
Image First or Text First? Optimising the Sequencing of Modalities in Large Language Model Prompting and Reasoning Tasks


Abstract
1. Introduction
- We systematically evaluated the impact of image and text prompt-sequencing on the reasoning performance of three multi-modal LLMs: GPT-4o, Gemini-1.5-Flash, and Claude-3-Haiku. Our findings demonstrate that modality sequencing significantly affects performance, particularly in complex reasoning tasks.
- We identified specific attributes within image and text modalities that exhibit higher sensitivity to sequencing. The results indicate that different reasoning tasks benefit from distinct sequencing strategies.
- We derived a set of practical guidelines in the form of multi-modal heuristics seeking to maximise user experience by instructing users on creating prompts based on our empirical findings, and we validated them through a user interaction study.
2. Related Work
2.1. Multi-Modal Prompting Techniques
2.2. Image Sequencing
2.3. Multi-Modal Fusion Strategies and Positional Bias
2.4. Human-Centred Approaches to Navigating Complexity and Uncertainty in Interactive AI
2.5. Research Questions
- RQ1: To what extent does the sequencing of image and text modalities in prompts affect the reasoning performance of multi-modal LLMs having unknown and potentially different multi-modal fusion strategies, across different benchmark datasets and question types?
- RQ2: How do specific attributes of questions, such as nested structure, subject domain, and complexity, interact with modality sequencing to influence LLM performance, and how does this vary across different LLMs?
- RQ3: To what degree is the impact of modality sequencing on LLM performance attributable to the order of information presentation rather than the inherent properties of different modalities, and how can these insights be applied to optimise multi-modal prompt construction?
- RQ4: Can practical heuristics and guidelines be developed to assist users in constructing multi-modal prompts that optimise both their reasoning accuracy and enable a more effective user experience with interactive intelligent systems?
3. Methodology
3.1. Datasets
3.1.1. M3Exam Dataset


3.1.2. M3COTS Dataset

3.2. LLMs
3.3. Experimental Design
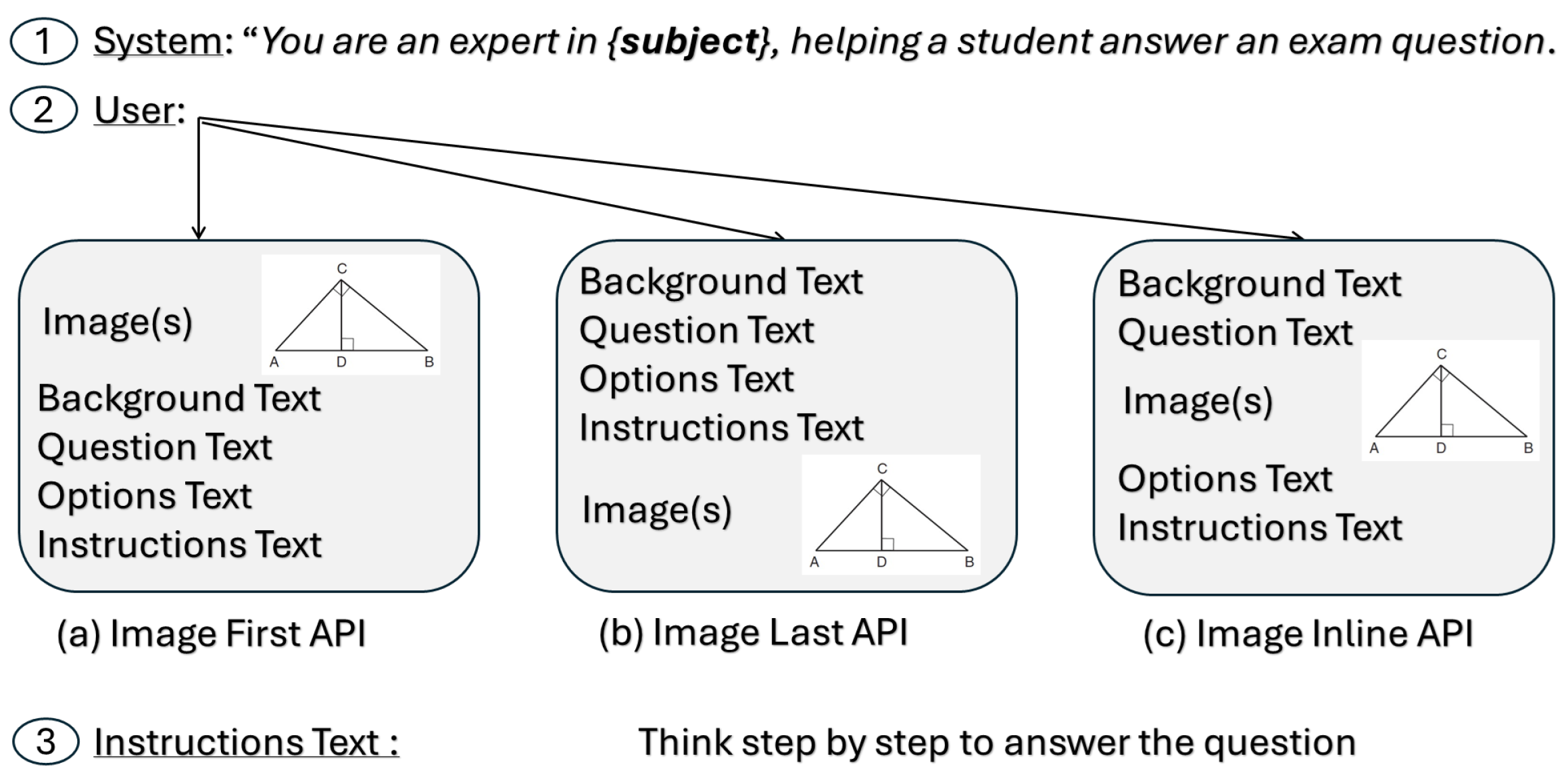
3.3.1. Image–Text Sequence Variation
- Image First (IF): The model processes the image x before the text q, represented by the function .
- Text First (TF): The model processes the text q before the image x, represented by the function .
- Interleaved (IN): The model processes blocks of text () interspersed with the image x, integrating these inputs in sequence, represented by the function .
3.3.2. Image–Text Sequence: Image Versus Instructions Analysis
- Image First (IF): The model processes the extracted text from the image before the textual query q. This is represented by the function .
- Text First (TF): The model processes the textual query q before the extracted text from the image , represented by the function .
- Interleaved (IN): The model processes blocks of text () interspersed with the extracted text from the image , integrating these inputs in sequence, represented by the function .
3.3.3. Image–Text Sequence: Attribute-Based Analysis
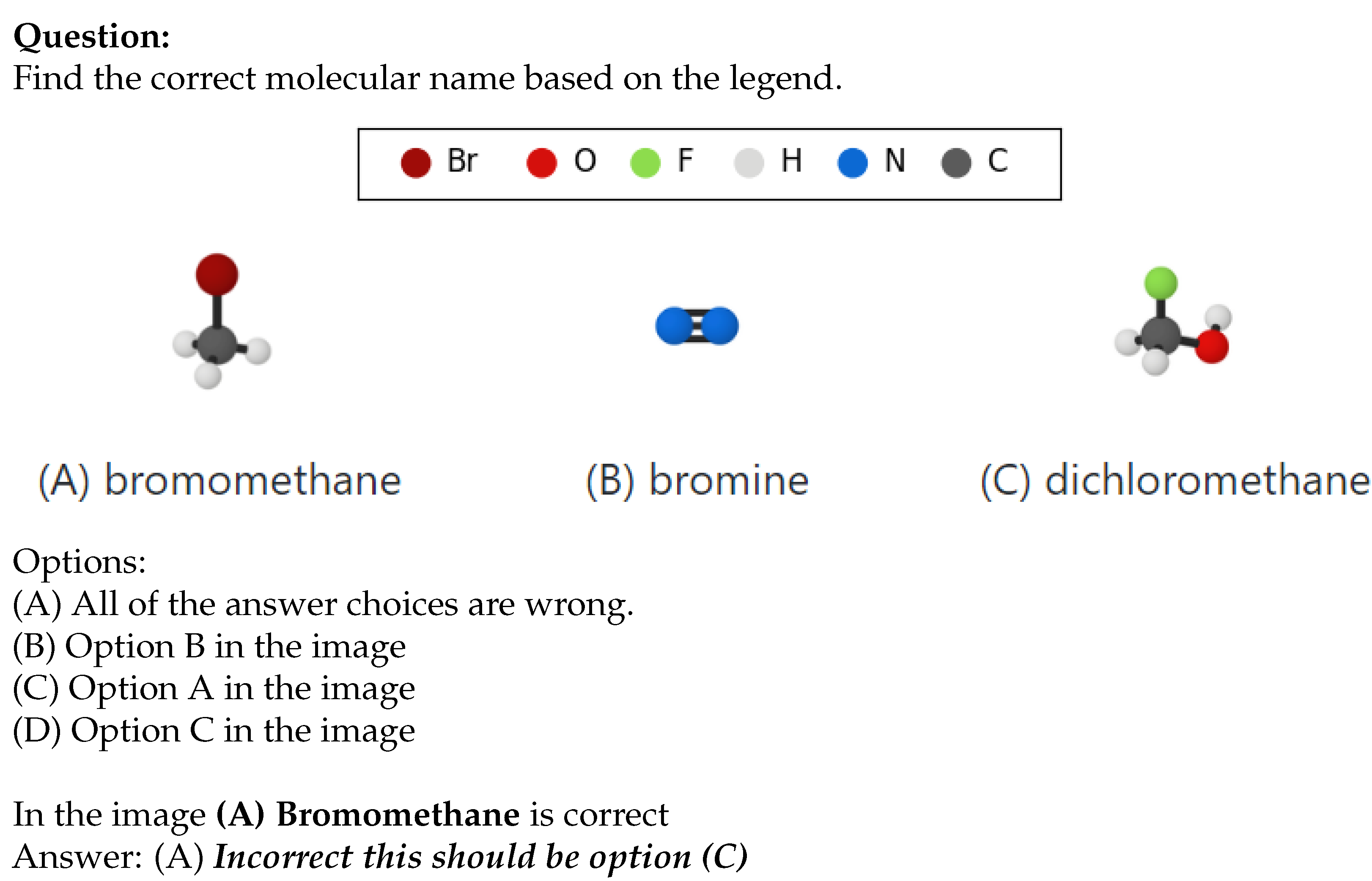
- Image type: The model’s performance is evaluated based on different types of images—purely visual (images with no text), text-based (images primarily containing text, like formulas), and mixed (images containing both visual elements and text) images.
- Prompt length: Various lengths of prompts are tested to observe how the length of the text portion affects the model’s accuracy and reasoning capabilities.
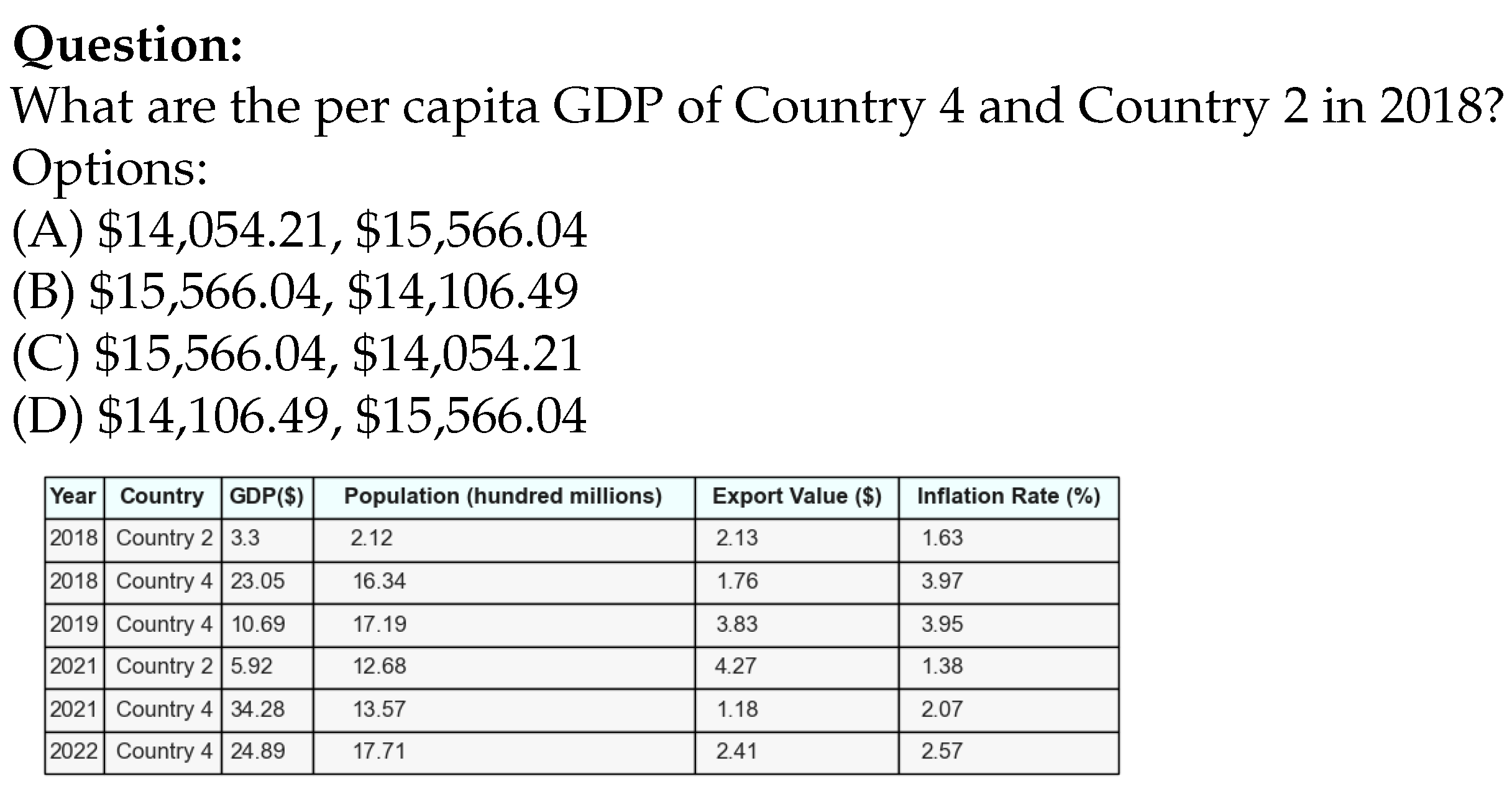
- Educational level and question type: The experiment evaluates how different educational levels with the M3Exam dataset and question types within the M3COTS dataset—representing the topics or reasoning skills being tested (for example, event ordering or economics per capita GDP comparison)—influence the model’s performance.
3.3.4. User Interaction and Heuristic Evaluation
3.4. Evaluation
4. Results
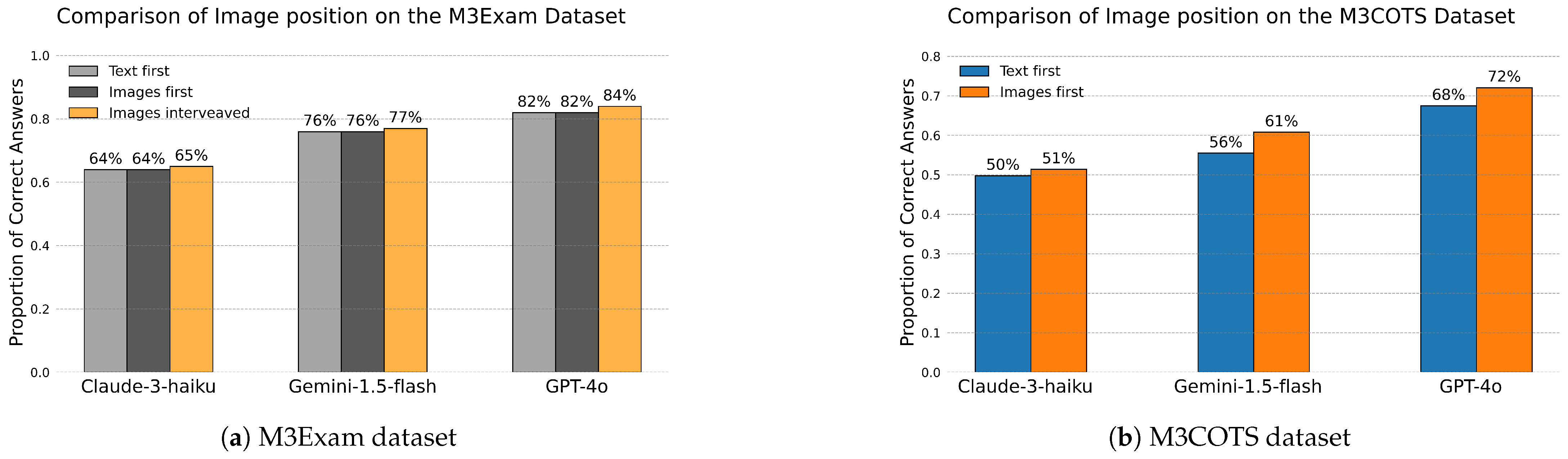
4.1. Image–Text Sequence Variation
4.2. Image–Text Sequence: Image Versus Instructions Analysis
4.3. Image–Text Sequence: Attribute-Based Analysis
4.4. Heuristic Development and User Interaction Study
4.4.1. Correlating Exam Question Structure with Sequencing
4.4.2. Heuristic Definition
4.4.3. User Interaction Study Results
5. Discussion
5.1. Effects of Text and Image Sequencing
5.2. Question Complexity and Sequencing Sensitivity
5.3. Information Order vs. Modality Properties
5.4. Implications and Practical Guidelines
- Educational tutoring systems: In systems designed to assist with learning, integrating textual explanations with diagrams or problem images can enhance student understanding.
- Healthcare diagnostics: Diagnostic tools that combine patient records with medical imaging (e.g., X-rays and MRI) can benefit from optimised modality sequencing.
- Legal document analysis: Legal professionals often need to analyse case documents that include both textual information and visual evidence (e.g., diagrams and charts), enabling the optimisation of the sequencing of these modalities to facilitate more accurate and efficient case analyses.
- Customer support systems: In customer support applications, combining textual queries with product images can improve the accuracy of automated responses.
5.5. Advancing Human-Centred AI in Multi-Modal Interaction
5.6. Limitations
5.7. Future Research
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Appendix: Image–Text Sequence: Attribute-Based Analysis
Appendix A.1. M3Exam Data

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TF | IF | IN | TF vs. IF | TF vs. IN | IF vs. IN | |
|---|---|---|---|---|---|---|
| GPT-4o [14] | ||||||
| Images Only | 0.80 | 0.78 | 0.80 | (Stat. = 20.0, ) | (Stat. = 13.0, ) | (Stat. = 19.0, ) |
| Mixture | 0.84 | 0.83 | 0.86 | (Stat. = 23.0, ) | (Stat. = 21.0, ) | (Stat. = 16.0, ) |
| Text Only | 1.00 | 1.00 | 1.00 | (Stat. = 0.0, ) | (Stat. = 0.0, ) | (Stat. = 0.0, ) |
| Gemini-1.5 [15] | ||||||
| Images Only | 0.69 | 0.71 | 0.72 | (Stat. = 22.0, ) | (Stat. = 19.0, ) | (Stat. = 19.0, ) |
| Mixture | 0.78 | 0.78 | 0.80 | (Stat. = 43.0, ) | (Stat. = 32.0, ) | (Stat. = 27.0, ) |
| Text Only | 1.00 | 1.00 | 1.00 | (Stat. = 0.0, ) | (Stat.= 0.0, ) | (Stat. = 0.0, ) |
| Claude-3 [16] | ||||||
| Images Only | 0.53 | 0.56 | 0.55 | (Stat. = 19.0, ) | (Stat. = 23.0, ) | (Stat. = 20.0, ) |
| Mixture | 0.70 | 0.67 | 0.70 | (Stat. = 38.0, ) | (Stat. = 41.0, ) | (Stat. = 29.0, ) |
| Text Only | 1.00 | 1.00 | 1.00 | (Stat. = 0.0, ) | (Stat. = 0.0, ) | (Stat.= 0.0, ) |
| TF | IF | IN | TF vs. IF | TF vs. IN | IF vs. IN | |
|---|---|---|---|---|---|---|
| GPT-4o [14] | ||||||
| High school (USA) | 0.80 | 0.79 | 0.82 | (Stat. = 31.0, ) | (Stat. = 23.0, ) | (Stat. = 25.0, ) |
| Middle school (USA) | 0.84 | 0.86 | 0.85 | (Stat. = 5.0, ) | (Stat. = 7.0, ) | (Stat. = 6.0, ) |
| Elementary school (USA) | 0.85 | 0.90 | 0.86 | (Stat. = 3.0, ) | (Stat. = 3.0, ) | (Stat. = 3.0, ) |
| Gemini-1.5 [15] | ||||||
| High school (USA) | 0.72 | 0.72 | 0.73 | (Stat. = 45.0, ) | (Stat. = 35.0, ) | (Stat. = 36.0, ) |
| Middle school (USA) | 0.80 | 0.80 | 0.82 | (Stat. = 10.0, ) | (Stat. = 6.0, ) | (Stat. = 7.0, ) |
| Elementary school (USA) | 0.84 | 0.86 | 0.87 | (Stat. = 10.0, ) | (Stat.= 5.0, ) | (Stat. = 8.0, ) |
| Claude-3 [16] | ||||||
| High school (USA) | 0.60 | 0.60 | 0.60 | (Stat. = 45.0, ) | (Stat. = 43.0, ) | (Stat. = 44.0, ) |
| Middle school (USA) | 0.72 | 0.72 | 0.74 | (Stat. = 14.0, ) | (Stat. = 9.0, ) | (Stat. = 12.0, ) |
| Elementary school (USA) | 0.69 | 0.64 | 0.69 | (Stat. = 7.0, ) | (Stat. = 2.0, ) | (Stat.= 8.0, ) |
Appendix A.2. M3COTS Data
| TF | IF | IN | TF vs. IF | TF vs. IN | IF vs. IN | |
|---|---|---|---|---|---|---|
| GPT-4o [14] | ||||||
| Images Only | 0.58 | 0.64 | 0.62 | (Stat. = 12.0, ) | (Stat. = 17.0, ) | (Stat. = 16.0, ) |
| Mixture | 0.65 | 0.70 | 0.70 | (Stat. = 121.0, ) | (Stat. = 129.0, ) | (Stat. = 124.0, ) |
| Text Only | 0.77 | 0.82 | 0.86 | (Stat. = 30.0, ) | (Stat. = 18.0, ) | (Stat. = 13.0, ) |
| Gemini-1.5 [15] | ||||||
| Images Only | 0.51 | 0.55 | 0.54 | (Stat. = 26.0, ) | (Stat. = 17.0, ) | (Stat. = 14.0, ) |
| Mixture | 0.53 | 0.58 | 0.58 | (Stat. = 194.0, ) | (Stat. = 160.0, ) | (Stat. = 148.0, ) |
| Text Only | 0.68 | 0.71 | 0.71 | (Stat. = 49.0, ) | (Stat. = 49.0, ) | (Stat. = 48.0, ) |
| Claude-3 [16] | ||||||
| Images Only | 0.43 | 0.45 | 0.48 | (Stat. = 20.0, ) | (Stat. = 19.0, ) | (Stat. = 13.0, ) |
| Mixture | 0.47 | 0.48 | 0.50 | (Stat. = 149.0, ) | (Stat. = 138.0, ) | (Stat. = 148.0, ) |
| Text Only | 0.59 | 0.62 | 0.60 | (Stat. = 40.0, ) | (Stat. = 24.0, ) | (Stat. = 47.0, ) |
| TF | IF | IN | TF vs. IF | TF vs. IN | IF vs. IN | |
|---|---|---|---|---|---|---|
| Gemini-1.5-Flash | ||||||
| Materials | 0.87 | 0.99 | 0.94 | (Stat. = 1.0, ) | (Stat. = 3.0, ) | (Stat. = 1.0, ) |
| Elementary Algebra | 0.23 | 0.34 | 0.30 | (Stat. = 5.0, ) | (Stat. = 7.0, ) | (Stat. = 6.0, ) |
| Precalculus | 0.22 | 0.11 | 0.39 | (Stat. = 1.0, ) | (Stat. = 0.0, ) | (Stat. = 1.0, ) |
| grammar-Sentences, fragments, and run-ons | 0.96 | 0.79 | 0.98 | (Stat. = 1.0, ) | (Stat. = 0.0, ) | (Stat. = 1.0, ) |
| biology-Scientific names | 0.90 | 0.93 | 0.91 | (Stat. = 2.0, ) | (Stat. = 3.0, ) | (Stat. = 3.0, ) |
| chemistry-Atoms and Molecules Recognize | 0.25 | 0.42 | 0.42 | (Stat. = 4.0, ) | (Stat. = 4.0, ) | (Stat. = 4.0, ) |
| physics-Particle motion and energy | 0.82 | 0.95 | 0.95 | (Stat. = 1.0, ) | (Stat. = 2.0, ) | (Stat. = 2.0, ) |
| physics-Magnets | 0.59 | 0.66 | 0.59 | (Stat. = 8.0, ) | (Stat. = 8.0, ) | (Stat. = 8.0, ) |
| physics-Velocity, acceleration, and forces | 0.60 | 0.64 | 0.48 | (Stat. = 5.0, ) | (Stat. = 7.0, ) | (Stat. = 7.0, ) |
| physics-Thermal Conductivity Comparison | 0.35 | 0.85 | 0.85 | (Stat. = 2.0, ) | (Stat. = 0.0, ) | (Stat. = 2.0, ) |
| cognitive-science-Abstract Tangram Recognition | 0.42 | 0.39 | 0.35 | (Stat. = 6.0, ) | (Stat. = 8.0, ) | (Stat. = 6.0, ) |
| economics-Fiscal Surpluses Calculation | 0.59 | 0.51 | 0.44 | (Stat. = 4.0, ) | (Stat. = 3.0, ) | (Stat. = 7.0, ) |
| economics-Per Capita Wage Calculation | 0.72 | 0.40 | 0.35 | (Stat. = 2.0, ) | (Stat. = 3.0, ) | (Stat. = 3.0, ) |
| geography-Climate Analysis | 0.76 | 0.59 | 0.76 | (Stat. = 2.0, ) | (Stat. = 5.0, ) | (Stat. = 1.0, ) |
| TF | IF | IN | TF vs. IF | TF vs. IN | IF vs. IN | |
|---|---|---|---|---|---|---|
| GPT-4o | ||||||
| Materials | 0.99 | 0.94 | 0.97 | (Stat. = 0.0, ) | (Stat. = 1.0, ) | (Stat. = 0.0, ) |
| Elementary Algebra | 0.40 | 0.54 | 0.66 | (Stat. = 10.0, ) | (Stat. = 5.0, ) | (Stat. = 2.0, ) |
| Precalculus | 0.42 | 0.53 | 0.63 | (Stat. = 2.0, ) | (Stat. = 2.0, ) | (Stat. = 0.0, ) |
| grammar-Sentences, fragments, and run-ons | 0.96 | 1.00 | 0.98 | (Stat. = 0.0, ) | (Stat. = 0.0, ) | (Stat. = 0.0, ) |
| biology-Scientific names | 0.94 | 0.95 | 0.98 | (Stat. = 1.0, ) | (Stat. = 0.0, ) | (Stat. = 0.0, ) |
| chemistry-Atoms and Molecules Recognize | 0.32 | 0.67 | 0.72 | (Stat. = 5.0, ) | (Stat. = 5.0, ) | (Stat. = 9.0, ) |
| physics-Particle motion and energy | 0.61 | 0.98 | 1.00 | (Stat. = 1.0, ) | (Stat. = 0.0, ) | (Stat. = 0.0, ) |
| physics-Magnets | 0.85 | 0.85 | 0.73 | (Stat. = 5.0, ) | (Stat. = 2.0, ) | (Stat. = 3.0, ) |
| physics-Velocity, acceleration, and forces | 0.86 | 0.88 | 0.88 | (Stat. = 4.0, ) | (Stat. = 4.0, ) | (Stat. = 2.0, ) |
| physics-Thermal Conductivity Comparison | 0.90 | 0.80 | 0.65 | (Stat. = 2.0, ) | (Stat. = 1.0, ) | (Stat. = 2.0, ) |
| cognitive-science-Abstract Tangram Recognition | 0.42 | 0.50 | 0.50 | (Stat. = 6.0, ) | (Stat. = 8.0, ) | (Stat. = 10.0, ) |
| economics-Fiscal Surpluses Calculation | 0.59 | 0.63 | 0.56 | (Stat. = 4.0, ) | (Stat. = 3.0, ) | (Stat. = 3.0, ) |
| economics-Per Capita Wage Calculation | 0.72 | 0.57 | 0.47 | (Stat. = 2.0, ) | (Stat. = 2.0, ) | (Stat. = 4.0, ) |
| geography-Climate Analysis | 0.76 | 0.59 | 0.76 | (Stat. = 2.0, ) | (Stat. = 5.0, ) | (Stat. = 1.0, ) |
| TF | IF | IN | TF vs. IF | TF vs. IN | IF vs. IN | |
|---|---|---|---|---|---|---|
| GPT-4o [14] | ||||||
| Chemistry-Atoms and Molecules Recognize | 0.32 | 0.67 | 0.72 | (Stat. = 5.0, ) | (Stat. = 5.0, ) | (Stat. = 9.0, ) |
| Physics-Velocity, acceleration, and forces | 0.86 | 0.88 | 0.88 | (Stat. = 4.0, ) | (Stat. = 4.0, ) | (Stat. = 2.0, ) |
| Economics-Per Capita Wage Calculation | 0.73 | 0.58 | 0.48 | (Stat. = 2.0, ) | (Stat. = 2.0, ) | (Stat.= 4.0, ) |
| Gemini-1.5 [15] | ||||||
| Chemistry-Atoms and Molecules Recognize | 0.25 | 0.43 | 0.43 | (Stat. = 4.0, ) | (Stat. = 4.0, ) | (Stat. = 4.0, ) |
| Physics-Velocity, acceleration, and forces | 0.60 | 0.64 | 0.48 | (Stat. = 5.0, ) | (Stat.= 7.0, ) | (Stat. = 7.0, ) |
| Economics-Per Capita Wage Calculation | 0.30 | 0.40 | 0.35 | (Stat. = 3.0, ) | (Stat. = 2.0, ) | (Stat.= 3.0, ) |
| Claude-3 [16] | ||||||
| Chemistry-Atoms and Molecules Recognize | 0.27 | 0.28 | 0.33 | (Stat. = 10.0, ) | (Stat. = 7.0, ) | (Stat. = 7.0, ) |
| Physics-Velocity, acceleration, and forces | 0.48 | 0.18 | 0.26 | (Stat. = 3.0, ) | (Stat. = 5.0, ) | (Stat.= 3.0, ) |
| Economics-Per Capita Wage Calculation | 0.40 | 0.28 | 0.35 | (Stat. = 3.0, ) | (Stat. = 4.0, ) | (Stat.= 1.0, ) |
Appendix A.3. Comparison of Prompt Lengths

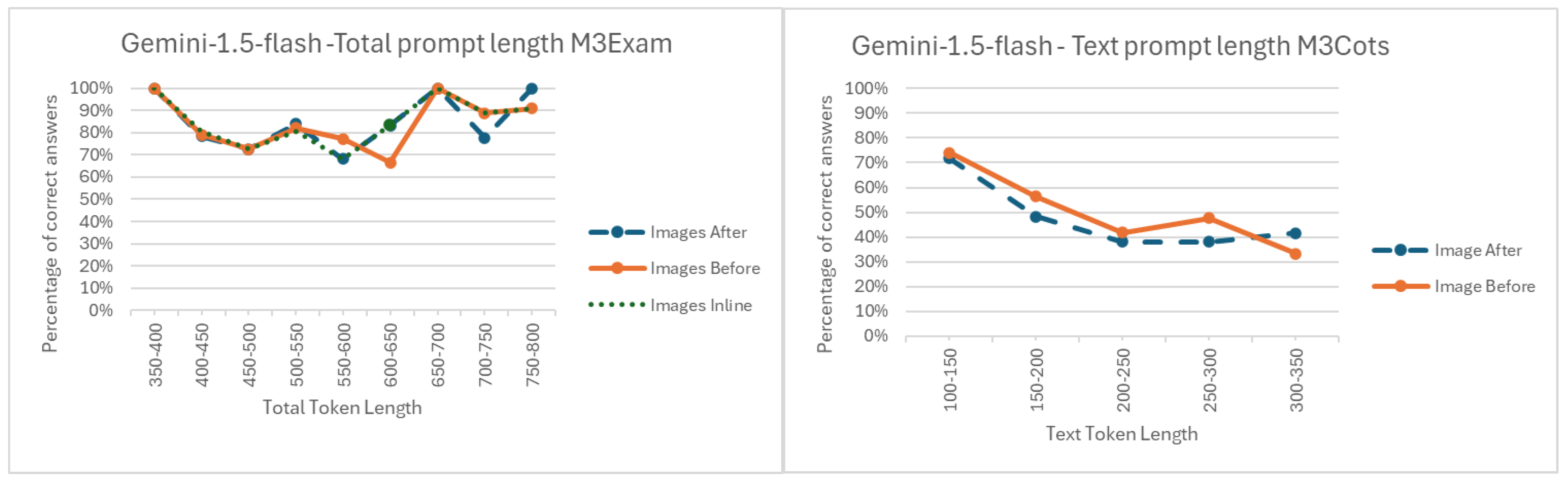
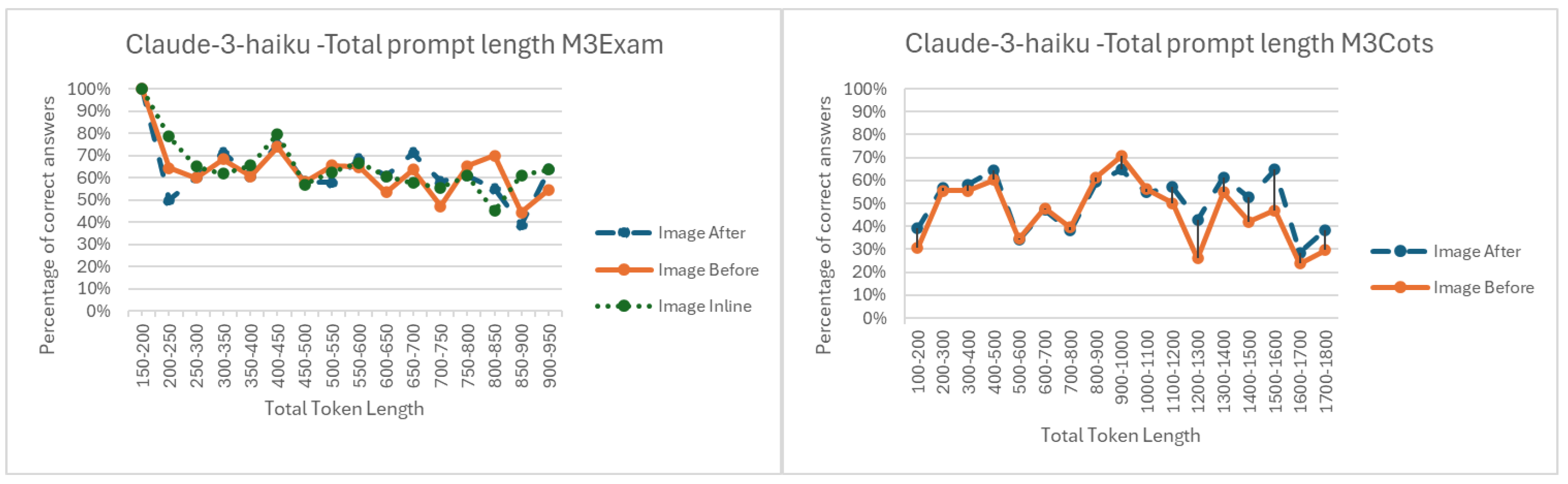
References
- Royce, C.S.; Hayes, M.M.; Schwartzstein, R.M. Teaching critical thinking: A case for instruction in cognitive biases to reduce diagnostic errors and improve patient safety. Acad. Med. 2019, 94, 187–194. [Google Scholar] [CrossRef] [PubMed]
- Kosinski, M. Evaluating large language models in theory of mind tasks. Proc. Natl. Acad. Sci. USA 2024, 121, e2405460121. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Aljunied, M.; Gao, C.; Chia, Y.K.; Bing, L. M3Exam: A Multilingual, Multimodal, Multilevel Benchmark for Examining Large Language Models. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S., Eds.; Curran Associates, Inc.: San Francisco, CA, USA, 2023; Volume 36, pp. 5484–5505. [Google Scholar]
- Chen, Q.; Qin, L.; Zhang, J.; Chen, Z.; Xu, X.; Che, W. M3CoT: A Novel Benchmark for Multi-Domain Multi-step Multi-modal Chain-of-Thought. In Proceedings of the ACL, Bangkok, Thailand, 11–16 August 2024. [Google Scholar]
- Mcintosh, T.R.; Liu, T.; Susnjak, T.; Watters, P.; Halgamuge, M.N. A Reasoning and Value Alignment Test to Assess Advanced GPT Reasoning. ACM Trans. Interact. Intell. Syst. 2024, 14, 3. [Google Scholar] [CrossRef]
- Guo, Y.; Shi, D.; Guo, M.; Wu, Y.; Cao, N.; Chen, Q. Talk2Data: A Natural Language Interface for Exploratory Visual Analysis via Question Decomposition. ACM Trans. Interact. Intell. Syst. 2024, 14, 8. [Google Scholar] [CrossRef]
- McIntosh, T.R.; Susnjak, T.; Liu, T.; Watters, P.; Ng, A.; Halgamuge, M.N. A Game-Theoretic Approach to Containing Artificial General Intelligence: Insights from Highly Autonomous Aggressive Malware. IEEE Trans. Artif. Intell. 2024, 5, 6290–6303. [Google Scholar] [CrossRef]
- Feng, T.H.; Denny, P.; Wuensche, B.; Luxton-Reilly, A.; Hooper, S. More Than Meets the AI: Evaluating the performance of GPT-4 on Computer Graphics assessment questions. In Proceedings of the 26th Australasian Computing Education Conference, Sydney, NSW, Australia, 29 January–2 February 2024; pp. 182–191. [Google Scholar]
- Pal, A.; Sankarasubbu, M. Gemini Goes to Med School: Exploring the Capabilities of Multimodal Large Language Models on Medical Challenge Problems & Hallucinations. arXiv 2024, arXiv:2402.07023. Available online: http://arxiv.org/abs/2402.07023 (accessed on 26 July 2024).
- Stribling, D.; Xia, Y.; Amer, M.K.; Graim, K.S.; Mulligan, C.J.; Renne, R. The model student: GPT-4 performance on graduate biomedical science exams. Sci. Rep. 2024, 14, 5670. [Google Scholar] [CrossRef]
- Liu, Y.; Duan, H.; Zhang, Y.; Li, B.; Zhang, S.; Zhao, W.; Yuan, Y.; Wang, J.; He, C.; Liu, Z.; et al. MMBench: Is Your Multi-modal Model an All-around Player? arXiv 2024, arXiv:2307.06281. Available online: http://arxiv.org/abs/2307.06281 (accessed on 26 July 2024).
- Lu, P.; Mishra, S.; Xia, T.; Qiu, L.; Chang, K.W.; Zhu, S.C.; Tafjord, O.; Clark, P.; Kalyan, A. Learn to explain: Multimodal reasoning via thought chains for science question answering. Adv. Neural Inf. Process. Syst. 2022, 35, 2507–2521. [Google Scholar]
- Li, B.; Wang, R.; Wang, G.; Ge, Y.; Ge, Y.; Shan, Y. SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension. arXiv 2023, arXiv:2307.16125. Available online: http://arxiv.org/abs/2307.16125 (accessed on 26 July 2024).
- OpenAI. GPT-4 Technical Report. arXiv 2024, arXiv:2303.08774. Available online: http://arxiv.org/abs/2303.08774 (accessed on 27 July 2024).
- Reid, M.; Savinov, N.; Teplyashin, D.; Lepikhin, D.; Lillicrap, T.; Alayrac, J.b.; Soricut, R.; Lazaridou, A.; Firat, O.; Schrittwieser, J.; et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv 2024, arXiv:2403.05530. [Google Scholar]
- Anthropic, A. The claude 3 model family: Opus, sonnet, haiku. Claude-3 Model Card 2024, 1. [Google Scholar]
- Crisp, V.; Sweiry, E. Can a picture ruin a thousand words? Physical aspects of the way exam questions are laid out and the impact of changing them. In Proceedings of the British Educational Research Association Annual Conference, Edinburgh, Scotland, 10–13 September 2003. [Google Scholar]
- Liu, N.F.; Lin, K.; Hewitt, J.; Paranjape, A.; Bevilacqua, M.; Petroni, F.; Liang, P. Lost in the Middle: How Language Models Use Long Contexts. Trans. Assoc. Comput. Linguist. 2024, 12, 157–173. [Google Scholar] [CrossRef]
- Lu, Y.; Bartolo, M.; Moore, A.; Riedel, S.; Stenetorp, P. Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; Muresan, S., Nakov, P., Villavicencio, A., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 8086–8098. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, H.; Li, X.; Huang, K.H.; Han, C.; Ji, S.; Kakade, S.M.; Peng, H.; Ji, H. Eliminating Position Bias of Language Models: A Mechanistic Approach. arXiv 2024, arXiv:2407.01100. [Google Scholar]
- Gao, J.; Lanchantin, J.; Soffa, M.L.; Qi, Y. Black-box generation of adversarial text sequences to evade deep learning classifiers. In Proceedings of the 2018 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 24 May 2018; pp. 50–56. [Google Scholar]
- Garg, S.; Ramakrishnan, G. BAE: BERT-based Adversarial Examples for Text Classification. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Webber, B., Cohn, T., He, Y., Liu, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 6174–6181. [Google Scholar] [CrossRef]
- Leidinger, A.; van Rooij, R.; Shutova, E. The language of prompting: What linguistic properties make a prompt successful? In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; Bouamor, H., Pino, J., Bali, K., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 9210–9232. [Google Scholar] [CrossRef]
- Chu, K.; Chen, Y.P.; Nakayama, H. A Better LLM Evaluator for Text Generation: The Impact of Prompt Output Sequencing and Optimization. arXiv 2024, arXiv:2406.09972. [Google Scholar]
- Levy, M.; Jacoby, A.; Goldberg, Y. Same task, more tokens: The impact of input length on the reasoning performance of large language models. arXiv 2024, arXiv:2402.14848. [Google Scholar]
- Mitra, C.; Huang, B.; Darrell, T.; Herzig, R. Compositional Chain-of-Thought Prompting for Large Multimodal Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 14420–14431. [Google Scholar]
- Zhou, Q.; Zhou, R.; Hu, Z.; Lu, P.; Gao, S.; Zhang, Y. Image-of-Thought Prompting for Visual Reasoning Refinement in Multimodal Large Language Models. arXiv 2024, arXiv:2405.13872. Available online: http://arxiv.org/abs/2405.13872 (accessed on 26 July 2024).
- Zheng, G.; Yang, B.; Tang, J.; Zhou, H.; Yang, S. DDCoT: Duty-Distinct Chain-of-Thought Prompting for Multimodal Reasoning in Language Models. Adv. Neural Inf. Process. Syst. 2023, 36, 5168–5191. Available online: https://proceedings.neurips.cc/paper_files/paper/2023/file/108030643e640ac050e0ed5e6aace48f-Paper-Conference.pdf (accessed on 26 July 2024).
- Luan, B.; Feng, H.; Chen, H.; Wang, Y.; Zhou, W.; Li, H. TextCoT: Zoom In for Enhanced Multimodal Text-Rich Image Understanding. arXiv 2024, arXiv:2404.09797. Available online: http://arxiv.org/abs/2404.09797 (accessed on 26 July 2024).
- Zhang, Z.; Zhang, A.; Li, M.; Zhao, H.; Karypis, G.; Smola, A. Multimodal Chain-of-Thought Reasoning in Language Models. arXiv 2024, arXiv:2302.00923. Available online: http://arxiv.org/abs/2302.00923 (accessed on 27 July 2024).
- Susnjak, T.; McIntosh, T.R. ChatGPT: The End of Online Exam Integrity? Educ. Sci. 2024, 14, 656. [Google Scholar] [CrossRef]
- Johnson-Laird, P.N. Mental models and human reasoning. Proc. Natl. Acad. Sci. USA 2010, 107, 18243–18250. [Google Scholar] [CrossRef]
- Mitchell, M. Debates on the nature of artificial general intelligence. Science 2024, 383, eado7069. [Google Scholar] [CrossRef]
- Mitchell, M. AI’s challenge of understanding the world. Science 2023, 382, eadm8175. [Google Scholar] [CrossRef] [PubMed]
- Wei, J.; Tay, Y.; Bommasani, R.; Raffel, C.; Zoph, B.; Borgeaud, S.; Yogatama, D.; Bosma, M.; Zhou, D.; Metzler, D.; et al. Emergent Abilities of Large Language Models. Trans. Mach. Learn. Res. 2022. [Google Scholar]
- Mialon, G.; Fourrier, C.; Swift, C.; Wolf, T.; LeCun, Y.; Scialom, T. Gaia: A benchmark for general ai assistants. arXiv 2023, arXiv:2311.12983. [Google Scholar]
- Mialon, G.; Dessì, R.; Lomeli, M.; Nalmpantis, C.; Pasunuru, R.; Raileanu, R.; Rozière, B.; Schick, T.; Dwivedi-Yu, J.; Celikyilmaz, A.; et al. Augmented Language Models: A Survey. arXiv 2023, arXiv:2302.07842. Available online: http://arxiv.org/abs/2302.07842 (accessed on 26 June 2024).
- LeCun, Y. A path towards autonomous machine intelligence version. Open Rev. 2022, 62, 1–62. Available online: https://openreview.net/pdf?id=BZ5a1r-kVsf (accessed on 26 June 2024).
- Kambhampati, S. Can large language models reason and plan? Ann. N. Y. Acad. Sci. USA 2024, 1534, 15–18. [Google Scholar] [CrossRef]
- West, P.; Lu, X.; Dziri, N.; Brahman, F.; Li, L.; Hwang, J.D.; Jiang, L.; Fisher, J.; Ravichander, A.; Chandu, K.; et al. THE GENERATIVE AI PARADOX: “What It Can Create, It May Not Understand”. In Proceedings of the The Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- McIntosh, T.R.; Susnjak, T.; Liu, T.; Watters, P.; Halgamuge, M.N. The Inadequacy of Reinforcement Learning from Human Feedback-Radicalizing Large Language Models via Semantic Vulnerabilities. IEEE Trans. Cogn. Dev. Syst. 2024, 16, 1561–1574. [Google Scholar] [CrossRef]
- Chang, Y.; Wang, X.; Wang, J.; Wu, Y.; Yang, L.; Zhu, K.; Chen, H.; Yi, X.; Wang, C.; Wang, Y.; et al. A Survey on Evaluation of Large Language Models. ACM Trans. Intell. Syst. Technol. 2024, 15, 39. [Google Scholar] [CrossRef]
- Wang, J.; Huang, Y.; Chen, C.; Liu, Z.; Wang, S.; Wang, Q. Software Testing With Large Language Models: Survey, Landscape, and Vision. IEEE Trans. Softw. Eng. 2024, 50, 911–936. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Kojima, T.; Gu, S.S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large language models are zero-shot reasoners. Adv. Neural Inf. Process. Syst. 2022, 35, 22199–22213. [Google Scholar]
- Yu, Z.; He, L.; Wu, Z.; Dai, X.; Chen, J. Towards Better Chain-of-Thought Prompting Strategies: A Survey. arXiv 2023, arXiv:2310.04959. Available online: http://arxiv.org/abs/2310.04959 (accessed on 6 June 2024).
- Wang, B.; Min, S.; Deng, X.; Shen, J.; Wu, Y.; Zettlemoyer, L.; Sun, H. Towards Understanding Chain-of-Thought Prompting: An Empirical Study of What Matters. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023; Rogers, A., Boyd-Graber, J., Okazaki, N., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 2717–2739. [Google Scholar] [CrossRef]
- Ranasinghe, K.; Shukla, S.N.; Poursaeed, O.; Ryoo, M.S.; Lin, T.Y. Learning to Localize Objects Improves Spatial Reasoning in Visual-LLMs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 12977–12987. [Google Scholar]
- Chen, B.; Xu, Z.; Kirmani, S.; Ichter, B.; Driess, D.; Florence, P.; Sadigh, D.; Guibas, L.; Xia, F. SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 14455–14465. [Google Scholar] [CrossRef]
- Asch, S.E. Forming impressions of personality. J. Abnorm. Soc. Psychol. 1946, 41, 258. [Google Scholar] [CrossRef]
- Baddeley, A.D.; Hitch, G. The recency effect: Implicit learning with explicit retrieval? Mem. Cogn. 1993, 21, 146–155. [Google Scholar] [CrossRef]
- Wang, Y.; Cai, Y.; Chen, M.; Liang, Y.; Hooi, B. Primacy Effect of ChatGPT. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; Bouamor, H., Pino, J., Bali, K., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 108–115. [Google Scholar] [CrossRef]
- Zhang, Z.; Yu, J.; Li, J.; Hou, L. Exploring the Cognitive Knowledge Structure of Large Language Models: An Educational Diagnostic Assessment Approach. In Proceedings of the Findings of the Association for Computational Linguistics EMNLP 2023, Singapore, 6–10 December 2023; Bouamor, H., Pino, J., Bali, K., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 1643–1650. [Google Scholar] [CrossRef]
- Eicher, J.E.; Irgolič, R. Compensatory Biases Under Cognitive Load: Reducing Selection Bias in Large Language Models. arXiv 2024, arXiv:2402.01740. [Google Scholar]
- Goolge. Image Understanding. 2024. Available online: https://cloud.google.com/vertex-ai/generative-ai/docs/multimodal/image-understanding (accessed on 15 July 2024).
- Hatzakis, S. When-Processing-a-Text-Prompt-Before-It-or-After-It. 2023. Available online: https://community.openai.com/t/when-processing-a-text-prompt-before-it-or-after-it/247801/3 (accessed on 15 July 2023).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Zhao, F.; Zhang, C.; Geng, B. Deep Multimodal Data Fusion. ACM Comput. Surv. 2024, 56, 216. [Google Scholar] [CrossRef]
- Tsai, Y.H.H.; Bai, S.; Liang, P.P.; Kolter, J.Z.; Morency, L.P.; Salakhutdinov, R. Multimodal transformer for unaligned multimodal language sequences. In Proceedings of the Conference. Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 2019, p. 6558. [Google Scholar]
- Team, C. Chameleon: Mixed-modal early-fusion foundation models. arXiv 2024, arXiv:2405.09818. [Google Scholar]
- Gan, Z.; Chen, Y.C.; Li, L.; Zhu, C.; Cheng, Y.; Liu, J. Large-scale adversarial training for vision-and-language representation learning. Adv. Neural Inf. Process. Syst. 2020, 33, 6616–6628. [Google Scholar]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar] [CrossRef]
- Liang, P.P.; Lyu, Y.; Fan, X.; Wu, Z.; Cheng, Y.; Wu, J.; Chen, L.; Wu, P.; Lee, M.A.; Zhu, Y.; et al. Multibench: Multiscale benchmarks for multimodal representation learning. Adv. Neural Inf. Process. Syst. 2021, 2021, 1. [Google Scholar] [PubMed]
- Dou, Z.Y.; Xu, Y.; Gan, Z.; Wang, J.; Wang, S.; Wang, L.; Zhu, C.; Zhang, P.; Yuan, L.; Peng, N.; et al. An empirical study of training end-to-end vision-and-language transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18166–18176. [Google Scholar]
- Shukor, M.; Fini, E.; da Costa, V.G.T.; Cord, M.; Susskind, J.; El-Nouby, A. Scaling Laws for Native Multimodal Models. arXiv 2025, arXiv:2504.07951. [Google Scholar]
- Peysakhovich, A.; Lerer, A. Attention sorting combats recency bias in long context language models. arXiv 2023, arXiv:2310.01427. [Google Scholar]
- Giaccardi, E.; Murray-Rust, D.; Redström, J.; Caramiaux, B. Prototyping with Uncertainties: Data, Algorithms, and Research through Design. ACM Trans. Comput.-Hum. Interact. 2024, 31, 68. [Google Scholar] [CrossRef]
- Thieme, A.; Rajamohan, A.; Cooper, B.; Groombridge, H.; Simister, R.; Wong, B.; Woznitza, N.; Pinnock, M.A.; Wetscherek, M.T.; Morrison, C.; et al. Challenges for Responsible AI Design and Workflow Integration in Healthcare: A Case Study of Automatic Feeding Tube Qualification in Radiology. ACM Trans. Comput.-Hum. Interact. 2025. [Google Scholar] [CrossRef]
- Zając, H.D.; Andersen, T.O.; Kwasa, E.; Wanjohi, R.; Onyinkwa, M.K.; Mwaniki, E.K.; Gitau, S.N.; Yaseen, S.S.; Carlsen, J.F.; Fraccaro, M.; et al. Towards Clinically Useful AI: From Radiology Practices in Global South and North to Visions of AI Support. ACM Trans. Comput.-Hum. Interact. 2025, 32, 20. [Google Scholar] [CrossRef]
- Chen, C.; Nguyen, C.; Groueix, T.; Kim, V.G.; Weibel, N. MemoVis: A GenAI-Powered Tool for Creating Companion Reference Images for 3D Design Feedback. ACM Trans. Comput.-Hum. Interact. 2024, 31, 67. [Google Scholar] [CrossRef]
- August, T.; Wang, L.L.; Bragg, J.; Hearst, M.A.; Head, A.; Lo, K. Paper Plain: Making Medical Research Papers Approachable to Healthcare Consumers with Natural Language Processing. ACM Trans. Comput.-Hum. Interact. 2023, 30, 74. [Google Scholar] [CrossRef]
- Huang, T.; Yu, C.; Shi, W.; Peng, Z.; Yang, D.; Sun, W.; Shi, Y. Prompt2Task: Automating UI Tasks on Smartphones from Textual Prompts. ACM Trans. Comput.-Hum. Interact. 2025. [Google Scholar] [CrossRef]
- Nguyen, X.P.; Zhang, W.; Li, X.; Aljunied, M.; Tan, Q.; Cheng, L.; Chen, G.; Deng, Y.; Yang, S.; Liu, C.; et al. SeaLLMs–Large Language Models for Southeast Asia. arXiv 2023, arXiv:2312.00738. [Google Scholar]
- Liu, C.; Zhang, W.; Zhao, Y.; Luu, A.T.; Bing, L. Is Translation All You Need? A Study on Solving Multilingual Tasks with Large Language Models. arXiv 2024, arXiv:2403.10258. [Google Scholar]
- Hendrycks, D.; Burns, C.; Kadavath, S.; Arora, A.; Basart, S.; Tang, E.; Song, D.; Steinhardt, J. Measuring Mathematical Problem Solving With the MATH Dataset. arXiv 2021, arXiv:2103.03874. [Google Scholar]
- Hessel, J.; Hwang, J.D.; Park, J.S.; Zellers, R.; Bhagavatula, C.; Rohrbach, A.; Saenko, K.; Choi, Y. The abduction of sherlock holmes: A dataset for visual abductive reasoning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 558–575. [Google Scholar]
- Wu, Y.; Zhang, P.; Xiong, W.; Oguz, B.; Gee, J.C.; Nie, Y. The role of chain-of-thought in complex vision-language reasoning task. arXiv 2023, arXiv:2311.09193. [Google Scholar]
- Wang, X.; Wei, J.; Schuurmans, D.; Le, Q.; Chi, E.; Narang, S.; Chowdhery, A.; Zhou, D. Self-Consistency Improves Chain of Thought Reasoning in Language Models. arXiv 2023, arXiv:2203.11171. Available online: http://arxiv.org/abs/2203.11171 (accessed on 6 June 2024).
- McIntosh, T.R.; Susnjak, T.; Arachchilage, N.; Liu, T.; Xu, D.; Watters, P.; Halgamuge, M.N. Inadequacies of Large Language Model Benchmarks in the Era of Generative Artificial Intelligence. IEEE Trans. Artif. Intell. 2025; early access. 1–18. [Google Scholar] [CrossRef]


| Experiment | Description | Configurations | Variables Analysed |
|---|---|---|---|
| Image–Text Sequence Variation | Evaluate effect of sequencing on model performance | Image First (IF) Text First (TF) Interleaved (IN) | Impact of sequencing on reasoning performance |
| Image vs. Instructions Analysis | Determine if observed sequencing impact is due to the visual modality itself or the sequencing of instructional information | Image First (IF) Text First (TF) Interleaved (IN) | Impact of sequencing on extracted text from images |
| Image–Text Sequence: Attribute-Based Analysis | Investigate whether the relationships or trends observed in the overall dataset hold for each of the attributes | Image First (IF) Text First (TF) Interleaved (IN) | Effects of question attributes: - Image type; - Prompt length; - Educational level; - Question type. |
| User Interaction and Heuristic Evaluations | Determine the usability and effectiveness of the heuristics | Image First (IF) Text First (TF) Interleaved (IN) | Ability to use the derived heuristics to guide optimal image sequencing to enhance reasoning performance |
| Claude-3 | Gemini-1.5 | GPT-4o | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Subject | TF | IF | IN | TF | IF | IN | TF | IF | IN |
| English | 0.81 | 0.90 | 0.90 | 0.94 | 1.00 | 0.94 | 0.97 | 1.00 | 1.00 |
| Algebra1 | 0.58 | 0.42 | 0.42 | 0.42 | 0.58 | 0.63 | 0.58 | 0.68 | 0.68 |
| Algebra2 | 0.19 | 0.50 | 0.38 | 0.56 | 0.50 | 0.63 | 0.63 | 0.56 | 0.63 |
| Geometry | 0.31 | 0.29 | 0.31 | 0.49 | 0.47 | 0.47 | 0.63 | 0.59 | 0.59 |
| Math | 0.39 | 0.37 | 0.42 | 0.59 | 0.58 | 0.60 | 0.64 | 0.70 | 0.69 |
| Chemistry | 0.67 | 0.60 | 0.73 | 0.60 | 0.80 | 0.73 | 0.87 | 0.80 | 0.80 |
| Environment | 0.79 | 0.82 | 0.81 | 0.92 | 0.92 | 0.93 | 0.98 | 0.96 | 0.94 |
| Physics | 0.43 | 0.37 | 0.36 | 0.63 | 0.63 | 0.71 | 0.77 | 0.79 | 0.85 |
| Science | 0.79 | 0.79 | 0.81 | 0.88 | 0.86 | 0.89 | 0.88 | 0.89 | 0.90 |
| Earth | 0.61 | 0.61 | 0.62 | 0.70 | 0.69 | 0.68 | 0.75 | 0.73 | 0.80 |
| History | 0.94 | 0.96 | 0.96 | 1.00 | 0.98 | 0.96 | 1.00 | 1.00 | 1.00 |
| Social | 0.87 | 0.81 | 0.84 | 0.90 | 0.93 | 0.94 | 0.94 | 0.95 | 0.95 |
| Mean Rank | 2.1 | 2.2 | 1.7 | 2.2 | 2.2 | 1.7 | 2.2 | 2.0 | 1.8 |
| Claude-3 | Gemini-1.5 | GPT-4o | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Subject | TF | IF | IN | TF | IF | IN | TF | IF | IN |
| language-science | 0.79 | 0.73 | 0.79 | 0.88 | 0.84 | 0.90 | 0.95 | 0.94 | 0.96 |
| natural-science | 0.53 | 0.53 | 0.53 | 0.59 | 0.64 | 0.63 | 0.70 | 0.78 | 0.76 |
| social-science | 0.35 | 0.32 | 0.36 | 0.39 | 0.45 | 0.44 | 0.55 | 0.59 | 0.60 |
| physical-commonsense | 0.60 | 0.82 | 0.86 | 0.77 | 0.88 | 0.83 | 0.86 | 0.84 | 0.88 |
| social-commonsense | 0.63 | 0.70 | 0.69 | 0.68 | 0.74 | 0.73 | 0.76 | 0.80 | 0.79 |
| temporal-commonsense | 0.75 | 0.80 | 0.78 | 0.75 | 0.87 | 0.84 | 0.89 | 0.86 | 0.90 |
| algebra | 0.21 | 0.31 | 0.24 | 0.28 | 0.35 | 0.38 | 0.44 | 0.57 | 0.67 |
| geometry | 0.24 | 0.36 | 0.31 | 0.36 | 0.39 | 0.40 | 0.34 | 0.33 | 0.41 |
| theory | 0.33 | 0.38 | 0.24 | 0.24 | 0.43 | 0.38 | 0.29 | 0.48 | 0.52 |
| Mean Rank | 2.5 | 1.7 | 1.8 | 2.9 | 1.4 | 1.7 | 2.6 | 2.2 | 1.2 |
| Question Type | Claude-3 | Gemini-1.5 | GPT-4o | ||||||
|---|---|---|---|---|---|---|---|---|---|
| TF | IF | IN | TF | IF | IN | TF | IF | IN | |
| Elementary Algebra (multi-modal) | 0.32 | 0.39 | 0.25 | 0.27 | 0.38 | 0.36 | 0.45 | 0.55 | 0.64 |
| Elementary Algebra (text) | 0.27 | 0.35 | 0.34 | 0.25 | 0.43 | 0.41 | 0.35 | 0.64 | 0.66 |
| Grammar (multi-modal) | 0.80 | 0.82 | 0.85 | 0.94 | 0.79 | 0.92 | 0.95 | 0.96 | 0.97 |
| Grammar (text) | 0.91 | 0.88 | 0.87 | 0.92 | 0.85 | 0.94 | 0.96 | 0.98 | 0.98 |
| Claude-3 | Gemini-1.5 | GPT-4o | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Subject | TF | IF | IN | TF | IF | IN | TF | IF | IN |
| Chemistry-Atoms and Molecules Recognize | 0.27 | 0.28 | 0.33 | 0.25 | 0.43 | 0.43 | 0.32 | 0.67 | 0.72 |
| Physics-Velocity, acceleration, and forces | 0.48 | 0.18 | 0.26 | 0.60 | 0.64 | 0.48 | 0.86 | 0.88 | 0.88 |
| Economics-Per Capita Wage Calculation | 0.40 | 0.28 | 0.35 | 0.30 | 0.40 | 0.35 | 0.73 | 0.58 | 0.48 |
| Claude-3 | Gemini-1.5 | GPT-4o | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Exam Question Pattern | TF | IF | IN | TF | IF | IN | TF | IF | IN |
| Image First (104) | 0.89 | 0.89 | 0.89 | 0.92 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 |
| Interleaved instructions IN1 (517) | 0.62 | 0.62 | 0.64 | 0.73 | 0.73 | 0.75 | 0.80 | 0.81 | 0.83 |
| Interleaved logic IN2 (135) | 0.54 | 0.59 | 0.57 | 0.75 | 0.75 | 0.76 | 0.82 | 0.81 | 0.84 |
| Text First (39) | 0.56 | 0.36 | 0.41 | 0.64 | 0.62 | 0.62 | 0.72 | 0.54 | 0.59 |
| Claude-3 | Gemini-1.5 | GPT-4o | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Exam Question Pattern | TF | IF | IN | TF | IF | IN | TF | IF | IN |
| Image First (415) | 0.55 | 0.56 | 0.59 | 0.62 | 0.68 | 0.67 | 0.71 | 0.75 | 0.75 |
| Interleaved instructions IN1 (635) | 0.72 | 0.82 | 0.83 | 0.85 | 0.88 | 0.90 | 0.92 | 0.92 | 0.96 |
| Interleaved logic IN2 (251) | 0.40 | 0.46 | 0.43 | 0.43 | 0.49 | 0.51 | 0.58 | 0.69 | 0.74 |
| Text First (1017) | 0.39 | 0.31 | 0.33 | 0.42 | 0.45 | 0.42 | 0.58 | 0.59 | 0.55 |
| Heuristics | How to Apply | When to Apply |
|---|---|---|
| Image First Pattern | Structure the prompt by placing all images at the beginning, preceding any textual instructions. | Apply when the task requires immediate analysis or interpretation of visual content without relying on preceding textual information, or when instructions explicitly reference the image at the beginning of the prompt (e.g., “…the image above…”). This heuristic is particularly effective for Gemini-1.5 and GPT-4o; occasionally, for these models and especially Claude-3, following an IN1 or IN2 structure would at least yield comparable results. |
| Reference-Based Image Positioning (IN1) | Integrate images within the text at specific points where they are referenced. For instance, if the text states “…the image below…”, place the corresponding image immediately after that reference in the prompt. | Use when textual instructions specifically indicate the placement of images within the prompt or when images are intended to clarify specific parts of the instructions or context. This approach is particularly beneficial for Claude-3, Gemini-1.5, and GPT-4o, where this interleaved sequencing improves performance in specific question types. |
| Logical Flow Alignment (IN2) | Position images in the prompt to align with the logical steps or components of the reasoning process. Ensure each image corresponds to relevant sections of the text to support multi-step reasoning. | Implement for tasks involving multiple reasoning steps or layered information, where images correspond to specific stages or components of the reasoning process. This heuristic is especially effective for Gemini-1.5 and GPT-4o in complex reasoning tasks, such as nested multiple-choice questions, where interleaved sequencing (IN2) leads to improved performance. However, in the case of Claude-3, some preference is exhibited towards the IF prompt structure instead. |
| Text First Pattern | Organise the prompt by placing all textual instructions and data first, followed by images. Ensure that the text provides comprehensive context and details before introducing visual elements. | Apply to prompts with extensive textual content, detailed explanations, or substantial numerical data, where establishing textual background is foundational before introducing visual elements. This heuristic is consistently effective for Claude-3, Gemini-1.5, and GPT-4o. |
| GPT-4o | ||||
|---|---|---|---|---|
| TF | IF | IN | User | |
| Accuracy | 40.8% | 58.3% | 41.8% | 62.1% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wardle, G.; Sušnjak, T. Image First or Text First? Optimising the Sequencing of Modalities in Large Language Model Prompting and Reasoning Tasks. Big Data Cogn. Comput. 2025, 9, 149. https://doi.org/10.3390/bdcc9060149
Wardle G, Sušnjak T. Image First or Text First? Optimising the Sequencing of Modalities in Large Language Model Prompting and Reasoning Tasks. Big Data and Cognitive Computing. 2025; 9(6):149. https://doi.org/10.3390/bdcc9060149
Chicago/Turabian StyleWardle, Grant, and Teo Sušnjak. 2025. "Image First or Text First? Optimising the Sequencing of Modalities in Large Language Model Prompting and Reasoning Tasks" Big Data and Cognitive Computing 9, no. 6: 149. https://doi.org/10.3390/bdcc9060149
APA StyleWardle, G., & Sušnjak, T. (2025). Image First or Text First? Optimising the Sequencing of Modalities in Large Language Model Prompting and Reasoning Tasks. Big Data and Cognitive Computing, 9(6), 149. https://doi.org/10.3390/bdcc9060149