The Potential of Open Data to Automatically Create Learning Resources for Smart Learning Environments †

 , and
, and {kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Current State of the Art
- We created learning resources out of several integrated datasets available in the Web. Thus, we would be able to obtain a more complete collection of entities from different sources of the Web of Data.
- We automatically contextualized these learning resources taking into account their topic and the physical locations where they may be relevant. Thus, we would enable an SLE to offer learning resources to students according to their learning interests and their physical context.
- We do not only consider resources that assess factual knowledge. Thus, we would also promote higher-level thinking.
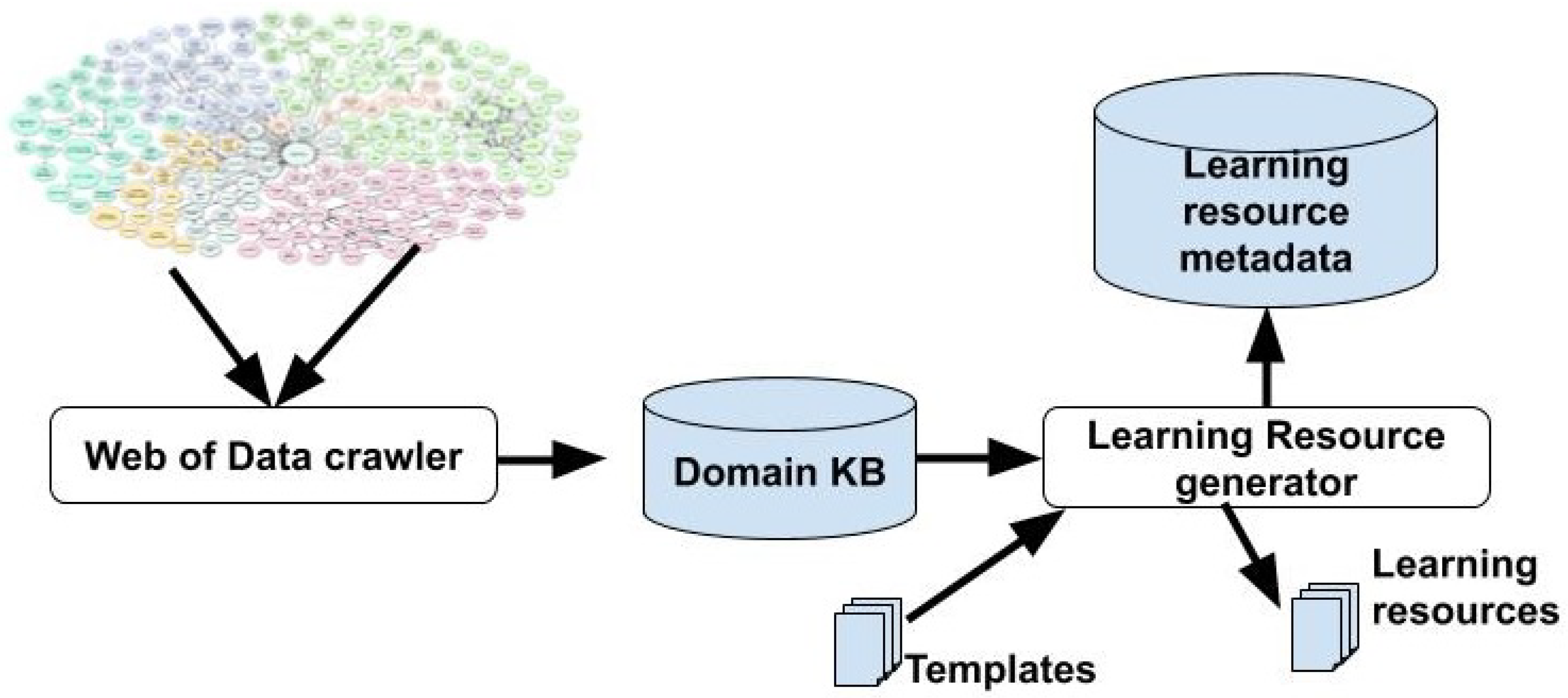
3. Technical Approach
- Extractor. This script collects entities from an open data source that includes a SPARQL endpoint and relate them to the ontology used in the Domain Knowledge Base.
- Descriptor. This script collects the description of the entities extracted from that same data source and relates it to the ontology used in the Domain Knowledge Base. The descriptions obtained should include the owl:sameAs relationships stated in the data source for each element.
- Enricher. This script further describes each entity by extracting descriptions from other data sources and relates the data collected to the ontology used in the Domain Knowledge Base. This is done by exploiting the owl:sameAs relationships obtained by the Descriptor.
- Parser. This script collects data from other datasets that are available on the Web of Data but are not offered through a SPARQL endpoint, nor provide explicit relationships to the previous datasets (these datasets are typically offered in Open Data portals as downloable files). The script relates the data provided by these datasets to the ontology used in the Domain Knowledge Base.
- Integrator. This script integrates all the data obtained by the previous scripts. As the entities are described using the same ontology, the integration focuses on resolving the entities of not-linked datasets.
4. Conclusions
- Definition of an ontology. The definition of the ontology for the domain knowledge base is a critical step as it states the vocabulary for the description of the domain. This vocabulary should include the abstractions used by teachers and students; it should also cover the concepts that are relevant for a particular topic in a particular course, so it should take into account the course syllabus.
- Integration of datasets. The integration of datasets is a very well-known issue that is facilitated for those 5-star linked datasets. Unfortunately, not all the relevant datasets published on the Web are rated with 5 stars. For those not-linked open datasets, the identity resolution becomes a problem. For our example, we tried to overcome this problem by exploiting the entities’ geolocalization (i.e., we understood that two entities are the same if, and only if, they are located in the same place); however, this approach seems not to be enough. Hence, we will explore other algorithms to overcome this problem.
- Definition of resource’s templates. The definition of templates becomes very relevant to obtain resources out of the domain knowledge base. In our current prototype, these templates are defined by a technician. However, we will explore how to allow teachers to define these templates by manipulating a resource-creation application.
- Integration of resources in an SLE. Another relevant issue is how the resources created can be exploited in the context of an SLE. We foresee that a mobile application could be integrated into an SLE in order to offer relevant resources to the students according to their contexts. Some gamification techniques may also be useful to help the adoption of such mobile application.
Funding
Conflicts of Interest
References
- Hwang, G. Definition, framework and research issues of smart learning environments—A context-aware ubiquitous learning perspective. Smart Learn. Environ. 2014, 1, 1–14. [Google Scholar] [CrossRef]
- Gros, B. The design of smart educational environments. Smart Learn. Environ. 2016, 3, 15. [Google Scholar] [CrossRef]
- Alsubait, T.; Parsia, B.; Sattler, U. Ontology-Based Multiple Choice Question Generation. KI-Künstliche Intell. 2016, 30, 183–188. [Google Scholar] [CrossRef]
- Foulonneau, M. Generating Educational Assessment Items from Linked Open Data: The Case of DBpedia. The Semantic Web: ESWC 2011 Workshops; García-Castro, R., Fensel, D., Antoniou, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 16–27. [Google Scholar]
- Heath, T.; Bizer, C. Linked Data: Evolving the Web into a Global Data Space, 1st ed.; Synthesis Lectures on the Semantic Web: Theory and Technology; Morgan & Claypool: San Rafael, California (USA), 2011; Available online: http://linkeddatabook.com/editions/1.0/ (accessed on 7 November 2019).
- Tarasowa, D.; Khalili, A.; Auer, S. Crowdlearn: Crowd-sourcing the creation of highly-structured e-learning content. Int. J. Eng. Pedagog. 2015, 5, 47–54. [Google Scholar] [CrossRef]
- Šimko, M.; Barla, M.; Bieliková, M. ALEF: A framework for adaptive web-based learning 2.0. In Proceedings of the IFIP International Conference on Key Competencies in the Knowledge Society, Brisbane, Australia, 20–23 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 367–378. [Google Scholar]
- Leo, J.; Kurdi, G.; Matentzoglu, N.; Parsia, B.; Sattler, U.; Forge, S.; Donato, G.; Dowling, W. Ontology-Based Generation of Medical, Multi-term MCQs. Int. J. Artif. Intell. Educ. 2019, 29, 145–188. [Google Scholar] [CrossRef]
- Berners-Lee, T. Linked Data-Design Issues. 2006. Available online: http://www.w3.org/DesignIssues/LinkedData.html (accessed on 7 November 2019).
- Nahhas, S.; Bamasag, O.; Khemakhem, M.; Bajnaid, N. Added Values of Linked Data in Education: A Survey and Roadmap. Computers 2018, 7, 45–70. [Google Scholar] [CrossRef]
- Zavala, L.; Mendoza, B. On the Use of Semantic-Based AIG to Automatically Generate Programming Exercises. In Proceedings of the 49th ACM Technical Symposium on Computer Science Education, Baltimore, MD, USA, 21–24 February 2018; ACM: Baltimore, MD, USA, 2018; pp. 14–19. [Google Scholar]
- Vega-Gorgojo, G. Clover Quiz: A trivia game powered by DBpedia. Semant. Web J. 2019, 10, 779–793. [Google Scholar] [CrossRef]
- Ruiz-Calleja, A.; Bote-Lorenzo, M.L.; Vega-Gorgojo, G.; Serrano-Iglesias, S.; Asensio-Pérez, J.I.; Dimitriadis, Y.; Gómez-Sánchez, E. Exploiting the Web of Data to bridge formal and informal learning experiences. In Proceedings of the Seventh International Conference on Technological Ecosystems for Enhancing Multiculturality (TEEM 19), León, Spain, 16–18 October 2019; ACM: León, Spain, 2019. in press. [Google Scholar]



© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ruiz-Calleja, A.; Bote-Lorenzo, M.L.; Vega-Gorgojo, G.; Serrano-Iglesias, S.; Asensio-Pérez, J.I.; Dimitriadis, Y.; Gómez-Sánchez, E. The Potential of Open Data to Automatically Create Learning Resources for Smart Learning Environments. Proceedings 2019, 31, 61. https://doi.org/10.3390/proceedings2019031061
Ruiz-Calleja A, Bote-Lorenzo ML, Vega-Gorgojo G, Serrano-Iglesias S, Asensio-Pérez JI, Dimitriadis Y, Gómez-Sánchez E. The Potential of Open Data to Automatically Create Learning Resources for Smart Learning Environments. Proceedings. 2019; 31(1):61. https://doi.org/10.3390/proceedings2019031061
Chicago/Turabian StyleRuiz-Calleja, Adolfo, Miguel L. Bote-Lorenzo, Guillermo Vega-Gorgojo, Sergio Serrano-Iglesias, Juan I. Asensio-Pérez, Yannis Dimitriadis, and Eduardo Gómez-Sánchez. 2019. "The Potential of Open Data to Automatically Create Learning Resources for Smart Learning Environments" Proceedings 31, no. 1: 61. https://doi.org/10.3390/proceedings2019031061
APA StyleRuiz-Calleja, A., Bote-Lorenzo, M. L., Vega-Gorgojo, G., Serrano-Iglesias, S., Asensio-Pérez, J. I., Dimitriadis, Y., & Gómez-Sánchez, E. (2019). The Potential of Open Data to Automatically Create Learning Resources for Smart Learning Environments. Proceedings, 31(1), 61. https://doi.org/10.3390/proceedings2019031061