1. Introduction
Volatility prediction in financial markets is essential for various fields, such as portfolio optimization, risk management, and option pricing. Over the years, significant efforts have been made to develop reliable models that can accurately forecast market volatility. Traditionally, statistical time series models, such as Generalized Autoregressive Conditional Heteroskedasticity (GARCH), have predominantly been used for this purpose [
1,
2]. While GARCH models have proven effective in many contexts, recent advances have positioned deep learning algorithms at the forefront of volatility prediction [
3]. In particular, Long Short-Term Memory (LSTM) models have gained prominence in the financial domain due to their ability to effectively capture long-term dependencies in time series data [
4,
5]. Despite the ability of deep learning models to effectively learn time series patterns, integrating domain knowledge is essential to account for the complexities and non-stationarity of financial markets [
6]. While deep learning models have made significant strides, the integration of domain-specific knowledge remains a critical gap, especially in financial markets, where non-stationarity and regime shifts are prevalent. Models that are developed without a proper understanding of the specific characteristics of financial markets are at a higher risk of overfitting, which can undermine the generalizability of their predictive performance [
7].
One of the primary challenges in volatility prediction in financial markets is regime changes, or shifts in market states. Markets experience alternating periods of economic growth and recession, each characterized by distinct volatility patterns. These changes can reduce the predictive power of models that do not consider regime changes. Consequently, various approaches that incorporate regime changes have been proposed. In particular, estimation of the time-varying Hurst exponent has received considerable attention as a way to capture long memory and structural changes in financial markets. To detect these changes, Melike and Özgür Ömer introduced a fractal-based GARCH model that accounts for long memory and volatility clustering [
8]. Choi utilized the Hurst exponent through multifractal detrended fluctuation analysis (MFDFA) to assess dynamic market efficiency [
9], and analyzed time-series variations in dynamic volatility spillovers to identify key points of market state transitions [
10]. The Hurst exponent is a valuable tool for quantifying the long memory characteristics and autocorrelation structure of time series data, making it particularly effective in capturing the complex volatility patterns in financial markets [
11]. In this context, Morales et al. proposed a dynamic Hurst exponent tool for monitoring unstable periods in financial time series [
12]. Trinidad Segovia et al. employed the Hurst exponent via the fractal-based FD4 algorithm to detect volatility clusters [
13]. Notably, the Hurst exponent can effectively detect non-stationarity and volatility clustering in markets, aiding in the identification of subtle patterns that traditional statistical models may overlook [
14]. Eom et al. empirically investigated the relationship between market efficiency and the predictability of future price changes using the Hurst exponent [
15]. Furthermore, the dynamic Hurst exponent, which evolves over time, can be used to track changes in financial market conditions in real-time, offering a more refined approach for detecting regime changes [
16]. In these studies, wavelet-based estimators, parametric filtering techniques, and detrended fluctuation analysis (DFA/MFDFA) are frequently employed to estimate the time-varying Hurst exponent [
17,
18,
19,
20,
21], each providing valuable insights into the dynamic structure of financial time series. According to the Fractal Market Hypothesis, the Hurst exponent, which reflects the multi-time scale characteristics of financial markets, plays a crucial role in identifying market instability and structural changes, thereby improving predictive accuracy across diverse market environments [
22].
In addition to this perspective, recent literature on volatility modeling has proposed rough volatility models based on fractional Brownian motion (fBm), which suggest that the Hurst exponent is significantly smaller than
when estimated on log-transformed realized volatility series [
23,
24,
25]. These models challenge the traditional interpretation of long memory and suggest that volatility is rough, exhibiting anti-persistent behavior, rather than being persistent. While our approach does not adopt the log-transformation of high-frequency realized volatility, we instead compute the Hurst exponent of daily returns. This choice was motivated by empirical observations that the Hurst exponent of daily returns tends to fluctuate around
, allowing the detection of regime shifts as the market transitions between persistent (
) and anti-persistent (
) dynamics. For instance, during turbulent periods such as 2020,
H consistently falls below
, aligning with a notable decrease in predictive performance. This suggests that the predictive difficulty associated with anti-persistent regimes, as also reported in the rough volatility literature [
24], holds true in our empirical setting. While volatility estimates derived from daily returns are known to exhibit strong serial dependence, which may enhance predictability, we emphasize that this property is shared across all benchmark models used in our evaluation.
While regime changes describe temporal shifts, another important challenge in predicting volatility in financial time series is the structural interdependence among assets, influenced by various stakeholders. Stock prices are not determined in isolation; they are influenced by interactions with other stocks, exchange rates, and other economic factors [
26]. The international financial market network is fully connected, strongly globalized, and intricately entangled, consisting of modular structures with similar efficiency dynamics [
27]. Consequently, a model that simultaneously accounts for these financial stakeholders is essential, and various approaches have been proposed to address this issue. For example, Baltakys et al. proposed a graph neural network (GNN) approach to predict the trading behavior of socially connected investors, thereby enhancing market surveillance and detecting abnormal transactions [
28]. Similarly, Chen and Robert utilized GNNs to model interactions between financial assets, which improves the accuracy of multivariate realized volatility forecasting [
29]. Das et al. employed GNNs to model relationships among financial entities, integrating sentiment analysis to capture sentiment dynamics and structural dependencies [
30]. Recent studies have increasingly adopted GNNs in financial forecasting, due to their ability to model complex relationships among financial entities. Unlike recurrent neural networks (RNN), GNNs reflect the relationships and structures between entities, making them a powerful tool for analyzing graph-structured data [
31]. In particular, a Graph Convolutional Network (GCN), a prominent variation of GNNs, applies convolution operations to graph data to efficiently aggregate and propagate information from neighboring nodes [
32]. These models are well suited for capturing relationships and interactions in complex network structures, making them particularly useful for analyzing multidimensional, interconnected data such as financial markets [
33]. To effectively utilize GNN-based models, information about the interactions between entities is crucial, and various approaches have been developed to infer these relationships. Traditionally, statistical techniques and information theory have been used to measure correlation and causality. For example, Lu et al. presented a Pearson-correlation-based graph attention network that captures internal relationships between electroencephalography signal segments within brain regions to improve sleep stage classification [
34]. Similarly, Jia and Benson proposed a framework that enhances GNN regression by modeling residual correlations using a parameterized multivariate Gaussian distribution, leading to improved prediction outcomes [
35]. On the other hand, Wein et al. proposed a GNN-based causality network to infer causal relationships in brain networks, improving the accuracy of identifying directed dependencies between brain regions [
36]. Zheng et al. developed a Granger causality-inspired graph neural network to model causal relationships in brain networks for interpretable psychiatric diagnosis [
37]. Granger causality is a widely used technique for analyzing causality in time series data, assessing whether changes in one variable influence another [
38]. However, this method can only determine the presence of information flow, and is limited when quantifying the magnitude or strength of the information transfer. To address this, research has been conducted using mutual information, based on information theory, to assess the quantity of information transferred. While mutual information is useful for measuring the dependence between two variables, it does not capture the directionality of the information flow. To overcome this limitation, Transfer Entropy (TE) was proposed, which is gaining attention as a metric that simultaneously estimates the direction and quantity of information transfer [
39]. In line with this, Duan et al. presented a GNN that utilizes TE to capture causal relationships in multivariate time series, achieving superior forecasting performance across various real-world datasets [
40]. However, TE can quantify causal relationships by measuring changes in probability distributions but suffers from issues related to finite sample effects and the presence of noise, which can degrade the accuracy of estimations [
41]. To address these problems, Effective Transfer Entropy (ETE), which provides a more precise measurement of the direction and strength of information transfer, has been introduced [
42].
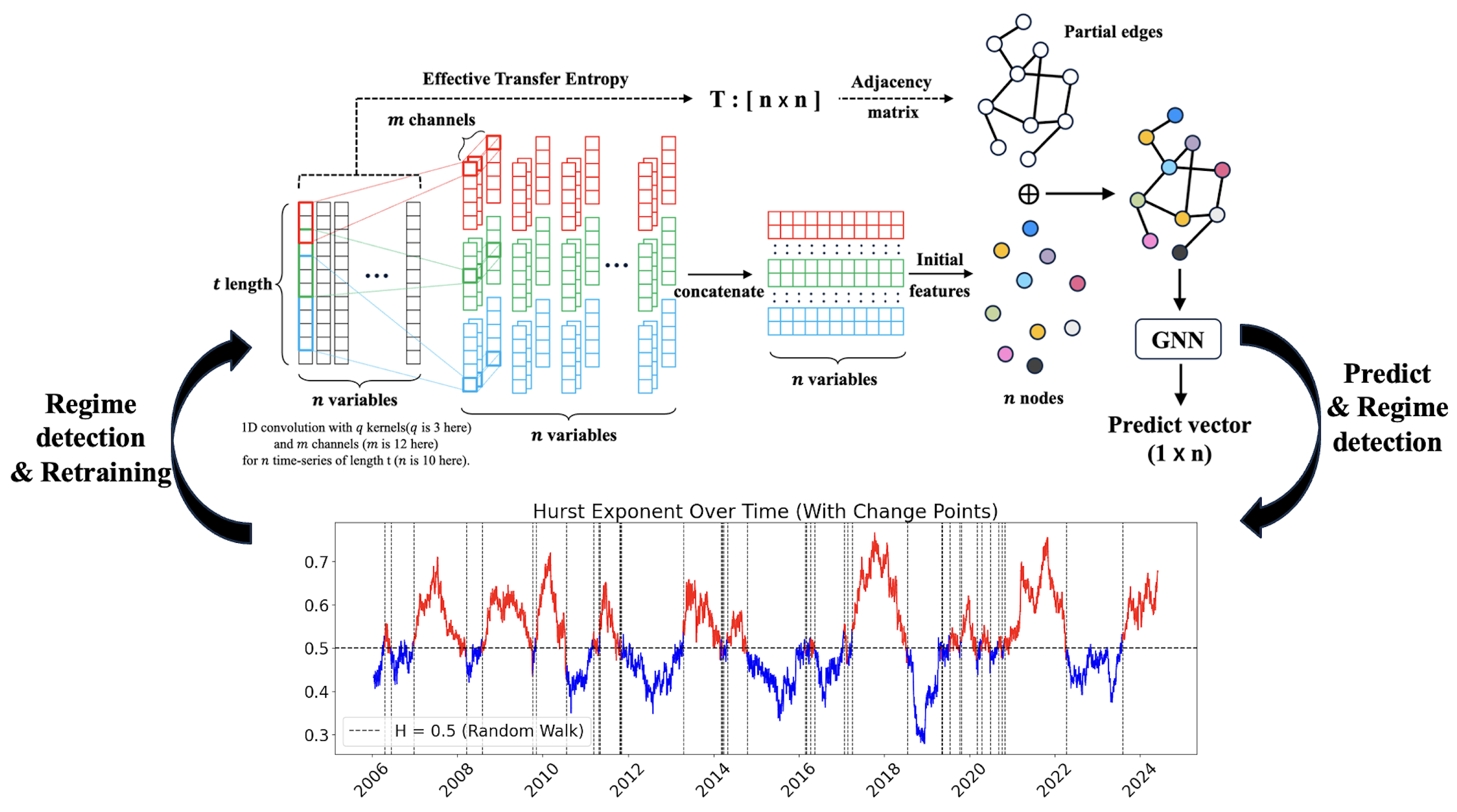
This study proposes a novel model that simultaneously considers the influence of multiple stakeholders, while adapting to regime changes by retraining the graph structure based on the Hurst exponent. First, the model quantifies information flows among ten country exchange-traded funds (ETFs) using effective transfer entropy. Second, it constructs a graph convolutional network utilizing ETE-based graphs to forecast one-day-ahead realized volatility. Third, the model detects regime changes through the Hurst exponent and dynamically retrains the graph when a regime change is identified. In comparison to prior works that relied on linear causality measures such as Granger causality or Pearson correlation, our approach captures nonlinear and directional causality more effectively through the use of ETE. Furthermore, we introduce a novel regime adaptation strategy that leverages the Hurst exponent to avoid unnecessary retraining during stable market trends, and focus updates only when structural changes are detected. The key contributions of this study are threefold. First, we develop a GNN-based forecasting framework that effectively captures nonlinear inter-asset dependencies by constructing adjacency matrices using ETE. Second, we propose a dynamic graph updating mechanism using the Hurst exponent, enabling the model to adapt to long-term memory dynamics and market regime shifts. Third, we empirically demonstrate that our hybrid model significantly outperformed various benchmarks, including GNNs using alternative causality measures and RNN-based models, in forecasting volatility over 19 years of ETF data. These results have practical implications for portfolio managers and risk analysts, as more accurate volatility forecasts can enhance asset allocation, hedging strategies, and option pricing. Theoretically, our framework advances the understanding of financial markets by integrating GNNs with nonlinear causality measures and a regime-adaptive mechanism based on the Hurst exponent, which captures varying memory characteristics across different market phases. The novelty of this study lies in being the first to integrate ETE-based graphs to capture collective dynamics among assets, while simultaneously accounting for regime changes using the Hurst exponent. Empirical results indicate that the proposed hybrid model improved the accuracy of realized volatility forecasts. These findings can contribute to a deeper understanding of fractal dynamics in financial markets, offering valuable insights for financial stakeholders.
The remainder of this paper is structured as follows:
Section 2, which outlines the foundations of the ETE, causality graph neural network, and Hurst exponent;
Section 3, which details the experimental approach and provides a statistical analysis of the financial time-series data;
Section 4, which presents a comprehensive analysis of forecasting the realized volatility of ETFs; and
Section 5, which interprets the findings and offers conclusions.
5. Discussion and Conclusions
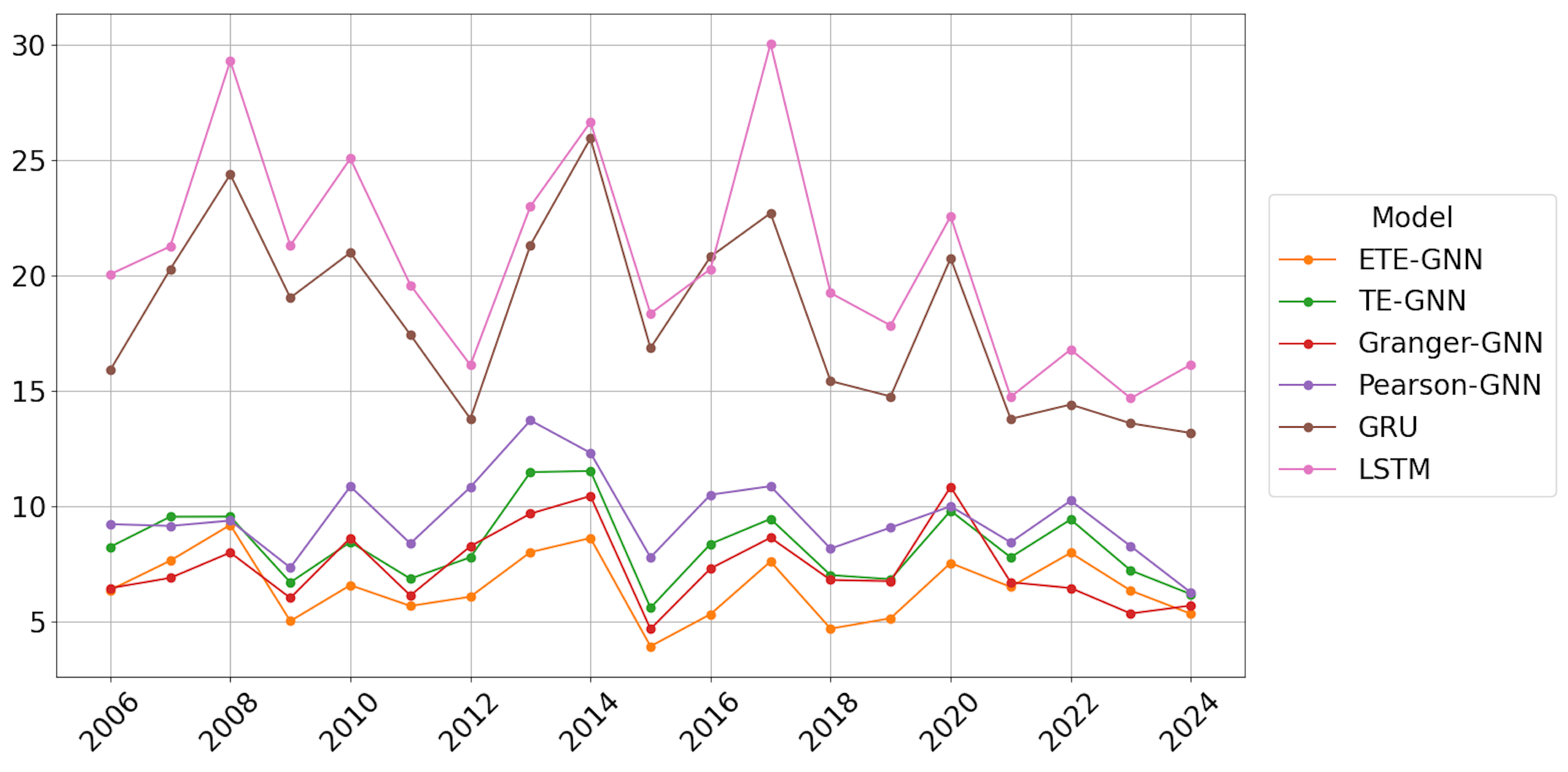
This paper introduces a hybrid model, H-ETE-GNN, which combines the ETE to estimate nonlinear inter-asset causality with GNNs, while dynamically reflecting market regime changes using the Hurst exponent. The primary contributions of this study are clearly outlined as follows: First, a framework is developed that effectively analyzes data structures reflecting inter-asset causality through an adjacency matrix composed of ETE. By utilizing this approach, GNNs can interpret the network structure of financial markets and systematically analyze the impact of interactions between nodes on prediction performance, unlike traditional RNN models based on sequential learning. Second, the study introduces a strategy that monitors the long-term dependency characteristics of financial markets using the Hurst exponent. By detecting regime changes based on this, the model dynamically retrains the ETE graph and parameters, demonstrating the potential for a prediction system that adapts flexibly to structural market fluctuations. Third, the effectiveness of the proposed H-ETE-GNN was validated by analyzing 19 years of data from 10 national ETFs. When compared to various benchmark models, the H-ETE-GNN showed superior performance in volatility forecasting, confirming its applicability. In addition to these contributions, the novelty of our work lies in the comprehensive comparison against benchmark models. In contrast to prior works that relied on linear causality measures, such as Granger causality or Pearson correlation, our approach highlighted the superior ability of the GNN model based on ETE to capture nonlinear and directional causality. Moreover, the incorporation of Hurst-exponent-based regime change detection adds significant value, enhancing the model’s adaptability to shifting market dynamics.
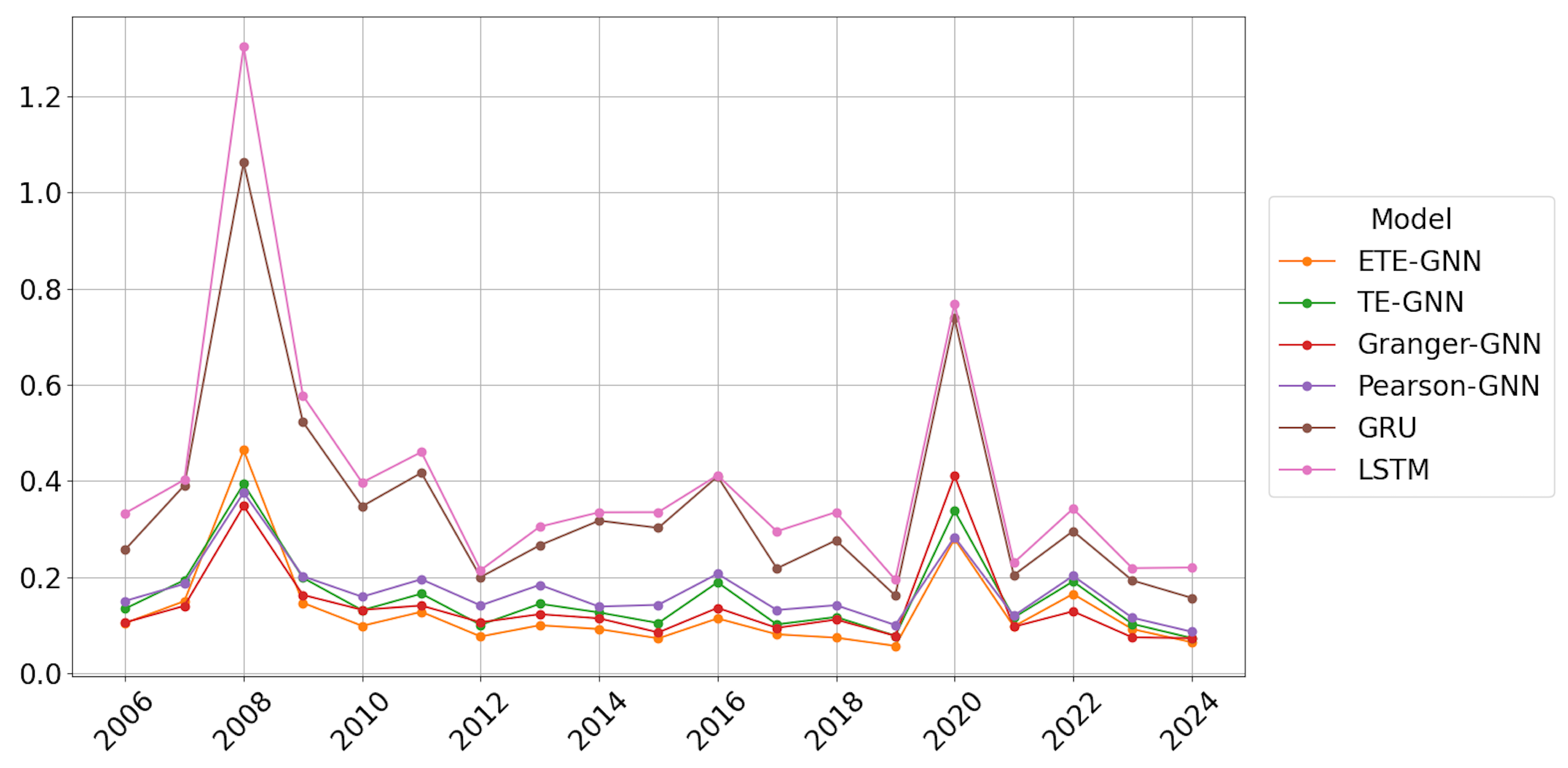
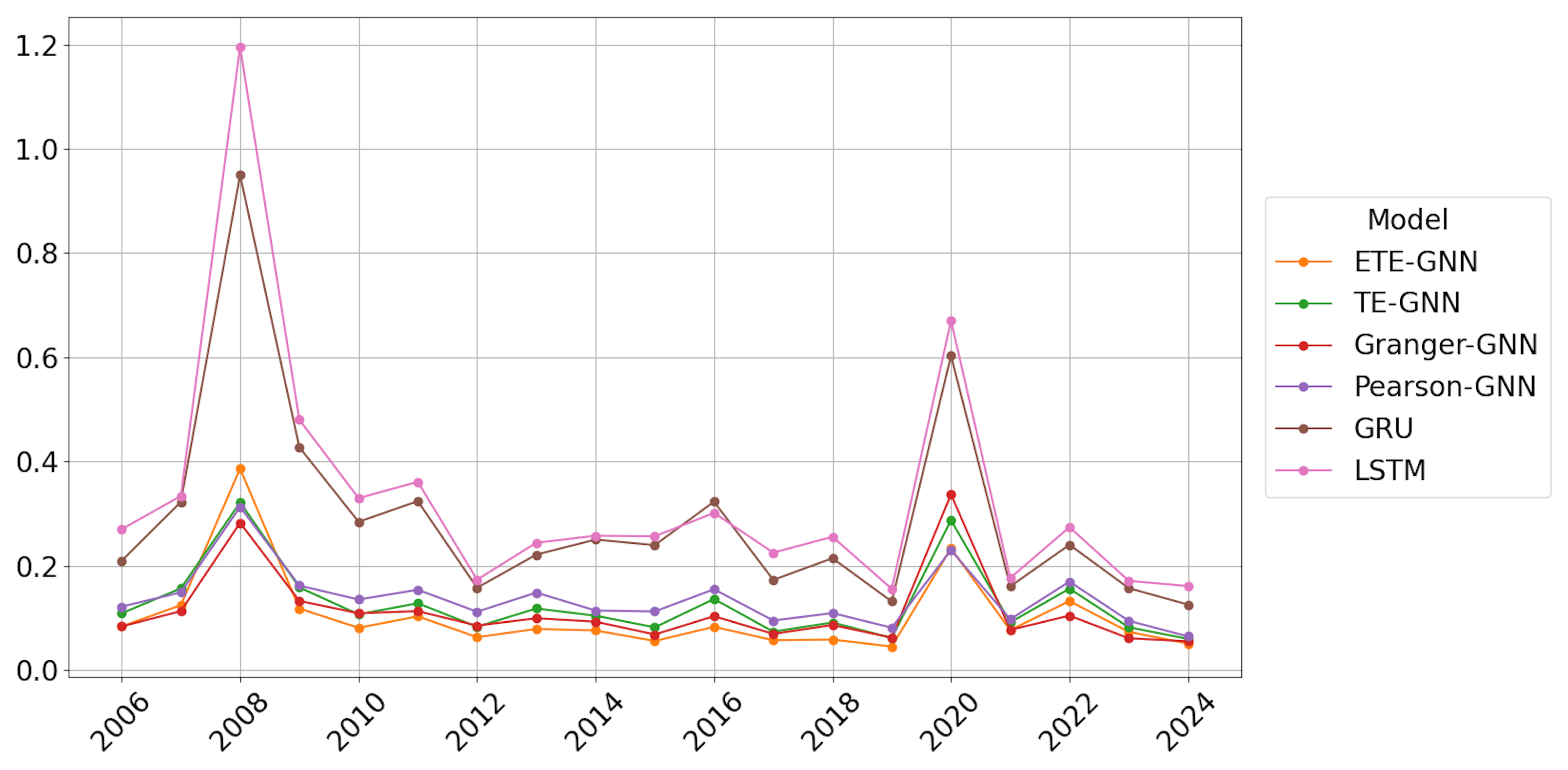
In this study, a series of benchmark experiments revealed that the GNN model based on ETE outperformed those based on TE, Granger causality, and Pearson correlation. This highlights that ETE’s ability to effectively capture nonlinear information flow contributes to improved prediction performance. Furthermore, when compared to RNN-based models under the same conditions, the GNN-based models, which reflected structural interactions between assets, generally demonstrated superior performance. Additionally, the strategy incorporating Hurst-exponent-based regime change detection outperformed Periodic retraining, underscoring the value of adapting models to long-term memory dependencies in the market.
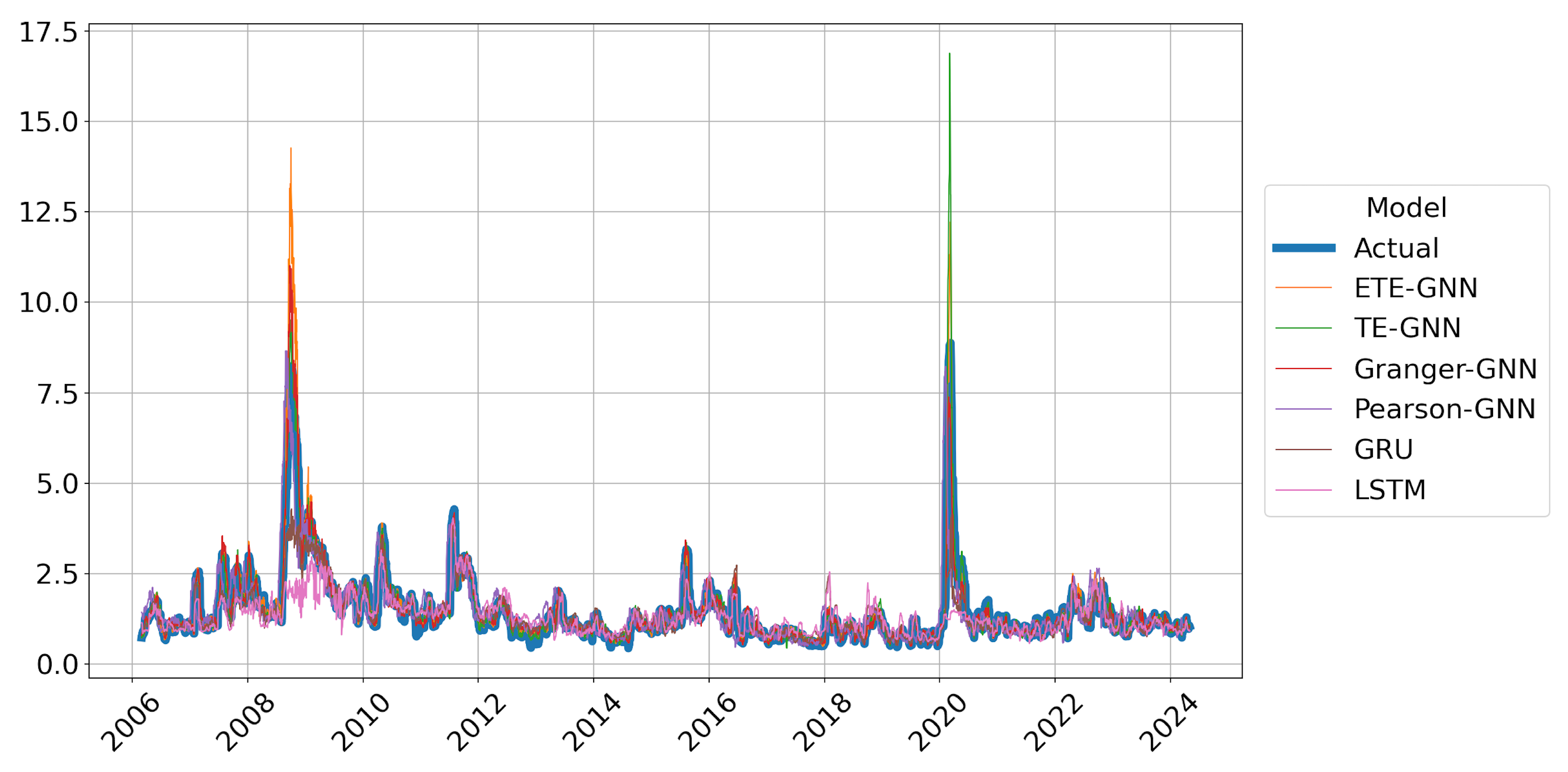
The proposed H-ETE-GNN efficiently balances both accuracy and effectiveness by avoiding unnecessary retraining during stable market trends and only retraining at regime change points. This adaptive mechanism allows for more efficient deployment in real-world systems where computational resources are limited, and market dynamics are highly variable. However, during periods of rapid market collapse, such as the 2008 financial crisis or the 2020 COVID-19 pandemic, the model’s performance temporarily deteriorated. This suggests that the current modeling approach, while effective under typical conditions, has limitations in capturing abrupt and extreme market behaviors. This can be attributed to the fact that the Hurst exponent operates under a monofractal assumption, which may not fully capture the asymmetric and complex nature of the market structure. Additionally, while ETE improves causal inference compared to traditional TE, it has limitations in detecting extreme, localized nonlinear interactions, potentially missing crucial regime changes. These findings imply that, although H-ETE-GNN offers a promising solution for volatility forecasting in complex markets, its current structure may need further enhancement to deal with sudden and extreme market fluctuations and rapidly changing dependency structures. Thus, future research should focus on developing algorithms that can sensitively incorporate event significance or extreme probabilities to enhance causal inference stability during extreme market conditions. Recent studies have suggested that asymmetric multifractal Hurst exponents positively impact volatility forecasting [
4], and the potential use of Rényi-entropy-based Transfer Entropy to better capture key information flow has also been explored [
63]. Building on these advancements, future work could focus on hybridizing H-ETE-GNN with asymmetric multifractal analysis and Renyi transfer entropy, thereby increasing its robustness and adaptability across diverse market regimes, including crises. Another promising future direction involves incorporating high-frequency financial data to estimate realized volatility more accurately. While our current model relies on daily-return-based volatility estimates, applying ETE and GNN techniques to realized volatility derived from intraday data may improve responsiveness and granularity, particularly during volatile or rapidly evolving market conditions. Additionally, future research could explore integrating past volatility values directly into the model architecture. While our current GNN framework is designed around return-based node features, incorporating volatility information may enhance prediction performance if implemented carefully. To avoid potential overfitting due to increased input dimensionality, a hybrid approach such as LSTM-GNN could be adopted to jointly capture temporal and cross-sectional dependencies—an extension that lies beyond the scope of the present study but offers a promising avenue for future work.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}