1. Introduction
In this paper, we develop our approach by extracting definitions of terms being used or introduced. Extracting definitions helps to track the continuity and frequency dynamics of terminology used in scientific and technical documents over time. In the absence of large-scale Russian corpora with labeled terms, the problem is relevant. The results of this paper can be used as the basis for terminology extraction tools in analytical systems such as iFORA (
https://issek.hse.ru/en/ifora/, accessed on 22 April 2025), SciApp (
https://sciapp.ru/, accessed on 22 April 2025), Neopoisk (
https://neopoisk.ru/publ/, accessed on 22 April 2025), and others. Information plays a crucial role in the decision-making process to rule R&D in research institutions, universities, and companies. As the information overhead grows year by year, the natural language processing community is challenged to bring a method that allows orientation in this endless amount of papers. To stay on the cutting edge of the field or quickly get to know the new one, it is nice to have some ways to make it easier. One can say that terms and their definitions are the basic blocks of any study. It would be a handful to have a method that can extract them from literature in order for the learner to get familiar with them. It is also useful when analyzing a large amount of scientific data. To analyze the development of scientific and technological directions, it is important to identify the terminology used and introduced by the authors. Classical approaches in scientific and technical analytics use methods of extracting terminology from texts [
1,
2,
3] in the form of words and phrases.
The mainstream approach for classification problems is to use neural networks. Their ability to model complex, nonlinear relationships in data makes them highly effective wide range of applications, including terminology and its definition extraction. Their architecture allows them to learn hierarchical feature representations from raw input, improving performance with increased data and computational resources. Additionally, advances in deep learning, such as attention mechanisms and Transformer architecture, have significantly enhanced their capability to handle text data. The availability of large datasets and improvements in hardware, particularly GPUs, have further facilitated the training of deep neural networks, making them a preferred choice. Lastly, extensive open-source libraries and community support have accelerated their adoption and implementation across various fields. However, they require a large amount of annotated data to be trained. The vast number of parameters in neural networks, especially deep learning models, necessitates extensive training data to prevent overfitting and to generalize well to new, unseen data. Labeled data provides the ground truth that helps the network adjust its weights effectively during training, leading to improved accuracy and performance. Additionally, the diversity present in large datasets aids in capturing the variability in real-world scenarios, ensuring the model’s robustness. Insufficient labeled data can lead to poor model performance, making extensive datasets crucial for successful neural network training.
One of the recent resources dedicated to the abovementioned task is the DEFT corpus [
4]. Developing for the SemEval 2020 task [
5] consists of the English texts from free e-books with tree-layer annotation: whether the text has a definition, annotation of terms and definitions as named entities, and relations between them. The problem is that other languages lack such resources, such as Russian. It would be great to somehow automatically transfer the existing English DEFT dataset into other languages to obtain a starting point. Further, such a transferred dataset could be corrected by human annotators, which is easier and cheaper than crafting the dataset from scratch.
While general text classification annotation could be transferred by the language translation, the transferring of the named entity annotation from one language to another is challenging since the matched spans in the source and target languages must be found. Recently, the large language models (LLMs) have demonstrated high effectiveness in a broad variety of NLP tasks. Unlike traditional NLP methods that rely heavily on manual feature engineering and rule-based systems, LLMs leverage the Transformer architecture to learn patterns and contextual relationships from vast amounts of text data. This approach allows LLMs to perform tasks such as translation [
6] and named entity recognition (NER) [
7] with greater efficiency and adaptability across different languages and contexts. LLMs surpass traditional methods by eliminating the need for extensive task-specific programming and by excelling in zero-shot and few-shot learning scenarios, where little to no task-specific data are available. They bring improvements in scalability, as they can be fine-tuned for numerous applications with minimal adjustments, and they enhance performance by capturing nuanced language subtleties that traditional models may overlook. Furthermore, LLMs have shown the ability to generalize across tasks, providing a unified model capable of addressing diverse NLP challenges. This versatility reduces the need for multiple specialized systems, ultimately streamlining the development process. Motivated by these advantages, we utilize LLMs for the cross-language annotation transfer by using them as a “smart” translator that can preserve the named entity spans while translating the text. We hypothesize that they can automate the process of adaptation of an annotated dataset from different languages, allowing one to obtain a quick baseline or giving a solid start in the annotation process. We limit this work only to English–Russian language pairs, leaving other languages for future work.
To summarize, the contribution of our work is as follows:
We show how we transfer the NER annotation using LLMs on the English and Russian language pairs.
We analyze the translation quality of several modern LLMs from English to Russian for this particular task. It includes ChatGPT, Llama3.1-8B [
8], DeepSeek, and Qwen.
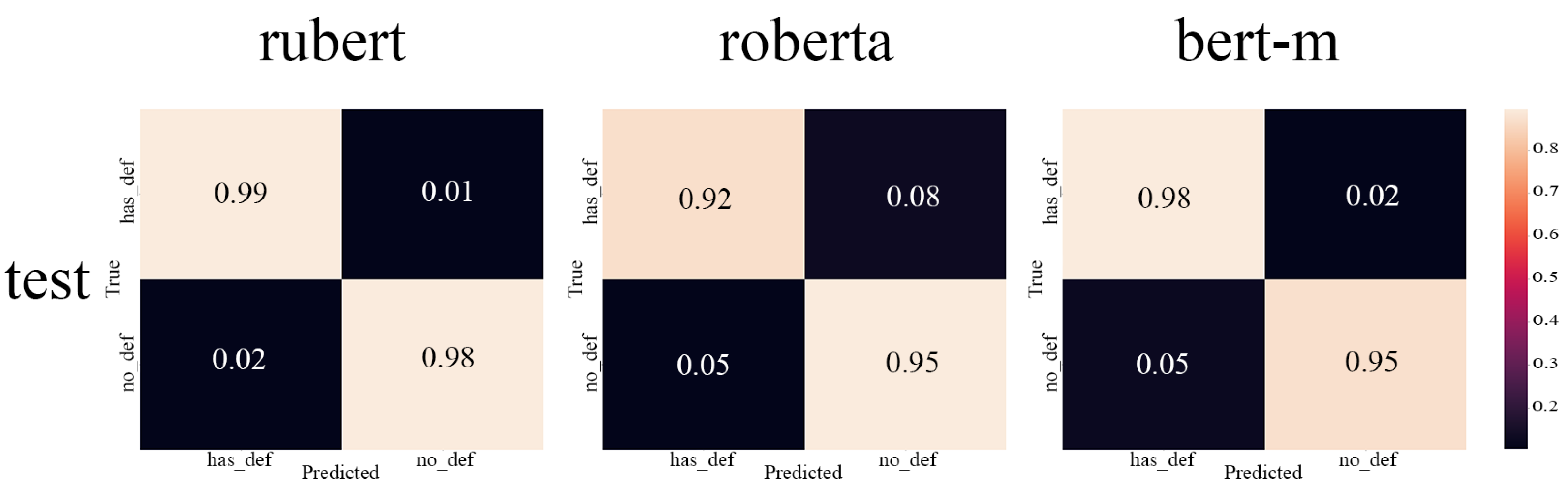
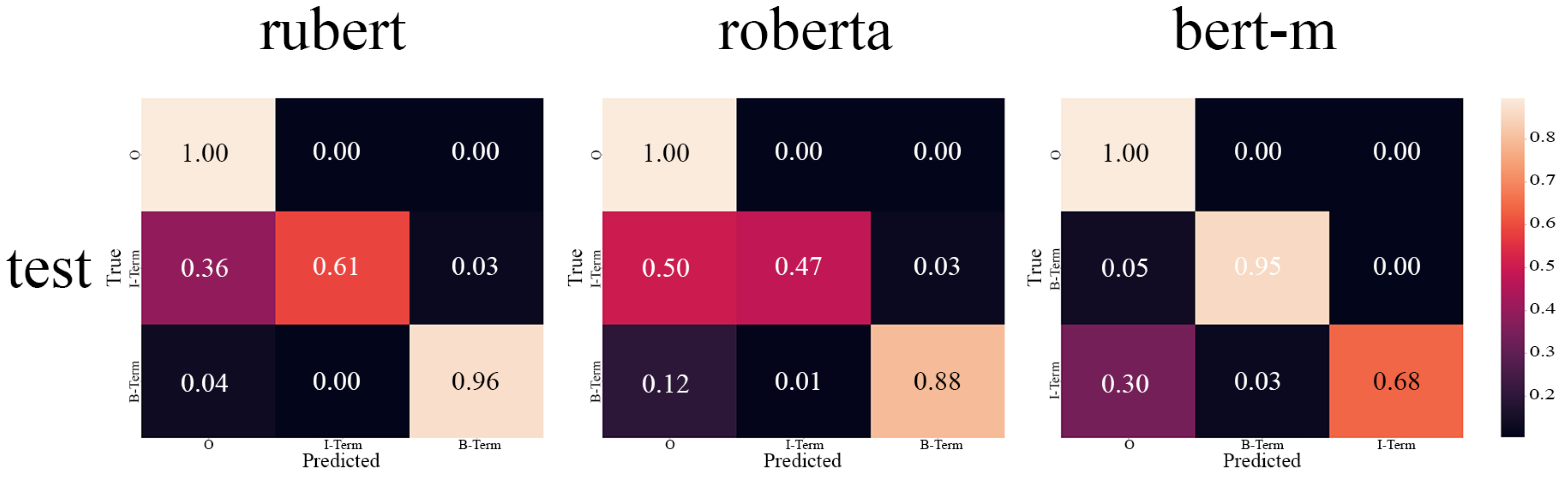
We provide the result of the BERT-like models trained to make a baseline for two of the three original DEFT tasks: detection of texts with definitions and named entity recognition. In addition, we provide the results of our pipeline for the Wikipedia part of the WCL dataset.
2. Related Work
The task of term and definition extraction has a long story because it is tightly related to the desire to structure the information from various texts. Starting from rule-based systems [
9], which relies on handcrafted rules, it evolves to statistical methods [
10,
11,
12] and lastly to a deep learning system [
13,
14]. The statistical methods operate either by automatically mining the patterns from the dataset or by constructing a set of features that fit into a machine learning model. The deep learning methods fully rely on neural networks like LSTM [
15] or, recently, Transformer-based architecture [
16].
Frequently, statistical or deep learning-based papers come with their datasets. The WCL dataset [
17] was developed as a part of the work in [
10]. This is a dataset with annotated definitions and hypernyms composed of Wikipedia pages and a subset of the ukWaC Web corpus. The SymDef dataset comes from [
18] and approaches the problem of bounding the mathematical symbols with their definitions in scientific papers parsed from arXiv. Speaking about the lack of resources, it is worth mentioning that for the Russian language, it is easy to find only the RuSERRC dataset [
19] in which the terms were annotated. The Russian datasets with definition annotation are unknown.
With the rise of the LLMs, researchers have started to investigate the method of using them in dataset annotation or generation. In the work [
20] researchers employ ChatGPT to be an annotator with an explain-than-annotate technique. They compared its performance with crowdsourcing annotation and obtained promising results that ChatGPT is on par with crowdsourcing. Regularly, researchers issue the best practices about how to obtain the best from LLMs as annotators, like in [
21]. LLMs are used in interesting annotation projects, like creativity dataset creation [
22], where the LLM produces some ideas of how to use an unrelated set of items to solve a particular task, and humans only verify these ideas. In some cases, the LLM is used directly for dataset synthesis [
23,
24].
3. Materials and Methods
3.1. DEFT Corpus
The DEFT corpus is a collection of text from free books available on
https://cnx.org/ (accessed on 22 April 2025). The texts cover topics like biology, history, physics, psychology, economics, sociology, and government. NER annotation includes the term and definition labels as primary annotation and supportive annotation for the cases as aliases, orders, and referents for both terms and definitions. For the task of detecting a sentence that contains a definition, the annotation is produced straightforwardly from the presence of the definition NER annotation in a sentence. The relation annotation bounds terms and definitions. For a detailed description of the tags, annotation process, and challenges, we refer to the original paper. We use the available DEFT corpus on GitHub (
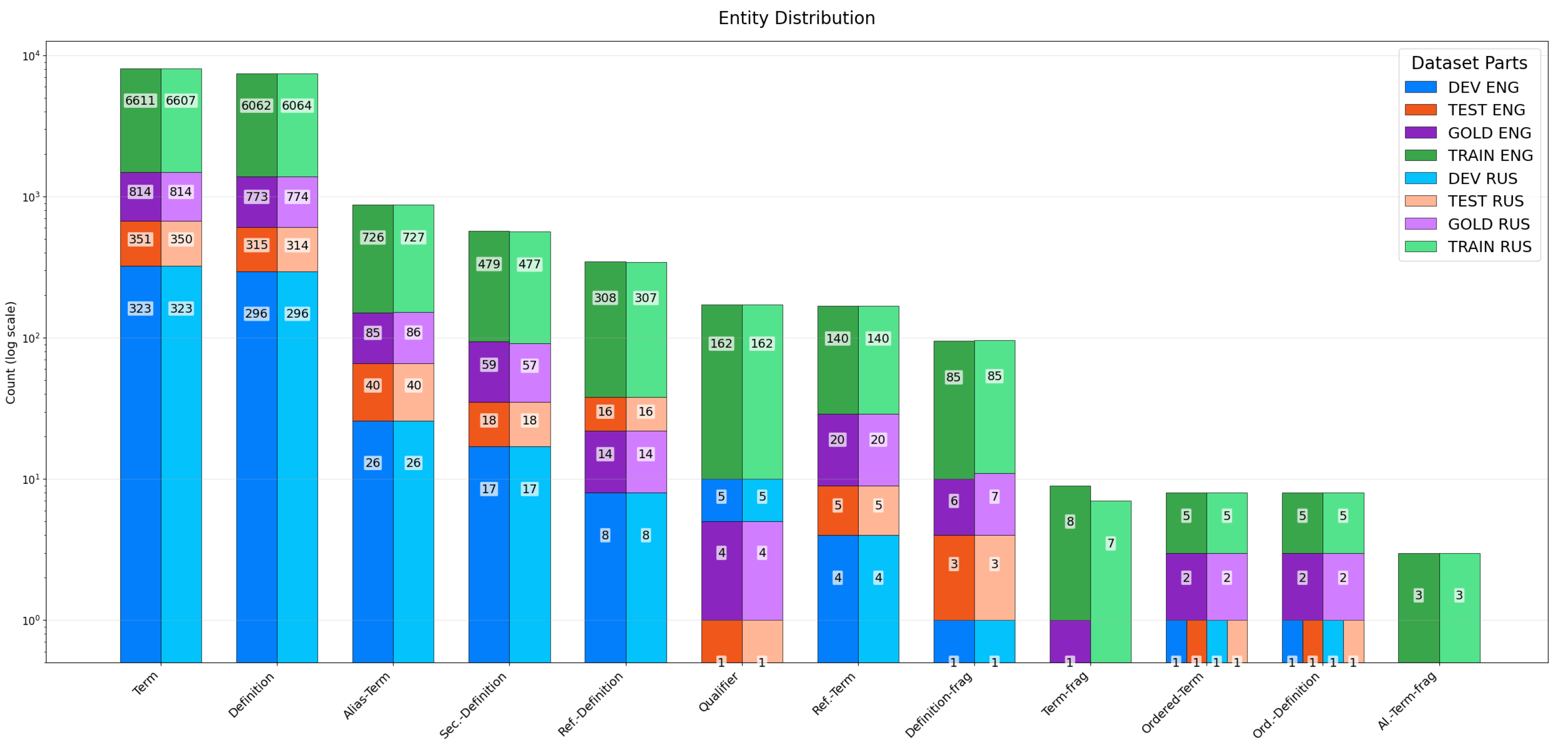
https://github.com/adobe-research/deft_corpus, accessed on 22 April 2025, version of the corpus from 16 January 2020, commit is db8c95565c2e58d861537cb8cb4621c50b75cd13). The entity statistics are provided in
Figure 1 in “ENG” legend parts for train, dev test, and the prepared gold set, which we talk about in the section “Preparing the gold set”. We also want to point out that we will not experiment with a third annotation with a relation between terms and definitions. We leave it for future work.
To work with our pipeline, we had to convert the original CoNLL-like (Conference on Natural Language Learning) format into the Hugging Face Datasets library [
25]. Basically, the dataset can be represented as a list of dictionaries (objects) that can be easily converted to and from JSON. In turn, it makes it easy to communicate with LLMs in the latter format.
We noticed two issues while preprocessing the original files of the corpus. The first one is a tokenization error when two sentences containing the wide span are wrongly separated. As a consequence, the second sentence starts with the token having an “I” tag, which is illegal in the IOB (inside, outside, beginning) format.
While the first issue was found just once, the second issue with data duplicates occurs more often. We count 2187 duplicate sentences. Moreover, these duplicates have different annotations. It seems that the merging error occurred when the corpus was being compiled.
3.2. WCL Corpus
In addition, to make our research broader, we apply our pipeline to the Wikipedia part of the WCL dataset. We chose this part because of a clear understanding of the structure, where all data were divided into two files: one file contains sentences with definitions and another file contains just regular sentences. All these sentences have an annotation of the term token, but not for the definition itself.
We convert the dataset from its original format to the common Hugging Face structure, resampling what we obtain from converting the DEFT dataset. All in all, we obtain 2822 sentences with no definitions and 1869 sentences with definitions. We next divide the whole dataset into train, dev, and test splits in the proportion 70/10/20.
Nevertheless, our main focus is the DEFT dataset.
3.3. Large Language Models
We benchmarked a diverse set of state-of-the-art LLMs to assess their performance on our tasks. The specific model checkpoints evaluated are as follows:
llama-3.1-8b-instruct
gpt-3.5-turbo
gpt-4o-mini
gpt-4.1-nano
gpt-4.1-mini
deepseek-chat-v3-0324
deepseek-r1
qwen-2.5-72b-instruct
To simplify the experimental setup and ensure reproducibility, we leveraged the bothub.chat service (
https://bothub.chat/, accessed on 22 April 2025) as a unified proxy for accessing the aforementioned models. This service provides a streamlined interface to various APIs—including OpenAI’s ChatGPT, DeepSeek, Llama, and QWEN—thereby abstracting the need for direct API integration. This approach not only facilitated rapid testing and experimentation but also allowed for systematic documentation of any associated computational costs, which were primarily linked to underlying API usage fees. Detailed statistics on time and monetary expenditures are provided in
Appendix E.
3.4. Methodology
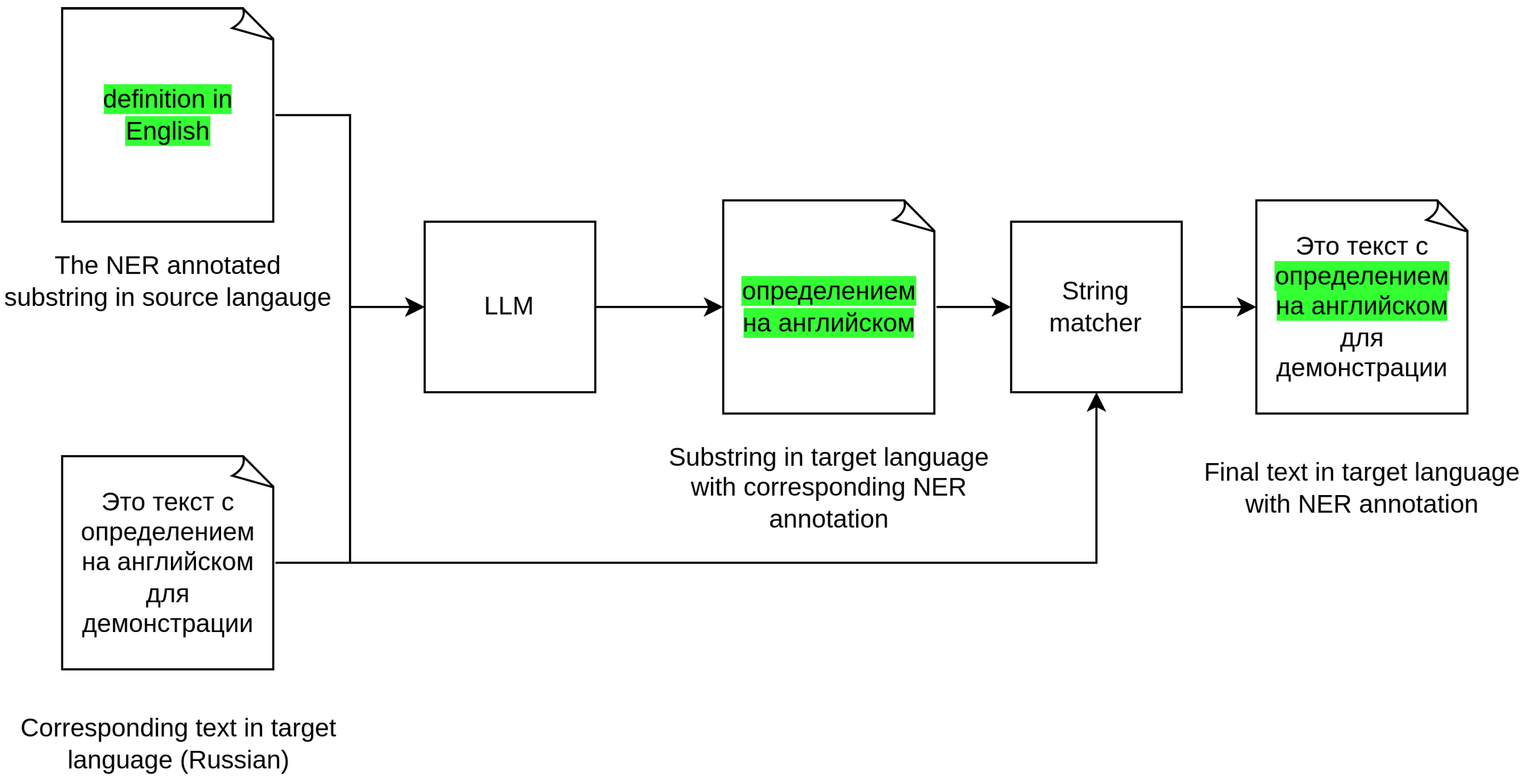
On a high level, the methodology consists of three steps: preparing the gold set, automatic translation, and annotation transfer. We describe each of them in separate paragraphs. The overview of the methodology steps is visualized in
Figure 2.
3.4.1. Preparing the Gold Set
To be able to estimate the output quality of our steps, we need a reliable set that was manually checked in terms of the translation and NER annotation. To do that, we translate the whole dev set and a small part of the train set with the API Google Translate. We obtain 1179 sentences from the dev set and 3010 out of 24,184 randomly selected sentences from the train set. (There is no specific reason why exactly 3010 from the train part were sampled; it just happened once, and we decided to let it be). Next, we select only the sentences with NER annotation, which gives us 870 sentences from the dev and train sets. Then we manually transfer the NER annotation from English text to Russian using Label Studio [
26]. While transferring, when we saw that the translation was semantically incorrect, we skipped these sentences and later translated them manually. The source of incorrectness originates commonly from the catchphrases and the specific language. The statistics of the NER labels of the gold set are available in
Figure 1.
For the purpose of evaluating the translation, we sampled 200 sentences with no NER annotation and also checked them for adequate translation.
Finally, the statistics of our gold set are next: 870 sentences have the NER annotation, and 200 sentences do not. Overall, we have 1070 sentences with manually verified translations into Russian.
3.4.2. Transferring NER Annotation Using LLMs
For the task of NER annotation transferring, we test several LLMs, such as Llama3.1-8B and Qwen-2.5-72B, variants of DeepSeek, and variants of GPT-4 and ChatGPT3.5-turbo from OpenAI. They vary in scale, which directly influences the cost and generation time. The latter is crucial when one works with a large amount of data. Also, while OpenAI’s models are closed-sourced, it is of high interest how the open-sourced models such as Llama3.1, Qwen, or DeepSeek are suitable for such tasks, as many researchers and companies cannot rely on third-party API because of data privacy.
As a note, we use Qwen2.5-72B because it was released during this work, so we decided to include a bigger LLM of the fresh release and not Llama3.1-72B.
To build the prompt, we try several standard prompt techniques like zero-shot, few-shot, and chain-of-thoughts [
27]. We select 20 examples from the gold dataset in the early stages of the prompt development. That means we reject some prompt-building strategies if they cannot deal with most of this subset. The only prompts that achieve more than 15 cases of correct annotation transferring will be selected for further testing.
At first, we formulate the task for the LLM as follows: given the source English text and the list of annotation span triplets consisting of start index, end index, and label name, we ask the model to find in a given Russian text span triplets that correspond to English ones. Unfortunately, this approach failed to give a good output quality, as we show in the “Results” section. So, we reformulated the task to find a substring in Russian that corresponds to a substring in English that is actually an NER span. See
Figure 3 for a visual explanation of the resulting approach.
After obtaining a prompt that beats the simple test, we evaluate it on the whole gold dataset, where we manually transfer the annotation. As a metric, we use the number of matches between the gold transfer and LLM in different situations:
Exact matches count the cases when the indices of the gold and transferred spans are equal;
Wider partial matches count the cases when the transferred span is wider than the original one;
Narrower partial matches count the cases when the transferred span is narrower than the original one;
Mismatches are self-explained cases;
Total spans checked accounts for the processed cases. Note that it differs between LLMs, as some examples could not be handled correctly, even after several retries.
3.4.3. Translating the Text Using LLMs
The translation task is pretty straightforward. Given the text in English, we ask the LLM to translate it into Russian. From the previous research [
6], we know that LLMs are good enough in this task, though they still perform worse than supervised systems. Nevertheless, we are interested in building a monolithic pipeline based solely on LLMs. To ensure the quality of the translation, based on our gold set of translated DEFT, we test the translation abilities of our chosen LLMs with a BLEU score and two metrics based on embeddings.
The BLEU score [
28] is a widely used metric in machine translation. The mechanism of this metric is to calculate the overlap between n-grams of the gold translation and the translation provided by the system. The known disadvantage of this approach is that lexical overlap does not guarantee meaning preservation. To estimate to which the sense is preserved, we use embedding-based metrics as they operate on a semantic level.
We use the LaBSE model [
29] as a cross-lingual encoder for texts, as it encodes semantically close texts in different languages to close points in one embedding space. This allows us to measure the translation quality in two ways.
First, we calculate the mean distance between the corresponding English text and its gold Russian translation, then we do it in the same way between the English text and the translated one. Next, we compare two means by substituting the latter for the former. The closer to the zero metric is, the more likely that model-translated text conveys the same meaning as the gold-translated text. We call this metric Parallel Comparison.
Second, resembling the BLEU approach, we compare the mean distances between gold Russian text embeddings and translated ones. If the BLEU operates on a lexical level, this metric does this on a semantic level and relies on the abovementioned property of cross-lingual encoders. We name this metric BLEU-like.
We reuse the best prompt from the annotation transferring task, only changing the task description. As we will show in the result section, they perform similarly, so we provided the one that we use in
Appendix C.
5. Discussion
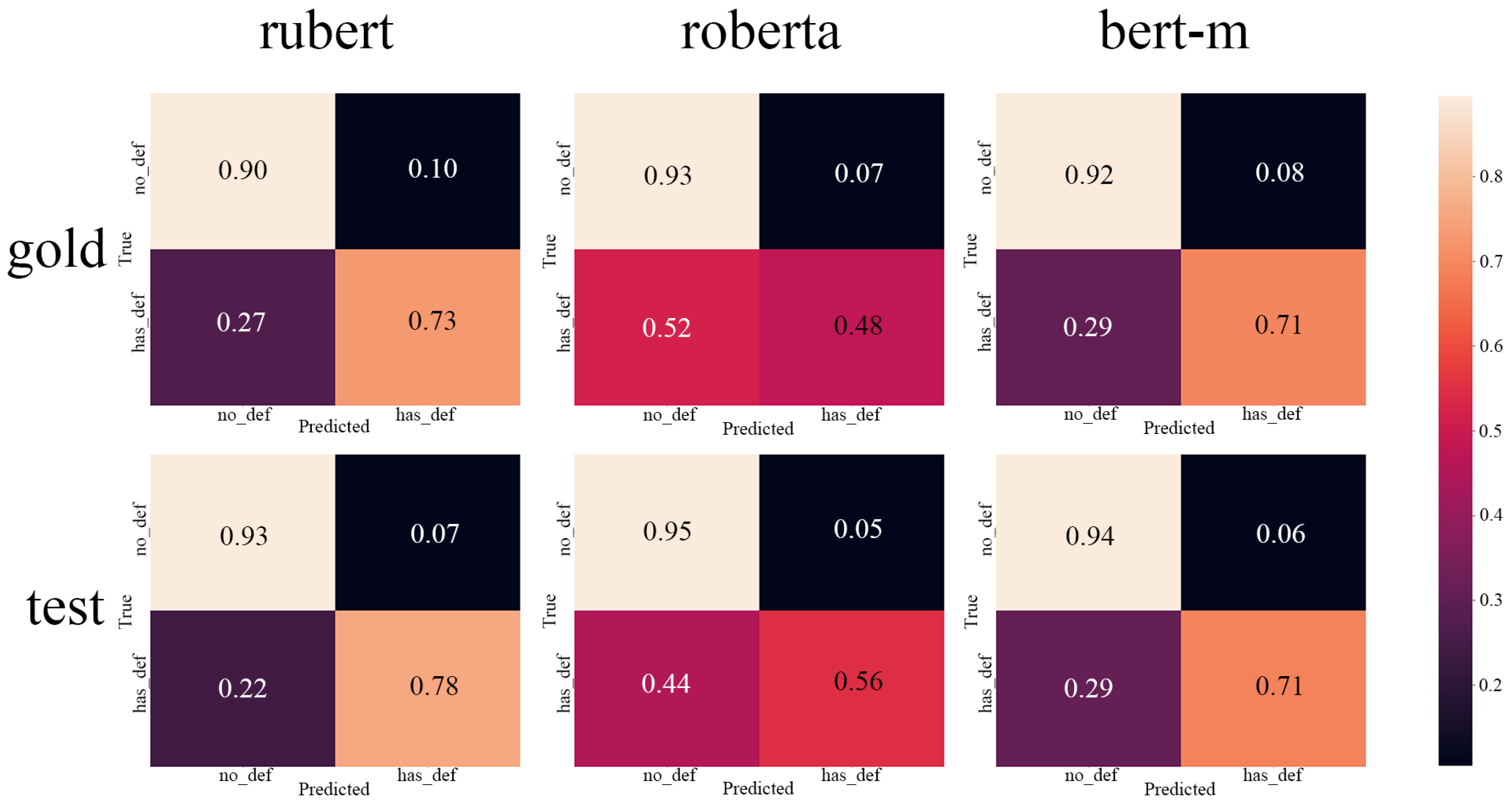
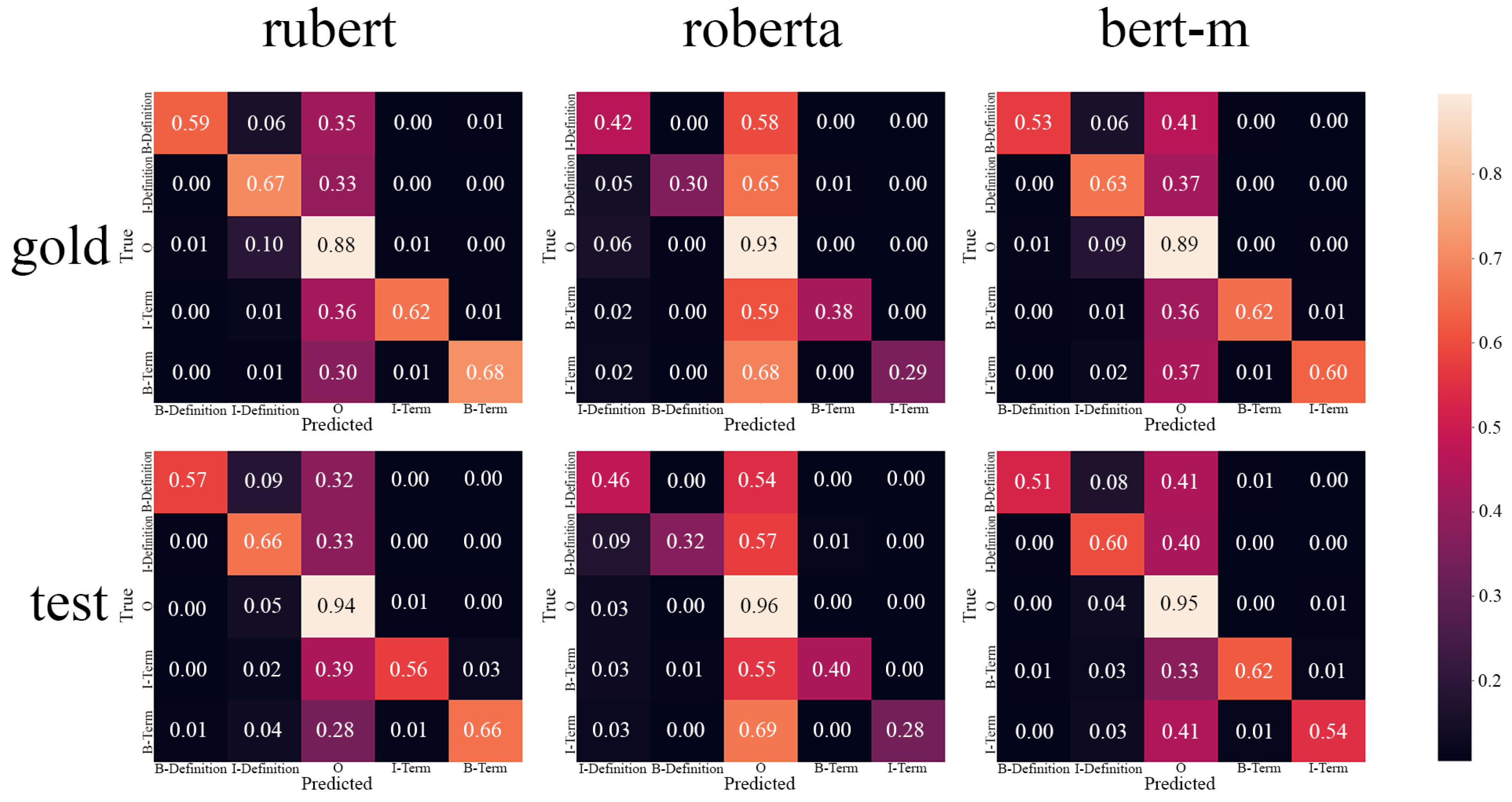
In this work, we show that the current abilities of LLMs can be used to transfer datasets between languages. While the dataset certainly will remain only “silver”-grade quality, the effort difference between creating such a dataset from scratch and adapting from another language with further verification is huge. Especially when we talk about nontrivial annotations like NER that require the exact positioning in text. The focus of our experiment was the DEFT dataset, which contains a quite challenging task of term and definition recognition. This dataset is important to facilitate the trend analysis tools and models for Russian, which are helpful for the decision-making processes in R&D. We train the BERT-based models on the whole transferred dataset to show that these data actually can be used to train real models to establish a baseline. However, we see that the NER model is weak, which implies verifying the transferred annotation more carefully. In addition, we apply our pipeline to the Wikipedia part of the WCL dataset and show that models show quite good results.
As a side effect, we discover that some tasks might be easier for LLMs to understand than others, and that difference may be significant in terms of output quality. We hypothesize that it depends on several cognitive steps that need to be performed for task solving. We also discovered some shortcomings in the DEFT dataset that should be fixed.
The obvious limitations of our work are that we do not show how the LLM itself would be strong on DEFT tasks. Another one is that we do not compare the quality of supervised translators with LLMs, because it is shown that supervised translators are still better than LLMs.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}