


Cybercrime Risk Found in Employee Behavior Big Data Using Semi-Supervised Machine Learning with Personality Theories


Abstract
1. Introduction
1.1. Research Rationale Driving the Current Study
1.2. Literature Review of Empirical Studies Focused on Cybercrime Risk
1.3. Literature Review of Non-Empirical Studies Focused on Cybercrime Risk
1.4. Personality Theory Overview from the Literature
1.5. Literature Summary and Research Question in the Current Study
2. Materials and Methods
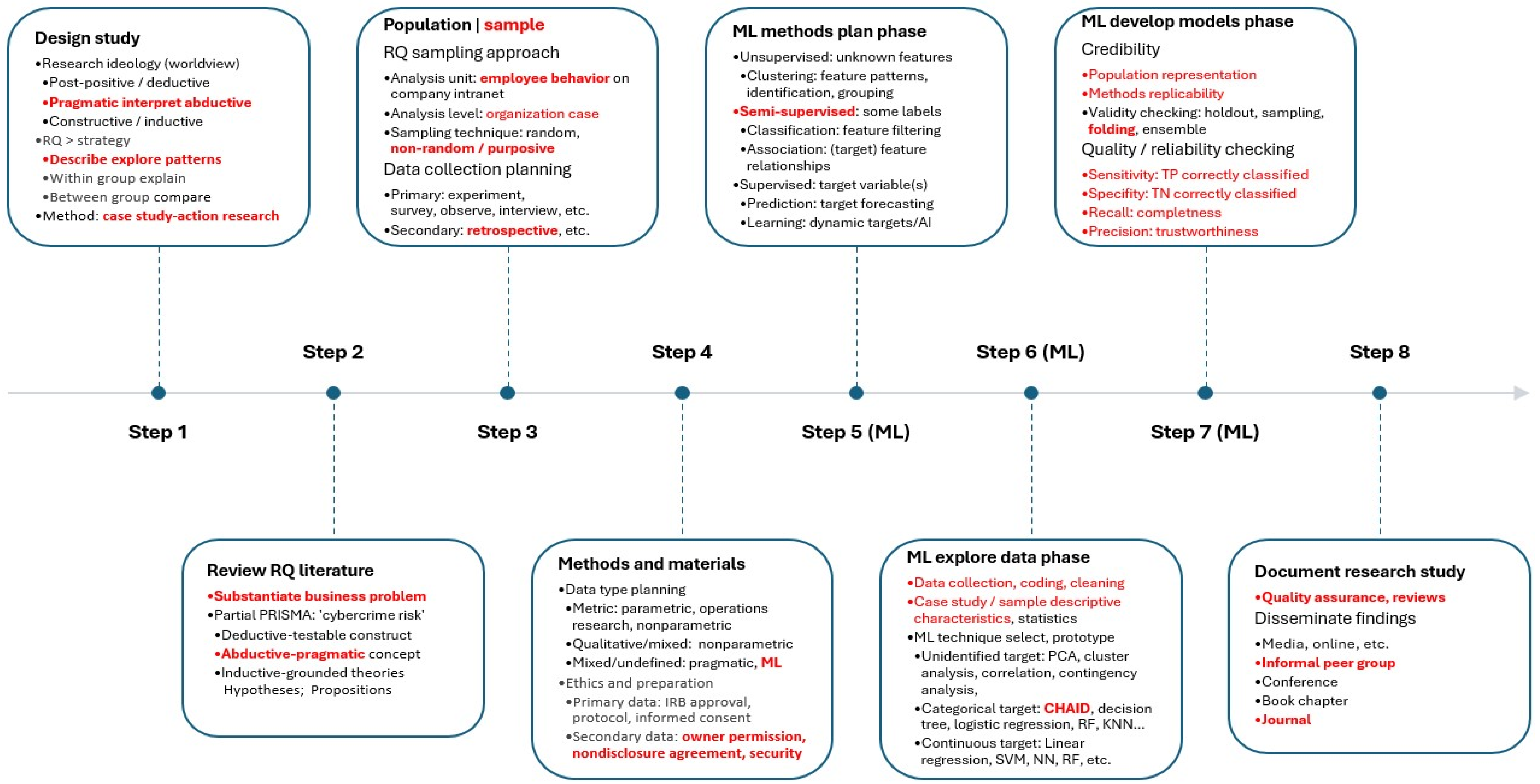
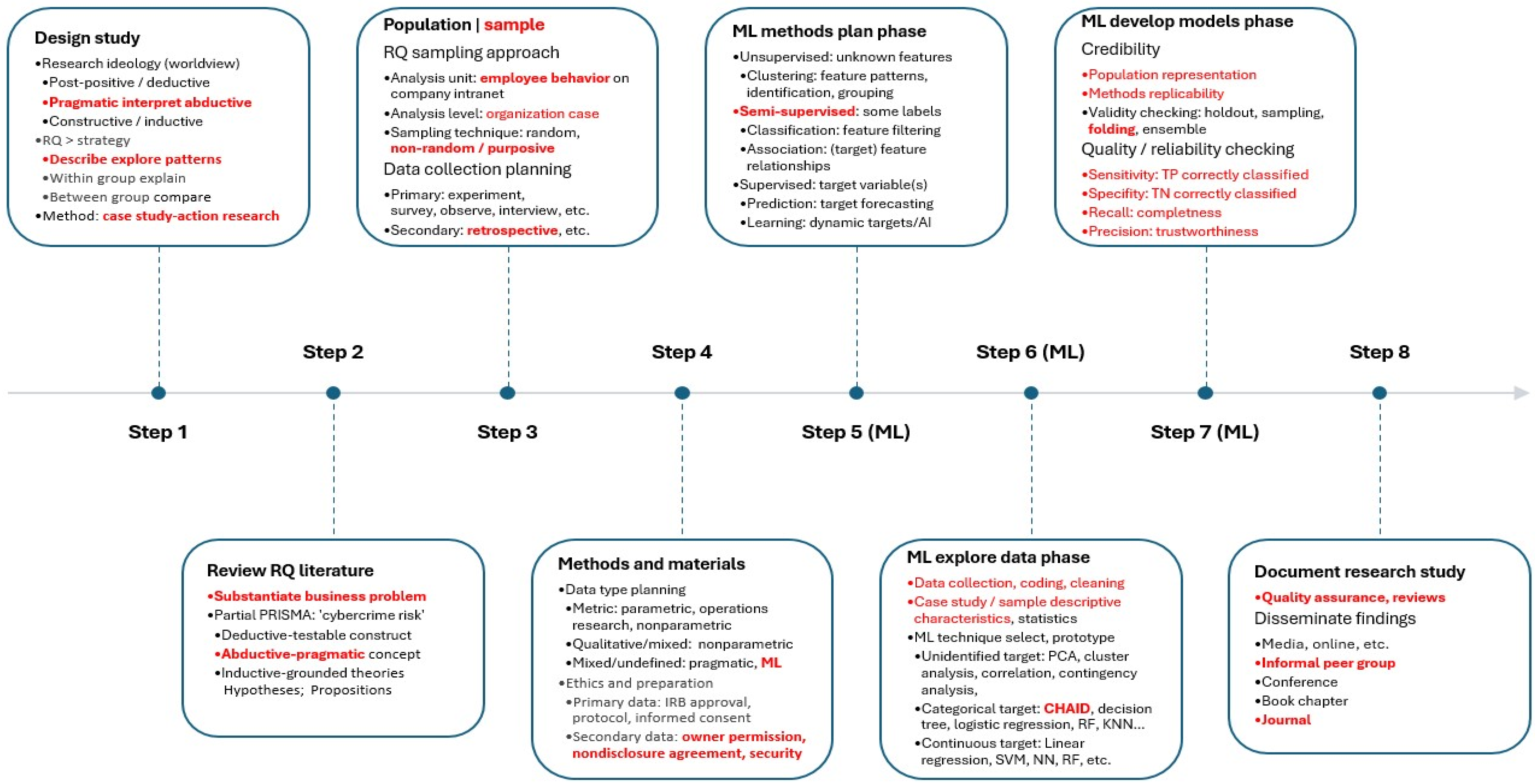
2.1. Research Design Summary
- (1)
- Design study (ideology: pragmatic, strategy: abductive, nature: exploratory);
- (2)
- Review RQ-related literature (abductive strategy focused on relevant topics);
- (3)
- Identify the population (sample technique, unit of analysis, analysis level, data);
- (4)
- Methods and materials (data types, relevant method ML, ethics, permission);
- (5)
- ML: methods plan phase (semi-supervised ML, some labels, classification);
- (6)
- ML: explore data phase (data collection/cleaning, CHAID decision tree);
- (7)
- ML: develop models phase (credibility, validity: 20-folds, reliability checks);
- (8)
- Document research study (quality assurance, dissemination to journal).
2.2. Research Ideology, Strategy, and Overall Methodology
2.3. Literature Review Approach
2.4. Population and Sampling
2.5. Ethics and Big Data Access Permission
2.6. ML Technique Planning
2.7. Big Data Exploration with Selected ML Techniques
2.8. Big Data Analysis, Training Model Development, and Evaluation with ML
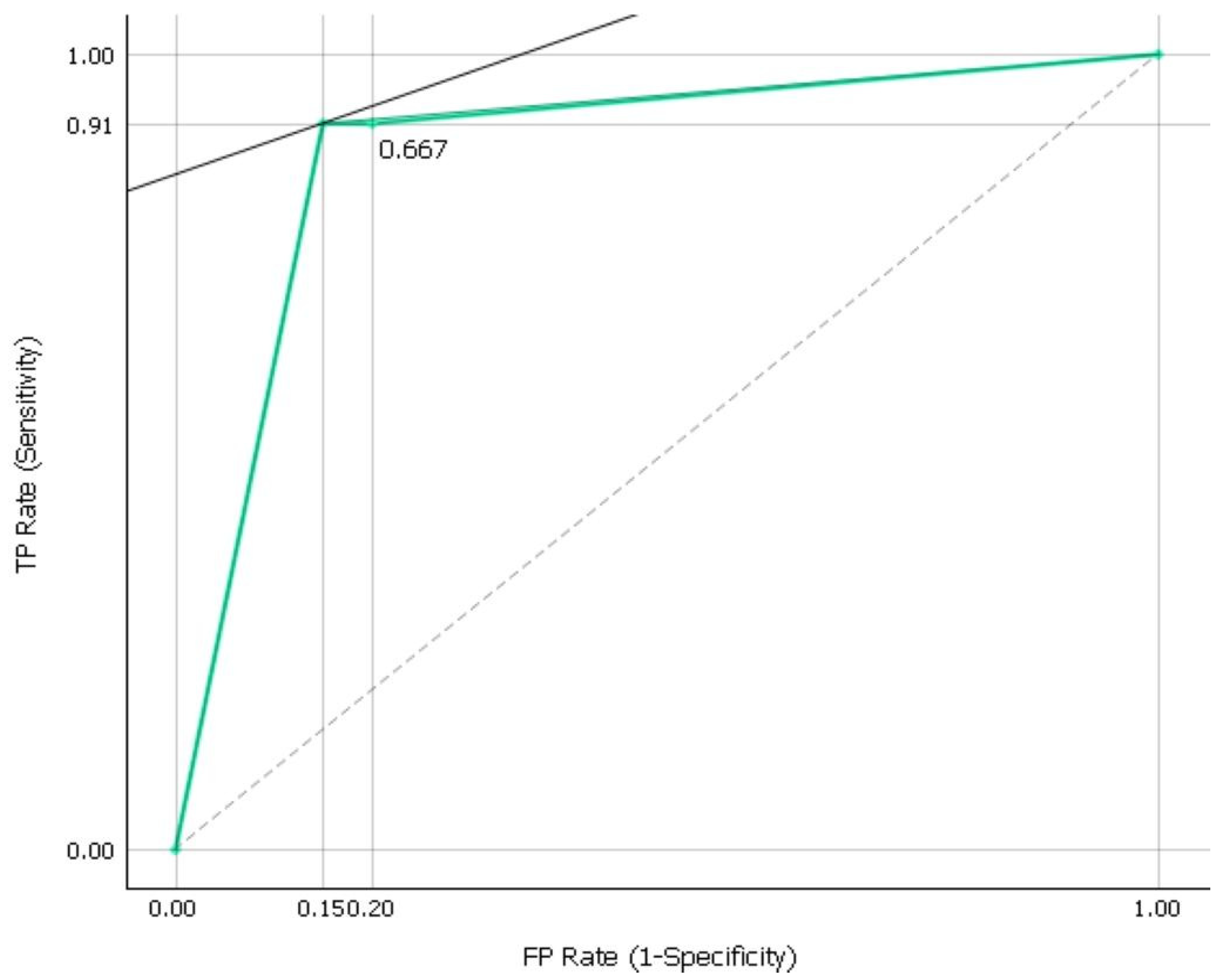
- 0.9–1.0 = outstanding quality;
- 0.8–0.9 = excellent/superior quality;
- 0.7–0.8 = acceptable/fair quality;
- 0.6–0.7 = poor quality;
- 0.5–0.6 = zero quality.
- 0.00–0.20 = low agreement with the null model, benchmark acceptable score;
- 0.20–0.40 = weak agreement with the null model, baseline acceptance score;
- 0.40–0.60 = moderate agreement with the null model, borderline to poor score;
- 0.60–0.80 = good agreement with the null model, poor score;
- 0.80–1.00 = high agreement with the null model, unacceptable score.
2.9. Plan to Finalize and Disseminate Research Study Findings
3. Results and Discussion
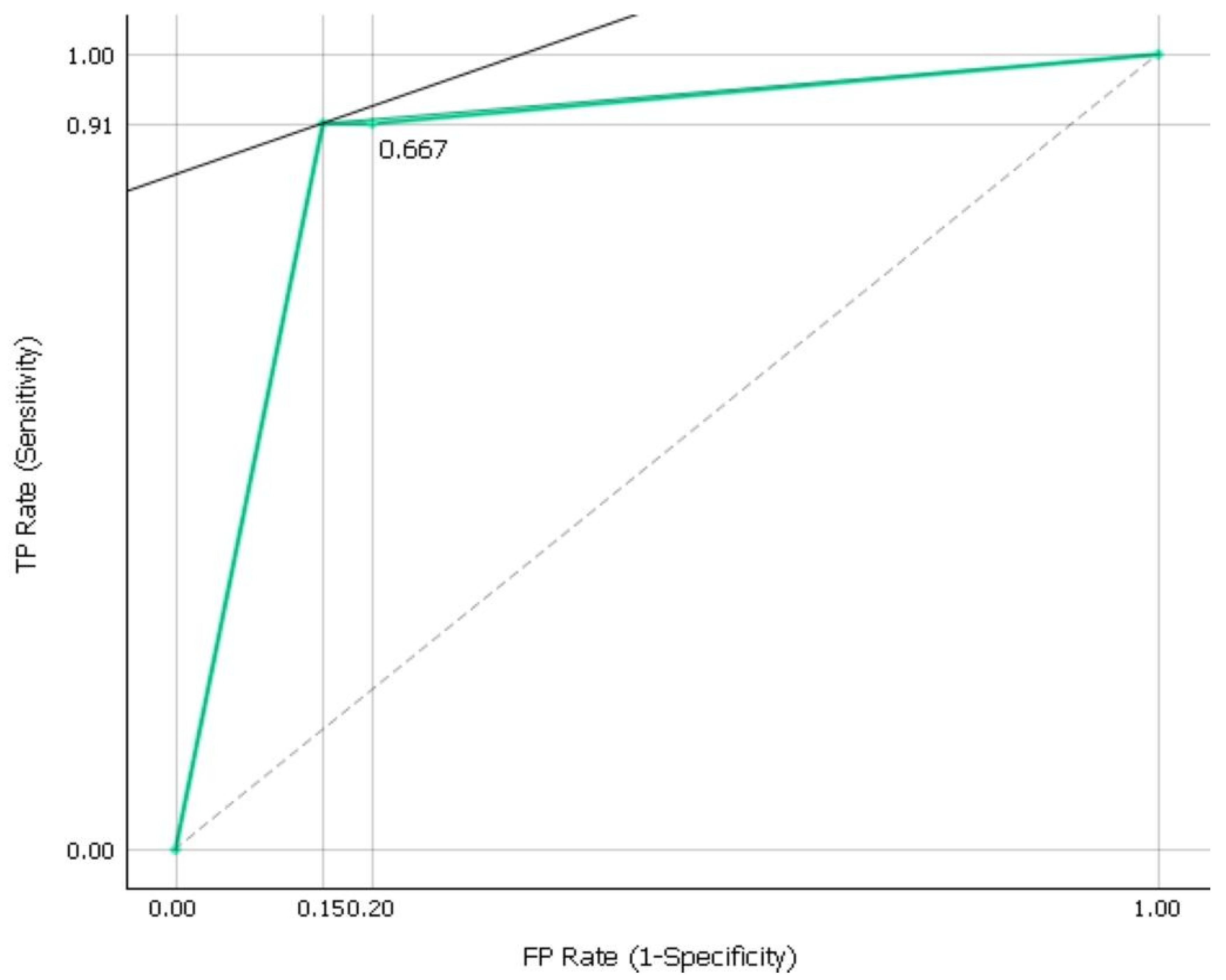
3.1. Quality Scores from ML Training Model Development and Testing
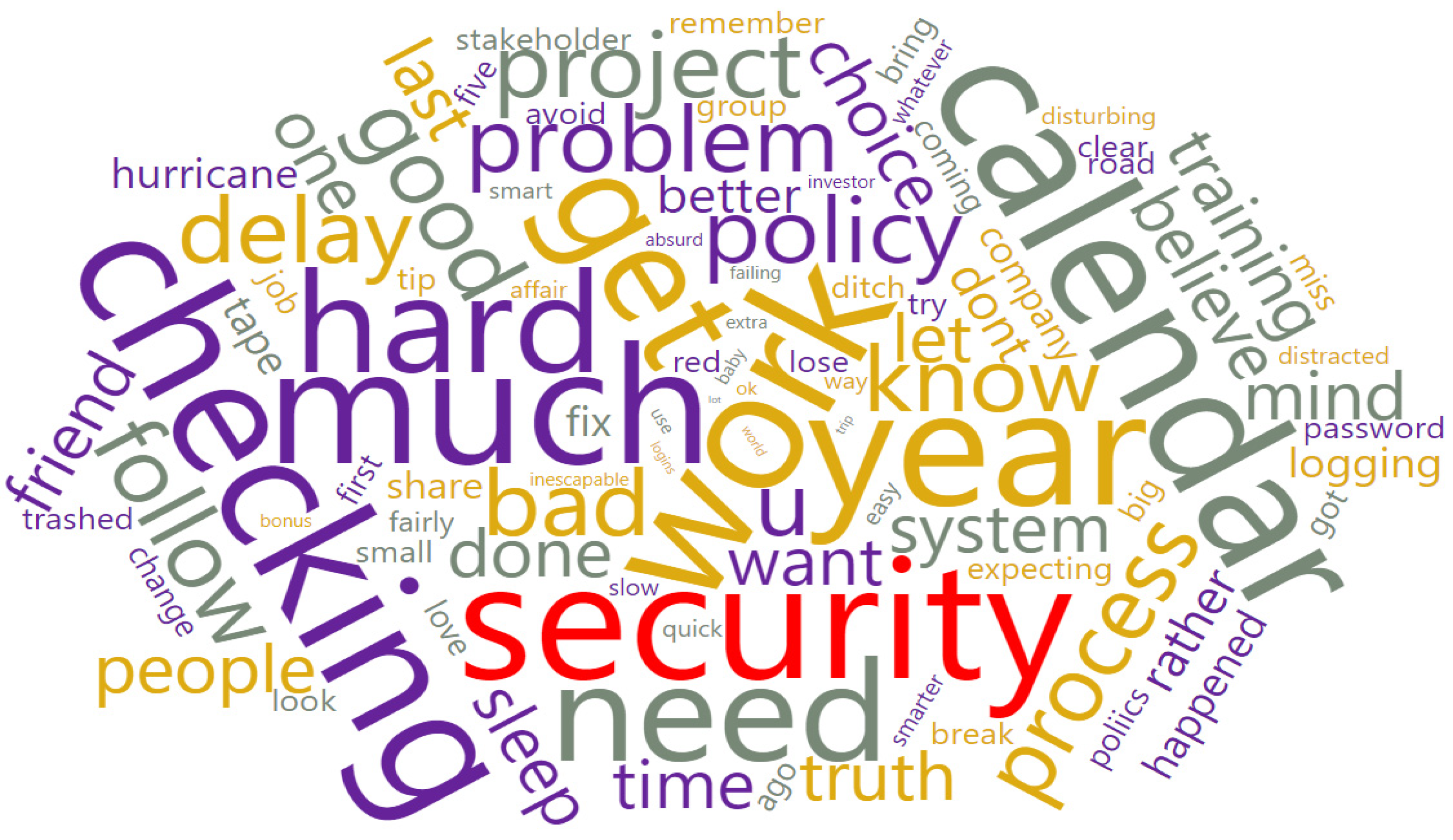
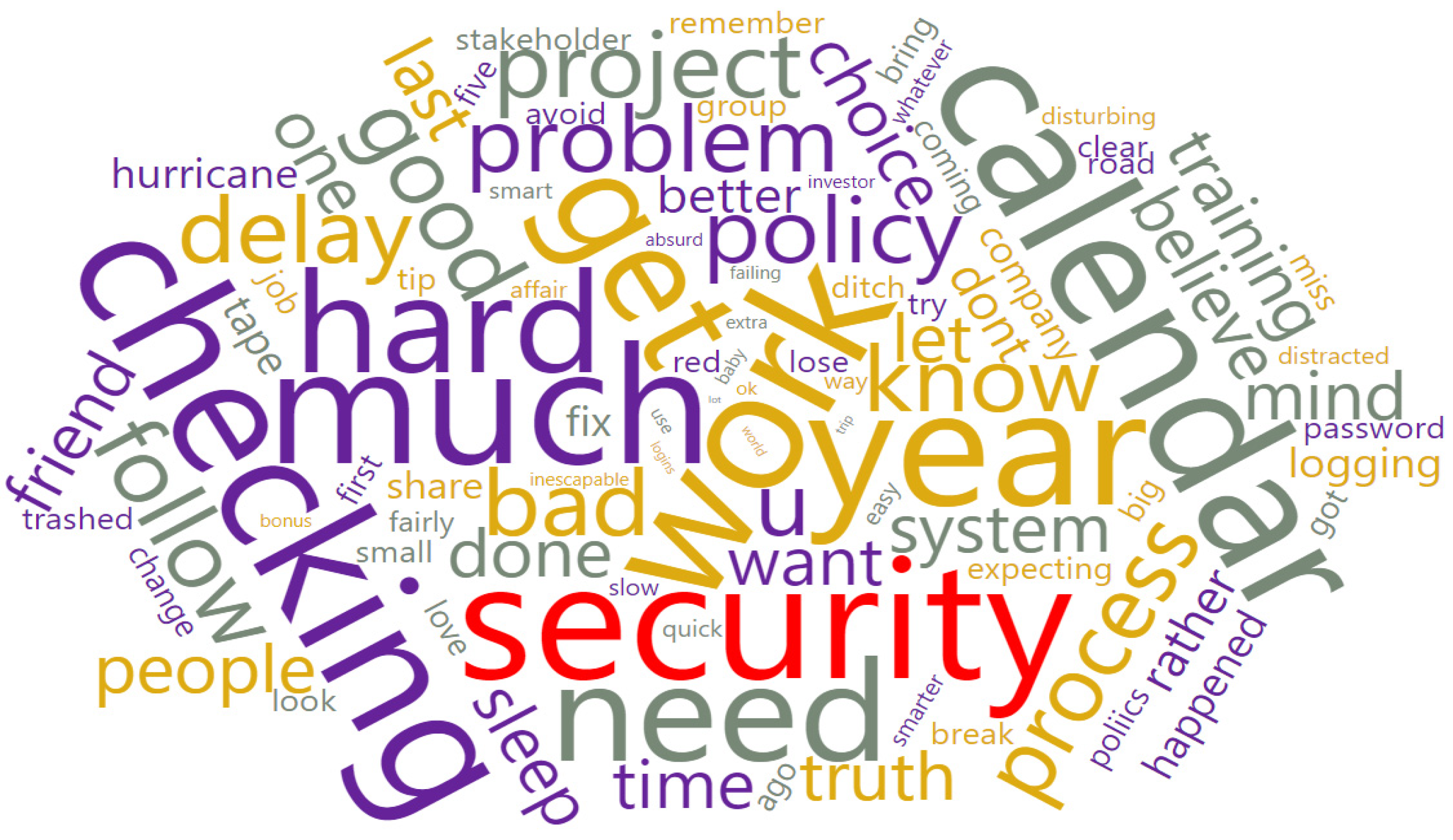
3.2. Cybercrime Risk Keyword Association Analysis
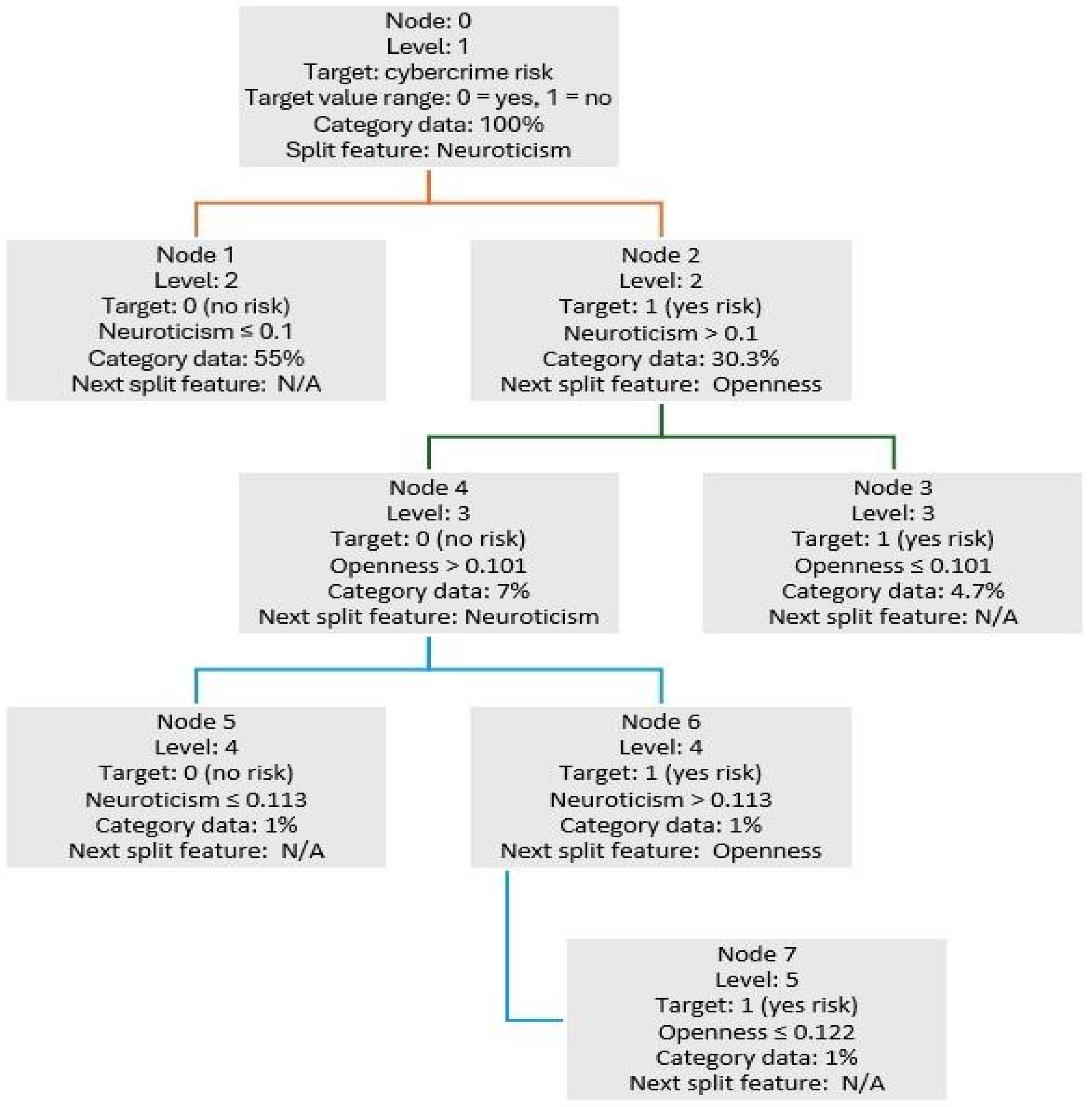
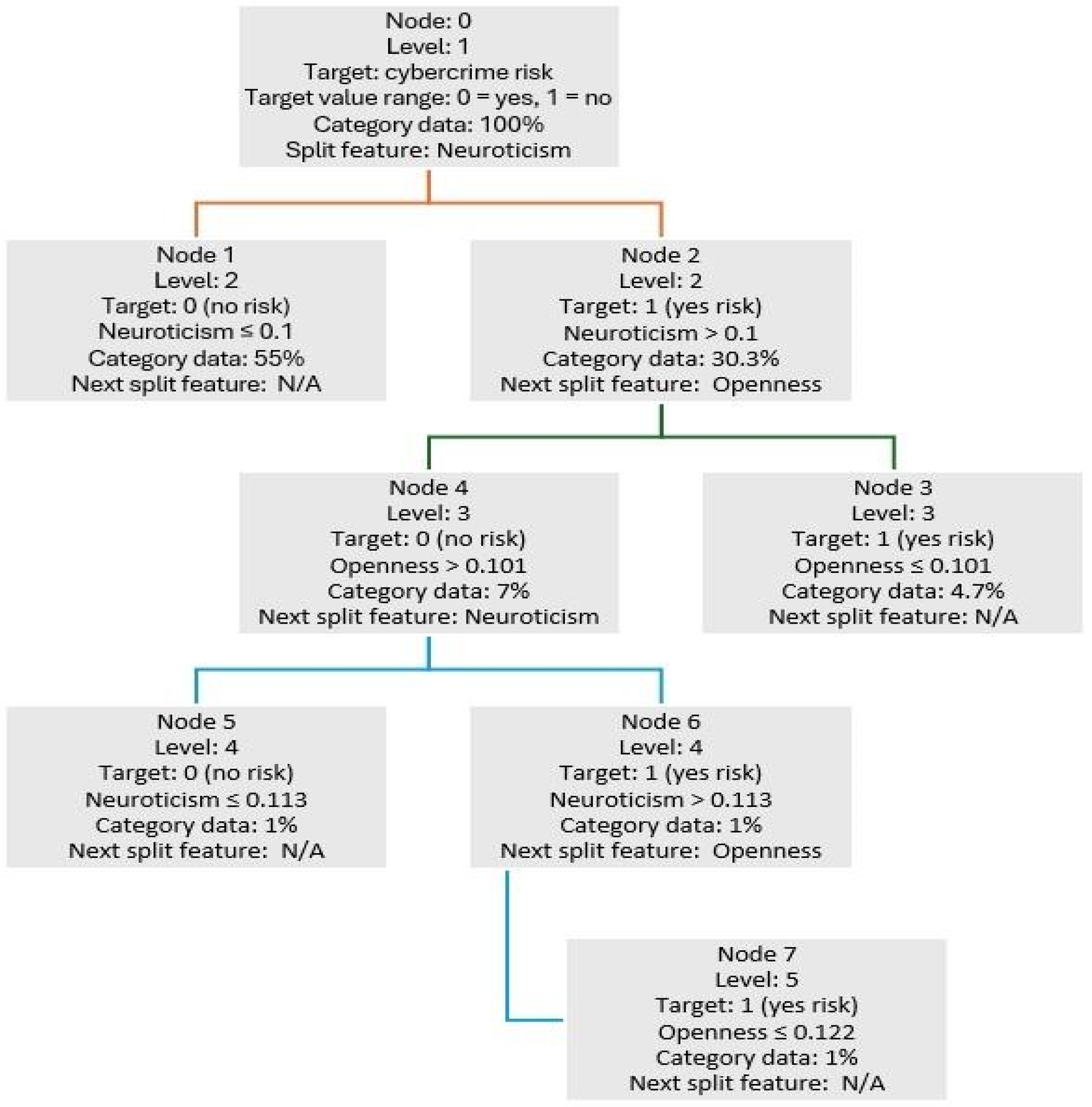
3.3. Cybercrime Risk Learning Tree Analysis
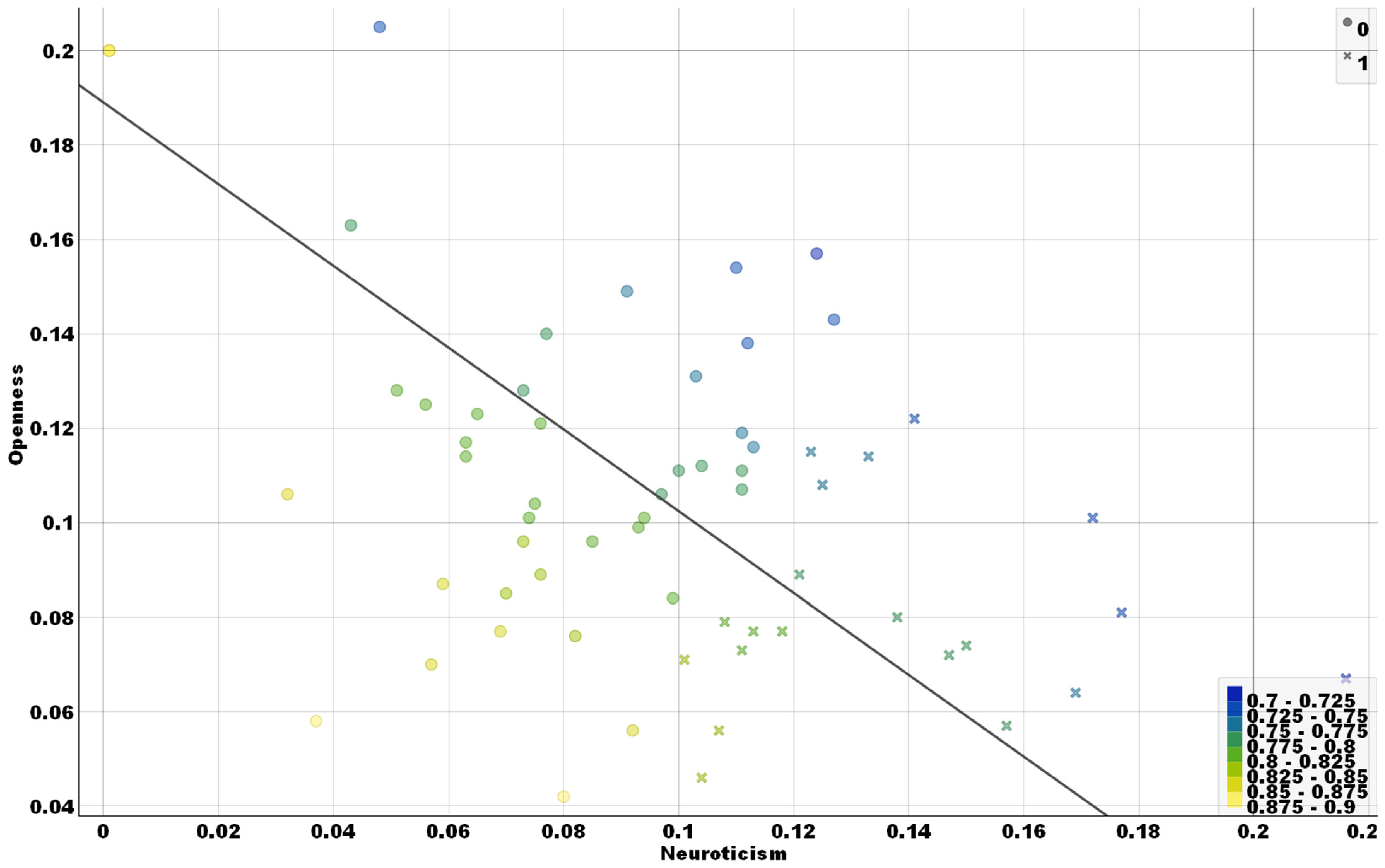
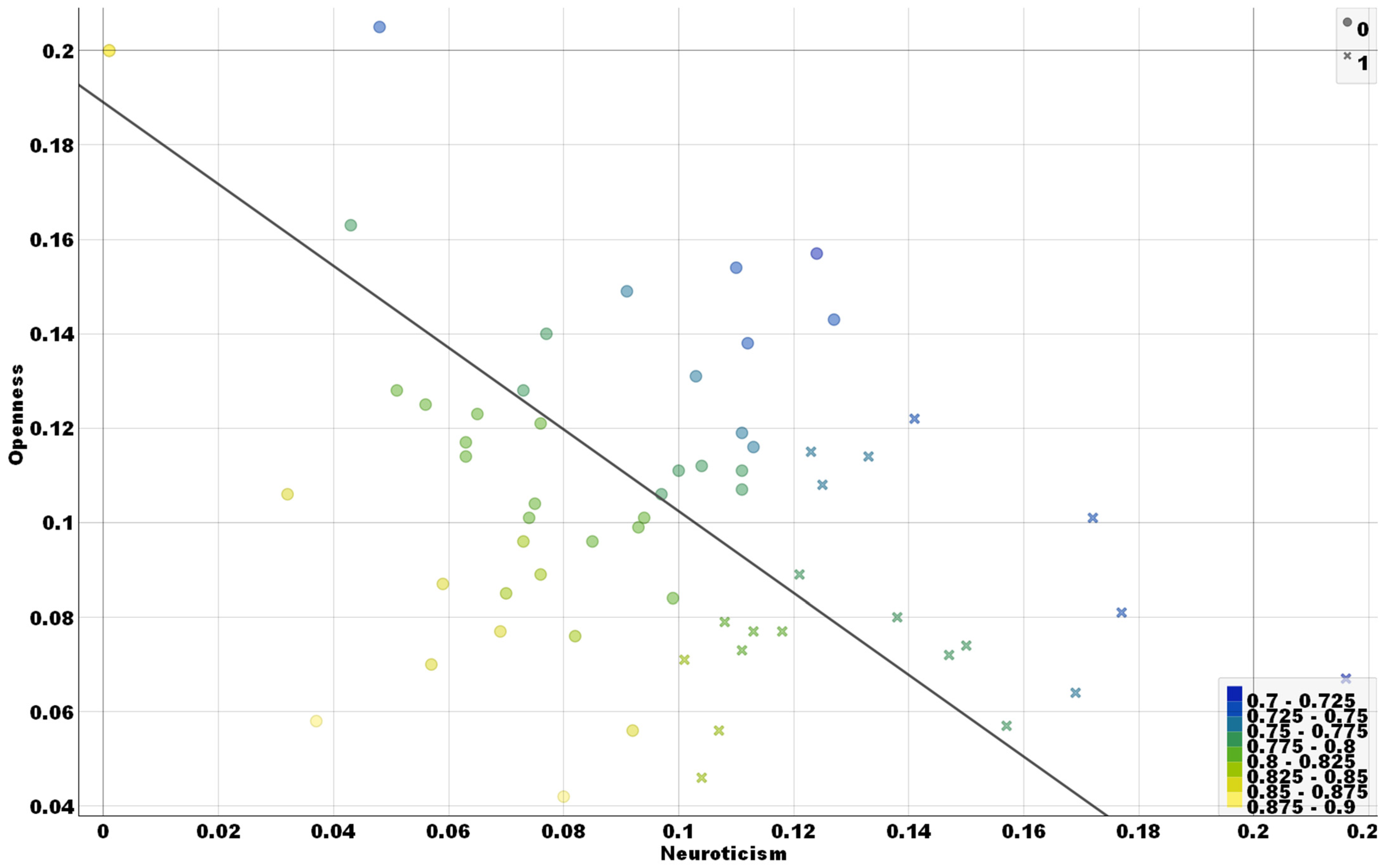
3.4. Cybercrime Risk Feature Scatter Plot Analysis
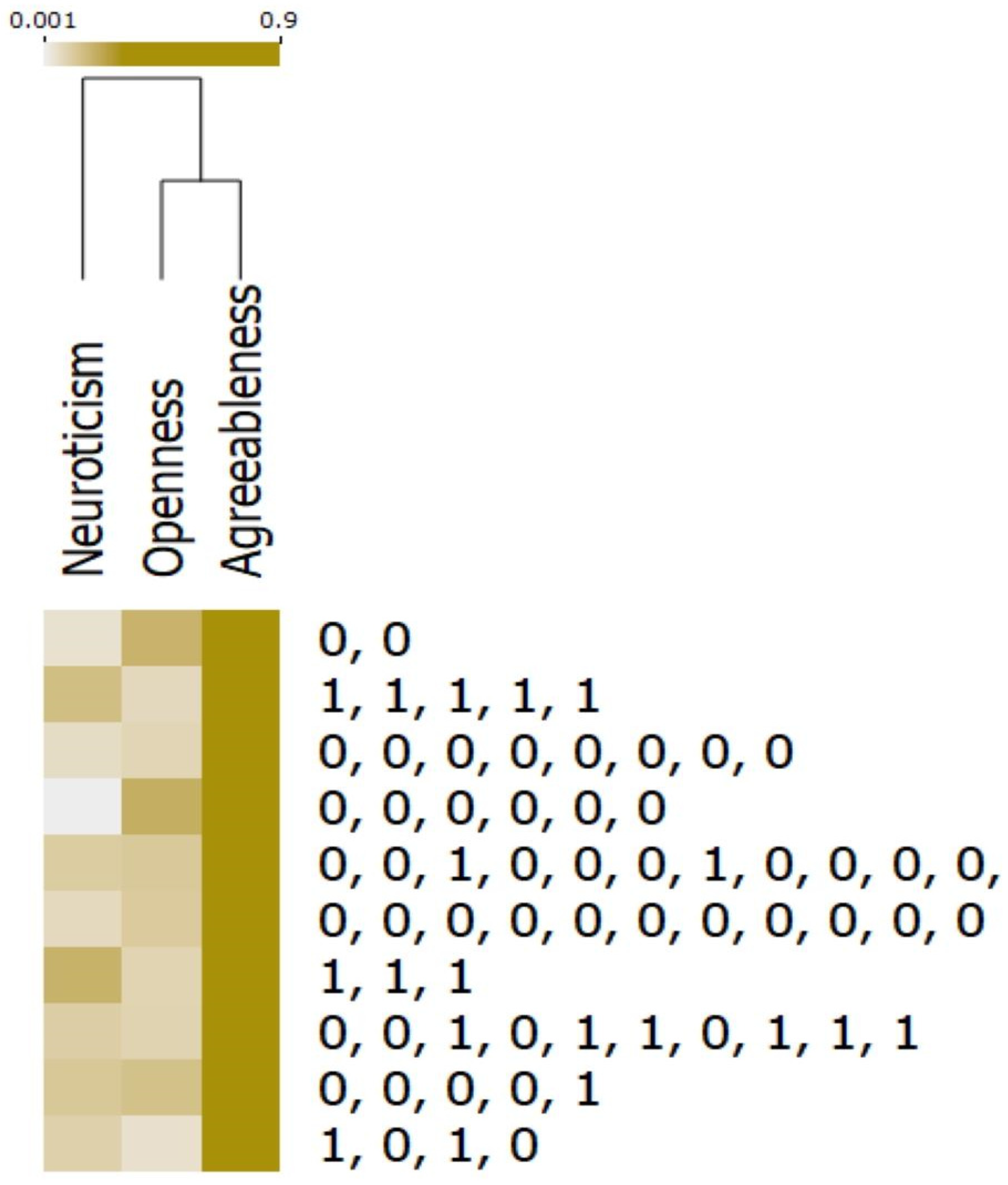
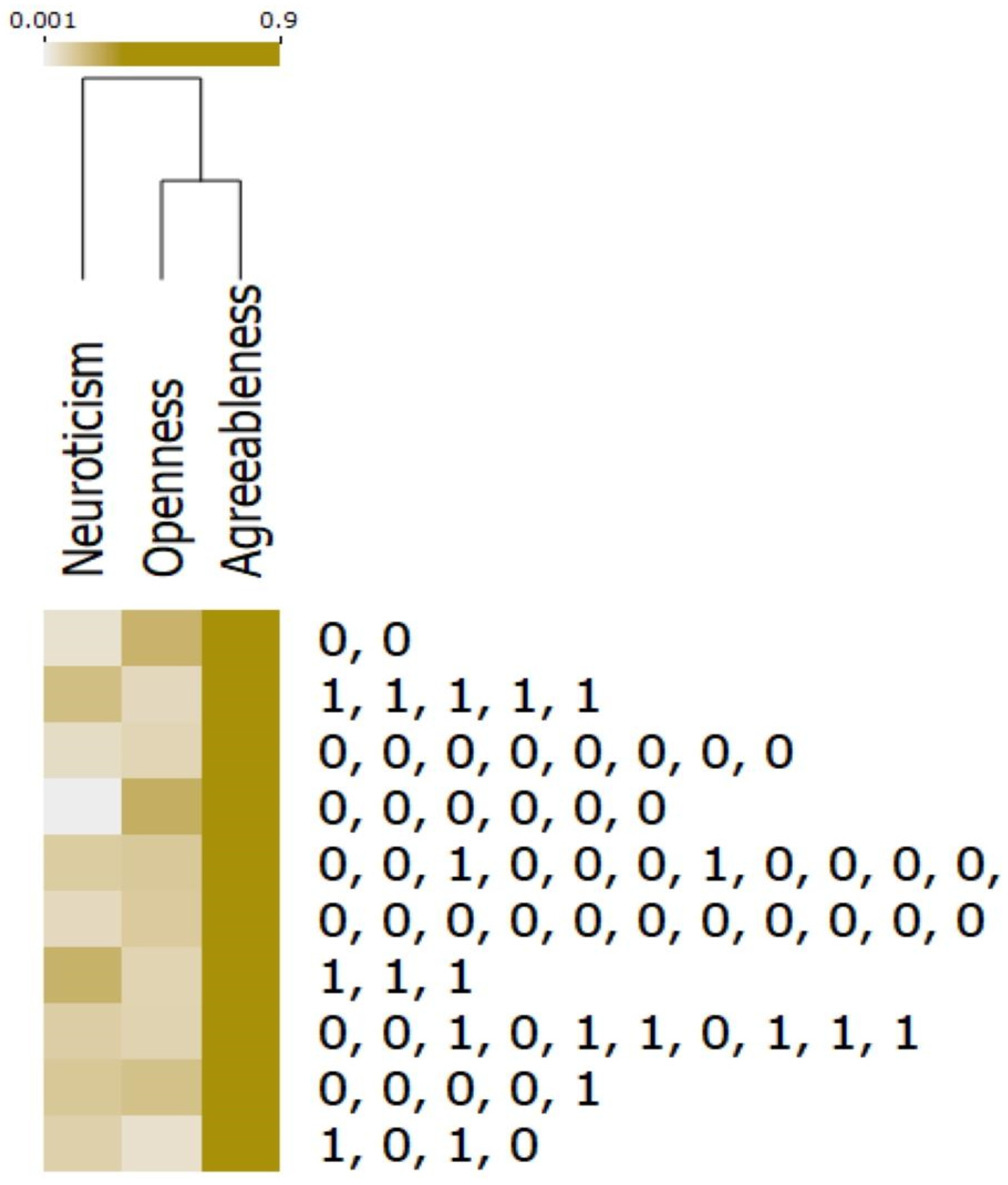
3.5. Cybercrime Risk Feature Heat Map Analysis
4. Conclusions
4.1. Literature Contrasts, Detailed Implications, and Generalizations
4.2. Limitations and Caveats
4.3. Future Study Recommendations
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Trim, P.R.J.; Lee, Y.-I. Managing Cybersecurity Threats, and Increasing Organizational Resilience. Big Data Cogn. Comput. 2023, 7, 177. [Google Scholar] [CrossRef]
- Raimi, L. Business Continuity and Disaster Recovery Strategies as Resilience Tools after Cyberattacks in Toxic Entrepreneurship Ecosystems. In Cybersecurity for Decision Makers; CRC/Taylor & Francis: Boca Raton, FL, USA, 2023; pp. 349–364. [Google Scholar] [CrossRef]
- Parikh, R. An Introduction to Cybercrime and Cybersecurity: The Whys and Whos of Cybersecurity. In Cybersecurity for Decision Makers; CRC/Taylor & Francis: Boca Raton, FL, USA, 2023; pp. 57–70. [Google Scholar]
- FBI. Internet Crime Complaint Center Internet Crime Report, Including COVID-19 Scam Statistics; US Federal Bureau of Investigations (FBI): Washington, DC, USA, 2020. Available online: www.fbi.gov/news/press-releases/press-releases/fbi-releases-the-internet-crime-complaint-center-2020-internet-crime-report-including-covid-19-scam-statistics (accessed on 1 March 2024).
- Martineau, M.; Spiridon, E.; Aiken, M. A Comprehensive Framework for Cyber Behavioral Analysis Based on a Systematic Review of Cyber Profiling Literature. Forensic Sci. 2023, 3, 452–477. [Google Scholar] [CrossRef]
- Hiremath, S.; Shetty, E.; Prakash, A.J.; Sahoo, S.P.; Patro, K.K.; Rajesh, K.N.V.P.S.; Pławiak, P. A New Approach to Data Analysis Using Machine Learning for Cybersecurity. Big Data Cogn. Comput. 2023, 7, 176. [Google Scholar] [CrossRef]
- Mallin, A.; Barr, L. DOJ Seizes Millions in Ransom Paid by Colonial Pipeline; ABC News: New York, NY, USA, 2021; Available online: https://abcnews.go.com/Politics/doj-seizes-millions-ransom-paid-colonial-pipeline/story?id=78135821 (accessed on 1 March 2024).
- Lickiewicz, J. Cyber Crime Psychology—Proposal of an Offender Profile. Probl. Forensic Sci. 2011, 2, 239–252. Available online: https://arch.ies.gov.pl/images/PDF/2011/vol_87/87_Lickiewicz.pdf (accessed on 1 March 2024).
- Dalal, S.; Lilhore, U.K.; Faujdar, N.; Simaiya, S.; Ayadi, M.; Almujally, N.A.; Ksibi, A. Next-generation cyber-attack prediction for IoT systems: Leveraging multi-class SVM and optimized CHAID decision tree. J. Cloud Comp. 2023, 12, 137. [Google Scholar] [CrossRef]
- Almansoori, A.; Al-Emran, M.; Shaalan, K. Exploring the Frontiers of Cybersecurity Behavior: A Systematic Review of Studies and Theories. Appl. Sci. 2023, 13, 5700. [Google Scholar] [CrossRef]
- Schoenmakers, K.; Greene, D.; Stutterheim, S.; Lin, H.; Palmer, M.J. The security mindset: Characteristics, development, and consequences. J. Cybersecur. 2023, 9, 1. [Google Scholar] [CrossRef]
- Kranenbarg, M.W.; van-Gelder, J.L.; Barends, A.J.; de-Vries, R.E. Is there a cybercriminal personality? Comparing cyber offenders and offline offenders on HEXACO personality domains and their underlying facets. Comput. Hum. Behav. 2023, 140, 107576. [Google Scholar] [CrossRef]
- Cram, W.A.; D’Arcy, J. What a waste of time: An examination of cybersecurity legitimacy. Inf. Syst. J. 2023, 33, 1396–1422. [Google Scholar] [CrossRef]
- Sun, Z. Handbook of Research on Driving Socioeconomic Development with Big Data; IGI-Global: Hershey, PA, USA, 2023; pp. 1–421. [Google Scholar] [CrossRef]
- Microsoft News Center. AI for Everyone—Microsoft’s Push Gains Momentum: Democratizing AI for Every Person and Every Organization; Microsoft Corporation: Redmond, WA, USA, 2023; Available online: https://news.microsoft.com/features/democratizing-ai/ (accessed on 1 March 2024).
- Lim, A.; Chai, D.S. Action Research Applied with Two Single Case Studies. In Handbook of Research Design in Business and Management; Palgrave Macmillan US: New York, NY, USA, 2015; pp. 375–393. Available online: https://link.springer.com/book/10.1057/9781137484956 (accessed on 1 March 2024).
- Baskerville, R.L.; Wood-Harper, A.T. A critical perspective on action research as a method for information systems research. J. Inf. Technol. 1996, 11, 235–246. [Google Scholar] [CrossRef]
- Eden, C.; Huxham, C. Action research for management research. Br. J. Manag. 1996, 7, 75–86. [Google Scholar] [CrossRef]
- Lantz, B. Machine Learning with R: Learn How to Use R to Apply Powerful Machine Learning Methods and Gain an Insight into Real-World Applications; Packt Publishing: Birmingham, UK, 2019; ISBN 9781788295864. Available online: https://www.oreilly.com/library/view/machine-learning-with/9781788295864/ (accessed on 1 March 2024).
- Ramasubramanian, K.; Singh, A. Machine Learning Using R: With Time Series and Industry-Based Use Cases in R; Apress Media: New Delhi, India, 2019; ISBN 978-1-4842-4214-8. [Google Scholar] [CrossRef]
- Goldberg, L.R. The development of markers for the Big-Five factor structure. Psychol. Assess. 1992, 4, 26–42. [Google Scholar] [CrossRef]
- Costa, P.T., Jr.; McCrae, R.R.; Zonderman, A.B.; Barbano, H.E.; Lebowitz, B.; Larson, D.M. Cross-sectional studies of personality in a national sample: 2. Stability in neuroticism, extraversion, and openness. Psychol. Aging 1986, 1, 144–149. Available online: https://pubmed.ncbi.nlm.nih.gov/3267391/ (accessed on 1 March 2024). [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Neuroticism | Openness | Agreeableness | Conscientiousness | Extroversion |
|---|---|---|---|---|
| stressed | create creative | interested | prepared | party parties |
| worried | imagination | sympathize | detail detailed | conversation |
| upset | ideas | comfort | exact | attention |
| pissed | complexity | gratitude | accurate | talk discuss |
| moody | new newness | follow | plan | friends |
| angry | try | accept | attention | social |
| revenge | experiment | listen | quality | fun |
| Predicted | |||
|---|---|---|---|
| Actual | 0 (Risk = No) | 1 (Risk = Yes) | Total |
| 0 (risk = no) | 63.6% | 6.1% | 69.7% |
| 1 (risk = yes) | 6.1% | 24.2% | 30.3% |
| Total | 69.7% | 30.3% | 100% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Strang, K.D. Cybercrime Risk Found in Employee Behavior Big Data Using Semi-Supervised Machine Learning with Personality Theories. Big Data Cogn. Comput. 2024, 8, 37. https://doi.org/10.3390/bdcc8040037
Strang KD. Cybercrime Risk Found in Employee Behavior Big Data Using Semi-Supervised Machine Learning with Personality Theories. Big Data and Cognitive Computing. 2024; 8(4):37. https://doi.org/10.3390/bdcc8040037
Chicago/Turabian StyleStrang, Kenneth David. 2024. "Cybercrime Risk Found in Employee Behavior Big Data Using Semi-Supervised Machine Learning with Personality Theories" Big Data and Cognitive Computing 8, no. 4: 37. https://doi.org/10.3390/bdcc8040037
APA StyleStrang, K. D. (2024). Cybercrime Risk Found in Employee Behavior Big Data Using Semi-Supervised Machine Learning with Personality Theories. Big Data and Cognitive Computing, 8(4), 37. https://doi.org/10.3390/bdcc8040037