
Research on High-Reliability Energy-Aware Scheduling Strategy for Heterogeneous Distributed Systems


Abstract
1. Introduction
- We propose a novel search-based optimal energy frequency adjustment algorithm (SEFFA). Predicated on the assumption that all nodes are pre-allocated, this algorithm strives to minimize energy consumption while fulfilling reliability prerequisites through strategic frequency adjustments.
- We introduce an energy-aware scheduling algorithm based on the weight method under reliability constraints (EAWRS). This methodology integrates both the out-degree and in-degree of the DAG and employs a combination of task completion times, energy consumption metrics, and reliability factors, expressed through normalized and linear combinations, to optimize node allocation.
- The efficacy of the proposed algorithms is validated through comprehensive experimental simulations. The findings demonstrate that these methods outperform existing techniques in terms of energy consumption and makespan.
2. Related Work
3. Models
3.1. System Model
3.2. Energy Model
3.3. Reliability Model
3.4. Problem Description
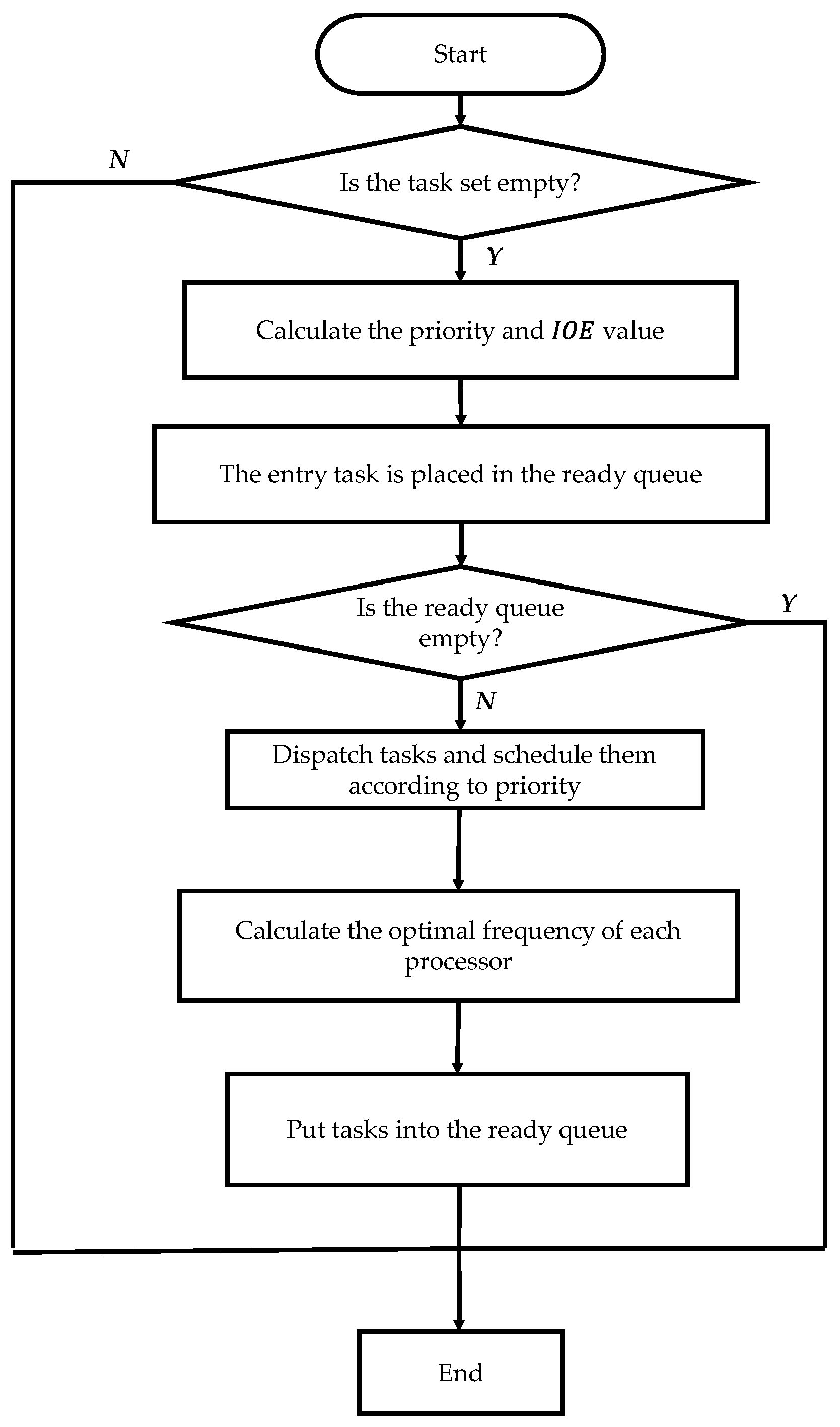
4. Energy-Aware Weighted Scheduling Algorithm with Reliability Constraints
4.1. The Task Priority Ordering Phase
4.2. The Processor Allocation Phase
| Algorithm 1: EAWRS | |
| Input: , Output: | |
| 1: | Calculate of all tasks |
| 2: | Calculate according to Equation (14) |
| 3: | Push valuese into queue |
| 4: | Push values into queue in decreasing order |
| 5: | for (∀,) do |
| 6: | if then |
| 7: | Assign to processor satisfying: |
| 8: | |
| 9: | else |
| 10: | Assign to processor satisfying: |
| 11: | |
| 12: | end if |
| 13: | end for |
| 14: | return ) |
- Calculate the value for each task.
- Place the calculated IOE values in queue in decreasing order.
- If task is within the range of , it indicates a high criticality level, and it is then assigned to processor withwhere represents the completion time of task on processor .
- If task is within the range of , it indicates a lower criticality level, and it should then be assigned to processor with .
- Calculate the upward rank values () for each task and assign tasks to the appropriate processors according to Formulas (14) and (15). The final result is a scheduling solution.
5. Search-Based Optimal Energy Frequency Adjustment Algorithm
| Algorithm 2: SEFFA | |
| Input: Output: | |
| 1: | Initialize Fibonacci sequence with sufficient length |
| 2: | Compute the upper and lower bounds of the search region and |
| 3: | while do |
| 4: | = length_of_ |
| 5: | Compute and |
| 6: | for each processor do: |
| 7: | = , = |
| 8: | while ( − > ) do |
| 9: | = ( + /2 |
| 10: | if < then |
| 11: | = |
| 12: | else |
| 13: | = |
| 14: | end if |
| 15: | end while |
| 16: | for each task allocated to the processor do |
| 17: | = |
| 18: | end for |
| 19: | Compute |
| 20: | if < then |
| 21: | = |
| 22: | else |
| 23: | = |
| 24: | end if |
| 25: | Update for next iteration |
| 26: | end while |
| 27: | return |
6. Experiments
6.1. Comparative Algorithms
6.2. Experimental Platform and DAG Applications
6.3. Evaluation Metrics
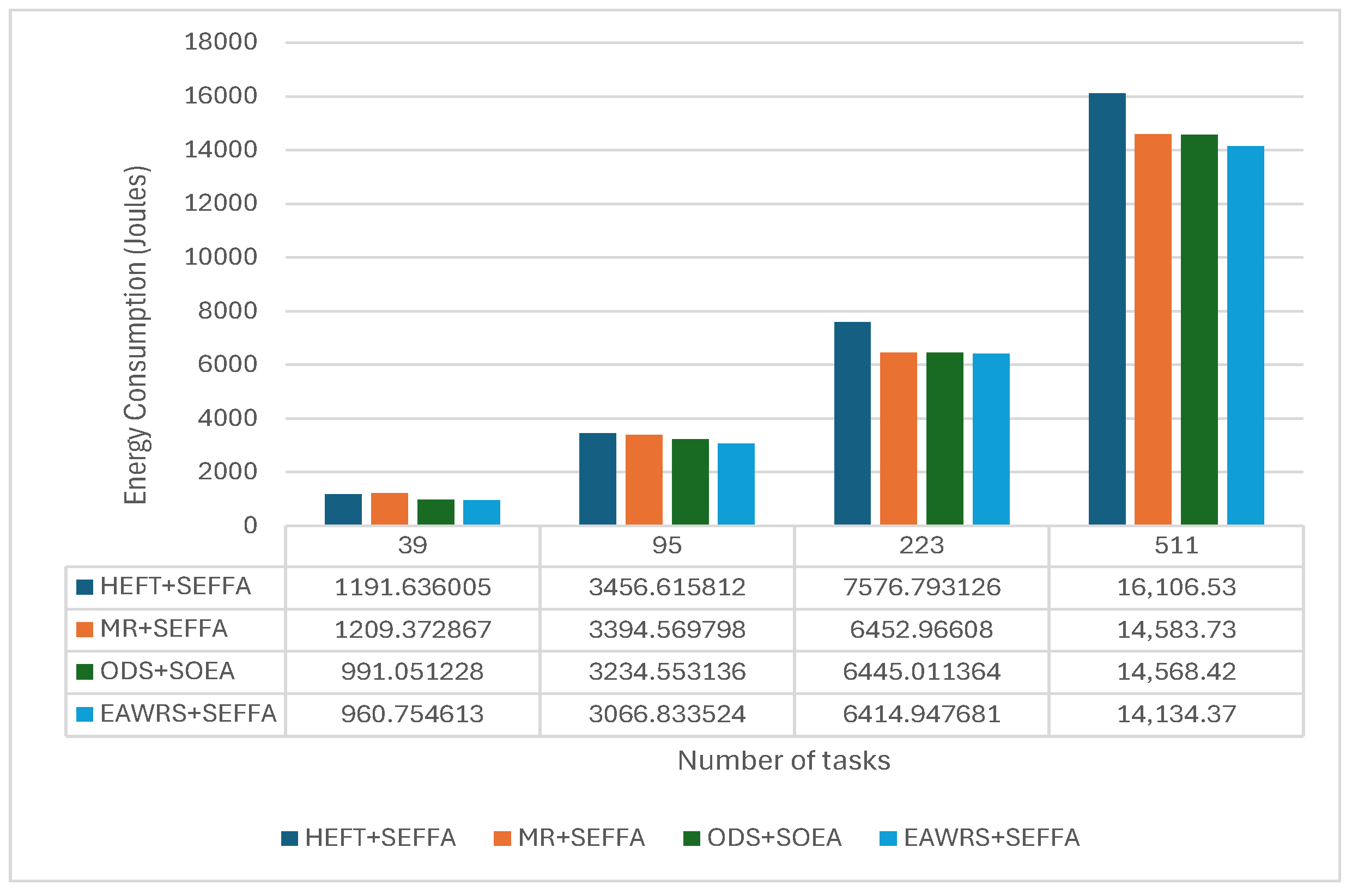
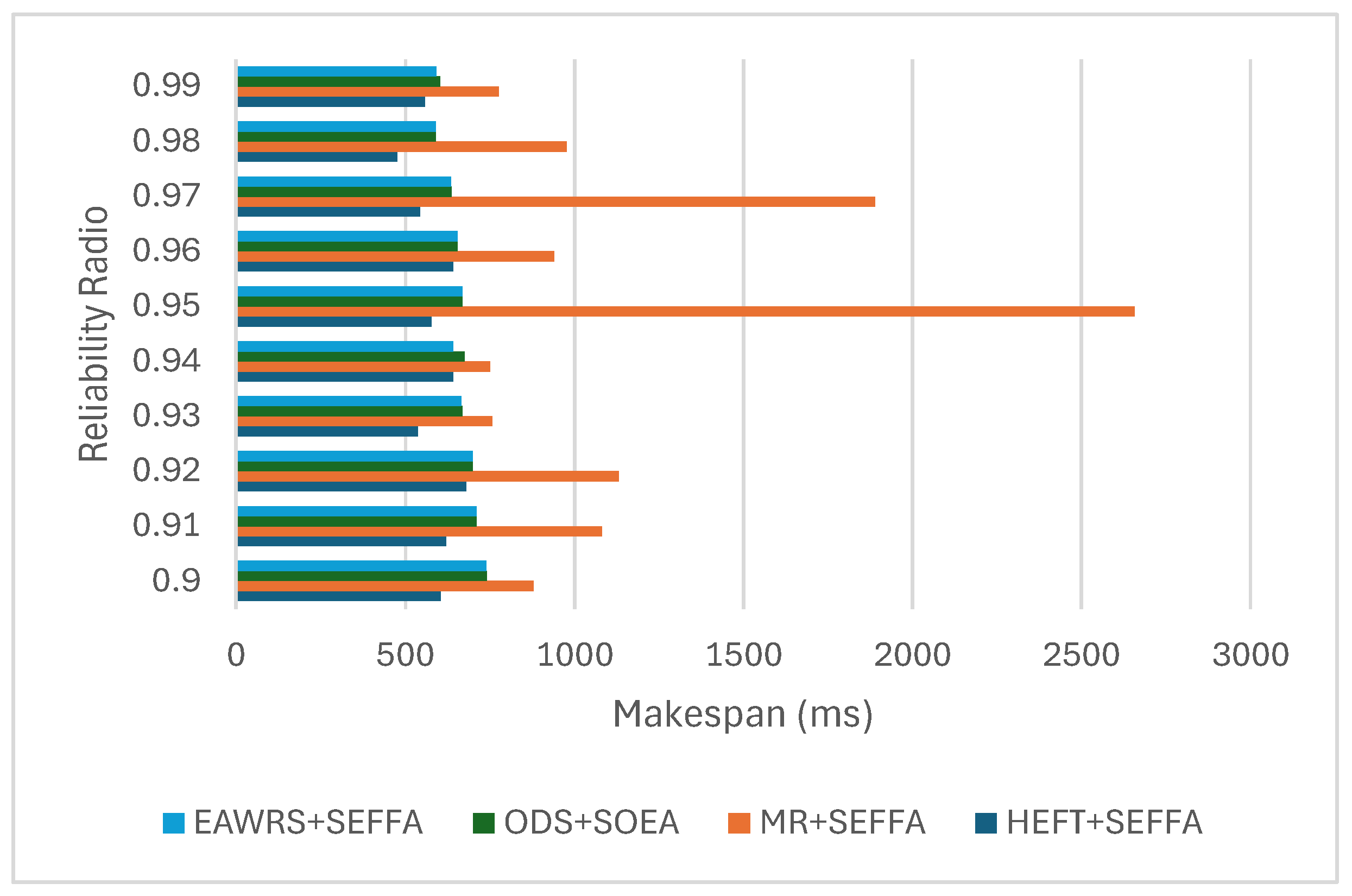
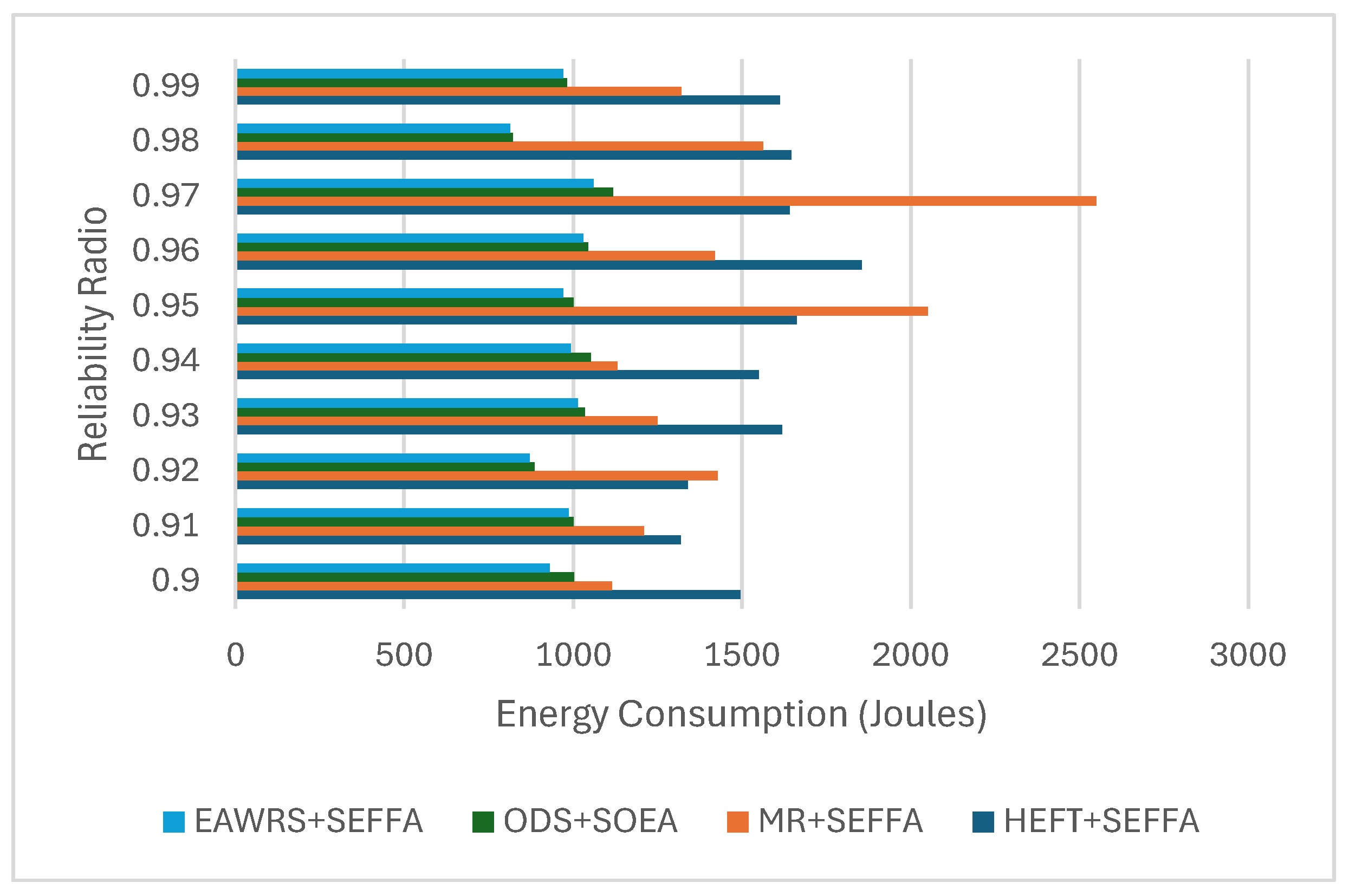
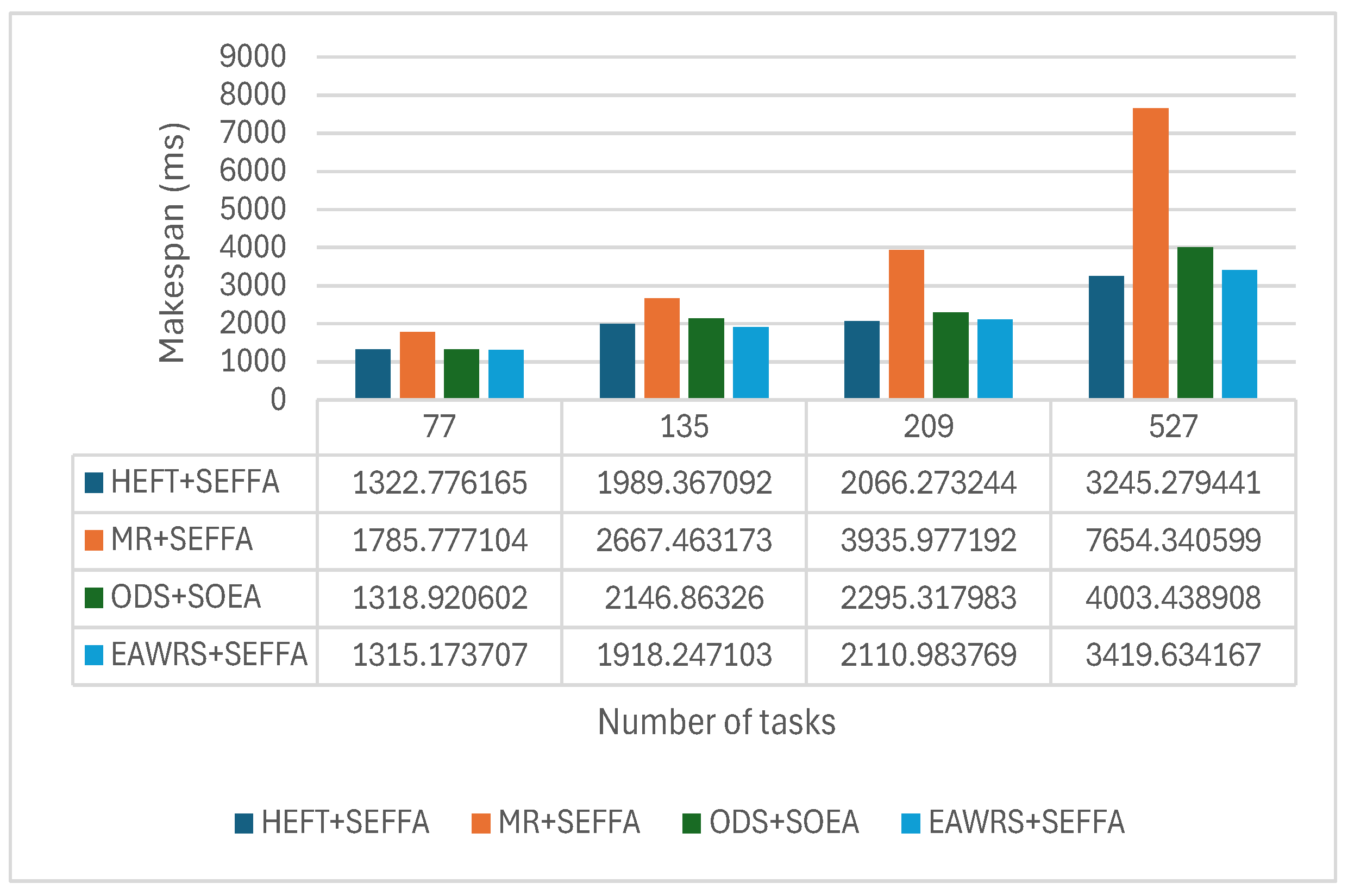
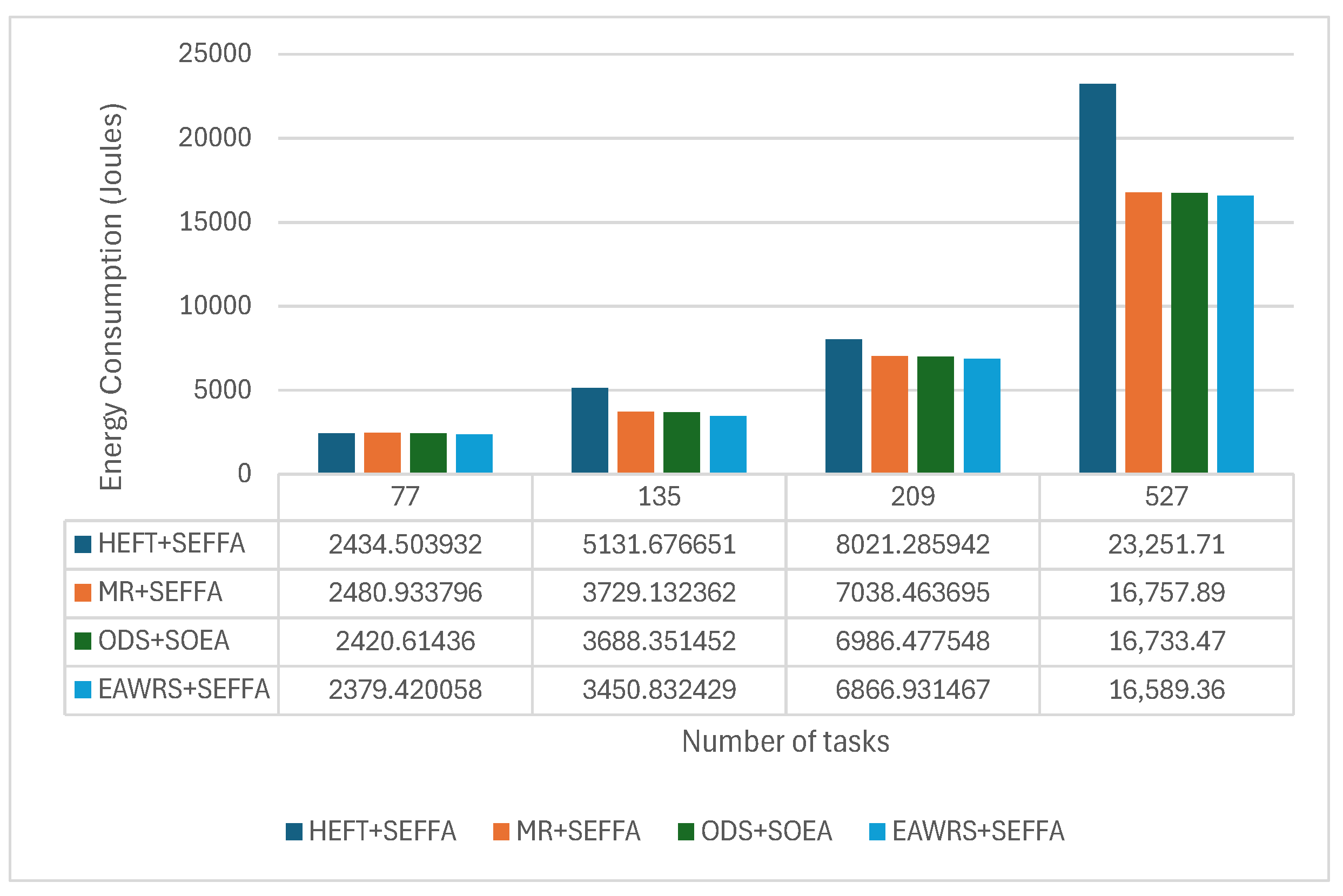
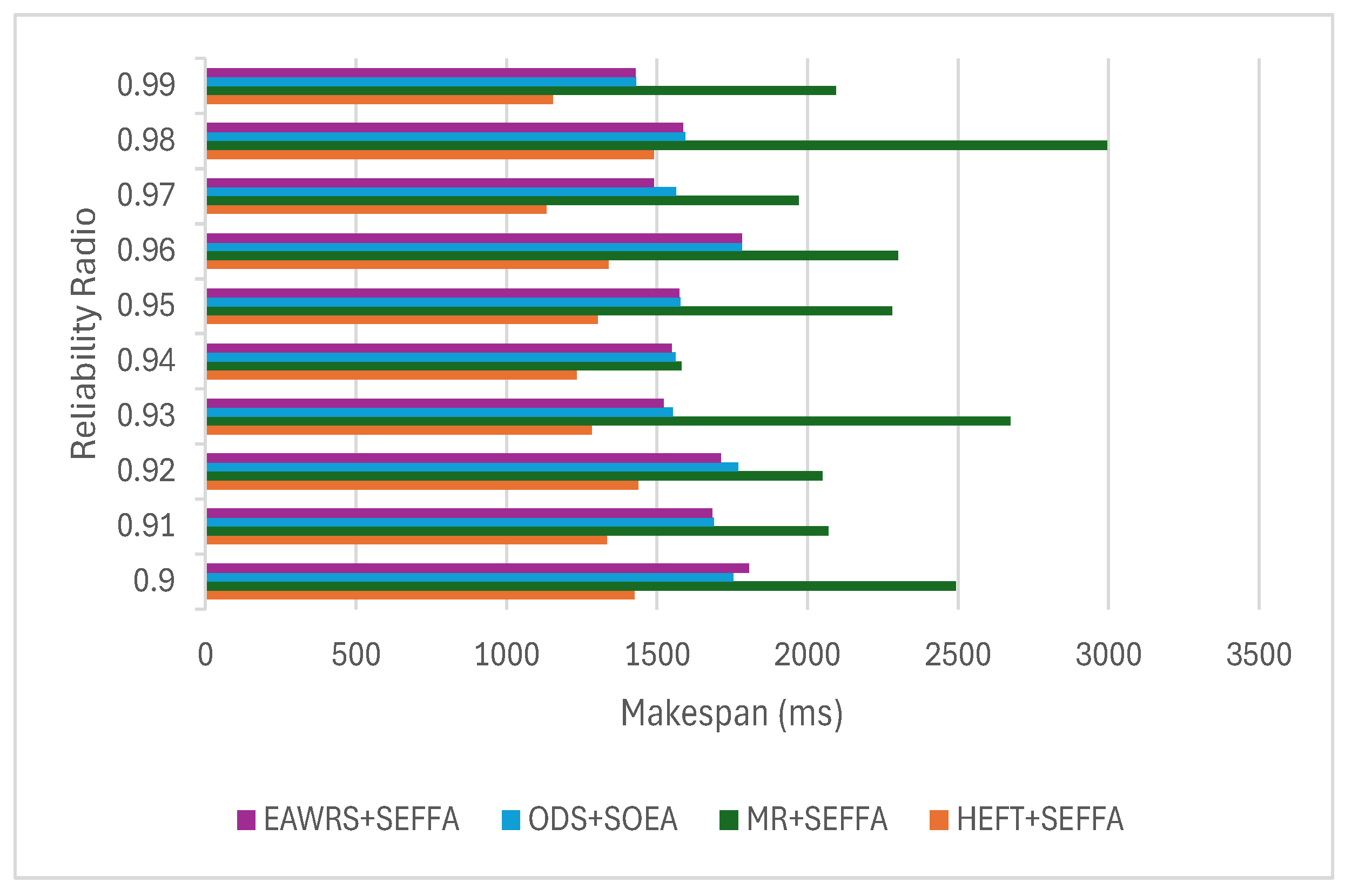
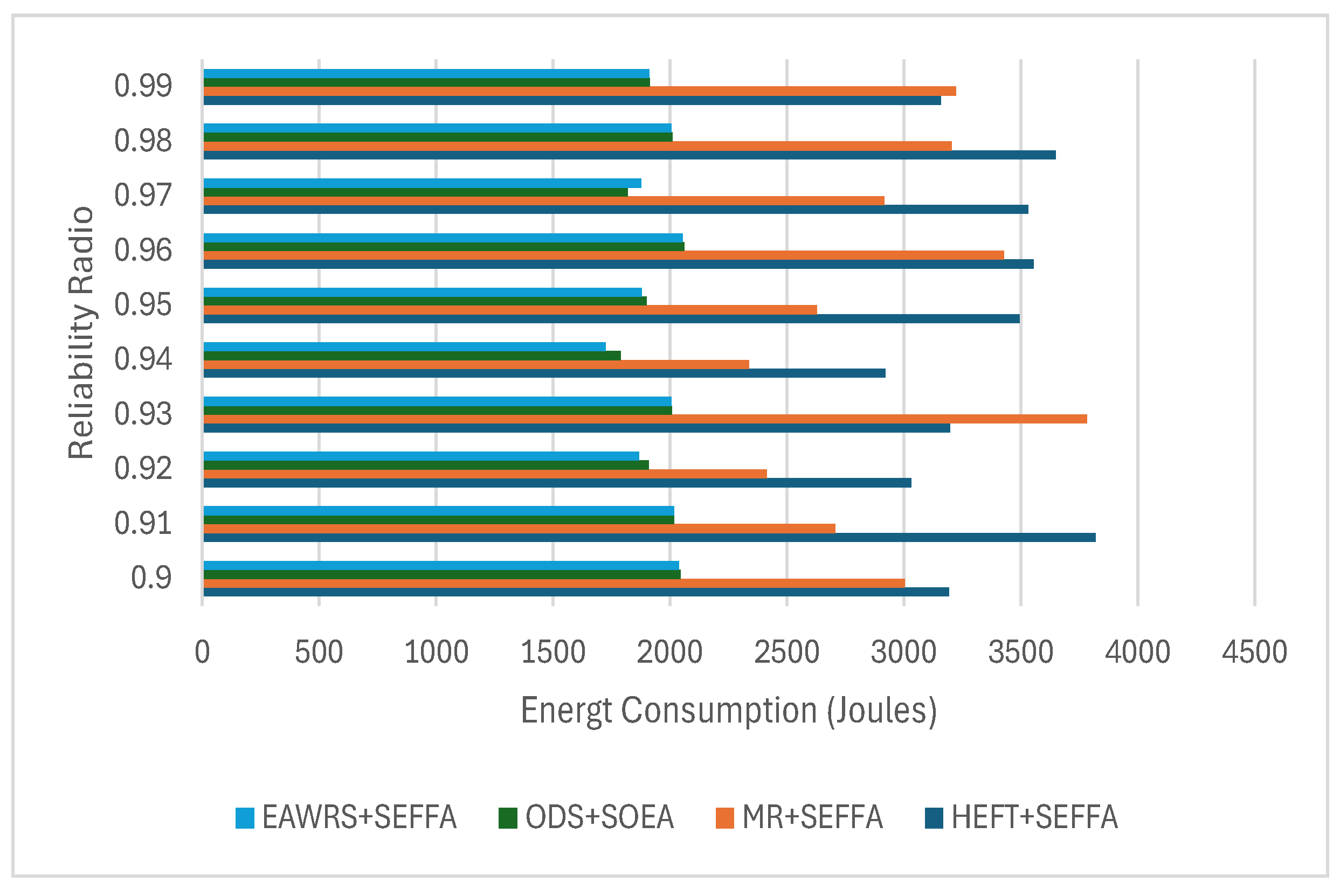
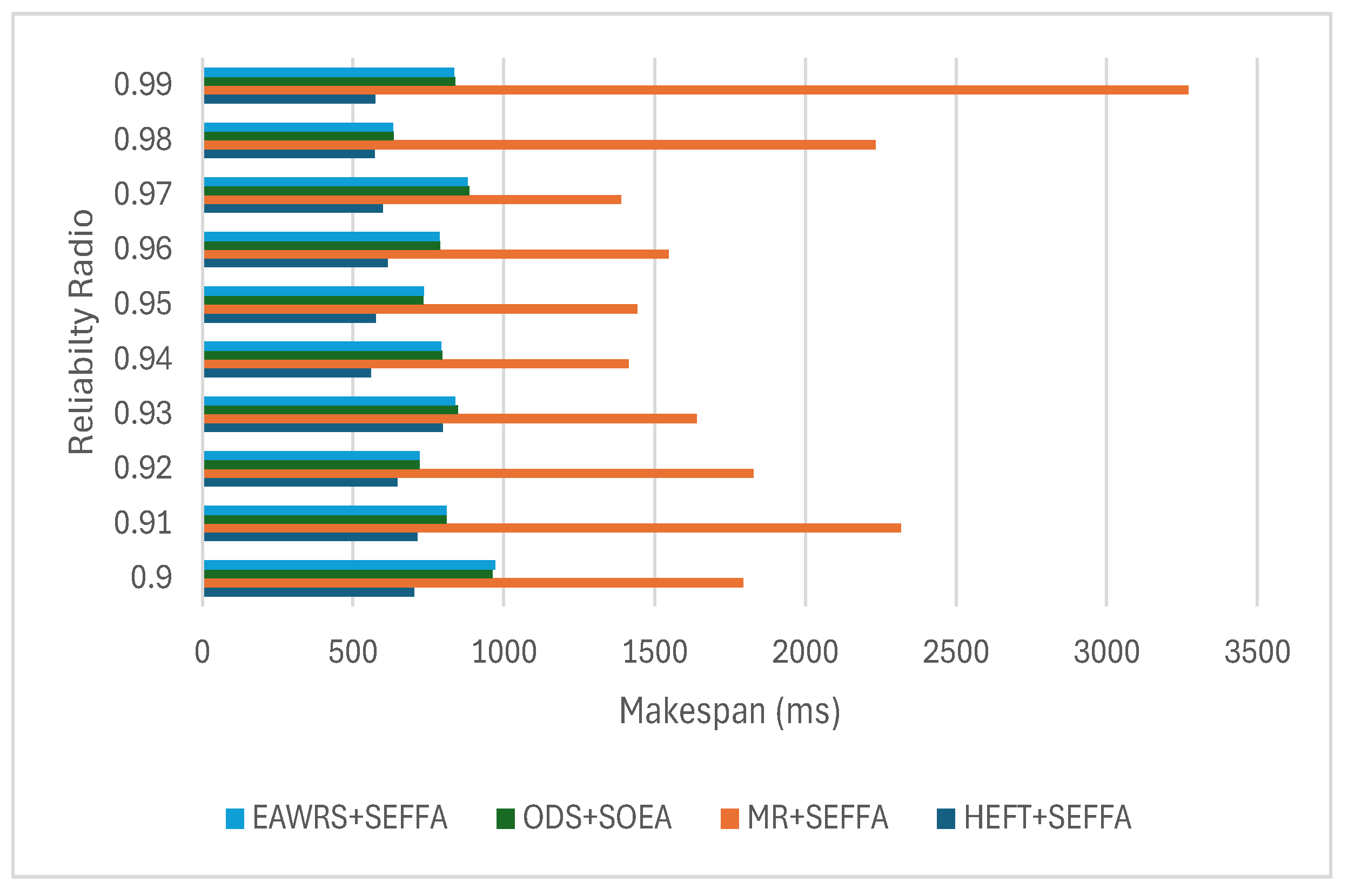
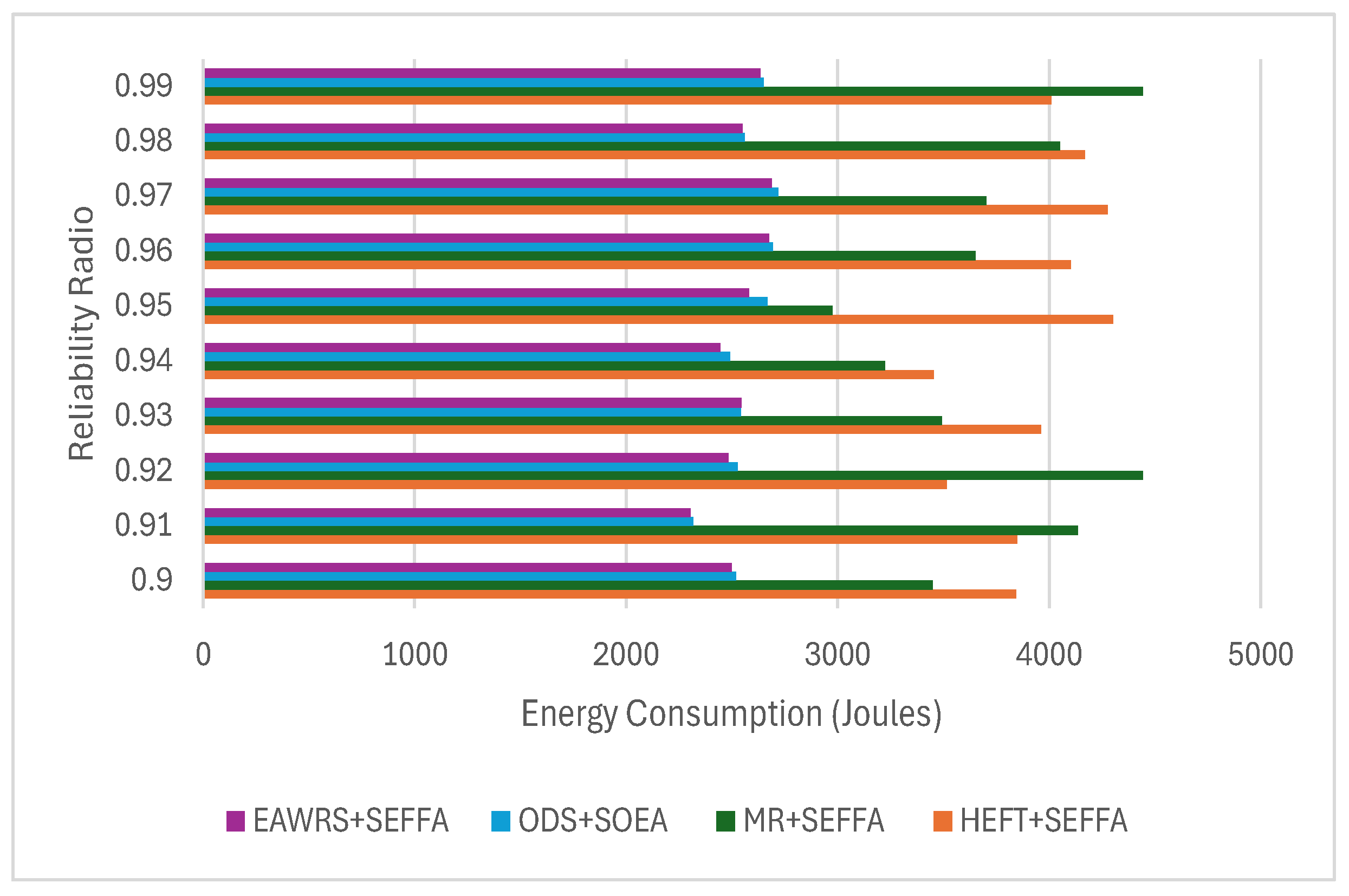
6.4. Results and Analysis
6.5. Key Limitations
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rinaldi, M.; Wang, S.; Geronel, R.S.; Primatesta, S. Application of Task Allocation Algorithms in Multi-UAV Intelligent Transportation Systems: A Critical Review. Big Data Cogn. Comput. 2024, 8, 177. [Google Scholar] [CrossRef]
- Ibrahim, I.M. Task scheduling algorithms in cloud computing: A review. Turk. J. Comput. Math. Educ. TURCOMAT 2021, 12, 1041–1053. [Google Scholar]
- Liu, Y.; Liu, S.; Wang, Y.; Zhao, H.; Liu, S. Video steganography: A review. Neurocomputing 2019, 335, 238–250. [Google Scholar] [CrossRef]
- Li, F.; Feng, R.; Han, W.; Wang, L. Ensemble model with cascade attention mechanism for high-resolution remote sensing image scene classification. Opt. Express 2020, 28, 22358–22387. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Zheng, Z. Task migration for mobile edge computing using deep reinforcement learning. Future Gener. Comput. Syst. 2019, 96, 111–118. [Google Scholar] [CrossRef]
- Liu, F.; He, Y.; He, J.; Gao, X.; Huang, F. Optimization of Big Data Parallel Scheduling Based on Dynamic Clustering Scheduling Algorithm. J. Signal Process. Syst. 2022, 94, 1243–1251. [Google Scholar] [CrossRef]
- Wu, J. Energy-efficient scheduling of real-time tasks with shared resources. Future Gener. Comput. Syst. 2016, 56, 179–191. [Google Scholar] [CrossRef]
- Gao, K.; Huang, Y.; Sadollah, A.; Wang, L. A review of energy-efficient scheduling in intelligent production systems. Complex Intell. Syst. 2020, 6, 237–249. [Google Scholar] [CrossRef]
- Casini, D.; Biondi, A.; Nelissen, G.; Buttazzo, G. A holistic memory contention analysis for parallel real-time tasks under partitioned scheduling. In Proceedings of the 2020 IEEE Real-Time and Embedded Technology and Applications Symposium (RTAS), Sydney, NSW, Australia, 21–24 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 239–252. [Google Scholar]
- Xie, G.; Xiao, X.; Peng, H.; Li, R.; Li, K. A survey of low-energy parallel scheduling algorithms. IEEE Trans. Sustain. Comput. 2021, 7, 27–46. [Google Scholar] [CrossRef]
- Ghafari, R.; Kabutarkhani, F.H.; Mansouri, N. Task scheduling algorithms for energy optimization in cloud environment: A comprehensive review. Clust. Comput. 2022, 25, 1035–1093. [Google Scholar] [CrossRef]
- Azizi, S.; Shojafar, M.; Abawajy, J.; Buyya, R. Deadline-aware and energy-efficient IoT task scheduling in fog computing systems: A semi-greedy approach. J. Netw. Comput. Appl. 2022, 201, 103333. [Google Scholar] [CrossRef]
- Baciu, M.D.; Capota, E.A.; Stângaciu, C.S.; Curiac, D.-I.; Micea, M.V. Multi-Core Time-Triggered OCBP-Based Scheduling for Mixed Criticality Periodic Task Systems. Sensors 2023, 23, 1960. [Google Scholar] [CrossRef] [PubMed]
- Taghinezhad-Niar, A.; Pashazadeh, S.; Taheri, J. Energy-efficient workflow scheduling with budget-deadline constraints for cloud. Computing 2022, 104, 601–625. [Google Scholar] [CrossRef]
- Deng, Z.; Cao, D.; Shen, H.; Yan, Z.; Huang, H. Reliability-aware task scheduling for energy efficiency on heterogeneous multiprocessor systems. J. Supercomput. 2021, 77, 11643–11681. [Google Scholar] [CrossRef]
- Wen, Y.; Wang, Z.; O’boyle, M.F.P. Smart multi-task scheduling for OpenCL programs on CPU/GPU heterogeneous platforms. In Proceedings of the 2014 21st International Conference on High Performance Computing (HiPC), Goa, India, 17–20 December 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1–10. [Google Scholar]
- Babaei, M.A.; Hasanzadeh, S.; Karimi, H. Cooperative energy scheduling of interconnected microgrid system considering renewable energy resources and electric vehicles. Electr. Power Syst. Res. 2024, 229, 110167. [Google Scholar] [CrossRef]
- Qin, Y.; Zeng, G.; Kurachi, R.; Matsubara, Y.; Takada, H. Execution-variance-aware task allocation for energy minimization on the big. little architecture. Sustain. Comput. Inform. Syst. 2019, 22, 155–166. [Google Scholar]
- Tang, X.; Fu, Z. CPU–GPU utilization aware energy-efficient scheduling algorithm on heterogeneous computing systems. IEEE Access 2020, 8, 58948–58958. [Google Scholar] [CrossRef]
- Stewart, R.; Raith, A.; Sinnen, O. Optimising makespan and energy consumption in task scheduling for parallel systems. Comput. Oper. Res. 2023, 154, 106212. [Google Scholar] [CrossRef]
- Hosseinioun, P.; Kheirabadi, M.; Tabbakh, S.R.K.; Ghaemi, R. A new energy-aware tasks scheduling approach in fog computing using hybrid meta-heuristic algorithm. J. Parallel Distrib. Comput. 2020, 143, 88–96. [Google Scholar] [CrossRef]
- Abd Elaziz, M.; Xiong, S.; Jayasena, K.P.N.; Li, L. Task scheduling in cloud computing based on hybrid moth search algorithm and differential evolution. Knowl.-Based Syst. 2019, 169, 39–52. [Google Scholar] [CrossRef]
- Zhang, Y.W.; Zheng, H. Energy-aware fault-tolerant scheduling for imprecise mixed-criticality systems with semi-clairvoyance Journal of Systems Architecture. J. Syst. Archit. 2024, 151, 103141. [Google Scholar] [CrossRef]
- Quan, Z.; Wang, Z.-J.; Ye, T.; Guo, S. Task scheduling for energy consumption constrained parallel applications on heterogeneous computing systems. IEEE Trans. Parallel Distrib. Syst. 2019, 31, 1165–1182. [Google Scholar] [CrossRef]
- Topcuoglu, H.; Hariri, S.; Wu, M.-Y. Performance-effective and low-complexity task scheduling for heterogeneous computing. IEEE Trans. Parallel Distrib. Syst. 2002, 13, 260–274. [Google Scholar] [CrossRef]
- Xie, G.; Chen, Y.; Xiao, X.; Xu, C.; Li, R.; Li, K. Energy-efficient fault-tolerant scheduling of reliable parallel applications on heterogeneous distributed embedded systems. IEEE Trans. Sustain. Comput. 2017, 3, 167–181. [Google Scholar] [CrossRef]
- Xie, G.; Zeng, G.; Chen, Y.; Bai, Y.; Zhou, Z.; Li, R.; Li, K. Minimizing redundancy to satisfy reliability requirement for a parallel application on heterogeneous service-oriented systems. IEEE Trans. Serv. Comput. 2017, 13, 871–886. [Google Scholar] [CrossRef]
- Huang, J.; Li, R.; Jiao, X.; Jiang, Y.; Chang, W. Dynamic DAG scheduling on multiprocessor systems: Reliability, energy, and makespan. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2020, 39, 3336–3347. [Google Scholar] [CrossRef]
- Schieber, B.; Samineni, B.; Vahidi, S. Interweaving real-time jobs with energy harvesting to maximize throughput. In Proceedings of the International Conference and Workshops on Algorithms and Computation, Hsinchu, Taiwan, 22–24 March 2023; Springer Nature: Cham, Switzerland, 2023; pp. 305–316. [Google Scholar]
- Ghajari, G.; Ghajari, E.; Mohammadi, H.; Amsaad, F. Intrusion Detection in IoT Networks Using Hyperdimensional Computing: A Case Study on the NSL-KDD Dataset. arXiv 2025, arXiv:2503.03037. [Google Scholar]
- Ghajari, G.; Ghimire, A.; Ghajari, E.; Amsaad, F. Network Anomaly Detection for IoT Using Hyperdimensional Computing on NSL-KDD. arXiv 2025, arXiv:2503.03031. [Google Scholar]
- Rastgoo, S.; Mahdavi, Z.; Nasab, M.A.; Zand, M.; Padmanaban, S. Using an intelligent control method for electric vehicle charging in microgrids. World Electr. Veh. J. 2022, 13, 222. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| Execution time of task in processor | |
| The edge between task and task | |
| Communication time from to | |
| Average execution time of task | |
| Dynamic power consumption independent of processor frequency | |
| Static energy consumption | |
| System state | |
| Power consumption related to processor frequency | |
| The effective capacitance of processor | |
| Dynamic power index of processor | |
| Energy consumption of application | |
| Reliability value of task in processor | |
| Reliability value of application | |
| Upward rank value of task | |
| The successor to task | |
| The finish time of executing task on processor | |
| The minimum values of finish time of executing task | |
| The maximum values of finish time of executing task | |
| Reliability requirement of application | |
| Reliability value of task under the minimum redundancy of the task | |
| Reliability value of task under the maximum redundancy of the task | |
| The execution time of sub-task on a processor with its maximum frequency | |
| Failure rate of processor |
| Task | |||
|---|---|---|---|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Wu, J.; Cheng, L.; Tao, T. Research on High-Reliability Energy-Aware Scheduling Strategy for Heterogeneous Distributed Systems. Big Data Cogn. Comput. 2025, 9, 160. https://doi.org/10.3390/bdcc9060160
Chen Z, Wu J, Cheng L, Tao T. Research on High-Reliability Energy-Aware Scheduling Strategy for Heterogeneous Distributed Systems. Big Data and Cognitive Computing. 2025; 9(6):160. https://doi.org/10.3390/bdcc9060160
Chicago/Turabian StyleChen, Ziyu, Jing Wu, Lin Cheng, and Tao Tao. 2025. "Research on High-Reliability Energy-Aware Scheduling Strategy for Heterogeneous Distributed Systems" Big Data and Cognitive Computing 9, no. 6: 160. https://doi.org/10.3390/bdcc9060160
APA StyleChen, Z., Wu, J., Cheng, L., & Tao, T. (2025). Research on High-Reliability Energy-Aware Scheduling Strategy for Heterogeneous Distributed Systems. Big Data and Cognitive Computing, 9(6), 160. https://doi.org/10.3390/bdcc9060160