7.1. Experimental Setup
For our experiments, we used previously validated Transformer and attention-based GRU model hyperparameters to evaluate their performance on our multiple semantic reasoning tasks, i.e., predicting/generating object phrases, given the subject and predicate phrases (see
Table 3). Due to the fact that our KBs are smaller than the datasets used for Neural Machine Translation (NMT) by the authors of [
39,
40] to introduce these models, we decided to use the smallest architectures they reported.
In the case of the standard Transformer model [
39], we used a source and target sequence lengths of
, a model dimension of
(the input and positional word embeddings), an output Feed Forward Layer (FFL) dimension of
(denoted as
in the original paper), a number of attention heads of
, attention key and value embedding dimensions of
, and a number of transformer blocks of
. In addition, we considered the possibility that such a “small” model is still too big for our KBs (the largest one has ∼652k triples) compared to the 4.5 million sentence pairs this model consumed in the original paper for NMT tasks. Therefore, we also included an alternative version of the base model using only one Transformer block (
) in both the encoder and decoder (in the case of the decoder, a single Transformer block refers to two self-attention layers (
), whereas
refers to three of these layers (i.e., the decoder’s number of blocks is
with respect to the encoder).), while keeping all other hyperparameters of the
model.
In the case of the attention-based GRU model, we adopted the hyperparameters specified in the corresponding original proposals [
40,
42] to build baseline recurrent models. In addition, we considered previous work where the additional architecture hyperparameters of Transformers and recurrent models were compared in their performance [
59]. Namely, we included two contrasting recurrent architectures (for both encoder and decoder): the first one was labeled as GRU-W (GRU Wide): sequence lengths of
and
, number of hidden states (units)
, each with an embedding dimension of
, and training batch size of 128. The second one was labeled GRU-S (GRU Squared): sequence lengths of
and
, number of hidden states (units)
, each with an embedding dimension of
, and training batch size of 32.
The models were trained using different KBs constructed from different sources to select the semantic reasoning task and the model that best generalizes the OpenNCDKB validation set. Using the four source KBs and the OpenNCDKB, we obtained four mixed KBs used for training the models (see
Section 5.3): ConceptNet+NCD (CN+NCD, for short), OIE-GP+NCD, Concepnet+IOE-GP+NCD (CN+OIE-GP+NCD, for short). Using each of these KBs, we trained eight Transformer models, four models with
(i.e., Transformer 1) and four models with
(i.e., Transformer 2). In the case of the baseline recurrent models, GRU-W and GRU-S, these were trained with the OIE-GP+NCD and CN+OIE-GP+NCD KBs separately. Thus, we trained four baseline models across different KBs, contrasting architectural dimensionalities through two configurations: GRU-W (wide: large hidden units with smaller embeddings) and GRU-S (squared: balanced hidden/embedding dimensions).
We compared and analyzed the test semantic reasoning tasks using performance metrics (i.e., sparse categorical cross-entropy) of the eight Transformer models and the four GRU models (training and test). We set 40 epochs max. to train and test the models with each KB, but with patience=10 for a minimum improvement of .
We also performed an STS-based hypothesis test on all resulting test and validation data (see
Section 4.6). The overall outcome of this STS-based hypothesis test was to verify whether the STS measurements with respect to the true object phrases and with respect to random baselines come from different distributions; that is, to decide whether the null hypothesis, i.e.,
Hypothesis 0 (H
0)
semantic similarity measurements with respect to true object phrases and with respect to random baselines come from the same distribution,
can be rejected with confidence and whether this holds for both the test and validation datasets.
The neural word embeddings we used for Meaning-Based Selectional Preference Test (MSPT) were trained on the Wikipedia corpus to obtain good coverage of the set difference between the vocabulary of the test and validation data (PubMed paper abstracts contain a simpler vocabulary than the paper itself, while Wikipedia contains a relatively technical vocabulary). The word embedding method used was FastText, which has shown better performance in representing short texts [
60]. The phrase embedding method used to represent object phrases was a simple embedding summation; this was because, at the phrase level, even functional words (e.g., prepositions, copulative and auxiliary verbs) can change the meaning of the represented linguistic sample [
48].
Additionally, we investigate how the demands of semantic reasoning tasks differ from those of neural machine translation (NMT), where GRU hyperparameters have been extensively validated. To this end, we conducted a sensitivity analysis for attention-based GRU and LSTM models trained on our largest combined KB (CN+OIE-GP+NCD) to provide a broader performance evaluation of these standard attentional models, which are less explored in reasoning tasks compared to Transformers. The analysis evaluates the impact of embedding dimensionality, number of hidden units (a.k.a. steps, or states), number of layers, and dropout probability (regularization) on accuracy and loss. To this end, we conducted two sensitivity studies—one for the attention-based GRU (311 trials) and the other for the attention-based LSTM (168 trials). All models were trained on the same KB, ran on four RTX-4090 GPUs, and were tuned with Bayesian optimization; a random forest surrogate model supplied the feature-importance and the Spearman correlations (for all our hyperparameter search analysis, we used the weights and biases (
https://shorturl.at/SHw6Y (accessed on 2 June 2025)) Python API).
At the end, we manually inspected and discussed the natural language predictions of the best models using both test and validation data. To do this, we randomly selected five input samples from the test subject–predicate phrases and fed them to the SANLMs that exhibited the highest confidence during our MSPT. We analyzed the predicted object phrases to explore their meaning and the semantic regularities they demonstrated. We then repeated this inspection using validation data from the OpenNCDKB, randomly selecting five subject–predicate inputs not seen during training. This allowed us to verify whether the semantic regularities identified in the test predictions were reproduced in the validation predictions.
7.6. Attention Matrix
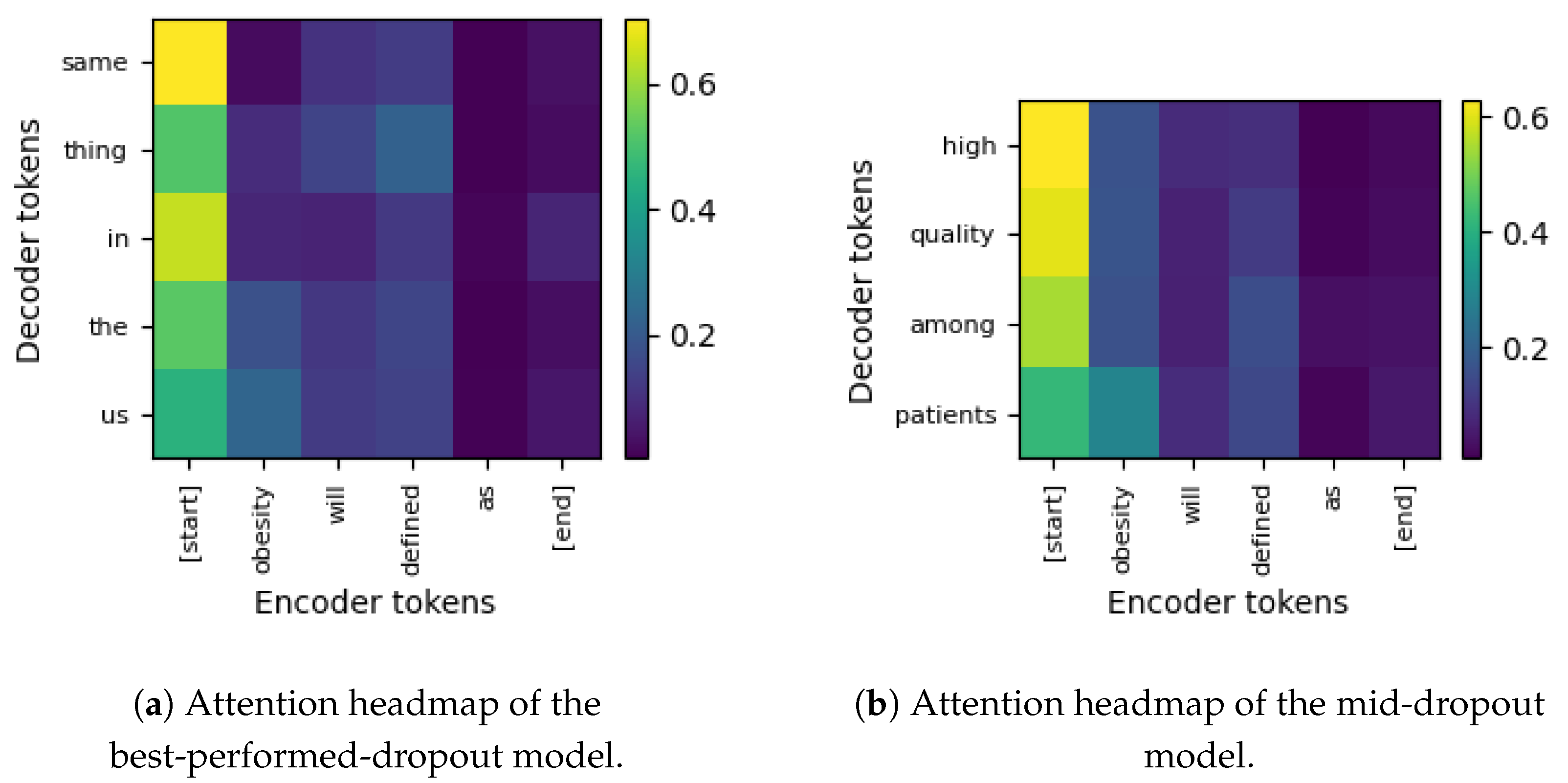
We see in
Figure 9 that we have the attention matrices of best-performing models with high and middle regularization probabilities.
Figure 9a shows the attention matrix of the best-performing model according to the validation loss (the global minimum among the 311 experiments).
The attention matrix of the model reveals how the model aligns encoder and decoder tokens to generate object phrases. The matrix shows attention weights between the encoder tokens ([start], obesity, will, defined, as, [end]) on the x axis and decoder tokens (same, thing, in, the, us) on the y axis, with a color gradient from purple (low attention, ≈0.0) to yellow (high attention, >0.6). The model’s hyperparameters and metrics are dropout = 0.765, embeddingDim = 512, nSteps = 512, numLayers = 1, and val_loss = 2.271.
The attention matrix of the model reveals how the model aligns encoder and decoder tokens to generate object phrases. The matrix shows attention weights between encoder tokens ([start], obesity, will, defined, as, [end]) on the x-axis and decoder tokens (same, thing, in, the, us) on the y-axis, with a color gradient from purple (low attention, ≈0.0) to yellow (high attention, >0.6). The model’s hyperparameters and metrics are: dropout = 0.765, embeddingDim = 512, nSteps = 512, numLayers = 1, and val_loss = 2.271.
Mid attention (green, ≈0.5) from [start] to us or the suggests the model prioritizes the start token to initiate decoding, establishing context for the phrase. For example, a token that appears at [start] is critical because it sets the context for all subsequent processing. In addition, on the one hand, tokens marked explicitly for position (in)—or those acting as connectors (for example “as”)—may serve a syntactic function and therefore receive less emphasis. On the other hand, higher attention weights to these kind of word could indicate that localization or purpose/role context is critical. High attention weights to [start] also mean that the model relies strongly on the opening context, especially if the token implies or carries thematic content or creative semantic cues. In this sense, we think that since the start of a sentence often defines the overall tone or gist, high attention here, and depending on how the model learned to do so, ensures that these salient cues are not diluted as the sequence unfolds.
Mid attention (green, ≈0.5) from [start] to us or the suggests that the model prioritizes the start token to initiate decoding, establishing context for the phrase. For example, a token that appears at [start] is critical because it sets the context for all subsequent processing. In addition, on the one hand, tokens marked explicitly for position (in)—or those acting as connectors (for example “as”)—may serve a syntactic function and therefore receive less emphasis. On the other hand, higher attention weights to these kinds of word could indicate that localization or purpose/role context is critical. High attention weights to [start] also mean that the model strongly relies on the opening context, especially if the token implies or carries thematic content or creative semantic cues. In this sense, we think that since the start of a sentence often defines the overall tone or gist, high attention—depending on how the model learned to do so—here ensures that these salient cues are not diluted as the sequence unfolds.
Moderate-to-low attention (blue, ≈0.2–0.3) from obesity to us or the indicates the model links the key entity (obesity) to determinants followed by entity, suggesting in this case entity-centric (with respect to the U.S., as a country) and geographical reasoning for phrases like in the us in the context of defining obesity. Notice that the low (but >0.2) attention from defined to thing, which suggests that the model learns to link the verb with the generated (although generic) object. The model uses 1 layer, aligning with the sensitivity analysis’s recommendation (importance 0.363, correlation 0.515) for shallow architectures. The high dropout = 0.765 (importance 0.288, correlation −0.095; higher dropout group > 0.625 also) regularizes the model, supporting the tendency observed in the importance-correlation analysis (higher regularization associated to lower validation loss) by preventing over-specialization on specific tokens.
We have now the attention matrix of the attention-based GRU model that performed the best within the mid-dropout group of models, i.e., dropout
. It had the following configuration:
dropout = 0.613,
embeddingDim = 1024,
nEpochs = 5,
nSteps (hidden units) = 512,
numLayers = 1, and
validation loss = 2.358, visualized as a heatmap in
Figure 9b. The matrix maps attention between encoder tokens (
[start], obesity, will, defined, as, [end]) and decoder tokens (
high, quality, among, patients). Compared to the previous attention matrix, this one shows mid to low attention from
obesity to
patients, and from
defined to
among. Due to this learned association, the decoder tokens (
patients, among, high, quality) can jointly be related to the NCD domain, indicating the adaptation of the model to NCD phrases. This is in contrast with the generic previous tokens (“same thing in the us”), where the context barely resembles the location of the disease (according to training data). As in the previous case, this model learned to weigh the verb (
defined) with the decoder sequence, but not with a noun this time. In this matrix, the same attention pattern is observed for
[start] (to the first token in the decoder) and
[end] (low attention to the ending token of the decoder) than that observed previously in the best-performing model.
Now, we have the attention matrix of the best performing model with a lower dropout group (<0.0375). See
Figure 10. In this case, the dropout = 0.271, and configuration is
embeddingDim = 256,
nSteps = 1024,
numLayers = 1, and
val_loss = 2.409. We observe that, while in the mid-regularized model generic NCD-specific phrases (
patients,
among,
high,
quality) are generated, in the high-dropout (best-performing) and low-dropout (this) models, generic phrases are generated. Broader context is observed (
world,
we,
be,
on) for this low-dropout model (but best-performing), possibly indicating a shift to general semantic reasoning. Notice that, now, with a lower dropout, the lower embedding Dim = 256 (vs. 512 and 1024) may limit nuanced medical focus, while nSteps = 1024 broadens the learned scope (to the world). Similarly to the above mentioned patterns,
defined as is mapped to the decoders phrase
world we.
7.7. Attention Matrix of the GRU-W Model
As we observed in the matrices analyzed thus far, only the best-performing mid-dropout model in
Figure 9b generated a phrase that can be related (though generic) to medical domains. This result prompted us to revisit the Bahdanau-style configuration [
42], which we label GRU-W (embedding dimension 256; hidden units 2048; one recurrent layer). GRU-W has twice as many hidden units (wide) but half the embedding dimensions of the mid-dropout model, reshaping the network’s capacity rather than merely enlarging it. We therefore ask whether a setup proven effective for machine-translation tasks can also foster richer semantic reasoning. At first glance, our 311 experiments show that these configurations tend towards overfitting, due to the relatively large number of hidden units (the larger this number, the larger the loss, according to
Table 4).
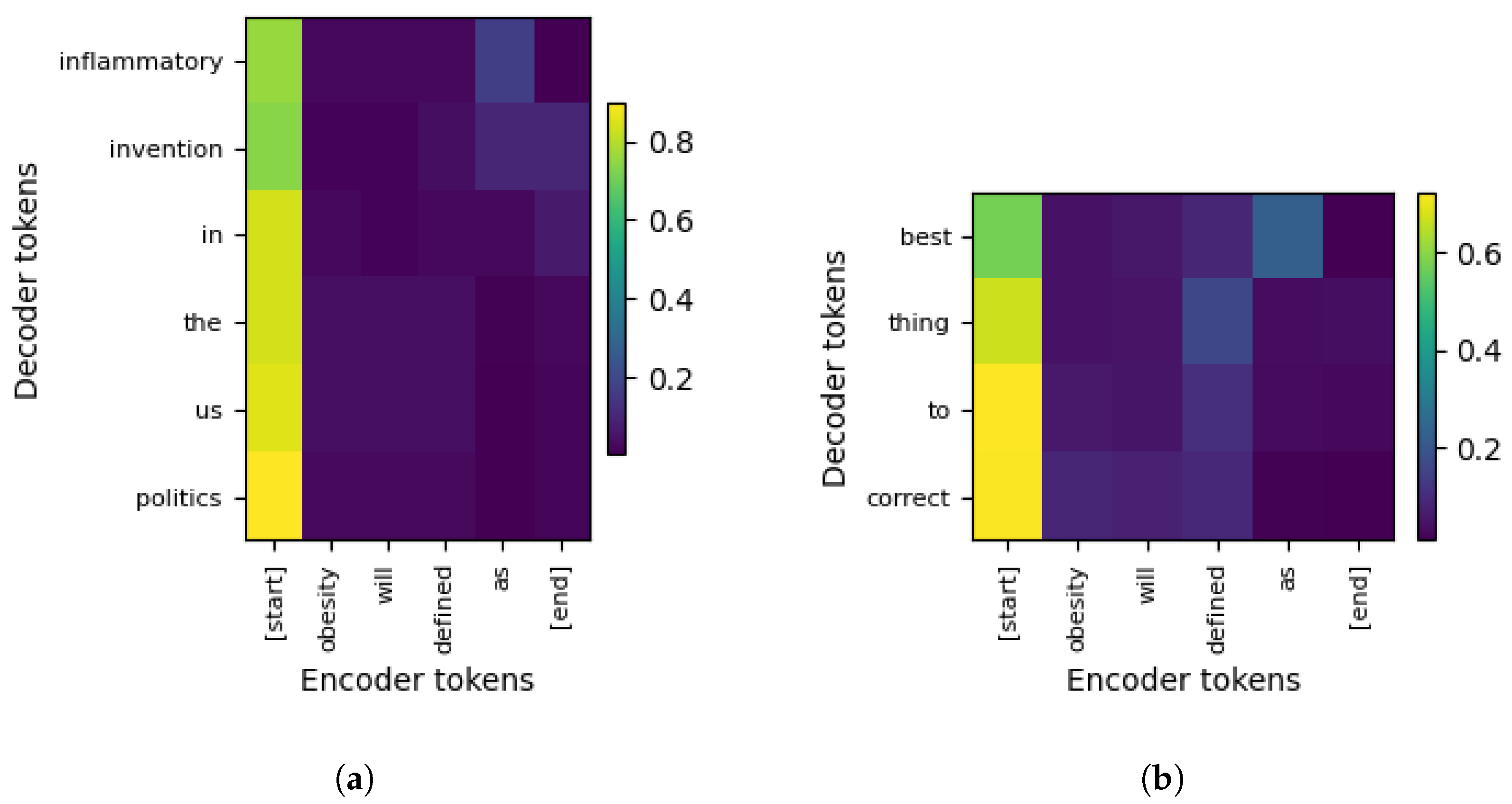
In
Figure 11a, we have the GRU-W model with a high dropout = 0.834. The encoder tokens form the same phrase as before and the decoder tokens are
american,
epidemic,
of,
american,
flag. The model shows very similar attention pattern with respect to most of the models analyzed at this moment from
[start] and
[end] tokens. The heat-map shows three salient off-diagonal peaks. Firstly, low attention from
obesity to
american suggests that the decoder re-uses the noun
obesity to predict that the frame [X] is related to or characteristic of the United States, a plausible medical trope. Secondly, attention from
defined as to
american epidemic—low weights also—indicate lexical coupling through the verb, and repeating the adjective (
american) can be a possible side-effect of noisy OpenIE tuples. Minimal weights on the positional token
[end] reflect the heavy regularization; the model does not over-rely on boundary cues, consistent with the importance–correlation analysis in
Table 4. Although semantically evocative (“American epidemic”), the model over-fits rare co-occurrences—possibly mirrored by its highest validation loss (2.422).
We have a more superficial interpretation without having access to more information (at this moment): the pattern shows focused attention on specific semantic relationships, with a thematic shift toward cultural or symbolic phrases, indicating content-driven generation over positional cues. More specifically, in this example, the model shows thematic reasoning by inferring that obesity is a societal issue (“American epidemic”), while also showing symbolic reasoning over NCD-specific focus, e.g., “obesity is defined as a flag of American epidemic”. We think this can be due to the presence of Common Sense Knowledge in the training data. The val_loss = 2.422 is the highest among all to this point.
Now, we see that, in the low-dropout GRU-W model (dropout = 0.084, see
Figure 11b), the graduated attention from
[start]—starting at mid-high attention (terms), escalating to very-high attention (of, zimbabwe), and peaking at highest attention (for, newer, direction)—indicates a strong reliance on the start token to drive the entire decoding process, with increasing emphasis on later tokens that suggest purpose and progression.
Although there is information regarding the scientific community’s concern regarding Zimbabwe’s health crisis, we see a lack of disease entity-driven reasoning with obesity directly. Rather, the top-to-bottom sequence (terms, of, zimbabwe, for, newer, direction) suggests a phrase like “terms of Zimbabwe for a newer direction”, possibly framing obesity management in a specific geographical and forward-looking context. The high attention from [start] to zimbabwe, for, newer, and direction supports this focus. The task’s open-vocabulary nature allows for geographical references like Zimbabwe, and the model’s focus on newer and direction aligns with a more general NCD literature’s emphasis on innovation.
The lowest attention from will, as, and [end](except very-low attention for for from [end]) indicates that these tokens have little influence on decoding, reinforcing the dominance of [start] and the lack of content-driven focus beyond defined’s minor role. This pattern is consistent with prior matrices, where auxiliary tokens had minimal impact, though defined’s slight low attention to later tokens suggests a minor definitional role.
Given that, at this point we observed that GRU-W models showed improved entity-driven semantic reasoning, we decided to train separately two additional models with this configuration (number of hidden units is 2048 and embedding dimension of 256). This time, we used 10 epochs (instead of five like in the previous 311 experiments). In
Figure 12, we see the attention matrices of the models with similar (to
Figure 11) dropout (0.831, not equal due to random sampling) to that of the best performance (0.834), and with the lower dropout (0.012) and best performance according to the validation loss (3.583, and 2.927, respectively).
Figure 12a, re-run from
Figure 11a, now with dropout = 0.831, shows generic NCD-specific entity focus. The attention from
[start] varies from green (high) to
inflammatory and
invention, suggesting that the model uses
[start] to initiate decoding with a focus on medical and innovative terms (
inflammatory,
invention) and increases with contextual connectors (
in,
the,
us). Yellow (very high) for
politics, and greener yellow (higher) for
in,
the, and
us, indicates a strong positional influence on prepositional and national context tokens. The highest attention peak to
politics, suggests that
[start] drives the decoding toward a societal or political conclusion.
Read semantically from top to bottom, the decoder tokens suggest a phrase like “inflammatory invention in the US politics”. In the NCD context, this could imply “inflammatory invention in the US politics related to obesity”, focusing on a medical innovation within a national political framework. The lowest attention across most decoder tokens from will and defined indicates negligible impact from these tokens; low attention from as for inflammatory and very-low attention for invention suggest a minor influence in assigning roles to these medical terms. The lowest to very-low attention from obesity across all decoder tokens suggests that the model seems to neglect the central NCD entity.
Now,
Figure 12b shows the re-run from
Figure 11b, but now with dropout = 0.012 and 10 epochs. Moderately high attention is observed from
[start] to
best, suggesting that the model begins decoding with an evaluative term. Very-high attention from
[start] to
thing indicates a strong positional influence on a general noun. The highest goes from
[start] to
to and
correct: This peak attention suggests that the start token drives the decoding towards a corrective action with strong structural emphasis. Again, the key NCD entity obesity has almost no influence on decoding, which is unexpected for the task. And again, low attention (but not the lowest) is assigned from
defined to
thing, and from
as to
best, indicating the certain importance of the definitional role of
best thing, together with
to correct. The NCD task often involves corrective strategies, and the model’s focus on correct aligns with this goal, though the lack of obesity focus undermines its relevance.
Sensitivity Analysis for Attention-Based LSTM Models
To understand the impact of hyperparameters on our attention-based LSTM models’ performance, we conducted a sensitivity analysis from a total of 168 experiments to evaluate their importance in influencing the loss function (val_loss). This analysis, complemented by Bayesian optimization, aimed to optimize semantic reasoning for object phrase generation. We assessed which hyperparameters contribute most to changes in the loss function. The findings were somewhat similar to those for the GRU models, with key differences influenced by a more constrained hyperparameter search space, so making our analysis more cost-effective. That is, we explored only one and two layers (compared to up to 4 for GRUs) and a discrete set of dropout values {0.01, 0.5, 0.9} (instead of continuous samples in [0, 1]). These modifications notably shifted the perceived importance of certain hyperparameters. Again, in this case, we used our largest KB (the ConceptNet+OIE-GP+NCD KB) and the same hardware as for the attention-based GRU models.
Table 5 presents the importance scores and Spearman correlation coefficients for the varied hyperparameters of our attention-based LSTM models, sorted by importance in descending order. Constant hyperparameters such as batch size (64), number of epochs (5), and sequence length (30) were not varied and are thus excluded from this part of the analysis. Importance scores (0 to 1) quantify the influence on the loss function, while Spearman correlations (−1 to 1) indicate the direction of this influence (positive correlation means that a higher hyperparameter value is associated with a higher loss/poorer performance).
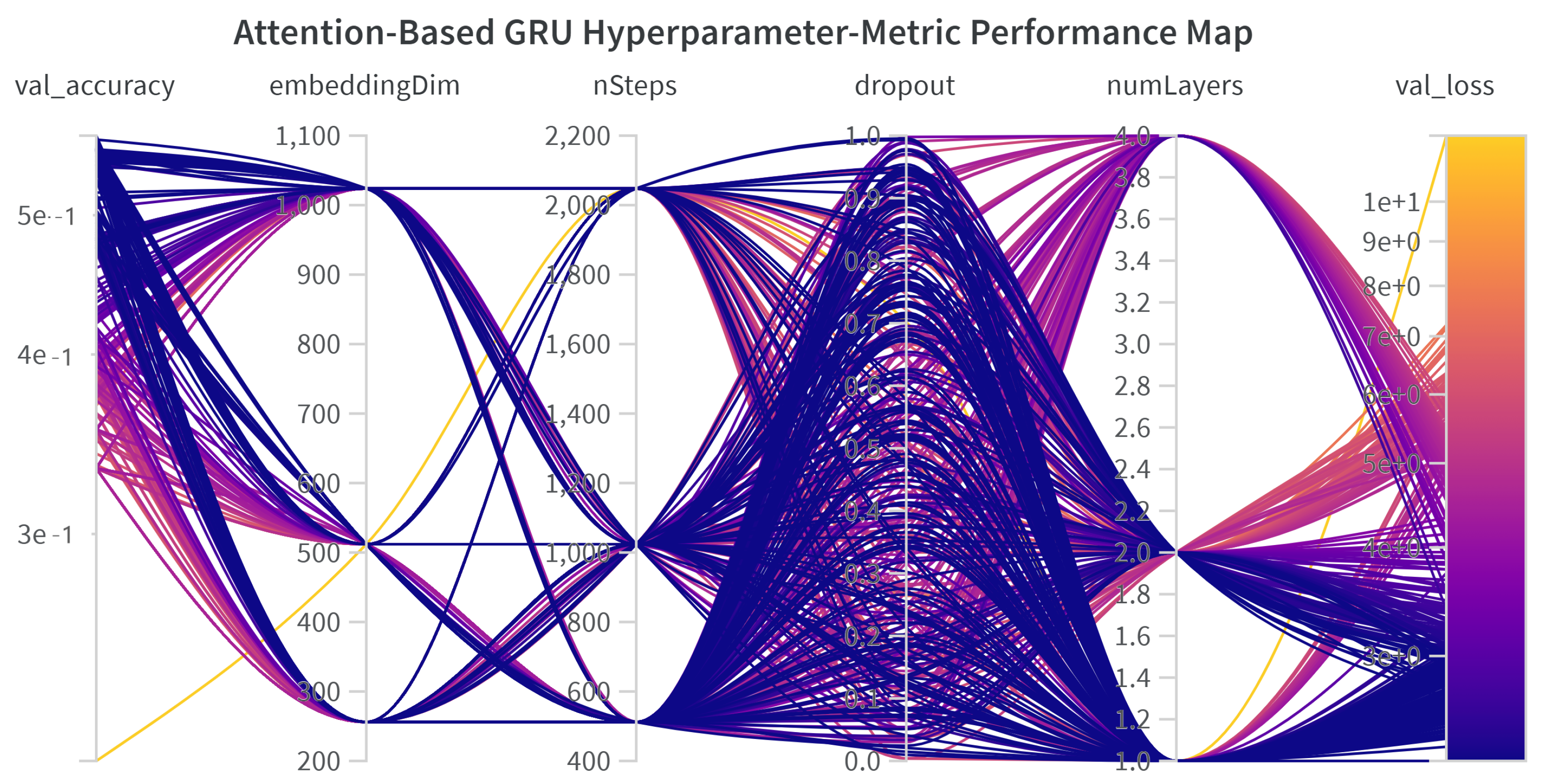
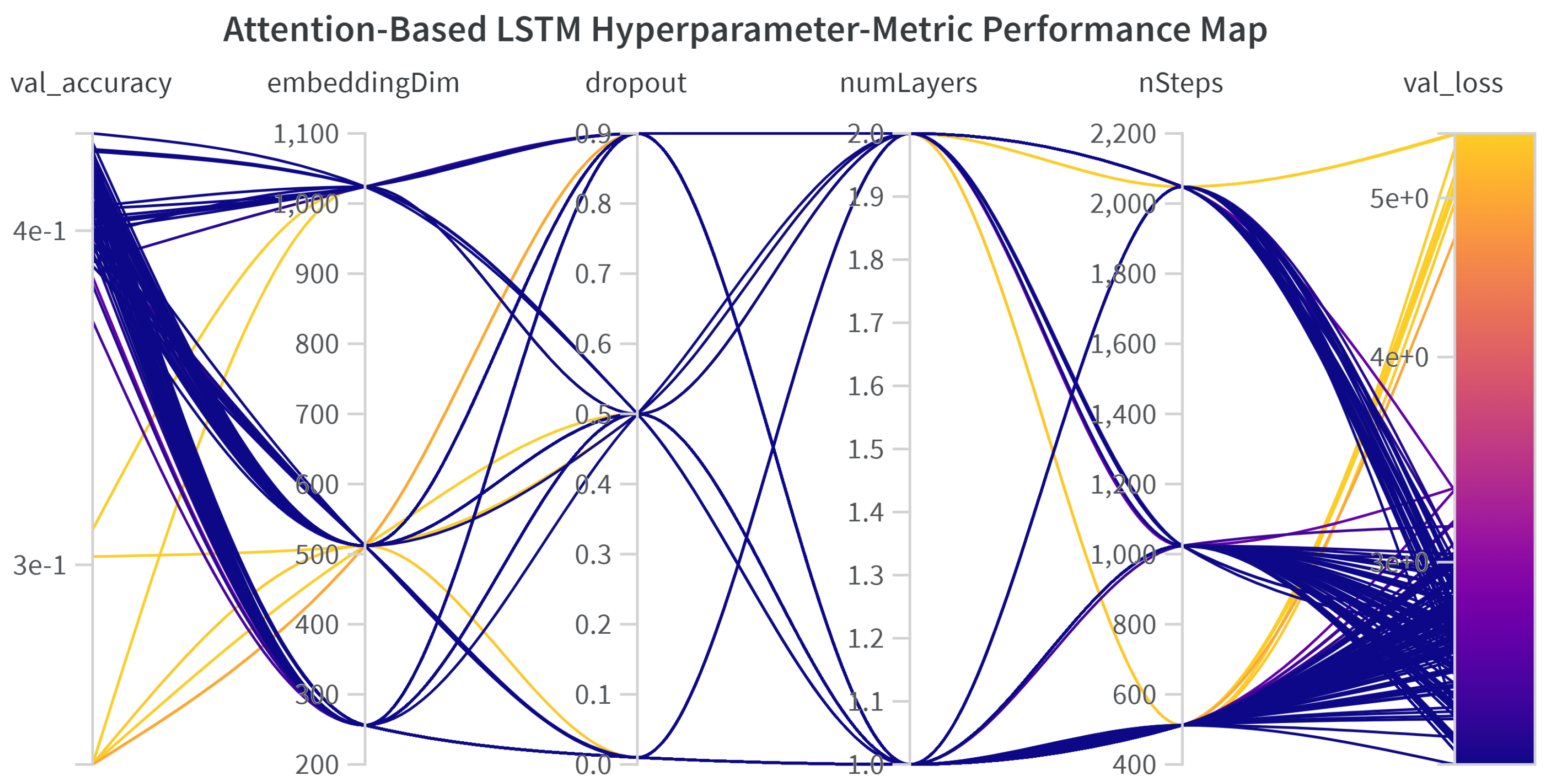
The global view of these experiments is captured in
Figure 13. In this plot, the lines connect hyperparameter values to performance metrics. The color of the lines is determined by
val_loss (purple = low loss, indicating better performance; yellow = high loss, indicating poorer performance). The
val_accuracy is explicitly shown on the leftmost axis, where higher values signify better performance. Ideally, purple lines (low loss) should correspond to high
val_accuracy.
7.12. Attention Matrix
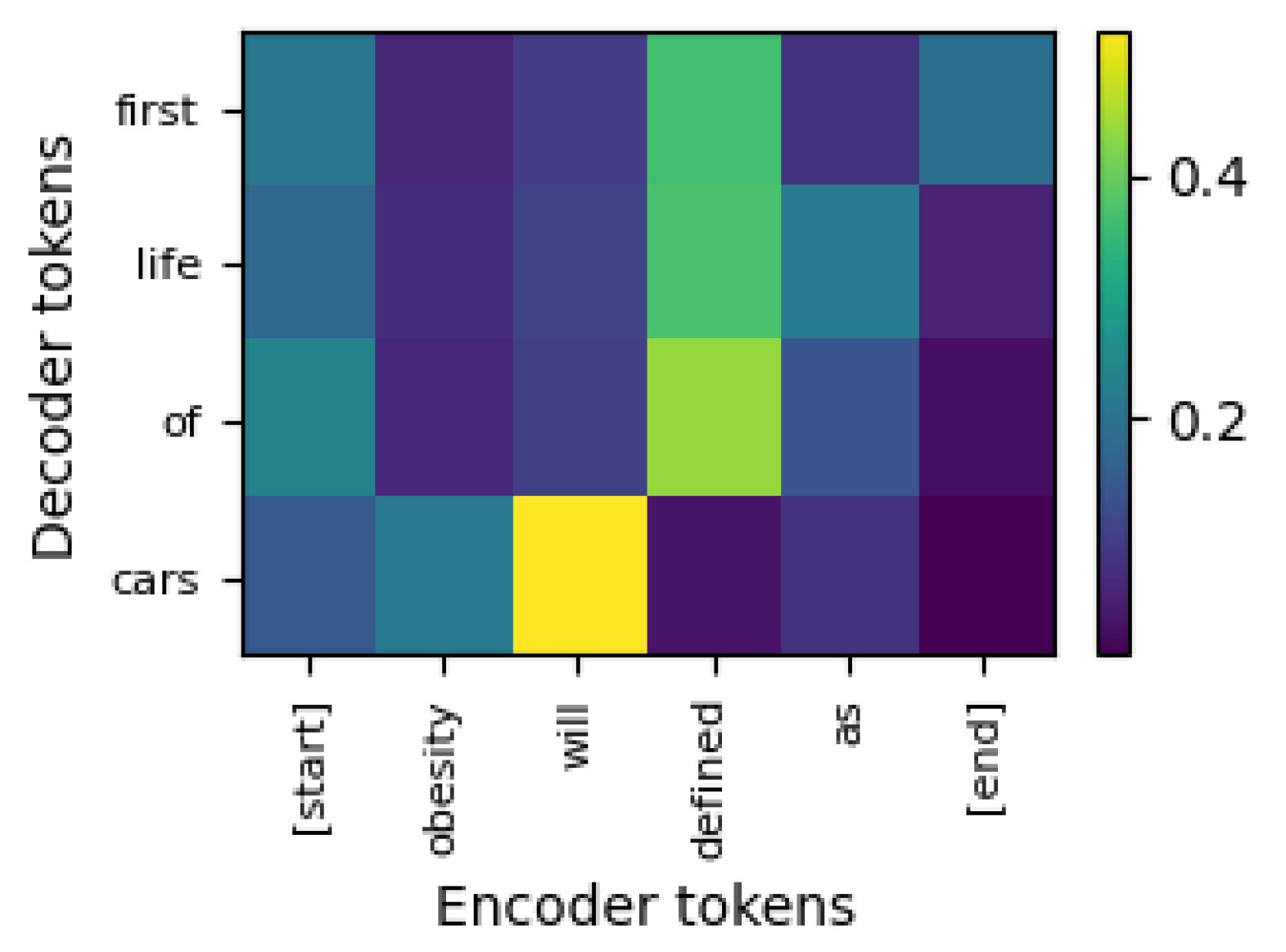
To analyze the attention matrices of some representative LSTM models, we selected those that performed the best under certain conditions. First, in
Figure 14, we have a heatmap of the attention matrix of the LSTM model that resulted in the lowest validation loss among the 168 experiments. This has a dropout = 0.9; embedding dim. = 256; number of hidden units = 512 and
val_loss = 2.904. When generating the token
first, the model primarily focused on the input word
defined, and to a lesser extent on the beginning and end of the sequence (
[start],
[end]). This suggests that
defined as is a key context for initiating the generated object phrase with
first. The token
life, has very similar pattern, mainly differing in that less focus is observed at the end of the input sequence, but increased focus is observed for
defined as. In general, the formed sentence is well formed, but senseless (
Obesity will [be] defined as first life of cars).
The next attention heatmap corresponds to the model that performed the best with the mid-dropout regularization (see
Figure 15a): dropout = 0.5; embedding dim. = 256; number of hidden units = 2048 and
val_loss = 2.674. It again generated a senseless object phrase, albeit showing normal attention patterns and an interesting small attention peak from the predicate to the adjective of the object phrase. The correspondence is structurally semantically sound, but with the wrong meanings selected.
Lastly, (in
Figure 15b), we have the model that performed the best with the lowest dropout = 0.01; embedding dim. = 256; number of hidden units = 1024 (
val_loss = 2.674). This model, although a generated senseless object phrase, it is nearer to the thematic context of its input. The object phrase makes reference to international context of obesity, which may be prompted by the attention of the decoder to the main thematic word in the encoder (
obesity) and the future auxiliary (
will). Notice, in addition, that this also represents an overgeneralization of the input context, such as it occurred with the GRU models.
7.12.1. MSPT on Best-Performed GRU and LSTM Models
In
Table 6, we show the key hyperparameters resulting the best from the point of view of the validation loss (through the whole set of experiments) and with different degrees of dropout regularization: high, mid and low. In the case of the LSTM models, we set only three values: 0.9, 0.5, and 0.01. In the case of the GRU models, the values were grouped (high, mid, and low) from those available in the pool generated by Bayesian optimization using continuous range in [0, 1]. We labeled the models such that it is easy to identify their main hyperparameters in the subsequent analysis (see the second column of the table). For instance,
BestHdropSembMstep1L stands for
Best of all with
[H]igh
[drop]out,
[S]mall
[emb]edding dimension,
[M]id amount of hidden (
[s]teps) units and
[1 L]ayer. We decided to include two-layered models here thinking about, in the event of that relying solely on the validation loss, we may miss interesting results from the point of view of our MSPT.
In
Table 7, we have the best-performig attention-based GRU models analyzed at this moment, but now seen from the lens of our MSPT. The best of them reached 2.959 bits of cross-entropy loss. It has 2048 hidden units, 256 embedding dimensions, one layer, and was regularized with 0.834 dropout probability (marked in bold). This model reached
between its NCD test predictions and the corresponding gold standard, with a gap of 10.02% (
).
An interesting result is that NAtt GRU models can even surpass the gap attained by attentional models in validation data, being comparable only to the 1-layered LdropSembHstep1L attentional model. The p-value of the best NAtt GRU model in test data is twenty magnitude orders higher than the best 1-layered attentional model. When think that this means that attentional models have more generalization ability to new domains, while NAtt models are better at the training domain.
Figure 16 illustrates how our GRU-W model’s cosine similarity scores differ when computed against truly matching object phrases versus random baseline phrases, on both the NCD test set (
Figure 16a) and the validation set (
Figure 16b). The blue histogram (and Kernel Density Estimation, KDE, curve) for the NCD test set shows similarities between model predictions and random baseline phrases: it peaks around ≈0.51 and is relatively wide, with very little (and vanishing) mass above ≈0.8. The orange curve for model-to-true object pairs is shifted slightly to the right (mean
0.53) and has more density in the upper range (above 0.8). The vertical dashed lines mark these means and the annotated “Gap = 4.22%” (with
1.71 ×
) quantifies a small but highly significant advantage of matching over random.
For the validation set (
Figure 16b), the random baseline distribution is centred lower (
0.33) and remains tightly clustered with virtually no mass near 1.0. The true-object distribution sits higher (
0.43), with a broader tail toward 1.0. The “Gap = 9.42%” (with
p effectively 0) shows an even larger, statistically significant separation on the validation split.
In
Table 8, we have the best-performing attention-based LSTM models analyzed at this moment, but now seen from the lens of our MSPT. The best of them reached 2.92 bits of cross-entropy loss. It has 2048 hidden units, 256 embedding dimensions, one layer and was regularized with 0.5 dropout probability (marked in bold). This model reached
between its NCD test predictions and the corresponding gold standard, with a gap of 9.16% (
). Regarding
NAtt LSTM models, the tendency to learn the training domain is more pronounced, as they barely achieve significance in the test NCD domain, while an increased gap is observed in the validation data.
Argument for GRU-W Configuration Advantage
While the attention-based LSTM models analyzed at this point offer evidence of that their generated phrases are not purely random (best result was for
MdropMembHstep2L reaching
with 4.90% gap w.r.t 0.535 of the random baseline,
), they generated senseless sentences, out of context with respect to the input subject and object phrases. Therefore, attention-based LSTMs serve as baseline references but are still a bit far away from the performance showed by attention-based GRU models in the different scenarios analyzed. Particularly the GRU-W configuration (EmbDim = 256, nSteps = 2048) offers a potential advantage over standard models due to its enhanced semantic flexibility, which we observed via the attention matrix analysis and our MPST (i.e., GRU-
HdropSembHstep2L with 5.3% gap w.r.t 0.529 of the random baseline,
). An additional and very important observation arises: the 1-layered GRU-
LdropSembHstep1L model architecture resulted to have the best balanced result both, in validation and test KBs: test gap = 8.24% (
) and validation gap = 9.24% (
p = 0). See
Table 7.
More specifically, 1-layered high dropout GRU-W generates evocative phrases like “American epidemic of American flag” and “inflammatory invention in the US politics”, indicating thematic and symbolic reasoning from Common Sense Knowledge and NCD literature, unlike the generic outputs of high (“same thing in the us”) and low (“world we be on”) dropout models. Its balanced regularization (e.g., Drop 0.834) and reshaped capacity (twice the hidden units, half the embedding dimension vs. mid-dropout) prevent over-specialization, supported by the sensitivity analysis (dropout importance 0.288, correlation −0.095). Extended training (10 epochs) improves decoding patterns, suggesting adaptability, though overfitting risks remain. The low dropout GRU-W (10 epochs) aligns with corrective NCD themes (“best thing to correct”), hinting at potential entity focus with refinement, unlike other models’ narrower focus.
Table 9 compares the analyzed GRU models with key hyperparameters and attention performance insights. For instance, in the fisrt row we have
mid * [start] →
us/the; low *
obesity → us/the, where
mid stands for mid attention weighting from the encoder
*-associated token. That is, mid attention is assigned from the
[start] token to the
us/the tokens, and so on.
7.12.2. Final Meaning-Based Selectional Preference Test (MSPT)
In this final MSPT, we first compared predictions of the attention-based GRU models using mixed KBs. First, an OpenIE-derived KB (OIE-GP+NCD, relatively small) and then this later including common sense knowledge (CN+OIE-GP+NCD, our largest KB). After that, we used these KBs along with an additional pair of small and large KBs (OpenNCDKB and CN+NCD) to train two transformer models from scratch (one- and two-block models). As introduced in
Section 4.6, this evaluation takes into account three sources of information: the predicted (
pred) and the ground truth object phrases, as well as the randomized ground truth object phrases (
rdn, i.e., randomized gold standard or baseline). This latter serves to simulate a perturbation in selectional preferences, where the subject and predicate influence the generation of the object phrase.
This operation, as in previous sections, was performed on validation data and test data separately. The validation data refers to the validation subset of the training KB (e.g., CN+NCD). The test data is the test subset of our OpenNCDKB, which contains only NCD-related (noisy) OpenIE triples. This is for testing how the trained models behave in a purely (OpenIE-derived) biomedical domain considering the minimal vocabulary to which they were exposed during training.
In
Table 10 (penultimate row), we show our most significant recurrent model, this model architecture is supported by having the best result both in validation and test data (see
LdropSembHstep1L in
Table 7: dropout = 0.553; test gap = 8.24% (
p ≈ 1.71e-40) and validation gap = 9.24% (
p = 0.0). Now this model architecture (GRU-W) was evaluated using the CN+OIE-GP+NCD KB for which we had the the best global result. With this, the null hypothesis can be safely rejected with probability
(gap 0.641-0.542→12.1%), which notably didn’t require dropout to attain its performance. Its mean similarity with respect to the ground truth in the NCD test KB was 0.641 (
p∼
), while in the validation KB it was
, with gap 0.541-0.334 → 20.7%.
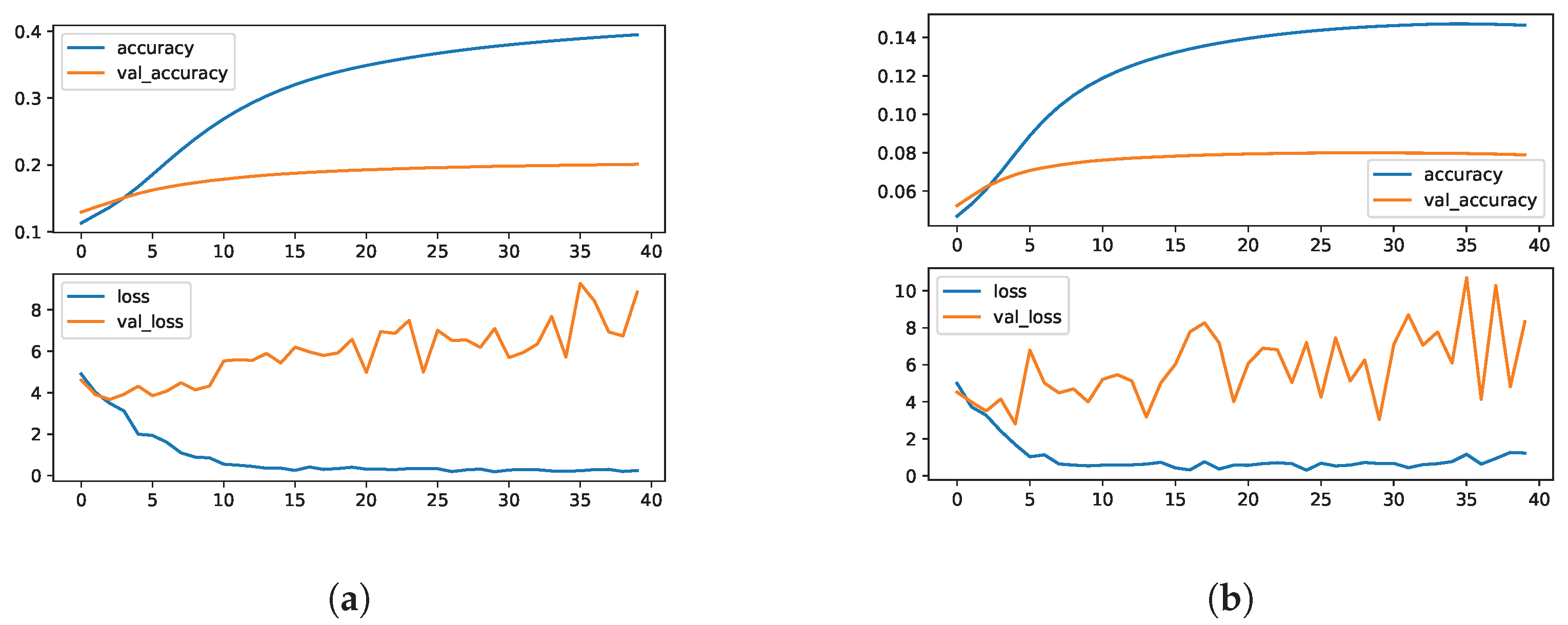
Based on these indicators, we believe that the GRU-W SANLM generates object phrase meanings and selectional preferences quite similar to those in the test and validation KBs. However, our analysis of the learning curves for this model (
Figure 3a) shows that the model generates different words than the ground truth. Nonetheless, when considering both analyses together and the nature of the sentence embeddings used to represent the model predictions, we think that semantic selectional preferences with respect to the ground object phrases are strongly present in the meanings generated by the GRU-W model. This, we think, can be considered a manifestation of
generalization through semantic relatedness and selectional preference in semantic reasoning.
In
Figure 17, we see the cosine similarity distributions and their KDEs for the MPST of the GRU-W model trained on the CN+OIE-GP+NCD KB.
Figure 17a shows that the STS distribution of the
NCD test set pairs made between model predictions and random baseline phrases (blue bars and KDE) form a bell–shaped density centred at
(
,
) and drop sharply beyond
. When the same predictions are compared with their gold object phrases (orange), the density flattens and shifts rightward, accumulating probability near
and yielding a higher mean of
(
). The
relative gap is highly significant (
,
).
In
Figure 17b we see the
validation set MSPT. The pattern persists in general: model–gold similarities remain right-shifted (
) and pile up close to
, whereas model–random baseline similarities contract further and centre at
(gap
;
,
). Together, both figures therefore confirm that the model aligns far better with the true object phrases than with random baselines across both data splits.
Now, in
Table 11, we show a comparison of the Transformer models’ predictions using MSPTs between the predicted and ground truth object phrases (
pred), and between the predicted and randomized ground truth object phrases (
rdn). Our most significant model resulted when using the CN+NCD KB for training the Transformer-1, so the null hypothesis can be safely rejected. The mean similarity with respect to the ground truth in the NCD test KB was
(
p∼
) with gap of 4% w.r.t the corresponding random baseline of 0.511 (
p∼
), while in the validation KB it was
. Such model required one Transformer block (encoder/decoder) and 20 training epochs. This performance was followed by the remaining Transformer-1 models trained with the CN+OIE-GP+NCD (
p∼
in the test KB), OpenNCDKB, and OIE-GP+NCD KBs.
In the case of the two-block Transformer models, most of their predictions on the NCD-related validation data can be confidently regarded as random (the null hypothesis holds). Even those predictions of the model trained with our largest KB (CN+OIE-GP+NCD). From these Transformer-2 models, only the one trained with CN+NCD proved to be significantly reliable, but with relatively low mean similarity w.r.t. the ground truth on the validation data (
,
). Based on the corresponding performance analysis (
Section 7.2.1), which showed that the two-block models generalized well but underperformed on the test data, we believe that their low-confidence MSPT measurements in the validation predictions (and therefore for the test set) may be due to task-level overfitting, potentially attributed to model size, as smaller models like GRU-W performed much better. Despite this, the predictions of the one-block models trained with CN+OIE-GP+NCD and CN+NCD were the most confident in distinguishing from the random baseline in test data.
The only two-block model that resulted significant barely reached , which was trained with the CN+NCD KB. These models trained with the smaller KBs (OIE-GP+NCD and OpenNCDKB) evidenced their poor performance (which initially appeared to be generalization), as their predictions can be reliably discarded as random (regarding meanings and selectional preferences) in both the test and validation data (p∼). Note that the MSPT results for these models reveal only modest gaps between each prediction and its shuffled counterpart (pred–rdn). The largest gap in validation data, (10.5%), is obtained with the second–ranked transformer—the one-block models trained on CN+OIE-GP+NCD. In contrast, the best dropout-regularized GRU attains a 5.3% gap (). It is worth mentioning that the Transformer-1 model trained with the O IE-GP+NCD KB is interesting because it reached relatively good evaluation results (cross-entropy loss and MSPT), both in test and validation data, despite the small size of the training data, which is infeasible to the GRU models.
Figure 18 illustrates how the Transformer-1 model’s cosine-similarity scores differ when computed against ground truth object phrases versus random baselines, on both the NCD test set (a) and the validation set (b). In the case of the
NCD test set, the blue histogram (and KDE) for model–random baseline STS peaks at
(
0.19,
) and falls off sharply beyond 0.8 with no mass near to 1.0. In contrast, the orange histogram for model–true-object pairs shifts rightward to
(
0.207), accumulating more density beyond STS > 0.8. The vertical dashed lines mark these means, and the annotated “Gap = 3.94%” (
,
) quantifies a modest but highly significant advantage of correct over random matches. For the validation set, random-baseline similarities (blue) are tightly clustered at a lower mean of
(
0.134,
), with virtually no mass near 1.0. True-object similarities (orange) rise to
(
0.204), displaying a pronounced tail toward (and peaking again) 1.0. Here the “Gap = 9.91 %” (
,
) indicates an even larger, statistically significant separation. Together, both panels confirm that Transformer-1 predictions align substantially better with true object phrases than with random baselines across both splits.
Together, these MSPT density plots reveal not only the numerical gaps between random baselines and true-object similarities but also how each model behaves when it is trained primarily on commonsense knowledge yet evaluated on the domain-specific NCD corpus. In particular, GRU-W produces a similarity distribution that is more tightly clustered and shifted toward 1.0 for true-object phrases—and more narrowly concentrated at lower values for random baselines—than the Transformer-1 model.
Overall, our MSPTs indicated that only the largest KBs provided the necessary knowledge for the SANLMs to consistently and confidently distinguish themselves from the random baseline in generating and selecting meanings. We interpret this as high stability in the semantic reasoning decisions made by the models. The best-performing models generated meanings that were consistently related to and selected in concordance with the ground truth. While this does not completely rule out the possibility of overfitting, the results of our MSPT-based evaluation method suggest that cross-entropy is effective for training the models but not necessarily for evaluating them from the perspective of semantic reasoning.
7.12.3. Manual Inspection of Common Sense Knowledge Predictions (Qualitative Error Analysis)
In the following manual inspections, Selectional Preferences—the tendency of a predicate to favor certain types of arguments—have been indirectly evaluated through the identification of frame shifts, semantic role misalignments, domain generalization failures. Specifically, we have examined whether the generated predictions by the models maintain the expected argument structure and intended communicative function of the predicate from the gold standard or if they introduce implausible or unrelated arguments.
In
Table 12, we show predictions of the most significant baseline model GRU-W for five subject-predicate randomly sampled from the CN+OIE-GP validation KB. Consider the statement "music is a form of communication" as the Ground Truth. The prediction in question is “music is a form of sound.” When analyzing the predicate “is a,” we recognize it activates a hypernymy frame. This requires the object of the sentence to specify a category that adequately describes the subject. In this case, the subject is “music.”
In terms of roles, “music” (the Theme) should align with a hypernym that fits its abstract and communicative nature. For the Ground Truth, "communication" is a fitting hypernym, as it reflects the socially meaningful and expressive function of music. However, the prediction "music is a form of sound" violates this alignment. "Sound" is a broader, more physical-category hypernym that does not capture music’s communicative purpose effectively.
7.12.4. Manual Inspection of Common Sense Knowledge Predictions (Qualitative Error Analysis)
In the following manual inspections, Selectional Preferences—the tendency of a predicate to favor certain types of arguments—have been indirectly evaluated through the identification of frame shifts, semantic role misalignments, and domain generalization failures. Specifically, we examined whether the generated predictions by the models maintain the expected argument structure and intended communicative function of the predicate from the gold standard or if they introduce implausible or unrelated arguments.
In
Table 12, we show predictions of the most significant baseline model GRU-W for five subject–predicate samples randomly sampled from the CN+OIE-GP validation KB. Consider the statement “music is a form of communication” as the ground truth. The prediction in question is “music is a form of sound”. When analyzing the predicate “is a”, we recognize it activates a hypernym frame. This requires the object of the sentence to specify a category that adequately describes the subject. In this case, the subject is “music”.
In terms of roles, “music” (the theme) should align with a hypernym that fits its abstract and communicative nature. For the ground truth, “communication” is a fitting hypernym, as it reflects the socially meaningful and expressive function of music. However, the prediction “music is a form of sound” violates this alignment. “Sound” is a broader, more physical category than hypernym that does not capture music’s communicative purpose effectively.
The Ground Truth “car receives action [start] propel by gasoline or electricity [end]” specifies a relevant action for a car. The prediction “train to jump” is nonsensical and unrelated to the function of a car. The frame activated by “receives action” requires an action performed on the subject that is relevant to its function. The Ground Truth satisfies the constraints by specifying “propel by gasoline or electricity” as a relevant action for a car. However, the prediction violates these constraints by introducing “train to jump,” which is irrelevant and nonsensical for a car. This results in a semantically incoherent prediction that fails to meet selectional preferences.
The gold standard (“music is a form of communication”) satisfies the necessary constraints, indicating that “communication” is an appropriate category for music. Conversely, the prediction (“music is a form of sound”) overgeneralizes due to hypernymic bias, failing to meet the selectional preferences for contextual specificity. Therefore, the prediction exhibits partial plausibility: it is semantically related but overgeneralizes, resulting in a failure to capture the specific communicative essence of music.
In the second example, the ground truth “ride a bicycle motivated by goal "enjoy riding a bicycle” specifies a hedonic motive for the action. The prediction “the car to be safe” introduces a functional goal that is not aligned with the activity of riding a bicycle. The frame activated by “motivated by goal” requires a purpose or motive that fits the activity’s enjoyment or purpose.
The gold standard satisfies the constraints by using “enjoy” as a hedonic motive, fitting the activity of riding a bicycle. However, the prediction violates these constraints by introducing “to be safe” as a functional goal and incorrectly assigning “car” as the object of “ride”. This results in a mismatch from the semantic roles point of view and reflects lexical substitution bias. Therefore, the prediction is nonsensical, failing to capture the hedonic motive and introducing an irrelevant object.
The ground truth “car receives action [start] propel by gasoline or electricity [end]” specifies a relevant action for a car. The prediction “train to jump” is nonsensical and unrelated to the function of a car. The frame activated by “receives action” requires an action performed on the subject that is relevant to its function. The ground truth satisfies the constraints by specifying “propel by gasoline or electricity” as a relevant action for a car. However, the prediction violates these constraints by introducing “train to jump”, which is irrelevant and nonsensical for a car. This results in a semantically incoherent prediction that fails to meet selectional preferences.
In example 4, the ground truth “an Indian restaurant used for selling Indian meals” specifies the primary function of an Indian restaurant. The prediction “curry style” is vague and does not specify the restaurant’s primary function. The frame activated by “used for” requires a function or purpose related to the subject’s primary purpose. The gold standard satisfies the constraints by explicitly describing the primary function of the restaurant—serving and selling food. However, the prediction is too vague and does not clearly convey the function of an Indian restaurant, merely suggesting an aesthetic or general characteristic without specifying its role. Therefore, the prediction exhibits partial plausibility: it is semantically related but too vague, failing to capture the specific function of the restaurant.
In example 5, the ground truth “mediators capable of settle a disagreement” specifies a relevant ability for mediators. The prediction “beat word” is nonsensical and unrelated to mediation. The frame activated by “capable of” requires an ability or capacity related to the subject’s role. The ground truth satisfies the constraints by specifying “settle a disagreement” as a relevant ability for mediators. However, the prediction violates these constraints by introducing “beat word”, which is nonsensical and unrelated to mediation. This results in a semantically incoherent prediction that fails to meet selectional preferences.
In
Table 13, we present the predictions of the most significant Transformer models for five subject-predicate concatenations randomly sampled from the ConceptNet KB. In general, all generated outputs maintain structurally valid sentence formations from a syntactic and grammatical perspective. However, Transformers tend to produce more fluent yet formulaic noun phrases—e.g.,
“a form of expression” versus the GRU-generated
“form of sound”—possibly reflecting differences in attention mechanisms.
For the case of “music is a”, Transformer 1 (trained with CN+OIE-GP+NCD) correctly predicted the gold-standard object phrase “a form of communication”, satisfying selectional preferences. However, when trained on CN+NCD (N = 1 and N = 2), the same model instead generated “a form of expression”. While the latter may sound pragmatically appropriate in the context of the arts, replacing “communication” with “expression” introduces semantic misalignments that alter the original intent of the statement.
From a Frame Semantics perspective, the gold standard activates a communication frame, where music operates as a structured system for meaning transmission. The models’ output, however, activates an expression frame, which does not necessarily entail interaction or message interpretation. This shows that the model overgeneralizes the function of music beyond its original communicative intent. Models trained on CN+NCD substitute “expression”, broadening the category to subjective output (e.g., personal creativity). While “expression” is semantically related, it violates the SP for interactive meaning transmission, resulting in partial plausibility.
In the next example, “ride a bicycle motivated by goal [enjoy riding a bicycle]”, the models replace the emotional concept (positive emotion) of “enjoying” an activity (riding a bicycle) with a simpler idea conveying the purpose which a bicycle is conceived for (its functional definition). By testing Frame Semantics here, instead of framing cycling as an enjoyable activity, it suggests fatigue as a primary factor—potentially implying that cycling is a consequence of being tired rather than an activity performed for enjoyment. This activates an unintended exhaustion frame, rather than an intrinsic motivation or recreational activity frame. The case of Transformer 1 (CN+NCD): “you need to get somewhere” and “like to play” (Transformer 2 CN+NCD) are similar by shifting to transport and recreation frames, respectively. These violate SP constraints: “motivated by goal” requires intentionality tied to the activity itself, not external factors (fatigue) or unrelated actions (play).
Although in this later example the Transformer 2 model (CN+NCD) partially retained the idea of enjoyment (“to play”), it actually misrepresents the activity as a form of play rather than an intentional recreational or fitness activity. The phrase “like to play” broadens the interpretation beyond cycling, making the meaning more ambiguous. While cycling can be playful, the gold-standard phrase refers specifically to the enjoyment of cycling itself, not general play. More specifically, the term play may be age-dependent, commonly associated with children rather than adults cycling for recreation or fitness. This adds an unintended layer of interpretation (i.e., pragmatic misalignment), potentially distorting real-world applicability such as AI systems predicting user behaviors or preferences.
A similar pattern is observed in the following sample (3), “car receives action [propel by gasoline or electricity]”. From a syntactic and grammatical perspective, all generated outputs are structurally valid and fluent. However, they semantically diverge from the gold standard, leading to significant shifts in meaning and function. The gold standard emphasizes that the car’s movement is powered by a specific energy source—a crucial detail for understanding its operational mechanism. The predicate “receives action” activates, for example, a mechanical propulsion frame, where the car (Patient) is acted upon by an energy source (Instrument).
The gold standard satisfies selectional preferences with “gasoline/electricity” as valid energy sources in the corresponding frame. All predictions violate this later: in the case of “drive by car” (CN+OIE-GP+NCD and CN+NCD, Transformer 1), although the model invokes a driving frame—typically associated with the human action of operating a vehicle, it incorrectly assigns the car as Agent (implying self-propulsion). This makes the predictions semantically incompatibles with the subject–predicate input. Notice also that “find in car” (CN+NCD, Transformer 2) introduces an unrelated location frame.
In the fourth example, the ground truth states “an Indian restaurant used for [selling Indian meals]”. The predicate “used for” activates a commerce frame, requiring the object to specify the restaurant’s (Theme) transactional functioning. The gold standard assigns “selling meals”, (Function) satisfying SP by emphasizing economic exchange, which is what the restaurant is used for. Predictions (“eat a meal”, “eating”) shift to a consumption frame, changing the restaurant’s role to a consumer action, which can occur in various contexts and does not capture the specificity of the food service industry. While semantically related (meals are eaten), this violates selectional preferences by ignoring the commercial function (selling), resulting in the partial plausibility of the formed sentences.
Entry number five shows distinct failures in generating a contextually appropriate object phrase. In this case, the model was prompted by the phrase “mediators capable of”—which, in theory, should trigger an object related to the mediators’ (Agent) role in the conflict resolution frame in which the ground truth agrees with “settle disagreement” (Action). Instead, the models generated “eat cat food”. Although the Action role is maintained and agrees with the predicate, this output clearly deviates from the intended function of mediators frame. This is a clear violation of selectional preferences, as the predicted verb does not fit the expected argument type.
The issue appears to arise because the model relies on statistical co-occurrence rather than proper semantic role labeling. The phrase “capable of” should have prompted an output indicating the mediators’ ability to “settle a disagreement” or perform a related conflict resolution task. However, the model instead generated ’eat cat food’, likely due to common associations in the training data where ’eat’ is frequently linked with routine consumption actions, even if the resulting pairing (like with cat food) is unusual.
Moreover, while the generated verb “eat” might seem to be treated as the main verb, it is important to note that it was generated solely as the output corresponding to the input “mediators capable of”. The error, therefore, lies in the model’s failure to link the modifier “capable of” with the correct domain-specific action. Instead of reinforcing a conflict resolution frame, the output triggers an irrelevant eating frame.
Note that, in general, the random samples analyzed so far showed that the two-block models did not learn semantic agreement between the elements of the semantic structures, even when they managed to distinguish themselves from the random baseline according to our MSPT. This suggests that, to be more confident about the knowledge acquired by the model, it must pass the MSPT with high significance on both the test and validation data.
7.12.5. Manual Inspection of Biomedical Predictions (Qualitative Error Analysis)
In
Table 14, we have the predictions of the GRU-W model on test data from the OpenNCDKB. See that, in the first example, there is a plausible substitution made by the model by using
“with various roots” instead of
“to clinical variables”. Although the two phrases are not semantically related on their own, they are semantically related when looking at the subject–predicate phrase provided to the model (
“these subtypes are closely correlate”), even when no specific subject noun is present, i.e.,
“these subtypes”. We observe that the model uses the contexts associated to
“are closely correlate” in the NCD-related data to perform its inference, the most probable word sequence. The model overuses frequent noun phrases (
“various roots”), failing to keep the correlation frame by shifting to non-clinical, ambiguous referent frame unrelated to medical discourse.In addition, the themes linked by the model,
“subtypes”, and
“root causes” result in semantically nonsensical sentence because selectional preferences are violated in that the model ignored that predicate
“correlated” requires co-varying quantitative entities.
In the second example, the generated object phrase has a grammatical error (potentially → potential). In addition, the prediction “independent potentially treatment venture” is nonsensical due to the frame being shifted by replacing the medical innovation frame (induced by the predicate “are opening up”) with business venture. Also, “venture” could not fulfill the Result role in a medical context, which leads to role misassignment. Therefore, selectional preferences were violated because the model failed to meet semantic constraints for “opening up” by generating a non-medical, but commercial term.
The third example involves more specific concepts, i.e., “glycemic targets” and “comorbid conditions” in the subject and object phrases, respectively. The generated sentence states that “Glycemic targets should reflect for the association between dietary factors, including chronic hyperglycemia in the evening”, which has no major syntactic or grammatical errors. The prediction presents frame shift as it replaces medical adjustment with the epidemiological association frame induced by the predicate (“reflect”). Also, “dietary factors” and “hyperglycemia” cannot fulfill the Factor role in a clinical guideline context, so there is a role misassignment. Therefore, semantic preferences are violated because the model fails to meet constraints for the predicate, which requires its object to be a clinically actionable factor (e.g., comorbid conditions like hypertension or kidney disease) that directly influences treatment decisions.
The fourth prediction “a combination of factors such as age gender cardiovascular risk factor” is semantically implausible in the context of the subject and predicate. This is because the model replaces opportunity for intervention frame with factor enumeration. Also, “Combination of factors” cannot fulfill the “Outcome” role in the ground truth, thereby showing role misassignment. Thus, the resulting sentence is nonsensical as the model fails to meet constraints for “provide” being an outcome (bust be an actionable opportunity, e.g., “reduce deaths”) by generating non-actionable and descriptive terms (age/gender/cardiovascular risk), which are input variables instead.
The fifth prediction “all their care in the primary care setting” is also semantically implausible. This is because the predicate “have” activates the Health Disparity frame, emphasizing inequitable health outcomes (e.g., poor diabetes control) linked to marginalized groups. However, the model shifts to a Healthcare Logistics frame (“primary care setting”), focusing on care delivery rather than health outcomes. Also, the theme “Ethnic minorities” appropriately serves as the group experiencing inequity. However, the model misassigns the attribute role to a logistical descriptor, stripping the sentence of its equity focus, i.e., “Worse diabetes control” fulfills the role of a measurable, inequitable outcome. Therefore, the model failed to meet constraints for “have” because “Care in the primary care setting” describes a process, not an outcome.
Now, we analyze the performed predictions on five randomly selected triples in the noncommunicable diseases domain (OpenNCDKB) using Transformer models. These are listed them in
Table 15. In the case of the inputs (1) and (4), the models predict the most likely and grammatically well-formed phrases, e.g.,
“cardiovascular disease” given
“subtypes closely correlated”. This is not factual at all as there is no a concrete subject in the input (
“these subtypes” and
“these factors”). The two-block model generated many more free constructions for these inputs.
In the second input, “Immune-based interventions are opening up” (2), we observe behavior similar to that of the previously analyzed GRU-W model. The models generate generic phrasing with simpler terms—such as “to treat the disease” and “to cure individuals”—instead of the gold standard’s “entirely novel therapeutic avenues”. This tendency to avoid more creative or domain-specific compounds was consistently observed across the test data.
Specifically, Transformer 1 (CN+OIE-GP+NCD) fails to capture the notion of novelty inherent in the gold standard. Rather than emphasizing new therapeutic approaches, it suggests a standard treatment objective (“to treat the disease”), thereby losing critical domain-specific details. In contrast, Transformer 1 (CN+NCD) exhibits a frame shift and conceptual error by generating “[UNK] to cure individuals”. Here, the model should have generated an output reflecting the novelty and expansion of therapeutic possibilities. Instead, it produces a generic curative action, losing the sense of innovation. Transformer 2 (CN+NCD) further misaligns the meaning with “to the development of the disease”, which completely inverts the intended message (from the gold standard) by implying disease progression rather than pioneering therapeutic strategies. This semantic drift results in a pragmatic misalignment that fails to capture the transformative impact of immune-based interventions.
In the case of the input
“glycemic targets should reflect”, the gold standard establishes a broad medical principle by linking glycemic targets to the
“presence of comorbid conditions”, emphasizing individualized treatment adjustments based on coexisting health factors. The Transformer models violated selectional preferences, as the expected argument type for the predicate in the input (
“reflect”) was ignored because it typically takes arguments related to measurable or guiding factors for treatment (a clinically actionable factor). The Transformer 1 model trained with the CN+OIE-GP+NCD KB instead predicted
“the risk of gastric cancer”. This represents a frame shift from the original
“Medical Treatment Planning” frame to a
“Risk Assessment” frame, altering the intended focus. Additionally, the model fails to preserve the correct semantic roles: while the theme (
“glycemic targets”) and model predicate (
“should reflect”) are implied in the ground truth, the model’s prediction instead introduces an incorrect attribute (
“the risk of gastric cancer”), i.e., a non-actionable factor that does not directly inform glycemic target adjustments. While diabetes can influence cancer risk [
62], this prediction disrupts the intended message by failing to capture the adaptive nature of glycemic target recommendations.
The Transformer 1 model trained with the CN+NCD KB predicted
“the risk of microvascular complications such as retinopathy in patients with type 2 diabetes mellitus”, which this time resulted differently than it did with previous predictions. While this output remains within the diabetes domain and is demonstrated to be valid medical knowledge [
63], it overspecifies details rather than generalizing appropriately. The model shifts the focus from a medical adjustment frame to a more specific diabetes-specific complication frame (microvascular complications in diabetes). This results in a semantic misalignment, as the model retains the attribute role but introduces unnecessary roles (example role:
“such as retinopathy”, Experiencer role:
“patients with type 2 diabetes mellitus”) while still omitting the theme and predicate roles. The model’s output does not generalize excessively but rather overcommits to a specific medical scenario, reducing applicability across different patient contexts. Therefore, selectional preferences are in conflict because the predicate
“reflect” requires arguments that are quantifiable and relevant to treatment decisions (e.g., comorbidities like hypertension or kidney disease), not descriptive, or redundant details (e.g., specific complications). The Transformer 2 model was unable to generate a coherent output, producing a sequence of unknown tokens. This represents a complete failure in meaning generation, preventing any valid frame from being formed and resulting in a prediction that is semantically unusable.
The analysis of the fifth input “Ethnic minorities to have worse control of their diabetes” reveals that the models struggle to maintain the intended focus on health disparities related to diabetes management. Instead, they introduce either entirely different diseases or vague likelihood statements that fail to capture the original meaning. The first prediction, “the risk of lung cancer”, shifts the focus from disparities in diabetes control to a disease risk assessment frame, replacing the original attribute (worse control of diabetes) with a health outcome (risk of lung cancer). The verb “have” suggests possession or experience, but the generated phrase “treatment of gastric cancer” is not an appropriate argument under its selectional preferences. This substitution suggests that the model is relying on statistical co-occurrences in the training data rather than preserving structured reasoning about health disparities. The shift may also indicate bias amplification, as lung cancer is frequently discussed in medical literature, potentially reinforcing an unintended link between minorities and cancer.
The second prediction, “more likely to be high among patients”, lacks specificity and fails to form a coherent argument structure. The attribute role is left vague, and the theme (ethnic minorities) is missing entirely, making the statement ambiguous and disconnected from the intended meaning. This suggests a failure to establish a meaningful frame alignment, preventing the model from producing a clear assertion about disparities.
The third prediction, “the treatment of gastric cancer”, introduces yet another frame shift—this time, from health disparities to medical treatment, entirely replacing the original attribute role (“worse control of …”) with an unrelated concept (“treatment of gastric cancer”). Selectional preferences are also violated because “have” requires a health outcome, but “treatment of gastric cancer” is a clinical action, not an outcome. This not only distorts the intended message but also introduces another instance of bias reinforcement, as the model again links minorities to a severe illness that was never present in the input.
Across all three cases, the models fail to preserve key semantic roles, either omitting the theme (ethnic minorities) or replacing the intended attribute (worse diabetes control) with related medical concepts. The frequent frame shifts and role assignments indicate that the models are not reasoning about disparities in a structured way but are instead defaulting to generalized medical associations from the training data. This behavior ultimately leads to semantic drift and bias reinforcement, distorting the intended meaning and producing outputs that do not align with the original purpose of the input.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}