1. Introduction
The purpose of text summarization [
1,
2,
3] is to highlight crucial details for better contextual understanding of a relatively longer text [
4]. Achieving accurate summarization involves employing a variety of methodologies, with machine learning (ML), deep learning (DL), and statistical approaches currently dominating the field [
5]. Text summarization primarily employs two approaches: Extractive and Abstractive (See
Figure 1) [
6,
7].
This study prioritizes abstractive BTS for its ability to generate coherent, fluent, and contextually enriched summaries, unlike extractive methods that merely extract key sentences. Given Bengali language’s complexity, abstractive techniques better capture semantic meaning and align with human-like summarization, making them more effective for real-world applications. However, abstractive summarization is more challenging due to its reliance on natural language generation and deeper semantic understanding. This work aims to explore these challenges and improve the effectiveness of Bengali Text Summarization (BTS).
In recent years, transformer-based models have fundamentally reshaped the landscape of NLP. Notably, BERT (Bidirectional Encoder Representations from Transformers) [
11], GPT (Generative Pre-trained Transformer) pioneered a paradigm shift by pre-training on extensive textual data, ushering a new era of contextually correct summaries [
12]. The central focus of this research is to perform an extensive research review for Abstractive summarization models that are specifically developed for the Bengali language. Before delving into the main discussions,
Table 1 shows the list of key abbreviations used in this paper.
1.1. Problem Statement and Research Gap in Bengali Abstractive Summarization
Recently, there have been remarkable advancements with the emergence of transformer models like BERT, GPT, etc. However, an in-depth look into this topic reveals that particularly for Bengali language text summarization, performance investigation of transformer models remains largely unexplored [
13,
14,
15,
16].
BTS presents a number of issues and problems that need to be resolved. In this research study, the following issues have been observed as the root causes for the lack of research in this field:
- 1.
Complex Language Constructs: Bengali exhibits distinct language structures, such as the subject-object-verb (SOV) word order (see
Figure 2), alongside morphological complexities like inflections and de-lexicalised verbs [
17,
18,
19,
20]. These intricacies pose significant challenges for summarization and comprehension [
21,
22].
The earlier generation of deep learning models for summarization relied on Seq2Seq architecture, typically constructed using LSTM (Long Short-Term Memory) cells. However, these models often struggled to capture the intricate contextual nuances necessary for generating meaningful summaries. Additionally, even when capable of producing summaries, it demanded a significant number of epochs, rendering it computationally expensive [
23] (see
Figure 3).
Transformer models (e.g., GPT3.5 model) excel over LSTM with parallel computation, attention, and efficient capture of long-range dependencies. Yet, resource scarcity, especially insufficient training data, can lead to rational discrepancies in summarization. This is evident in the peculiar outputs observed when random Bengali news texts are used from a popular newspaper “Prothom-alo” as inputs (see
Figure 4).
In 2021, Chowdhury et al. proposed BenSumm model, which till today is recognized as a prominent model for BTS [
24]. However, the performance shows that Abstractive summarization scores are significantly lower (see
Table 2).
Figure 2.
Parse tree of Bengali sentence illustrates that the language structures in contrast with that of English language impose extra challenges.
Figure 2.
Parse tree of Bengali sentence illustrates that the language structures in contrast with that of English language impose extra challenges.
Figure 3.
Early Seq2Seq models (LSTM-based) lacked nuanced context understanding, requiring many epochs, making them computationally expensive.
Figure 3.
Early Seq2Seq models (LSTM-based) lacked nuanced context understanding, requiring many epochs, making them computationally expensive.
Figure 4.
Bengali text generated with ChatGPT 3.5 model showing lack of coherence. The sentences often feel disjointed and lacking a logical flow. There are grammatical mistakes and word choices are ambiguous.
Figure 4.
Bengali text generated with ChatGPT 3.5 model showing lack of coherence. The sentences often feel disjointed and lacking a logical flow. There are grammatical mistakes and word choices are ambiguous.
- 2.
Limited Resources: Bengali is a low-resource language, lacking adequate language resources such as efficient tokenizers [
25,
26]. This scarcity further exacerbates the challenges faced by open-source language models. Current models predominantly cater to English language, neglecting the need for specialized models tailored to Bengali [
20,
27,
28,
29,
30,
31]. Dedicated efforts are required to develop and optimize Abstractive summarization models for Bengali language, drawing upon architectures like BERT and GPT [
32].
- 3.
Lack of Datasets: The absence of benchmark datasets for Bengali hampers research progress [
6,
33,
34]. Publicly available datasets are crucial for facilitating experimentation and evaluation in this field.
By addressing these challenges and research gaps, this study conducted extensive literature survey followed by investigated transformer model performance evaluation to contribute towards the development of robust and effective Abstractive summarization models tailored to the Bengali language, thereby advancing Bengali NLP.
In this study, the primary research gap lies in the limited exploration of transformer-based models for Bengali Text Summarization (BTS). While significant work has been done in other languages, particularly English, there is a lack of comprehensive studies on the effectiveness of transformers for Bengali. This review specifically addresses these gaps, aiming to provide a detailed analysis of transformer-based models and the challenges posed by the Bengali language in the context of abstractive summarization.
1.2. Research Objective
A comprehensive scoping review of BTS has been conducted in this work. It has covered transformer technologies, datasets, model techniques, and evaluation metrics. Key focuses include dataset analysis, preprocessing methods, accuracy assessment, and summarization evaluation metrics. The intents are:
To analyze different methods of text summarization for the Bangla language.
To analyze various performance metrics for the assessment of the Transformer model.
To examine evaluation methods to ascertain the caliber of the text produced for the current Transformer model.
The study identifies opportunities and challenges associated with utilizing Transformer models for Bengali summarization, evaluates state-of-the-art models to assess their performance on Bengali text. While abstractive summarization is well-studied in high-resource languages, transformer-based approaches for Bengali remain underdeveloped (see
Figure 4). Hence, this research fills a crucial gap by systematically analyzing contemporary models and their applicability to Bengali language.
1.3. Contribution
This research systematically identified and evaluated relevant primary studies from several research paper repositories, afterwards conducted a systematic Literature Review (SLR). A total of 106 primary studies were meticulously mapped, encompassing a range of methodologies, datasets, and evaluation metrics in Bengali summarization methods, particularly leveraging Transformer models. The study’s contributions are multifaceted, addressing various critical aspects of BTS:
Comprehensive Mapping: 106 primary studies were mapped methodically using the PRISMA framework. This exhaustive mapping provides a holistic view of the research landscape, facilitating a nuanced analysis of existing methodologies and trends.
Methodological Study: A thorough examination of Bengali summarization methods was conducted, covering diverse approaches such as Extractive and Abstractive summarization, linguistic resources, and data-driven techniques.
Evaluation of Transformer Models: The performance of Transformer models in Bengali summarization was rigorously evaluated, considering linguistic nuances, cultural significance, and domain-specific challenges. Transformer models were scrutinized in the context of BTS.
The structure of this paper is as follows:
Section 1 discusses the challenges of BTS, along with the research objectives and contributions.
Section 2 explores relevant literature, covering transformer-based models, multilingual model performance, and evaluation methodologies, with a particular focus on the mT5 model for BTS.
Section 3 outlines the research methodology, including quality assessment, key research questions, data preprocessing steps, and the experimental framework.
Section 4 describes the experimental setup, detailing the tools and libraries used, datasets employed, and fine-tuning techniques for summarization.
Section 5 presents the findings, including insights from systematic mapping studies, an analysis of reviewed data sources, and the performance assessment of the mT5 model.
Section 6 provides an analysis of the results in relation to prior studies, identifies key challenges such as limited dataset availability, and underscores the importance of developing customized resources for Bengali NLP. Lastly,
Section 7 highlights key takeaways, emphasizing contributions and suggesting directions for future research in BTS.
2. Literature Review
Since 2007, BTS has seen significant progress through various models and approaches aimed to generate concise summaries for large context. The initial efforts by Nizam et al. [
35] utilized Java-based techniques such as location, cue, term frequency, and numerical data analysis, using the Prothom-alo corpus to select the top 40% of sentences for summarization. This was followed by Iftekharul et al.’s [
36] sentence scoring and ranking methods, and Majharul et al.’s [
37] clustering techniques.
In 2016, Majharul et al. [
38] introduced TF-IDF methods for sentence ranking and scoring, evaluated with the ROUGE package, although they did not disclose assessment metrics for summary quality. The next year saw the advancements in Abstractive summarization by Anirudha et al. [
39], using term frequency and DBSCAN for similarity detection.
Several studies in 2017 explored Extractive summarization: Abujar et al. [
40] developed integrated heuristic methods, Sumya et al. [
41] applied K-means clustering, and Sohini et al. [
42] utilized Latent Semantic Analysis (LSA). In 2018, Partha et al. [
43] focused on preprocessing and ranking methods, then Tumpa et al. [
44], Porimol et al. [
45] proposed distinctive models for enhancement of Extractive summarization methods.
Avik et al. (2018) [
46] suggested a method relying on tokenization, stop word removal, and lemmatization, emphasizing semantic similarity. In 2019, Ashraful et al. [
47] explored Bi-directional RNN with LSTM for Abstractive summarization but faced challenges in producing summaries with predefined word counts. Abujar et al. [
48] employed Word2Vector for Extractive summarization, and Kaisar et al. [
49] developed a model using sentence similarity techniques.
The recent years witnessed developments in both Extractive and Abstractive summarization models. Alvee et al. (2020) [
50] combined stemming, tokenization, and stop word removal, while Sheikh et al. (2020) [
51] utilized RNN-LSTM for summarizing social media data. Prithwirai et al. (2021) [
52] introduced an Abstractive model using seq2seq-based LSTM with encoder-decoder attention, showing improvements in human evaluation. However, many studies, for an instance Fatema et al. (2021) [
53] and Muhaiminul et al. (2021) [
54] in separate studies proposed summarization model frameworks, however there were lacking in transparency in evaluation report assessment metrics results, hindering a comprehensive evaluation of model efficacy.
Despite significant advancements, the recurring challenge remains, which is the lack of transparency in reporting assessment metrics, which continues to hinder the comprehensive evaluation of the models’ efficacy.
2.1. Transformer Based Models
Researchers have increasingly explored Transformer-based models (see
Table 3) for BTS [
12,
13,
25,
55,
56,
57]. Masum et al. [
49] investigated Abstractive summarization for Bengali using Transformer architectures, achieving promising results in generating concise summaries by leveraging sentence similarity techniques. Recently, Mukherjee et al. [
25] proposed a modified version of Transformer model for Bengali, addressing linguistic complexities and achieving notable improvements in summary quality.
Additionally, Sultana et al. [
58,
59,
60] explored Transformer models’ efficacy in handling long-form Bengali documents, introducing novel attention mechanisms and positional encoding strategies to generate concise summaries while preserving key information and coherence.
Table 3.
Cutting edge Transformer Models.
Table 3.
Cutting edge Transformer Models.
| Paper | Model | Language | Description | Libraries | Remarks |
|---|
| [61] | mBART, IT5 | Italian (Italiano) | Summarization, Translation, Vocal Bursts Valence Prediction | PyTorch | Used translated datasets |
| [62] | ViT5, ViT5 Large | Vietnamese | Summarization, Named Entity Recognition (NER) | TensorFlow, PyTorch | Leading Summarization, Competitive results in NER |
| [63] | Transformer LM | English | 12-layer Transformer, 135M parameters, CNN Daily Mail dataset | TensorFlow | Improved efficiency, Text summarization gains |
| [64] | XLNet | English | Summarization (specifically on CNN Daily Mail dataset) | PyTorch, OpenNMT, Hugging Face Transformers for XLNet | CNN/Daily Mail dataset |
| [65] | Pegasus | English | Abstractive summarization | PyTorch, Tensorflow | Calibration benefits scale with model size. |
| [66] | Seq2seq | English | Abstractive summarization | Tensorflow | Outperforms baseline. Dataset: EDUSum |
| [67] | BART (Textbox 2.0) | English | Abstractive text generation | TextBox 2.0 | Pre-trained Language Models (PLMs) |
| [68] | BART IT | Italian (Italiano) | Italian summarization | Transformers, PyTorch | Proficient Italian summarization |
| [61] | mBART | Italian (Italiano) | Abstractive Text Synopsis, Human Assessment | PyTorch | Training with translated datasets |
The attention mechanism in Transformer architecture [
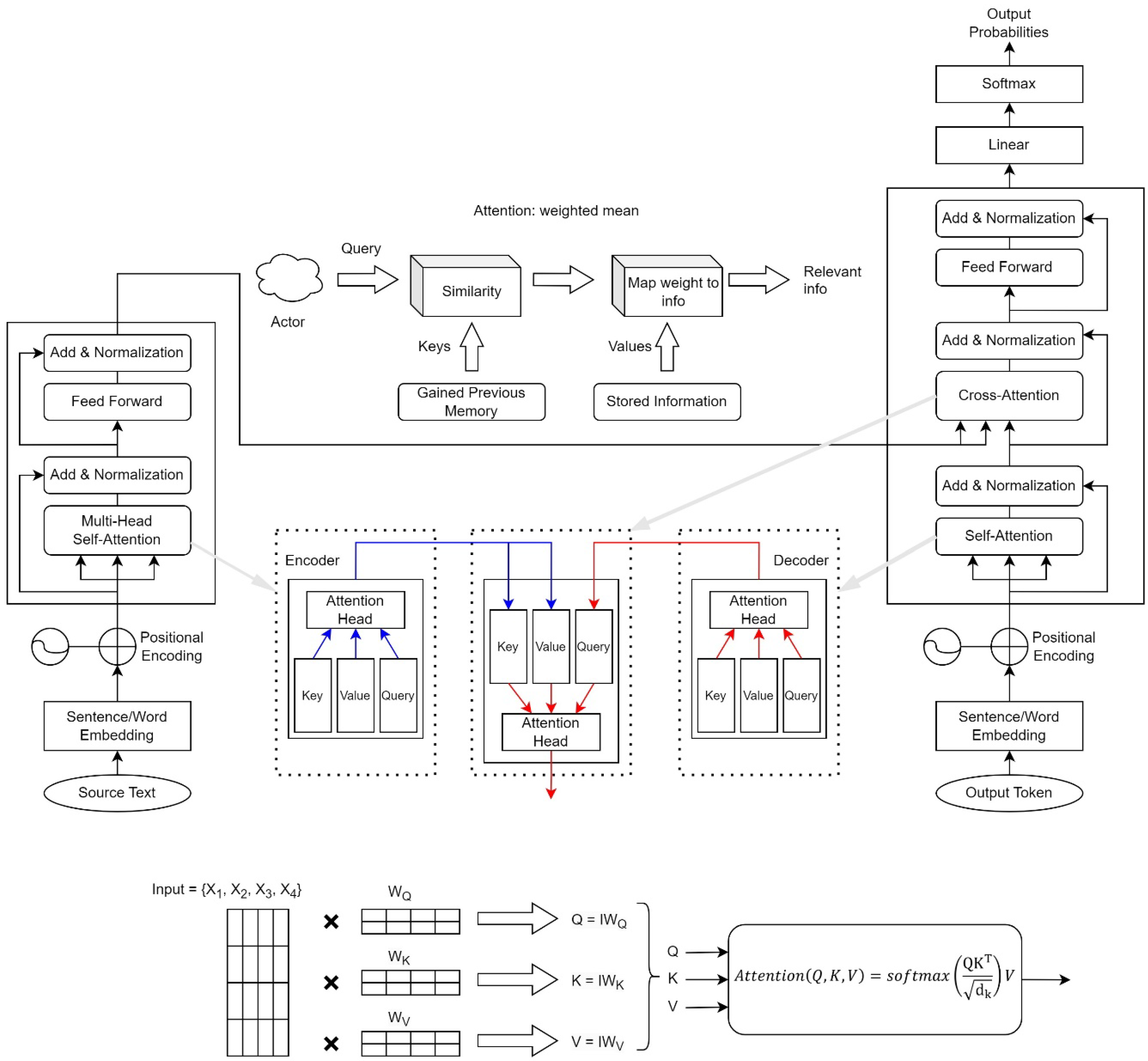
69] has revolutionized text summarization, enabling effective capture of contextual nuances and dependencies across sequences. Transformer-based models are pivotal in modern NLP, setting unprecedented standards for automated summarization by comprehending intricate linguistic nuances and producing human-like summaries. These models consist of encoder and decoder components, each with multiple layers incorporating self-attention mechanisms and feed-forward networks.
2.1.1. Encoder
Encoder is one of the core components of Transformer model [
11,
32]. Each layer has two main sub-layers:
- 1.
Self-Attention layer: enhances the matrix quality and learns token relations.
- 2.
Feed-Forward Network (FFN): learns position wise token relations.
Sequentially oriented
identical encoder layers are incorporated into the model:
where
represents the input sequence embedding vector and
is the output of the final encoder layer [
54,
58,
70].
where,
,
,
and
correspond to Query, Key, Value and Attention matrices respectively,
,
, and
are weight matrices,
is the output matrix from the previous layer.
b is the bias and
represents the keyed vector dimension. The position-wise Feed-Forward Network
is expressed as follows:
2.1.2. Decoder
The decoder [
71,
72] creates the output vector by using the input vector and the output that was previously created by the decoder model itself. Similar to encoding process, decoder is a pile of
N multiple head self-attention identical layers. Each layer integrates with position-wise fully connected feedforward network (see Equations (
1) and (
2)). Hence, the Decoder is:
The The input vector and output generation process are identical to encoder (see Equation (
1)).
Figure 5 provides a detailed representation of the Transformer architecture, crucial for understanding abstractive BTS. The encoder processes input tokens through self-attention and feed-forward layers, generating contextual embeddings. These embeddings are passed to the decoder, which integrates self-attention, cross-attention (using encoder outputs), and feed-forward layers to generate output tokens.
2.1.3. Attention Mechanism
In Transformer architecture, attention [
69] mechanism is the key element for capturing contextual cues and enhancing word relationships. Unlike RNNs (Recurrent Neural Networks), Transformers process sequences in parallel, using self-attention to efficiently handle long-range dependencies. Self-attention calculates attention vectors for each word, culminating in a final attention vector derived from the weighted average of multiple attention vectors per word, processed by an FFN (see
Figure 5).
The multi-head attention mechanism generates context vector for each element. The overall model is:
During the training process, loss is minimized for predicted output sequence and the actual sequence .
2.2. Multilingual Models
Transformer models are now widely used in modern applications as handy tools for text summarization. Hugging Face is a pre-trained transformer model repository for various cutting-edge applications of NLP used in this research scope. The study carefully looks at Extractive and Abstractive methods for summarizing data in Bengali models hosted in huggingfaces. The main goal was to carefully evaluate how well they performed, with a focus on accuracy.
2.2.1. Multilingual Model Performance
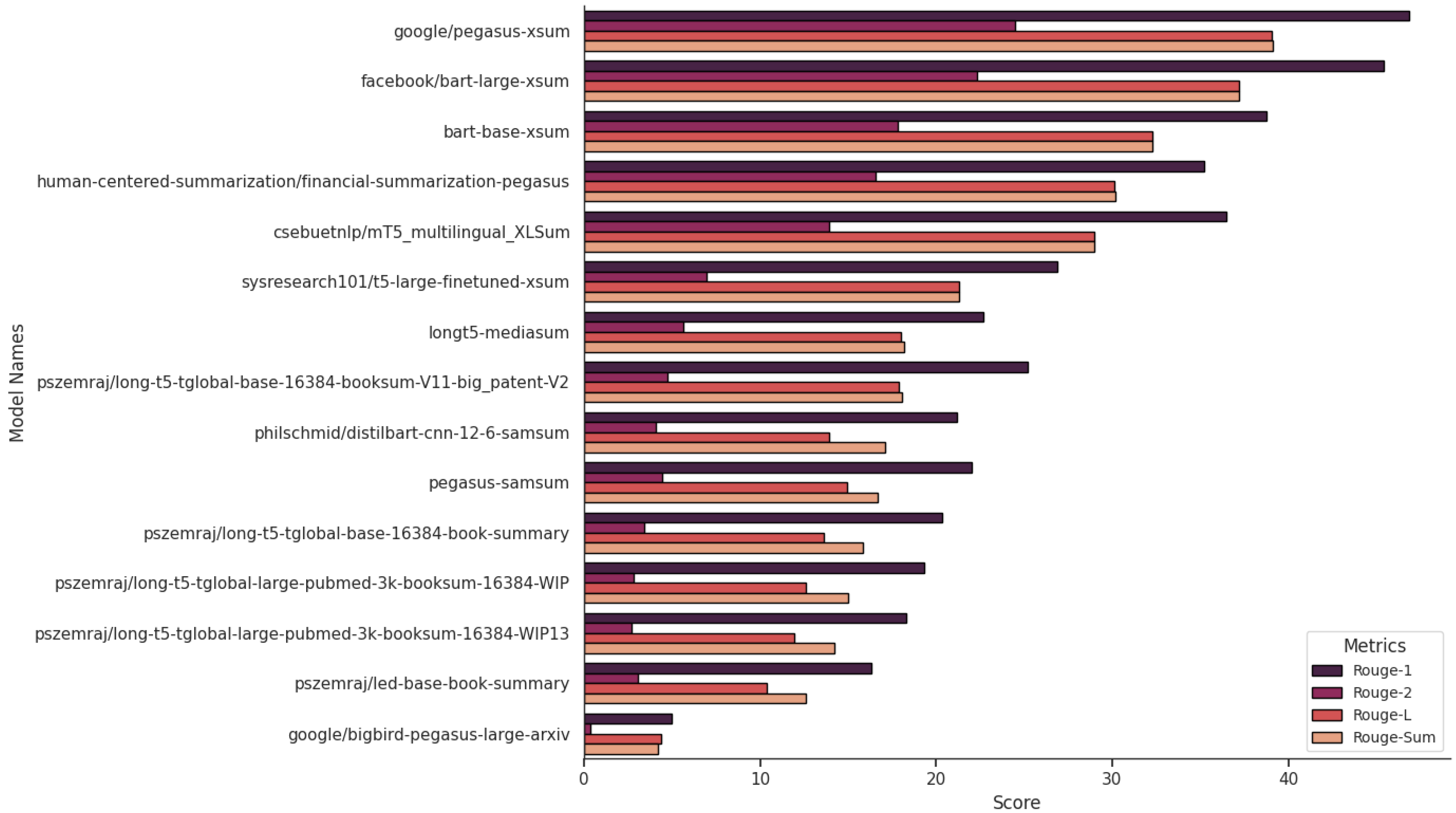
Some of the performances of models are illustrated in
Figure 6. The results shown in
Figure 6 are derived from monolingual open-source models available on Hugging Face for text summarization. This is evaluated based on ROUGE scores (see
Section 2.3). These models were evaluated to identify the best performing ones for multilingual text summarization, including Bengali. Since this research focuses on leveraging off-the-shelf models for Bengali abstractive summarization, the initial step was to analyze multilingual models to determine their effectiveness before narrowing down to monolingual alternatives.
Highest Rouge scores were achieved with the google pegasus-xsum model (46.86 Rouge-1) and facebook bart-large-xsum (45.45 Rouge-1). The bart-base-xsum (38.74 Rouge-1) shows a clear performance gap. Models like pszemraj exhibit a wider range of performance. Some do achieve respectable scores (around 18 Rouge-1). This demonstrates that fine-tuning may not always be as effective for summarization tasks on the xSum dataset. The google bigbird-pegasus-large-arxiv has exceptionally low Rouge scores (around 5 Rouge-1), which indicate specific configuration issues with this model that hinder its summarization ability and it requires further investigation. Based on Rouge scores, LLMs (Large Language Models) like pegasus-xsum appear to be the most adept at text summarization on the xSum dataset. The size of the model appears to be correlated with performance. In fact, larger models generally achieved better results.
The Bart CNN model developed by Facebook is competitive for multilingual summarization [
73]. The model was trained with CNN and Daily Mail news dataset [
74]. For Bengali, fine-tuning is necessary. Pegasus models by Hugging Face need multilingual corpus training. BLOOM lacks Bengali data in its implementation.
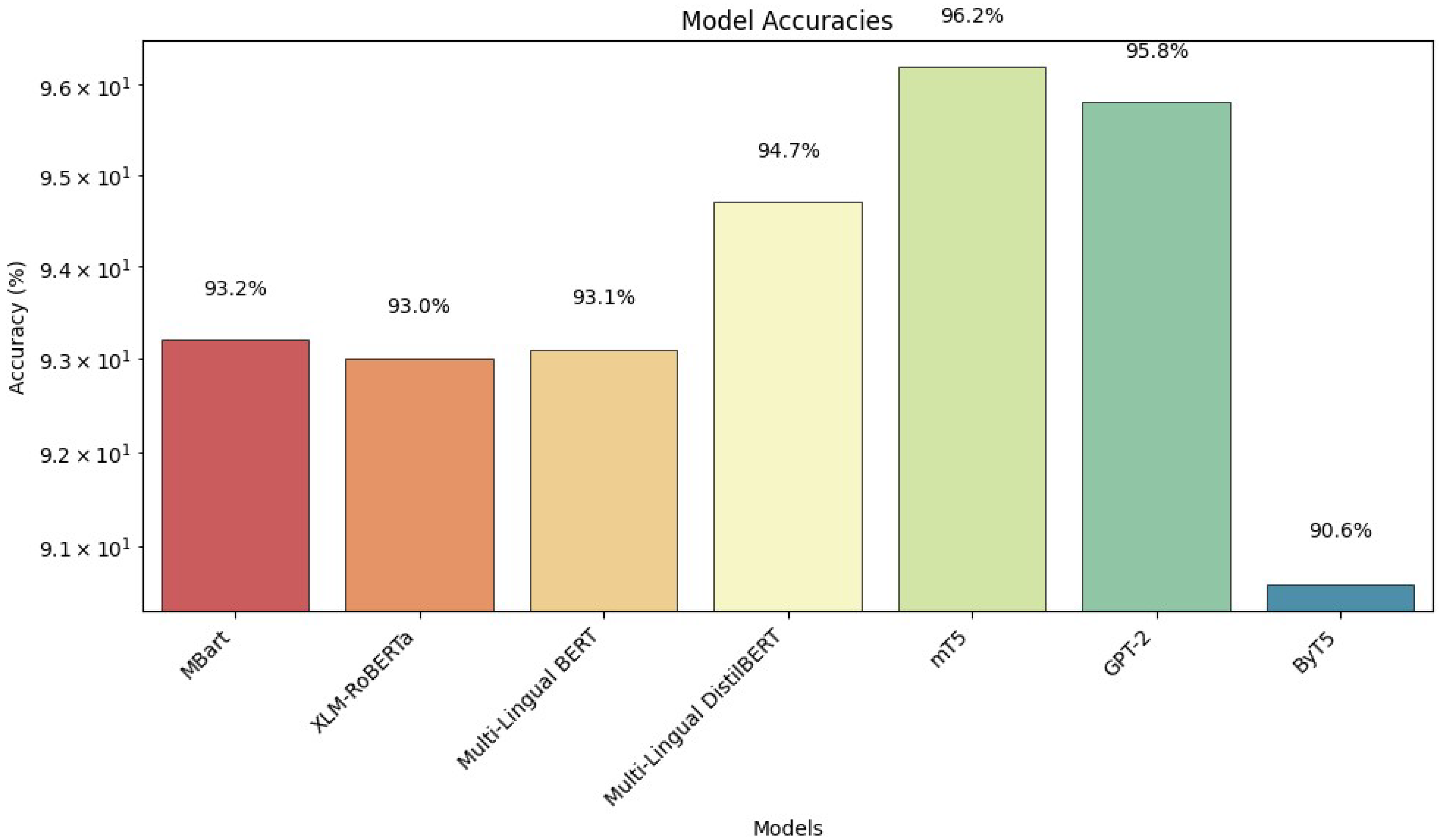
The performances of the models in
Figure 6 were evaluated based on their effectiveness in text summarization. Models such as BERT, Pegasus and T5 have shown prominence in this domain. However, certain models such as ChatGPT could not be evaluated due to the limited public availability of its versions. A claim supported by numerous studies discussed in this literature review is that the transformer-based models (which are given priority) offer superior semantic understanding. Since not all models were explicitly designed for text summarization, classification task accuracy was used as an alternative metric to assess performance in
Figure 7. This approach ensures a more comprehensive evaluation, allowing us to identify the most suitable models for further investigation in Bengali abstractive text summarization.
Figure 7 illustrates the performance of various language models in classifying partisan news articles, with accuracy percentages depicted along the y-axis. Among the models evaluated, mT5 is revealed as the most promising, achieving accuracy rate of 96.2%. Following closely behind that is Multi-Lingual DistilBERT, exhibiting a notable accuracy of 94.7%. Other models such as MBart, XLM-RoBERTa, and Multi-Lingual BERT demonstrate similar levels of accuracy, ranging between 93.0% and 93.2%. However, GPT-2 and ByT5 exhibit comparatively lower accuracy, standing at 90.8% and 90.6%, respectively. The chart underscores the effectiveness of advanced language models, particularly mT5 and Multi-Lingual DistilBERT, in accurately discerning partisan content within Dutch news articles, offering valuable insights into the capabilities of these models for partisanship detection tasks.
2.2.2. mT5 Model for BTS
The MT5 model is a popular, publicly available Transformer model [
25,
71,
75,
76,
77]. This T5 model has the capability to support multiple languages. It showed promising results in this research experiment. From the experimental results, mT5 model demonstrated slightly better accuracy as illustrated in
Figure 7. The mT5 (multilingual T5) model is chosen for experiments in the research study for several reasons:
- 1.
Fine-Tuning: The mT5 model is pre-trained on multilingual corpus in an unsupervised manner. It can be fine-tuned for specific language like Bengali. It allows the model to adapt the linguistic nuances and patterns of specific language. Hence, it improved performance for summarization tasks [
78,
79,
80].
- 2.
Versatility and Task Handling: T5, upon which mT5 is built, is known for its ability to handle multiple natural language processing tasks within a single model [
79,
81,
82]. By leveraging the capabilities inherited from T5, mT5 can effectively handle summarization tasks for Bengali text. [
83]
- 3.
Pre-trained Model Availability: The pre-trained mT5 model is accessible through platforms like Hugging Face, which provides easy integration into research process. Researchers can leverage the pre-trained mT5 model for summarization tasks without the need for additional fine-tuning, although fine-tuning may still be beneficial for specific tasks or datasets.
Overall, multilingual mT5 provides versatility, ease of access to datasets, fine-tuning abilities for the Bengali language, and effectiveness in handling summarization tasks.
2.3. Evaluation of the Model
It is expected that the summary will incorporate all significant terms from given context. One of the most frequently used evaluation methods for summarization task is ROUGE [
15,
84]. ROUGE evaluation method quantifies the overlap of n-gram tokens between the reference and generated summaries. The longest common substrings (LCS) are considered in the computation of variations such as ROUGE-L and ROUGE-Lsum.
ROUGE Evaluation
ROUGE denoted as ROUGE-N [
15,
84], where
,
n; 1 represents unigrams single token, 2 for bigrams double token and
N denotes the value of
n number of grams or tokens. Precision, Recall and F1 score for ROUGE can be expressed as follows:
where,
g represents the Unigram or Bi-gram token,
R represents the reference summary, and
C is the generated summary from the context.
3. Methodology
This study conducts an extensive review of BTS using PRISMA techniques (see
Figure 8).
This approach is recommended by Arksey and O’Malley and some literature [
85,
86,
87]. Hence, contemporary relevant research on BTS are taken into consideration meticulously. Thorough Search was conducted on databases including IEEE Xplore, ScienceDirect, Springer, and Conference papers, with a focus on articles published between December 2007 to December 2022.
3.1. Selection of Studies and Screening Process
A systematic review was conducted to find relevant literature that uses different types of summarization methods to summarize Bengali text. IEEE Xplore, ScienceDirect, Springer and the most pertinent sources and important scientific works were included. The search criteria was specified, and chosen research mainly focused on Bengali-language literature. “Bengali text” AND (“abstractive” OR “extractive”) AND “summarization algorithm” was the search term used in the databases. Using particular inclusion criteria, a thorough screening and selection process was followed to find pertinent studies on Bengali text summarization. Publications only in English-language were taken into consideration; these included research papers, news articles, and summaries created by humans that were released between December 2022 and 2007. The inclusion and exclusion criteria were applied consistently throughout this procedure. The following requirements were met for inclusion:
Presented in English and published in reputed conferences or journals.
Articles submitted for consideration must have appeared in English between December of 2007 and December of 2023.
The main focus is on summarizing Bengali text, using models or algorithms to summarize news in Bengali.
Articles that use machine learning or natural language processing without suggesting or utilizing text generation techniques were not considered.
3.2. Quality Assessment
The 106 selected studies were evaluated using the Quality Assessment Criteria (QAC) to ensure their relevance to the objectives of this systematic review. The assessment questions were formulated based on established guidelines for systematic literature reviews, focusing on research clarity, methodological soundness, evaluation metrics, comparative analysis, and discussion of results. Ten questions (see
Table 4) were designed to assess the significance and reliability of each study. Adapted from widely accepted review methodologies in NLP and text summarization, the criteria ensure consistency in the selection process. Each study was assessed using a ‘Yes’ or ‘No’ response format, and only those meeting the quality standards were included in the final review.
3.3. Research Questions
Research questions are segregated into three aspects, which are fundamental for advancing abstractive BTS. First crucial point is that the transformer-based architectures have revolutionized natural language processing (NLP) but their effectiveness in BTS requires empirical validation. Secondly, high-quality benchmark datasets are the backbone of any machine learning model’s success. Identifying widely used datasets for training, fine-tuning, and evaluation ensures reproducibility and meaningful performance comparisons. Lastly, the summarization quality is often subjective and it depends on different metrics (e.g., ROUGE). Accurate performance estimation helps refine models and improve summarization quality. Together, these questions provide a comprehensive framework for assessing transformers in BTS, guiding dataset selection, and ensuring reliable performance evaluation.
Hence, this research study investigated the following research questions:
RQ1: How effective is the transformer model in the area of Abstractive BTS?
RQ2: What are the benchmark standard datasets for Training, Fine-Tuning and performance comparison for Bengali language Text summarization?
RQ3: How to estimate the performance of text summarization models?
3.4. Experimental Setup
The Experimental setup involves several key steps: data pre-processing, model application, and evaluation of the generated summaries. Below is a detailed description of each step:
Data Pre-Processing
The following pre-processing steps were applied to the XLSum dataset for conducting experiments:
Cleaning: One of the major steps of NLP is data cleaning since dataset might contain irrelevant tokens such as irrelevant characters, special symbols, HTML tags, and extra white spaces. The raw text dataset was cleaned to remove any unwanted tokens. This process ensures consistency.
Tokenization: The cleaned text was then tokenized into individual words or tokens. Tokenization splits the text into smaller units to process input by the model.
Stemming: This process converts words to their base or root form. Hence, tokens are normalized. Model can handle different linguistic variations of a word, ensures that words with the same root are treated similarly.
4. Experiments
4.1. Software and Libraries Used
Two cutting-edge libraries: TensorFlow (version 2.12.0) and Hugging Face Transformer (version 4.29.0) are used mainly for obtaining publicly available models and datasets. Along with these libraries, other libraries and packages are Pandas (version 2.0.0), Numpy (version 1.24.3), PyTorch (version 1.13.1), Keras (version 2.12.0), and sci-kit-learn (version 1.3.0), which have been applied during the experiments for dataset munging, pre-processing, and handling model hyper-parameters and variables. Machine configuration details are given in
Table 5.
4.2. Transformer Model Dataset
Our study focuses on the task of BTS using the XLSum dataset [
88]. A comparative research review for transformer model dataset is stated in
Table 6.
4.3. Experiment Dataset
The CSEBUETNLP XLSum dataset [
88] has been utilized, sourced from the repository of Hugging Face, renowned for its extensive coverage of large-scale multilingual Abstractive summarization. This dataset contains 1.35 million annotated pairs of text articles and reference summary pairs which is collected from one of the largest news provider BBC articles. Mainly CSEBUETNLP XLSum was prepared from XL-Sum. This dataset was used to train various state-of-the-art models. There are total about 10,126 samples (8102 for training and 1012 for testing and validation) for Bengali. Some publicly available models that use XL-Sum dataset are listed in
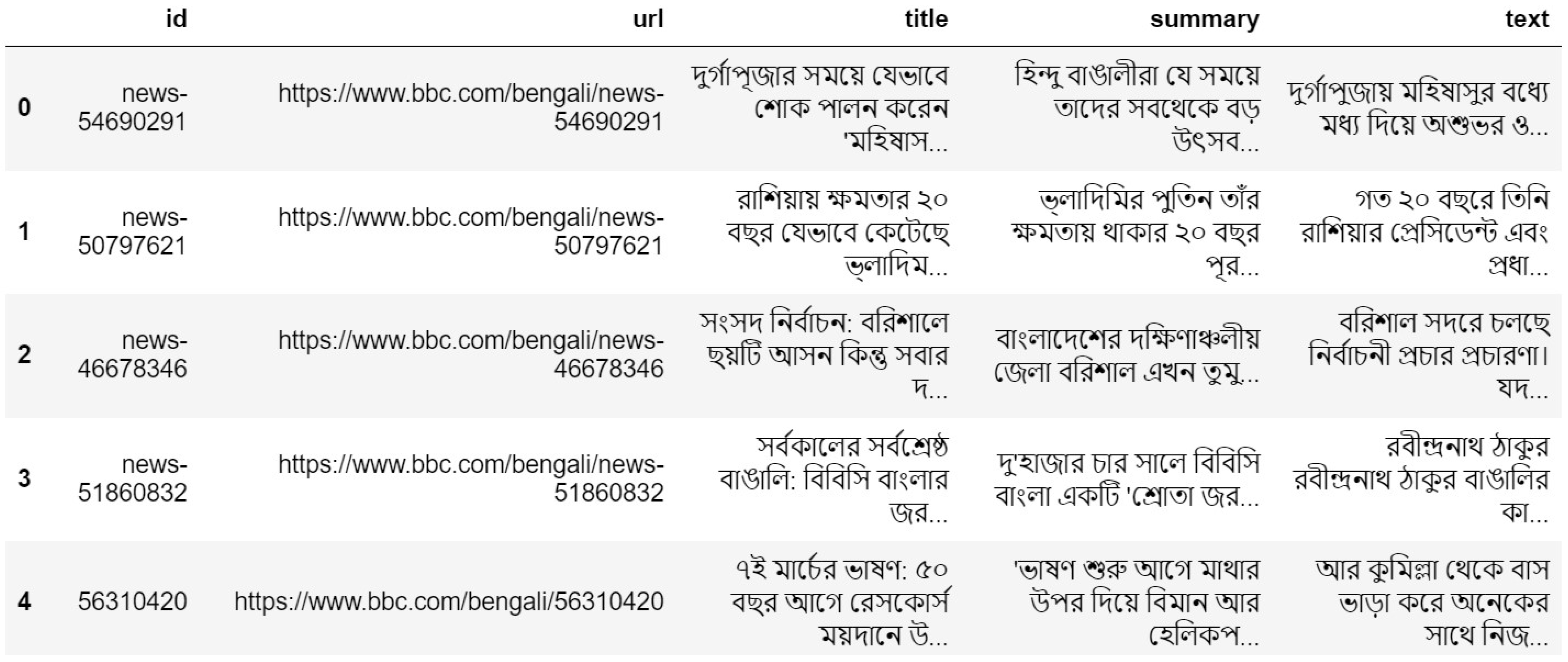
Table 7. The dataset supports 45 languages, including Bengali. The experiments employed Hugging Face Transformers alongside libraries such as pandas, sci-kit-learn, PyTorch, TensorFlow, and Keras. The structured format of the CSEBUETNLP XLSum dataset, provided by CSEBUETNLP, includes essential features (title, summary, Text) for analysis [
34,
88]. This dataset follows a structured format that includes the following features:
’id’: An array that holds the article ID.
’URL’: A string of characters representing the article’s URL.
’title’: The string representation of the article title.
’summary’: An array holding the synopsis of the article.
’text’: An array that holds the text of the article.
Figure 9 displays a tabular overview of the XLM-SUM dataset, illustrating sample entries with attributes such as article ID, URL, title, summary, and full text. This representation highlights the dataset structure and essential elements for BTS. The dataset was divided to support effective model training and evaluation. 70% of the data was used for training, enabling the model to learn patterns from a diverse range of examples. 15% was allocated for validation to fine-tune the model and prevent overfitting. The remaining 15% was reserved for testing, ensuring an objective assessment of the model’s summarization performance. This distribution follows a widely used approach in machine learning to achieve reliable generalization and evaluation.
4.4. Experimental Setup
Experiments were conducted with encoder-decoder Transformer architecture summarization models. The following steps were followed:
DataLoader Creation: Utilized PyTorch’s DataLoader to create a Dataloader for the test dataset. The dataset is converted to the “torch” format, and the collate fn function (data collator) is used to collate batches.
Tokenization Function: tokenize sentence - This function takes an argument, tokenizes it using the T5 tokenizer, and returns the tokens.
Batch Iteration: Iterates through the DataLoader to obtain batches of data.
Model Prediction: Utilizes the model’s generate method to generate predictions for the input sequences in the batch. Various parameters, such as num beams, no repeat ngram size, and max length are set for generation.
Evaluation ROUGE Score Computation Function: metrics func - This function takes evaluation arguments, replaces values, decodes token IDs to text, inserts line breaks in each sentence, and computes ROUGE scores using the custom tokenization function tokenize sentence.
Fine-Tuning for Summarization
Initially, the default hyperparameter values recommended in prior research on mT5-based summarization models were adopted. Based on the model’s performance on the validation set, key parameters were systematically adjusted—such as learning rate, batch size, and weight decay—to enhance stability and prevent overfitting. Since the mT5 model is pre-trained, the fine-tuning process primarily focused on optimizing the final layers of the architecture to generate high-quality summaries tailored to Bengali abstractive summarization.
To fine tune summarization model, the HuggingFace transformer trainer class is utilized [
114], which contains
Seq2Seq Trainer, and the
Seq2Seq Training Arguments huggingface class. Converting words into IDs (Tokenization) is the first step. Pre-trained mT5 model is used as a tokenizer model (see
Table 8).
There were a few more parameters that need to be declared during the fine-tuning process. These default parameters’ values were unchanged. To enhance the performance of the mT5 model for BTS, specific adjustments were made manually. While grid search techniques could have been used for hyperparameter optimization, they require extensive computational resources and significantly increase training time. Since the primary objective was to investigate the best-performing models, this work opted for a more targeted manual tuning approach instead. The learning rate was set to ensure effective learning from the provided dataset. An epoch size of 5 was chosen to help the model better adapt to the dataset. Additionally, parameters such as beam search size, repetition penalty, and maximum sequence lengths were fine-tuned based on default settings.
5. Results
5.1. Reviewed Paper Data Source
For the 25 studies reviewed, various sources were used to obtain data for testing and training the models. Of the 25 studies, 17 (68%) used newspaper articles. This indicates that newspaper articles were the most popular choice. With data sources from 24% of the studies (6/25), the Daily Prothom-alo was the most often used newspaper. Daily Kaler Kantho (8%), Daily Jugantor (4%), Bangladesh Protidin (4%), and Anandabazar Patrika (4%), among other newspapers, are also employed. 7 studies out of 25 (28%) used social media platforms (SMPs) to collect data [
46,
47,
48,
50,
51,
53,
54]. Group posts, personal posts, and page posts were the most frequently used social media platforms (SMPs) as data sources, with a prevalence of 28%. Online blogs (8%) and Twitter (12%) were among the other SMPs. These studies used SMP (Social Media Platform) posts as their datasets, but they did not specify the size of the datasets. Ninety-eight thousand five hundred twenty-five words were gathered by one study out of the 25 included from the West Bengal Bangla Academy [
39].
The Bangla Natural Language Processing Community provided data for a different study as a secondary source [
115], and additional sources included an online review platform [
116] and first-hand accounts [
40]. A few research projects used datasets without citing the source [
42,
49]. 19 studies out of 25 that included newspaper articles had dataset sizes that were not specified (36%) [
35,
41,
44,
45,
46,
47,
48,
58,
70]. Dataset sizes ranged from 45 articles at minimum to 19,000 articles at maximum for the remaining studies. 3 studies used 400 and 1000 articles, while 2 used sample sizes between 40 and 50 articles [
36,
37,
38,
39,
115]. A maximum of 19,000 news articles were included in two research that used sample sizes greater than 2000. Large datasets ranging from 1000 to 3000 posts were used in social media studies [
53,
54], and 1 study used 102 articles without citing the data source [
42]. Finally, 98,525 words from a West Bengal Bangla Academy dataset were used in 1 study [
39]. The reviewed studies did not specifically address ethical issues regarding managing and gathering social media data. Notably, although information about ethical approval was withheld, data from 2 studies that used Kaggle were made available to the public [
58,
117].
5.2. Systematic Mapping Study Result
This study critically examined 85 studies in this section from a variety of angles, including text summarization methodology, quality metric, dataset, data source, data pre-processing, and application.
Figure 10 shows the sources of the data.
Research on BTS employs both Extractive and Abstractive approaches. Initial studies, such as Uddin et al. (2007) [
35] and Efat et al. (2013) [
36], focused on Extractive summarization using methods like sentence frequency, cue methods, and location methods. Subsequent works, including Haque et al. (2015) [
37] and Masum et al. (2019) [
49], expanded on these techniques by incorporating sentence ranking, clustering, and fuzzy algorithms. Islam et al. (2020) [
115] further explored sentence scoring and text ranking for Extractive summarization. On the other hand, Abstractive summarization began with Tumpa et al. (2018) [
44] and Chandro et al. (2018) [
45], who introduced methods involving sentence scoring and synchronized summary generation. Sarkar et al. (2018) [
46] integrated term frequency with semantic sentence similarity while Talukder et al. (2019) [
47] utilized LSTM and BI-RNN models. Rahman et al. (2019) [
50] focused on sentence similarity, and Dhar et al. (2021) [
70] employed advanced techniques like BANS, Pointer networks, and Bi-LSTM. More recent work by Banik et al. (2022) [
117] has explored attention-based mechanisms, GRUs, and Seq2Seq models. Overall, the transition from conventional methods like Latent Semantic Analysis (LSA) and TF-IDF to sophisticated neural network models marks the evolution of BTS research.
Table 9 illustrates the most common approaches and techniques used for BTS.
Now, here are the answers to the questioned raised before:
RQ1: The performance of several Transformer models was assessed using ROUGE-1, ROUGE-2, ROUGE-L, and ROUGE-SUM scores in order to ascertain their correctness and efficacy. The experiments and results sections (
Section 4 and
Section 5) include comprehensive findings and analysis. Illustrative examples have been shown previously in
Figure 6 and
Figure 7.
RQ2: In the reviewed studies, various sources were used to obtain data for testing and training the models. Please see the
Section 5.1 which already has described various papers’ data sources.
RQ3: Several performance metrics were used in the reviewed research on BTS to evaluate the models’ efficacy. Precision, recall, F-measure for ROUGE scores are the most common metrics. While some studies included numerical evaluation data, others merely stated what they expected to happen and did not specify any metrics. Notably, the assessment details were not disclosed by Majharul et al. [
38], Anirudha et al. [
39], or Nizam et al. [
35]. In order to fully comprehend the model efficacy in BTS, it is imperative that the reported evaluation metrics be standardized and transparent [
35,
36,
37,
38,
39,
40,
41,
42,
43,
44,
45,
46,
47,
48,
49,
50,
51,
52,
53,
54,
58,
70,
115,
116,
117].
Table 10 illustrates the data pre-processing techniques used in the included studies. It signifies the usage of specific techniques in pre-processing for summarization.
Table 11 shows which methods have been used in the included studies and count of usage of specific models.
5.3. mT5 Model Performance
Using the XL-Sum dataset, the mT5 model displayed exceptional performance in text summarization, producing concise and coherent summaries. The evaluation on the XL-Sum test sets yielded the following scores (see
Figure 11 for details). ROUGE-1: 29.5653, ROUGE-2: 12.1095, and ROUGE-L: 25.1315. Additionally, the summarization model’s metrics at Step 2200 were outlined, indicating a training loss of 2.3946, validation loss of 2.457034, ROUGE-1 of 0.427435, ROUGE-2 of 0.253420, ROUGE-L of 0.351782, and ROUGE-Lsum of 0.370063.
6. Discussion
While numerous review articles exist on BTS, none has specifically focused on transformer-based abstractive summarization for the Bengali language. This research takes a structured approach by initially distinguishing between extractive and abstractive summarization, then further narrowing the scope to transformer-based models. Including all basic models would extend beyond the study’s objective of conducting an in-depth analysis of advanced architectures. Given that transformer-based models have already demonstrated superior performance in various NLP tasks, they are prioritized over traditional approaches. Therefore, basic models were excluded to maintain the research focus and provide a comprehensive evaluation of transformer-based abstractive summarization for Bengali language.
This study carefully selected 25 research papers based on their relevance to transformer-based abstractive summarization for the Bengali language. Given the limited availability of studies specifically addressing this area, priority was given to the high-quality, peer-reviewed papers that directly contribute to the research objectives. Expanding the selection to include more generic NLP or summarization studies would have diluted the focus on transformer-based approaches for Bengali. The goal was to provide an in-depth analysis of chosen domain.
Traditional LSTM-based models, while effective in sequential data processing, struggle with contextual understanding and require extensive computational resources for training. Transformer-based models, particularly mT5, have significantly improved summarization quality by capturing long-range dependencies and contextual information more effectively. However, these advancements are hindered by the scarcity of high-quality annotated Bengali datasets, limiting model generalizability. While the XL-SUM dataset serves as a benchmark, it lacks diversity, restricting broader applicability. Overcoming these challenges requires the development of larger, domain-specific datasets and optimization techniques tailored for Bengali NLP.
7. Conclusions
A comprehensive review from 2007 to 2023 on the Bengali Text Summarization (BTS) is provided. It highlights the progress and challenges in this domain. Through systematic mapping of 106 primary studies using the PRISMA framework, it offered a holistic view of existing methodologies, datasets, and evaluation metrics in BTS. Experiment results revealed that the mT5 model outperformed other contemporary transformer models. In terms of precision, recall, F1 score for ROUGE metrics, abstractive summarization shows that larger model (mT5-xxl) exhibited better performance. Although promising results were observed with mT5 model, during the experiments, only XLSUM dataset was used. Since, there was a lacking of annotated datasets for the Bengali language, it remains a significant challenge to cross validate results with various dataset. This research study compared multiple models using the same dataset. Indeed, the scarcity of annotated Bengali datasets remains a significant barrier to further advancements. Key findings of this work are:
The introduction of transformer models, particularly mT5, significantly improved abstractive summarization quality, outperforming previous architectures.
The XL-SUM dataset emerged as a widely used benchmark for Bengali abstractive summarization, but the lack of diverse datasets limits the generalizability of the findings.
Despite progress, challenges persist due to linguistic complexities, limited resources, and the absence of large-scale, high-quality annotated datasets for Bengali summarization.
These findings suggest that with multiple datasets, further research can be conducted to evaluate the performance of the same model across different datasets. This approach will help in benchmarking and identifying the most effective summarization techniques for Bengali language. The study underscores the importance of methodological diversity in BTS, covering both extractive and abstractive approaches, and highlights the need for better linguistic resources and more annotated datasets. Addressing these gaps will facilitate the development of more robust and accurate summarization models, ultimately advancing the field of Bengali Text Summarization.
Author Contributions
This research was a collaborative effort, with significant contributions from all authors. M.I.M. led the research design, conducted experiments, and was the primary writer of the manuscript, also serving as the corresponding author. M.H.M. played an equally crucial role by contributing to the writing, performing an in-depth literature review, and handling data analysis and figure creation. A.-S.K.P. provided critical supervision, offering essential guidance and analytical insights that shaped the research’s direction and ensured its academic rigor. Additionally, A.-S.K.P. reviewed the manuscript, enhancing its clarity and coherence. A.F.M.S.A. contributed by critically reviewing the manuscript, providing valuable feedback that strengthened the final version. All authors share equal responsibility for the content of this manuscript and made essential contributions to the research’s successful completion. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Conflicts of Interest
The authors declare that they have no competing interests.
References
- El-Kassas, W.S.; Salama, C.R.; Rafea, A.A.; Mohamed, H.K. Automatic Text Summarization: A Comprehensive Survey. Expert Syst. Appl. 2021, 165, 113679. [Google Scholar] [CrossRef]
- Widyassari, A.P.; Rustad, S.; Shidik, G.F.; Noersasongko, E.; Syukur, A.; Affandy, A. Review of Automatic Text Summarization Techniques & Methods. J. King Saud-Univ.-Comput. Inf. Sci. 2022, 34, 1029–1046. [Google Scholar]
- Ferreira, R.; de Souza Cabral, L.; Lins, R.D.; Silva, G.P.; Freitas, F.; Cavalcanti, G.D.; Lima, R.; Simske, S.J.; Favaro, L. Assessing Sentence Scoring Techniques for Extractive Text Summarization. Expert Syst. Appl. 2013, 40, 5755–5764. [Google Scholar] [CrossRef]
- Verma, P.; Verma, A. A review on text summarization techniques. J. Sci. Res. 2020, 64, 251–257. [Google Scholar] [CrossRef]
- Gambhir, M.; Gupta, V. Recent automatic text summarization techniques: A survey. Artif. Intell. Rev. 2017, 47, 1–66. [Google Scholar] [CrossRef]
- Mridha, M.F.; Lima, A.A.; Nur, K.; Das, S.C.; Hasan, M.; Kabir, M.M. A survey of automatic text summarization: Progress, process and challenges. IEEE Access 2021, 9, 156043–156070. [Google Scholar] [CrossRef]
- Liu, Q.; Cheng, G.; Gunaratna, K.; Qu, Y. Entity summarization: State of the art and future challenges. J. Web Semant. 2021, 69, 100647. [Google Scholar] [CrossRef]
- Muneera, N.M.; Sriramya, P. Abstractive text summarization employing ontology-based knowledge-aware multi-focus conditional generative adversarial network (OKAM-CGAN) with hybrid pre-processing methodology. Multimed. Tools Appl. 2022, 82, 23305–23331. [Google Scholar]
- Yadav, D.; Desai, J.; Yadav, A.K. Automatic text summarization methods: A comprehensive review. arXiv 2022, arXiv:2204.01849. [Google Scholar]
- Sharma, G.; Sharma, D. Automatic Text Summarization Methods: A Comprehensive Review. SN Comput. Sci. 2022, 4, 33. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Yenduri, G.; Srivastava, G.; Maddikunta, P.K.R.; Jhaveri, R.H.; Wang, W.; Vasilakos, A.V.; Gadekallu, T.R. Generative Pre-trained Transformer: A Comprehensive Review on Enabling Technologies, Potential Applications, Emerging Challenges, and Future Directions. arXiv 2023, arXiv:2305.10435. [Google Scholar] [CrossRef]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. AI Open 2022, 3, 111–132. [Google Scholar] [CrossRef]
- Lu, L.; Liu, Y.; Xu, W.; Li, H.; Sun, G. From task to evaluation: An automatic text summarization review. Artif. Intell. Rev. 2023, 56, 2477–2507. [Google Scholar] [CrossRef]
- Bhandari, M.; Gour, P.N.; Ashfaq, A.; Liu, P.; Neubig, G. Re-evaluating Evaluation in Text Summarization. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP); 2020; pp. 9347–9359. [Google Scholar]
- Khilji, A.F.U.R.; Sinha, U.; Singh, P.; Ali, A.; Pakray, P. Abstractive Text Summarization Approaches with Analysis of Evaluation Techniques. In Proceedings of the International Conference on Computational Intelligence in Communications and Business Analytics; Springer International Publishing: Cham, Switzerland, 2021; pp. 243–258. [Google Scholar]
- Mukta, A.P.; Mamun, A.A.; Basak, C.; Nahar, S.; Arif, M.F.H. A phrase-based machine translation from English to Bangla using rule-based approach. In Proceedings of the 2019 International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’s Bazar, Bangladesh, 7–9 February 2019; pp. 1–5. [Google Scholar]
- Hossain, N.; Ahnaf, A. BERT-based Text Simplification Approach to Reduce Linguistic Complexity of Bangla Language. In Proceedings of the 2021 International Conference on Intelligent Technology, System and Service for Internet of Everything (ITSS-IoE), Sana’a, Yemen, 1–2 November 2021; pp. 1–5. [Google Scholar]
- Shetu, S.F.; Saifuzzaman, M.; Parvin, M.; Moon, N.N.; Yousuf, R.; Sultana, S. Identifying the Writing Style of Bangla Language using Natural Language Processing. In Proceedings of the 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–3 July July 2020; pp. 1–6. [Google Scholar]
- Sen, O.; Fuad, M.; Islam, M.N.; Rabbi, J.; Hasan, K.; Baz, M.; Masud, M.; Awal, A.; Fime, A.; Fuad, T.H.; et al. Bangla Natural Language Processing: A Comprehensive Analysis of Classical, Machine Learning, and Deep Learning-Based Methods. IEEE Access 2022, 10, 38999–39044. [Google Scholar] [CrossRef]
- Sikder, R.; Hossain, M.M.; Robi, F.M.R.H. Automatic text summarization for Bengali language including grammatical analysis. Int. J. Sci. Technol. Res. 2019, 8, 288–292. [Google Scholar]
- Mridha, M.F.; Ohi, A.Q.; Hamid, M.A.; Monowar, M.M. A study on the challenges and opportunities of speech recognition for Bengali language. Artif. Intell. Rev. 2022, 55, 3431–3455. [Google Scholar] [CrossRef]
- Masum, A.K.M.; Abujar, S.; Talukder, M.A.I.; Rabby, A.S.A.; Hossain, S.A. Abstractive method of text summarization with sequence to sequence RNNs. In Proceedings of the 2019 10th international conference on computing, communication and networking technologies (ICCCNT), Kanpur, India, 6–8 July 2019; pp. 1–5. [Google Scholar]
- Chowdhury, R.R.; Nayeem, M.T.; Mim, T.T.; Chowdhury, M.S.R.; Jannat, T. Unsupervised abstractive summarization of bengali text documents. arXiv 2021, arXiv:2102.04490. [Google Scholar]
- Mukherjee, A. Developing Bengali Text Summarization with Transformer Base Model. Doctoral Dissertation, National College of Ireland, Dublin, Ireland, 2022. [Google Scholar]
- King, B.P. Practical Natural Language Processing for Low-Resource Languages. Ph.D. Dissertation, University of Michigan, Ann Arbor, MI, USA, 2015. [Google Scholar]
- Bhattacharjee, A.; Hasan, T.; Ahmad, W.U.; Shahriyar, R. Banglanlg: Benchmarks and resources for evaluating low-resource natural language generation in bangla. arXiv 2022, arXiv:2205.11081. [Google Scholar]
- Alam, F.; Hasan, A.; Alam, T.; Khan, A.; Tajrin, J.; Khan, N.; Chowdhury, S.A. A review of Bangla natural language processing tasks and the utility of transformer models. arXiv 2021, arXiv:2107.03844. [Google Scholar]
- Karim, M.A. (Ed.) Technical Challenges and Design Issues in Bangla Language Processing; IGI Global: Hershey, PA, USA, 2013. [Google Scholar]
- Gupta, A.; Vavre, A.; Sarawagi, S. Training data augmentation for code-mixed translation. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, June 2021; pp. 5760–5766. [Google Scholar]
- Hoque, O.B.; Jubair, M.I.; Akash, A.A.; Islam, S. Bdsl36: A dataset for Bangladeshi sign letters recognition. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Zhang, X.; Wei, F.; Zhou, M. HIBERT: Document level pre-training of hierarchical bidirectional transformers for document summarization. arXiv 2019, arXiv:1905.06566. [Google Scholar]
- Sen, O.; Fuad, M.; Islam, N.; Rabbi, J.; Hasan, K.; Awal, A.; Fime, A.A.; Fuad, T.H.; Sikder, D.; Iftee, D.A.R. Bangla Natural Language Processing: A Comprehensive Review of Classical Machine Learning and Deep Learning Based Methods. arXiv 2021, arXiv:2105.14875. [Google Scholar] [CrossRef]
- Hasan, T.; Bhattacharjee, A.; Samin, K.; Hasan, M.; Basak, M.; Rahman, M.S.; Shahriyar, R. Not Low-Resource Anymore: Aligner Ensembling, Batch Filtering, and New Datasets for Bengali-English Machine Translation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November November 2020; pp. 2612–2623. [Google Scholar] [CrossRef]
- Uddin, M.N.; Khan, S.A. A study on text summarization techniques and implement few of them for Bangla language. In Proceedings of the 2007 10th International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 27–29 December 2007; pp. 1–4. [Google Scholar] [CrossRef]
- Efat, M.I.A.; Ibrahim, M.; Kayesh, H. Automated Bangla text summarization by sentence scoring and ranking. In Proceedings of the 2013 International Conference on Informatics, Electronics and Vision (ICIEV), Dhaka, Bangladesh, 17–18 May 2013; pp. 1–5. [Google Scholar]
- Haque, M.M.; Pervin, S.; Begum, Z. Automatic Bengali news documents summarization by introducing sentence frequency and clustering. In Proceedings of the 2015 18th International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 21–23 December 2015; pp. 156–160. [Google Scholar]
- Haque, M.M.; Pervin, S.; Begum, Z. Enhancement of keyphrase-based approach of automatic Bangla text summarization. In Proceedings of the 2016 IEEE Region 10 Conference (TENCON), Singapore, 22–25 November 2016; pp. 42–46. [Google Scholar]
- Paul, A.; Imtiaz, M.T.; Latif, A.H.; Ahmed, M.; Adnan, F.A.; Khan, R.; Kadery, I.; Rahman, R.M. Bangla news summarization. In Proceedings of the Computational Collective Intelligence: 9th International Conference, ICCCI 2017, Nicosia, Cyprus, 27–29 September 2017; Proceedings, Part II 9. Springer: Berlin/Heidelberg, Germany, 2017; pp. 479–488. [Google Scholar]
- Abujar, S.; Hasan, M.; Shahin, M.; Hossain, S.A. A heuristic approach of text summarization for Bengali documentation. In Proceedings of the 2017 8th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Delhi, India, 3–5 July 2017; pp. 1–8. [Google Scholar]
- Akter, S.; Asa, A.S.; Uddin, M.P.; Hossain, M.D.; Roy, S.K.; Afjal, M.I. An extractive text summarization technique for Bengali document(s) using K-means clustering algorithm. In Proceedings of the 2017 IEEE International Conference on Imaging, Vision & Pattern Recognition (icivpr), Honolulu, HI, USA, 21–26 July 2017; pp. 1–6. [Google Scholar]
- Chowdhury, S.R.; Sarkar, K.; Dam, S. An approach to generic Bengali text summarization using latent semantic analysis. In Proceedings of the 2017 International Conference on Information Technology (ICIT), Singapore, 27–29 December 2017; pp. 11–16. [Google Scholar]
- Ghosh, P.P.; Shahariar, R.; Khan, M.A.H. A rule based extractive text summarization technique for Bangla news documents. Int. J. Mod. Educ. Comput. Sci. 2018, 10, 44. [Google Scholar] [CrossRef]
- Tumpa, P.; Yeasmin, S.; Nitu, A.; Uddin, M.; Afjal, M.; Mamun, M. An improved extractive summarization technique for bengali text(s). In Proceedings of the 2018 International Conference on Computer, Communication, Chemical, Material and Electronic Engineering (IC4ME2), Dhaka, Bangladesh, 8–9 February 2018; pp. 1–4. [Google Scholar]
- Chandro, P.; Arif, M.F.H.; Rahman, M.M.; Siddik, M.S.; Rahman, M.S.; Rahman, M.A. Automated bengali document summarization by collaborating individual word & sentence scoring. In Proceedings of the 2018 21st International Conference of Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 21–23 December 2018; pp. 1–6. [Google Scholar]
- Sarkar, A.; Hossen, M.S. Automatic bangla text summarization using term frequency and semantic similarity approach. In Proceedings of the 2018 21st International Conference of Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 21–23 December 2018; pp. 1–6. [Google Scholar]
- Talukder, M.A.I.; Abujar, S.; Masum, A.K.M.; Faisal, F.; Hossain, S.A. Bengali abstractive text summarization using sequence to sequence RNNs. In Proceedings of the 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kanpur, India, 6–8 July 2019; pp. 1–5. [Google Scholar]
- Abujar, S.; Masum, A.K.M.; Mohibullah, M.; Hossain, S.A. An approach for bengali text summarization using word2vector. In Proceedings of the 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kanpur, India, 6–8 July 2019; pp. 1–5. [Google Scholar]
- Masum, A.K.M.; Abujar, S.; Tusher, R.T.H.; Faisal, F.; Hossain, S.A. Sentence similarity measurement for Bengali abstractive text summarization. In Proceedings of the 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kanpur, India, 6–8 July 2019; pp. 1–5. [Google Scholar]
- Rahman, A.; Rafiq, F.M.; Saha, R.; Rafian, R.; Arif, H. Bengali text summarization using TextRank, fuzzy C-Means and aggregate scoring methods. In Proceedings of the 2019 IEEE Region 10 Symposium (TENSYMP), Kolkata, India, 7–9 June 2019; pp. 331–336. [Google Scholar]
- Abujar, S.; Masum, A.K.M.; Sanzidul Islam, M.; Faisal, F.; Hossain, S.A. A bengali text generation approach in context of abstractive text summarization using rnn. Innov. Comput. Sci. Eng. Proc. 7th Icicse 2020, 103, 509–518. [Google Scholar]
- Bhattacharjee, P.; Mallick, A.; Saiful Islam, M. Bengali abstractive news summarization (BANS): A neural attention approach. In Proceedings of the International Conference on Trends in Computational and Cognitive Engineering: Proceedings of TCCE 2020; Springer: Berlin/Heidelberg, Germany, 2021; pp. 41–51. [Google Scholar]
- Fouzia, F.A.; Rahat, M.A.; Alie-Al-Mahdi, M.T.; Masum, A.K.M.; Abujar, S.; Hossain, S.A. A Bengali Text Summarization Using Encoder-Decoder Based on Social Media Dataset. In Proceedings of the Emerging Technologies in Data Mining and Information Security: Proceedings of IEMIS 2020; Springer: Berlin/Heidelberg, Germany, 2021; Volume 2, pp. 539–549. [Google Scholar]
- Islam, M.M.; Islam, M.; Masum, A.K.M.; Abujar, S.; Hossain, S.A. Abstraction Based Bengali Text Summarization Using Bi-directional Attentive Recurrent Neural Networks. In Proceedings of the Emerging Technologies in Data Mining and Information Security: Proceedings of IEMIS 2020; Springer: Berlin/Heidelberg, Germany, 2021; Volume 2, pp. 317–327. [Google Scholar]
- Gupta, A.; Chugh, D.; Anjum; Katarya, R. Automated news summarization using transformers. In Proceedings of the Sustainable Advanced Computing: Select Proceedings of ICSAC 2021, LNEE, Singapore, 31 March 2022; Volume 840, pp. 249–259. [Google Scholar]
- Ranganathan, J.; Abuka, G. Text summarization using transformer model. In Proceedings of the 2022 Ninth International Conference on Social Networks Analysis, Management and Security (SNAMS), Milan, Italy, 28 November–1 December 2022; pp. 1–5. [Google Scholar]
- Kumar, S.; Solanki, A. An Abstractive Text Summarization Technique Using Transformer Model with Self-Attention Mechanism. Neural Comput. Appl. 2023, 35, 18603–18622. [Google Scholar] [CrossRef]
- Sultana, M.; Chakraborty, P.; Choudhury, T. Bengali abstractive news summarization using Seq2Seq learning with attention. In Proceedings of the Cyber Intelligence and Information Retrieval: Proceedings of CIIR 2021; Springer: Berlin/Heidelberg, Germany, 2022; pp. 279–289. [Google Scholar]
- Hoque Barsha, F.A.; Uddin, M.N. Comparative Analysis of BanglaT5 and Pointer Generator Network for Bengali Abstractive Story Summarization. In Proceedings of the 2023 International Conference on Information and Communication Technology for Sustainable Development (ICICT4SD), Dhaka, Bangladesh, 21–23 September 2023; pp. 84–88. [Google Scholar] [CrossRef]
- Bhattacharjee, A.; Hasan, T.; Ahmad, W.U.; Shahriyar, R. BanglaNLG and BanglaT5: Benchmarks and Resources for Evaluating Low-Resource Natural Language Generation in Bangla. In Proceedings of the Findings of the Association for Computational Linguistics: EACL 2023, Dubrovnik, Croatia, 2–6 May 2023; Vlachos, A., Augenstein, I., Eds.; pp. 726–735. [Google Scholar] [CrossRef]
- Landro, N.; Gallo, I.; La Grassa, R.; Federici, E. Two New Datasets for Italian-Language Abstractive Text Summarization. Information 2022, 13, 228. [Google Scholar] [CrossRef]
- Phan, L.; Tran, H.; Nguyen, H.; Trinh, T.H. Vit5: Pretrained Text-to-Text Transformer for Vietnamese Language Generation. arXiv 2022, arXiv:2205.06457. [Google Scholar]
- Khandelwal, U.; Clark, K.; Jurafsky, D.; Kaiser, L. Sample Efficient Text Summarization using a Single Pre-trained Transformer. arXiv 2019, arXiv:1905.08836. [Google Scholar]
- Guan, W.; Smetannikov, I.; Tianxing, M. Survey on automatic text summarization and transformer models applicability. In Proceedings of the 2020 1st International Conference on Control, Robotics and Intelligent System, Xiamen, China, 27–29 October 2020; pp. 176–184. [Google Scholar]
- Zhao, Y.; Khalman, M.; Joshi, R.; Narayan, S.; Saleh, M.; Liu, P.J. Calibrating sequence likelihood improves conditional language generation. arXiv 2022, arXiv:2210.00045. [Google Scholar]
- Zhao, S.; Li, Q.; He, T.; Wen, J. A Step-by-Step Gradient Penalty with Similarity Calculation for Text Summary Generation. Neural Process. Lett. 2023, 55, 4111–4126. [Google Scholar] [CrossRef]
- Tang, T.; Li, J.; Chen, Z.; Hu, Y.; Yu, Z.; Dai, W.; Wen, J.R. TextBox 2.0: A Text Generation Library with Pre-trained Language Models. arXiv 2022, arXiv:2212.13005. [Google Scholar]
- La Quatra, M.; Cagliero, L. BART-IT: An Efficient Sequence-to-Sequence Model for Italian Text Summarization. Future Internet 2023, 15, 15. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Dhar, N.; Saha, G.; Bhattacharjee, P.; Mallick, A.; Islam, M.S. Pointer over attention: An improved bangla text summarization approach using hybrid pointer generator network. In Proceedings of the 2021 24th International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 18–20 December 2021; pp. 1–5. [Google Scholar]
- Bani-Almarjeh, M.; Kurdy, M.B. Arabic Abstractive Text Summarization using RNN-based and Transformer-based Architectures. Inf. Process. Manag. 2023, 60, 103227. [Google Scholar] [CrossRef]
- Núñez-Robinson, D.; Talavera-Montalto, J.; Ugarte, W. A Comparative Analysis on the Summarization of Legal Texts Using Transformer Models. In Proceedings of the International Conference on Advanced Research in Technologies, Information, Innovation and Sustainability, Cham, Switzerland, 21–23 October 2022; pp. 372–386. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Nallapati, R.; Zhou, B.; Gulcehre, C.; Xiang, B. Abstractive Text Summarization using Sequence-to-Sequence RNNs and Beyond. arXiv 2016, arXiv:1602.06023. [Google Scholar]
- Farahani, M.; Gharachorloo, M.; Manthouri, M. Leveraging ParsBERT and Pretrained mT5 for Persian Abstractive Text Summarization. In Proceedings of the 2021 26th International Computer Conference, Computer Society of Iran (CSICC), Tehran, Iran, 3–4 March 2021; pp. 1–6. [Google Scholar]
- Reda, A.; Salah, N.; Adel, J.; Ehab, M.; Ahmed, I.; Magdy, M.; Khoriba, G.; Mohamed, E.H. A Hybrid Arabic Text Summarization Approach Based on Transformers. In Proceedings of the 2022 2nd International Mobile, Intelligent, and Ubiquitous Computing Conference (MIUCC), Cairo, Egypt, 8–9 May 2022; pp. 56–62. [Google Scholar]
- Borah, M.P.; Dadure, P.; Pakray, P. Comparative Analysis of T5 Model for Abstractive Text Summarization on Different Datasets. 2022; preprint. [Google Scholar]
- Hossen, M.A.; Govindaiah, A.; Sultana, S.; Bhuiyan, A.A. Bengali sign language recognition using deep convolutional neural network. In Proceedings of the 2018 Joint 7th International Conference on Informatics, Electronics & Vision (ICIEV) and 2018 2nd International Conference on Imaging, Vision & Pattern Recognition (icIVPR), Kitakyushu, Japan, 25–29 June 2018; pp. 369–373. [Google Scholar]
- Xue, L.; Constant, N.; Roberts, A.; Kale, M.; Al-Rfou, R.; Siddhant, A.; Barua, A.; Raffel, C. mT5: A massively multilingual pre-trained text-to-text transformer. arXiv 2020, arXiv:2010.11934. [Google Scholar]
- Fuad, A.; Al-Yahya, M. Cross-Lingual Transfer Learning for Arabic Task-Oriented Dialogue Systems Using Multilingual Transformer Model mT5. Mathematics 2022, 10, 746. [Google Scholar] [CrossRef]
- Zhang, J.; Luan, H.; Sun, M.; Zhai, F.; Xu, J.; Zhang, M.; Liu, Y. Improving the transformer translation model with document-level context. arXiv 2018, arXiv:1810.03581. [Google Scholar]
- Abadi, V.N.M.; Ghasemian, F. Enhancing Persian Text Summarization Using the mT5 Transformer Model: A Three-Phased Fine-Tuning Approach and Reinforcement Learning. Sci. Rep. 2023, 15, 80. [Google Scholar]
- Goyal, N.; Du, J.; Ott, M.; Anantharaman, G.; Conneau, A. Larger-scale transformers for multilingual masked language modeling. arXiv 2021, arXiv:2105.00572. [Google Scholar]
- Ganesan, K. Rouge 2.0: Updated and improved measures for evaluation of summarization tasks. arXiv 2018, arXiv:1803.01937. [Google Scholar]
- Westphaln, K.K.; Regoeczi, W.; Masotya, M.; Vazquez-Westphaln, B.; Lounsbury, K.; McDavid, L.; Lee, H.; Johnson, J.; Ronis, S.D. From Arksey and O’Malley and Beyond: Customizations to enhance a team-based, mixed approach to scoping review methodology. MethodsX 2021, 8, 101375. [Google Scholar] [CrossRef]
- Tricco, A.C.; Lillie, E.; Zarin, W.; O’Brien, K.K.; Colquhoun, H.; Levac, D.; Moher, D.; Peters, M.D.; Horsley, T.; Weeks, L.; et al. PRISMA extension for scoping reviews (PRISMA-ScR): Checklist and explanation. Ann. Intern. Med. 2018, 169, 467–473. [Google Scholar] [CrossRef]
- Kumar, Y.; Kaur, K.; Kaur, S. Study of automatic text summarization approaches in different languages. Artif. Intell. Rev. 2021, 54, 5897–5929. [Google Scholar] [CrossRef]
- Hasan, T.; Bhattacharjee, A.; Islam, M.S.; Mubasshir, K.; Li, Y.F.; Kang, Y.B.; Rahman, M.S.; Shahriyar, R. XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021; 2021; pp. 4693–4703. [Google Scholar]
- Grusky, M.; Naaman, M.; Artzi, Y. Newsroom: A dataset of 1.3 million summaries with diverse extractive strategies. arXiv 2018, arXiv:1804.11283. [Google Scholar]
- Fabbri, A.R.; Li, I.; She, T.; Li, S.; Radev, D.R. Multi-news: A large-scale multi-document summarization dataset and abstractive hierarchical model. arXiv 2019, arXiv:1906.01749. [Google Scholar]
- Liu, P.J.; Saleh, M.; Pot, E.; Goodrich, B.; Sepassi, R.; Kaiser, L.; Shazeer, N. Generating Wikipedia by Summarizing Long Sequences. arXiv 2018, arXiv:1801.10198. [Google Scholar]
- Ladhak, F.; Durmus, E.; Cardie, C.; McKeown, K. WikiLingua: A New Benchmark Dataset for Cross-Lingual Abstractive Summarization. arXiv 2020, arXiv:2010.03093. [Google Scholar]
- Ghalandari, D.G.; Hokamp, C.; Pham, N.T.; Glover, J.; Ifrim, G. A Large-scale Multi-document Summarization Dataset from the Wikipedia Current Events Portal. arXiv 2020, arXiv:2005.10070. [Google Scholar]
- Wojciech, K.; Nazneen, R.; Divyansh, A.; Caiming, X.; Dragomir, R. Booksum: A Collection of Datasets for Long-form Narrative Summarization. arXiv 2021, arXiv:2105.08209. [Google Scholar]
- Zhang, R.; Tetreault, J. This Email Could Save Your Life: Introducing the Task of Email Subject Line Generation. arXiv 2019, arXiv:1906.03497. [Google Scholar]
- Yasunaga, M.; Kasai, J.; Zhang, R.; Fabbri, A.R.; Li, I.; Friedman, D.; Radev, D.R. Scisummnet: A Large Annotated Corpus and Content-Impact Models for Scientific Paper Summarization with Citation Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 7386–7393. [Google Scholar]
- Cohan, A.; Dernoncourt, F.; Kim, D.S.; Bui, T.; Kim, S.; Chang, W.; Goharian, N. A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents. arXiv 2018, arXiv:1804.05685. [Google Scholar]
- Chowdhury, T.; Chakraborty, T. CQASumm: Building References for Community Question Answering Summarization Corpora. In Proceedings of the ACM India Joint International Conference on Data Science and Management of Data, Kolkata, India, 3–5 January 2019; pp. 18–26. [Google Scholar]
- Sayali, K.; Sheide, C.; Wan, Z.; Fei, S.; Eugene, I. AquaMUSE: Automatically Generating Datasets for Query-based Multi-Document Summarization. arXiv 2020, arXiv:2010.12694. [Google Scholar]
- Zhang, J.; Liu, Y.; Wei, P.; Zhao, X.; Shou, L.; Palangi, H.; Gao, J.; Shen, Y.; Dolan, B. PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization. 2019. Available online: https://huggingface.co/google/pegasus-xsum (accessed on 23 April 2024).
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. 2020. Available online: https://huggingface.co/facebook/bart-large-xsum (accessed on 23 April 2024).
- Moreno, L.Q. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. Available online: https://huggingface.co/morenolq/bart-base-xsum (accessed on 23 April 2024).
- Passali, T.; Gidiotis, A.; Chatzikyriakidis, E.; Tsoumakas, G. Financial Summarization Pegasus. 2023. Available online: https://huggingface.co/human-centered-summarization/financial-summarization-pegasus (accessed on 5 April 2023).
- Kapre, R. T5 Large Fine-tuned XSum. 2024. Available online: https://huggingface.co/sysresearch101/t5-large-finetuned-xsum (accessed on 5 May 2024).
- Szemraj, P. Long T5 TGlobal Base 16384 Booksum V11 Big Patent V2. 2024. Available online: https://huggingface.co/pszemraj/long-t5-tglobal-base-16384-booksum-V11-big_patent-V2 (accessed on 18 January 2024).
- Broad, N. LongT5 Base Global MediaSum. 2024. Available online: https://huggingface.co/nbroad/longt5-base-global-mediasum (accessed on 5 May 2024).
- Nimmagadda, S.D.; Paleti, K. Pegasus Samsum. 2024. Available online: https://huggingface.co/dhyutin/pegasus-samsum (accessed on 18 January 2024).
- Schmid, P. DistilBART CNN 12-6 Samsum. 2024. Available online: https://huggingface.co/philschmid/distilbart-cnn-12-6-samsum (accessed on 18 January 2024).
- Szemeraj, P. Long T5 TGlobal Base 16384 Book Summary. 2022. Available online: https://huggingface.co/pszemraj/long-t5-tglobal-base-16384-book-summary (accessed on 30 November 2022).
- Szemeraj, P. Long T5 TGlobal Large PubMed 3k Book Sum 16384 WIP. 2022. Available online: https://huggingface.co/pszemraj/long-t5-tglobal-large-pubmed-3k-booksum-16384-WIP (accessed on 30 November 2022).
- Szemraj, P. Long T5 TGlobal Large PubMed 3k Book Sum 16384 WIP13. 2022. Available online: https://huggingface.co/pszemraj/long-t5-tglobal-large-pubmed-3k-booksum-16384-WIP13 (accessed on 30 November 2022).
- Szemraj, P. LED Base Book Summary. 2022. Available online: https://huggingface.co/pszemraj/led-base-book-summary (accessed on 30 November 2022).
- Zaheer, M.; Guruganesh, G.; Dubey, A.; Ainslie, J.; Alberti, C.; Ontanon, S.; Pham, P.; Ravula, A.; Wang, Q.; Yang, L.; et al. Big Bird: Transformers for Longer Sequences. 2021. Available online: https://huggingface.co/google/bigbird-pegasus-large-arxiv (accessed on 18 January 2024).
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. NLP: Datasets, metrics, and evaluation methods for natural language processing in 100+ languages. arXiv 2020, arXiv:2012.09571. [Google Scholar]
- Islam, M.; Majumdar, F.N.; Galib, A.; Hoque, M.M. Hybrid text summarizer for Bangla document. Int. J. Comput. Vis. Sig. Process 2020, 1, 27–38. [Google Scholar]
- Islam, M.J.; Ahammad, K.; Chowdhury, M.K.H. Summarizing online product reviews in Bengali based on similarity using sequence to sequence RNNs. In Proceedings of the 2020 11th International Conference on Electrical and Computer Engineering (ICECE), Dhaka, Bangladesh, 17–19 December 2020; pp. 33–36. [Google Scholar]
- Banik, N.; Saha, C.; Ahmed, I.; Shapna, K.A. Bangla text generation system by incorporating attention in sequence-to-sequence model. World J. Adv. Res. Rev. 2022, 14, 080–094. [Google Scholar] [CrossRef]
Figure 1.
Illustration of diverse pathways and methodologies employed in the text summarization process. (T5 multi-lingual transformer model is the point of interest for Bengali Text Abstractive summarization).
Figure 1.
Illustration of diverse pathways and methodologies employed in the text summarization process. (T5 multi-lingual transformer model is the point of interest for Bengali Text Abstractive summarization).
Figure 5.
Transformer-based model architecture.
Figure 5.
Transformer-based model architecture.
Figure 6.
Performances of the off-the-shelf models for Text Summarization. The models are ranked based on their scores, with the highest performing models shown at the top.
Figure 6.
Performances of the off-the-shelf models for Text Summarization. The models are ranked based on their scores, with the highest performing models shown at the top.
Figure 7.
Transformer-based model architecture performance comparison.
Figure 7.
Transformer-based model architecture performance comparison.
Figure 8.
PRISMA Flow diagram illustrating the study selection for scoping review process.
Figure 8.
PRISMA Flow diagram illustrating the study selection for scoping review process.
Figure 9.
A glimpse of Bengali summarization model training dataset sample collected by Hugging Face API shown by pandas.
Figure 9.
A glimpse of Bengali summarization model training dataset sample collected by Hugging Face API shown by pandas.
Figure 10.
The number of collected papers in 2007-2023 in this research study.
Figure 10.
The number of collected papers in 2007-2023 in this research study.
Figure 11.
Performance Comparison of Multilingual Google T5 Models in Abstractive Summarization Using Rouge-L, Rouge-1, and Rouge-2 Evaluation Metrics.
Figure 11.
Performance Comparison of Multilingual Google T5 Models in Abstractive Summarization Using Rouge-L, Rouge-1, and Rouge-2 Evaluation Metrics.
Table 1.
List of key abbreviations used in this paper.
Table 1.
List of key abbreviations used in this paper.
| Abbreviation | Meaning |
|---|
| BTS | Bengali Text Summarization |
| SOV | Subject Object Verb |
| LSTM | Long Short Term Memory |
| TM | Tokenization Method |
| SW | Stop Word |
| SM | Stemming Method |
| LM | Lemmatization Method |
| ST | Split Text |
| CM | Contraction Method |
| RR | Regular Repression |
| DC | Data Cleaning |
| LA | Lexical Analysis |
| SS | Sentence Scoring |
| RNN | Recurrent Neural Network |
| S2S | Sequence-to-Sequence |
| SF | Sentence Frequency |
| Bi-RNN | Bidirectional Recurrent Neural Networks |
| SR | Sentence Ranking |
| TR | Text Ranking |
| WS | Word Scoring |
| TF | Term Frequency |
| FM | Frequency Matrix |
| SC | Sentence Clustering |
| KB | Keyphrase Based |
| W2V | Word2vec |
| SSi | Sentence Similarity |
| KC | K-means Clustering |
| SSS | Semantic Sentence Similarity |
| TFIDF | Term Frequency-Inverse Document Frequency |
| LSA | Latent Semantic Analysis |
| GRU | Gated Recurrent Unit |
| AB | Attention-Based |
| CM | Cue Method |
| LM | Location Method |
| PV | Positional Value |
| GS | Graph Scoring |
Table 2.
Comparison of some models for Abstractive summarization for Bengali language [
24].
Table 2.
Comparison of some models for Abstractive summarization for Bengali language [
24].
| Models | Rouge-1 | Rouge-2 | Rouge-L |
|---|
| GreedyKL | 10.01 | 1.84 | 9.46 |
| LexRank | 10.65 | 1.78 | 10.04 |
| TextRank | 10.69 | 1.62 | 9.98 |
| SumBasic | 10.57 | 1.85 | 10.09 |
| BenSumm
Model | 12.17 | 1.92 | 11.35 |
Table 4.
Quality assessment questions of Research articles for articles to be selected in systematic review.
Table 4.
Quality assessment questions of Research articles for articles to be selected in systematic review.
| RQs | Questions |
|---|
| Q1 | Are the goals of the research clearly defined? |
| Q2 | How well defined is the suggested methodology? |
| Q3 | Is there a clear explanation of the text generation approaches? |
| Q4 | Have the performance measures for assessing the quality of summaries been fully established? |
| Q5 | What kinds of data sources have been utilized for the research? |
| Q6 | Are the findings presented intelligible and clear? |
| Q7 | Does the study compare its findings with the prior methods currently in use for Bengali summarization? |
| Q8 | Have the findings been appropriately discussed and determined? Does the study’s conclusion accurately represent its findings? |
| Q9 | Does the study discuss possible drawbacks and difficulties with Bengali summarization using text summarization models? |
| Q10 | Does the article discuss current and anticipated paths for the Bengali summarization study? |
Table 5.
Software and Hardware Configuration.
Table 5.
Software and Hardware Configuration.
| Configuration Details |
|---|
| Python 3.10.9 |
| torch 1.13.1 |
| Tensorflow 2.12.0 |
| pyrouge 0.1.3 |
| Keras 2.12.0 |
| Versions are used |
| Machine: AMD CPU RYZEN 7 4000 series (Company: Advanced Micro Devices (AMD), Santa Clara, CA, USA) |
| Graphics card: Radeon 16 |
| CPU: 2.9 GHz |
| RAM: 16 GB |
Table 6.
Data sources for Transformer models.
Table 6.
Data sources for Transformer models.
| Dataset | Remarks |
|---|
| CNN DailyMail [74] | Summarization, trained on Tesla K40, uses Gigaword. |
| CORNELL NEWSROOM [89] | Summarization, sentiment analysis, developed by Cornell. |
| Multi News [90] | Multi-doc summarization, MMR-Attention, Pointer-generator. |
| Wikipedia [91] | Abstractive multi-doc summarization, coherence, factuality. |
| WikiLingua [92] | Language-agnostic summarization, compatible with ML libraries. |
| WCEP-MDS [93] | Multilingual discourse analysis, NLP libraries. |
| BOOKSUM [94] | Literary summaries for paragraphs, chapters, and books. |
| AESLC [95] | Email subject line generation, surpasses baselines. |
| ScisummNet [96] | Summarization of scientific literature, annotated summaries. |
| arXiv, PubMed [97] | Abstractive summarization, incorporates discourse structures. |
| CQASUMM [98] | Summarization of community QA content. |
| AQUAMUSE [99] | Query-focused summarization, enhanced by multiple models. |
Table 7.
Models on XL-Sum dataset.
Table 7.
Models on XL-Sum dataset.
| Refs | Transformer Models |
|---|
| [88] | csebuetnlp mT5 multilingual XLSum |
| [100] | google pegasus-xsum |
| [101] | facebook bart-large-xsum |
| [102] | bart-base-xsum |
| [103] | human-centered-summarization financial-summarization-pegasus |
| [104] | sysresearch101 t5-large-finetuned-xsum |
| [105] | pszemraj long-t5 global-base-16384-booksum-V11-big patent-V2 |
| [106] | longt5-mediasum |
| [107] | pegasus-samsum |
| [108] | philschmid distilbart-cnn-12-6-samsum |
| [109] | pszemraj/long-t5 global-base-16384-book-summary |
| [110,111] | pszemraj long-t5 global-large-pubmed-3k-booksum |
| [112] | pszemraj led-base-book-summary |
| [113] | google bigbird-pegasus-large-arxiv |
Table 8.
Pre-trained mT5 model hyparparameters settings.
Table 8.
Pre-trained mT5 model hyparparameters settings.
| Parameters | Values |
|---|
| mt5 tokenizer (Auto T5 model tokenizer) | google/mt5 |
| mt5 config (Auto T5 model configuration from pre-trained) | google/mt5 |
| num train epochs (Total training epochs) | 10 |
| learning rate (Initial learning rate) | 0.0005 |
| optim (Optimizer used for training) | adafactor |
| predict with generate (Use generation for predictions) | True |
| generation max length (Max length for generated sequences) | 128 |
| length penalty (Length penalty) | 0.6 |
Table 9.
Text Summarization approaches for the Bengali language.
Table 9.
Text Summarization approaches for the Bengali language.
| Approaches | Techniques |
|---|
| Extractive [35,36,37,39,40,41,42,43,44,45,46,48,49,50,51,52,115] | Sentence frequency, Cue method, Location method, Sentence ranking or scoring, Sentence clustering, Frequency matrix, Keyphrase based, Word scoring, Graph scoring; K-means clustering; LSA etc. |
| Abstractive [38,47,53,54,58,70,116,117] | Sentence scoring, Word scoring, Term frequency, Semantic sentence similarity; BI-RNN, Word2Vector; Fuzzy C-Means, TextRank, Sentence similarity; RNN, Seq2Seq; Text ranking, Keyword ranking; Bi-LSTM, BANS, RNN, Seq2Seq, LSTM, GRU, Attention-based Deep Learning. |
Table 10.
Techniques for data pre-processing used in the included studies.
Table 10.
Techniques for data pre-processing used in the included studies.
| Refs | SW | SM | TM | LM | CM | LA | ST | RR | DC | LT | Total |
|---|
| [36] | * | * | * | | | | | | | | 3 |
| [37] | | * | | | | | | | | * | 2 |
| [38] | * | * | | | | | | | | | 2 |
| [40] | * | * | * | | | | | | | | 3 |
| [41] | | * | * | | | | | | | | 2 |
| [43] | * | * | * | | | | | | | | 3 |
| [44] | | * | * | | | | | | | | 2 |
| [45] | * | * | * | | | | | | | | 3 |
| [46] | * | | * | * | | | | | | | 3 |
| [47] | | | | | * | | * | | | | 2 |
| [48] | * | | | | | | * | | | | 2 |
| [49] | * | * | * | | | | | | | | 3 |
| [50] | * | | | | | | | * | | | 2 |
| [51] | * | | | | | | | | | | 1 |
| [53] | | | | * | | | | | | | 1 |
| [54] | * | | | | | | | | | | 1 |
| [52] | | | | | | | | | * | | 1 |
| [58] | * | * | | * | * | * | | | | | 5 |
| [115] | * | | * | | | | | | | | 2 |
| [116] | | * | | * | * | * | | | | | 4 |
| [117] | | | * | | | | | | | | 1 |
| Total | 13 | 11 | 10 | 4 | 3 | 2 | 2 | 1 | 1 | 1 | 48 |
Table 11.
Models used in the included studies.
Table 11.
Models used in the included studies.
| Refs | LSTM | SS | RNN | S2S | SF | BiRNN | SR | TR | WS | SS | CM | AB | W2V | KB | LSA | KC | Total |
|---|
| [35] | | * | | | * | | | | | | * | | | | | | 3 |
| [36] | | | | | * | | | | | | * | | | | | | 2 |
| [37] | | | | | * | | * | | | | | | | | | | 2 |
| [38] | | | | | | | * | | | | | | | | | | 1 |
| [39] | | | | | | | | | | | | | * | | | | 1 |
| [40] | | * | | | | | | | * | | | | | | | | 2 |
| [41] | | | | | | | | | | | | | | | | * | 1 |
| [42] | | | | | | | | | | | | | | * | | | 1 |
| [43] | | * | | | | | * | | | | | | | | | | 2 |
| [44] | | * | | | | | | | * | | | | | | | | 2 |
| [45] | | * | | | | | | | | | | | | | | | 1 |
| [46] | | | | | | | | | | * | | | | | | | 1 |
| [47] | * | | | | * | | | | | | | | | | | | 2 |
| [48] | | | | | | | | | | | | | * | | | | 1 |
| [49] | | | | | | | | * | | | | | | | | | 1 |
| [50] | | | | | | | | | | * | | | | | | | 1 |
| [51] | * | | * | | | | | | | | | | | | | | 2 |
| [52] | * | | | * | | | | | | | | | | | | | 2 |
| [53] | * | | * | | | | | | | | | | | | | | 2 |
| [54] | * | | | * | | * | | | | | | | | | | | 3 |
| [58] | * | | * | * | | * | | | | | | | | | | | 4 |
| [70] | * | | * | | | | | | | | | | | | | | 2 |
| [115] | | * | | | | | | * | | | | | | | | | 2 |
| [116] | * | | * | * | | | | | | | | | | | | | 3 |
| [117] | * | | | * | | | | | | | | * | | | | | 3 |
| Total | 9 | 6 | 5 | 5 | 3 | 3 | 3 | 4 | 4 | 4 | 4 | 1 | 1 | 1 | 1 | 1 | 55 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).



 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}