
Laor Initialization: A New Weight Initialization Method for the Backpropagation of Deep Learning


Abstract
1. Introduction
2. Background and Related Works
2.1. Weight Initialization
- Random Initialization: This method employs small random values drawn from either a uniform or Gaussian distribution, expressed asIt effectively breaks symmetry but suffers from uncontrolled variance propagation, causing vanishing or exploding gradients [16]. Recent enhancements introduce structured randomness, using chaotic maps such as logistic, tent, and Chebyshev polynomials to improve weight space diversity [17].
- Xavier (Glorot) Initialization: Specifically developed for tanh and sigmoid activations, Xavier Initialization ensures balanced signal propagation in both forward and backward passes [4]. The weights are sampled as
- He Initialization: Tailored for ReLU and its variants, He Initialization adjusts the variance to mitigate the neuron deactivation problems typical with ReLU [5]. It is defined as
- Data-Driven Initialization: This approach leverages data to compute the initial weights, enhancing convergence. Examples include initializing CNN filters using PCA or clustering [18] or adopting pre-trained weights from related tasks [19]. Despite offering performance gains, its challenges include high data costs, a susceptibility to noise, and limitations on its interpretability [20,21]. Hybrid frameworks combining data-driven insights with domain knowledge have emerged to overcome these limitations [21].
- Orthogonal Initialization: Maintaining orthogonality in weight matrices enhances stability and generalization by preserving variance during training [22,23]. Applications span from graph neural networks (GNNs) to feedforward neural networks (FNNs), where it effectively addresses gradient instability issues.
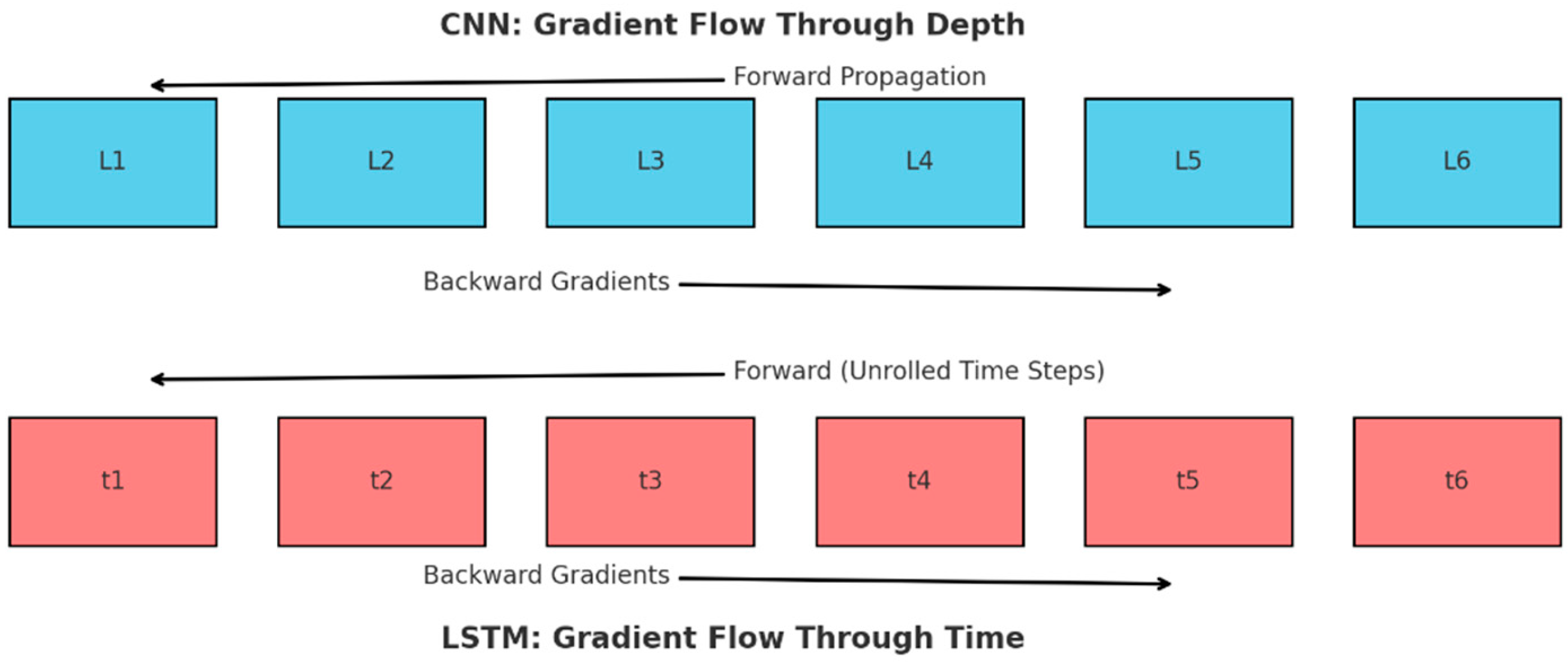
2.2. Vanishing and Exploding Gradient Problems
2.3. Related Works
3. Laor Initialization Method
3.1. Data Collection
3.2. Setting Parameters for Experiment
3.3. Procedure of Laor Initialization Method
3.3.1. Weight Initialization Using K-Means Clustering
- Random Weight Initialization: Start by generating several random weight vectors (candidates for initialization). Each weight vector is sampled from a distribution, for example, , where μ is the mean, and σ2 is the variance of the normal distribution.
- Feedforward Computation: Each potential weight vector undergoes a forward pass on the training dataset to generate the predictions. If denotes the -th feature of the -th training sample, then the predicted output for sample is calculated as the weighted sum of inputs using the candidate weights,
- Compute RMSE Error: Evaluate the prediction error of each weight candidate using the Root Mean Square Error (RMSE) over all training samples. For a given weight vector, the RMSE is calculated aswhere is the true target value for sample . A lower indicates that this weight initialization performs better on the first forward pass.
- K-Means Clustering: Once errors are computed for each candidate weight vector, apply k-means clustering to group these error values into clusters. Denote the set of error values in cluster as where is the index set of weight candidates belonging to that cluster.
- Optimal Cluster Selection: Identify which cluster has the lowest average error. Formally, selecting meaning cluster yields the smallest mean RMSE. This cluster represents the group of initial weight vectors that performed best in the first forward pass.
- Weight Initialization with Cluster Mean: Compute the new initial weights as the average of the weight vectors in the best cluster . Let be the weight vector for candidate . The chosen initialization is that which is the mean of all weight vectors in the lowest-error cluster. This averaged weight vector serves as the initialized weight for the network, providing a data-informed starting point for training.
3.3.2. Feedforward Computation
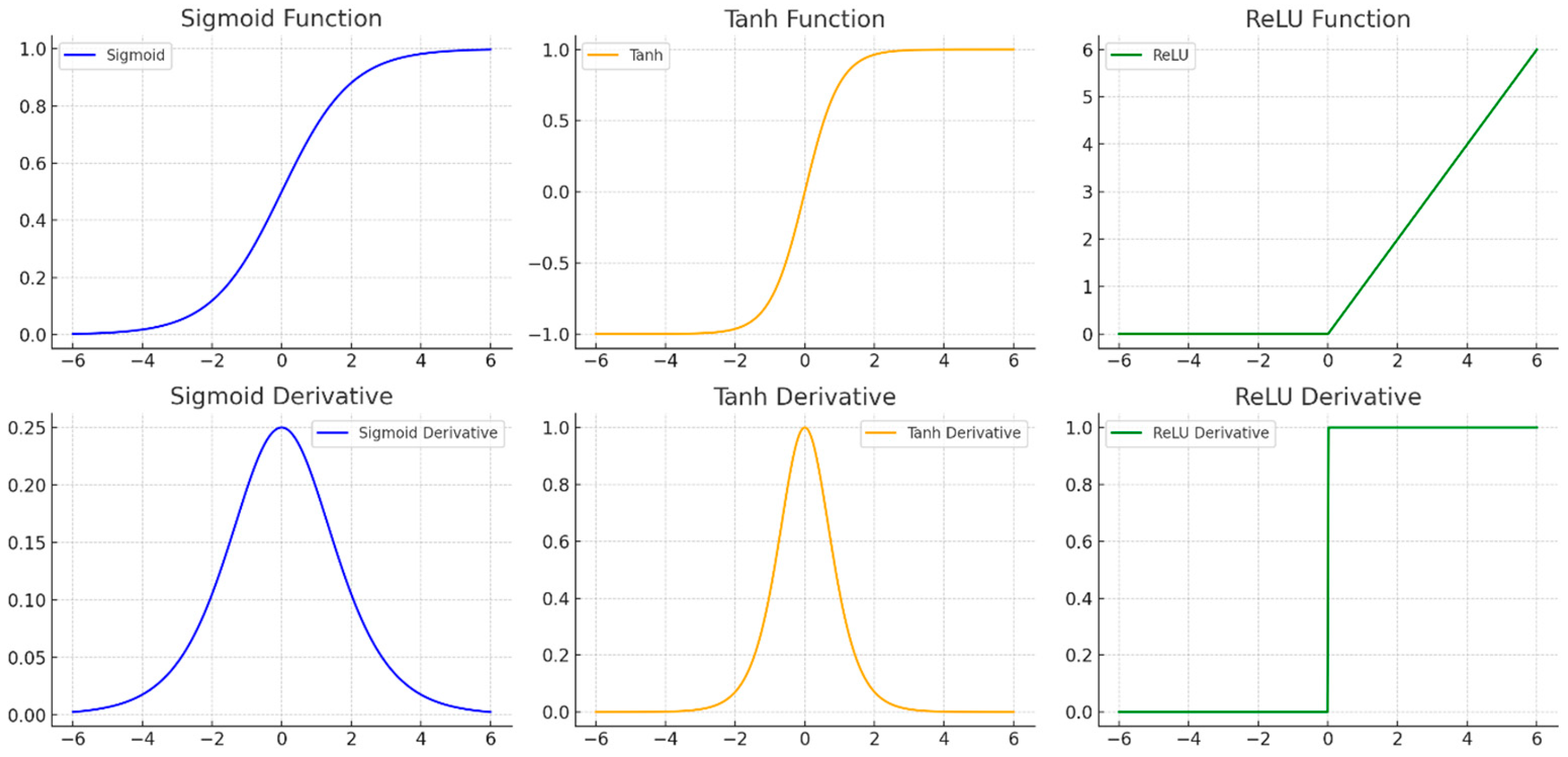
- Hidden Layer Activation (ReLU): As input data propagates through each hidden layer, apply the Rectified Linear Unit activation to the weighted sum plus bias. For a given hidden neuron with a weight vector and bias , the activation is The ReLU function outputs 0 for any negative input and passes positive values through unchanged, introducing nonlinearity and mitigating the vanishing gradient problem in deep networks.
- Output Layer Activation (sigmoid): For binary classification or output probabilities, sigmoid activation is used at the output layer. If is the linear combination of the final hidden layer outputs, the sigmoid produces , which squashes into the range [0, 1] [0, 1] [0, 1]. This output can be interpreted as a probability or a scaled prediction. (For regression tasks, a linear output might be used instead of a sigmoid).
3.3.3. Loss Function Calculation
3.3.4. Backpropagation and Weight Updates
- Weight Update Using Adam Optimizer: The gradient of the loss with respect to each weight is computed through backpropagation. The weights are then updated in the opposite direction to the gradient. For example, a simple gradient descent update at iteration would bewhere η is the learning rate. The Adam optimizer improves upon the basic gradient descent by adapting the learning rate for each weight using momentum and RMSprop techniques. It keeps moving averages of past gradients and squared gradients to formulate an adaptive update, but the core idea remains adjusting slightly in the direction that most reduces the loss.
3.3.5. Performance Metrics’ Evaluation
- Convergence Check: Continuously monitor the loss during training. If falls below a predefined threshold (i.e., if < ), or if stops changing significantly, the training can be stopped early. This check prevents overtraining and saves time once the model converges.
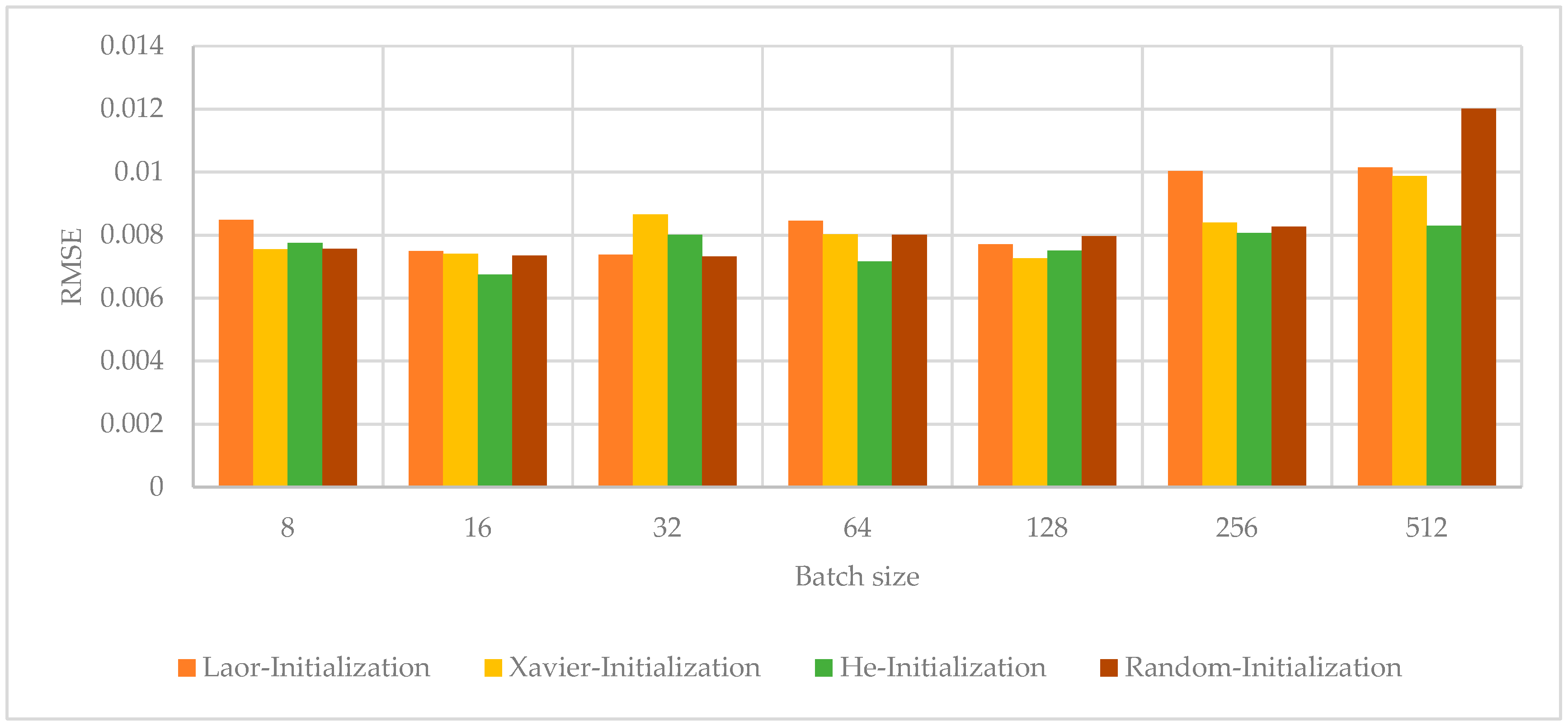
- Batch Size Analysis: The choice of mini-batch size (number of samples per gradient update) can affect training speed and stability. Common batch sizes to try are 8, 16, 32, 64, 128, 256, etc. The RMSE can be evaluated for different s to see which yields the best trade-off. Smaller batches introduce more stochastic noise in the gradient, whereas larger batches provide more stable and accurate gradient estimates but may converge to sharp minima or take longer per epoch.
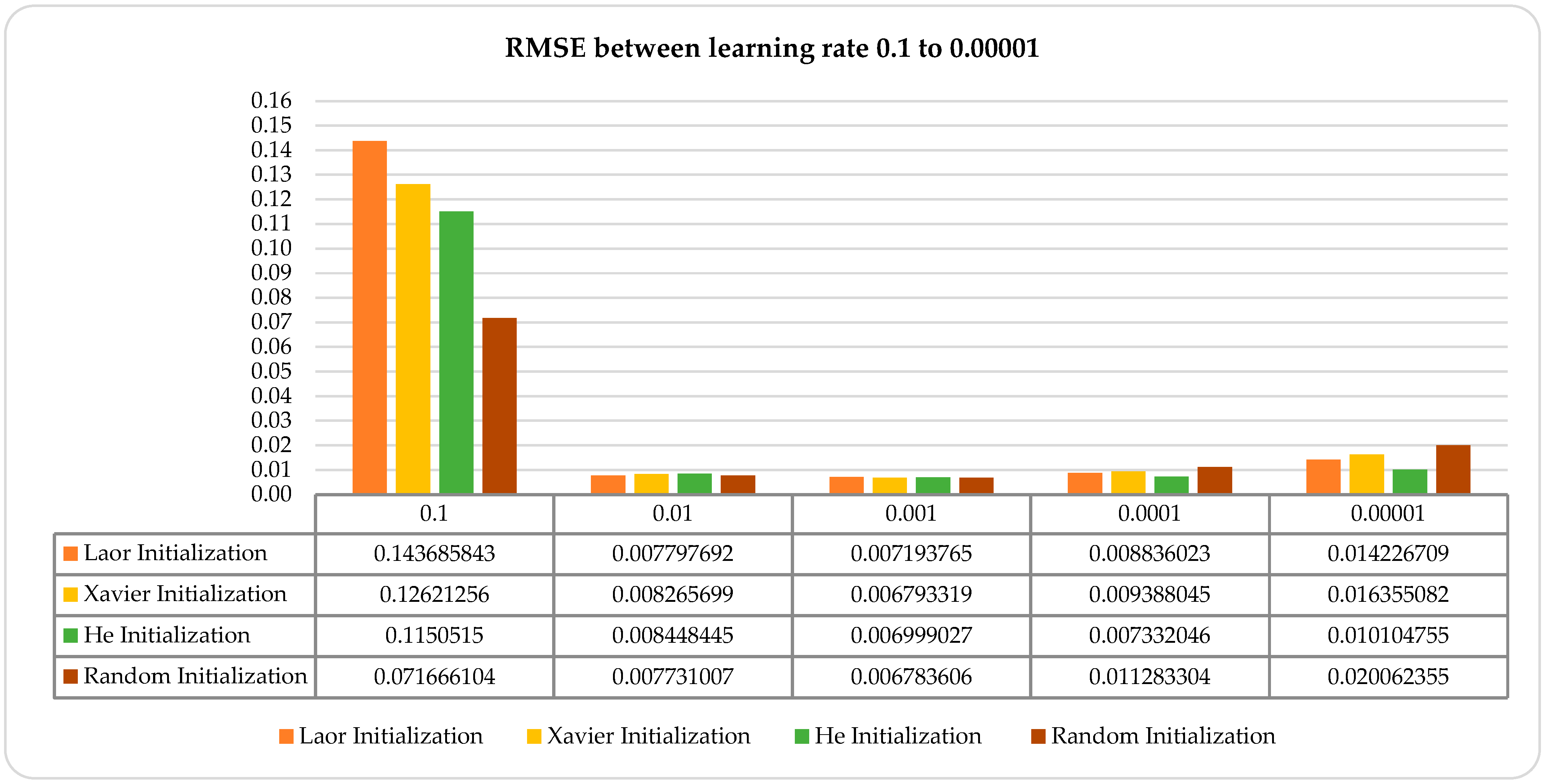
- Learning Rate Optimization: Test multiple learning rates to find an optimal value. The learning rate controls the step size during the weight updates. If η is too high, the training might diverge or oscillate; if it is too low, the convergence will be very slow. An optimal value of η minimizes the training time while maintaining stability.
- Cross-Validation (K-Fold): To ensure the model generalizes well, use -fold cross-validation. Split the dataset into folds and perform the training times, each time holding out one fold as the validation set and using the remaining folds for training. Compute the validation loss for each fold , then calculate the average validation lossA low and consistent across folds indicates good generalization. This technique helps in selecting hyperparameters (like and η above) and in detecting overfitting.
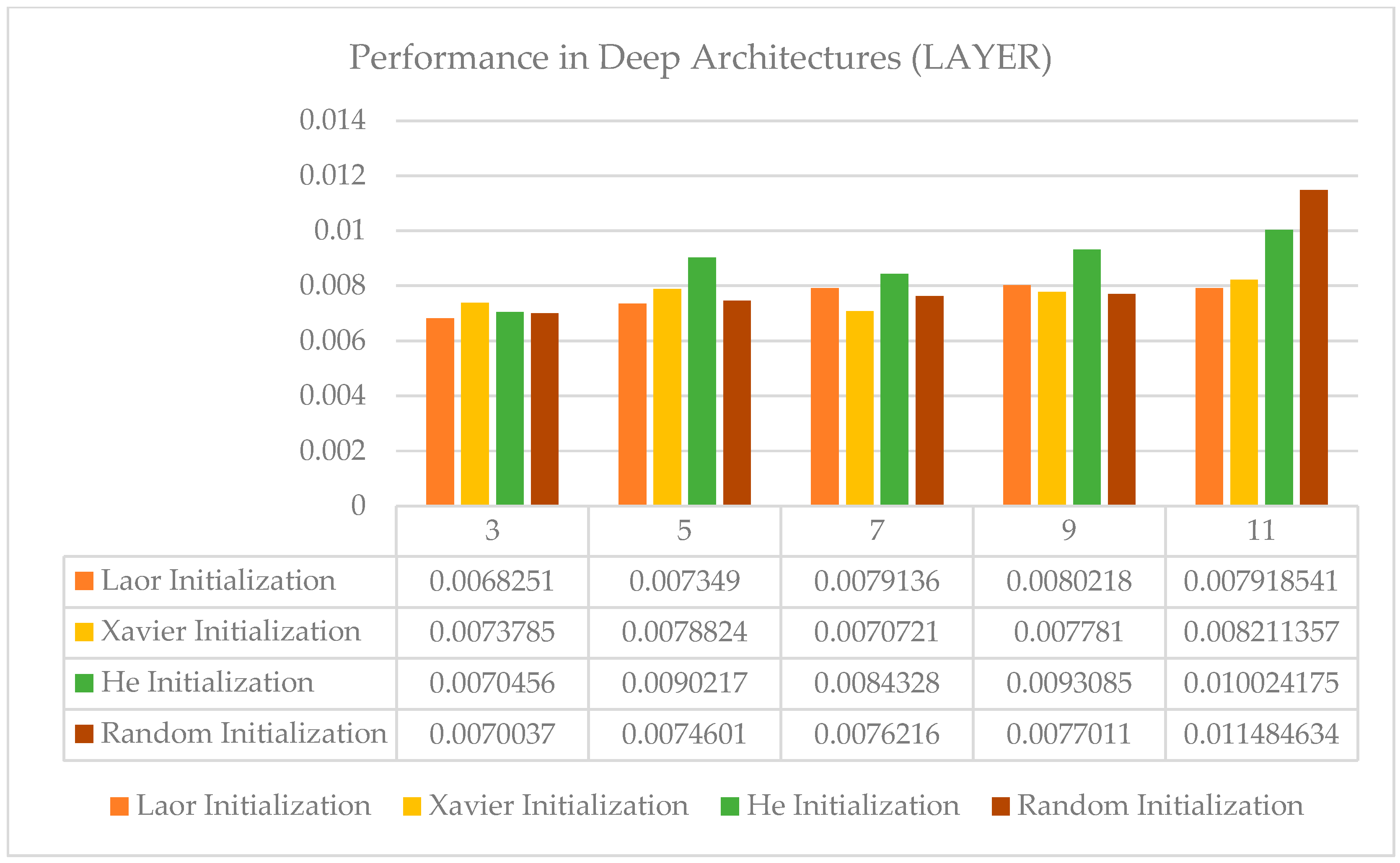
- Network Depth Effect: Experiments with different network depths (number of layers), such as 3, 5, 7, 9, and 11 layers, and a comparison of their resulting RMSEs. Increasing the depth can allow the model to learn more complex patterns, but it may also introduce challenges, such as vanishing gradients or overfitting. By tracking the performance, one can determine whether a deeper network actually improves the accuracy or whether a simpler architecture is sufficient.
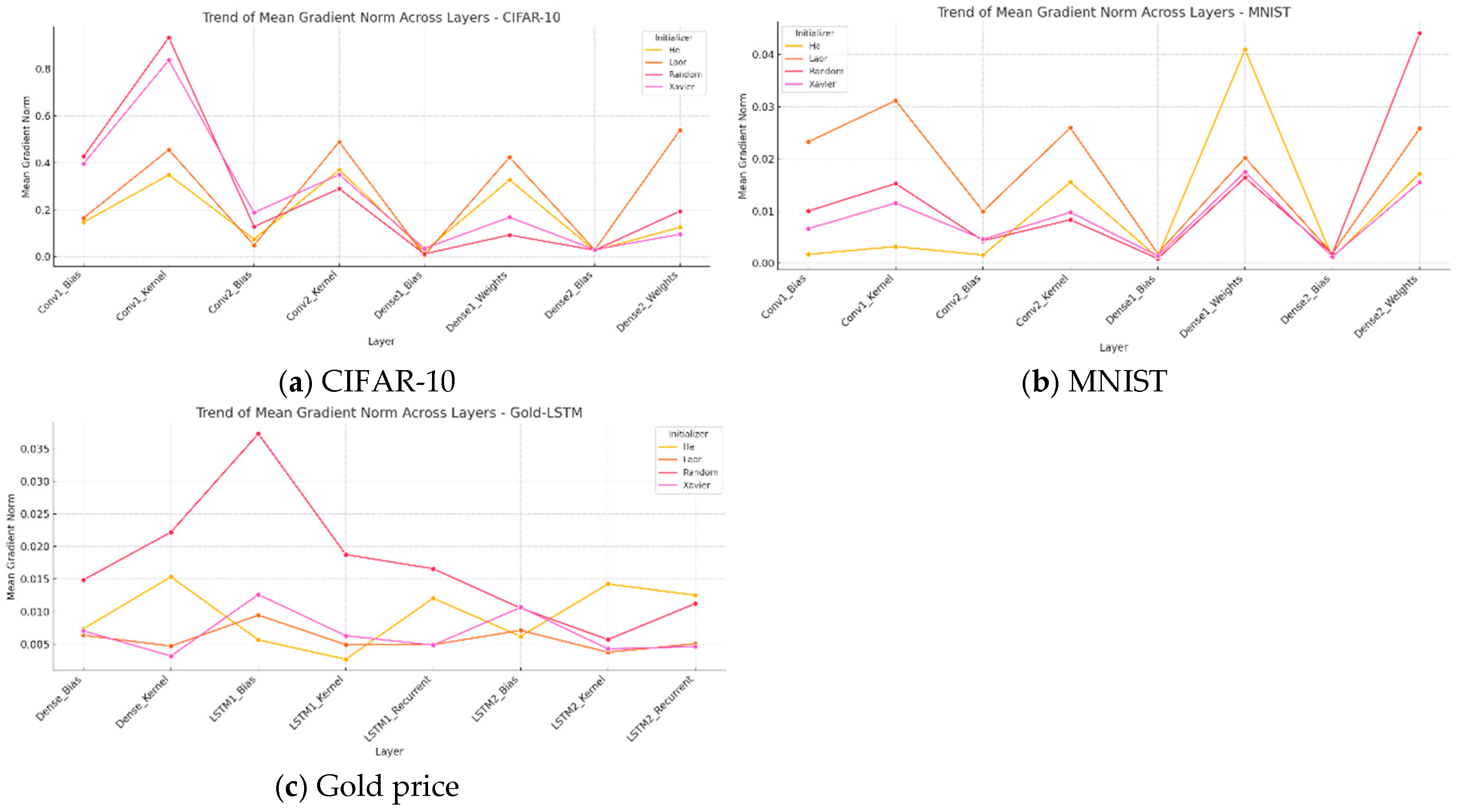
- Gradient Norm Analysis: A method for diagnosing the gradient scale during neural network training that provides insights into the error signal propagation through layers. By calculating the L2 norm of the loss function gradient relative to the model parameters, this approach assesses whether the gradients can effectively update the weights. Low-gradient norms indicate vanishing gradients, hindering learning by preventing significant weight updates in the deep models. Conversely, excessive gradient norms can lead to exploding gradients and unstable learning. Gradient Norm Analysis uses the average gradient norm per layer, standard deviation (SD), and coefficient of variation (CV) to evaluate magnitude and consistency. Categorizing norms into vanishing (norm < 0.01), stable (0.01 ≤ norm ≤ 1.0), and exploding (norm > 1.0) groups helps to identify susceptible layers and assess weight initialization effects.
4. Results and Discussion
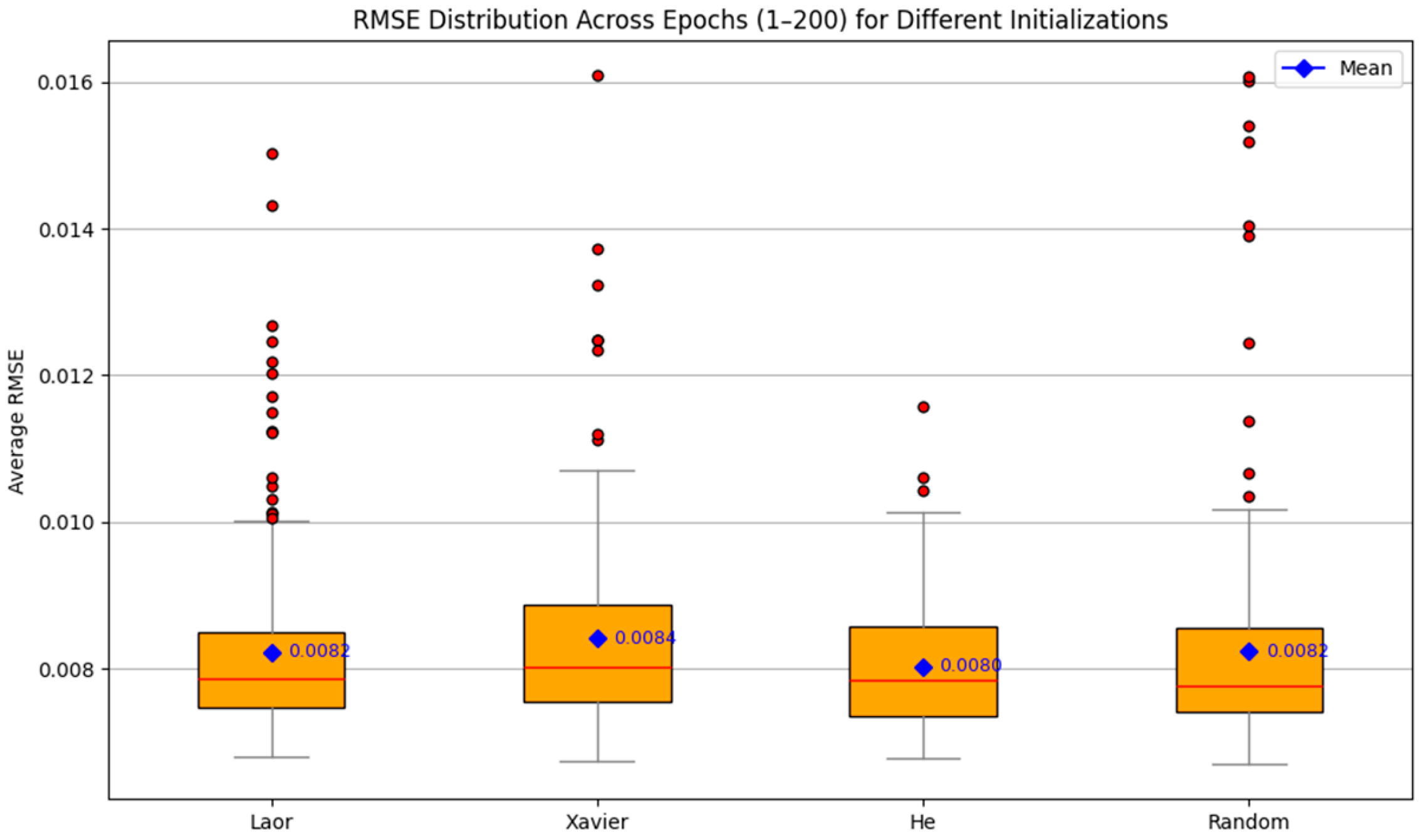
4.1. RMSE Trajectories over Epochs
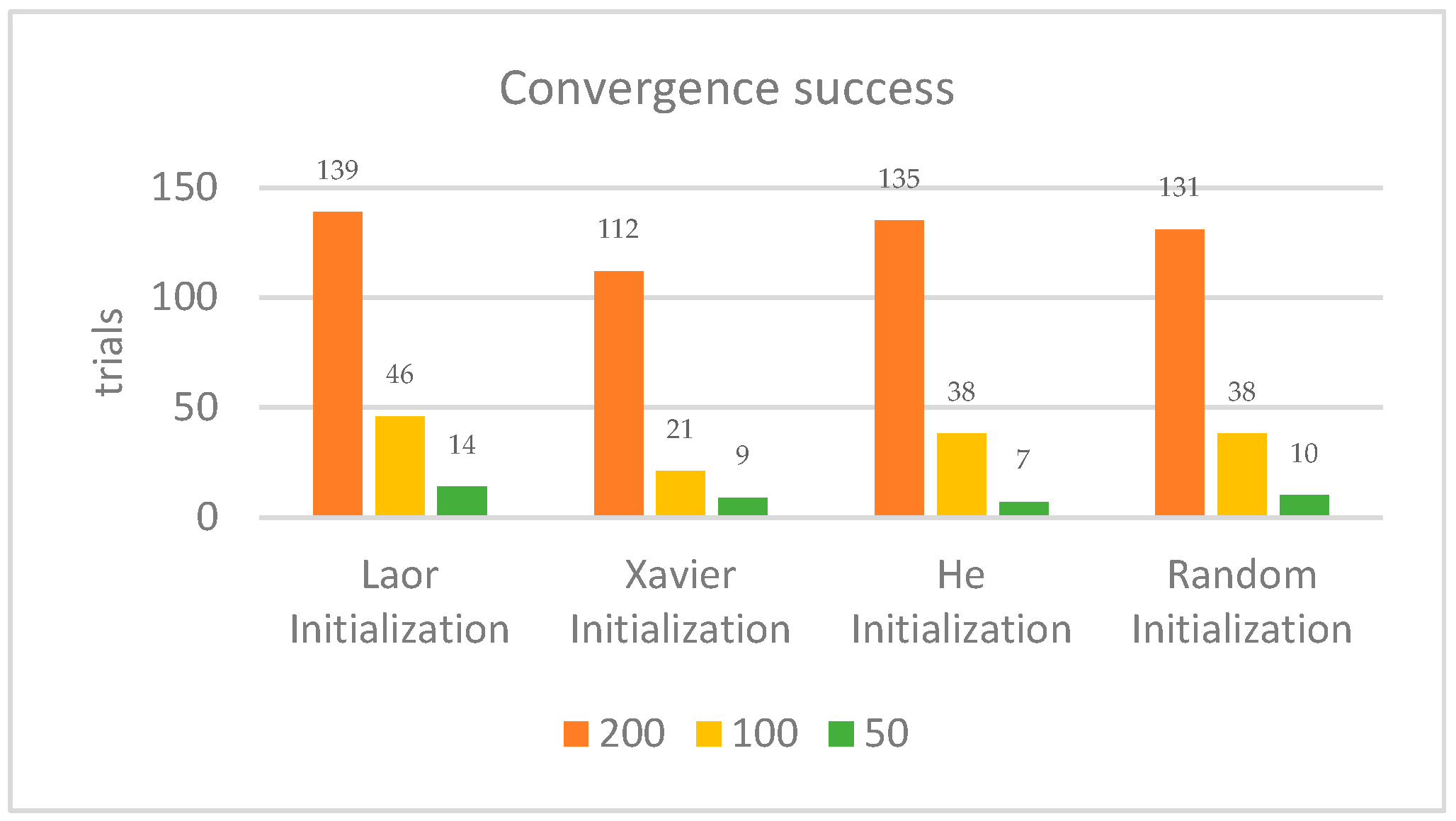
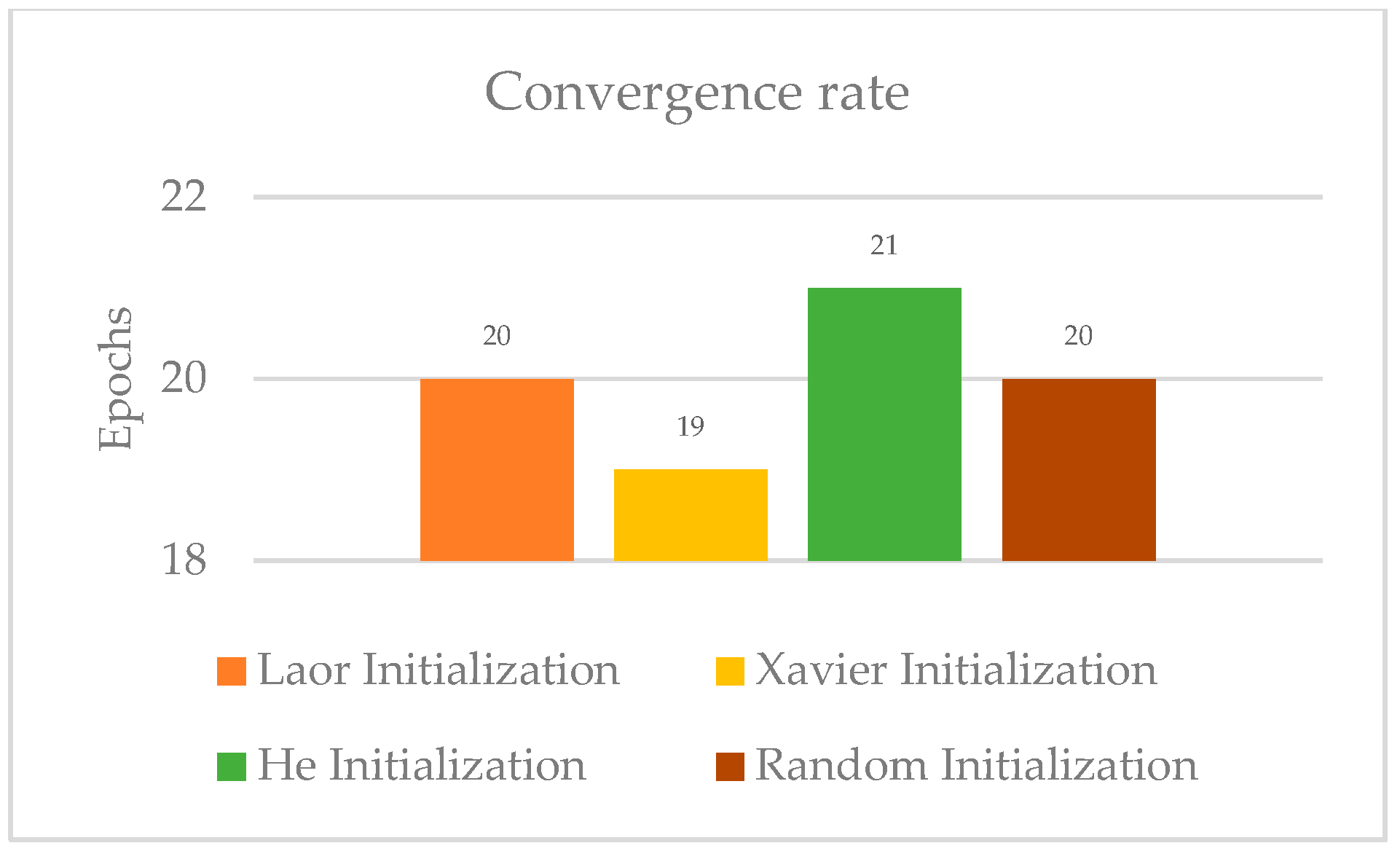
4.2. Convergence Success and Rate
4.3. Interaction with Batch Size
4.4. Sensitivity to Learning Rate
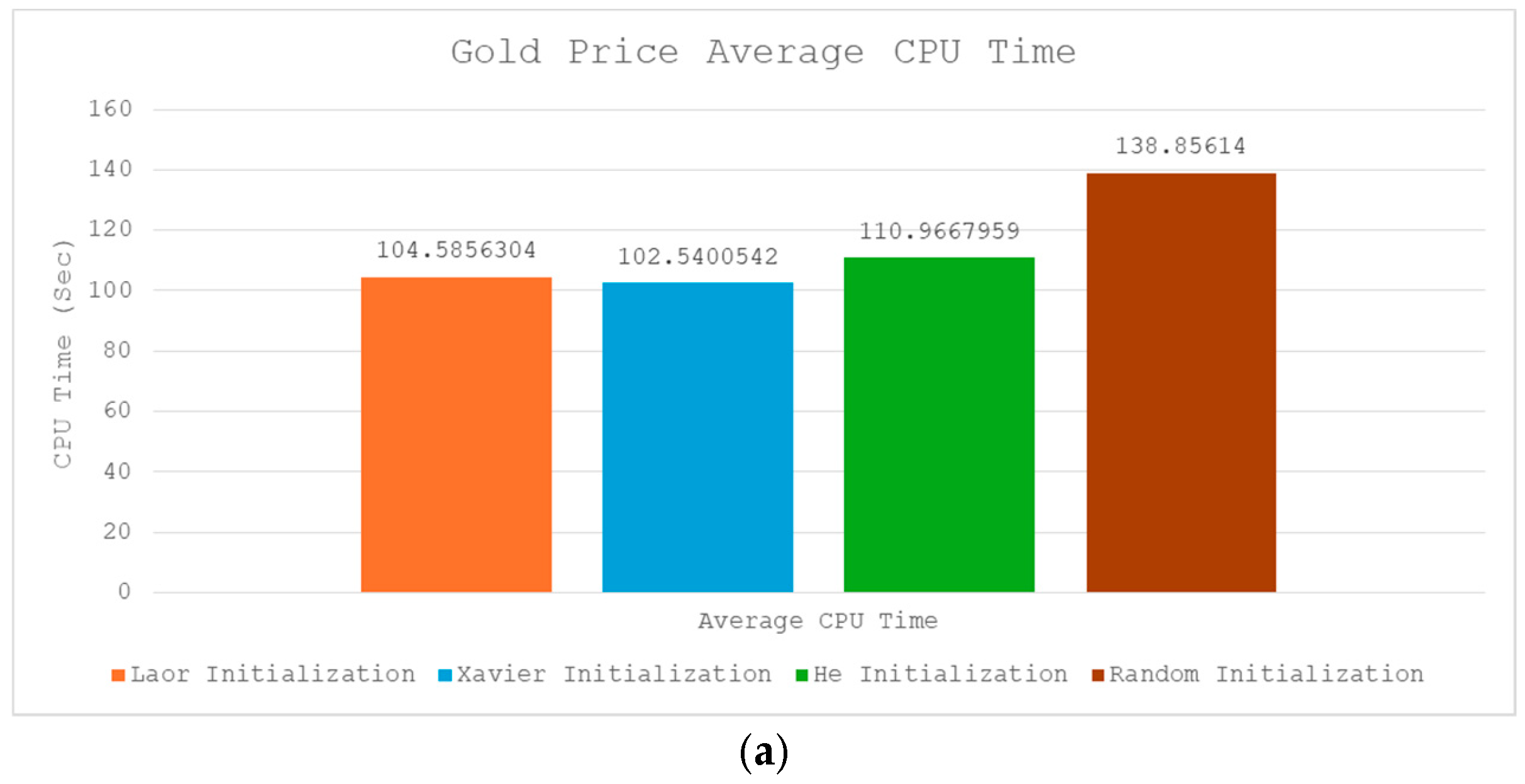
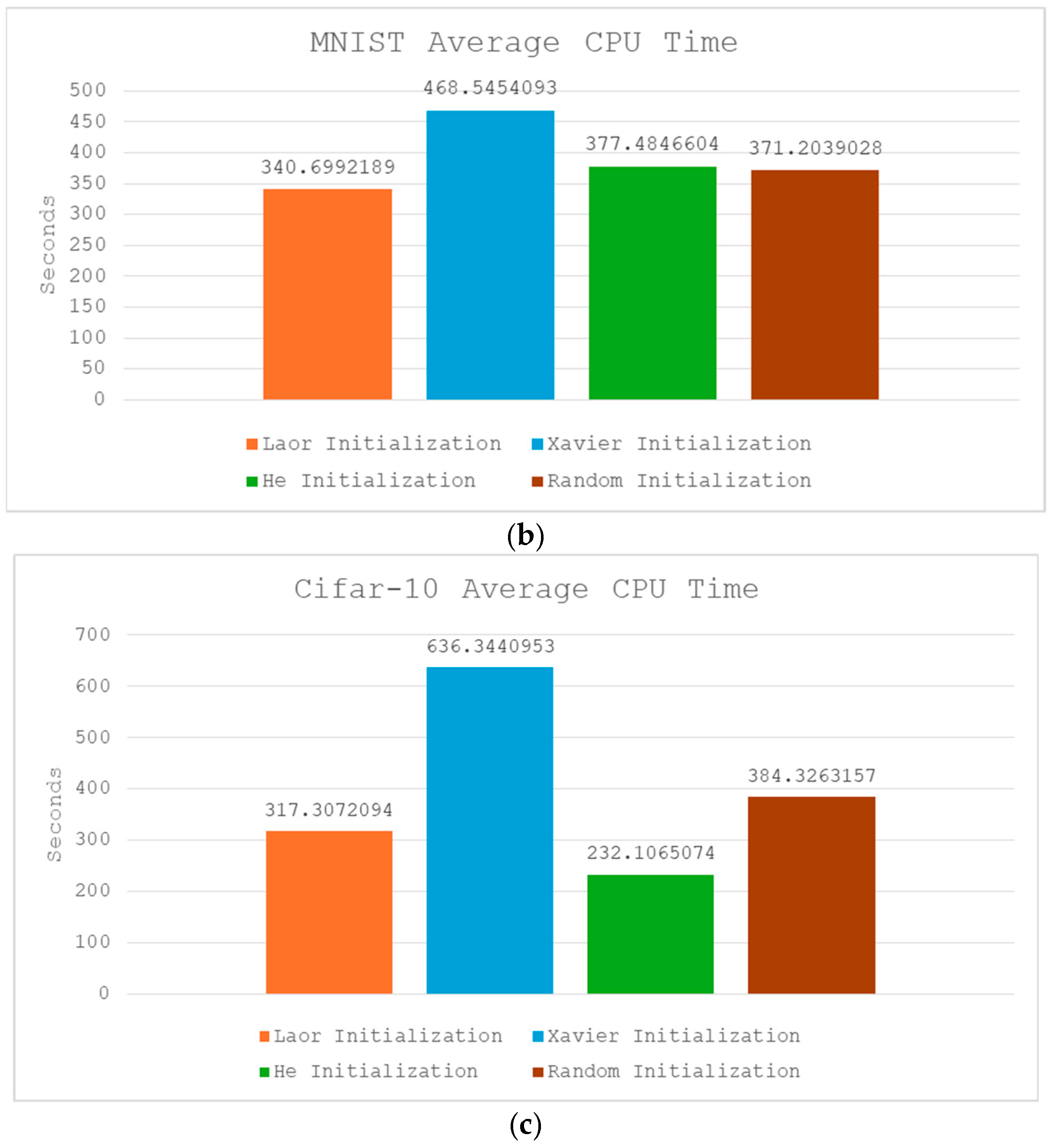
4.5. Computational Overhead and Efficiency (CPU Time)
4.6. Generalization via K-Fold Cross-Validation
4.7. Depth Scalability: Performance in Deep Architectures (LAYER)
4.8. Gradient Norm Stability Analysis
4.9. Summary of Findings and Proposed Improvements
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kumar, S. On weight initialization in deep neural networks. arXiv 2017, arXiv:1704.08863. [Google Scholar] [CrossRef]
- Lyu, Z.; Karns, J.; Desell, T.; Mkaouer, M.; Elsaid, A. An Experimental Study of Weight Initialization and Lamarckian Inheritance on Neuroevolution. In International Conference on the Applications of Evolutionary Computation (EvoApplications 2021); Springer: Cham, Switzerland, 2021; pp. 584–600. [Google Scholar] [CrossRef]
- Zucchet, N.; Orvieto, A. Recurrent neural networks: Vanishing and exploding gradients are not the end of the story. arXiv 2024, arXiv:2405.21064. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics (AISTATS 2010), Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2015), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Saxe, A.M.; McClelland, J.L.; Ganguli, S. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. arXiv 2013, arXiv:1312.6120. [Google Scholar] [CrossRef]
- Narkhede, M.V.; Bartakke, P.P.; Sutaone, M.S. A review on weight initialization strategies for neural networks. Artif. Intell. Rev. 2021, 55, 291–322. [Google Scholar] [CrossRef]
- Darrell, T.; Donahue, J.; Krähenbühl, P.; Doersch, C. Data-dependent initializations of convolutional neural networks. arXiv 2015, arXiv:1511.06856. [Google Scholar] [CrossRef]
- Jia, B.; Guo, Z.; Huang, T.; Guo, F.; Wu, H. A generalized Lorenz system-based initialization method for deep neural networks. Appl. Soft Comput. 2024, 167, 112316. [Google Scholar] [CrossRef]
- Zhou, X.; Liu, S.; Qin, A.K.; Tan, K.C. Evolutionary neural architecture search for transferable networks. IEEE Trans. Emerg. Top. Comput. Intell. 2024, 9, 1556–1568. [Google Scholar] [CrossRef]
- Xu, Z.; Chen, Y.; Vishniakov, K.; Liu, Z. Initializing models with larger ones. In Proceedings of the 12th International Conference on Learning Representations (ICLR 2024), Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Wang, Z.; Bhoyar, P.H.; Teoh, C.; Irfan, S.A. K-means Clustering. In Machine Learning Algorithms for Industrial Applications; Bentham Science: Sharjah, United Arab Emirates, 2023; pp. 194–211. [Google Scholar] [CrossRef]
- Liu, M.; Du, X.; Shang, M.; Jin, L.; Chen, L. Activated Gradients for Deep Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 2156–2168. [Google Scholar] [CrossRef]
- Al-Abri, S.; Zhang, F.; Lin, T.X.; Tao, M. A Derivative-Free Optimization Method with Application to Functions with Exploding and Vanishing Gradients. IEEE Control Syst. Lett. 2020, 5, 587–592. [Google Scholar] [CrossRef]
- Wong, K.; Dornberger, R.; Hanne, T. An Analysis of Weight Initialization Methods in Connection with Different Activation Functions for Feedforward Neural Networks. Evol. Intell. 2024, 17, 2081–2089. [Google Scholar] [CrossRef]
- Li, H.; Perin, G.; Krcek, M. A Comparison of Weight Initializers in Deep Learning-Based Side-Channel Analysis. In Proceedings of the International Conference on Computational Intelligence and Security, Las Vegas, NV, USA, 22–23 December 2023. [Google Scholar]
- Mansour, H.A.A. Analysis, Study and Optimization of Chaotic Bifurcation Parameters Based on Logistic/Tent Chaotic Maps. In Artificial Intelligence and Bioinspired Computational Methods; Springer Nature: Cham, Switzerland, 2020; pp. 642–652. [Google Scholar] [CrossRef]
- Honda, K.; Ichihashi, H.; Notsu, A.; Nonoguchi, R. PCA-Guided k-Means Clustering with Incomplete Data. In Proceedings of the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Taipei, Taiwan, 27–30 June 2011. [Google Scholar] [CrossRef]
- Cui, T.; Jasra, A.; Dong, J.; Tong, X. Convergence Speed and Approximation Accuracy of Numerical MCMC. arXiv 2022, arXiv:2203.03104. [Google Scholar] [CrossRef]
- Kim, J.W.; Nam, J.; Lee, S.W.; Kim, G.Y. AI-Based Surface Quality Prediction Model for CFRP Milling Process. Int. J. Precis. Eng. Manuf.-Smart Technol. 2023, 1, 35–47. [Google Scholar] [CrossRef]
- Nie, J.; Wang, H.; Li, Y.; Jiang, J.; Ercisli, S.; Lv, L. Data and Domain Knowledge Dual-Driven Artificial Intelligence: Survey, Applications, and Challenges. Expert Syst. 2023, 42, e13425. [Google Scholar] [CrossRef]
- Guo, K.; Hu, X.; Li, Y.; Wang, X.; Chang, Y.; Zhou, K. Orthogonal Graph Neural Networks. Proc. AAAI Conf. Artif. Intell. 2022, 36, 3996–4004. [Google Scholar] [CrossRef]
- Huang, L.; Liu, X.; Wang, Y.; Yu, A.; Lang, B.; Li, B. Orthogonal Weight Normalization: Solution to Optimization over Multiple Dependent Stiefel Manifolds in Deep Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 3272–3278. [Google Scholar] [CrossRef]
- Peng, Y.; Sun, K.; Yang, X.; He, S. Parameter Estimation of a Complex Chaotic System with Unknown Initial Values. Eur. Phys. J. Plus 2018, 133, 305. [Google Scholar] [CrossRef]
- Zhang, P.; Zhang, H.; Yang, X.; Yang, R.; Lu, Y.; Yang, R.; Xu, B.; Xu, C.; Ren, G.; Cai, Y. Parameter Estimation for Fractional-Order Chaotic Systems by Improved Bird Swarm Optimization Algorithm. Int. J. Mod. Phys. C 2019, 30, 1950086. [Google Scholar] [CrossRef]
- Wang, L.; Yang, G.; Chen, Z. A Polynomial Chaos Expansion Approach for Nonlinear Dynamic Systems with Interval Uncertainty. Nonlinear Dyn. 2020, 101, 2489–2508. [Google Scholar] [CrossRef]
- Galimberti, C.L.; Xu, L.; Furieri, L.; Ferrari-Trecate, G. Hamiltonian Deep Neural Networks Guaranteeing Nonvanishing Gradients by Design. IEEE Trans. Autom. Control 2023, 68, 3155–3162. [Google Scholar] [CrossRef]
- Ma, W.-D.; Lewis, J.; Kleijn, W. The HSIC Bottleneck: Deep Learning without Back-Propagation. arXiv 2019, arXiv:1908.01580. [Google Scholar] [CrossRef]
- Qin, H.; Wei, Z.; Shen, M.; Gong, R.; Song, J.; Liu, X.; Yu, F. Forward and Backward Information Retention for Accurate Binary Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2247–2256. [Google Scholar] [CrossRef]
- Shrestha, Q.; Wu, Q.; Qiu, H.; Fang, H. Approximating Backpropagation for a Biologically Plausible Local Learning Rule in Spiking Neural Networks. In Proceedings of the 7th Annual Neuro-Inspired Computational Elements (NICE) Workshop, ACM, Albany, NY, USA, 23 July 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Choi, Y.; El-Khamy, M.; Lee, J. Learning Sparse Low-Precision Neural Networks with Learnable Regularization. IEEE Access 2020, 8, 96963–96974. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Abdullahi, M.; Naing, N.N.N.; Hossain, M.S.; Htet, S.A.; Ismail, S.; Mahadzir, S.L. A Comparison of Weight Initializers in Deep Learning. In Proceedings of the 2023 IEEE 21st Student Conference on Research and Development (SCOReD), Kuala Lumpur, Malaysia, 13–14 December 2023. [Google Scholar]
- Arjovsky, M.; Shah, A.; Bengio, Y. Unitary Evolution Recurrent Neural Networks. In Proceedings of the 33rd International Conference on Machine Learning (ICML 2016), New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Qiao, J.; Li, S.; Li, W. Mutual Information-Based Weight Initialization Method for Sigmoidal Feedforward Neural Networks. Neurocomputing 2016, 207, 676–683. [Google Scholar] [CrossRef]
- Hasan, M.S.; Alam, R.; Adnan, M.A. Neuroscientific Analysis of Weights in Neural Networks. Int. J. Pattern Recognit. Artif. Intell. 2021, 35, 2152021. [Google Scholar] [CrossRef]
- Yahoo Finance. Historical Gold Prices (XAU/USD). Available online: https://finance.yahoo.com (accessed on 6 July 2024).
- Papers with Code. CIFAR10MNIST Dataset. Available online: https://paperswithcode.com/dataset/cifar10mnist (accessed on 22 January 2025).
- Kandel, M.; Castelli, M. The effect of batch size on the generalizability of the convolutional neural networks on a histopathology dataset. ICT Express 2020, 6, 312–315. [Google Scholar] [CrossRef]
- Bengio, Y. Practical recommendations for gradient-based training of deep architectures. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 437–478. [Google Scholar] [CrossRef]
- Suliman, Y.; Zhang, A. A review on back-propagation neural networks in the application of remote sensing. J. Earth Sci. Eng. 2015, 5, 52–65. [Google Scholar]
- Feng, J.; Li, X.; Wang, H.; Zhang, Q. Revisiting weight initialization in deep learning under modern training settings. IEEE Access 2021, 9, 85741–85750. [Google Scholar]
- Sun, Y.; Wang, X.; Li, C.; Zhang, Y. Robust weight initialization for deep neural networks via layer-wise learning dynamics. Neural Netw. 2021, 142, 252–265. [Google Scholar] [CrossRef]
- Zhou, K.; Li, J.; Chen, M.; Wang, S. Adaptive weight initialization for deep neural networks with layer-wise sensitivity control. Pattern Recognit. 2023, 141, 109626. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Initialization Method | Objective | Target Architecture | Key Advantage | References |
|---|---|---|---|---|
| Orthogonal | Variance preservation | Deep CNNs, RNNs, LSTMs | Stabilizes deep and recurrent models | [6,34] |
| Chaos-Based (Lorenz) | Structured randomness | Complex nonlinear models | Enhances diversity, accelerates convergence | [9] |
| Mutual Information (MIWI) | Information maximization | Sigmoid-based MLPs | Reduces saturation, improves signal sensitivity | [35] |
| Genetic/PSO Optimization | Global search optimization | General | Avoids poor local minima, robust initial states | [7,11] |
| Linear Product Structure (LPS) | Polynomial-based weight calculation | Polynomial-structured nets | Algebraically optimized initialization | [13] |
| Brain-Inspired (Lognormal, Skewed) | Biologically realistic weight distribution | Deep CNNs, general | Mimics synaptic diversity; boosts accuracy and convergence | [36] |
| No | Date | Close (USD) |
|---|---|---|
| 1 | 3 September 2019 | 1545.90 |
| 2 | 4 September 2019 | 1550.30 |
| 3 | 5 September 2019 | 1515.40 |
| 4 | 6 September 2019 | 1506.20 |
| 5 | 9 September 2019 | 1502.20 |
| 6 | 10 September 2019 | 1490.30 |
| 7 | 11 September 2019 | 1494.40 |
| 8 | 12 September 2019 | 1498.70 |
| 9 | 13 September 2019 | 1490.90 |
| 10 | 16 September 2019 | 1503.10 |
| No. | Number of Neurons | Stimulating Function | Type of Layer |
|---|---|---|---|
| 1 | 6 | ReLU | Input layer |
| 2 | 8 | ReLU | Hidden layer |
| 3 | 4 | ReLU | Hidden layer |
| 4 | 2 | ReLU | Hidden layer |
| 5 | 1 | sigmoid | Output layer |
| Parameters | Values |
| Epoch | 1–200 |
| Batch size | 8, 16, 32, 64, 128, 256, 512 |
| Optimizer | Adam |
| Loss function | Root Mean Square Error (RMSE) |
| Learning rate | 0.1, 0.01, 0.001, 0.0001 |
| Validation Methods | Hold-Out Validation Method (80% train and 20% test) K-Fold Cross-Validation Method |
| Dataset | Initializer | Mean Gradient Norm | Std Gradient Norm | CV (Mean) | Vanishing Layers | Exploding Layers | Stable Layers |
|---|---|---|---|---|---|---|---|
| CIFAR-10 | He | 0.1802 | 0.1462 | 0.4456 | 0 | 0 | 8 |
| Laor | 0.2695 | 0.2290 | 0.3448 | 1 | 0 | 7 | |
| Random | 0.2629 | 0.3043 | 0.3633 | 0 | 0 | 8 | |
| Xavier | 0.2624 | 0.2685 | 0.3034 | 0 | 0 | 8 | |
| Gold price | He | 0.0095 | 0.0046 | 0.4366 | 4 | 0 | 4 |
| Laor | 0.0058 | 0.0018 | 0.5997 | 8 | 0 | 0 | |
| Random | 0.0171 | 0.0096 | 0.4451 | 1 | 0 | 7 | |
| Xavier | 0.0067 | 0.0033 | 0.3841 | 6 | 0 | 2 | |
| MNIST | He | 0.0103 | 0.0141 | 0.4365 | 5 | 0 | 3 |
| Laor | 0.0175 | 0.0114 | 0.2230 | 3 | 0 | 5 | |
| Random | 0.0126 | 0.0139 | 0.3926 | 5 | 0 | 3 | |
| Xavier | 0.0085 | 0.0061 | 0.3755 | 5 | 0 | 3 |
| Criteria | Laor | Xavier | He | Random |
|---|---|---|---|---|
| Convergence Success Rate | Low (0.00822) | Highest (0.00842) | Lowest (0.00803) | Moderate (0.00824) |
| Convergence Rate | Moderate (20) | Fastest (19) | Slowest (21) | Moderate (20) |
| RMSE Stability (IQR) | Narrow | Wide | Moderate | Widest |
| Gradient Stability | Best | Poor at deep networks | Moderate | Frequent vanishing/exploding |
| Depth Scalability (11 Layers) | Best (0.00792) | Unstable (0.00821) | Unstable (0.01002) | Unstable (0.01148) |
| Batch Size Sensitivity | Stable | Sensitive | Stable | Unstable |
| Learning Rate Sensitivity | Sensitive | Handles high LR | stable | unstable |
| CPU Time | Fastest on MNIST Moderate on CIFAR-10 and Gold Price | Fastest on Gold price Slowest on CIFAR-10 and MNIST | Fastest on CIFAR-10 Moderate on MNIST and Gold Price | Slowest on Gold price Moderate on CIFAR-10 and MNIST |
| Cross-Validation Robustness | Lowest RMSE | High RMSE | Moderate | High RMSE |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boongasame, L.; Muangprathub, J.; Thammarak, K. Laor Initialization: A New Weight Initialization Method for the Backpropagation of Deep Learning. Big Data Cogn. Comput. 2025, 9, 181. https://doi.org/10.3390/bdcc9070181
Boongasame L, Muangprathub J, Thammarak K. Laor Initialization: A New Weight Initialization Method for the Backpropagation of Deep Learning. Big Data and Cognitive Computing. 2025; 9(7):181. https://doi.org/10.3390/bdcc9070181
Chicago/Turabian StyleBoongasame, Laor, Jirapond Muangprathub, and Karanrat Thammarak. 2025. "Laor Initialization: A New Weight Initialization Method for the Backpropagation of Deep Learning" Big Data and Cognitive Computing 9, no. 7: 181. https://doi.org/10.3390/bdcc9070181
APA StyleBoongasame, L., Muangprathub, J., & Thammarak, K. (2025). Laor Initialization: A New Weight Initialization Method for the Backpropagation of Deep Learning. Big Data and Cognitive Computing, 9(7), 181. https://doi.org/10.3390/bdcc9070181