

Predicting the Damage of Urban Fires with Grammatical Evolution




Abstract
1. Introduction
2. Materials and Methods
2.1. The Used Datasets
2.2. Grammatical Evolution
- The set N represents the non-terminal symbols of the grammar. Each non-terminal symbol can be replaced with a series of terminal symbols with the assistance of some associated production rules.
- The set T contains the terminal symbols.
- S is considered as the start symbol of the grammar with the assumption .
- The set P contains the production rules of the grammar, used to replace non-terminal symbols with series of terminal ones.
- Obtain the next element V from the chromosome that is processed.
- Select the production rule as Rule = V mod R, where R defines the total number of production rules for the non-terminal symbol that is under processing.
2.3. Neural Network Construction Using Grammatical Evolution
- Initialization Step.
- (a)
- Set as the number of chromosomes and as the number of allowed generations.
- (b)
- Set as the selection rate with and as the mutation rate with .
- (c)
- Initialize randomly each chromosome as a set of randomly selected integers.
- (d)
- Set as the generation counter.
- Fitness Calculation Step.
- (a)
- For , do
- Create using the grammar of Figure 2 the corresponding neural network for the chromosome .
- Set as the fitness of the chromosome the training error of neural network .
- (b)
- End For
- Application of Genetic Operations.
- (a)
- Application of selection. The best chromosomes are copied to the next generation. The remaining are substituted by chromosomes produced during crossover and mutation.
- (b)
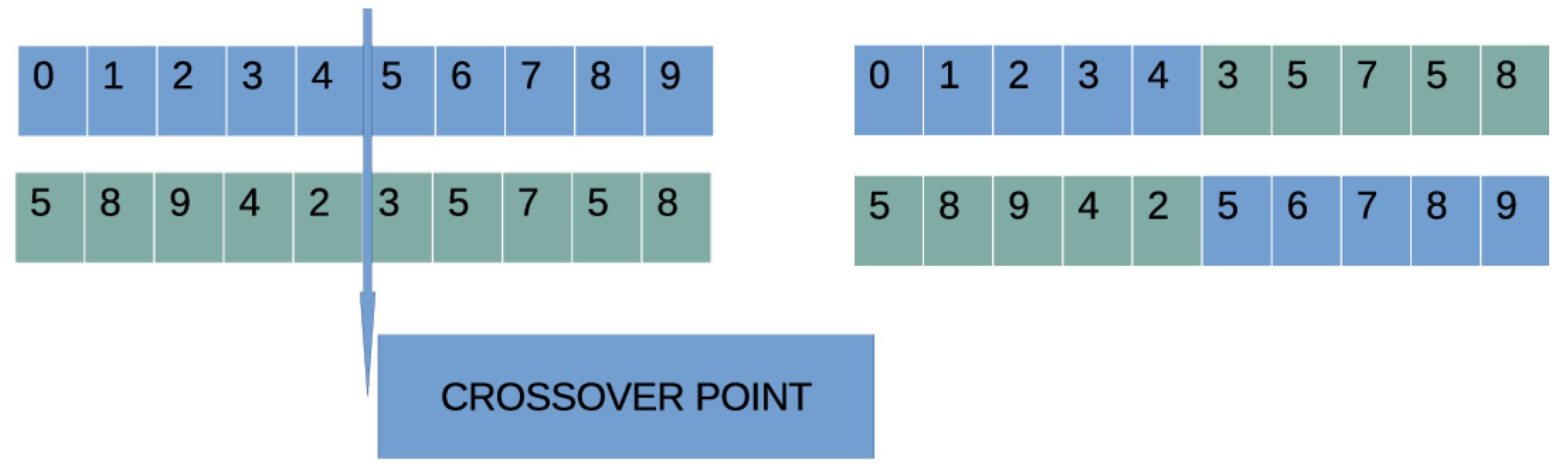
- Application of crossover. During this procedure, new chromosomes will be created from selected chromosomes from the current generation. For each pair of produced chromosomes, two chromosomes and will be selected from the current population using tournament selection. The new chromosomes will be produced using one-point crossover [72], which is graphically illustrated in Figure 3.
- (c)
- Application of mutation. For every element of each chromosome, a random number is drawn. The corresponding element is altered randomly when .
- Termination Check Step.
- (a)
- Set
- (b)
- If , then go to fitness calculation step.
- Testing step.
- (a)
- Obtain the chromosome with the lowest fitness value in the population.
- (b)
- Create the corresponding neural network and apply it to the test set and report the associated error.
2.4. Feature Construction Using Grammatical Evolution
- Initialization step.
- (a)
- Define as the number of chromosomes and as the number of allowed generations.
- (b)
- Define the selection rate and the mutation rate .
- (c)
- Define as the number of constructed features.
- (d)
- Initialize the chromosomes as vectors of randomly selected integers.
- (e)
- Set , the generation counter.
- Fitness calculation step.
- (a)
- For , do
- Create artificial features for the chromosome . The production is performed using the grammar of Figure 4.
- Modify the train set of the objective problem using the features .
- Apply a machine learning model to the modified set and define as the fitness value the corresponding training error.
- (b)
- End For
- Application of genetic operations. Apply the same genetic operations as in the case of Neural Construction method of Section 2.3.
- Termination check step.
- (a)
- Set .
- (b)
- If , go to fitness calculation step.
- Testing step.
- (a)
- Obtain the chromosome with the lowest fitness value.
- (b)
- Produce the features for this chromosome.
- (c)
- Modify the test set of the objective problem using the previously created features.
- (d)
- Apply any machine learning model to the test set and report the associated error.
2.5. Create Classification Rules Using Grammatical Evolution
- Initialization step.
- (a)
- Define as the total number of chromosomes and with the allowed number of generations.
- (b)
- Define the selection rate and the mutation rate .
- (c)
- Initialize as vectors of randomly selected integers the chromosomes .
- (d)
- Set , the generation counter.
- Fitness calculation step.
- (a)
- For , do
- Create using the Grammatical Evolution procedure and the grammar depicted in Figure 5 a classification program for the corresponding chromosome .
- Set the fitness asfor the corresponding training set . The values denote the input patterns and the value the expected outcome for pattern .
- (b)
- End For
- Genetic operation step. Apply the same genetic operations as in the case of Neural Construction method of Section 2.3.
- Termination check step.
- (a)
- Set .
- (b)
- If , then go to fitness calculation step.
- Testing step.
- (a)
- Obtain the best chromosome and produce the associated classification program .
- (b)
- Apply the classification program to the test set of the problem and report the result.
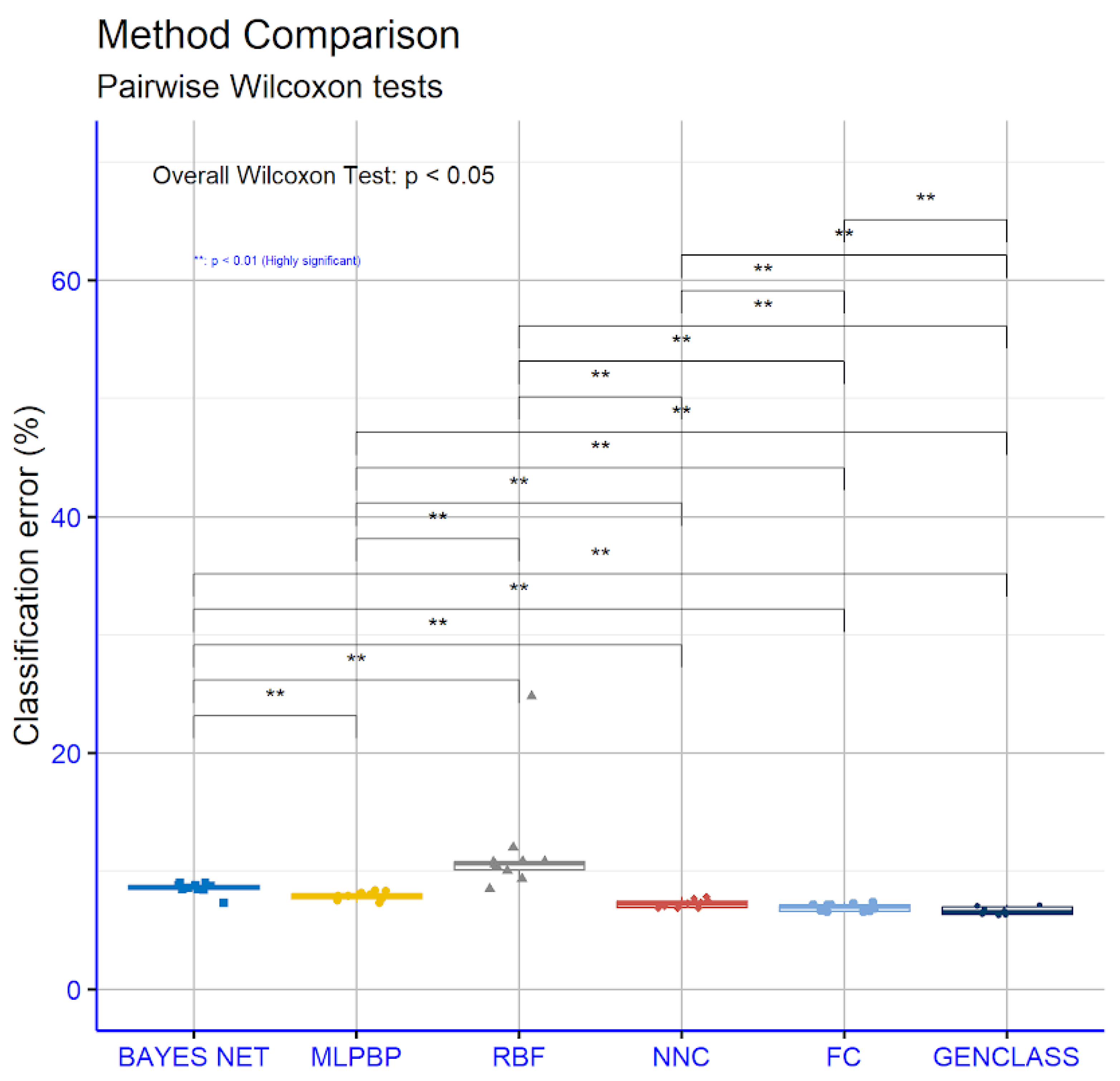
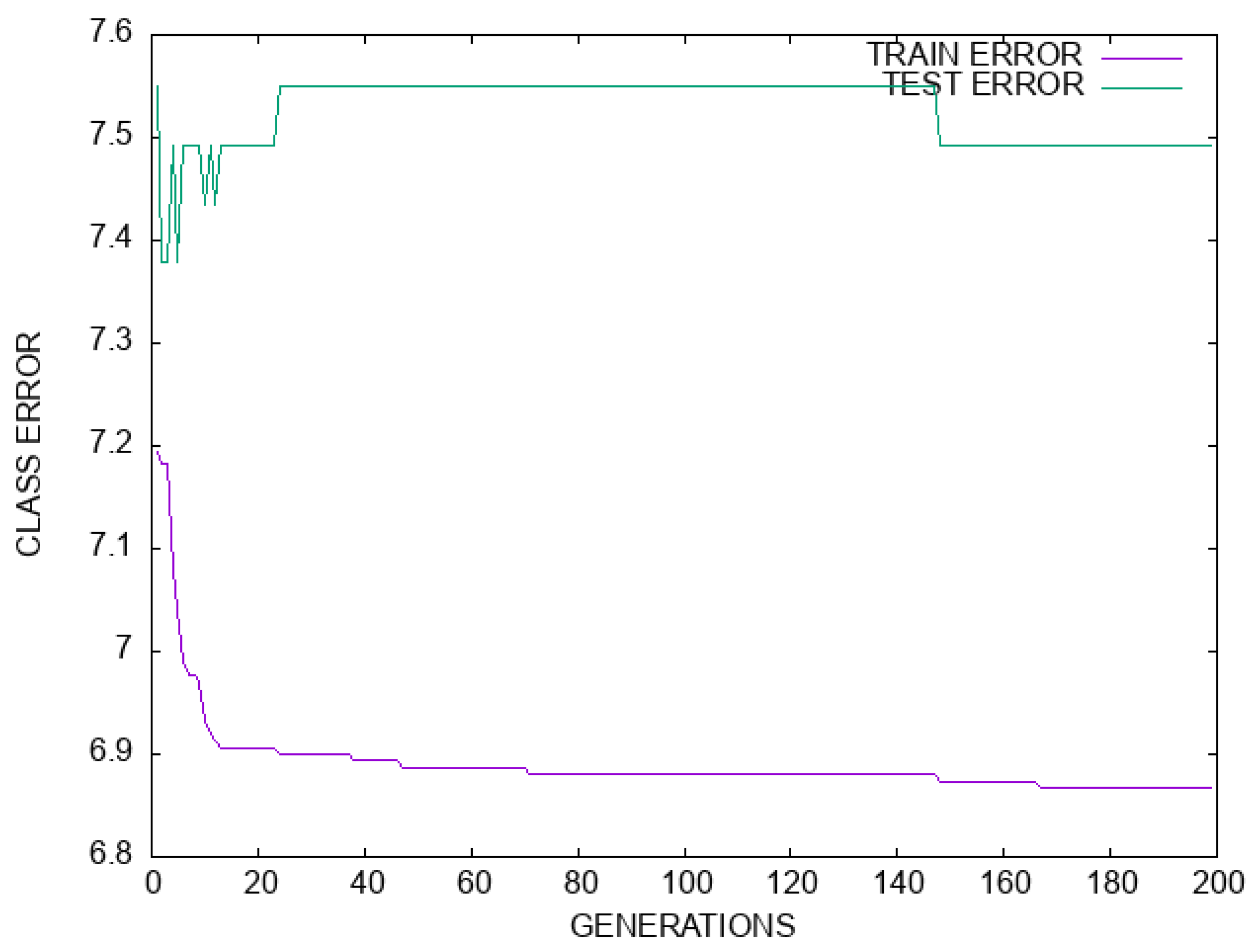
3. Results
- The year column denotes the year for which the methods were applied.
- The patterns column denotes the number of patterns in the test set for every year.
- The RBF column denotes the use of a Radial Basis Function network with processing nodes.
- The NNC column represents the use of the neural network construction method described in Section 2.3.
- The FC column stands for the use of the feature construction method provided in Section 2.4.
- The GENCLASS column denotes the use of the method that creates classification rules, described in Section 2.5.
- The final row, average, represents the average classification error for all the years between 2014 and 2023.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fires—Wildfires and Urban Fires. Juniata County Appendix CMulti-Jurisdictional Hazard Mitigation Plan Hazard Profiles. 2008, pp. 15–19. Available online: https://juniataco.org/docs/hmp/Appendix%20C%20-%2004-Fire-Urban%20and%20Rural.pdf (accessed on 7 March 2025).
- Hossain, M.R.; Smirnov, O. Analyzing the risk factors of residential fires in urban and rural census tracts of Ohio using panel data analysis. Appl. Geogr. 2023, 151, 102863. [Google Scholar] [CrossRef]
- Hellenic Fire Service. Open Data. Incident Record. Available online: https://www.fireservice.gr/el_GR/synola-dedomenon (accessed on 7 March 2025).
- Greek Wikipedia. The Trial Regarding MATI’s Wildfire. Available online: https://el.wikipedia.org/wiki/%CE%94%CE%AF%CE%BA%CE%B7_%CE%B3%CE%B9%CE%B1_%CF%84%CE%BF_%CE%9C%CE%AC%CF%84%CE%B9 (accessed on 27 February 2025).
- Xanthopoulos, G.; Athanasiou, M. Uniting Our Global Wildfire Community; Wildfire, International Association of Wildland Fire: Missoula, MT, USA, 2019; Volume 28.2. [Google Scholar]
- World Health Organization (WHO). Burns. 13 October 2023. Available online: https://www.who.int/news-room/fact-sheets/detail/burns (accessed on 13 March 2025).
- Natural Hazards Research Australia. Understanding the Black Summer Bushfires Through Research: A Summary of Key Finding from the Bushfire and Natural Hazards CRC. January 2023. Available online: https://www.naturalhazards.com.au/sites/default/files/2023-01/Understanding%20the%20Black%20Summer%20bushfires%20through%20research_final_web_NHRA.pdf (accessed on 13 March 2025).
- Australian Government; Australian Public Service Commission. Black Summer. State of the Service Report 2019–20. Available online: https://www.apsc.gov.au/state-service/state-service-report-2019-20/chapter-1-commitment-service/black-summer (accessed on 13 March 2025).
- NASA Earth Observatory. Fires Char the Siberian Arctic. 10 July 2024. Available online: https://earthobservatory.nasa.gov/images/153087/fires-char-the-siberian-arctic (accessed on 17 March 2025).
- NASA. Landsat Image Gallery. Available online: https://landsat.visibleearth.nasa.gov/view.php?id=153087 (accessed on 17 March 2025).
- Latypova, L. Raging Wildfires Devastate Russia’s Far East Sakha Republic. The Moscow Times. 23 July 2024. Available online: https://www.themoscowtimes.com/2024/07/23/raging-wildfires-devastate-russias-far-east-sakha-republic-a85802 (accessed on 17 March 2025).
- Sommer, L. Here’s How Climate Change Fueled the Los Angeles Fires. National Public Radio. 29 January 2025. Available online: https://www.npr.org/2025/01/29/nx-s1-5273676/la-fires-climate-change-rainfall-extreme-weather (accessed on 17 March 2025).
- McCarthy, J.; Richter, J. Graphics Explain Los Angeles. Rare and Devastating January Fires. World Resources Institute. Wri org. 5 February 2025. Available online: https://www.wri.org/insights/los-angeles-fires-january-2025-explained (accessed on 17 March 2025).
- NASA Earth Observatory. Fire Grows Unusually Large in Japan. Available online: https://earthobservatory.nasa.gov/images/154008/fire-grows-unusually-large-in-japan (accessed on 17 March 2025).
- Keun-tae, P. Cities Face Rising Fire Risks from Climate Change Without Emission Cuts. ChosunBiz. 3 March 2025. Available online: https://biz.chosun.com/en/en-science/2025/03/05/FXRLKFRXJJB5LK4YXKPLVETVJM/ (accessed on 17 March 2025).
- Ceyhan, E.; Ertugay, K.; Duzgun, S. Exploratory and inferential methods for spatio-temporal analysis of residential fire clustering in urban areas. Fire Saf. J. 2013, 58, 226–239. [Google Scholar] [CrossRef]
- Clare, J.; Garis, L.; Plecas, D.; Jennings, C. Reduced frequency and severity of residential fires following delivery of fire prevention education by on-duty fire fighters: Cluster randomized controlled study. J. Saf. Res. 2012, 43, 123–128. [Google Scholar] [CrossRef]
- Alkis, S.; Aksoy, E.; Akpinar, K. Risk Assessment of Industrial Fires for Surrounding Vulnerable Facilities Using a Multi-Criteria Decision Support Approach and GIS. Fire 2021, 4, 53. [Google Scholar] [CrossRef]
- Jiang, Y.; Lv, A.; Yan, Z.; Yang, Z. A GIS-Based Multi-Criterion Decision-Making Method to Select City Fire Brigade: A Case Study of Wuhan, China. Int. J. Geo-Inf. ISPRS 2021, 10, 777. [Google Scholar] [CrossRef]
- Noori, S.; Mohammadi, A.; Ferreira, T.; Miguel, G.; Gilandeh, A.; Ghaffari, M.; Ardabili, S.; Seyed, J. Modelling and Mapping Urban Vulnerability Index against Potential Structural Fire-related Risks: An Integrated GIS-MCDM Approach. Fire 2023, 6, 107. [Google Scholar] [CrossRef]
- Lee, C.-A.; Sung, Y.-C.; Lin, Y.-S.; Hsiao, G.K.-K. Evaluating the severity of building fires with the analytical hierarchy process, big data analysis, and remote sensing. Nat. Hazards 2020, 103, 1843–1856. [Google Scholar] [CrossRef]
- Pamučar, D.; Ecer, F.; Cirovic, G.; Arlasheedi, M.A. Application of improved best worst method (BWM) in real-world problems. Mathematics 2020, 8, 1342. [Google Scholar] [CrossRef]
- Taherdoost, H.; Madanchian, M. Multi-criteria decision making (MCDM) methods and concepts. Encyclopedia 2023, 3, 77–87. [Google Scholar] [CrossRef]
- Nyimbili, P.H.; Erden, T. Comparative evaluation of GIS-based best—Worst method (BMW) for emergency facility planning: Perspectives from two decision-maker groups. Nat. Hazards 2021, 105, 1031–1067. [Google Scholar] [CrossRef]
- KC, K.; Ardianto, R.; Chhetri, P.; Corcoran, J. Geographic patterns of urban fires in the global south: The case of Kathmandu, Nepal. GeoJournal 2024, 89, 137. [Google Scholar] [CrossRef]
- Nishino, T.; Hokugo, A. A stochastic model for time series prediction of the number of post—Earthquake fire ignition in buildings based on the ignition record for the 2011 Tohoku Earthquake. Earthq. Spectra 2019, 36, 232–249. [Google Scholar] [CrossRef]
- Nishino, T. Physics-based urban fires spread simulation coupled with stochastic occurrence of spot fires. Stoch. Environ. Res. Risk Assess. 2019, 33, 451–463. [Google Scholar] [CrossRef]
- Nishino, T. Probabilistic urban cascading multi-hazard risk assessment methodology for ground shaking and post-earthquake fires. Nat. Hazards 2023, 116, 3165–3200. [Google Scholar] [CrossRef]
- Jennings, C.R. Social and economic characteristics as determinants of residential fire risk in urban neighborhoods: A review of the literature. Fire Saf. J. 2013, 62, 13–19. [Google Scholar] [CrossRef]
- Rohde, D.; Corcoran, J.; Chhetri, P. Spatial forecasting of residential urban fires: A Bayesian approach. Comput. Environ. Urban Syst. 2010, 34, 58–69. [Google Scholar] [CrossRef]
- Ardianto, R.; Chhetri, P. Modeling Spatial-Temporal Dynamic of Urban Residential Fire Risk Using a Markov Chain Technique. Int. J. Disaster Risk Sci. 2019, 10, 57–73. [Google Scholar] [CrossRef]
- Suthaharan, S. Support vector machine. In Machine Learning Models and Algorithms for Big Data Classification: Thinking with Examples for Effective Learning; Springer: Boston, MA, USA, 2016; pp. 207–235. [Google Scholar]
- Maniatis, Y.; Doganis, A.; Chatzigeorgiadis, M. Fire Risk Probability Mapping Using Machine Learning Tools and Multi-Criteria Decision Analysis in the GIS Environment: A Case Study in the National Park Forest Dadia-Lefkimi-Soufli, Greece. Appl. Sci. 2022, 12, 2938. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Rigatti, S.J. Random forest. J. Insur. 2017, 47, 31–39. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Dey, A.; Heger, A.; England, D. Urban Fire Station Planning using Predicted Demand and Service Quality Index; Springer Nature: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Walia, B.S.; Hu, Q.; Chen, J.; Chen, F.; Lee, J.; Kuo, N.; Narang, P.; Batts, J.; Arnold, G.; Madaio, M. A Dynamic pipeline for Spatio-Temporal Fire Risk Prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 764–773. [Google Scholar]
- Jin, G.; Wang, Q.; Zhu, C.; Feng, Y.; Huang, J.; Hu, X. Urban Fire Situation Forecasting: Deep sequence learning with Spatio–temporal dynamics. Appl. Soft Comput. 2020, 97, 106730. [Google Scholar] [CrossRef]
- Sahebi, A.; Havasy, B.; Veisani, Y. Predicting firefighting operation time in urban areas using machine learning: Identifying key determinants for improved emergency response. Discov. Appl. Sci. 2025, 7, 250. [Google Scholar] [CrossRef]
- Yuan, Y.; Wylie, A.G. Comparing Machine Learning and Time Series Approaches in Predictive Modeling of Urban Fire Incidents: A Case Study of Austin, Texas. ISPRS Int. J. Geo-Inf. 2024, 13, 149. [Google Scholar] [CrossRef]
- Zhou, Y.; Lin, P.; Wang, N. A deep neural network approach for regional-scale 30-day accumulated urban fire occurrence forecast. Fire Saf. J. 2025, 152, 104331. [Google Scholar] [CrossRef]
- Liu, Z.; Zhuang, Y. An investigation using resampling techniques and explainable machine learning to minimize fire losses in residential buildings. J. Build. Eng. 2024, 95, 110080. [Google Scholar] [CrossRef]
- Schmidt, A.; Gemmil, E.; Hoskins, R. Machine Learning Based Risk Analysis and Predictive Modeling of Structure Fire Related Casualties. Mach. Learn. Appl. 2025, 20, 100645. [Google Scholar] [CrossRef]
- Seo, M.S.; Castillo-Osorio, E.E.; Yoo, H.H. Fire Risk Prediction Analysis Using Machine Learning Techniques. Sens. Mater. 2023, 35, 3241–3255. [Google Scholar] [CrossRef]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. Berkeley Symp. Math. Statist. Prob. 1967, 1967, 281–297. [Google Scholar]
- Lizhi, W.; Aizhu, R. Urban Fire Risk Clustering Method Based on Fire Statistics. Tsinghua Sci. Technol. 2008, 13, 418–422. [Google Scholar]
- Ishola, A.A.; Valles, D. Enhancing safety and Efficiency in Firefighting Operations via Deep Learning and Temperature Forecasting Modeling in Autonomous Unit. Sensors 2023, 23, 4628. [Google Scholar] [CrossRef]
- Di Martino, T.; Le Saux, B.; Guinvarc’h, R.; Thirion-Lefevre, L.; Colin, E. Detection of forest fires through deep unsupervised learning modeling of Sentinel-1 time series. ISPRS Int. J. Geo-Inf. 2023, 12, 332. [Google Scholar] [CrossRef]
- Çiftçioğlu, A.Ö.; Naser, M.Z. Unsupervised Machine Learning for Fire Resistance Analysis. In Proceedings of the International Conference on Science, Engineering Management and Information Technology, Ankara, Turkey, 2–3 February 2022; Springer Nature: Cham, Switzerland, 2022; pp. 211–221. [Google Scholar]
- Rahimi, I.; Duarte, L.; Teodoro, A.C. Unsupervised Image Classification Algorithms Applied to Fire-Prone Area Detection. In Proceedings of the 11th International Conference on Geographical Information Systems Theory, Applications and Management (GISTAM 2025), Porto, Portugal, 1–3 April 2025. [Google Scholar]
- O’Neill, M.; Ryan, C. Grammatical evolution. IEEE Trans. Evol. Comput. 2001, 5, 349–358. [Google Scholar] [CrossRef]
- Bishop, C. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Control Signals Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Nawi, N.M.; Atomi, W.H.; Rehman, M.Z. The effect of data pre-processing on optimized training of artificial neural networks. Procedia Technol. 2013, 11, 32–39. [Google Scholar] [CrossRef]
- Backus, J.W. The Syntax and Semantics of the Proposed International Algebraic Language of the Zurich ACM-GAMM Conference. In Proceedings of the International Conference on Information Processing, UNESCO, Paris, France, 15–20 June 1959; pp. 125–132. [Google Scholar]
- Ryan, C.; Collins, J.; O’Neill, M. Grammatical evolution: Evolving programs for an arbitrary language. In Genetic Programming; Banzhaf, W., Poli, R., Schoenauer, M., Fogarty, T.C., Eds.; EuroGP 1998. Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1998; Volume 1391. [Google Scholar]
- O’Neill, M.; Ryan, M.C. Evolving Multi-line Compilable C Programs. In Genetic Programming; Poli, R., Nordin, P., Langdon, W.B., Fogarty, T.C., Eds.; EuroGP 1999. Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1999; Volume 1598. [Google Scholar]
- Ryan, C.; O’Neill, M.; Collins, J.J. Grammatical evolution: Solving trigonometric identities. In Proceedings of the Mendel 1998: 4th International Mendel Conference on Genetic Algorithms, Optimisation Problems, Fuzzy Logic, Neural Networks, Rough Sets, Brno, Czech Republic, 24–26 June 1998; Volume 98. [Google Scholar]
- Puente, A.O.; Alfonso, R.S.; Moreno, M.A. Automatic composition of music by means of grammatical evolution. In Proceedings of the APL ’02: Proceedings of the 2002 Conference on APL: Array Processing Languages: Lore, Problems, and Applications, Madrid, Spain, 22–25 July 2002; pp. 148–155. [Google Scholar]
- De Campos, L.M.L.; de Oliveira, R.C.L.; Roisenberg, M. Optimization of neural networks through grammatical evolution and a genetic algorithm. Expert Syst. Appl. 2016, 56, 368–384. [Google Scholar] [CrossRef]
- Soltanian, K.; Ebnenasir, A.; Afsharchi, M. Modular Grammatical Evolution for the Generation of Artificial Neural Networks. Evol. Comput. 2022, 30, 291–327. [Google Scholar] [CrossRef]
- Dempsey, I.; Neill, M.O.; Brabazon, A. Constant creation in grammatical evolution. Int. J. Innov. Appl. 2007, 1, 23–38. [Google Scholar] [CrossRef]
- Galván-López, E.; Swafford, J.M.; O’Neill, M.; Brabazon, A.; PacMan, E.a.M. Controller Using Grammatical Evolution. In Applications of Evolutionary Computation. EvoApplications 2010; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6024. [Google Scholar]
- Shaker, N.; Nicolau, M.; Yannakakis, G.N.; Togelius, J.; O’Neill, M. Evolving levels for Super Mario Bros using grammatical evolution. In Proceedings of the 2012 IEEE Conference on Computational Intelligence and Games (CIG), Granada, Spain, 11–14 September 2012; pp. 304–331. [Google Scholar]
- Martínez-Rodríguez, D.; Colmenar, J.M.; Hidalgo, J.I.; Micó, R.J.V.; Salcedo-Sanz, S. Particle swarm grammatical evolution for energy demand estimation. Energy Sci. Eng. 2020, 8, 1068–1079. [Google Scholar] [CrossRef]
- Sabar, N.R.; Ayob, M.; Kendall, G.; Qu, R. Grammatical Evolution Hyper-Heuristic for Combinatorial Optimization Problems. IEEE Trans. Evol. Comput. 2013, 17, 840–861. [Google Scholar] [CrossRef]
- Ryan, C.; Kshirsagar, M.; Vaidya, G.; Cunningham, A.; Sivaraman, R. Design of a cryptographically secure pseudo random number generator with grammatical evolution. Sci. Rep. 2022, 12, 8602. [Google Scholar] [CrossRef]
- Tsoulos, I.G.; Gavrilis, D.; Glavas, E. Neural network construction and training using grammatical evolution. Neurocomputing 2008, 72, 269–277. [Google Scholar] [CrossRef]
- Papamokos, G.V.; Tsoulos, I.G.; Demetropoulos, I.N.; Glavas, E. Location of amide I mode of vibration in computed data utilizing constructed neural networks. Expert Syst. Appl. 2009, 36, 12210–12213. [Google Scholar] [CrossRef]
- Tsoulos, I.G.; Gavrilis, D.; Glavas, E. Solving differential equations with constructed neural networks. Neurocomputing 2009, 72, 2385–2391. [Google Scholar] [CrossRef]
- Poli, R.; Langdon, W.B. Genetic Programming with One-Point Crossover; Springer: London, UK, 1998; pp. 180–189. [Google Scholar]
- Gavrilis, D.; Tsoulos, I.G.; Dermatas, E. Selecting and constructing features using grammatical evolution. Pattern Recognit. Lett. 2008, 29, 1358–1365. [Google Scholar] [CrossRef]
- Park, J.; Sandberg, I.W. Universal Approximation Using Radial-Basis-Function Networks. Neural Comput. 1991, 3, 246–257. [Google Scholar] [CrossRef]
- Yu, H.; Xie, T.; Paszczynski, S.; Wilamowski, B.M. Advantages of Radial Basis Function Networks for Dynamic System Design. IEEE Trans. Ind. Electron. 2011, 58, 5438–5450. [Google Scholar] [CrossRef]
- Tsoulos, I.G. Creating classification rules using grammatical evolution. Int. J. Comput. Intell. Stud. 2020, 9, 161–171. [Google Scholar]
- Anastasopoulos, N.; Tsoulos, I.G.; Tzallas, A. GenClass: A parallel tool for data classification based on Grammatical Evolution. SoftwareX 2021, 16, 100830. [Google Scholar] [CrossRef]
- Hall, M.; Frank, F.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Ben-Gal, I. Bayesian Networks. In Encyclopedia of Statistics in Quality and Reliability; Ruggeri, F., Kenett, R.S., Faltin, F.W., Eds.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2008. [Google Scholar]
- Koski, T.; Noble, J. Bayesian Networks: An Introduction; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Chen, T.; Zhong, S. Privacy-Preserving Backpropagation Neural Network Learning. IEEE Trans. Neural Netw. 2009, 20, 1554–1564. [Google Scholar] [CrossRef] [PubMed]
- Wilcoxon, F. Individual Comparisons by Ranking Methods. Int. Biom. Soc. 1945, 1, 80–83. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Country | Year | Causes of Forest Fires | Carbon Emissions | Hectares | Casualties |
|---|---|---|---|---|---|
| Australia (Black Summer) [7,8] | 2019–2020 | Dry winters, drought | 900 million tons | 19 million | 33 people 3000 Houses and Buildings Billions of wild animals |
| Russia (Arctic fires) [9,10,11] | 2019–2020 | Dryer surface, higher temperature | 31.1 megatons | 24 million | None reported |
| USA (LA) [12,13] | 2025 | High temperature | 4.4 megatons | 57,000 | 30 people 2,000,000 evacuated 16,000 houses burnt |
| Japan (Ofunato) [14] | 2025 | High temperature | None reported | 2900 | 1 person 4000 evacuated 210 buildings damaged |
| Feature | Min Value | Max Value |
|---|---|---|
| Fire station | 1 | 275 |
| Region code | 1 | 51 |
| Month code | 1 | 12 |
| Season code | 1 | 4 |
| Area (Building type) | 1 | 147 |
| Persons involved | 1 | |
| Number of injuries | 0 | |
| Number of Burnt Victims | 0 | |
| Number of Fatalities | 0 | |
| Number of Vehicles involved | 1 | |
| Firefighters involved | 1 |
| Parameter | Meaning | Value |
|---|---|---|
| Number of chromosomes | 500 | |
| Maximum number of generations | 200 | |
| Selection rate | 0.10 | |
| Mutation rate | 0.05 | |
| Number of produced features | 2 | |
| H | Number or processing nodes | 10 |
| Year | Patterns | BAYES NET | MLP | RBF | NNC | FC | GENCLASS |
|---|---|---|---|---|---|---|---|
| 2014 | 1287 | 9.01% | 8.34% | 11.97% | 7.82% | 7.35% | 7.03% |
| 2015 | 1686 | 8.75% | 7.63% | 10.79% | 7.13% | 6.78% | 6.65% |
| 2016 | 1735 | 8.99% | 8.13% | 10.73% | 7.48% | 7.10% | 7.05% |
| 2017 | 1736 | 8.43% | 8.29% | 10.78% | 7.68% | 7.24% | 7.13% |
| 2018 | 1637 | 8.38% | 7.99% | 9.33% | 7.30% | 7.11% | 6.74% |
| 2019 | 1971 | 7.31% | 7.78% | 24.81% | 7.33% | 7.15% | 6.26% |
| 2020 | 1990 | 8.70% | 7.86% | 10.03% | 6.99% | 6.66% | 6.47% |
| 2021 | 1883 | 8.58% | 7.88% | 10.37% | 6.87% | 6.55% | 6.39% |
| 2022 | 2036 | 8.80% | 7.29% | 8.45% | 6.86% | 6.52% | 6.32% |
| 2023 | 1978 | 8.46% | 7.50% | 10.56% | 6.87% | 6.58% | 6.20% |
| Average | 8.54% | 7.87% | 11.78% | 7.23% | 6.90% | 6.62% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kopitsa, C.; Tsoulos, I.G.; Miltiadous, A.; Charilogis, V. Predicting the Damage of Urban Fires with Grammatical Evolution. Big Data Cogn. Comput. 2025, 9, 142. https://doi.org/10.3390/bdcc9060142
Kopitsa C, Tsoulos IG, Miltiadous A, Charilogis V. Predicting the Damage of Urban Fires with Grammatical Evolution. Big Data and Cognitive Computing. 2025; 9(6):142. https://doi.org/10.3390/bdcc9060142
Chicago/Turabian StyleKopitsa, Constantina, Ioannis G. Tsoulos, Andreas Miltiadous, and Vasileios Charilogis. 2025. "Predicting the Damage of Urban Fires with Grammatical Evolution" Big Data and Cognitive Computing 9, no. 6: 142. https://doi.org/10.3390/bdcc9060142
APA StyleKopitsa, C., Tsoulos, I. G., Miltiadous, A., & Charilogis, V. (2025). Predicting the Damage of Urban Fires with Grammatical Evolution. Big Data and Cognitive Computing, 9(6), 142. https://doi.org/10.3390/bdcc9060142