
Fusion of Sentiment and Market Signals for Bitcoin Forecasting: A SentiStack Network Based on a Stacking LSTM Architecture

Abstract
1. Introduction
2. Methodology
2.1. Dataset
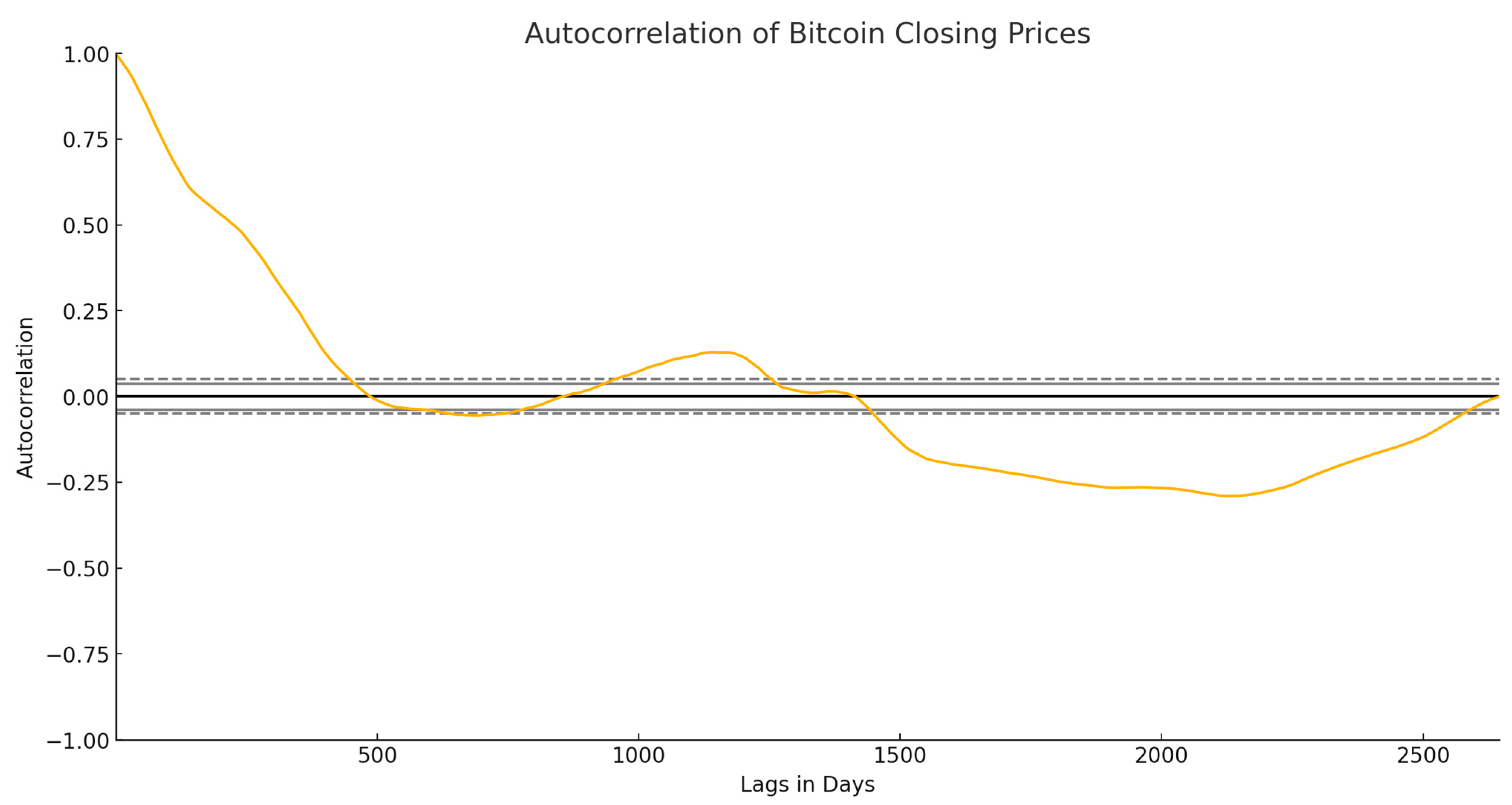
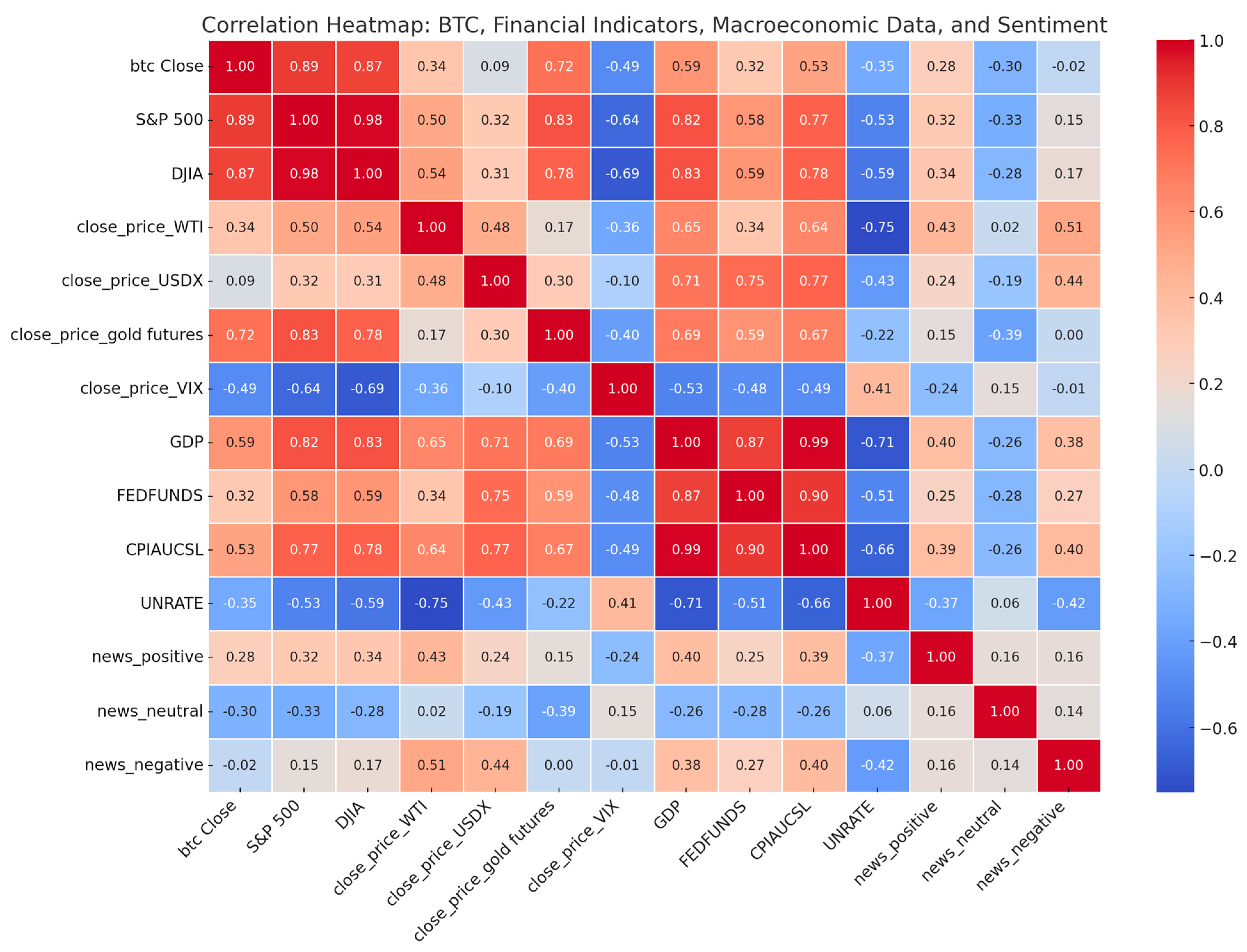
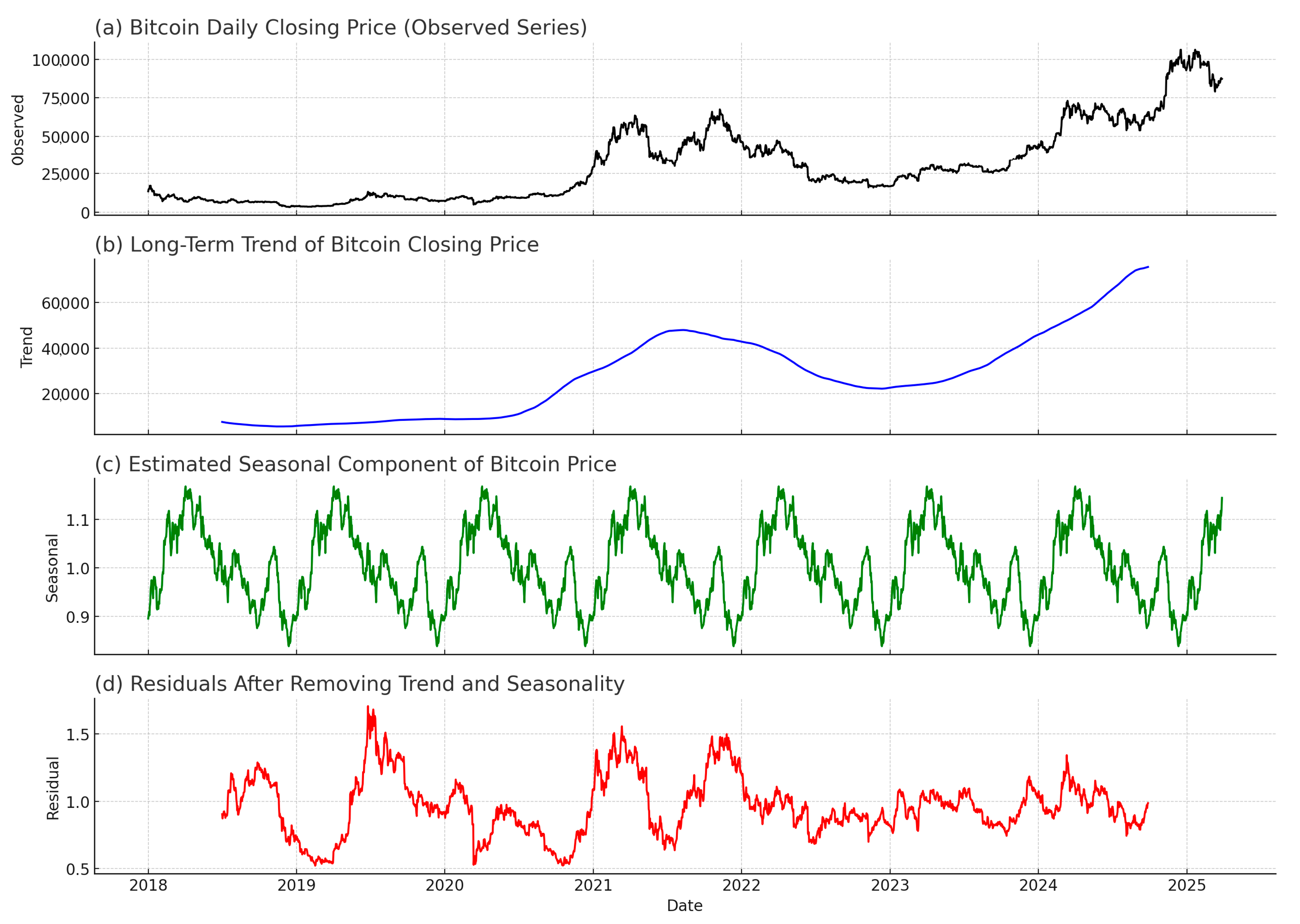
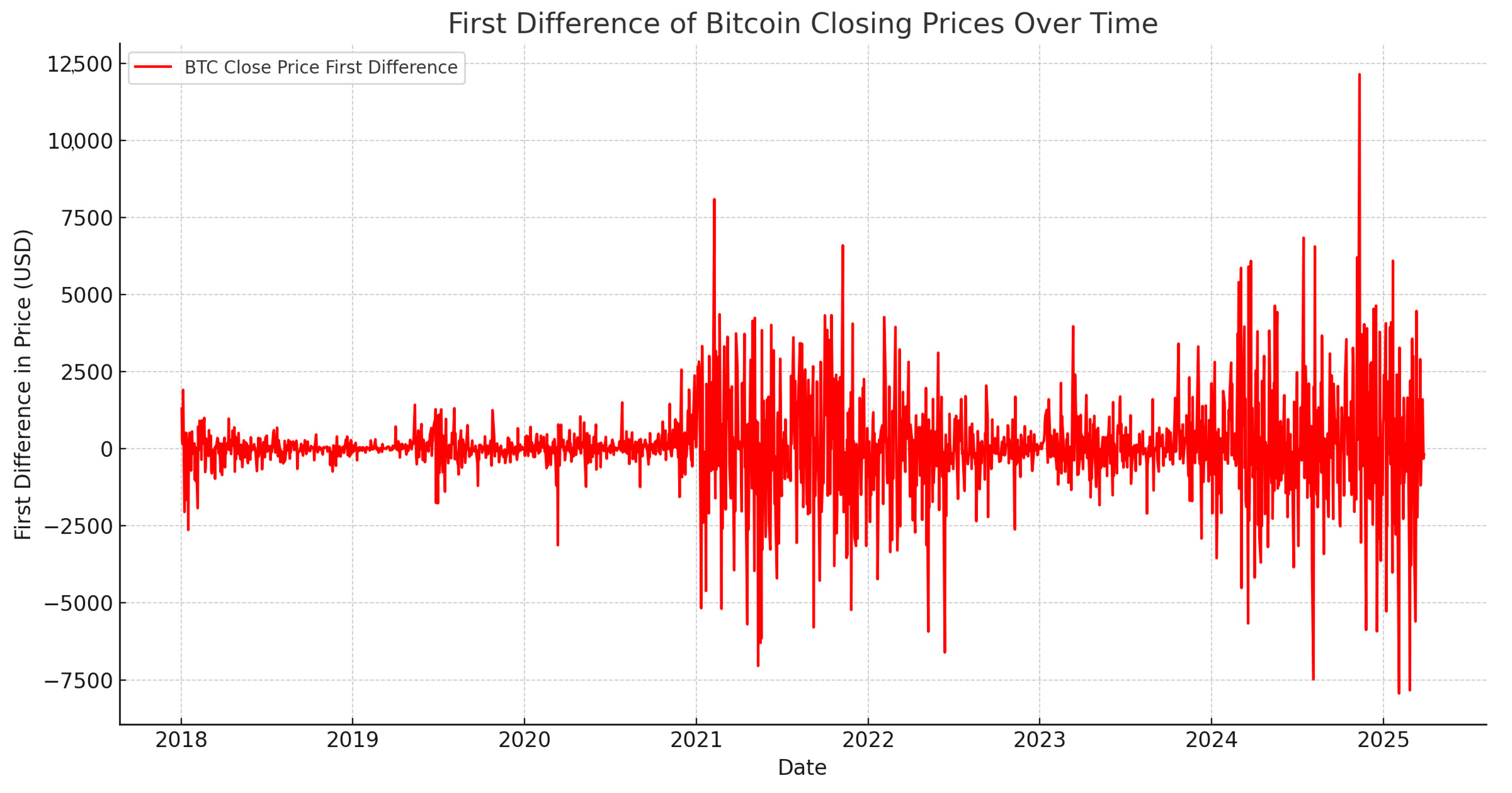
2.2. Data Cleaning
| Algorithm 1. Workflow of data cleaning and preprocessing for Multimodal Bitcoin Price Forecasting |
| Inputs: |
| Raw market data (Price, Volume, Technical indicators) |
| Raw macroeconomic data (GDP, CPI, Unemployment, Interest Rates) |
| Raw textual data (Twitter posts, Financial news) |
| Outputs: |
| Cleaned and aligned multimodal dataset ready for modeling |
| Procedure: |
| 1. Load Raw Data: |
| -Load market data from Bitstamp (prices, volumes, OHLCV) |
| -Load macroeconomic data from FRED (GDP, CPI, Unemployment Rate, Interest Rate) |
| -Load textual data from Twitter API and financial news platforms |
| 2. Market Data Cleaning: |
| For each feature in market data: |
| If missing values exist: |
| -Forward-fill missing values |
| -If forward-fill impossible (no previous value), backward-fill |
| 3. Macroeconomic Data Cleaning: |
| For each macroeconomic indicator: |
| -Convert quarterly/monthly frequency to daily: |
| For each missing daily value: |
| -Forward-fill the last known monthly/quarterly value |
| -Ensure all days have consistent values |
| 4. Textual Data Cleaning (Twitter/News): |
| For each text entry (tweets/news articles): |
| -Remove URLs, special characters, emojis, hashtags, mentions |
| -Convert text to lowercase |
| -Remove posts containing promotional terms ("giveaway", "cashback", etc.) |
| -Exclude tweets from users with fewer than 10 followers |
| -Tokenize and preprocess text for DeepSeek model |
| Generate sentiment embeddings: |
| -Apply DeepSeek model to cleaned texts |
| -Extract sentiment scores (polarity and intensity) |
| 5. Data Alignment and Synchronization: |
| -Align market data, macroeconomic data, and sentiment data on a daily timestamp |
| -Drop dates with incomplete data across modalities, if any remain |
| 6. Feature Engineering: |
| -Generate lagged variables (t − 1, t − 2, t − 3) from market and macroeconomic data |
| -Calculate technical indicators (e.g., SMA, EMA, RSI, MACD, Bollinger Bands) |
| -Construct feature matrix with numerical and sentiment features |
| 7. Data Normalization: |
| -Apply Min–Max scaling or Z-score normalization to numerical features |
| 8. Save cleaned data: |
| -Export final cleaned and normalized dataset to CSV files |
| Return: |
| Cleaned and structured dataset suitable for machine-learning models |
2.3. Feature Engineering
| Algorithm 2. Workflow of preparing multimodal sentiment data from DeepSeek |
| Input: |
| NewsCorpus ← Collection of news and social media articles (raw text) |
| MarketIndicators ← Time-series data (price, volume, volatility, etc.) |
| Output: |
| SentimentScores ← Scored sentiment signals |
| FG Index ← Composite Fear & Greed index over time |
| 1: Initialize DeepSeek model with pretrained weights |
| 2: for each document in NewsCorpus do |
| 3: Clean the text (remove URLs, emojis, special tokens) |
| 4: Tokenize and normalize text for model input |
| 5: Feed text into DeepSeek to obtain: |
| 6: sentiment_score ∈ [−1, 1] //sentiment polarity |
| 7: polarity_label ∈ {Positive, Neutral, Negative} |
| 8: intensity ∈ {Mild, Moderate, Strong} |
| 9: confidence ∈ [0, 1] |
| 10: Store results in SentimentScores table with timestamp |
| 11: end for |
| 12: Aggregate SentimentScores by time period (e.g., daily average) |
| 13: Merge aggregated sentiment with MarketIndicators: |
| 14: -Normalize metrics (volume, RSI, MACD, volatility) |
| 15: -Apply weighting scheme to components |
| 16: -Define FG_Index_t = w1 * Sentiment_t + w2 * Volatility_t |
| + w3 * Momentum_t + w4 * Volume_t |
| 17: Smooth FG_Index using moving average |
| 18: Output FG_Index and aligned sentiment series |
| Return: Sentiment Scores, Fear and Greed Index |
2.4. Algorithm Framework
| Algorithm 3. Workflow for back testing and finding the optimal machine-learning model |
| 1: Set random seed to ensure reproducibility |
| 2: Load dataset, clean and forward-fill missing values |
| 3: Create lagged features (t − 1, t − 2, t − 3) |
| 4: Compute technical indicators: SMA, EMA, Volatility |
| 5: Encode categorical features (e.g., Sentiment) |
| 6: Split data: |
| └─ Features ← All columns except Date & btc Close |
| └─Target ← btc Close |
| 7: Chronologically split into training and testing sets (70%/30%) |
| 8: Select model from: |
| {‘random_forest’, ‘xgboost’, ‘lstm’, ‘lstm_attention_model’, |
| ‘stacking_lstm’, ‘lstm_attention_tuned’} |
| 9: model optimization: |
| └─ Perform GridSearchCV with TimeSeriesSplit (10-fold) |
| └─ Normalize and reshape to (samples, timesteps, features) |
| └─ Build and train the architecture |
| └─ Predict and inverse transform |
| 10: Evaluate model on test set using: |
| └─ RMSE, MAE, R2 |
| 11: Compute: |
| └─ 5% movement prediction accuracy |
| └─ Strategy returns from 5% signal and multi-factor rules |
| └─ Strategy returns from multi-factor rules |
| 12: Simulate and compare multiple strategies: |
| └─ Movement Threshold-based, Multi-factor, Buy & Hold, Random, Stratified |
| 13: Visualize cumulative returns across strategies |
| 14: Perform Feature Ablation Study: |
| └─ Run models on subsets: Market, Technical, Sentiment, Macro, Index |
| └─ Compare results using RMSE, MAE, R2 |
| 15: Visualize ablation metrics with horizontal bar plots |
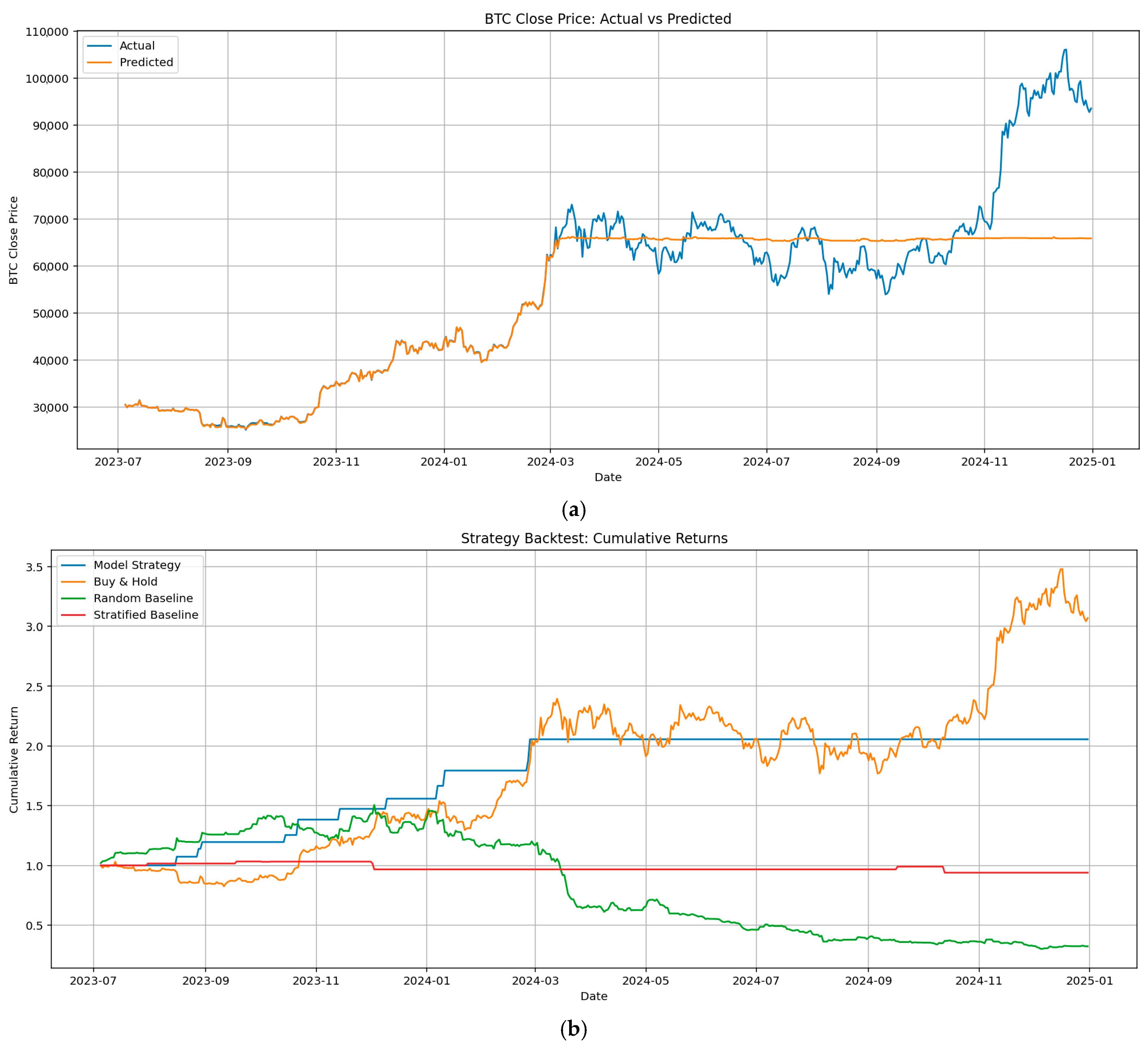
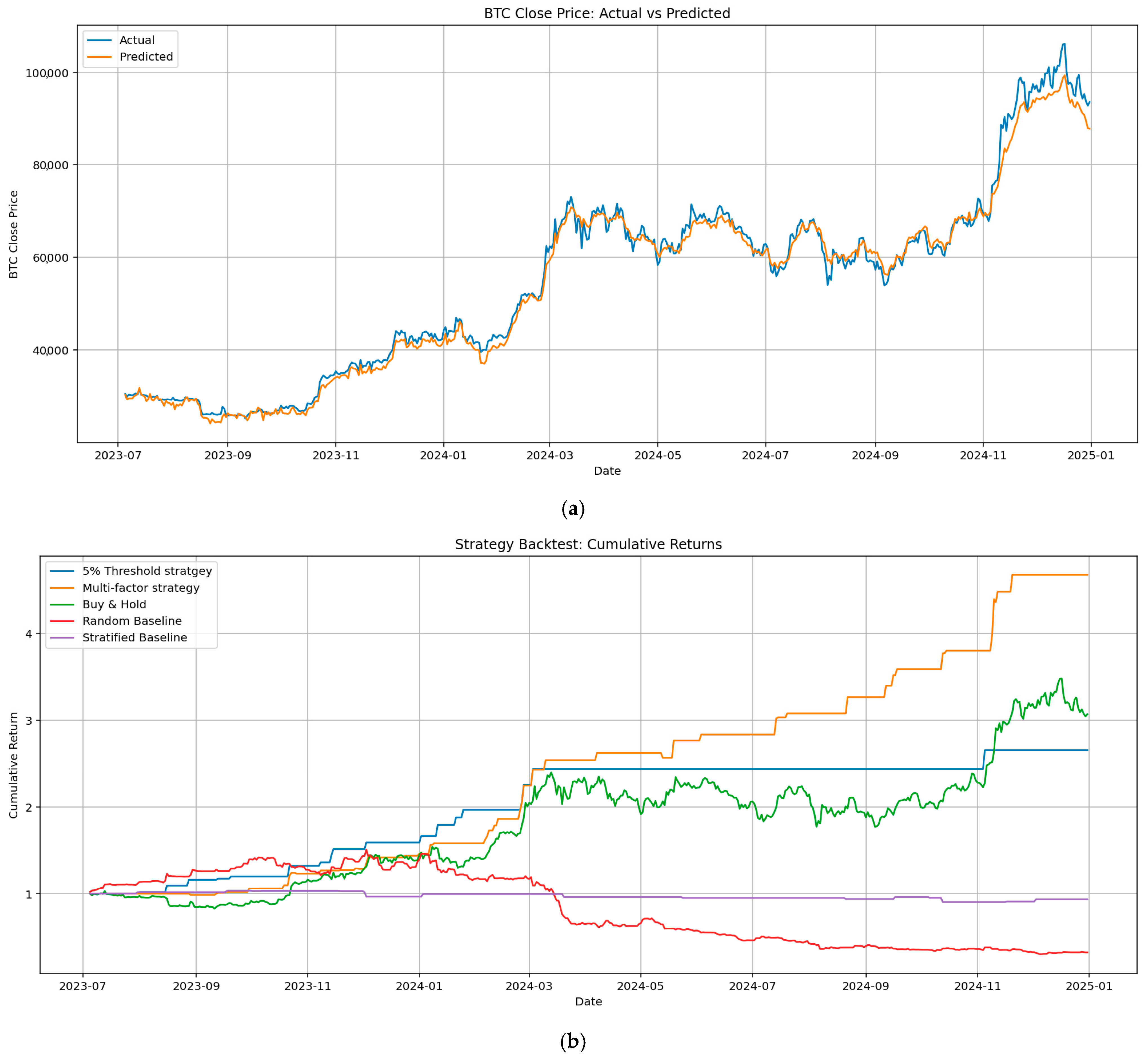
2.5. Trading Strategy
3. Results
4. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nakamoto, S.; Bitcoin, A. A Peer-to-Peer Electronic Cash System. 2008. Available online: https://bitcoin.org/bitcoin.pdf (accessed on 15 June 2025).
- Yermack, D. Is Bitcoin a real currency? An economic appraisal. In Handbook of Digital Currency; Elsevier: Amsterdam, The Netherlands, 2024; pp. 29–40. [Google Scholar]
- Mai, F.; Shan, Z.; Bai, Q.; Wang, X.; Chiang, R.H.L. How does social media impact Bitcoin value? A test of the silent majority hypothesis. J. Manag. Inf. Syst. 2018, 35, 19–52. [Google Scholar] [CrossRef]
- Le, H.H.; Viviani, J.-L. Predicting bank failure: An improvement by implementing a machine-learning approach to classical financial ratios. Res. Int. Bus. Financ. 2018, 44, 16–25. [Google Scholar] [CrossRef]
- García Nieto, P.J.; García-Gonzalo, E.; Álvarez Antón, J.C.; González Suárez, V.M.; Mayo Bayón, R.; Mateos Martín, F. A comparison of several machine learning techniques for the centerline segregation prediction in continuous cast steel slabs and evaluation of its performance. J. Comput. Appl. Math. 2018, 330, 877–895. [Google Scholar] [CrossRef]
- Patel, N.P.; Parekh, R.; Thakkar, N.; Gupta, R.; Tanwar, S.; Sharma, G.; Davidson, I.E.; Sharma, R. Fusion in Cryptocurrency Price Prediction: A Decade Survey on Recent Advancements, Architecture, and Potential Future Directions. IEEE Access 2022, 10, 34511–34538. [Google Scholar] [CrossRef]
- Wang, J.; Ma, F.; Bouri, E.; Guo, Y. Which factors drive Bitcoin volatility: Macroeconomic, technical, or both? J. Forecast. 2023, 42, 970–988. [Google Scholar] [CrossRef]
- Zou, Y.; Herremans, D. PreBit—A multimodal model with Twitter FinBERT embeddings for extreme price movement prediction of Bitcoin. Expert Syst. Appl. 2023, 233, 120838. [Google Scholar] [CrossRef]
- Zhang, W.; Zhao, L.; Xia, H.; Sun, S.; Sun, J.; Qin, M.; Li, X.; Zhao, Y.; Zhao, Y.; Cai, X.; et al. A Multimodal Foundation Agent for Financial Trading: Tool-Augmented, Diversified, and Generalist. arXiv 2024, arXiv:2402.18485. [Google Scholar]
- Chen, Y.-F.; Huang, S.-H. Sentiment-influenced trading system based on multimodal deep reinforcement learning. Appl. Soft Comput. 2021, 112, 107788. [Google Scholar] [CrossRef]
- Anbaee Farimani, S.; Jahan, M.V.; Milani Fard, A. An Adaptive Multimodal Learning Model for Financial Market Price Prediction. IEEE Access 2024, 12, 121846–121863. [Google Scholar] [CrossRef]
- Che, W.; Wang, Z.; Jiang, C.; Abedin, M.Z. Predicting financial distress using multimodal data: An attentive and regularized deep learning method. Inf. Process. Manag. 2024, 61, 103703. [Google Scholar] [CrossRef]
- Daiya, D.; Lin, C. Stock Movement Prediction and Portfolio Management via Multimodal Learning with Transformer. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; IEEE: Toronto, ON, Canada, 2021; pp. 3305–3309. [Google Scholar] [CrossRef]
- Sheng, Y.; Qu, Y.; Ma, D. Stock price crash prediction based on multimodal data machine learning models. Financ. Res. Lett. 2024, 62, 105195. [Google Scholar] [CrossRef]
- Chen, Z.; Li, C.; Sun, W. Bitcoin price prediction using machine learning: An approach to sample dimension engineering. J. Comput. Appl. Math. 2020, 365, 112395. [Google Scholar] [CrossRef]
- Lee, S.I.; Yoo, S.J. Multimodal deep learning for finance: Integrating and forecasting international stock markets. J. Supercomput. 2020, 76, 8294–8312. [Google Scholar] [CrossRef]
- Mutemi, A.; Bacao, F. A numeric-based machine learning design for detecting organized retail fraud in digital marketplaces. Sci. Rep. 2023, 13, 12499. [Google Scholar] [CrossRef]
- D’Amato, V.; Levantesi, S.; Piscopo, G. Deep learning in predicting cryptocurrency volatility. Phys. Stat. Mech. Its Appl. 2022, 596, 127158. [Google Scholar] [CrossRef]
- Fang, F.; Chung, W.; Ventre, C.; Basios, M.; Kanthan, L.; Li, L.; Wu, F. Ascertaining price formation in cryptocurrency markets with machine learning. Eur. J. Financ. 2024, 30, 78–100. [Google Scholar] [CrossRef]
- Chen, W.; Xu, H.; Jia, L.; Gao, Y. Machine learning model for Bitcoin exchange rate prediction using economic and technology determinants. Int. J. Forecast. 2021, 37, 28–43. [Google Scholar] [CrossRef]
- Shahbazi, Z.; Byun, Y.-C. Improving the Cryptocurrency Price Prediction Performance Based on Reinforcement Learning. IEEE Access 2021, 9, 162651–162659. [Google Scholar] [CrossRef]
- Kim, G.; Shin, D.-H.; Choi, J.G.; Lim, S. A Deep Learning-Based Cryptocurrency Price Prediction Model That Uses On-Chain Data. IEEE Access 2022, 10, 56232–56248. [Google Scholar] [CrossRef]
- Jaquart, P.; Köpke, S.; Weinhardt, C. Machine learning for cryptocurrency market prediction and trading. J. Financ. Data Sci. 2022, 8, 331–352. [Google Scholar] [CrossRef]
- Jaquart, P.; Dann, D.; Weinhardt, C. Short-term bitcoin market prediction via machine learning. J. Financ. Data Sci. 2021, 7, 45–66. [Google Scholar] [CrossRef]
- Kim, H.-M.; Bock, G.-W.; Lee, G. Predicting Ethereum prices with machine learning based on Blockchain information. Expert Syst. Appl. 2021, 184, 115480. [Google Scholar] [CrossRef]
- Windsor, E.; Cao, W. Improving exchange rate forecasting via a new deep multimodal fusion model. Appl. Intell. 2022, 52, 16701–16717. [Google Scholar] [CrossRef] [PubMed]
- Elbagir, S.; Yang, J. Twitter Sentiment Analysis Using Natural Language Toolkit and VADER Sentiment. In Proceedings of the International MultiConference of Engineers and Computer Scientists 2019, Hong Kong, China, 13–15 March 2019. [Google Scholar]
- Acosta, J.; Lamaute, N.; Luo, M.; Finkelstein, E.; Cotoranu, A. Sentiment Analysis of Twitter Messages Using Word2Vec. In Proceedings of the 2019 Sixth International Conference on Social Networks Analysis, Management and Security (SNAMS), Granada, Spain, 22–25 October 2019. [Google Scholar]
- Sun, M.; Huang, X.; Ji, H.; Liu, Z.; Liu, Y. (Eds.) Lecture Notes in Computer Science. In Proceedings of the Chinese Computational Linguistics: 18th China National Conference, CCL 2019, Kunming, China, 18–20 October 2019; Springer International Publishing: Cham, Switzerland, 2019; Volume 11856. [Google Scholar] [CrossRef]
- Lu, H.; Liu, W.; Zhang, B.; Wang, B.; Dong, K.; Liu, B.; Sun, J.; Ren, T.; Li, Z.; Yang, H.; et al. DeepSeek-VL: Towards Real-World Vision-Language Understanding. arXiv 2024, arXiv:2403.05525. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need (Nips). arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Dai, D.; Deng, C.; Zhao, C.; Xu, R.; Gao, H.; Chen, D.; Li, J.; Zeng, W.; Yu, X.; Wu, Y. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models. arXiv 2024, arXiv:2401.06066. [Google Scholar]
- Liu, A.; Feng, B.; Wang, B.; Wang, B.; Liu, B.; Zhao, C.; Dengr, C.; Ruan, C.; Dai, D.; Guo, D. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. arXiv 2024, arXiv:2405.04434. [Google Scholar]
- Zhao, L.; Lai, Y.; Shi, S.; Cheng, G.; Qiu, Z.; Xie, Z. Research on Financial Time Series Prediction Based on LSTM and Attention Mechanism. In Proceedings of the 2025 Asia-Europe Conference on Cybersecurity, Internet of Things and Soft Computing (CITSC), Rimini, Italy, 10–12 January 2025; IEEE: New York, NY, USA, 2025; pp. 347–351. [Google Scholar]
- Shakri, I.H. Time series prediction using machine learning: A case of Bitcoin returns. Stud. Econ. Financ. 2022, 39, 458–470. [Google Scholar] [CrossRef]
- Saheed, Y.K.; Ayobami, R.M.; Orje-Ishegh, T. A comparative study of regression analysis for modelling and prediction of bitcoin price. In Blockchain Applications in the Smart Era; Springer: Cham, Switzerland, 2022; pp. 187–209. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model/Architecture | Data Types | Novelty/Pros and Cons | Ref |
|---|---|---|---|
| PreBit Multimodal Hybrid Model | Tweets, OHLCV, technical indicators, Ethereum, gold prices | Combines FinBERT and SVM; complex to train | [8] |
| FinAgent Multimodal LLM Trading Agent | Price, news, charts, indicators, expert guidance | Multimodal, tool-augmented, explainable; complex, stock-focused | [9] |
| Multimodal Deep Reinforcement Learning | Price data, news sentiment | Adds influence model; robust, real-time, complex, limited interpretability | [10] |
| ABM-BCSIM Adaptive Fusion Model | News, mood, indicators, prices, sentiment scores | 40% error drop; adaptive, accurate, high computational cost | [11] |
| Attentive Regularized Deep Learning | Financial ratios, current reports, interfirm network data | Attention mechanisms, entropy regularization; accurate, complex, yet highly interpretable | [12] |
| Transformer Dilated Convolution Event Network | Financial indicators, news articles, event embeddings, technical indicator data | Multimodal Transformer improves accuracy; effective, interpretable, computationally intensive, complex training | [13] |
| LightGBM Multimodal Graph Data Model | Market data, graph data, textual sentiment data, technical indicators | Enhanced accuracy; innovative graph integration; profitable, interpretable, handles imbalance | [14] |
| Logistic Regression, LSTM, RF | Bitcoin daily, high-frequency, gold price, Google/Baidu trends data | Sample dimension engineering improves prediction; different methods per frequency | [15] |
| Multimodal Deep Neural Networks | Stock indices data (U.S./Korea), opening/high/low/closing market prices | Multimodal fusion enhances accuracy; highly effective, complex model integration | [16] |
| Numeric-based ML Fraud Detection | Buyer/seller behaviors, transaction numeric data from digital retail marketplaces | Detects organized retail fraud; highly accurate, scalable, handles imbalance | [17] |
| Jordan Recurrent Neural Network | Cryptocurrency returns: Bitcoin, Ethereum, Ripple daily price volatility data | High predictability in cryptocurrency volatility; parsimonious, superior to traditional methods | [18] |
| LSTM Multilabel Cryptocurrency Predictor | Cryptocurrency tick-level mid-price, order-book data from multiple currencies | High accuracy on tick prediction; lean model; requires frequent retraining | [19] |
| ANN-RF-LSTM Hybrid Model | Economic indicators, blockchain data, Google trends, tweets, currency ratios | Integrates economic determinants; superior accuracy, non-linear factor importance evaluation | [20] |
| Reinforcement Learning Prediction Model | Blockchain data, Litecoin, Monero historical price and transaction information | Reinforcement learning enhances prediction; transparent, secure, better volatility | [21] |
| SAM-LSTM Cryptocurrency Price Predictor | On-chain Bitcoin data (transactions, mining, difficulty, blocks), historical prices | Novel attention-LSTM structure, excellent performance; computationally intensive, complex training | [22] |
| LSTM-GRU Crypto Trading Ensemble | Crypto daily prices, market capitalization, returns, transaction data, risk-free rate. | Technical indicators, market capitalization, historical price of 100 cryptocurrencies | [23] |
| GRU-GB Classifier Bitcoin Prediction | Blockchain features, sentiment data, technical indicators, asset-based information | Highly accurate short-term predictions; profits before fees, fees negate returns | [24] |
| Ethereum Blockchain ML Predictor | Ethereum-specific blockchain (gas, uncle blocks), economic, Bitcoin blockchain data | Ethereum-specific blockchain analysis; accurate predictions; comprehensive, insightful factors identified | [25] |
| Data Name | Source | Type | Frequency |
|---|---|---|---|
| Bitcoin OHLCV Prices | Bitstamp API | Numerical | Daily |
| Bitcoin Trading Volume | Bitstamp API | Numerical | Daily |
| S&P 500 Index, DJIA | Yahoo Finance | Numerical | Daily |
| Gold Price | Yahoo Finance | Numerical | Daily |
| Crude Oil Price (WTI) | TradingEconomics.com | Numerical | Daily |
| GDP (U.S.) | FRED | Macroeconomic Indicator | Quarterly |
| CPI (Consumer Price Index) | FRED | Macroeconomic Indicator | Monthly |
| Unemployment Rate (U.S.) | FRED | Macroeconomic Indicator | Monthly |
| Federal Funds Rate | FRED | Macroeconomic Indicator | Monthly |
| Twitter Sentiment Data | Twitter API | Textual/Sentiment | Daily (aggregated) |
| Financial News Sentiment | CryptoPanic, CoinDesk, Yahoo Finance | Textual/Sentiment | Daily (aggregated) |
| Category | Feature Engineering Method | Description |
|---|---|---|
| Temporal Features | Lagged Features | Created btc_Close_t − 1, t − 2, t − 3 to include past price dynamics. |
| Statistical Transformation | Returns and Volatility | Computed 1-day return (Return_1d) and 5-day rolling volatility (Volatility_5). |
| Technical Indicators | SMA, EMA, RSI, MACD, Bollinger Bands, VWAP, OBV, ATR | Extracted multiple standard technical indicators from Bitcoin OHLC data. |
| Normalization | MinMaxScaler | Scaled input features for LSTM and stacking models. |
| Sentiment Features | Fear & Greed Index, News Sentiment | Incorporated sentiment category scores (positive, neutral, negative) and FG Index as behavioral signals. |
| Categorical Encoding | LabelEncoder | Converted Sentiment column into numerical form for model input. |
| Feature Ablation | Grouped Feature Testing | Evaluated the impact of removing feature groups (e.g., sentiment, macro) on model performance. |
| Model Name | Type | Key Parameters | Tuning Method |
|---|---|---|---|
| Random Forest | RandomForestRegressor | n_estimators = [50, 100] max_depth = [10] min_samples_split = [5] min_samples_leaf = [1] | GridSearchCV (10-fold TSCV) |
| LSTM | Sequential (Keras) | LSTM(50, activation = ‘relu’) Dense(1) epochs = 50 batch_size = 32 | GridSearchCV (10-fold TSCV) |
| LSTM + Attention | Functional API (Keras) | LSTM(50, return_sequences = True) Attention() Dense(50, relu) epochs = 50 batch_size = 32 | RandomSearch (Keras Tuner, 10-fold TSCV) |
| SentiStack Network | Ensemble (3 LSTMs + Ridge) | Base: LSTM(32/64/128) Meta: Ridge() epochs = 30 batch_size = 32 | GridSearchCV (10-fold TSCV) |
| XGBoost | XGBRegressor | n_estimators = [50, 100] max_depth = [5, 10] learning_rate = [0.05, 0.1] subsample = [0.8, 1.0] | GridSearchCV (10-fold TSCV) |
| Models | RMSE | MAE | R2 | MAPE | 5% Daily Price Movement Accuracy |
|---|---|---|---|---|---|
| Random Baseline Model | 45,737 | 37,316 | −2.41 | 53.19% | 72% |
| RandomForest | 9884 | 4596 | 0.76 | 5.79% | 71.43% |
| LSTM + Attention | 9187 | 6805 | 0.79 | 5.65% | 54.55% |
| XGBOOSTRegressor | 9693 | 4628 | 0.77 | 5.95% | 77.78% |
| SentiStack Network | 2003 | 1488 | 0.99 | 2.68% | 83.33% |
| LSTM | 2179 | 1684 | 0.9883 | 3.19% | 58.33% |
| Strategy | Profit % | Sortino | Sharp | Max Drawdown % | Win Rate of Total Trades % | Number of Trades |
|---|---|---|---|---|---|---|
| Random Baseline | −67.69 | −1.58 | −1.456 | 79.964 | 43.25 | 115 |
| Buy & Hold | 206 | 2.36 | 1.48 | 26 | 51.7 | 1 |
| SentiStack Network (5% daily price Movement Event-driven Trading Backtest) | 165 | No loss | 2.65 | 0 | 100 | 16 |
| SentiStack Network (Multi-Factor strategy) | 367 | 7.15 | 3.63 | 2.16 | 89.58 | 37 |
| LSTM (5% Movement Event-driven Trading Backtest) | 64.95 | No loss | 1.71 | 0 | 100 | 6 |
| LSTM (Multi-Factor strategy) | 233.64 | 2.70 | 2.84 | 6.51 | 73.47 | 39 |
| LSTM + attention [34] (5% Movement Event-driven Trading Backtest) | 92.35 | inf | 2.12 | 1.50 | 93.33 | 12 |
| LSTM + attention [34] (Multi-Factor strategy) | 220.23 | 7.82 | 3.02 | 2.28 | 83.78 | 33 |
| Random Forest (5% Movement Event-driven Trading Backtest) | 105 | No loss | 2.2 | 0 | 100 | 11 |
| XGBOOSTRegressor (5% Movement Event-driven Trading Backtest) | 122 | No loss | 2.31 | 0 | 100 | 11 |
| Model | Architecture | Input Modalities | Key Innovations | Task Type | Performance Metrics |
|---|---|---|---|---|---|
| SentiStack | 3 × LSTM → Ridge Regression (Stacking Ensemble) | Market, sentiment (DeepSeek), macroeconomic | Stacked LSTM, sentiment, macro data, real trading strategy | Regression + Trading Strategy | R2 = 0.99, MAE = 1402, RMSE = 1935, MAPE = 2.68%, Sharpe = 3.91, Sortino = 7.49, 5% classification Accuracy = 83%; |
| PreBit [8] | CNN + SVM + meta-SVM | Price, Twitter (FinBERT) | Movement prediction (±5%); FinBERT; ensemble classifier | Classification (±5%) | F1 = 0.38; Accuracy = 66.2%; Trading profit ≈ +56% |
| LSTM [19] | LSTM + Autoencoder + Dense | Tick-level order book data, trades, market microstructure | Tick-level retraining, volatility | Multilabel classification | Accuracy = 78%; Precision = 0.79; F1 = 0.78 |
| Random Forest [35] | RF, MLR, MLP, AMT, M5 Tree | Economic indicators, exchange rates, gold/oil/S&P returns | Macro inputs, ML benchmark | Regression | Best model: RF with R2 = 0.9883, MAE = 272.5, RMSE = 611.35 |
| BoostStack-Regressor [36] | Ensemble of the six regressors | Bitcoin historical data (2014–2020) | Multi-model regression ensemble | Regression | R2 = 0.92; MAE = 41.5; RMSE = 66.2; MAPE = 8.1%; RMSLE = 0.025 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Jiang, C.; Lu, M. Fusion of Sentiment and Market Signals for Bitcoin Forecasting: A SentiStack Network Based on a Stacking LSTM Architecture. Big Data Cogn. Comput. 2025, 9, 161. https://doi.org/10.3390/bdcc9060161
Zhang Z, Jiang C, Lu M. Fusion of Sentiment and Market Signals for Bitcoin Forecasting: A SentiStack Network Based on a Stacking LSTM Architecture. Big Data and Cognitive Computing. 2025; 9(6):161. https://doi.org/10.3390/bdcc9060161
Chicago/Turabian StyleZhang, Zhizhou, Changle Jiang, and Meiqi Lu. 2025. "Fusion of Sentiment and Market Signals for Bitcoin Forecasting: A SentiStack Network Based on a Stacking LSTM Architecture" Big Data and Cognitive Computing 9, no. 6: 161. https://doi.org/10.3390/bdcc9060161
APA StyleZhang, Z., Jiang, C., & Lu, M. (2025). Fusion of Sentiment and Market Signals for Bitcoin Forecasting: A SentiStack Network Based on a Stacking LSTM Architecture. Big Data and Cognitive Computing, 9(6), 161. https://doi.org/10.3390/bdcc9060161