
Image Dehazing Based on Local and Non-Local Features




Abstract
:1. Introduction
2. Materials and Methods
2.1. Fractional Derivative
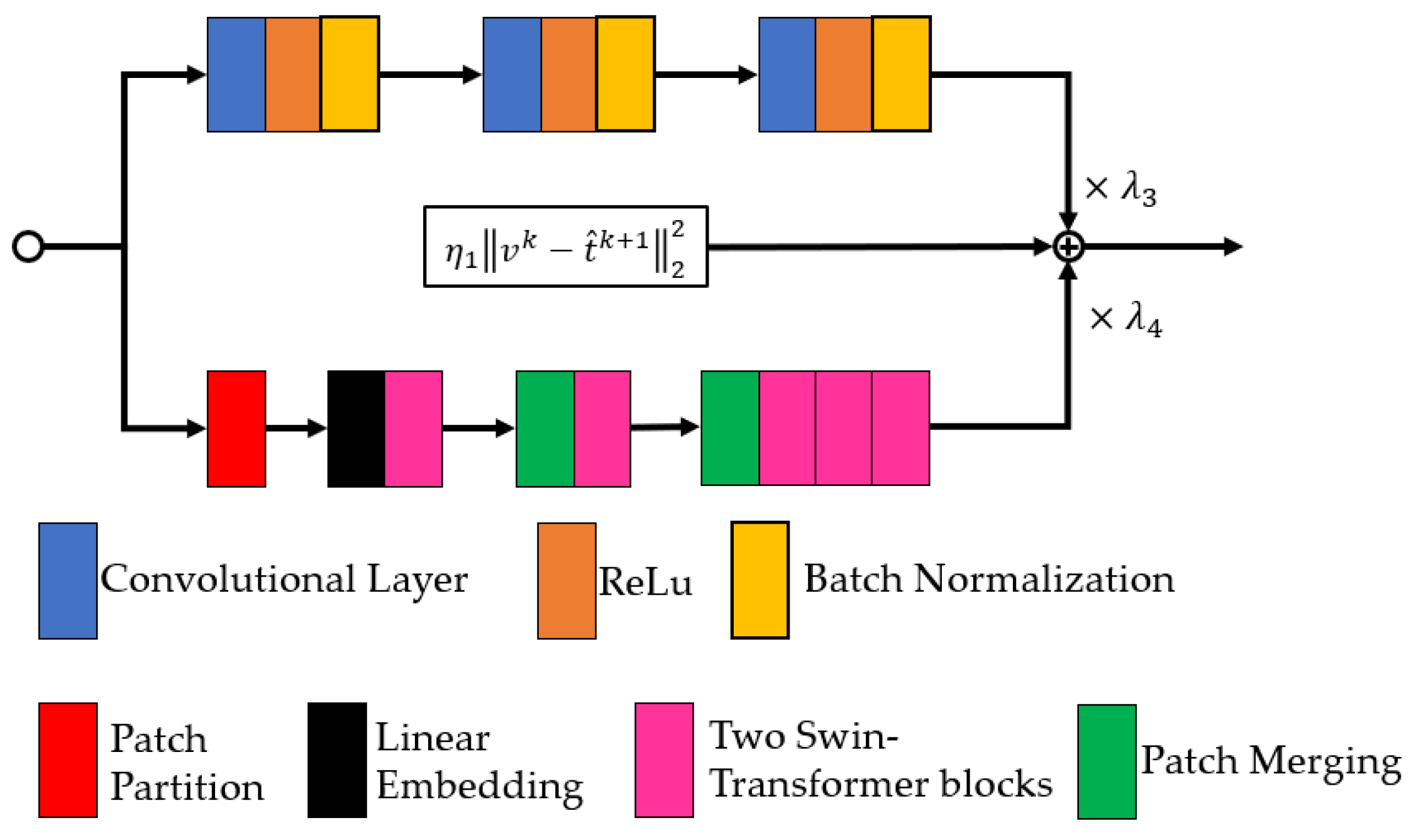
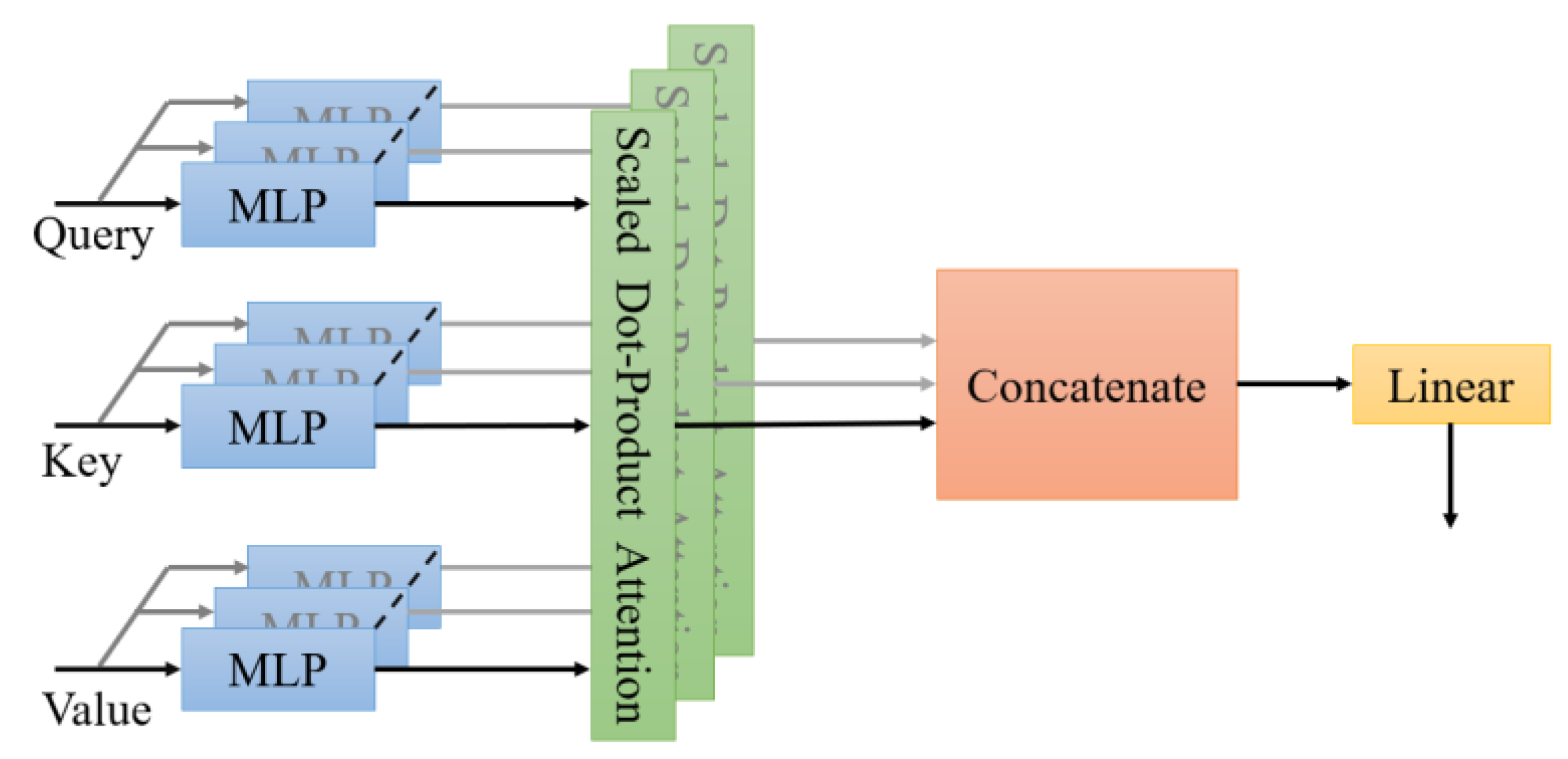
2.2. Proposed Dehazing Model
2.3. Subproblem v
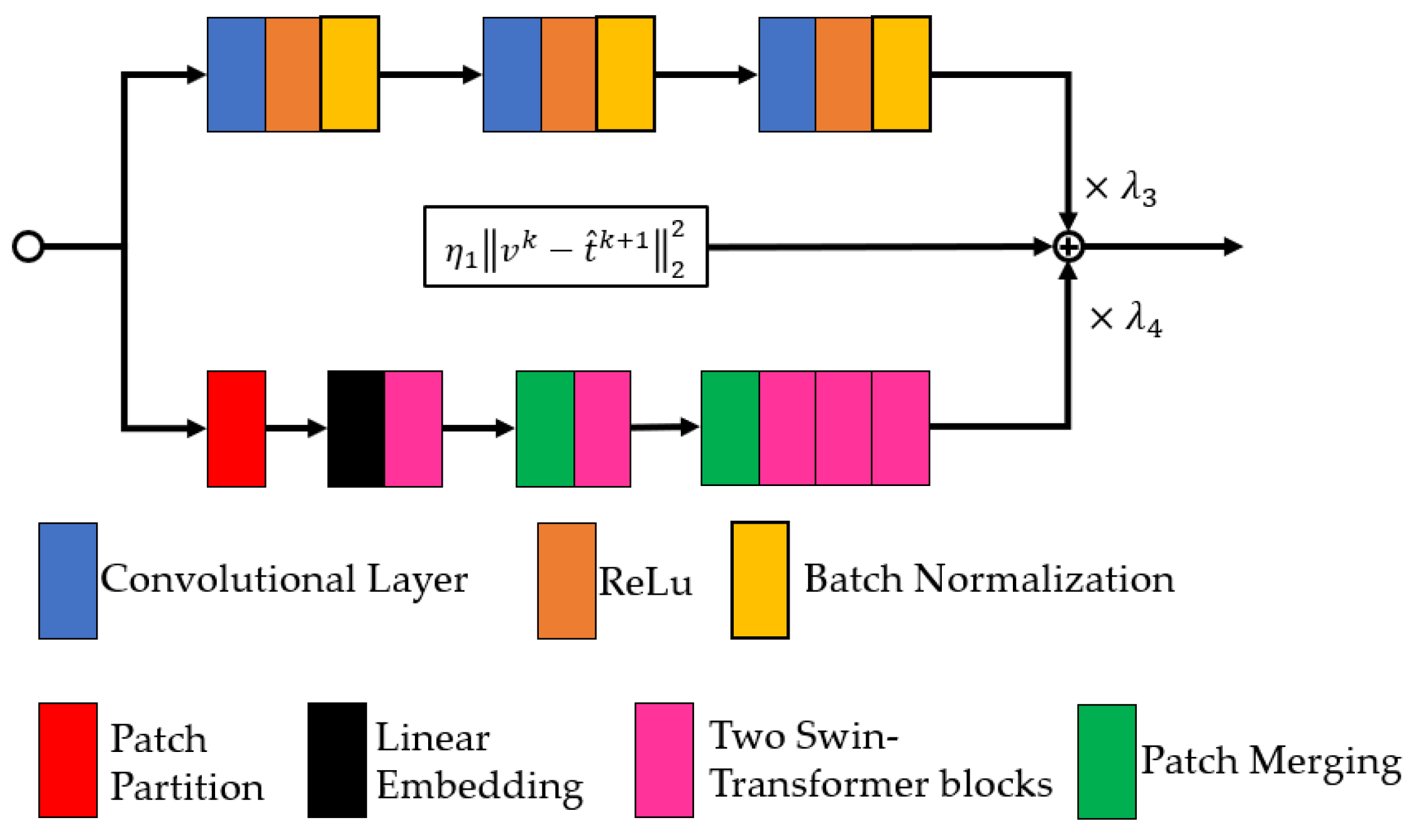
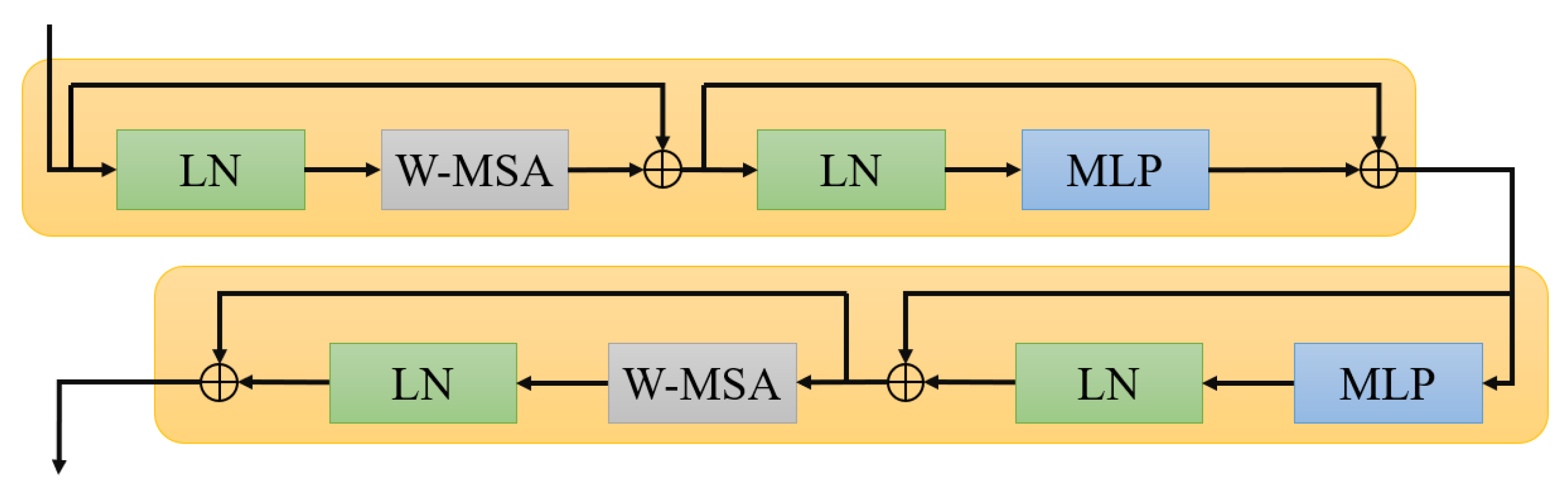
2.4. Other Subproblems
2.5. The Estimation of Atmospheric Light
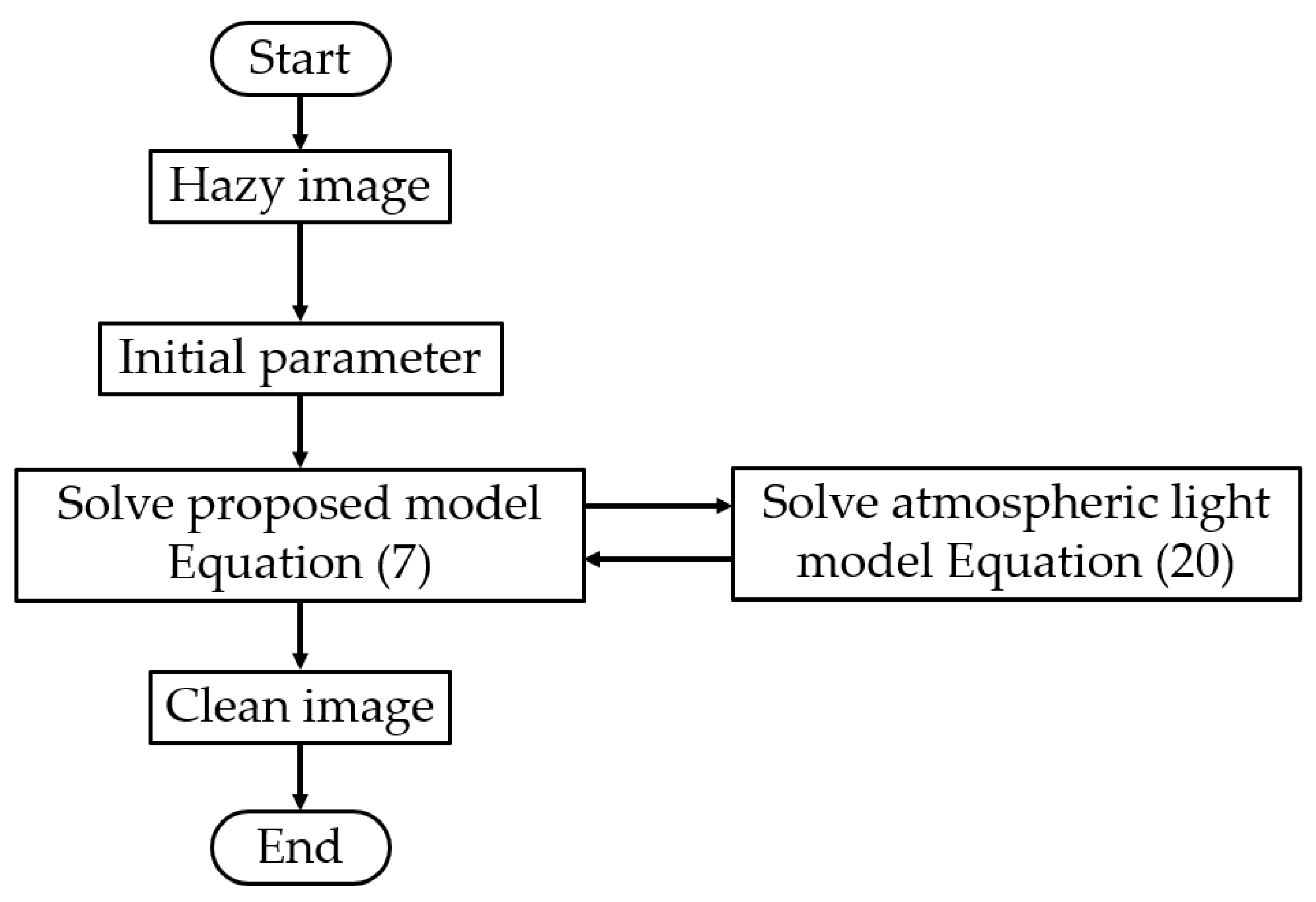
2.6. The Steps of the Proposed Method
- Input: hazy image.
- Output: clean image.
- Step 1: Estimate the rough transmission map and the initial atmospheric light. Establish the nitial parameters, and set k1=1 and k2=1;
- Step 2: Solve Equations (16) and (17), the trained network, and Equation (18);
- Step 3: Solve Equation (19) and Equations (26)–(28);
- Step 4: Repeat Step 3, until the iteration exit condition of the atmospheric light estimation is satisfied;
- Step 5: Repeat Steps 2, 3 and 4, until the iteration exit condition of the transmission map is satisfied;
- Step 6: Output the transmission map and clean the image.
3. Results
3.1. Evaluation of Initial Atmospheric Light
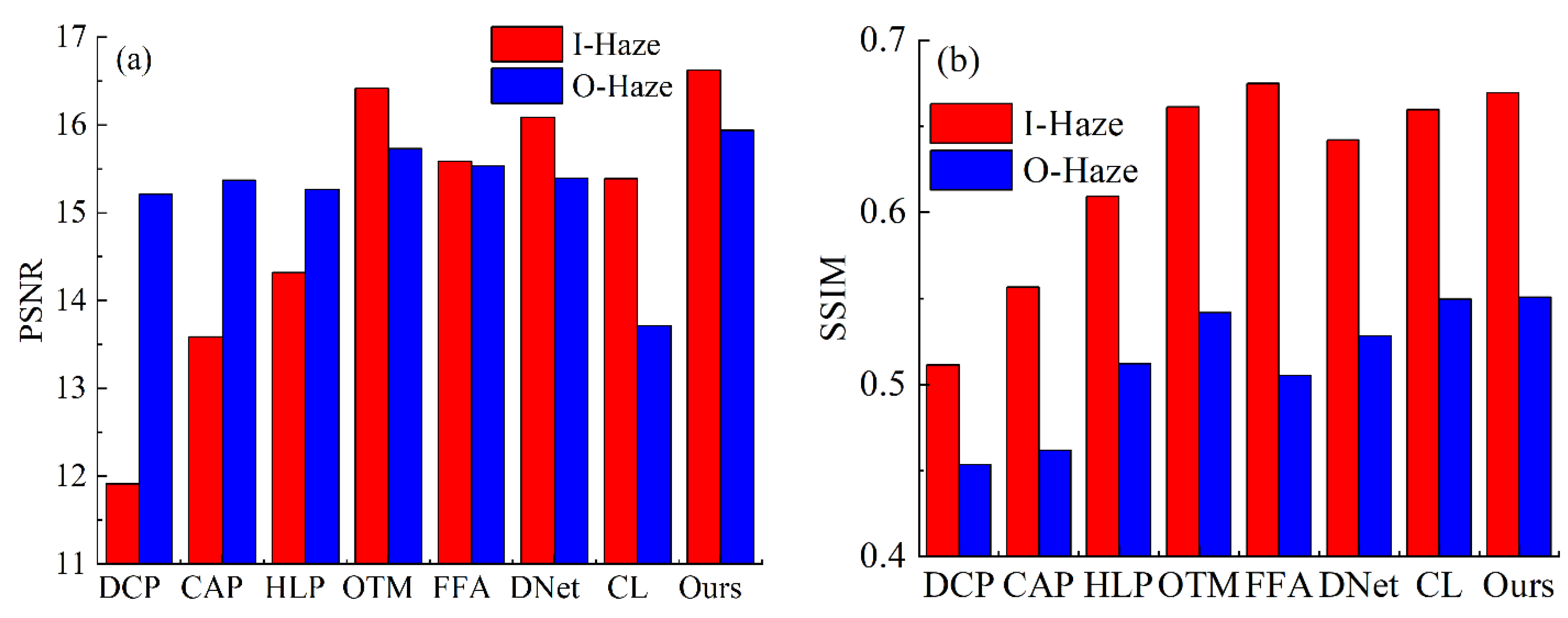
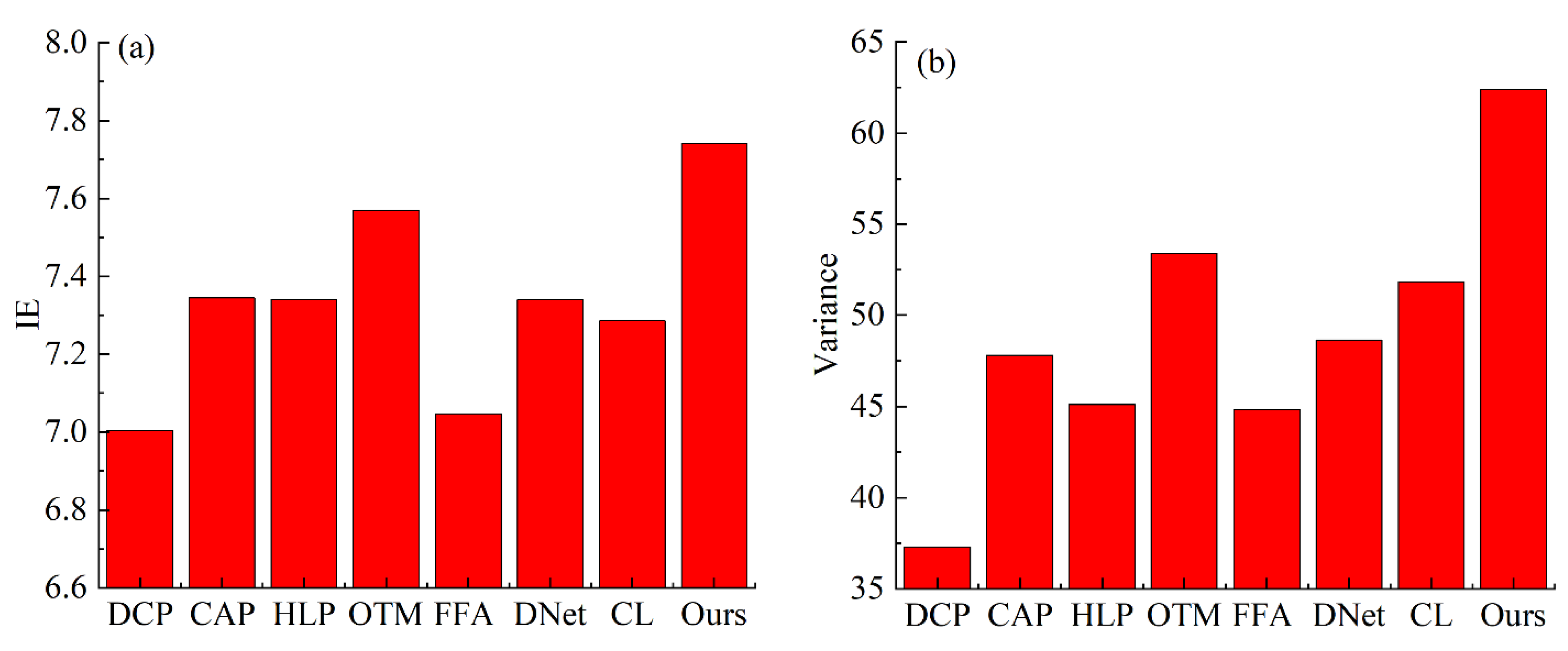
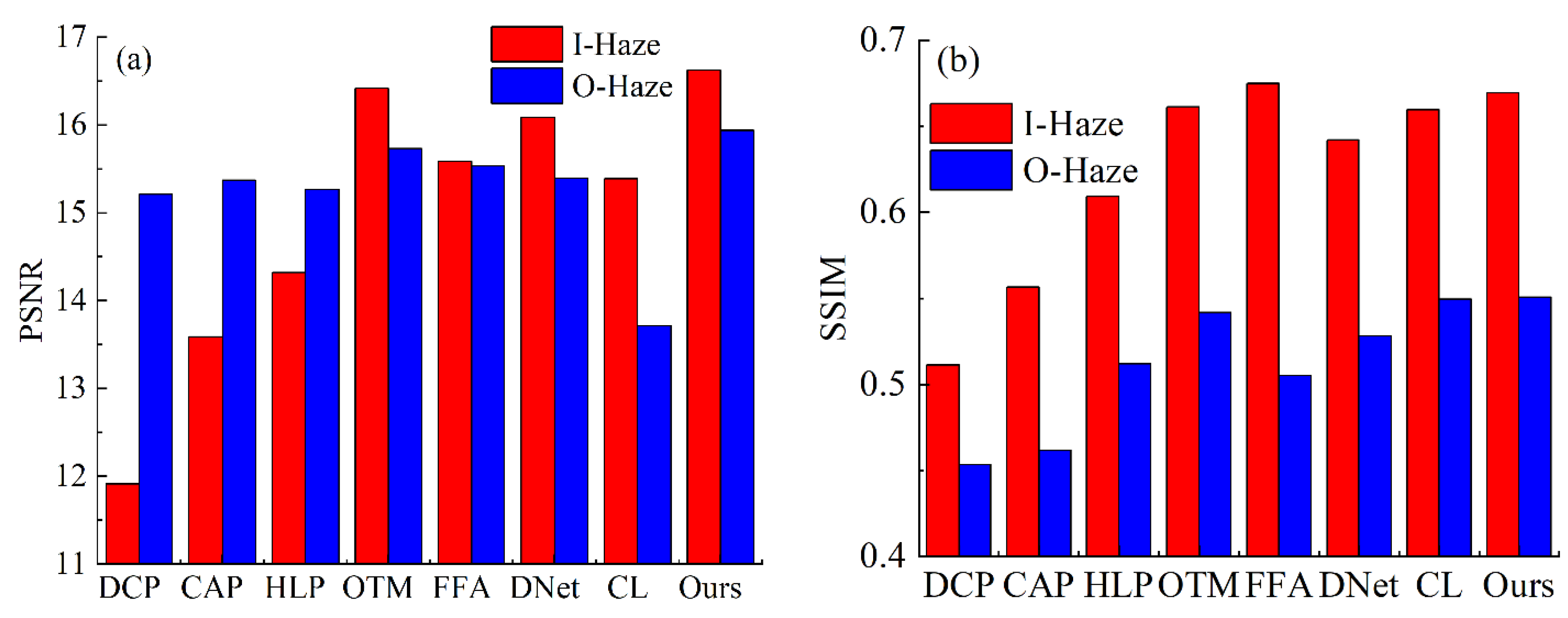
3.2. Evaluation on Synthetic Images
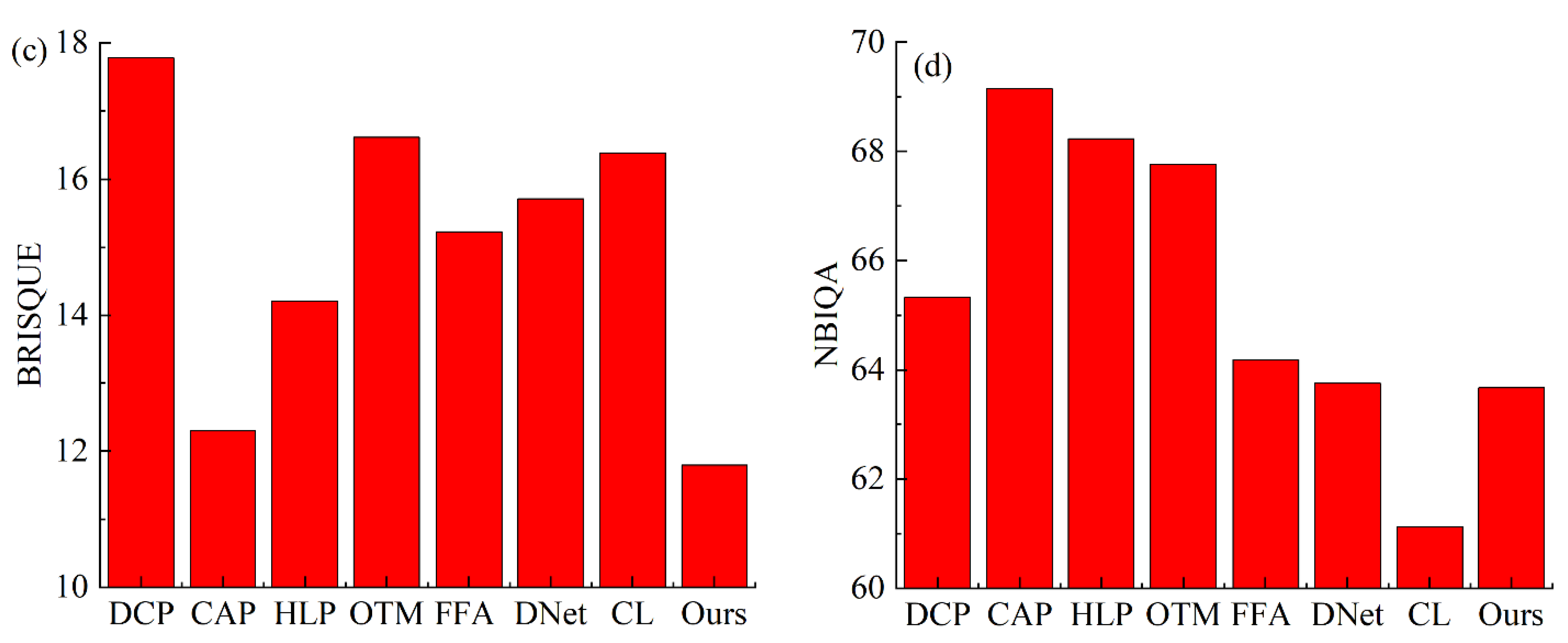
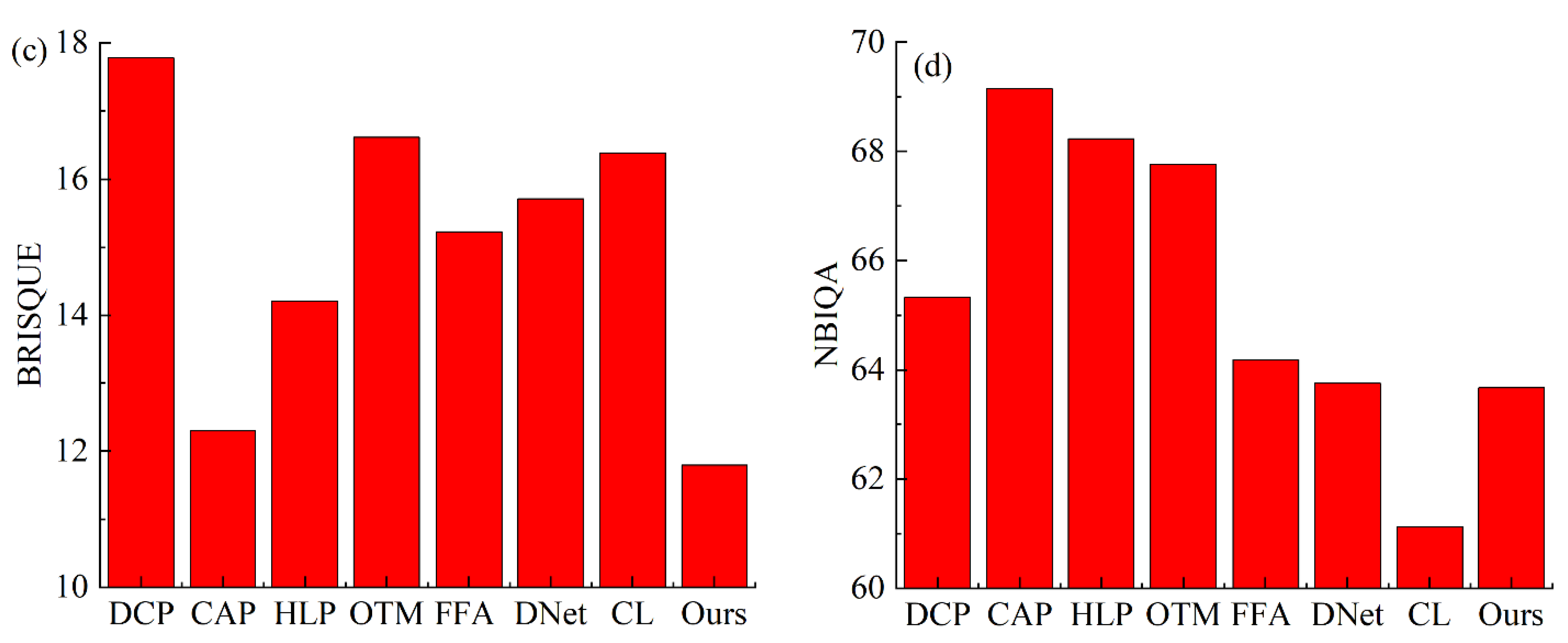
3.3. Evaluation on Real-World Images
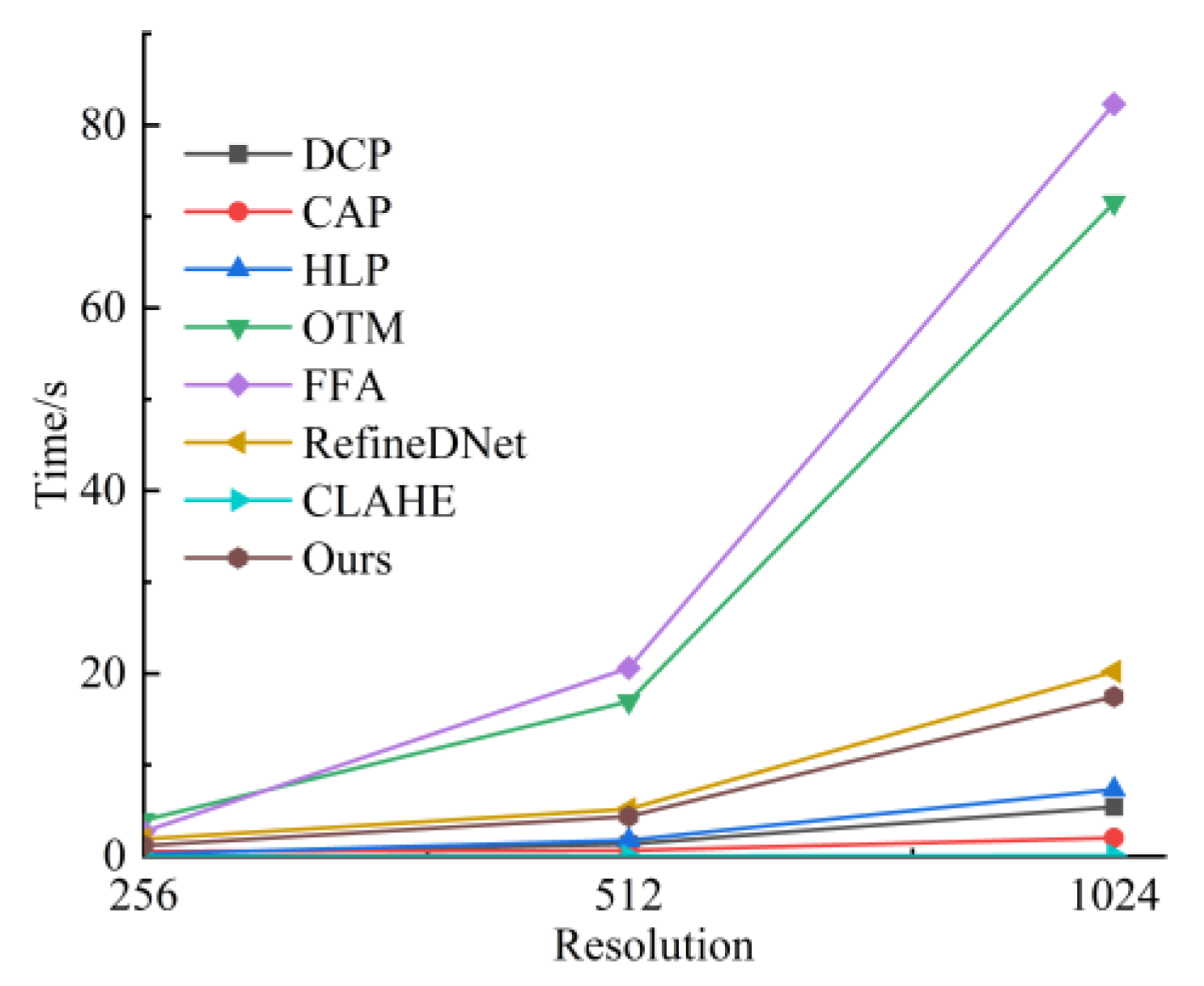
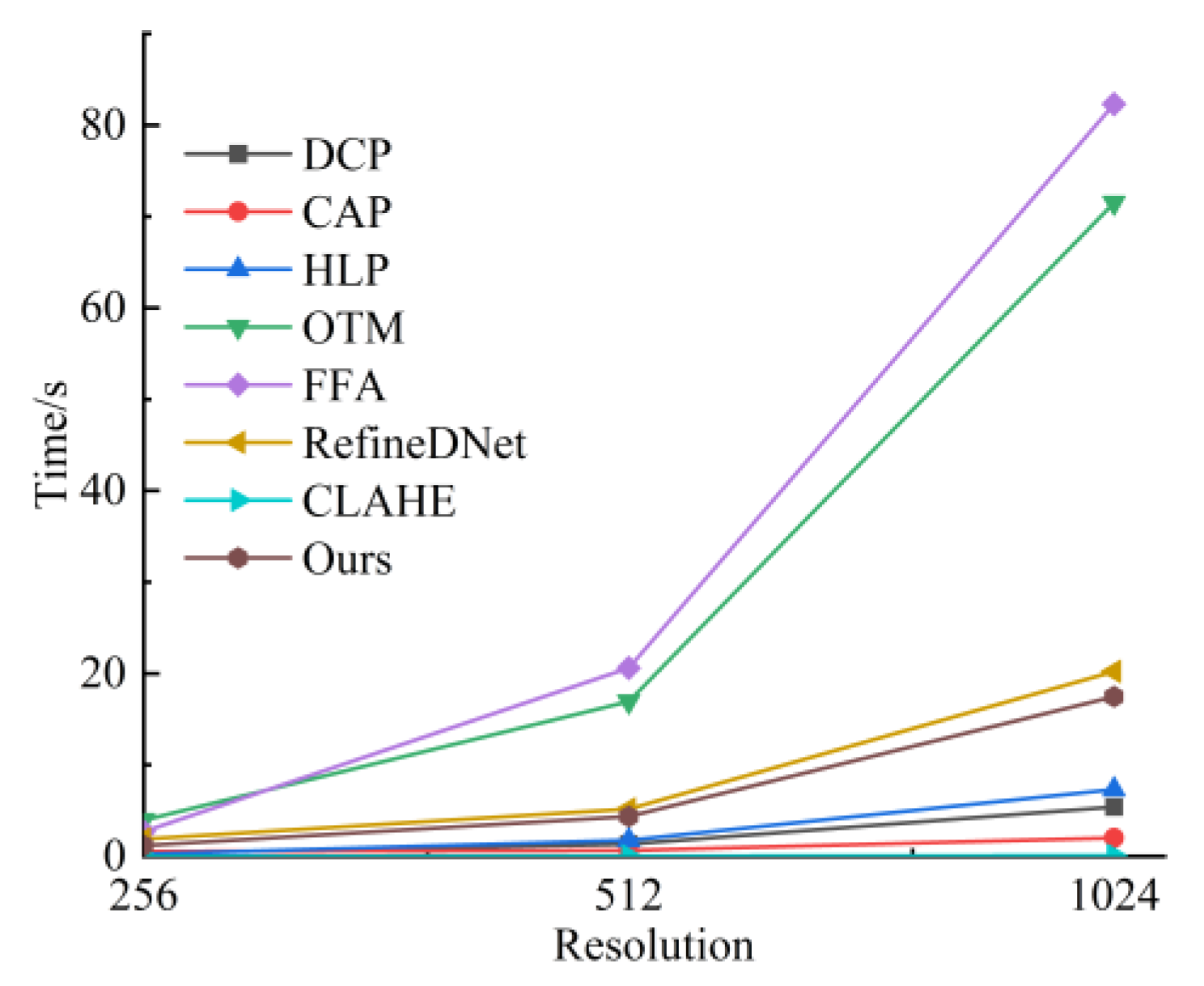
3.4. Running Time Analyze
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Symbol | Annotation | Type |
|---|---|---|---|
| 1 | A | Atmospheric light | Vector |
| 2 | Local regularization term | Function | |
| 3 | Horizontal direction right fractional operator | Operator | |
| 4 | Horizontal direction left fractional operator | Operator | |
| 5 | Horizontal direction composite fractional operator | Operator | |
| 6 | Vertical direction right fractional operator | Operator | |
| 7 | Vertical direction right fractional operator | Operator | |
| 8 | Vertical direction composite fractional operator | Operator | |
| 9 | Size of key in MSA | Number | |
| 10 | The proposed network | Function | |
| 11 | E | Unit matrix | Matrix |
| 12 | I | Hazy image | Matrix |
| 13 | Optimized hazy image via CLAHE | Matrix | |
| 14 | I | Pixel coordinates | Number |
| 15 | J | Ideal image | Matrix |
| 16 | Ideal image, variable | Matrix | |
| 17 | J | Pixel coordinates | Number |
| 18 | K | Key of MSA | Matrix |
| 19 | K | Gird size of standard discretization technique | Number |
| 20 | Iterations number of transmission map estimation | Number | |
| 21 | Iterations number of atmospheric light estimation | Number | |
| 22 | L | Number of train data | Number |
| 23 | M | Size of image | Number |
| 24 | M | Number of grids of standard discretization technique | Number |
| 25 | N | Size of image | Number |
| 26 | Q | Query of MSA | Matrix |
| 27 | Symbolic function | Function | |
| 28 | T | Transmission map | Matrix |
| 29 | Transmission map, variable | Matrix | |
| 30 | Non-local regularization term | Function | |
| 31 | V | Value of MSA only in Equation (14) | Matrix |
| 32 | V | Atmospheric veil | Matrix |
| 33 | V | Auxiliary variable | Matrix |
| 34 | W | Auxiliary variable | Matrix |
| 35 | X | Auxiliary variable | Matrix |
| 36 | order | Number | |
| 37 | Regularization parameter | Number | |
| 38 | Penalty parameter | Number | |
| 39 | Θ | The proposed network parameters | Matrix |
| 40 | Balance parameter in Equation (15) | Number | |
| 41 | 1-norm, 2-norm | Function |
References
- Galdran, A.; Javier, V.C.; David, P.; Marcelo, B. Enhanced Variational Image Dehazing. SIAM J. Imaging Sci. 2015, 8, 1519–1546. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Sun, J.; Tang, X. Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [CrossRef] [PubMed]
- Berman, D.; Treibitz, T.; Avidan, S. Single Image Dehazing Using Haze-Lines. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 720–734. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Q.; Mai, J.; Shao, L. A Fast Single Image Haze Removal Algorithm Using Color Attenuation Prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar] [CrossRef] [Green Version]
- He, K.M.; Sun, J.; Tang, X.O. Guided Image Filtering. IEEE Trans. Pattern Anal. 2013, 35, 1397–1409. [Google Scholar] [CrossRef]
- Li, Z.; Zheng, J.; Zhu, Z.; Yao, W.; Wu, S. Weighted Guided Image Filtering. IEEE Trans. Image Process. 2014, 24, 120–129. [Google Scholar] [CrossRef]
- Kou, F.; Chen, W.; Wen, C.; Li, Z. Gradient Domain Guided Image Filtering. IEEE Trans. Image Process. 2015, 24, 4528–4539. [Google Scholar] [CrossRef]
- Ochotorena, C.N.; Yamashita, Y. Anisotropic Guided Filtering. IEEE Trans. Image Process. 2019, 29, 1397–1412. [Google Scholar] [CrossRef]
- Selesnick, I. Generalized Total Variation: Tying the Knots. IEEE Signal Process. Lett. 2015, 22, 2009–2013. [Google Scholar] [CrossRef] [Green Version]
- Bredies, K.; Kunisch, K.; Pock, T. Total generalized variation. SIAM J. Imaging Sci. 2010, 3, 492–526. [Google Scholar] [CrossRef]
- Gilboa, G.; Sochen, N.; Zeevi, Y.Y. Image enhancement and denoising by complex diffusion processes. IEEE T. Pattern Anal. 2004, 26, 1020–1036. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.; Gao, X.; He, L.; Lu, W. Single Image Dehazing with Depth-Aware Non-Local Total Variation Regularization. IEEE Trans. Image Process. 2018, 27, 5178–5191. [Google Scholar] [CrossRef] [PubMed]
- Jiao, Q.; Liu, M.; Li, P.; Dong, L.; Hui, M.; Kong, L.; Zhao, Y. Underwater Image Restoration via Non-Convex Non-Smooth Variation and Thermal Exchange Optimization. J. Mar. Sci. Eng. 2021, 9, 570. [Google Scholar] [CrossRef]
- Parisotto, S.; Lellmann, J.; Masnou, S.; Schönlieb, C.-B. Higher-Order Total Directional Variation: Imaging Applications. SIAM J. Imaging Sci. 2020, 13, 2063–2104. [Google Scholar] [CrossRef]
- Chan, R.H.; Lanza, A.; Morigi, S.; Sgallari, F. An Adaptive Strategy for the Restoration of Textured Images using Fractional Order Regularization. Numer. Math. Theory Methods Appl. 2013, 6, 276–296. [Google Scholar] [CrossRef]
- Bilgi, C.Y.; Mürvet, K. Fractional Differential Equation-Based Instantaneous Frequency Estimation for Signal Reconstruction. Fractal Fract. 2021, 5, 83. [Google Scholar]
- Svynchuk, O.; Barabash, O.; Nikodem, J.; Kochan, R.; Laptiev, O. Image Compression Using Fractal Functions. Fractal Fract. 2021, 5, 31. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, R.; Ren, J.; Gui, Q. Adaptive Fractional Image Enhancement Algorithm Based on Rough Set and Particle Swarm Optimization. Fractal Fract. 2022, 6, 100. [Google Scholar] [CrossRef]
- Xu, K.; Liu, J.; Miao, J.; Liu, F. An improved SIFT algorithm based on adaptive fractional differential. J. Ambient Intell. Humaniz. Comput. 2018, 10, 3297–3305. [Google Scholar] [CrossRef]
- Luo, X.; Zeng, T.; Zeng, W.; Huang, J. Comparative analysis on landsat image enhancement using fractional and integral differential operators. Computing 2019, 102, 247–261. [Google Scholar] [CrossRef]
- Yuan, H.; Liu, C.; Guo, Z.; Sun, Z. A Region-Wised Medium Transmission Based Image Dehazing Method. IEEE Access 2017, 5, 1735–1742. [Google Scholar] [CrossRef]
- Guo, F.; Qiu, J.; Tang, J. Single Image Dehazing Using Adaptive Sky Segmentation. IEEJ Trans. Electr. Electron. Eng. 2021, 16, 1209–1220. [Google Scholar] [CrossRef]
- Liu, Y.; Li, H.; Wang, M. Single Image Dehazing via Large Sky Region Segmentation and Multiscale Opening Dark Channel Model. IEEE Access 2017, 5, 8890–8903. [Google Scholar] [CrossRef]
- Wang, W.; Yuan, X.; Wu, X.; Liu, Y. Dehazing for images with large sky region. Neurocomputing 2017, 238, 365–376. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Chen, Z.H.; Sheng, B.; Li, P.; Kim, J.; Wu, E.H. AFF-Dehazing: Attention-based feature fusion network for low-light image Dehazing. Comput. Animat. Virt. Worlds 2021, 32, e2011. [Google Scholar] [CrossRef]
- Sun, Z.; Zhang, Y.; Bao, F.; Shao, K.; Liu, X.; Zhang, C. ICycleGAN: Single image dehazing based on iterative dehazing model and CycleGAN. Comput. Vis. Image Underst. 2020, 203, 103133. [Google Scholar] [CrossRef]
- Zhang, S.; He, F. DRCDN: Learning deep residual convolutional dehazing networks. Vis. Comput. 2019, 36, 1797–1808. [Google Scholar] [CrossRef]
- Li, B.; Gou, Y.; Gu, S.; Liu, J.Z.; Zhou, J.T.; Peng, X. You Only Look Yourself: Unsupervised and Untrained Single Image Dehazing Neural Network. Int. J. Comput. Vis. 2021, 129, 1754–1767. [Google Scholar] [CrossRef]
- Golts, A.; Freedman, D.; Elad, M. Unsupervised Single Image Dehazing Using Dark Channel Prior Loss. IEEE Trans. Image Process. 2020, 29, 2692–2701. [Google Scholar] [CrossRef] [Green Version]
- Kumar, A.; Ahmad, M.O.; Swamy, M.N.S. Image Denoising Based on Fractional Gradient Vector Flow and Overlapping Group Sparsity as Priors. IEEE Trans. Image Process. 2021, 30, 7527–7540. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Zeng, F. Numerical Methods for Fractional Calculus, 3rd ed.; CRC Press: Abingdon, UK, 2015; pp. 97–124. [Google Scholar]
- Diethelm, K. An Algorithm for The Numerical Solution of Differential Equations of Fractional Order. Electron. Trans. Numer. Anal. 1997, 5, 1–6. [Google Scholar]
- Huang, L.D.; Zhao, W.; Wang, J.; Sun, Z.B. Combination of contrast limited adaptive histogram equalisation and discrete wavelet transform for image enhancement. IET Image Process. 2015, 9, 908–915. [Google Scholar]
- Cui, T.; Tian, J.D.; Wang, E.D.; Tang, Y.D. Single image dehazing by latent region- segmentation based transmission estimation and weighted L 1 -norm regularization. IET Image Process. 2017, 11, 145–154. [Google Scholar] [CrossRef] [Green Version]
- Aubert, G.; Vese, L. A Variational Method in Image Recovery. SIAM J. Numer. Anal. 1997, 34, 1948–1979. [Google Scholar] [CrossRef]
- Cheng, K.; Du, J.; Zhou, H.; Zhao, D.; Qin, H. Image super-resolution based on half quadratic splitting. Infrared Phys. Technol. 2020, 105, 103193. [Google Scholar] [CrossRef]
- Zhang, S.; He, F.; Ren, W. NLDN: Non-local dehazing network for dense haze removal. Neurocomputing 2020, 410, 363–373. [Google Scholar] [CrossRef]
- Dekel, T.; Michaeli, T.; Irani, M.; Freeman, W.-T. Revealing and Modifying Non-Local Variations in a Single Image. ACM T. Graph. 2015, 34, 227. [Google Scholar] [CrossRef] [Green Version]
- Hu, H.-M.; Zhang, H.; Zhao, Z.; Li, B.; Zheng, J. Adaptive Single Image Dehazing Using Joint Local-Global Illumination Adjustment. IEEE Trans. Multimed. 2019, 22, 1485–1495. [Google Scholar] [CrossRef]
- Karen, S.; Andrew, Z. Two-Stream Convolutional Networks for Action Recognition in Videos. arXiv 2014, arXiv:1406.2199. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Sun, G.; Jia, X.; Wu, L.; Zhang, A.; Ren, J.; Fu, H.; Yao, Y. Spectral–Spatial Self-Attention Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.H.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Fan, H.; Xiong, B.; Mangalam, K.; Li, Y.; Yan, Z.; Malik, J.; Feichtenhofer, C. Multiscale Vision Transformers. arXiv 2021, arXiv:2104.11227. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, B.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.-L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2015, arXiv:1405.0312. [Google Scholar]
- Chambolle, A.; Pock, T. A First-Order Primal-Dual Algorithm for Convex Problems with Applications to Imaging. J. Math. Imaging Vis. 2010, 40, 120–145. [Google Scholar] [CrossRef] [Green Version]
- He, N.; Wang, J.-B.; Zhang, L.-L.; Lu, K. Convex optimization based low-rank matrix decomposition for image restoration. Neurocomputing 2016, 172, 253–261. [Google Scholar] [CrossRef]
- Yu, K.; Cheng, Y.; Li, L.; Zhang, K.; Liu, Y.; Liu, Y. Underwater Image Restoration via DCP and Yin–Yang Pair Optimization. J. Mar. Sci. Eng. 2022, 10, 360. [Google Scholar] [CrossRef]
- Tare, J.P.; Hautière, N. Fast visibility restoration from a single color or gray level image. In Proceedings of the IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009. [Google Scholar]
- Ngo, D.; Seungmin, L.; Kang, B.S. Robust Single-Image Haze Removal Using Optimal Transmission Map and Adaptive At-mospheric Light. Robust Single-Image Haze Removal Using Optimal Transmission Map and Adaptive Atmospheric Light. Remote Sens. 2020, 12, 2233. [Google Scholar] [CrossRef]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature Fusion Attention Network for Single Image Dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 17–19 January 2019. [Google Scholar]
- Zhao, S.; Zhang, L.; Shen, Y.; Zhou, Y. RefineDNet: A Weakly Supervised Refinement Framework for Single Image Dehazing. IEEE Trans. Image Process. 2021, 30, 3391–3404. [Google Scholar] [CrossRef]
- Ancuti, C.O.; Ancuti, C.; Timofte, R.; Christophe, D.V. O-HAZE: A dehazing benchmark with real hazy and haze-free outdoor images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Ancuti, C.O.; Ancuti, C.; Timofte, R.; Christophe, D.V. I-HAZE: A dehazing benchmark with real hazy and haze-free indoor images. In Proceedings of the Advanced Concepts for Intelligent Vision Systems, Poitiers, France, 24–27 September 2018. [Google Scholar]
- Mittal, A.; Moorthy, A.K.; Bovik, A. No-Reference Image Quality Assessment in the Spatial Domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef] [PubMed]
- Ou, F.-Z.; Wang, Y.-G.; Zhu, G. A Novel Blind Image Quality Assessment Method Based on Refined Natural Scene Statistics. In Proceedings of the IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 December 2019. [Google Scholar]









| Method | I-Hazy | O-Hazy | ||
|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | |
| DCP | 16.42 | 0.67 | 15.94 | 0.55 |
| CAP | 16.37 | 0.66 | 15.87 | 0.58 |
| HLP | 16.48 | 0.64 | 15.89 | 0.56 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiao, Q.; Liu, M.; Ning, B.; Zhao, F.; Dong, L.; Kong, L.; Hui, M.; Zhao, Y. Image Dehazing Based on Local and Non-Local Features. Fractal Fract. 2022, 6, 262. https://doi.org/10.3390/fractalfract6050262
Jiao Q, Liu M, Ning B, Zhao F, Dong L, Kong L, Hui M, Zhao Y. Image Dehazing Based on Local and Non-Local Features. Fractal and Fractional. 2022; 6(5):262. https://doi.org/10.3390/fractalfract6050262
Chicago/Turabian StyleJiao, Qingliang, Ming Liu, Bu Ning, Fengfeng Zhao, Liquan Dong, Lingqin Kong, Mei Hui, and Yuejin Zhao. 2022. "Image Dehazing Based on Local and Non-Local Features" Fractal and Fractional 6, no. 5: 262. https://doi.org/10.3390/fractalfract6050262
APA StyleJiao, Q., Liu, M., Ning, B., Zhao, F., Dong, L., Kong, L., Hui, M., & Zhao, Y. (2022). Image Dehazing Based on Local and Non-Local Features. Fractal and Fractional, 6(5), 262. https://doi.org/10.3390/fractalfract6050262