1. Introductory Notes
The matrix sign function, also known as the matrix signum function or simply matrix sign, is a mathematical function that operates on matrices, returning a matrix of the same size with elements representing the signs of the corresponding elements in the input matrix. The concept of the sign function can be traced back to the scalar sign function, which operates on individual real numbers ([
1], Chapter 11). The scalar sign function offers +1 for positive numbers,
for negative numbers, and 0 for zero.
The extension of the sign function to matrices emerged as a natural generalization. This function was introduced to facilitate the study of matrix theory and to develop new algorithms for solving matrix equations and systems. This function provides valuable information about the structure and properties of matrices. The earliest references to the matrix sign could be found in the mathematical literature in the late 1960s and early 1970s [
2]. This function for a square nonsingular matrix
, i.e.,
can be expressed as follows [
3] (p. 107):
where
I is is the unit matrix.
Several authors who contributed to the development and study of the matrix sign function include Nicholas J. Higham, Charles F. Van Loan, and Gene H. Golub; see the textbook [
3]. Since its introduction, it has found applications in various areas of mathematics and scientific computing. It has been utilized in numerical analysis, linear algebra algorithms, control theory, graph theory, and stochastic differential equations; see, e.g., [
4]. In recent years, research has focused on refining algorithms for efficiently computing the matrix sign function, higher-order iterative methods, and exploring its connections to other matrix functions and properties. This function has proven to be a fruitful tool for characterizing and manipulating matrices in a wide range of disciplines. Expanding the discussion, the work by Al-Mohy and Higham [
5], while primarily centered on the matrix exponential, introduced a highly influential algorithm that serves as a fundamental basis for computing various other matrix functions, including (
1).
Here are some areas where this function finds utility. 1. Stability analysis: In control theory and dynamical systems, the matrix sign function is employed to analyze the stability of linear time-invariant systems. By examining the signs of the eigenvalues of a system’s matrix representation, the matrix sign function helps determine stability properties, such as asymptotic stability or instability [
6]. 2. Matrix fraction descriptions: This function plays a key appearance in representing matrix fraction descriptions of linear time-invariant sets. Matrix fractions are used in system theory to describe transfer functions, impedance matrices, and other related quantities. Then, (
1) is employed in the realization theory of these matrix fractions [
7]. 3. Robust control: Robust control techniques aim to design control systems that can handle uncertainties and disturbances. This function is utilized in robust control algorithms to assess the stability and performance of uncertain systems. It helps analyze the worst-case behavior of the system under varying uncertain conditions [
2]. 4. Discrete-time systems: In the analysis and design of discrete-time systems, the matrix sign function aids in studying the stability and convergence properties of difference equations. It allows one the examination of the spectral radius of a matrix and determination of the long-term behavior of discrete-time systems [
3]. 5. Matrix equations: This function is employed in solving matrix equations. For example, it can be employed in the calculation of the matrix square root or the matrix logarithm, which have applications in numerical methods, optimization, and signal processing [
8].
It is an interesting choice to compute (
1) by numerical iterative methods which are mainly constructed by resolving the following nonlinear matrix equations:
The matrix
from (
1) is the solution of (
3) since it satisfies the definition of
. In this work, we focus on proposing a new solver for (
3) in the scalar format and then extending for the matrix environment in order to be computationally economic when compared to the famous iteration solvers of the same type to find (
1) of a nonsingular matrix.
The remainder of this work is arranged as follows. In
Section 2, we look at some important methods for figuring out the sign of a matrix. Then, in
Section 3, we explain why higher-order methods are useful and introduce a solver for solving nonlinear scalar equations. We extend this solver to work with matrices and prove its effectiveness through detailed analysis, showing that it has a convergence order of four. We also examine the attraction basins to ensure the solver works globally and covers a wider range compared to similar methods. We discuss its stability as well. In
Section 4, we present the results of our numerical study to validate our theoretical findings, demonstrating the usefulness of our method. Finally, in
Section 5, we provide our conclusions.
2. Iteration Methods
Kenney and Laub in [
9] presented a general and important family of iterations for finding (
1) via the application of the Padé approximations:
We assume now that the
-Padé fraction approximate to
is given as
where
Q,
P are polynomials of suitable degrees in the Padé approximation and
. Then, [
9] discussed that the iteration method below,
converges with convergence speed
to
. Thus, the second-order Newton’s method (NIM) can be constructed as follows:
where
is the starting matrix and
M represents the input matrix as given in (
1). We note that the reciprocal Padé-approximations can be defined based on reciprocals of (
4). Newton’s method provides an iterative approach to approximating (
1). It starts with an initial matrix and then improves the approximation in each iteration until convergence is achieved. This iterative nature makes it useful when dealing with complex matrices or large matrices where direct methods may be computationally expensive.
Newton’s iterative scheme plays an important role in finding (
1) due to its effectiveness in approximating the solution iteratively. Some reasons highlighting the importance of Newton’s iteration for computing (
1) lie in the advantages of iterative approximation (see [
10]). It has quadratic convergence properties, especially when the initial matrix is close to the desired solution. Also, it needs the calculation of the derivative of the function being approximated. In the case of finding (
1), this involves the derivative of the sign function, which can be derived analytically. Utilizing the derivative information can help guide the iterative process towards the solution.
Employing (
4), the subsequent renowned techniques, namely the locally convergent inversion-free Newton–Schulz solver,
and Halley’s solver,
can be extracted, as in [
11]. A quartically convergent solver is proposed in [
12] as follows:
Parameter
is an independent real constant. Additionally, two alternative quartically convergent methods are derived from (
4) with global convergence, which can be expressed as follows:
3. A New Numerical Method
Higher-order iteration solvers to compute (
1) offer several advantages compared to lower-order methods [
13,
14]. To discuss further, higher-order iterative methods typically converge faster than lower-order methods. By incorporating more information from the matrix and its derivatives, these methods can achieve faster convergence rates, leading to fewer iterations required to reach a desired level of accuracy. This can improve the computational efficiency of the matrix sign function computation.
Higher-order iterative methods may provide higher accuracy in approximating the matrix sign function. This is particularly beneficial when dealing with matrices that have small eigenvalues or require high precision computations. Such methods often exhibit improved robustness compared to lower-order methods. They are typically more stable and less sensitive to variations in the input matrix. This robustness is particularly advantageous in situations where the matrix may have a non-trivial eigenvalue distribution or when dealing with ill-conditioned matrices. Higher-order methods can provide more reliable and accurate results in such cases. In addition, such iterations are applicable to a wide range of matrix sizes and types. They can handle both small and large matrices efficiently. Moreover, these methods can be adapted to handle specific matrix structures or properties, such as symmetric or sparse matrices, allowing for versatile applications across different domains.
It is significant to note that the choice of the appropriate iterative method relies on various factors, including the characteristics of the matrix, computational resources, desired accuracy, and specific application requirements. While higher-order iterative methods offer advantages, they may also come with increased memory requirements if not treated well. Thus, a careful consideration of these trade-offs is necessary and an efficient method must be constructed. To propose an efficient one, we proceed as follows.
We now examine the scalar form of Equation (
3), that is to say,
. Here,
is the scalar version of the nonlinear matrix Equation (
3), which means that
. In this paper, we employ uppercase letter “
H” when addressing matrices, while utilizing lowercase letter “
h” to denote scalar inputs. We propose a refined adaptation of the Newton’s scheme, comprising three sequential steps as outlined below:
where
is a divided difference operator. For further insights into solving nonlinear scalar equations using high-order iterative methods, refer to works [
15,
16,
17]. Additionally, valuable information can be found in modern textbooks such as [
18,
19] or classical textbooks like [
20]. The second substep in (
12) represents a significant improvement over the approach presented in [
21]. The coefficients involved in this substep are computed through a method of unknown coefficients, which involves rigorous computations. Initially, these coefficients are considered unknown, and then they are carefully determined to achieve a fourth order of convergence. Furthermore, this process is designed to expand the basins of attraction, providing an advantage over other solvers with similar characteristics.
Theorem 1. Assume as a simple root of , which is an enough smooth function. By considering an enough close guess the method (12) converges to ρ and the rate of convergence is four. Proof. The proof entails a meticulous derivation of Taylor’s expansion for each sub-step of the iterative process around the simple root
. Nonetheless, it is observed that (
12) satisfies the subsequent error equation,
where
and
. Considering that the method (
12) belongs to the category of fixed-point type methods, similar to Newton’s method, its convergence is local. This implies that the initial guess
should be sufficiently close to the root to guarantee convergence. The proof finishes now. □
To illustrate more on the mathematical derivation of the second substep (
12), in fact, first, we consider (
12) as follows:
which offers the following error equation:
The relationship (
16) results in selecting
, consequently transforming the error equation into
Therefore, we need to determine the remaining unspecified coefficients in a way that ensures
, reducing the term in (
16). Moreover, their selection should aim to minimize the subsequent error equation, namely
. This leads us to a choice of
,
and
.
Now, we can solve (
3) by the iterative method (
12). Pursuing this yields
with the initial value (
6). To clarify the derivation in detail, we provide a simple yet efficient Mathematica code for this purpose as follows:
ClearAll[‘‘Global‘*’’]
f[x_] := x^2 - 1
fh = f[h];
fh1 = f’[h];
y = h - fh/fh1;
fy = f[y];
x = h - ((21 fh - 22 fy)/(21 fh - 43 fy)) fh/fh1 // FullSimplify;
ddo1 = (x - h)^-1 (f[x] - f[h]);
h1 = x - f[x]/ddo1 // FullSimplify
Likewise, we acquire the reciprocal expression of (
17) through the following procedure:
Theorem 2. Let be an appropriate initialization and M is nonsingular. Then, (18) (or (17)) tends to N with fourth convergence order. Proof. We consider
B to be a non-singular, non-unique transformation matrix, and represent the Jordan canonical form in the following form:
where the eigenvalues of
M are distinct
and
. For function
f which possesses
degrees of differentiability at
for
, [
22] and is given on the spectrum of
M, the matrix function
can be expressed by
wherein
with
Considering
as the
jth Jordan block size associated to
, we have
To continue, we employ the Jordan block matrix
J and decompose
M by utilizing a nonsingular matrix
B of identical dimensions, leading to the following decomposition:
Through the utilization of this decomposition and an analysis of the solver’s structure, we derive an iterative sequence for the eigenvalues from iterate
l to iterate
in the following manner:
where
In a broad sense and upon performing certain matrix simplifications, the iterative process (
25) reveals that the eigenvalues converge to
, viz.,
Equation (
27) indicates the convergence of the eigenvalues toward
. With each iteration, the eigenvalues tend to cluster closer to
. Having analyzed the theoretical convergence of the method, we now focus on examining the rate of convergence. For this purpose, we consider
Utilizing (
28) and recognizing that
represents rational functions of
M while also demonstrating commutativity with
N within a similar manner as
M, we can express
Using (
29) and a 2-norm, it is possible to obtain
This shows the convergence rate of order four under a suitable selection of the initial matrix, such as (
6). □
We note that the proofs of the theorems in this section are new and were obtained for our proposed method.
Attraction basins are useful in understanding the global convergence behavior of iteration schemes to calculate (
1). In the context of iterative methods, the basins of attraction refer to regions in the input space where the iterative process converges to a specific solution or behavior. When designing a solver for computing (
1), it is crucial to ensure that the method tends to the desired solution regardless of the initial guess. The basins of attraction provide insights into the convergence behavior by identifying the regions of the input space that lead to convergence and those that lead to divergence or convergence to different solutions.
By studying the basins of attraction, one can analyze the stability and robustness of an iterative method for computing (
1). In general, here is how basins of attraction help in understanding global convergence [
23]:
Convergence Analysis: Basins of attraction provide information about the convergence properties of the iterative sequence. The regions in the input space that belong to the basin of attraction of a particular solution indicate where the method converges to that solution. By analyzing the size, shape, and location of these basins, one can gain insights into the convergence behavior and determine the conditions under which convergence is guaranteed.
Stability Assessment: Basins of attraction reveal the stability of the iterative method. If the basins of attraction are well-behaved and do not exhibit fractal or intricate structures, it indicates that the method is stable and robust. On the other hand, if the basins are complex and exhibit fractal patterns, it suggests that the method may be sensitive to initial conditions and can easily diverge or converge to different solutions.
Optimization and Method Refinement: Analyzing the basins of attraction can guide the optimization and refinement of the iterative method. By identifying regions of poor convergence or instability, adjustments can be made to the algorithm to improve its performance. This may involve modifying the iteration scheme, incorporating adaptive techniques, or refining the convergence criteria.
Algorithm Comparison: Basins of attraction can be used to compare various iteration methods for finding (
1). By studying the basins associated with different methods, one can assess their convergence behavior, stability, and efficiency. This information can aid in selecting the most suitable method for a particular problem or in developing new algorithms that overcome the limitations of existing approaches.
We introduced techniques (
17) and (
18) with the aim of expanding the attraction regions pertaining to these methods in the solution of
. To provide greater clarity, we proceed to explore how the proposed methods exhibit global convergence and enhanced convergence radii by visually representing their respective attraction regions in the complex domain,
when solving
. In pursuit of this objective, we partition the complex plane into numerous points using a mesh, and subsequently assess the behavior of each point as an initial value to ascertain whether it converges or diverges. Upon convergence, the point is shaded in accordance with the number of iterations, leading to the following termination criterion:
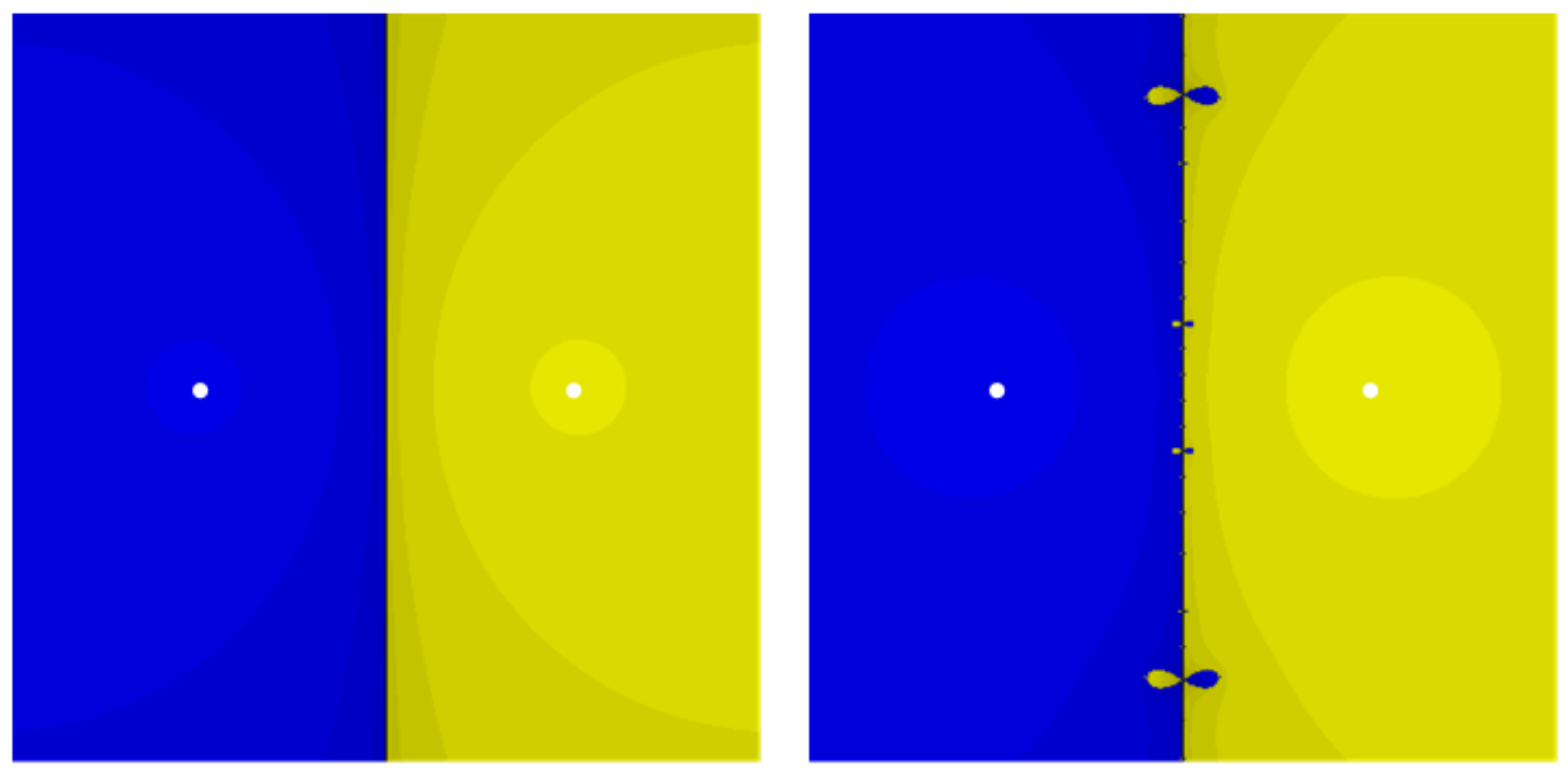
Figure 1,
Figure 2 and
Figure 3 include the basins of attractions for different methods. We recal that the fractal behavior of iterative methods in a complex plane determine their local or global convergence under certain conditions. They reveal that for (
17) and (
18), they own larger radii of convergence in comparison to their same-order competitors from (
4). The presence of a lighter area indicates the expansion of the convergence radii as they extend to encompass (
1).
Theorem 3. According to Equation (18) and assuming an invertible matrix M, the sequence with is asymptotically stable. Proof. We consider a perturbed calculation of
in the
iterate of performing the numerical solver,; for more, see [
24]. And we define the following relation per cycle:
Throughout the remainder of the proof, we assume the validity of relation
for
, which holds true under the condition of performing a first-order error analysis, considering the smallness of
. We obtain
In the phase of convergence, it is considered that
utilizing the following established facts (pertaining to the invertible matrix
H and an arbitrary matrix
E) as referenced in [
25] (p. 188),
We also utilize
and
(which are special cases of
) and
,
) to obtain
By further simplifications and using
, we can find
This leads to the conclusion that (
18) at the iterate
is bounded, thus offering us
Therefore, the sequence
produced via (
17) is stable. □
We end this section by noting that our proposed method comes with error estimation techniques that enable the estimation of the approximation error during the computation. This provides valuable information about the quality of the calculated resolution. Additionally, its higher-order nature allows for better control over the accuracy of the approximation by adjusting the order of the method or specifying convergence tolerances. Additionally, our method can take advantage of parallel computing architectures to accelerate the computation process. It can be parallelized to distribute the computational workload across multiple processing units, enabling faster computations for large matrices or in high-performance computing environments.
4. Computational Study
Here, we evaluate the performance of the proposed solvers for various types of problems. The whole implementations are run by Mathematica (see [
26]). Computational issues such as convergence detection are considered. We divide the tests into two parts, tests of theoretical values and tests of practical values. The following methods are compared: (
5) denoted by NIM, (
8), denoted by HM, (
11), shown by Padé, (
17) shown by P1, (
18) shown by P2. We also compare the results with the Zaka Ullah et al. method (ZM) [
21] as follows:
For all the compared iterative methods, we employ the initial matrix
by (
6). The calculation of the absolute error is performed as follows:
Here,
represents the stopping value. Observing that the reported times are based on a single execution of the entire program, it is important to note that these reported times encompass all calculations, including the computation of norm residuals and other relevant operations.
Example 1. Ten real random matrices are generated using a random seed and their matrix sign functions are computed and compared. We produce ten random matrices in the interval of the sizes till under .
Numerical comparisons for Example 1 are presented in
Table 1 and
Table 2, substantiating the effectiveness of the methods proposed in this paper. Notably, both P1 and P2 contribute to a decrease in the required number of iterations for determining the matrix sign, resulting in a noticeable reduction in elapsed CPU time (measured in seconds). This reduction is evident in the average CPU times across ten randomly generated matrices of varying dimensions.
Example 2. In this test, the matrix sign function is computed for ten complex random matrices with the same seed as in Example 1 under by the piece of Mathematica code below:number = 10;
Table[M[n] = RandomComplex[{-20 - 20 I,
20 + 20 I}, {100 n, 100 n}];, {n, number}];
Table 3 and
Table 4 provide numerical comparisons for Example 2, further reaffirming the efficiency of the proposed method in determining the sign of ten randomly generated complex matrices. Comparable computational experiments conducted for various analogous problems consistently corroborate the aforementioned findings, with P1 emerging as the superior solver.
Stabilized Solution of a Riccati Equation
We take into account the ARE, also known as the algebraic Riccati equation, arising in optimal control problems in continuous/discrete time as follows [
27]:
where
is positive definite,
is positive semi-definite,
,
, and
are the unknown matrix. Typically, we seek a solution that stabilizes the system, meaning the eigenvalues of
have negative real parts. It is important to notice that if the pair
is stabilizable, and
is detectable, then there exists a stabilizing unique resolution
Y for Equation (
40) in
. Furthermore, this solution
Y is both symmetric and positive semi-definite. Assuming
Y is the stabilizing resolution for the ARE in Equation (
40), all eigenvalues of
have negative real parts, which can be seen from the following equation:
We obtain
for a suitable matrix
K, wherein
Now, we find
Y as follows:
and thus
which implies
After determining the sign of
H, solving the required solution becomes feasible by addressing the overdetermined system (
46). This can be achieved through standard algorithms designed for solving such systems. In our test scenario, we utilize P1 with the termination condition (
39) in the infinity norm, along with a tolerance of
to compute the sign of
H during the solution of the ARE (
40). As a practical instance, this procedure involves the following input matrices:
The resulting matrix, which serves as the solution to (
40), is
To verify the accuracy of matrix
Y, we calculate the residual norm of (
40) in
using (
51), resulting in
. This value affirms the precision of the approximation we attained for (
40) through the matrix sign function and P1 approach.





 ,
, 


{kind=link}
{kind=link}
{kind=link}