1. Introduction
In order to appreciate the transition from CCS to SIPS, it is informative to go back to the origins of computer science as a discipline in the 1960s. According to Professor Wegner [
1] p. 24, “Computer science is concerned with information in much the same sense that physics is concerned with energy… The computer scientist is interested in discovering the pragmatic means by which information can be transformed”.
By viewing algorithms as vehicles of transformations of input to output in the form of symbols, ACM adapted an algorithmic approach to computation; this is made explicit in the next sentence of his report: “This interest leads to inquiry into effective ways to represent information, effective algorithms to transform information, effective languages with which to express algorithms… and effective ways to accomplish these at a reasonable cost”. Having a central algorithmic concern analogous to the concern with energy in physics helped to establish CCS as a legitimate academic discipline on par with physics.
The digital computing machines [
2,
3,
4] made possible by John von Neumann’s stored program implementation of the Turing machine (TM) using algorithms to transform symbols allowed information processing to extend our cognitive abilities of observation, modeling, memory, reasoning, and action to rearrange the structures both in the physical and mental worlds. The Church–Turing thesis deals with computing functions that are easily described by a list of formal, mathematical rules or sequences of event-driven actions such as modeling, simulation, business workflows, interaction with devices, etc. All algorithms that are Turing computable fall within the boundaries of the Church–Turing thesis which can be stated as “a function on the natural numbers is computable by a human being following an algorithm, ignoring resource limitations, if and only if it is computable by a Turing machine”. The resources here are the fuel for computation consisting of the CPU and memory.
Both symbolic computing and sub-symbolic computing (using neural networks) have allowed us to model and analyze various observations (including both mental and physical processes) and use the information and knowledge to optimize our interactions with each other and with our environment. In turn, our understanding of information processing structures in nature using both physical and computer experiments is pointing us to a new direction going beyond the current boundaries of the Church–Turing thesis and requiring a foundational architecture upgrade:
Today’s business services demand non-stop operation, and their performance is adjusted in real-time to meet rapid fluctuations in service demand or the resources available. The speed with which the quality of service has to be adjusted to meet the demand is becoming faster than the time it takes to orchestrate the myriad infrastructure components distributed across multiple geographies and owned by different providers with different profit motives. Church–Turing thesis’s boundaries are challenged [
5,
6] when rapid, non-deterministic fluctuations drive the demand for finite-resource readjustment in real-time. Today’s choice is between single vendor lock-in or multi-vendor product integration, operation and management complexity, and tool fatigue.
Current business processes and their automaton assume trusted relationships between the participants in various transactions. Unfortunately, global connectivity and non-deterministic fluctuations in the participants and information processing structures make it difficult to assure trust and complete transactions securely preventing fraud. In order to predict and minimize risk in real-time, end-to-end application security management has to decouple itself from IaaS and PaaS security management. To maintain security and stability, the system must manage “low trust” or “no trust” among the participating entities, whether they are other service components, people, or devices.
In essence, the distributed information processing system behaves like a complex adaptive system where several distributed entities with autonomy and control of local resources participate in a collaborative transaction and is prone to exhibit emergence (a phenomenon which occurs as a result of the composition of complex adaptive systems as an array of independent, interacting agents) when rapid fluctuations in the demand or availability of resources occur. In order to predict and prevent destabilization of the end-to-end transaction behavior, current IT systems must evolve to support global optimization processes while accommodating local constraints and responding to fluctuations in distributed resources and their management. This is very similar to how the neocortex evolved to globally optimize the responses to internal and external fluctuations using the various senses that the reptilian brain manages autonomously or semi-autonomously using embedded, embodies, extended, and enactive (4E cognition).
In
Section 2, we discuss the current limitations posed by classical computer science. In
Section 3, we present the new science of information processing structures derived from [
7] general theory of information (GTI). In
Section 4, we discuss how autopoiesis and cognition work utilizing symbolic computing and sub-symbolic computing. In
Section 5, we discuss the design of digital automata, called autopoietic machines [
8,
9,
10], with autopoietic and cognitive behaviors using digital genes and digital neurons. In
Section 6, we conclude with some observations on current attempts to implement autopoietic machines.
2. Limitations of Classical Computer Science
Limitations of classical computer science fall into two categories:
End-to-end Transaction Resiliency: Fluctuations cause instabilities in distributed computing structures, and CCS falls short in dealing with them efficiently at scale and in real-time without disrupting end-to-end transaction;
Limitations in Current AI: While we gain insights about hidden correlations, extract features, and distinguish categories, we lack transparency of reasoning behind these conclusions. More importantly, there is a lack of integration of common sense and ontological-model-based knowledge with AI algorithms. Deep learning models might be the best at perceiving patterns, yet they cannot comprehend what the patterns mean and lack the ability to model their behaviors and reason about them.
The root causes of these limitations are foundational and cannot be dealt with successfully with operational processes and even more automation. which serve only as band-aids. John von Neumann [
11] touches upon various shortcomings in discussing how computers behave differently from cellular organisms. Cellular organisms are autonomic. As von Neumann pointed out [
11] p.71, “It is very likely that on the basis of philosophy that every error has to be caught, explained, and corrected, a system of the complexity of the living organism would not last for a millisecond”.
Cockshott et al. [
12] p. 215 conclude their book
Computation and Its Limits with the following paragraph: “The key property of general-purpose computer is that they are general purpose. We can use them to deterministically model any physical system, of which they are not themselves a part, to an arbitrary degree of accuracy. Their logical limits arise when we try to get them to model a part of the world that includes themselves”.
True intelligence involves generalizations from observations, creating models, and deriving new insights from the models through reasoning. In addition, human intelligence also creates history and uses past experience in making decisions. Turing machine [
2,
3,
4] implementations of information processing structures, as Gödel proved, suffer from incompleteness and recursive self-reference not moored to external reality and therefore require external agents to provide self-regulating mechanisms and guide their local behaviors to provide system-level stability. This requires a sense of “self” and system-level agreement on self-regulation which accommodates local constraints. Finally, the Church–Turing thesis ignores resource limitations and managing finite resources, under the influence of fluctuations in their availability and the demand for them, requires a new approach.
It is not an exaggeration to say that all living organisms face very similar issues every day, every minute, and every second in managing their “life” processes [
13,
14,
15]. They addressed these problems by evolving to become autopoietic and cognitive. Autopoiesis refers to a system with a well-defined identity and is capable of reproducing and maintaining itself. Cognition, on the other hand, is the ability to process information, apply knowledge, and change the circumstance. A living organism is a unique autonomous system made up of components and relationships changing over time without changing the unity of the system. The genome contains the knowledge that is required to build the components using physical and chemical processes and physical resources. Information processing structures in the form of genes and neurons provide the means to build, operate and manage the stability of the system while interacting with the external world, where the interactions are often non-deterministic in nature and are subject to large fluctuations. Our understanding of how these information processing structures operate comes from the analysis of the genome, experiments in neuroscience, and the studies of cognitive behaviors in living organisms.
3. The Science of Information Processing Structures
GTI tells us that information is represented, processed, and communicated using physical structures. The physical universe, as we know it, is made up of structures that deal with matter and energy. As Mark Burgin points out, “Information is related to knowledge as energy is related to matter”.
An information unit is described by the existence or non-existence (1 or 0) of an entity or an object that is physically observed or mentally conceived. The difference between an entity and an object is that the entity is an abstract concept with attributes such as a computer with memory and CPU. An object is an instance of an entity with an identity, defined by two components, which are the object-state and object-behavior. An attribute is a key-value pair with an identity (name) and a value associated with it. The attribute state is defined by its value.
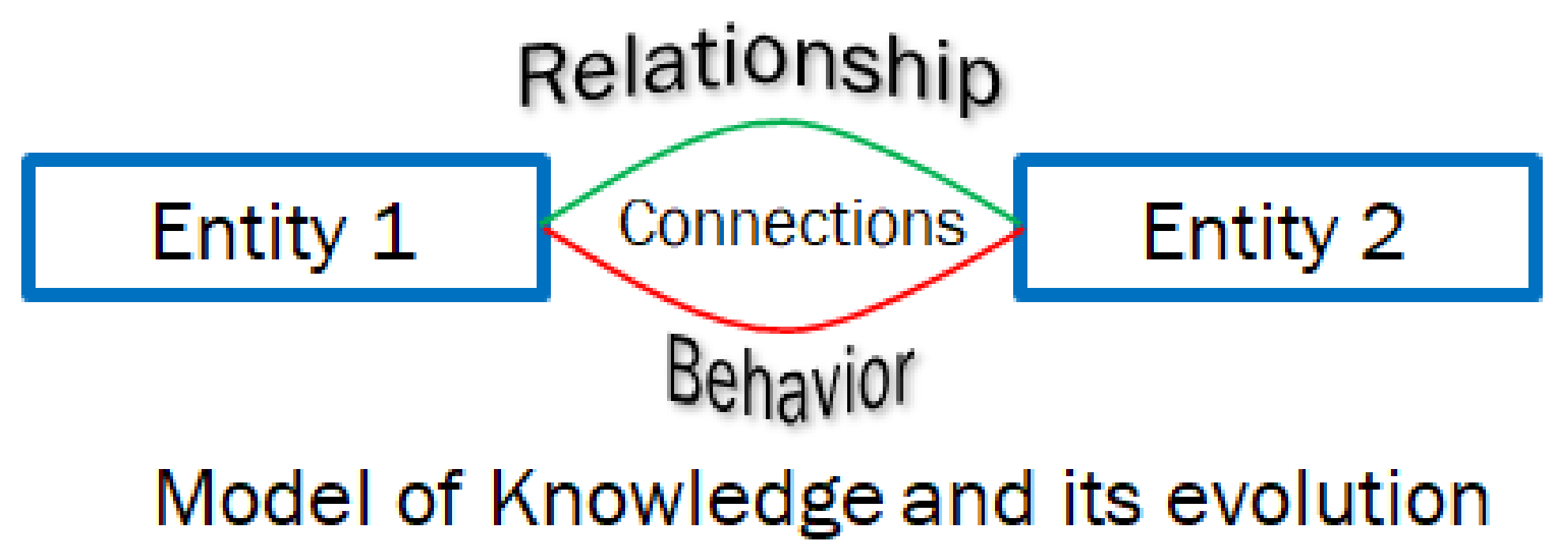
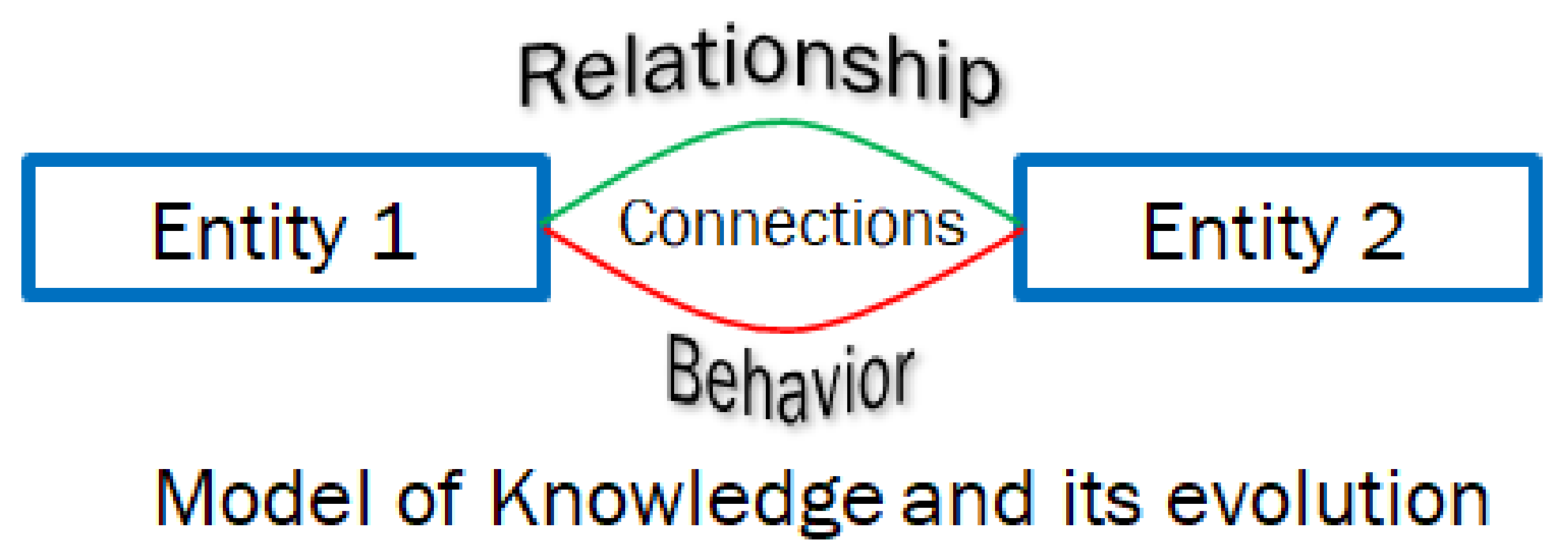
Knowledge is defined by the relationships between various entities and their interactions (behaviors) when the values of the attributes change. A named set is a fundamental triad that defines the knowledge about two different entities.
A knowledge structure (depicted in
Figure 1) defines various triadic relationships between all the entities that are contained in a system. The knowledge structure provides the schema and various operations to evolve the schema from one state to another. Various instances of the knowledge structure schema are used to model the domain knowledge and process information changes as they evolve with changes in their entities and their attributes and behaviors. Knowledge structures, therefore, integrate the dynamics of the system with the static data structures representing its state.
The structural machine is an information processing structure that represents the knowledge structures as schema and performs operations on them to evolve information changes in the system from one instant to another when any of the attributes of any of the objects change.
4. Modeling Autopoiesis and Cognition in Biological Systems
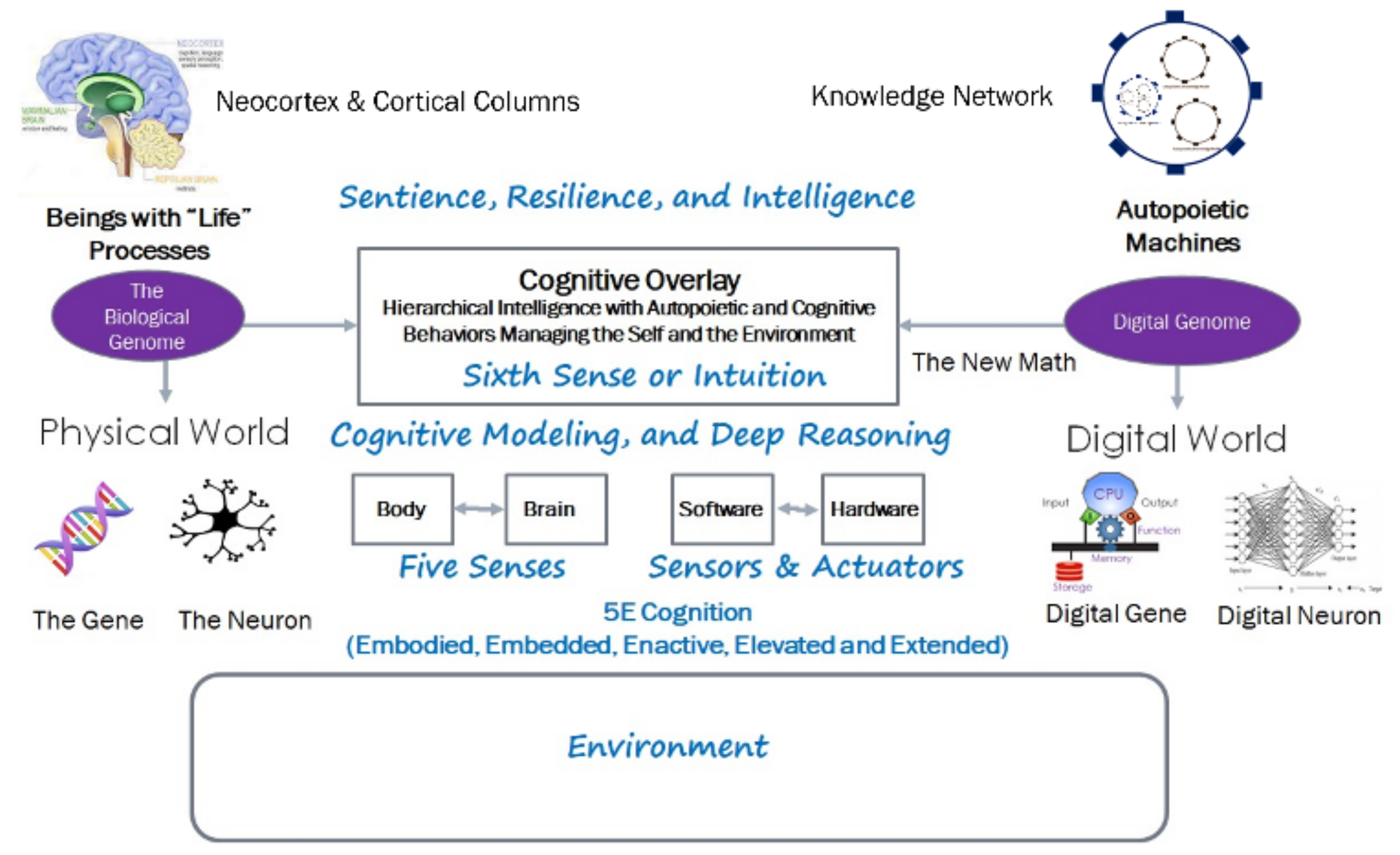
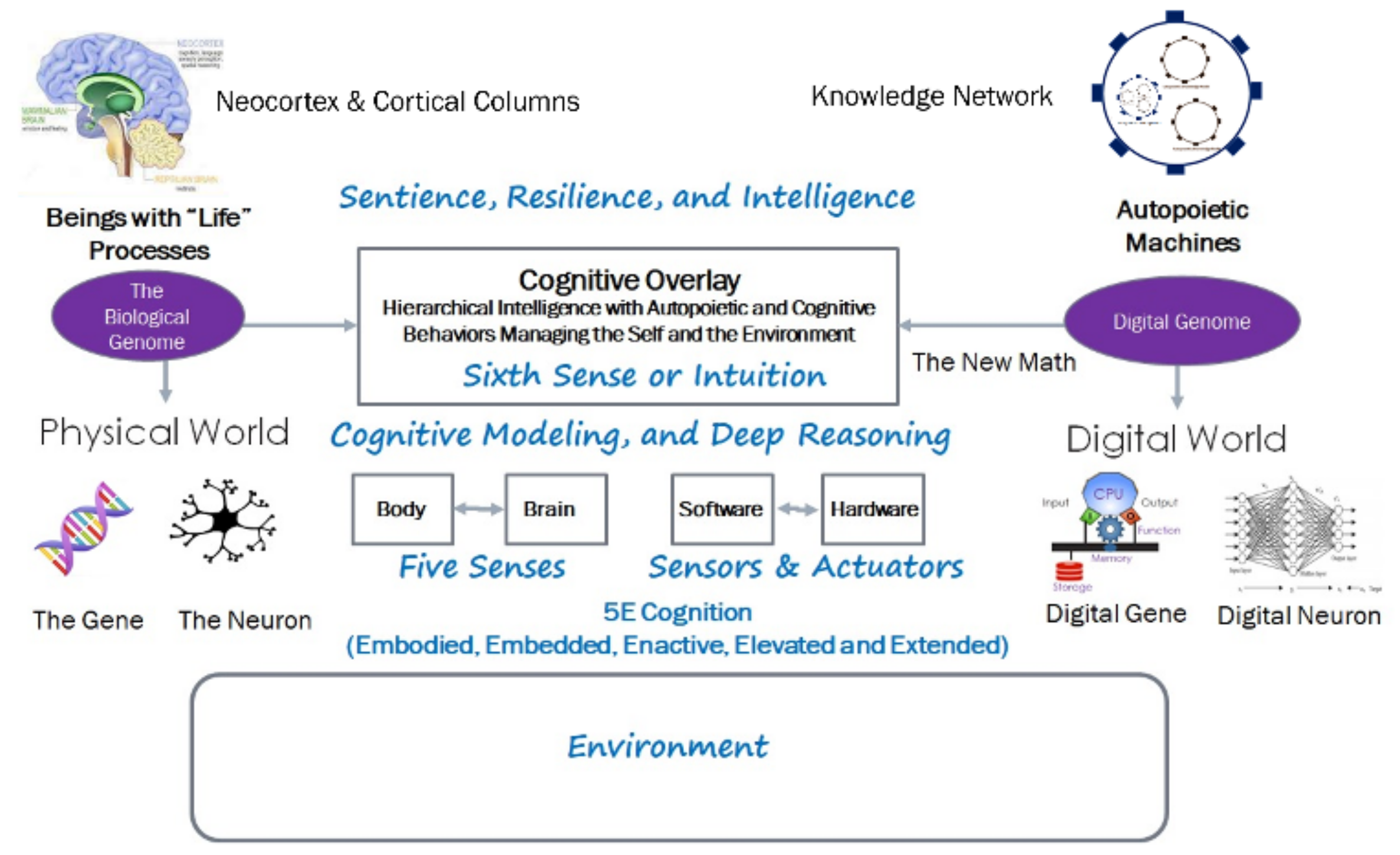
The genome in the physical world is knowledge coded in the executable form in deoxyribonucleic (DNA) and executed by ribonucleic acid (RNA). DNA and RNA use the knowledge of the physical and chemical processes to discover the resources in the environment using the cognitive apparatuses in the form of genes and neurons. They build and evolve the hardware utilizing various embedded, embodied, enacted, elevated, and extended (5E) cognitive (sentient, resilient, intelligent, and efficient) processes to manage both the self and the environment. The genome encapsulates both autopoietic and cognitive behaviors. A genome in the language of the General Theory of Information (GTI) encapsulates [
16] “knowledge structures” coded in the form of DNA and executed using the “structural machines”.
Figure 2 shows the organization of genes and neurons as networks.
5. Making Digital Automata, Autopoietic, and Cognitive
Structural machines and knowledge structures allow us to design a new class of digital automata that supersede the current Turing-machine-based automata. By incorporating the dynamics of the system, the knowledge structures supersede the data structures and provide a uniform representation of knowledge independent of how the knowledge is acquired, whether through symbolic computing or sub-symbolic computing.
Figure 2 also shows the autopoietic and cognitive structures in autopoietic digital automata. The structural machine eventually uses cognizing agents (called “oracles” as a generalized form of Turing Oracle mentioned in his thesis) to configure, monitor, and implement transaction processes on downstream knowledge structures. Processors downstream, execute individual transactions required to implement the global transaction. At each level, the transaction is managed for consistency in the downstream network. Each transaction specifies the operations on the knowledge structure representing the application and its behavior as a graph (nodes, links, and their relationships and behaviors). Thus, the operation on the knowledge structures is independent of the content and solely manages the structure by reconfiguring the knowledge nodes as a network of networks [
10]. All nodes that are wired together fire together to exhibit the intended behavior.
6. Conclusions
The purpose of this paper is to show that the general theory of information and its tools provide a path to go beyond the current limitations of classical computer science and define a new science of information-processing structures. The limitations of classical computer science come from the inability to include the model of the computer and the computed as Cockshott et al, describe in their book,
Computation and Its Limits [
12] p. 215. The structural machines and the knowledge structures derived from the general theory of information show the path to designing and implementing autopoietic and cognitive digital automata. Although GTI has been around for a while, SIPS is in its infancy. Only time will tell how important the science of information structures is in advancing our current implementations of digital information systems using various implementations that are currently being pursued by different groups. Can we build self-aware robots? Can we implement self-managing software applications?



{kind=link}
{kind=link}