



Swarm Cooperative Navigation Using Centralized Training and Decentralized Execution


Abstract
1. Introduction
1.1. Related Work
1.2. Contributions
- The development of a scalable, real-time, autonomous MARL-based collaborative navigation approach for a swarm of UAVs using centralized training and decentralized execution.
- The training of the proposed collaborative navigation approach based on a combination of curriculum learning and early stopping using a reward formulation that encourages cooperative behavior during decentralized execution by means of positive reinforcement.
- Demonstration of the proposed collaborative navigation approach in a load delivery scenario and in swarm formation.
- Extensive testing of the proposed approach across various initial conditions, swarm sizes, UAV speeds, UAV loads, and environment sizes.
2. Methods
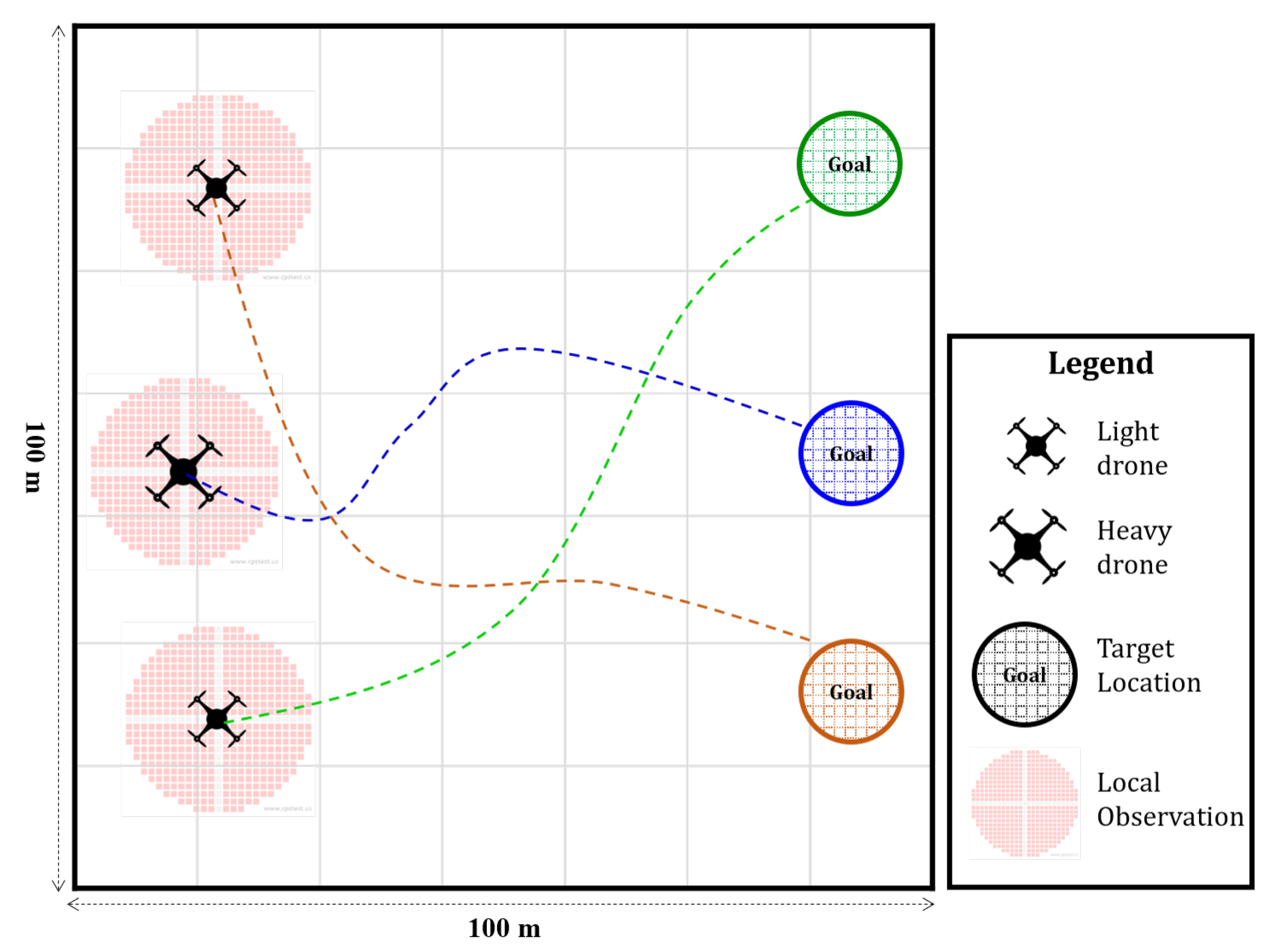
2.1. Task Description
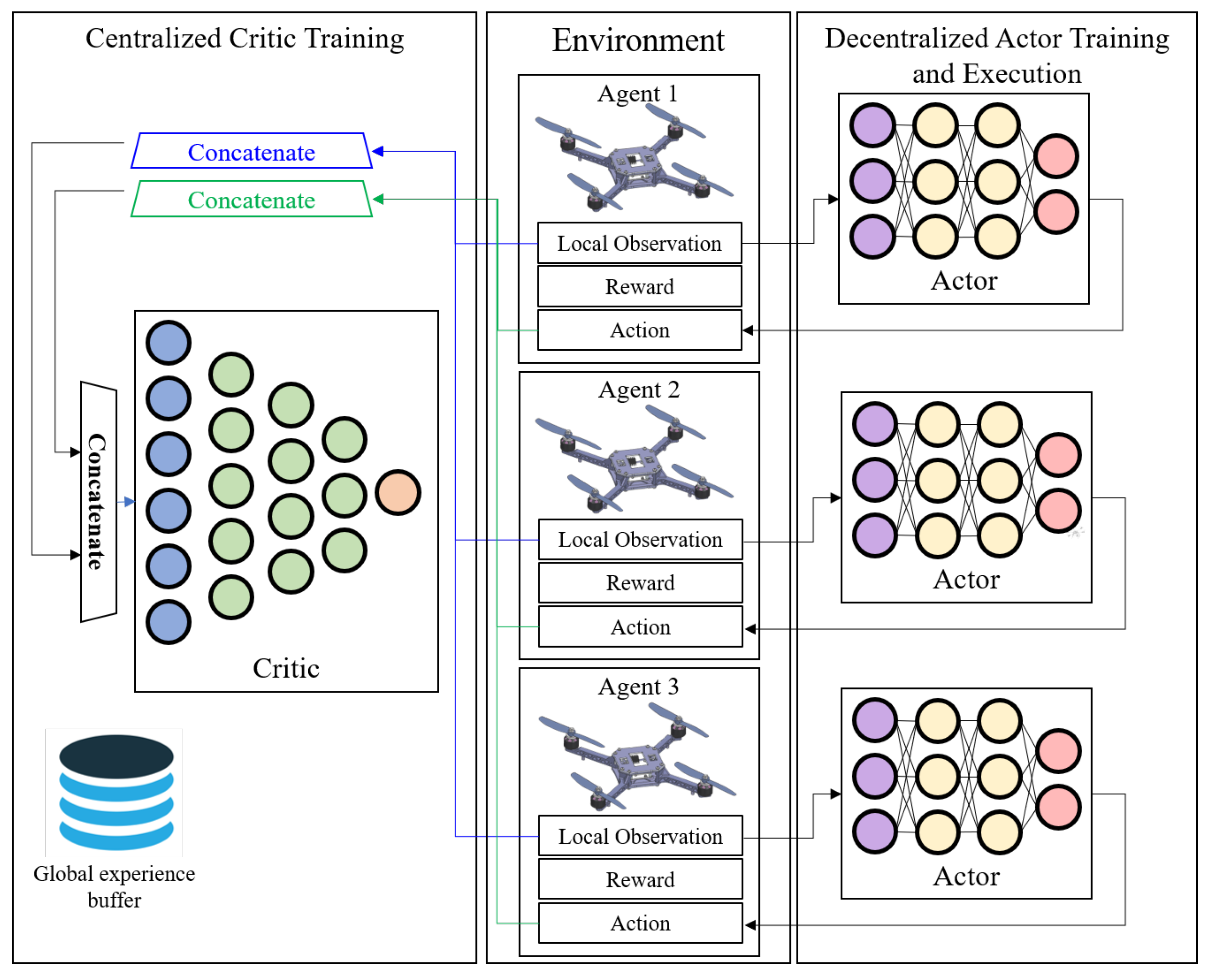
2.2. Centralized Training and Decentralized Execution
- State space (): the global setting of the environment including all the agents.
- Observation space (): the set of individual observations that agents perceive from the environment.
- Action space (): a set of actions that the agents execute in the environment.
- Reward (R): the incentives that agents receive upon acting in the environment.
- Transition function (): defines how agents transition from one state to another.
2.3. Proposed Model
2.3.1. Actor and Critic Architecture
2.3.2. State Space and Action Space
2.3.3. Reward Formulation
2.4. Curriculum Learning
2.5. UAV Dynamics
3. Results and Discussion
3.1. Model Training
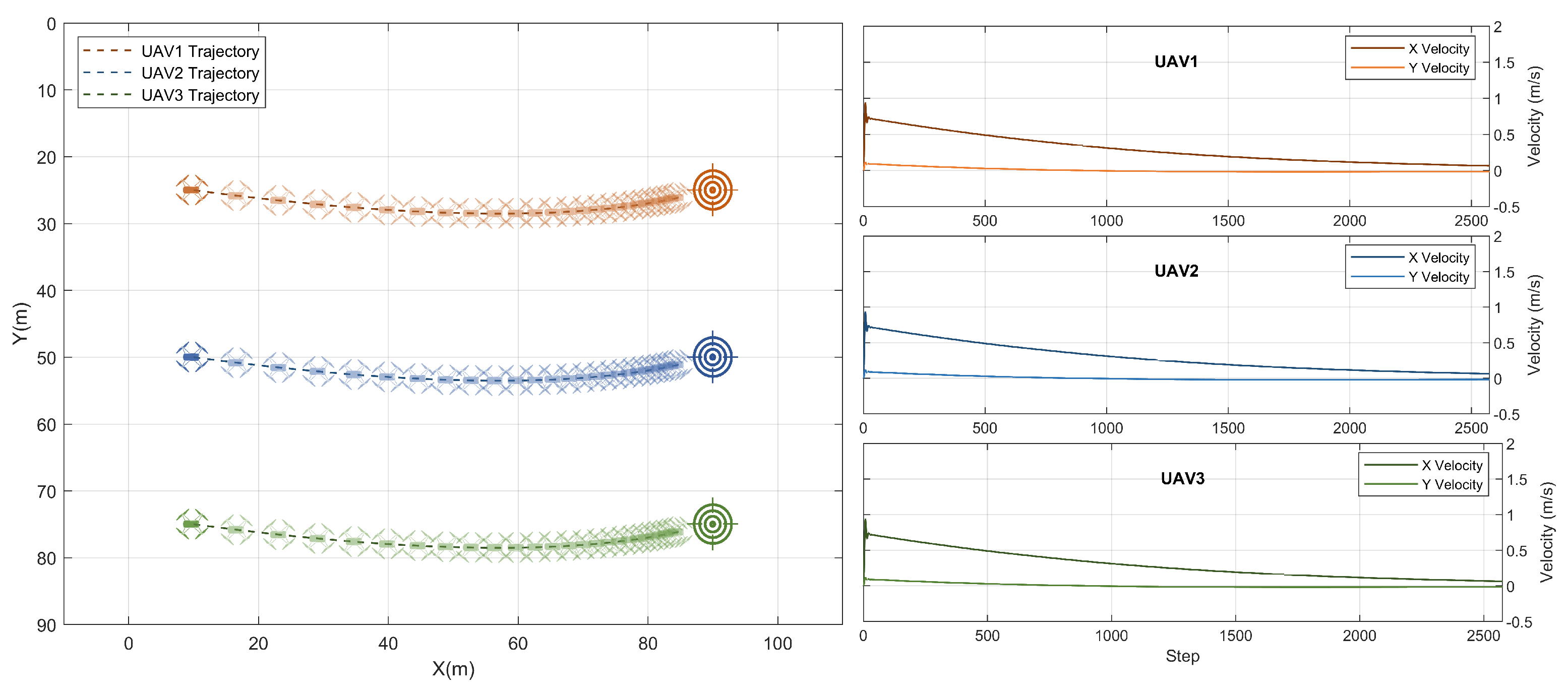
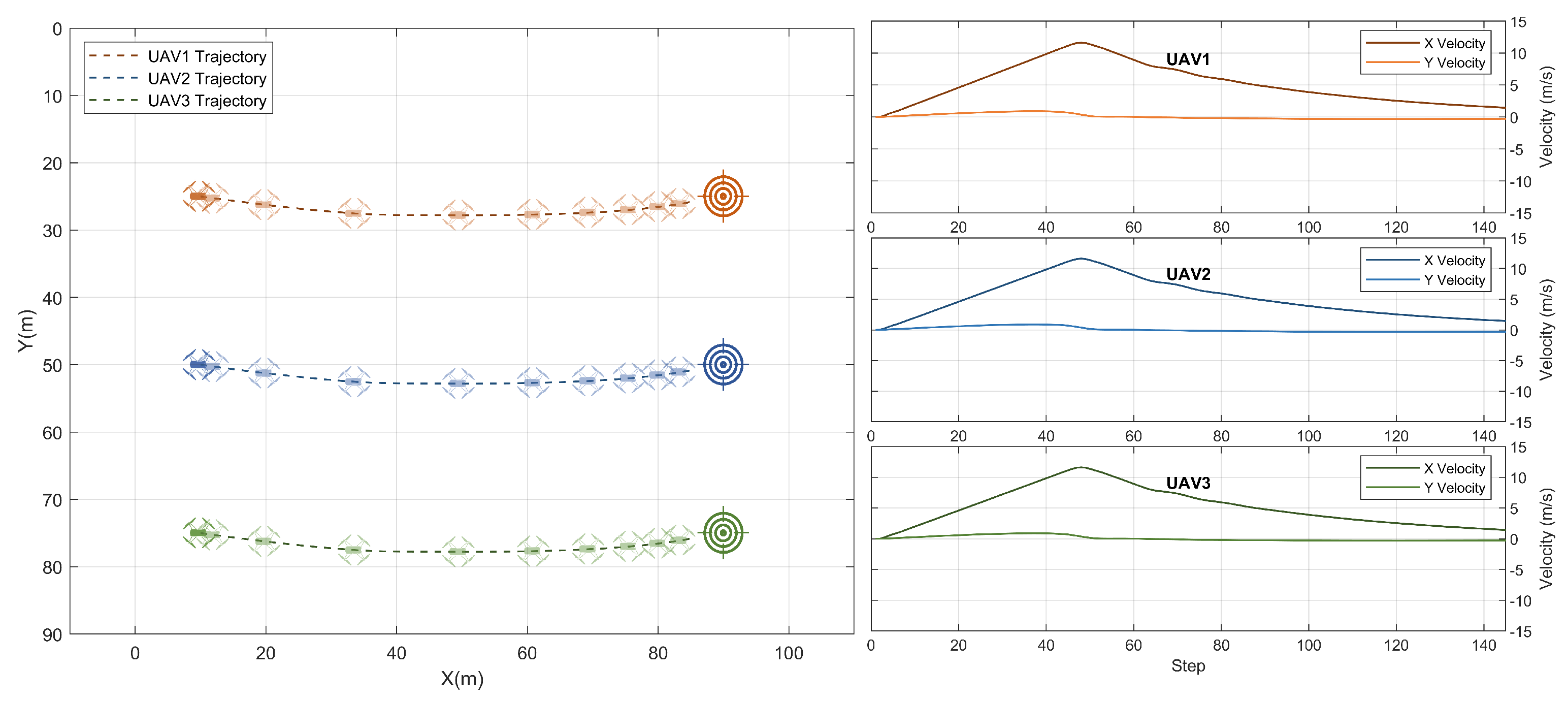
3.2. Testing with Variable Swarm Speeds
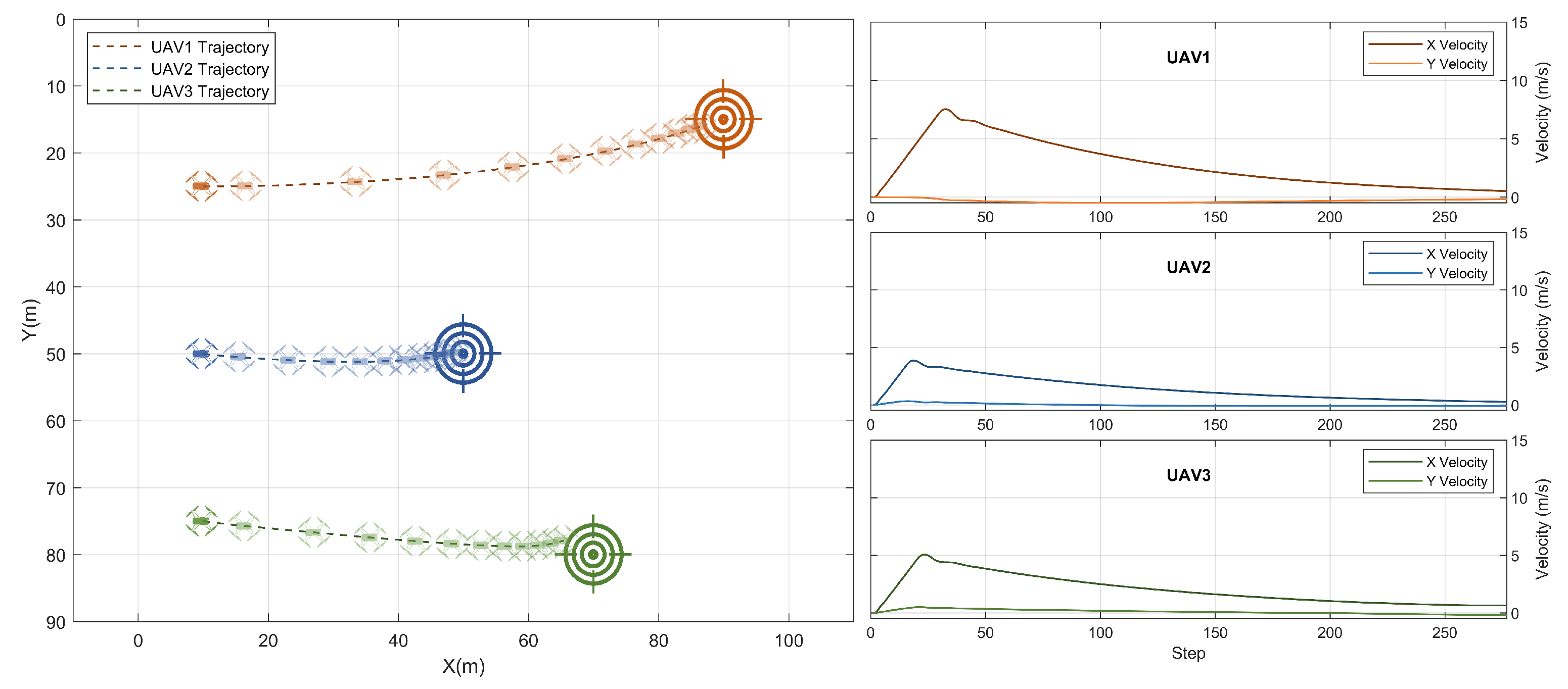
3.3. Testing with Different Goal Positions
3.4. Load Drop-Off Scenario in a Large Environment
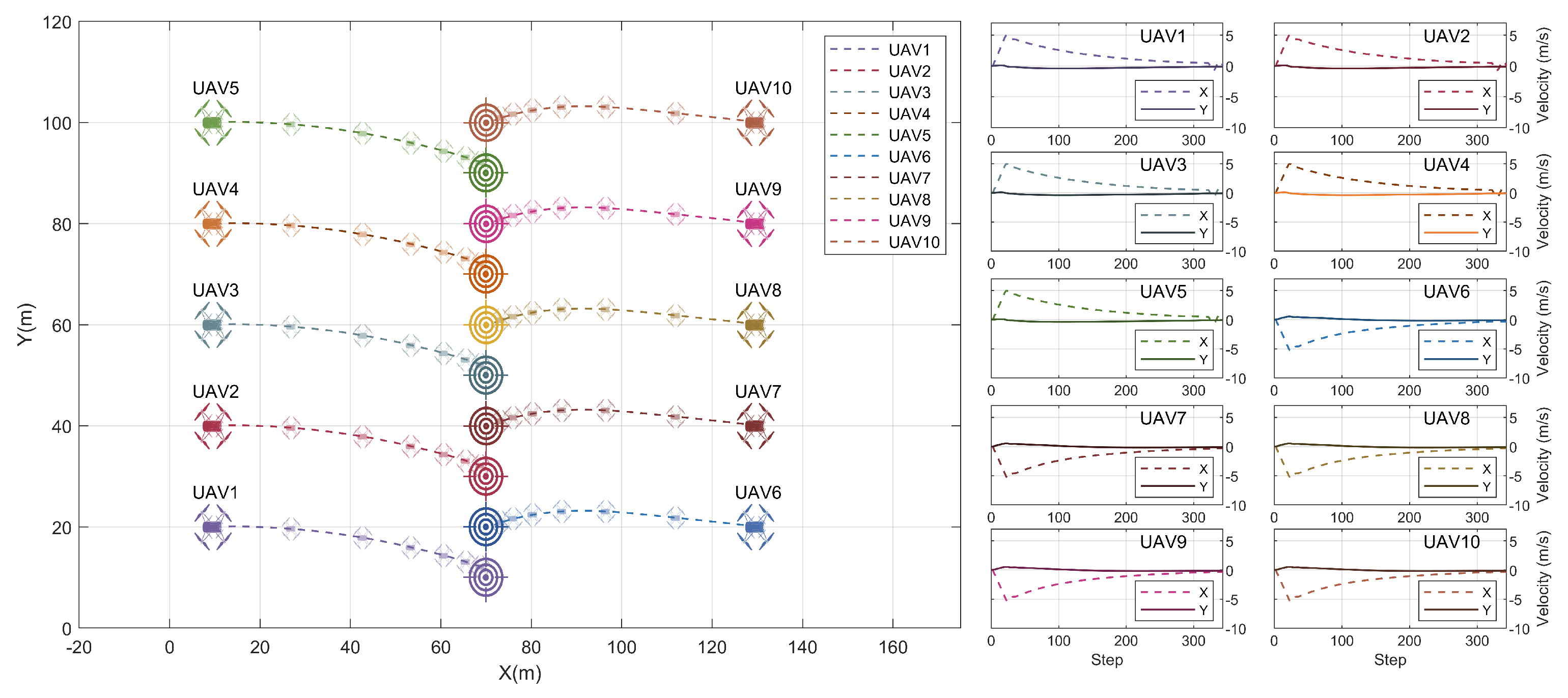
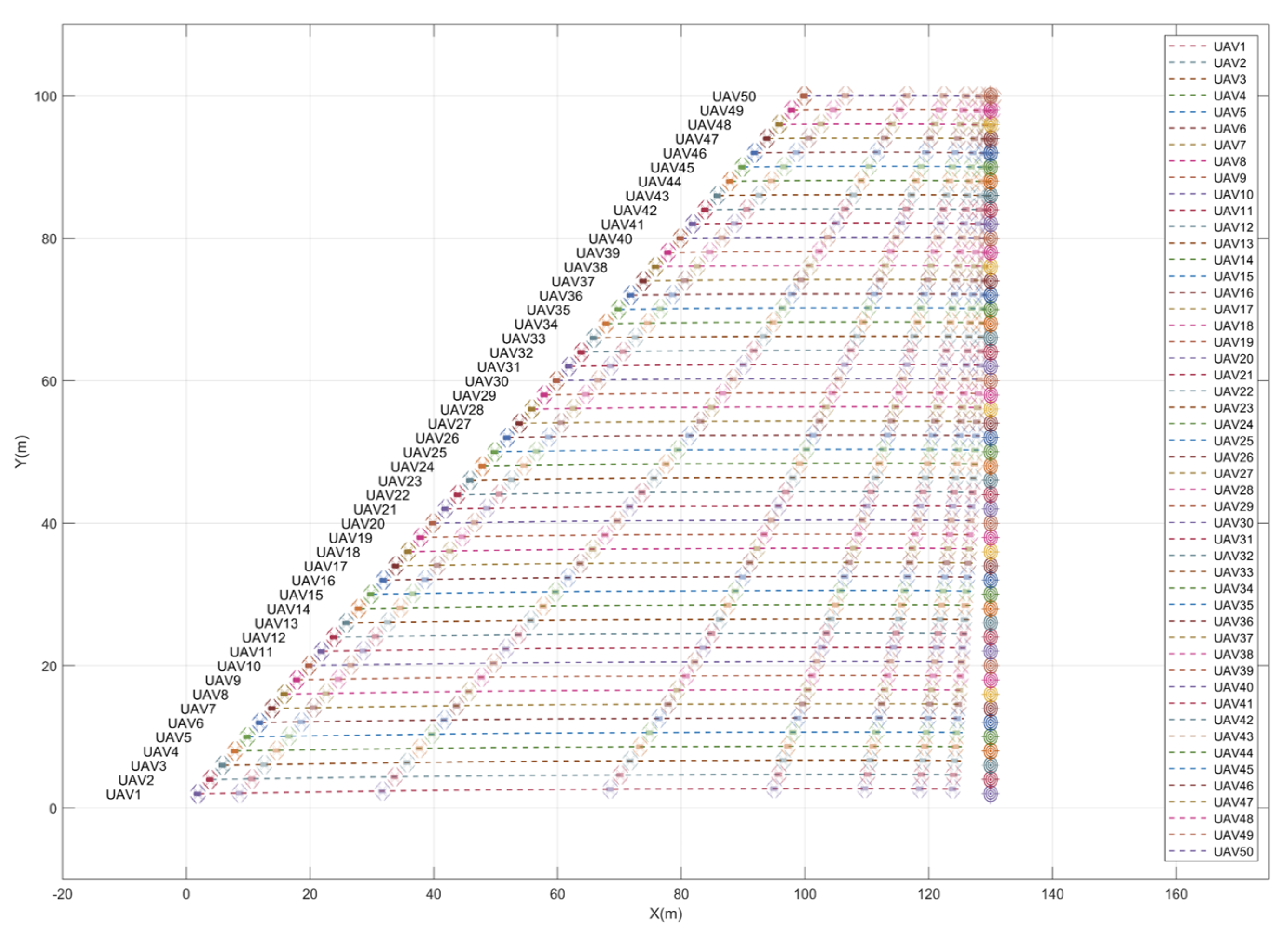
3.5. Testing with Variable Swarm Sizes
3.6. Action Smoothness
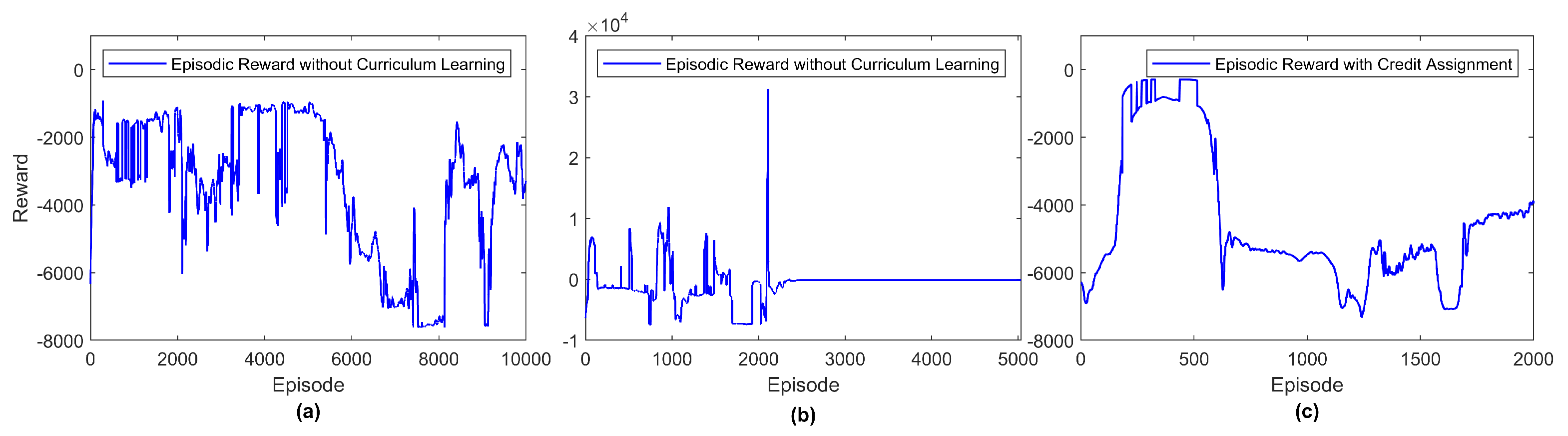
3.7. Training Convergence
3.8. Centralized Collaborative Navigation
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cavone, G.; Epicoco, N.; Carli, R.; Del Zotti, A.; Paulo Ribeiro Pereira, J.; Dotoli, M. Parcel Delivery with Drones: Multi-criteria Analysis of Trendy System Architectures. In Proceedings of the 29th Mediterranean Conference on Control and Automation (MED), Bari, Italy, 22–25 June 2021; pp. 693–698. [Google Scholar] [CrossRef]
- Saunders, J.; Saeedi, S.; Li, W. Autonomous Aerial Delivery Vehicles, a Survey of Techniques on how Aerial Package Delivery is Achieved. arXiv 2021, arXiv:2110.02429. [Google Scholar]
- Li, M.; Richards, A.; Sooriyabandara, M. Asynchronous Reliability-Aware Multi-UAV Coverage Path Planning. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 10023–10029. [Google Scholar] [CrossRef]
- Alotaibi, E.T.; Alqefari, S.S.; Koubaa, A. LSAR: Multi-UAV Collaboration for Search and Rescue Missions. IEEE Access 2019, 7, 55817–55832. [Google Scholar] [CrossRef]
- Jiang, Y.; Bai, T.; Wang, Y. Formation Control Algorithm of Multi-UAVs Based on Alliance. Drones 2022, 6, 431. [Google Scholar] [CrossRef]
- Abichandani, P.; Lobo, D.; Muralidharan, M.; Runk, N.; McIntyre, W.; Bucci, D.; Benson, H. Distributed Motion Planning for Multiple Quadrotors in Presence of Wind Gusts. Drones 2023, 7, 58. [Google Scholar] [CrossRef]
- Huang, Y.; Tang, J.; Lao, S. Cooperative Multi-UAV Collision Avoidance Based on a Complex Network. Appl. Sci. 2019, 9, 3943. [Google Scholar] [CrossRef]
- Plaat, A. Deep Reinforcement Learning. arXiv 2022, arXiv:2201.02135. [Google Scholar]
- Zhang, K.; Yang, Z.; Basar, T. Multi-Agent Reinforcement Learning: A Selective Overview of Theories and Algorithms. arXiv 2019, arXiv:1911.10635. [Google Scholar]
- Chen, Y.; Dong, Q.; Shang, X.; Wu, Z.; Wang, J. Multi-UAV Autonomous Path Planning in Reconnaissance Missions Considering Incomplete Information: A Reinforcement Learning Method. Drones 2023, 7, 10. [Google Scholar] [CrossRef]
- Yan, P.; Bai, C.; Zheng, H.; Guo, J. Flocking Control of UAV Swarms with Deep Reinforcement Leaming Approach. In Proceedings of the 2020 3rd International Conference on Unmanned Systems (ICUS), Harbin, China, 27–28 November 2020; pp. 592–599. [Google Scholar] [CrossRef]
- Reynolds, C.W. Flocks, Herds and Schools: A Distributed Behavioral Model. SIGGRAPH Comput. Graph. 1987, 21, 25–34. [Google Scholar] [CrossRef]
- Wu, D.; Wan, K.; Tang, J.; Gao, X.; Zhai, Y.; Qi, Z. An Improved Method towards Multi-UAV Autonomous Navigation Using Deep Reinforcement Learning. In Proceedings of the 2022 7th International Conference on Control and Robotics Engineering (ICCRE), Beijing, China, 15–17 April 2022; pp. 96–101. [Google Scholar] [CrossRef]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments. arXiv 2017, arXiv:1706.02275. [Google Scholar]
- Thumiger, N.; Deghat, M. A Multi-Agent Deep Reinforcement Learning Approach for Practical Decentralized UAV Collision Avoidance. IEEE Control. Syst. Lett. 2022, 6, 2174–2179. [Google Scholar] [CrossRef]
- Yue, L.; Yang, R.; Zuo, J.; Zhang, Y.; Li, Q.; Zhang, Y. Unmanned Aerial Vehicle Swarm Cooperative Decision-Making for SEAD Mission: A Hierarchical Multiagent Reinforcement Learning Approach. IEEE Access 2022, 10, 92177–92191. [Google Scholar] [CrossRef]
- Xu, D.; Guo, Y.; Yu, Z.; Wang, Z.; Lan, R.; Zhao, R.; Xie, X.; Long, H. PPO-Exp: Keeping Fixed-Wing UAV Formation with Deep Reinforcement Learning. Drones 2023, 7, 28. [Google Scholar] [CrossRef]
- Li, S.; Jia, Y.; Yang, F.; Qin, Q.; Gao, H.; Zhou, Y. Collaborative Decision-Making Method for Multi-UAV Based on Multiagent Reinforcement Learning. IEEE Access 2022, 10, 91385–91396. [Google Scholar] [CrossRef]
- Wang, W.; Wang, L.; Wu, J.; Tao, X.; Wu, H. Oracle-Guided Deep Reinforcement Learning for Large-Scale Multi-UAVs Flocking and Navigation. IEEE Trans. Veh. Technol. 2022, 71, 10280–10292. [Google Scholar] [CrossRef]
- Shen, G.; Lei, L.; Li, Z.; Cai, S.; Zhang, L.; Cao, P.; Liu, X. Deep Reinforcement Learning for Flocking Motion of Multi-UAV Systems: Learn From a Digital Twin. IEEE Internet Things J. 2022, 9, 11141–11153. [Google Scholar] [CrossRef]
- Sunehag, P.; Lever, G.; Gruslys, A.; Czarnecki, W.M.; Zambaldi, V.F.; Jaderberg, M.; Lanctot, M.; Sonnerat, N.; Leibo, J.Z.; Tuyls, K.; et al. Value-Decomposition Networks For Cooperative Multi-Agent Learning. arXiv 2017, arXiv:1706.05296. [Google Scholar]
- Feng, L.; Xie, Y.; Liu, B.; Wang, S. Multi-Level Credit Assignment for Cooperative Multi-Agent Reinforcement Learning. Appl. Sci. 2022, 12, 6938. [Google Scholar] [CrossRef]
- Foerster, J.N.; Farquhar, G.; Afouras, T.; Nardelli, N.; Whiteson, S. Counterfactual Multi-Agent Policy Gradients. arXiv 2017, arXiv:1705.08926. [Google Scholar] [CrossRef]
- Li, J.; Kuang, K.; Wang, B.; Liu, F.; Chen, L.; Wu, F.; Xiao, J. Shapley Counterfactual Credits for Multi-Agent Reinforcement Learning. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Online, 14–18 August 2021; ACM: New York, NY, USA, 2021. [Google Scholar] [CrossRef]
- Huang, S.; Zhang, H.; Huang, Z. Multi-UAV Collision Avoidance Using Multi-Agent Reinforcement Learning with Counterfactual Credit Assignment. arXiv 2022, arXiv:2204.08594. [Google Scholar] [CrossRef]
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum Learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; Association for Computing Machinery: New York, NY, USA, 2009; Volume ICML ’09, pp. 41–48. [Google Scholar] [CrossRef]
- AlKayas, A.Y.; Chehadeh, M.; Ayyad, A.; Zweiri, Y. Systematic Online Tuning of Multirotor UAVs for Accurate Trajectory Tracking Under Wind Disturbances and In-Flight Dynamics Changes. IEEE Access 2022, 10, 6798–6813. [Google Scholar] [CrossRef]
- Pounds, P.; Mahony, R.; Corke, P. Modelling and control of a large quadrotor robot. Control. Eng. Pract. 2010, 18, 691–699. [Google Scholar] [CrossRef]
- Chehadeh, M.S.; Boiko, I. Design of rules for in-flight non-parametric tuning of PID controllers for unmanned aerial vehicles. J. Frankl. Inst. 2019, 356, 474–491. [Google Scholar] [CrossRef]
- Ayyad, A.; Chehadeh, M.; Awad, M.I.; Zweiri, Y. Real-Time System Identification Using Deep Learning for Linear Processes With Application to Unmanned Aerial Vehicles. IEEE Access 2020, 8, 122539–122553. [Google Scholar] [CrossRef]
- Lee, T.; Leok, M.; McClamroch, N.H. Geometric tracking control of a quadrotor UAV on SE (3). In Proceedings of the 49th IEEE Conference on Decision and Control (CDC), Atlanta, GA, USA, 15–17 December 2010; IEEE: PIscatway, NJ, USA, 2010; pp. 5420–5425. [Google Scholar]
- Ayyad, A.; Chehadeh, M.; Silva, P.H.; Wahbah, M.; Hay, O.A.; Boiko, I.; Zweiri, Y. Multirotors From Takeoff to Real-Time Full Identification Using the Modified Relay Feedback Test and Deep Neural Networks. IEEE Trans. Control. Syst. Technol. 2021, 1–17. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https://www.tensorflow.org (accessed on 15 September 2022).
- Ibarz, J.; Tan, J.; Finn, C.; Kalakrishnan, M.; Pastor, P.; Levine, S. How to Train Your Robot with Deep Reinforcement Learning; Lessons We’ve Learned. arXiv 2021, arXiv:2102.02915. [Google Scholar]
- Azzam, R.; Chehadeh, M.; Hay, O.A.; Boiko, I.; Zweiri, Y. Learning to Navigate Through Reinforcement Across the Sim2Real Gap. arXiv 2022, arXiv:20138960. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Transfer Function | Type | Purpose | Symbols |
|---|---|---|---|
| (9) | First order plus time delay | Maps ESC inputs to force/torque output | : propulsion static gain : propulsion system delay : propulsion time constant |
| (10) | First order system with an integrator | Models attitude and altitude dynamics | : time constant - drag dynamics : system inertia |
| (11) | cascaded with | Maps ESC commands to UAV attitude and altitude | : total inner dynamics’ delay |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Azzam, R.; Boiko, I.; Zweiri, Y. Swarm Cooperative Navigation Using Centralized Training and Decentralized Execution. Drones 2023, 7, 193. https://doi.org/10.3390/drones7030193
Azzam R, Boiko I, Zweiri Y. Swarm Cooperative Navigation Using Centralized Training and Decentralized Execution. Drones. 2023; 7(3):193. https://doi.org/10.3390/drones7030193
Chicago/Turabian StyleAzzam, Rana, Igor Boiko, and Yahya Zweiri. 2023. "Swarm Cooperative Navigation Using Centralized Training and Decentralized Execution" Drones 7, no. 3: 193. https://doi.org/10.3390/drones7030193
APA StyleAzzam, R., Boiko, I., & Zweiri, Y. (2023). Swarm Cooperative Navigation Using Centralized Training and Decentralized Execution. Drones, 7(3), 193. https://doi.org/10.3390/drones7030193