
Ensemble FARIMA Prediction with Stable Infinite Variance Innovations for Supermarket Energy Consumption


Abstract
:1. Introduction
2. The FARIMA Model
- when , , ;
- when , ;
- when , ;
- when , ;
- when , .
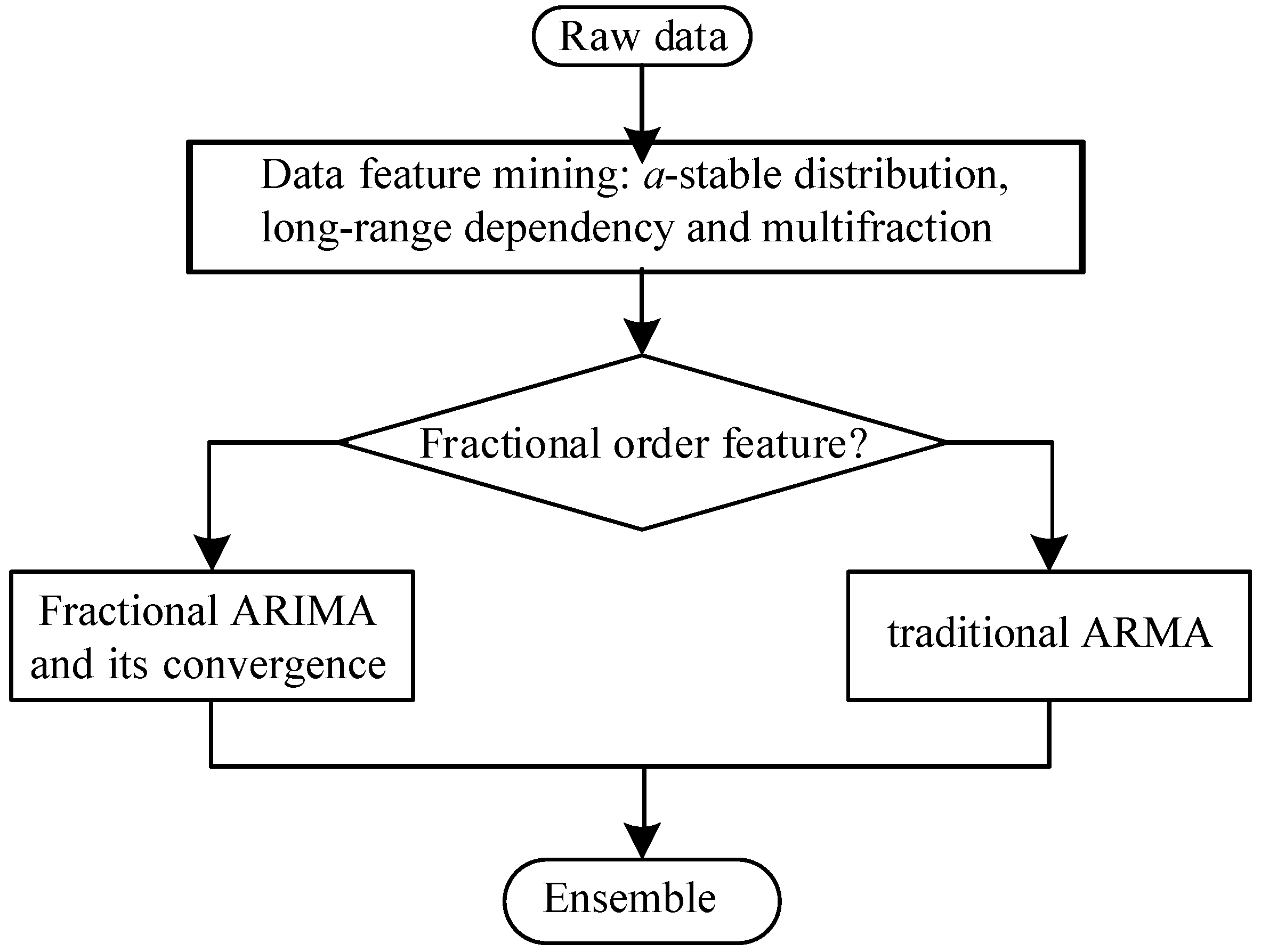
3. Fractional Analytics for Industrial Data
3.1. General Framework
3.2. Fractional Feature Extraction
4. Study Case
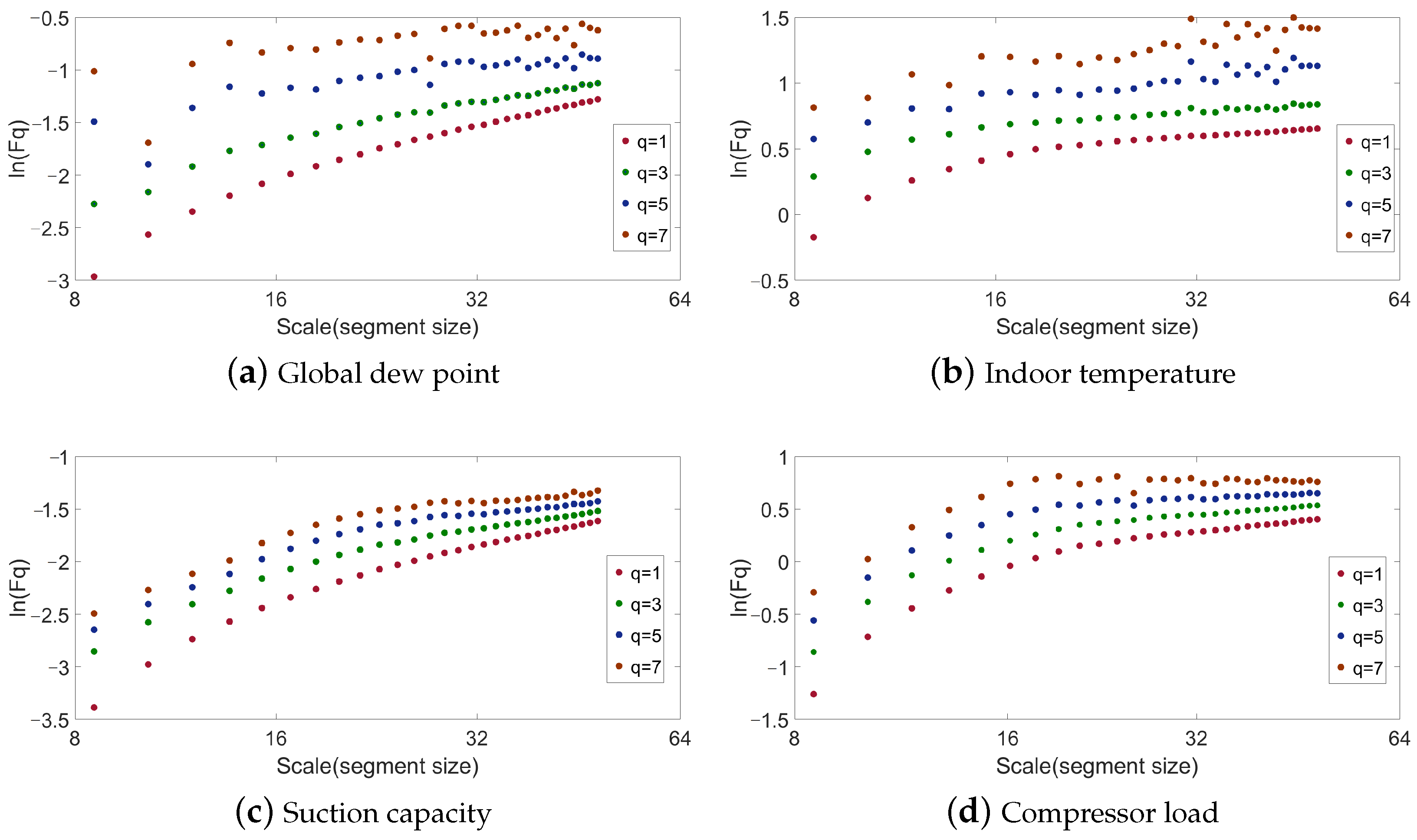
4.1. Fractional Feature Extraction
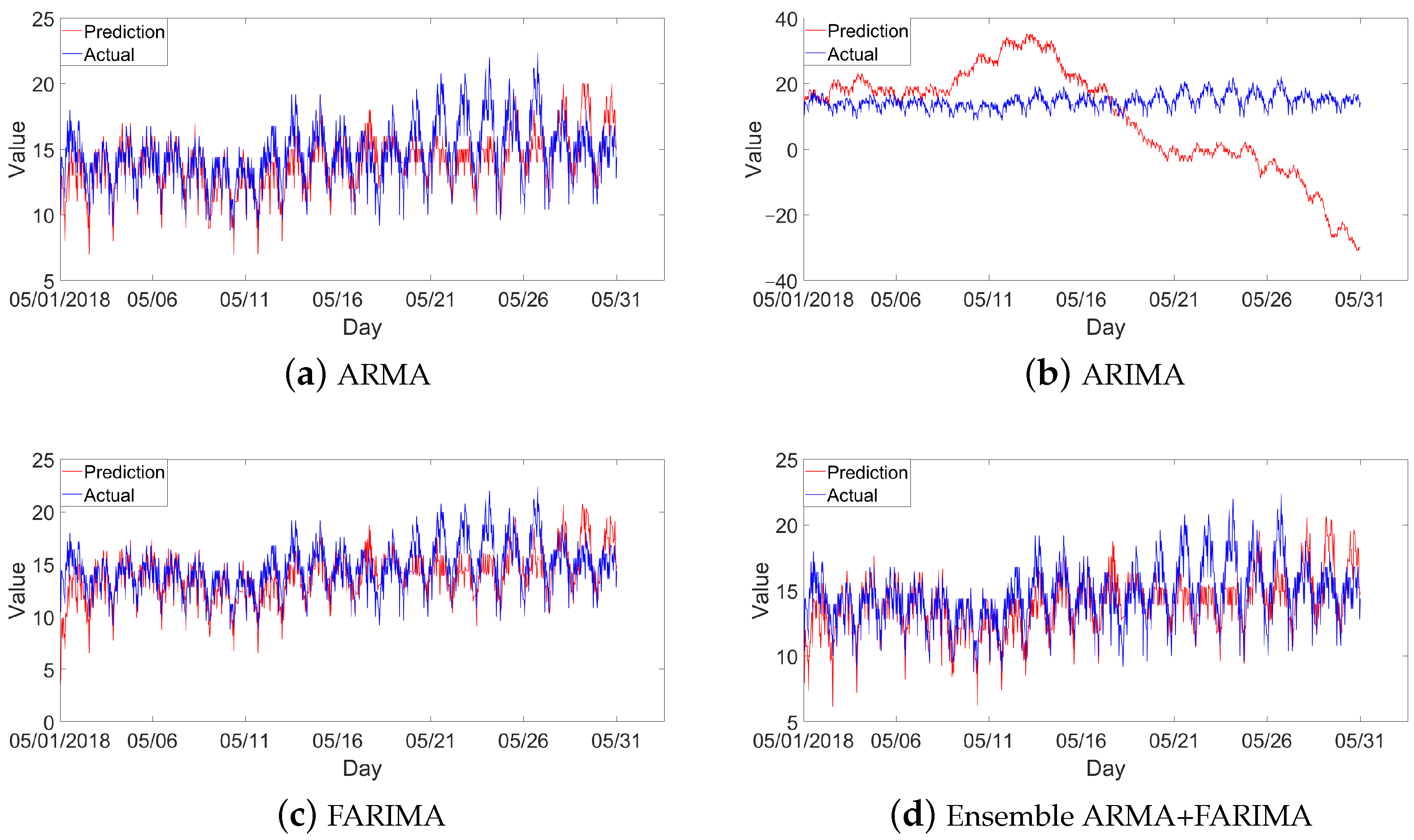
4.2. Energy Prediction Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Albada, V.S.J.; Robinson, P.A. Transformation of arbitrary distributions to the normal distribution with application to eeg test-retest reliability. J. Neurosci. Methods 2018, 161, 205–211. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sakia, R.M. The Box-Cox transformation technique: A review. Statistician 1992, 41, 169–178. [Google Scholar] [CrossRef]
- Zhang, X.F.; Chen, Y.Q. Admissibility and robust stabilization of continuous linear singular fractional order systems with the fractional order α: The 0 < α < 1 case. ISA Trans. 2018, 82, 42–50. [Google Scholar] [PubMed]
- Andrews, B.; Calder, M.; Davis, R.A. Maximum likelihood estimation for α-stable autoregressive processes. Ann. Stat. 2009, 37, 1946–1982. [Google Scholar] [CrossRef]
- Wang, J.; Wang, J.Q.; Chen, Y.Q.; Zhang, Y.Z. Fractional Stochastic Configuration Networks-Based Nonstationary Time Series Prediction and Confidence Interval Estimation. Expert Syst. Appl. 2022, 192, 116357. [Google Scholar] [CrossRef]
- Li, X.; Wang, S.; Fan, L. Mixture approximation to the amplitude statistics of isotropic α-stable clutter. Signal Process. 2014, 99, 86–91. [Google Scholar] [CrossRef]
- Diego, S.G.; Ercan, E.K.; Diego, P.R. Modelling and Assessing Differential Gene Expression Using the Alpha Stable Distribution. Int. J. Biostat. 2009, 5, 16. [Google Scholar]
- Zhang, X.F.; Huang, W.K. Adaptive neural network sliding mode control for nonlinear singular fractional order systems with mismatched uncertainties. Fractal Fract. 2020, 4, 50. [Google Scholar] [CrossRef]
- Zhang, J.X.; Yang, G.H. Fault-tolerant output-constrained control of unknown Euler-Lagrange systems with prescribed tracking accuracy. Automatica 2020, 111, 108606. [Google Scholar] [CrossRef]
- Zhang, J.X.; Yang, G.H. Fuzzy adaptive output feedback control of uncertain nonlinear systems with prescribed performance. IEEE Trans. Cybern. 2018, 48, 1342–1354. [Google Scholar] [CrossRef]
- Wang, J.; Shao, C.F.; Chen, Y.Q. Fractional order sliding mode control via disturbance observer for a class of fractional order systems with mismatched disturbance. Mechatronics 2018, 53, 8–19. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, R.; Ren, J.; Gui, Q. Adaptive Fractional Image Enhancement Algorithm Based on Rough Set and Particle Swarm Optimization. Fractal Fract. 2022, 6, 100. [Google Scholar] [CrossRef]
- Zhang, X.; Dai, L. Image Enhancement Based on Rough Set and Fractional Order Differentiator. Fractal Fract. 2022, 6, 214. [Google Scholar] [CrossRef]
- Yan, H.; Zhang, J.; Zhang, X. Injected Infrared and Visible Image Fusion via L1 Decomposition Model and Guided Filtering. IEEE Trans. Comput. Imaging 2022, 8, 162–173. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, Y.H.; Qiu, T.S. Improved time difference of arrival estimation algorithms for cyclostationary signals in α-stable impulsive noise. Digit. Signal Process. 2018, 76, 94–105. [Google Scholar] [CrossRef]
- Ihlen, A.; Espen, F. The influence of power law distributions on long-range trial dependency of response times. J. Math. Psychol. 2013, 57, 215–224. [Google Scholar] [CrossRef]
- Clauset, A.; Shalizi, C.R.; Newman, M.E.J. Power-law distributions in empirical data. Siam Rev. 2009, 51, 661–703. [Google Scholar] [CrossRef] [Green Version]
- Lel, W.E.; Taqqu, M.S.; Willinger, W. On the self-similar nature of ethernet traffic. Acm Sigcomm Comput. Commun. Rev. 1995, 25, 202–213. [Google Scholar]
- Kourtsoyiannis, D.; Climate, C. The Hurst phenomenon and hydrological statistics. Int. Assoc. Sci. Hydrol. Bull. 2003, 48, 3–24. [Google Scholar] [CrossRef]
- Bregni, S.; Primerano, L. Using the modified allan variance for accurate estimation of the hurst parameter of long-range dependent traffic. IEEE Trans. Commun. 2008, 56, 1900–1906. [Google Scholar] [CrossRef]
- Grech, D.; Pamua, G. The local Hurst exponent of the financial time series in the vicinity of crashes on the Polish stock exchange market. Phys. A Stat. Mech. Its Appl. 2008, 387, 4299–4308. [Google Scholar] [CrossRef]
- Tyralis, H.; Dimitriadis, P.; Koutsoyiannis, D. On the long-range dependence properties of annual precipitation using a global network of instrumental measurements. Adv. Water Resour. 2018, 111, 301–318. [Google Scholar] [CrossRef]
- Pandit, P.; Ardakan, M.S.; Amini, A.A. High-dimensional bernoulli autoregressive process with long range dependence. arXiv 2019, arXiv:1903.09631. [Google Scholar]
- Chen, Y.; Ye, X.; Zhang, J. Effects of trends and seasonalities on robustness of the Hurst parameter estimators. IET Signal Process. 2012, 6, 849–856. [Google Scholar]
- Pianese, A.; Bianchi, S. Fast and unbiased estimator of the time-dependent Hurst exponent. Chaos 2018, 28, 031102. [Google Scholar] [CrossRef]
- Karp, A.; Vuuren, G.V. Investment implications of the fractal market hypothesis. Ann. Financ. Econ. 2019, 14, 1950001. [Google Scholar] [CrossRef]
- Yu, Q.Y.; Dai, Z.X. Estimation of sandstone permeability with sem images based on fractal theory. Transp. Porous Media 2019, 126, 701–712. [Google Scholar] [CrossRef]
- Hu, K.; Ivanov, P.C.; Chen, Z. Effect of trends on detrended fluctuation analysis. Phys. Rev. E Stat. Nonlin Soft Matter Phys. 2001, 64, 011114. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Ivanov, P. Effect of nonstationarities on detrended fluctuation analysis. Phys. Rev. E Stat. Nonlin Soft Matter Phys. 2002, 65, 041107. [Google Scholar] [CrossRef] [Green Version]
- Kantelhardt, J.W.; Zschiegner, S.A. Multifractal detrended uctuation analysis of nonstationary time series. Phys. A Stat. Mech. Appl. 2002, 316, 87–114. [Google Scholar] [CrossRef] [Green Version]
- Zhu, H.; Zhang, W. Multifractal property of Chinese stock market in the CSI 800 index based on MF-DFA approach. Phys. A Stat. Mech. Appl. 2018, 490, 497–503. [Google Scholar] [CrossRef]
- Hillmer, S.C.; Tiao, G.C. An ARIMA-model-based approach to seasonal adjustment. Publ. Am. Stat. Assoc. 1982, 77, 63–70. [Google Scholar] [CrossRef]
- Hedrea, E.L.; Precup, R.E.; Roman, R.C.; Petriu, E.M. Tensor product-based model transformation approach to tower crane systems modeling. Asian J. Control. 2021, 23, 1313–1323. [Google Scholar] [CrossRef]
- Kataria, A.; Ghosh, S.; Karar, V. Data Prediction of Electromagnetic Head Tracking using Self Healing Neural Model for Head-Mounted Display. Rom. J. Inf. Sci. Technol. 2020, 23, 354–367. [Google Scholar]
- Greff, K.; Srivastava, R.K.; Koutnik, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, J.Q.; Du, Y.; Wang, J. Lstm based long-termenergy consumption prediction with periodicity. Energy 2021, 197, 117197. [Google Scholar] [CrossRef]
- Scardapane, S.; Wang, D.H. Randomness in neural networks: An overview. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2017, 7, 1–8. [Google Scholar] [CrossRef]
- Zhang, X. Relationship between integer order systems and fractional order system and its two applications. IEEE/CAA J. Autom. Sin. 2018, 5, 639–643. [Google Scholar] [CrossRef]
- Kun, H.; Jun, W. A botnet detection method based on FARIMA and hill-climbing algorithm. Int. J. Mod. Phys. B. 2019, 32, 1850356. [Google Scholar] [CrossRef]
- Sheng, H.; Chen, Y.Q. FARIMA with stable innovations model of great salt lake elevation time series. Signal Process. 2011, 91, 553–561. [Google Scholar] [CrossRef]
- Suhail, Y.; Upadhyay, M.; Chhibber, A. Machine Learning for the Diagnosis of Orthodontic Extractions: A Computational Analysis Using Ensemble Learning. Bioengineering 2020, 7, 55. [Google Scholar] [CrossRef] [PubMed]
- Xiao, Q.Y.; Chang, H.H.; Geng, G.; Yang, L.Y. An ensemble machine-learning model to predict historical PM2.5 concentrations in China from satellite data. Environ. Sci. Technol. 2018, 52, 13260–13269. [Google Scholar] [CrossRef] [PubMed]
- Ortigueira, M.D.; Magin, R.L. On the Equivalence between Integer- and Fractional Order-Models of Continuous-Time and Discrete-Time ARMA Systems. Fractal Fract. 2022, 6, 242. [Google Scholar] [CrossRef]
- Ortigueira, M.D.; Coito, F.J.V.; Trujillo, J.J. Discrete-time differential systems. Signal Process. 2015, 107, 198–217. [Google Scholar] [CrossRef]
- Granger, C.W.J.; Joyeux, R. An introduction to long-memory time series and fractional differencing. J. Time Ser. Anal. 1980, 1, 15–30. [Google Scholar] [CrossRef]
- Mikosch, T.; Gadrich, T.; Kluppelberg, C.; Adler, R.J. Parameter estimation for ARMA models with inifite variance innovations. Ann. Stat. 1995, 23, 305–326. [Google Scholar] [CrossRef]
- Kokoszka, P.S.; Taqqu, M.S. Fractional ARIMA with stable innovations. Stoch. Process. Their Appl. 1995, 60, 19–47. [Google Scholar] [CrossRef] [Green Version]
- Zheng, T.; Chen, R. Dirichlet ARMA models for compositional time series. J. Multivar. Anal. 2017, 158, 31–46. [Google Scholar] [CrossRef] [Green Version]
- Salasgonzalez, D.; Gorriz, J.M.; Ramirez, J. Parameterization of the distribution of white and grey matter in MRI using the α-stable distribution. Comput. Biol. Med. 2013, 43, 559–567. [Google Scholar] [CrossRef]
- Althoff, M.; Stursberg, O.; Buss, M. Estimating the parameters of an α-stable distribution using the existence of moments of order statistics. Stat. Probab. Lett. 2014, 90, 78–84. [Google Scholar]
- Tierra, A.; Luna, M.; Staller, A. Hurst coefficient estimation by rescaled range and wavelet of the ENU Coordinates time series in GNSS network. IEEE Lat. Am. Trans. 2018, 16, 1064–1069. [Google Scholar] [CrossRef]
- Moulines, E.; Roueff, F.; Taqqu, M.S. A wavelet whittle estimator of the memory parameter of a nonstationary Gaussian time series. Ann. Stat. 2008, 36, 1925–1956. [Google Scholar] [CrossRef]
- Leonardo, R.G.; Galib, H.; Jurgen, K.; Dirk, W. MFDFA: Efficient multifractal detrended fluctuation analysis in python. Comput. Phys. Commun. 2022, 273, 108254. [Google Scholar]
- Ihlen, E.A.F. Introduction to multifractal detrended fluctuation analysis in Matlab. Front. Physiol. 2021, 3, 141. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Hurst | ||||
|---|---|---|---|---|---|
| Global dew point temp. | 1.6845 | 1 | 2.1572 | 56.0584 | 0.9199 |
| Indoor temperature | 1.7927 | −1 | 0.7185 | 72.5350 | 0.9342 |
| Suction capacity | 1.4950 | 0.1196 | 1.0821 | 50.7036 | 0.8126 |
| Compressor load | 1.9798 | 1 | 1.7060 | 16.3246 | 0.9798 |
| Variable | |||||
|---|---|---|---|---|---|
| Global dew point temp. | 0.6896 | 0.5021 | 0.3271 | 0.2599 | 0.4297 |
| Indoor temperature | 0.7265 | 0.5582 | 0.5044 | 0.4741 | 0.2524 |
| Suction capacity | 0.2791 | 0.1913 | 0.2298 | 0.2697 | 0.0878 |
| Compressor load | 0.5902 | 0.4783 | 0.3970 | 0.3208 | 0.2694 |
| Training | Testing | ||||
|---|---|---|---|---|---|
| Model | RMSE | MAE | RMSE | Max Error | Predict Mean |
| ARMA | 1.1035 | 1.5613 | 2.0244 | 7.6000 | 14.6497 |
| ARIMA | 2.0942 | 13.7962 | 17.3131 | 24.6000 | 9.9240 |
| FARIMA | 0.3591 | 1.5497 | 2.0372 | 8.0000 | 14.6479 |
| ARMA + FARIMA | − | 1.5301 | 1.9980 | 7.8000 | 14.6488 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Liu, Y.; Wu, H.; Lu, S.; Zhou, M. Ensemble FARIMA Prediction with Stable Infinite Variance Innovations for Supermarket Energy Consumption. Fractal Fract. 2022, 6, 276. https://doi.org/10.3390/fractalfract6050276
Wang J, Liu Y, Wu H, Lu S, Zhou M. Ensemble FARIMA Prediction with Stable Infinite Variance Innovations for Supermarket Energy Consumption. Fractal and Fractional. 2022; 6(5):276. https://doi.org/10.3390/fractalfract6050276
Chicago/Turabian StyleWang, Jing, Yi Liu, Haiyan Wu, Shan Lu, and Meng Zhou. 2022. "Ensemble FARIMA Prediction with Stable Infinite Variance Innovations for Supermarket Energy Consumption" Fractal and Fractional 6, no. 5: 276. https://doi.org/10.3390/fractalfract6050276
APA StyleWang, J., Liu, Y., Wu, H., Lu, S., & Zhou, M. (2022). Ensemble FARIMA Prediction with Stable Infinite Variance Innovations for Supermarket Energy Consumption. Fractal and Fractional, 6(5), 276. https://doi.org/10.3390/fractalfract6050276