to a lower dimension, thereby reducing computational complexity and extracting the key features of the data. (3) The KGLPP algorithm computes based on the similarity matrix of fingerprint data, which is obtained through the collection by the drone APs. (4) By using the KGLPP algorithm for dimensionality reduction, we can effectively analyze and process the data collected by the drone APs while preserving the local relationships and global structure of the fingerprint data.
We applied the KGLPP algorithm to both the offline and online training phases of fingerprint data to improve the accuracy and efficiency of fingerprint localization. In the online phase of fingerprint localization, an improved weighted k-nearest neighbor (IWKNN) algorithm was used for position estimation. Compared the with traditional k-nearest neighbor algorithms, the IWKNN algorithm can adaptively select the required number of fingerprints for location based on the needs and weight them according to the distance and similarity of the fingerprint information, thus achieving more-accurate and -reliable fingerprint position prediction. Therefore, combining the use of the KGLPP algorithm and IWKNN algorithm can effectively help us process fingerprint data and significantly improve the accuracy of fingerprint localization. The experimental results showed that the algorithm proposed in this paper was significantly better than several other fingerprint-localization algorithms. In summary, our contributions are as follows:
Using drones to replace APs for localization is a new approach that has several advantages compared to the traditional AP method. Drones can maneuver freely and obtain comprehensive information, with relatively low requirements for application scenarios. Its hovering function and built-in sensors can provide more-accurate data; with a low cost and rapid response, it is suitable for various practical application scenarios.
In this study, we propose a novel fingerprint-localization algorithm based on kernel global locally preserving projection (KGLPP). The algorithm was trained using both an offline fingerprint database and online fingerprint vectors. The KGLPP method improves localization accuracy by combining global and local features, and its kernel-based feature extraction exhibits powerful nonlinear mapping capabilities, making it suitable for complex environments. The method also reduces computational complexity and provides the real-time performance and responsiveness required for practical applications. Furthermore, the KGLPP method exhibits robustness to interference and changes in actual environments, thereby improving the accuracy and stability of fingerprint-based positioning.
In the localization process, an improved weighted k-nearest neighbor (IWKNN) algorithm is used. This algorithm introduces a cumulative contribution parameter and limits its range between 0 and 1, allowing it to adaptively select the required number of nearest neighbors, thus avoiding the overfitting or underfitting problems that may occur when directly specifying the k value and improving the accuracy of the algorithm.
The organizational structure of this paper is as follows. In
Section 2, we review some background techniques on the KGLPP algorithm. In
Section 3, we introduce the system framework. In
Section 4, the details of the algorithm are introduced. The explanatory results of the simulation and experiment are provided in
Section 5. The paper is concluded in
Section 6.
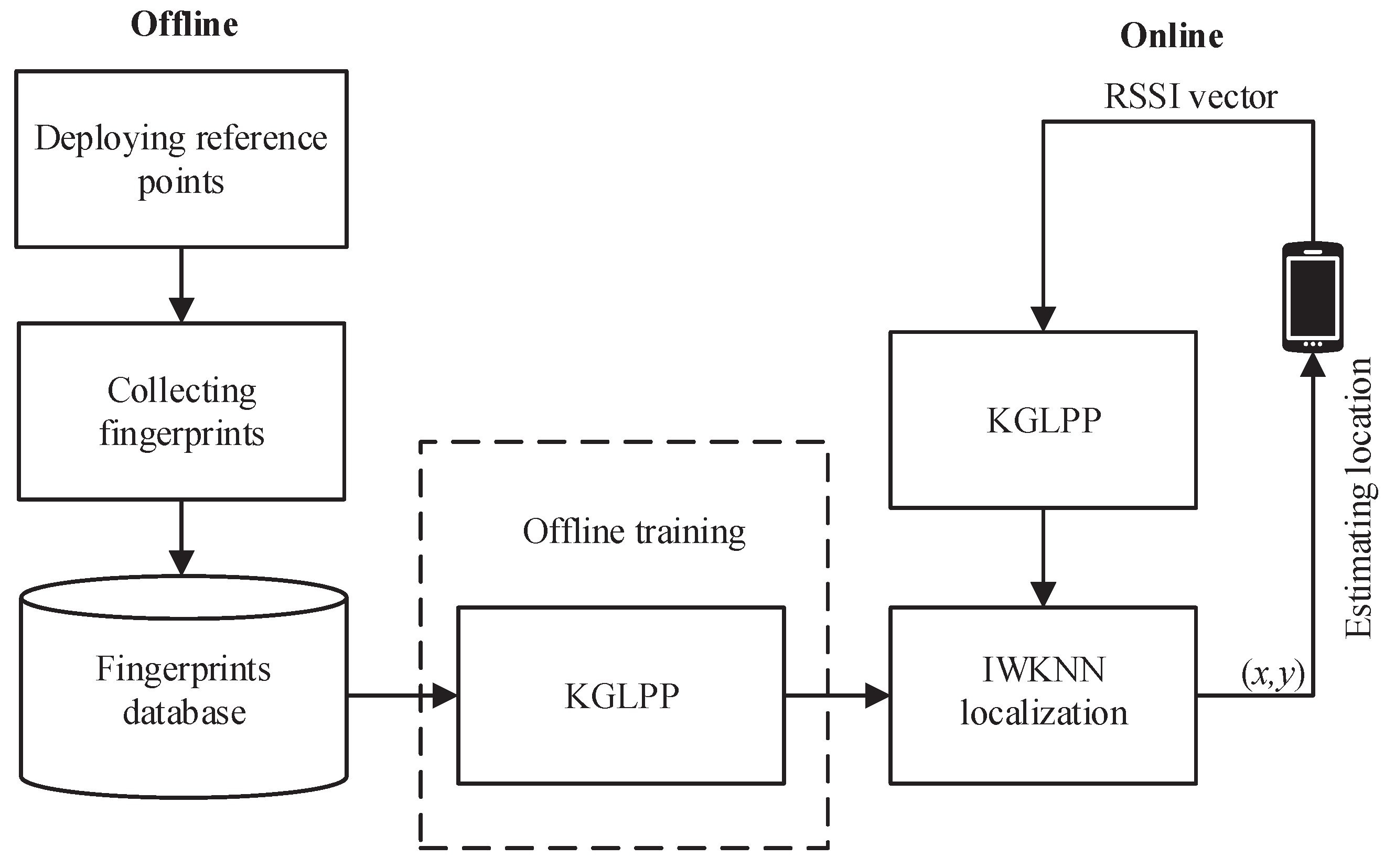
3. System Framework
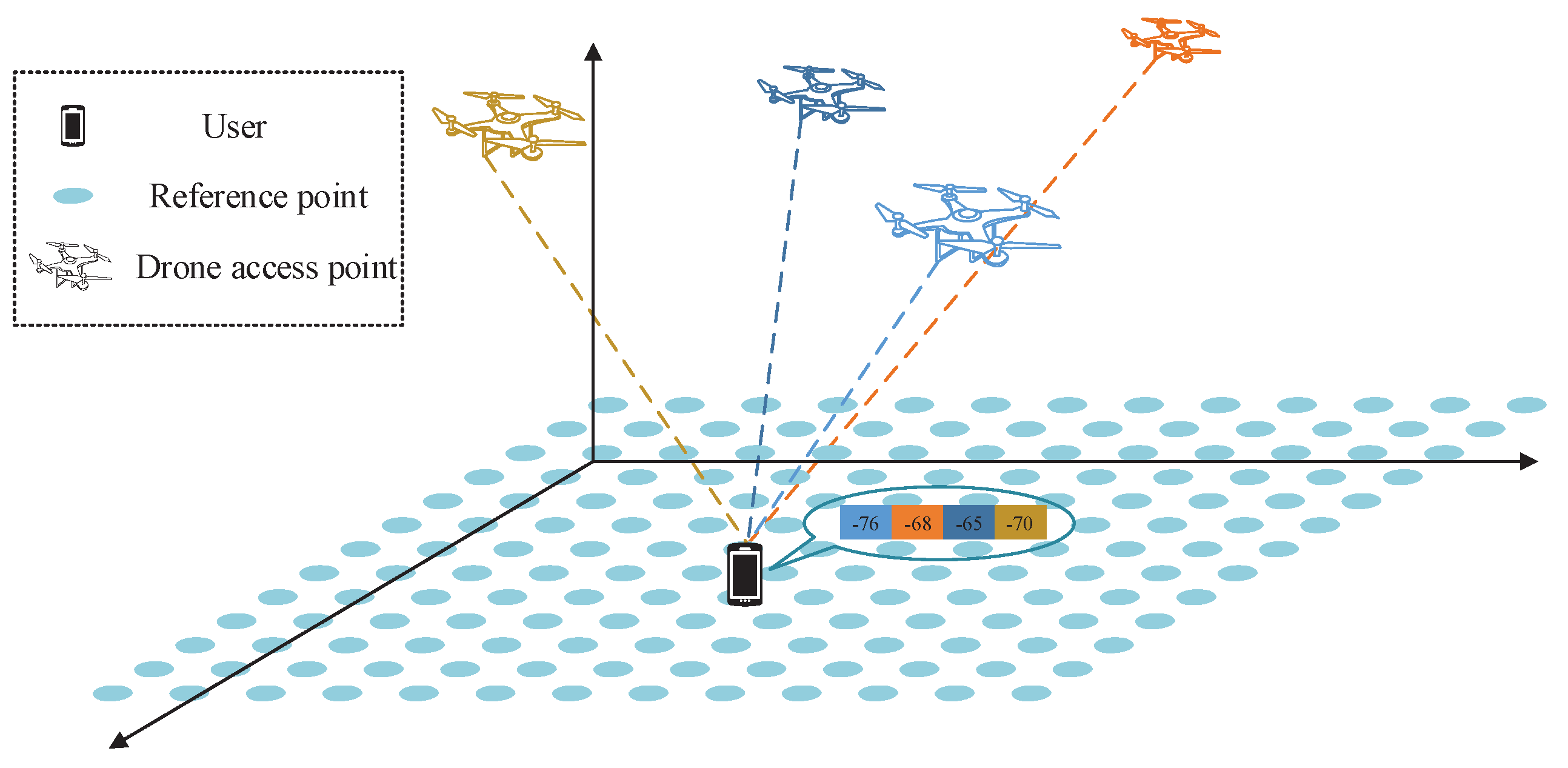
To clearly articulate the system architecture and facilitate subsequent research and analysis, we first establish some basic symbols, and the system framework is shown in
Figure 1. Assume there are
n drone access points (dAPs) and
M reference points (RPs) within this localization area, to construct a complete network coverage range and provide accurate location information. The position coordinates of each RP are recorded as
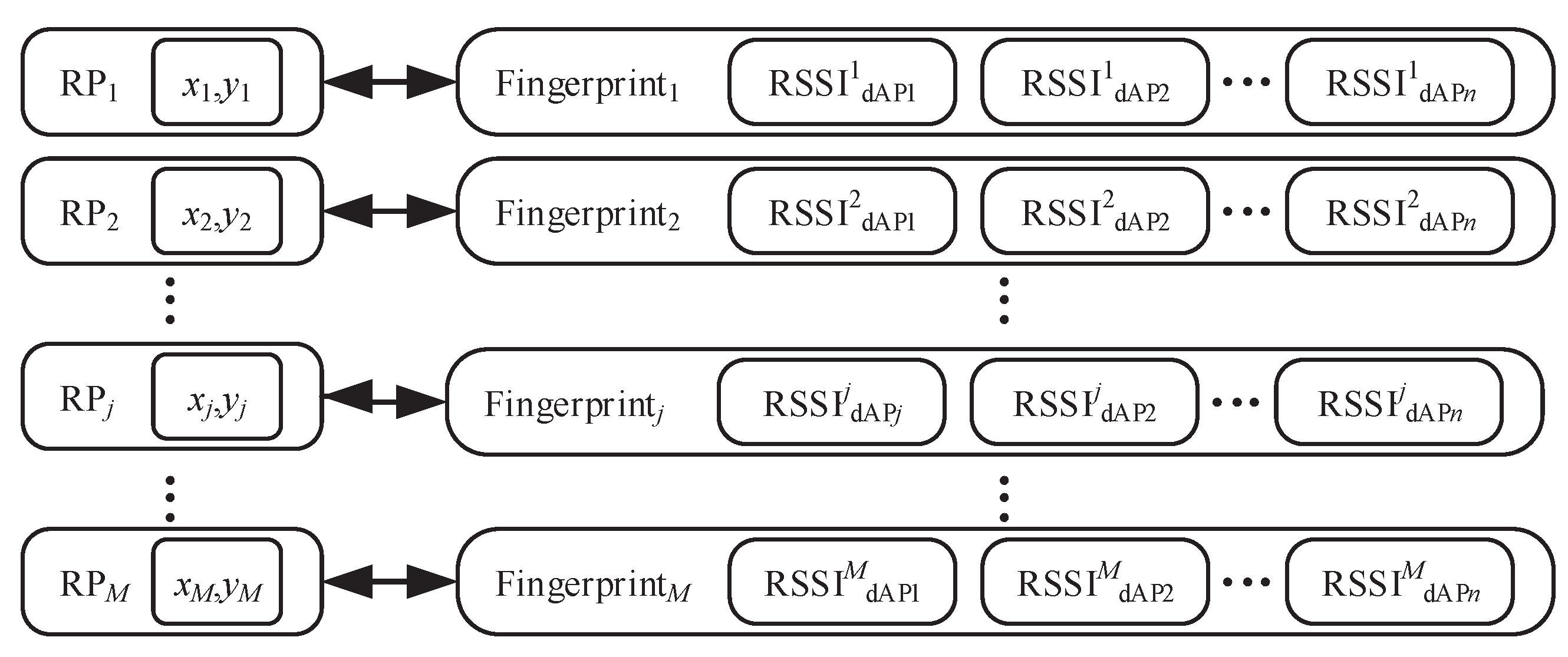
, and the information of these
M reference points (RPs) forms a position space
. Next, we collected RSSI signals from
n dAPs at each RP. To obtain a stable RSSI value, we need to perform
q acquisitions for each reference node and then average the RSSI values of these
q acquisitions and use them as the original location fingerprint information of this reference node
. This results in an
n-dimensional vector
of original location fingerprints, where each dimension corresponds to a dAP and contains the mean RSSI value of that dAP at that reference node, where
in this vector represents the mean RSSI value from the
jth dAP after
q samples. The original location fingerprint information of each reference node is stored in the offline fingerprint database by a data storage technique, forming an original location fingerprint space
containing
dimensions, as shown in
Figure 2.
Each row vector in the matrix
is a vector consisting of multiple features, which reflect the location fingerprints of the reference nodes. The raw location fingerprint data are trained by using the KGLPP method, from which features for localization are extracted. The feature location fingerprint space
consists of the extracted localization features and corresponds to the original location fingerprint space
, that is the feature location fingerprint of
is
. During online positioning, we collected
g samples of RSSI signals at the target location to be positioned. By calculating the average value, we used it as the online fingerprint
for online fingerprinting, as shown in
Figure 3. Next, we applied the KGLPP algorithm to
to extract the online feature fingerprint vector
. Then, a modified weighted
k-nearest neighbor (IWKNN) algorithm was used to estimate the location of the target by comparing
with the feature location fingerprint vector in the offline location fingerprint library.
5. Simulation and Experiment
In this paper, we used simulation data to verify the effectiveness of our proposed algorithm. We selected the following four existing algorithms for comparison, which have been widely used for similar problems:
- (1)
KNN [
33]: During online localization, the Euclidean distance is used to find the RPs closest to the target, and the average position of these RPs is used to estimate the position of the target.
- (2)
WKNN [
34]: WKNN differs from KNN in that it assigns different weights to different RPs when estimating the target location.
- (3)
KPCA-IWKNN [
25]: The KPCA-IWKNN algorithm combines the KPCA and IWKNN algorithms, using the KPCA algorithm to downscale and extract features from the data, then using the IWKNN algorithm to localize the target.
- (4)
KLPP-IWKNN [
31]: The KLPP-IWKNN algorithm uses the KLPP algorithm for feature extraction and dimensionality reduction first and then uses the improved IWKNN algorithm for localization.
In this experiment, we evaluated and compared five different methods using three metrics: mean error (
ME), localization accuracy, and cumulative distribution function (CDF). The mean error is the average distance between the estimated position of the positioning system and the real position. Assuming that the real position of target
j is
and its estimated position is
according to the prediction of the localization system, the localization error is
, and the
ME is obtained according to
N times of localization as
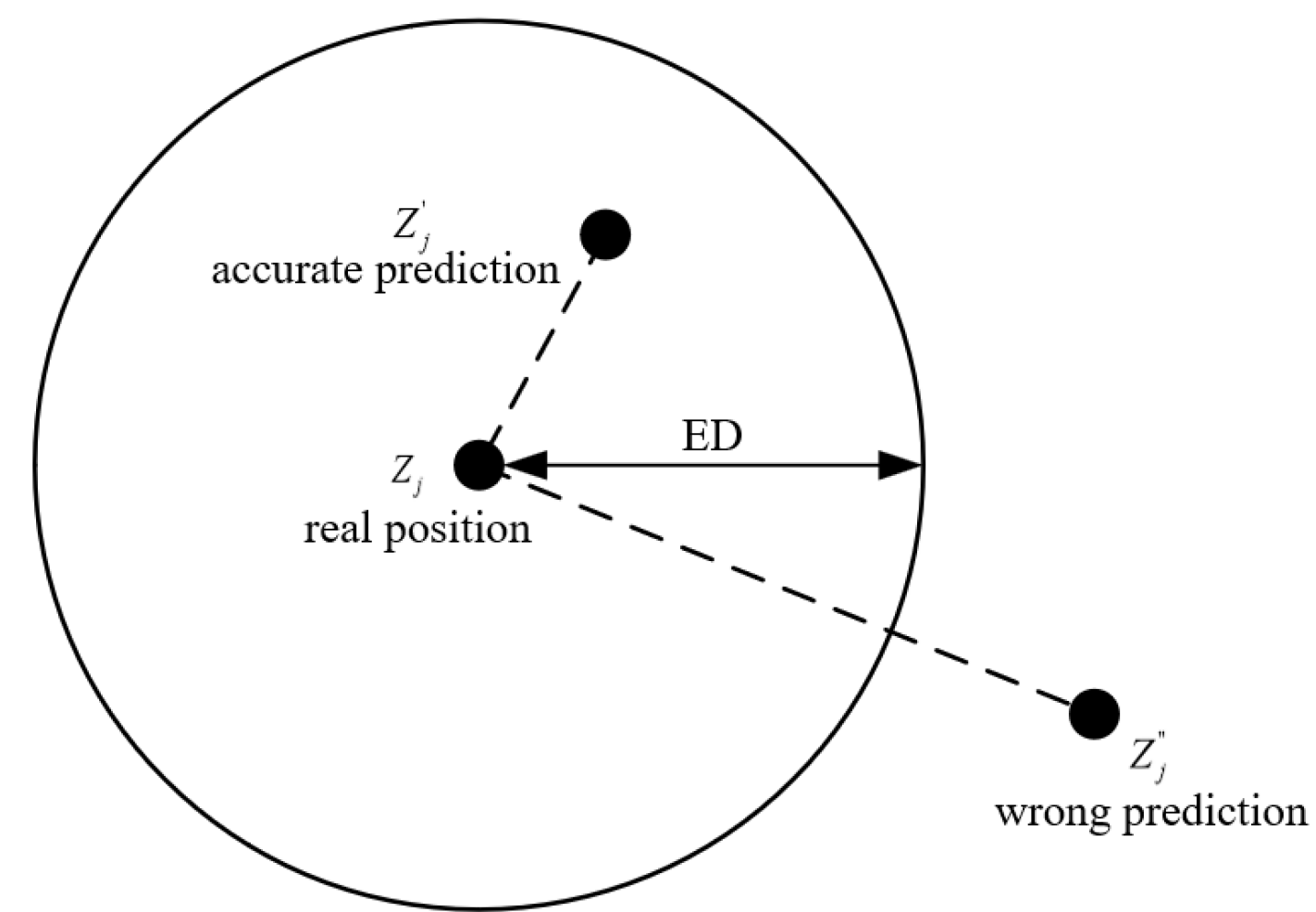
Localization accuracy is an important metric for assessing the performance of a localization system and measures the degree of agreement between the localization results and the true position [
25]. Localization errors are known to be an unavoidable problem in localization systems because they are influenced by a variety of factors. Therefore, in practical applications, the localization error is acceptable for a certain range, but if the localization error exceeds this range, then it may lead to the degradation of system performance and unsatisfactory application results. Suppose the actual position of the target to be measured is
for a given allowable error distance (
ED) and the position of the target is predicted by the localization system to obtain the predicted position as
. If the distance between the predicted position
and the real position
is less than
ED, we can assume that this localization is accurate. That is, if
, then
is accurate localization; conversely, if
, then
is the wrong localization. The concept of accurate localization is illustrated in
Figure 5. Specifically, localization accuracy is the ratio of the number of accurate positions to the total number of positions when the localization system performs multiple localization tasks. Assuming the total number of localization is
B, the number of accurate localization is
C, and the accuracy of localization is
E, the expression for the accuracy of localization is:
5.1. Simulation Settings
In this paper, we verified the algorithm using simulation data to evaluate the performance of the algorithm. In this simulation experiment, we used a specific simulation environment with the following relevant parameters. We used an Asus laptop (Asus, Taipei, Taiwan) as the hardware device and implemented the algorithm on the Matlab 2016a software platform.
To better simulate real-world scenarios, a two-ray ground reflection (TRGR) channel path loss model was adopted to construct the fingerprint database [
35]. Specifically, the path loss of the TRGR channel is expressed as follows:
where
s represents the length of the line-of-sight (LOS) path,
represents the length of the ground reflection path, while
d represents the horizontal distance between the transmitter and receiver.
represents the height of the transmitter, and
represents the height of the receiver.
represents the combined antenna gain along the LOS path;
represents the combined antenna gain along the ground reflection path;
denotes the wavelength of transmission;
represents the reflection coefficient, where
and
is the noise.
To simulate a realistic wireless communication environment, the parameters for the TRGR model path loss were set as follows: the length of was 2.5 m; the length of was 1.55 m; was 0.123 m (where the carrier frequency was 2440 MHz); , where , was used to represent the relative permittivity of dry soil.
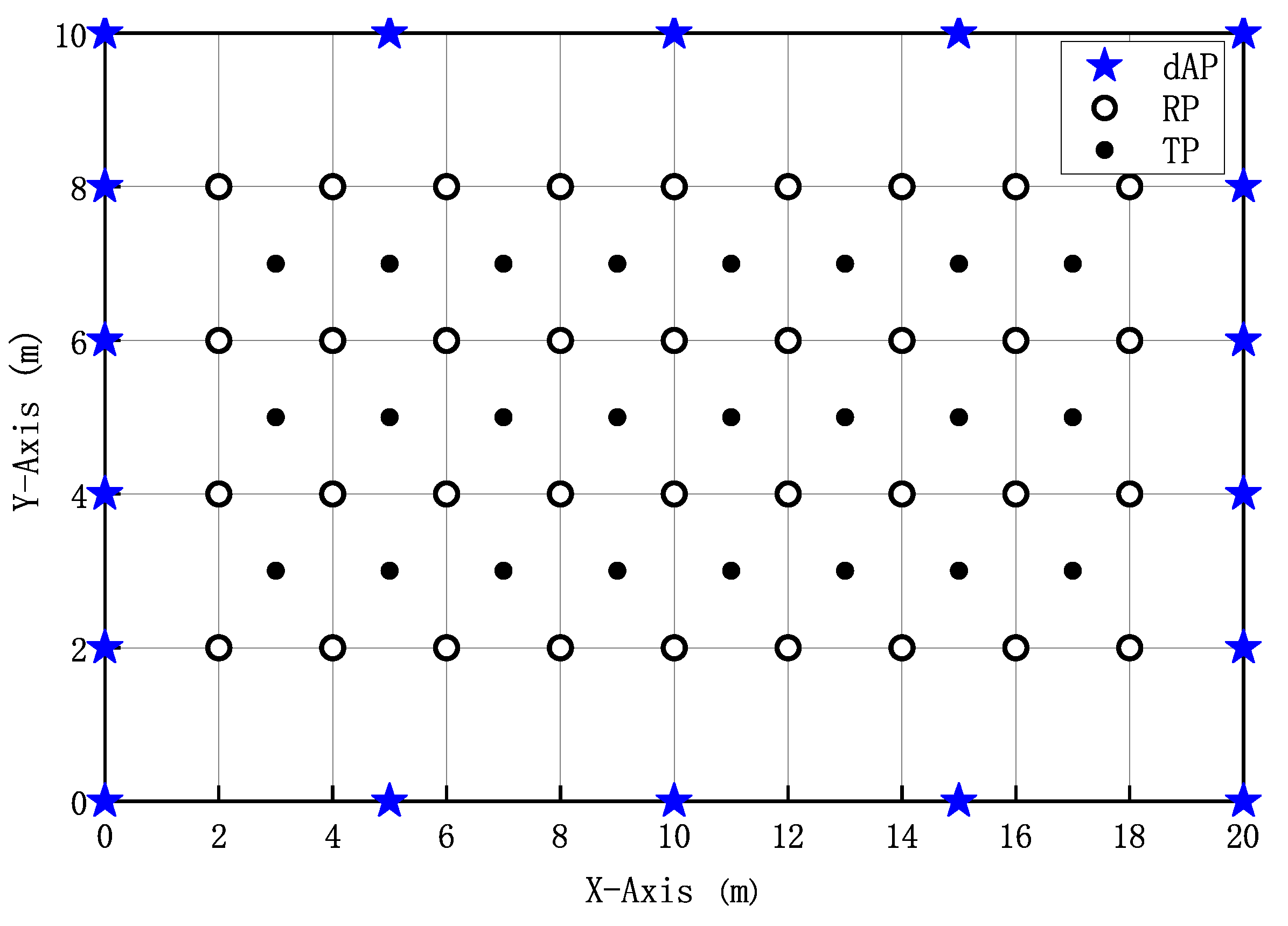
In order to verify the effectiveness of the algorithm, we needed to establish a reliable test environment first. We chose a basic fingerprint location method and set up a topographic map as a base before testing. As shown in
Figure 6. The topographic map was 20 m
m; the size of the RP grid was 2 m; the number of dAPs was 18. To ensure accuracy, the RSSI data of each RP and TP were collected 100 times. By averaging the collected data, more reliable and stable mean values can be obtained, enabling a more-accurate assessment of the signal strength between the RPs and TPs.
During the simulation process, we employed the Gaussian kernel function as the kernel function for KGLPP, KPCA, and KLPP. The width of the Gaussian kernel function was empirically set to 2. For the WKNN and KNN algorithms, we chose the four nearest neighbors to compute the similarity. The value of was set to be 0.3.
5.2. Illustrative Results
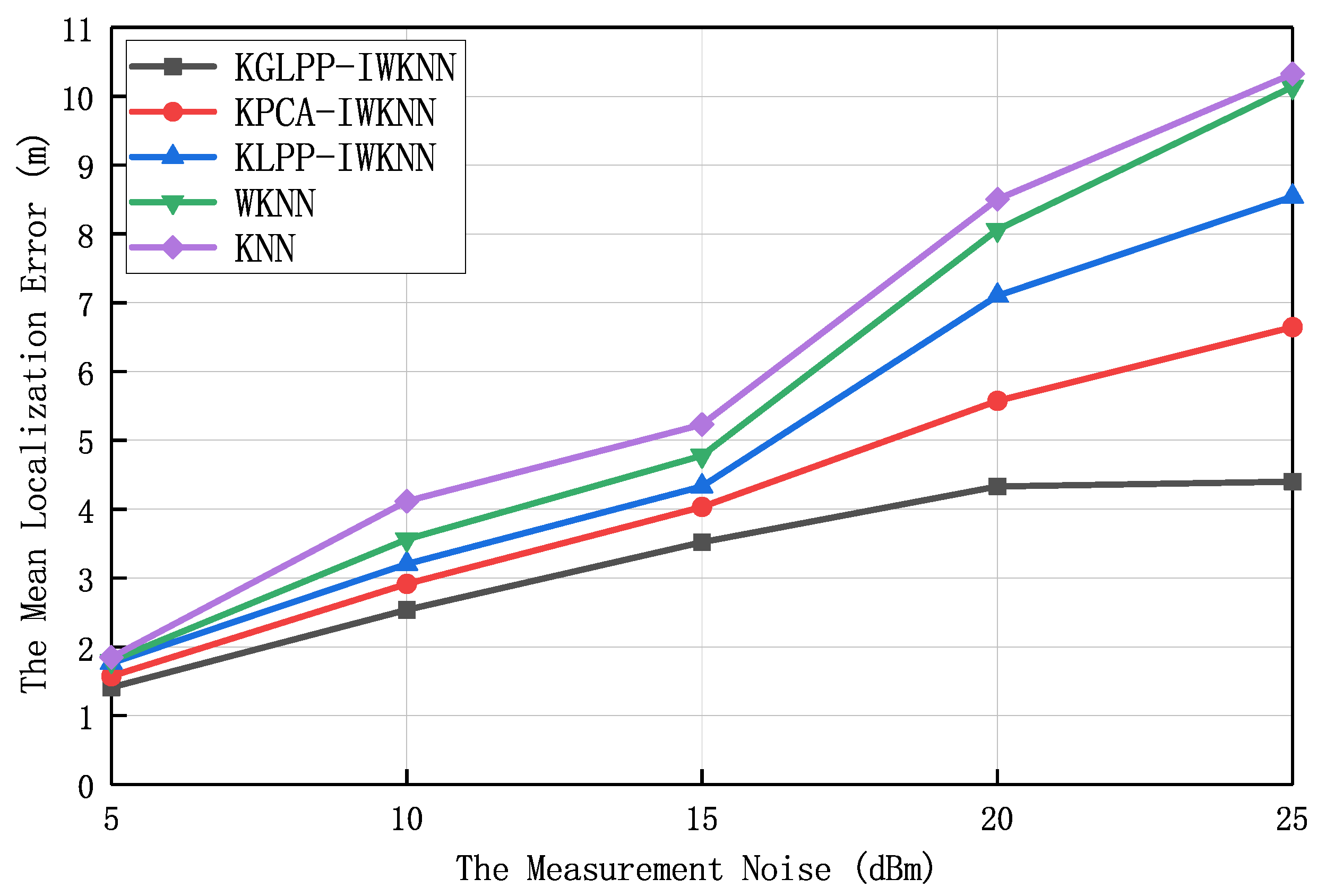
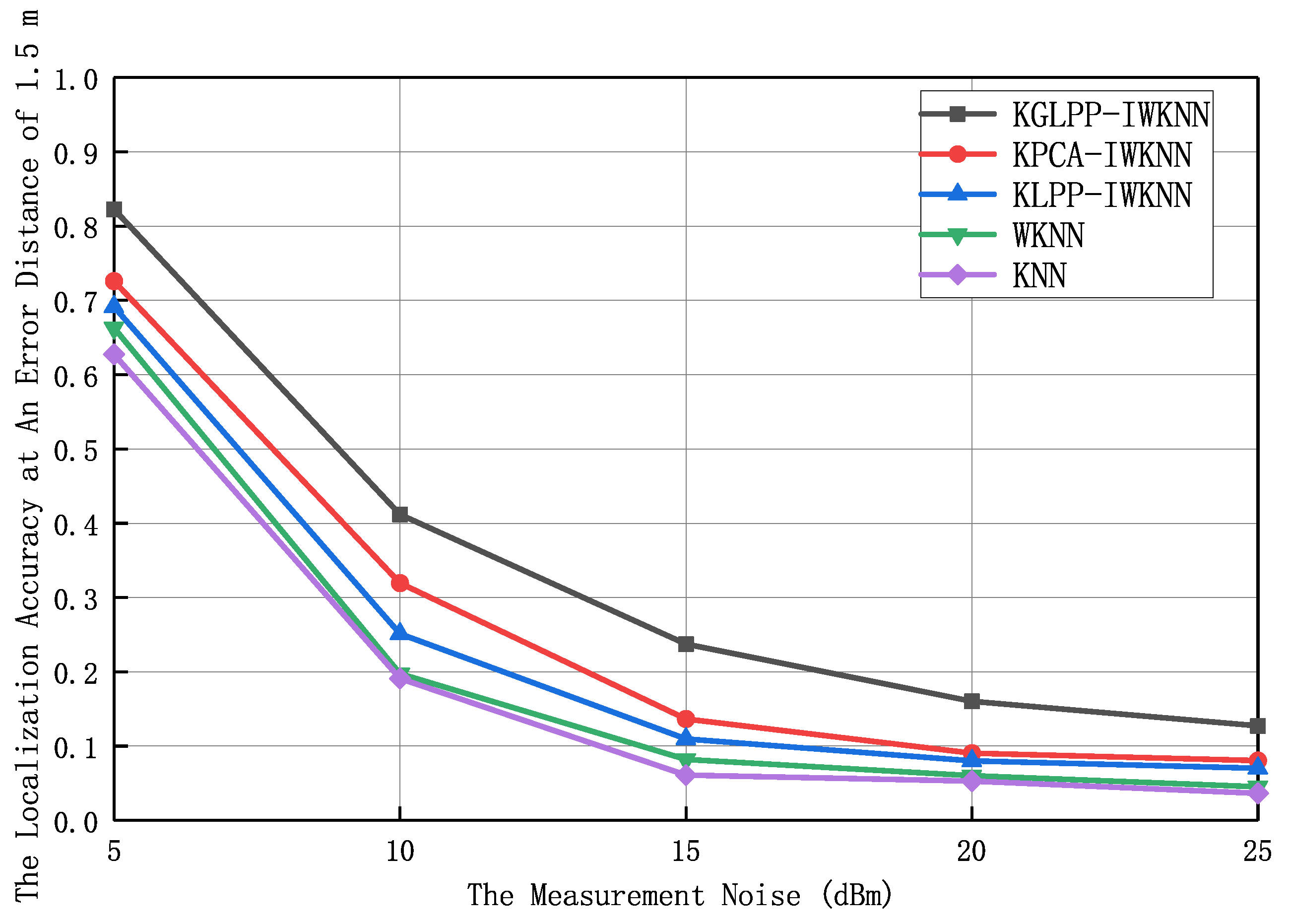
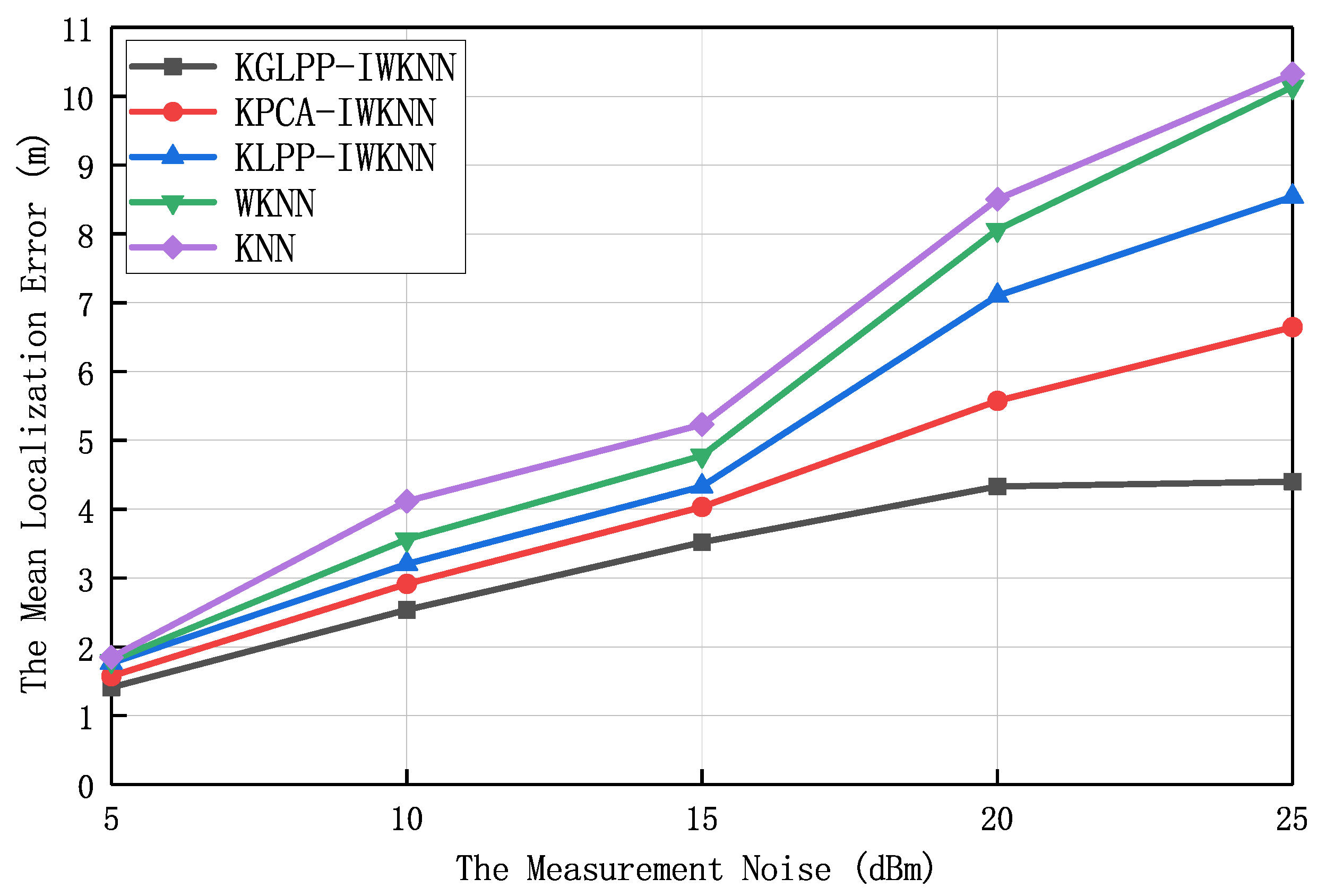
Figure 7 and
Figure 8 illustrate the trend of algorithmic localization accuracy variation when the random noise intensity (The random noise intensity refers to the degree or strength of the random noise introduced into the fingerprint data during the simulation process. It is a parameter in the simulation environment used to control the intensity and range of the noise impact.) was within the range of 5 dBm to 25 dBm, with an average localization error and error distance of 1.5 m. In this experiment, the number of dAPs was 18, the value of
was 0.3, and the dimension of the feature location fingerprint space was eight. The results in the figures show that the localization performance and localization accuracy of all localization algorithms gradually decreased when the noise increased. The algorithm proposed in this paper outperformed the other four algorithms in terms of average positioning error and positioning accuracy. This advantage stemmed from the ability of KGLPP to maintain both global and local structural information during the dimensionality reduction process. It takes into account not only the similarity between data samples (local structure), but also the characteristics of the overall data distribution (global structure). By constructing a graphical structure in high-dimensional space and using the graph Laplacian operator for dimensionality reduction, KGLPP is able to preserve the relationships between data samples, thereby maintaining the structure and geometric properties of the data as much as possible after dimensionality reduction. When there is noise present, KPCA and KLPP often suffer from interference, leading to distorted results after dimensionality reduction. In contrast, KGLPP effectively mitigates the negative impact of noise by preserving structural information. This is because KGLPP takes into account the similarity between samples when constructing the graphical structure, mapping similar samples to neighboring positions in the reduced-dimensionality space. This similarity constraint helps suppress the influence of noise on the dimensionality-reduction results, thereby improving the accuracy and reliability of the data after dimensionality reduction. With the increase of noise, KGLPP-IWKNN exhibited better performance compared to KPCA-IWKNN and KLPP-IWKNN. This is because KGLPP can better preserve structural information, while KPCA and KLPP perform dimensionality reduction without considering global and local structures, making them susceptible to noise interference. Additionally, KGLPP possesses the characteristics of nonlinear mapping, which enables it to better adapt to the distribution of complex data and further enhance robustness against noise. Therefore, KGLPP-IWKNN can provide more-accurate localization results in the presence of noise.
In the following localization simulation experiments, the random noise in the simulation environment was 20 dBm.
With 100 localization experiments performed,
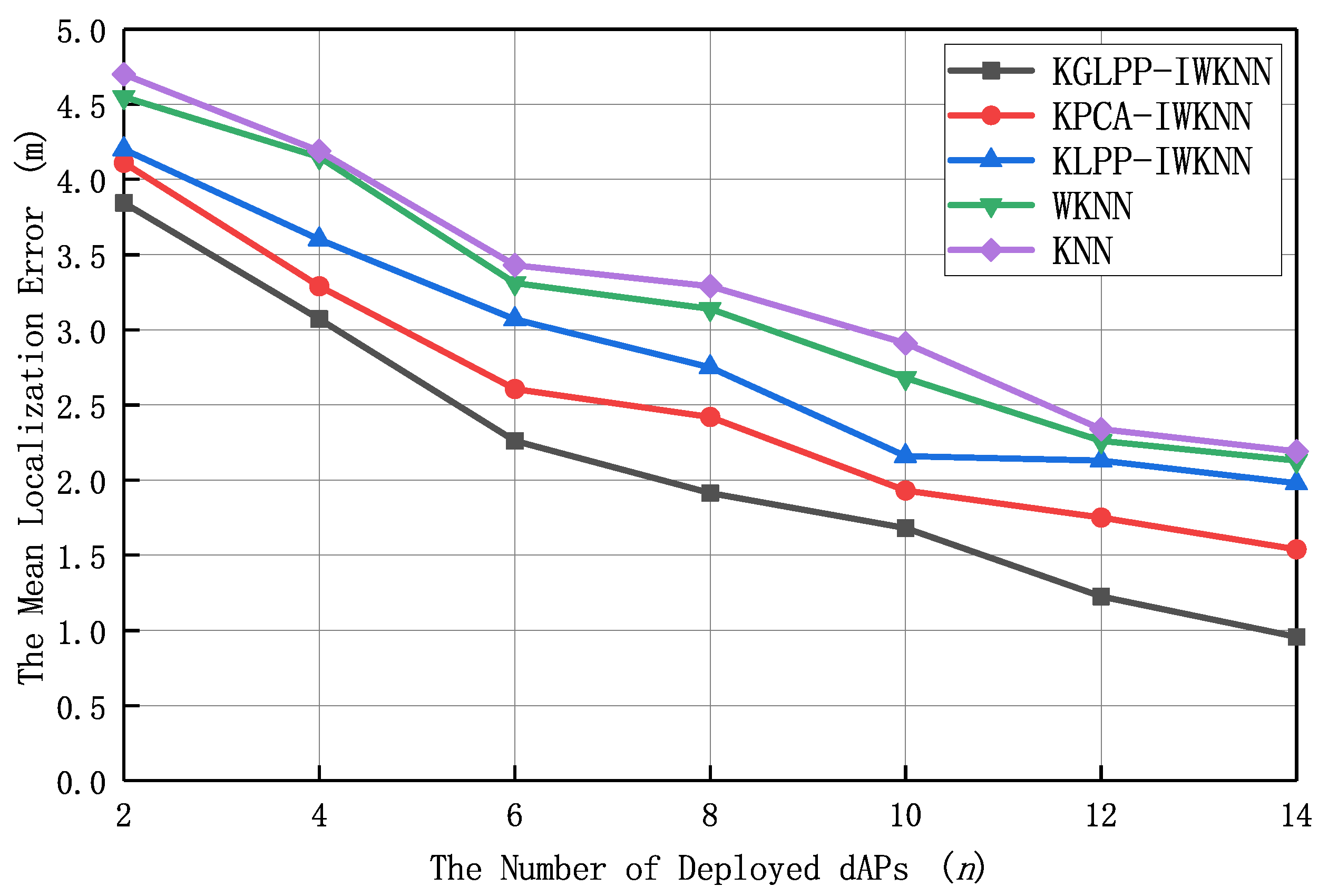
Figure 9 presents the curve of the mean localization error with the number of dAPs when the number of offline deployed dAPs was in the range of 2 to 14. In this experiment, the number of dAPs was 14, the value of
was 0.3, and the dimension of the feature location fingerprint space was eight. As the number of dAPs deployed offline gradually increased, the localization error of all algorithms gradually decreased. This is because the increased number of dAPs led to more matching dimensions, which improved the accuracy of RP matching. In addition, according to the results in
Figure 9, when the number of dAPs in the localization area was small, KGLPP-IWKNN exhibited higher localization accuracy compared to other algorithms. This is because KGLPP employs a global–local structure-preservation method during the dimensionality-reduction process, aiming to preserve the spatial layout features of fingerprint data and the relationships between neighboring samples to the greatest extent possible. This global–local structure preservation helps reduce information loss during the dimensionality-reduction process and improves localization accuracy. Moreover, KGLPP also exhibits strong adaptability by dynamically adjusting the projection method during the dimensionality-reduction process based on different signal features. As the number of dAPs increased, the signal features in indoor environments became more diverse and complex. However, KGLPP was able to adapt better to this situation, thereby improving the accuracy of localization. In addition, KGLPP obtained more-representative and -discriminative fingerprint features through feature extraction during the dimensionality reduction process. Compared to methods such as KPCA and KLPP, KGLPP is able to better preserve useful information, effectively differentiate different fingerprint samples when projecting data into a lower-dimensional space, and reduce localization errors.
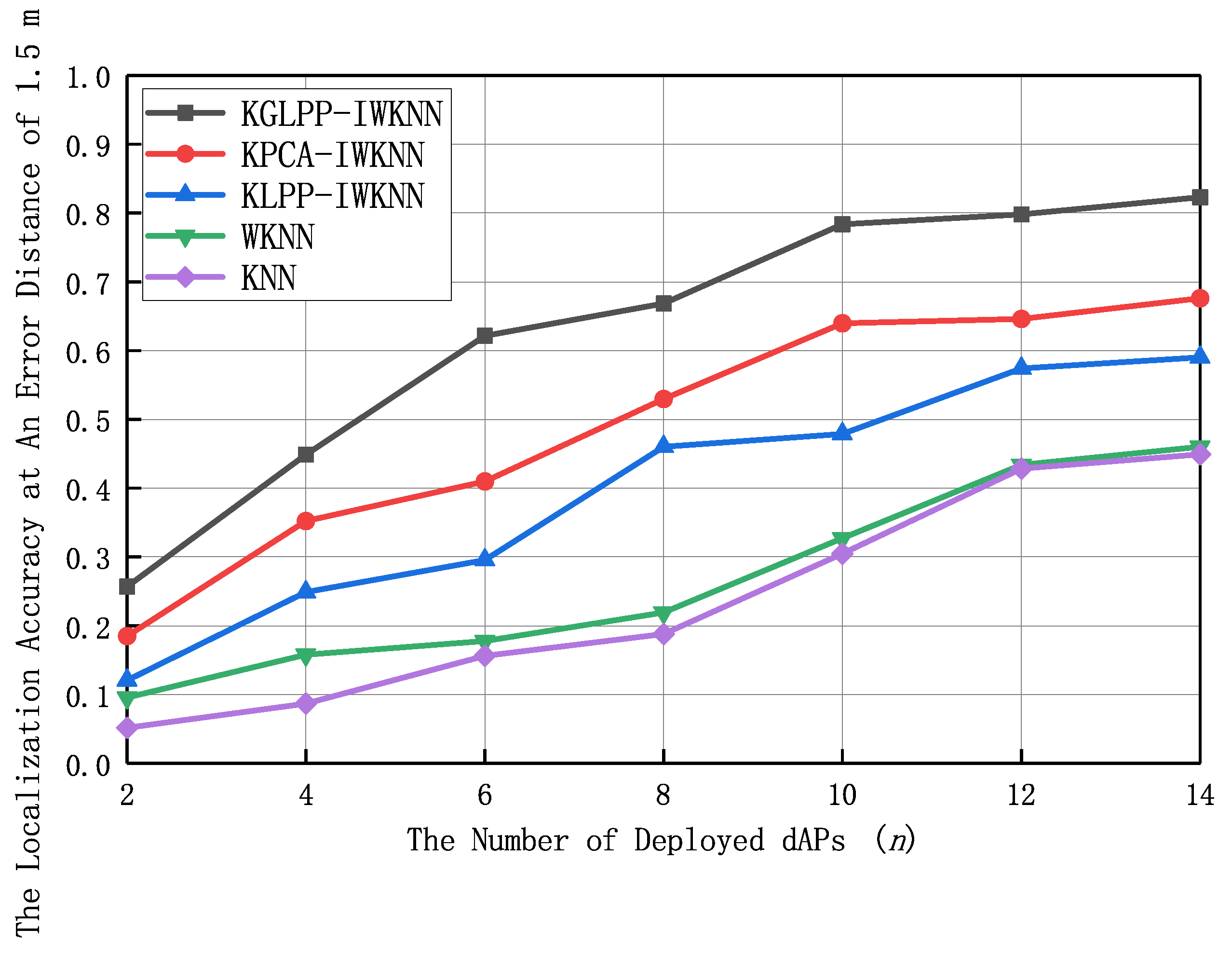
With an error distance of 1.5 m,
Figure 10 shows the trend of improved localization accuracy of all algorithms with an increase in the number of dAPs, indicating that the proposed algorithm in this paper had higher localization accuracy compared to the other algorithms. In this experiment, the number of dAPs was 14, the value of
was 0.3, and the dimension of the feature location fingerprint space was eight. When the number of dAPs was six, the proposed algorithm in this paper achieved a localization accuracy of 62%, while other comparative algorithms required more dAPs to achieve this accuracy. This indicated that the algorithm proposed in this paper had higher efficiency in terms of dAP utilization and could achieve higher localization accuracy with a limited number of dAPs.
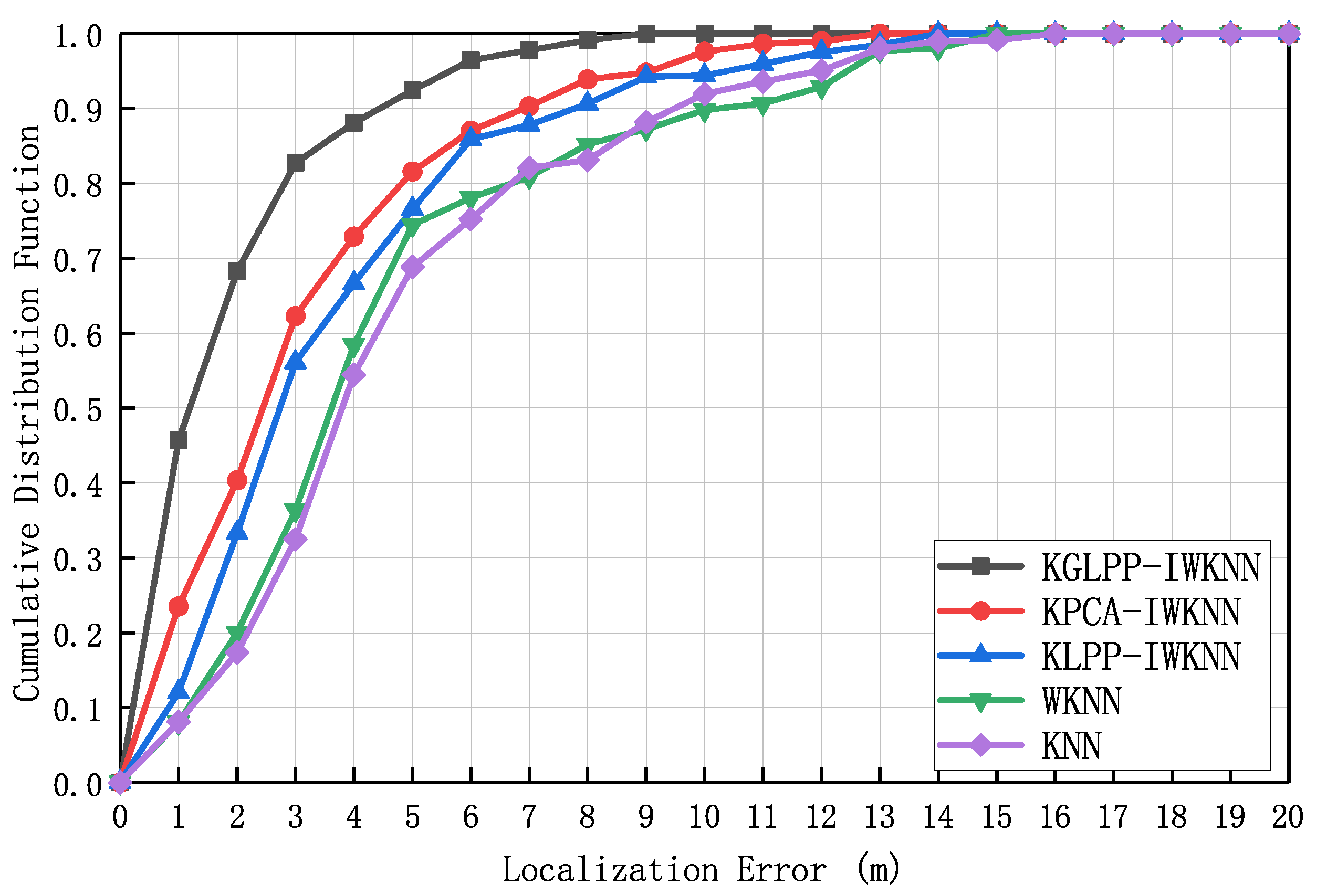
Figure 11 illustrates the cumulative distribution function curve of the localization error. In this experiment, the number of dAPs was 14, the value of
was 0.3, and the dimension of the feature location fingerprint space was eight. Compared with the other algorithms, KGLPP can effectively reduce the data noise and redundancy, preserve useful features, and improve the robustness and discriminability of features. These advantages enable KGLPP to more accurately identify the relationship between the signal strength and location during the localization process, thereby improving the accuracy of localization.
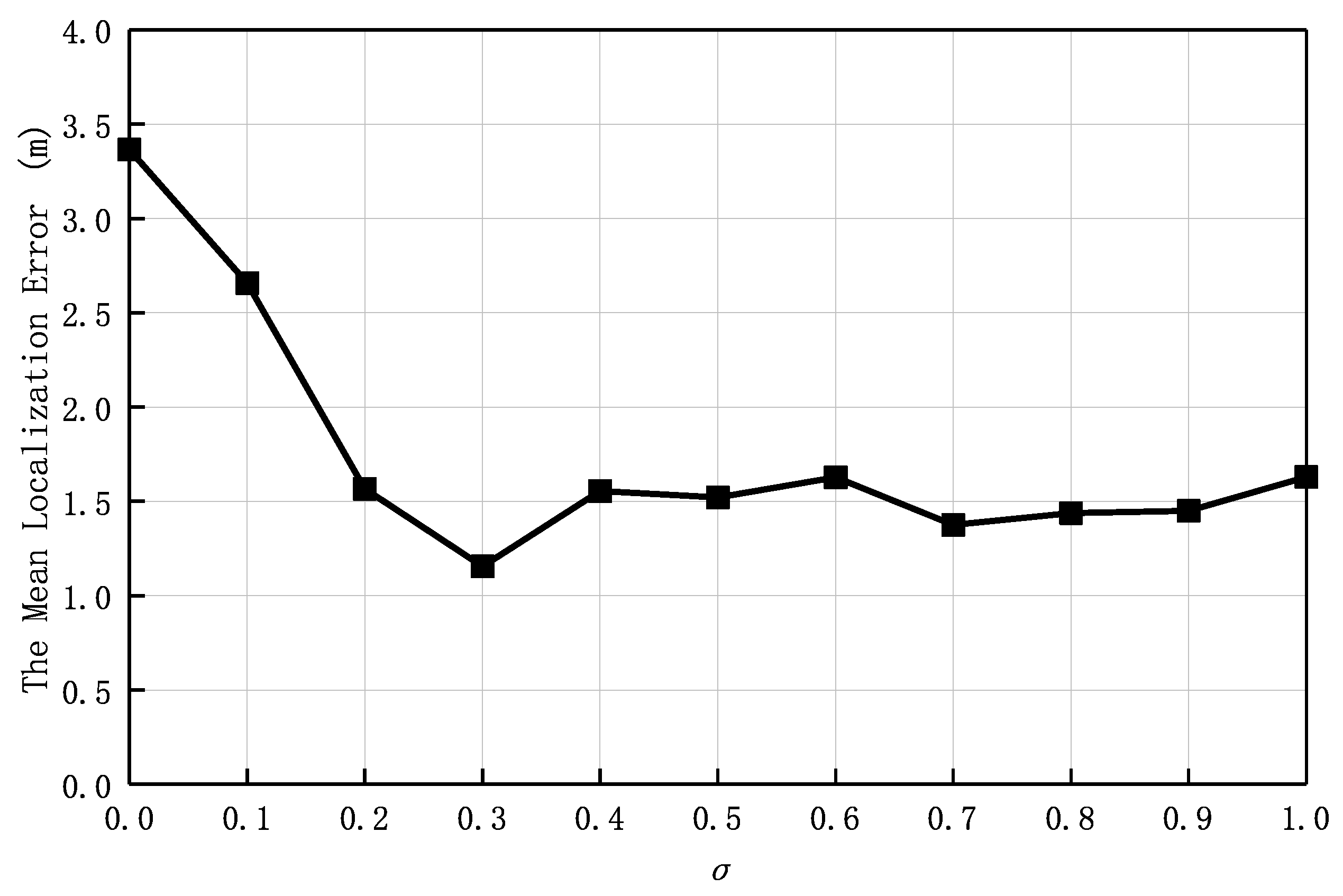
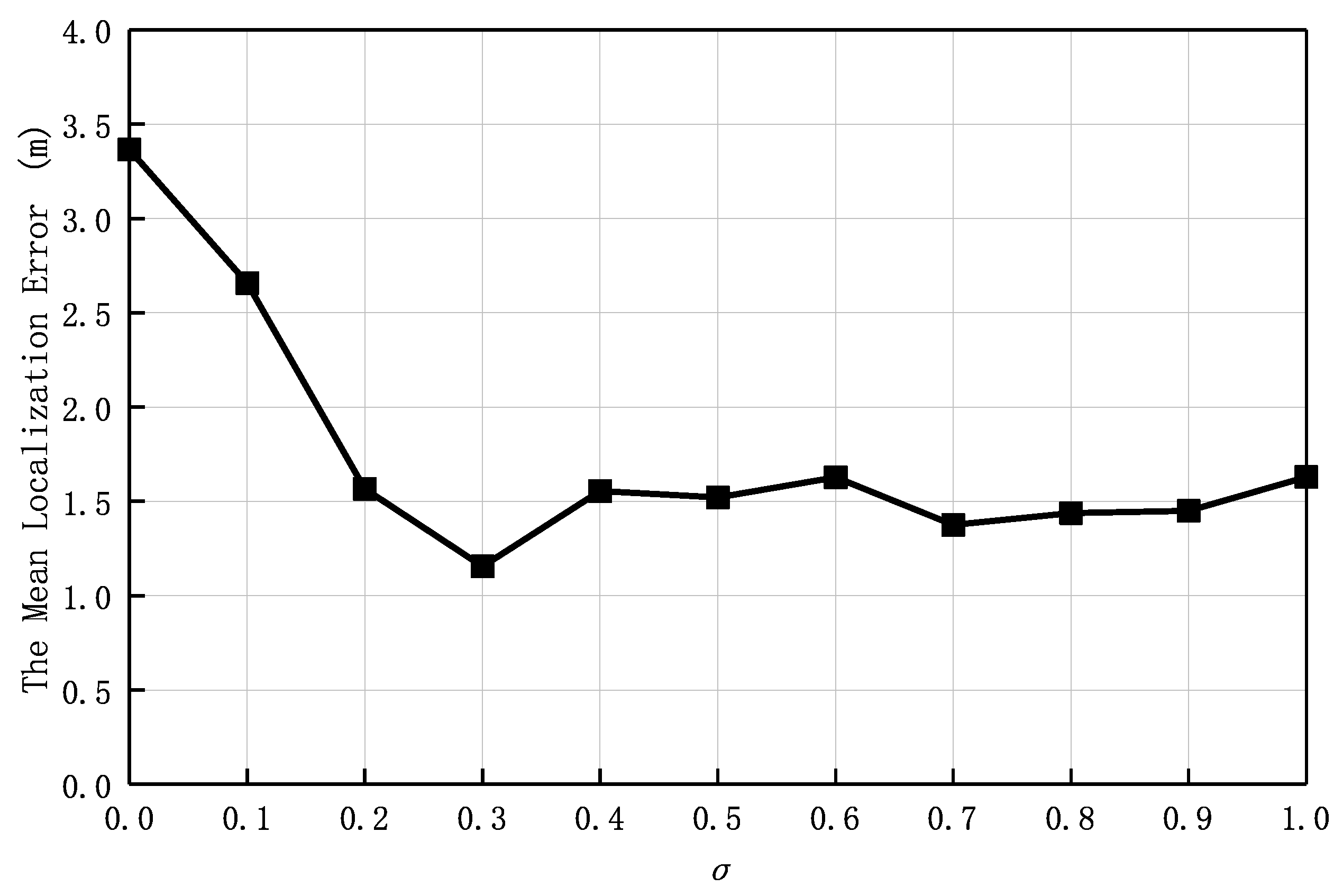
Figure 12 shows the variation of the average localization error of the proposed algorithm with respect to the change of the
value. When
, the nearest neighbor was used for localization, and the localization error was the highest because only one RP was used for localization, making it very difficult to achieve high-precision localization. As
increased, the number of neighbors required for localization by the IWKNN algorithm also increased, which could more accurately reflect the contribution of RPs and reduce localization error. Therefore, as the
value increased, the average localization error correspondingly decreased. It was found in the experiment that the average localization error reached the minimum value when
was set to 0.3; However, when
was greater than 0.8, in order to improve the accuracy, the algorithm used more neighboring nodes for localization, but these redundant location fingerprints would bring more errors, resulting in an increase in the mean localization error. Therefore, the value of
was set to 0.3 in the experiment to reduce localization errors.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}