


Robust Design of Two-Level Non-Integer SMC Based on Deep Soft Actor-Critic for Synchronization of Chaotic Fractional Order Memristive Neural Networks





Abstract
1. Introduction
- ○
- Existing research often relies heavily on either linear or nonlinear components in the suggestion of control techniques, limiting the comprehensiveness of the approaches.
- ○
- In many instances, the utilization of SMC methods is accompanied by chattering phenomena that are not acceptable.
- ○
- Most of these works simplify system definitions by neglecting uncertainties, external distributions, and input saturations, which are essential aspects of real-world systems.
- ○
- Almost all these methods have selected the control parameters by classic error trials for simulation.
- •
- Development of a Novel Control Methodology: The study proposes a model-free -SMC methodology, specifically designed for synchronizing chaotic with delays and input saturation.
- •
- Two-Level Sliding Surface Design: The methodology introduces a two-level control approach. The initial sliding surface addresses chaotic system dynamics, while the second -sliding surface, based on proportional-integral (PI) rules, enhances system stability and robustness.
- •
- Finite-Time Synchronization: The proposed control method guarantees finite-time synchronization of delayed FOMNNSs, overcoming the challenge of delays, input saturations, and system uncertainties that previous approaches have struggled to handle effectively.
- •
- System Independence: The control laws are designed to be independent of the specific functions governing the system’s behavior. This is achieved through the norm-boundedness property of chaotic system states, making the methodology more adaptable to a wide range of chaotic systems.
- •
- Optimization via Soft Actor-Critic (SAC) Algorithm: The study utilizes SAC algorithm-based deep Q-learning to optimally adjust the controller parameters. This approach improves the adaptability and performance of the controller by maximizing a reward signal through the deep neural network of the SAC agent.
- •
- Extensive Validation: The effectiveness of the proposed control strategy is demonstrated through comprehensive simulation results and two numerical examples, confirming its applicability in practical engineering scenarios.
- •
- Practical Relevance: The proposed method’s robustness in handling chaotic dynamics, delays, and input saturation shows significant potential for real-world engineering applications, particularly in areas requiring advanced control of complex systems.
2. Preliminary Concepts and Description of the Problem
2.1. Preliminaries
2.2. Description of the Problem
3. Finite Time -SMC Technique Design
- Initial Sliding Surface:
- •
- State Trajectories: The initial sliding surface is introduced to guide the state trajectories of the chaotic system towards a more controlled behavior. This surface is a function of the system’s state variables and is typically designed to simplify the system’s dynamics, making it easier to manage the chaotic behavior.
- •
- Robustness: Although the initial sliding surface provides some level of control, it primarily serves as the foundation for more robust control mechanisms. It reduces the complexity of the system’s chaotic dynamics, but further refinement is needed to handle uncertainties and external disturbances effectively.
- -Sliding Surface:
- •
- Proportional-Integral (PI) Rules: The -sliding surface is designed using PI rules, which combine proportional and integral actions to improve control performance. The addition of the fractional-order element (denoted by φ) allows the surface to better manage the memory and hereditary effects inherent in fractional-order systems, resulting in more precise control over the state trajectories.
- •
- Robustness Against Uncertainties: This surface is designed to be robust against system uncertainties, input saturations, and delays. By incorporating both PI control and fractional-order dynamics, the -sliding surface ensures that the system can reach and maintain desired states even in the presence of significant disturbances and nonlinearities.
- Lyapunov Stability:
- •
- Finite-Time Asymptotic Stability: The stability of both the initial and -sliding surfaces is analyzed using the fractional-order Lyapunov stability theory. This theory helps demonstrate that the system’s state trajectories will converge to the sliding surfaces within a finite time and remain there, ensuring that the chaotic behavior is effectively controlled and synchronization is achieved.
- •
- Lyapunov Function: A Lyapunov function is typically constructed to prove that the sliding surfaces are stable. The function is chosen such that it decreases over time, guaranteeing that the system’s state will move towards the sliding surface and stay there, leading to finite-time synchronization of the delayed FOMNNS.
4. Design of Finite Time -SMC Based on Deep SAC Learning
4.1. Principle Concepts of MDP and RL Algorithm
- •
- is the set of system observations (states).
- •
- is the set of actions.
- •
- is the transition function, where this function indicates the probability of mapping from current observation to next step observation under action .
- •
- is a reward signal which is emitted from the environment after applying the action .
- •
- A history stores all the transitions of actions and observations.
4.2. Soft Actor-Critic Strategy
4.3. Design of -Sliding Model Control Based on SAC
- Sample Efficiency: SAC is known for its sample efficiency, meaning it requires fewer interactions with the environment to learn effective policies. This is crucial for optimizing control parameters in systems where obtaining data can be costly or time-consuming.
- Stability and Robustness: SAC utilizes off-policy learning and stable target networks, which contribute to its robustness and stability during training. This is particularly advantageous for managing the inherent uncertainties and chaotic behavior of FOMNNSs, ensuring reliable parameter optimization.
- Continuous Action Space: SAC is well suited for continuous action spaces, making it an ideal choice for optimizing control parameters in scenarios where control inputs are continuous rather than discrete. This aligns well with the needs of fine-tuning the PI^φ-SMC controller.
- Entropy Regularization: SAC incorporates entropy regularization to encourage exploration and prevent premature convergence to suboptimal solutions. This feature helps in finding more robust and optimal control policies by balancing exploration and exploitation.
- High Dimensionality Handling: SAC effectively manages high-dimensional state and action spaces, which is beneficial for complex systems like FOMNNSs where the control problem may involve numerous parameters and intricate dynamics.
5. Numerical Simulations
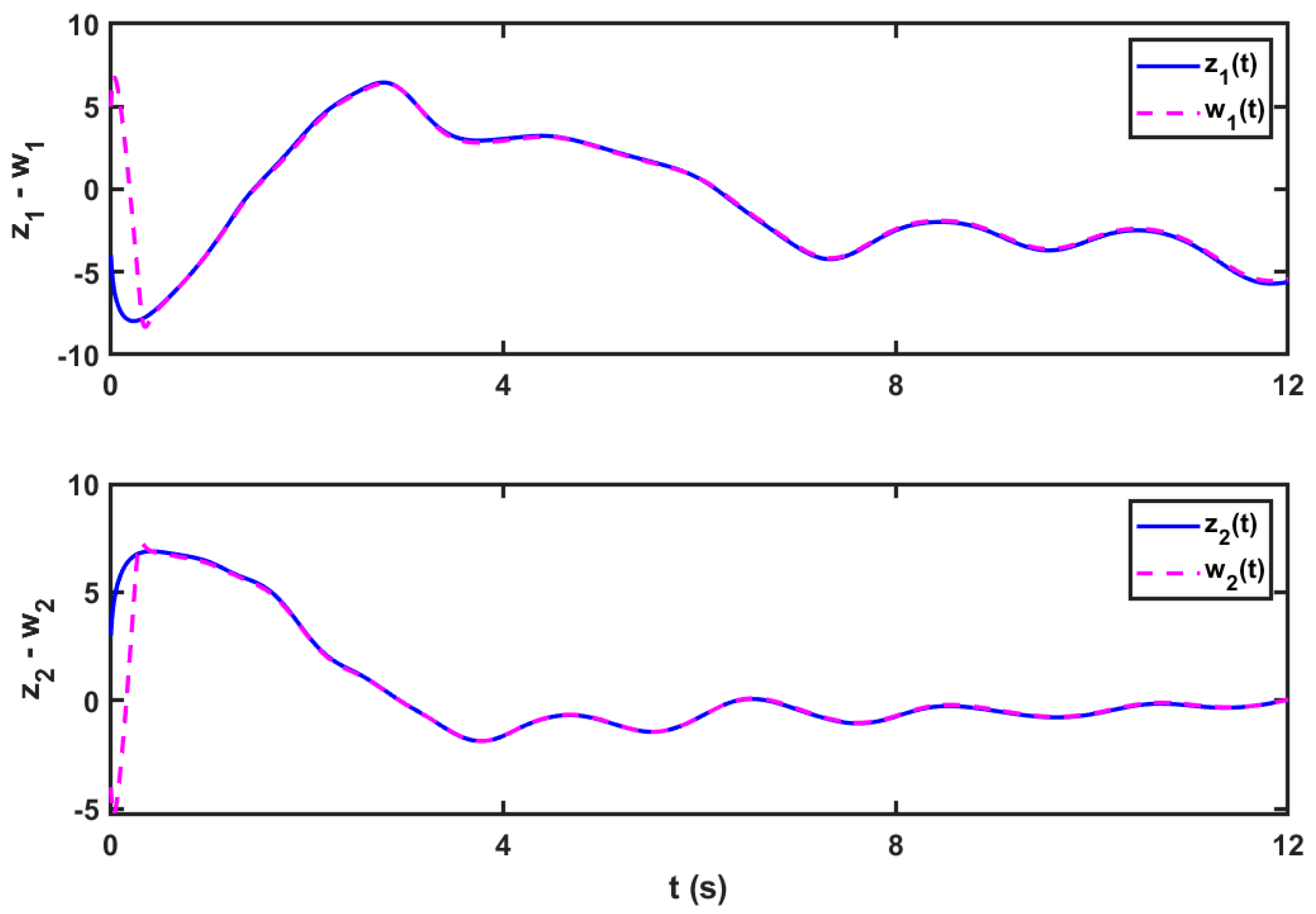
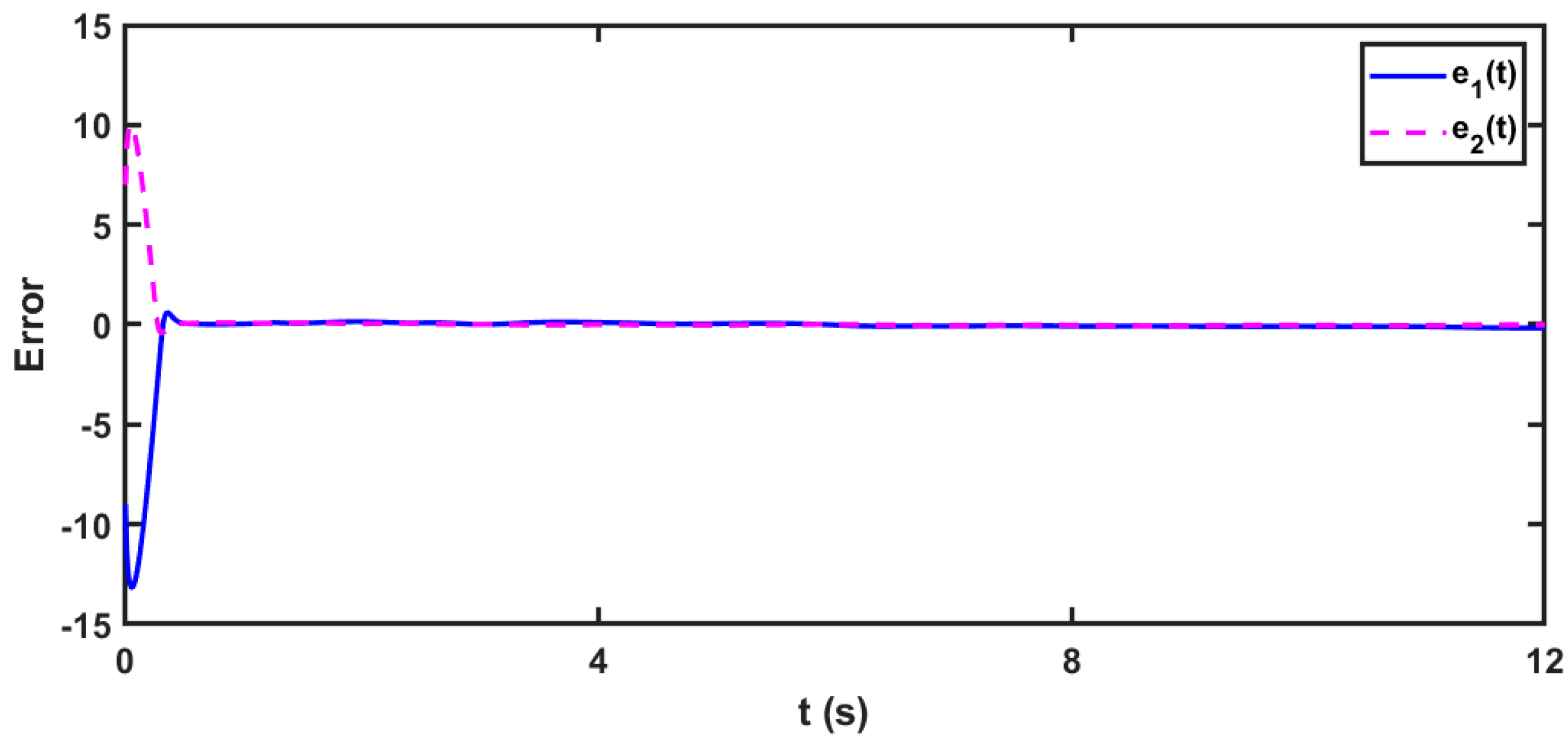
5.1. Scenario 1: In the Case of 2D Complex Delayed FOMNNSs
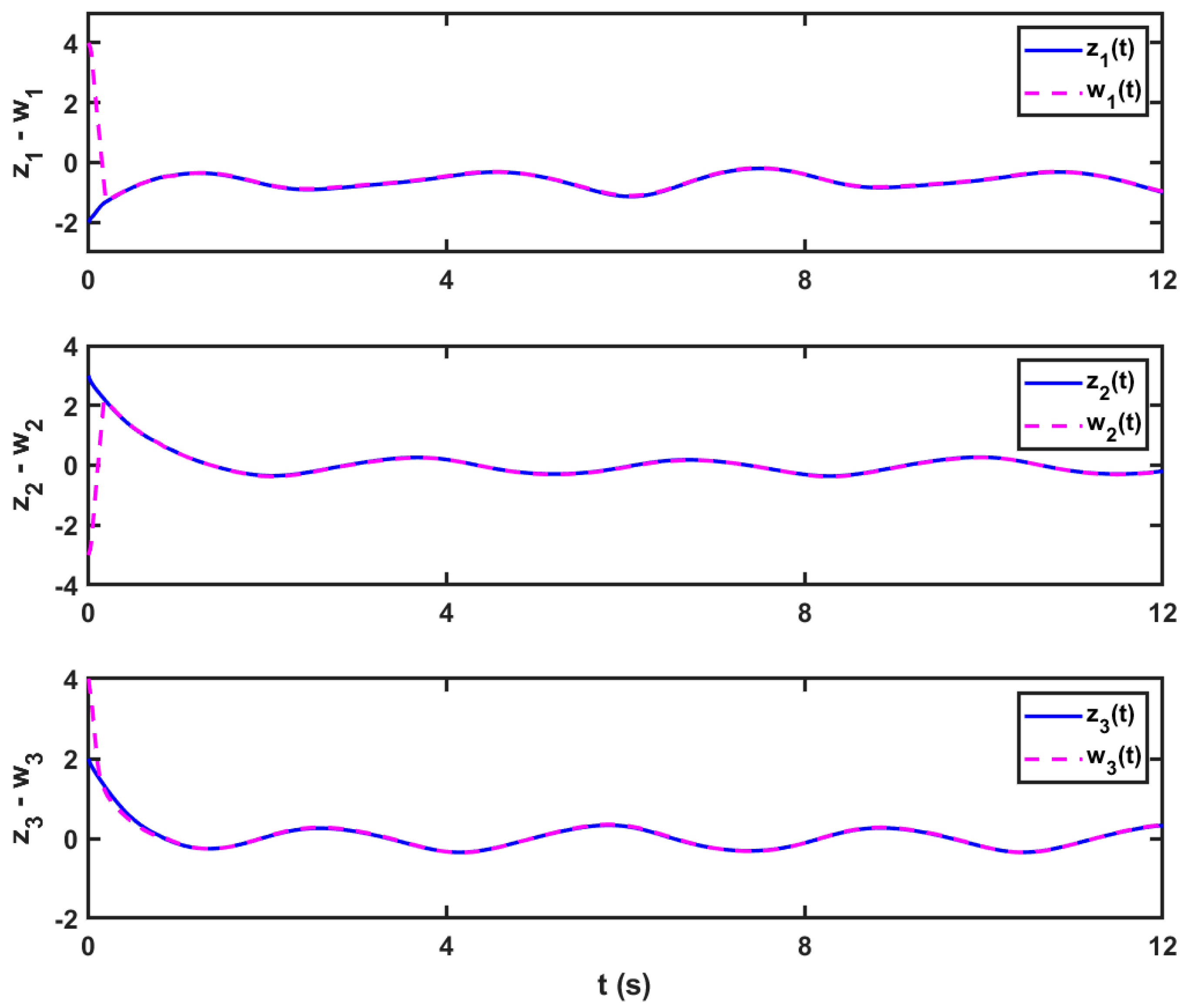
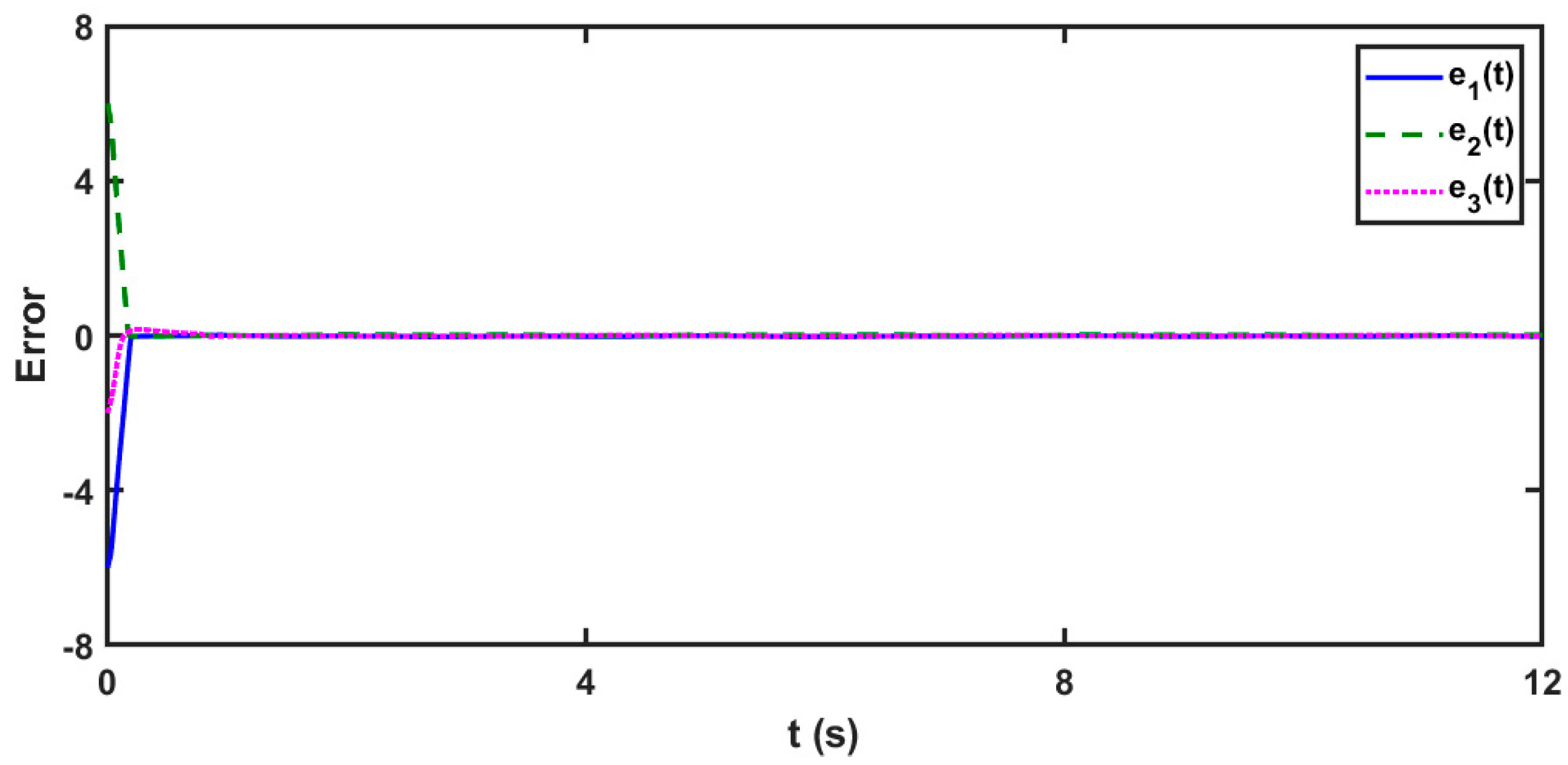
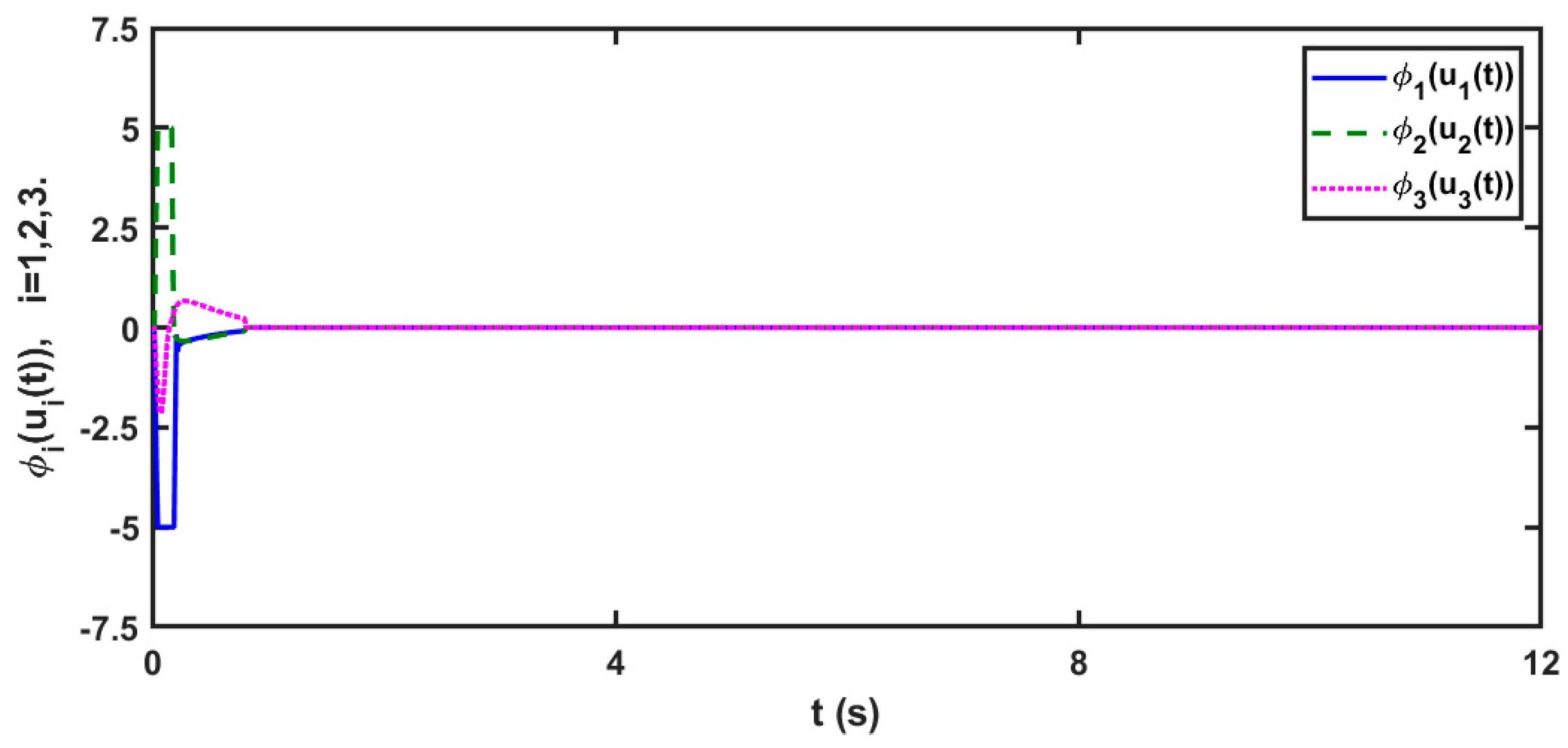
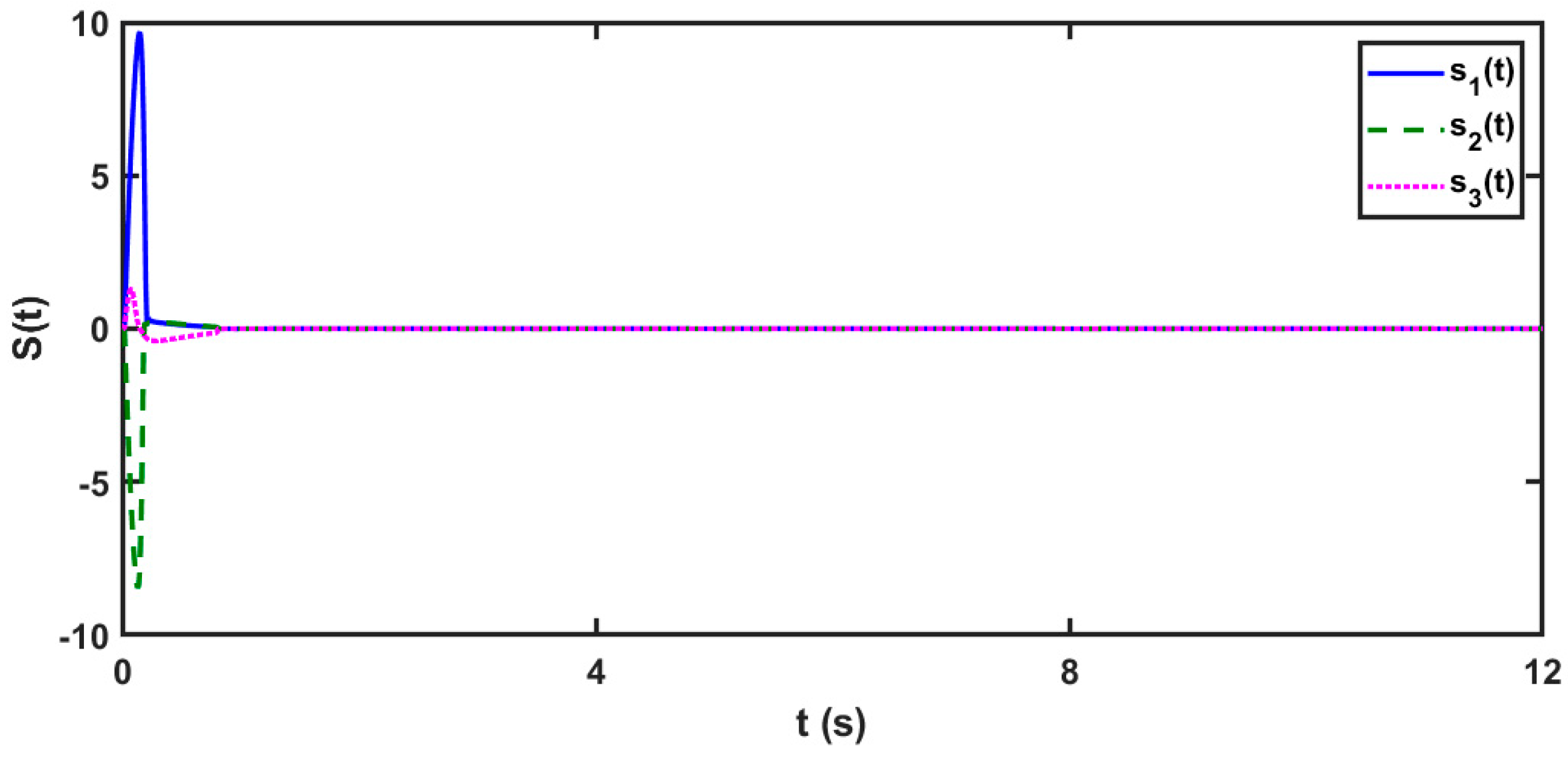
5.2. Scenario 2: In the Case of 3D Unknown Delayed FOMNNSs
6. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cao, Y.; Kao, Y.; Wang, Z.; Yang, X.; Park, J.H.; Xie, W. Sliding mode control for uncertain fractional-order reaction–diffusion memristor neural networks with time delays. Neural Netw. 2024, 178, 106402. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Liu, S.; Wu, X.; Sun, J.; Qiao, W. Synchronization of Fractional Delayed Memristive Neural Networks with Jump Mismatches via Event-Based Hybrid Impulsive Controller. Fractal Fract. 2024, 8, 297. [Google Scholar] [CrossRef]
- Roohi, M.; Zhang, C.; Taheri, M.; Basse-O’Connor, A. Synchronization of Fractional-Order Delayed Neural Networks Using Dynamic-Free Adaptive Sliding Mode Control. Fractal Fract. 2023, 7, 682. [Google Scholar] [CrossRef]
- He, Y.; Zhang, W.; Zhang, H.; Cao, J.; Alsaadi, F.E. Finite-time projective synchronization of fractional-order delayed quaternion-valued fuzzy memristive neural networks. Nonlinear Anal. Model. Control. 2024, 29, 401–425. [Google Scholar] [CrossRef]
- Chen, L.; Gong, M.; Zhao, Y.; Liu, X. Finite-Time Synchronization for Stochastic Fractional-Order Memristive BAM Neural Networks with Multiple Delays. Fractal Fract. 2023, 7, 678. [Google Scholar] [CrossRef]
- Liu, X.; He, H.; Cao, J. Event-Triggered Bipartite Synchronization of Delayed Inertial Memristive Neural Networks With Unknown Disturbances. IEEE Trans. Control. Netw. Syst. 2023, 1–12. [Google Scholar] [CrossRef]
- Meng, D.; Yang, S.; De Jesus, A.M.P.; Fazeres-Ferradosa, T.; Zhu, S.-P. A novel hybrid adaptive Kriging and water cycle algorithm for reliability-based design and optimization strategy: Application in offshore wind turbine monopile. Comput. Methods Appl. Mech. Eng. 2023, 412, 116083. [Google Scholar] [CrossRef]
- Zhang, Y.; Dong, Y.; Frangopol, D.M. An error-based stopping criterion for spherical decomposition-based adaptive Kriging model and rare event estimation. Reliab. Eng. Syst. Saf. 2024, 241, 109610. [Google Scholar] [CrossRef]
- Jia, D.-W.; Wu, Z.-Y. An improved adaptive Kriging model for importance sampling reliability and reliability global sensitivity analysis. Struct. Saf. 2024, 107, 102427. [Google Scholar] [CrossRef]
- Alikhanov, A.A.; Asl, M.S.; Huang, C.; Khibiev, A. A second-order difference scheme for the nonlinear time-fractional diffusion-wave equation with generalized memory kernel in the presence of time delay. J. Comput. Appl. Math. 2024, 438, 115515. [Google Scholar] [CrossRef]
- Alikhanov, A.A.; Asl, M.S.; Huang, C. Stability analysis of a second-order difference scheme for the time-fractional mixed sub-diffusion and diffusion-wave equation. Fract. Calc. Appl. Anal. 2024, 27, 102–123. [Google Scholar] [CrossRef]
- Narayanan, G.; Ali, M.S.; Karthikeyan, R.; Rajchakit, G.; Sanober, S.; Kumar, P. Adaptive Strategies and its Application in the Mittag-Leffler Synchronization of Delayed Fractional-Order Complex-Valued Reaction-Diffusion Neural Networks. IEEE Trans. Emerg. Top. Comput. Intell. 2024, 1–14. [Google Scholar] [CrossRef]
- Birs, I.; Muresan, C.; Nascu, I.; Ionescu, C. A Survey of Recent Advances in Fractional Order Control for Time Delay Systems. IEEE Access 2019, 7, 30951–30965. [Google Scholar] [CrossRef]
- Rasooli Berardehi, Z.; Zhang, C.; Taheri, M.; Roohi, M.; Khooban, M.H. Implementation of TS fuzzy approach for the synchronization and stabilization of non-integer-order complex systems with input saturation at a guaranteed cost. Trans. Inst. Meas. Control. 2023, 45, 2536–2553. [Google Scholar] [CrossRef]
- Xie, S.; Sun, H.; Xie, Y.; Chen, X. Tuning of fuzzy controller with arbitrary triangular input fuzzy sets based on proximal policy optimization for time-delays system. J. Process Control. 2023, 129, 103059. [Google Scholar] [CrossRef]
- Roohi, M.; Mirzajani, S.; Haghighi, A.R.; Basse-O’Connor, A. Robust stabilization of fractional-order hybrid optical system using a single-input TS-fuzzy sliding mode control strategy with input nonlinearities. AIMS Math. 2024, 9, 25879–25907. [Google Scholar] [CrossRef]
- Makhbouche, A.; Boudjehem, B.; Birs, I.; Muresan, C.I. Fractional-Order PID Controller Based on Immune Feedback Mechanism for Time-Delay Systems. Fractal Fract. 2023, 7, 53. [Google Scholar] [CrossRef]
- Liu, S.; Wang, H.; Li, T. Adaptive composite dynamic surface neural control for nonlinear fractional-order systems subject to delayed input. ISA Trans. 2023, 134, 122–133. [Google Scholar] [CrossRef]
- Dong, H.Q.; Gam, N.T.; Cuong, H.M.; Tuan, L.A. Fractional-order fast terminal back-stepping sliding mode control of autonomous robotic excavators. J. Frankl. Inst. 2024, 361, 106686. [Google Scholar] [CrossRef]
- Yan, Y.; Zhang, H.; Sun, J.; Wang, Y. Sliding Mode Control Based on Reinforcement Learning for T-S Fuzzy Fractional-Order Multiagent System With Time-Varying Delays. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 1–12. [Google Scholar] [CrossRef]
- Johnson, M.; Mohan Raja, M.; Vijayakumar, V.; Shukla, A.; Nisar, K.S.; Jahanshahi, H. Optimal control results for impulsive fractional delay integrodifferential equations of order 1 < r < 2 via sectorial operator. Nonlinear Anal. Model. Control. 2023, 28, 468–490. [Google Scholar] [CrossRef]
- Roohi, M.; Mirzajani, S.; Basse-O’Connor, A. A No-Chatter Single-Input Finite-Time PID Sliding Mode Control Technique for Stabilization of a Class of 4D Chaotic Fractional-Order Laser Systems. Mathematics 2023, 11, 4463. [Google Scholar] [CrossRef]
- Ren, Z.; Tong, D.; Chen, Q.; Zhou, W. Sliding Mode Control for Uncertain Fractional-Order Systems with Time-Varying Delays. Circuits Syst. Signal Process. 2024, 43, 3979–3995. [Google Scholar] [CrossRef]
- Cheng, Y.; Hu, T.; Xu, W.; Zhang, X.; Zhong, S. Fixed-time synchronization of fractional-order complex-valued neural networks with time-varying delay via sliding mode control. Neurocomputing 2022, 505, 339–352. [Google Scholar] [CrossRef]
- Jia, T.; Chen, X.; He, L.; Zhao, F.; Qiu, J. Finite-Time Synchronization of Uncertain Fractional-Order Delayed Memristive Neural Networks via Adaptive Sliding Mode Control and Its Application. Fractal Fract. 2022, 6, 502. [Google Scholar] [CrossRef]
- Chen, T.; Yang, H.; Yuan, J. Event-Triggered Adaptive Neural Network Backstepping Sliding Mode Control for Fractional Order Chaotic Systems Synchronization With Input Delay. IEEE Access 2021, 9, 100868–100881. [Google Scholar] [CrossRef]
- Ren, F.; Wang, X.; Zeng, Z. Improved Fixed-Time Stabilization of Fuzzy Neural Networks With Distributed Delay via Adaptive Sliding Mode Control. IEEE Trans. Fuzzy Syst. 2023, 31, 2029–2043. [Google Scholar] [CrossRef]
- Dalir, M.; Bigdeli, N. An Adaptive neuro-fuzzy backstepping sliding mode controller for finite time stabilization of fractional-order uncertain chaotic systems with time-varying delays. Int. J. Mach. Learn. Cybern. 2021, 12, 1949–1971. [Google Scholar] [CrossRef]
- Chen, T.; Yuan, J.; Yang, H. Event-triggered adaptive neural network backstepping sliding mode control of fractional-order multi-agent systems with input delay. J. Vib. Control. 2021, 28, 23–24. [Google Scholar] [CrossRef]
- Gao, J.; Chen, X.; Qiu, J.; Wang, C.; Jia, T. Adaptive Sliding Mode Fixed-/Preassigned-Time Synchronization of Stochastic Memristive Neural Networks with Mixed-Delays. Neural Process. Lett. 2024, 56, 205. [Google Scholar] [CrossRef]
- Fan, H.; Rao, Y.; Shi, K.; Wen, H. Time-Varying Function Matrix Projection Synchronization of Caputo Fractional-Order Uncertain Memristive Neural Networks with Multiple Delays via Mixed Open Loop Feedback Control and Impulsive Control. Fractal Fract. 2024, 8, 301. [Google Scholar] [CrossRef]
- Wen, G.; Chen, C.P.; Li, W.N. Simplified optimized control using reinforcement learning algorithm for a class of stochastic nonlinear systems. Inf. Sci. 2020, 517, 230–243. [Google Scholar] [CrossRef]
- Bian, T.; Jiang, Z.-P. Reinforcement learning and adaptive optimal control for continuous-time nonlinear systems: A value iteration approach. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 2781–2790. [Google Scholar] [CrossRef]
- Yuan, X.; Wang, Y.; Zhang, R.; Gao, Q.; Zhou, Z.; Zhou, R.; Yin, F. Reinforcement learning control of hydraulic servo system based on TD3 algorithm. Machines 2022, 10, 1244. [Google Scholar] [CrossRef]
- Chen, S.; Qiu, X.; Tan, X.; Fang, Z.; Jin, Y. A model-based hybrid soft actor-critic deep reinforcement learning algorithm for optimal ventilator settings. Inf. Sci. 2022, 611, 47–64. [Google Scholar] [CrossRef]
- Ren, Y.; Duan, J.; Li, S.E.; Guan, Y.; Sun, Q. Improving generalization of reinforcement learning with minimax distributional soft actor-critic. 2020 IEEE 23rd Int. Conf. Intell. Transp. Syst. 2020, 1–6. [Google Scholar]
- Podlubny, I. Fractional Differential Equations: An Introduction to Fractional Derivatives, Fractional Differential Equations, to Methods of Their Solution and Some of Their Applications; Elsevier Science: Amsterdam, The Netherlands, 1998. [Google Scholar]
- Asl, M.S.; Javidi, M. Numerical evaluation of order six for fractional differential equations: Stability and convergency. Bull. Belg. Math. Soc. -Simon Stevin 2019, 26, 203–221. [Google Scholar] [CrossRef]
- Li, C.; Deng, W. Remarks on fractional derivatives. Appl. Math. Comput. 2007, 187, 777–784. [Google Scholar] [CrossRef]
- Li, Y.; Chen, Y.; Podlubny, I. Stability of fractional-order nonlinear dynamic systems: Lyapunov direct method and generalized Mittag–Leffler stability. Comput. Math. Appl. 2010, 59, 1810–1821. [Google Scholar] [CrossRef]
- Curran, P.F.; Chua, L.O. Absolute Stability Theory and the Synchronization Problem. Int. J. Bifurc. Chaos 1997, 7, 1375–1382. [Google Scholar] [CrossRef]
- Roohi, M.; Aghababa, M.P.; Haghighi, A.R.J.C. Switching adaptive controllers to control fractional—order complex systems with unknown structure and input nonlinearities. Complexity 2015, 21, 211–223. [Google Scholar] [CrossRef]
- Haklidir, M.; Temeltaş, H. Guided soft actor critic: A guided deep reinforcement learning approach for partially observable Markov decision processes. IEEE Access 2021, 9, 159672–159683. [Google Scholar] [CrossRef]
- Tang, H.; Wang, A.; Xue, F.; Yang, J.; Cao, Y. A novel hierarchical soft actor-critic algorithm for multi-logistics robots task allocation. Ieee Access 2021, 9, 42568–42582. [Google Scholar] [CrossRef]
- Alikhanov, A.A.; Asl, M.S.; Huang, C.; Apekov, A.M. Temporal second-order difference schemes for the nonlinear time-fractional mixed sub-diffusion and diffusion-wave equation with delay. Phys. D Nonlinear Phenom. 2024, 464, 134194. [Google Scholar] [CrossRef]
- Asl, M.S.; Javidi, M.; Ahmad, B. New predictor-corrector approach for nonlinear fractional differential equations: Error analysis and stability. J. Appl. Anal. Comput. 2019, 9, 1527–1557. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Value | Description | Value |
|---|---|---|---|
| Learning rate (actor) | 0.001 | Discount factor (γ) | 0.98 |
| Learning rate (critic) | 0.0001 | Activation function | ReLU |
| Target smoothing coefficient | 0.005 | Batch size | 256 |
| Number of hidden layers | 2 | Mini-batch size | 64 |
| Number of neurons in hidden layers | 200 300 | Optimizer | Adam |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roohi, M.; Mirzajani, S.; Haghighi, A.R.; Basse-O’Connor, A. Robust Design of Two-Level Non-Integer SMC Based on Deep Soft Actor-Critic for Synchronization of Chaotic Fractional Order Memristive Neural Networks. Fractal Fract. 2024, 8, 548. https://doi.org/10.3390/fractalfract8090548
Roohi M, Mirzajani S, Haghighi AR, Basse-O’Connor A. Robust Design of Two-Level Non-Integer SMC Based on Deep Soft Actor-Critic for Synchronization of Chaotic Fractional Order Memristive Neural Networks. Fractal and Fractional. 2024; 8(9):548. https://doi.org/10.3390/fractalfract8090548
Chicago/Turabian StyleRoohi, Majid, Saeed Mirzajani, Ahmad Reza Haghighi, and Andreas Basse-O’Connor. 2024. "Robust Design of Two-Level Non-Integer SMC Based on Deep Soft Actor-Critic for Synchronization of Chaotic Fractional Order Memristive Neural Networks" Fractal and Fractional 8, no. 9: 548. https://doi.org/10.3390/fractalfract8090548
APA StyleRoohi, M., Mirzajani, S., Haghighi, A. R., & Basse-O’Connor, A. (2024). Robust Design of Two-Level Non-Integer SMC Based on Deep Soft Actor-Critic for Synchronization of Chaotic Fractional Order Memristive Neural Networks. Fractal and Fractional, 8(9), 548. https://doi.org/10.3390/fractalfract8090548