

Distributed Adaptive Optimization Algorithm for Fractional High-Order Multiagent Systems Based on Event-Triggered Strategy and Input Quantization




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- (1)
- Unlike [27,33], where algorithms are developed for the consensus problem in MASs, this paper introduces an adaptive control protocol for the DOP. Agents in the MASs not only reach consensus, but also achieve the optimal solution of the global objective function. Besides, each agent in the FOMASs is described by nonstrict-feedback MIMO dynamics, which is more general and complex to design the control protocol.
- (2)
- Different from [16,17,18,19,20,21,22,23,24,25,26], where the DOPs are investigated for first-order or second-order MASs, this paper dedicates to solve the fractional high-order DOP, which means that MASs and the DOP in this paper are close to the engineering systems. Besides, the MASs in this paper includes nonlinear uncertain terms in each order. Thus, RBFNNs technique is adopted to approximate and compensate for the unknown dynamics. In addition, to reduce the transmitting and computational costs, this paper combines the event-trigger mechanism and input quantization technique together to deal with the high-order DOP for the first time.
- (3)
- In contrast to the algorithms in aforementioned works which are only effective in integer order MASs, this paper investigates the high-order DOP in uncertain nonlinear FOMASs with MIMO agents and an adaptive NNs based algorithm is developed. To avoid the ’computation complexity’, this paper utilizes the fractional order DSC (FODSC) method and the fractional derivatives for virtual controllers are obtained in the meantime.
2. Preliminaries
3. Problem Formulation
3.1. Hysteresis Quantizer
3.2. Graph Theory
3.3. Multi-Agent Systems
3.4. Distributed Optimization Problem
4. Main Results
4.1. Neural Networks Approximation
4.2. Controller Design
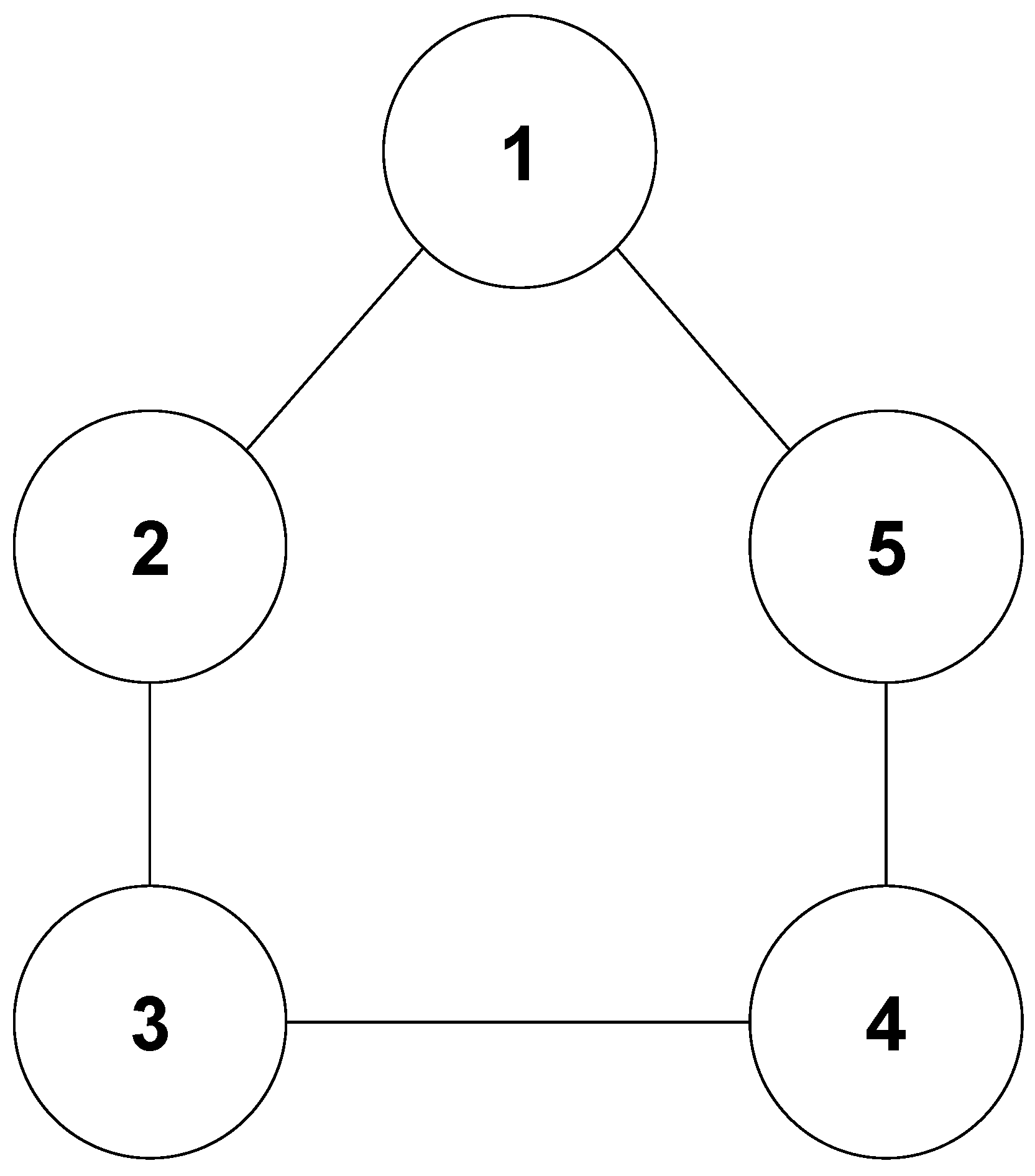
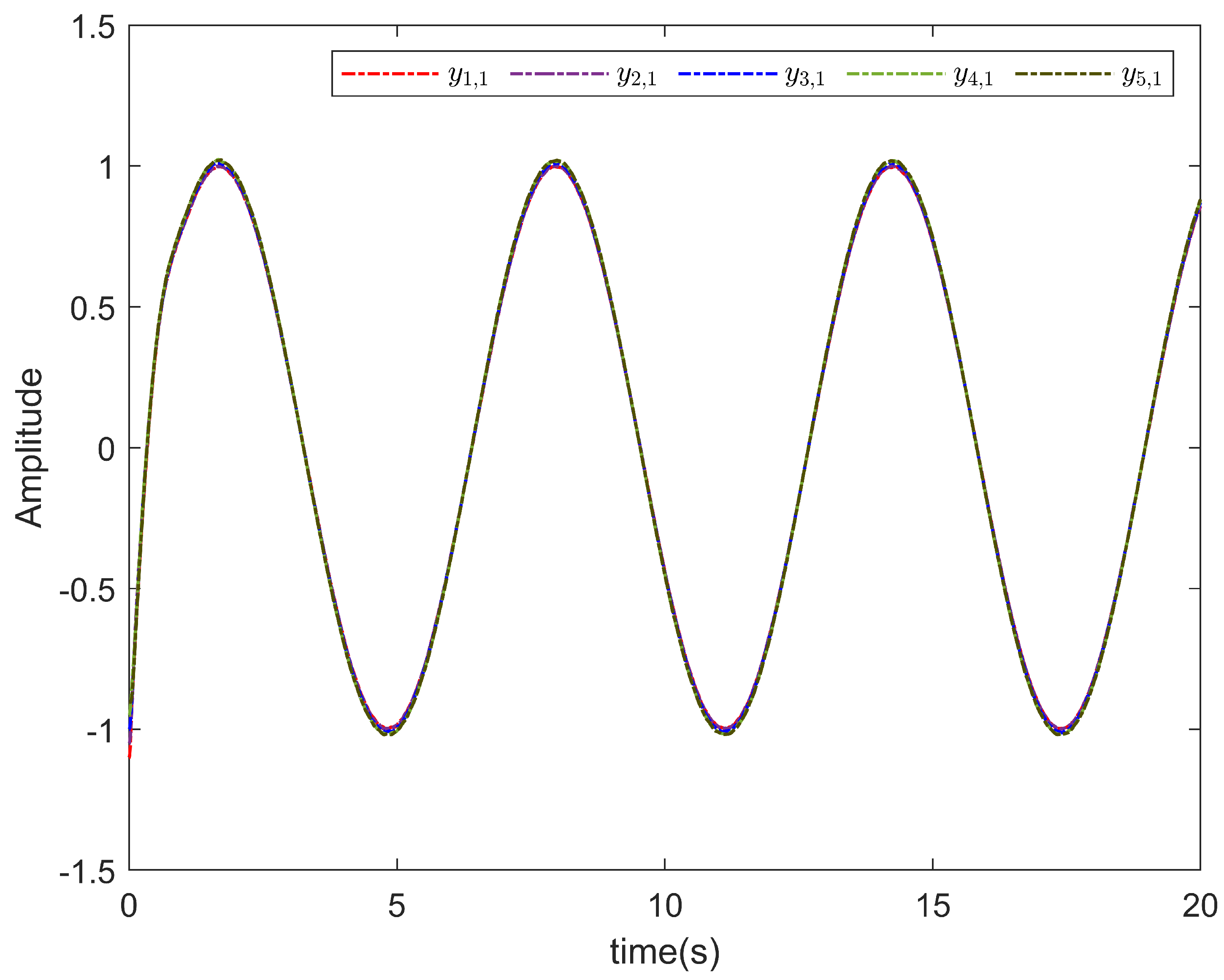
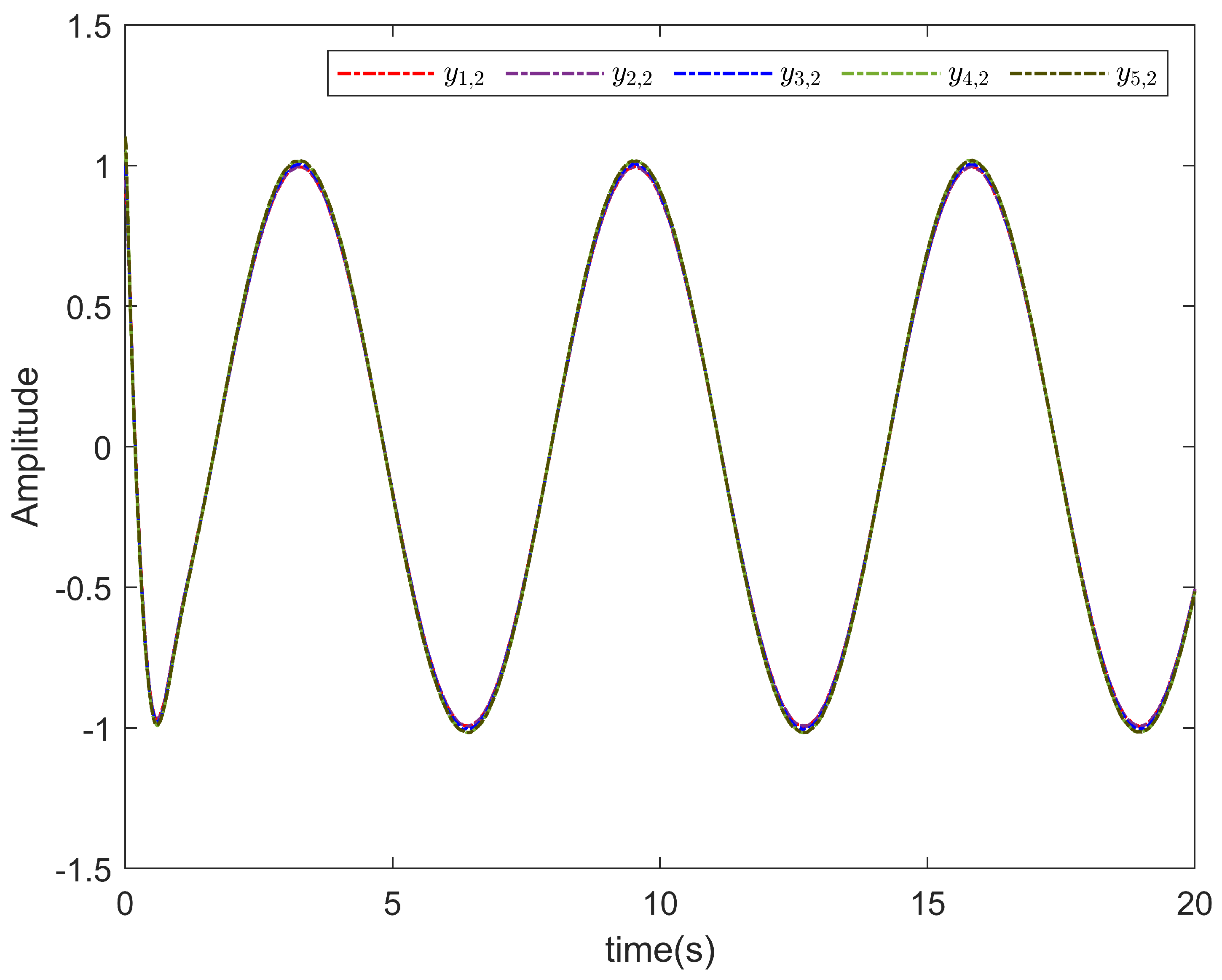
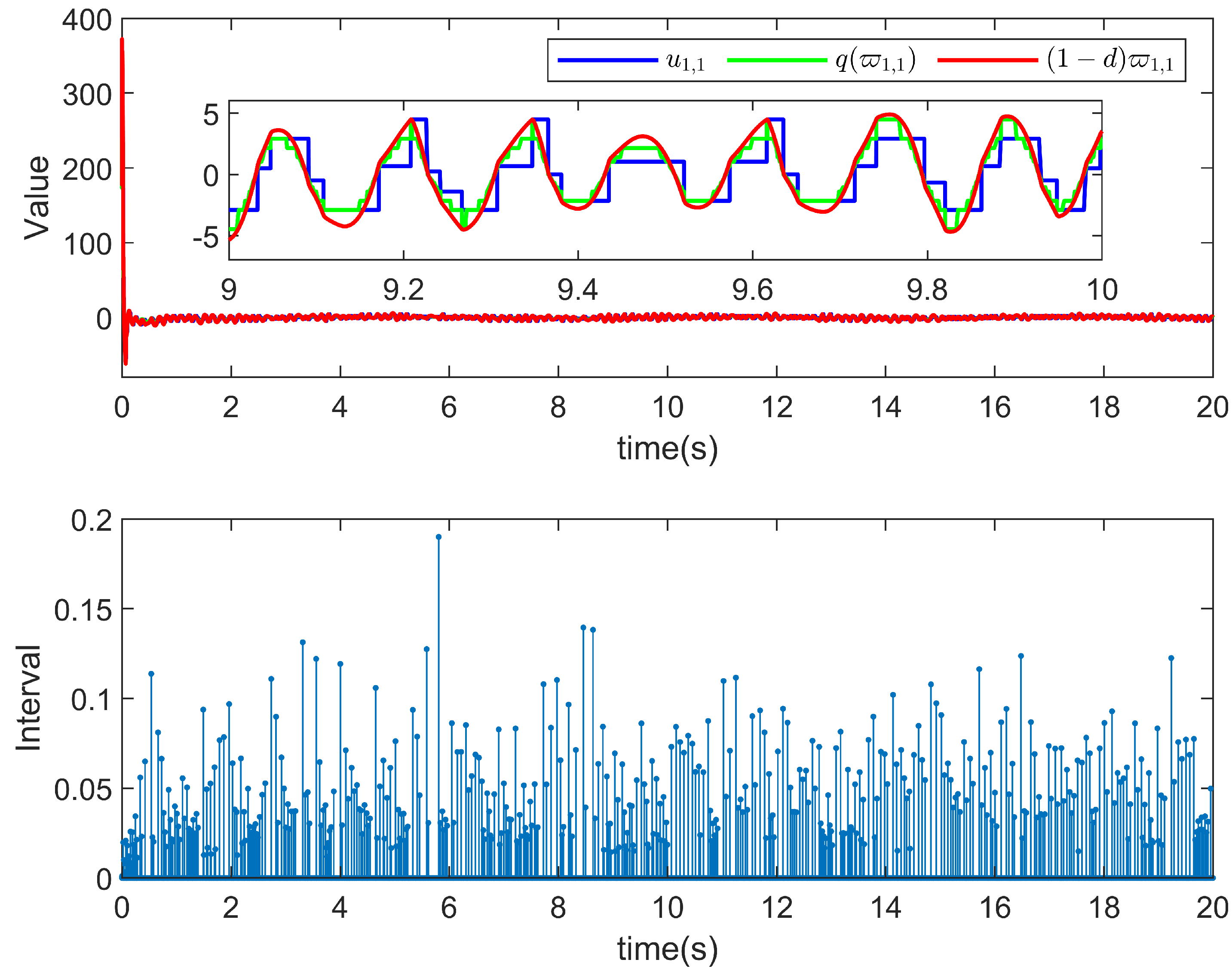
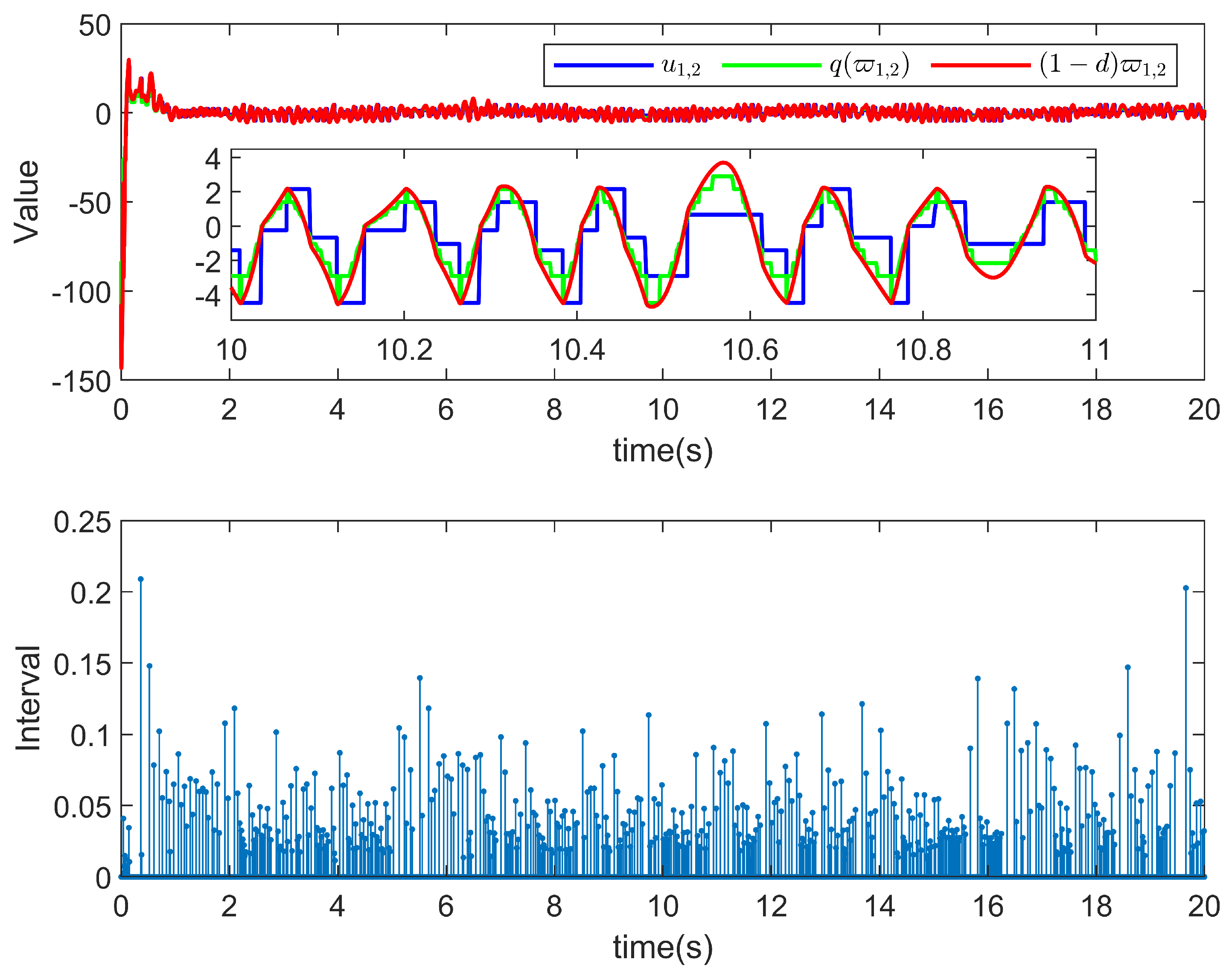
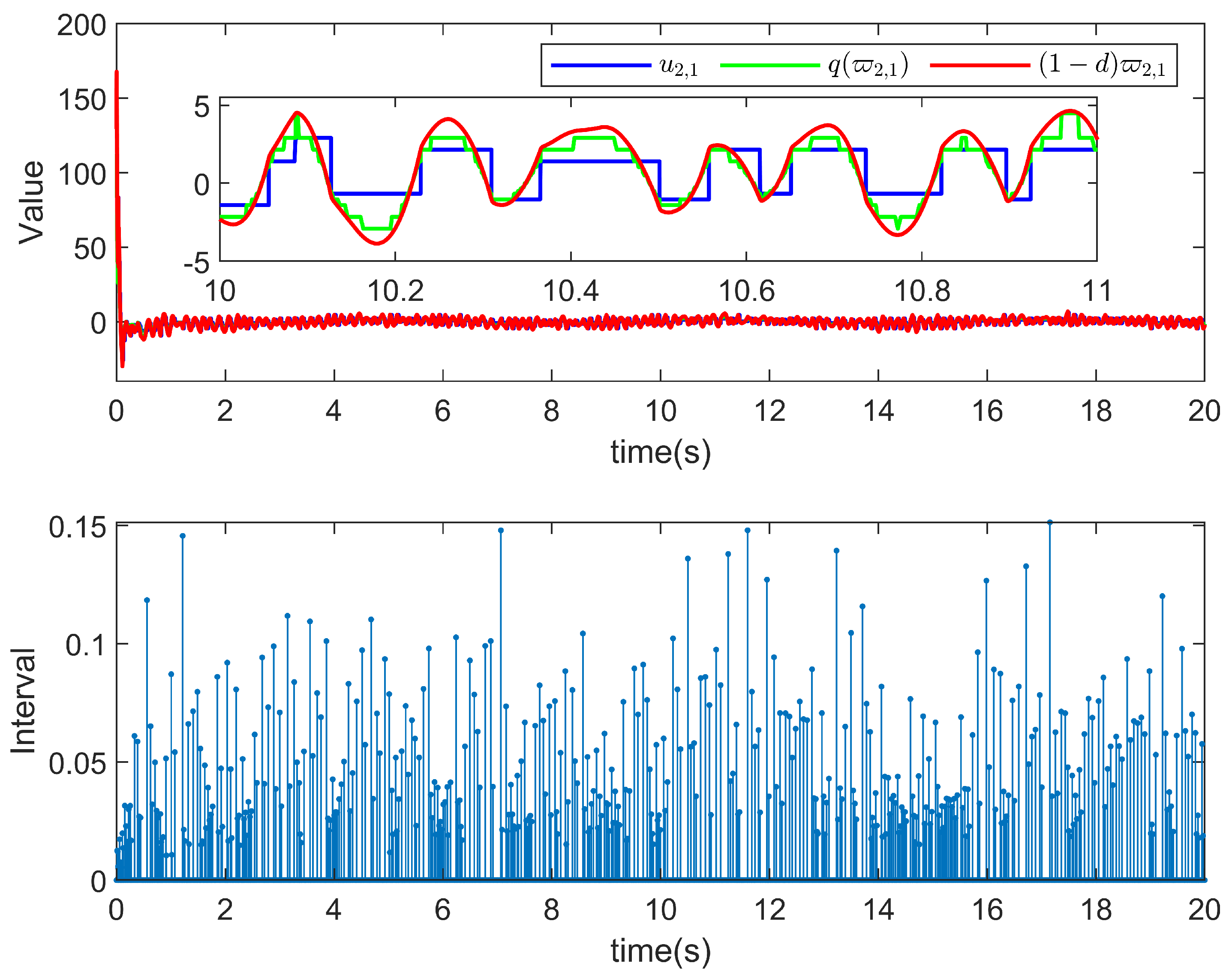
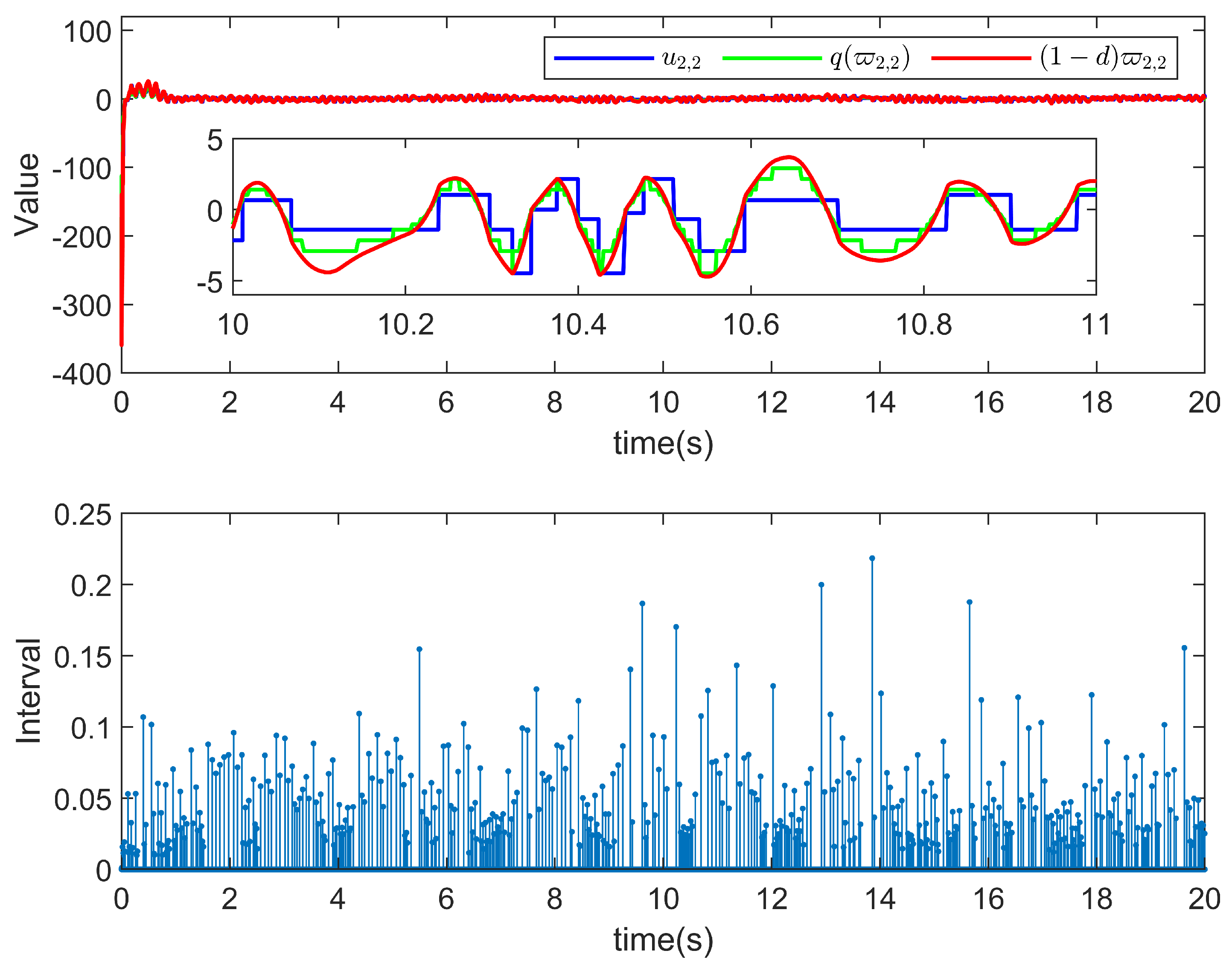
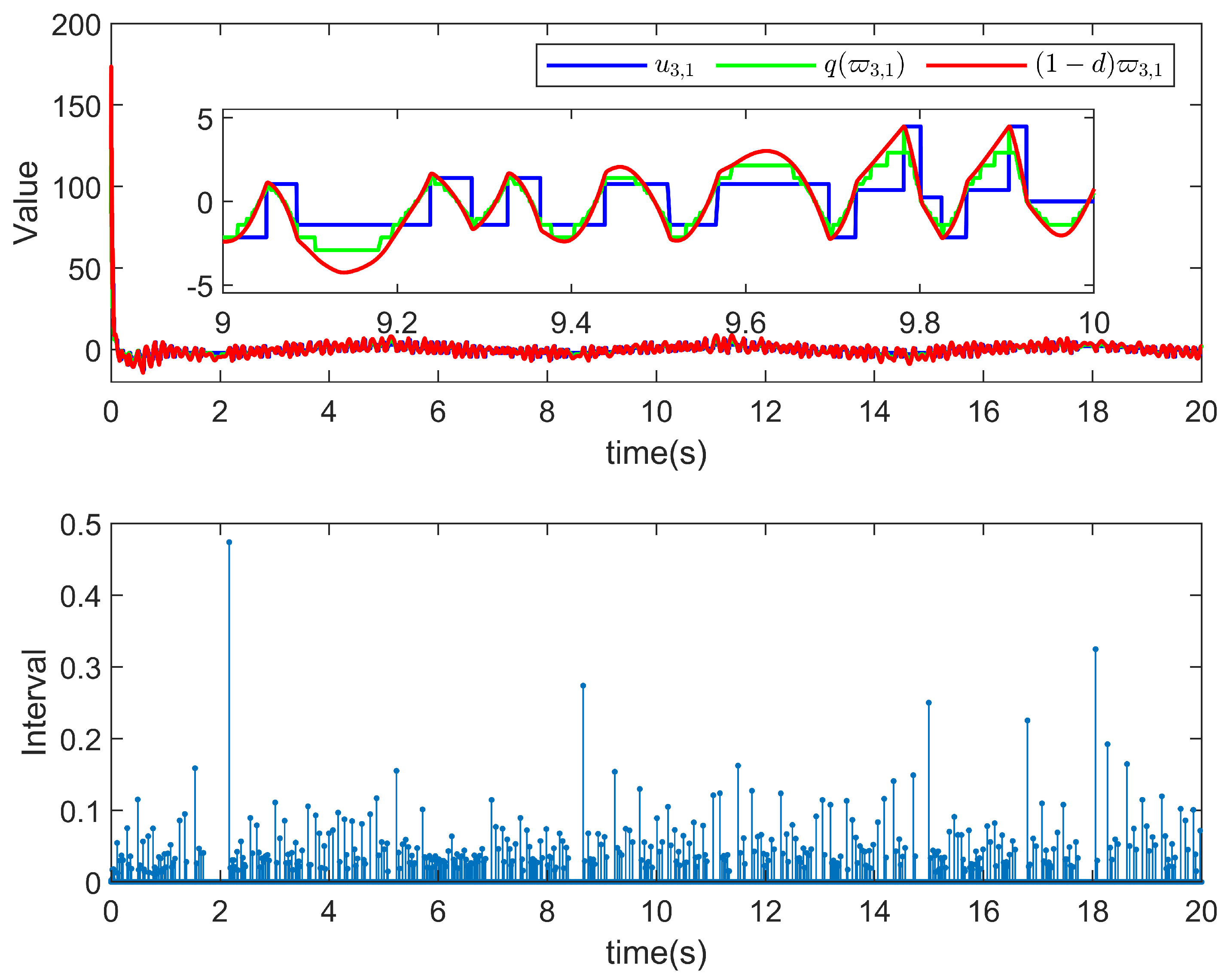
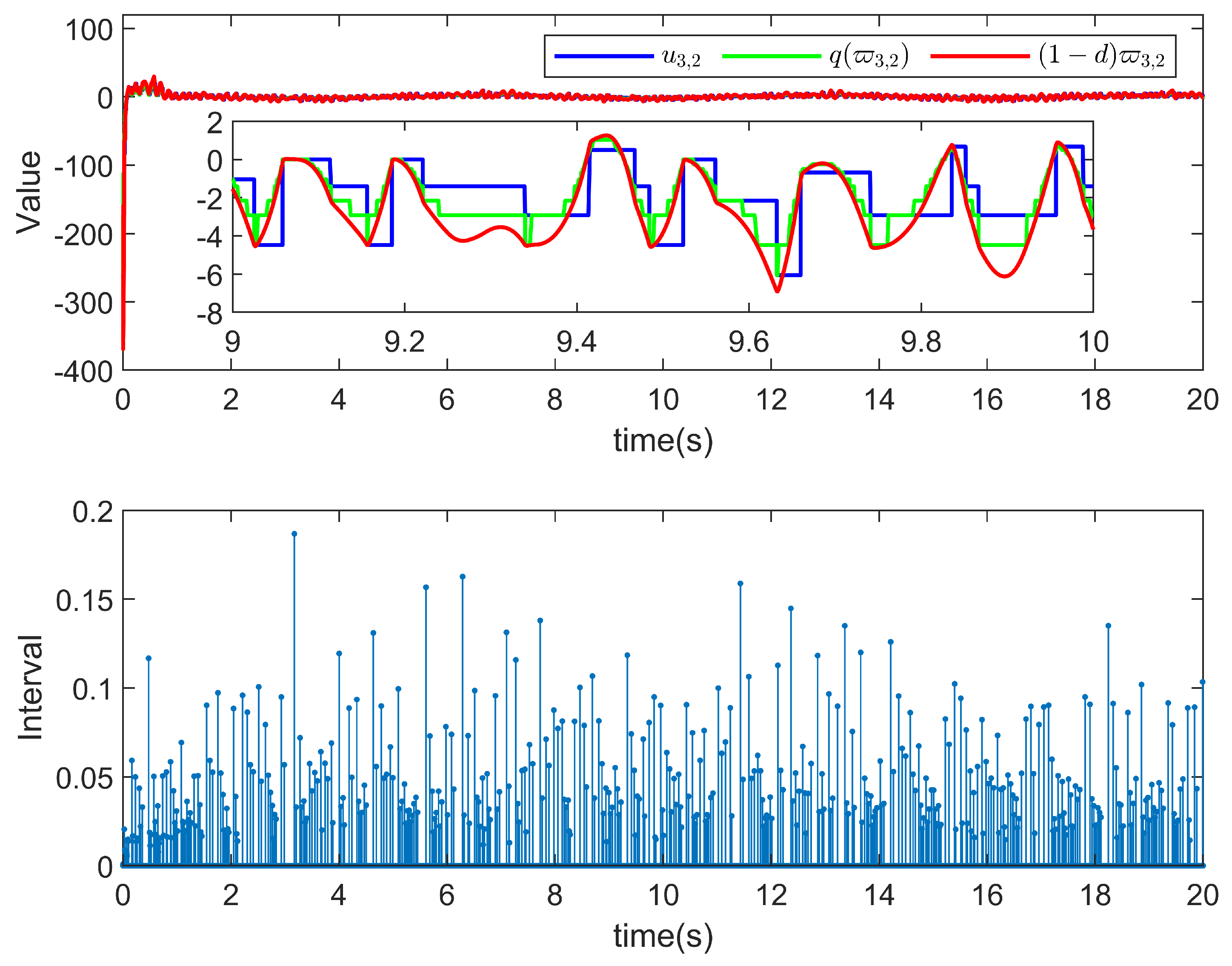
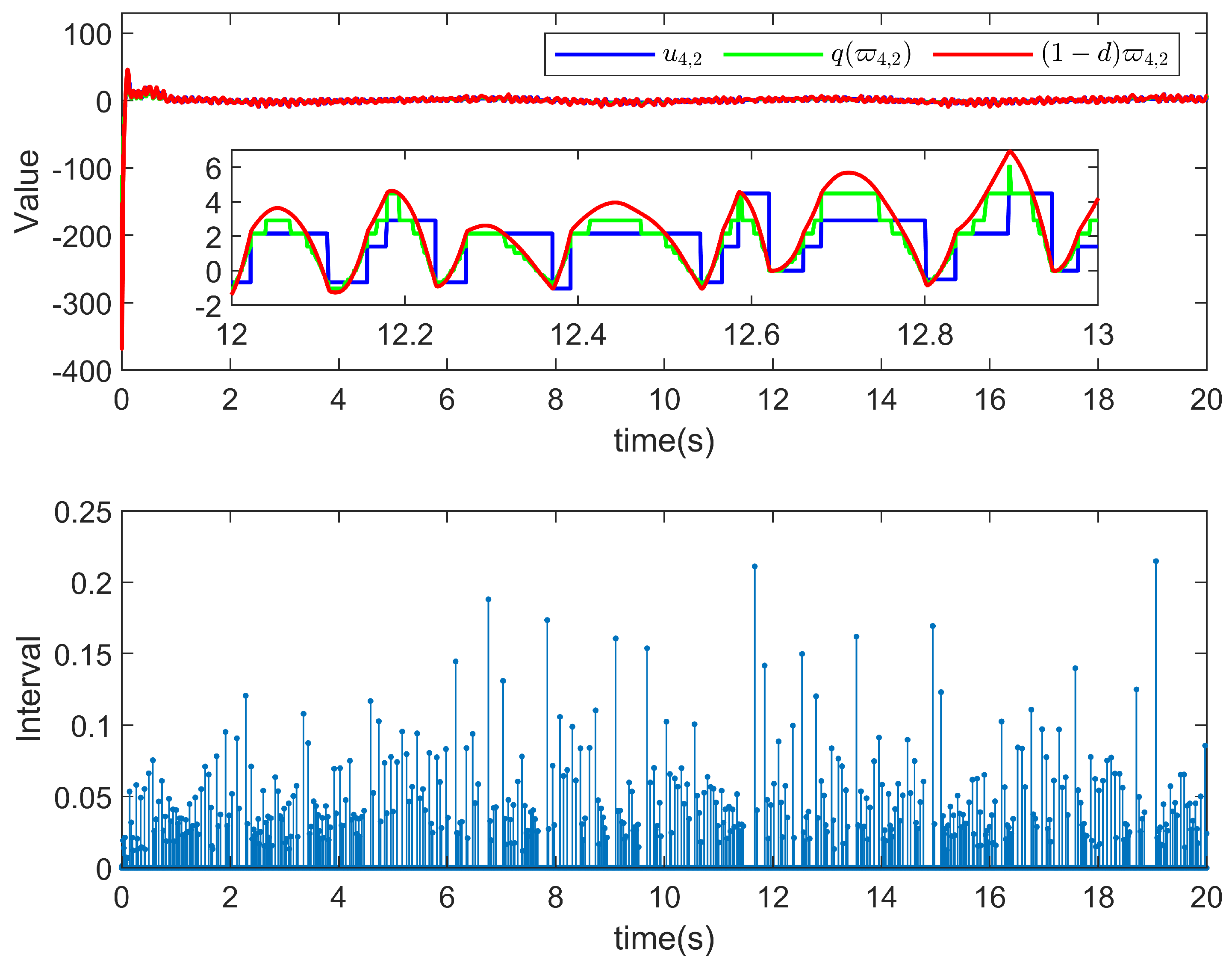
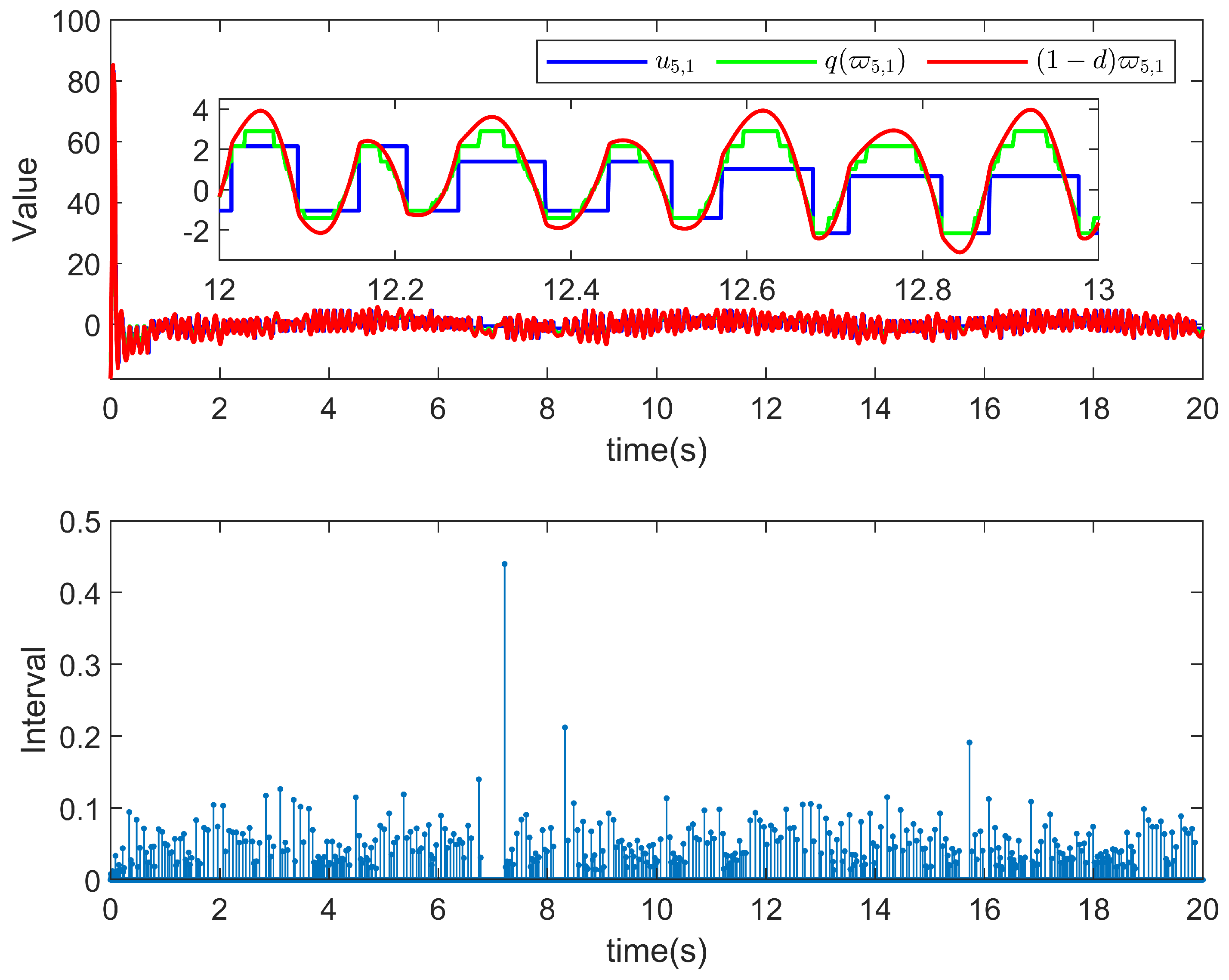
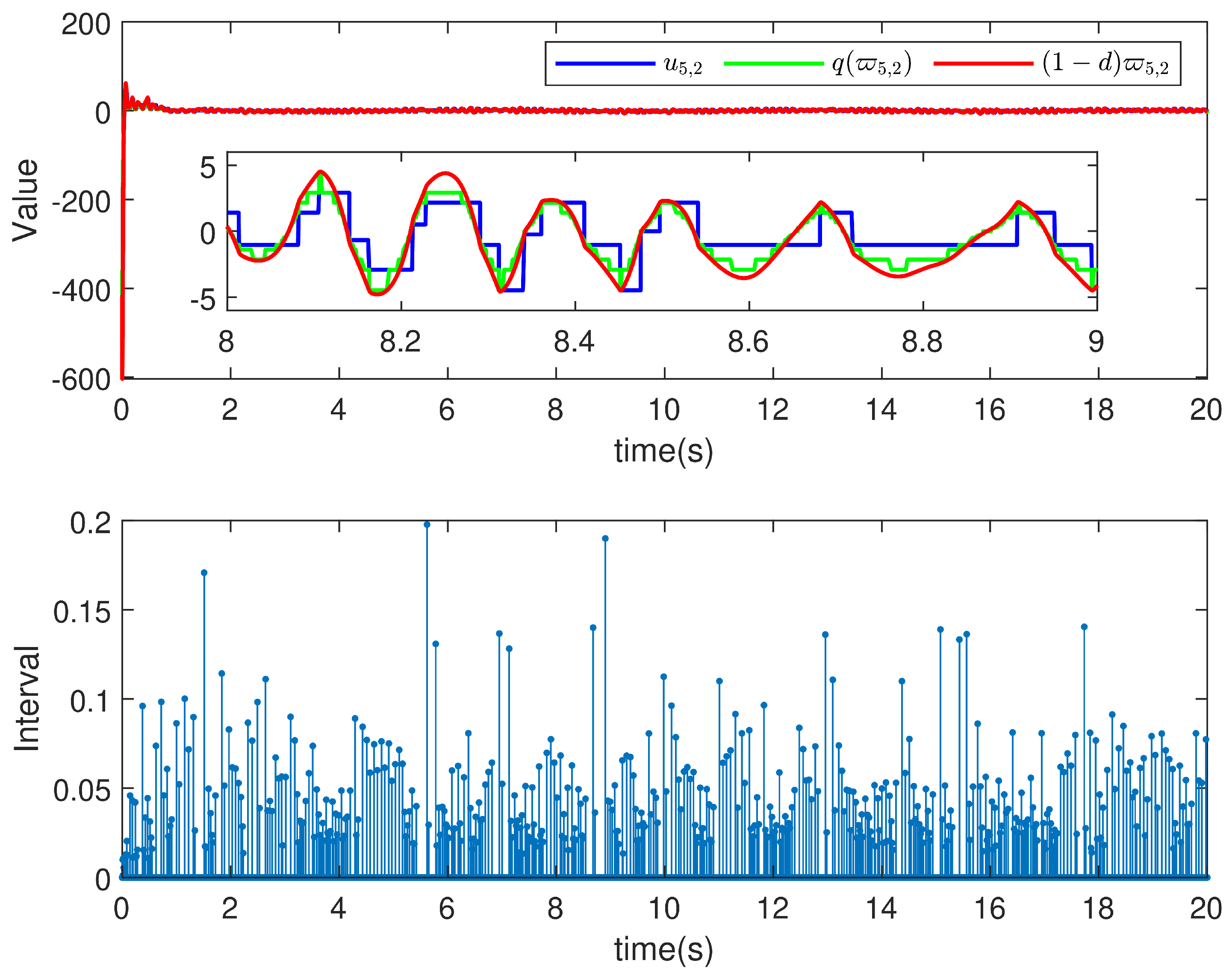
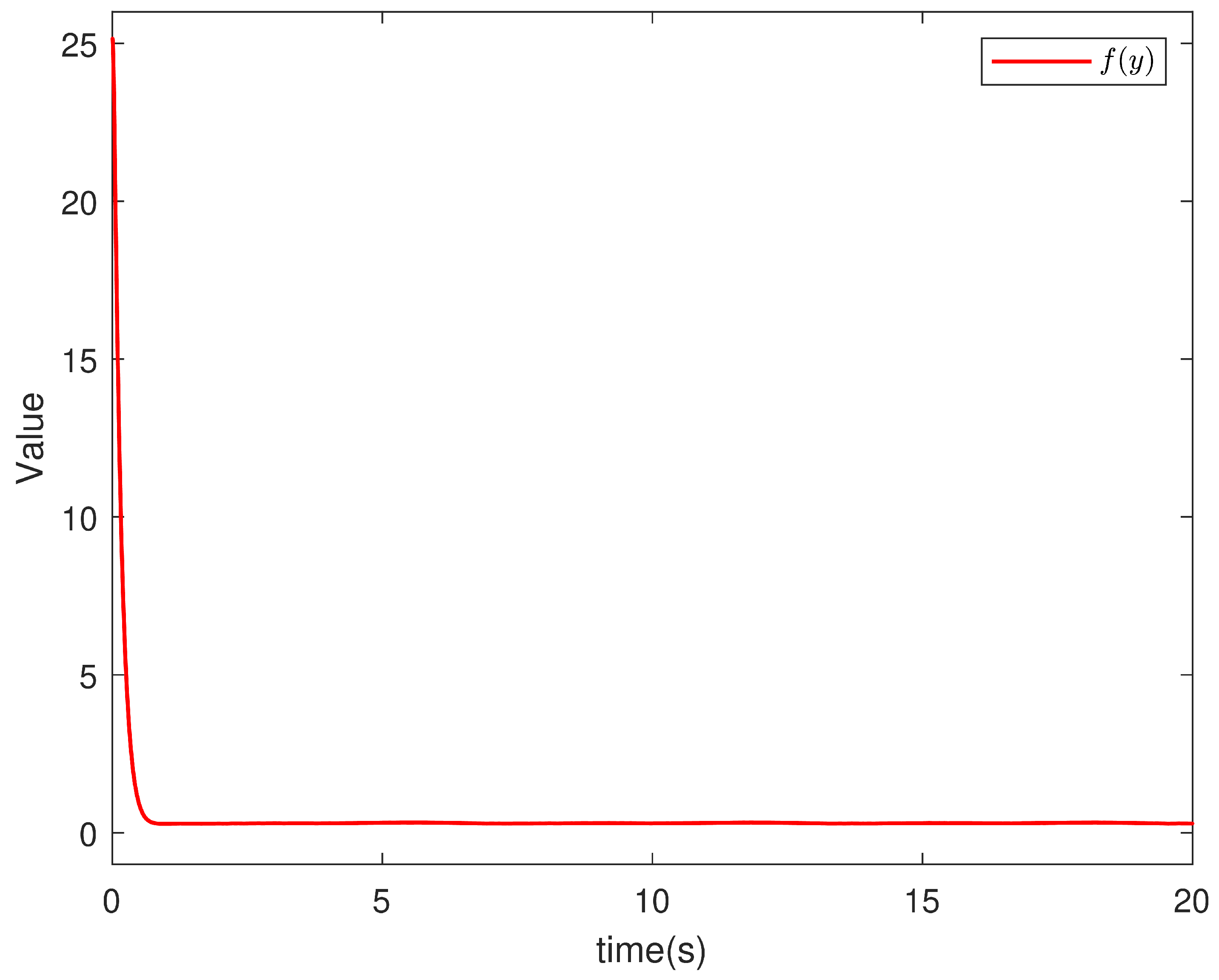
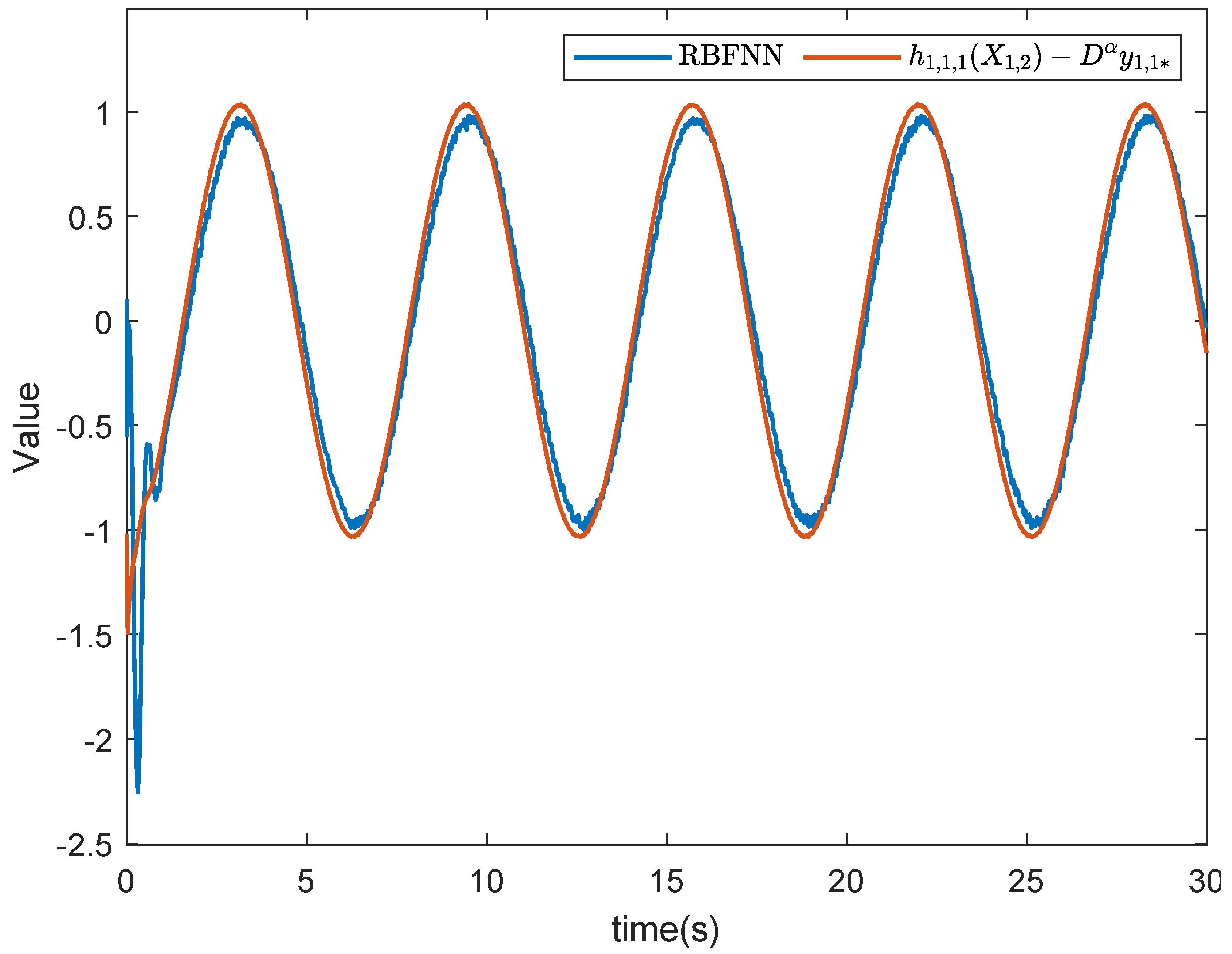
5. Simulation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tang, Y.; Deng, Z.; Hong, Y. Optimal output consensus of high-order multiagent systems with embedded technique. IEEE Trans. Cybern. 2018, 49, 1768–1779. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Wang, X.; Li, S. Finite-time distributed approximate optimization algorithms of higher order multiagent systems via penalty-function-based method. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 6174–6182. [Google Scholar] [CrossRef]
- Zhang, Y.; Lou, Y.; Hong, Y.; Xie, L. Distributed projection-based algorithms for source localization in wireless sensor networks. IEEE Trans. Wirel. Commun. 2015, 14, 3131–3142. [Google Scholar] [CrossRef]
- Chen, Q.; Ge, M.F.; Liang, C.D.; Gu, Z.W.; Liu, J. Distributed optimization of networked marine surface vehicles: A fixed-time estimator-based approach. Ocean Eng. 2023, 284, 115275. [Google Scholar] [CrossRef]
- Chen, G.; Ren, J.; Feng, E.N. Distributed finite-time economic dispatch of a network of energy resources. IEEE Trans. Smart Grid 2016, 8, 822–832. [Google Scholar] [CrossRef]
- Huang, B.; Liu, L.; Zhang, H.; Li, Y.; Sun, Q. Distributed optimal economic dispatch for microgrids considering communication delays. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 1634–1642. [Google Scholar] [CrossRef]
- Yang, X.; Zhao, W.; Yuan, J.; Chen, T.; Zhang, C.; Wang, L. Distributed Optimization for Fractional-Order Multi-Agent Systems Based on Adaptive Backstepping Dynamic Surface Control Technology. Fractal Fract. 2022, 6, 642. [Google Scholar] [CrossRef]
- Yang, X.; Yuan, J.; Chen, T.; Zhang, C.; Yang, H.; Hu, S. Distributed convex optimization of higher order nonlinear uncertain multi-agent systems with switched parameters and topologies. J. Vib. Control 2023, 10775463231179271. [Google Scholar] [CrossRef]
- Meng, X.; Sun, J.; Liu, Q.; Chi, G. A discrete-time distributed optimization algorithm for cooperative transportation of multi-robot system. Complex Intell. Syst. 2023, 1–13. [Google Scholar] [CrossRef]
- Lu, K.; Xu, H. Online distributed optimization with strongly pseudoconvex-sum cost functions and coupled inequality constraints. Automatica 2023, 156, 111203. [Google Scholar] [CrossRef]
- Yu, Z.; Sun, J.; Yu, S.; Jiang, H. Fixed-time distributed optimization for multi-agent systems with external disturbances over directed networks. Int. J. Robust Nonlinear Control 2023, 33, 953–972. [Google Scholar] [CrossRef]
- Meng, X.; Liu, Q. A consensus algorithm based on multi-agent system with state noise and gradient disturbance for distributed convex optimization. Neurocomputing 2023, 519, 148–157. [Google Scholar] [CrossRef]
- Liu, Y.; Xia, Z.; Gui, W. Multi-objective distributed optimization via a predefined-time multi-agent approach. IEEE Trans. Autom. Control 2023, 1–8. [Google Scholar] [CrossRef]
- He, X.; Wei, B.; Wang, H. A fixed-time gradient algorithm for distributed optimization with inequality constraints. Neurocomputing 2023, 532, 106–113. [Google Scholar] [CrossRef]
- Yu, Z.; Sun, J.; Yu, S.; Jiang, H. Fixed-time consensus for multi-agent systems with objective optimization on directed detail-balanced networks. Inf. Sci. 2022, 607, 1583–1599. [Google Scholar] [CrossRef]
- Guo, F.; Chen, X.; Yue, M.; Jiang, H.; Chen, S. Distributed Optimization for Resource Allocation Problem with Dynamic Event-Triggered Strategy. Entropy 2023, 25, 1019. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Wang, M.; Sun, H.; Qin, S. An adaptive finite-time neurodynamic approach to distributed consensus-based optimization problem. Neural Comput. Appl. 2023, 35, 20841–20853. [Google Scholar] [CrossRef]
- Chen, G.; Yi, P.; Hong, Y.; Chen, J. Distributed Optimization With Projection-Free Dynamics: A Frank-Wolfe Perspective. IEEE Trans. Cybern. 2023, 1–12. [Google Scholar] [CrossRef]
- Kang, J.; Guo, G. Distributed Optimization of Disturbed Nonlinear Multi-agent Systems via Adaptive Fault-tolerant Output Regulation. IEEE Trans. Circuits Syst. II Express Briefs 2023, 1. [Google Scholar] [CrossRef]
- Hu, Z.; Yang, J. Distributed finite-time optimization for second order continuous-time multiple agents systems with time-varying cost function. Neurocomputing 2018, 287, 173–184. [Google Scholar] [CrossRef]
- Deng, Z. Distributed algorithm design for resource allocation problems of second-order multiagent systems over weight-balanced digraphs. IEEE Trans. Syst. Man Cybern. Syst. 2019, 51, 3512–3521. [Google Scholar] [CrossRef]
- Li, S.; Nian, X.; Deng, Z. Distributed optimization of second-order nonlinear multiagent systems with event-triggered communication. IEEE Trans. Control Netw. Syst. 2021, 8, 1954–1963. [Google Scholar] [CrossRef]
- Wang, X.; Wang, G.; Li, S. Distributed finite-time optimization for disturbed second-order multiagent systems. IEEE Trans. Cybern. 2020, 51, 4634–4647. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Yang, Y.; Qin, S. A Distributed Optimization Algorithm for Fixed-Time Flocking of Second-Order Multiagent Systems. IEEE Trans. Netw. Sci. Eng. 2023, 1–10. [Google Scholar] [CrossRef]
- Wang, D.; Zhou, J.; Wen, G.; Lü, J.; Chen, G. Event-Triggered Optimal Consensus of Second-Order MASs With Disturbances and Cyber Attacks on Communications Edges. IEEE Trans. Netw. Sci. Eng. 2023, 1–12. [Google Scholar] [CrossRef]
- Huang, F.; Duan, M.; Su, H.; Zhu, S. Distributed Optimal Formation Control of Second-Order Multiagent Systems with Obstacle Avoidance. IEEE Control Syst. Lett. 2023, 7, 2647–2652. [Google Scholar] [CrossRef]
- Yuan, J.; Zhang, C.; Chen, T. Command Filtered Adaptive Neural Network Synchronization Control of Nonlinear Stochastic Systems With Lévy Noise via Event-Triggered Mechanism. IEEE Access 2021, 9, 146195–146202. [Google Scholar] [CrossRef]
- Cao, Y.; Zhao, L.; Zhong, Q.; Wen, S.; Shi, K.; Xiao, J.; Huang, T. Adaptive fixed-time output synchronization for complex dynamical networks with multi-weights. Neural Netw. 2023, 163, 28–39. [Google Scholar] [CrossRef] [PubMed]
- Jiang, B.; Karimi, H.R.; Zhang, X.; Wu, Z. Adaptive neural-network-based sliding mode control of switching distributed delay systems with Markov jump parameters. Neural Netw. 2023, 165, 846–859. [Google Scholar] [CrossRef]
- Gao, T.; Li, T.; Liu, Y.J.; Tong, S.; Liu, L. Adaptive Event-Triggered Fuzzy Control of State-Constrained Stochastic Nonlinear Systems Using IBLFs. IEEE Trans. Fuzzy Syst. 2023, 1–13. [Google Scholar] [CrossRef]
- Hou, Y.; Liu, Y.J.; Tang, L.; Tong, S. Adaptive Fuzzy-based Event-Triggered Control for MIMO Switched Nonlinear System with Unknown Control Directions. IEEE Trans. Fuzzy Syst. 2023, 1–11. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, H.; Liu, J.; Wang, Q.; Wang, J. Adaptive prescribed settling time periodic event-triggered control for uncertain robotic manipulators with state constraints. Neural Netw. 2023, 166, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Tong, S. Observer-Based Adaptive Fuzzy Consensus Control of Nonlinear Multi-Agent Systems Encountering Deception Attacks. IEEE Trans. Ind. Inform. 2023, 1–9. [Google Scholar] [CrossRef]
- Olfati-Saber, R. Flocking for multi-agent dynamic systems: Algorithms and theory. IEEE Trans. Autom. Control 2006, 51, 401–420. [Google Scholar] [CrossRef]
- Radwan, A.G.; Taher Azar, A.; Vaidyanathan, S.; Munoz-Pacheco, J.M.; Ouannas, A. Fractional-order and memristive nonlinear systems: Advances and applications. Complexity 2017, 2017, 3760121. [Google Scholar] [CrossRef]
- Yuan, J.; Chen, T. Switched fractional order multiagent systems containment control with event-triggered mechanism and input quantization. Fractal Fract. 2022, 6, 77. [Google Scholar] [CrossRef]
- Yuan, J.; Chen, T. Observer-based adaptive neural network dynamic surface bipartite containment control for switched fractional order multi-agent systems. Int. J. Adapt. Control Signal Process. 2022, 36, 1619–1646. [Google Scholar] [CrossRef]
- Chen, T.; Yuan, J.; Yang, H. Event-triggered adaptive neural network backstepping sliding mode control of fractional-order multi-agent systems with input delay. J. Vib. Control 2022, 28, 3740–3766. [Google Scholar] [CrossRef]
- Chen, T.; Cao, D.; Yuan, J.; Yang, H. Observer-based adaptive neural network backstepping sliding mode control for switched fractional order uncertain nonlinear systems with unmeasured states. Meas. Control 2021, 54, 1245–1258. [Google Scholar] [CrossRef]
- Hu, L.; Yu, H.; Xia, X. Fuzzy adaptive tracking control of fractional-order multi-agent systems with partial state constraints and input saturation via event-triggered strategy. Inf. Sci. 2023, 646, 119396. [Google Scholar] [CrossRef]
- Xia, X.; Bai, J.; Li, X.; Wen, G. Containment control for fractional order MASs with nonlinearity and time delay via pull-based event-triggered mechanism. Appl. Math. Comput. 2023, 454, 128094. [Google Scholar] [CrossRef]
- Li, Y.; Chen, Y.; Podlubny, I. Mittag–Leffler stability of fractional order nonlinear dynamic systems. Automatica 2009, 45, 1965–1969. [Google Scholar] [CrossRef]
- Podlubny, I. An Introduction to Fractional Derivatives, Fractional Differential Equations, to Methods of Their Solution and Some of Their Applications; Mathematics in Science and Engineering; Academic Press: San Diego, CA, USA, 1999; Volume 198, p. 340. [Google Scholar]
- Wang, X.; Chen, Z.; Yang, G. Finite-time-convergent differentiator based on singular perturbation technique. IEEE Trans. Autom. Control 2007, 52, 1731–1737. [Google Scholar] [CrossRef]
- Liu, W.; Lim, C.C.; Shi, P.; Xu, S. Backstepping fuzzy adaptive control for a class of quantized nonlinear systems. IEEE Trans. Fuzzy Syst. 2016, 25, 1090–1101. [Google Scholar] [CrossRef]
- Sun, W.; Wu, J.; Su, S.F.; Zhao, X. Neural network-based fixed-time tracking control for input-quantized nonlinear systems with actuator faults. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Wang, G.; Li, S. A distributed fixed-time optimization algorithm for multi-agent systems. Automatica 2020, 122, 109289. [Google Scholar] [CrossRef]
- Wang, D.; Huang, J. Neural network-based adaptive dynamic surface control for a class of uncertain nonlinear systems in strict-feedback form. IEEE Trans. Neural Netw. 2005, 16, 195–202. [Google Scholar] [CrossRef] [PubMed]
- Yu, J.; Shi, P.; Dong, W.; Chen, B.; Lin, C. Neural network-based adaptive dynamic surface control for permanent magnet synchronous motors. IEEE Trans. Neural Netw. Learn. Syst. 2014, 26, 640–645. [Google Scholar] [CrossRef]
- Liu, D.; Shen, M.; Jing, Y.; Wang, Q.G. Distributed Optimization of Nonlinear Multiagent Systems via Event-Triggered Communication. IEEE Trans. Circuits Syst. II Express Briefs 2022, 70, 2092–2096. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Yuan, J.; Chen, T.; Yang, H. Distributed Adaptive Optimization Algorithm for Fractional High-Order Multiagent Systems Based on Event-Triggered Strategy and Input Quantization. Fractal Fract. 2023, 7, 749. https://doi.org/10.3390/fractalfract7100749
Yang X, Yuan J, Chen T, Yang H. Distributed Adaptive Optimization Algorithm for Fractional High-Order Multiagent Systems Based on Event-Triggered Strategy and Input Quantization. Fractal and Fractional. 2023; 7(10):749. https://doi.org/10.3390/fractalfract7100749
Chicago/Turabian StyleYang, Xiaole, Jiaxin Yuan, Tao Chen, and Hui Yang. 2023. "Distributed Adaptive Optimization Algorithm for Fractional High-Order Multiagent Systems Based on Event-Triggered Strategy and Input Quantization" Fractal and Fractional 7, no. 10: 749. https://doi.org/10.3390/fractalfract7100749
APA StyleYang, X., Yuan, J., Chen, T., & Yang, H. (2023). Distributed Adaptive Optimization Algorithm for Fractional High-Order Multiagent Systems Based on Event-Triggered Strategy and Input Quantization. Fractal and Fractional, 7(10), 749. https://doi.org/10.3390/fractalfract7100749