Abstract
This study presents a comprehensive evaluation of embedding techniques and large language models (LLMs) for Information Retrieval (IR) and question answering (QA) across languages, focusing on English and Italian. We address a significant research gap by providing empirical evidence of model performance across linguistic boundaries. We evaluate 12 embedding models on diverse IR datasets, including Italian SQuAD and DICE, English SciFact, ArguAna, and NFCorpus. We assess four LLMs (GPT4o, LLama-3.1 8B, Mistral-Nemo, and Gemma-2b) for QA tasks within a retrieval-augmented generation (RAG) pipeline. We evaluate them on SQuAD, CovidQA, and NarrativeQA datasets, including cross-lingual scenarios. The results show multilingual models perform more competitively than language-specific ones. The embed-multilingual-v3.0 model achieves top nDCG@10 scores of 0.90 for English and 0.86 for Italian. In QA evaluation, Mistral-Nemo demonstrates superior answer relevance (0.91–1.0) while maintaining strong groundedness (0.64–0.78). Our analysis reveals three key findings: (1) multilingual embedding models effectively bridge performance gaps between English and Italian, though performance consistency decreases in specialized domains, (2) model size does not consistently predict performance, and (3) all evaluated QA systems exhibit a critical trade-off between answer relevance and factual groundedness. Our evaluation framework combines traditional metrics with innovative LLM-based assessment techniques. It establishes new benchmarks for multilingual language technologies while providing actionable insights for real-world IR and QA system deployment.
1. Introduction
The exponential growth of digital information has made efficient information access and retrieval a critical challenge. Two key technologies have emerged to address this need: Information Retrieval (IR) and question answering (QA). IR systems excel at searching through large data collections to find relevant content, while QA systems go a step further by extracting and formulating precise answers to specific queries. Together, these technologies form the backbone of modern information access systems, enabling users to navigate and extract meaning from vast amounts of digital content. These capabilities are essential for applications ranging from enterprise search to personal digital assistants, making IR and QA fundamental technologies in our data-driven world.
1.1. Technological Context and Challenges
Recent Natural Language Processing (NLP) breakthroughs have transformed the landscape of IR and QA. Two technological advances have been particularly influential: large language models (LLMs) [1,2] and sophisticated embedding techniques [3,4]. LLMs have revolutionized text understanding and generation capabilities, while embedding techniques have enabled more nuanced semantic search and retrieval. The current state-of-the-art in IR and QA reflects rapid technological advancement, particularly in multilingual capabilities. Recent industry developments have introduced models like Mistral-Nemo [5] and Gemma [6], specifically targeting the performance gap between high-resource and lower-resource languages. This evolution responds to the growing demand for efficient multilingual solutions that serve diverse markets without language-specific models while ensuring factual accuracy through retrieval-augmented approaches. Three key technological trends have emerged from these developments:
- Transformer-based architectures [7], particularly BERT [8] and its variants, have revolutionized the field by capturing sophisticated semantic relationships across languages [9].
- Dense retrieval methods have superseded traditional term-based approaches, significantly improving IR task performance.
- Retrieval-augmented generation (RAG) [10,11] has enhanced QA systems by combining neural information retrieval with context-aware text generation, enabling more accurate responses through external knowledge integration.
Despite these advances, significant challenges persist in cross-lingual and domain-specific information access:
- The effectiveness of these models varies considerably across languages and domains, with performance patterns not yet systematically documented or understood.
- Critical questions remain about the trade-offs between model size, computational efficiency, and multilingual performance.
- The capability of models to maintain consistent performance across both language boundaries and specialized domains requires thorough investigation.
1.2. Research Focus on the English–Italian Language Pair
Our focus on English and Italian is strategically motivated by four compelling factors:
- Linguistic diversity: Italian represents a morphologically rich Romance language with complex verbal systems and agreement patterns, providing an excellent test case for model robustness compared to English’s relatively more straightforward morphological structure [12].
- Research gap: While English dominates NLP research, Italian, despite being spoken by approximately 68 million people (https://en.wikipedia.org/wiki/Italian_language, accessed on 15 March 2025) worldwide and being a major European language, remains under-represented in large-scale NLP evaluations.
- Industrial relevance: Italy’s significant technological sector and growing AI industry make Italian language support crucial for practical applications. The country’s diverse industrial domains (e.g., manufacturing, healthcare, finance, and tourism) present unique challenges for domain-specific IR and QA systems.
- Cross-family evaluation: The comparison between Germanic (English) and Romance (Italian) language families offers insights into the cross-linguistic transfer capabilities of modern language models.
This language pair selection enables us to investigate linguistically motivated questions about cross-lingual transfer and practically oriented concerns about multilingual system deployment.
1.3. Research Questions
Building on the current state-of-the-art and identified challenges, our study investigates four fundamental questions at the intersection of IR, QA, and language technologies:
- Embedding effectiveness: How do state-of-the-art embedding techniques perform across English and Italian IR tasks, and what factors influence their cross-lingual effectiveness?
- LLM impact: What are the quantitative and qualitative effects of integrating LLMs into RAG pipelines for multilingual QA tasks, particularly regarding answer accuracy and factuality?
- Cross-domain and cross-language generalization: To what extent do current models maintain performance across domains and languages in zero-shot scenarios, and what patterns emerge in their generalization capabilities?
- Evaluation methodology: How can we effectively assess multilingual IR and QA systems, and what complementary insights do traditional and LLM-based metrics provide?
1.4. Contributions
Our research makes five significant contributions to the field of IR and QA:
- Comprehensive performance analysis: Our systematic evaluation encompasses 12 embedding models and 4 LLMs across 7 diverse datasets, utilizing 11 distinct evaluation metrics. Our analysis distinguishes itself from previous studies like BEIR [13] and MTEB [14] in three fundamental dimensions. First, we employ a multifaceted evaluation approach that combines traditional performance metrics with reference-free LLM-based assessments, providing a more holistic view of model capabilities. Second, we evaluate groundedness and answer relevance dimensions, often overlooked in standard benchmarks, addressing critical concerns in modern retrieval-augmented systems. Third, while most existing evaluations focus primarily on high-resource languages, our study explicitly examines the English–Italian language pair. Thus, we offer valuable insights into model performance for Italian, an important European language that remains underexplored. Our methodologically diverse approach provides a practical understanding of model behavior across languages and domains, complementing existing benchmark studies.
- Cross-lingual insights: An in-depth investigation of English–Italian language pair dynamics, offering valuable insights into the challenges and opportunities in bridging high-resource and lower-resource European languages.
- Evaluation framework: Development and application of a comprehensive evaluation methodology that combines traditional IR metrics with LLM-based assessments, enabling a more nuanced understanding of model performance across languages and domains.
- RAG pipeline insights: We offer detailed insights into the effectiveness of integrating LLMs into RAG pipelines for QA tasks, highlighting both the potential and limitations of this approach.
- Practical implications: Our findings provide valuable guidance for practitioners in selecting appropriate models and techniques for specific IR and QA applications, considering factors such as language, domain, and computational resources.
These contributions advance theoretical understanding and practical implementation of multilingual IR and QA systems. Our findings have direct applications in developing more effective search engines, cross-lingual information systems, and domain-specific QA tools. They also identify promising directions for future research in multilingual language technologies.
1.5. Paper Organization
The remainder of this paper is organized as follows: Section 2 provides a comprehensive review of related work. Section 3 details our methodology, including the datasets, models, and evaluation metrics used. Section 4 presents our experimental results and analysis. Section 5 discusses the implications of our findings and their broader impact on the field. Finally, Section 6 concludes the paper and outlines directions for future research.
2. Related Work
Recent advances in Information Retrieval (IR) and question answering (QA) have been driven by two major technological shifts: the emergence of sophisticated embedding techniques and the development of large language models (LLMs). We structure our review around five key themes that highlight the most relevant prior work:
- Evolution of IR and QA systems: Recent surveys and benchmark frameworks that have shaped our understanding of modern IR and QA systems.
- Embedding models for Information Retrieval: Specialized embedding models designed for IR tasks.
- LLM Integration in question answering: The transformation of QA systems through large language models.
- RAG architecture: The development of retrieval-augmented generation (RAG) systems.
- Evaluation methodologies: Assessment metrics and methodologies for modern IR and QA systems.
This structure allows us to systematically examine the current state-of-the-art, identify existing gaps, and position our research within the broader landscape of IR and QA advancements.
2.1. Evolution of IR and QA Systems
The IR and QA field has evolved rapidly, with comprehensive surveys and benchmarks addressing three critical aspects: system architectures, interpretability, and performance benchmarking. From an architectural perspective, Hambarde and Proença [15] systematically categorize IR approaches, tracing the progression from traditional statistical methods to modern deep learning approaches through discrete, dense, and hybrid retrieval techniques. For explainable systems, Anand et al. [16] introduced the concept of Explainable Information Retrieval (ExIR), identifying three fundamental approaches: (i) Post-hoc interpretability: Techniques for explaining trained model decisions. (ii) Interpretability by design: Architectures with inherent explanatory capabilities. (iii) IR principle grounding: Methods verifying adherence to established IR fundamentals.
Performance evaluation has advanced significantly through several benchmark frameworks. Thakur et al. [13] introduced BEIR, a comprehensive zero-shot evaluation framework spanning 18 diverse domains, establishing new standards for assessing model generalization. Building on this foundation, Muennighoff et al. [14] developed MTEB, expanding evaluation to eight distinct embedding tasks across multiple languages and providing a valuable performance leaderboard (MTEB Leaderboard https://huggingface.co/spaces/mteb/leaderboard, accessed on 15 March 2025).
Recent specialized frameworks have addressed emerging challenges in modern IR and QA systems. Tang et al. [17] focus on evaluating document-level retrieval and reasoning in RAG pipelines, while Zhang et al. [18] examine adaptive retrieval for open-domain QA. Gao et al. [19] contribute valuable insights to LLM-based evaluation methodologies, particularly exploring human-LLM collaboration in assessment.
Despite these advances, a critical gap remains in comprehensive multilingual evaluation. While benchmarks like MTEB include multiple languages, they rarely provide an in-depth analysis of cross-lingual performance patterns or domain adaptation challenges across linguistic boundaries, particularly for morphologically rich European languages like Italian. Our study addresses this limitation by offering an in-depth English and Italian analysis.
2.2. Embedding Models for Information Retrieval
Information retrieval has fundamentally transformed from traditional term-based methods to sophisticated neural approaches. Dense retrieval methods, which represent documents and queries as dense vectors in a shared semantic space, are at the core of this evolution. Unlike traditional term-frequency approaches, these methods excel at capturing complex semantic relationships, enabling more nuanced retrieval for sophisticated queries. Pioneering dense retrieval methods include DPR [20], ColBERT [21], and ANCE [22]. These approaches leverage powerful embedding models like BERT [8] and its variants to create effective semantic representations. Research has increasingly focused on specialized architectures for retrieval effectiveness. Nogueira et al. [23] introduced doc2query, which expands documents with predicted queries, enhancing performance even with traditional retrieval methods. More recent works have focused on creating specialized embedding models for IR. Gao and Callan [24] proposed Condenser, a pre-training architecture designed explicitly for dense retrieval. At the same time, Wang et al. [25] introduced E5, a family of text embedding models trained on diverse tasks and languages. Multilingual retrieval has seen significant innovation, with models like BGE (BAAI General Embeddings) [26] (https://github.com/FlagOpen/FlagEmbedding, accessed on 15 March 2025) demonstrating robust performance across languages and retrieval tasks. These models leverage advanced pre-training methods like RetroMAE [27,28] on large-scale paired data through contrastive learning. Complementing these approaches, language-specific models like BERTino [29], an Italian DistilBERT variant, have emerged to address unique linguistic characteristics.
Despite these advances, three critical gaps remain:
- Comprehensive cross-lingual evaluation, particularly for morphologically rich languages like Italian.
- Systematic assessment of domain adaptation capabilities across languages.
- Comparative analysis of language-specific vs. multilingual models.
Our study addresses these gaps by providing a rigorous evaluation framework across linguistic and domain boundaries, offering insights into the adaptability of contemporary embedding models in both English and Italian contexts.
2.3. LLM Integration in Question Answering
Large language models (LLMs) have fundamentally transformed question answering, enabling sophisticated contextual understanding, multi-step reasoning, and natural, human-like responses beyond what traditional information extraction methods could achieve.
A pivotal development was the introduction of Retrieval-Augmented Generation (RAG) by Lewis et al. [10], which combined neural retrievers with generation models to create a powerful framework for knowledge-intensive NLP tasks. This approach allows QA systems to dynamically access and integrate external knowledge, proving valuable in applications requiring accuracy and contextual understanding.
Brown et al. [1] further transformed the QA landscape by demonstrating the remarkable few-shot learning capabilities of GPT-3. This breakthrough showed that large-scale language models could achieve sophisticated reasoning and response generation with minimal task-specific training, establishing new performance benchmarks.
However, recent research has identified important challenges in LLM applications. Liu et al. [30] revealed the “Lost in the Middle” problem, where models struggle to maintain attention across long input contexts—a critical limitation for QA systems processing extensive documents or integrating information from multiple sources.
The effectiveness of LLMs across different languages and specialized domains remains an active area of investigation with limited systematic evaluation. Our study addresses this research gap by evaluating state-of-the-art models (GPT4o, Llama 3.1, Mistral-Nemo, and Gemma2) in multilingual QA scenarios. Our findings contribute to a deeper understanding of their capabilities and constraints in real-world, multilingual applications.
2.4. RAG Architecture
Retrieval-augmented generation (RAG) has emerged as a pivotal architecture in modern information systems, with diverse implementations addressing different aspects of knowledge integration and generation [31,32,33,34,35]. Modern RAG architectures incorporate several critical components:
- Advanced document-splitting mechanisms that preserve semantic coherence.
- Intelligent chunking strategies that optimize information density.
- Sophisticated retrieval mechanisms leveraging state-of-the-art embedding models.
- Integration with powerful language generation models.
Combining these components creates systems capable of producing more accurate and contextually appropriate responses than either pure retrieval or generation approaches alone.
Our research contributes to the current understanding of RAG systems through a systematic evaluation across multiple dimensions. We assess various RAG configurations in monolingual and cross-lingual settings, particularly in English and Italian. This comprehensive evaluation is motivated by two critical factors in modern AI system development: First, cross-lingual knowledge transfer capabilities are essential for developing truly multilingual AI systems. Second, domain adaptation flexibility is crucial for real-world deployments. Our approach distinguishes itself through three key innovations:
- Systematic assessment of cross-lingual performance with focused attention on English–Italian language pairs.
- Comprehensive evaluation of domain adaptability across various sectors.
- Integration of cutting-edge embedding models and LLMs within RAG pipelines.
This multifaceted evaluation provides valuable insights for both researchers and practitioners developing robust, multilingual information systems.
2.5. Evaluation Methodologies
The evolution of evaluation methodologies for IR and QA systems reflects the increasing sophistication of neural models and LLMs, necessitating multifaceted performance assessment approaches spanning traditional metrics, semantic evaluation, and emerging LLM-based frameworks.
Traditional metrics [36] such as precision, recall, and F1 score remain relevant but often insufficiently capture the nuanced performance of modern systems, particularly regarding the quality and relevance of generated responses. For QA tasks, metrics like BLEU [37] and ROUGE [38] have been widely used to evaluate generated answer quality.
A significant advancement came with BERTScore by Zhang et al. [39], which leverages contextual embeddings to capture semantic similarities. This marked a shift toward more sophisticated evaluation techniques better aligned with human judgments, particularly valuable for assessing systems that generate diverse yet semantically correct responses.
Recently, specialized evaluation frameworks have emerged for modern IR and QA architectures. Es et al. [40] introduced RAGAS, addressing the unique challenges of evaluating LLM-based QA systems by incorporating multiple assessment dimensions. Katranidis et al. [41] developed FAAF, a fact-verification approach leveraging function-calling capabilities of LMs. Saad-Falcon et al. [42] introduced ARES, an automated evaluation system assessing RAG systems across context relevance, answer faithfulness, and answer relevance.
Our research synthesizes these approaches, combining traditional metrics with contemporary LLM-based assessment techniques to provide a comprehensive evaluation framework assessing the following:
- Cross-lingual effectiveness across language boundaries.
- Adaptation capabilities across diverse domains.
- Quality and relevance of generated responses.
- Retrieval precision and efficiency metrics.
Through this holistic methodology, we offer insights into both the technical performance and practical applicability of modern IR and QA systems, contributing to a more nuanced understanding of their capabilities and limitations.
2.6. Research Gaps and Our Contributions
While significant progress has been made in IR and QA technologies, our comprehensive literature review reveals several critical gaps that currently limit the effectiveness of multilingual information systems. Across the survey areas discussed in Section 2.1, Section 2.2, Section 2.3, Section 2.4 and Section 2.5, we identify three overarching limitations:
- Insufficient cross-lingual evaluation frameworks that can assess performance across diverse language families, particularly for morphologically rich languages like Italian. This gap is especially critical as global deployment increases, yet our understanding of system behavior across different linguistic contexts remains limited.
- Limited understanding of domain adaptation challenges when moving from general to specialized contexts across languages. While effective in general domains, current systems often struggle with specialized fields like healthcare, legal, and technical domains, where terminology and reasoning patterns demand sophisticated adaptation. This complexity increases in multilingual settings, where RAG systems face significant challenges in maintaining consistency and accuracy across language barriers.
- Inadequate evaluation methodologies that can capture both technical performance and practical utility in multilingual settings. Traditional metrics may not adequately reflect real-world reliability across different languages and use cases. Ethical considerations compound this limitation regarding bias, fairness, and representation that require systematic investigation.
Our research addresses these challenges through two major contributions:
- A comprehensive evaluation framework spanning both English and Italian, offering insights into model performance across linguistic boundaries.
- An evaluation methodology combining traditional metrics with LLM-based assessment techniques.
These contributions establish a foundation for developing more effective, adaptable, and equitable multilingual IR and QA systems. The insights and methodologies we present contribute to creating more robust and inclusive language technologies serving diverse linguistic communities and specialized domains.
3. Methodology and Evaluation Framework
This section presents our comprehensive methodology for evaluating embedding techniques and large language models (LLMs) in Information Retrieval (IR) and question answering (QA) tasks. We begin with an overview of our approach (Section 3.1), followed by a detailed description of the RAG pipeline implementation (Section 3.2). We then present the datasets selected for both IR and QA evaluations (Section 3.3) and the various models employed, including embedding models for retrieval and LLMs for answer generation (Section 3.4). The evaluation framework is described through detailed metrics for assessing both IR and QA performance in Section 3.5. Our experimental design is thoroughly documented in Section 3.6, including hardware specifications, procedural workflows for both IR and QA processing, and reproducibility measures. We conclude with important considerations regarding the ethical implications of our research and a transparent discussion of the limitations and potential biases in our methodology (Section 3.7).
3.1. Overview of Approach
Our research employs a systematic comparative evaluation framework designed to address four specific research questions (see Section 1.3). This framework integrates quantitative performance metrics with qualitative analysis across two dimensions: cross-lingual capabilities and domain specialization. Figure 1 illustrates how our methodology directly connects to these research objectives through a multi-stage evaluation process encompassing both IR and QA tasks across diverse linguistic contexts.
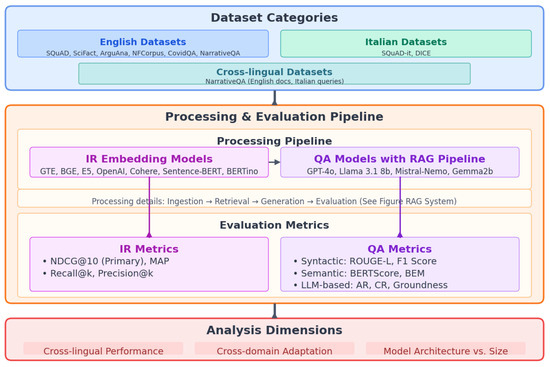
Figure 1.
Comprehensive evaluation framework illustrating the relationships between datasets, models, metrics, and analysis dimensions. The diagram shows how our methodology systematically evaluates multilingual capabilities across both IR and QA tasks, with the RAG pipeline (detailed in Figure 2) serving as a key component of the processing pipeline.
Our comprehensive methodology encompasses four key components:
- Retrieval-augmented generation: We implement a structured RAG pipeline with distinct phases for ingestion, retrieval, generation, and evaluation.
- Dataset selection: We employ diverse datasets spanning general knowledge and specialized domains in both English and Italian to assess cross-lingual and cross-domain capabilities.
- Model evaluation: We systematically evaluate 12 embedding models for IR tasks and 4 LLMs within RAG pipelines for QA tasks.
- Multifaceted assessment: We utilize a comprehensive set of evaluation metrics to capture different aspects of performance across languages and domains.
Figure 1 provides a visual overview of our evaluation framework, illustrating the relationships between datasets, models, and evaluation metrics.
The framework incorporates three main components: (1) diverse dataset categories, including cross-lingual configurations; (2) a processing and evaluation pipeline that includes both IR models and QA models within our RAG system; and (3) multiple evaluation metrics encompassing syntactic, semantic, and LLM-based assessments. Through this structured approach, we can analyze model performance across linguistic and domain boundaries, focusing on the three key analysis dimensions shown at the bottom of the diagram: cross-lingual performance, cross-domain adaptation, and model architecture effects.
3.2. RAG Pipeline
Our RAG pipeline implements a four-phase architecture designed to systematically process, retrieve, generate, and evaluate information, as illustrated in Figure 2.

Figure 2.
Architecture of the implemented RAG system, showing the four main components: ingestion, retrieval, generation, and evaluation.
Ingestion. The initial phase processes input documents to create manageable and searchable chunks. This is achieved by segmenting the documents into smaller parts, referred to as “chunks”. Different chunking strategies can be implemented, and for visual-oriented input documents like PDFs, we exploit Document Layout Analysis to recognize more significant splitting of the document. These chunks are then converted into vector representations. This embedding process transforms the textual information into high-dimensional vectors that capture the semantic essence of each chunk. These semantic vectors are subsequently ingested into a vector store such as Pinecone (Pinecone https://www.pinecone.io/, accessed on 15 March 2025), Weaviate (Weaviate https://weaviate.io/, accessed on 15 March 2025), and Milvus (Milvus https://milvus.io/, accessed on 15 March 2025). These vector databases are designed for efficient similarity search operations. This encoding and indexing process is critical for facilitating rapid and accurate retrieval of information relevant to user queries.
Retrieval. Upon receiving a query, the system employs the same embedding model to convert the query into its vector form. This query vector undergoes a similarity search within the vector store to identify the k most similar embeddings corresponding to previously indexed chunks. The similarity search leverages the vector space to find chunks whose content is most relevant to the query, thereby ensuring that the information retrieved is pertinent and comprehensive. This step is pivotal in narrowing down the vast amount of available information to the most relevant chunks for answer generation.
Generation. In this phase, a large language model (LLM) processes the query enriched with retrieved context to generate the final answer. The system first formats retrieved chunks into structured prompts, which are combined with the original query. The LLM synthesizes this information to construct a coherent and informative response, leveraging its ability to understand context and generate natural language answers.
Evaluation. The final phase of the system involves evaluating the quality of the generated answers. We employ both ground-truth-dependent and independent metrics. Ground-truth-dependent metrics require a set of pre-defined correct answers against which the system’s outputs are compared, allowing for the assessment of correctness. In contrast, ground-truth-independent metrics evaluate the responses based on the answer’s relevance to the question and are independent of a predefined answer set. This dual evaluation approach enables a comprehensive assessment of the system’s performance, providing insights into both its correctness in relation to known answers and the overall quality of its generated text. In addition, the system can receive human evaluation of question–answer pairs as input and use it to evaluate the reliability of metrics and correspondence to expectations.
3.3. Datasets for Information Retrieval and Question Answering
We utilize a diverse set of datasets to evaluate models across different languages, domains, and task types. This diversity enables us to assess the models’ generalization capabilities and domain adaptability. Table 1 provides an overview of the key datasets used in this study, and Figure 3 illustrates their distribution.

Table 1.
Overview of datasets used for evaluating IR and QA performance. RC = Reading comprehension.
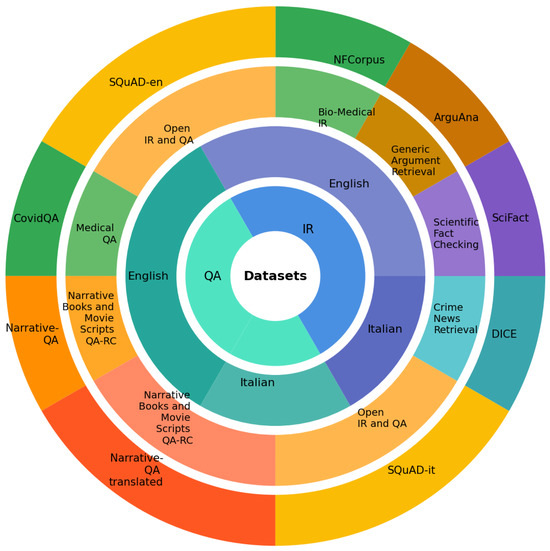
Figure 3.
Distribution of datasets across different tasks and languages. The circular visualization shows the hierarchical organization of datasets used in the study, including IR and QA tasks in both English and Italian.
Below, we provide detailed descriptions of each dataset, including their specific characteristics and how they are used in our study:
3.3.1. SQuAD-en
SQuAD (Stanford Question Answering Dataset) (SQuAD Explorer https://github.com/rajpurkar/SQuAD-explorer, accessed on 15 March 2025, https://rajpurkar.github.io/SQuAD-explorer/, accessed on 15 March 2025) is a benchmark dataset focused on reading comprehension for question answering and Passage Retrieval tasks. The initial release, SQuAD 1.1 [43], comprises over 100K question–answer pairs about passages from 536 articles. These pairs were created through crowdsourcing, with each query linked to both its answer and the source passage. A subsequent release, SQuAD 2.0 [44], introduced an additional 50K unanswerable questions designed to evaluate systems’ ability to identify when no answer exists in the given passage. SQuAD Open was developed for passage retrieval based on SQuAD 1.1 [45,46]. This variant uses the original crowdsourced questions but enables open-domain search across the Wikipedia content dump. Each SQuAD entry contains four key elements:
- (i)
- id: Unique entry identifier.
- (ii)
- title: Wikipedia article title.
- (iii)
- context: Source passage containing the answer.
- (iv)
- answers: Gold-standard answers with context position indices.
Our study used SQuAD 1.1 for both IR and QA tasks. Due to resource constraints, 150 tuples (1.5%) were selected from the validation set of 10.6k entries. We employed random sampling with a fixed seed of 433 for reproducibility to select the samples. We ensured these selections matched the corresponding SQuAD-it samples to enable direct cross-lingual comparison.
The choice of SQuAD-en as our reference dataset is motivated by three key factors: (1) its widespread adoption in the NLP community as a standard benchmark for evaluating text comprehension and question answering capabilities, (2) the availability of a high-quality Italian translation (SQuAD-it), enabling direct cross-lingual comparison, and (3) its diverse coverage of knowledge domains and question types.
We acknowledge, however, that SQuAD has several limitations, including over-representation of encyclopedic texts from Wikipedia and limited inferential complexity, which may influence the generalizability of results to more specialized domains. To mitigate these limitations, we complement our analysis with domain-specific datasets like SciFact, ArguAna, and NFCorpus.
For IR, we processed the documents by splitting them into paragraphs and generating embeddings for each paragraph. We used the same splits for QA to evaluate our RAG pipeline’s ability to generate answers.
3.3.2. SQuAD-it
The SQuAD 1.1 dataset has been translated into several languages, including Italian and Spanish. SQuAD-it (SQuAD-it https://github.com/crux82/squad-it, accessed on 15 March 2025, http://sag.art.uniroma2.it/demo-software/squadit/, accessed on 15 March 2025) [47], the Italian version of SQuAD 1.1, contains over 60K question–answer pairs translated from the original English dataset. For our evaluation of both Italian IR and QA capabilities, we selected 150 tuples from the test set of 7.6k entries (1.9% of the test set), using random seed 433 to ensure reproducibility while working with limited resources. These samples directly correspond to the selected English SQuAD tuples, enabling parallel evaluation across languages. As with the English version, we processed the documents for IR by splitting them into paragraphs and generating embeddings for each segment, and used the same splits for QA evaluation.
3.3.3. DICE
Dataset of Italian Crime Event news (DICE) (DICE https://github.com/federicarollo/Italian-Crime-News, accessed on 15 March 2025) [48] is a specialized corpus for Italian NLP tasks, containing 10.3k online crime news articles from Gazzetta di Modena. The dataset includes automatically annotated information for each article. Each entry contains the following key fields:
- (i)
- id: Unique document identifier.
- (ii)
- url: Article URL.
- (iii)
- title: Article title.
- (iv)
- subtitle: Article subtitle.
- (v)
- publication date: Article publication date.
- (vi)
- event date: Date of the reported crime event.
- (vii)
- newspaper: Source newspaper name.
We used DICE to evaluate IR performance in the specific domain of Italian crime news. In our experimental setting, we used the complete dataset (10.3k articles), with article titles serving as queries and their corresponding full texts as the retrieval corpus. The task involves retrieving the complete article text given its title, creating a one-to-one correspondence between queries and passages.
3.3.4. SciFact
SciFact (Available in BEIR datasets: https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/, accessed on 15 March 2025) [49] is a dataset designed for scientific fact-checking, containing 1.4K expert-written scientific claims paired with evidence from research abstracts. In the retrieval task, claims serve as queries to find supporting evidence from the scientific literature. The complete dataset contains 5183 research abstracts, with multiple abstracts potentially providing supporting evidence for each claim. For our evaluation, we used the BEIR version (beir-2.0.0) (SciFact https://huggingface.co/datasets/BeIR/scifact, accessed on 15 March 2025) of the dataset, which preserves all passages from the original collection. We specifically used 300 queries from the original test set. Each corpus entry contains the following:
- (i)
- id: Unique text identifier.
- (ii)
- title: Scientific article title.
- (iii)
- text: Article abstract.
3.3.5. ArguAna
ArguAna (ArguAna http://argumentation.bplaced.net/arguana/data, accessed on 15 March 2025) [50] is a dataset of argument–counterargument pairs collected from the online debate platform iDebate (Idebate FKA idebate.org https://idebate.net/, accessed on 15 March 2025). The corpus contains 8674 passages, comprising 4299 arguments and 4375 counterarguments. The dataset is designed to evaluate retrieval systems’ ability to find relevant counterarguments for given arguments. The evaluation set consists of 1406 arguments serving as queries, each paired with a corresponding counterargument. The dataset is accessible through the BEIR datasets loader (BEIR datasets https://github.com/beir-cellar/beir/tree/main/beir/datasets, accessed on 15 March 2025). Each corpus entry contains the following:
- (i)
- id: Unique argument identifier.
- (ii)
- title: Argument title.
- (iii)
- text: Argument content.
3.3.6. NFCorpus
NFCorpus [51] is a dataset designed to evaluate the retrieval of scientific nutrition information from PubMed. The dataset comprises 3244 natural language queries in non-technical English, collected from NutritionFacts.org (NutritionFacts website https://nutritionfacts.org/, accessed on 15 March 2025). These queries are paired with 169,756 automatically generated relevance judgments across 9964 medical documents. For our evaluation, we used the BEIR version of the dataset, containing 3633 passages and 323 queries selected from the original set. The dataset allows multiple relevant passages per query. Each corpus entry contains the following:
- (i)
- id: Unique document identifier.
- (ii)
- title: Document title.
- (iii)
- text: Document content.
3.3.7. CovidQA
CovidQA (CovidQA https://huggingface.co/datasets/castorini/covid_qa_castorini, accessed on 15 March 2025) [52] is a manually curated question answering dataset focused on COVID-19 research, built from Kaggle’s COVID-19 Open Research Dataset Challenge (CORD-19) (CORD-19 https://www.kaggle.com/datasets/allen-institute-for-ai/CORD-19-research-challenge, accessed on 15 March 2025) [53]. Although too small for training purposes, the dataset is valuable for evaluating models’ zero-shot capabilities in the COVID-19 domain. The dataset contains 124 question–answer pairs referring to 27 questions across 85 unique research articles. Each query includes the following:
- (i)
- category: Semantic category.
- (ii)
- subcategory: Specific subcategory.
- (iii)
- query: Keyword-based query.
- (iv)
- question: Natural language question form.
Each answer entry contains the following:
- (i)
- id: Answer identifier.
- (ii)
- title: Source document title.
- (iii)
- answer: Answer text.
In our evaluation, we used the complete CovidQA dataset to assess domain-specific QA capabilities. For each query, which is associated with a set of potentially relevant paper titles, our system retrieves chunks of 512 tokens from the vector store and generates answers. Since multiple answers are generated for a query (one for each title), we compute the mean value of evaluation metrics per query. Due to slight variations in paper titles between CovidQA and CORD-19, we matched documents using Jaccard similarity with a 0.7 threshold.
3.3.8. NarrativeQA
NarrativeQA (NarrativeQA https://huggingface.co/datasets/deepmind/narrativeqa, accessed on 15 March 2025) [54] is an English dataset for question answering over long narrative texts, including books and movie scripts. The dataset spans diverse genres and styles, testing models’ ability to comprehend and respond to complex queries about extended narratives. The NarrativeQA training set contains 1102 documents divided into 548 books and 552 movie scripts; it also contains over 32k question–answer pairs. The test set contains 355 documents divided into 177 books and 178 movie scripts; it also contains over 10k question–answer pairs. Each entry contains the following:
- (i)
- document: Source book or movie script.
- (ii)
- question: Query to be answered.
- (iii)
- answers: List of valid answers.
For our evaluation, we used a balanced subsample of the test set (1%, 100 pairs total), consisting of 50 questions from books (covering 41 unique books) and 50 questions from movie scripts (covering 42 unique scripts). This sampling strategy, using random seed 42 for reproducibility, was chosen to manage OpenAI API costs while maintaining balanced representation across both narrative types. We processed documents using 512-token chunks, retrieving relevant segments from the source document for each query.
3.3.9. NarrativeQA-Cross-Lingual
To evaluate cross-lingual capabilities, we created an Italian version of the NarrativeQA test set by maintaining the original English documents but translating the question–answer pairs into Italian. This approach allows us to assess how well LLMs can bridge the language gap between source documents and queries.
3.4. Models
3.4.1. Models Used for Information Retrieval
We evaluated a diverse set of embedding models, focusing on their performance in both English and Italian. All models were used with their default pre-trained weights without any additional fine-tuning. Table 2 provides an overview of these models.
Table 2.
Embedding model configurations.
Rationale: This selection covers both language-specific and multilingual models, enabling us to assess cross-lingual performance and the effectiveness of specialized vs. general-purpose embeddings.
3.4.2. Large Language Models for Question Answering
For QA tasks, we focus on retrieval-augmented generation (RAG) pipelines, which integrate dense retrieval with LLMs for answer generation. For the retrieval component of our RAG pipeline, we selected the Cohere embed-multilingual-v3.0 model based on its superior performance in our IR experiments. This model achieved the highest consistent scores across both English (0.90) and Italian (0.86) tasks, making it ideal for cross-lingual retrieval applications. We configured it to retrieve the top 10 passages for each query, balancing comprehensive context capture with computational efficiency. We tested different LLMs for answer generation and compared a widely used commercial API model with open-source alternatives. Table 3 provides an overview of the LLMs used in our study.
Table 3.
Large language model configurations. Because the chosen QA task requires a short answer, we set the response max tokens to 100.
Rationale: In selecting our experimental model portfolio, we deliberately incorporated a range of model sizes and architectures that span the performance-efficiency spectrum, allowing us to comprehensively assess their impact on QA performance. GPT-4o serves as our high-performance benchmark with multimodal capabilities. Llama 3.1 8B balances strong performance with open-weight flexibility for fine-tuning. Mistral-Nemo was chosen for its instruction-following reliability and reasonable computational demands. Gemma 2B represents the ultra-efficient end of the spectrum, enabling deployment in resource-constrained environments. This strategic selection enables us to quantify the precise trade-offs among model size, computational requirements, and task performance across diverse applications, thereby revealing optimal deployment strategies that minimize resource utilization without sacrificing essential capabilities.
3.5. Evaluation Metrics
We employed a comprehensive set of evaluation metrics to assess both IR and QA performance. For IR tasks, we focused primarily on NDCG, while for QA tasks, we utilized a combination of reference-based (e.g., BERTScore and ROUGE) and reference-free metrics (e.g., answer relevance and groundedness). This diverse set of metrics enables a multifaceted evaluation, capturing different aspects of model performance. To facilitate comparison across these diverse evaluation dimensions, Table 4 presents a comprehensive overview of all metrics utilized in this study. This structured presentation categorizes each metric according to its application domain (IR or QA) and methodological approach (syntactic or semantic), and it provides essential information regarding formulation, range, advantages, and limitations.
Table 4.
Comprehensive evaluation metrics.
As shown in Table 4, our evaluation framework incorporates both traditional metrics (e.g., NDCG@k, Precision@k) and innovative approaches (e.g., LLM-based assessments). This integration enables a more nuanced understanding of model performance, allowing us to assess not only retrieval effectiveness but also semantic accuracy and factual reliability. The combination of syntactic and semantic metrics provides complementary perspectives on model quality, while the inclusion of both reference-based and reference-free metrics addresses the limitations inherent in any single evaluation approach.
3.5.1. IR Evaluation Metric
For IR tasks, we employed several standard evaluation metrics, with NDCG@10 serving as our primary performance indicator.
- Normalized Discounted Cumulative Gain (NDCG@k) [36]:
- Definition: A ranking quality metric comparing rankings to an ideal order, where the relevant items are at the top.
- Formula: , where is the Discounted Cumulative Gain at k, and is the Ideal at k, with k as a chosen cutoff point. measures the total item relevance in a list with a discount that helps address the diminishing value of items further down the list.
- Range: Values from 0 to 1, where 1 indicates a perfect match with the ideal order.
- Use: Primary metric for evaluating ranking quality, with k typically set to 10. is used for experimental evaluation in different IR works such as [58,59].
- Rationale: NDCG is chosen as our sole IR metric because it effectively captures the quality of ranking, considering both the relevance and position of retrieved items. It is particularly useful for evaluating systems where the order of the results matters, making it well-suited for assessing the performance of our embedding models in retrieval tasks.
- Implementation: Available in PyTorch, TensorFlow, and the BEIR framework.
Additionally, we employ the following complementary metrics to provide a more comprehensive assessment:
- Mean Average Precision (MAP@k) [36]:
- Definition: A retrieval quality metric that measures both the relevance of items and the system’s ability to rank the most relevant items higher.
- Formula: , where is the Average Precision at k (a chosen cutoff point) for query q, calculated as an average of Precision values at all relevant positions within k, and is the total number of queries.
- Range: Values from 0 to 1, where 1 indicates perfect retrieval and ranking.
- Use: Common metric for evaluating retrieval systems, with k typically set based on application needs. is used for experimental evaluation in different IR works such as [60,61].
- Rationale: MAP is valuable because it provides a single score that summarizes precision at various recall levels, emphasizing the importance of retrieving relevant items early in the result list. It effectively captures both precision and recall aspects of retrieval quality.
- Limitations: There is no relevance value, so a document needs to be relevant or irrelevant.
- Implementation: Available in PyTorch, TensorFlow, and the BEIR framework.
- Recall@k [36]:
- Definition: A retrieval completeness metric for measuring the proportion of relevant documents successfully retrieved within the top k results.
- Formula: , where is the number of true positives (relevant documents) in the top k results, and is the number of false negatives (relevant documents not retrieved in the top k).
- Range: Values from 0 to 1, where 1 indicates all relevant documents have been retrieved.
- Use: Essential metric for evaluating retrieval completeness, particularly in applications requiring comprehensive coverage. is used for experimental evaluation in different IR works such as [58,62].
- Rationale: Recall@k is valuable for assessing a system’s ability to find all relevant information, highlighting the model’s true positive recognition capability. It provides insight into how thoroughly a system captures the full set of relevant documents, making it particularly important in legal, medical, or research contexts, where missing relevant information could have significant consequences.
- Limitations: Recall@k does not consider the ranking order of retrieved documents within the top k results. The metric is undefined when there are no relevant documents in the test set (the denominator becomes zero). Although it effectively measures completeness, it provides only a partial view of system performance and is often insufficient when used alone, as it does not account for precision or ranking quality.
- Implementation: Available in Scikit-learn, PyTorch, TensorFlow, and the BEIR framework.
- Precision@k [36]:
- Definition: A retrieval accuracy metric for measuring the proportion of retrieved documents in the top k results that are relevant.
- Formula: , where is the number of true positives (relevant documents) in the top k results, and is the number of false positives (non-relevant documents) in the top k results.
- Range: Values from 0 to 1, where 1 indicates all retrieved documents are relevant.
- Use: Essential metric for evaluating retrieval accuracy, particularly in applications where result quality is critical. is used for experimental evaluation in different IR works such as [60,63].
- Rationale: Precision@k is valuable for assessing a system’s ability to return accurate results, highlighting the model’s false positive rate. It indicates the probability that a retrieved document is truly relevant, making it particularly important in contexts where delivering relevant information is more critical than finding all relevant documents.
- Limitations: Precision@k does not consider the ranking order within the top k results. When there are no relevant documents in the test collection, the metric becomes problematic: if no documents are returned, the denominator becomes zero, and the metric is undefined; if only non-relevant documents are returned, precision is zero. The metric focuses solely on false positive generation rate, providing only a partial view of system performance.
- Implementation: Available in Scikit-learn, PyTorch, TensorFlow, and the BEIR framework.
3.5.2. QA Evaluation Metrics
For QA tasks, we employed both reference-based and reference-free metrics. Reference-based metrics use provided gold answers and may focus on either word overlap or semantic similarity. Reference-free metrics do not require gold answers; instead, they use LLMs to evaluate candidate answers along different dimensions.
- Reference-based metrics:
- BERTScore [39]: This measures semantic similarity using contextual embeddings. BERTScore is a language generation evaluation metric based on pre-trained BERT contextual embeddings [8]. It computes the similarity of two sentences as a sum of cosine similarities between their tokens’ embeddings. This metric can handle such cases where two sentences are semantically similar but differ in form. This evaluation method has been used in many papers, like [64,65]. This metric is often used in question answering, summarization, and translation. It can be implemented using different libraries, including TensorFlow and HuggingFace.
- BEM (BERT-based Evaluation Metric) [66]: This uses a fine-tuned BERT trained to assess answer equivalence. This model receives a question, a candidate answer, and a reference answer as input and returns a score quantifying the similarity between the candidate and the reference answers. This evaluation method is used in some recent papers like [67,68]. This metric can be implemented using TensorFlow. The model trained to perform the answer equivalence task is available on the TensorFlow hub.
- ROUGE [38]: This evaluates n-gram overlap between generated and reference answers. ROUGE (Recall-Oriented Understudy for Gisting Evaluation) evaluates the overlap of n-grams between generated and reference answers. In detail, it is a set of different metrics (ROUGE-1, ROUGE-2, and ROUGE-L) used to evaluate text summarization and machine comprehension systems:
- ROUGE-N: This is defined as an n-gram recall between a predicted text and a ground truth text: , where is the maximum number of n-grams of size n co-occurring in a candidate text and the ground truth text. The denominator is the total sum of the number of n-grams occurring in the ground truth text.
- ROUGE-L: This calculates an F-measure using the Longest Common Subsequence (LCS); the idea is that the longer the LCS of two texts is, the more similar the two summaries are. Given two texts, the ground truth X of length m and the prediction Y of length n, the formal definition is where and .
ROUGE metrics are very popular in Natural Language Processing-specific tasks involving text generation like summarization and question answering [69]. The advantage of ROUGE is that it allows us to estimate the quality of a generative model’s output in common NLP tasks without dependencies on language. The main disadvantages are that it does not consider words to be semantic and is sensitive to word choice and sentence structure. Rouge metrics are implemented in PyTorch, TensorFlow, and Huggingface. - F1 Score: The harmonic mean of precision and recall of word overlap. The F1 score is defined as the harmonic mean of precision and recall of word overlap between generated and reference answers. . This score summarizes the information on both aspects of a classification problem, focusing on precision and recall. F1 score is a very popular metric to evaluate the performance of Artificial Intelligence and Machine Learning systems on classification tasks [70]. In question answering, two popular benchmark datasets that use F1 as one of the metrics for evaluation are SQuAD [43] and TriviaQA [71]. The advantages of the F1 score are the following:
- It can handle unbalanced classes well.
- It captures and summarizes both the aspects of Precision and Recall in a single metric.
The main disadvantage is that, if left alone, the F1 score can be harder to interpret. The F1 score could be used in both Information Extraction and question answering settings. The F1 score is implemented in all the popular libraries of machine/deep learning and Data Analysis, such as Scikit-learn, PyTorch, and TensorFlow.
- Reference-free metrics:
Additionally, we analyzed reference-free LLM-based metrics: context relevance, groundedness, and answer relevance. These metrics are implemented using TruLens, which utilizes the GPT-3.5-turbo model. We implemented all metrics using standard libraries and custom scripts, ensuring a comprehensive evaluation of our models across various IR and QA performance aspects. The combination of traditional IR metrics, reference-based QA metrics, and novel reference-free metrics provides a holistic view of model capabilities, allowing for nuanced comparisons across different approaches and datasets. LLM-based metrics are relatively recent developments, referenced in several contemporary papers such as [11]. Retrieval Augmented Generation Assessment (RAGA), an evaluation framework introduced in [40], employs large language models to evaluate RAG pipelines. These metrics are implemented in ARES (ARES https://github.com/stanford-futuredata/ARES, accessed on 15 March 2025) [42] and in a library called TruLens. We used TruLens with GPT-3.5-turbo in this paper.
- Context relevance: Evaluates retrieved context relevance to the question. It assesses whether the passage returned is relevant for answering the given query. Therefore, this measure is useful for evaluating IR after obtaining the answer.
- Groundedness or faithfulness: Assesses the degree to which the generated answer is supported by retrieved documents obtained in a RAG pipeline. Therefore, it measures if the generated answer is faithful to the retrieved passage or if it contains hallucinated or extrapolated statements beyond the passage.
- Answer relevance: Measures the relevance of the generated answer to the query and retrieved passage.
- Metric Classification:
We can classify all the previous metrics into two categories based on their capabilities to evaluate the answer to exploit pure syntactic or also semantic aspects:
- Syntactic metrics evaluate formal response aspects, including BLEU [72], ROUGE [38], precision, recall, F1, and Exact Match [43]. These focus on text properties rather than semantic meaning. These metrics are generally considered less indicative of the semantic value of the generated responses. This is due to their focus on the text’s formal properties rather than its content or inherent meaning.
- Semantic metrics evaluate response meaning, including BERTScore [39] and BEM score [66]. The BEM score is preferred to BERTScore for its correlation with human evaluations, as reported in the original study we refer to, and because we empirically found that BERTScore tends to take values in a very short subset of values in the range. The LLM-based metrics also belong to this group.
- Manual Evaluation:
We conducted manual evaluations using a 5-point Likert scale. This method, while less commonly used due to its high costs in terms of both money and time and the substantial expert human effort required, serves as an important validation tool. We employed manual evaluation primarily to verify the reliability of our automated evaluation metrics. Three independent human annotators with relevant expertise evaluated the generated answers. The annotators were selected based on the following criteria: (1) holding at least an M.Sc. degree, (2) professional experience in NLP evaluation (minimum 3 years of experience), (3) native or C2-level proficiency in both English and Italian to ensure accurate cross-lingual assessment, and (4) domain familiarity with the subject areas covered in our datasets. Before evaluation, the annotators participated in a training session and received detailed guidelines with example assessments across the evaluation spectrum. For each evaluation session, the annotators were presented with the original question, the RAG system’s generated answer, and the ground truth from the dataset or customer answers. The annotators used a 5-point Likert scale to assess the quality of the generated answer in relation to the posed question, considering relevance, accuracy, and coherence. The criteria for scoring were as follows:
- Very Poor: The generated answer is totally incorrect or irrelevant to the question. This case indicates a failure of the system to comprehend the query or retrieve pertinent information.
- Poor: The generated answer is predominantly incorrect but with glimpses of relevance, suggesting some level of understanding or appropriate retrieval.
- Neither: The generated answer mixes relevant and irrelevant information almost equally, showcasing the system’s partial success in addressing the query.
- Good: The generated answer is largely correct but includes minor inaccuracies or irrelevant details, demonstrating a strong understanding and response to the question.
- Very Good: Reserved for completely correct and fully relevant answers, reflecting an ideal outcome where the system accurately understood and responded to the query.
We acknowledge that manual evaluation using Likert scales has inherent limitations, including potential subjectivity and inconsistency among annotators. To mitigate these challenges, we implemented several methodological safeguards: (1) standardized training for all evaluators with calibrated examples for each level of the Likert scale, (2) detailed evaluation guidelines with specific criteria for each rating point, (3) randomized presentation of responses without model identification to prevent bias, and (4) consensus discussions to reconcile divergent ratings.
This structured process helped mitigate individual biases while preserving the diverse viewpoints essential for comprehensive evaluation. While these measures cannot eliminate subjectivity entirely, they establish reasonable confidence in the reliability of our manual assessments and provide important validation for our system’s automated evaluation metrics.
- Inter-metric Correlation:
We used Spearman Rank Correlation [73] to assess automated metric reliability against human evaluation. This non-parametric measure evaluates the statistical dependence between the rankings of two variables through a monotonic function. Computed on ranked data, it enables the analysis of ordinal and continuous variables. The correlation coefficient () ranges from to 1, where 1 indicates a perfect positive correlation, 0 indicates no correlation, and indicates a perfect negative correlation.
3.6. Experimental Design
Our experimental methodology aims to comprehensively evaluate embedding models and LLMs across multiple dimensions of IR and QA tasks. We structure our investigation around two complementary areas: (i) Information Retrieval performance, which evaluates embedding models across various domains and languages, and (ii) question answering capabilities, which assesses LLM performance in RAG pipelines.
In the IR domain, we first evaluated embedding model performance across different domains, using datasets that span from general knowledge (SQuAD) to specialized scientific and medical content (SciFact, ArguAna, and NFCorpus). We complement this with cross-language evaluation using Italian datasets (SQuAD-it and DICE) to assess how both language-specific and multilingual models perform in non-English contexts. To evaluate cross-lingual capabilities, we tested multilingual models (e.g., E5, BGE) on both English and Italian datasets without fine-tuning and compared their performance against monolingual models (BERTino for Italian). Additionally, we analyzed the impact of retrieval size by varying the number of retrieved documents (), with particular attention to recall metrics.
Our evaluation encompasses several dimensions for QA tasks. We assessed LLM performance using both reference-based metrics (ROUGE-L, F1, BERTScore, and BEM) and reference-free metrics (answer relevance, context relevance, and groundedness). We specifically tested system capabilities in general domains using SQuAD for both English and Italian languages, in specialized domains using CovidQA for medical knowledge, and in narrative domains using NarrativeQA for narrative understanding. The cross-lingual aspect was explored using NarrativeQA with English documents and Italian queries, allowing us to measure the effectiveness of language transfer in QA contexts.
Across both IR and QA domains, we examined the relationship between model size and performance to understand scaling effects. Additionally, we conducted manual assessments of system outputs to validate automated metrics and gain insights into real-world effectiveness.
3.6.1. Hardware and Software Specifications
We conducted our experiments using the Google Colab platform (Google Colab https://colab.google/, accessed on 15 March 2025). Our implementation used Python (evaluate 0.4.3) with the following key components: (i) Langchain framework for RAG pipeline implementation, (ii) Milvus vector store for efficient similarity search, (iii) HuggingFace endpoints, OpenAI and Cohere APIs for embedding models, and (iv) OpenAI and HuggingFace endpoints for large language models.
3.6.2. Experimental Procedure
To ensure systematic evaluation, we implemented the experiments following a structured procedure:
- Data preparation: We processed and indexed all documents using each embedding model.
- Processing: We implemented specific processing workflows for both IR and QA tasks.
- Evaluation: We applied our comprehensive set of evaluation metrics.
We detail below the procedures for IR and QA.
- IR Pipeline.
For IR activities, we followed this procedure:
- Data preparation:
- (a)
- Indexed all documents in the corpus using each embedding model.
- (b)
- For documents exceeding the maximum token limit, we considered single-chunk truncation, following BEIR settings.
- Processing:
- Query Processing: Encoded each query using the corresponding embedding model.
- Retrieval:
- (a)
- Used Milvus for efficient similarity search.
- (b)
- Retrieved top-k documents for each query (), with extensive experiments reported for .
- Evaluation:
- (a)
- Computed nDCG@10, MAP@10, Recall@10, and Precision@10 for each model on each dataset, focusing on nDCG@10 as the primary metric.
- (b)
- Used existing relevance judgments where available; for datasets without explicit judgments (e.g., DICE), we considered documents relevant if matching the ground truth.
- QA Pipeline.
For QA tasks, we employed the following protocol:
- Data preparation:
- (a)
- Indexed documents using Cohere embed-multilingual-v3.0 (best-performing IR model based on nDCG@10).
- (b)
- Split documents into passages of 512 tokens without sliding windows, balancing semantic integrity with information relevance.
- Processing:
- Query processing: Encoded each query using the corresponding embedding model.
- Retrieval stage: Used Cohere embed-multilingual-v3.0 to retrieve the top-10 passages.
- Answer generation:
- (a)
- Constructed bilingual prompts, combining questions and retrieved passages.
- (b)
- Applied consistent prompt templates across all models and datasets as shown in Table 5.
Table 5. Standardized prompts used for English and Italian QA tasks.
- (c)
- Generated answers using each LLM.
During generation, we employed the prompt structure shown in Table 5 for both English and Italian tasks. This prompt structure provides explicit instructions and context to the language model while encouraging concise and truthful answers without fabrication.
- Evaluation:
- (a)
- Computed reference-based metrics (BERTScore, BEM, ROUGE, BLEU, EM, F1) using generated answers and ground truth.
- (b)
- Used GPT-3.5-turbo to compute reference-free metrics (answer relevance, groundedness, context relevance) through prompted evaluation.
3.6.3. Reproducibility Measures
We implemented comprehensive measures to ensure experimental reproducibility:
- Randomization control: Fixed random seeds for all processes requiring randomization.
- Sampling strategy:
- −
- Used standard dataset splits where available.
- −
- Selected statistically valid representative subsets when working with large datasets:
- ∗
- A total of 150 tuples from the SQuAD-en validation set (1.5% of dev set).
- ∗
- A total of 150 tuples from the SQuAD-it test set, enabling direct cross-lingual comparison (1.9% of test set).
- ∗
- A total of 100 balanced tuples from NarrativeQA (50 books, 50 movie scripts).
- Model configuration:
- −
- Used default pre-trained weights without fine-tuning for all models.
- −
- Maintained consistent parameters across experiments (e.g., 512-token chunk size).
- Implementation environment:
- −
- Google Colab platform.
- −
- Python with Langchain framework.
- −
- Milvus vector store.
- −
- Standardized evaluation protocols and thresholds.
All configurations, datasets (including NarrativeQA-translated), and detailed protocols are available in our public repository: https://staff.icar.cnr.it/oro/resources/multilingual-ir-qa/.
3.7. Ethical Considerations and Limitations
3.7.1. Ethical Considerations
In conducting our experiments, we prioritized responsible research practices:
- Data ethics: Ensured strict compliance with dataset licenses and usage agreements while maintaining transparency of data sources and processing methods.
- Model usage: Adhered to API providers’ usage policies and rate limits, particularly for commercial models like GPT-4o.
- Transparency: Thoroughly documented model limitations and potential output biases to ensure transparent reporting of system capabilities and constraints.
- Resource efficiency: Designed experiments to minimize computational resource usage while maintaining statistical validity.
This commitment to ethical research practices forms the foundation of our work, supporting both reproducibility and responsible advancement of multilingual language technologies.
3.7.2. Limitations and Potential Biases
Although our methodology implements a comprehensive evaluation framework, several important limitations should be considered when interpreting our results:
- Dataset coverage limitations: Our dataset selection, though diverse, represents only a fraction of potential real-world scenarios across languages and domains. While our datasets span general knowledge (SQuAD), scientific content (SciFact), and specialized domains (NFCorpus), they cannot capture the full spectrum of linguistic variations and domain-specific applications.
- Model accessibility constraints: Access limitations to proprietary models and computational constraints prevented exhaustive experimentation with all available models. This particularly affects comparisons involving commercial models with limited architectural details transparency.
- Evaluation metric limitations: Current evaluation metrics, while diverse, may not capture all nuanced aspects of model performance, particularly for complex tasks requiring sophisticated reasoning. The challenge of quantifying dimensions like answer relevance and factual accuracy remains an active research area.
- Cross-lingual analysis constraints: Our cross-lingual analysis, while valuable, is limited to the English–Italian language pair. This specific focus means our findings may not generalize to language pairs with greater linguistic distance or to languages with significantly different morphological characteristics.
- Resource and sampling constraints: Practical resource constraints necessitated using dataset subsets rather than complete datasets. We ensured statistical validity through careful sampling strategies (fixed random seeds, balanced representation). Our consistent findings across multiple metrics suggest the patterns observed likely represent broader trends.
- Temporal considerations: Our results represent a snapshot of model capabilities at a specific point in time. Given the rapid evolution of NLP technology, future developments may shift the relative performance characteristics we observed, particularly as new models and architectures emerge.
To address these constraints, we have carried out the following: (i) maintained complete transparency in our experimental setup, (ii) documented all assumptions and methodological choices, (iii) employed diverse evaluation metrics where possible, and (iv) provided detailed documentation of our implementation choices. Despite these limitations, our comprehensive analysis provides valuable insights into multilingual IR and QA system performance while highlighting avenues for future research, including expanded language coverage, more diverse domain representation, and more nuanced evaluation frameworks.
4. Results
Our investigation into the capabilities of embedding techniques and large language models (LLMs) reveals a complex landscape of performance patterns across Information Retrieval (IR) and question answering (QA) tasks. Through systematic evaluation, we have uncovered several intriguing findings that challenge common assumptions about multilingual model performance.
4.1. Information Retrieval Performance
The effectiveness of embedding models proves to be highly nuanced, with performance varying significantly across languages and domains. Our zero-shot evaluation reveals that while models generally maintain strong performance across languages, the degree of success depends heavily on the specific task and domain context.
Although we report nDCG@10 for all models and datasets as our primary comparison metric (Table 6), we present a comprehensive multi-metric evaluation for representative English and Italian datasets in Table 7.
Table 6.
nDCG@10 scores for English and Italian, as well as different domain datasets.
Table 7.
Comprehensive evaluation with multiple IR metrics for SQuAD-en (English) and SQuAD-it (Italian).
As shown in Table 6, the multilingual models demonstrate remarkable consistency across tasks. The embed-multilingual-v3.0 model achieves particularly noteworthy results, maintaining strong performance not only in general tasks (nDCG@10 scores of 0.90 and 0.86 for English and Italian SQuAD, respectively) but also in specialized domains like DICE (0.72). This robust cross-domain performance suggests that recent architectural advances are successfully addressing the historical challenges of multilingual modeling. Interestingly, the comparison between the base and large model variants suggests that architectural design choices may have more impact than model size alone, as larger models do not consistently outperform their smaller counterparts.
The multi-metric evaluation presented in Table 7 provides additional validation of our findings. For instance, multilingual-e5-large shows consistently strong performance not only in nDCG@10 (0.91) but also in MAP (0.88), R@10 (1.00), and P@10 (0.10) for SQuAD-en. Similarly, embed-multilingual-v3.0 maintains strong performance across all metrics for both English and Italian benchmarks. These consistent patterns across different evaluation metrics reinforce our conclusions about the relative effectiveness of these embedding models for cross-lingual retrieval tasks. Notably, the results show that model rankings remain largely stable regardless of which metric is used, suggesting that our observations about multilingual models outperforming language-specific alternatives are robust across different evaluation perspectives.
Figure 4 provides a comprehensive visualization of how different models perform across tasks and domains, revealing several key patterns in information retrieval performance. The visualization demonstrates the general superiority of multilingual models, which is particularly evident in their consistently strong performance on SQuAD-type tasks. However, it also illustrates an important performance gradient: although models excel in general-domain tasks, their effectiveness tends to decrease when handling specialized domains. This performance drop in specialized areas suggests a crucial direction for future research and improvements in model development, especially for domain-specific applications.
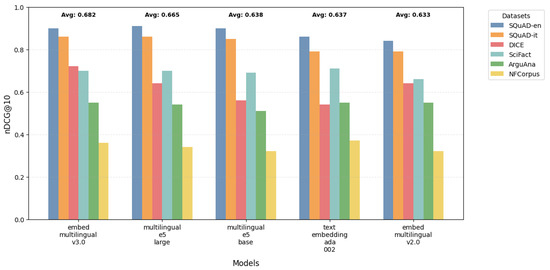
Figure 4.
Comparison of nDCG@10 scores across different embedding models and datasets. The visualization shows the performance of multilingual models on various IR tasks.
4.1.1. Cross Domain Results
The conducted tests on English datasets compared state-of-the-art embedding models across the SQuAD, SciFact, ArguAna, and NFCorpus datasets to evaluate cross-domain effectiveness. Table 6 presents the performance results measured by nDCG@10 across these diverse domains. Key observations from cross-domain evaluation:
- Performance varies significantly by domain, with no single model achieving universal superiority across all tasks.
- Multilingual-e5-large achieves the highest performance on general domain tasks, with an nDCG@10 of 0.91 on SQuAD-en.
- The BGE models demonstrate particular strength in specialized content, achieving top performance on ArguAna (0.64) and SciFact (0.75).
- The GTE and BGE architectures show robust adaptability to scientific and medical domains, maintaining strong performance across SciFact and NFCorpus datasets.
4.1.2. Cross-Language Results
We evaluated cross-lingual capabilities through benchmark tests comparing multilingual and Italian-specific models using two datasets: (i) The Italian translation of SQuAD for general domain assessment, and (ii) the DICE dataset (Italian Crime Event news) for domain-specific evaluation For DICE evaluation, we used news titles as queries to retrieve relevant corpus documents.
Table 6 presents comparative results between multilingual and Italian-specific models.
Key findings from cross-lingual analysis:
- Multilingual models consistently outperform Italian-specific models (e.g., BERTino) across both datasets.
- Multilingual-e5-large achieves top performance on SQuAD-it (nDCG@10: 0.86).
- Embed-multilingual-v3.0 demonstrates exceptional versatility, excelling in both SQuAD-it (0.86) and DICE (0.72).
- The performance gap between multilingual and monolingual models suggests superior domain adaptation capabilities in larger multilingual architectures.
4.1.3. Retrieval Size Impact
We systematically analyzed how retrieval size affects model performance, using multilingual-e5-large on the DICE dataset as our test case. Table 8 and Figure 5 present Recall@k scores across different retrieval sizes (k).
Table 8.
Recall@k for e5-multilingual-large on DICE.
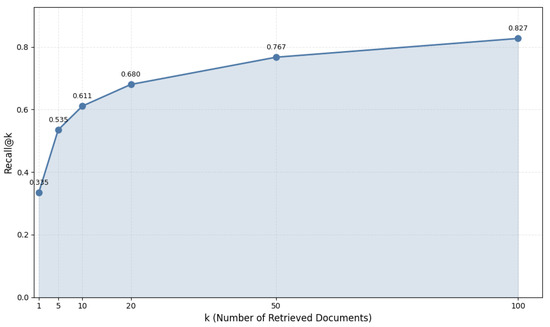
Figure 5.
Evolution of Recall@k in increasing values of k on the DICE dataset. The plot demonstrates how retrieval performance improves with larger k values.
The data reveals three distinct performance phases: (i) Rapid growth (k = 1 to k = 20): Recall more than doubles from 0.335 to 0.680. (ii) Moderate improvement (k = 20 to k = 50): Recall increases by 0.087. (iii) Diminishing returns (k > 50): Marginal improvements decrease significantly.
Figure 5 transforms these data into a clear visual pattern, revealing three distinct phases in recall improvement: a steep initial climb (k = 1 to k = 20), a moderate growth period (k = 20 to k = 50), and a plateau phase (beyond k = 50). This characteristic logarithmic curve illustrates the diminishing returns phenomenon in retrieval system performance, where increasing k continuously improves results but with progressively smaller gains as k increases. The non-linear relationship provides valuable guidance for system designers who must balance higher recall potential against computational costs and response time requirements. This analysis has important practical implications for implementation. Although recall continues to improve up to k = 100, where it reaches 80%, the diminishing returns suggest that smaller retrieval sizes might be more efficient. A promising approach would be to use a moderate initial retrieval size (around k = 50) followed by sophisticated re-ranking techniques on the retrieved passages, optimizing both computational efficiency and retrieval effectiveness.
4.2. Question Answering Performance
4.2.1. Model Performance Across Tasks and Languages
We evaluated different LLMs within a retrieval-augmented generation (RAG) pipeline, utilizing Cohere embed-multilingual-v3.0 for the retrieval phase based on its superior performance in embedding evaluations. Our analysis spans multiple datasets: SQuAD-en, SQuAD-it, CovidQA, and NarrativeQA (books and movie scripts), as well as their translated versions (NarrativeQA-translated). We assessed performance through three complementary perspectives: syntactic accuracy, semantic similarity, and reference-free evaluation.
Table 9, Table 10 and Table 11 present the performance of different LLMs on the various datasets, considering syntactic, semantic, and LLM-based ground truth-free metrics, respectively.
Table 9.
(Syntactic) Results for English and Italian and different domain datasets. ROUGE-L and F1 score.
Table 10.
Results for English and Italian and different domain datasets. BERTscore_f1, and BEM score.
Table 11.
Ground truth-free results for English and Italian and different domain datasets. Answer relevance/context relevance/groundness.
The syntactic evaluation results in Table 9 reveal notable performance variations across models and tasks. Llama 3.1 8b demonstrates superior performance on general question answering tasks (SQuAD-en: 0.72/0.69, SQuAD-it: 0.57/0.54), while Mistral-Nemo shows stronger capabilities in specialized domains (CovidQA: 0.27/0.17, NaQA-B: 0.23/0.21). Figure 6 visualizes the variation in syntactic metric performance across different models and datasets.
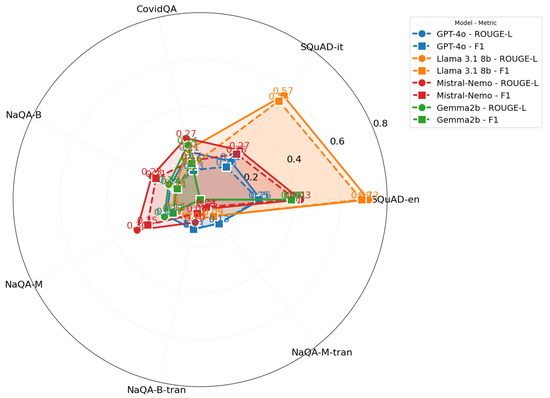
Figure 6.
Syntactic metrics comparison across models and datasets. The radar chart visualizes ROUGE-L and F1 scores for each model, showing the performance patterns across different datasets.
Semantic evaluation results (Table 10) consistently show higher scores compared to syntactic metrics, particularly in BERTScore values. This pattern suggests that models often generate semantically appropriate answers even when they deviate lexically from reference answers. Figure 7 visualizes the variation in semantic metric performance across different models and datasets.
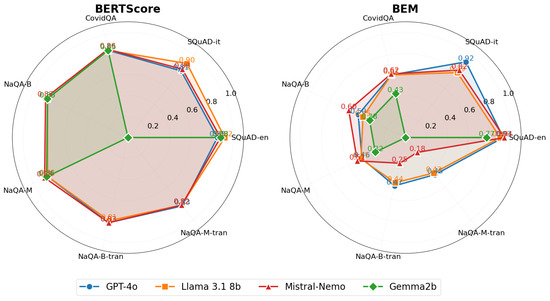
Figure 7.
Semantic metrics comparison across models and datasets. The visualization shows BERTScore and BEM scores, providing insights into the semantic quality of model outputs.
Our reference-free evaluation (Table 11) reveals several key patterns: (i) Models consistently achieve higher scores in answer relevance compared to groundedness. (ii) GPT-4o excels in cross-lingual scenarios, particularly on translated narrative tasks. (iii) Mistral-Nemo demonstrates strong performance across domains while maintaining reasonable groundedness. (iv) Complex narratives pose greater challenges for maintaining factual accuracy. Figure 8 visualizes the variation in LLM-based metrics performance across different models and datasets.

Figure 8.
LLM-based metrics comparison across models and datasets. The radar charts display answer relevance, context relevance, and groundedness scores for each model.
Key findings from our comprehensive evaluation include the following:
- Model specialization: (i) Llama 3.1 8b excels in syntactic accuracy on general domain tasks. (ii) GPT-4o demonstrates superior cross-lingual capabilities. (iii) Mistral-Nemo achieves consistent performance across diverse tasks.
- Performance patterns: (i) BERTScores indicate strong semantic understanding across all models. (ii) Groundedness scores decrease in complex domains. (iii) Semantic metrics consistently outperform syntactic measures.
- Domain effects: (i) Factual domains (CovidQA) show higher groundedness scores. (ii) Narrative domains pose greater challenges for factual accuracy. (iii) Cross-lingual performance remains robust in structured tasks.
4.2.2. Metrics Effectiveness vs. Human Evaluation
Our analysis of human judgment correlation in Table 12 provides valuable insights into metric reliability across different content types. On NarrativeQA books, BEM shows a strong correlation with human judgment (0.735) compared to answer relevance metrics (0.436). This pattern persists for NarrativeQA movies (BEM: 0.704; answer relevance: 0.565).
Table 12.
Spearman correlations on NarrativeQA books and movies subsample.
Although the stronger correlation between BEM scores and human judgments might seem expected given that both rely on reference-based evaluation, the magnitude of this difference offers practical insights. The substantially higher correlation coefficient suggests that reference-based metrics remain significantly more reliable proxies for human assessment than even advanced reference-free alternatives, particularly for evaluating answers to complex questions.
Based on qualitative observations during our annotation process, we noted that human evaluators tended to consider the overall semantic correctness of answers, often being more forgiving of stylistic or phrasing differences when the core information was accurate. In contrast, automated metrics like BEM, despite their strong correlation with human judgment, sometimes penalized responses that were factually correct but expressed in different terms than the reference answers.
These findings have significant implications for system development and evaluation. Although BEM offers a reasonable approximation of human judgment (with correlations >0.7), the remaining gap indicates that human evaluation remains essential for high-stakes applications, particularly in specialized domains where nuanced understanding is critical.
5. Discussion
Our comprehensive evaluation of embedding models and large language models reveals a complex landscape of capabilities and limitations in multilingual information retrieval and question answering. The results demonstrate how these systems perform across different languages and domains, challenging some common assumptions while reinforcing others. The findings offer important insights for both theoretical understanding and practical applications while highlighting critical areas for future development.
5.1. The Domain Specialization Challenge
Our analysis reveals distinct patterns of domain specialization impact across both Information Retrieval and question answering tasks.
Looking at IR performance (Table 6), we observe a clear degradation pattern as tasks become more specialized. The embed-multilingual-v3.0 model demonstrates this trend clearly in English tasks, achieving 0.90 nDCG@10 on the general domain (SQuAD), dropping to 0.70 on scientific literature (SciFact), further declining to 0.55 on argument retrieval (ArguAna), and reaching its lowest performance of 0.36 on medical domain tasks (NFCorpus). See Figure 9 for a visualization of this pattern. Similar patterns are observed across other models, with multilingual-E5-large showing comparable degradation: 0.91 (SQuAD), 0.70 (SciFact), 0.54 (ArguAna), and 0.34 (NFCorpus).
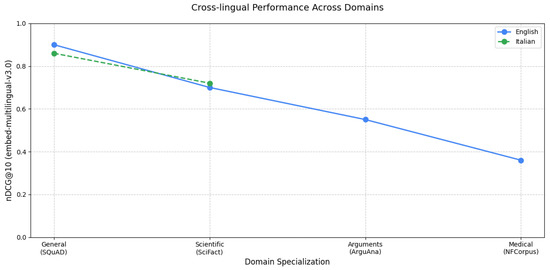
Figure 9.
Cross-domain performance comparison showing nDCG@10 scores for embed-multilingual-v3.0 model across different domains. The plot demonstrates the performance degradation pattern from general to specialized domains in both English (solid line) and Italian (dashed line) tasks.
In Italian IR tasks, while we have fewer domain-specific datasets, the pattern persists, as shown in Table 6 and illustrated in Figure 9. The embed-multilingual-v3.0 model achieves 0.86 nDCG@10 on the general domain (SQuAD-it) and 0.72 on the specialized news domain (DICE). Language-specific models like BERTino show more pronounced degradation, with performance dropping from 0.64 on SQuAD-it to 0.40 on DICE.
For question answering tasks, the domain specialization effect is evident across different evaluation metrics. Looking at syntactic metrics (Table 9), Llama 3.1 8b shows strong general domain performance (ROUGE-L: 0.72/0.69 on SQuAD-en) but drops significantly on specialized medical content (CovidQA: 0.22/0.15). Mistral-Nemo follows a similar pattern, declining from 0.43/0.41 on SQuAD-en to 0.27/0.17 on CovidQA.
Semantic metrics (Table 10) show more stability across domains but still reflect the specialization challenge. The BERTScore results for Llama 3.1 8b decrease from 0.92 in the general domain to 0.85 in the medical domain, and BEM scores show a more pronounced drop from 0.90 to 0.61. This pattern is consistent across models.
The reference-free metrics (Table 11) provide additional insight into domain adaptation challenges. Although answer relevance remains relatively high across domains (ranging from 0.86 to 1.0), groundedness scores show significant degradation when moving from general to specialized domains. For instance, Mistral-Nemo’s groundedness drops from 0.78 on SQuAD to 0.64 on CovidQA, while GPT-4o shows a decline from 0.79 to 0.61.
These results demonstrate a consistent pattern: although models perform well in general domains, their effectiveness decreases substantially as domain specificity increases, regardless of the evaluation metric or language used. This degradation is particularly pronounced in medical and technical domains, suggesting that current approaches face significant challenges in handling specialized knowledge. This gradient reveals fundamental challenges in domain adaptation that persist across all models, regardless of their size or architectural sophistication. This suggests that current pre-training approaches might not sufficiently capture domain-specific nuances across languages.
5.2. Cross-Lingual Performance: A Tale of Two Languages
Our analysis reveals distinct cross-lingual performance patterns across both IR and QA tasks. In Information Retrieval, the results from Table 6 show that multilingual models achieve competitive performance across languages. The embed-multilingual-v3.0 model maintains strong performance with nDCG@10 scores of 0.90 for English and 0.86 for Italian on SQuAD tasks. Similar patterns are seen with multilingual-e5-large, achieving 0.91 and 0.86 for English and Italian, respectively. In contrast, language-specific models like BERTino show limited performance (0.64 on SQuAD-it), suggesting that multilingual architectures have become more effective than language-specific approaches.
In question answering tasks, the cross-lingual performance shows more variation across different metrics. For syntactic measures (Table 9), we see larger gaps between languages: Llama 3.1 8b achieves ROUGE-L scores of 0.72/0.69 for English but drops to 0.57/0.54 for Italian, and Mistral-Nemo shows scores of 0.43/0.41 for English, reducing to 0.27/0.25 for Italian. Semantic evaluation metrics (Table 10) reveal more stable cross-lingual performance. The BERTScore results show closer parity between languages, with scores ranging from 0.85–0.92 for English and 0.81–0.90 for Italian across models. GPT-4o maintains relatively consistent performance (BERTScore: 0.85: English; 0.81: Italian), and Llama 3.1 8b achieves 0.92 for English and 0.90 for Italian. The ground truth-free metrics (Table 11) provide additional insights into cross-lingual capabilities. Answer relevance remains high across languages (0.98–1.0 for both), but groundedness shows interesting variations. Mistral-Nemo achieves comparable groundedness scores in both languages (0.78: English; 0.78: Italian), while GPT-4o shows a slight variation (0.79: English; 0.81: Italian). These patterns suggest that while modern architectures have made significant progress in bridging the cross-lingual gap, particularly in IR tasks and semantic understanding, challenges remain in maintaining consistent quality across languages in QA tasks. Our analysis revealed a concerning pattern across all tested models: consistently higher scores in answer relevance (0.91–1.0) compared to groundedness (0.64–0.78). This systematic gap represents a critical challenge for real-world deployment of multilingual QA systems, particularly in domains requiring high factual accuracy, and suggests that current evaluation metrics prioritizing fluency and relevance may inadequately capture factual reliability.
These findings have important implications for both research and the practical deployment of multilingual IR and QA systems. Although current models show promising cross-lingual capabilities in general domains, practitioners should carefully consider domain-specific requirements, particularly when working with non-English languages in specialized fields.
Though our analysis focused specifically on the English–Italian language pair, the consistent performance of models like embed-multilingual-v3.0 across both languages indicates broader implications for other Romance languages (Spanish, French, and Portuguese), which share morphological patterns with Italian. However, we would expect the performance gap to widen for typologically distant languages (e.g., Finnish, Hungarian, or non-European languages), a hypothesis supported by patterns observed in multilingual embedding benchmarks like MTEB [14], where performance typically clusters by language family.
Future research should focus on two key areas: (1) developing groundedness-focused evaluation metrics in multilingual QA assessment, and (2) creating techniques to better preserve performance across both linguistic and domain boundaries, possibly through more effective pre-training strategies or domain adaptation methods. Explicit testing of cross-family generalizations would be particularly valuable for confirming the projected patterns across more diverse language groups.
5.3. The Architecture vs. Scale Debate
Our results demonstrate that architectural efficiency and the type of training matter more than raw parameter count, challenging the common assumption that larger models necessarily perform better.
In IR tasks (Table 6), comparing architectures of different sizes reveals interesting patterns. When comparing the multilingual-E5 base (278M parameters) and large (560M parameters) variants, we find minimal performance differences of just 0.01–0.02 nDCG@10 points, and GTE-base is similar to GTE-large, indicating that model size alone does not guarantee superior performance.
In English QA tasks (Table 9), we observe varied performance patterns across different model sizes. The 8B parameter Llama 3.1 achieves the highest ROUGE-L scores (0.72/0.69) on SQuAD-en, outperforming both the larger GPT-4o (0.26/0.25) and the 12.2B parameter Mistral-Nemo (0.43/0.41). However, this advantage does not hold consistently across all tasks; on CovidQA, the performance of Llama 3.1 8b (0.22/0.15) is comparable to that of other models. The semantic evaluation metrics (Table 10) show a different pattern. While Llama 3.1 8b maintains strong BERTScore performance (0.92/0.90), GPT-4o and Mistral-Nemo show competitive results (0.85/0.93 and 0.88/0.94, respectively) despite their architectural differences. Looking at ground truth-free metrics (Table 11), we see consistent answer relevance scores across architectures (ranging from 0.98 to 1.0), regardless of model size. Groundedness scores show more variation, with Mistral-Nemo (0.78) and GPT-4o (0.79) performing similarly on SQuAD-en despite their different architectures.
This pattern holds true across different tasks and domains, suggesting that clever design might be more crucial than sheer size. The comparable or sometimes superior performance of smaller models compared to bigger ones in specific tasks indicates that efficient architectural design and training approaches can effectively compete with larger models.
5.4. Patterns in Model Evaluation Metrics
Our evaluation across different metrics and human judgments reveals distinct patterns in model performance assessment. The discrepancies observed between reference-based and reference-free metrics highlight the importance of using diverse evaluation approaches, especially for complex QA tasks where a single “correct” answer may not exist.
For QA tasks, syntactic metrics (Table 9) show relatively low scores, with ROUGE-L ranging from 0.26 to 0.72 for English SQuAD and 0.21 to 0.57 for Italian SQuAD. These scores decline further on specialized domains, with CovidQA showing ROUGE-L scores between 0.21 and 0.27. Semantic metrics (Table 10) consistently show higher scores across all models. BERTScore ranges from 0.85 to 0.92 for English tasks and 0.81 to 0.90 for Italian tasks. BEM scores show similar patterns but with greater variation, ranging from 0.77 to 0.94 for general domain tasks and dropping for specialized domains. As a result, we observe a consistent divide between semantic metrics (BERTScore: 0.85–0.92) and syntactic metrics (ROUGE-L: 0.21–0.72). BEM scores show a strong correlation with human evaluation (0.735), suggesting that modern models may be better at capturing meaning than current syntactic evaluation metrics might indicate.
Reference-free metrics (Table 11) reveal a consistent gap between answer relevance and groundedness. Answer relevance scores remain high across all models (0.98–1.0 for SQuAD-en, 0.98–0.99 for SQuAD-it), while groundedness scores are notably lower (0.67–0.79 for SQuAD-en, 0.71–0.81 for SQuAD-it). Lower groundedness scores compared to answer relevance scores across all models highlight a critical challenge in LLM-based QA systems. This gap is remarkably consistent across different models and languages, suggesting a fundamental challenge in maintaining factual accuracy while generating natural responses. Models sometimes generate plausible but unfaithful answers, emphasizing the need for improved mechanisms to ensure answer fidelity to the provided context.
The correlation analysis with human judgments (Table 12) provides crucial insights into metric reliability. On NarrativeQA books, BEM shows a strong correlation with human judgment (0.735) compared to answer relevance metrics (0.436). Similar patterns emerge for NarrativeQA movies, where BEM correlates at 0.704 with human judgment, while answer relevance shows a correlation of 0.565. These results suggest that BEM more closely aligns with human assessment of answer quality than reference-free metrics.
Looking at the IR results (Table 6), we see that the nDCG@10 scores provide yet another perspective on quality assessment, showing clear performance gradients across domains and languages while maintaining consistency within similar task types.
This multi-metric analysis demonstrates that different evaluation approaches capture distinct aspects of model performance.
5.5. Practical Implications and Ethical Considerations
Our comprehensive evaluation reveals critical implications for the practical deployment of these systems, particularly in domains where accuracy directly impacts human welfare. The story told by our empirical results raises important considerations about how these systems should be implemented and monitored in real-world applications.
The journey from general to specialized domains reveals a particularly concerning pattern in our IR results. Looking at the embed-multilingual-v3.0 model’s performance in Table 6, we see a dramatic decline in effectiveness as tasks become more specialized. Starting with an impressive nDCG@10 score of 0.90 in general domains, the performance plummets to just 0.36 in medical contexts (NFCorpus). This substantial drop of 0.54 points is not just a number—it represents a significant degradation in the system’s ability to retrieve relevant information in medical contexts, where accuracy can have direct implications for healthcare decisions.
The story becomes even more nuanced when we examine our QA results. Table 11 reveals a fascinating but troubling pattern in how models handle factual accuracy vs. answer relevance. Take Mistral-Nemo’s performance on CovidQA, for instance. While it achieves an impressive answer relevance score of 0.91, its groundedness score sits much lower at 0.64. We see similar patterns with GPT-4o, which shows a relevance score of 0.89 but a groundedness score of only 0.61 on specialized medical content. This gap between a model’s ability to generate plausible-sounding answers and its ability to maintain factual accuracy raises serious concerns, particularly in medical and legal contexts, where factual precision is of paramount importance.
The importance of human oversight in these systems is not just a theoretical consideration—it is supported by our empirical findings. Our correlation analysis in Table 12 demonstrates that human judgment remains a crucial component in evaluating system performance. This finding reinforces what the performance gaps have already suggested: while these systems show remarkable capabilities, they cannot be deployed without appropriate human supervision and robust verification mechanisms.
These patterns in our data point to several crucial requirements for responsible system deployment. We need robust fact-checking mechanisms, particularly in specialized domains, where performance degradation is most severe. We need clear protocols for human oversight, supported by our correlation analysis findings. Most importantly, we need transparent communication about system limitations, backed by our documented performance patterns.
6. Conclusions
Our analysis of embedding models and large language models across English and Italian has revealed several significant patterns that both advance our understanding and challenge common assumptions about multilingual AI systems. The patterns we observe suggest that while current approaches have made significant strides in bridging linguistic divides, particularly in general domains, substantial work remains in handling specialized knowledge and maintaining factual accuracy across languages.
The empirical results demonstrate clear performance patterns across languages and domains. In IR tasks, embed-multilingual-v3.0 maintains consistent performance across languages with minimal gaps (0.90 vs. 0.86 nDCG@10 for English and Italian SQuAD, respectively). However, performance degrades significantly in specialized domains, dropping to 0.36 for medical content (NFCorpus) in English tasks. In QA tasks, our results showed varying patterns across different evaluation metrics. Syntactic metrics revealed larger cross-lingual gaps (ROUGE-L scores of 0.72/0.69 vs. 0.57/0.54 for Llama 3.1 8b on English vs. Italian), and semantic metrics showed more stability (BERTScores ranging from 0.85–0.92 for English and 0.81–0.90 for Italian). The consistent gap between answer relevance (0.91–1.0) and groundedness (0.64–0.78) across models highlights a fundamental challenge in maintaining factual accuracy.
These findings have significant implications for both research and practice:
- The success of well-designed smaller models suggests that focused architectural innovation may be more valuable than simply scaling up existing approaches.
- The consistent pattern of domain-specific performance degradation indicates a need for more sophisticated approaches to specialized knowledge transfer across languages.
- The challenge of maintaining answer groundedness while preserving natural language generation capabilities emerges as a critical area for future work.
Building on these insights, our analysis identifies several critical areas for future research:
- Dataset diversity: Future work should expand to include a wider range of languages and domains to further validate the cross-lingual and domain adaptation capabilities of these models.
- Domain adaptation: The documented performance drop from general (0.90 nDCG@10) to specialized domains (0.36 nDCG@10) calls for more sophisticated domain adaptation mechanisms.
- Cross-lingual knowledge transfer: The varying performance gaps between English and Italian, particularly in specialized domains, suggest the need for improved cross-lingual transfer methods. There is a need to explore methods for leveraging high-resource language models to improve performance on low-resource languages, potentially through zero-shot or few-shot learning approaches.
- Improved groundedness: Develop techniques to enhance the faithfulness of LLM-generated answers to the provided context, possibly through modified training objectives or architectural changes.
- Architectural innovation: The comparable performance of different-sized models (e.g., multilingual-E5-base vs. large shows minimal differences in nDCG@10) indicates that architectural efficiency may be more crucial than model scale. Therefore, developing more efficient architectures that maintain performance across languages without requiring massive computational resources is necessary.
- Long-context LLMs for QA: There is a need to explore the potential of emerging long-context LLMs (e.g., Claude 3 and GPT-4 with extended context) in handling complex, multi-hop QA tasks without the need for separate retrieval steps. To address long documents, we will compare this approach with a smart selection of chunks through structural document representation (Document Object Model).
- Dynamic retrieval: Investigate adaptive retrieval methods that can dynamically adjust the number of retrieved passages based on query complexity or ambiguity.
- Multimodal IR and QA: Extend the current work to include multimodal information retrieval and question answering, incorporating text, images, and potentially other modalities.
- Evaluation methodologies: Advance our understanding of how to assess both technical performance and practical utility in real-world applications. Develop better factual accuracy metrics given the observed groundedness challenges.
- Development of specialized multilingual metrics: Evaluation metrics specifically designed for multilingual and cross-lingual scenarios are needed. Future research should focus on creating metrics that better capture the unique challenges of cross-lingual knowledge transfer and factual groundedness across languages, potentially incorporating language-specific linguistic features and cultural contexts.
- Model updates: Given the rapid pace of development in NLP, regular re-evaluations with newly released models will be necessary to keep findings current.
- Interpretability and explainability: Develop methods for better understanding and interpreting the decision-making processes of dense retrievers and LLMs in IR and QA tasks.
- Ethical AI in IR and QA: Further investigation into bias mitigation and fairness across languages and cultures in IR and QA systems. Develop frameworks for ethical deployment of AI-powered systems, including methods for bias detection and mitigation and strategies for clearly communicating model limitations to end-users.
This comprehensive analysis serves not just as a benchmark of recent capabilities but as evidence-based guidance for future development in this rapidly evolving field. As we move forward, the focus must remain on creating systems that are not only more accurate and efficient but also ethical, transparent, and truly beneficial to diverse linguistic communities worldwide while maintaining practical applicability.
Author Contributions
Conceptualization, E.O.; methodology, E.O.; software, E.O. and F.M.G.; validation, E.O., F.M.G. and M.R.; formal analysis, E.O. and F.M.G.; investigation, E.O. and F.M.G.; resources, M.R.; data curation, F.M.G.; writing—original draft preparation, E.O. and F.M.G.; writing—review and editing, E.O., F.M.G. and M.R.; visualization, E.O.; supervision, E.O.; funding acquisition, E.O. and M.R. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partly supported by project FAIR—Future AI Research (PE00000013), under the NRRP MUR program funded by the EU-NGEU.
Data Availability Statement
All data used in this research are described, and relevant URLs are indicated in Section 3.3 and Table 1, Table 2 and Table 3 of this paper. The custom NarrativeQA-translated dataset is openly available in our research repository at https://staff.icar.cnr.it/oro/resources/multilingual-ir-qa (accessed on 15 March 2025).
Conflicts of Interest
Authors Francesco Maria Granata and Massimo Ruffolo are employed by the company Altilia srl, TechNest. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Newry, UK, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. PaLM: Scaling language modeling with pathways. J. Mach. Learn. Res. 2023, 24, 11324–11436. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; pp. 3982–3992. [Google Scholar] [CrossRef]
- Ni, J.; Qu, C.; Lu, J.; Dai, Z.; Ábrego, G.H.; Ma, J.; Zhao, V.Y.; Luan, Y.; Hall, K.B.; Chang, M.W.; et al. Large Dual Encoders Are Generalizable Retrievers. arXiv 2021, arXiv:2112.07899. [Google Scholar]
- Mistral AI. Mistral Nemo: Introducing Our New Model. 2024. Available online: https://mistral.ai/news/mistral-nemo/ (accessed on 29 March 2025).
- Gemma Team. Gemma: Open Models Based on Gemini Research and Technology. arXiv 2024, arXiv:2403.08295. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Newry, UK, 2017; Volume 30. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Volume 1 (Long and Short Papers), pp. 4171–4186. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.t.; Rocktäschel, T.; et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NIPS ’20), Red Hook, NY, USA, 6–12 December 2020. [Google Scholar]
- Gao, Y.; Xiong, Y.; Gao, X.; Jia, K.; Pan, J.; Bi, Y.; Dai, Y.; Sun, J.; Guo, Q.; Wang, M.; et al. Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv 2024, arXiv:2312.10997. [Google Scholar]
- Cotterell, R.; Mielke, S.J.; Eisner, J.; Roark, B. Are All Languages Equally Hard to Language-Model? In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Walker, M., Ji, H., Stent, A., Eds.; Volume 2 (Short Papers), pp. 536–541. [Google Scholar] [CrossRef]
- Thakur, N.; Reimers, N.; Rücklé, A.; Srivastava, A.; Gurevych, I. BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models. arXiv 2021, arXiv:2104.08663. [Google Scholar]
- Muennighoff, N.; Tazi, N.; Magne, L.; Reimers, N. MTEB: Massive Text Embedding Benchmark. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, Dubrovnik, Croatia, 2–6 May 2023; Vlachos, A., Augenstein, I., Eds.; pp. 2014–2037. [Google Scholar] [CrossRef]
- Hambarde, K.A.; Proença, H. Information Retrieval: Recent Advances and Beyond. IEEE Access 2023, 11, 76581–76604. [Google Scholar] [CrossRef]
- Anand, A.; Lyu, L.; Idahl, M.; Wang, Y.; Wallat, J.; Zhang, Z. Explainable Information Retrieval: A Survey. arXiv 2022, arXiv:2211.02405. [Google Scholar]
- Tang, Y.; Yang, Y. MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries. arXiv 2024, arXiv:2401.15391. [Google Scholar]
- Zhang, Z.; Fang, M.; Chen, L. RetrievalQA: Assessing Adaptive Retrieval-Augmented Generation for Short-form Open-Domain Question Answering. arXiv 2024, arXiv:2402.16457. [Google Scholar]
- Gao, M.; Hu, X.; Ruan, J.; Pu, X.; Wan, X. LLM-based NLG Evaluation: Current Status and Challenges. arXiv 2024, arXiv:2402.01383. [Google Scholar] [CrossRef]
- Karpukhin, V.; Oguz, B.; Min, S.; Lewis, P.; Wu, L.; Edunov, S.; Chen, D.; Yih, W.T. Dense Passage Retrieval for Open-Domain Question Answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Webber, B., Cohn, T., He, Y., Liu, Y., Eds.; pp. 6769–6781. [Google Scholar] [CrossRef]
- Khattab, O.; Zaharia, M. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’20), Xi’an, China, 25–30 July 2020; pp. 39–48. [Google Scholar] [CrossRef]
- Xiong, L.; Xiong, C.; Li, Y.; Tang, K.F.; Liu, J.; Bennett, P.; Ahmed, J.; Overwijk, A. Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval. arXiv 2020, arXiv:2007.00808. [Google Scholar]
- Nogueira, R.; Yang, W.; Lin, J.; Cho, K. Document Expansion by Query Prediction. arXiv 2019, arXiv:1904.08375. [Google Scholar]
- Gao, L.; Callan, J. Condenser: A Pre-Training Architecture for Dense Retrieval. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online and Punta Cana, Dominican Republic, 7–11 November 2021; Moens, M.F., Huang, X., Specia, L., Yih, S.W.T., Eds.; pp. 981–993. [Google Scholar] [CrossRef]
- Wang, L.; Yang, N.; Huang, X.; Jiao, B.; Yang, L.; Jiang, D.; Majumder, R.; Wei, F. Text Embeddings by Weakly-Supervised Contrastive Pre-training. arXiv 2024, arXiv:2212.03533. [Google Scholar]
- Xiao, S.; Liu, Z.; Zhang, P.; Muennighoff, N.; Lian, D.; Nie, J.Y. C-Pack: Packaged Resources To Advance General Chinese Embedding. arXiv 2024, arXiv:2309.07597. [Google Scholar]
- Xiao, S.; Liu, Z.; Shao, Y.; Cao, Z. RetroMAE: Pre-Training Retrieval-Oriented Language Models Via Masked Auto-Encoder. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; Goldberg, Y., Kozareva, Z., Zhang, Y., Eds.; pp. 538–548. [Google Scholar] [CrossRef]
- Liu, Z.; Xiao, S.; Shao, Y.; Cao, Z. RetroMAE-2: Duplex Masked Auto-Encoder For Pre-Training Retrieval-Oriented Language Models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; Rogers, A., Boyd-Graber, J., Okazaki, N., Eds.; Volume 1: Long Papers, pp. 2635–2648. [Google Scholar] [CrossRef]
- Muffo, M.; Bertino, E. BERTino: An Italian DistilBERT model. arXiv 2023, arXiv:2303.18121. [Google Scholar]
- Liu, N.F.; Lin, K.; Hewitt, J.; Paranjape, A.; Bevilacqua, M.; Petroni, F.; Liang, P. Lost in the Middle: How Language Models Use Long Contexts. Trans. Assoc. Comput. Linguist. 2024, 12, 157–173. [Google Scholar] [CrossRef]
- Guu, K.; Lee, K.; Tung, Z.; Pasupat, P.; Chang, M. Retrieval Augmented Language Model Pre-Training. In Proceedings of the 37th International Conference on Machine Learning (ICML 2020), Online, 13–18 July 2020; Volume 119, pp. 3929–3938. [Google Scholar]
- Khattab, O.; Potts, C.; Zaharia, M. Relevance-guided Supervision for OpenQA with ColBERT. arXiv 2021, arXiv:2007.00814. [Google Scholar] [CrossRef]
- Shuster, K.; Poff, S.; Chen, M.; Kiela, D.; Weston, J. Retrieval Augmentation Reduces Hallucination in Conversation. arXiv 2021, arXiv:2104.07567. [Google Scholar]
- Huo, S.; Arabzadeh, N.; Clarke, C. Retrieving Supporting Evidence for Generative Question Answering. In Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region, Beijing, China, 26–28 November 2023; pp. 11–20. [Google Scholar] [CrossRef]
- Zhang, T.; Patil, S.G.; Jain, N.; Shen, S.; Zaharia, M.; Stoica, I.; Gonzalez, J.E. RAFT: Adapting Language Model to Domain Specific RAG. arXiv 2024, arXiv:2403.10131. [Google Scholar]
- Carterette, B.; Voorhees, E.M. Overview of information retrieval evaluation. In Current Challenges in Patent Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2011; pp. 69–85. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; Isabelle, P., Charniak, E., Lin, D., Eds.; pp. 311–318. [Google Scholar] [CrossRef]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the Workshop on Text Summarization Branches Out (WAS 2004), Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore: Evaluating Text Generation with BERT. In Proceedings of the 8th International Conference on Learning Representations (ICLR 2020), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Es, S.; James, J.; Espinosa Anke, L.; Schockaert, S. RAGAs: Automated Evaluation of Retrieval Augmented Generation. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, St. Julians, Malta, 17–22 March 2024; Aletras, N., De Clercq, O., Eds.; pp. 150–158. [Google Scholar]
- Katranidis, V.; Barany, G. FaaF: Facts as a Function for the evaluation of RAG systems. arXiv 2024, arXiv:2403.03888. [Google Scholar]
- Saad-Falcon, J.; Khattab, O.; Potts, C.; Zaharia, M. ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Mexico City, Mexico, 16–21 June 2024; Duh, K., Gomez, H., Bethard, S., Eds.; Volume 1: Long Papers, pp. 338–354. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD: 100,000+ Questions for Machine Comprehension of Text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; Su, J., Duh, K., Carreras, X., Eds.; pp. 2383–2392. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Jia, R.; Liang, P. Know What You Don’t Know: Unanswerable Questions for SQuAD. arXiv 2018, arXiv:1806.03822. [Google Scholar]
- Chen, D.; Fisch, A.; Weston, J.; Bordes, A. Reading Wikipedia to Answer Open-Domain Questions. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Barzilay, R., Kan, M.Y., Eds.; Volume 1: Long Papers, pp. 1870–1879. [Google Scholar] [CrossRef]
- Zhang, Y.; Nie, P.; Geng, X.; Ramamurthy, A.; Song, L.; Jiang, D. DC-BERT: Decoupling Question and Document for Efficient Contextual Encoding. arXiv 2020, arXiv:2002.12591. [Google Scholar]
- Croce, D.; Zelenanska, A.; Basili, R. Neural Learning for Question Answering in Italian. In Proceedings of the International Conference of the Italian Association for Artificial Intelligence (AI*IA 2018), Trento, Italy, 20–23 November 2018; Ghidini, C., Magnini, B., Passerini, A., Traverso, P., Eds.; pp. 389–402. [Google Scholar]
- Bonisoli, G.; Di Buono, M.P.; Po, L.; Rollo, F. DICE: A Dataset of Italian Crime Event News. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’23), Taipei, Taiwan, 23–27 July 2023; pp. 2985–2995. [Google Scholar] [CrossRef]
- Wadden, D.; Lin, S.; Lo, K.; Wang, L.L.; van Zuylen, M.; Cohan, A.; Hajishirzi, H. Fact or Fiction: Verifying Scientific Claims. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Webber, B., Cohn, T., He, Y., Liu, Y., Eds.; pp. 7534–7550. [Google Scholar] [CrossRef]
- Wachsmuth, H.; Syed, S.; Stein, B. Retrieval of the Best Counterargument Without Prior Topic Knowledge. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Gurevych, I., Miyao, Y., Eds.; Volume 1: Long Papers, pp. 241–251. [Google Scholar] [CrossRef]
- Boteva, V.; Ghalandari, D.G.; Sokolov, A.; Riezler, S. A full-text learning to rank dataset for medical information retrieval. In Advances in Information Retrieval, Proceedings of the 38th European Conference on IR Research (ECIR 2016), Padua, Italy, 20–23 March 2016; Lecture Notes in Computer Science; Ferro, N., Crestani, F., Moens, M.F., Mothe, J., Silvestri, F., Nunzio, G.M.D., Hauff, C., Silvello, G., Eds.; Springer: Cham, Switzerland, 2016; Volume 9626, pp. 716–722. [Google Scholar]
- Tang, R.; Nogueira, R.; Zhang, E.; Gupta, N.; Cam, P.; Cho, K.; Lin, J. Rapidly Bootstrapping a Question Answering Dataset for COVID-19. arXiv 2020, arXiv:2004.11339. [Google Scholar]
- Wang, L.L.; Lo, K.; Chandrasekhar, Y.; Reas, R.; Yang, J.; Burdick, D.; Eide, D.; Funk, K.; Katsis, Y.; Kinney, R.; et al. CORD-19: The COVID-19 Open Research Dataset. arXiv 2020, arXiv:2004.10706. [Google Scholar]
- Kočiský, T.; Schwarz, J.; Blunsom, P.; Dyer, C.; Hermann, K.M.; Melis, G.; Grefenstette, E. The NarrativeQA Reading Comprehension Challenge. Trans. Assoc. Comput. Linguist. 2018, 6, 317–328. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, X.; Zhang, Y.; Long, D.; Xie, P.; Zhang, M. Towards General Text Embeddings with Multi-stage Contrastive Learning. arXiv 2023, arXiv:2308.03281. [Google Scholar]
- Grattafiori, A.; Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Vaughan, A.; et al. The Llama 3 Herd of Models. arXiv 2024, arXiv:2407.21783. [Google Scholar]
- Gemma Team. Gemma 2: Improving Open Language Models at a Practical Size. arXiv 2024, arXiv:2408.00118. [Google Scholar]
- Wrzalik, M.; Krechel, D. CoRT: Complementary Rankings from Transformers. arXiv 2021, arXiv:2010.10252. [Google Scholar]
- Tang, H.; Sun, X.; Jin, B.; Wang, J.; Zhang, F.; Wu, W. Improving Document Representations by Generating Pseudo Query Embeddings for Dense Retrieval. arXiv 2021, arXiv:2105.03599. [Google Scholar]
- Lawrie, D.; Yang, E.; Oard, D.W.; Mayfield, J. Neural Approaches to Multilingual Information Retrieval. arXiv 2023, arXiv:2209.01335. [Google Scholar]
- Esteva, A.; Kale, A.; Paulus, R.; Hashimoto, K.; Yin, W.; Radev, D.; Socher, R. CO-Search: COVID-19 Information Retrieval with Semantic Search, Question Answering, and Abstractive Summarization. arXiv 2020, arXiv:2006.09595. [Google Scholar]
- Zhan, J.; Mao, J.; Liu, Y.; Zhang, M.; Ma, S. RepBERT: Contextualized Text Embeddings for First-Stage Retrieval. arXiv 2020, arXiv:2006.15498. [Google Scholar]
- Yang, Y.; Jin, N.; Lin, K.; Guo, M.; Cer, D. Neural Retrieval for Question Answering with Cross-Attention Supervised Data Augmentation. arXiv 2020, arXiv:2009.13815. [Google Scholar]
- Durmus, E.; He, H.; Diab, M. FEQA: A Question Answering Evaluation Framework for Faithfulness Assessment in Abstractive Summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar] [CrossRef]
- Goyal, T.; Li, J.J.; Durrett, G. News Summarization and Evaluation in the Era of GPT-3. arXiv 2023, arXiv:2209.12356. [Google Scholar]
- Bulian, J.; Buck, C.; Gajewski, W.; Börschinger, B.; Schuster, T. Tomayto, Tomahto. Beyond Token-level Answer Equivalence for Question Answering Evaluation. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; Goldberg, Y., Kozareva, Z., Zhang, Y., Eds.; pp. 291–305. [Google Scholar] [CrossRef]
- Kamalloo, E.; Dziri, N.; Clarke, C.L.A.; Rafiei, D. Evaluating Open-Domain Question Answering in the Era of Large Language Models. arXiv 2023, arXiv:2305.06984. [Google Scholar]
- Lerner, P.; Ferret, O.; Guinaudeau, C. Cross-modal Retrieval for Knowledge-based Visual Question Answering. arXiv 2024, arXiv:2401.05736. [Google Scholar]
- Blagec, K.; Dorffner, G.; Moradi, M.; Ott, S.; Samwald, M. A global analysis of metrics used for measuring performance in natural language processing. arXiv 2022, arXiv:2204.11574. [Google Scholar]
- Blagec, K.; Dorffner, G.; Moradi, M.; Samwald, M. A critical analysis of metrics used for measuring progress in artificial intelligence. arXiv 2021, arXiv:2008.02577. [Google Scholar]
- Joshi, M.; Choi, E.; Weld, D.S.; Zettlemoyer, L. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. arXiv 2017, arXiv:1705.03551. [Google Scholar]
- Lin, C.Y.; Hovy, E. Automatic Evaluation of Summaries Using N-gram Co-occurrence Statistics. In Proceedings of the 2003 Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics, Edmonton, AB, Canada, 27 May–1 June 2003; pp. 150–157. [Google Scholar]
- Weaver, K.F.; Morales, V.; Dunn, S.L.; Godde, K.; Weaver, P.F. Pearson’s and Spearman’s correlation. In An Introduction to Statistical Analysis in Research; John Wiley and Sons, Ltd.: Hoboken, NJ, USA, 2017; pp. 435–471. [Google Scholar] [CrossRef]
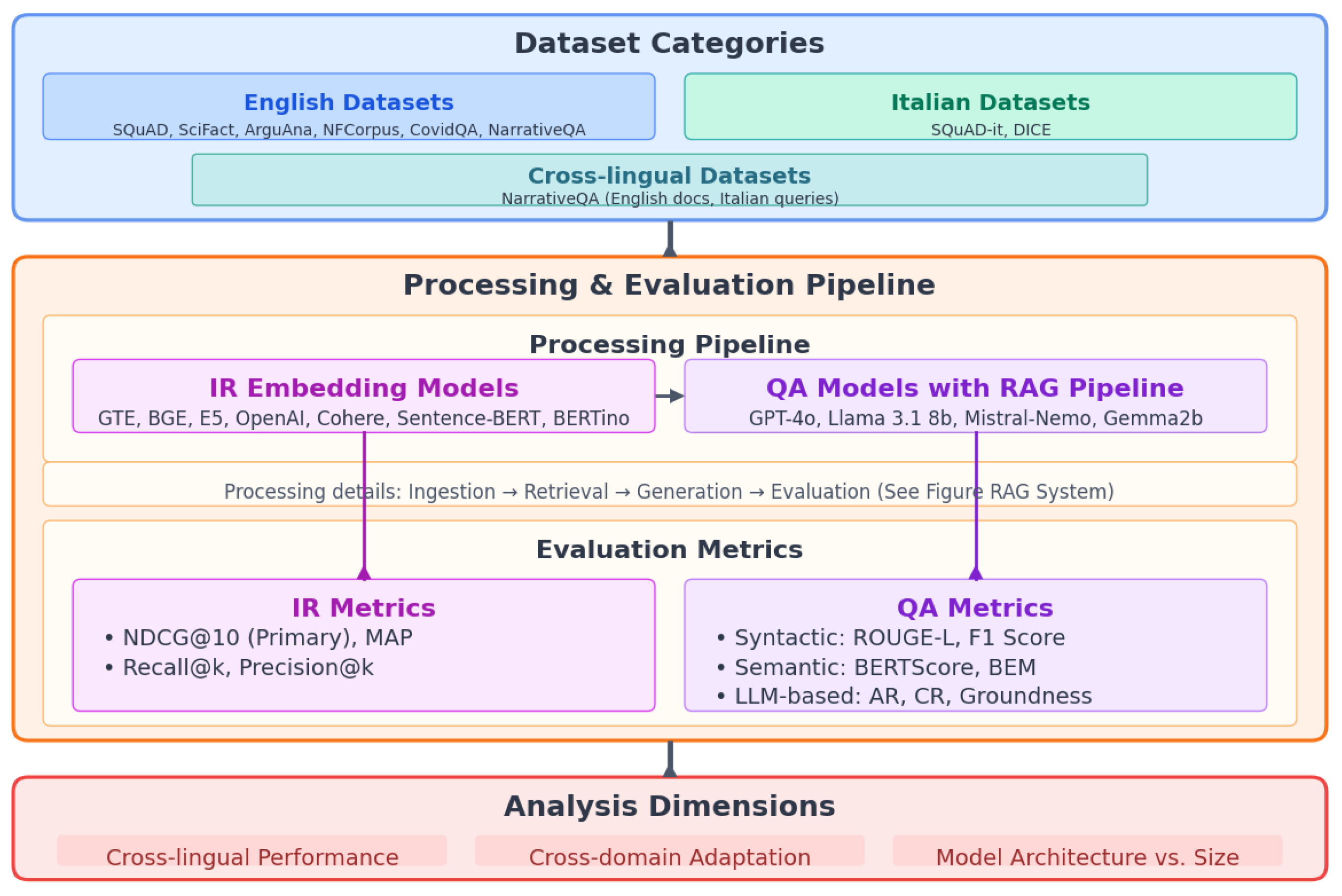
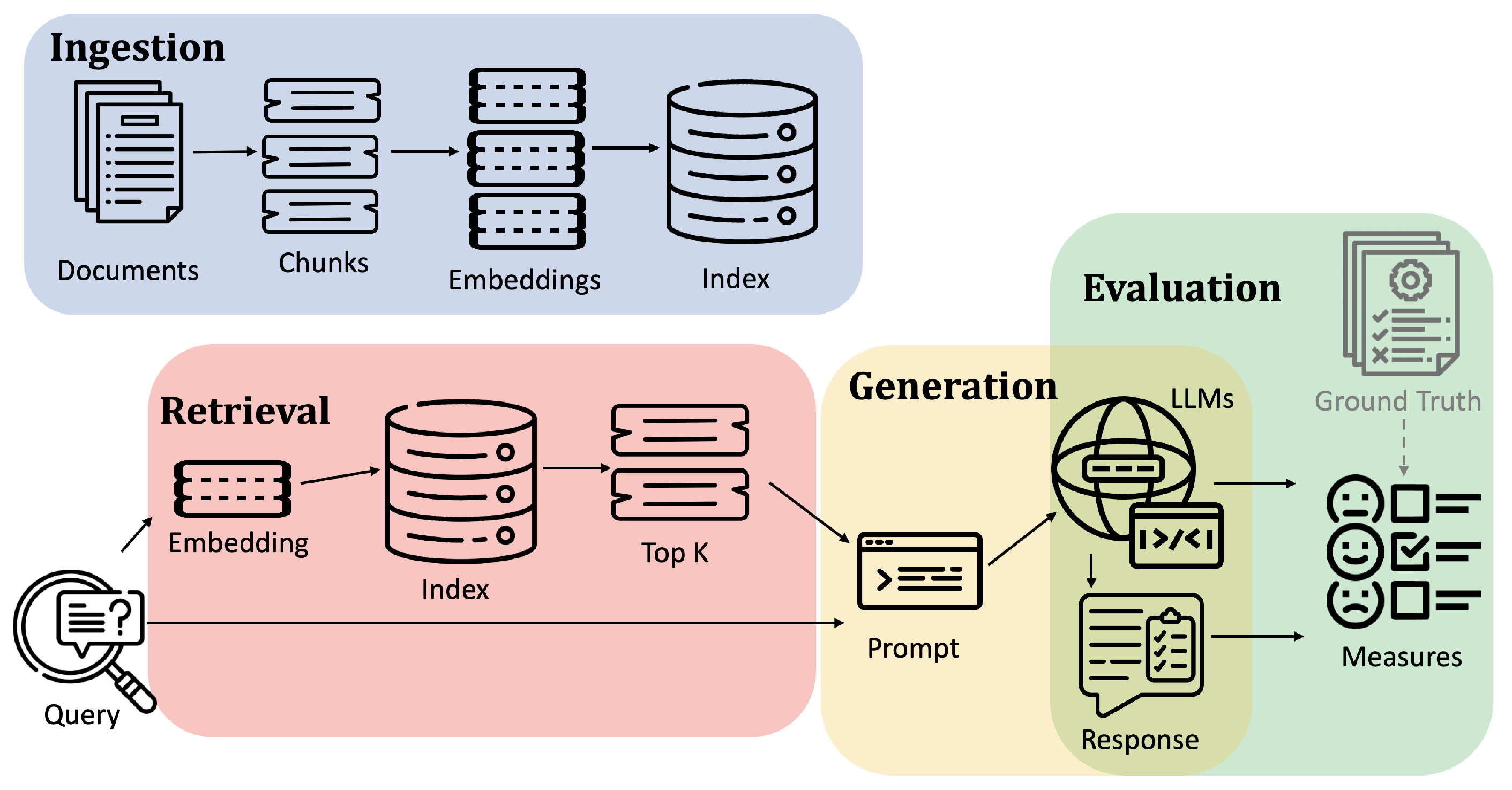
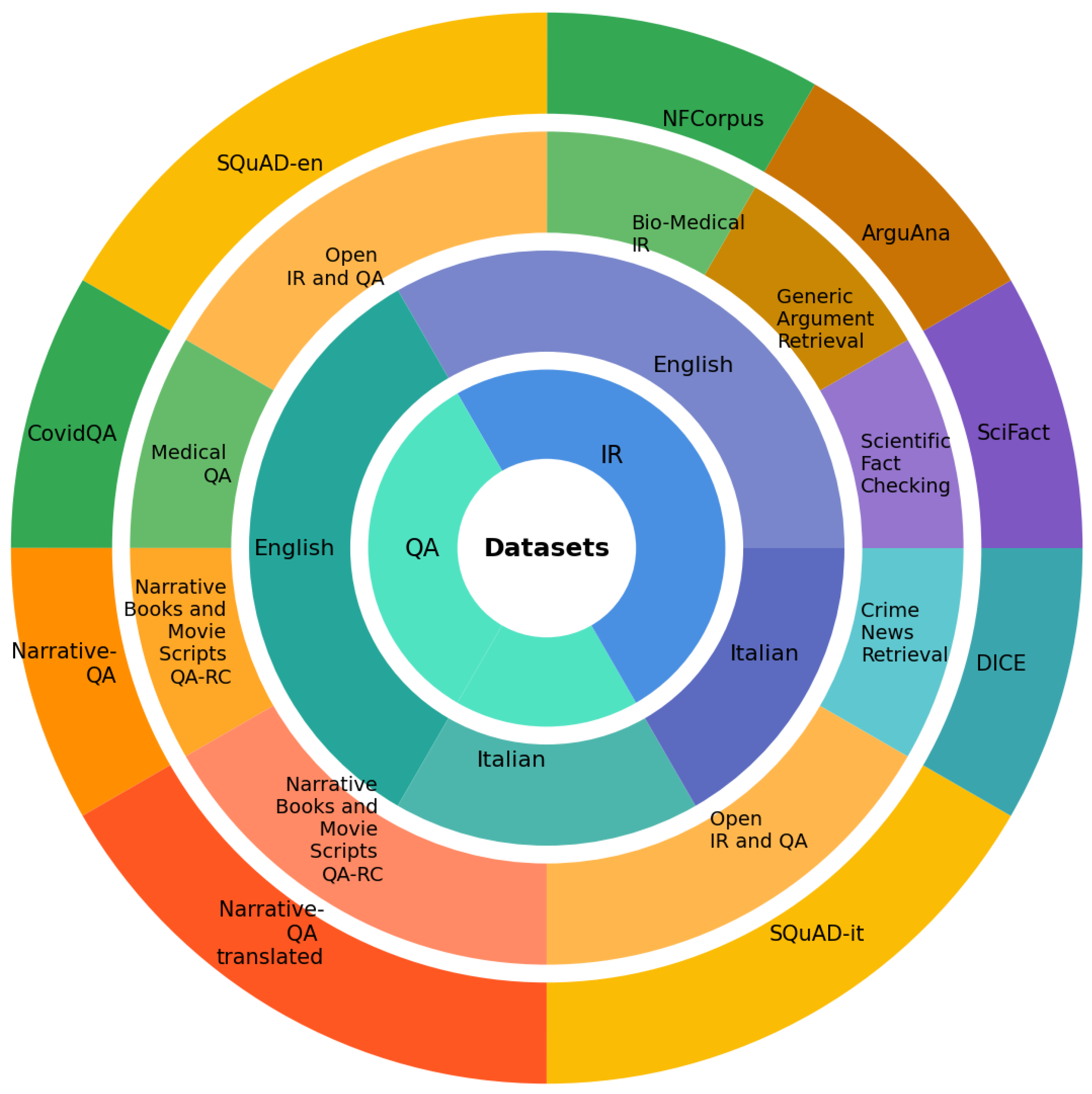
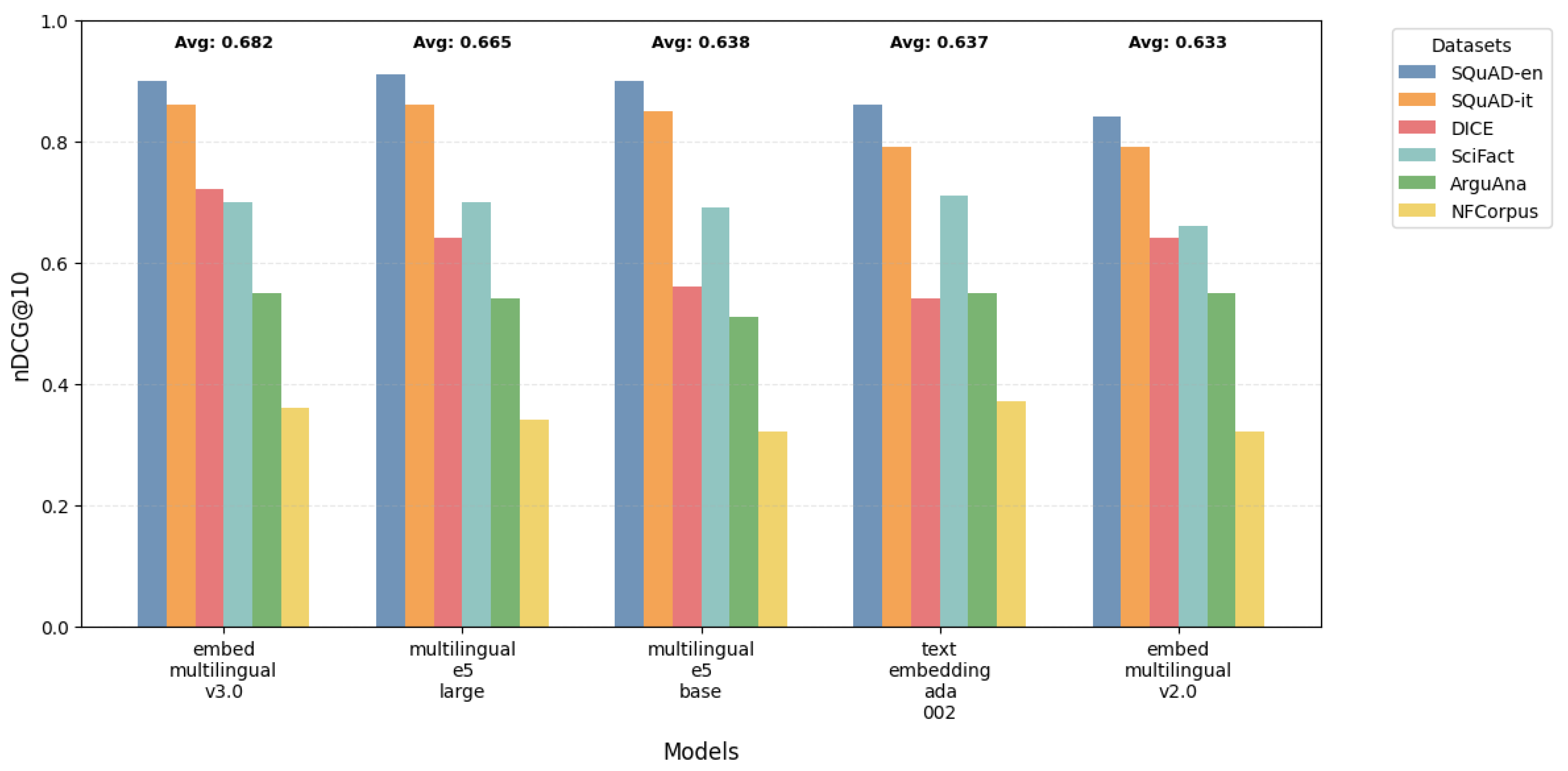
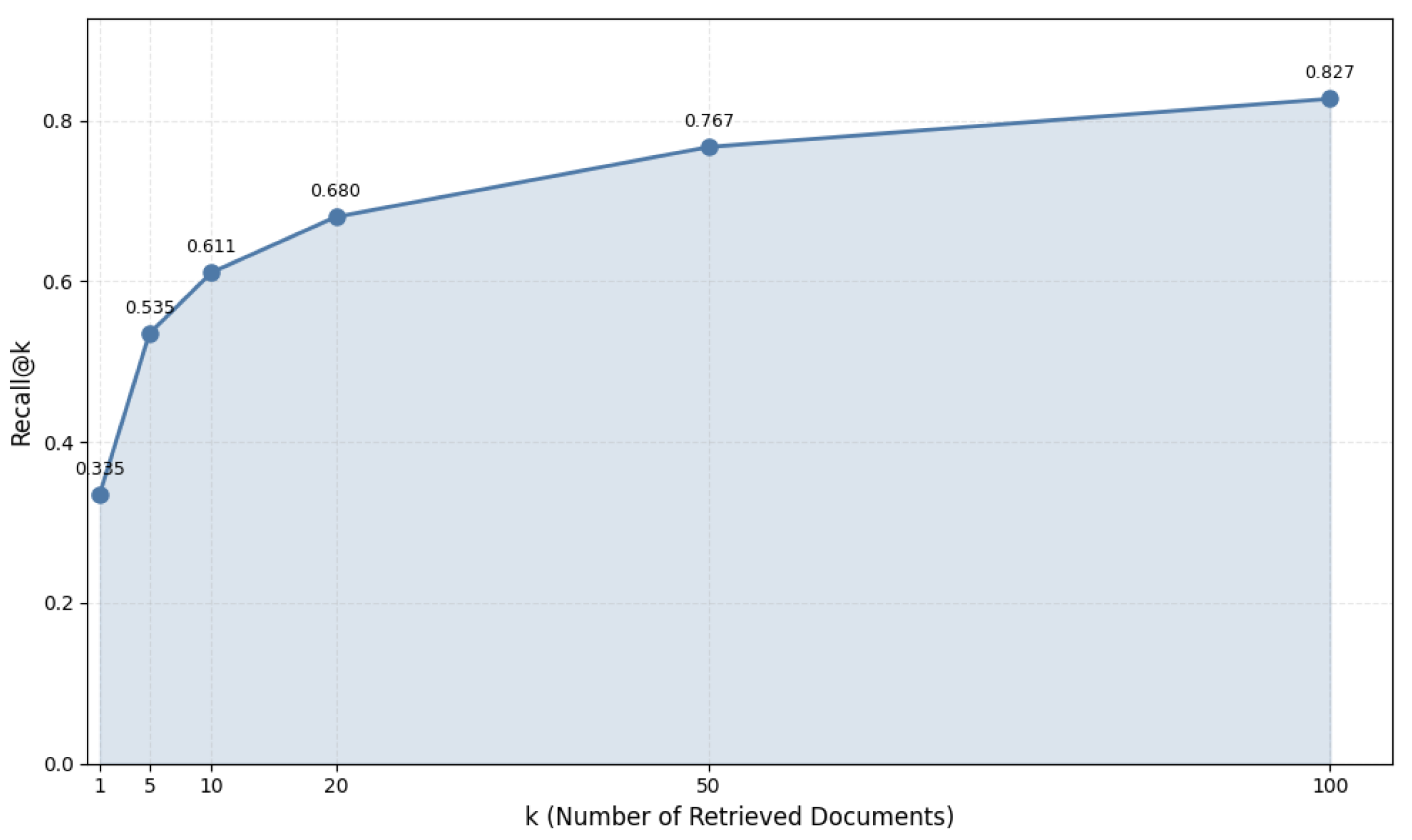
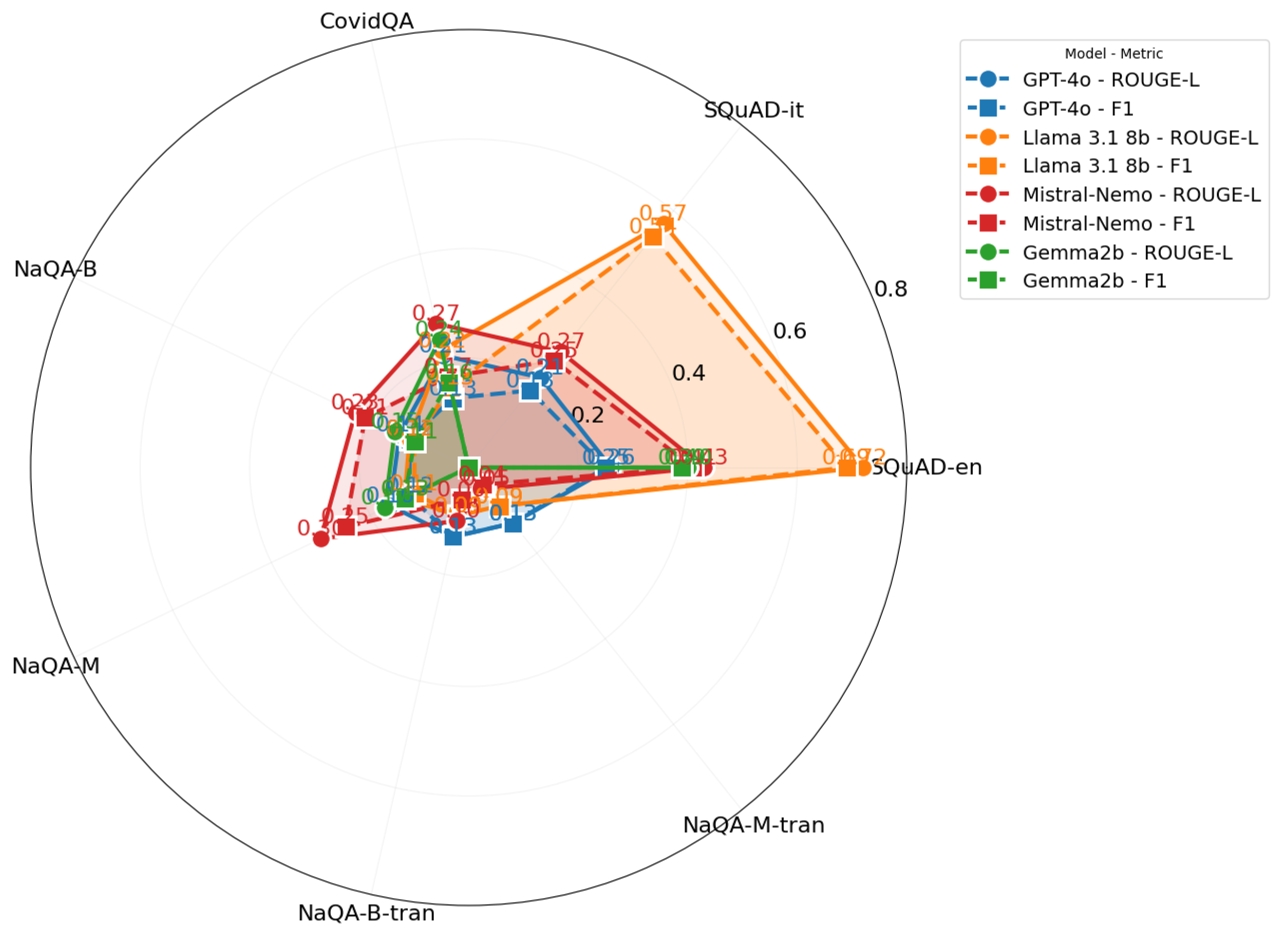
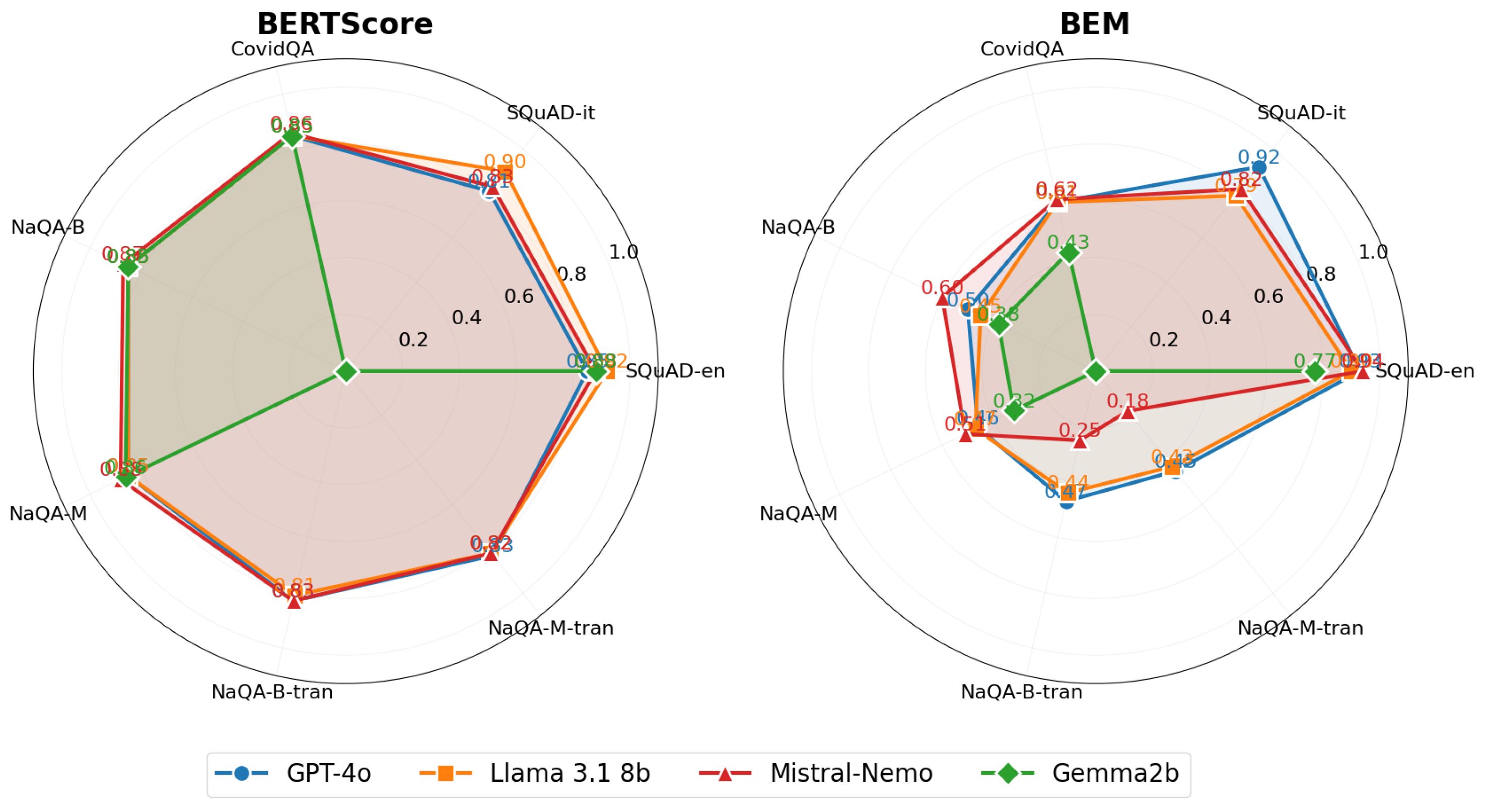
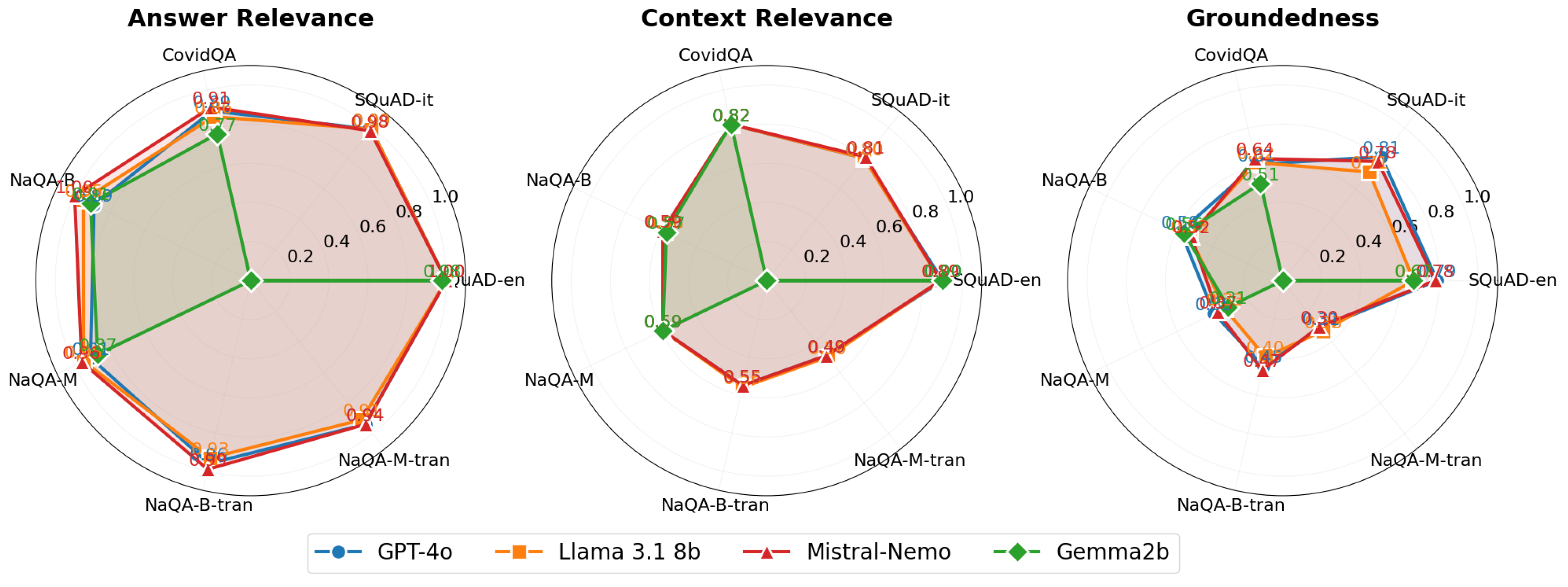
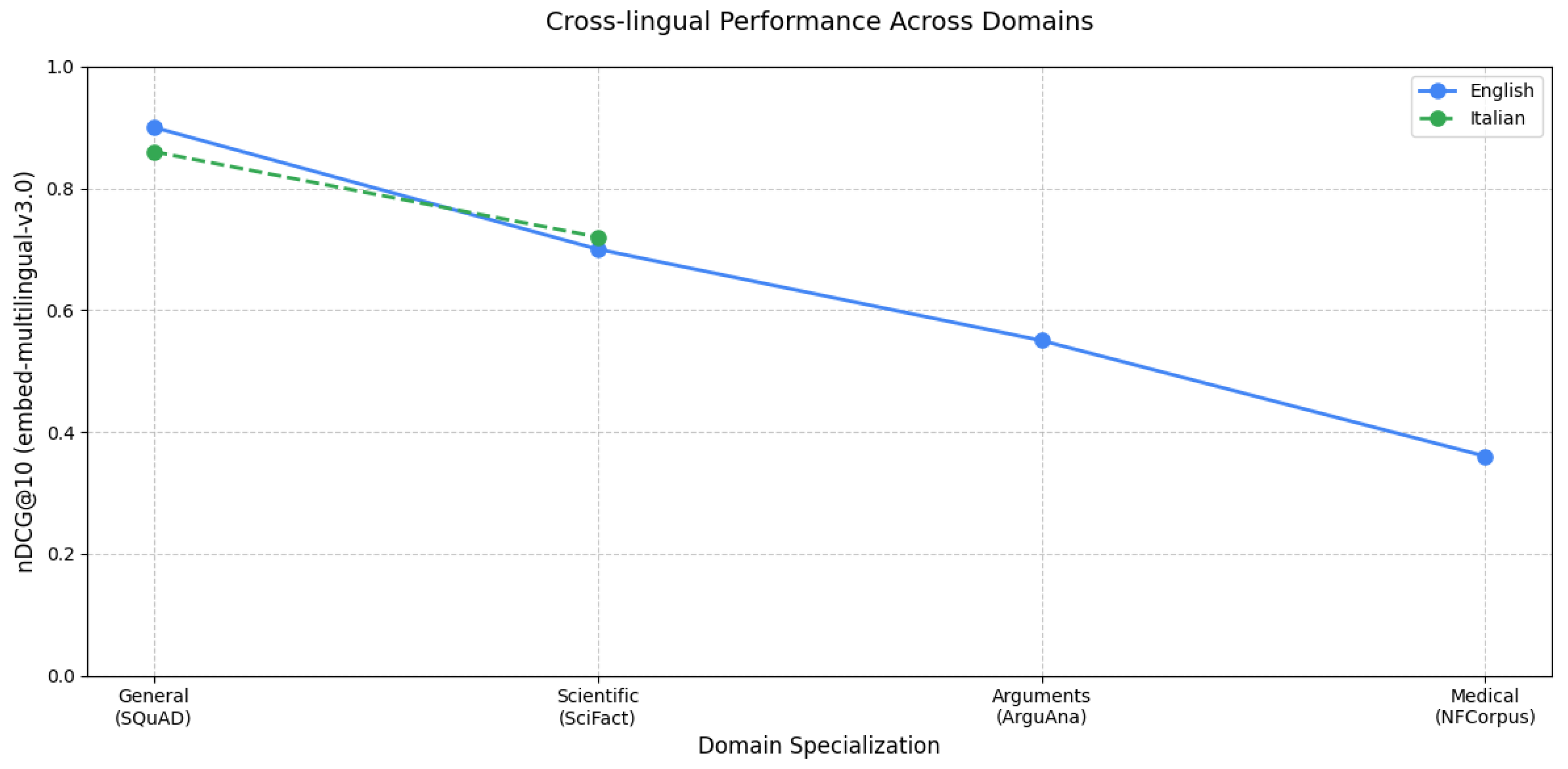
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).