

Efficient Uncertainty Propagation in Model-Based Reinforcement Learning Unmanned Surface Vehicle Using Unscented Kalman Filter


Abstract
1. Introduction
- 1.
- Algorithmically, the proposed FPMPC-UKF first attempts to extend the potential of UKF uncertainty propagation to the GP-based MBRL. It not only contributes to a more effective solution to trade off the control performance and computational burden compared with the existing approaches with MPC-based policy [30,31,32] but also demonstrates the broad prospects of traditional optimal filtering methods in enhancing related MBRL approaches based on different prediction horizons [25] in more challenging control tasks.
- 2.
- On the side of traditional optimal filtering technologies, this work can be seen as extending the current state-of-the-art optimal filtering implementations in unmanned systems [36,37,38,39] to the trial-and-error RL framework. It expanded the usage of optimal filters in unmanned systems by adaptively obtaining an efficient filter to propagate system uncertainties without human prior knowledge of the target model.
- 3.
- On the side of the application of MBRL, a USV control system based on FPMPC-UKF was developed. We investigated the effect of sparse GP scales on both control capability and model prediction error in position-keeping and target-reaching tasks under different levels of disturbances. The proposed method significantly outperformed existing MBRL systems specific to USV [31,32] with over less offset while reducing more than computational burden. It enabled the higher control frequency in the existing work without damaging control performance and therefore expanded the practicability of probabilistic MBRL in the USV domain.
2. Preliminaries
2.1. Markov Decision Process of USV
2.2. Model-Based Reinforcement Learning
3. Approach
3.1. Probabilistic Model of USV
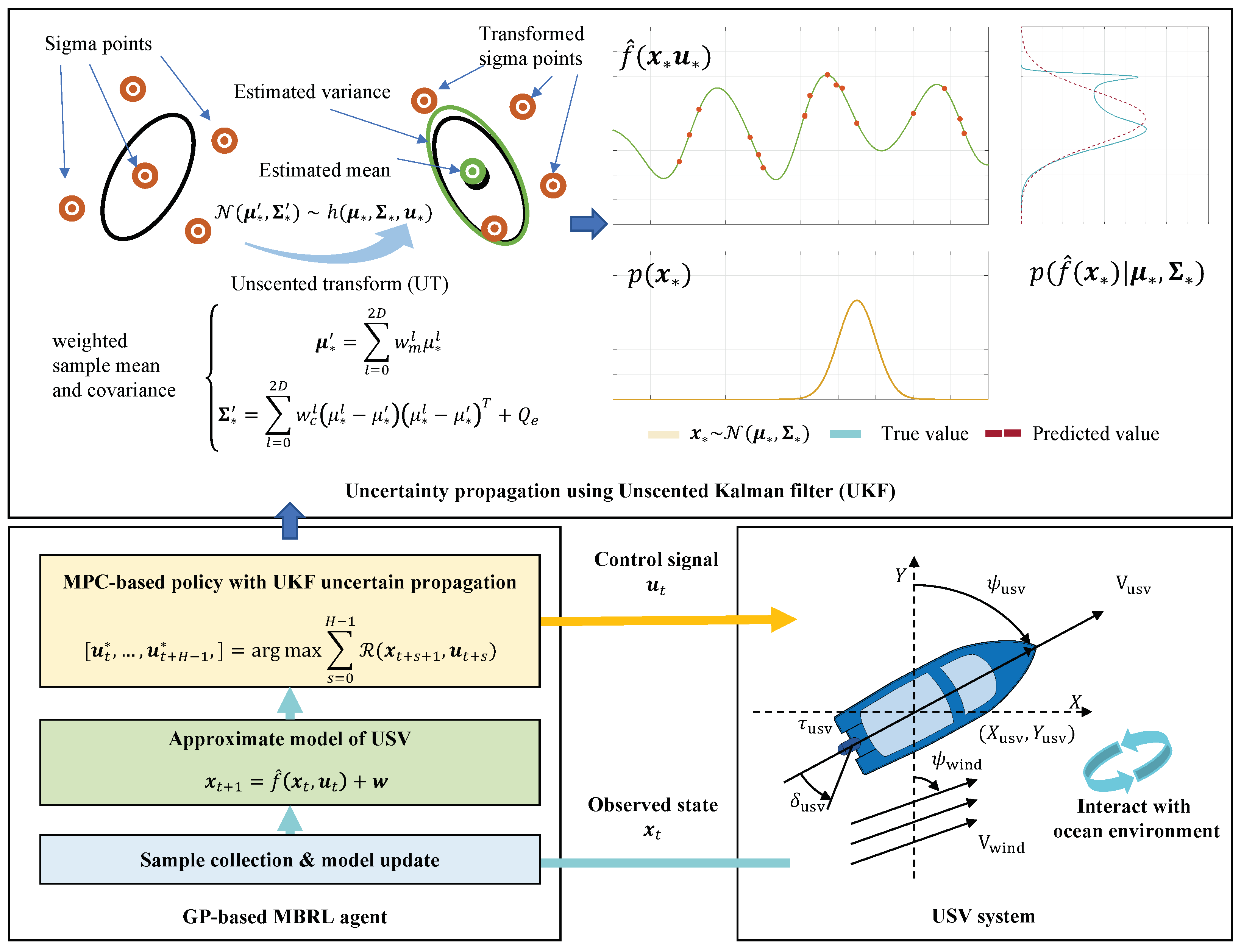
3.2. Uncertainty Propagation Using Unscented Kalman Filter
3.3. Filtered Probabilistic Model Predictive Control Using UKF
| Algorithm 1:Learning loop of FPMPC-UKF USV control system |
 |
4. Experimental Results
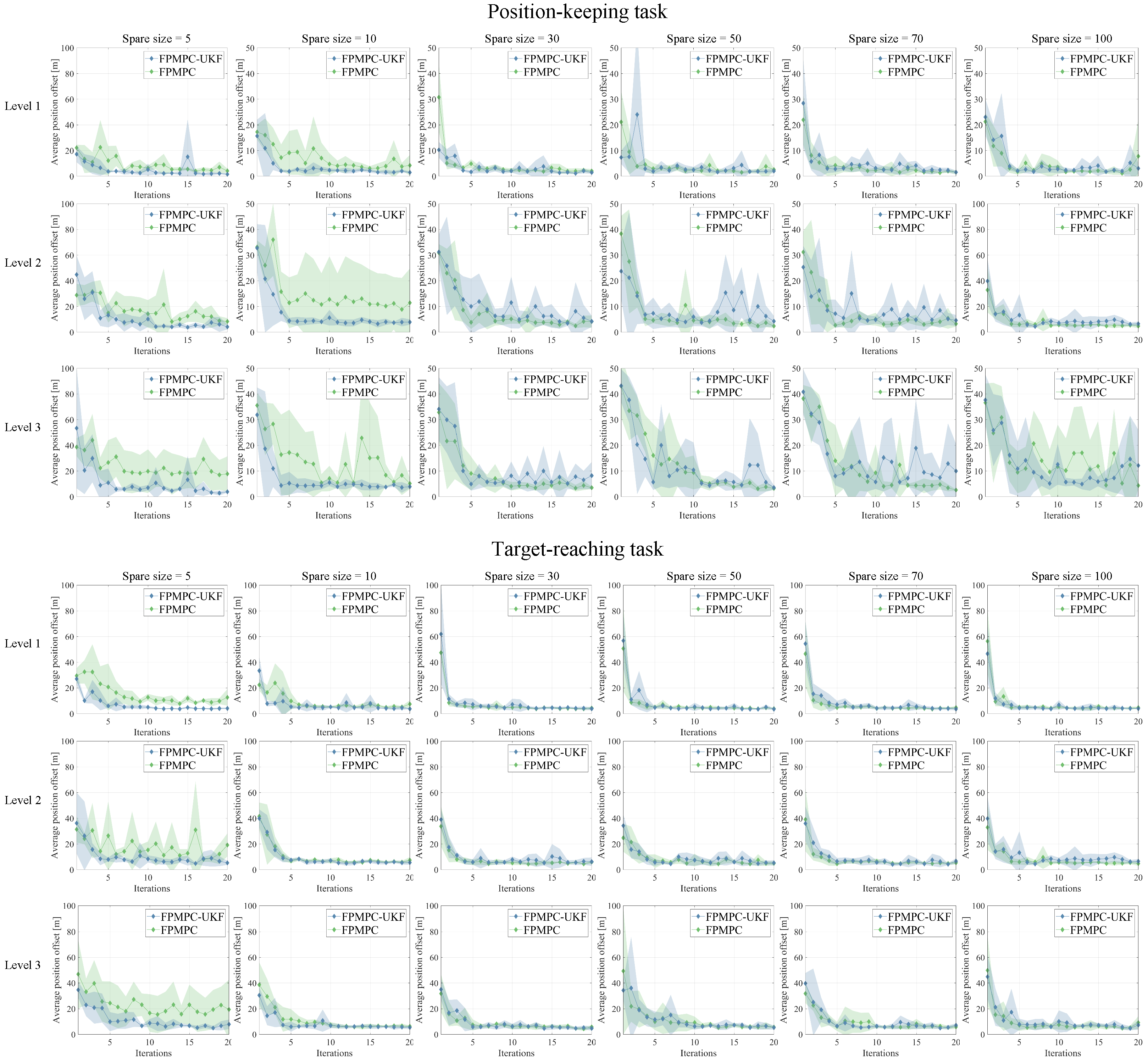
4.1. Simulation Settings
- ∗
- Level 1, , , m/s, m/s,
- ∗
- Level 2, , , m/s, m/s,
- ∗
- Level 3, , , m/s, m/s.
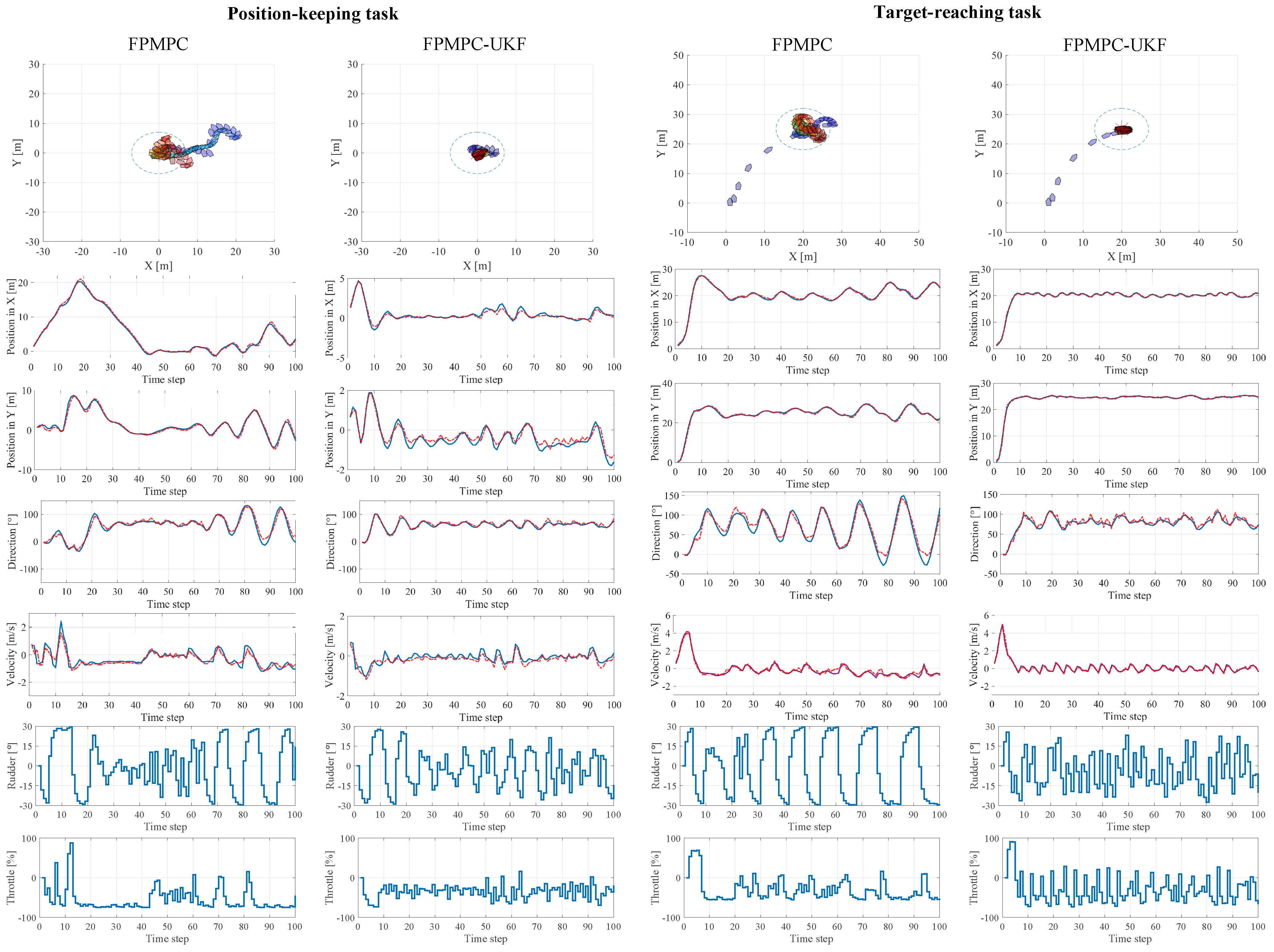
4.2. Evaluation of Learning Capability
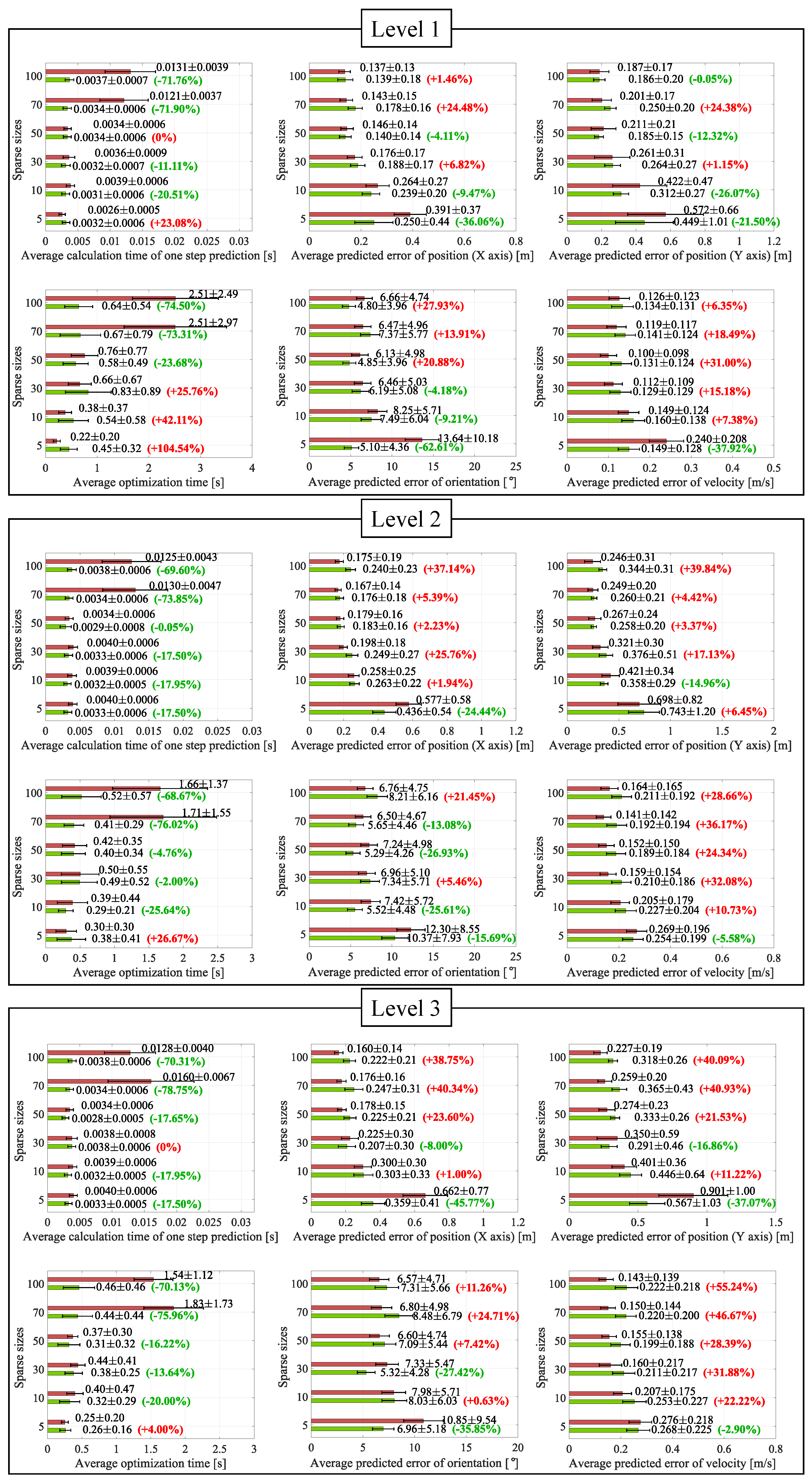
4.3. Evaluation of Computational Efficiency and Model Quality
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| USV | Unmanned Surface Vehicle |
| RL | Reinforcement Learning |
| MDP | Markov Decision Process |
| POMDP | Partially observed Markov Decision Process |
| MBRL | Model-based Reinforcement Learning |
| PILCO | Probabilistic Inference for Learning Control |
| GP | Gaussian Processes |
| MPC | Model Predictive Control |
| SPMPC | Sample-efficient Probabilistic Model Predictive Control |
| FPMPC | Filtered Probabilistic Model Predictive Control |
| UKF | Unscented Kalman Filter |
| UGV | Unmanned Ground Vehicle |
| UAV | Unmanned Aerial Vehicle |
| FPMPC-UKF | Filtered Probabilistic Model Predictive Control with Unscented Kalman Filter |
| UT | Unscented Transform |
References
- Sarda, E.I.; Qu, H.; Bertaska, I.R.; von Ellenrieder, K.D. Station-keeping control of an unmanned surface vehicle exposed to current and wind disturbances. Ocean. Eng. 2016, 127, 305–324. [Google Scholar] [CrossRef]
- Guo, G.; Zhang, P. Asymptotic Stabilization of USVs With Actuator Dead-Zones and Yaw Constraints Based on Fixed-Time Disturbance Observer. IEEE Trans. Veh. Technol. 2020, 69, 302–316. [Google Scholar] [CrossRef]
- Zhou, W.; Wang, Y.; Ahn, C.K.; Cheng, J.; Chen, C. Adaptive Fuzzy Backstepping-Based Formation Control of Unmanned Surface Vehicles With Unknown Model Nonlinearity and Actuator Saturation. IEEE Trans. Veh. Technol. 2020, 69, 14749–14764. [Google Scholar] [CrossRef]
- Yang, Y.; Wu, J.; Zheng, W. Station-keeping control for a stratospheric airship platform via fuzzy adaptive backstepping approach. Adv. Space Res. 2013, 51, 1157–1167. [Google Scholar] [CrossRef]
- Vu, M.T.; Le Thanh, H.N.N.; Huynh, T.T.; Thang, Q.; Duc, T.; Hoang, Q.D.; Le, T.H. Station-keeping control of a hovering over-actuated autonomous underwater vehicle under ocean current effects and model uncertainties in horizontal plane. IEEE Access 2021, 9, 6855–6867. [Google Scholar] [CrossRef]
- Wang, N.; Karimi, H.R. Successive Waypoints Tracking of an Underactuated Surface Vehicle. IEEE Trans. Ind. Informatics 2020, 16, 898–908. [Google Scholar] [CrossRef]
- Zhao, Z.; Zhu, B.; Zhou, Y.; Yao, P.; Yu, J. Cooperative Path Planning of Multiple Unmanned Surface Vehicles for Search and Coverage Task. Drones 2023, 7, 21. [Google Scholar] [CrossRef]
- Qin, H.; Wu, Z.; Sun, Y.; Chen, H. Disturbance-Observer-Based Prescribed Performance Fault-Tolerant Trajectory Tracking Control for Ocean Bottom Flying Node. IEEE Access 2019, 7, 49004–49013. [Google Scholar] [CrossRef]
- Wu, Y.; Low, K.H.; Lv, C. Cooperative Path Planning for Heterogeneous Unmanned Vehicles in a Search-and-Track Mission Aiming at an Underwater Target. IEEE Trans. Veh. Technol. 2020, 69, 6782–6787. [Google Scholar] [CrossRef]
- Wang, N.; He, H. Extreme Learning-Based Monocular Visual Servo of an Unmanned Surface Vessel. IEEE Trans. Ind. Informatics 2021, 17, 5152–5163. [Google Scholar] [CrossRef]
- Divelbiss, A.W.; Wen, J.T. Trajectory tracking control of a car-trailer system. IEEE Trans. Control. Syst. Technol. 1997, 5, 269–278. [Google Scholar] [CrossRef]
- Yu, R.; Shi, Z.; Huang, C.; Li, T.; Ma, Q. Deep reinforcement learning based optimal trajectory tracking control of autonomous underwater vehicle. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017; pp. 4958–4965. [Google Scholar]
- Eriksen, B.O.H.; Breivik, M.; Wilthil, E.F.; Flåten, A.L.; Brekke, E.F. The branching-course model predictive control algorithm for maritime collision avoidance. J. Field Robot. 2019, 36, 1222–1249. [Google Scholar] [CrossRef]
- Wang, N.; Su, S.F.; Pan, X.; Yu, X.; Xie, G. Yaw-guided trajectory tracking control of an asymmetric underactuated surface vehicle. IEEE Trans. Ind. Informatics 2018, 15, 3502–3513. [Google Scholar] [CrossRef]
- United Nations Conference on Trade and Development. Review of Maritime Transport 2018; United Nations: Geneva, Switzerland, 2018; p. 115. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction. MIT Press: Cambridge, UK, 1998. [Google Scholar]
- Kober, J.; Bagnell, J.A.; Peters, J. Reinforcement learning in robotics: A survey. Int. J. Robot. Res. 2013, 32, 1238–1274. [Google Scholar] [CrossRef]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Wang, N.; Gao, Y.; Zhang, X. Data-Driven Performance-Prescribed Reinforcement Learning Control of an Unmanned Surface Vehicle. IEEE Trans. Neural Networks Learn. Syst. 2021, 32, 1–12. [Google Scholar] [CrossRef]
- Zhao, Y.; Qi, X.; Ma, Y.; Li, Z.; Malekian, R.; Sotelo, M.A. Path Following Optimization for an Underactuated USV Using Smoothly-Convergent Deep Reinforcement Learning. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1–13. [Google Scholar] [CrossRef]
- Zhao, L.; Roh, M.I. COLREGs-compliant multiship collision avoidance based on deep reinforcement learning. Ocean Eng. 2019, 191, 106436. [Google Scholar] [CrossRef]
- Woo, J.; Yu, C.; Kim, N. Deep reinforcement learning-based controller for path following of an unmanned surface vehicle. Ocean Eng. 2019, 183, 155–166. [Google Scholar] [CrossRef]
- Wang, N.; Zhang, Y.; Ahn, C.K.; Xu, Q. Autonomous Pilot of Unmanned Surface Vehicles: Bridging Path Planning and Tracking. IEEE Trans. Veh. Technol. 2022, 71, 2358–2374. [Google Scholar] [CrossRef]
- Woo, J.; Kim, N. Collision avoidance for an unmanned surface vehicle using deep reinforcement learning. Ocean Eng. 2020, 199, 107001. [Google Scholar] [CrossRef]
- Deisenroth, M.P.; Fox, D.; Rasmussen, C.E. Gaussian Processes for Data-Efficient Learning in Robotics and Control. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 408–423. [Google Scholar] [CrossRef] [PubMed]
- Rasmussen, C.E.; Williams, C.K. Gaussian Processes for Machine Learning; MIT Press: Cambridge, UK, 2006. [Google Scholar]
- Girard, A.; Rasmussen, C.E.; Candela, J.Q.; Murray-Smith, R. Gaussian process priors with uncertain inputs application to multiple-step ahead time series forecasting. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, UK, 2003; pp. 545–552. [Google Scholar]
- Bischoff, B.; Nguyen-Tuong, D.; van Hoof, H.; McHutchon, A.; Rasmussen, C.E.; Knoll, A.; Peters, J.; Deisenroth, M.P. Policy search for learning robot control using sparse data. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 3882–3887. [Google Scholar]
- Cutler, M.; How, J.P. Efficient reinforcement learning for robots using informative simulated priors. In Proceedings of the 2015 IEEE international conference on robotics and automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 2605–2612. [Google Scholar]
- Kamthe, S.; Deisenroth, M. Data-Efficient Reinforcement Learning with Probabilistic Model Predictive Control. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Laguna Hills, CA, USA, 25–26 March 2018; pp. 1701–1710. [Google Scholar]
- Cui, Y.; Osaki, S.; Matsubara, T. Autonomous boat driving system using sample-efficient model predictive control-based reinforcement learning approach. J. Field Robot. 2021, 38, 331–354. [Google Scholar] [CrossRef]
- Cui, Y.; Peng, L.; Li, H. Filtered Probabilistic Model Predictive Control-Based Reinforcement Learning for Unmanned Surface Vehicles. IEEE Trans. Ind. Informatics 2022, 18, 6950–6961. [Google Scholar] [CrossRef]
- Snelson, E.; Ghahramani, Z. Sparse Gaussian processes using pseudo-inputs. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, UK, 2005; Volume 18. [Google Scholar]
- Wan, E.A.; Van Der Merwe, R. The unscented Kalman filter. In Kalman Filtering and Neural Networks; Oregon Graduate Institute of Science & Technology: Beaverton, OR, USA, 2001; pp. 221–280. [Google Scholar]
- Ko, J.; Klein, D.J.; Fox, D.; Haehnel, D. GP-UKF: Unscented Kalman filters with Gaussian process prediction and observation models. In Proceedings of the 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 29–30 June 2007; pp. 1901–1907. [Google Scholar]
- Ostafew, C.J.; Schoellig, A.P.; Barfoot, T.D. Robust constrained learning-based NMPC enabling reliable mobile robot path tracking. Int. J. Robot. Res. 2016, 35, 1547–1563. [Google Scholar] [CrossRef]
- Liu, Z.; Li, Y.; Wu, Y.; He, S. Formation control of nonholonomic unmanned ground vehicles via unscented Kalman filter-based sensor fusion approach. ISA Trans. 2022, 125, 60–71. [Google Scholar] [CrossRef]
- Zhai, C.; Wang, M.; Yang, Y.; Shen, K. Robust vision-aided inertial navigation system for protection against ego-motion uncertainty of unmanned ground vehicle. IEEE Trans. Ind. Electron. 2020, 68, 12462–12471. [Google Scholar] [CrossRef]
- Song, W.; Wang, J.; Zhao, S.; Shan, J. Event-triggered cooperative unscented Kalman filtering and its application in multi-UAV systems. Automatica 2019, 105, 264–273. [Google Scholar] [CrossRef]
- Wang, Y.; Chai, S.; Nguyen, H.D. Unscented Kalman filter trained neural network control design for ship autopilot with experimental and numerical approaches. Appl. Ocean. Res. 2019, 85, 162–172. [Google Scholar] [CrossRef]
- Shen, H.; Wen, G.; Lv, Y.; Zhou, J.; Wang, L. USV Parameter Estimation: Adaptive Unscented Kalman Filter-Based Approach. IEEE Trans. Ind. Informatics 2022, 1–10. [Google Scholar] [CrossRef]
- Deisenroth, M.P. Efficient Reinforcement Learning using Gaussian Processes. Ph.D. Thesis, Fakultat fur Informatik, Karlsruhe, Germany, 2010. [Google Scholar] [CrossRef]
- Matthews, A.G.d.G.; Van Der Wilk, M.; Nickson, T.; Fujii, K.; Boukouvalas, A.; León-Villagrá, P.; Ghahramani, Z.; Hensman, J. GPflow: A Gaussian Process Library using TensorFlow. J. Mach. Learn. Res. 2017, 18, 1–6. [Google Scholar]
- Powell, M.J. The BOBYQA Algorithm for Bound Constrained Optimization without Derivatives; Cambridge NA Report NA2009/06; University of Cambridge: Cambridge, UK, 2009; Volume 26, pp. 1–39. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Uncertainty Propagation | MBRL | MPC | USV |
|---|---|---|---|---|
| PILCO [25] | analytic moment-matching | ◯ | × | × |
| GP-MPC [30] | analytic moment-matching | ◯ | ◯ | × |
| SPMPC [31], FPMPC [32] | analytic moment-matching | ◯ | ◯ | ◯ |
| RC-LB-NMPC [36] | UKF | × | ◯ | × |
| RBFNN-UKF [40] | UKF | × | × | × |
| FPMPC-UKF (proposed) | UKF | ◯ | ◯ | ◯ |
| Disturbances | Method | Sparse Sizes | Average Offset [m] | Median Offset [m] | Success Rate (Final) | Success Rate (Overall) |
|---|---|---|---|---|---|---|
| Level 1 | FPMPC | 5 | ||||
| 10 | ||||||
| 30 | ||||||
| 50 | ||||||
| 70 | ||||||
| 100 | ||||||
| FPMPC-UKF | 5 | |||||
| 10 | ||||||
| 30 | ||||||
| 50 | ||||||
| 70 | ||||||
| 100 | ||||||
| Level 2 | FPMPC | 5 | ||||
| 10 | ||||||
| 30 | ||||||
| 50 | ||||||
| 70 | ||||||
| 100 | ||||||
| FPMPC-UKF | 5 | |||||
| 10 | ||||||
| 30 | ||||||
| 50 | ||||||
| 70 | ||||||
| 100 | ||||||
| Level 3 | FPMPC | 5 | ||||
| 10 | ||||||
| 30 | ||||||
| 50 | ||||||
| 70 | ||||||
| 100 | ||||||
| FPMPC-UKF | 5 | |||||
| 10 | ||||||
| 30 | ||||||
| 50 | ||||||
| 70 | ||||||
| 100 |
| Disturbances | Method | Sparse Sizes | Average Offset [m] | Median Offset [m] | Success Rate (Final) |
|---|---|---|---|---|---|
| Level 1 | FPMPC | 5 | |||
| 10 | |||||
| 30 | |||||
| 50 | |||||
| 70 | |||||
| 100 | |||||
| FPMPC-UKF | 5 | ||||
| 10 | |||||
| 30 | |||||
| 50 | |||||
| 70 | |||||
| 100 | |||||
| Level 2 | FPMPC | 5 | |||
| 10 | |||||
| 30 | |||||
| 50 | |||||
| 70 | |||||
| 100 | |||||
| FPMPC-UKF | 5 | ||||
| 10 | |||||
| 30 | |||||
| 50 | |||||
| 70 | |||||
| 100 | |||||
| Level 3 | FPMPC | 5 | |||
| 10 | |||||
| 30 | |||||
| 50 | |||||
| 70 | |||||
| 100 | |||||
| FPMPC-UKF | 5 | ||||
| 10 | |||||
| 30 | |||||
| 50 | |||||
| 70 | |||||
| 100 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Xia, L.; Peng, L.; Li, H.; Cui, Y. Efficient Uncertainty Propagation in Model-Based Reinforcement Learning Unmanned Surface Vehicle Using Unscented Kalman Filter. Drones 2023, 7, 228. https://doi.org/10.3390/drones7040228
Wang J, Xia L, Peng L, Li H, Cui Y. Efficient Uncertainty Propagation in Model-Based Reinforcement Learning Unmanned Surface Vehicle Using Unscented Kalman Filter. Drones. 2023; 7(4):228. https://doi.org/10.3390/drones7040228
Chicago/Turabian StyleWang, Jincheng, Lei Xia, Lei Peng, Huiyun Li, and Yunduan Cui. 2023. "Efficient Uncertainty Propagation in Model-Based Reinforcement Learning Unmanned Surface Vehicle Using Unscented Kalman Filter" Drones 7, no. 4: 228. https://doi.org/10.3390/drones7040228
APA StyleWang, J., Xia, L., Peng, L., Li, H., & Cui, Y. (2023). Efficient Uncertainty Propagation in Model-Based Reinforcement Learning Unmanned Surface Vehicle Using Unscented Kalman Filter. Drones, 7(4), 228. https://doi.org/10.3390/drones7040228