Abstract
Motivated by the increase in practical applications of fractional calculus, we study the classical gradient method under the perspective of the -Hilfer derivative. This allows us to cover several definitions of fractional derivatives that are found in the literature in our study. The convergence of the -Hilfer continuous fractional gradient method was studied both for strongly and non-strongly convex cases. Using a series representation of the target function, we developed an algorithm for the -Hilfer fractional order gradient method. The numerical method obtained by truncating higher-order terms was tested and analyzed using benchmark functions. Considering variable order differentiation and step size optimization, the -Hilfer fractional gradient method showed better results in terms of speed and accuracy. Our results generalize previous works in the literature.
Keywords:
fractional calculus; ψ-Hilfer fractional derivative; fractional gradient method; optimization MSC:
26A33; 65K99; 35R11; 49M99
1. Introduction
The gradient descent method is a classical convex optimization method. It is widely used in many areas of computer science, such as in image processing [1,2], machine learning [3,4,5], and control systems [6]. Its use on a large scale is essentially due to its intuitive structure, ease of implementation, and accuracy. In recent years, there has been an increase in interest in the application of fractional calculus techniques to develop and implement fractional gradient methods (FGM). The first work dealing with such methods is in [2,7], which addresses problems in the fields of signal processing and adaptive learning. The design of fractional least mean squares algorithms is another example of the application of FGM [8,9,10]. Recently, some applications of FGM have focused on artificial intelligence subjects such as machine learning, deep learning, and neural networks (see [11,12,13] and references therein).
Replacing the first-order integer derivative with a fractional derivative in a gradient can improve its convergence, because long-term information can be included. However, there are some convergence issues in the numerical implementation of the FGM because the real extreme value of the target function is not always the same as the fractional extreme value.
In [14], the authors propose a new FGM to overcome this problem, considering an iterative update of the lower limit of integration in the fractional derivative to shorten the memory characteristic presented in the fractional derivative and truncating the higher order terms of the series expansion associated with the target function. Afterward, Wei et al. [15] designed another method involving variable fractional order to solve the convergence problem.
In the field of fractional calculation, several definitions of fractional and derivative integrals varying in their kernel size can be found. This diversity allows certain problems to be tackled with specific fractional operators. To establish a general operator, a -fractional integral operator with respect to function was proposed in [16,17], where the kernel depends on a function with specific properties. To incorporate as many fractional derivative definitions as possible into a single formulation, the concept of a fractional derivative of a function with respect to the function was introduced. In 2017, Almeida [18] proposed the -Caputo fractional derivative and studied its main properties. A similar approach can be used to define the -Riemann–Liouville fractional derivative. In 2018, Sousa and Oliveira [19] unified both definitions using Hilfer’s concept and introduced the -Hilfer fractional derivative. This approach offers the flexibility of choosing the differentiation type, as Hilfer’s definition interpolates smoothly between fractional derivatives of Caputo and Riemann–Liouville types. Additionally, by choosing the function , we obtain well-known fractional derivatives, such as Caputo, Riemann–Liouville, Hadamard, Katugampola, Chen, Jumarie, Prabhakar, Erdélyi-Kober, and Weyl, among others (see Section 5 in [19]).
The aim of this work is to propose a FGM with a -Hilfer fractional derivative. Using this type of general derivative allows us to deal with several fractional derivatives in the literature at the same time. It also allows us to study cases where the target function is a composition of functions. In the first section, we show some auxiliary results concerning the chain rule and solutions of some fractional partial differential equations to study the convergence of the continuous -fractional gradient method for strongly and non-strongly convex target functions. In the second section, we introduce and implement numerical algorithms for the -Hilfer FGM in one- and two-dimensional cases, generalizing the ideas presented in [14,15]. The proposed algorithms were tested using benchmark functions. The numerical results had better performance compared with the classical gradient in terms of accuracy and number of iterations.
In summary, this paper is organized as follows: in Section 2, we recall some basic concepts about the -Hilfer derivative and the two-parameter Mittag–Leffler function. We present some auxiliary results in Section 3, which are then used to analyze the continuous gradient method for strongly and non-strongly convex target functions in Section 4. In the last section of the paper, we design and implement numerical algorithms for the -Hilfer FGM by replacing the lower limit of the fractional integral with the last iterate and by using the variable order of differentiation with the optimization of the step size in each iteration. The convergence, accuracy, and speed of the algorithms are analyzed using different examples.
2. General Fractional Derivatives and Special Functions
In this section, we recall some concepts related to fractional integrals and derivatives of a function with respect to another function (for more details, see [16,18,19]).
Definition 1.
(cf. [19], Def. 4) Let be a finite or infinite interval on the real line and . In addition, let ψ be an increasing and positive monotone function on . The left Riemann–Liouville fractional integral of a function f with respect to another function ψ on is defined by
Now, we introduce the definition of the so-called -Hilfer fractional derivative of a function f with respect to another function.
Definition 2.
(cf. [19], Def. 7) Let , , and be a finite or infinite interval on the real line and of two functions such that ψ is a positive monotone increasing function and , for all . The ψ-Hilfer left fractional derivative of order α and type is defined by
We observe that when , we recover the left fractional derivative -Riemann–Liouville (see Definition 5 in [19]) and when , we obtain the left -Caputo fractional derivative (see Definition 6 in [19]). The following list shows some fractional derivatives that are encompassed in Definition 2 for specific choices of the function and parameter
- Riemann–Liouville: , , and ;
- Caputo: , , and ;
- Katugampola: , with , , and ;
- Caputo-Katugampola: , with , , and ;
- Hadamard: , , and ;
- Caputo-Hadamard: , , and .
For a more complete list, please refer to Section 5 in [19]. By considering partial fractional integrals and derivatives, previous definitions can be defined for higher dimensions (see Chapter 5 in [16]). Furthermore, the -Hilfer fractional derivative of an n-dimensional vector function is defined component-wise as
Next, we present some technical results related to previously introduced operators.
Theorem 1.
(cf. [19], Thm. 5) If , , , and , then
where and
Lemma 1.
(cf. [19], Lem. 5) Given , consider the function , where . Then, for and , we have
Some results of the paper are given in terms of the two-parameter Mittag–Leffler function, which is defined by the following power series (see [20])
For with and the two-parameter Mittag–Leffler function has the following asymptotic expansion (see Equation (4.7.36) in [20]):
3. Auxiliary Results
In this section, we present some auxiliary results needed for our work. These extend some results presented in [21] to the -Hilfer derivative of arbitrary type .
We start by presenting a representation formula for the solution of a Cauchy problem involving the -Hilfer derivative. Let us consider and . We obtain the following results.
Proposition 1.
Let and . A continuous function f is a solution of the problem
if and only if f is given by
Proof.
Now, we present some results concerning the fractional derivative of a composite function. Let us consider , , ∇ as the classical gradient operator, and the -Hilfer fractional derivative of an n-dimensional vector function as (3).
Theorem 2.
Let , , , and the function ψ to be in the conditions of Definition 2. For , let us define the function by setting
where
The following identity holds
Proof.
By the Newton–Leibniz formula, for each component of the function f, one has
From (3), for , we have
For the second term in (11), taking (1) and the Leibniz rule for differentiation under the integral sign into account, we obtain
Hence, we can write
which implies, by integrating by parts, that
As , we have by L’Hôpital’s rule that
Corollary 1.
Let , , , and the function ψ have the conditions of Definition 2. If is of class and convex, i.e.,
then
Proof.
From (18), it follows that for ,
On the other hand, based on Theorem 2, we have the following for
Combining the two previous expressions, we obtain our results. □
If we consider , which corresponds to the -Riemann–Liouville case, the previous results reduce to Proposition 3.3 and Corollary 3.4 in [21], respectively. Moreover, the correspondent results for the -Caputo case () are presented in Proposition 3.1 of [21].
Now, we present an auxiliary result involving the two-parameter Mittag–Leffler function.
Proposition 2.
Let , , and . Moreover, let ψ be in the conditions of Definition 2, such that . Then, the following limit holds
Proof.
Taking into account Theorem 5.1 in [22] for the case of a homogeneous equation, the solution of the initial value problem
is given by
Hence, by Proposition 1, we have
Taking the limit when on both sides and considering the asymptotic expansion (6), we conclude that the left-hand side tends to approach zero and the first term of the right-hand side also tends to approach zero. Hence, we obtain
which leads to our results. □
The case when , i.e., the -Caputo case, was already studied in [21] and corresponds to Lemma 3.7.
4. Continuous Gradient Method via the -Hilfer Derivative
Assume that we aim to determine the minimum of a function . To achieve this, the gradient descent method is used, starting with an initial prediction of the local minimum and producing a sequence based on the following recurrence relation:
where the step size is either constant or varying at each iteration k. The sequence generated by the gradient descent method is monotonic, i.e., , and is expected to converge to a local minimum of f. Typically, the stopping criterion is in the form , where . By expressing (20) as
we can interpret (21) as the discretization of the initial value problem
using the explicit Euler scheme with step size . The system (22) is known as the continuous gradient method (see [21]). Assuming that f is both strongly convex and smooth, the solutions of (20) and (22) converge to the unique stationary point at an exponential rate. In general, if a convergence result is shown for a continuous method, then we can construct various finite difference schemes for the solution of the associated Cauchy problem. Let us now consider the following -fractional version of (22)
such that , , , , and , where the last expression is evaluated at the limit . For , let us define the following sum of squares error function:
4.1. The Convex Case
Here, we investigate (23) under the assumption of non-strongly convexity of f.
Theorem 3.
Proof.
By the properties of (see Definition 2), the previous expression is equivalent to
If we consider in the previous result, we recover Theorem 4.2 in [21].
4.2. The Strongly Convex Case
Here, we show that under the assumption of strong convexity of the function f, the solution of (23) admits a Mittag–Leffler convergence, which is a general type of exponential convergence to the stationary point. Recall the definition of a strongly convex function.
Definition 3.
(cf. [21]) A function is strongly convex with parameter if
where ∇ stands for the gradient operator.
Theorem 4.
Let and . Suppose that f is of class and is strongly convex. Considering the ψ-fractional differential Equation (23), where the step size θ is a constant, then the solution converges to , with the upper bound
where .
4.3. Convergence at an Exponential Rate
Theorem 4 establishes the Mittag–Leffler convergence rate for the solution of (23) to a stationary point. Specifically, when , the exponential rate of the continuous gradient method (22) is recovered for any .
Theorem 5.
Let , , and ψ satisfy the conditions of Definition 2 with . Let be a function that is , convex, and Lipschitz smooth with constant , that is,
If the solution of (23) converges to at the exponential rate , then .
Proof.
Let be a solution of (23) converging to the stationary point at the rate . Then, there exists a greater or equal to a, such that
By contradiction, let us assume that . We can then set
From Formula (4.11.4b) in [20],
we can find with the property that
By Proposition 1, is of the following form
which is equivalent to
Now, denoting and using (36), we obtain
By the mean value theorem (applied to the function ), there exists such that
which implies that, as and ,
Hence, taking the limit of when , we obtain
This implies that , which is a contradiction. □
5. -Hilfer Fractional Gradient Method
The aim of this section is to construct and implement a numerical method for the -Hilfer FGM in one- and two-dimensional cases. For both cases, we perform numerical simulations using benchmark functions.
5.1. The One-Dimensional Case
5.1.1. Design of the Numerical Method
The gradient descent method typically takes steps proportional to the negative gradient (or approximate gradient) of a function at the current iteration, that is, is updated by the following law
where is the step size or learning rate, and is the first derivative of f evaluated at . We assume that admits a local minimum at the point in , for some , and f admits a Taylor series expansion centered at ,
with domain of convergence such that . As we want to consider the fractional gradient in the -Hilfer sense, our first (and natural attempt) is to consider the iterative method
where is the -Hilfer derivative of order and type , given by (2), and the function is in the conditions of Definition 2. However, a simple example shows that (42) is not the correct approach. In fact, let us consider the quadratic function with a minimum at . For this function, we have that
where if and if . As , the iterative method (42) does not converge to the real minimum point. This example shows that the -Hilfer FGM with a fixed lower limit of integration does not converge to the minimum point. This is due to the influence of long-time memory terms, which is an intrinsic feature of fractional derivatives. In order to address this problem and inspired by the ideas presented in [14,15], we replace the starting point a in the fractional derivative by the term of the previous iteration, that is,
where , , and . This eliminates the long-time memory effect during the iteration procedure. In this sense, and taking into account the series representation (41) and differentiation rule (5), we obtain
where if or if . Thus, the representation formula (45) depends only on or With this modification in the -Hilfer FGM, we obtain the following convergence results.
Theorem 6.
Proof.
Let be the minimum point of . We prove that the sequence converges to by contradiction. Assume that converges to a different and . As the algorithm is convergent, we have that . Moreover, for any small positive , there exists a sufficiently large number , such that
for any . Thus,
must hold. From (45) we have
Considering
we have, from the previous expression,
The geometric series in the previous expression is convergent for sufficiently large k. Hence, we obtain
which is equivalent to
where
On the other hand, from the assumption (46), we have
which contradicts (51). This completes the proof. □
Sometimes, the function f is not smooth enough to admit a series representation in the form (41), and therefore, the implementation of (44) using the series (45) is not possible. For implementation in practice, we need to truncate the series. In our first approach, we consider only the term of the series containing , as it is the most relevant for the gradient method. Thus, the -Hilfer FGM (44) simplifies to
Furthermore, in order to avoid the appearance of complex numbers, we introduce the modulus in the expression (52), that is,
The pseudocode associated to (53) is presented in Algorithm 1. As (53) is independent of the parameter, from now on we call the method -FGM. Following the same arguments as in the proof of Theorem 6, we obtain the following results.
Theorem 7.
In the following pseudocode, we describe the implementation of the algorithm (53).
| Algorithm 1:-FGM with higher order truncation. |
 |
As we have seen, it is possible to construct a -FGM that converges to the minimum point of a function. To improve the convergence of the proposed method, we can consider variable order differentiation in each iteration. Some examples of are given by (see [15]):
where and we consider the loss function to be minimized in each iteration. The consideration of the square in the loss function guarantees its non-negativity. All examples given satisfy
where the second limit results from the fact that as Variable order differentiation turns the -FGM into a learning method, because as x gradually approaches , The -FGM with variable order is given by
Theorem 6 remains valid for this variation of Algorithm 1.
5.1.2. Numerical Simulations
Now, we provide some examples that show the validity of the previous algorithms applied to the quadratic function , which is one of the simplest benchmark functions. This function is a convex function with a unique global minimum at . For the -derivative, we consider the following cases:
- Caputo and Riemann–Liouville fractional derivatives: , , and ;
- Hadamard fractional derivative: , , and ;
- Katugampola fractional derivative: , , and . In this case, a cannot coincide with the lower limit of the interval I because is not defined at .
Figure 1, Figure 2 and Figure 3 show the numerical results of Algorithm 1 applied to the composite functions , , and choosing different parameters. In Figure 1, we consider , , , and different orders of differentiation .
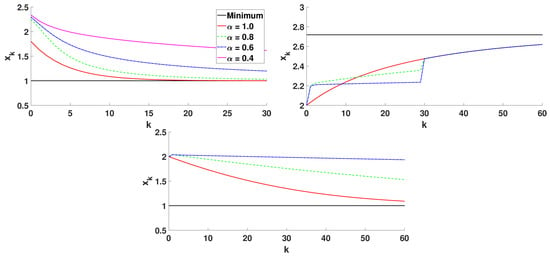
Figure 1.
Algorithm 1 for different orders of differentiation, .
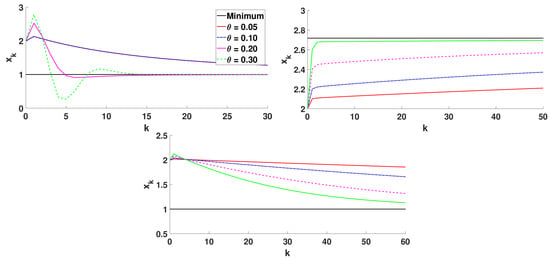
Figure 2.
Algorithm 1 for different step sizes, .
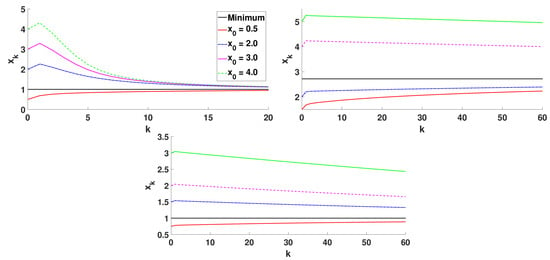
Figure 3.
Algorithm 1 for different initial approximations, .
Analyzing the plots in Figure 1, we see that the convergence of the -FGM in the non-integer case is slower, in general, than in the integer case (). In Figure 2, we consider , , , and different step sizes .
The plots in Figure 2 show that the increment of the step size makes convergence faster. The optimization of the step size in each iteration would lead to the optimal convergence of the method in a few iterations. In Figure 3, we consider different initial approximations , and the values , , and . As expected, convergence becomes faster as approaches the minimum point.
Now, we show the numerical simulations of Algorithm 1 with a variable order of differentiation . In Figure 4, we consider , , , , and the variable order Functions (54)–(58). In Figure 5, we exhibit the behaviour of the algorithm for given by (58) and different values of .
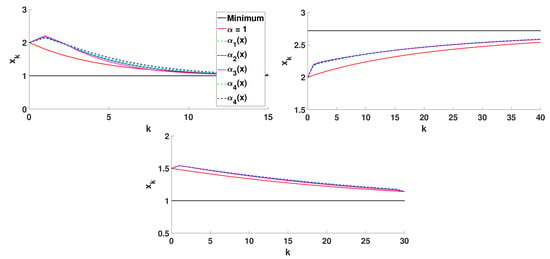
Figure 4.
Algorithm 1 for different variable orders of differentiation.
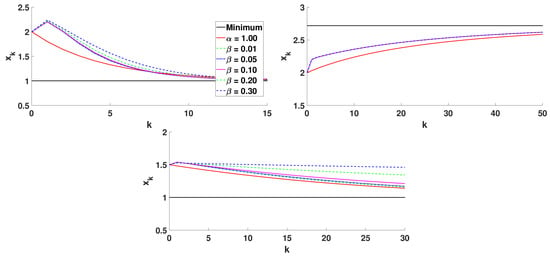
Figure 5.
Algorithm 1 with and different values of .
From these plots, we conclude that in the one-dimensional case, the consideration of variable order differentiation can speed up the convergence, but it is, in general, slower than the classical gradient descent method with integer derivative. A further improvement of the algorithm could be made by considering a variable step size optimized in each iteration. This idea is implemented in the next section, where we consider optimization problems in .
5.2. The Two-Dimensional Case
5.2.1. Untrained Approach
Motivated by the ideas presented in [14,15], we extend the results presented in Section 5.1 to the two-dimensional case. We consider a function in the conditions of Definition 2 and the vector-valued function given by with . Moreover, let be a function that admits a local minimum at the point in for some . We want to find a local minimum point of the function , with , through the iterative method
We assume that f admits a Taylor series centered at the point , given by
with a domain of convergence , such that Then, the -Hilfer fractional gradient in (60) is given by
where and denote the partial -Hilfer derivatives of f, with respect to x and y, of order , type , and with the lower limit of integration replaced by and respectively. Taking into account (61) and (5), we have the following expressions for the components of (62)
where
The iterative method proposed in (60) takes into account the short memory characteristics of the fractional derivatives and, as in the one-dimensional case, we can see from (63) and (64) that the method does not depend on the type of derivative . Furthermore, due to the freedom of choice of the parameter ( or ) and the function, we can deal with several fractional derivatives (see Section 5 in [19]). We obtain the following convergence results:
Theorem 8.
Proof.
Let be the minimum point of . We prove that the sequence converges to by contradiction. Assume that converges to a different and . As the algorithm is convergent, we have that . Moreover, for any small positive , there exists a sufficiently large number , such that
and
for any . Thus,
must hold. From (62)–(64) we have
Considering
from the previous expression, we obtain
The double series that appears in the previous expression are of a geometric type with positive radius less than 1. Hence, by the sum of a geometric series, we have
which is equivalent to
where
and
Despite the convergence of (60), it is important to point out that sometimes the function is not smooth enough. In these cases, the algorithm involving the double series (63) and (64) cannot be implemented. Moreover, in the same way as was done for the one-dimensional case, assuming that f is at least of the class we only consider the following terms of (63) and (64)
Thus, the higher order terms are eliminated and we have the following update of (62):
To avoid the appearance of complex numbers, we also consider
The implementation of (73) is presented in Algorithm 2. In a similar way as it was done in Theorem 8, we can state the following results.
Theorem 9.
| Algorithm 2: 2D -FGM with higher order truncation. |
 |
5.2.2. The Trained Approach
In this section, we refine Algorithm 2 in two ways that train our algorithm in each iteration to find the most accurate . First, we consider a variable step size that is updated in each iteration by minimizing the following function
In the second refinement, we adjust the order of integration with . More precisely, if f is a non-negative function with a unique minimum point , we can consider any of the functions (54)–(58). In our approach, we only consider the following variable fractional order
where the loss function is . From (74), we infer that when , one has , and when , one has . As a consequence of the previous refinements, we have the following iterative method:
where the fractional gradient is given by
The implementation of (76) is presented in Algorithm 3. Likewise, with a variable fractional order , the following theorem follows.
Theorem 10.
The proof of this result follows the same reasoning of the proof of Theorem 8, and therefore, is omitted.
| Algorithm 3: 2D -FGM with variable fractional order and optimized step size. |
 |
5.2.3. Numerical Simulations
In this section, we implement Algorithms 2 and 3 for finding the local minimum point of the function for particular choices of f and . For the function f, we consider the following cases:
- with minimum point at ,
- Matyas function: with minimum point at ,
- Wayburn and Seader No. 1 function: with minimum point at .
The function is a classic convex quadratic function in and can be considered an academic example for implementing our algorithms. The choice of functions and is due to the fact that they are benchmark functions used to test and evaluate several characteristics of optimization algorithms, such as convergence rate, precision, robustness, and general performance. More precisely, the Matyas function has a plate shape and the Wayburn and Seader No. 1 function has a valley shape, which implies slow convergence to the minimum point of the corresponding function. For the functions in the vector function we consider the choices
- , with ,
- , with ,
- with .
For the numerical simulations, we consider some combinations of the functions , , and , , and compare the results in the following scenarios:
- Algorithm 3 with that corresponds to the classical 2D gradient descent method,
- Algorithm 2 with and step size ,
- Algorithm 3 with with .
Figure 6 shows the target functions and , both with a local minimum point at . Figure 7 and Figure 8 show the iterates in the corresponding contour plots of the functions. The plots on the right show the amplification close to the minimum point. The results of numerical simulations are summarized in Table 1. The stopping criterion used was .
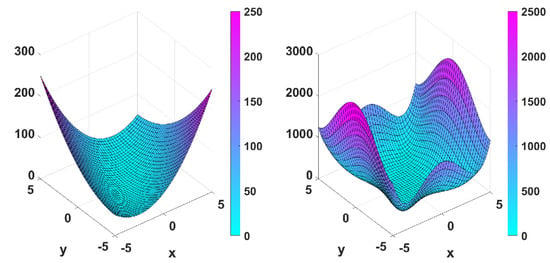
Figure 6.
Graphical representations of and .
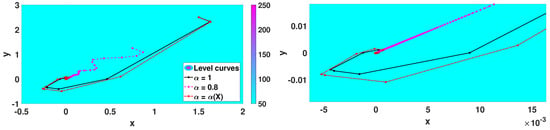
Figure 7.
Iterates for .
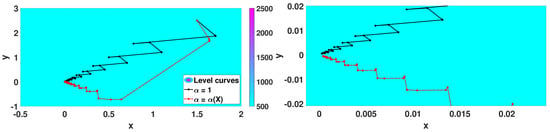
Figure 8.
Iterates for .

In Table 1, we present the information concerning the iterates of the implemented algorithms. When we consider , we achieve the global minimum point in the three cases; however, it is clear that Algorithm 2 leads to the worst results in terms of speediness, whereas the classical case and Algorithm 3 have similar results. If we consider and we restrict our analysis to the two fastest algorithms, we conclude that, in this case, Algorithm 3 provides a more accurate approximation in fewer iterations. We point out that the objective function is a function with less convexity near the minimum point when compared with the objective function , which leads to an optimization problem that is more challenging under the numerical point of view.
In the next set of figures and tables, we consider the Matyas function to test our algorithms. More precisely, we consider the functions with local minimum at the point , and with local minimum at the point .
Figure 9 shows both functions and with a plate-like shape. Considering the same stopping criteria, we have the following results.
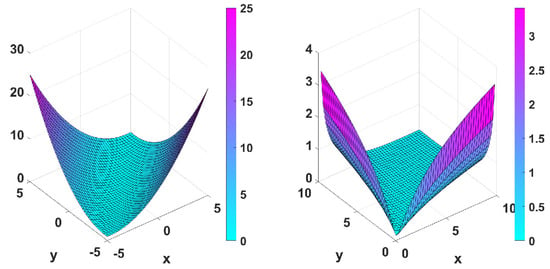
Figure 9.
Graphical representations of and .
From the analysis of Table 2, we see that the three methods converge in the case of , but Algorithm 2 is the worst in terms of iterations. The classic case and Algorithm 3 have similar results in terms of precision; however, Algorithm 3 presents better performance in terms of the number of iterations. In the case of , the Algorithm 2 diverges and the other two are convergent. Algorithm 3 required half of the iterations compared with the classical gradient method.
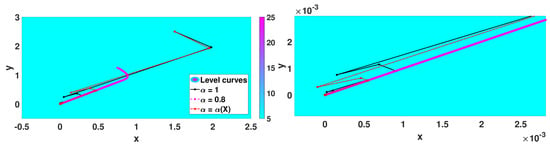
Figure 10.
Iterates for .
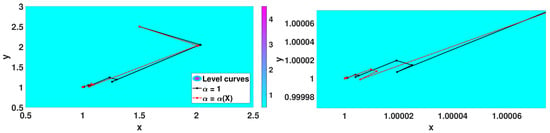
Figure 11.
Iterates for .
In the final set of figures and tables, the function is composed with and . Taking into account the results obtained previously for the Matyas function, where it is clear that Algorithm 2 leads to worse results in terms of rapidness and accuracy, we only implemented the classical gradient method and Algorithm 3. The following figure shows the graphical representation of with local minimum at the point and with local maximum at (or a local minimum of the function ).
The plots in Figure 12 show that both functions are valley-shaped. Figure 13 and Figure 14 and Table 3 show the obtained numerical results.
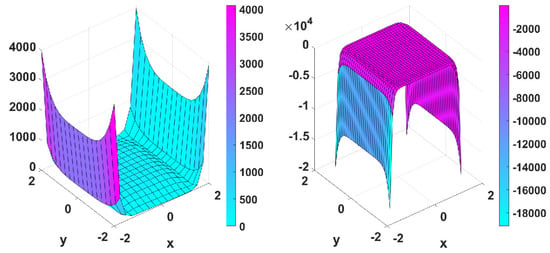
Figure 12.
Graphical representations of and .
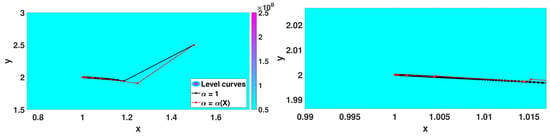
Figure 13.
Iterates for .
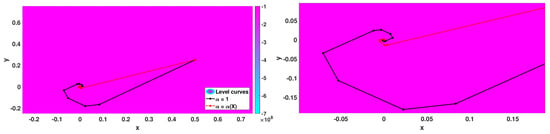
Figure 14.
Iterates for .
In this last case, we see that the classic gradient method and Algorithm 3 provide very good approximations. Algorithm 3 performs better in terms of the number of iterations. For instance, in the case of , the number of iterations decreased around 97% in comparison with the classical gradient method.
6. Conclusions
In this work, we study the classical gradient method from the perspective of the -Hilfer fractional derivative. In the first part of the article, we consider the continuous gradient method and perform the convergence analysis for strongly and non-strongly convex cases. The identification of functions of the Lyapunov type, together with the auxiliary results demonstrated, allowed us to establish the convergence of the generating trajectories in the case of -Hilfer.
In the second part of the paper, we first show that the -Hilfer FGM with the -Hilfer gradient given as a power series can converge to a point different from the extreme point. To work out this problem, we propose an algorithm with a variable lower bound of integration, reducing the influence of long-time memory terms. By truncating the higher order terms, we obtain the -FGM, which allows easy implementation in practice. Furthermore, we optimized the step size in each iteration and considered a variable order of differentiation to increase the precision and speed of the method. These two tunable parameters improved the performance of the method in terms of speed of convergence.
Our numerical simulations showed that the proposed FGM achieved the approximation with equal or better precision, but in much fewer iterations compared with the classical gradient method with optimized step size. We emphasize that in our 2D numerical simulations, the Matyas function and the Wayburn and Seader No. 1 functions are well-known benchmark functions used to test optimization methods. These functions have the shapes of plates and valleys, respectively, representing an extra challenge in numerical simulations.
In future works, it would be interesting to further develop this theory to see its application in the field of convolutional neural networks.
Author Contributions
Conceptualization, N.V., M.M.R. and M.F.; investigation, N.V., M.M.R. and M.F.; writing—original draft, N.V., M.M.R. and M.F.; writing—review and editing, N.V., M.M.R. and M.F. All authors have read and agreed to the published version of the manuscript.
Funding
The work of the authors was supported by Portuguese funds through the CIDMA (Center for Research and Development in Mathematics and Applications) and FCT (Fundação para a Ciência e a Tecnologia), within projects UIDB/04106/2020 and UIDP/04106/2020. N. Vieira was also supported by FCT via the 2018 FCT program of Stimulus of Scientific Employment—Individual Support (Ref: CEECIND/01131/2018).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lin, J.Y.; Liao, C.W. New IIR filter-based adaptive algorithm in active noise control applications: Commutation error-introduced LMS algorithm and associated convergence assessment by a deterministic approach. Automatica 2008, 44, 2916–2922. [Google Scholar] [CrossRef]
- Pu, Y.F.; Zhou, J.L.; Zhang, Y.; Zhang, N.; Huang, G.; Siarry, P. Fractional extreme value adaptive training method: Fractional steepest descent approach. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 653–662. [Google Scholar] [CrossRef] [PubMed]
- Ge, Z.W.; Ding, F.; Xu, L.; Alsaedi, A.; Hayat, T. Gradient-based iterative identification method for multivariate equation-error autoregressive moving average systems using the decomposition technique. J. Frankl. Inst. 2019, 356, 1658–1676. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Wong, C.C.; Chen, C.C. A hybrid clustering and gradient descent approach for fuzzy modeling. IEEE Trans. Syst. Man Cybern. Part B Cybern. 1999, 29, 686–693. [Google Scholar] [CrossRef] [PubMed]
- Ren, Z.G.; Xu, C.; Zhou, Z.C.; Wu, Z.Z.; Chen, T.H. Boundary stabilization of a class of reaction-advection-difffusion systems via a gradient-based optimization approach. J. Frankl. Inst. 2019, 356, 173–195. [Google Scholar] [CrossRef]
- Tan, Y.; He, Z.; Tian, B. A novel generalization of modified LMS algorithm to fractional order. IEEE Signal Process. Lett. 2015, 22, 1244–1248. [Google Scholar] [CrossRef]
- Cheng, S.S.; Wei, Y.H.; Chen, Y.Q.; Li, Y.; Wang, Y. An innovative fractional order LMS based on variable initial value and gradient order. Signal Process. 2017, 133, 260–269. [Google Scholar] [CrossRef]
- Raja, M.A.Z.; Chaudhary, N.I. Two-stage fractional least mean square identification algorithm for parameter estimation of CARMA systems. Signal Process. 2015, 107, 327–339. [Google Scholar] [CrossRef]
- Shah, S.M.; Samar, R.; Khan, N.M.; Raja, M.A.Z. Design of fractional-order variants of complex LMS and NLMS algorithms for adaptive channel equalization. Nonlinear Dyn. 2017, 88, 839–858. [Google Scholar] [CrossRef]
- Viera-Martin, E.; Gómez-Aguilar, J.F.; Solís-Pérez, J.E.; Hernández-Pérez, J.A.; Escobar-Jiménez, R.F. Artificial neural networks: A practical review of applications involving fractional calculus. Eur. Phys. J. Spec. Top. 2022, 231, 2059–2095. [Google Scholar] [CrossRef] [PubMed]
- Sheng, D.; Wei, Y.; Chen, Y.; Wang, Y. Convolutional neural networks with fractional order gradient method. Neurocomputing 2020, 408, 42–50. [Google Scholar] [CrossRef]
- Wang, Y.L.; Jahanshahi, H.; Bekiros, S.; Bezzina, F.; Chu, Y.M.; Aly, A.A. Deep recurrent neural networks with finite-time terminal sliding mode control for a chaotic fractional-order financial system with market confidence. Chaos Solitons Fractals 2021, 146, 110881. [Google Scholar] [CrossRef]
- Chen, Y.Q.; Gao, Q.; Wei, Y.H.; Wang, Y. Study on fractional order gradient methods. Appl. Math. Comput. 2017, 314, 310–321. [Google Scholar] [CrossRef]
- Wei, Y.; Kang, Y.; Yin, W.; Wang, Y. Generalization of the gradient method with fractional order gradient direction. J. Frankl. Inst. 2020, 357, 2514–2532. [Google Scholar] [CrossRef]
- Samko, S.G.; Kilbas, A.A.; Marichev, O.I. Fractional Integrals and Derivatives: Theory and Applications; Gordon and Breach: New York, NY, USA, 1993. [Google Scholar]
- Kilbas, A.A.; Srivastava, H.M.; Trujillo, J.J. Theory and Applications of Fractional Differential Equations; North-Holland Mathematics Studies; Elsevier: Amsterdam, The Netherlands, 2006; Volume 204. [Google Scholar]
- Almeida, R. A Caputo fractional derivative of a function with respect to another function. Commun. Nonlinear Sci. Numer. Simul. 2017, 44, 460–481. [Google Scholar] [CrossRef]
- Sousa, J.V.C.; Oliveira, E.C. On the ψ-Hilfer derivative. Commun. Nonlinear Sci. Numer. Simulat. 2018, 60, 72–91. [Google Scholar] [CrossRef]
- Gorenflo, R.; Kilbas, A.A.; Mainardi, F.; Rogosin, S.V. Mittag-Leffler Functions, Related Topics and Applications; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Hai, P.V.; Rosenfeld, J.A. The gradient descent method from the perspective of fractional calculus. Math. Meth. Appl. Sci. 2021, 44, 5520–5547. [Google Scholar] [CrossRef]
- Kucche, K.D.; Mali, A.D.; Sousa, J.V.C. On the nonlinear ψ-Hilfer fractional differential equations. Comput. Appl. Math. 2019, 38, 73. [Google Scholar] [CrossRef]














Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).