1. Introduction
Text-based person search (TPS) [
1,
2,
3,
4,
5,
6,
7,
8] has revolutionized cross-modal retrieval by enabling targeted individual identification from large-scale image databases through natural language queries. This technology holds transformative potential for public security and intelligent surveillance systems [
9,
10], in which precise person retrieval from textual descriptions is critical for real-world applications like suspect tracking and missing person identification.
The existing approaches primarily focus on two technical paradigms to bridge the visual–textual gap: (i) global-matching methods [
11,
12,
13], which extract holistic features via contrastive learning, and (ii) local-matching methods [
14,
15,
16,
17], which align textual entities to visual body regions for fine-grained matching. Recent advancements [
1,
18,
19,
20] further integrate pre-trained vision–language models, such as CLIP [
21], BLIP [
22], and ALBEF [
23], to enhance feature representation. However, these methods predominantly operate on limited-scale datasets (e.g., CUHK-PEDES [
2], ICFG-PEDES [
24], and RSTPReid [
25] with approximately 40,000 images), thus limiting their capacity to handle complex linguistic variations in real-world scenarios. Researchers in other fields also pay great attention to and utilize machine learning to solve this problem. For instance, entity alignment in multi-lingual, temporal, and probabilistic knowledge graphs has been explored in dynamic contexts, such as weather forecasting and medical diagnosis [
26], emphasizing the need for reasoning over uncertain and structurally complex information. Similarly, tweet prediction models in social media utilize machine learning to infer semantic and contextual nuances in short informal text sequences [
27].
In real-world surveillance and public safety scenarios, the accuracy of text-based person search directly influences the timeliness and reliability of identity verification tasks. Descriptions collected from eyewitnesses or field operators often contain ambiguous or redundant language, which significantly challenges the current retrieval systems. Specifically, two fundamental linguistic challenges remain under-addressed in the current TPS systems. First, the ambiguous attribute–noun association (AANA) problem arises from syntactic complexity in natural language. As illustrated in
Figure 1, the description “a yellow shirt, black and loose fitting pants” may erroneously associate “black” with “shirt” owing to parsing ambiguities, substantially reducing the retrieval accuracy. Although recent work [
1] attempts cross-modal alignment, it overlooks the structured linguistic analysis critical to addressing these challenges. Second, textual noise and relevance imbalance (TNRI) occurs when non-discriminative tokens (e.g., “wearing”) dominate text representations, obscuring critical visual attributes. Addressing issues such as attribute–noun ambiguity and irrelevant token interference is essential for improving the reliability of these systems in high-stakes environments like criminal investigations or emergency response.
To address these limitations, we propose the dependency-aware entity–attribute alignment network (DEAAN), a novel framework integrating grammatical analysis with adaptive feature selection. Our key innovations include the following:
Extensive experiments validate the effectiveness of the DEAAN across multiple TPS benchmarks. In particular, ablation studies demonstrate that our two key modules (DAIR and RATS) not only function effectively in isolation but also work synergistically to significantly improve performance. Our work advances TPS by integrating linguistic structural analysis with adaptive feature learning, setting new directions for robust text–visual alignment. In the next section, we review the related work on TPS and attention mechanisms incorporating syntactic information.
2. Related Work
In this section, we first discuss the general challenges in TPS, followed by an overview of global and local matching techniques, and then we explore methods incorporating syntactic information into attention mechanisms.
2.1. Text-Based Person Search
Text-based person search (TPS) is a novel and challenging task that aims to match a person image with a given natural language description [
2,
4,
18,
28,
29,
30,
31,
32,
33]. The existing TPS methods could be roughly classified into two groups according to their alignment levels, i.e., global-matching methods [
11,
25,
34] and local-matching methods [
16,
17,
35]. The former try to learn cross-modal embeddings in a common latent space by employing textual and visual backbones with a matching loss (e.g., CMPM/C loss [
12] and Triplet Ranking loss [
36]) for TPS. However, these methods mainly focus on global features while ignoring the fine-grained interactions between local features, which limits their performance improvement. To achieve fine-grained interactions, some of the latter methods explore explicit local alignments between body regions and textual entities for more refined alignments. However, these methods require more computational resources due to the complex local-level associations. Recently, inspired and benefited from vision–language pre-training models [
37], some methods [
1,
21,
38] expect to use the learned rich alignment knowledge of pre-trained models for local- or global alignments.
CLIP offers strong zero-shot alignment but lacks task-specific grounding; BLIP improves grounded generation via caption pre-training; ALBEF introduces momentum distillation for more stable multimodal learning. Although these methods achieve promising performance, they often fail to capture fine-grained attribute–entity relations, particularly when facing ambiguous or complex syntax structures.
Although TPS is primarily framed as a supervised task that leverages annotated image–text identity pairs, recent work [
39,
40] has shown the potential benefits of unsupervised learning as an auxiliary strategy. For instance, Sinaga and Yang [
40] proposed a globally collaborative multi-view k-means clustering method (G-CoMVKM) that balances local view-specific features with global alignment via entropy-regularized dimensionality reduction. Recent TPS works [
1,
18,
24,
41,
42,
43,
44] have followed this trend. They enhance robustness to noise, or adapt to unlabeled surveillance data. At the global and local scales, SSAN [
24] embeds visual features and text features into potential common spaces and brings similar graphic and text pairs closer to assist in its supervised learning. Another similar process is RASA [
18]. SRCF [
41] first performs unsupervised segmentation of text features and the foreground and background of visual features to achieve noise filtering and then conducts supervised learning on the obtained clean features. IRRA [
1] proposes Similarity Distribution Matching (SDM), which minimizes the KL divergence between image–text similarity score distributions and image–text matching distributions. It can effectively enlarge the variance between non-matching pairs and the correlation between matching pairs.
2.2. Attention Using Syntactic Information
An attention mechanism is crucial in the field of natural language processing, helping models to focus on key parts of input. However, a traditional attention mechanism [
45] often does not fully consider the syntactic structure of language, which can be a shortcoming in tasks requiring in-depth understanding of language relationships. Thus, researchers have explored a variety of ways to incorporate syntactic information into attention mechanisms. We divide these approaches into two main categories: syntactic-directed attention and syntactic-fused attention.
Those methods [
46,
47,
48,
49] based on syntactic-directed attention basically operate between features according to the dependency parsing tree of the sentence. Among them, SynGen [
47] aligns attention maps with syntactic bindings between entities and attributes to improve the faithfulness of text-to-image generation. Duan [
48] proposed a syntax-aware data augmentation strategy that adjusts word replacement probabilities based on syntactic roles, improving translation quality and structural coherence.
The syntactic-fused attention approach deeply imparts syntactic information into the process of attention calculation so that the model’s attention allocation is closely integrated with the syntactic structure. Specifically, such methods [
50,
51,
52,
53] encode information such as dependencies (or syntactic distances) into a dependency mask (or weight) matrix, which is then used as syntactic knowledge and fused with the attention map. Bugliarello [
50] integrated a parameter-free dependency-aware self-attention mechanism into the transformer architecture to enhance machine translation, especially in long or low-resource sentences. Li [
51] developed a syntax-aware local attention mechanism for BERT, allowing the model to focus more effectively on syntactically relevant words, thus improving sentence-level tasks.
In addition, we adopt the SpaCy [
54] parser. The SpaCy dependency parser is a widely used tool for syntactic analysis that parses input text into a dependency tree, where each node corresponds to a word and the directed edges represent grammatical relationships (e.g., subject–object and adjectival modifier). It provides a solid foundation for the DAIR module, allowing the DEAAN framework to resolve ambiguous attribute–noun associations by leveraging the syntactic structure of the sentence.
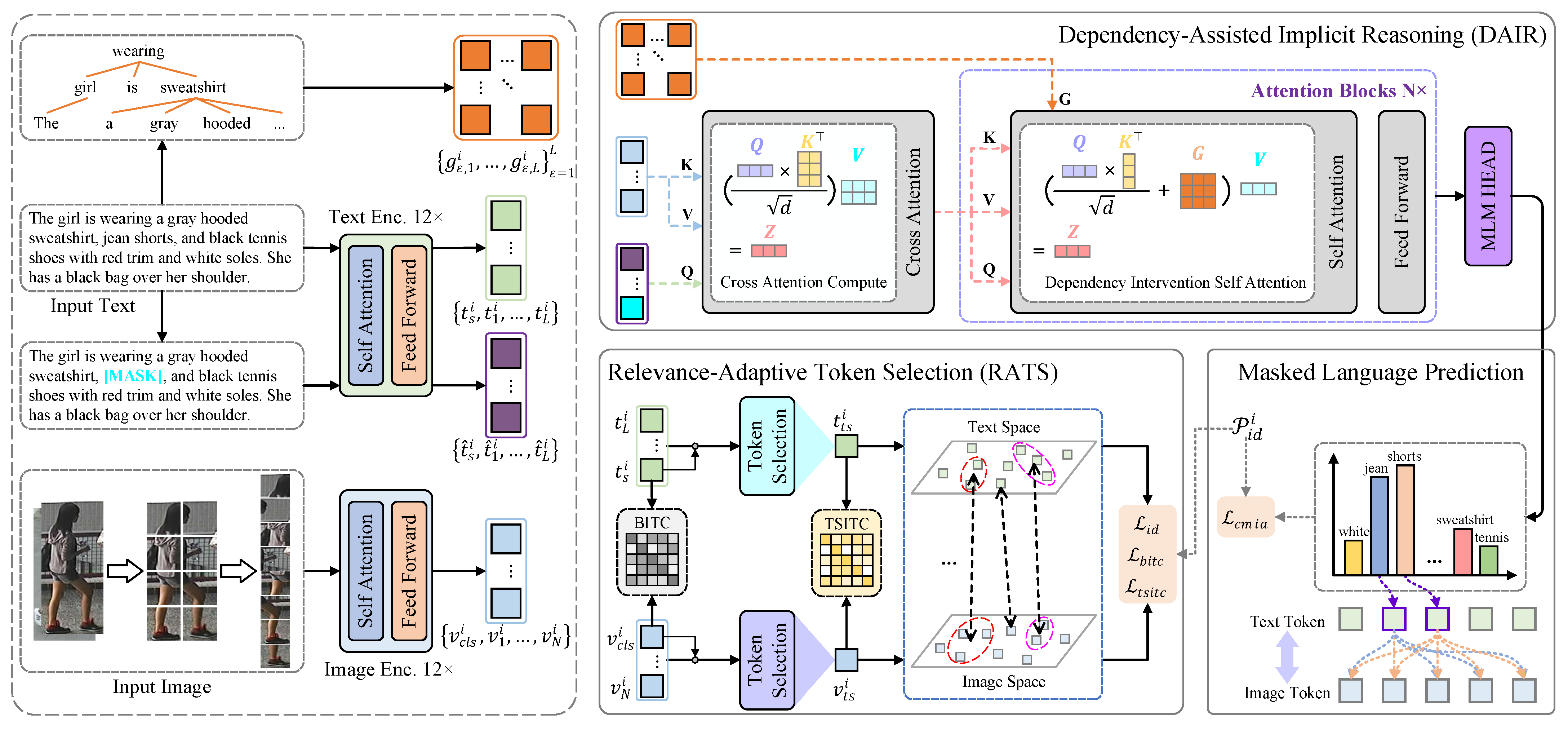
3. Methodology
In this section, we introduce the dependency-aware entity–attribute alignment network (DEAAN), illustrated in
Figure 2. The methodology is divided into three main components: (1) dual-stream feature extraction, (2) dependency-aware alignment, and (3) relevance-adaptive token selection.
3.1. Variable and Abbreviation Definitions
All variable and abbreviation definitions used in this section are summarized in
Table 1 and
Table 2 to avoid ambiguity and ensure a comprehensive understanding of the DEAAN framework.
3.2. Feature Extraction Encoder
Our framework adopts a dual-stream encoder to extract discriminative features from both visual and textual modalities, building upon the CLIP architecture.
Visual Feature Extraction. Given an input image
, the image encoder (IE) of CLIP based on a transformer architecture extracts an image feature. Specifically, the image is partitioned into
N fixed-size patches, each projected into a high-dimensional vector. These vectors are processed through multiple transformer layers to encode
N features as follows:
where
, as a class token, represents the global image representation.
Textual Feature Extraction. For an input text description
, we first tokenize it using Byte-Pair Encoding (BPE) [
55] with a vocabulary size of 49,152. The token sequence, added with two special tokens (i.e., start of sequence [SOS] and end of sequence [EOS]), is encoded by a transformer-based text encoder (TE) as follows:
where
and
are the features of [SOS] and [EOS] tokens, and
, as a class token, captures global textual semantics.
L is the number of the word-level local features.
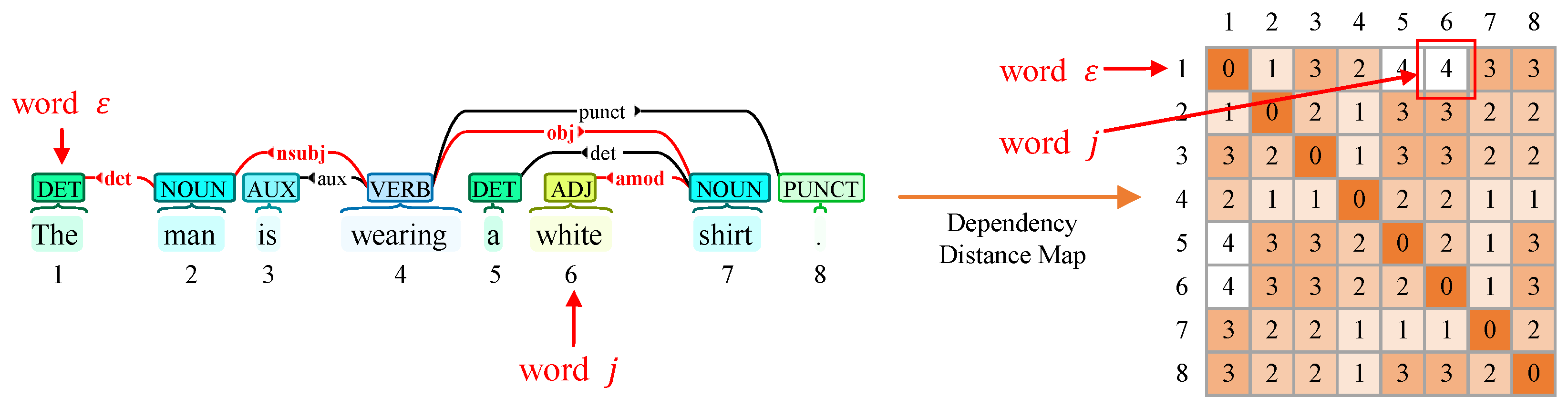
3.3. Dependency Mask Calculation
This subsection details our syntactic dependency integration strategy through four key steps:
Step 1: Dependency Tree Construction. Using SpaCy dependency parser, we first parse the input text into a syntactic dependency tree. Each node represents a word, with directed edges indicating grammatical relationships (e.g., nominal subject and adjectival modifier).
Step 2: Word-to-Word Dependency. Let
denote the dependency distance (i.e., the number of arrows) between each word and the word
in the dependency tree. We construct a dependency distance matrix
, where each element is as follows:
Step 3: Gaussian Mask Regularization. We transform discrete distances into continuous attention guidance through Gaussian smoothing:
where
controls spatial decay. The zero-centered Gaussian (
) prioritizes the word itself. As shown in
Figure 3, an example of the word
“The” and the word
j “white” is highlighted in red.
3.4. Dependency-Assisted Implicit Reasoning
This subsection outlines a novel module that enhances transformer-based models by integrating grammatical dependencies and visual context, detailing the dependency intervention self-attention mechanism and Masked Language Modeling with visual interaction.
3.4.1. Dependency Intervention Self-Attention
We propose a syntax-enhanced attention mechanism that injects grammatical dependencies into the transformer architecture. Given the standard self-attention formulation,
Dependency intervention self-attention (DISA) integrates the dependency mask
(from Equation (
4)) through additive intervention:
where
is a hyperparameter that controls the influence of the dependency information on the attention scores.
Q,
K, and
V are the query, key, and value matrices, respectively.
d is the dimension of the key vectors, serving as a scaling factor to stabilize the gradients.
3.4.2. Masked Language Modeling with Visual Context
We utilize MLM to predict masked textual tokens not only by the rest of unmasked textual tokens but also by the visual tokens. First, 15% of text tokens are randomly replaced with [MASK] [
1], defined as
The masked text sequence interacts with visual features via cross-modal attention. The output of the interaction is fed to a special transformer architecture, defined as
, whose self-attention mechanism is refined to our proposed
.
where
and
denote the layer-normalization and the multi-head cross-attention, respectively. For masked position
, we use a Multi-Layer Perception (MLP) classifier to predict corresponding probability with original tokens
. The implicit alignment loss combines language reconstruction with identity-aware balancing as follows:
where
denotes the index set of masked text tokens and
is the size of vocabulary
.
is the class weight for identity label; rare classes can be assigned higher weights in the statistical process.
3.5. Relevance-Adaptive Token Selection
This subsection introduces a RATS module that enhances image–text alignment by leveraging basic and token-selected contrastive learning, coupled with a novel relevance enhancement loss to capture fine-grained cross-modal correspondences.
3.5.1. Basic Image–Text Contrast
For any image–text pair
, we can directly use the global features of [CLS] and [SOS] tokens to compute similarity as basic image–text contrast (BITC) by the cosine similarity as follows:
However, optimizing the BITC similarities alone may not capture the fine-grained interactions between two modalities, which will limit performance improvement. To address this issue, in
Section 3.5.2, we exploit the local features of informative tokens to learn more discriminative embedding representations, thus mining the fine-grained correspondences.
3.5.2. Token-Selected Image–Text Contrast
Significant Token Selection. We select informative tokens based on the correlation between local tokens and class token [
4,
56]. Specifically, for image
and text
, the attention maps
and
are extracted from the last transformer block of image encoder and text encoder, respectively. Then, we select top-
tokens using first-row attention weights (class-to-local correlation) and record them as the set of indices
for the selected local tokens as follows:
where
controls selection ratio,
denotes round down, and
is the maximum input sequence length of
.
Cross-Modal Feature Aggregation. We perform an embedding transformation on these selected token features to obtain subtle representations. Specifically, taking image
as an example,
is obtained by selecting the local tokens of
according to the index set
. Then, transform selected tokens into compact representations by an embedding module like the residual block [
57].
where
is the max-pooling function;
is a linear layer. The same operation can be applied to
to obtain
. Finally, we compute the cosine similarity between
and
.
3.5.3. Relevance Enhancement Loss
By clustering in a shared semantic space, direct semantic interference between different identities can be avoided. Based on the ITC [
37] loss, we introduce a novel relevance enhancement (RE) loss to assist BITC and TSITC from a joint constraint.
For BITC, we define bidirectional contrastive objectives as
. The image-to-text loss formulated as
where
is the identity frequency weight, updated according to the identity label distribution of the current batch at each training step.
is mentioned in Equation (
9);
is the smoothing coefficient, which is set to 0.1.
is the count of samples, and
denotes the count of person identity
i in current batch. The calculation of text-to-image
is the same as Equation (
14):
For TSITC, given
and
,
can be obtained by the calculation procedure of Equations (
14) and (
16). The overall model loss
is formulated as a weighted sum of three key loss terms as follows:
where
is commonly utilized ID loss [
34].
,
, and
are hyperparameters that balance the contribution of each loss, and we empirically set them to 1, 0.5, and 0.5, respectively.
4. Experimental Setup and Evaluation
In this section, we describe the experimental setup, including the datasets used for evaluation, the experimental settings, and the evaluation metrics. We then present the results of our experiments to assess the performance of the proposed model.
4.1. Datasets
In the experiments, we use the CHUK-PEDES [
2], ICFGPEDES [
24], and RSTPReid [
25] datasets to evaluate our RDE. We split the datasets into training, validation, and test sets, wherein the ICFG-PEDES dataset only has training and validation sets. More details are provided in
Appendix A.5.
4.2. Experimental Settings
Evaluation Metrics. We utilize the popular Rank-k metrics () as our principal assessment measures. Rank-k reports the probability of finding at least one matching person image within the top-k candidate list when given a textual description as a query. To ensure a holistic appraisal, we additionally incorporate mean average precision (mAP) as supplementary criteria for evaluating retrieval efficacy. A superior Rank-k value, alongside elevated mAP scores, denote more proficient system performance.
Implementation Details. As mentioned earlier, we adopt the pre-trained model CLIP [
37] for our modality-specific encoders. The dependency-aware entity–attribute alignment network (DEAAN) method uses a pre-trained image encoder, i.e., CLIP-ViTB/16, a pre-trained text encoder, i.e., CILP text transformer, and a random-initialized multimodal interaction encoder applied to DAIR module. During training, we introduce data augmentations to increase the diversity of the training data. Specifically, we utilize random horizontal flipping, random crop with padding, and random erasing to augment the training images. For training texts, we employ random masking, replacement, and removal for the word tokens as the data augmentation. Moreover, the input size of images is
, and the maximum length of input word tokens is set to 77. We employ the Adam [
58] optimizer to train our model for 60 epochs with a cosine learning rate decay strategy. The initial learning rate is
for the original model parameters of CLIP, and the initial one for the network parameters of DAIR is initialized to
. The batch size is 64. We adopt an early training process with a gradually increasing learning rate. More detailed implementation settings can be found in
Appendix A.
4.3. Comparison with State-of-the-Art Methods
Table 3 presents a comprehensive comparison of the proposed model with state-of-the-art methods using Rank-1 (R@1), Rank-5 (R@5), and Rank-10 (R@10) metrics on three widely recognized datasets: CUHK-PEDES, ICFG-PEDES, and RSTPReid.
Performance Comparisons on CUHK-PEDES. We evaluate DEAAN on the widely used CUHK-PEDES benchmark. As detailed in performance metrics, DEAAN achieves a Rank-1 accuracy of 76.71%, surpassing the previous state-of-the-art method, RDE, which records 75.94%—a notable improvement of +0.77%. In terms of mAP, DEAAN reaches 69.07%, outperforming IRRA at 66.13%, TBPS-CILP at 65.38%, and RDE at 67.56% by 2.94%, 3.69%, and 1.51%, respectively. Higher-rank metrics further highlight DEAAN’s strength, with Rank-5 and Rank-10 accuracies of 90.37% and 94.56%, compared to RDE at 90.14% and 94.12%. This consistent outperformance across all metrics emphasizes DEAAN’s enhanced retrieval precision and robustness on this dataset. The growing reliance on transformer-based backbones for TPS remains evident, underscoring the demand for powerful feature extraction in achieving these gains.
Performance Comparisons on ICFG-PEDES. Results on the ICFG-PEDES dataset showcase DEAAN’s competitive performance. It achieves a Rank-1 accuracy of 67.73%, slightly ahead of RDE at 67.68% by +0.05%, and an mAP of 41.42%, improving over RDE at 40.06% by +1.36%. These results affirm DEAAN’s leading position, even on a dataset with greater scope and complexity, although modest improvements suggest room for further optimization in challenging retrieval scenarios.
Performance Comparisons on RSTPReid. On the newer RSTPReid dataset, DEAAN demonstrates competitive performance against state-of-the-art methods. These results highlight DEAAN’s strengths in broader retrieval (Rank-5 and Rank-10) and overall ranking quality (mAP) relative to prior methods, although it narrowly lags behind RDE in top-1 precision and mAP. This mixed performance underscores DEAAN’s adaptability across diverse camera perspectives and identities, positioning it as a robust yet balanced solution for complex retrieval tasks on RSTPReid.
Performance Comparisons on Different Text Backbones. On CUHK-PEDES, BiLSTM and RAN achieve Rank-1 of 63.27% and 67.13%, respectively, which are significantly lower than DEAAN (76.71%). Similar trends are observed on ICFG-PEDES and RSTPReid, confirming DEAAN’s consistent superiority over both non-transformer and transformer baselines.
4.4. Ablation Study
To fully demonstrate the impact of different components in DEAAN, we conducted a comprehensive empirical analysis on two public datasets (i.e., CUHK-PEDES and ICFG-PEDES). The Rank-1, Rank-5, and Rank-10 accuracies (%) are reported in
Table 4. The baseline (No. 0) builds on CLIP with Masked Language Modeling (MLM).
DAIR learns relations between attributes and nouns through dependency intervening, which can be easily integrated with other transformer-based methods to facilitate fine-grained attribute–noun correspondence. The efficacy of DAIR is revealed via the experimental results of No. 0 vs. No. 1, No. 2 vs. No. 5, No. 3 vs. No. 6, and No. 4 vs. No. 7. Merely adding the DAIR to baseline improves the Rank-1 accuracy by 2.54% and 1.98% on CUHK-PEDES and ICFG-PEDES datasets, respectively.
To demonstrate the effectiveness of our proposed RATS module, we compare it with the baseline on two public datasets. First, basic image–text contrast (BITC) greatly improves the retrieval accuracy (No. 0 vs. No. 2 and No. 1 vs. No. 5). After local token selecting through token-selected image–text contrast (TSITC), the retrieval accuracy is further improved (No. 2 vs. No. 4). It can also be noted that the improvement in BITC is small compared to TSITC (No. 2 vs. No. 3). This shows that there is some noise information interference in BITC image–text matching, which affects the retrieval.
4.5. Parametric Analysis
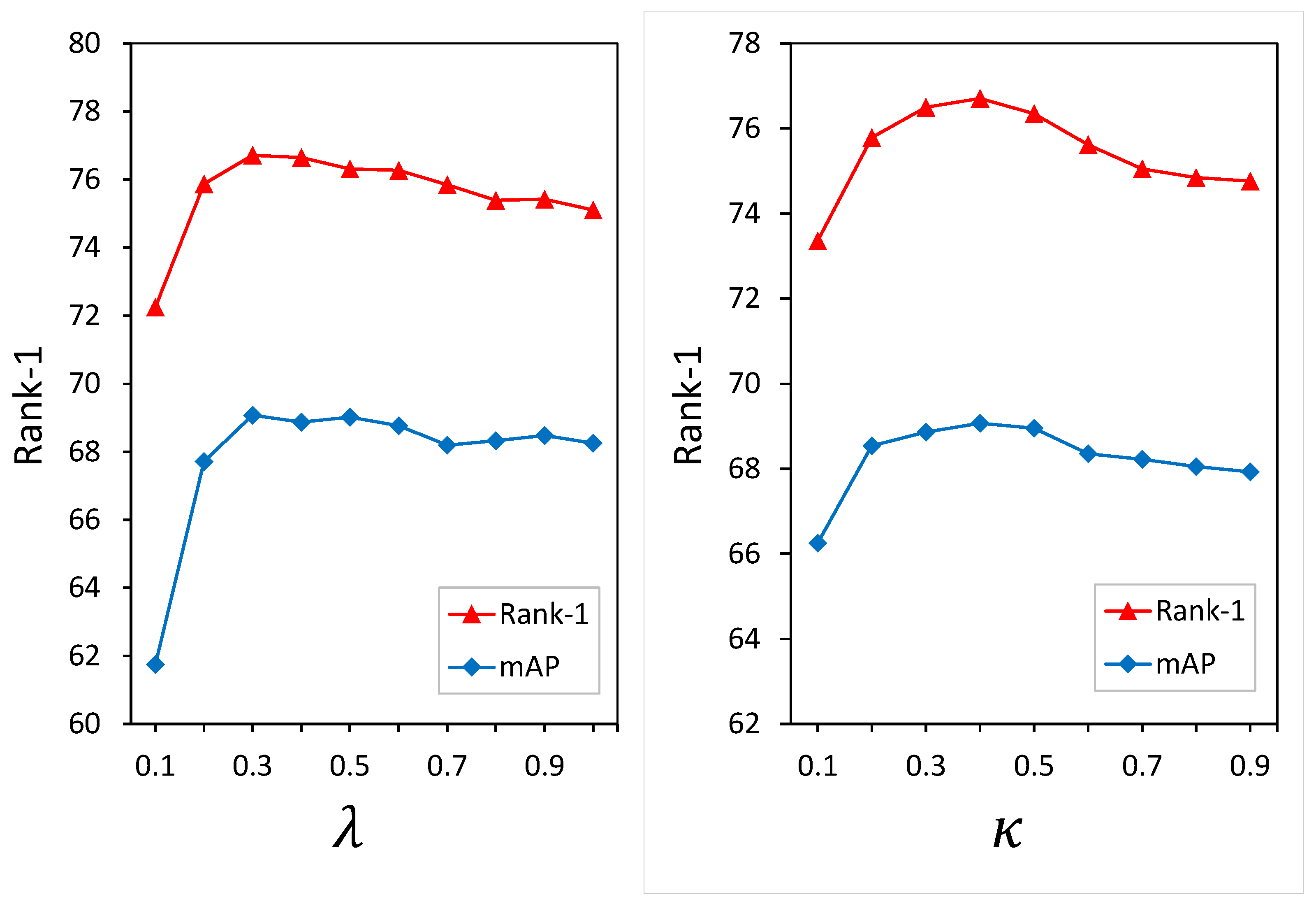
To study the impact of different hyperparameter settings on performance, we perform sensitivity analyses for key hyperparameters on the CHUK-PEDES, ICFG-PEDES, and RSTPReid datasets. The key parameters analyzed include the hyperparameter in the dependency intervention self-attention (DISA) mechanism and the selection ratio in the RATS module.
Hyperparameter (from Equation (6)) Analysis. The hyperparameter
controls the influence of syntactic dependency information in DISA. As shown in
Table 5 and
Figure 4, performance peaks at
, achieving the highest Rank-1 accuracy of 76.71% on CUHK-PEDES. Smaller values (e.g.,
) underutilize syntactic cues, while larger values (e.g.,
) overly bias the attention mechanism, suppressing critical semantic information. These results indicate that moderate integration of dependency structure yields the best balance for disambiguating attribute–noun associations.
Hyperparameter (from Equation (11)) Analysis. In the RATS module,
determines the proportion of top informative tokens selected for fine-grained alignment. As shown in
Table 6 and
Figure 4, Rank-1 accuracy peaks at 76.71% when
, with both smaller and larger values leading to degraded performance. A low
risks missing key features, while a high
introduces noise. Thus,
offers an optimal trade-off between token saliency and noise suppression.
Similarly, we conducted parameter experiments with and on the ICFG-PEDES and RSTPReid datasets. The results show that still, when and , DEAAN reaches the optimum. This indicates that and are not dataset-sensitive.
4.6. Qualitative Results
This subsection presents a qualitative analysis of DEAAN’s performance, focusing on retrieval results and visual attention comparisons against the baseline, highlighting the effectiveness of the DAIR and RATS modules in improving retrieval accuracy and semantic understanding across complex language structures and visual attributes.
4.6.1. Retrieval Result Analysis
Figure 5 compares the top-10 retrieval results from the baseline (from
Table 4) and our proposed DEAAN. As the figure shows, DEAAN achieves much more accurate retrieval results and obtains accurate retrieval results when baseline fails to retrieve them. In the case of text query with more complex language structure, our method can still maintain good retrieval results. This is mainly due to the robustness of the dependency-assisted implicit reasoning (DAIR) module in analyzing complex language structures.
In addition, we have observed that DEAAN retrieval results often have critical information. This shows that the retention of local token selectivity in the relevance-adaptive token selection (RATS) module ensures that the search space is biased towards the correct match of the positive sample. These components together contribute to superior performance in Rank-k and mAP, demonstrating the model’s ability to handle both positive and negative samples effectively.
4.6.2. Visual Analysis
In
Figure 6, several visual comparisons between the baseline (from
Table 4) and DEAAN are presented. Specifically, Grad-CAM algorithm [
62] was employed to extract attention maps from the cross-attention, each corresponding to the attention of a single word in the whole person image. In the figure, some attribute chunks were chosen to highlight the effect of the dependency structures.
It can be intuitively observed from the figure that baseline’s understanding of multiple attribute–noun combinations in the text (such as “blue pants”, “brown boots”, etc.) has obvious ambiguity and positioning bias. Its heat map shows that it is difficult to accurately focus on a specific visual area in the description text.
In DEAAN, dependency structure (DAIR module) is used to clearly distinguish and accurately locate the target region corresponding to each attribute. This fine-grained semantic understanding and visual attention not only improve the accuracy of the model’s feature capture but also significantly enhance the robustness of the model’s description of complex languages.
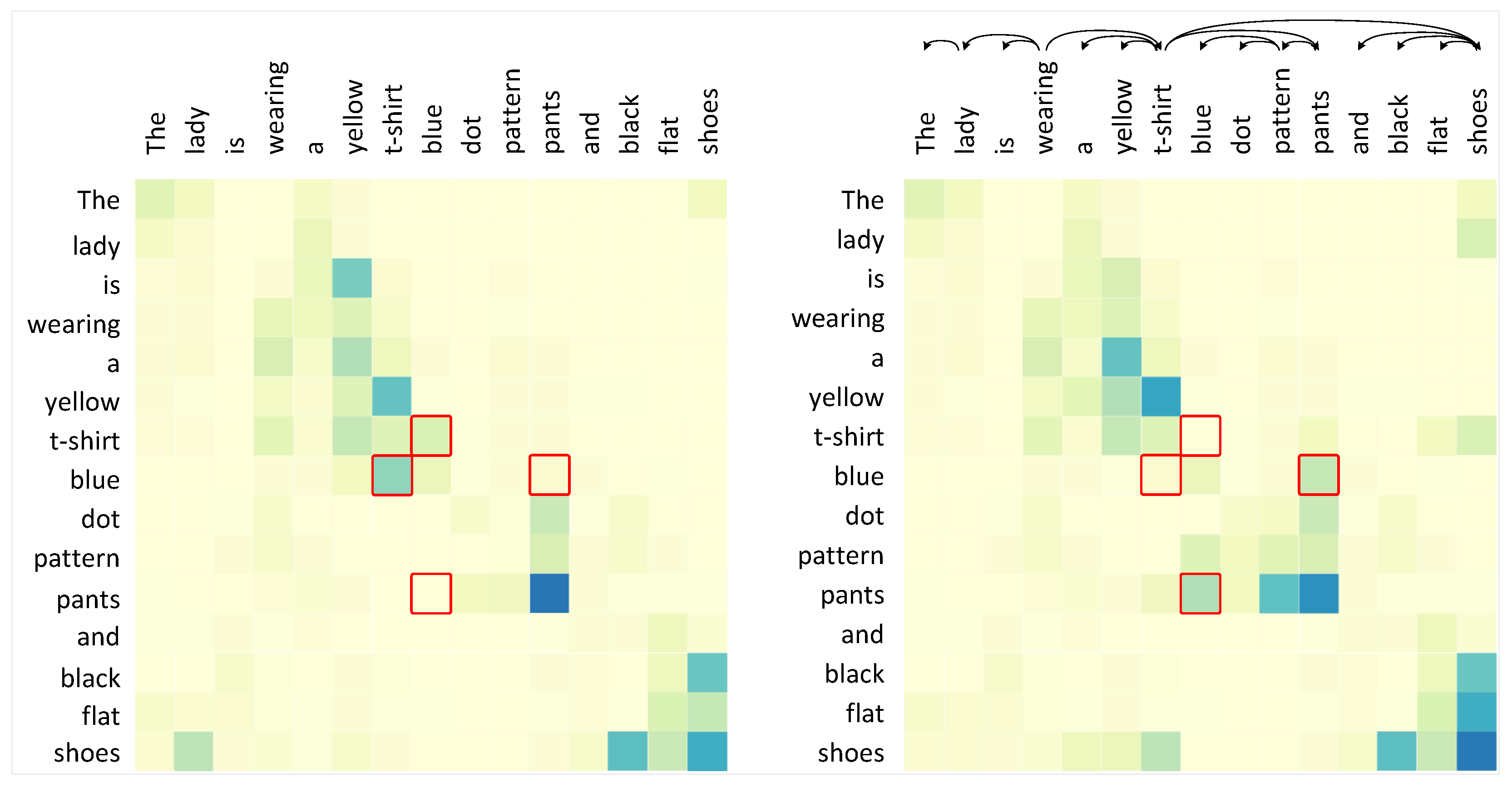
In
Figure 7, we compare the syntax attention and the ordinary attention using a heat-map of attention scores. The heatmap excludes punctuation, [CLS] and [SEP] tokens to establish a clearer correlation among the other tokens. We observe that the DISA exhibits the capacity to correctly recognize associations between attributes and nouns. For example, after incorporating syntactic information, attention scores between “t-shirt” and “blue” change from high to low, and attention scores between “pants” and “blue” change from low to high. This finding provides a compelling explanation for the effectiveness of DISA.
5. Conclusions
In this study, we introduced the dependency-aware entity–attribute alignment network (DEAAN), a novel framework tackling ambiguous attribute–noun association (AANA) and textual noise and relevance imbalance (TNRI) in text-based person search (TPS). By integrating dependency-assisted implicit reasoning (DAIR) and relevance-adaptive token selection (RATS), the DEAAN combines syntactic parsing with adaptive token filtering to enhance text–visual alignment, achieving state-of-the-art performance. The DEAAN bridges structured linguistic analysis with adaptive feature selection, advancing robust cross-modal retrieval. Its core, DAIR, which resolves attribute–noun ambiguities, and RATS, which suppresses noise, work synergistically to improve alignment precision.
Extensive experiments demonstrate that the DEAAN achieves state-of-the-art results, notably reaching 76.71% Rank-1 and 69.07% mAP on CUHK-PEDES, outperforming the previous best by +0.77% and +1.51%, respectively. The DEAAN also maintains superior performance on ICFG-PEDES and RSTPReid, validating its generalization across diverse datasets. These results confirm that integrating syntactic dependency parsing with adaptive token filtering significantly enhances text–visual alignment accuracy in TPS. Overall, this sets a new direction for TPS, offering a framework that is adaptable to broader cross-modal tasks.
We summarize the key advantages of the DEAAN: (1) the DAIR module significantly improves attribute–noun association in ambiguous expressions through dependency-enhanced attention, and (2) the RATS module enables discriminative token selection, enhancing local visual–textual alignment while suppressing noise. Nonetheless, the DEAAN also has limitations. Its reliance on syntactic parsers may introduce errors, especially in noisy or colloquial texts. Additionally, the marginal performance gains on ICFG-PEDES indicate room for improvement in diverse-data scenarios.
In future work, we will include a detailed discussion of the DEAAN’s theoretical scalability, highlighting its modular design, CLIP’s generalization, and optimization strategies (e.g., lightweight parsers and distributed training). We will also consider parser-agnostic modeling and robustness enhancements under real-world surveillance inputs. Furthermore, ensemble learning approaches have demonstrated success in customer churn prediction by modeling user behavior under high-dimensional sparse features [
63], providing methodological inspiration for future extensions of the DEAAN in real-world retrieval or recommendation systems.
Author Contributions
Conceptualization, W.X. and X.Y.; formal analysis, W.X.; funding acquisition, X.Y.; investigation, W.X.; methodology, W.X.; project administration, X.Y.; resources, W.G.; software, W.G.; supervision, X.Y.; validation, W.G.; visualization, W.G.; writing—original draft, W.X. and X.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Natural Science Foundation of Hunan Province (Grants 2025JJ70028, 2025JJ81178, and 2024JJ9550) and the Scientific Research Project of Education Department of Hunan Province (Grant No. 24A0401).
Data Availability Statement
Acknowledgments
We are grateful to the Bioinformatics Center, Furong Laboratory and Bioinformatics Center, Xiangya Hospital, Central South University for partial support of this work.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Reproducibility
To ensure reproducibility of our proposed dependency-aware entity–attribute alignment network (DEAAN), we provide the full methodology and training configurations used in our experiments.
Appendix A.1. Platform Settings
Hardware Information:
- -
CPU: AMD Ryzen 5 5700X;
- -
RAM: 64GB;
- -
Storage: 2TB;
- -
GPU: Nvidia V100 32 GB.
Software Information:
- -
OS: Ubuntu 20.04.5 LTS;
- -
Architecture: Pytorch v1.9.0 + torchvision v0.10.0 + Mindspore v2.2.1.
Appendix A.2. Environment Settings
Backbone Models:
- -
Image encoder: CLIP-ViT/B-16 (pre-trained);
- -
Text encoder: CLIP text transformer (pre-trained);
- -
DAIR module: randomly initialized.
Dependency Parser:
- -
SpaCy v3.6.1 with en_core_web_sm model;
- -
Dependency tree pruning: not applied (full tree used).
Optimization:
- -
- -
Initial learning rate: (CLIP), (DAIR);
- -
Scheduler: cosine annealing with warm-up (first 5 epochs).
Training Settings:
- -
Batch size: 64;
- -
Epochs: 60;
- -
Image size: ;
- -
Max token length: 77 (BPE tokens);
- -
Random seed: 42 (torch, numpy, random).
Appendix A.3. Data Augmentation
For image augmentation, we randomly apply three mutually independent operations:
- -
Random horizontal flip ();
- -
Random crop with 4-pixel padding ();
- -
Random erasing (, area ratio ).
For text augmentation, we randomly apply three token-level operations:
- -
Token masking with a probability of 15%, following BERT-style [MASK] replacement;
- -
Token removal (randomly drops 10% of tokens);
- -
Token replacement (replaces 10% of tokens with synonyms or noise).
Appendix A.4. Model-Specific Hyperparameters
Appendix A.5. Dataset Configuration
The datasets used are introduced in detail here.
CUHK-PEDES contains 40,206 images of 13,003 distinct identities, with 80,412 textual annotations. However, as the dataset is relatively clean and controlled, it may not fully capture the complexities of real-world surveillance scenarios with noisy text.
ICFG-PEDES expands upon CUHK-PEDES and consists of 54,522 images and 4102 identities from MSMT17 [
64]. We acknowledge that this dataset offers a broader variety, but, as with CUHK-PEDES, it may not represent the full spectrum of noise found in real-world surveillance.
RSTPReid contains 20,505 images across 4101 identities, with each identity captured from five different camera perspectives. This dataset is particularly useful for evaluating the robustness of models in dealing with variations in camera perspectives, but, like the previous datasets, it remains relatively clean and may not reflect the noise encountered in natural-world applications.
The data partitioning is shown in
Table A1. All experiments are repeated 5 times with different seeds to compute statistical significance.
Table A1.
Data partitioning of CUHK-PEDES, ICFG-PEDES, and RSTPReid.
Table A1.
Data partitioning of CUHK-PEDES, ICFG-PEDES, and RSTPReid.
| Set | CUHK-PEDES | ICFG-PEDES | RSTPReid |
|---|
|
Train
|
Validation
|
Test
|
Train
|
Test
|
Train
|
Validation
|
Test
|
|---|
| Number of id | 11,003 | 1000 | 1000 | 3102 | 1000 | 3701 | 200 | 200 |
| Number of image | 34,054 | 3078 | 3074 | 34,674 | 19,848 | 18,505 | 1000 | 1000 |
| Number of text | 68,108 | 6156 | 6148 | 34,674 | 19,848 | 37,010 | 2000 | 2000 |
Appendix A.6. Evaluation Protocol
Metrics: Rank-1, Rank-5, Rank-10, and mean average precision (mAP).
Significance Test: Paired t-tests used to validate improvements over baseline methods.
Appendix B. Extended Experiments
Appendix B.1. Statistics Significance Tests
Regarding state-of-the-art performance about DEAAN reported by
Table 3, we further perform a 5-run repeated evaluation and paired
t-tests to confirm the statistical significance of the reported Rank-1 gains, which are significant with
p < 0.05. Detailed results are summarized in
Table A2.
Table A2.
Statistics significance tests of state-of-the-art performance.
Table A2.
Statistics significance tests of state-of-the-art performance.
| Datasets | R@1 | R@5 | R@10 | mAP |
|---|
| CUHK-PEDES | 76.50 ± 0.24 | 90.27 ± 0.17 | 94.45 ± 0.12 | 68.97 ± 0.13 |
| ICFG-PEDES | 67.59 ± 0.16 | 82.07 ± 0.12 | 86.54 ± 0.09 | 41.37 ± 0.09 |
| RSTPReid | 64.97 ± 0.17 | 84.31 ± 0.15 | 90.26 ± 0.10 | 50.43 ± 0.12 |
Appendix B.2. Model Size and Retrieval Efficiency
Our DEAAN model achieves a favorable balance between accuracy and efficiency. As shown in
Table A3, although its parameter size (164.85 M) is moderate compared to methods such as TIPCB (184.75 M) and NAFS (188.75 M), DEAAN significantly outperforms them in Rank-1 accuracy (+13.08% over ViTAA and +13.35% over NAFS). Furthermore, its inference time (41.94 ms) remains acceptable for real-time or near-real-time applications, showing a good trade-off between performance and computational cost.
Table A3.
Comparisons of model size and retrieval efficiency. Retrieval time is computed by retrieving all text queries (6156) through the whole image gallery (3074) of CUHK-PEDES test set.
Table A3.
Comparisons of model size and retrieval efficiency. Retrieval time is computed by retrieving all text queries (6156) through the whole image gallery (3074) of CUHK-PEDES test set.
| Methods | Param (M) | Times (ms) | GPU | R@1 (%) |
|---|
| ViTAA [65] | 176.53 | 22.96 | 1x V100 | 54.92 |
| NAFS [35] | 188.75 | 74.62 | - | 59.36 |
| TIPCB [59] | 184.75 | 200.97 | 1x V100 | 63.63 |
| TextReID [38] | 60.20 | 24.53 | 1x V100 | 64.08 |
| DEAAN (Ours) | 164.85 | 41.94 | 1x V100 | 76.71 |
Appendix B.3. Computational Overhead Analysis
To evaluate the computational overhead of the proposed modules, we report the runtime (ms) and GPU memory usage (GB) on the CUHK-PEDES dataset using a single Nvidia V100 GPU 32 GB.
These results in
Table A4 show that DAIR introduces a minimal increase of 6.47 ms and 0.63 GB memory, while RATS adds 4.85 ms and 0.38 GB. The full DEAAN framework increases total runtime by 14.72 ms per sample and memory by 0.76 GB over the baseline. We believe this moderate overhead is acceptable given the significant performance gains.
Table A4.
Analysis of computational overhead introduced by the DAIR and RATS modules. Retrieval time is computed by retrieving all text queries (6156) through the whole image gallery (3074) of CUHK-PEDES test set.
Table A4.
Analysis of computational overhead introduced by the DAIR and RATS modules. Retrieval time is computed by retrieving all text queries (6156) through the whole image gallery (3074) of CUHK-PEDES test set.
| Methods | Time (ms) | Memory (GB) |
|---|
| Baseline (CLIP + MLM) | 27.22 | 3.20 |
| + DAIR | 33.69 | 3.83 |
| + RATS | 32.07 | 3.58 |
| DEAAN (DAIR + RATS) | 41.94 | 3.96 |
Appendix B.4. Backbones and Experiments
Apart from CLIP, we also apply DEAAN on other backbones: ALBEF and BLIP. We conducted backbone comparison experiments on CUHK-PEDES.
As shown in
Table A5, no matter whether ALBEF or BLIP is adopted as the backbone, DEAAN always brings consistent improvements in terms of all metrics. Meanwhile, a stronger backbone can lead to better performance. For example, in terms of Rank-1,
achieves the best performance with 76.71%, while
and
achieved secondary performance, being 69.89% and 71.73%, respectively.
Table A5.
Comparison with other backbones on CUHK-PEDES. adopts ALBEF as the backbone, uses BLIP as the backbone, while adopts CLIP as the backbone.
Table A5.
Comparison with other backbones on CUHK-PEDES. adopts ALBEF as the backbone, uses BLIP as the backbone, while adopts CLIP as the backbone.
| Methods | R@1 | R@5 | R@10 | mAP |
|---|
| ALBEF | 60.28 | 79.52 | 86.34 | 56.67 |
| 69.89 | 85.77 | 91.37 | 60.85 |
| BLIP | 64.36 | 83.36 | 88.78 | 58.18 |
| 71.73 | 88.97 | 93.29 | 62.22 |
| CLIP | 70.36 | 86.40 | 91.13 | 61.84 |
| (Ours) | 76.71 | 90.37 | 94.56 | 69.07 |
We think there are three factors that have brought about such a significant difference. (1) CLIP’s training on 400 million image–text pairs with contrastive learning enables superior generalization for person search across diverse and complex scenarios. (2) BLIP’s focus on image-grounded captioning and generation tasks makes it less optimized for retrieval-intensive TPS compared to CLIP. (3) ALBEF’s training on only 14 million image–text pairs limits its understanding of diverse visual–textual associations, making it less effective for TPS compared to CLIP’s 400 million pair dataset.
Appendix B.5. Extended Parametric Analysis
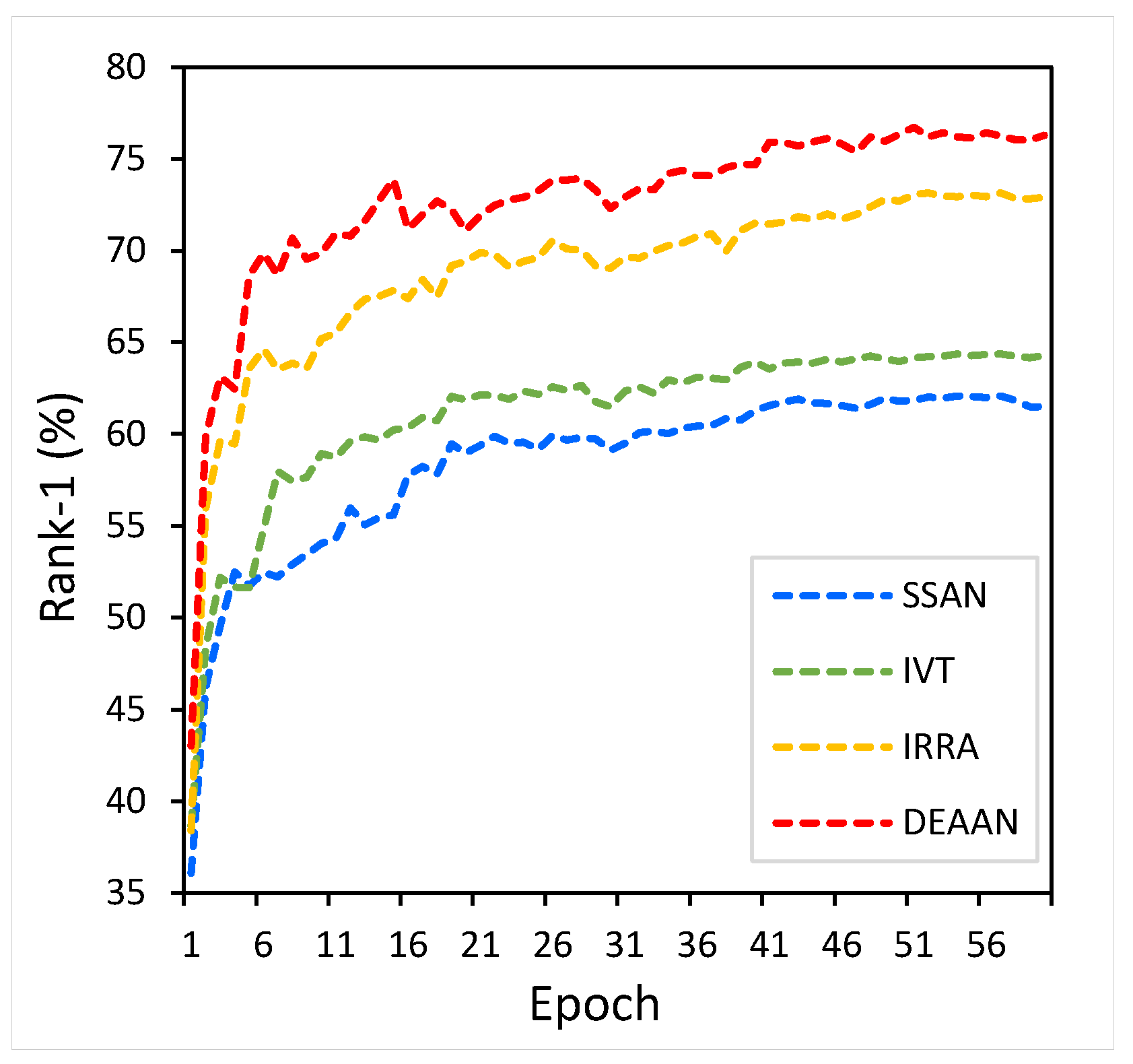
Figure A1 shows the changes in Rank-1 of SSAN, IVT, IRRA, and the DEAAN we proposed with the increase in epochs on the CUHK-PEDES dataset. It can be observed that, among these several models, DEAAN achieves the optimal Rank-1 accuracy and consistently outperforms the other models.
Figure A1.
The training situations of different models on CUHK-PEDES dataset.
Figure A1.
The training situations of different models on CUHK-PEDES dataset.
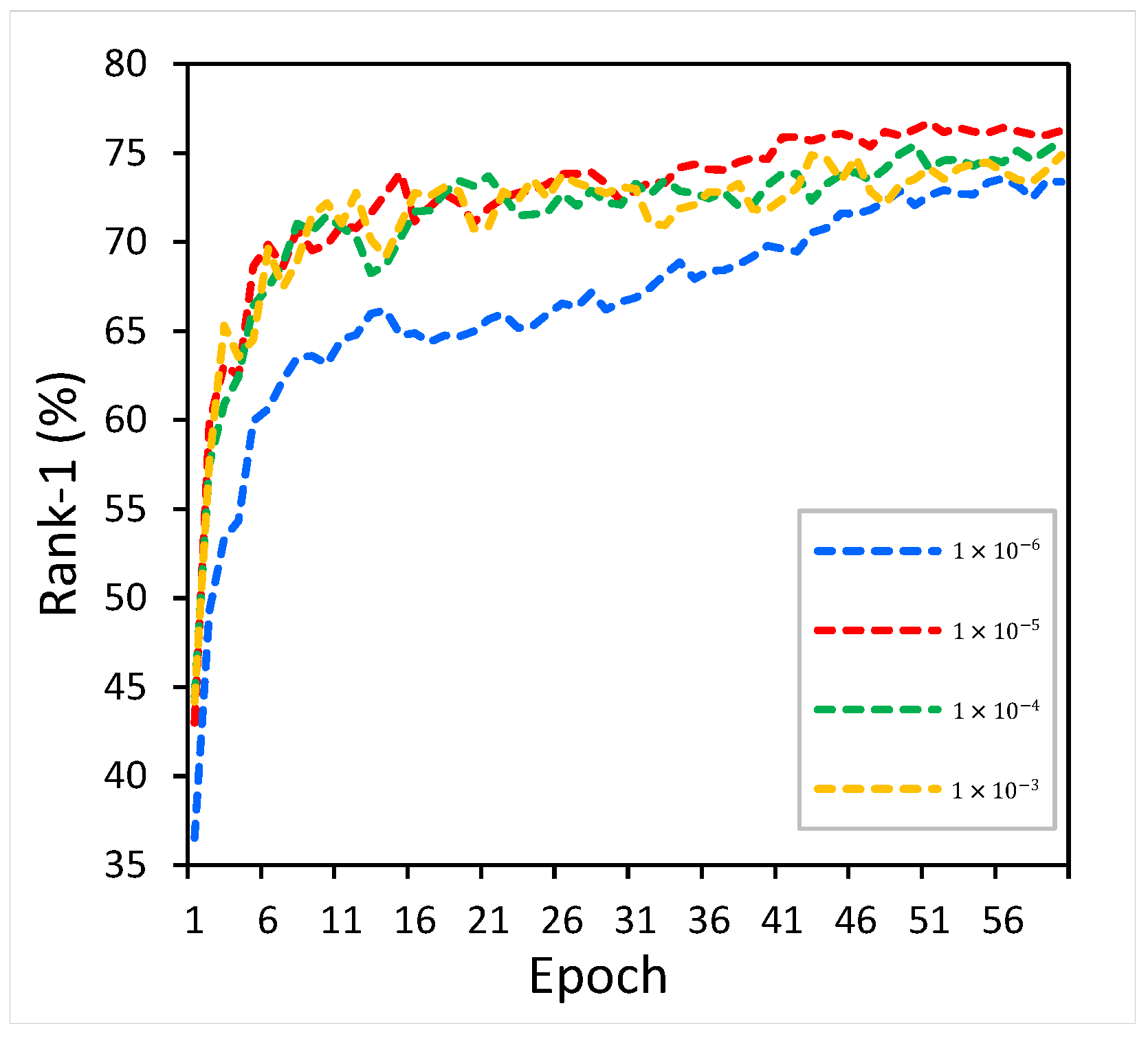
Figure A2 shows the variation in DEAAN in Rank-1 with the increase in epochs when different learning rates are set on the CUHK-PEDES dataset. It can be observed that, when the learning rate is
, DEAAN achieves the optimal Rank-1 accuracy.
Figure A2.
The training situations of different learning rates on CUHK-PEDES dataset.
Figure A2.
The training situations of different learning rates on CUHK-PEDES dataset.
Table A6 compares the effects of different optimizers on the CUHK-PEDES dataset. It can be seen that the Adam optimizer is the best in optimizing our model.
Table A6.
The comparisons of different optimizers on CUHK-PEDES dataset.
Table A6.
The comparisons of different optimizers on CUHK-PEDES dataset.
| Optimizer | R@1 | R@5 | R@10 | mAP |
|---|
| SGD | 62.86 | 80.40 | 87.42 | 59.58 |
| AdamW | 73.59 | 88.75 | 91.68 | 65.92 |
| Adam | 76.71 | 90.37 | 94.56 | 69.07 |
Appendix B.6. Token-Filtering Methods
Compared to classical token-filtering strategies such as TF-IDF or attention pruning, our proposed RATS module offers several key advantages. TF-IDF-based filtering is unsuited for cross-modal tasks since it operates without considering the visual context or query specificity. Attention pruning focuses on computational reduction by eliminating tokens with low intra-modal relevance, while RATS dynamically selects cross-modal informative tokens using class-guided attention scores. This ensures RATS emphasizes discriminative attributes for alignment rather than reducing model complexity alone. The integration of both global (BITC) and local (TSITC) contrastive supervision further boosts its semantic filtering effectiveness.
Table A7 presents, based on the DEAAN model, the performance of TF-IDF and our RATS on CUHK-PEDES.
Table A7.
The comparisons of different token-filtering methods on CUHK-PEDES dataset.
Table A7.
The comparisons of different token-filtering methods on CUHK-PEDES dataset.
| Methods | R@1 | R@5 | R@10 | mAP |
|---|
| TF-IDF | 68.46 | 81.73 | 88.13 | 58.80 |
| RAST (Ours) | 76.71 | 90.37 | 94.56 | 69.07 |
Appendix C. Supplementary Explanations
Appendix C.1. Dependency Parser
TPS task usually involves extracting text features from surveillance video or image descriptions and combining them with visual features for matching. Processing speed is crucial for real-time applications or large-scale datasets. In our work, we selected SpaCy as the dependency parser for the DAIR module primarily due to the following reasons.
(1) SpaCy offers a good trade-off between parsing speed and accuracy, which is essential for real-time or large-scale person search tasks. It achieves near state-of-the-art performance on English Universal Dependencies while maintaining fast inference speed, which is superior to
Stanza (accessed on 4 June 2025) and
UDPipe (accessed on 4 June 2025) in terms of latency.
(2) SpaCy integrates well with subword-tokenized pipelines, which aligns with our CLIP-based architecture. In contrast, tools like Stanza often require more complex bridging to maintain alignment between raw tokens and subword embeddings.
Appendix C.2. Failure Case Analyses
In this section, we analyze and discuss the possible reasons for the occurrence of DEAAN retrieval failure cases As shown in
Figure A3, we have summarized four possible reasons as follows.
(a) Occlusion. In crowded or partially obstructed views, the visual encoder lacks sufficient cues to confirm the attribute referred to in text (e.g., “blue pants”), leading to incorrect matching even if the dependency tree clearly indicates “blue → pants.”
(b) Illumination Variance. Poor or uneven lighting can distort color perception. For example, in a night image, “light blue shirt” may appear dark blue or indistinct, causing DEAAN to fully match all the key attributes.
(c) Multi-Person Image. In cases where multiple individuals appear in the image, the model may mistakenly align attributes to the wrong person. Although the syntactic parsing correctly associates “purple backpack” with the query subject, the visual encoder may associate it with a nearby pedestrian, leading to mismatches.
(d) Image Blur. When the query image is blurred due to motion or camera quality, fine-grained details such as “purple shoes” or “bag” become ambiguous. As a result, DEAAN’s visual–textual alignment is degraded despite accurate syntactic parsing.
Figure A3.
Four representative scenarios where attribute misalignment may occur despite syntactic alignment.
Figure A3.
Four representative scenarios where attribute misalignment may occur despite syntactic alignment.
Appendix C.3. Pseudocode of DEAAN
Algorithm A1 presents the complete pseudocode of the proposed DEAAN. The pseudocode outlines the dual-stream feature extraction, DAIR, and RATS modules in a step-by-step fashion.
| Algorithm A1 DEAAN Framework |
- Input:
Text and image pairs . - Output:
Final loss . - 1:
Extract visual features using CLIP image encoder - 2:
Extract textual features using CLIP text encoder - 3:
Parse into dependency tree using SpaCy, and transform dependency tree to dependency distance matrix - 4:
Map to Gaussian mask - 5:
Apply DISA to integrate into transformer - 6:
Perform Masked Language Modeling with visual–textual cross-attention via - 7:
Compute for masked token reconstruction with identity weighting - 8:
Select top- informative visual/textual tokens via class-to-local attention - 9:
Aggregate selected tokens into compact features and - 10:
Compute image–text similarity scores using BITC and TSITC - 11:
Calculate final loss:
|
References
- Jiang, D.; Ye, M. Cross-modal implicit relation reasoning and aligning for text-to-image person retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 2787–2797. [Google Scholar]
- Li, S.; Xiao, T.; Li, H.; Zhou, B.; Yue, D.; Wang, X. Person search with natural language description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1970–1979. [Google Scholar]
- Wu, Z.; Ma, B.; Chang, H.; Shan, S. Refined knowledge transfer for language-based person search. IEEE Trans. Multimed. 2023, 25, 9315–9329. [Google Scholar]
- Qin, Y.; Chen, Y.; Peng, D.; Peng, X.; Zhou, J.T.; Hu, P. Noisy-correspondence learning for text-to-image person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 27197–27206. [Google Scholar]
- Xue, J.; Wang, Z.; Dong, G.N.; Zhu, A. Eesso: Exploiting extreme and smooth signals via omni-frequency learning for text-based person retrieval. Image Vis. Comput. 2024, 142, 104912. [Google Scholar] [CrossRef]
- Bao, L.; Wei, L.; Zhou, W.; Liu, L.; Xie, L.; Li, H.; Tian, Q. Multi-granularity matching transformer for text-based person search. IEEE Trans. Multimed. 2023, 26, 4281–4293. [Google Scholar]
- Li, Y.; Xu, H.; Xiao, J. Hybrid attention network for language-based person search. Sensors 2020, 20, 5279. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Lu, A.; Huang, Y.; Li, C.; Wang, L. Joint token and feature alignment framework for text-based person search. IEEE Signal Process. Lett. 2022, 29, 2238–2242. [Google Scholar]
- Eom, C.; Ham, B. Learning disentangled representation for robust person re-identification. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 5297–5308. [Google Scholar]
- Wang, Z.; Hu, R.; Yu, Y.; Liang, C.; Huang, W. Multi-level fusion for person re-identification with incomplete marks. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1267–1270. [Google Scholar]
- Shu, X.; Wen, W.; Wu, H.; Chen, K.; Song, Y.; Qiao, R.; Ren, B.; Wang, X. See finer, see more: Implicit modality alignment for text-based person retrieval. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 624–641. [Google Scholar]
- Zhang, Y.; Lu, H. Deep cross-modal projection learning for image-text matching. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 686–701. [Google Scholar]
- Wu, Y.; Yan, Z.; Han, X.; Li, G.; Zou, C.; Cui, S. LapsCore: Language-guided person search via color reasoning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1624–1633. [Google Scholar]
- Jing, Y.; Si, C.; Wang, J.; Wang, W.; Wang, L.; Tan, T. Pose-guided multi-granularity attention network for text-based person search. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11189–11196. [Google Scholar]
- Niu, K.; Huang, Y.; Ouyang, W.; Wang, L. Improving description-based person re-identification by multi-granularity image-text alignments. IEEE Trans. Image Process. 2020, 29, 5542–5556. [Google Scholar]
- Wang, C.; Luo, Z.; Lin, Y.; Li, S. Text-based person search via multi-granularity embedding learning. In Proceedings of the IJCAI, Montreal, BC, Canada, 19–27 August 2021; pp. 1068–1074. [Google Scholar]
- Shao, Z.; Zhang, X.; Fang, M.; Lin, Z.; Wang, J.; Ding, C. Learning granularity-unified representations for text-to-image person re-identification. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 5566–5574. [Google Scholar]
- Bai, Y.; Cao, M.; Gao, D.; Cao, Z.; Chen, C.; Fan, Z.; Nie, L.; Zhang, M. RaSa: Relation and sensitivity aware representation learning for text-based person search. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, Macao, China, 19–25 August 2023; pp. 555–563. [Google Scholar]
- Lin, D.; Peng, Y.X.; Meng, J.; Zheng, W.S. Cross-Modal Adaptive Dual Association for Text-to-Image Person Retrieval. IEEE Trans. Multimed. 2024, 26, 6609–6620. [Google Scholar] [CrossRef]
- Qi, C.; Yang, X.; Wang, N.; Gao, X. Granularity-Aware Hyperbolic Representation for Text-based Person Search. IEEE Trans. Inf. Forensics Secur. 2025, 20, 5745–5757. [Google Scholar]
- Yan, S.; Dong, N.; Zhang, L.; Tang, J. Clip-driven fine-grained text-image person re-identification. IEEE Trans. Image Process. 2023, 32, 6032–6046. [Google Scholar] [CrossRef]
- Li, J.; Li, D.; Xiong, C.; Hoi, S. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 12888–12900. [Google Scholar]
- Li, J.; Selvaraju, R.; Gotmare, A.; Joty, S.; Xiong, C.; Hoi, S.C.H. Align before fuse: Vision and language representation learning with momentum distillation. Adv. Neural Inf. Process. Syst. 2021, 34, 9694–9705. [Google Scholar]
- Ding, Z.; Ding, C.; Shao, Z.; Tao, D. Semantically self-aligned network for text-to-image part-aware person re-identification. arXiv 2021, arXiv:2107.12666. [Google Scholar]
- Zhu, A.; Wang, Z.; Li, Y.; Wan, X.; Jin, J.; Wang, T.; Hu, F.; Hua, G. Dssl: Deep surroundings-person separation learning for text-based person retrieval. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 209–217. [Google Scholar]
- Li, Y. Entity Alignment in Multi-Lingual, Temporal, and Probabilistic Knowledge Graphs. Ph.D. Thesis, Swinburne University of Technology, Melbourne, Australia, 2025. [Google Scholar]
- Fattah, M.; Haq, M.A. Tweet Prediction for Social Media using Machine Learning. Eng. Technol. Appl. Sci. Res. 2024, 14, 14698–14703. [Google Scholar] [CrossRef]
- Bai, Y.; Wang, J.; Cao, M.; Chen, C.; Cao, Z.; Nie, L.; Zhang, M. Text-based person search without parallel image-text data. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 757–767. [Google Scholar]
- Cao, M.; Bai, Y.; Zeng, Z.; Ye, M.; Zhang, M. An empirical study of clip for text-based person search. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 26–27 February 2024; Volume 38, pp. 465–473. [Google Scholar]
- Li, S.; Xu, X.; Yang, Y.; Shen, F.; Mo, Y.; Li, Y.; Shen, H.T. DCEL: Deep cross-modal evidential learning for text-based person retrieval. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 6292–6300. [Google Scholar]
- Ma, Y.; Sun, X.; Ji, J.; Jiang, G.; Zhuang, W.; Ji, R. Beat: Bi-directional one-to-many embedding alignment for text-based person retrieval. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 4157–4168. [Google Scholar]
- Shen, F.; Shu, X.; Du, X.; Tang, J. Pedestrian-specific bipartite-aware similarity learning for text-based person retrieval. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 8922–8931. [Google Scholar]
- Zhou, J.; Huang, B.; Fan, W.; Cheng, Z.; Zhao, Z.; Zhang, W. Text-based person search via local-relational-global fine grained alignment. Knowl.-Based Syst. 2023, 262, 110253. [Google Scholar]
- Zheng, Z.; Zheng, L.; Garrett, M.; Yang, Y.; Xu, M.; Shen, Y.D. Dual-path convolutional image-text embeddings with instance loss. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2020, 16, 1–23. [Google Scholar]
- Gao, C.; Cai, G.; Jiang, X.; Zheng, F.; Zhang, J.; Gong, Y.; Peng, P.; Guo, X.; Sun, X. Contextual non-local alignment over full-scale representation for text-based person search. arXiv 2021, arXiv:2101.03036. [Google Scholar]
- Faghri, F.; Fleet, D.J.; Kiros, J.R.; Fidler, S. Vse++: Improving visual-semantic embeddings with hard negatives. arXiv 2017, arXiv:1707.05612. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Han, X.; He, S.; Zhang, L.; Xiang, T. Text-based person search with limited data. arXiv 2021, arXiv:2110.10807. [Google Scholar]
- Yuenyong, S.; Wongpatikaseree, K. Improving natural language person description search from videos with language model fine-tuning and approximate nearest neighbor. Big Data Cogn. Comput. 2022, 6, 136. [Google Scholar] [CrossRef]
- Sinaga, K.P.; Yang, M.S. A Globally Collaborative Multi-View k-Means Clustering. Electronics 2025, 14, 2129. [Google Scholar]
- Suo, W.; Sun, M.; Niu, K.; Gao, Y.; Wang, P.; Zhang, Y.; Wu, Q. A Simple and Robust Correlation Filtering Method for Text-Based Person Search. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 726–742. [Google Scholar]
- Li, S.; Xu, X.; He, C.; Shen, F.; Yang, Y.; Shen, H.T. Cross-modal Uncertainty Modeling with Diffusion-based Refinement for Text-based Person Retrieval. IEEE Trans. Circuits Syst. Video Technol. 2024, 35, 2881–2893. [Google Scholar]
- He, C.; Li, S.; Wang, Z.; Shen, F.; Yang, Y.; Xu, X. Diverse Embedding Modeling with Adaptive Noise Filter for Text-based Person Retrieval. In Proceedings of the 2024 IEEE International Conference on Multimedia and Expo (ICME), Niagara Falls, ON, Canada, 15–19 July 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar]
- Ke, X.; Liu, H.; Xu, P.; Lin, X.; Guo, W. Text-based person search via cross-modal alignment learning. Pattern Recognit. 2024, 152, 110481. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Zhang, M.; Li, Z.; Fu, G.; Zhang, M. Syntax-enhanced neural machine translation with syntax-aware word representations. arXiv 2019, arXiv:1905.02878. [Google Scholar]
- Rassin, R.; Hirsch, E.; Glickman, D.; Ravfogel, S.; Goldberg, Y.; Chechik, G. Linguistic binding in diffusion models: Enhancing attribute correspondence through attention map alignment. Adv. Neural Inf. Process. Syst. 2023, 36, 3536–3559. [Google Scholar]
- Duan, S.; Zhao, H.; Zhang, D. Syntax-aware data augmentation for neural machine translation. IEEE/ACM Trans. Audio Speech Lang. Process. 2023, 31, 2988–2999. [Google Scholar] [CrossRef]
- Zeng, P.; Gao, L.; Lyu, X.; Jing, S.; Song, J. Conceptual and syntactical cross-modal alignment with cross-level consistency for image-text matching. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 2205–2213. [Google Scholar]
- Bugliarello, E.; Okazaki, N. Enhancing Machine Translation with Dependency-Aware Self-Attention. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 1618–1627. [Google Scholar]
- Li, Z.; Zhou, Q.; Li, C.; Xu, K.; Cao, Y. Improving BERT with Syntax-aware Local Attention. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; pp. 645–653. [Google Scholar]
- Xie, Y.; Zhu, Z.; Cheng, X.; Huang, Z.; Chen, D. Syntax matters: Towards spoken language understanding via syntax-aware attention. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; pp. 11858–11864. [Google Scholar]
- Xu, Z.; Guo, D.; Tang, D.; Su, Q.; Shou, L.; Gong, M.; Zhong, W.; Quan, X.; Jiang, D.; Duan, N. Syntax-Enhanced Pre-trained Model. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 5412–5422. [Google Scholar]
- Honnibal, M.; Johnson, M. An improved non-monotonic transition system for dependency parsing. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, EMNLP 2015, Lisbon, Portugal, 17–21 September 2015; Association for Computational Linguistics (ACL): Kerrville, TX, USA, 2015; pp. 1373–1378. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 1715–1725. [Google Scholar]
- Zhu, H.; Ke, W.; Li, D.; Liu, J.; Tian, L.; Shan, Y. Dual cross-attention learning for fine-grained visual categorization and object re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 4692–4702. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Chen, Y.; Zhang, G.; Lu, Y.; Wang, Z.; Zheng, Y. TIPCB: A simple but effective part-based convolutional baseline for text-based person search. Neurocomputing 2022, 494, 171–181. [Google Scholar] [CrossRef]
- Shao, Z.; Zhang, X.; Ding, C.; Wang, J.; Wang, J. Unified pre-training with pseudo texts for text-to-image person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 11174–11184. [Google Scholar]
- He, S.; Luo, H.; Jiang, W.; Jiang, X.; Ding, H. VGSG: Vision-guided semantic-group network for text-based person search. IEEE Trans. Image Process. 2023, 33, 163–176. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Alotaibi, M.Z.; Haq, M.A. Customer churn prediction for telecommunication companies using machine learning and ensemble methods. Eng. Technol. Appl. Sci. Res. 2024, 14, 14572–14578. [Google Scholar] [CrossRef]
- Wei, L.; Zhang, S.; Gao, W.; Tian, Q. Person transfer gan to bridge domain gap for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 79–88. [Google Scholar]
- Wang, Z.; Fang, Z.; Wang, J.; Yang, Y. Vitaa: Visual-textual attributes alignment in person search by natural language. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 402–420. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}