
Survey on the Role of Mechanistic Interpretability in Generative AI


Abstract
1. Introduction
- Structuring knowledge composition Unravelling the composition of knowledge in model architectures by investigating the components that enable knowledge acquisition;
- Acquiring knowledge encoding Exploring the content of intermediate representations by discerning the acquired knowledge from the behavioural emergent patterns;
- Emergent abilities Understanding the mechanisms that lead togeneralisationn in the training process, outlining the boundary withinmemorisationn and the surrounding phenomena.
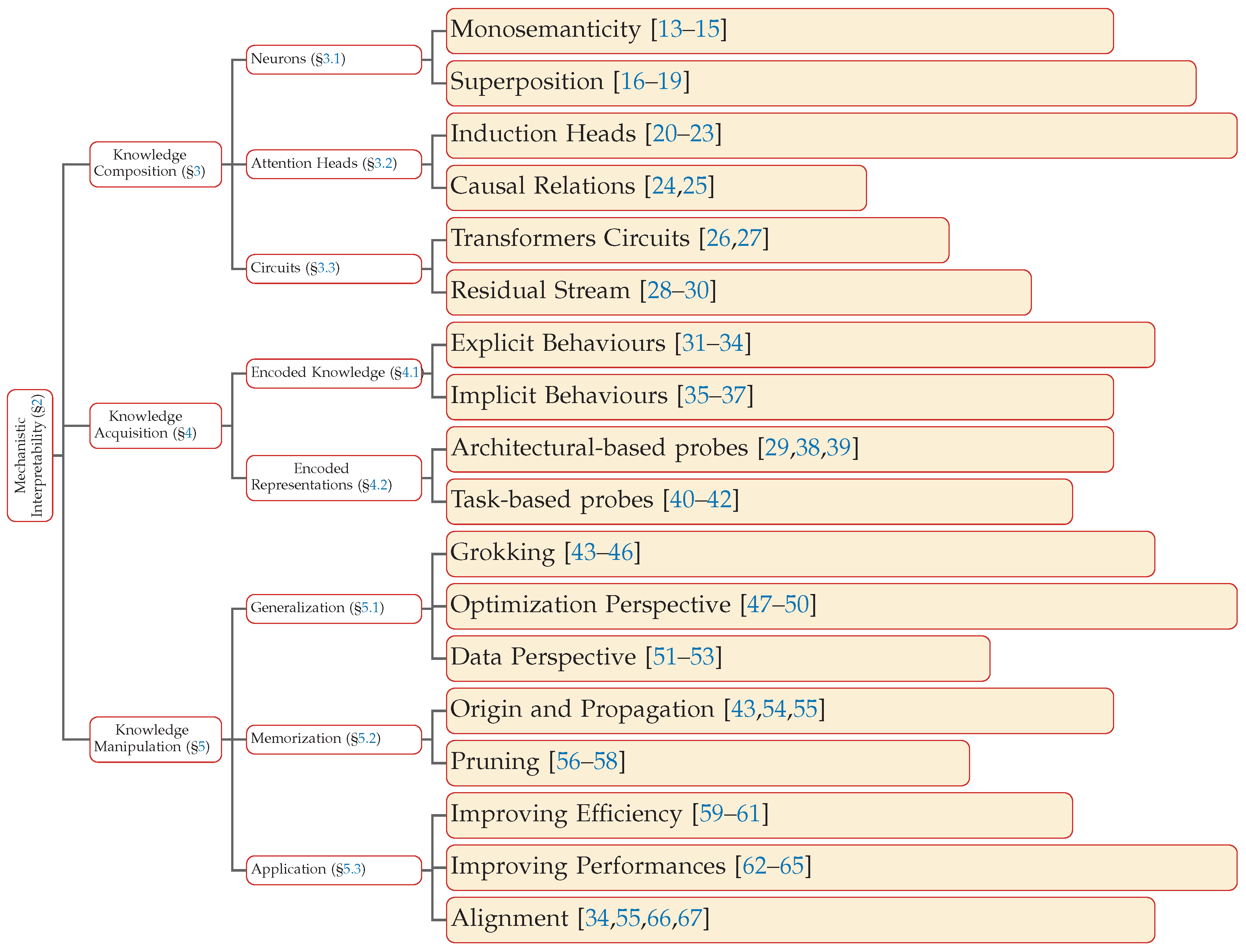
2. A New Paradigm: Mechanistic Interpretability
The Role of Mechanistic Interpretability
- Implementation Perspective: Mechanistic interpretability aims to decipher the complexities and mechanisms present in pre-trained models without needing to build models that can be explained explicitly by adapting to existing architectures [79].
- Vision Perspective: Mechanistic interpretability brings a global view as it aims to comprehend models as a whole through the lens of high-level concepts and circuits. In contrast, traditional explicability approaches focus on explaining specific predictions made by models, e.g., feature-attribution techniques, which have a limited view of the whole phenomenon [80].
- Operation Perspective: Mechanistic interpretability aligns with white-box analysis, as direct access to a model’s internal parameters and activations is required. In contrast to black-box explainability tools (e.g., LIME [81] and SHAP [82]), which operate solely based on model inputs and outputs, mechanistic interpretability operates on internal mechanisms by handling unique features.
3. The Knowledge Composition
3.1. Neurons
3.1.1. Monosematicity
3.1.2. Superposition
3.2. Attention Heads
3.3. Circuits
4. Acquiring Knowledge
4.1. The Seek of Knowledge
4.2. Role of Layer Depth and Model Scale
5. The Boundary Position: Generalization vs. Memorization
5.1. Generalization Beyond Memorization
5.1.1. Optimization Perspective
5.1.2. Data Perspective
5.2. Memorization
5.3. Application
5.4. Improving Efficiency
5.5. Improving Performances
5.6. Mechanistic Interpretability to Refine Models’ Capabilities
6. Final Discussion and Future Challenges
7. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
| Paper | Methods Covered/Categorization | Strengths | Weaknesses | Main Applications/Use Cases |
|---|---|---|---|---|
| [65] | Local/Global, Self-explaining/Post-hoc; Reviews feature importance, surrogate models, example-driven, provenance-based, declarative induction; Summarizes explainability and visualization techniques | Connects operations, visualization, and evaluation; Lists representative papers for each technique; Points out gaps and challenges | Focus is broad, not LLM-specific; Limited depth on transformer-based models; | Explanation of NLP model predictions; Resource for model developers; Trust-building in NLP systems |
| [69] | Organises XAI challenges and future directions; Thematic: General, Design, Development, Deployment; analyses multidisciplinary aspects and societal, regulatory, user needs | Systematic, multi-level challenge analysis; Addresses regulatory and human-centric perspectives; | Not specific to NLP or LLMs; Less focus on concrete methods; Little technical comparison of approaches | Identifying open research challenges; Guiding research agendas; Human-AI trust, regulatory compliance |
| [70] | Classifies LLM explainability: Local vs Global; Local: Feature attribution, perturbation, gradient-based, vector-based; Global: Probing, mechanistic interpretability, circuit discovery; | Focused on LLMs/transformers; Critical evaluation of strengths/limits for each method; Discusses evaluation metrics and datasets; Connects explainability to model enhancement (editing, alignment) | Some coverage is high-level; Ongoing field: not all methods are mature; Few real-world benchmarks for all techniques | LLM transparency; Model editing and control; Reducing hallucination, improving alignment |
| [12] | Reviews interpretability in neural NLP; Structural analysis (probing classifiers); | Explains main lines of analysis with examples; Discusses limitations and future directions; Covers both theory and hands-on tools | Lacks systematic empirical comparison; More pedagogical than evaluative; Pre-dates some LLM developments | Education for NLP/ML community; Foundation for newcomers; Understanding neural network behaviour in NLP |
| [78] | Structured taxonomy of mechanistic interpretability methods; Covers observational, interventional, intrinsic and developmental interpretability; Strong focus on MI for AI safety and alignment | Methods and safety motivations; Discusses challenges and future directions; Connects MI to societal/AI safety needs | Primarily focused on technical MI, less coverage of global/external XAI methods; Societal and regulatory implications are more briefly addressed; Open challenges remain in scalability and full automation | Mechanistic analysis of neural networks; Model transparency and AI safety; Reverse engineering model behaviour; |
References
- Marques, N.; Silva, R.R.; Bernardino, J. Using ChatGPT in Software Requirements Engineering: A Comprehensive Review. Future Internet 2024, 16, 180. [Google Scholar] [CrossRef]
- Ranaldi, L.; Pucci, G. Knowing Knowledge: Epistemological Study of Knowledge in Transformers. Appl. Sci. 2023, 13, 677. [Google Scholar] [CrossRef]
- Peng, J.; Zhong, K. Accelerating and Compressing Transformer-Based PLMs for Enhanced Comprehension of Computer Terminology. Future Internet 2024, 16, 385. [Google Scholar] [CrossRef]
- Ranaldi, L.; Fallucchi, F.; Zanzotto, F.M. Dis-Cover AI Minds to Preserve Human Knowledge. Future Internet 2022, 14, 10. [Google Scholar] [CrossRef]
- Gifu, D.; Silviu-Vasile, C. Artificial Intelligence vs. Human: Decoding Text Authenticity with Transformers. Future Internet 2025, 17, 38. [Google Scholar] [CrossRef]
- Li, J.; Maiti, A. Applying Large Language Model Analysis and Backend Web Services in Regulatory Technologies for Continuous Compliance Checks. Future Internet 2025, 17, 100. [Google Scholar] [CrossRef]
- Petrillo, L.; Martinelli, F.; Santone, A.; Mercaldo, F. Explainable Security Requirements Classification Through Transformer Models. Future Internet 2025, 17, 15. [Google Scholar] [CrossRef]
- Tenney, I.; Das, D.; Pavlick, E. BERT Rediscovers the Classical NLP Pipeline. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Korhonen, A., Traum, D., Màrquez, L., Eds.; pp. 4593–4601. [Google Scholar] [CrossRef]
- Lampinen, A.; Dasgupta, I.; Chan, S.; Mathewson, K.; Tessler, M.; Creswell, A.; McClelland, J.; Wang, J.; Hill, F. Can language models learn from explanations in context? In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2022, Abu Dhabi, United Arab Emirates, 7–11 December 2022; Goldberg, Y., Kozareva, Z., Zhang, Y., Eds.; pp. 537–563. [Google Scholar] [CrossRef]
- Aggrawal, S.; Magana, A.J. Teamwork Conflict Management Training and Conflict Resolution Practice via Large Language Models. Future Internet 2024, 16, 177. [Google Scholar] [CrossRef]
- Babaey, V.; Ravindran, A. GenSQLi: A Generative Artificial Intelligence Framework for Automatically Securing Web Application Firewalls Against Structured Query Language Injection Attacks. Future Internet 2025, 17, 8. [Google Scholar] [CrossRef]
- Belinkov, Y.; Gehrmann, S.; Pavlick, E. Interpretability and Analysis in Neural NLP. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: Tutorial Abstracts; Savary, A., Zhang, Y., Eds.; Association for Computational Linguistics: Kerrville, TX, USA, 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Golechha, S.; Dao, J. Position Paper: Toward New Frameworks for Studying Model Representations. arXiv 2024, arXiv:2402.03855. [Google Scholar] [CrossRef]
- Jermyn, A.S.; Schiefer, N.; Hubinger, E. Engineering monosemanticity in toy models. arXiv 2022, arXiv:2211.09169. [Google Scholar] [CrossRef]
- Bricken, T.; Templeton, A.; Batson, J.; Chen, B.; Jermyn, A.; Conerly, T.; Turner, N.; Anil, C.; Denison, C.; Askell, A.; et al. Towards Monosemanticity: Decomposing Language Models With Dictionary Learning. Transformer Circuits Thread. 2023. Available online: https://transformer-circuits.pub/2023/monosemantic-features/index.html (accessed on 1 January 2025).
- Elhage, N.; Hume, T.; Olsson, C.; Schiefer, N.; Henighan, T.; Kravec, S.; Hatfield-Dodds, Z.; Lasenby, R.; Drain, D.; Chen, C.; et al. Toy Models of Superposition. Transformer Circuits Thread. 2022. Available online: https://transformer-circuits.pub/2022/toy_model/index.html (accessed on 28 April 2024).
- Scherlis, A.; Sachan, K.; Jermyn, A.S.; Benton, J.; Shlegeris, B. Polysemanticity and capacity in neural networks. arXiv 2022, arXiv:2210.01892. [Google Scholar]
- Gurnee, W.; Nanda, N.; Pauly, M.; Harvey, K.; Troitskii, D.; Bertsimas, D. Finding Neurons in a Haystack: Case Studies with Sparse Probing. arXiv 2023, arXiv:2305.01610. [Google Scholar] [CrossRef]
- Lecomte, V.; Thaman, K.; Schaeffer, R.; Bashkansky, N.; Chow, T.; Koyejo, S. What Causes Polysemanticity? An Alternative Origin Story of Mixed Selectivity from Incidental Causes. In Proceedings of the ICLR 2024 Workshop on Representational Alignment, Vienna, Austria, 11 May 2024. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. arXiv 2020, arXiv:2005.14165. [Google Scholar] [CrossRef]
- Olsson, C.; Elhage, N.; Nanda, N.; Joseph, N.; DasSarma, N.; Henighan, T.; Mann, B.; Askell, A.; Bai, Y.; Chen, A.; et al. In-Context Learning and Induction Heads. Transformer Circuits Thread. 2022. Available online: https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html (accessed on 1 January 2025).
- Sakarvadia, M.; Khan, A.; Ajith, A.; Grzenda, D.; Hudson, N.; Bauer, A.; Chard, K.; Foster, I. Attention Lens: A Tool for Mechanistically Interpreting the Attention Head Information Retrieval Mechanism. arXiv 2023, arXiv:2310.16270. [Google Scholar] [CrossRef]
- Edelman, B.L.; Edelman, E.; Goel, S.; Malach, E.; Tsilivis, N. The Evolution of Statistical Induction Heads: In-Context Learning Markov Chains. arXiv 2024, arXiv:2402.11004. [Google Scholar] [CrossRef]
- Chan, L.; Garriga-Alonso, A.; Goldwosky-Dill, N.; Greenblatt, R.; Nitishinskaya, J.; Radhakrishnan, A.; Shlegeris, B.; Thomas, N. Causal Scrubbing, A Method for Rigorously Testing Interpretability Hypotheses. AI Alignment Forum. 2022. Available online: https://www.alignmentforum.org/posts/JvZhhzycHu2Yd57RN/causal-scrubbing-a-method-for-rigorously-testing (accessed on 1 January 2025).
- Neo, C.; Cohen, S.B.; Barez, F. Interpreting Context Look-ups in Transformers: Investigating Attention-MLP Interactions. arXiv 2024, arXiv:2402.15055. [Google Scholar] [CrossRef]
- Conmy, A.; Mavor-Parker, A.N.; Lynch, A.; Heimersheim, S.; Garriga-Alonso, A. Towards Automated Circuit Discovery for Mechanistic Interpretability. arXiv 2023, arXiv:2304.14997. [Google Scholar] [CrossRef]
- Elhage, N.; Nanda, N.; Olsson, C.; Henighan, T.; Joseph, N.; Mann, B.; Askell, A.; Bai, Y.; Chen, A.; Conerly, T.; et al. A Mathematical Framework for Transformer Circuits. Transformer Circuits Thread. 2021. Available online: https://transformer-circuits.pub/2021/framework/index.html (accessed on 1 January 2025).
- Yu, Z.; Ananiadou, S. Locating Factual Knowledge in Large Language Models: Exploring the Residual Stream and analysing Subvalues in Vocabulary Space. arXiv 2024, arXiv:2312.12141. [Google Scholar]
- Todd, E.; Li, M.L.; Sharma, A.S.; Mueller, A.; Wallace, B.C.; Bau, D. Function Vectors in Large Language Models. arXiv 2024, arXiv:2310.15213. [Google Scholar] [CrossRef]
- Shai, A.S.; Marzen, S.E.; Teixeira, L.; Oldenziel, A.G.; Riechers, P.M. Transformers represent belief state geometry in their residual stream. arXiv 2024, arXiv:2405.15943. [Google Scholar] [CrossRef]
- Meng, K.; Bau, D.; Andonian, A.; Belinkov, Y. Locating and Editing Factual Associations in GPT. Adv. Neural Inf. Process. Syst. 2022, 35, 17359–17372. [Google Scholar]
- Zou, A.; Phan, L.; Chen, S.; Campbell, J.; Guo, P.; Ren, R.; Pan, A.; Yin, X.; Mazeika, M.; Dombrowski, A.K.; et al. Representation Engineering: A Top-Down Approach to AI Transparency. arXiv 2023, arXiv:2310.01405. [Google Scholar] [CrossRef]
- Liu, W.; Wang, X.; Wu, M.; Li, T.; Lv, C.; Ling, Z.; Zhu, J.; Zhang, C.; Zheng, X.; Huang, X. Aligning large language models with human preferences through representation engineering. arXiv 2023, arXiv:2312.15997. [Google Scholar] [CrossRef]
- Lee, A.; Bai, X.; Pres, I.; Wattenberg, M.; Kummerfeld, J.K.; Mihalcea, R. A Mechanistic Understanding of Alignment Algorithms: A Case Study on DPO and Toxicity. arXiv 2024, arXiv:2401.01967. [Google Scholar] [CrossRef]
- Hazineh, D.S.; Zhang, Z.; Chiu, J. Linear Latent World Models in Simple Transformers: A Case Study on Othello-GPT. arXiv 2023, arXiv:2310.07582. [Google Scholar] [CrossRef]
- Marks, S.; Tegmark, M. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets. arXiv 2023, arXiv:2310.06824. [Google Scholar] [CrossRef]
- Burns, C.; Ye, H.; Klein, D.; Steinhardt, J. Discovering Latent Knowledge in Language Models Without Supervision. arXiv 2024, arXiv:2212.03827. [Google Scholar] [CrossRef]
- Li, K.; Hopkins, A.K.; Bau, D.; Viégas, F.; Pfister, H.; Wattenberg, M. Emergent world representations: Exploring a sequence model trained on a synthetic task. arXiv 2022, arXiv:2210.13382. [Google Scholar]
- Gurnee, W.; Tegmark, M. Language models represent space and time. arXiv 2023, arXiv:2310.02207. [Google Scholar]
- Ju, T.; Sun, W.; Du, W.; Yuan, X.; Ren, Z.; Liu, G. How Large Language Models Encode Context Knowledge? A Layer-Wise Probing Study. arXiv 2024, arXiv:2402.16061. [Google Scholar] [CrossRef]
- Wu, Z.; Arora, A.; Wang, Z.; Geiger, A.; Jurafsky, D.; Manning, C.D.; Potts, C. ReFT: Representation Finetuning for Language Models. arXiv 2024, arXiv:2404.03592. [Google Scholar] [CrossRef]
- Jin, M.; Yu, Q.; Huang, J.; Zeng, Q.; Wang, Z.; Hua, W.; Zhao, H.; Mei, K.; Meng, Y.; Ding, K.; et al. Exploring Concept Depth: How Large Language Models Acquire Knowledge at Different Layers? arXiv 2024, arXiv:2404.07066. [Google Scholar] [CrossRef]
- Nanda, N.; Chan, L.; Lieberum, T.; Smith, J.; Steinhardt, J. Progress measures for grokking via mechanistic interpretability. arXiv 2023, arXiv:2301.05217. [Google Scholar] [CrossRef]
- Power, A.; Burda, Y.; Edwards, H.; Babuschkin, I.; Misra, V. Grokking: Generalization beyond overfitting on small algorithmic datasets. arXiv 2022, arXiv:2201.02177. [Google Scholar] [CrossRef]
- Murty, S.; Sharma, P.; Andreas, J.; Manning, C.D. Grokking of Hierarchical Structure in Vanilla Transformers. arXiv 2023, arXiv:2305.18741. [Google Scholar] [CrossRef]
- Huang, Y.; Hu, S.; Han, X.; Liu, Z.; Sun, M. Unified View of Grokking, Double Descent and Emergent Abilities: A Perspective from Circuits Competition. arXiv 2024, arXiv:2402.15175. [Google Scholar] [CrossRef]
- Liu, Z.; Michaud, E.J.; Tegmark, M. Omnigrok: Grokking beyond algorithmic data. arXiv 2022, arXiv:2210.01117. [Google Scholar]
- Thilak, V.; Littwin, E.; Zhai, S.; Saremi, O.; Paiss, R.; Susskind, J.M. The Slingshot Effect: A Late-Stage Optimization Anomaly in Adaptive Gradient Methods. Transactions on Machine Learning Research. 2024. Available online: https://machinelearning.apple.com/research/slingshot-effect (accessed on 1 January 2025).
- Furuta, H.; Minegishi, G.; Iwasawa, Y.; Matsuo, Y. Interpreting Grokked Transformers in Complex Modular Arithmetic. arXiv 2024, arXiv:2402.16726. [Google Scholar] [CrossRef]
- Chen, S.; Sheen, H.; Wang, T.; Yang, Z. Training Dynamics of Multi-Head Softmax Attention for In-Context Learning: Emergence, Convergence, and Optimality. arXiv 2024, arXiv:2402.19442. [Google Scholar]
- Liu, Z.; Kitouni, O.; Nolte, N.S.; Michaud, E.; Tegmark, M.; Williams, M. Towards understanding grokking: An effective theory of representation learning. Adv. Neural Inf. Process. Syst. 2022, 35, 34651–34663. [Google Scholar]
- Zhu, X.; Fu, Y.; Zhou, B.; Lin, Z. Critical data size of language models from a grokking perspective. arXiv 2024, arXiv:2401.10463. [Google Scholar] [CrossRef]
- Wang, B.; Yue, X.; Su, Y.; Sun, H. Grokked Transformers are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization. arXiv 2024, arXiv:2405.15071. [Google Scholar] [CrossRef]
- Rajendran, G.; Buchholz, S.; Aragam, B.; Schölkopf, B.; Ravikumar, P. Learning Interpretable Concepts: Unifying Causal Representation Learning and Foundation Models. arXiv 2024, arXiv:2402.09236. [Google Scholar] [CrossRef]
- Tamkin, A.; Askell, A.; Lovitt, L.; Durmus, E.; Joseph, N.; Kravec, S.; Nguyen, K.; Kaplan, J.; Ganguli, D. Evaluating and mitigating discrimination in language model decisions. arXiv 2023, arXiv:2312.03689. [Google Scholar] [CrossRef]
- Doshi, D.; Das, A.; He, T.; Gromov, A. To grok or not to grok: Disentangling generalization and memorization on corrupted algorithmic datasets. arXiv 2023, arXiv:2310.13061. [Google Scholar]
- Kumar, T.; Bordelon, B.; Gershman, S.J.; Pehlevan, C. Grokking as the Transition from Lazy to Rich Training Dynamics. arXiv 2023, arXiv:2310.06110. [Google Scholar]
- Hase, P.; Bansal, M.; Kim, B.; Ghandeharioun, A. Does localization inform editing? surprising differences in causality-based localization vs. knowledge editing in language models. arXiv 2023, arXiv:2301.04213. [Google Scholar] [CrossRef]
- Stolfo, A.; Belinkov, Y.; Sachan, M. A mechanistic interpretation of arithmetic reasoning in language models using causal mediation analysis. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; pp. 7035–7052. [Google Scholar]
- Hou, Y.; Li, J.; Fei, Y.; Stolfo, A.; Zhou, W.; Zeng, G.; Bosselut, A.; Sachan, M. Towards a Mechanistic Interpretation of Multi-Step Reasoning Capabilities of Language Models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; Bouamor, H., Pino, J., Bali, K., Eds.; pp. 4902–4919. [Google Scholar] [CrossRef]
- Prakash, N.; Shaham, T.R.; Haklay, T.; Belinkov, Y.; Bau, D. Fine-Tuning Enhances Existing Mechanisms: A Case Study on Entity Tracking. arXiv 2024, arXiv:2402.14811. [Google Scholar] [CrossRef]
- Cohen, R.; Biran, E.; Yoran, O.; Globerson, A.; Geva, M. Evaluating the ripple effects of knowledge editing in language models. arXiv 2023, arXiv:2307.12976. [Google Scholar] [CrossRef]
- Xu, D.; Zhang, Z.; Zhu, Z.; Lin, Z.; Liu, Q.; Wu, X.; Xu, T.; Zhao, X.; Zheng, Y.; Chen, E. Editing Factual Knowledge and Explanatory Ability of Medical Large Language Models. arXiv 2024, arXiv:2402.18099. [Google Scholar] [CrossRef]
- Stoehr, N.; Gordon, M.; Zhang, C.; Lewis, O. Localizing Paragraph Memorization in Language Models. arXiv 2024, arXiv:2403.19851. [Google Scholar] [CrossRef]
- Sharma, A.S.; Atkinson, D.; Bau, D. Locating and Editing Factual Associations in Mamba. arXiv 2024, arXiv:2404.03646. [Google Scholar] [CrossRef]
- Yang, Y.; Duan, H.; Abbasi, A.; Lalor, J.P.; Tam, K.Y. Bias A-head? analysing Bias in Transformer-Based Language Model Attention Heads. arXiv 2023, arXiv:2311.10395. [Google Scholar]
- Jin, Z.; Cao, P.; Yuan, H.; Chen, Y.; Xu, J.; Li, H.; Jiang, X.; Liu, K.; Zhao, J. Cutting Off the Head Ends the Conflict: A Mechanism for Interpreting and Mitigating Knowledge Conflicts in Language Models. arXiv 2024, arXiv:2402.18154. [Google Scholar] [CrossRef]
- Danilevsky, M.; Qian, K.; Aharonov, R.; Katsis, Y.; Kawas, B.; Sen, P. A Survey of the State of Explainable AI for Natural Language Processing. In Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing, Suzhou, China, 4–7 December 2020; Wong, K.F., Knight, K., Wu, H., Eds.; pp. 447–459. [Google Scholar]
- Saeed, W.; Omlin, C. Explainable AI (XAI): A Systematic Meta-Survey of Current Challenges and Future Opportunities. arXiv 2021, arXiv:2111.06420. [Google Scholar] [CrossRef]
- Luo, H.; Specia, L. From Understanding to Utilization: A Survey on Explainability for Large Language Models. arXiv 2024, arXiv:2401.12874. [Google Scholar] [CrossRef]
- Ferrando, J.; Sarti, G.; Bisazza, A.; Costa-jussà, M.R. A Primer on the Inner Workings of Transformer-based Language Models. arXiv 2024, arXiv:2405.00208. [Google Scholar] [CrossRef]
- Papageorgiou, E.; Chronis, C.; Varlamis, I.; Himeur, Y. A Survey on the Use of Large Language Models (LLMs) in Fake News. Future Internet 2024, 16, 298. [Google Scholar] [CrossRef]
- Hang, C.N.; Yu, P.D.; Morabito, R.; Tan, C.W. Large Language Models Meet Next-Generation Networking Technologies: A Review. Future Internet 2024, 16, 365. [Google Scholar] [CrossRef]
- Krueger, D.S. Mechanistic Interpretability as Reverse Engineering (Follow-Up to “Cars and Elephants”) — AI Alignment Forum — alignmentforum.org. 2022. Available online: https://www.alignmentforum.org/posts/kjRGMdRxXb9c5bWq5/mechanistic-interpretability-as-reverse-engineering-follow (accessed on 28 April 2024).
- Olah, C.; Cammarata, N.; Schubert, L.; Goh, G.; Petrov, M.; Carter, S. Zoom In: An Introduction to Circuits. Distill. 2020. Available online: https://distill.pub/2020/circuits/zoom-in (accessed on 28 April 2024).
- Geva, M.; Caciularu, A.; Wang, K.; Goldberg, Y. Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; Goldberg, Y., Kozareva, Z., Zhang, Y., Eds.; pp. 30–45. [Google Scholar] [CrossRef]
- Hanna, M.; Liu, O.; Variengien, A. How does GPT-2 compute greater-than? Interpreting mathematical abilities in a pre-trained language model. arXiv 2023, arXiv:2305.00586. [Google Scholar]
- Bereska, L.; Gavves, E. Mechanistic Interpretability for AI Safety—A Review. arXiv 2024, arXiv:2404.14082. [Google Scholar]
- Friedman, D.; Wettig, A.; Chen, D. Learning Transformer Programs. arXiv 2023, arXiv:2306.01128. [Google Scholar] [CrossRef]
- Zimmermann, R.S.; Klein, T.; Brendel, W. Scale Alone Does not Improve Mechanistic Interpretability in Vision Models. arXiv 2024, arXiv:2307.05471. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. arXiv 2016, arXiv:1602.04938. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4768–4777. [Google Scholar]
- Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling Laws for Neural Language Models. arXiv 2020, arXiv:2001.08361. [Google Scholar] [CrossRef]
- Hoffmann, J.; Borgeaud, S.; Mensch, A.; Buchatskaya, E.; Cai, T.; Rutherford, E.; de Las Casas, D.; Hendricks, L.A.; Welbl, J.; Clark, A.; et al. Training Compute-Optimal Large Language Models. arXiv 2022, arXiv:2203.15556. [Google Scholar] [CrossRef]
- Das, A.; Rad, P. Opportunities and Challenges in Explainable Artificial Intelligence (XAI): A Survey. arXiv 2020, arXiv:2006.11371. [Google Scholar] [CrossRef]
- Xu, B.; Poo, M.m. Large language models and brain-inspired general intelligence. Natl. Sci. Rev. 2023, 10, nwad267. [Google Scholar] [CrossRef]
- Sharkey, L.; Braun, D.; beren. Interim Research Report Taking Features out of Superposition with Sparse Autoencoders. 2022. Available online: https://www.lesswrong.com/posts/z6QQJbtpkEAX3Aojj/interim-research-report-taking-features-out-of-superposition (accessed on 23 January 2024).
- McDougall, C.; Conmy, A.; Rushing, C.; McGrath, T.; Nanda, N. Copy suppression: Comprehensively understanding an attention head. arXiv 2023, arXiv:2310.04625. [Google Scholar] [CrossRef]
- Cammarata, N.; Goh, G.; Carter, S.; Schubert, L.; Petrov, M.; Olah, C. Curve Detectors. Distill. 2020. Available online: https://distill.pub/2020/circuits/curve-detectors (accessed on 28 April 2024).
- Schubert, L.; Voss, C.; Cammarata, N.; Goh, G.; Olah, C. High-Low Frequency Detectors. Distill. 2021. Available online: https://distill.pub/2020/circuits/frequency-edges (accessed on 28 April 2024).
- Olah, C.; Cammarata, N.; Voss, C.; Schubert, L.; Goh, G. Naturally Occurring Equivariance in Neural Networks. Distill. 2020. Available online: https://distill.pub/2020/circuits/equivariance (accessed on 28 April 2024).
- Nanda, N.; Lee, A.; Wattenberg, M. Emergent linear representations in world models of self-supervised sequence models. arXiv 2023, arXiv:2309.00941. [Google Scholar] [CrossRef]
- Li, M.; Davies, X.; Nadeau, M. Circuit Breaking: Removing Model behaviours with Targeted Ablation. arXiv 2024, arXiv:2309.05973. [Google Scholar]
- Li, K.; Patel, O.; Viégas, F.; Pfister, H.; Wattenberg, M. Inference-time intervention: Eliciting truthful answers from a language model. Adv. Neural Inf. Process. Syst. 2024, 36, 41451–41530. [Google Scholar]
- Azaria, A.; Mitchell, T. The internal state of an llm knows when its lying. arXiv 2023, arXiv:2304.13734. [Google Scholar] [CrossRef]
- CH-Wang, S.; Van Durme, B.; Eisner, J.; Kedzie, C. Do Androids Know They’re Only Dreaming of Electric Sheep? arXiv 2023, arXiv:2312.17249. [Google Scholar]
- Wei, J.; Tay, Y.; Bommasani, R.; Raffel, C.; Zoph, B.; Borgeaud, S.; Yogatama, D.; Bosma, M.; Zhou, D.; Metzler, D.; et al. Emergent Abilities of Large Language Models. arXiv 2022, arXiv:2206.07682. [Google Scholar] [CrossRef]
- Thilak, V.; Littwin, E.; Zhai, S.; Saremi, O.; Paiss, R.; Susskind, J.M. The Slingshot Mechanism: An Empirical Study of Adaptive Optimizers and the Grokking Phenomenon. In Proceedings of the Has it Trained Yet? NeurIPS 2022 Workshop, New Orleans, LA, USA, 2 December 2022. [Google Scholar]
- Bhaskar, A.; Friedman, D.; Chen, D. The Heuristic Core: Understanding Subnetwork Generalization in Pretrained Language Models. arXiv 2024, arXiv:2403.03942. [Google Scholar] [CrossRef]
- Bushnaq, L.; Mendel, J.; Heimersheim, S.; Braun, D.; Goldowsky-Dill, N.; Hänni, K.; Wu, C.; Hobbhahn, M. Using Degeneracy in the Loss Landscape for Mechanistic Interpretability. arXiv 2024, arXiv:2405.10927. [Google Scholar] [CrossRef]
- Golechha, S. Progress Measures for Grokking on Real-world Datasets. arXiv 2024, arXiv:2405.12755. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Lyu, K.; Jin, J.; Li, Z.; Du, S.S.; Lee, J.D.; Hu, W. Dichotomy of Early and Late Phase Implicit Biases Can Provably Induce Grokking. arXiv 2023, arXiv:2311.18817. [Google Scholar]
- Mohamadi, M.A.; Li, Z.; Wu, L.; Sutherland, D. Grokking modular arithmetic can be explained by margin maximization. In Proceedings of the NeurIPS 2023 Workshop on Mathematics of Modern Machine Learning, New Orleans, LA, USA, 16 December 2023. [Google Scholar]
- Merrill, W.; Tsilivis, N.; Shukla, A. A Tale of Two Circuits: Grokking as Competition of Sparse and Dense Subnetworks. arXiv 2023, arXiv:2303.11873. [Google Scholar] [CrossRef]
- Nakkiran, P.; Kaplun, G.; Bansal, Y.; Yang, T.; Barak, B.; Sutskever, I. Deep double descent: Where bigger models and more data hurt. J. Stat. Mech. Theory Exp. 2021, 2021, 124003. [Google Scholar] [CrossRef]
- Davies, X.; Langosco, L.; Krueger, D. Unifying Grokking and Double Descent. arXiv 2023, arXiv:2303.06173. [Google Scholar] [CrossRef]
- Chen, W.; Song, J.; Ren, P.; Subramanian, S.; Morozov, D.; Mahoney, M.W. Data-Efficient Operator Learning via Unsupervised Pretraining and In-Context Learning. arXiv 2024, arXiv:2402.15734. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Wu, M.; Liu, W.; Wang, X.; Li, T.; Lv, C.; Ling, Z.; Zhu, J.; Zhang, C.; Zheng, X.; Huang, X. Advancing Parameter Efficiency in Fine-tuning via Representation Editing. arXiv 2024, arXiv:2402.15179. [Google Scholar] [CrossRef]
- Held, W.; Yang, D. Shapley Head Pruning: Identifying and Removing Interference in Multilingual Transformers. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, Dubrovnik, Croatia, 2–6 May 2023; Vlachos, A., Augenstein, I., Eds.; pp. 2416–2427. [Google Scholar] [CrossRef]
- Jain, S.; Kirk, R.; Lubana, E.S.; Dick, R.P.; Tanaka, H.; Grefenstette, E.; Rocktäschel, T.; Krueger, D.S. Mechanistically analysing the effects of fine-tuning on procedurally defined tasks. arXiv 2023, arXiv:2311.12786. [Google Scholar]
- Turner, A.; Thiergart, L.; Udell, D.; Leech, G.; Mini, U.; MacDiarmid, M. Activation addition: Steering language models without optimization. arXiv 2023, arXiv:2308.10248. [Google Scholar] [CrossRef]
- Geiger, A.; Wu, Z.; Potts, C.; Icard, T.; Goodman, N. Finding alignments between interpretable causal variables and distributed neural representations. In Proceedings of the Causal Learning and Reasoning, PMLR, Los Angeles, CA, USA, 1–3 April 2024; pp. 160–187. [Google Scholar]
- Cao, N.D.; Aziz, W.; Titov, I. Editing Factual Knowledge in Language Models. arXiv 2021, arXiv:2104.08164. [Google Scholar] [CrossRef]
- Hernandez, E.; Li, B.Z.; Andreas, J. Inspecting and Editing Knowledge Representations in Language Models. arXiv 2023, arXiv:2304.00740. [Google Scholar] [CrossRef]
- Zhang, F.; Nanda, N. Towards Best Practices of Activation Patching in Language Models: Metrics and Methods. arXiv 2024, arXiv:2309.16042. [Google Scholar] [CrossRef]
- Campbell, J.; Ren, R.; Guo, P. Localizing Lying in Llama: Understanding Instructed Dishonesty on True-False Questions Through Prompting, Probing, and Patching. arXiv 2023, arXiv:2311.15131. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ranaldi, L. Survey on the Role of Mechanistic Interpretability in Generative AI. Big Data Cogn. Comput. 2025, 9, 193. https://doi.org/10.3390/bdcc9080193
Ranaldi L. Survey on the Role of Mechanistic Interpretability in Generative AI. Big Data and Cognitive Computing. 2025; 9(8):193. https://doi.org/10.3390/bdcc9080193
Chicago/Turabian StyleRanaldi, Leonardo. 2025. "Survey on the Role of Mechanistic Interpretability in Generative AI" Big Data and Cognitive Computing 9, no. 8: 193. https://doi.org/10.3390/bdcc9080193
APA StyleRanaldi, L. (2025). Survey on the Role of Mechanistic Interpretability in Generative AI. Big Data and Cognitive Computing, 9(8), 193. https://doi.org/10.3390/bdcc9080193