
Large Language Model-Based Topic-Level Sentiment Analysis for E-Grocery Consumer Reviews



 , ,
, ,
Abstract
1. Introduction
- We propose a TLSA framework that leverages the power of LLM-based models (BERT, GPT) for both subtasks: topic detection and sentiment analysis. The advantage is that the resulting topics are more meaningful, since contextual embeddings of BERT-based clustering can capture meaning beyond word co-occurrence of TFIDF-based LDA. Furthermore, sentiment analysis leverages transfer learning from pre-trained GPT models that already understand many nuances of language. This framework does not need a sentiment dictionary or labelled data training, unlike previous frameworks.
- In this work, we demonstrate BERT-based soft clustering, which has not been considered before for topic detection. We comprehensively evaluate BERT-based clustering methods in the topic detection task of LLM-based TLSA. The results show that soft clustering, i.e., fuzzy c-means (FCM), produces more coherent topics in structured datasets. In contrast to soft clustering, HDBSCAN produces more diverse topics, and K-Means appears to be the most balanced method for achieving coherence and diversity. Thus, by selecting clustering methods, BERT-based clustering can produce more semantically coherent topics.
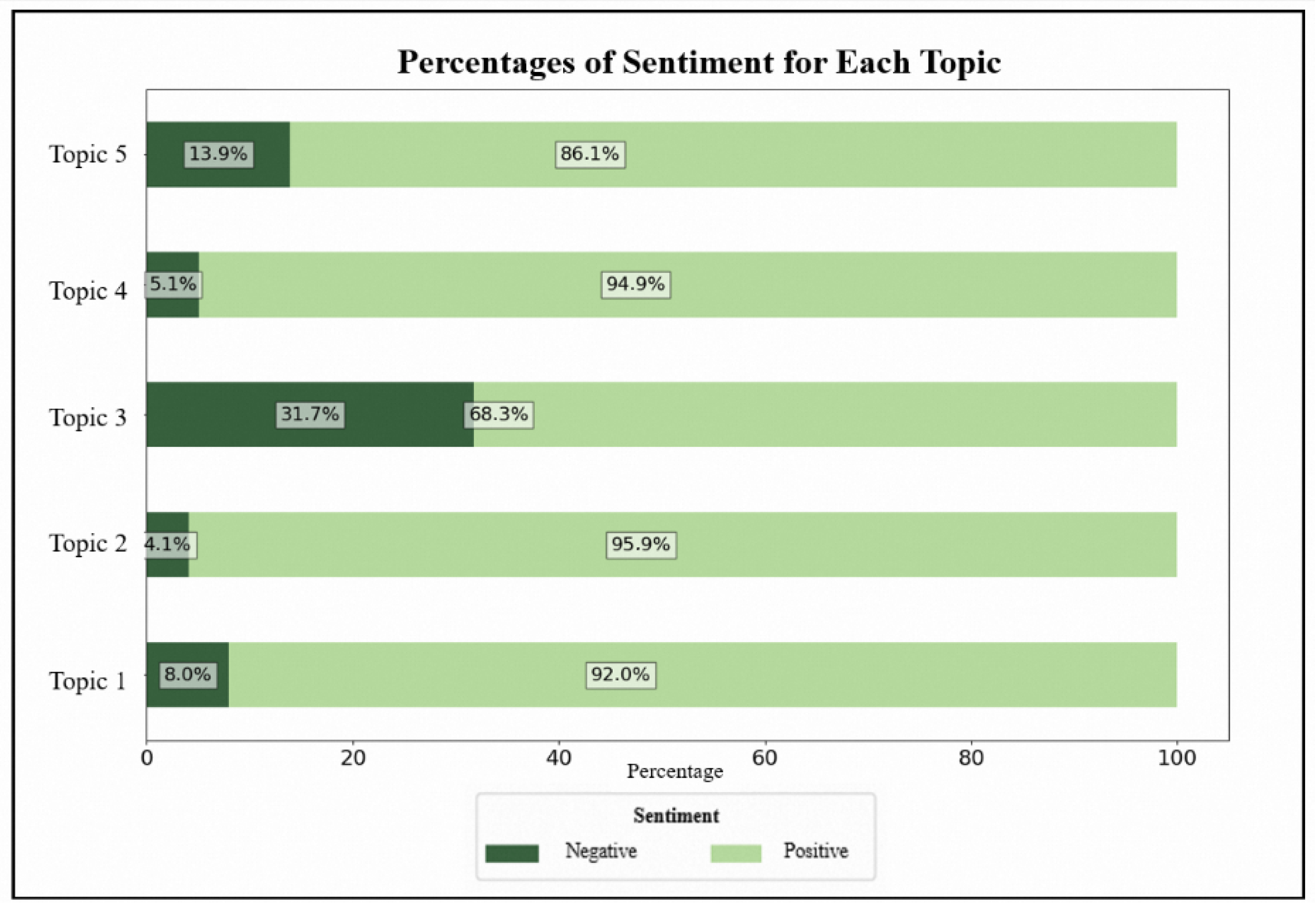
- From a practical perspective, this research highlights the TLSA of the Indonesian e-grocery sector using real-world customer feedback data. The study identifies specific customer concerns such as affordability and packaging, fresh fruit and vegetable delivery, overall service experience, fresh produce quality, and fresh shopping satisfaction. Furthermore, topic-based sentiment polarization adds analytical depth by revealing what issues matter to customers and how these issues elicit divergent emotional reactions, enabling more targeted managerial responses. For example, this research reveals that 31.7% of all negative sentiment concentrates on the topic of the “shopping experience,” despite an overall positive sentiment trend.
2. Related Works
3. Methods
| Algorithm 1 Topic-level sentiment analysis. |
| Input: A, p, K Output: |
3.1. Topic Detection
| Algorithm 2 Clustering-based topic detection. |
| Input: A, p, K Output: |
3.1.1. Text Representation
3.1.2. Dimension Reduction
3.1.3. Clustering
3.1.4. Topic Representation
3.1.5. Topic Interpretation
3.2. Sentiment Analysis
3.3. Sentiment–Topic Aggregation
| Algorithm 3 Sentiment-topic aggregation. |
| Input: , , K Output: , |
4. Experiments
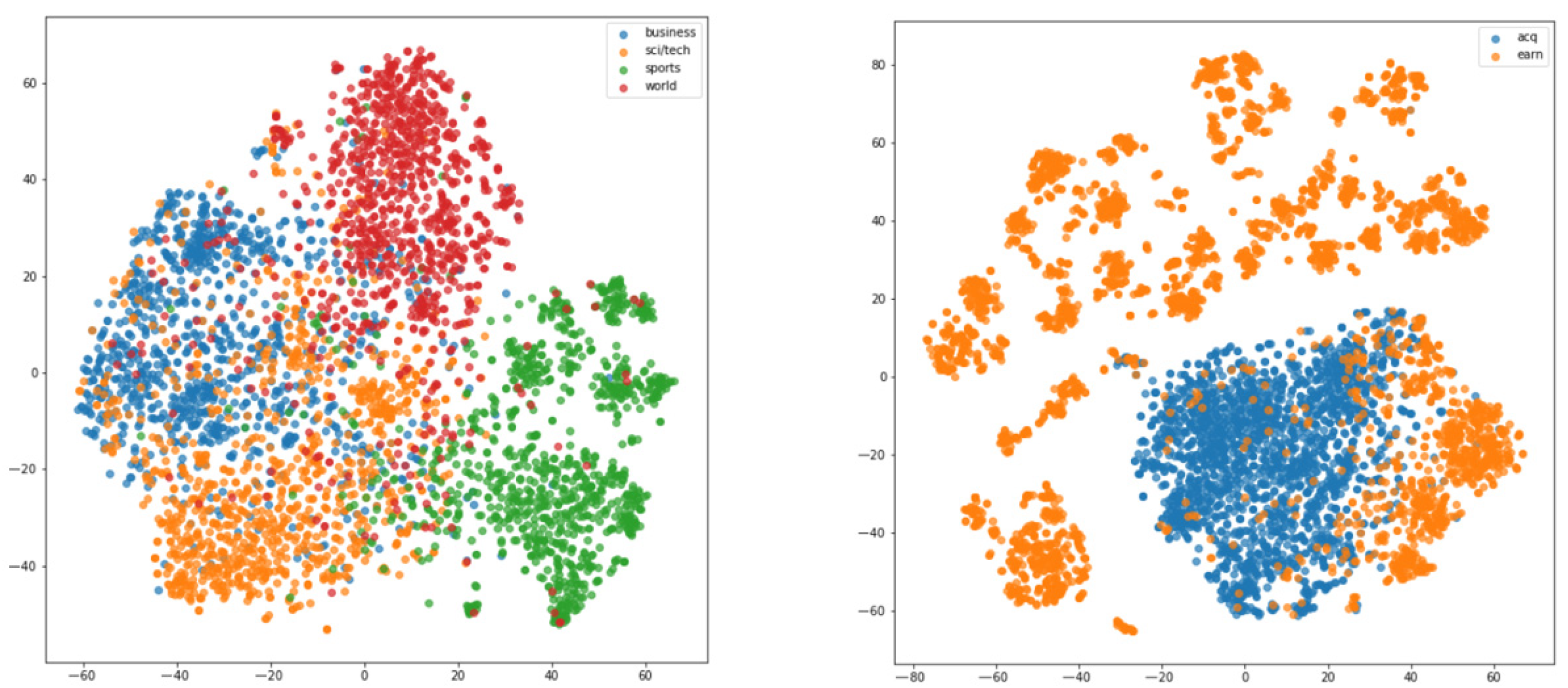
4.1. Analysis of BERT-Based Clustering for Topic Detection
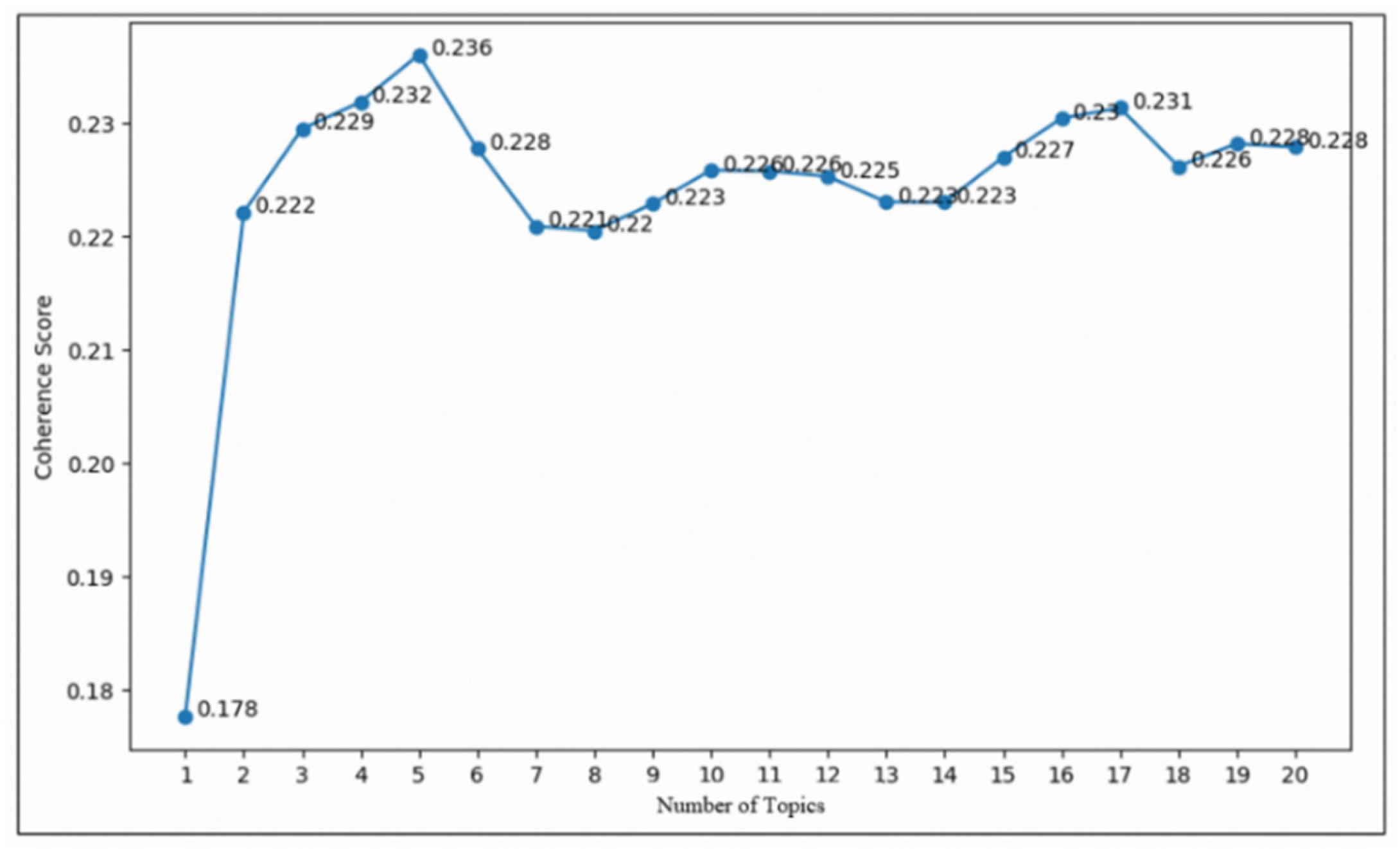
4.1.1. Sensitivity Analysis of the BERT-Based Fuzzy C-Means
4.1.2. Comparative Evaluation of BERT-Based Clustering
4.2. Analysis of Indonesian E-Grocery Customer Reviews
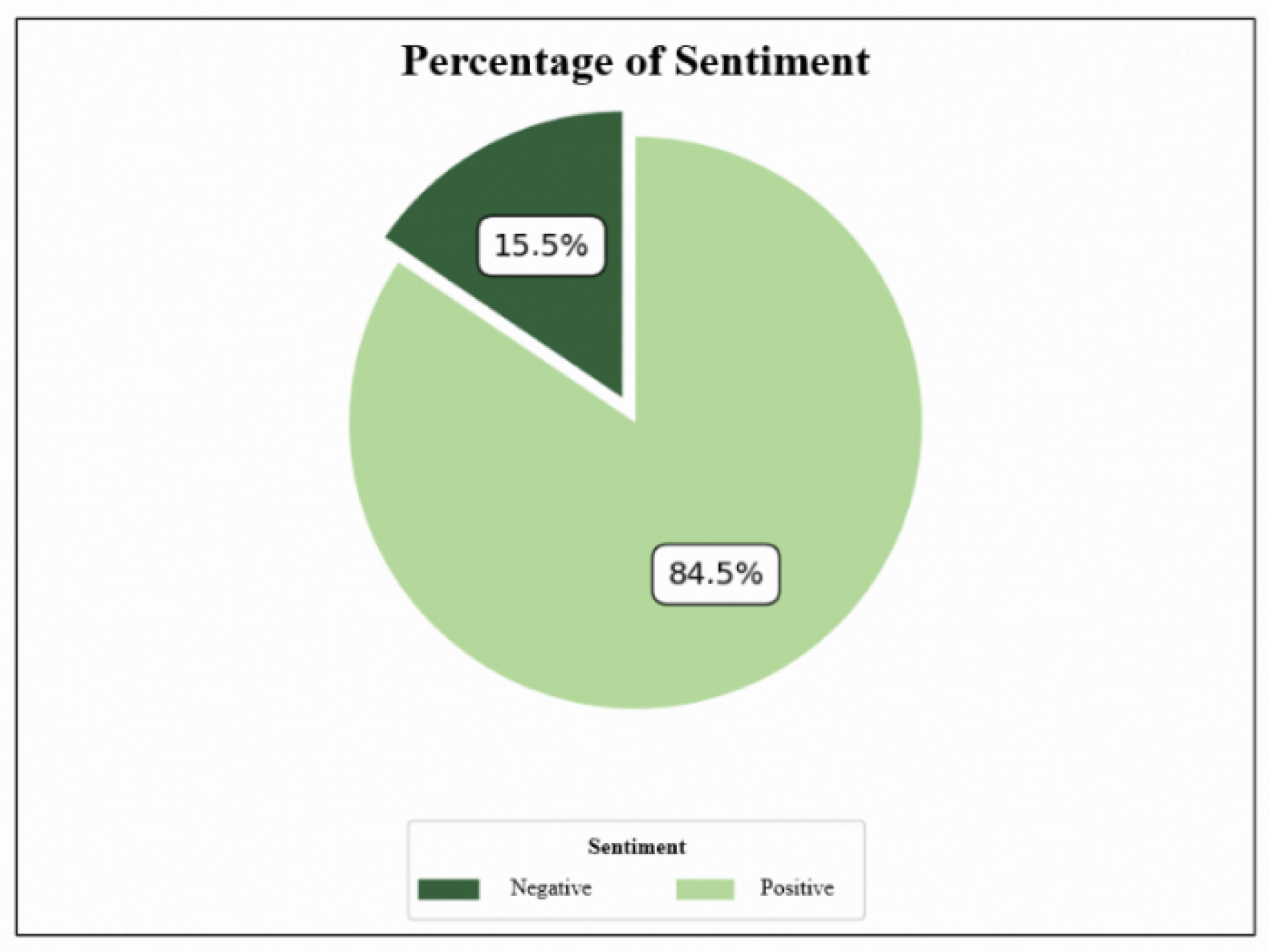
4.2.1. Findings and Discussion
4.2.2. Potential Biases and Their Impact on the Conclusions
5. Conclusions
6. Limitations and Future Work
6.1. Limitation
6.1.1. Binary Sentiment Classification
6.1.2. Interpretability in Soft Clustering
6.1.3. Computational Complexity
6.1.4. Limited Domain and Language Scope
6.2. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Grande-Ramírez, J.R.; Roldán-Reyes, E.; Aguilar-Lasserre, A.A.; Juárez-Martínez, U. Integration of Sentiment Analysis of Social Media in the Strategic Planning Process to Generate the Balanced Scorecard. Appl. Sci. 2022, 12, 12307. [Google Scholar] [CrossRef]
- Nasrabadi, N.; Wicaksono, H.; Valilai, O.F. Shopping marketplace analysis based on customer insights using social media analytics. MethodsX 2024, 13, 102868. [Google Scholar] [CrossRef] [PubMed]
- Indonesia.go.id., Konsumsi Masyarakat Masih Tinggi, Produk Lokal Paling Laku di Harbolnas 2024. 2025. Available online: https://indonesia.go.id/kategori/editorial/8889/konsumsi-masyarakat-masih-tinggi-produk-lokal-paling-laku-di-harbolnas (accessed on 24 March 2025).
- Titipku Research Team. Indonesia E-Grocery Report 2022; Titipku Research Team: Tangerang, Indonesia, 2022. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pretraining of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Alaparthi, S.; Mishra, M. Bidirectional Encoder Representations from Transformers (BERT): A sentiment analysis odyssey. arXiv 2020. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pretraining. 2018. Available online: https://gluebenchmark.com/leaderboard (accessed on 31 March 2025).
- Krugmann, J.O.; Hartmann, J. Sentiment Analysis in the Age of Generative AI. Cust. Needs Solut. 2024, 11, 3. [Google Scholar] [CrossRef]
- Qiu, Y.; Jin, Y. ChatGPT and fine-tuned BERT: A comparative study for developing intelligent design support systems. Intell. Syst. Appl. 2024, 21, 200308. [Google Scholar] [CrossRef]
- Marrese-Taylor, E.; Velásquez, J.D.; Bravo-Marquez, F. A novel deterministic approach for aspect-based opinion mining in tourism products reviews. Expert Syst. Appl. 2014, 41, 7764–7775. [Google Scholar] [CrossRef]
- Thet, T.T.; Na, J.-C.; Khoo, C.S.G. Aspect-based sentiment analysis of movie reviews on discussion boards. J. Inf. Sci. 2010, 36, 823–848. [Google Scholar] [CrossRef]
- Zhang, S.; Ly, L.; Mach, N.; Amaya, C. Topic Modeling and Sentiment Analysis of Yelp Restaurant Reviews. Int. J. Inf. Syst. Serv. Sect. 2022, 14, 1–16. [Google Scholar] [CrossRef]
- Garcia, K.; Berton, L. Topic detection and sentiment analysis in Twitter content related to COVID-19 from Brazil and the USA. Appl. Soft Comput. 2021, 101, 107057. [Google Scholar] [CrossRef] [PubMed]
- Uthirapathy, S.E.; Sandanam, D. Topic Modelling and Opinion Analysis On Climate Change Twitter Data Using LDA and BERT Model. Procedia Comput. Sci. 2023, 218, 908–917. [Google Scholar] [CrossRef]
- Jelodar, H.; Wang, Y.; Orji, R.; Huang, S. Deep Sentiment Classification and Topic Discovery on Novel Coronavirus or COVID-19 Online Discussions: NLP Using LSTM Recurrent Neural Network Approach. IEEE J. Biomed. Health Inform. 2020, 24, 2733–2742. [Google Scholar] [CrossRef] [PubMed]
- Kwon, H.-J.; Ban, H.-J.; Jun, J.-K.; Kim, H.-S. Topic Modeling and Sentiment Analysis of Online Review for Airlines. Information 2021, 12, 78. [Google Scholar] [CrossRef]
- Carvache-Franco, O.; Carvache-Franco, M.; Carvache-Franco, W.; Iturralde, K. Topic and sentiment analysis of crisis communications about the COVID-19 pandemic in Twitter’s tourism hashtags. Tour. Hosp. Res. 2023, 23, 44–59. [Google Scholar] [CrossRef]
- Abiola, O.; Abayomi-Alli, A.; Tale, O.A.; Misra, S.; Abayomi-Alli, O. Sentiment analysis of COVID-19 tweets from selected hashtags in Nigeria using VADER and Text Blob analyser. J. Electr. Syst. Inf. Technol. 2023, 10, 5. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar] [CrossRef]
- Qiao, F.; Williams, J. Topic Modelling and Sentiment Analysis of Global Warming Tweets. J. Organ. End User Comput. 2021, 34, 18. [Google Scholar] [CrossRef]
- Pathak, A.R.; Pandey, M.; Rautaray, S. Topic-level sentiment analysis of social media data using deep learning. Appl. Soft Comput. 2021, 108, 107440. [Google Scholar] [CrossRef]
- Gui, L.; Leng, J.; Zhou, J.; Xu, R.; He, Y. Multi Task Mutual Learning for Joint Sentiment Classification and Topic Detection. IEEE Trans. Knowl. Data Eng. 2020, 34, 1915–1927. [Google Scholar] [CrossRef]
- Nur, K.; Najahaty, I.; Hidayati, L.; Murfi, H.; Nurrohmah, S. Combination of singular value decomposition and K-means clustering methods for topic detection on Twitter. In Proceedings of the 2015 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Depok, Indonesia, 10–11 October 2015; Institute of Electrical and Electronics Engineers: New York, NY, USA, 2015; pp. 123–128. [Google Scholar] [CrossRef]
- Tounsi, A.; Elkefi, S.; Bhar, S.L. Exploring the Reactions of Early Users of ChatGPT to the Tool using Twitter Data: Sentiment and Topic Analyses. In Proceedings of the 2023 IEEE International Conference on Advanced Systems and Emergent Technologies (IC_ASET), Hammamet, Tunisia, 29 April–1 May 2023; Institute of Electrical and Electronics Engineers: New York, NY, USA, 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Grootendorst, M. BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar] [CrossRef]
- Murfi, H. A scalable eigenspace-based fuzzy c-means for topic detection. Data Technol. Appl. 2021, 55, 527–541. [Google Scholar] [CrossRef]
- Muliawati, T.; Murfi, H. Eigenspace-based fuzzy c-means for sensing trending topics in Twitter. AIP Conf. Proc. 2017, 1862, 030140. [Google Scholar] [CrossRef]
- Murfi, H. The Accuracy of Fuzzy C-Means in Lower-Dimensional Space for Topic Detection. In Smart Computing and Communication; Qiu, M., Ed.; Springer International Publishing: Cham, Switzerland, 2018; pp. 321–334. [Google Scholar]
- Kheiri, K.; Karimi, H. SentimentGPT: Exploiting GPT for Advanced Sentiment Analysis and its Departure from Current Machine Learning. arXiv 2023, arXiv:2307.10234. [Google Scholar] [CrossRef]
- Koto, F.; Lau, J.H.; Baldwin, T. IndoBERTweet: A Pretrained Language Model for Indonesian Twitter with Effective Domain-Specific Vocabulary Initialization. arXiv 2021, arXiv:2109.04607. [Google Scholar] [CrossRef]
- Dumais, S.T. Latent semantic analysis. Annu. Rev. Inf. Sci. Technol. 2004, 38, 188–230. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar] [CrossRef]
- McQueen, J.B. Some methods of classification and analysis of multivariate observations. In Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, SC, USA, 21 June–18 July 1965; pp. 281–297. [Google Scholar]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise; AAAI Press: Munchen, Germany, 1996. [Google Scholar]
- Campello, R.J.G.B.; Moulavi, D.; Sander, J. Density-Based Clustering Based on Hierarchical Density Estimates. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Macau, China, 14–17 April 2019; Springer: Berlin/Heidelberg, Germany, 2019; Volume 7819, pp. 160–172. [Google Scholar]
- Joachims, T. A Probabilistic Analysis of the Rocchio Algorithm with TFIDF for Text Categorization. In Proceedings of the Fourteenth International Conference on Machine Learning (ICML’97), Nashville, TN, USA, 8—12 July 1997; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1997; pp. 143–151. [Google Scholar]
- Zhang, X.; Zhao, J.; Lecun, Y. Text Understanding from Scratch. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation; MIT Press: Cambridge, MA, USA, 2015; pp. 649–657. [Google Scholar]
- Winkler, R.; Klawonn, F.; Kruse, R. Fuzzy C-means in high dimensional spaces. Int. J. Fuzzy Syst. Appl. 2011, 1, 1–16. [Google Scholar] [CrossRef]
- Zhou, K.; Fu, C.; Yang, S. Fuzziness parameter selection in fuzzy c-means: The perspective of cluster validation. Sci. China Inf. Sci. 2014, 57, 1–8. [Google Scholar] [CrossRef]
- Subakti, A.; Murfi, H.; Hariadi, N. The performance of BERT as data representation of text clustering. J. Big Data 2022, 9, 15. [Google Scholar] [CrossRef]
- O’Callaghan, D.; Greene, D.; Carthy, J.; Cunningham, P. An analysis of the coherence of descriptors in topic modeling. Expert Syst. Appl. 2015, 42, 5645–5657. [Google Scholar] [CrossRef]
- Dieng, A.B.; Ruiz, F.J.R.; Blei, D.M. Topic Modeling in Embedding Spaces. arXiv 2019, arXiv:1907.04907. [Google Scholar] [CrossRef]
- Liu, D.; Deng, Z.; Zhang, W.; Wang, Y.; Kaisar, E.I. Design of sustainable urban electronic grocery distribution network. Alex. Eng. J. 2021, 60, 145–157. [Google Scholar] [CrossRef]
- Huang, H.; Zavareh, A.A.; Mustafa, M.B. Sentiment Analysis in E-Commerce Platforms: A Review of Current Techniques and Future Directions. IEEE Access 2023, 11, 90367–90382. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prompt |
|---|
| I have a topic described by the following keywords: [TOP WORDS] The following documents are associated with the topic: [DOCUMENTS] Using the information above, identify a suitable short label for the given topic. |
| Prompt |
|---|
| I am conducting sentiment analysis on customer reviews of [APPLICATION]. Instruction: Answer with only one word: “positive” or “negative”! <text>[DATA]</text> |
| Notation | Hyperparameter | Hyperparameter Space |
|---|---|---|
| Encoder Layer of BERT | {‘last_hidden’, ‘second_to_last’, ‘concat_last_four’} | |
| The data dimension (p) | ||
| The fuzzification constant of FCM (m) |
| Datasets | Metrics | FCM | K-Means | DBSCAN | HDBSCAN |
|---|---|---|---|---|---|
| AG News | Topic Coherence | 0.1924 ± 0 | 0.1912 ± 0.0006 | 0.1762 ± 0.0033 | 0.1841 ± 0.0022 |
| Topic Diversity | 0.95 ± 0 | 0.925 ± 0 | 0.95 ± 0 | 0.95 ± 0 | |
| Quality Score | 0.1828 ± 0 | 0.1738 ± 0.0015 | 0.1673 ± 0.0032 | 0.1749 ± 0.0021 | |
| R2 | Topic Coherence | 0.1796 ± 0 | 0.1882 ± 0 | 0.1862 ± 0.0024 | 0.1852 ± 0.0024 |
| Topic Diversity | 1 ± 0 | 1 ± 0 | 1 ± 0 | 1 ± 0 | |
| Quality Score | 0.1796 ± 0 | 0.1882 ± 0 | 0.1862 ± 0.0024 | 0.1852 ± 0.0024 | |
| Yahoo! Answers | Topic Coherence | 0.2419 ± 0.0046 | 0.2653 ± 0.0081 | 0.2450 ± 0.0024 | 0.2323 ± 0.009 |
| Topic Diversity | 0.694 ± 0.0089 | 0.878 ± 0.0075 | 0.844 ± 0.0049 | 0.946 ± 0.0156 | |
| Quality Score | 0.1678 ± 0.0010 | 0.2329 ± 0.0056 | 0.2068 ± 0.0021 | 0.2196 ± 0.0064 |
| Topic | Interpretation |
|---|---|
| Topic 1 | Affordability and packaging |
| Topic 2 | Delivery of fresh vegetables and fruits |
| Topic 3 | Experience and impressions of the service |
| Topic 4 | Quality of fresh products |
| Topic 5 | Satisfaction with shopping for fresh products |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wangsa, J.I.P.; Agung, Y.J.; Rahmi, S.R.; Murfi, H.; Hariadi, N.; Nurrohmah, S.; Satria, Y.; Za’in, C. Large Language Model-Based Topic-Level Sentiment Analysis for E-Grocery Consumer Reviews. Big Data Cogn. Comput. 2025, 9, 194. https://doi.org/10.3390/bdcc9080194
Wangsa JIP, Agung YJ, Rahmi SR, Murfi H, Hariadi N, Nurrohmah S, Satria Y, Za’in C. Large Language Model-Based Topic-Level Sentiment Analysis for E-Grocery Consumer Reviews. Big Data and Cognitive Computing. 2025; 9(8):194. https://doi.org/10.3390/bdcc9080194
Chicago/Turabian StyleWangsa, Julizar Isya Pandu, Yudhistira Jinawi Agung, Safira Raissa Rahmi, Hendri Murfi, Nora Hariadi, Siti Nurrohmah, Yudi Satria, and Choiru Za’in. 2025. "Large Language Model-Based Topic-Level Sentiment Analysis for E-Grocery Consumer Reviews" Big Data and Cognitive Computing 9, no. 8: 194. https://doi.org/10.3390/bdcc9080194
APA StyleWangsa, J. I. P., Agung, Y. J., Rahmi, S. R., Murfi, H., Hariadi, N., Nurrohmah, S., Satria, Y., & Za’in, C. (2025). Large Language Model-Based Topic-Level Sentiment Analysis for E-Grocery Consumer Reviews. Big Data and Cognitive Computing, 9(8), 194. https://doi.org/10.3390/bdcc9080194